
IBM Research © 2006 IBM Corporation Cell Broadband Engine (BE) Processor Tutorial Michael Perrone...
40
IBM Research © 2006 IBM Corporation Cell Broadband Engine (BE) Processor Tutorial Michael Perrone Manager, Cell Solutions Dept.
-
date post
20-Dec-2015 -
Category
Documents
-
view
223 -
download
3
Transcript of IBM Research © 2006 IBM Corporation Cell Broadband Engine (BE) Processor Tutorial Michael Perrone...

IBM Research
© 2006 IBM Corporation
Cell BroadbandEngine (BE) ProcessorTutorial
Michael PerroneManager, Cell Solutions Dept.

IBM Research
© 2006 IBM Corporation 2
Outline
Cell Overview
Cell Architecture
Cell Programming

IBM Research
© 2006 IBM Corporation 3
Cell BE Processor Overview
IBM, SCEI/Sony, Toshiba Alliance formed in 2000
Design Center opened in March 2001
Based in Austin, Texas
~$400M Investment
February 7, 2005: First technical disclosures
Designed for Sony PlayStation3
– Commodity processor
Cell is an extension to IBM Power family of processors
Sets new performance standards for computation & bandwidth
High affinity to HPC workloads
– Seismic processing, FFT, BLAS, etc.

IBM Research
© 2006 IBM Corporation 4
Peak GFLOPs (Cell SPEs only)
0
20
40
60
80
100
120
140
160
180
200
SinglePrecision
DoublePrecision
FreeScale
DC 1.5 GHz
PPC 970
2.2 GHz
AMD DC
2.2 GHz
Intel SC
3.6 GHz
Cell
3.0 GHz

IBM Research
© 2006 IBM Corporation 5
Peak GFLOPS (PPE & SPEs)
Single Precision Floating Point (SP FP)
– 230 SP GFLOPS per BE @ 3.2 GHz:• 25.6 GFLOPS per SPE, 8 SPE’s per BE chip,
8x32 = 256 GFLOPS• 25.6 GFLOPs from the PU/VMX, 1 PU per
BE chip
Double Precision Floating Point (DP FP)
- 21.0 DP GFLOPS per BE @ 3.2 GHz: 1.83 DP GFLOPs per SPE, 8 SPE’s per BE
chip, 8x1.83= 14.6 GFLOPs 6.4 DP GFLOPs per PU, 1 PU per BE chip
Other architectures for reference (2005)
Peak Performance, floating point instructions per second Net Delta
Intel IA32 @ 4 GHz (SSE3) SPFP: 32 GFLOPs; DPFP: 16 GFLOPs Cell Advantage (4 GHz): 7.2x SP & 1.3x DP
Intel IA64 @ 3 GHz SPFP: 12 GFLOPs; DPFP: 12 GFLOPs Cell Advantage (3 GHz) : 19x SP & 1.7x DP
AMD Opteron @ 3 GHz (SSE) SPFP: 24 GFLOPS; DPFP: 12 GFLOPs Cell Advantage (3 GHz): 9.6x SP & 1.7x DP
Power 5 @ 3 GHz SPFP: 12 GFLOPs; DPFP: 12 GFLOPs Cell Advantage (3 GHz): 19x SP & 1.7x DP
Power 4 @ 2.5 GHz SPFP: 10 GFLOPs; DPFP: 10 GFLOPs Cell Advantage (3 GHz): 23x SP & 2.1x DP
1st Generation Cell (peak floating point operations per second)

IBM Research
© 2006 IBM Corporation 6
Cell BE Architecture Combines multiple high performance processors in
one chip
9 cores, 10 threads
A 64-bit Power Architecture™ core (PPE)
8 Synergistic Processor Elements (SPEs) for data-intensive processing
Current implementation—roughly 10 times the performance of Pentium for computational intensive tasks
Clock: 3.2 GHz (measured at >4GHz in lab)
Cell Pentium D
Peak I/O BW 75 GB/s ~6.4 GB/s
Peak SP Performance ~230 GFLOPS ~30 GFLOPS
Area 221 mm² 206 mm²
Total Transistors 234M ~230M

IBM Research
© 2006 IBM Corporation 7
Cell BE Processor Features
Heterogeneous multi-core system architecture
– Power Processor Element for control tasks
– Synergistic Processor Elements for data-intensive processing
Synergistic Processor Element (SPE) consists of
– Synergistic Processor Unit (SPU)
– Synergistic Memory Flow Control (SMF)
• Data movement and synchronization
• Interface to high-performance Element Interconnect Bus
16B/cycle (2x)16B/cycle
BIC
FlexIOTM
MIC
Dual XDRTM
16B/cycle
EIB (up to 96B/cycle)
16B/cycle
64-bit Power Architecture with VMX
PPE
SPE
LS
SXUSPU
SMF
PXUL1
PPU
16B/cycle
L232B/cycle
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF

IBM Research
© 2006 IBM Corporation 8
Power Processor Element PPE handles operating system and control tasks
– 64-bit Power ArchitectureTM with VMX
– In-order, 2-way hardware simultaneous multi-threading (SMT)
– Coherent Load/Store with 32KB I & D L1 and 512KB L2

IBM Research
© 2006 IBM Corporation 9
Element Interconnect Bus
EIB data ring for internal communication
– Four 16 byte data rings, supporting multiple transfers
– 96B/cycle peak bandwidth
– Over 100 outstanding requests

IBM Research
© 2006 IBM Corporation 10
Element Interconnect Bus
Coherent SMP Bus
– Supports over 100 outstanding requests
– Address Collision Detection
High Bandwidth
– Operates at ½ processor frequency
– Up to 96 Bytes/cycle – over 300 GB/s at 3.2 GHz processor
• 8 Bytes/cycle master and 8 Bytes/cycle slave per element port• 12 Element ports
Modular Design for Scalability
– Physical modularity for flexibility
Independent Command/Address and Data Networks
Split Command / Data Transactions

IBM Research
© 2006 IBM Corporation 11
Bus Interface Controller

IBM Research
© 2006 IBM Corporation 12
Bus Interface Controller Two configurable scalable interfaces
– 7 bytes total outbound / 5 bytes total inbound chip capacity• Rambus FlexIOTM physical• 60 GB/s raw bandwidth at 5 Gb/s per differential pair
– BIF/IOIF0• Configurable protocol
– Broadband Engine Interface (BIF) coherent protocol– I/O Interface (IOIF) non-coherent protocol
• Scalable from 1 to 6 bytes outbound / 1 to 5 bytes inbound– 5 to 30 GB/s outbound / 5 to 25 GB/s inbound
– IOIF1• IOIF protocol • Scalable from 1 to 2 bytes outbound / 1 to 2 bytes inbound
– 5 to 10 GB/s outbound / 5 to 10 GB/s inbound
• 4KB, 64KB, 1MB, 16MB page size support per segment• Storage protection at page granularity

IBM Research
© 2006 IBM Corporation 13
Cell BE Processor Can Support Many Systems Game console systems Blades HDTV Home media servers HPC …
Cell BEProcessor
XDRtm XDRtm
IOIF0 IOIF1
Cell BEProcessor
XDRtm XDRtm
IOIF BIF
Cell BEProcessor
XDRtm XDRtm
IOIF
Cell BEProcessor
XDRtm XDRtm
IOIFBIF
Cell BEProcessor
XDRtm XDRtm
IOIF
Cell BEProcessor
XDRtm XDRtm
IOIF
BIF
Cell BEProcessor
XDRtm XDRtm
IOIFSW

IBM Research
© 2006 IBM Corporation 14
Dual XDRTM Controller (25.6 GB/s @ 3.2 Gbps)

IBM Research
© 2006 IBM Corporation 15
Synergistic Processor Element SPE provides computational performance
– Dual issue, up to 16-way 128-bit SIMD
– Dedicated resources: 128 128-bit RF, 256KB Local Store
– Each can be dynamically configured to protect resources
– Dedicated DMA engine: Up to 16 outstanding requests

IBM Research
© 2006 IBM Corporation 16
SPE Highlights Dual-issue, in-order
– Even: float, fixed, byte– Odd: shuffle, L/S, channel, branch
Direct programmer control– DMA/DMA-list (no cache)– Branch hint (no branch prediction)
VMX-like SIMD dataflow– Broad set of operations– Graphics SP-Float– IEEE DP-Float
Unified register file– 128 entry x 128 bit
256KB Local Store– Combined Instruction, Data & Stack– 16B/cycle L/S bandwidth– 128B/cycle DMA bandwidth
LS
LS
LS
LS
GPR
FXU ODD
FXU EVN
SFPDP
CO
NT
RO
L
CHANNEL
DMA SMMATO
SBIRTB
BE
B
FWD
14.5mm2 (90nm SOI)

IBM Research
© 2006 IBM Corporation 17
SIMD “Cross-Element” Instructions VMX and SPE architectures include “cross-element” instructions
– shifts and rotates
– permutes / shuffles
Permute / Shuffle Example
Reg VA
Reg VB
vector regs shuffle VT,VA,VB,VC
A.0 A.1 A.2 A.3 A.4 A.5 A.6 A.7 A.8 A.9 A.a A.b A.c A.d A.e A.f
B.0 B.1 B.2 B.3 B.4 B.5 B.6 B.7 B.8 B.9 B.a B.b B.c B.d B.e B.f
01 14 18 10 06 15 19 1a 1c 1c 1c 13 08 1d 1b 0e
A.1 B.4 B.8 B.0 A.6 B.5 B.9 B.a B.c B.c B.c B.3 A.8 B.d B.b A.eReg VT
Reg VC

IBM Research
© 2006 IBM Corporation 18
Software Management of SPE Memory An SPE has load/store & instruction-fetch access only to its local store
– Movement of data and code into and out of SPE local store is via DMA
DMA transfers
– 1-, 2-, 4-, 8-, and 16-byte naturally aligned transfers
– 16-byte through 16-KB block transfers (16-byte aligned)
• 128B alignment is preferable
DMA queues
– each SPE has a 16-element DMA command queue
DMA tags
– each DMA command is tagged with a 5-bit identifier
– same identifier can be used for multiple commands
– tags used for polling status or waiting on completion of DMA commands
DMA lists
– a single DMA command can cause execution of a list of transfer requests (in LS)
– lists implement scatter-gather functions
– a list can contain up to 2K transfer requests

IBM Research
© 2006 IBM Corporation 19
Cell Programming
16B/cycle (2x)16B/cycle
BIC
FlexIOTM
MIC
Dual XDRTM
16B/cycle
EIB (up to 96B/cycle)
16B/cycle
64-bit Power Architecture with VMX
PPE
SPE
LS
SXU
SPU
SMF
PXUL1
PPU
16B/cycle
L232B/cycle
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF
LS
SXU
SPU
SMF

IBM Research
© 2006 IBM Corporation 20
High-Level Programming View
Code Generation
– Write PPE & SPE code• Individually• With OpenMP pragmas (not in current SDK)• single-source compiler in progress...
– Compile and link into single executable
Run-Time Flow
– Run executable on PPE
– PPE creates memory map(s)
– PPE Spawns SPE threads• PPE pointer to SPE code in main memory• DMA code to SPE• SPE runs code independently

IBM Research
© 2006 IBM Corporation 21
Typical CELL Software Development Flow
Algorithm complexity study
Data traffic analysis
Control/Compute partitioning of the algorithm
Develop PPE control code & PPE scalar code
Port PPE scalar code to SPE scalar code
– SPE thread creation
– Communication & synchronization
– DMA code for data movement
– Overlay management (if needed)
Transform SPE scalar code to SPE SIMD code
– Implement with vector variables using vector intrinsics
– Latency handling: multi-buffering, loop unrolling, etc.
Re-balance the computation / data movement
Other optimization considerations
– PPE SIMD, system bottle-necks, load balancing
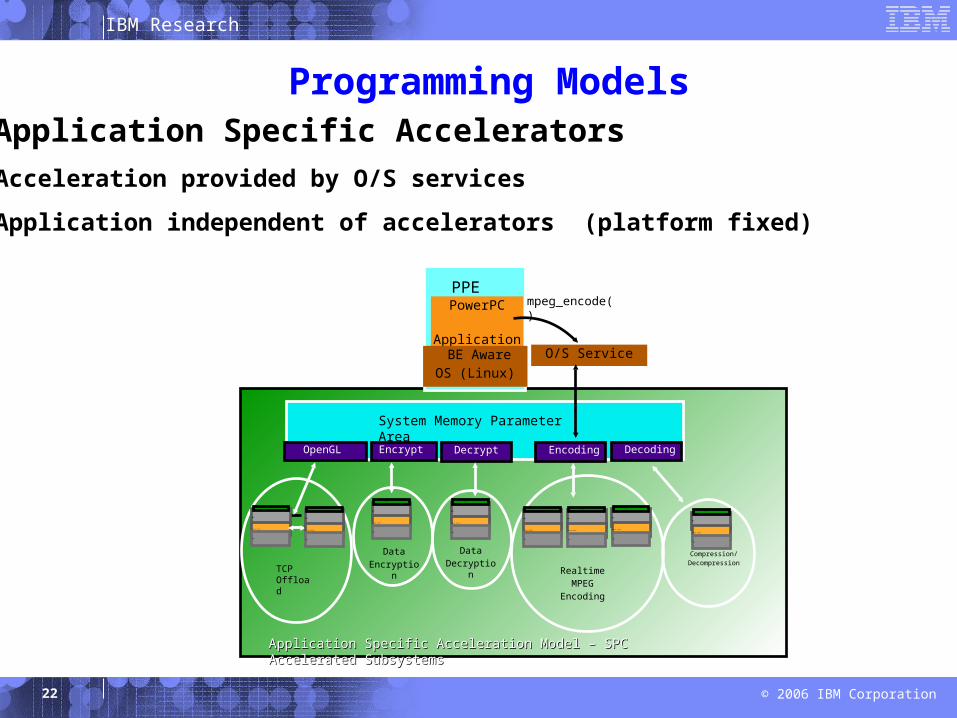
IBM Research
© 2006 IBM Corporation 22
Application Specific Acceleration Model – SPC Accelerated SubsystemsApplication Specific Acceleration Model – SPC Accelerated Subsystems
System Memory Parameter Area
PPEPowerPC
Application
BE AwareOS (Linux)
Compression/Decompression
RealtimeMPEG
Encoding
TCP Offload
DataEncryption
DataDecryption
OpenGL Encrypt Decrypt Encoding
O/S Service
mpeg_encode()
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
MFC
Local Store
SPU
AUC
Decoding
1. Application Specific AcceleratorsAcceleration provided by O/S services
Application independent of accelerators (platform fixed)
Programming Models

IBM Research
© 2006 IBM Corporation 23
Programming Models
Power Processor
(PPE)
System Memory
SPU
Local Store
MFC
N
SPU
Local Store
MFC
N
Multi-stage Pipeline SPU
Local Store
MFC
N
SPU
Local Store
MFC
N
SPU
Local Store
MFC
N
Parallel-stages
Power Processor
(PPE)
System Memory
2. Function OffloadSPE function provided by libraries
Predetermined functions
Application calls standard Libraries
Single source compilation
SPE working set fits in Local Store
O/S handles SPE allocation

IBM Research
© 2006 IBM Corporation 24
Power Processor
(PPE)
SPU
Local Store
MFC
N
SPE Puts Results
PPEPuts
Initial TextStatic DataParameters System Memory
SPE IndependentlyStages Text & Intermediate Data
Transfers while executing
Power Processor
(PPE)
SPU
Local Store
MFC
N
PPEGets
Results
PPEPutsText
Static DataParameters
SPE executes
3. Computational AccelerationUser created RPC libraries
User acceleration routines
User compiles SPE code
Local Data
Data and Parameters passed in call
Global Data
Data and Parameters passed in call
SPE Code manages global data
Programming Models

IBM Research
© 2006 IBM Corporation 25
Structured – Easier for memory fetch & SIMD operations– Data prefetch possible – Non branchy instruction pipeline; – Data more tolerant, but has the same caution
Multiple Operations on Data– Many operations on same data before
reloading
Easy Parallelize and SIMD– Little or nor collective communication
required– No Global or Shared memory or nested loops
Compute Intense– Determined by ops per byte
Fits Streaming Model – Small computation kernel through which you
stream a large body of data– Algorithms that fit Graphics Processing Units– GPU’s are being used for more than just
graphics today thanks to PCI Express
Target Areas Data Manipulation
–Digital Media–Image processing–Video processing–Visualization of output–Compression/decompression–Encryption /decryption–DSP–Audio processing, language translation?
Graphics–Transformation between domains (viewpoint
transformation; time vs space; 2D vs 3D)–Lighting–Ray Tracing / Ray casting
Floating Point Intensive Applications (SP)–Single precision Physics –Single precision HPC–Sonar
Pattern Matching–Bioinformatics–String manipulation (search engine)–Parsing, transformation,translation (XSLT)–Audio processing, language translation?–Filtering & Pruning
Offload Engines–TCP/IP –Compiler for gaming applications–Network Security, Virus Scan and Intrusion
Ideal Cell Software

IBM Research
© 2006 IBM Corporation 26
Cell High Affinity Workloads Cell excels at processing of rich media content in the context of broad
connectivity– Digital content creation (games and movies)– Game playing and game serving– Distribution of dynamic, media rich content– Imaging and image processing– Image analysis (e.g. video surveillance)– Next-generation physics-based visualization– Video conferencing– Streaming applications (codecs etc.)– Physical simulation & science
Cell is an excellent match for any applications that require:– Parallel processing– Real time processing– Graphics content creation or rendering– Pattern matching– High-performance SIMD capabilities

IBM Research
© 2006 IBM Corporation 27
Non Ideal Software Branchy data
– Instruction “branchiness” may be partially mitigated through different methods (e.g. calculating both sides of the branch and using select)
Not structured
– Not SIMD friendly
Pointer Indirection or Multiple levels of pointer indirection
– fetching becomes hard
Data load granularity less than 16 bytes
– BW performance degradation
– DMA <128 Byte
– SPE to local store is 16 Byte
Not easily parallelized
Tightly coupled algorithms requiring synchronization

IBM Research
© 2006 IBM Corporation 28
BACKUP SLIDES

IBM Research
© 2006 IBM Corporation 29
Node-Level Parallelism (e.g., MPI)
Original Parallelism
Nested ParallelismHyper Parallelism
PPE
SPE

IBM Research
© 2006 IBM Corporation 30
Additional Information http://www-306.ibm.com/chips/techlib/techlib.nsf/products/Cell
– Cell Broadband Engine Architecture V1.0 – Synergistic Processor Unit (SPU): Instruction Set Architecture V1.0 – SPU Application Binary Interface: Specification V1.3 – SPU Assembly Language: Specification V1.2 – SPU C/C++ Language: Extensions V2.0
http://www.research.ibm.com/cell

IBM Research
© 2006 IBM Corporation 31
(c) Copyright International Business Machines Corporation 2005.All Rights Reserved. Printed in the United Sates April 2005.
The following are trademarks of International Business Machines Corporation in the United States, or other countries, or both. IBM IBM Logo Power Architecture
Other company, product and service names may be trademarks or service marks of others.
All information contained in this document is subject to change without notice. The products described in this document are NOT intended for use in applications such as implantation, life support, or other hazardous uses where malfunction could result in death, bodily injury, or catastrophic property damage. The information contained in this document does not affect or change IBM product specifications or warranties. Nothing in this document shall operate as an express or implied license or indemnity under the intellectual property rights of IBM or third parties. All information contained in this document was obtained in specific environments, and is presented as an illustration. The results obtained in other operating environments may vary.
While the information contained herein is believed to be accurate, such information is preliminary, and should not be relied upon for accuracy or completeness, and no representations or warranties of accuracy or completeness are made.
THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN "AS IS" BASIS. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained in this document.
IBM Microelectronics Division The IBM home page is http://www.ibm.com1580 Route 52, Bldg. 504 The IBM Microelectronics Division home page is Hopewell Junction, NY 12533-6351 http://www.chips.ibm.com

IBM Research
© 2006 IBM Corporation 32
A Change in thinking….“What we have in the Cell chip is a ½ speed JS20 (chip) that can sprint
to as much 50-100x performance increases when properly leveraged…
…if you can get past the memory and programming optimization issues - and these really aren’t much tougher than traditional graphics programming or even device driver development or HPC applications…
…and if you can get a proper hardware design around it.”

IBM Research
© 2006 IBM Corporation 33
SXU ISA – Floating Point
Single precision is extended range
– range is 1.2E-38 to 6.8E38
Single precision does not implement full IEEE standard, e.g:
– truncation toward zero is only supported rounding mode
– NaN not supported as an operand and not produced as a result
– denorms not supported and treated as zero
– except for denorms, NaNs, and infinities, format is same as IEEE
Double precision is IEEE standard
– normal IEEE semantics and definitions apply
– all rounding modes supported
– precise exceptions not supported
All instructions are inherently SIMD
– scalar ops in preferred slot (managed by compiler)

IBM Research
© 2006 IBM Corporation34
SXU ISA Differences with VMX
In VMX, not SPU– saturating math– sum-across– Log2 and 2x
– ceil and floor– complete byte instructions
In SPU, not VMX– immediate operands– double precision floating point– sum of absolute difference– count ones in bytes– count leading zeros– equivalence– nand– or complement– extend sign– gather bits– form select mask– integer multiply and accumulate– multiply subtract– multiply float– shuffle byte special conditions– carry and borrow generate– sum bytes across– extended shift range

IBM Research
© 2006 IBM Corporation35
FFT Performance
16M-point, complex, single-precision FFT (+PPE)– Power5 @ 1.65GHz: 1.55 GFLOPS– Cell @ 3.2 GHz: 46.8 GLOPS (20% eff.)
64K-point, complex, single-precision FFT (all in LS)– Cell @ 3.0 GHz: 109 GFLOPS (57% eff.)

IBM Research
© 2006 IBM Corporation36
Single-SPE: Single Precision MatrixMultiply Performance (SGEMM)
Performance improved significantly with optimizations and tunings by
taking advantage of data level parallelism using SIMD
double buffering for concurrent data transfers and computation
optimizing dual issue rate, instruction scheduling, etc.
CPI Dual Issue Channel Stalls Other Stalls# of Used Registers
GFLOPs Effic’y
Original (scalar) 1.05 26.1% 11.4% 26.3% 47 0.42 1.6%
SIMD optimized 0.711 40.3% 3.0% 9.8% 60 10.96 42.8%
SIMD
double buf’d0.711 41.4% 2.6% 10.2% 65 11.12 43.4%
Optimized code 0.508 80.1% 0.2% 0.4% 69 25.12 98.1%

IBM Research
© 2006 IBM Corporation37
Parallel MatrixMultiply Performance (Single Precision)
Achieved near-linear scalability on 8 SPUs with close to 100% compute efficiency
Performed 8x better than a Pentium4 with SSE3 at 3.2GHz assuming it can achieve its peak single-precision floating point capability.
Performance of Parallelized Matrix Multiply
0
50
100
150
200
250
1 2 3 4 5 6 7 8
# of SPUs
GF
LO
Ps 512x512
1024x1024
Peal Gflops

IBM Research
© 2006 IBM Corporation38
Crypto Performance – SPE vs. IA32
Function SPE (Gbps) IA-32 (Gb/sec) SPE advantage
AES ECB Encrypt - 128 bit key 1.93 0.96 2.00
AES CBC Encrypt - 128 bit key 0.75 0.91 0.82
AES ECB Decrypt - 128 bit key 1.41 0.97 1.45
AES CBC Decrypt - 128 bit key 1.41 0.91 1.56
DES - encrypt ECB 0.46 0.40 1.16
TDES - encrypt ECB 0.16 0.12 1.31
MD5 2.30 2.68 0.86
SHA-1 1.98 0.85 2.35
SHA-256 0.80 0.49 1.65
Optimization efforts in loop unrolling register-based table lookup, dual issue rate, bit permutation, byte shuffling, etc.
– More registers give SPE significant advantage in using aggressive loop unrolling and in table lookup– Performance of a single SPE is better than an IA32 at the same frequency (up to 2.35x) in most cases

IBM Research
© 2006 IBM Corporation39
Transform-Light Performance on a Single SPE
Unrolled Loops
G5 2GHz (Mvtx/sec)
G5 2.7GHz (Scaled)
(Mvtx/sec)
SPE 3.2GHz (Mvtx/sec)
SPE Advantage
1 82.95 112 139.44 1.25
2 94.8 128 155.92 1.22
4 89.47 120 208.48 1.73
8 58.45 79 217.2 2.75
Optimization of transform-light has been focused on loop unrolling, branch avoidance, dual issue rate, streaming data, etc.
– More registers give SPE significant advantage with aggressive loop unrolling– an SPE can perform 1.7x better than a best of breed G5 with VMX

IBM Research
© 2006 IBM Corporation40
MPEG2 Decoder Performance on a Single SPE
# of Cycles # of Inst. CPI
Effective
CPI
# of Used
Registers
Frames/s
@3.2GHz
CIF (1Mbps) 63.4M 51.9M 1.22 1.42 126 1514
SDTV (5Mbps) 263M 220M 1.2 1.38 126 365
SDTV (8Mbps) 324M 290M 1.12 1.27 126 296
HDTV (18Mbps) 1.25G 1.01G 1.24 1.46 126 77
VLD (Variable Length decoding) in decoder is very branchy – needs a lot of optimization to run well on a SPE
MC (Motion Compensation) and IDCT deal with very structured 8-bit/16-bit data – can be highly optimized to take advantage of SPE’s 8-way/16-way SIMD capability
Pentium4 w/SSE2 at 3.06GHz can decode 310 frames/s (SDTV)– Each SPE can perform very much the same as a Pentium4 w/ SSE2 running at the same frequency
* Note: Results from simulator, ~10% error in SPCsim results.


















