
IBM ATS Deep Computing © 2007 IBM Corporation Introduction to Compilers HPC Workshop – University...
53
IBM ATS Deep Computing © 2007 IBM Corporation Introduction to Compilers HPC Workshop – University of Kentucky May 9, 2007 – May 10, 2007 Andrew Komornicki, Ph. D. Balaji Veeraraghavan, Ph. D.
-
Upload
reginald-summers -
Category
Documents
-
view
214 -
download
0
Transcript of IBM ATS Deep Computing © 2007 IBM Corporation Introduction to Compilers HPC Workshop – University...

IBM ATS Deep Computing
© 2007 IBM Corporation
Introduction to Compilers HPC Workshop – University of KentuckyMay 9, 2007 – May 10, 2007
Andrew Komornicki, Ph. D.Balaji Veeraraghavan, Ph. D.

IBM ATS Deep Computing
© 2007 IBM Corporation
Agenda
Introduction
Availability of compilers, GNU, Intel and IBM
Compiler naming and default setting
Memory management
32 vs. 64-bit, Memory allocation
Compiler performance optimization
Profile
Optimization level 0-5
-qhot
Target machine specification
Many others

IBM ATS Deep Computing
© 2007 IBM Corporation
Quick Reference Page – Cheat Sheet
Which IBM Fortran compiler to use
Language Sequential SMP MPI
Fortran 77 xlf xlf_r mpxlf
Fortran 90 xlf90 xlf90_r mpxlf90
Fortran 95 xlf95 xlf95_r mpxlf95
Compiler options for performance
-O3 -qarch=pwr5 -qtune=pwr5 (use these at minimum)
-hot (High order Transformation)
-pg (profiling)
-qstrict (do not alter the semantics of a program)
-qipa (inter procedural analysis)

IBM ATS Deep Computing
© 2007 IBM Corporation
XLF Fortran Documentation1.Installation Guide - XL Fortran Enterprise Edition V10.1 for AIX
2. Getting Started - XL Fortran Enterprise Edition V10.1 for AIX
3. Language Reference - XL Fortran Enterprise Edition V10.1 for AIX
4. Compiler Reference - XL Fortran Enterprise Edition V10.1 for AIX
5. Optimization and Programming Guide - XL Fortran Enterprise Edition V10.1 for AIX
6. Readme File - XL Fortran Enterprise Edition V10.1 for AIX
7. Readme updates for XL Fortran Enterprise Edition V10.1 for AIX (and many similar volumes for C, C++, and Linux)

IBM ATS Deep Computing
© 2007 IBM Corporation
Compiler Document on Your Systems
Compiler Document location
C /usr/vac/pdf/en_US
C++ /usr/vacpp/pdf/en_US
xlf /usr/lpp/xlf/pdf
C C++ xlf
Language Reference language.pdf language.pdf lg.pdf
Compiler Reference compiler.pdf compiler.pdf ug.pdf
Debugging debug.pdf debug.pdf
The “man” page $ man xlf – this one works! $ man xlC – I did not find man page

IBM ATS Deep Computing
© 2007 IBM Corporation
Compiler documentation on the Internet
www.software.ibm.com/
Products A-Z– X
>XLFORTRAN
>XLC/C++
Editions:
Linux on pSeries
AIX
Many IBM customers place IBM document on line and it’s often easier to find,
www.google.com

IBM ATS Deep Computing
© 2007 IBM Corporation
IBM Compiler Names
Compiler Command Name
C xlc xlc and Visual Age C (vac)
C++ xlC xlC and Visual Age C++ (vacpp)
FORTRAN xlf, xlf90, xlf95 XL FORTRAN
There are a lot more, including fort77, cc99_128, xlc128_r7…

IBM ATS Deep Computing
© 2007 IBM Corporation
IBM Compiler Versions
C C++ Fortran
Versions 6.0, 7.0, 8.0 6.0, 7.0, 8.0 8.1, 9.1, 10.1
StandardsExtended
ANSI CANSI C++
Fortran 77
Fortran 90
Fortran 95
Latest Release 2006 2006 2006
Installations /usr/vac /usr/vacpp /usr/lpp/xlf

IBM ATS Deep Computing
© 2007 IBM Corporation
C Compiler Invocations
Language SequentialReentrant
(for SMP)
Message Passing
ANSI C++ xlC xlC_r mpCC
ANSI C xlc xlc_r mpcc
Extended cc cc_r
Two C compilers:•C and C++•C is a subset of C++

IBM ATS Deep Computing
© 2007 IBM Corporation
Fortran Compiler Invocations
Language Sequential SMP MPI
Fortran 77 xlf xlf_r mpxlf
Fortran 90 xlf90 xlf90_r mpxlf90
Fortran 95 xlf95 xlf95_r mpxlf95
One Fortran compiler, multiple invocations.

IBM ATS Deep Computing
© 2007 IBM Corporation
r78n06:/u/komornic:516>
. setup.compilers (just source this script)
Using Visual Age C/C++ Version: 8.0
path to vacpp: /opt/ibmcmp/vacpp/8.0/bin
Using XL Fortran Version: 10.1
path to xlf Fortran: /opt/ibmcmp/xlf/10.1/bin
Finding your compiler and path

IBM ATS Deep Computing
© 2007 IBM Corporation
xlf_r and mpxlf Example: Hello, Worldprogram hello
print *, ‘Hello, World’end
% xlf_r hello.f –l hello <<< using xlf_r % helloHello, World
% mpxlf hello.f –l hello <<<< using mpxlf% helloERROR: 0031-808 Hostfile or pool must be used to request nodes% hello –procs 4 –hostfile hostfile Hello, WorldHello, WorldHello, WorldHello, World
mpxlf will enable the binary to run in SPMD mode across multiple CPUs

IBM ATS Deep Computing
© 2007 IBM Corporation
Environment Variables
LANG=en_US
NLSPATH=/usr/lib/nls/msg/%L/%N:/usr/lib/nls/msg/%L/%N.cat
For AIX
Libxlf90.a should be at /usr/lib or set the path:
LIBPATH = /my_xlf90_lib_path:/usr/lib
Fox Linux, the path should be
LD_LIBRARY_PATH=/usr/lib
You may also need LD_RUN_PATH= runtime library search path

IBM ATS Deep Computing
© 2007 IBM Corporation
xlf Version 10.1
Traditional allowable extensions:
.f
.F (will pass through cpp before compiling)
New allowable extensions:
.f77
.f90
.f95

IBM ATS Deep Computing
© 2007 IBM Corporation
Shifting to a Next Topic
32-bit, 64-bit and memory management

IBM ATS Deep Computing
© 2007 IBM Corporation
Address Mode: -q{32,64}
Available application modes:
-q32 (Default)
-q64
Also: environment variable OBJECT_MODE• export OBJECT_MODE={32,64}
Cannot mix -q32 objects with -q64 objects
Be aware of AIX kernel modes:
32-bit
64-bit
Application address mode is independent of AIX kernel mode

IBM ATS Deep Computing
© 2007 IBM Corporation
One more thing about 64-bit… If you use –q64:
Your job can use lots more memory than –q32
INTEGER*8 or long long operations are faster
If you use –q32:
You may run approximately (~10%) percent faster• Fewer bytes are used storing and moving pointers
You will have to learn AIX link options –bmaxdata• -bmaxdata:0x10000000 = 256 Mbyte = default• -bmaxdata:0x80000000 = 2 Gbyte• -bmaxdata:0xC0000000 = not widely publicized trick to use more than 2
Gbyte with –q32 “C” is the maximum
-q64 • –bmaxdata:0 = default = unlimited• Other –bmaxdata values will be enforced if set

IBM ATS Deep Computing
© 2007 IBM Corporation
Even more on 64-bit...(because it is so often confused)
• 64-bit floating point representation is higher precision•Fortran: REAL*8, DOUBLE PRECISION•C/C++: double• You can use 64-bit floating point with –q32 or –q64
• 64-bit addressing is totally different. It refers to how many bits are used to store memory addresses and ultimately how much memory one can access.
•Compile and link with –q64•Use file a.out myobj.o to query addressing mode
• The AIX kernel can be either a build that uses 32-bit addressing for kernel operations or uses 64-bit addressing, but that does not affect an application’s addressibilty.
• ls –l /unix to find out which kernel is used• Certain system limits depend on kernel chosen

IBM ATS Deep Computing
© 2007 IBM Corporation
Suggested Fortran Compiler Usage
xlf90_r –q64
Fortran 90 is the most portable standard
Consistent storage
Reentrant code (..._r)
• Required for:– phreads– Many other programming utilities
64-bit addressing:
Memory management

IBM ATS Deep Computing
© 2007 IBM Corporation
Suggested C Compiler Usage
xlc_r –q64
Reentrant code (..._r).– Required for:
> phreads> Many other programming utilities
64-bit addressing:
• Better memory management

IBM ATS Deep Computing
© 2007 IBM Corporation
Address Modes
ILP32
Integers, Long integers and Pointers are 32 bits
LP64
Long integers and Pointers are 64 bits
Standard C and C++ relationship:
sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long)

IBM ATS Deep Computing
© 2007 IBM Corporation
C and C++ Data Type Sizes
-q32 -q64
Data Type ILP32 LP64
Char 8 same
Short 16 same
Int 32 same
Long 32 64
Long long 64 same
Pointer 32 64
Enum 32 same
Float 32 same
Double 64 same
Long double 64 same
long and pointer change size with –q{32,64}

IBM ATS Deep Computing
© 2007 IBM Corporation
Fortran Data Type Sizes Data Type ILP32 LP64
integer 32 same
integer(2) 16 same
integer(4) 32 same
integer(8) 64 same
real 32 same
Real(4) 32 same
Real(8) 64 same
Real(16) 128 same
Double 64 same
Logical 32 same
Logical(2) 16 same
Logical(4) 32 same
Logical(8) 64 same
Pointer 32 64
pointers change size with –q{32,64}

IBM ATS Deep Computing
© 2007 IBM Corporation
Fortran Data Type Sizes
-q32 -q64
Default INTEGER
4 bytes 4 bytes
Default REAL 4 bytes 4 bytes
Loc() 4 bytes 8 bytes

IBM ATS Deep Computing
© 2007 IBM Corporation
Fortran Data Type Sizes
Type Default Kind=1 Kind=2 Kind=4 Kind=8 Kind=16 Kind=32
Logical 4 1 2 4 8 4 4
Integer 4 1 2 4 8 4 4
Real 4 4 4 4 8 16 4
complex 4 4 4 4 8 16 4
IBM ATS Deep Computing
© 2007 IBM Corporation
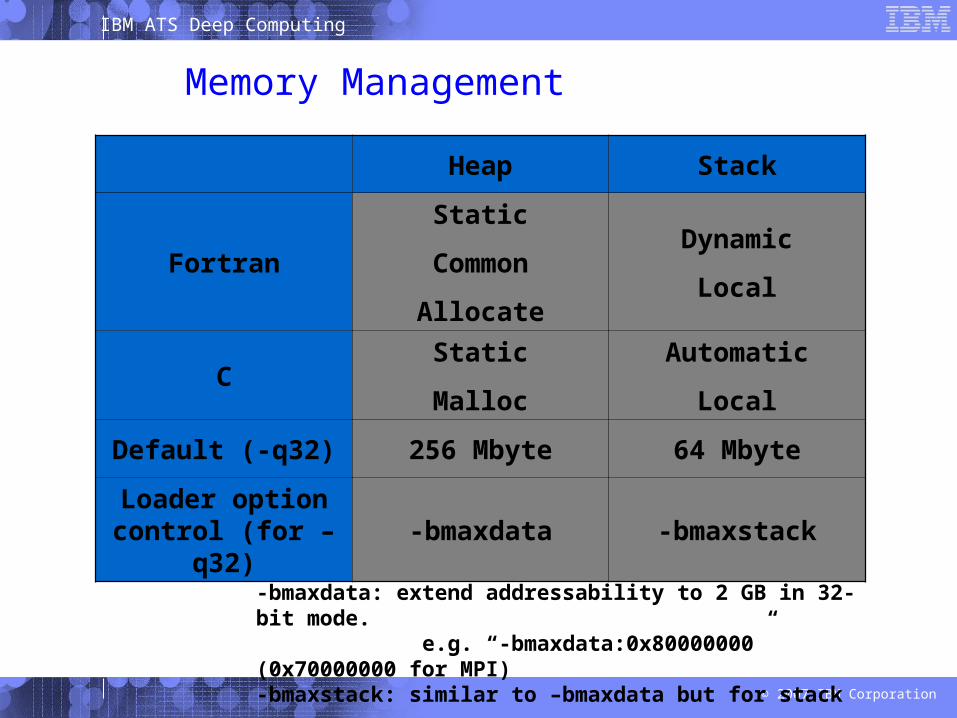
Memory Management
Heap Stack
Fortran
Static
Common
Allocate
Dynamic
Local
CStatic
Malloc
Automatic
Local
Default (-q32) 256 Mbyte 64 Mbyte
Loader option control (for –q32)
-bmaxdata -bmaxstack
-bmaxdata: extend addressability to 2 GB in 32-bit mode. e.g. “-bmaxdata:0x80000000” (0x70000000 for MPI)-bmaxstack: similar to –bmaxdata but for stack

IBM ATS Deep Computing
© 2007 IBM Corporation
ALLOCATE and malloc Arrays
Allocation occurs at statement execution
Heap operation• Inexpensive• Limited size
Maximum size specification (for 32-bit only):
$(LDR) ...-bmaxdata:0x80000000
Subroutine sub(n)Integer, allocatable, Dimension(:) :: A…Allocate(A(n))…Deallocate(A)end
void my_proc(){ long *A…A = (long *) malloc(n*sizeof(long));…free(A);}

IBM ATS Deep Computing
© 2007 IBM Corporation
Dynamic and Automatic Arrays Memory allocation occurs at subroutine entry
Stack operation
• Inexpensive
• Limited size
Maximum size specification:
$(LDR) ...-bmaxstack:256000000
Subroutine sub(n)integer A(n)….A(i) = ……returnend
void sub(int n){long A[n];….A[i] = ……return(0);}

IBM ATS Deep Computing
© 2007 IBM Corporation
Dynamic and Automatic Arrays
-q32 -q64 Comment
Default 64 Mbyte Unlimited
Maximum 2 GbyteUnlimited
(ulimit)-bmaxstack
Salve Default 4 Mbyte 4 Mbyte
Slave Max. 64 Mbyte 4 GbyteXLSMPOPTS \
stack=64000000
Note: Extra concern with pthreads or OpenMPDefault SLAVE stack is only 4 Mbyte.Use XLSMPOPTS=stack=…

IBM ATS Deep Computing
© 2007 IBM Corporation
Memory Allocation: Summary
Heap Stack
Control -bmaxdata -bmaxstack
-q32 2 Gbyte 256 Mbyte
-q64 Unlimited unlimited
•Programming advice: Fortran ALLOCATEC
malloc

IBM ATS Deep Computing
© 2007 IBM Corporation
Shifting to Next Topic
Compiler options

IBM ATS Deep Computing
© 2007 IBM Corporation
Fortran Compiler Options – 10 categories
Categories Commonly Used Options
Control input to the compiler -I, -qfixed -qfree
Specify locations of output file -d –o
Performance optimization -O0 to –O5, -p, -pg, -qarch, -qtune, -qhot, -qessl, -qipa, -qlargepage, -qsmp=omp, -qstrict, -qthreaded, -
qunroll
Error checking and debugging -C, -g, -qdbg, -qlanglvl,
Control listings and messages -qlist, -qreport –qversion –S -v
compatibility -qautodbl, -qbigdata, -qinit, -qrealsize, -qsave, -qxlf77, -qxlf90
Floating-point processing -qfloat, -qieee, -qstrictieeemod,
Control linking -c, -Ldir, -lkey,
Control other compiler operations -B, -Fconfig_file, -q32, -q64
Obsolete or not recommended -qcharlen, -qrecur

IBM ATS Deep Computing
© 2007 IBM Corporation
Summary: Commonly Used Options -q32, -q64
-O0, -O2,-O3,-O4,-O5
Large/medium memory page set up
-qmaxmem=-1(allow max mem for compiling)
-qarch=,-qtune=
-hot (High order Transformation)
-g (debugging)
-p, -pg (profiling)
-qstrict (no alter the semantics of a program)
-qstatic
-qipa (inter procedural analysis)
-qieee
-qlist (assembly lang report)
-qsmp
-qreport(smp list when –qsmp also used)

IBM ATS Deep Computing
© 2007 IBM Corporation
Profiling Your Code
1. Compile the code with –p (or –pg)
compiler will set up the object file for profile (or graph profile)
2. Execute the program. A mon.out (or gmon.out) file will be created
3. Use prof (or gprof) command to generate a profile
4. Or xprofiler a.out gmon.out (if you can open xwindow)
Example
xlf95 -p needs_tuning.f
a.out mon.out created prof
Example
xlf95 -pg needs_tuning.f
a.out gmon.out created gprof a.out gmon.out xprofiler a.out gmon.out

IBM ATS Deep Computing
© 2007 IBM Corporation
Large Pages Option -qlargepage
- This option enables large page usage
- It instructs the compiler to exploit large page heaps available on POWER4 and POWER5 systems
HINT to the compiler:
• Heap data will be allocated from large page pool• Actual control is from loader option –blpdata or
LDR_CNTRL=LARGE_PAGE_DATA
Compiler may divert large data from the stack to the heap
Compiler may bias optimization of heap or static data references

IBM ATS Deep Computing
© 2007 IBM Corporation
Compiler Optimizations for Performance Optimization
5 levels of optimization
No specification: same as –qnoopt, -O0
-O0: no optimization, same as –qnoopt. Eq. to default
-O2, -O3, -O4, -O5
Target machine specification
-qhot: (High Order Transformation)
-qipa: (Inter Procedural Analysis)
Many others
INLINE
UNROLL
etc

IBM ATS Deep Computing
© 2007 IBM Corporation
Optimization Levels
-O0
(not specified)(-qnoopt)
-O3Extensive
opt.May changesemantics
-OO2
Low levelopt.
Not enoughfor
performance
Stronglyrecommended
-O4Aggressive
opt.-qipa-qhot
-O5ipa=level2
Default

IBM ATS Deep Computing
© 2007 IBM Corporation
Optimization Level 0, 2
-O0
(not specified)-O2 = -O
Fast compilationComprehensive
low-level opt.
Full support
debugging
Global assign.
of user variables
No optimization
at all
Elim. redundant
or unused code
DEFAULTScheduling instr.
for target machine

IBM ATS Deep Computing
© 2007 IBM Corporation
Optimization Level 2 - 5
-O2 -O3 * -O4* -O5*
Comprehensive
low-level opt.Source manipulation
High Order
Transformations
(HOT)
More
aggressive
IPA, inlining
Global assign. Of
user variablesInner loop unrolling
InterProcedural
Analysis (IPA),
inlining
Elim. Of redundant
or unused codeSoftware pipelining
Automatic
architecture, tuning,
cache detection
Scheduling instr.
for target machine
Whole procedure
scope
* Use –qstrict to ensure semantics is unchanged
Strongly recommended for performance

IBM ATS Deep Computing
© 2007 IBM Corporation
Optimization Level Hierarchy
Base Optimization Level
Additional Options Implied by Base
Optimization Level
Additional Recommended
Options
Additional Options to Try with Base
Optimization Level
-O0None -qarch
-qtune
-g
-O2 -qmaxmem=2048* -qarch
-qtune
-qhot -g
-O3-qnostrict
-qmaxmem=-1*
-qarch
-qtune
-g –qhot=vector
-qstrict
-O4
All of –O3 plus:
-qhot
-qipa
-qarch=auto
-qtune=auto
-qcache=auto
-O5 -qipa=level=2
* Limit memory to be used by compiler for optimization

IBM ATS Deep Computing
© 2007 IBM Corporation
Effect of –O2 vs. –O3 Wider optimization scope
Replaces divide with reciprocal
Unrolls inner loops
Precision tradeoffs
Not strictly IEEE floating point rules
for (i=0;i<n;i++) b[i] = a[i]/s
rs=1/sfor (i=0;i<n;i=i+1) {b[i] = a[i]*rs b[i+1] = a[i+1]*rs}
-O3

IBM ATS Deep Computing
© 2007 IBM Corporation
Effect of –O2 vs –O3
0
100
200
300
400
500
600
700
800
900
Mfl
op
/s
B(i)=A(i)/s B(i)=s*A(i)+t a(i+1)=s*a(i)+t*a(i-1)
-O2
-O3
1.3 GHz POWER4
Replaces divide with reciprocal
Unrolls inner loops
"Regular" code runs well with -O2

IBM ATS Deep Computing
© 2007 IBM Corporation
-qessl Option
-qessl allows the use of the ESSL routines in place of Fortran 90 intrinsic procedures. This does not link in all other essl libraries
Rules
Be sure to add –lessl (or –lesslsmp) to link command
Use thread safe version of compiler xlf_r, xlf90_r or xlf95_r, since libessl.so and libesslsmp.so have a dependency on libxlf90_r.so, or specify –lxlf90_r on link command line
Example: c=MATMUL(a,b) may use ESSL routines
ESSL libraries are not shipped with the XLF compiler

IBM ATS Deep Computing
© 2007 IBM Corporation
High Order Transformations (HOT)
-qhot [=[no]vector | arraypad[=n]]
Transformation of loop nests
Hardware prefetch
Balance loop computation
Vector intrinsic library
Included at -O4 and higher level optimization

IBM ATS Deep Computing
© 2007 IBM Corporation
-qhot Transformation: Merge
0
100
200
300
Mfl
op
/s
-O3-O3 -qhotMerged
1.3 GHz POWER4
do i=1,n A(i) = A(i) + B(i)*send dodo i=1,n C(i) = C(i) + A(i)*send do
do i=1,n A(i) = A(i) + B(i)*s C(i) = C(i) + A(i)*send do
-qhot

IBM ATS Deep Computing
© 2007 IBM Corporation
-qhot Transformation: Loop Interchange
0100200300400500
Mfl
op
/s -O3-O3 -qhotInterchange
do i=1,m do j=1,n sum = sum + X(i)*A(i,j) end doend do
do j=1,n do i=1,m sum = sum + X(i)*A(i,j) end doend do
-qhot
1.3 GHz POWER4

IBM ATS Deep Computing
© 2007 IBM Corporation
-qhot Transformation: Vectorization
Extract intrinsic function, compute in batches
Lower latency
Better register utilization
Pipelined

IBM ATS Deep Computing
© 2007 IBM Corporation
Vectorization Example
SUBROUTINE VD(A,B,C,N)
REAL*8 A(N),B(N),C(N)
DO I = 1, N
A(I) = C(I) / SQRT(B(I))
END DO
END

IBM ATS Deep Computing
© 2007 IBM Corporation
-qhot Transformation: Vectorization
0
5
10
15
20
25
Mfl
op
/s -O3-O3 -qhot
do i=1,n A(i) = exp(B(i)) end do
CALL __vexp(a ,b,n)-qhot
1.3 GHz POWER4

IBM ATS Deep Computing
© 2007 IBM Corporation
Target Machine Specification -qarch
-qarch=[com,auto,ppc,pwr3,pwr4,pwr5,...]
Generate a subset of the Power instruction set
Arch Example
pwr5 POWER5 (recommend for iHPC)
Com
(default)
Code can run on any 64-bit power hardware platform
ppc Code can run on any 32-bit hardware platform
Auto Same architecture for compilation and execution
pwr5,
pwr5x
POWER5
POWER5+

IBM ATS Deep Computing
© 2007 IBM Corporation
Effect of -qarch
0
10
20
30
40
50
60
70
Mo
p/s
SQRT 1/SQRT
-qarch=com-qarch=pwr4
1.3 GHz POWER4

IBM ATS Deep Computing
© 2007 IBM Corporation
Target Machine Specification -qtune=processor Tunes instruction, scheduling, etc, for a given h/w
Does not imply anything about the ability to run correctly on a given machine
Affects performance but not instructions
Independent of –qarch option
If 90% of users are using PWR5, but 10% users are using PWR4, you can do –qarch=pwr4 –qtune=pwr5
Tune hardware Example for HPC
pwr5 POWER5Compile and run on your
machines
AutoSame arch for compile
and executionCompile and run
pwr4,
pwr5,
POWER4
POWER5

IBM ATS Deep Computing
© 2007 IBM Corporation
Questions ?


















