
I A Programming Tool for the Development of Parallel ... · A Programming Tool for the Development...
11
I I I I I A Programming Tool for the Development of Parallel Computer Vision and Image Processing Algorithms and Applications Odemir Martinez Bruno 1 , Luciano da Fontoura Costa 2 1 Department o f Computer Science and Statistics- ICMC, University of São Paulo Caixa postal668, CEP 13560-970, São Carlos, SP, Brazil { [email protected]} 2 Cybemetic Vision Research Group- IFS C, University ofSão Paulo Caixa Postal369, CEP 1 3560-970, São Carlos, SP, Brazil. {luciano@if .sc.usp .br} Abstract- Thís article presents thc developmcnt, implemcntation, and applications of the CYMP parallel programming tool for image processing and computer vision. Running on Borland Delphi and C++ BuiJdcr, this simple and easy-to-use tool incorporates visual programming and object orientcd capabilities, having already allowed a series of applications and results, which are also outlined. Keywords-lmage Processing, Parallel Computing I. INTRODUCTI ON Although parallel computing is posed to enhance image processing, computer vision and related areas, some obstacles have constrained its effective and broad application. One of the principal problems is the difficulty to implement concurrent programs, a consequence of the fact that most development tools for parallel programming are destined to experts in this area [BRU OOa] . This difficulty is aggravated by the existing variety of available programming environments and languages, each with its specific tools and parallel structures. As an altemative to these problems, a new methodology has been conceptualized in order to provide simple and effective access to parallel programming to those computer vision researchers and practitioners who are not experts in concurrent computation. The initial results of this enterprise, which are reported in the current paper, are based on the message-passing tool called CVMP (for Cybemetic Vision Message Passing). The project principal characteristics are: Popular Development Platform: The approach is based on a conventional and popular development platform, namely Borland Delphi and C++ Builder. Visual Programming: In order to speed up the development, visual programming concepts have been adopted. Object Oriented Programming: OOP represents one of the key points in CVMP, a ll owing simple and secure development, code reuse, and effective modeling of complex systems. The current paper presents the CVMP approach, covering its basic elements, some of the already obtained implementations and results, and the conc lusions and perspectives for future works. 11. THE CYMP TOOL. The CVMP approach includes a set of tools for the development of parallel programs in the Delphi/C++ Builder platforms, using concepts of visual programming and OOP. It is composed of a set of components (VCL - Visual Component Library), native in Delphi, and additional applicatives organized under the following five groups: CVMP basic, CVMP Extended, CVMP processar farm, CVMP image processing, Statistics and Launcher, which are discussed below. Figure 1 shows part of the CVMP components palette in the Borland Delphi environment. 222 Fig.l CVMP components palette in Delphi A. CVMP Basic The applicatives in this group include two components supplying the message passing primitives: a component for distributed memory MIMO systems (network connected PCs) and another for shared memory MIMO (multiple processors PCs). These two components provide the
Transcript of I A Programming Tool for the Development of Parallel ... · A Programming Tool for the Development...

I I I I I
A Programming Tool for the Development of Parallel Computer Vision and Image Processing
Algorithms and Applications Odemir Martinez Bruno1
, Luciano da Fontoura Costa2
1 Department o f Computer Science and Statistics- ICMC, University o f São Paulo Caixa postal668, CEP 13560-970, São Carlos, SP, Brazil
{ [email protected]} 2 Cybemetic Vision Research Group- IFSC, University ofSão Paulo
Caixa Postal369, CEP 13560-970, São Carlos, SP, Brazil. {[email protected]}
Abstract-Thís article presents thc developmcnt, implemcntation,
and applications of the CYMP parallel programming tool for image processing and computer vision. Running on Borland Delphi and C++ BuiJdcr, this simple and easy-to-use tool incorporates visual programming and object orientcd capabilities, having already allowed a series of applications and results, which are also outlined.
Keywords-lmage Processing, Parallel Computing
I. INTRODUCTION
Although parallel computing is posed to enhance image processing, computer vision and related areas, some obstacles have constrained its effective and broad application. One of the principal problems is the difficulty to implement concurrent programs, a consequence of the fact that most development tools for parallel programming are destined to experts in this area [BRU OOa] . This difficulty is aggravated by the existing variety of available programming environments and languages, each with its specific tools and parallel structures. As an altemative to these problems, a new methodology has been conceptualized in order to provide simple and effective access to parallel programming to those computer vision researchers and practitioners who are not experts in concurrent computation. The initial results of this enterprise, which are reported in the current paper, are based on the message-passing tool called CVMP (for Cybemetic Vision Message Passing). The project principal characteristics are:
Popular Development Platform: The approach is based on a conventional and popular development platform, namely Borland Delphi and C++ Builder.
Visual Programming: In order to speed up the development, visual programming concepts have been adopted.
Object Oriented Programming: OOP represents one of the key points in CVMP, allowing simple and secure development, code reuse, and effective modeling of complex systems.
The current paper presents the CVMP approach, covering its basic elements, some of the already obtained implementations and results, and the conclusions and perspectives for future works.
11. THE CYMP TOOL.
The CVMP approach includes a set of tools for the development of parallel programs in the Delphi/C++ Builder platforms, using concepts of visual programming and OOP. It is composed of a set of components (VCL -Visual Component Library), native in Delphi, and additional applicatives organized under the following five groups: CVMP basic, CVMP Extended, CVMP processar farm, CVMP image processing, Statistics and Launcher, which are discussed below. Figure 1 shows part of the CVMP components palette in the Borland Delphi environment.
222
Fig.l CVMP components palette in Delphi
A. CVMP Basic
The applicatives in this group include two components supplying the message passing primitives: a component for distributed memory MIMO systems (network connected PCs) and another for shared memory MIMO (multiple processors PCs). These two components provide the

ing processes. This feature, part of HPD standard, proved to be useful to debug parallel programs. lt allows debugging groups of processes with similar characteristics as well as selecting processes suspected to be erroneous by the programmer. This feature was also implemented successfully in the p2d2 and Node Prism parallel debuggers. The main difference here is the simplicity o f PADI, since selection can be done directly from buttons in the Main View.
In conjunction with the selection mechanism is the visualization of processes. Visualization has been applied in different areas of computer science, mainly to make interfaces more user-friendly. p2d2 created a very smart visualization grid, but it does not seem to scale well when lots o f processes are being debugged (the identification of processes becomes difficult when the number o f processes grows). The PADI approach uses the selection mechanism as a filter to processes visual ization, clearing the Processes Area and showing just processes being inspected. Besides, the PADI visualization area includes information like process states (by color), process names or pids and tids (internai ids).
Besides improving the prototype in order to prepare a version for initial distribution, future work includes providing different types of visualizations (currently there exists only one) and to develop runtime system interaction, so that PADI can receive specific information from a specific system and show this information in the interface (e.g., process creation, send and receive events, etc.).
REFERENCES
JBAROOJ M .BARRETO, R. ÁV ILA ANO P. NAVAUX "The MulliCluster Modelto the lntegrated Use of Mulliple Workstation Clusters". In Proceedillgs o f tire Jrd Workslwp 011 Pet~w11al Compute r Based NetiVorks o f Workstatio11s (PCNOW 2000). Cancun, volume 1800 of Lecture Notes in Computer Science, pages 7 1-800. Amsterdam, The Netherlands, 2000. Springer-Verlag.
(BUH96J P. A. BUHR ET AL, "KOB: a mulli-threaded debugger for multithrcaded applications". In Symposiam 011 Parai/e/ and Distribmed Tools. pages 80-87, Philadelphia, USA. 1996.
jCHAOOJ J. C HASStN DE KERGOMM EAUX, B. DE OLI VEIRA STEIN, P. BERNARO, "Pajé, an interactive visualizat.ion tool for tuning multithreaded parallel applications", Parai/e/ Compating 26, lO, aug 2000, p. 1253-1274 .
JCUN98J J .C. CUNHA, J . LOURENCO, J. VtElRA, B. MOSCAO, ANO O . PER EIRA. "A Framework to Suppon Parallel and Oistributed Oebugging". In Proceetlings of the lntematio11al Conjere11ce on HighPetformallce Compati11g a11d NetiVorking (HPCN'98), volume 1401 of Lecture Notes on Computer Science. pagcs 708-7 17. Amstcrdam. The Nethcrlands, April 1998. Springcr-Vcrlag.
JETNO IJ Etnus Inc. TotaiVicw Oebugger. available by www in http://www.etnus.com/products/totalview (Apr. 2001)
JGEI94J A. GEtST ET AL. " PVM: Parallel and Vinual Machine- A User's Guide and Tutorial for Networked Parallel Computing''. London: MIT, 1994
IHOR99] C. S. HORSTMANN ANO G. CORNELL "Core Java 2". Volumes I and 11, Sun Microsystems Press, 1999
22 1
[HPOOO] High Performance Oebugging Forurn, HPO Vers ion I Standard: Cornmand Interface for Parallel Ocbuggers, Sept. 1998. Availablc by www in http://www.ptools.org/hpdf/draft (in sept. 2000)
[H0099) R. Hooo. ''Thc p2d2 Project: Building a Ponable Oistributed Oebugger". Proceedi11gs of SPDT 96: SIGMETRICS Symposiam 011 Parai/e/ a11d Distribated Tools. ACM Inc., 1996 (p2d2 sitc available by www in: http://www.nas.nasa.gov/Groups!Tools/p2d21 - dcc. 1999)
[KRA97J 0. KRANZLMÜLLER, S. GRABNER ANO J. VOLKERT. ''Oebugging with the MAO Environment". Parai/e/ Compating, v. 23, p. 199-217. Feb. 1997
jLEB87] T. LEBLANC, J. MELLOR-CRUMMEY, "Oebugging Parallel Programs with lnstant Replay", IEEETransactiolls on Compmers C-36, 4, 1987, p. 47 1-481.
ILEU92] E. LEU, A. SCHt PER, "Execution rcplay: a mechanism for integrating a visualization tool with a symbolic debuggcr". in: CONPAR 92 - VAPP V, Y. Roben, L. Bougé, M. Cosnard, O. Trystrarn (ed.), LNCS, 634, Springcr-Verlag, september 1992.
[MC089J C. E. MCOOWELL, 0 . P. HELMBOLO, "Oebugging Concurrent Prograrns", ACM Computi11g Sarveys 21, 4, Oecember 1989. p. 593-622.
[PAC97J P. PACHECO "Parallel Programming with MPI", Morgan Kaufmann lnc, 1997.
[S IS94] S. StSTARE, 0 . ALLEN, R. BOWKER, K . JOUROENAIS. J . SIMONS ANO R . TITLE. "A Scalable Oebugger for Massively Parallel Message-Passing Prograrns" IEEE Parai/e/ a11d Distribwed Teclmology, v. 2, n. 2, p. 50-56. 1994
ISUNOIJ Sun HPC ClusterTools 3. 1 TM Available at http://www.sun.com/softwarelhpc/overview.html (july 200 I)
jWIS96J R. WtSMUELLER. M. OBERHUBER, J. KRAMMER ANO 0. HANSEN. " lnteractive debugging and performance analysis of rnassively parallel applications", Parai/e/ Computing. v. 22(3). pp. 415-442. March 1996

view are the interface intuitiveness, the programming models accepted and the platform. The goal of PADI isto be an easy to use tool available to popular parallel programming libraries (like PVM and MPI) and platforms (Linux clusters). Also, it will be available without costs and will be used for further research in on-line debugging and monitoring areas.
Some considerations about other tools were already done at the "Related work" section and are retaken in the "Conclusions" section. This one is more concerned in making some kind of practical comparisons with knowed tools like p2d2, Prism and TotalView. Unfortunately, a practical comparison with p2d2 is not possible, since it is not available for download and its use is restrict to NASA (see the p2d2 site in [H0099]). Prism was formely conceived at Thinking Machine Corporation and now is part of Sun HPC environment [SUNO I], hence it is not available for Linux clusters. Both accept PVM and MPI programming models.
Totalview is a commercial tool , but it has an evaluation distribution for Linux clusters and others (available in [ETNOI]). As a wide used commercial tool , TotalView is full implemented and has a lot o f useful features. A comparison, at least for while, can be made only at interface levei, that is the primary goal of PADI.
Let's consider the same PVM farmer/workers example presented at section "User interaction with PADI". When debugging that example with PADI it is easy to separate the farmer (mas ter I in figure I) and the workers (slaves) in to two groups. This can be done by selecting the farmer as user (just selecting its ellipse with the mouse) and choosing the User group to select it as the current group or choosing the Not use r to select the workers.
The notion of a group in Totalview is less ftexible. There are only two types of groups: the contra/ group and the share group. The control group includes the parent process and ali related processes. The share group is the set of processes within a control group that share the same source code. When debugging the same example with the Totalview defaults it is possible to experiment the effect of a control group by stepping the program. I f the Step g roup option from the pop-up menu is choosed, ali processes will do the step. Thus, the step can only be done individually or by ali processes in the control group (that are ali processes - farmer and workers- in this case).
The default breakpoint semantics is different in TotalView. When setting a breakpoint in a process it will be shared among processes with the same source code. By default, breakpoints follow the shared group semantics. The manual explains how to change the properties of an action point, but (at least apparently) this feature was not available in the tested evaluation version ofTotalView (Linux x86 Tota!View 4.1.0- 1 ).
One o f the main design choices o f PADI is to separate the
220
interface into two different kinds of views: one for parallel commands and other for individual commands. Such a structure clarifies the semantics of the debugger. In PADI it is possible to visualize ali processes that will be affected by a debugging command before it is actually sent to execution. The PADI's Main View is the responsible for ali distributed commands. The counterpart of this view in TotalView is the Root window, that is a textuallist of the debugging processes and its states. However, ali debugging commands are avalable by the pop-up menu from the processes views.
VII. CONCLUSION
PADI is a parallel on-line debugger interface whose main goal is to provide intuitive parallel debugging facilities. In order to achieve this goal, the two leveis of a parallel debugger (coordination and process leveis) were defined and implemented separately. Thus, the process levei was made completely fami liar to programmers, since it is very similar to traditional sequential debuggers. In addition, the coordination levei of PADI was developed to embody parallel features, like distributed commands, selection mechanism and parallel visualization.
The coordination levei of PADI is represented by its Main View. Severa! design choices contribute to making PADI intuitive and easy-to-use. The most important is the fact that the Main View embodies ali the parallel commands. Other choices contributing to the goal of intuitiveness and simplicity include the fact that parallel commands, similar to traditional, sequential ones, were made directly available as buttons. Another interesting feature is the definition of groups of processes, that allow programmers to select processes to receive parallel commands. This is very useful since applications can have many processes performing different tasks during execution. Finally, visualization of parallel processes makes the tool very easy-to-use, since users can easily identify processes and access their process levei view (the Process View) through their icons in the visualization area (Processes Area o f the Ma in View).
Comparing PADI with tools already mentioned in this paper, shows that existing tools inspired some important design decisions (evento adapt some good ideas or to choose a different design).
The first one is the decision of separating, at user levei (interface), the distributed commands from the serial ones. This approach is different from TotalView's approach since it is not possible to send any distributed debugging command from Tota!View's Main Window, but just to choose the processes to be debugged. PADI's approach proved to be clearer and more practical, since one window (the Main Window) concentrates ali the distributed actions, including the distributed debugging commands.
One o f these distributed actions is the possibility o f select-

MainView() I RunAcLion() SendO
i f action = run for all_procs
~ =mount_msg() do_verify() new RunAction() ifOK ~ood_<o_i1ddl<(m) 1\
new Send(run)
•••••
~ Proc() Break() Thread_recv()
doBreak(){ Proc p: m=recv _from_fiddlc() status = stopped p = get_in_server(tid) unpack_msg(m) updatc_interface() p.doBrcak() iftype = breakpoint } new Brcak()
1 Fig. 4: Example of the processing ftow in PADI: the boxes are the objects and the arrows are the relationship between them (creation or method invocation). The superior row of objects represents the processing flow to send a command (rrm in this case) to Fiddle. The inferior row represents the processing flow that occurs when an event from Fiddle (a breakpoint hiting in this case) is received until it is showed in PADI.
vocated by the interface and its processing ftow until it is sent to Fiddle. The objects responsible for the interface control (MainView() or ProcView()) receive the command and create the corresponding action object (the RunAction( ), in this case) to perform the verifications (status and selection). For each process that passes the verification, a Send() object will be created that mounts a message with required information about the command (the tid of the process and the run arguments in this case) and sends it to Fiddle.
After the sending of the run comrnand an asynchronous event can occur, like hitting a breakpoint. This situation and the event back ftow is also depicted in figure 4. There is a thread (named in figure 4 as the Thread .recv() object) that receives events like the arrival of a process at a breakpoint and creates the appropriate object to treat the event (the Break() object in the example). Then, this class gets the object reference to the process that caused the event and invokes the corresponding method in the Proc() class. This method (doBreak() in the example) updates the status ofthe process (that is stopped when arriving in a breakpoint) and also updates the interface: change the color of the process in the Processes Area and mark the corresponding tine at source code (i f the Process View is opened and showing the source code).
At this point it is important to note that commands like run can be distributed, what will create a number of Send() objects, one for each process. On the other hand, the responses are centralized in one thread that will receive ali the asyn-
219
chronous events from Fiddle. This centralized thread is used in order to establish a communication with Fiddle via a pipe mechanism. Meanwhile, Fiddle is being modified to accept Java clients, so the pipe is a temporary solution.
The PADI processes' objects (instances o f Proc( )) are created by load or attach commands. Then, when a debugging command, except of these two, is started in the interface, processes' objects states are verified. lf the command was originated in a process view, that saves the tid o f the owner, only the process' object holding this tid is verified and the command is sent only to it. I f the command was originated from the main view, ali processes' objects, whose references are maintained by the server, are verified and commands will be sent only to the tids that satisfy the conditions described earlier. This way o f proceeding may seem heavy, but the advantage is that it is made locally. In other words, it avoids that a command that cannot be executed by a process in any way be sent through the network and be renegated by the target process. For example, a process whose state is terminated cannot be stepped. A step command will be intercepted by PADI locally, avoiding unnecessary network traffic.
VI. PRELIMINARLY RESULTS
The PADI prototype can already be used such that it is possible to formulate some parctical comparisons with some existing tools. In the present phase o f the work, the most important characteristics to be analyzed from a practical point of

backbone onto which ali the other CVMP tools are implemented.
The communication between CVMP objects adopts the master-slave scheme. The nature of the CVMP Basic object, which can be either master or slave, is determined through one of its properties. Virtual channels between master/slave objects are established [BRU 97] [BRU OOb] [BRU OOa] in order to implement communication between objects, a concept inspired in the Transputer initiative [INM 88]. Figure 2 presents some of the possible configurations allowed by this flexible strategy.
li Machinc or L_j processar
- Vinunl Channcl
!BJ CVMP mastcr
[I] CVMP slavc
Fig.2 Two examples ofthe CVMP configurarions
The set of the CVMP primitives are shown and described in Table 1. These primitives consist of the properties and methods of the CVMP Basic object, that allow the communications between the processes (message exchange). An example of the CVMP Basic programming is shown in Figure 3, presenting the Delphi code for the parallel computation of four processes using two machines (master and slave).
Mastcr proccss algorithm
cvmp1.mp_iniL filefinit.i ni'); cvmp1.mp_master, cvmp1.mp_send("start');
~ cvmp1.mp_send(b); a:=cvmp1.mp_receive;
while f<>'end' do begin application.processmessages; f :=cvmp1.receive;
end; result2:=cvmp1.mp_receive; show (result1 , result2);
Slavc process algorithm
cvmp1.mp_iniLfile("cyv.ini'); cvmp1.mp_slave ; while f<>'start' do begin application.processmessages; f:=cvmp1.mp_receive;
end;
~ b:=cvmp1 .mp_receive; cvmp1.mp_send(a);
cvmp1 .mp_sendfend'); cvmp1.mp_ send(result2);
Fig.3 Delphi code example ofhow to use the CVMP Basic primitives.
223
TABLEI CVMPM. B . am astc pnmt tves
mp_init_file Property - Load the configuration file.
mp_ slave Method - Set the object as slave. mp_ master Method - Set the object as master.
mp _send( mens: str) Method - Sends a message through the Virtual Channel.
str:=mp_recei v e Method- Return the first message o f messages FIFO.
Setblocking Property - Set the messages as blocking.
sendfile(str) Method - Send a high granularity message (file) though the Virtual
Channel. receivefile(str) Method - Receive a high granularity
message (file). mp_ close Close a Virtual Channel connection.
B. CVMP Extended
This includes components similar to the CVMP Basic, but with additional properties and methods (encapsulated in the CVMP Basic), addressing the handling of message packets, message-passing synchronization, semaphores, as well as partition and distribution of images [ALM 94] [COD 94]. Often, parallel image processing algorithms require the partition o f the image in order that each portion is simultaneously processed in severa) distinct processors. The CVMP Extended is capable of partitioning the images in severa) ways. The images can be divided into portions of severa) sizes, in order to help the Joad balance in heterogeneous systems. In many situations, the simple division of the image implies data dependence (see Figure 4). A typical example is the convolution o f templates in the space domain, a technique underlying severa) image processing algorithms [GON 93] . In order to cope with this requirement, the pixels adjacent to each image portion are also enclosed. Different neighborhood sizes can be considered depending on the type o f data dependence.
Fig.4 Examples o f image partitioning with incorporation o f neighboring pixels.

C. CVMP Processar Farm
The processor farm paradigm [ALM 94], one of the most frequently adopted strategies in parallel image processing [BRU OOa], is characterized by a master which distributes the task to a number of supervised slaves (see Figure 5). The CVMP incorporates components specifically designed to implement this parallelization strategy, supporting configurations up to 16 slave machines or processes.
c==JSiavcs
Fig.5 The Processors Farm Paradigm.
Through the CYMP processor farm, the user easily implements a distributed application by using visual means, without the need o f a single code line. Indeed, it is enough to configure some properties of the master and slaves (e.g. number oftasks, network configuration, etc.) and to add the calls to the parallel algorithms into the slaves code.
D. CVMP Image Processing
This set incorporates components containing ready-touse image processing parallel algorithms, which can be included just by dragging them into the forms, make a few configurations, and add a few lines of code. Each technique is composed by combinations of master/slave components, following the CYMP. Currently, the following algorithms are available:
• Local operators - convolution m space domain [GON 93].
• Chromatic channels operations involving chromatic images, with parallel execution between the chromatic planes.
• Fourier transform. • Hough transform [SCH 89]. • Hough transform with backmapping, a technique
proposed by Gerig & Klein [GER 86] in order to enhance the peaks produced by the Hough transform.
• Fractal dimension: includes algorithms based on Minkowski's sausages and box-counting [TRI 95][KA Y 94].
224
E. CVMP Statistic
lncludes two components, one for statistical analysis and another for dynamic execution analysis, allowing proper statistical analysis of the behavior of the execution and message exchanges in concurrent programs developed in CYMP. The statistics component is capable of measuring the performance directly through the program code, which has to include calls to the statistic procedures at criticai points ofthe code, defined by the programmer.
Figure 6 presents two windows of the statistics application. lt is used to visualize the statistical data obtained through the CVMP statistics components. The first window considers four machines running concurrently, the x-axis indicates the time in milliseconds, and through the boxes it is possible observing the duration, start and finish time of each process. The second window shows the respective numerical information.
Fig.6 Windows ofthe Statistics application, used to visualize the CVMP statistics data.
F. CVMP Launcher
lncludes a component and a demon executing in background in the network machines, in order to enable the pro per triggering o f the processes in the network machines. Through calls to the object methods, the demon can trigger the execution o f a specific program in any specific machine in the network.

Ill. PARALLEL IMAGE PROCESSING ALGORITHMS
In this section there are presented four examples of parallel image processing algorithms (local operators, Hough transform, Hough transform backmapping and fractal dimension) implemented by using the CVMP. Each one is discussed in terms of implementation and performance. Because of its strong OOP base, CVMP allows any implemented algorithm (implemented by using CVMP) to be encapsulated and integrated into the CVMP lmage processing (see II.D).
A. Local Operators
This technique is broadly used in image processing and computer vision and provides a good example of local operator [GON 93]. Basically, it consists of the convolution of a template with the image, obtaining a processed image. The kind of processing (which can include low and high pass filtering, template matching, etc.) will be determined by the template characteristics.
The adopted parallel strategy consists in partitioning the image, distributing the slices to the machines, that is processed concurrently, and finally join the results of this processing, obtaining the processed image.
Figure 7 presents the parallel strategy using four machines. The involved stages are: the original image (I), image division and it distribution (Il), the processing of each image part in a different processar unit (III), results reconstruction (IV) and the combination o f the results (V). The load balance can be accomplished by controlling the size of the slices in such a way that the most powerful processors receive the larger si ices.
01~1:::::: ::::::::::::!!~10 11 T Ili l IV I v
Fig. 7 Parallel strategy for local opera to r algorithm using 4 processors units.
The reported experiment was performed on a computer network composed of 4 similar computers - AMD K6 li 375 MHz, connected by ethemet NE2000 of I O Mb/s and Fastethemet o f I 00 Mb/s. The considered operation was a low pass filtering [GON 93] involving the sum of the elements o f the mask for the number o f components o f the filter. The parallel and sequential algorithm execution times were measured while processing a image with 500x500
225
pixels by using operators with templates of different sizes (3x3, 5x5, 9x9, 15xl5, 3lx31 , 51x51, 7 l x7 1, 85x85 and IOJxiOI elements).
Figure 8 exhibits the comparison of the speed-ups obtained for execution in a ethemet based computer network (10 Mb/s) and fast-ethemet based (100 Mb/s) of a 500x500 pixels image. The faster communication allowed a substantial increase of the performance for the smaller filters (3x3, 5x5, 9x9 and 15x 15). For larger filters {31 x31 , 5Jx51, 7lx71 , 85x85 and IOlxlOI), the performances of both networks (10 Mb/s and lOO Mb/s) get closer because the processing becomes more highly compute bound, while the comrnunication time becomes relatively smaller.
3
a. :J
al 2 Q) a. (/)
11 I 3x3 5x5 9><9 15x15 31x31 51x51 71x71 85x85 101x101
templatcs
- 10Mbits/s D 100 Mbits/s
Fig.8 Caparison between ethemet I O Mb/s network and fast-ethemet I 00 Mb/s computer network.
8. Hough Transform
Introduced by Hough in 1959 to calculate particle trajectories [HOU 59], the Hough Transform is largely used on image analyses as a global pattem recognized method. The basic idea of the method consists to find curves on image that can be parameterized, such as line segments, polynomials, circles, ellipses, etc. The parallel Hough transform implemented in this paper was used to detect Iine segments on the image, which constitutes it most frequent use [SCH 89].
Fig.9 Parallel Hough transform architecture using four processing units.
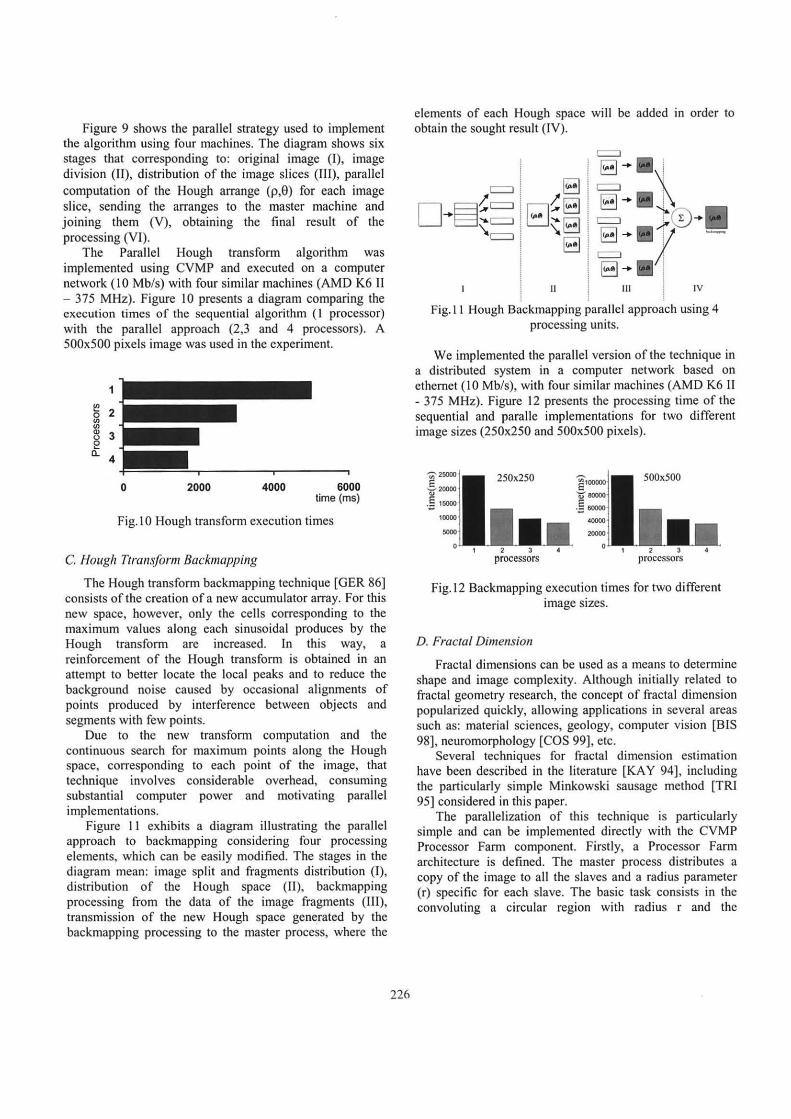
Figure 9 shows the parallel strategy used to implement the algorithm using four machines. The diagram shows six stages that corresponding to: original image (1), image division (li), distribution of the image slices (Ill), parallel computation of the Hough arrange (p,e) for each image slice, sending the arranges to the master machine and joining them (V), obtaining the final result of the processing (VI).
The Parallel Hough transform algorithrn was implemented using CVMP and executed on a computer network (LO Mb/s) with four similar machines (AMD K6 li - 375 MHz). Figure lO presents a diagram comparing the execution times o f the sequential algorithm ( I processo r) with the parallel approach (2,3 and 4 processors). A 500x500 pixels image was used in the experiment.
1
~ 2 "' "' ~ 3 e a.. 4
o 2000 4000 6000 time (ms)
Fig. l O Hough transform execution times
C. Hough Ttransform Backmapping
The Hough transform backmapping technique [GER 86] consists o f the creation o f a new accumulator array. For this new space, however, only the cells corresponding to the maximum values along each sinusoidal produces by the Hough transform are increased. In this way, a reinforcement of the Hough transform is obtained in an attempt to better locate the local peaks and to reduce the background noise caused by occasional alignrnents of points produced by interference between objects and segments with few points.
Due to the new transform computation and the continuous search for maximum points along the Hough space, corresponding to each point of the image, that technique involves considerable overhead, consuming substantial computer power and motivating parallel implementations.
Figure ll exhibits a diagram illustrating the parallel approach to backmapping considering four processing elements, which can be easily modified. The stages in the diagram mean: image split and fragments distribution (I), distribution of the Hough space (11), backmapping processing from the data of the image fragments (III), transmission of the new Hough space generated by the backmapping processing to the master process, where the
226
elements of each Hough space will be added in order to obtain the sought result (IV).
11
Fig.II Hough Backmapping parallel approach using 4 processing units.
We implemented the parallel version ofthe technique in a distributed system in a computer network based on ethemet ( 10 Mb/s), with four similar machines (AMD K6 11 - 375 MHz). Figure 12 presents the processing time of the sequential and paralle implementations for two different image sizes (250x250 and 500x500 pixels).
Fig. l2 Backmapping execution times for two different image sizes.
D. Fractal Dimension
Fractal dimensions can be used as a means to determine shape and image complexity. Although initially related to fractal geometry research, the concept of fractal dimension popu1arized quickly, allowing applications in severa) areas such as: material sciences, geology, computer vision [BIS 98], neuromorphology [COS 99], etc.
Severa) techniques for fractal dimension estimation have been described in the Jiterature [KA Y 94], including the particularly simple Minkowski sausage method [TRl 95] considered in this paper.
The parallelization of this technique is particularly simple and can be implemented directly with the CVMP Processor Farm component. Firstly, a Processor Farm architecture is defined. The master process distributes a copy of the image to ali the slaves and a radius parameter (r) specific for each slave. The basic task consists in the convoluting a circular region with radius r and the

respective area determination. The results (areas) are sent to the master as soon as the calculations are made.
The experiment was performed for a binary image with 512x512 pixels, considering 32 disks with radiuses varying by 2. Figure 12 presents the execution times, obtained through the CVMP statistics component, each subsequent box (represented in light and dark gray) indicates the execution of one process. Due to the small data flow implied by the message passes in the net, the system allowed particularly good performance and a small number of execution gaps. The excellent performance is corroborated by the fact that the parallel system with four heterogeneous machines (200 MHz, 250 MHz, 300 MHz and 375 MHz) is approximately 2.7 times faster than the sequential version executed in the fastest machine (375Mhz).
lM)RIJ~~~ !,.,u .. 'IM\11 11!
•·r '11• u ~ u u ~ ..
OI)•
Fig.1 2 Parallel fractal dimension algorithm executing time for four machines
IV. IMPLEMENTATIONS USING CVMP
CVMP is the current platform supporting the development of high performance applications in the Cybemetic Vision Research Group. Through its usage, computer vision and image processing researchers have benefited with parallelism in the development of severa! projects, some ofwhich are outlined in the following.
A. Cyvis-1
Fig.13 Cyvis- 1 Diagram.
227
The Cyvis- 1 project [COS 94][BRU 97](standing for Cybemetic Vision, version I) represents an attempt at obtaining versatile computer vision systems through the progressive incorporation of biological principies such as selective attention, Zeki and Shipp's multi-stage integration framework [ZEK 88][ZEK 93], and effective integration of top-down and bottom-up processing (see Figure 13). As such approaches inherently demand the use of paralle1ism in their respective implementation, the research on Cyvis-1 has strongly depended on the CVMP. The already obtained results include the integration of visual attributes, the distributed environment, and the incorporation of parallelism in severa! algorithms developed as part of the Cyvis- I project.
B. TreeVis
TreeVis [BRU OOa], an abbreviation for Tree Vision, is a system for the automated recognition of arboreal plants through the comprehensive extraction of features from images o f leaves and the respective statistical classification. The bases of the system consists of the systematic exploration of the leaves geometrical properties through a large number of visual features, that implicates on a Iarge time of processing (about tive minutes for each sample), justi fying a parallel solution. The parallelism in the TreeVis project has been implemented by using the CVMP Processar Farm components (see Figure 14), through the replication ofthe feature extraction module.
SI aves
,--------------lmagcs
Ocscrip1 ions
Ft>aturcs Lisls
DataB.1sc
6-~ I Se...,.,. , _____________ _
Master
Fig.l 4 Overall organization ofTreeVis.
On the experiment reported here, the system included six identical machines (Pentium 11 - 300 MHz) connected through a network (10 Mb/s). Figure 15 shows an execution time diagram for 12 samples, where each sample is represented as a block. Observe that each system machine executes a samp1e concurrently. A speed-up near the expected maximum (i.e. 6) was obtained, as the sample number is a multiple ofthe number ofsystem processors.

M, .............. .. M~ .............. ..
M~~-=== Ml~-M21 ................ .. Ml1 ................ ..
t(s)
Fig.IS Processor farm execution time.
The TreeVis approach is based on statistical analyses, needing severa! samples of each species for optimal training and classification. The performance of the processor farm approach reaches the optimal when the number of samples is a multiple of the number of the processors or is close to it. However, the performance decreases in two situations: (i) when the number o f samples is less than the number of processor and (ii) when the number o f samples is higher than the number o f processors, but it is not close to the multiple.
The Parallel implementation of Treevis has an automatic configuration architecture, capable of changing the parallel approach in execution time. The system compares the number of sample and the number of processors, and if one of the two situations (i) or (ii) are detected, the system change its parallel approach, in order to minimizes the execution time and improve its performance.
I Central
111\lJ;CS
Ocscriptions
Faatures List
Data Base
~'~~~~~ r.:=C=olor=~~~ : ~!:,. -u I Color
lhtogram I 1-------------M~~R
si aves
Fig.l6 - Concurrence between the submodules for feature extraction approach.
228
Figure 16 exhibits the concurrence between the feature extraction submodules approach (using three machines) and Figure 17 shows its execution time diagram for 3 'samples running on 6 machines. Although, it performance is worse than the processor farm approach (when the number of samples is a multiple of the processors number), its utilization guarantees the system speed-up for the two situations (i) and (ii) which the processor farms approach performance decreases.
MaciL I - - -l\lada.1 - - -Alikfli.l
M•mo .. Mtt •. S
1\lllâ.'
li O liD l{i}
Fig.17 Concurrence between submodules execution time.
C. I ynergos
The CVMP has also provided the basic support for parallelization in a project oriented to the integration of severa! important approaches in computer vision and pattern recogmtlon, such as algorithm validation, performance comparison, datamining, psychophysical experiments, artificial intelligence, etc [BRU98) [BRU O I]. Basically, it is expected that the severa! advantages and disadvantages of these approaches complement each other in order to catalyze the development and application of computer vision concepts and tools. More specifically, the CVMP has been used for the parallel implementation and execution o f the genetic algorithm, required for datamining tasks.
e p IDI t!ll tt.t m~•t
Fig.l8 Time diagram for the execution ofthe genetic algorithm in four different machines.

Figure 18 presents the time diagram for the parallel execution of the genetic algorithm in four different machines under CVMP, connected through IOMbit/s ethemet connection. Each subsequent box (represented in Iight and dark gray) indicates the execution of one of the basic algorithm steps.
V . CONCLUSION
This article has reported the development, implementation, and application of a tool designed to support parallelization in image analysis and computer vision. Its basic elements and some of its already successful applications have been described. The benefits of the CVMP have been substantiated in practice, helping severa! computer vision researchers to solve severa! distinct problems.
In addition to the continuation of the outlined projects (e.g. Cyvis-1 and TreeVis), future developments should include the implementation of other image analysis techniques and the extension o f CVMP in such a way that it interacts with MPI [PAC 97] or PVM [GEI 96].
REFERENCES
[ALM 94] ALMAS!, G. S.; GOTTLIEB, A. Highly Parai/e/ Computing. 2.ed. Califomia, The Benjamin!cummings Publishing, 1994.
[BIS 98] BISWAS, M. K. ; GHOSE, T. ; GUHA, S. ; BISWAS, K . K. Fractal dimension estimation for texture images: A parai/e/ approach. Pattem Recognition Letters, 19( 1998) pp.309-3 13, 1998.
[BRU 97] BRUNO, O. M. and COSTA, L. F. Versatile Real-Time Vision Based on a Distribllled System of Personal Computers. In: Proc. Third IEEE Intemational Conference on Engineering of Complex Computer Systems. Como, Itália, IEEE Computer Science, Los Alamitos-CA, p.174-9, Los Alamitos-CA, 1997.
[BRU 98] BRUNO, O. M., CESAR Jr., R.M., CONSULARO, L. A.; COSTA, L. F. Automatic fea/1/re selection for biological shape classification. in l:ynergos. In: Proceedings 1998 Intemational Symposium on Compu ter Graphics, lmage Processing and Vision, Rio de Janeiro, RJ, IEEE Computer Society Press, pp 363-370, 1998.
[BRU OOa] BRUNO, O. M. Parallelism in Natural and Artificial Vision, University of S. Paulo, Brazil, 2000 (Ph.D. Thesis in Portuguese).
[BRU OOb] BRUNO, O. M. ; COSTA, L. F. Eflective lmage Segmentation with Flexible ICM-Based Markov Random Fields in a Distributed Systems of Personal Computers. Real-Time lmaging, Academic Press, v. 6, p. 283-95, 2000.
[BRU OI] BRUNO, O. M.; CESAR Jr., R. M.; CONSULARO, L. A. ; COSTA, L. F. Synergos - Synergetic Vision Research Real-Time Systems, Kluwer, v. 21 , p. 7-42, 2001.
[COD 94] CODENOTI, B. ; LEONCINI, M.. lntroducing to Parai/e/ Processing. Addison-Wesley, 1994.
229
[COS 94] COSTA, L. F.; RODA, V. 0 .; KOBERLE, R. A biologically-lnspired System for Visual Pattern Recognition. In: Proc. IEEE lntemational Symposium on Industrial Electronics, Santiago, Chile, 1994.
[COS 99] COSTA, L. F.; VEL TE, T. Automatic characterization and classification of ganglion cel/s from the salamander retina. Joumal of Comparative Neurology, v.404, n.l , pp.33-51 , 1999
[GEI 96] GEIST, BEGUELIN, DONGARRA, et al. PVM: Parai/e/ Viril/a/ Machine, A User's Guide and Tlllorial for Parai/e/ Computing, MIT Press, 1996.
[GER 86) GERIG, G.; KLEIN, F. Fast Contour ldentification Through Efficient Hough Transform and Simplified lnterpretation Strategy. In: Proc. 8th lnt. Conference on Pattem Recognition, vol. l , pp. 498-500, Paris, France, 1986.
[GON 93] GONZALEZ, R. C.; WOODS, R. E. Digital lmage Processing. Addison-Wesley, New York, 1993.
[HOU 59] HOUGH, P. V .C. Machine Analysis of Bubble Chamber Pictures. In: lntemational Conference on High Energy Accelerators and lnstrumentation, CERN, 1959.
[INM 88] INMOS Limited. Transputer Reference Manual. Prentice Hall, New York, 1988.
[KA Y 94] Kaye, B. H. A Random Walk Through Fractal Dimensions: 2nd Edition. VCH Publishers, New York, 1994.
[PAC 97] PACHECO, Peter. Parai/e/ Programming with MP/. Morgan Kaufmann, 1997.
[SCH 89] SCHALKOFF, R. F. Digital image processing and compwer vision. John Wiley and Sons, I 989.
[TRJ 95) TRJCOT, C. Curves anel Fractal Dimensions. SpringerVerlag, Paris, 1995.
[ZEK 88] ZEKI, S.; SHIPP, S. The Functional Logic ofCortical Connections. Nature, Nature Publishing Group, v.355, p3 ll-31 7, September 1988.
[ZEK 93] ZEKI, S. A Vision of the Brain. Blackwell Science, 1993.


















