

Image: Maurice Peemen - Tecnalia · F.-F. Li, A. Karpathy, and J. Johnson, “Stanford CS231n:...
58
75 ▌ Image: Maurice Peemen
Transcript of Image: Maurice Peemen - Tecnalia · F.-F. Li, A. Karpathy, and J. Johnson, “Stanford CS231n:...

76 ▌ https://es.mathworks.com/help/nnet/convolutional-neural-networks.html

77 ▌ F.-F. Li, A. Karpathy, and J. Johnson, “Stanford CS231n: Convolutional Neural Networks for Visual Recognition”, 2016.

78 ▌
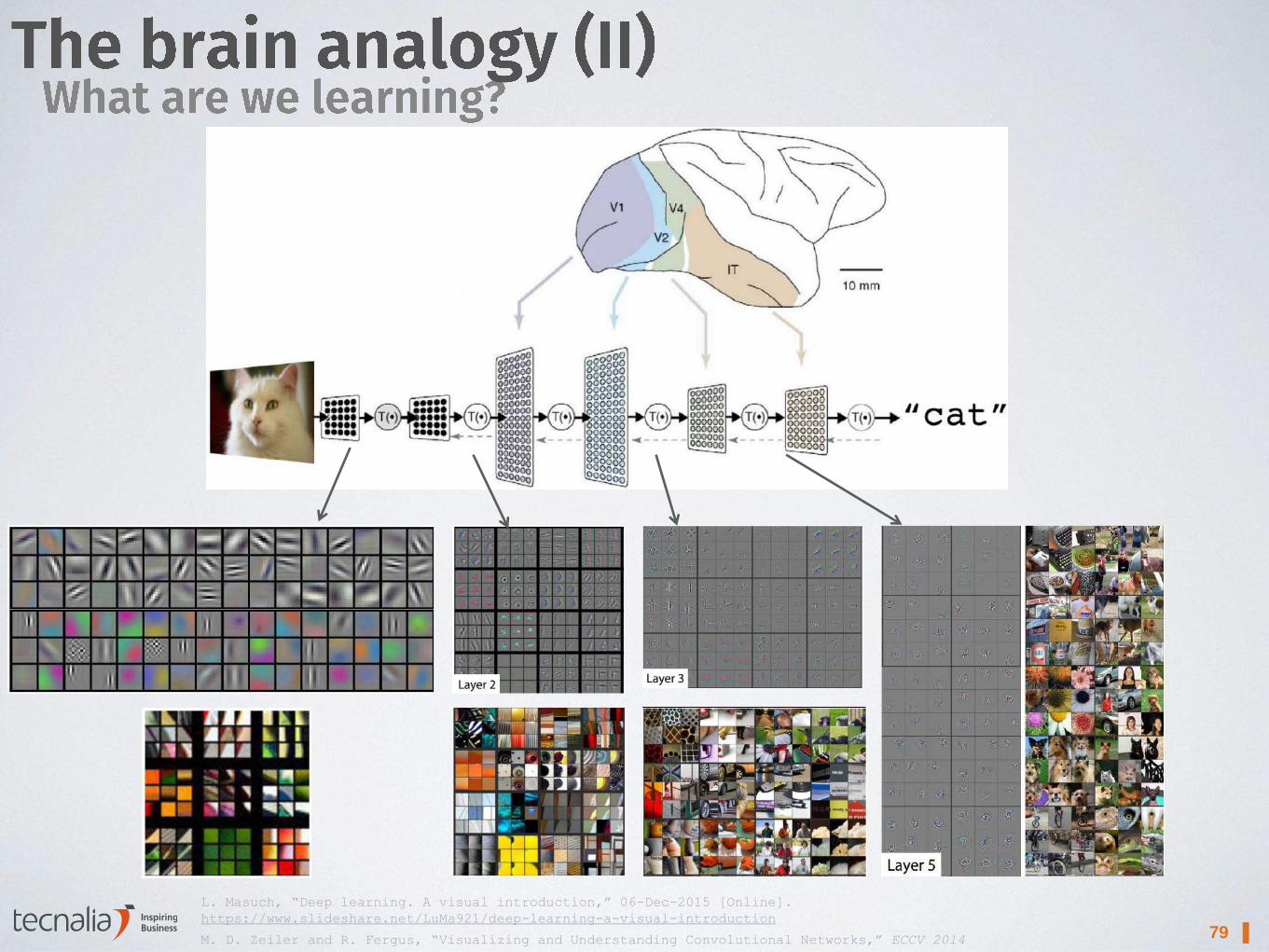
79 ▌ M. D. Zeiler and R. Fergus, “Visualizing and Understanding Convolutional Networks,” ECCV 2014
L. Masuch, “Deep learning. A visual introduction,” 06-Dec-2015 [Online].
https://www.slideshare.net/LuMa921/deep-learning-a-visual-introduction

80 ▌ M. D. Zeiler and R. Fergus, “Visualizing and Understanding Convolutional Networks,” ECCV 2014
L. Masuch, “Deep learning. A visual introduction,” 06-Dec-2015 [Online].
https://www.slideshare.net/LuMa921/deep-learning-a-visual-introduction

81 ▌
Source: https://adeshpande3.github.io/adeshpande3.github.io/A-
Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
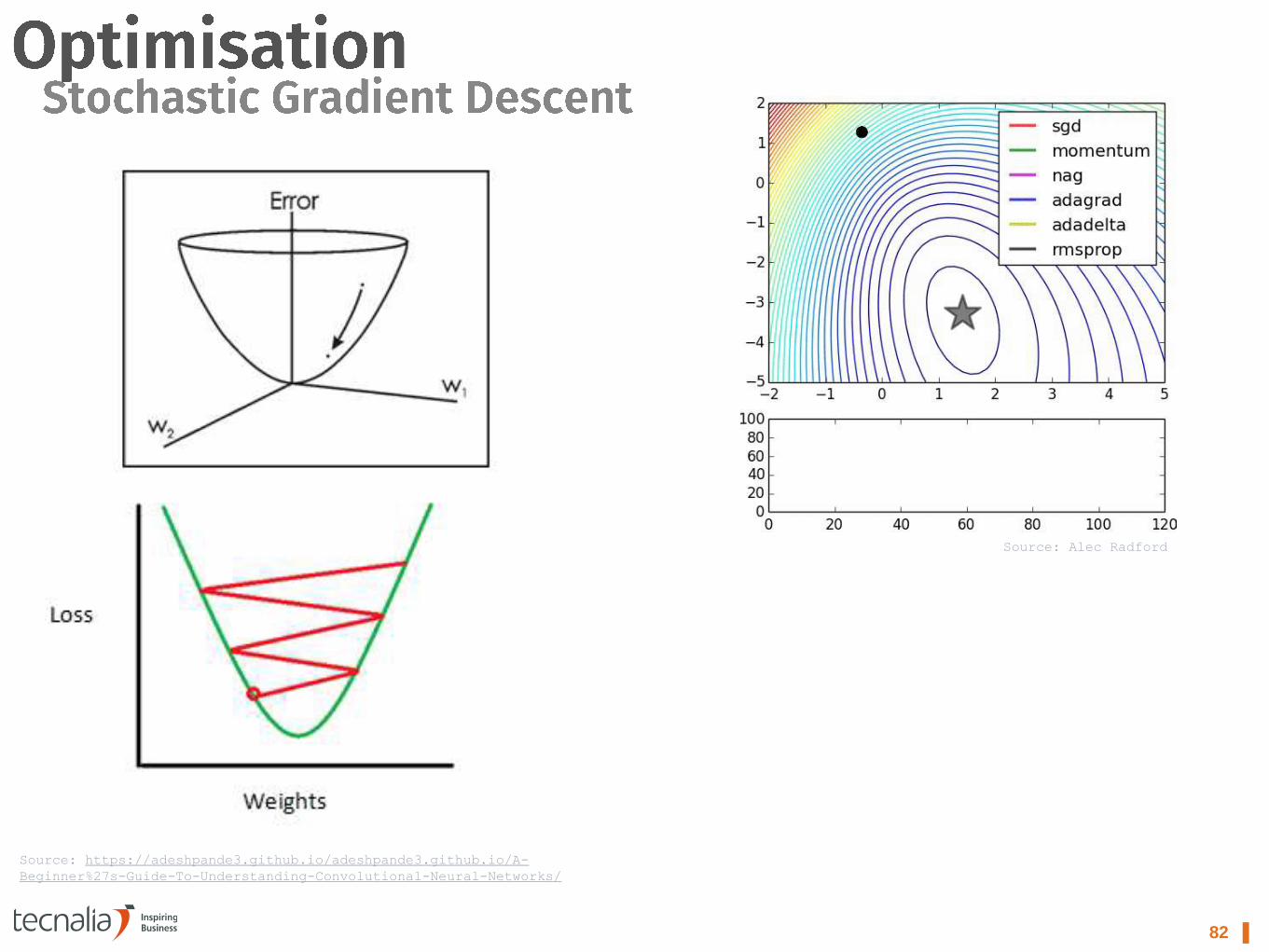
82 ▌
Source: https://adeshpande3.github.io/adeshpande3.github.io/A-
Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
Source: Alec Radford

83 ▌
Source: https://adeshpande3.github.io/adeshpande3.github.io/A-
Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
Source: Alec Radford

84 ▌ F.-F. Li, J. Johnson, and S. Yeung, “Stanford CS231n: Convolutional Neural Networks for Visual Recognition”, 2017.
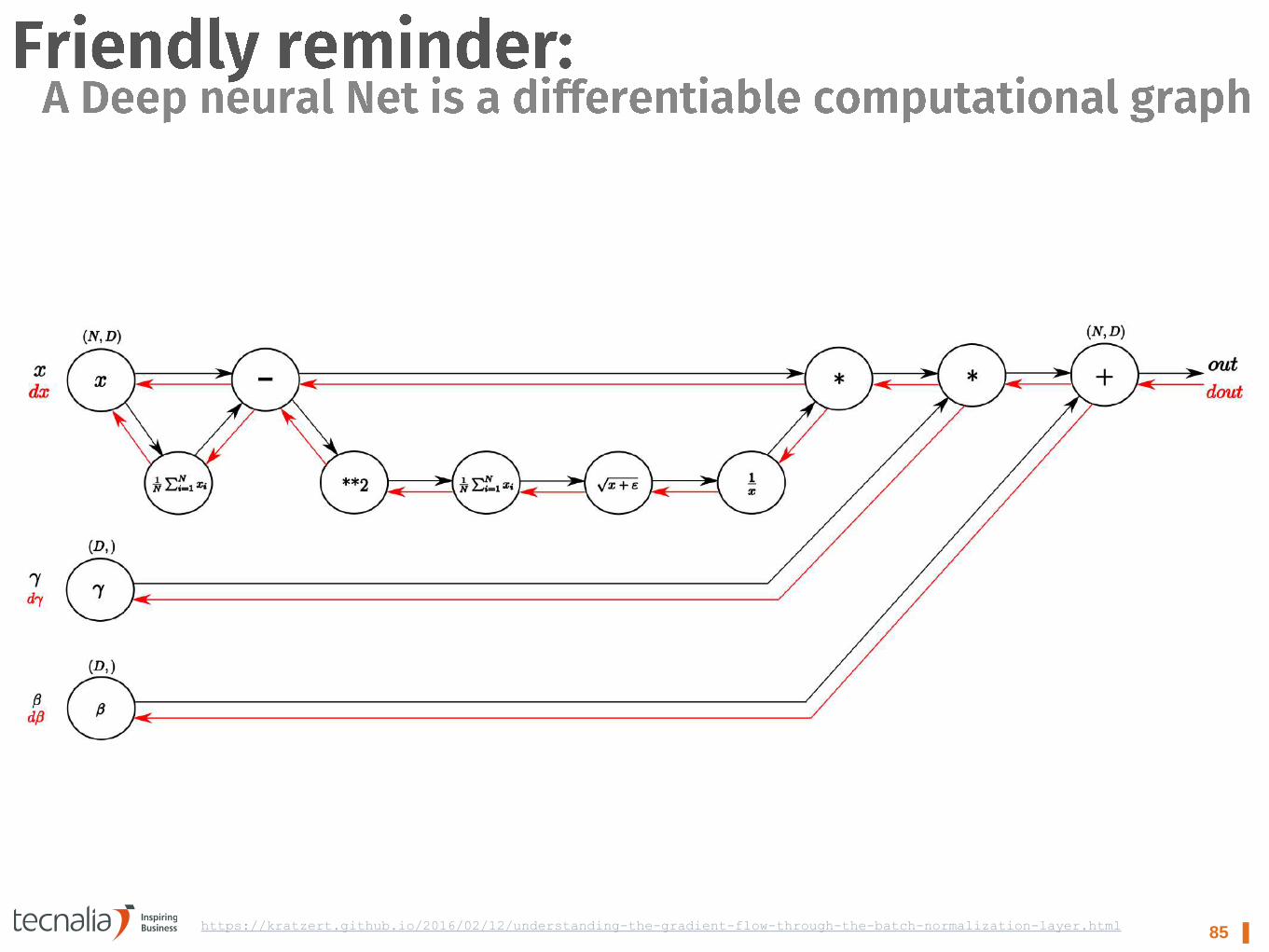
85 ▌ https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html

86 ▌ http://www.robots.ox.ac.uk/~vgg/practicals/cnn/

87 ▌ J. Redmon and A. Farhadi, “YOLO9000: Better, Faster, Stronger,” arXiv:1612.08242 [cs], Dec. 2016.

88 ▌ J. Redmon and A. Farhadi, “YOLO9000: Better, Faster, Stronger,” arXiv:1612.08242 [cs], Dec. 2016.
https://www.youtube.com/watch?v=VOC3huqHrss

89 ▌ V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image
segmentation,” arXiv preprint arXiv:1511.00561, 2015.

90 ▌ V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image
segmentation,” arXiv preprint arXiv:1511.00561, 2015.

91 ▌ K. He, G. Gkioxari, P. Dollár, and R. Girshick,
“Mask R-CNN,” arXiv:1703.06870 [cs], Mar. 2017.

92 ▌ K. He, G. Gkioxari, P. Dollár, and R. Girshick,
“Mask R-CNN,” arXiv:1703.06870 [cs], Mar. 2017.
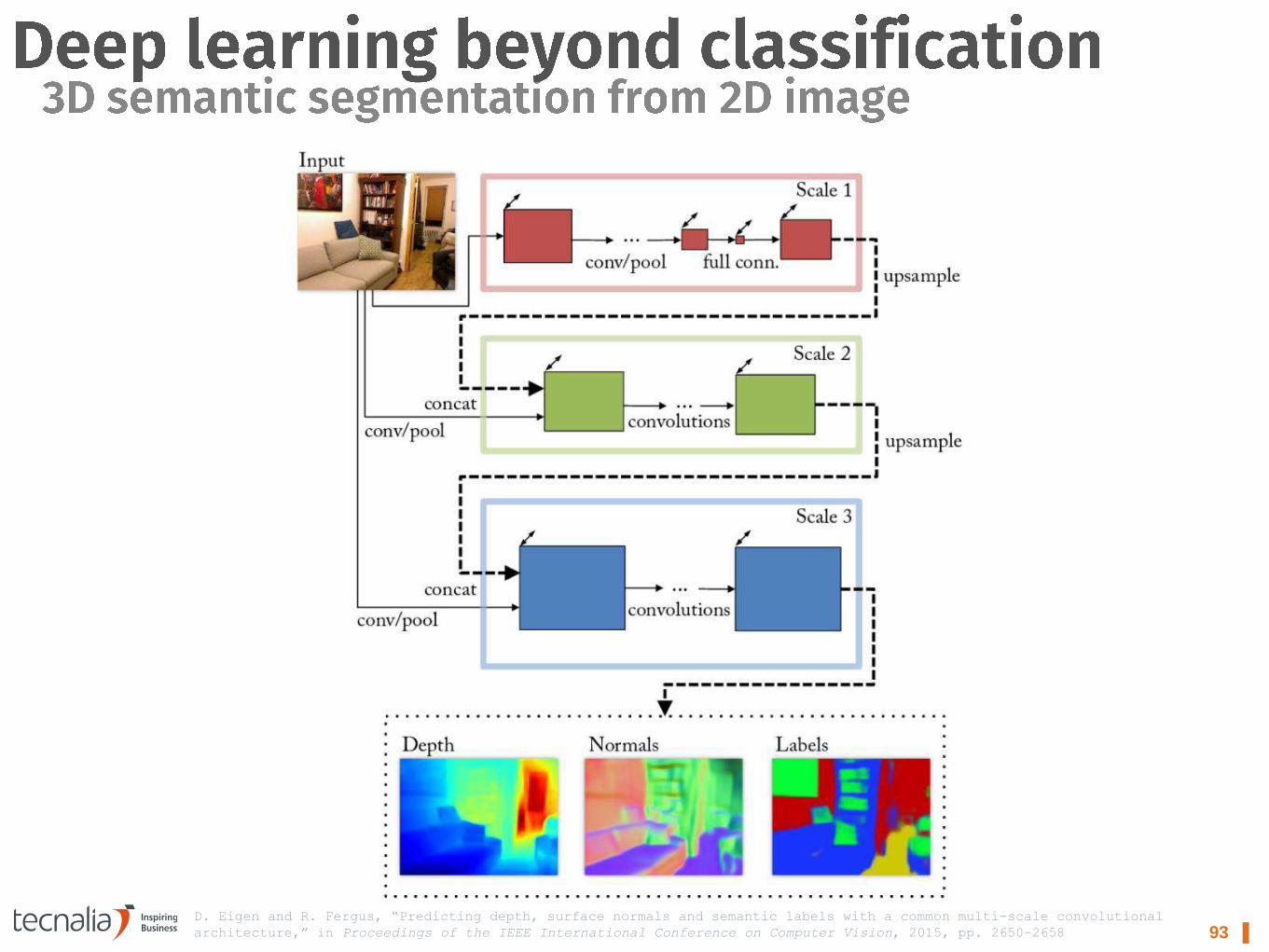
93 ▌ D. Eigen and R. Fergus, “Predicting depth, surface normals and semantic labels with a common multi-scale convolutional
architecture,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2650–2658

94 ▌ J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “SemanticFusion: Dense 3D Semantic Mapping with Convolutional
Neural Networks,” arXiv preprint arXiv:1609.05130, 2016.

95 ▌ https://medium.com/@samim/human-pose-detection-51268e95ddc2

96 ▌ https://medium.com/@samim/human-pose-detection-51268e95ddc2

97 ▌ S. Levine, P. Pastor, A. Krizhevsky, and D. Quillen, “Learning Hand-Eye Coordination for Robotic Grasping with Deep
Learning and Large-Scale Data Collection,” arXiv:1603.02199 [cs], Mar. 2016.

98 ▌ L. A. Gatys, A. S. Ecker, and M. Bethge, “A Neural Algorithm of Artistic Style,” arXiv:1508.06576 [cs, q-bio], Aug. 2015.

99 ▌ Source: marvel.com

100 ▌ F. Chollet, “Building powerful image classification models using very little data,” The Keras Blog, 05-Jun-2016.
Available: http://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html.
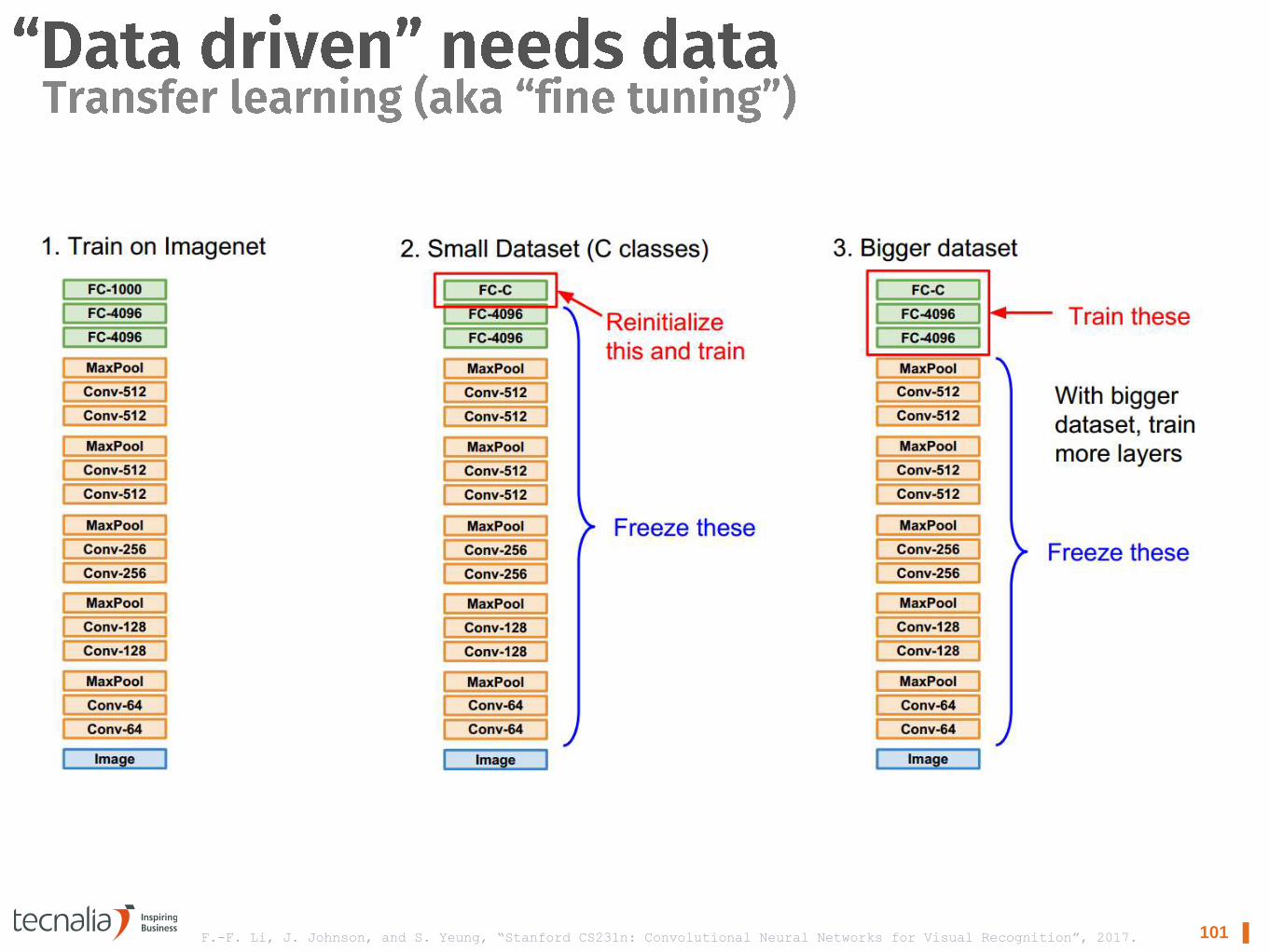
101 ▌ F.-F. Li, J. Johnson, and S. Yeung, “Stanford CS231n: Convolutional Neural Networks for Visual Recognition”, 2017.

102 ▌
D. Gandhi, L. Pinto, and A. Gupta, “Learning to Fly by Crashing,” arXiv:1704.05588 [cs], Apr. 2017.

103 ▌ A. Dosovitskiy et al., “FlowNet: Learning Optical Flow with Convolutional
Networks,” in IEEE International Conference on Computer Vision (ICCV), 2015.
D. Gandhi, L. Pinto, and A. Gupta, “Learning to Fly by Crashing,” arXiv:1704.05588 [cs], Apr. 2017.

104 ▌ Source: Nervana
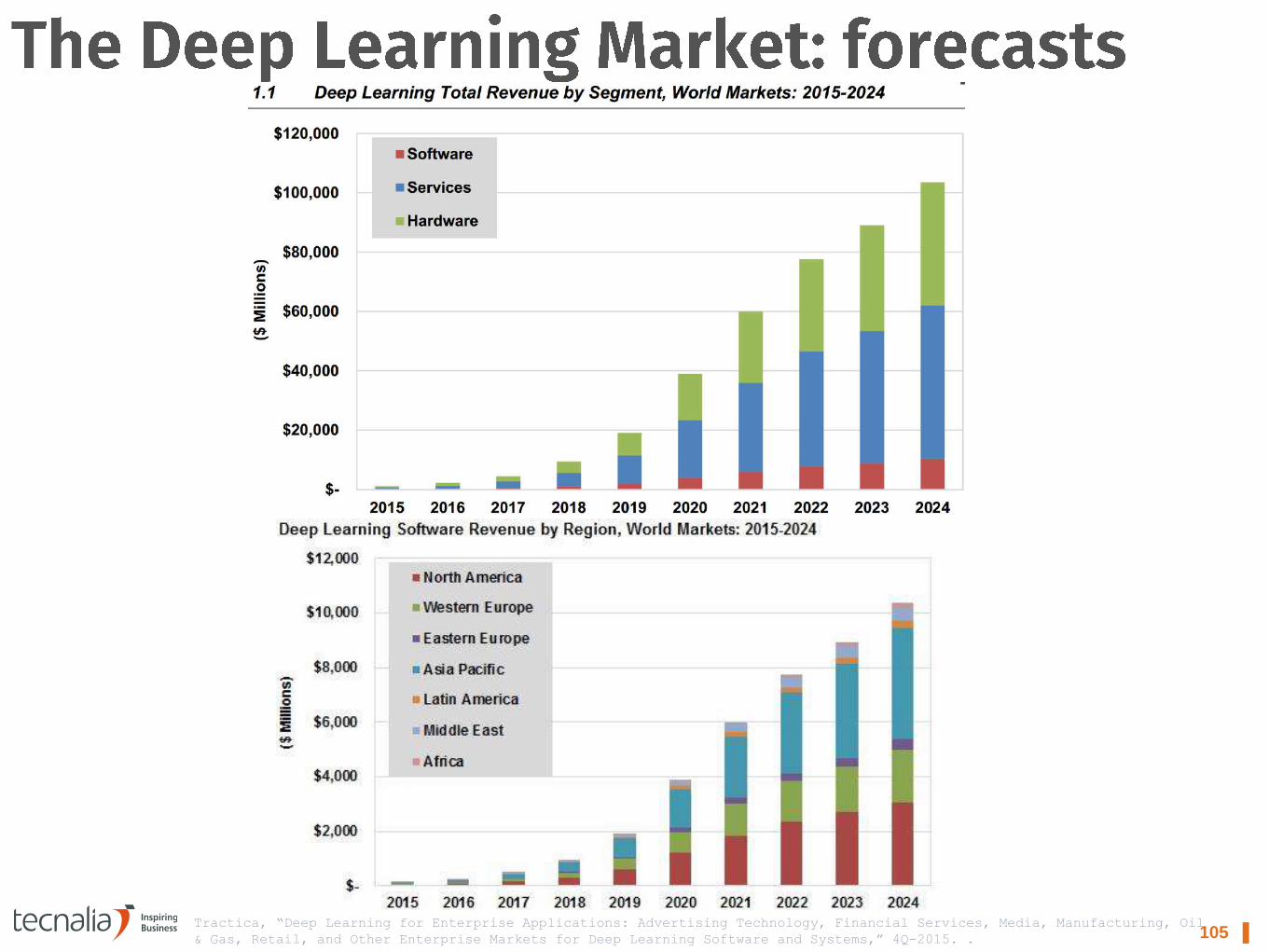
105 ▌ Tractica, “Deep Learning for Enterprise Applications: Advertising Technology, Financial Services, Media, Manufacturing, Oil
& Gas, Retail, and Other Enterprise Markets for Deep Learning Software and Systems,” 4Q-2015. .

106 ▌
C. Olah, “Understanding LSTM Networks -- colah’s blog,” 27-Aug-2015. [Online]. Available:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

107 ▌
C. Olah, “Understanding LSTM Networks -- colah’s blog,” 27-Aug-2015. [Online]. Available:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
A. Karpathy, “The Unreasonable Effectiveness of Recurrent Neural Networks,” 21-May-2015. [Online]. Available:
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
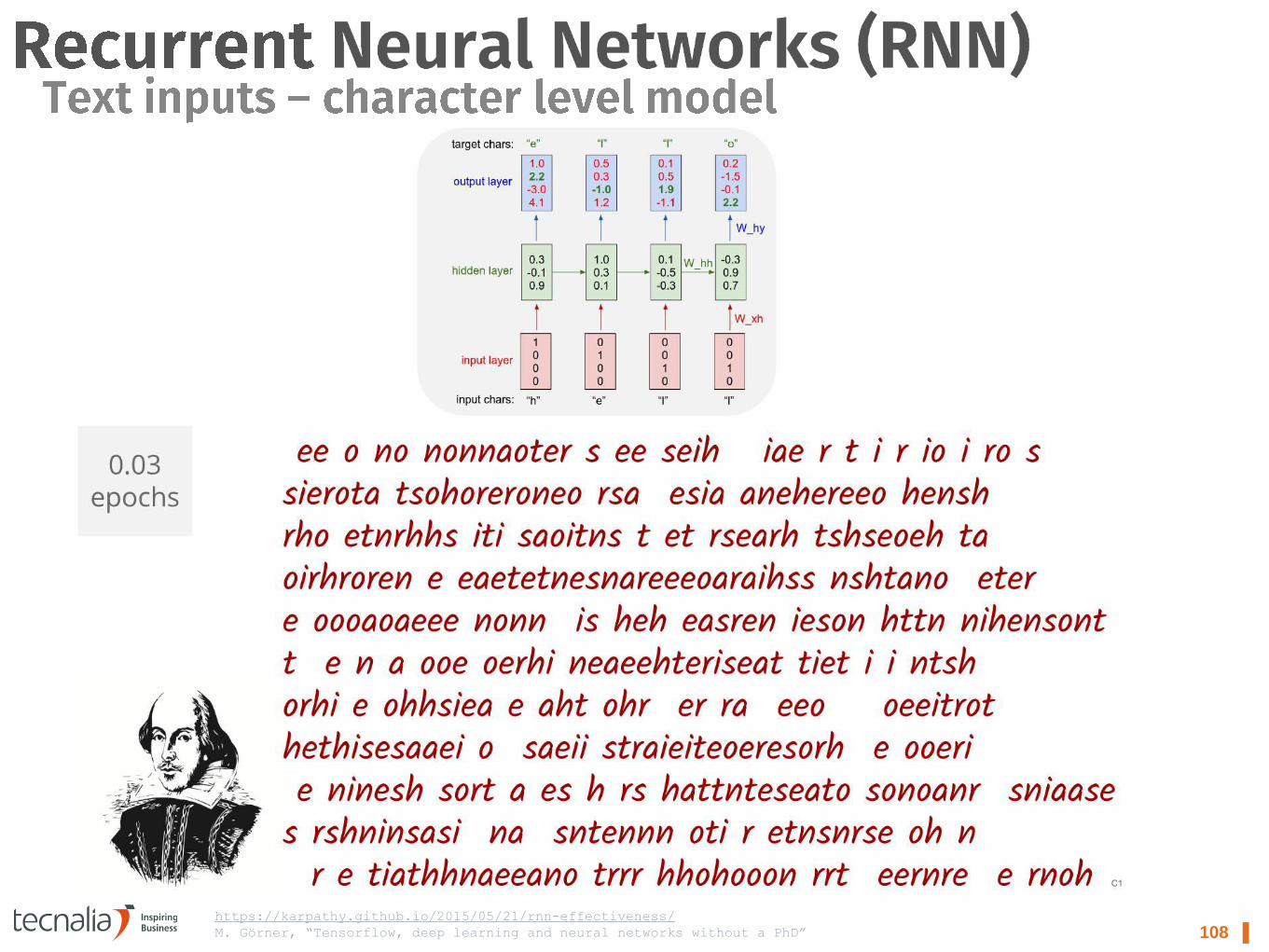
108 ▌ https://karpathy.github.io/2015/05/21/rnn-effectiveness/
M. Görner, “Tensorflow, deep learning and neural networks without a PhD”

109 ▌ https://karpathy.github.io/2015/05/21/rnn-effectiveness/
M. Görner, “Tensorflow, deep learning and neural networks without a PhD”

110 ▌ https://karpathy.github.io/2015/05/21/rnn-effectiveness/
M. Görner, “Tensorflow, deep learning and neural networks without a PhD”
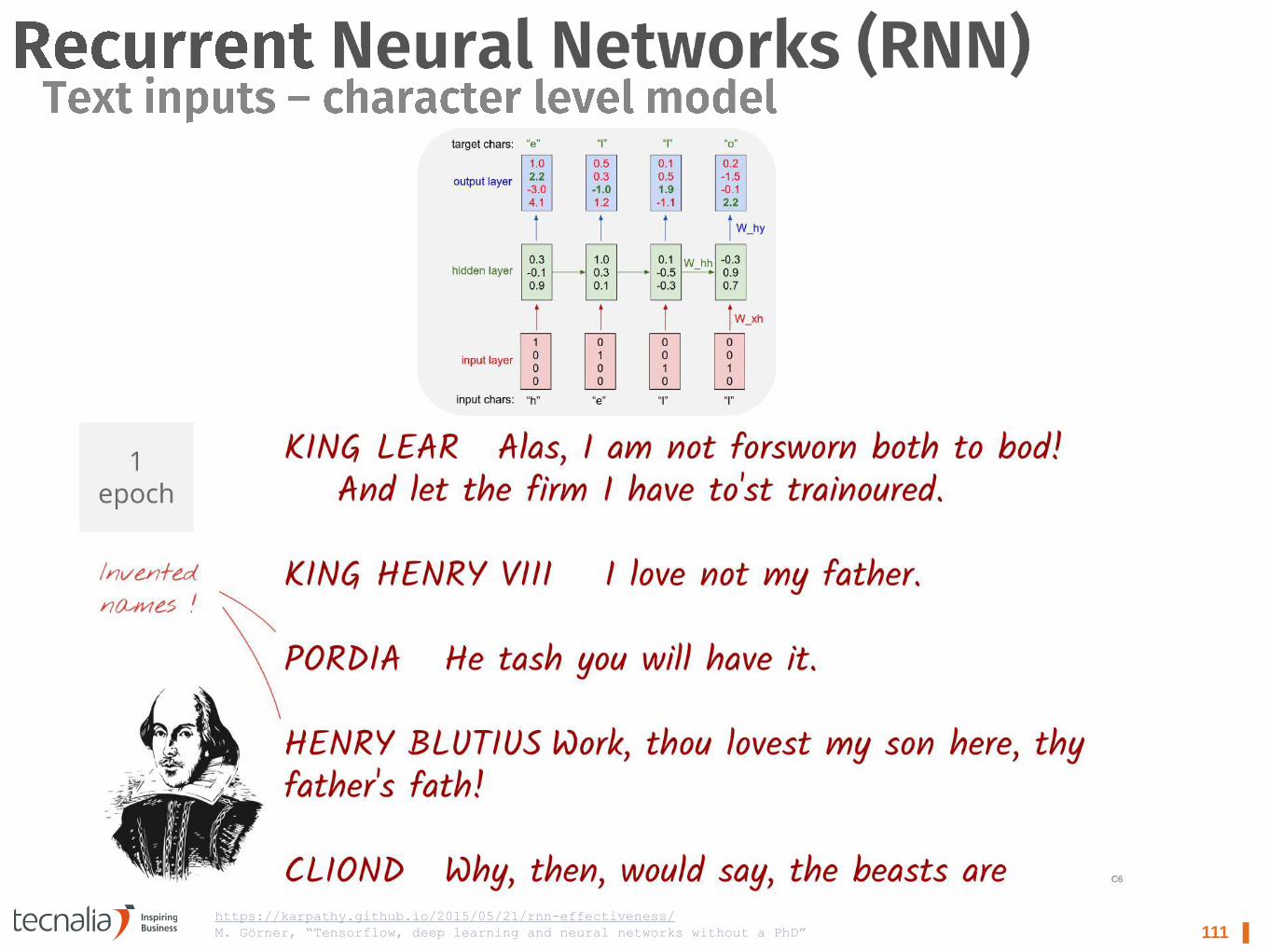
111 ▌ https://karpathy.github.io/2015/05/21/rnn-effectiveness/
M. Görner, “Tensorflow, deep learning and neural networks without a PhD”

112 ▌ https://karpathy.github.io/2015/05/21/rnn-effectiveness/
M. Görner, “Tensorflow, deep learning and neural networks without a PhD”
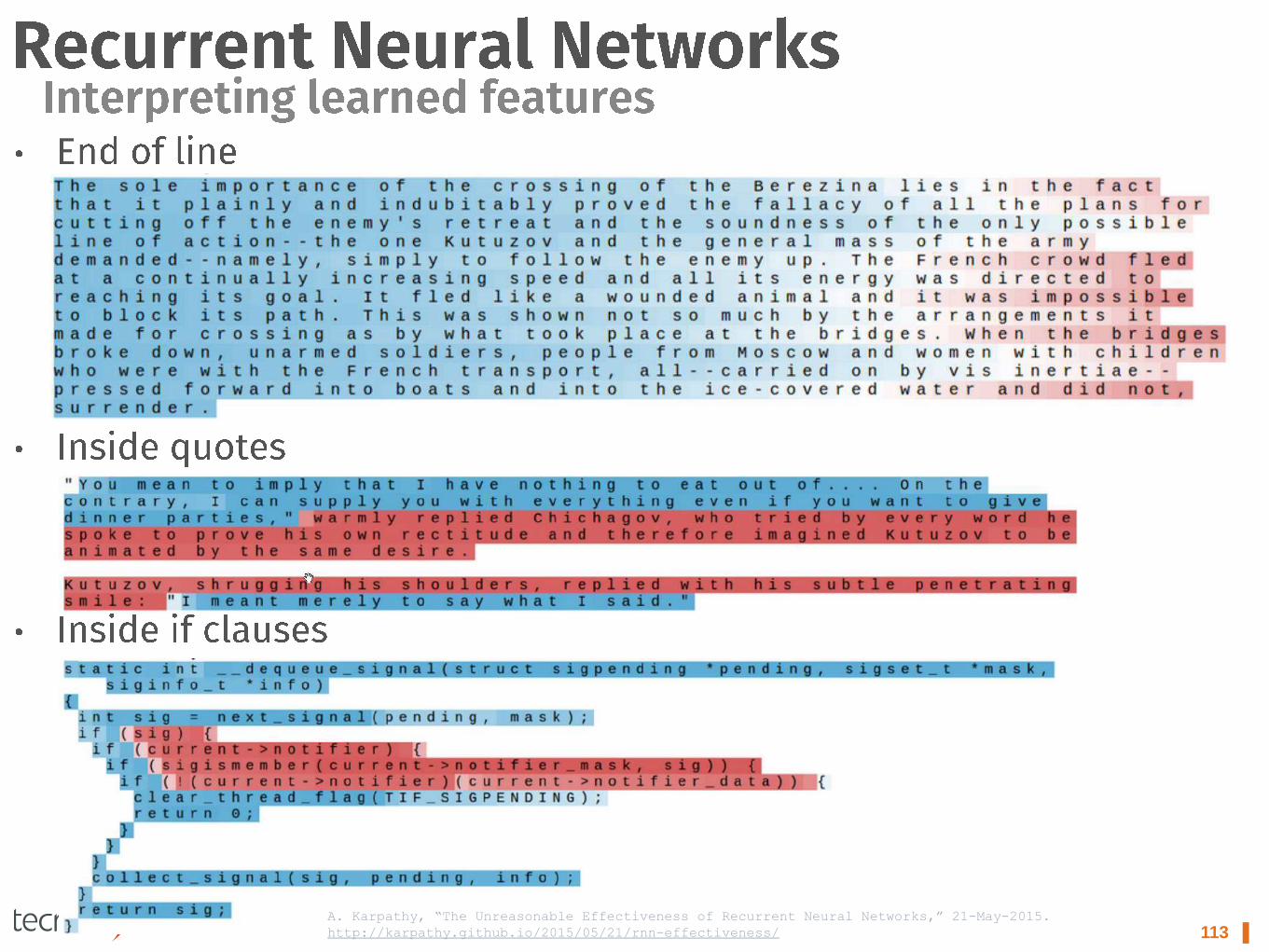
113 ▌ A. Karpathy, “The Unreasonable Effectiveness of Recurrent Neural Networks,” 21-May-2015.
http://karpathy.github.io/2015/05/21/rnn-effectiveness/

114 ▌
https://blog.openai.com/unsupervised-sentiment-neuron/

115 ▌
https://blog.openai.com/unsupervised-sentiment-neuron/
O. Vinyals et al., “Show and Tell: A Neural Image Caption
Generator,” CVPR 2015

116 ▌
https://blog.openai.com/unsupervised-sentiment-neuron/
O. Vinyals et al., “Show and Tell: A Neural Image Caption
Generator,” CVPR 2015 S. Antol et al., “VQA: Visual Question Answering,” ICCV 2015

117 ▌
https://blog.openai.com/unsupervised-sentiment-neuron/
O. Vinyals et al., “Show and Tell: A Neural Image Caption
Generator,” CVPR 2015 S. Antol et al., “VQA: Visual Question Answering,” ICCV 2015
J. Johnson et al., “DenseCap: Fully
Convolutional Localization Networks
for Dense Captioning,” CVPR 2016.

118 ▌ K. Xu et al., “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,” in Proceedings of the 32nd
International Conference on Machine Learning (ICML201515), 2015, pp. 2048–2057.

119 ▌ K. Xu et al., “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,” in Proceedings of the 32nd
International Conference on Machine Learning (ICML201515), 2015, pp. 2048–2057.

120 ▌

121 ▌
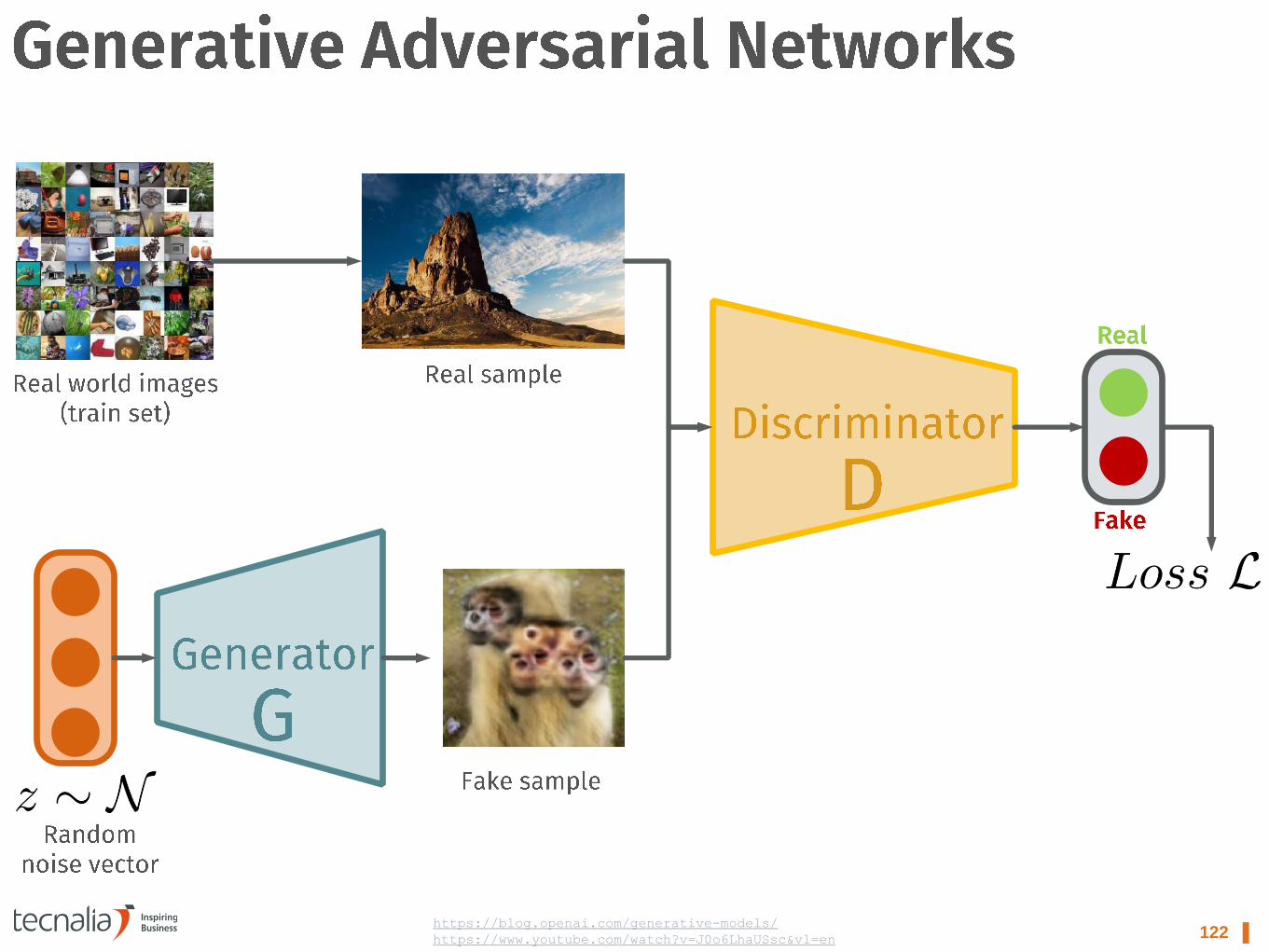
122 ▌ https://blog.openai.com/generative-models/
https://www.youtube.com/watch?v=J0o6LhaUSsc&vl=en
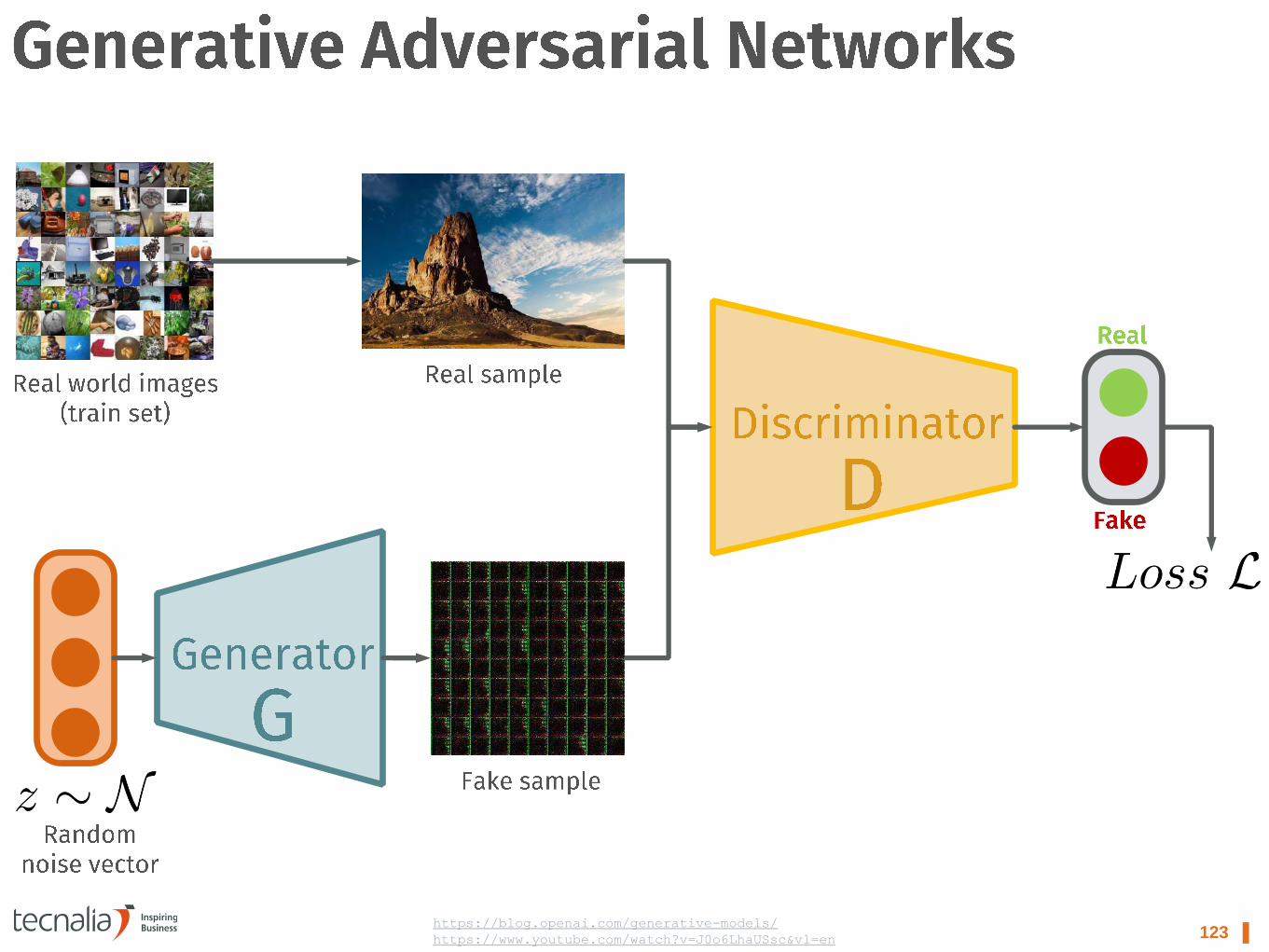
123 ▌ https://blog.openai.com/generative-models/
https://www.youtube.com/watch?v=J0o6LhaUSsc&vl=en

124 ▌ https://blog.openai.com/generative-models/
https://www.youtube.com/watch?v=J0o6LhaUSsc&vl=en

125 ▌ D. Berthelot, T. Schumm, and L. Metz, “BEGAN: Boundary Equilibrium Generative Adversarial Networks,” Mar. 2017.

126 ▌ https://affinelayer.com/pixsrv/
P. Isola et al. “Image-to-Image Translation
with Conditional Adversarial Networks,” arxiv,
2016.

127 ▌ https://twitter.com/ka92/status/835139879747014657

128 ▌ https://twitter.com/ka92/status/835139879747014657

129 ▌ H. Zhang et al., “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks,”
arXiv:1612.03242 [cs, stat], Dec. 2016.

130 ▌
M. H. S. Segler et al. “Generating Focussed Molecule Libraries for Drug Discovery
with Recurrent Neural Networks,” arXiv:1701.01329 [physics, stat], Jan. 2017.
“Project Dreamcatcher | Autodesk Research.” [Online]. Available:
https://autodeskresearch.com/projects/dreamcatcher
“No Man’s Sky”, by Hello games

131 ▌ Andrej Karpathy, “The state of Computer Vision and AI: we are really, really far away.” 22-Oct-2012. Available:
https://karpathy.github.io/2012/10/22/state-of-computer-vision

Visit our blog:
http://blogs.tecnalia.com/inspiring-blog/
www.tecnalia.com


















