
ICS 421 Spring 2010 Indexing (1) - lipyeow.github.io fileICS 421 Spring 2010 Indexing (1) Asst....
16
ICS 421 Spring 2010 Indexing (1) Asst. Prof. Lipyeow Lim Information & Computer Science Department University of Hawaii at Manoa 02/18/2010 1 Lipyeow Lim -- University of Hawaii at Manoa
Transcript of ICS 421 Spring 2010 Indexing (1) - lipyeow.github.io fileICS 421 Spring 2010 Indexing (1) Asst....

ICS 421 Spring 2010
Indexing (1)
Asst. Prof. Lipyeow Lim
Information & Computer Science Department
University of Hawaii at Manoa
02/18/2010 1Lipyeow Lim -- University of Hawaii at Manoa
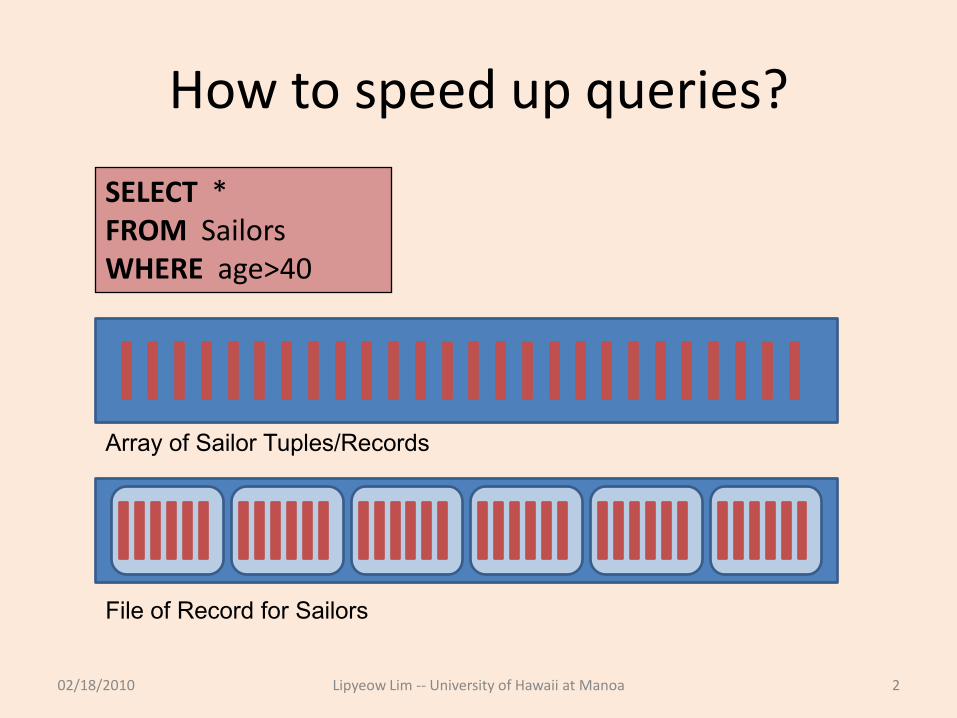
How to speed up queries?
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 2
SELECT *FROM SailorsWHERE age>40
File of Record for Sailors
Array of Sailor Tuples/Records
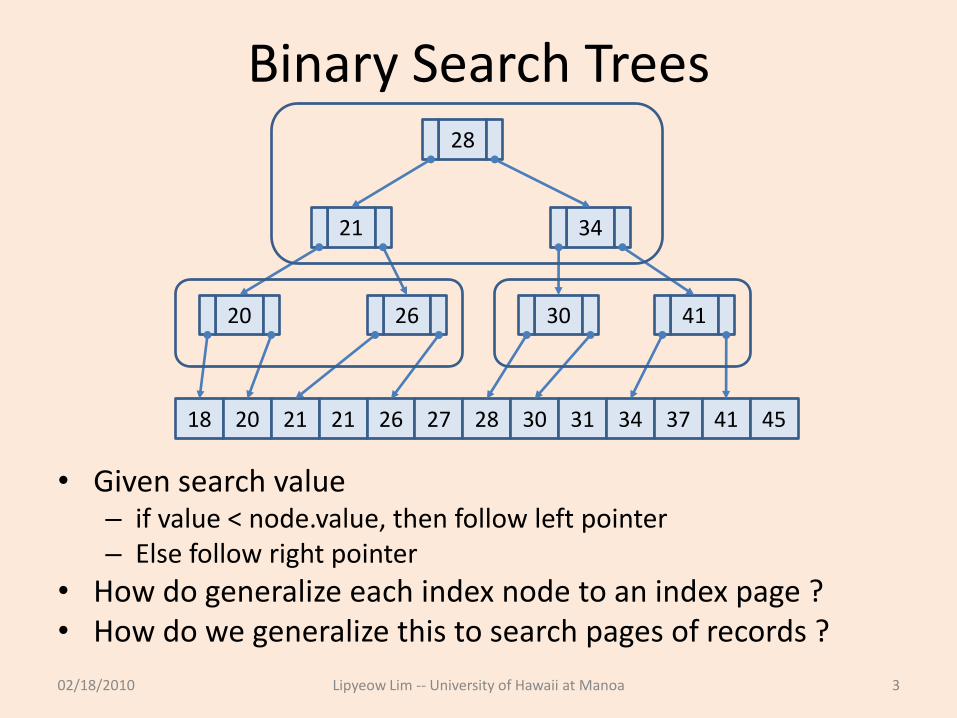
Binary Search Trees
• Given search value– if value < node.value, then follow left pointer– Else follow right pointer
• How do generalize each index node to an index page ?• How do we generalize this to search pages of records ?
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 3
28
21
18 20 21 21 26 27 28 30 31 34 37 41 45
34
20 26 30 41

Indexes• What do we store in the index nodes ? Let k
be the key value for an index entry:
1. Data record with key value k
2. <k, rid of data record with key value k>
3. <k, list of rids of data records with key value k>
• What kind of queries does the index support?
– Range
– Point (or equality)
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 4
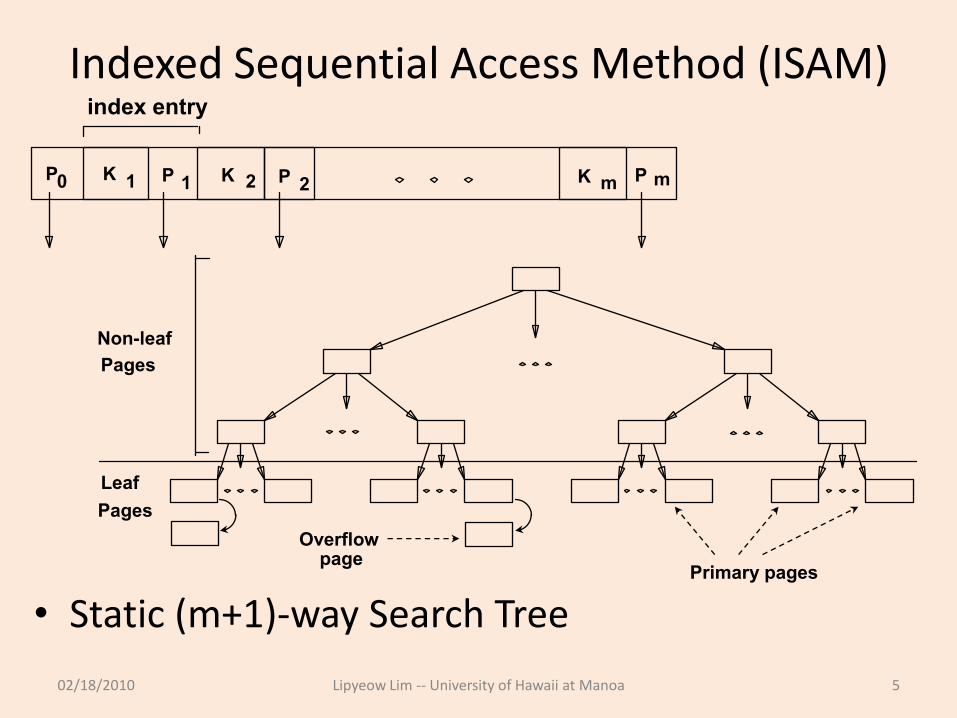
Indexed Sequential Access Method (ISAM)
• Static (m+1)-way Search Tree
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 5
P0 K 1 P 1 K 2 P 2 K m P m
index entry
Non-leaf
Pages
Pages
Overflow page
Primary pages
Leaf
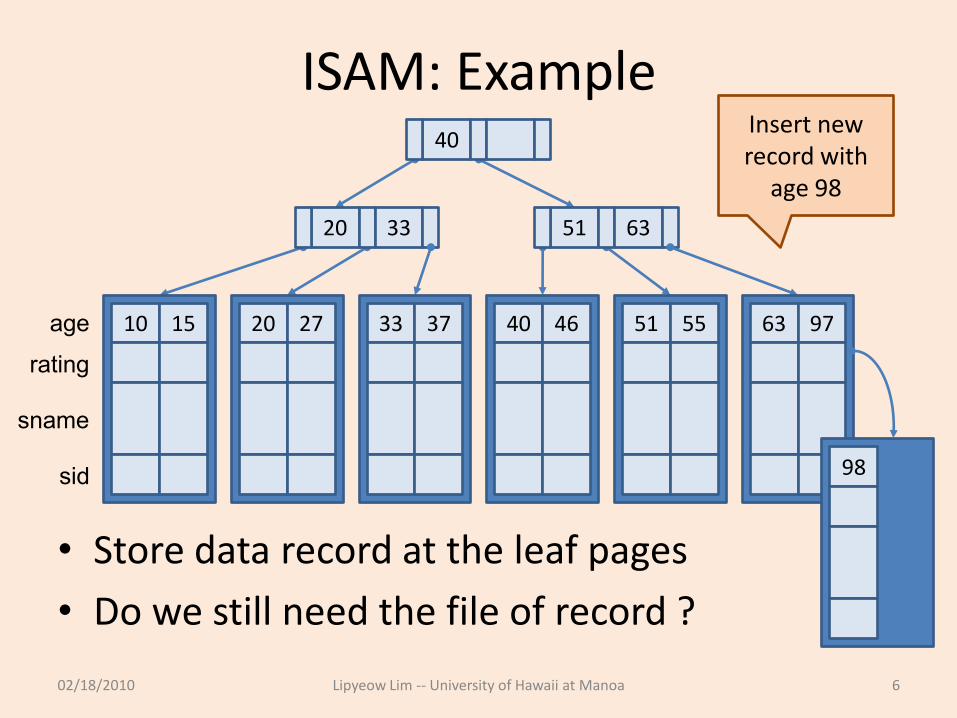
ISAM: Example
• Store data record at the leaf pages
• Do we still need the file of record ?
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 6
sid
sname
rating
age
40
20 33 51 63
10 15 20 27 33 37 40 46 51 55 63 97
98
Insert new record with
age 98

ISAM Facts• File creation: Leaf (data) pages allocated sequentially,
sorted by search key; then index pages allocated, then space for overflow pages.
• Index entries: <search key value, page id>; they `direct’ search for data entries, which are in leaf pages.
• Search: Start at root; use key comparisons to go to leaf. Cost=O(log F N) ; F = # entries/index pg, N = # leaf pgs
• Insert: Find leaf data entry belongs to, and put it there. If full, allocate and put in overflow page
• Delete: Find and remove from leaf; if empty overflow page, de-allocate.
• Static tree structure: inserts/deletes affect only leaf pages.
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 7
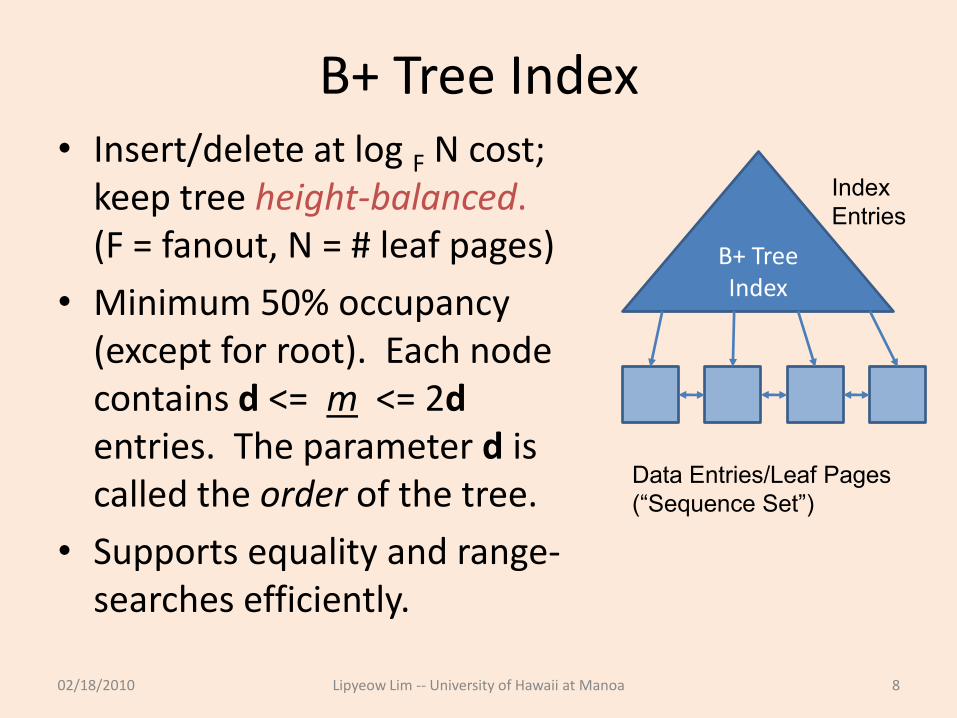
B+ Tree Index• Insert/delete at log F N cost;
keep tree height-balanced. (F = fanout, N = # leaf pages)
• Minimum 50% occupancy (except for root). Each node contains d <= m <= 2dentries. The parameter d is called the order of the tree.
• Supports equality and range-searches efficiently.
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 8
B+ TreeIndex
Data Entries/Leaf Pages
(“Sequence Set”)
Index
Entries
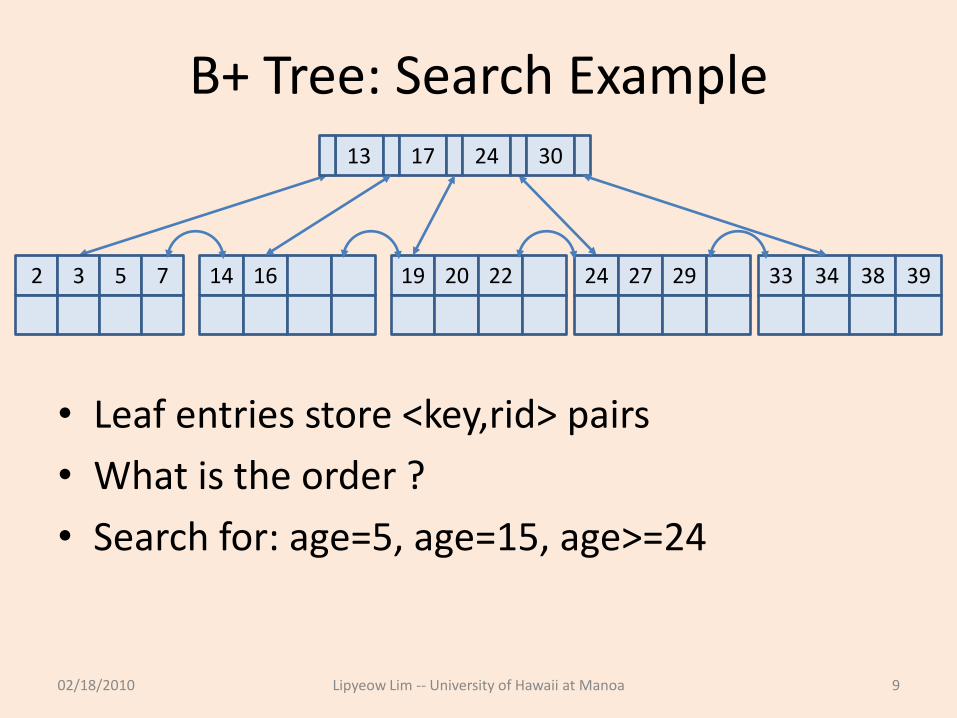
B+ Tree: Search Example
• Leaf entries store <key,rid> pairs
• What is the order ?
• Search for: age=5, age=15, age>=24
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 9
13 17 24 30
2 3 5 7 14 16 19 20 22 24 27 29 33 34 38 39

Inserting a new data entry• Find correct leaf L.
• Put data entry onto L.– If L has enough space, done!
– Else, must split L (into L and a new node L2)• Redistribute entries evenly, copy up middle key.
• Insert index entry pointing to L2 into parent of L.
• This can happen recursively– To split index node, redistribute entries evenly, but
push up middle key. (Contrast with leaf splits.)
• Splits “grow” tree; root split increases height. – Tree growth: gets wider or one level taller at top.
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 10

Example: Insert 8*
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 11
2 3 5 7 8
13 17 24 30
2 3 5 7 14 16 19 20 22 24 27 29 33 34 38 39
5 5 copied up to
parent node
5 13 24 30
17 pushed up
into parent node17

Deleting a data entry• Start at root, find leaf L where entry belongs.
• Remove the entry.– If L is at least half-full, done!
– If L has only d-1 entries,• Try to re-distribute, borrowing from sibling (adjacent
node with same parent as L).
• If re-distribution fails, merge L and sibling.
• If merge occurred, must delete entry (pointing to L or sibling) from parent of L.
• Merge could propagate to root, decreasing height.
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 12

Miscellaneous• How do we handle data with duplicates ?
– Overflow buckets
– Make rid part of the key
– Each data entry stores <key, list of rids>
• Clustered vs Unclustered indexes
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 13
Index entries
Data entries
direct search for
(Index File)
(Data file)
Data Records
data entries
Data entries
Data Records
CLUSTERED UNCLUSTERED

Bulk Loading a B+ Tree• If we have a large collection of records, and we
want to create a B+ tree on some field, doing so by repeatedly inserting records is very slow.
• Bulk Loading can be done much more efficiently.
• Initialization: Sort all data entries, insert pointer to first (leaf) page in a new (root) page.
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 14
3* 4* 6* 9* 10* 11* 12* 13* 20* 22* 23* 31* 35* 36* 38* 41* 44*
Sorted pages of data entries; not yet in B+ treeRoot

Bulk Loading (cont.)• Index entries for
leaf pages always entered into right-most index page just above leaf level. When this fills up, it splits. (Split may go up right-most path to the root.)
• Much faster than repeated inserts, especially when one considers locking!
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 15
3* 4* 6* 9* 10*11* 12*13* 20*22* 23* 31* 35*36* 38*41* 44*
Root
Data entry pages
not yet in B+ tree3523126
10 20
3* 4* 6* 9* 10* 11* 12*13* 20*22* 23* 31* 35*36* 38*41* 44*
6
Root
10
12 23
20
35
38
not yet in B+ tree
Data entry pages

Creating Indexes• Most DBMS (eg. DB2) supports only B+ tree indexes:
CREATE INDEX myIdx ON mytable(col1, col3)CREATE UNIQUE INDEX myUniqIdx ON mytable(col2, col5)CREATE INDEX myIdx ON mytable(col1, col3) CLUSTER
• If a primary key is specified in the CREATE TABLE statement, an (unclustered) index is automatically created for the PK.
• To create a clustered PK index:– Create table without PK constraint– Create index on PK with cluster option– Alter table to add PK constraint
• To get rid of unused indexes: DROP INDEX myIdx;
02/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 16


















