
id3 dan c4.5
18
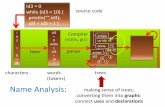
ALGORITMA ID3 Iterative Dichotomiser 3 (ID3) merupakan sebuah metode yang digunakan untuk membangkitkan pohon keputusan. Algoritma pada metode ini berbasis pada Occam’s razor: lebih memilih pohon keputusan yang lebih kecil (teori sederhana) dibanding yang lebih besar. Tetapi tidak dapat selalu menghasilkan pohon keputusan yang paling kecil dan karena itu occam’s razor bersifat heuristik. Occam’s razor diformalisasi menggunakan konsep dari entropi informasi. Berikut algoritma dari ID3: Adapun sample data yang digunakan oleh ID3 memiliki beberapa syarat, yaitu: 1. Deskripsi atribut-nilai. Atribut yang sama harus mendeskripsikan tiap contoh dan memiliki jumlah nilai yang sudah ditentukan. 2. Kelas yang sudah didefinisikan sebelumnya. Suatu atribut contoh harus sudah didefinisikan, karena mereka tidak dipelajari oleh ID3. 3. Kelas-kelas yang diskrit. Kelas harus digambarkan dengan jelas. Kelas yang kontinu dipecah-pecah menjadi kategori-kategori yang relatif, misalnya saja metal dikategorikan menjadi “hard, quite hard, flexible, soft, quite soft”. 4. Jumlah contoh (example) yang cukup. Karena pembangkitan induktif digunakan, maka dibutuhkan test case yang cukup untuk membedakan pola yang valid dari peluang suatu kejadian.
Transcript of id3 dan c4.5

ALGORITMA ID3
Iterative Dichotomiser 3 (ID3) merupakan sebuah metode yang digunakan untuk membangkitkan pohon keputusan. Algoritma pada metode ini berbasis pada Occam’s razor: lebih memilih pohon keputusan yang lebih kecil (teori sederhana) dibanding yang lebih besar. Tetapi tidak dapat selalu menghasilkan pohon keputusan yang paling kecil dan karena itu occam’s razor bersifat heuristik. Occam’s razor diformalisasi menggunakan konsep dari entropi informasi. Berikut algoritma dari ID3:
Adapun sample data yang digunakan oleh ID3 memiliki beberapa syarat, yaitu:1. Deskripsi atribut-nilai. Atribut yang sama harus mendeskripsikan tiap contoh dan
memiliki jumlah nilai yang sudah ditentukan.2. Kelas yang sudah didefinisikan sebelumnya. Suatu atribut contoh harus sudah
didefinisikan, karena mereka tidak dipelajari oleh ID3.3. Kelas-kelas yang diskrit. Kelas harus digambarkan dengan jelas. Kelas yang
kontinu dipecah-pecah menjadi kategori-kategori yang relatif, misalnya saja metal dikategorikan menjadi “hard, quite hard, flexible, soft, quite soft”.
4. Jumlah contoh (example) yang cukup. Karena pembangkitan induktif digunakan, maka dibutuhkan test case yang cukup untuk membedakan pola yang valid dari peluang suatu kejadian.

Pemillihan atribut pada ID3 dilakukan dengan properti statistik, yang disebut dengan information gain. Gain mengukur seberapa baik suatu atribut memisahkan training example ke dalam kelas target. Atribut dengan informasi tertinggi akan dipilih. Dengan tujuan untuk mendefinisikan gain, pertama-tama digunakanlah ide dari teori informasi yang disebut entropi. Entropi mengukur jumlah dari informasi yang ada pada atribut.
Contoh :Obyek penelitian adalah semua tipe kapal berbendera Indonesia diatas 500GT.
Data yang digunakan adalah data register kapal tahun 2006 yang dikeluarkan oleh Biro Klasifikasi Indonesia (BKI) dan data laporan hasil pemeriksaan kelaiklautan kapal serta mekanisme penentuan kelaiklautan kapal yang diatur didalam regulasi baik nasional maupun internasional. Berikut gambar skema kriteria yang mempengaruhi kelaiklautan kapal :

Variabel bebas (predictor) pada penelitian ini adalah : 1. Untuk kriteria nautis :
a. Dokumentasi b. Keselamatan pelayaran c. Alat-alat keselamatan d. Alat-alat pemadam e. Peralatan pemadam akomodasi & pelayanan
2. Untuk kriteria teknis : a. Sumber listrik darurat b. Sistem pencegahan kebakaran akibat listrik c. Mesin kemudi d. Instalasi kemudi & hidraulik e. Sistem keselamatan dari kebakaran f. Permesinan
3. Untuk kriteria radio : a. Sumber tenaga listrik b. Instalasi radio c. Alat-alat radio d. Dokumentasi
Sedangkan variabel tidak bebasnya (output) adalah status kelaiklautan kapal. Variabel ini menyatakan status kapal yang dikategorikan sebagai kapal yang laik dan tidak laik. Data set disajikan dalam bentuk tabel yang terdiri dari : 1. Untuk kriteria nautis terdiri atas 7 kolom atribut (1atribut sampel, 5 atribut bebas,
1atribut klas) dengan 243 record. 2. Untuk kriteria teknis terdiri atas 8 kolom atribut (1atribut sampel, 6 atribut bebas,
atribut klas) dengan 729 record. 3. Untuk kriteria radio terdiri atas 6 kolom atribut (1atribut sampel, 4 atribut bebas,
1atribut klas) dengan 127 record. Jadi total keseluruhan data yang dianalisa adalah berjumlah 1099 record.

ALGORITMA C4.5
Salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser 3). ID3 dikembangkan oleh J. Ross Quinlan. Dalam prosedur algoritma ID3, input berupa sampel training, label training dan atribut. Algoritma C4.5 merupakan pengembangan dari ID3. Sedangkan pada perangkat lunak open source WEKA mempunyai versi sendiri C4.5 yang dikenal sebagai J48.
Algoritma C4.5
Pohon dibangun dengan cara membagi data secara rekursif hingga tiap bagian terdiri dari data yang berasal dari kelas yang sama. Bentuk pemecahan (split) yang digunakan untuk membagi data tergantung dari jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani data numerik (kontinyu) dan diskret. Split untuk atribut numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum permulaan (threshold) M dari contoh-contoh yang ada dari kelas mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk atribut diskret A mempunyai bentuk value (A) ε X dimana X ⊂ domain(A).Jika suatu set data mempunyai beberapa pengamatan dengan missing value yaitu record dengan beberapa nilai variabel tidak ada, Jika jumlah pengamatan terbatas maka atribut dengan missing value dapat diganti dengan nilai rata-rata dari variabel yang bersangkutan.[Santosa,2007].

Untuk melakukan pemisahan obyek (split) dilakukan tes terhadap atribut dengan mengukur tingkat ketidakmurnian pada sebuah simpul (node). Pada algoritma C.45 menggunakan rasio perolehan (gain ratio). Sebelum menghitung rasio perolehan, perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep entropi.
S adalah ruang (data) sampel yang digunakan untuk pelatihan, p+ adalah jumlah yang bersolusi positif atau mendukung pada data sampel untuk kriteria tertentu dan p- adalah jumlah yang bersolusi negatif atau tidak mendukung pada data sampel untuk kriteria tertentu. ntropi(S) sama dengan 0, jika semua contoh pada S berada dalam kelas yang sama. Entropi(S) sama dengan 1, jika jumlah contoh positif dan negative dalam S adalah sama. Entropi(S) lebih dari 0 tetapi kurang dari 1, jika jumlah contoh positif dan negative dalam S tidak sama [Mitchell,1997].Entropi split yang membagi S dengan n record menjadi himpunan-himpunan S1 dengan n1 baris dan S2 dengan n2 baris adalah :
Kemudian menghitung perolehan informasi dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (y,A). Perolehan informasi, gain (y,A), dari atribut A relative terhadap output data y adalah:
nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan diatas adalah entropy total y dan term kedua adalah entropy sesudah dilakukan pemisahan data berdasarkan atribut A.
Untuk menghitung rasio perolehan perlu diketahui suatu term baru yang disebut pemisahan informasi (SplitInfo). Pemisahan informasi dihitung dengan cara :
bahwa S1 sampai Sc adalah c subset yang dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak c nilai. Selanjutnya rasio perolehan (gain ratio) dihitung dengan cara :

Contoh Aplikasi
Credit RiskBerikut ini merupakan contoh dari salah satu kasus resiko kredit (credit risk)
yang menggunakan decision tree untuk menentukan apakah seorang potential customer dengan karakteristik saving, asset dan income tertentu memiliki good credit risk atau bad credit risk.
Dapat dilihat pada gambar tersebut, bahwa target variable dari decision tree tersebut atau variable yang akan diprediksi adalah credit risk dengan menggunakan predictor variable : saving, asset, dan income. Setiap nilai atribut dari predictor variable akan memiliki cabang menuju predictor variable selanjutnya, dan seterusnya hingga tidak dapat dipecah dan menuju pada target variable.Penentuan apakah diteruskan menuju predictor variable (decision node) atau menuju target variable (leaf node) tergantung pada keyakinan (knowledge) apakah potential customer dengan nilai atribut variable keputusan tertentu memiliki keakuratan nilai target variable 100% atau tidak. Misalnya pada kasus di atas untuk saving medium,

ternyata knowledge yang dimiliki bahwa untuk seluruh potential customer dengan saving medium memiliki credit risk yang baik dengan keakuratan 100%. Sedangkan untuk nilai low asset terdapat kemungkinan good credit risk dan bad credit risk.
Jika tidak terdapat pemisahan lagi yang mungkin dilakukan, maka algoritma decision tree akan berhenti membentuk decision node yang baru. Seharusnya setiap branches diakhiri dengan “pure” leaf node, yaitu leaf node dengan target variable yang bersifat unary untuk setiap records pada node tersebut, di mana untuk setiap nilai predictor variable yang sama akan memiliki nilai target variable yang sama. Tetapi, terdapat kemungkinan decision node memiliki “diverse” atributes, yaitu bersifat non‐unary untuk nilai target variablenya, di mana untuk setiap record dengan nilai predictor variable yang sama ternyata memiliki nilai target variable yang berbeda. Kondisi tersebut menyebabkan tidak dapat dilakukan pencabangan lagi berdasarkan nilai predictor variable. Sehingga solusinya adalah membentuk leaf node yang disebut “diverse” leaf node, dengan menyatakan level kepercayaan dari diverse leaf node tersebut. Misalnya untuk contoh data berikut ini :
Dari training data tersebut kemudian disusunlah alternatif untuk candidate split, sehingga setiap nilai untuk predictor variable di atas hanya membentuk 2 cabang, yaitu sebagai berikut:

Kemudian untuk setiap candidate split di atas, dihitung variabel‐variabel berikut berdasarkan training data yang dimiliki. Adapun variabel‐variabel tersebut, yaitu :
,di mana
Adapun contoh hasil perhitungannya adalah sebagai berikut :
Dapat dilihat dari contoh perhitungan di atas, bahwa yang memiliki nilai goodness of split * Φ(s/t) + yang terbesar, yaitu split 4 dengan nilai 0.64275. Oleh karena itu split 4 lah yang akan digunakan pada root node, yaitu split dengan : assets = low dengan assets = {medium, high}.
Untuk penentuan pencabangan, dapat dilihat bahwa dengan assets=low maka didapatkan pure node leaf, yaitu bad risk (untuk record 2 dan 7). Sedangkan untuk assets = {medium, high} masih terdapat 2 nilai, yaitu good credit risk dan bad credit

risk. Sehingga pencabangan untuk assets = {medium, high} memiliki decision node baru. Adapun pemilihan split yang akan digunakan, yaitu dengan menyusun perhitungan nilai Φ(s/t) yang baru tanpa melihat split 4, record 2 dan 7.
Demikian seterusnya hingga akhirnya dibentuk leaf node dan membentuk decision tree yang utuh (fully grown form) seperti di bawah ini :

Sistem Pakar Diagnosa Penyakit (Kusrini)
Dalam aplikasi ini terdapat tabel-tabel sebagai berikut:
• Tabel Rekam_Medis, berisi data asli rekam medis pasien• Tabel Kasus, beisi data variabel yang dapat mempengaruhi kesimpulan
diagnosis dari pasien-pasien yang ada, misalnya Jenis Kelamin, Umur, Daerah_Tinggal, Gejala_1 s/d gejala_n, Hasil_Tes_1 s/d Hasi_Tes_n. Selain itu dalam tabel ini juga memiliki field Hasil_Diagnosis.
• Tabel Aturan, berisi aturan hasil ekstrak dari pohon keputusan.
Proses akuisisi pengetahuan yang secara biasanya dalam sistem pakar dilakukan oleh sistem pakar, dalam sistem ini akan dillakukan dengan urutan proses ditunjukkan pada gambar berikut:
Hasil pembentukan pohon keputusan bisa seperti pohon keputusan yang tampak pada gambar:

Lambang bulat pada pohon keputusan melambangkan sebagai node akar atau cabang (bukan daun) sedangkan kotak melambangkan node daun. Jika pengetahuan yang terbentuk beruka kaidah produksi dengan format:
Jika Premis Maka Konklusi Node-node akar akan menjadi Premis dari aturan sedangkan node daun akan menjadi bagian konklusinya. Dari gambar pohon keputusan pada gambar 4, dapat dibentuk aturan sebagai berikut:
1. Jika Atr_1 = N_1Dan Atr_2 = N_4Dan Atr_3 = N_9Maka H_1
2. Jika Atr_1 = N_1Dan Atr_2 = N_4Dan Atr_3 = N_10Dan Atr_4 = N_11Maka H_2

3. Jika Atr_1 = N_1Dan Atr_2 = N_4Dan Atr_3 = N_10Dan Atr_4 = N_12Maka H_2
4. Jika Atr_1 = N_1Dan Atr_2 = N_5Maka H_4
5. Jika Atr_1 = N_2Maka H_5
6. Jika Atr_1 = N_3Dan Atr_5 = N_6Maka H_6
7. Jika Atr_1 = N_3Dan Atr_5 = N_7Maka H_7
8. Jika Atr_1 = N_3Dan Atr_5 = N_8Maka H_8
Model case based reasoning dapat digunakan sebagai metode akuisisi pengetahuan dalam aplikasi system pakar diagnosis penyakit. Aturan yagn dihasilkan system ini mampu digunakan untuk mendiagnosis penyakit didasarkan pada data-data pasien. Dalam penentuan diagnosis penyakit belum diimplementasikan derajat kepercayaan terhadap hasil diagnosis tersebut.

ALGORITMA C5
Algoritme C5.0 adalah salah satu algoritme yang terdapat dalam klasifikasi data mining disamping algoritme CART, yang khususnya diterapkan pada teknik decision tree. C5.0 merupakan penyempurnaan algoritme terdahulu yang dibentuk oleh Ross Quinlan pada tahun 1987, yaitu ID3 dan C4.5. Dalam algoritme C5.0, pemilihan atribut yang akan diproses menggunakan information gain. Secara heuristik akan dipilih atribut yang menghasilkan simpul yang paling bersih (purest). Kalau dalam cabang suatu decision tree anggotanya berasal dari satu kelas maka cabang ini disebut pure. Kriteria yang digunakan adalah information gain. Jadi dalam memilih atribut untuk memecah obyek dalam beberapa kelas harus kita pilih atribut yang menghasilkan information gain paling besar.
Ukuran information gain digunakan untuk memilih atribut uji pada setiap node di dalam tree. Ukuran ini digunakan untuk memilih atribut atau node pada pohon. Atribut dengan nilai information gain tertinggi akan terpilih sebagai parent bagi node selanjutnya. Formula untuk information gain adalah (Kantardzic, 2003):
S adalah sebuah himpunan yang terdiri dari s data sampel. Diketahui atribut class adalah m dimana mendefinisikan kelas-kelas di dalamnya, Ci (for i= 1, …, m), si adalah jumlah sampel pada S dalam class Ci. untuk mengklasifikasikan sampel yang digunakan maka diperlukan informasi dengan menggunakan aturan seperti di atas (2.1). Dimana pi
adalah proporsi kelas dalam output seperti pada kelas Ci dan diestimasikan dengan si /s. Atribut A memiliki nilai tertentu {a1, a2, …, av}. Atribut A dapat digunakan pada partisi S ke dalam v subset, {S1, S2, …, Sv}, dimana Sj berisi sample pada S yang bernilai aj pada A. Jika A dipilih sebagai atribut tes (sebagai contoh atribut terbaik untuk split), maka subset ini akan berhubungan pada cabang dari node himpunan S. Sij adalah jumlah sample pada class Ci
dalam sebuah subset Sj. Untuk mendapatkan informasi nilai subset dari atribut A tersebut maka digunakan formula,
adalah jumlah subset j yang dibagi dengan jumlah sampel pada S, maka untuk mendapatkan nilai gain, selanjutnya digunakan formula
C5.0 memiliki fitur penting yang membuat algoritme ini menjadi lebih unggul dibandingkan dengan algoritme terdahulunya dan mengurangi kelemahan

yang ada pada algoritme decision tree sebelumnya. Fitur tersebut adalah (Quinlan, 2004) : 1. C5.0 telah dirancang untuk dapat menganalisis basis data subtansial yang berisi
puluhan sampai ratusan record dan satuan hingga ratusan field numerik dan nominal.
2. Untuk memaksimumkan tingkat penafsiran pengguna terhadap hasil yang disajikan, maka klasifikasi C5.0 disajikan dalam dua bentuk, menggunakan pohon keputusan dan sekumpulan aturan IF-then yang lebih mudah untuk dimengerti dibandingkan neural network.
3. C5.0 mudah digunakan dan tidak membutuhkan pengetahuan tinggi tentang statistik atau machine learning.
Contoh Dalam hal ini jumlah data/tetangga terdekat ditentukan oleh user yang dinyatakan
dengan k. Misalkan ditentukan k=5, maka setiap data testing dihitung jaraknya terhadap data training dan dipilih 5 data training yang jaraknya paling dekat ke data testing. Lalu periksa output atau labelnya masing-masing, kemudian tentukan output mana yang frekuensinya paling banyak. Lalu masukkan suatu data testing ke kelompok dengan output paling banyak. Misalkan dalam kasus klasifikasi dengan 3 kelas, lima data tadi terbagi atas tiga data dengan output kelas 1, satu data dengan output kelas 2 dan satu data dengan output kelas 3, maka dapat disimpulkan bahwa output dengan label kelas 1 adalah yang paling banyak. Maka data baru tadi dapat dikelompokkan ke dalam kelas 1. Prosedur ini dilakukan untuk semua data testing (Santosa, 2007). Gambar 4 berikut ini adalah bentuk representasi K-NN dengan 1, 2 dan 3 tetangga data terhadap data baru x (Pramudiono, 2003).
Untuk mendefinisikan jarak antara dua titik yaitu titik pada data training (x) .dan titik pada data testing (y) maka digunakan rumus Euclidean,
dengan d adalah jarak antara titik pada data training x dan titik data testing y yang akan diklasifikasi, dimana x=x1,x2,…,xi dan y=y1,y2,…,yi dan I merepresentasikan nilai atribut serta n merupakan dimensi atribut (Han & Kamber, 2001). Sebagai ilustrasi, pada Tabel 1 berikut ini disajikan contoh penerapan rumus Euclidean, pada empat data klasifikasi kualitas baik dan tidak baik sebuah kertas tisu yang dinilai berdasarkan daya tahan kertas tersebut dan fungsinya. Sebanyak tiga data yang sudah

terklasifikasi yaitu data no 1,2, dan 3 masing-masing data dihitung jaraknya ke data no 4 untuk mendapatkan kelas yang sesuai bagi data no 4 maka k=1 (Teknomo, 2006).
Tabel 1. Tabel klasifikasi kualitas baik atau tidak baik sebuah kertas tisu
No Fungsi Daya Tahan Klasifikasi 1 7 7 Tidak baik 2 7 4 Tidak baik 3 3 4 Baik 4 1 4 ?
Berikut ini disajikan pula perhitungan yang dilakukan terhadap tiga data yang
sudah terklasifikasi dengan data yang belum terklasifikasi pada Tabel 1 di atas. Jarak data no satu ke data no empat:
Dari hasil perhitungan di atas diperoleh jarak antara data no tiga dan data no empat adalah jarak yang terdekat maka kelas data no empat adalah baik. Teknik ini akan diujicobakan terhadap dataset akademik yang belum terklasifikasi atau data yang belum dikenal, untuk menemukan kelas yang sesuai dengan berdasarkan pada data tetangga terdekatnya yang sudah terklasifikasi. Tingkat ketepatan klasifikasi terhadap data dari kedua algoritma yang digunakan menjadi titik fokus analisa dalam penelitian.

CLUSTERING
Clustering adalah proses mengelompokkan objek berdasarkan informasi yang diperoleh dari data yang menjelaskan hubungan antar objek dengan prinsip untuk memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas/cluster. Tujuannya menemukan cluster yang berkualitas dalam waktu yang layak. Clustering dalam data mining berguna untuk menemukan pola distribusi di dalam sebuah data set yang berguna untuk proses analisa data. Kesamaan objek biasanya diperoleh dari kedekatan nilai-nilai atribut yang menjelaskan objek-objek data, sedangkan objek-objek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
Dengan menggunakan clustering, dapat diidentifikasi daerah yang padat, pola-pola distribusi secara keseluruhan dan keterkaitan yang menarik antara atribut-atribut data. Dalam data mining usaha difokuskan pada metode-metode penemuan untuk cluster pada basisdata berukuran besar secara efektif dan efisien. Banyaknya pendekatan clustering menyulitkan dalam menentukan ukuran kualitas yang universal. Namun, beberapa hal yang perlu diperhatikan adalah input parameter yang tidak menyulitkan user, cluster hasil yang dapat dianalisa, dan skalabilitas terhadap penambahan ukuran dimensi dan record dataset. Secara garis besar ada beberapa kategori algoritma clustering yang dikenal yaitu: a. Metode Partisi, dimana pemakai harus menentukan jumlah k partisi yang
diinginkan lalu setiap data dites untuk dimasukkan pada salah satu partisi sehingga tidak ada data yang overlap dan satu data hanya memiliki satu cluster. Contohnya: algoritma K-Means.
b. Metode Hierarki, yang menghasilkan cluster yang bersarang artinya suatu data dapat memiliki cluster lebih dari satu. Metode ini terbagi menjadi dua yaitu buttom-up yang menggabungkan cluster kecil menjadi cluster lebih besar dan top-down yang memecah cluster besar menjadi cluster yang lebih kecil. Kelemahan metode ini adalah bila salah satu penggabungan/pemecahan dilakukan pada tempat yang salah, tidak akan didapatkan cluster yang optimal. Contohnya: Agglomerative (FINDIT, PROCLUS), Divisive Hierarchical Clustering (CLIQUE, MAFIA, ENCLUE).
Subspace ClusteringSubspace clustering adalah suatu teknik clustering yang mencoba menemukan
cluster pada dataset multidimensi dengan pemilihan dimensi yang paling relevan untuk setiap cluster, karena pada data multidimensi kemungkinan terdapat dimensi-dimensi yang tidak relevan yang dapat membingungkan algoritma clustering sehingga bisa mengaburkan cluster sebenarnya yang seharusnya dapat ditemukan.

Masalah lainnya, cluster dapat saja berada dalam subspace yang berbeda, dimana setiap subspace dibentuk dari kombinasi dimensi yang berbeda-beda. Akibatnya, semakin banyak dimensi yang digunakan, cluster akan sulit ditemukan. Subspace clustering secara otomatis akan menemukan unit-unit yang padat pada tiap subspace. Pada Gambar diatas, mengilustrasikan bagaimana peningkatan jumlah dimensi mengakibatkan terpecahnya titik pada dataset.
Cara yang sudah dikenal untuk mengatasi peningkatan jumlah dimensi adalah menggunakan teknik reduksi dimensi atau feature selection. Dengan cara ini, dimensionalitas dataset dikurangi dengan menghilangkan beberapa dimensi, pendekatan ini berakibat pada hilangnya beberapa informasi dan sekaligus mengurangi efektifitas penemuan cluster yang mungkin melibatkan dimensi yang dihilangkan tersebut. Jika konsep ini diterapkan dalam kasus di Gambar di bawah, berakibat hilangnya satu atau dua cluster yang seharusnya ada, karena masingmasing dimensi menjadi bagian dari satu buah cluster.
Misalnya ada suatu dataset 3-dimensi yang mempunyai 2 cluster, satu cluster berada di bidang (x, y) dan (x, z). Untuk dataset seperti ini, metode reduksi dimensi dan feature selection tidak mampu memperoleh kembali semua struktur cluster, karena setiap dimensi merupakan salah satu subspace cluster yang terbentuk. Dengan menggunakan metode subspace clustering, dua cluster yang terbentuk pada Gambar 2-3 diharapkan dapat diperoleh karena teknik clustering ini dapat menemukan cluster dengan subspace yang berbeda dalam dataset. Berdasarkan strategi pencariannya algoritma susbsapce clustering dapat dikatagorikan ke dalam dua kategori yaitu metode top down search iterative dan metode bottom up search grid based. Algoritma

MAFIA termasuk algoritma yang menggunakan strategi metode bottom up search grid based.
Contoh :
Buttom-up Subspace Search Grid MethodAlgoritma Bottom-up ini menggunakan prinsip yang serupa dengan algoritma
Apriori untuk menghasilkan rule asosiasi.
Lemma 1 (monotonicity):Jika kumpulan titik S merupakan cluster dalam ruang dimensi–k maka S juga
merupakan bagian suatu cluster dalam ruang proyeksi dimensi-(k-1) Penjelasan:Suatu cluster C yang berdimensi-k memasukkan titik yang jatuh di dalam gabungan dense unit berdimensi-k yang masing-masing memiliki selectivity minimal. Proyeksi setiap unit u dalam C harus memiliki selectivity minimal agar bersifat padat. Karena semua unit dalam cluster terhubung, maka proyeksinya juga terhubung. Artinya, proyeksi titik dalam cluster C yang berdimensi-k juga berada dalam cluster yang sama pada proyeksi dimensi-(k-1).
Algoritma diproses level demi level. Pertama-tama, menentukan calon dense unit berdimensi 1 dengan melakukan pass over data. Setelah menentukan dense unit berdimensi-k-1, calon dense unit berdimensi-k ditentukan dengan menggunakan prosedur candidate generation. Algoritma berhenti jika tidak ada dense unit yang dibangkitkan. Prosedur candidat generation menyatakan Dk-1 sebagai kumpulan dense unit berdimensi (k-1). Prosedur ini mengembalikan superset kumpulan calon dense unit berdimensi-k yang akan di bandingkan dengan density treshold apakah layak atau tidak digunakan sebagai penentu cluster.





![Data Mining Modèles et Algorithmes - Erick STATTNER · Induction d'un arbre de décision ID3 [Quinlan 1986] a évolué jusqu'aux versions C4.5 et C5.0 principe de base : construire](https://static.fdocuments.net/doc/165x107/5b9d0eb609d3f2443d8b6432/data-mining-modeles-et-algorithmes-erick-induction-dun-arbre-de-decision.jpg)







![Classification: Decision Trees · Basic Algorithm for Top-Down Learning of Decision Trees [ID3, C4.5 by Quinlan] node= root of decision tree Main loop: 1. Aßthe “best” decision](https://static.fdocuments.net/doc/165x107/5ec67d03ae6d2609843381e5/classification-decision-trees-basic-algorithm-for-top-down-learning-of-decision.jpg)



