
IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014 ...
13
Low-Latency Digit-Serial Systolic Double Basis Multiplier over Using Subquadratic Toeplitz Matrix-Vector Product Approach Jeng-Shyang Pan, Senior Member, IEEE, Reza Azarderakhsh, Mehran Mozaffari Kermani, Member, IEEE, Chiou-Yng Lee, Senior Member, IEEE, Wen-Yo Lee, Che Wun Chiou, Member, IEEE, and Jim-Min Lin Abstract—Recently in cryptography and security, the multipliers with subquadratic space complexity for trinomials and some specific pentanomials have been proposed. For such kind of multipliers, alternatively, we use double basis multiplication which combines the polynomial basis and the modified polynomial basis to develop a new efficient digit-serial systolic multiplier. The proposed multiplier depends on trinomials and almost equally space pentanomials (AESPs), and utilizes the subquadratic Toeplitz matrix-vector product scheme to derive a low-latency digit-serial systolic architecture. If the selected digit-size is bits, the proposed digit-serial multiplier for both polynomials, i.e., trinomials and AESPs, requires the latency of , while traditional ones take at least clock cycles. Analytical and application-specific integrated circuit (ASIC) synthesis results indicate that both the area and the time area complexities of our proposed architecture are significantly lower than the existing digit-serial systolic multipliers. Index Terms—Subquadratic Toeplitz matrix-vector product, digit-serial systolic multiplier, double basis, elliptic curve cryptography 1 INTRODUCTION T HE Elliptic curve cryptography (ECC) [1], [2] has been attracted by the cryptography researchers in recent years. With the emergence of the ECC in public-key crypto-systems, several hardware implementations of the ECC applications have been also presented [3], [4]. We note that the NIST and the ANSI have also recommended finite fields for use in the ECDSA [5], [6]. NIST recommends five binary finite fields, i.e., , and . In the ECC-based cryptographic protocols, finite field multiplication is essential to compute the point multiplication. The efficient hardware realizations of crypto-systems are often constrained in terms of area cost, power consumption, and performance. For high-speed very-large-scale integration (VLSI) imple- mentations, systolic array architecture is a preferable ap- proach. In the extended binary field , various efficient systolic array multipliers have been presented and can be classified into architectures such as bit-parallel and bit-serial [7]–[12]. Efficient bit-parallel systolic multipliers usually employ either the least-significant bit first (LSB-first) or most-significant bit first (MSB-first) algorithms. The major advantage of bit-parallel systolic multipliers is the high throughout of the computations. However, these architectures for polynomial basis of require XOR gates, AND gates, 1-bit latches, and latency complexity. To reduce the time and space complexities, Lee et al. [8], [9], [13] showed that finite field multiplication for some specific polynomials, such as all-one polynomials, pentanomials, and trinomials, can use Toeplitz matrix-vector product (TMVP) to develop fully bit-parallel systolic multi- pliers. Bit-serial systolic array multipliers require only space complexity, but they impose longer computation delays. For reaching the tradeoff between the time and the space complexities between the bit-parallel and the bit-serial multi- pliers, the digit-serial systolic multipliers [14]–[20] have been proposed in the literature. The digit-serial shifted polynomial basis multiplier with digit-in parallel-out structure is pro- posed in [20]. In this multiplier, a field element of -bit length is subdivided into -bit sub-words. In every clock cycle, the multiplication of a -bit sub-word and an -bit multipli- cand produces one -bit product. A scalable and systolic multiplier using a fixed bit-parallel Hankel matrix- vector multiplier has been proposed in [15] and [16] whose latency is clock cycles. Digit-serial systolic multipliers using digit-in digit-out architectures are presented in [14], [17], and [18]. The latency of these multipliers is • J.-S. Pan is with Innovative Information Industry Research Center (IIIRC), Shenzhen Graduate School, Harbin Institute of Technology, Harbin, China. E-mail: [email protected]. • R. Azarderakhsh is with the Department of Electrical and Microelectronic Engineering, Rochester Institute of Technology, Rochester, NY. E-mail: [email protected]. • M. Mozaffari Kermani is with the Department of Electrical and Micro- electronic Engineering, Rochester Institute of Technology, Rochester, NY. E-mail: [email protected]. • C.-Y. Lee and W.-Y. Lee are with the Department of Computer Information and Network Engineering, Lunghwa University of Science and Technology, Taoyuan 33306, Taiwan. E-mail: {pp010, TristanWYLee}@mail.lhu.edu.tw. • C.W. Chiou is with the Department of Computer Science and Information Engineering, Chien Hsin University of Science and Technology, Chung-Li 320, Taiwan. E-mail: [email protected]. • J.-M. Lin is with the Department of Information Engineering and Computer Science, Feng Chia University, Taichung 407, Taiwan. E-mail: [email protected]. Manuscript received 20 Mar. 2012; revised 11 Jul. 2012; accepted 09 Sep. 2012; published online 1 Oct. 2012; date of current version 29 Apr. 2014. Recommended for acceptance by P. Montuschi. For information on obtaining reprints of this article, please send e-mail to: [email protected], and reference the Digital Object Identifier below. Digital Object Identifier no. 10.1109/TC.2012.239 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014 1169 0018-9340 © 2012 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
Transcript of IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014 ...

Low-Latency Digit-Serial Systolic Double BasisMultiplier over � � Using SubquadraticToeplitz Matrix-Vector Product Approach
Jeng-Shyang Pan, Senior Member, IEEE, Reza Azarderakhsh, Mehran Mozaffari Kermani, Member, IEEE,Chiou-Yng Lee, Senior Member, IEEE, Wen-Yo Lee, Che Wun Chiou, Member, IEEE, and Jim-Min Lin
Abstract—Recently in cryptography and security, the multipliers with subquadratic space complexity for trinomials and some specificpentanomials have been proposed. For such kind of multipliers, alternatively, we use double basis multiplication which combines thepolynomial basis and the modified polynomial basis to develop a new efficient digit-serial systolic multiplier. The proposed multiplierdepends on trinomials and almost equally space pentanomials (AESPs), and utilizes the subquadratic Toeplitz matrix-vector productscheme to derive a low-latencydigit-serial systolic architecture. If the selecteddigit-size is bits, the proposeddigit-serialmultiplier for bothpolynomials, i.e., trinomials and AESPs, requires the latency of , while traditional ones take at least clock cycles. Analytical
and application-specific integrated circuit (ASIC) synthesis results indicate that both the area and the time area complexities of ourproposed architecture are significantly lower than the existing digit-serial systolic multipliers.
Index Terms—Subquadratic Toeplitz matrix-vector product, digit-serial systolic multiplier, double basis, elliptic curve cryptography
1 INTRODUCTION
THE Elliptic curve cryptography (ECC) [1], [2] has beenattracted by the cryptography researchers in recent years.
With the emergence of the ECC in public-key crypto-systems,several hardware implementations of the ECC applicationshave been also presented [3], [4]. We note that the NIST andthe ANSI have also recommended finite fields for use in theECDSA [5], [6]. NIST recommends five binary finite fields, i.e.,
, and . In theECC-based cryptographic protocols, finite field multiplicationis essential to compute the point multiplication. The efficienthardware realizations of crypto-systems are often constrainedin terms of area cost, power consumption, and performance.
For high-speed very-large-scale integration (VLSI) imple-mentations, systolic array architecture is a preferable ap-proach. In the extended binary field , various efficientsystolic array multipliers have been presented and can beclassified into architectures such as bit-parallel and bit-serial[7]–[12]. Efficient bit-parallel systolic multipliers usuallyemploy either the least-significant bit first (LSB-first) ormost-significant bit first (MSB-first) algorithms. The majoradvantage of bit-parallel systolic multipliers is the highthroughout of the computations. However, these architecturesfor polynomial basis of require XOR gates,
AND gates, 1-bit latches, and latencycomplexity. To reduce the time and space complexities, Leeet al. [8], [9], [13] showed that finite field multiplication forsome specific polynomials, such as all-one polynomials,pentanomials, and trinomials, can use Toeplitz matrix-vectorproduct (TMVP) to develop fully bit-parallel systolic multi-pliers. Bit-serial systolic array multipliers require onlyspace complexity, but they impose longer computation delays.
For reaching the tradeoff between the time and the spacecomplexities between the bit-parallel and the bit-serial multi-pliers, the digit-serial systolic multipliers [14]–[20] have beenproposed in the literature. The digit-serial shifted polynomialbasis multiplier with digit-in parallel-out structure is pro-posed in [20]. In thismultiplier, a field element of -bit lengthis subdivided into -bit sub-words. In every clock cycle,the multiplication of a -bit sub-word and an -bit multipli-cand produces one -bit product. A scalable and systolicmultiplier using a fixed bit-parallel Hankel matrix-vector multiplier has been proposed in [15] and [16] whoselatency is clock cycles. Digit-serial systolicmultipliers usingdigit-in digit-out architectures are presentedin [14], [17], and [18]. The latency of these multipliers is
• J.-S. Pan is with Innovative Information Industry Research Center (IIIRC),Shenzhen Graduate School, Harbin Institute of Technology, Harbin, China.E-mail: [email protected].
• R. Azarderakhsh is with the Department of Electrical and MicroelectronicEngineering, Rochester Institute of Technology, Rochester, NY.E-mail: [email protected].
• M. Mozaffari Kermani is with the Department of Electrical and Micro-electronic Engineering, Rochester Institute of Technology, Rochester, NY.E-mail: [email protected].
• C.-Y. Lee and W.-Y. Lee are with the Department of Computer Informationand Network Engineering, Lunghwa University of Science and Technology,Taoyuan 33306, Taiwan. E-mail: {pp010, TristanWYLee}@mail.lhu.edu.tw.
• C.W. Chiou is with the Department of Computer Science and InformationEngineering, Chien Hsin University of Science and Technology, Chung-Li320, Taiwan. E-mail: [email protected].
• J.-M. Lin is with the Department of Information Engineering and ComputerScience, Feng Chia University, Taichung 407, Taiwan.E-mail: [email protected].
Manuscript received 20Mar. 2012; revised 11 Jul. 2012; accepted 09 Sep. 2012;published online 1 Oct. 2012; date of current version 29 Apr. 2014.Recommended for acceptance by P. Montuschi.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference the Digital Object Identifier below.Digital Object Identifier no. 10.1109/TC.2012.239
IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014 1169
0018-9340 © 2012 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

clock cycles. As mentioned above, low-complexity design ofsystolic finite field multipliers depends on the selected irre-ducible polynomials and the chosen basis representation. Wenote that these digit-serialmultipliers require high latencies toperform the operations.
Themaincontributionsofthisworkareasfollows.Referringto themodifiedpolynomialbasis (MPB)of introducedin [20], we combine the polynomial basis and theMPB to formthe double basis multiplication. Some finite field multiplica-tions can be obtained in bit-parallel architecture with sub-quadratic TMVP [21], [22]. In , irreducible trinomialsand pentanomials are widely applied in cryptographic appli-cations inwhich the field sizemay be large. In [23], it is shownthat the irreducible pentanomials of the form
with ≊ ≊ , and ≊ abundantlyexist in for > . This pentanomial is called the almostequally space pentanomial (AESP). By using the properties ofreduction polynomial for two polynomials (trinomials andAESPs), we propose a new digit-serial systolic double basismultiplier with subquadratic TMVP formulae. In case aToeplitz product is selected, the proposed architecture can
achieve very low latency of clock cycles, while tradi-
tional digit-serial multipliers require at least clockcycles, e.g., and for [17] and [21], respectively.
The rest of this paper is organized as follows. Section 2presents the preliminaries regarding themodifiedpolynomialbasis, double basis multiplication, basis conversion, and sub-quadratic TMVP. In Section 3, we present our proposed newdigit-serial systolic subquadratic multiplier for double basesof . In Section 4, time and space complexities areanalyzed. In Section 5, the results of our application-specificintegrated circuit (ASIC) synthesis ona65-nmCMOSstandard-cell library are presented. Finally, we conclude the proposedwork in Section 6.
2 MATHEMATICAL BACKGROUND
In this section, we briefly review the double basis multiplica-tion over and the subquadratic TMVP algorithm.
2.1 Modified Polynomial BasisLet the irreducible polynomial
be used to construct the field . Theset is called the polynomial basis (PB)of . Assume that an element in is repre-sented by
Then, we present the following definition.
Definition 1. [24]. Let a field be constructed by the irreducibletrinomial formed by . The correspondingmodified polynomial basis (MPB) representation is then definedas follows:
where
For example, is an irreduciblepolynomial in , then we have
. According to the relation of(3), the following remark is obtained.
Remark 1. If is an irreducible trinomial,then the corresponding modified binomial polynomial(MBP) can be represented by .Assume that with
< is an irreducible pentanomial of degree . If thecorresponding MPB is presented by ,where for and for
, then the corresponding modified quadrinomial(MQ) can be represented by .
2.2 DoubleBasisMultiplicationover � � forMBPIn this subsection, two basis representations, PB andMPB, areused to perform adouble basismultiplication. For clarity, let afield be constructed by an irreducible MBP. A double basismultiplication is performed by mod ,where ispresented by PB; and are represented byMPB. Applyingthe double basis representation in Definition 1, productcan be obtained as follows:
With theproperty ofRemark 1,we can obtain the followingformula
>
Let an element be repre-sented by double basis representation. Assume that twooperations are defined as
According to (5)–(7), we obtain that the product can beobtained as
Let two elements and in be represented bypolynomial basis and double basis representations, respec-tively. The product with double basis representation can berewritten as
From (9), the matrix could be formed by a Toeplitzmatrix. For clarity,weuse the following example to illustrate adouble basis multiplication.
1170 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014

Example 1. Let a field be generated by. Assume that
and are two elements in. By using (9), the product can be computed as
follows.
Referring to the abovematrix , it is required to computethe following terms:
for constructing the matrix .
2.3 Basis Conversion from MPB to PBAssume that a field is constructed from
. Let an element in be represented bydouble basis representation, e.g.,
, where for andfor . Thus, we obtain
where
Therefore, the basis conversion from MPB to PB requiresthe following complexities:
Space complexity: XOR gates,Time complexity: one delay.
It is noted that our proposed double basis multiplicationarchitecture does not need the basis conversion from PB toMPB.
2.4 Subquadratic Toeplitz Matrix-Vector ProductIn linear algebra, a Toeplitz matrix is a matrix in which eachdescending diagonal from left to right is constant. Assume
that is an Toeplitz matrix. If the entry of isdenoted by , then we have . The TMVP iswidely applied to compute finite field multiplication, suchas dual basis (DB), shifted polynomial basis, and normal basismultiplications. A Toeplitz matrix has the followingproperties:
Proposition 1. An Toeplitz matrix is determined by theentries appearing in the first row and the first column.
We can use the vector to define a Toeplitzmatrix .
Proposition 2. If and are two Toeplitz matrices, thenrequires XOR gates.
To reduce the time and the space complexities, a subqua-dratic TMVPapproach is recently proposed for implementingbinary fieldmultiplications [22]. In the following paragraphs,we briefly introduce the subquadratic TMVP multiplierapproach.
Let be a given vector and ,where is aToeplitz matrix defined by the vector .
A Toeplitz product is described as
By using divide-and-conquer method, (11) can be ex-pressed by
According to the structure of Toeplitz product multiplica-tion in (12), it involves three products, which has betterperformance than the original product multiplication in(11) that uses four products. According to (12), we can usea three-step procedure, e.g., evaluation, point-wise multipli-cation, and final reconstruction (FR), to implement a subqua-dratic TMVP multiplier.
Evaluation point step: From three-term products, , and in (12), we can
define two evaluation points, i.e., component matrixpoint (CMP) and component vector point (CVP). Twoevaluation points are described by
Point-wise multiplication step: Given the result of anevaluationpoint operation, the correspondingpoint-wisemultiplication (PWM) is defined by
Final reconstruction step: Based on (12), FR can be ob-tained as
As mentioned above, we can use recursive three-stepoperations to implement a TMVP multiplier. Assume that
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1171

we use an Toeplitz matrix with . Afteriterations byusing evaluation point step, allmatrix and vectorcomponents collapse into the corresponding single coeffi-cients. Both matrix and vector components can be trans-formed into point coefficients, e.g.,
and . Next, thepoint-wise multiplication step is based on (15) to perform theoperation
. Finally, the FR step uses (16) to recover the originalproduct result. According to the three-step implementations,Fig. 1 shows a subquadratic TMVP multiplier. By using therecursive three-step operations, Fan andHasan [21], [22] haveshown that for the structure of Fig. 1 with , the time andthe space complexities of each component arederived as listedin Table 1.
3 NEW DIGIT-SERIAL SYSTOLIC SUBQUADRATICMULTIPLIER FOR DOUBLE BASES OF � �
In this section,wedevelop anovel digit-serialmultiplier usingthe subquadratic TMVP approach.
3.1 Notation of ComputationIn what follows, we discuss the computations for trino-mials andpentanomials. First, let thefieldbe constructed fromthe trinomial with . From (6), thecomputation of is as follows:
where
From (17), we can obtain the following time and spacecomplexities.
Proposition 3. Assume that a field is constructed from irreducibletrinomials of degree . If an element is represented by MPB,then the computation requires XOR gates and onedelay.Next, let a field be constructed from pentanomials
with ≊ ≊ , and ≊ .Such type of pentanomial exists in for > [23].As mentioned before, this polynomial is denoted by AESP.Table 2 lists the AESPs with some specific values of .Therefore, for computing , we have:
where
Proposition 4. Assume that a field is constructed from an AESPof degree . If an element is represented by MPB, thencomputing requires XOR gates and one delay.
3.2 Partial Product to Form TMVPAssume that a field is constructed from an irreducible trino-mial of the form with .Let an element overbe represented by double basis representation, and let anelement be represented by polynomial basis representation,such that , whereand . Given the double
Fig. 1. Functional block of the subquadratic TMVPmultiplier architecture.
TABLE 1Complexities of Each Component of TMVP Multiplier for
(Based on [21] and [22])
TABLE 2List of the Irreducible AESPs of Degree for 160 < < 201
1172 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014

basis operation presented in the previous section, the partialproduct can be rewritten as
Let the selected digit-size be satisfied by < . Then,we obtain
We note that, generally, for can berepresented as
Observing the result of (20), with -bit lengthmeans that -bit digit
is inserted into the least significant bit of .Therefore, for computing a partial product , an element
should be translated into the element with -bits:
where
From , let the modifiedpolynomial be represented by
Algorithm 1 Computing the partial product
Inputs: and .
Output: .
Step 1. An element is converted to Toeplitz matrixcomponent based on (25) and (26).
Step 2. Compute component matrix and vector points using(13) and (14).
2.1. .
2.2. .
Step 3. Compute point-wise multiplication (PWM).
3.1. ,
.
Step 4. Final reconstruction.
4.1.
.
Step 5. Modular reduction.
5.1. .
Thus, the partial product is performed by the follow-ing steps:
Step 1. .Step 2. .Step 3. .Step 4. .As stated above, Step 1 is a grade-school multiplication,
Step 2 is performed by a simple modular operation, Step 3performs shift-by- -bit operation, and Step 4 calculates themodular reduction through polynomial . To dem-onstrate the above four-step operations, we use the field
to illustrate the partial multiplication through thefollowing example.
Example 2. Let a field be constructed from. The corresponding modified polynomial is
represented by and is presentedby polynomial basis, wherefor and 1. Another element
is presentedbydouble bases,wherefor and for . Assume thatthe selected digit-size is , then, based on (20), the elementis transferred to
, where for and for. In the following, we utilize the proposed four-
step operation to illustrate the partial product . In Step 1,we obtain the polynomial multiplication
, where , ,for , , and
. In Step 2, . Step 3obtains and finally, we obtain
Assume that , wherefor , and .
Moreover, we define two sub-words multiplication:
where both degrees of and are less than . Applying thefour-step operation, we have
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1173

where
Finally, the partial product can be obtained
With the matrix-vector representation,can be translated into the following
matrix-vector product.
From the above matrix-vector product, matrix isformed by a Toeplitz matrix, which is defined in the termsof the vector . Hence, thepartial product in (24) can be denoted as
Therefore, a partial product can be divided intoToeplitz matrix-vector multiplications and one modular re-duction polynomial . Consequently, we can use the sub-quadratic TMVP approach to realize a partial product .According to the structure of subquadratic TMVP in (26), onecan obtain Algorithm 1.
3.3 Proposed Digit-Serial Systolic MultiplierLet and be three elements in generated by theirreducible trinomial with . Theelement is presented by polynomial basis representation,and two elements and are presented by double basisrepresentation, where . Assume that
satisfies < , where is the selected digit-size. If is not amultiple of , then afield elementmust pad
-bit zeros to replace the most significant bit, like. Accordingly, an element
can be represented by , where
. The double basis multi-plication can be rewritten as
where
Algorithm 2 Digit-serial double basis multiplication
Inputs: and are represented by PB andMPB, respectively.
Output: , where is represented by MPB.
1. Initial step
.
.
2. Multiplication step
2.1. for to
2.2.
2.3.
2.4. for to
2.5. performs Step 1 ofAlgorithm 1
2.6. performs Step 2.1 of Algorithm 1
2.7. performs Step 2.2 of Algorithm 1
2.8. performs Step 3.1 ofAlgorithm 1
2.9.
2.10. endfor
2.11. endfor
3. Final reconstruction step:
3.1 performs Step 4 of Algorithm 1
4. Reduction modified polynomial step
4.1. performs Step 5 of Algorithm 1
1174 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014

We utilize the proposed partial product scheme for com-puting a partial product in (28) and is pre-computedby using the recursive computation
. Applying the structure of (8), is straight-forwardly performed by . After
for are computed, we can use (21) to
translate into a polynomial formation, and each term
utilizes (25) and (26) to construct -term Toe-plitz matrices, e.g., .
Therefore, the partial product in (28) can be rewritten as
where
Applying the developed partial product scheme in Algo-rithm 1, assume that is the point-wise multiplication of
and :
The partial product can be represented by
Since each term reconstruction in (33) is the same as the FRcircuit, the partial product can be recombined by
For clarification, Fig. 2(a) is the original structure of thecomputation of in (33), and Fig. 2(b) is the modifiedstructure of the computation of in (34). We use the cut-set retiming procedure so that Fig. 2(b) can be partitioned into
processing elements (PE) and one final reconstruction-reduction-polynomial (FRRP) module. Therefore, accord-ing to (27) and Algorithm 1, the proposed double basismultiplication is shown as Algorithm 2.
According to Algorithm 2, Fig. 3 shows the entire doublebasis multiplication architecture, which includes PEs (eachof which is shown in Fig. 4), R3 modules, and FRRPmodules. Each FRRP circuit is composed of one FR module
Fig. 2. (a) The original circuit for computing , (b) The recombined circuit for computing .
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1175

and one R2 module. R2 performs the compu-tation and R3 realizes . Each PE is composed ofone R1 module, one CMP module, one CVP module, onePWM module, XOR gates, and -bitlatches. Moreover, the R1 module performs .We note that in Fig. 3, the row of the systolic array doublebasis multiplication architecture computes .
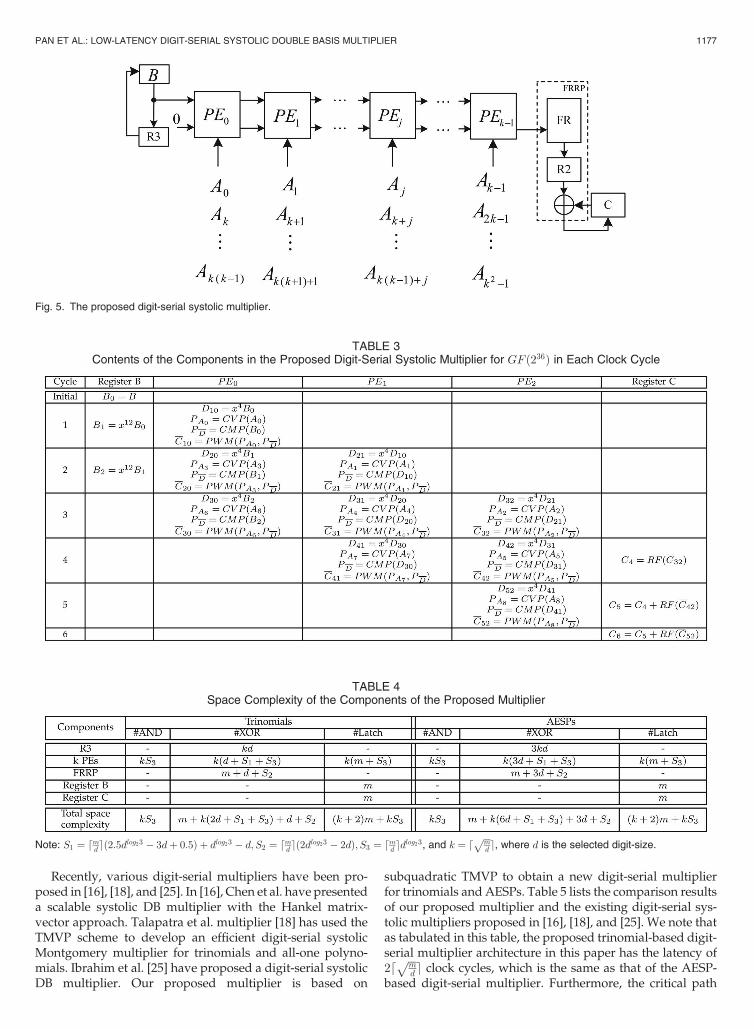
According to (28), we select the cells in the first row of Fig. 3to construct a new digit-serial systolic multiplier, as shown inFig. 5. In the initial step, the register is setwith the element ,and the register is set with zero. For clarity, we use the fieldGF(2 ) to present the proposed digit-serial multiplication.
Assume that the selected digit-size is , then, an elementcanbe representedas . Basedon
the structure of Fig. 5, Table 3 shows each PE operation in eachclock cycle. For this case, the proposed digit-serial systolicmultiplier requires 6 clock cycles.
4 TIME AND SPACE COMPLEXITIES
The proposed digit-serial systolic multiplier presented inFig. 5 is composed of PEs, two registers, one R3 module,and one FRRP module. Each PE is based on the TMVPstructure to construct the CMP and the CVP modules. EachCMP module is performed according to Step 2.7 of Algo-rithm2 to translate -termmatrix components, and theCVPmodule constructs one vector component. Applying CMPand CVP in the PE architecture, the PWM module requires
-bit point-wise multiplications. In the FRRP module,FR is based on the structure of PE to build -term recon-struction components. Therefore, based on the space com-plexity presented in Table 1, each CMP module requires
XOR gates, each CVP module needsXOR gates, each FRmodule requires
XOR gates, and the PWM module requires ANDgates. Table 4 shows the space complexity of our proposedarchitecture for trinomials andAESPs. As depicted in Table 4,it is shown that the hardware complexity of the AESP-baseddigit-serial multiplier is slightly increased (byXOR gates) as compared to the trinomial-based digit-serialmultiplier.
Fig. 3. The systolic array double basis multiplication architecture.
Fig. 4. The detailed circuit for the processing element (PE).
1176 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014
Recently, various digit-serial multipliers have been pro-posed in [16], [18], and [25]. In [16], Chen et al. have presenteda scalable systolic DB multiplier with the Hankel matrix-vector approach. Talapatra et al. multiplier [18] has used theTMVP scheme to develop an efficient digit-serial systolicMontgomery multiplier for trinomials and all-one polyno-mials. Ibrahim et al. [25] have proposed a digit-serial systolicDB multiplier. Our proposed multiplier is based on
subquadratic TMVP to obtain a new digit-serial multiplierfor trinomials and AESPs. Table 5 lists the comparison resultsof our proposed multiplier and the existing digit-serial sys-tolic multipliers proposed in [16], [18], and [25]. We note thatas tabulated in this table, the proposed trinomial-based digit-serial multiplier architecture in this paper has the latency of
clock cycles, which is the same as that of the AESP-based digit-serial multiplier. Furthermore, the critical path
Fig. 5. The proposed digit-serial systolic multiplier.
TABLE 3Contents of the Components in the Proposed Digit-Serial Systolic Multiplier for in Each Clock Cycle
TABLE 4Space Complexity of the Components of the Proposed Multiplier
Note: , and , where is the selected digit-size.
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1177

delay of is derived for both of these two archi-tectures, as shown in Table 5 for the trinomial-based digit-serial multiplier architecture.
Table 6 presents a comparison for the latencies of the digit-serial multipliers over GF( ). Form Table 6, it is shown thatthe latencies of our proposed architecture over forthedigit-size 2, 4, 8, 16, 32, and64are 30, 22, 16, 12, 8, and6clock cycles, respectively. Therefore, as seen in this table, thelatency of our proposed architecture is lower than othermultipliers under the same digit-size. Scalable multiplier[16] has the highest latency, comparably, as seen in Table 6.Under the same latency, e.g., 30 clock cycles, our proposedarchitecture utilizes small digit-sizes ( ) as compared tothe otherdigit-serialmultipliers inTable 6, e.g., Talapatra et al.[18] uses .
In the next section, we present and compare the results ofour ASIC synthesis to benchmark the time and hardwarecomplexities of the architectures on this hardware platform.
5 ASIC SYNTHESIS AND COMPARISONS
In this section,we present the results of ourASIC synthesis forboth the proposed multiplication scheme and the previously-presented multipliers. The synthesis through ASIC platformis a step-forward towardsmore accurate derivation of perfor-mance and area metrics.
5.1 ASIC SynthesisIn the previous section, we have compared our proposedarchitecture with various existing digit-serial multipliers.Based on Table 6, our multipliers can obtain low-latencyimplementations compared to the threemultipliers presentedin [16], [18], and [25]. For reaching results closer to realimplementations and to compare the performance and com-plexity metrics with two multipliers presented in Ibrahimet al. [25] and Talapatra et al. [18], this section utilizes a TSMC65-nm standard-cell library and the Synopsys Design
Compiler for obtaining the ASIC synthesis results. We notethat the multiplier in [18] is based on an irreducible trinomialto implement an efficient digit-serial systolicmultiplier. In theNIST standard, it is recommended that the irreducible trino-mial of the form is used to construct thefield GF( ). Therefore, we have considered the field GF( ) for trinomials to synthesize the multipliers in [18] and[25] and our multiplier architecture of Fig. 5. Then, the resultsof synthesis for the aforementioned multipliers have beenderived and tabulated in Tables 7 and 8.
Our multiplier is based on the subquadratic TMVP struc-ture and we have considered five different latencies, i.e., 4,6, 8, 10, and 12, for synthesizing and bothmultipliers [18], [25]are also synthesized for the same latencies. Moreover, thecorresponding digit-sizes of the two multipliers presented in[18] and [25], i.e., 205,137,103,82, and 69, respectively, arepresented in Table 7. For our proposed multiplier, theselatencies correspond to the digit-sizes 103, 46, 26, 17, and 12,respectively, which are listed in Table 8. We note that al-though a range of digit-sizes yields for themultiplierswith thedepicted latencies in tables,we choose the lowest digit-size forall the cases to have a consistent comparison among the casesbenchmarked. The derived results of synthesis include thearea in terms of , the critical path delay (CPD) latency(denoted hereafter as total-time) in terms of , andthe total-time area in terms of , as seen inTables 7 and 8. Given the two tables, it is shown that the digit-sizes for our presented multiplier for each latency are smallerthan those for [18] and [25]. For example, under the latency of10 clock cycles, our proposed multiplier has the digit-size of17, while both other multipliers require the digit-size of 82.
As seen in Table 7, the performance metrics of the multi-pliers in[18]and[25]aredepicted.Forbothofthesemultipliers,theareaandthetotal-timegolowerandhigher, respectively,asthe latency increases. As seen in this table, the performancemetrics of the multiplier in [18] (both area and total-time) arebetter thanthoseof themultiplier in[25].Wenotethat theworst
TABLE 5Comparisons of Various Digit-Serial Systolic Multipliers over GF( )
Note: , and , where is the selected digit-size.
TABLE 6Comparison of Latencies for Digit-Serial Multipliers over GF( )
1178 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014

total-time area of the multiplier in [18] is achieved for thedigit-size and latency of 103 and 8, respectively, i.e., 5, 139, 761
. However, for [25], this metric increases upto the lowest latency, as seen in Table 7.
As seen in Table 8, the area of the proposed multipliergets lower as the latency gets higher, i.e., fromfor the latency of 4 anddigit-size of 103 to for thelatency of 12 and digit-size of 12. Furthermore, the totaltime gets higher from to ,as seen in this table. Finally, the total-time area starts from
for the latency of 4 and digit-sizeof 103 and reaches its maximum of
for the latency of 8 and digit-size of 26 and getslower as the latency and the digit-size reach 12 to the total-time area of .
5.2 ComparisonsIn Tables 7 and 8, we have presented the synthesis results forour and two previously-presented digit-serial multipliers. Inwhat follows and through Table 9, we compare the total-time
area of these multipliers. This performance metric is usedcommonly to benchmark the efficiency of a multiplicationschemes as it, inherently, assesses the suitability of the schemefor combined low-area and high-speed applications. Beforeproceeding to Table 9, we note that compared to [18], theminimum area saving of ourmultiplier can be derived as 33%from Tables 7 and 8. Moreover, we can save at least 55% areacompared to the work presented in [25].
To compare the total-time area complexities, Table 9shows that our proposed multiplier can save at least 43.6% ascompared to twomultipliers [18], [25], although this saving ismuchmore for the case of the work presented in [25]. Finally,we note that the total-time area savings grow as thelatencies get lower, with the maximum saving achieved forthe lowest latency, as seen in Table 9.
As mentioned above, it is shown that our proposed digit-serial systolic multiplier using subquadratic TMVP scheme
has better performance compared to those of the twodigit-serial multipliers. We note that the multiplier pre-sented in [18] is based on the TMVP structure to developan efficient digit-serial systolic architecture; however, itsarchitecture is only suitable for special classes of polyno-mials over GF( ).
6 CONCLUSION
In this work, we have developed a novel digit-serial systolicarchitecture for double basis multiplication over .Through utilizing the subquadratic TMVP scheme, we haveproposed the presented digit-serial systolic multiplier over
for irreducible trinomials and AESPs. In this regard,our analytical results in this paper have shown that the areacomplexity of the AESP-based multiplier is slightly increasedby XOR gates as compared to the trinomial-based multiplier, where is the selected digit-size. We notethat the proposed architectures for trinomials and AESPsrequire clock cycles and are particularly suitable forimplementing the ECC cryptography and in the resource-constrained environments. We have performed ASIC synthe-sis to benchmark the performance of our proposed multiplierand it is shown that it outperforms its counterparts in terms ofarea and total-time area performance metrics. Moreover,our proposed architecture leverages the features of regularity,modularity, and concurrency, and is suitable for efficient andhigh-performance applications.
ACKNOWLEDGMENT
C.-Y. Lee is the corresponding author. The authorswould liketo thank the anonymous reviewers and the editor for carefullyreading the paper and for their great help in improving thepaper. They would also like to thank the National ScienceCouncil of the Republic of China for financially supportingthis research under Contract NSC 100-2221-E-262-014-MY3.
TABLE 7ASIC Synthesis Results for the Previously-Presented Multiplier Architectures over GF( ) for Different Digit-Sizes
Note: Total-time = CPD latency.
TABLE 8ASIC Synthesis Results for the Proposed Multiplier Architecture
(Trinomials) over GF( ) for Different Digit-Sizes
TABLE 9Comparison of the Total-Time Area between the Proposed
Multiplier and the Two Multipliers [25], [18]
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1179

REFERENCES
[1] N. Koblitz, “Elliptic curve cryptosystems,” Math. Comput., vol. 48,pp. 203–209, 1987.
[2] V. S. Miller, “Use of elliptic curves in cryptography,” in Proc. Adv.Cryptology (CRYPTO’85), 1986, pp. 417–426.
[3] W. Chelton and M. Benaissa, “Fast elliptic curve cryptography onFPGA,” IEEETrans. Very Large Scale Integr. (VLSI) Syst., vol. 16, no. 2,pp. 198–205, Feb. 2008.
[4] J. Lopez and R. Dahab, “Improved algorithms for elliptic curvearithmetic in ,” in Proc. 5th Annu. Int. Workshop Select. AreaCryptography (SAC), Kingston, ON, Canada, Aug. 17–18, 1998(Lecture Notes Comput. Sci., vol. 1556).
[5] IEEE Standard Specifications for Public-Key Cryptography, IEEE Stan-dard , Feb. 1998.
[6] Public Key Cryptography for the Financial Services Industry: The EllipticCurve Digital Signature Algorithm (ECDSA), ANSI Standard X9.62,1998.
[7] C.-S. Yeh, I. S. Reed, and T. K. Truong, “Systolicmultipliers for finitefields ,” IEEE Trans. Comput., vol. C-33, no. 4, pp. 357–360,Apr. 1984.
[8] C.-Y. Lee, E.-H. Lu, and J.-Y. Lee, “Bit-parallel systolicmultipliers forfields defined by all-one and equally spaced polynomials,”
IEEE Trans. Comput., vol. 50, no. 6, pp. 385–393, May 2001.[9] C.-Y. Lee, J.-S. Horng, I.-C. Jou, and E.-H. Lu, “Low-complexity bit-
parallel systolic montgomery multipliers for special classes of,” IEEETrans.Comput., vol. 54, no. 9,pp. 1061–1070,Sep. 2005.
[10] S. T. J. Fenn, D. Taylor, and M. Benaissa, “A dual basis bit-serialsystolic multiplier for ,” Integr. VLSI J., vol. 18, pp. 139–149,1995.
[11] B. B. Zhou, “Anew bit-serial systolic multiplier over ,” IEEETrans. Comput., vol. 37, pp. 749–751, 1988.
[12] P. K. Meher, “On efficient implementation of accumulation in finitefield over and its applications,” IEEE Trans. Very Large ScaleIntegr. (VLSI) Syst., vol. 17, no. 4, pp. 541–550, Apr. 2009.
[13] C. Y. Lee, “Low-complexity parallel systolic montgomery multi-pliers over using Toeplitz matrix-vector representation,”IEICE Trans. Fundam., vol. E91-A, no. 6, pp. 1470–1477, Jun. 2008.
[14] C. H. Kim, C. P. Hong, and S. Kwon, “A digit-serial multiplier forfinite field ,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst.,vol. 13, no. 4, pp. 476–483, Apr. 2005.
[15] C. Y. Lee and C. W. Chiou, “Scalable Gaussian normal basis multi-pliers over using Hankel matrix-vector representation,”J. Signal Process. Syst., vol. 69, no. 2, pp. 197–211, 2012.
[16] L. H. Chen, P. L. Chang, C. Y. Lee, and Y. K. Yang, “Scalable andsystolic dual basismultiplier over ,” Int. J. Innov. Comput. Inf.Control, vol. 7, no. 3, pp. 1193–1208, Mar. 2011.
[17] S. Talapatra, H. Rahaman, and J. Mathew, “Low complexity digitserial systolic montgomery multipliers for special class of ,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 18, no. 5,pp. 487–852, 2010.
[18] S. Talapatra, H. Rahaman, and S. K. Saha, “Unified digit serialsystolic montgomery multiplication architecture for special classesof polynomials over ,” in Proc. Euromicro Conf. Digital Syst.Des. Architectures Methods Tools, 2010, pp. 427–432.
[19] R. Azarderakhsh and A. Reyhani-Masoleh, “A modified low com-plexity digit-level Gaussian normal basis multiplier,” in Proc. Int.Workshop Arithmetic Finite Fields (WAIFI), 2010, pp. 275–240.
[20] A. Hariri and A. Reyhani-Masoleh, “Digit-serial structures for theshifted polynomial basis multiplication over binary extensionfields,” in Proc. Int. Workshop Arithmetic Finite Fields (WAIFI’08),2008, pp. 103–116.
[21] H. Fan and M. A. Hasan, “A new approach to sub-quadratic spacecomplexity parallel multipliers for extended binary fields,” IEEETrans. Comput., vol. 56, no. 2, pp. 224–233, Feb. 2007.
[22] H. Fan and M. A. Hasan, “Subquadratic computational complexityschemes for extended binary field multiplication using optimalnormal bases,” IEEE Trans. Comput., vol. 56, no. 10, pp. 1435–1437,Oct. 2007.
[23] J. Rajski and J. Tyszer, “Primitive polynomials over of degreeup to 660 with uniformly distributed coefficients,” J. Electron. Test.Theory Appl., vol. 19, pp. 645–657, 2003.
[24] C. Negre, “Quadrinomial modular multiplication using modifiedpolynomial basis,” in Proc. Int. Conf. Inf. Technol. Coding Comput.(ITCC’05), Las Vegas, NV, USA, Apr. 2005.
[25] M. K. Ibrahim and A. Aggoun, “Dual basis digit-serialmultiplier,” Int. J. Electron., vol. 89, no. 7, pp. 517–523, 2002.
Jeng-Shyang Pan received the BS degree inelectronic engineering from the National TaiwanUniversity of Science and Technology, Taipei, theMS degree in communication engineering fromthe National Chiao Tung University, Hsinchu,Taiwan, and the PhD degree in electrical engi-neering from the University of Edinburgh, U.K. in1986, 1988, and 1996, respectively. Currently, heis the doctoral advisor in Harbin Institute of Tech-nology,China, andProfessorwith theDepartmentof Electronic Engineering, National Kaohsiung
University of Applied Sciences, Taiwan. He has published more than400 papers in which 110 papers are indexed by SCI. He is the IET Fellow,UK and the Tainan Chapter Chair of IEEE Signal Processing Society. Hewas Awarded Gold Prize in the International Micro Mechanisms Contestheld in Tokyo, Japan, in 2010. He was also awarded Gold Medal in thePittsburgh Invention & New Product Exposition (INPEX) in 2010, GoldMedal in the International Exhibition of Geneva Inventions in 2011,and Gold Medal of the IENA, International “Ideas—Inventions—Newproducts,” Nuremberg, Germany. He was offered Thousand-Elite-Projectin China. He is on the editorial board of International Journal of InnovativeComputing, Information and Control, LNCS Transactions on Data Hidingand Multimedia Security, and Journal of Information Hiding and Multime-dia Signal Processing. His current research interests include soft comput-ing, robot vision, and cloud computing.
Reza Azarderakhsh received the BSc degree inelectrical and electronic engineering and the MScdegree in computer engineering from the SharifUniversity of Technology, Tehran, Iran, in 2002and 2005, respectively, and the PhD degree inelectrical and computer engineering from the Uni-versity of Western Ontario, London, Canada, in2011. He joined the Department of Electrical andComputer Engineering, University of WesternOntario, Canada, as a Limited Duties Instructor, inSeptember 2011. He has been an NSERC post-
doctoral research fellowwith theCenter forAppliedCryptographicResearchand the Department of Combinatorics and Optimization, University ofWaterloo, Waterloo, ON, Canada. Currently, he is with the Department ofComputer Engineering, Rochester Institute of Technology, Rochester,NY. His current research interests include finite field and its application,elliptic curve cryptography, and pairing based cryptography. He was arecipient of the prestigious Natural Sciences and Engineering ResearchCouncil of Canada (NSERC) Post-Doctoral Research Fellowship in 2011.
Mehran Mozaffari Kermani (M’11) received theBSc degree in electrical and computer engineer-ing from the University of Tehran, Tehran, Iran, in2005, and the MESc and PhD degrees from theDepartment of Electrical and Computer Engineer-ing, University of Western Ontario, London,Canada, in 2007 and 2011, respectively. Hejoined the Advanced Micro Devices as a seniorASIC/layout designer, integrating sophisticatedsecurity/cryptographic capabilities into a singleaccelerated processing unit. In 2012, he joined
the Electrical EngineeringDepartment, PrincetonUniversity, New Jersey,as an NSERC post-doctoral research fellow. Currently, he is with theDepartment of Electrical and Microelectronic Engineering, RochesterInstitute of Technology, Rochester, NY. His current research interestsinclude emerging security/privacy measures for deeply embedded sys-tems, cryptographic hardware systems, fault diagnosis and tolerance incryptographic hardware, VLSI reliability, and low-power secure and effi-cient FPGA and ASIC designs. He is elected as the guest editor of theIEEETransactions onEmerging Topics in Computing for the special issueof Emerging Security Trends for Deeply-Embedded Computing Systems(2014 and 2015). He is currently serving as the technical committeemember for a number of related conferences including on DFT, RFIDsec,LightSEC, andSPACE.He is an activeNSFpanelist and peer reviewer fora number of IEEETransactions journals including IEEETrans. Very LargeScale Integr. (VLSI) Syst., IEEE Trans. Comput., IEEE Trans. Emerg.TopicsComput., IEEETrans. Circuits Syst. I, IEEETrans. Circuits Syst. II,IEEE Trans. Mobile Comput., and IEEE Trans. Inf. Theory. He was arecipient of the prestigious Natural Sciences and Engineering ResearchCouncil of Canada Post-Doctoral Research Fellowship in 2011.
1180 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 5, MAY 2014

Chiou-YngLee received the bachelor’s degree in1986 inmedical engineering and theMSdegree inelectronic engineering in 1992, both from theChungYuanChristianUniversity, Zhongli, Taiwan,and the PhD degree in electrical engineeringfrom Chang Gung University, Taoyuan, Taiwan,in 2001. From 1988 to 2005, he was a researchassociate with Chunghwa TelecommunicationLaboratory, Taiwan. He joined the Department ofProject Planning. He taught those related fieldcourses at Ching Yun University. From 2005 to
now, he is a professor with the Department of Computer Information andNetwork Engineering, Lunghwa University of Science and Technology,Taoyuan, Taiwan. His research interests include computations in finitefields, error-control coding, signal processing, and digital transmissionsystem.Besides, he is a seniormember of the IEEEComputer society. Heis also an honor member of Phi Tao Phi in 2001.
Wen-Yo Lee received the BS, MS and PhD de-grees in electrical engineering at the Departmentof Electrical Engineering, National TaiwanUniver-sity and Technology, Taipei, in 1995, 1998, and2004, respectively.Hewasemployedby IndustrialTechnologyResearch Institute from1998 to 2003.He is currently an associate professor with theDepartment of Computer Information and Net-work Engineering, Lunghwa University Scienceand Technology, since 2003. His research inter-ests include designing, analyzing, and setting up
control system for the projects of mechatronics, biomedical engineering,and semiconductor.
Che Wun Chiou received the BS degree in elec-tronic engineering from Chung Yuan ChristianUniversity, Zhongli, Taiwan, in 1982, the MS andPhD degrees in electrical engineering from Na-tional Cheng Kung University, Tainan, Taiwan, in1984 and 1989, respectively. From 1990 to 2000,he was with the Chung Shan Institute of Scienceand Technology, Taiwan. He joined the Depart-ment of Electronic Engineering, Ching Yun Uni-versity in 2000. He is currently a professor with theDepartment of Computer Scienceand Information
Engineering, Chien Hsin University of Science and Technology (formerlyChing Yun University) Zhongli, Taiwan. His current research interestsinclude fault-tolerant computing, computer arithmetic, parallel processing,and cryptography.
Jim-Min Lin received the BS degree in engineer-ing science and the MS and the PhD degrees inelectrical engineering, all from National ChengKung University, Tainan, Taiwan, in 1985, 1987,and 1992, respectively. From February 1993 toJuly 2005, he was an associate professor with theDepartment of Information Engineering and Com-puter Science, Feng Chia University, TaichungCity, Taiwan. Since August 2005, he has been afull professor at the same department. SinceAugust 2009, he has been serving as the Chair-
man of the same department. From November 2008 to October 2011, healso served as the Secretary General of the Computer Society of theRepublic of China (CSROC). His research interests include testabledesign, embedded systems, software integration/reuse, operating sys-tems, and software agent technology.
▽ For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
PAN ET AL.: LOW-LATENCY DIGIT-SERIAL SYSTOLIC DOUBLE BASIS MULTIPLIER 1181


















