
HPSG’2005 The 12th International Conference on Head ...ahb/pubs/2005BrancoCostaSailer.pdf · The...
159
HPSG’2005 The 12th International Conference on Head-Driven Phrase Structure Grammar: Conference Notes Ant´ onio Branco Francisco Costa Manfred Sailer (eds.) DI–FCUL TR–05–10 June 2005 Departamento de Inform´ atica Faculdade de Ciˆ encias da Universidade de Lisboa Campo Grande, 1749–016 Lisboa Portugal Technical reports are available at http://www.di.fc.ul.pt/tech-reports. The files are stored in PDF, with the report number as filename. Alternatively, reports are available by post from the above address.
Transcript of HPSG’2005 The 12th International Conference on Head ...ahb/pubs/2005BrancoCostaSailer.pdf · The...

HPSG’2005
The 12th International Conference
on Head-Driven Phrase Structure
Grammar:
Conference Notes
Antonio BrancoFrancisco CostaManfred Sailer
(eds.)DI–FCUL TR–05–10
June 2005
Departamento de InformaticaFaculdade de Ciencias da Universidade de Lisboa
Campo Grande, 1749–016 LisboaPortugal
Technical reports are available at http://www.di.fc.ul.pt/tech-reports. The filesare stored in PDF, with the report number as filename. Alternatively, reports areavailable by post from the above address.


Contents
Preface v
Contributors vii
Noun incorporation in Tongan: a lexical sharing analysis 1 Douglas Ball
Towards a semantic analysis of argument/oblique alternations in HPSG 5 John Beavers
Integrating discourse information in grammar 11 Núria Bertomeu Valia Kordoni
The dual nature of Tswana infinitive forms 17 Denis Creissels Danièle Godard
Syncretism in German: a unified approach to underspecification, indeterminacy, and likeness of case 23 Berthold Crysmann
Coordination modules for a crosslinguistic grammar resource 29 Scott Drellishak Emily M. Bender
A new well-formedness criterion for semantics debugging 35 Dan Flickinger Alexander Koller Stefan Thater
Object-to-subject raising: an analysis of the Dutch passive 41 Frederik Fouvry Valia Kordoni Gertjan van Noord
A computational treatment of V-V compounds in Japanese 47 Chikara Hashimoto Francis Bond
i

On non-canonical clause linkage 53 Anke Holler
Gradience and parametric variation 59 Frank Keller Dora Alexopoulou
The syntax and semantics of multiple degree modification in English 63 Christopher Kennedy Louise McNally
It-extraposition in English: a constraint-based approach 69 Jong-Bok Kim Ivan A. Sag
Copy constructions and their interaction with the copula in Korean 73 Jong-Bok Kim Peter Sells
The scope interpretation of the light verb construction in Japanese 79 Yusuke Kubota
A new HPSG approach to Polish auxiliary constructions 87 Anna Kupść Jesse Tseng
A trace analysis of Korean UDCs 93 Sun-Hee Lee
An HPSG approach to the who/whom puzzle 99 Takafumi Maekawa
From “hand-written” to computationally implemented HPSG theories 103 Nurit Melnik
Phrasal or lexical resultative constructions? 109 Stefan Müller
Adverbial extraction: a defense of tracelessness 111 Ivan A. Sag
Selectional restrictions in HPSG: I’ll eat my hat! 117 Jan-Philipp Soehn
ii

Projecting RMRS from TIGER dependencies 123 Kathrin Spreyer Anette Frank
Free relatives in Persian 129 Mehran Taghvaipour
Plural comitative constructions in Polish 135 Beata Trawiński
Phrasal prenominals with peculiar properties 139 Frank Van Eynde
An HPSG account of closest conjunct agreement in NP coordination in Portuguese 145 Aline Villavicencio Louisa Sadler
iii

iv

Preface
The 12th International Conference on Head-Driven Phrase Structure took place in Lisbon, at theFaculty of Sciences of the University of Lisbon, in23-24 August, 2005. It has received a total of 39submission, out of which the program committeehas selected 18 papers for presentation. The localorganization managed to provide room for a postersession which includes the alternate papers and sixadditional posters.
The present conference booklet contains the ex-tended abstracts of the presentations, posters, and in-vited talks. The contributions are in alphabetic orderby the first author.
We are grateful to the Department of Informaticsof the University of Lisbon for providing the pos-sibility to publish the conference in their series oftechnical reports, and to the authors for being will-ing to re-format their contributions in order to allowfor the present homogeneous appearance of this pub-lication.
The present conference booklet is based on theformatting style for the ACL-2005 proceedings byHwee Tou Ng and Kemal Oflazer. Their style in turnwas based, among others, on the formats of earlierACL and EACL Conference proceedings.
This year’s program committee consisted of:Raul Aranovich (Davis),Doug Arnold (Colchester),Emily Bender (Washington),Olivier Bonami (Paris),Antonio Branco (Lisbon),Berthold Crysmann (Saarbrucken),Anke Holler (Heidelberg),Valia Kordoni (Saarbrucken),Palmira Marrafa (Lisbon),Tsuneko Nakazawa (Tokyo),Gerald Penn (Toronto),Alexander Rosen (Prague),Manfred Sailer (Gottingen, chair),Gautam Sengupta (Hyderabad),Jesse Tseng (Nancy),Stephen Wechsler (Austin), andShuly Winter (Haifa)
We wish to thank the program committee of the
conference and Jong-Bok Kim (Seoul), Nurit Mel-nik (Haifa) and Roland Schafer (Gottingen) for re-viewing the submitted abstracts.
The local organization committee consisted of:Antonio Branco (chair),Francisco Costa, andFilipe Nunes
from the NLX-Group, the Natural Language Groupof the Department of Informatics, University of Lis-bon.
We are grateful to the sponsors of the conference:
• FCT — Fundacao para a Ciencia e Tecnologia
• Departamento de Informatica da Faculdade deCiencias da Universidade de Lisboa
Gottingen and Lisbon, 20 June 2005
Antonio Branco, Francisco Costa, Manfred Sailer
v

vi

Contributors
Dora Alexopoulou [email protected]
Douglas Ball [email protected]
John Beavers [email protected]
Emily M. Bender [email protected]
Núria Bertomeu [email protected]
Francis Bond [email protected]
Denis Creissels [email protected]
Berthold Crysmann
Scott Drellishak [email protected]
Dan Flickinger [email protected]
Frederik Fouvry [email protected]
Anette Frank [email protected]
Danièle Godard [email protected]
Chikara Hashimoto [email protected]
Anke Holler [email protected]
Frank Keller [email protected]
Christopher Kennedy [email protected]
Jong-Bok Kim [email protected]
Alexander Koller [email protected]
Valia Kordoni [email protected]
Yusuke Kubota [email protected]
Anna Kup´s´c [email protected]
Sun-Hee Lee [email protected]
Takafumi Maekawa [email protected]
Louise McNally [email protected]
Nurit Melnik [email protected]
Stefan M¨uller [email protected]
Gertjan van Noord [email protected]
Louisa Sadler [email protected]
Ivan A. Sag [email protected]
Peter Sells [email protected]
Jan-Philipp Soehn [email protected]
Kathrin Spreyer [email protected]
vii

Mehran Taghvaipour [email protected]
Stefan Thater [email protected]
Beata Trawi´nski [email protected]
Jesse Tseng [email protected]
Frank Van Eynde [email protected]
Aline Villavicencio [email protected]
viii

Noun Incorporation in Tongan: A Lexical Sharing Analysis
Douglas BallDepartment of Linguistics
Stanford [email protected]
Noun incorporation in Tongan has been gener-ally viewed as having three morphosyntactic proper-ties: (i) it is a syntactic construction where the verband the incorporated noun are separate words, (ii)it is a construction where only single nouns appearin the incorporated position (Gerdts, 1998) and (iii)the construction’s syntactic valency is reduced com-pared with transitive clauses (Rosen, 1989; Runnerand Aranovich, 2003). However, with a closer ex-amination of the data, I propose that none of theseclaims is quite right for Tongan (and, in some cases,are outright incorrect), and so I propose an alter-nate analysis of Tongan noun incorporation, onethat builds on the mechanism of lexical sharing(Wescoat, 2002; Kim et al., 2004).
In Churchward’s (1953) grammar of Tongan, henotes the following minimal pair of an ordinarytransitive sentence and a sentence with incorpora-tion.
(1) a. Ordinary Transitive SentenceNa‘ePAST
inudrank
‘aABS
eDET
kavakava
‘eERG
Sione(name)‘Sione drank the kava.’
b. Sentence with IncorporationNa‘ePAST
inudrink
kavakava
‘aABS
Sione.(name)
‘Sione drank kava.’
As the second example shows, the sentence withincorporation differs in a number of respects withits ordinary transitive counterpart. First, the incor-porated noun is adjacent to the verb, and, in fact,the incorporated noun does not have the word order
flexibility that its corresponding phrase does in anordinary transitive sentence. Second, the prenom-inal case markers and determiners – including thedefinitive accent (the a in kava) – do not and cannotappear on or with the incorporated noun. Finally, thecase of the external argument must be absolutive inan incorporated sentence, contrasting with the erga-tive marking of external arguments in ordinary tran-sitive sentences.
However, Tongan noun incorporation exhibitsseveral other interesting, yet seemingly conflictingproperties. First, incorporated nouns can be accom-panied by modifiers and some other phrasal mate-rial. Examples of some of the possibilities are shownbelow:
(2) Conjoined NounsNa‘ePAST
toplant
maniokecassava
mo eand
talotaro
‘aABS
Sione(name)‘Sione planted cassava and taro.’
(3) Noun + modificational PPNa‘ePAST
fakama‘aclean
seachair
‘iin
falehouse
‘aABS
Sione(name)‘Sione cleaned chairs in the house.’
These modifiers also have a rigid placement, thesame as their placement within non-incorporatednominal expressions.
Second, though these incorporated expressionscan, to a degree, be phrasal, there is also a tightbond between the verb and the incorporated noun.
1

This can be shown from the behavior of the prenom-inal adjectives. This class of adjectives cannot in-corporate, even though semantically-identical post-nominal adjectives can. This is illustrated in (4a-b):
(4) a. *Na‘ePAST
toplant
ki‘ismall
maniokecassava
‘aABS
Sione.(name)Intended: ‘Sione planted a smallamount of cassava.’
b. Na‘ePAST
toplant
maniokecassava
iikismall
‘aABS
Sione.(name)‘Sione planted a small amount ofcassava.’
Further evidence for this tight bond comes fromnominalization – this evidence suggests that verband incorporated noun should be treated as singlelexical unit. Tongan verbs can be nominalized withthe suffix -‘anga. Single verbs can nominalized, asin (5a), as well as verb-incorporated noun units, asin (5b).
(5) a. nofo-‘angadwell-NOM
‘dwelling place’
b. inu-kava-‘angadrink-kava-NOM
‘place to drink kava’
This nominalization occurs just with the verb andincorporated noun – other parts of the incorporatedexpression may not be nominalized with verb andthe incorporated noun.
Given that there are both phrasal and morpholog-ical aspects to noun incorporation in Tongan, howmight Tongan noun incorporation be analyzed? Ipropose that the verb-incorporated noun unit is a sin-gle word, but it has two corresponding nodes – twoinstantiations – in the syntax, following the Lexi-cal Sharing analysis developed by Wescoat (2002).Thus, a unit like to-manioke, ‘plant cassava’, has alexical entry like as in (6) (following the notation ofKim et al. (2004)):
(6)
word
PHON⟨
t o-manioke⟩
INSTS
⟨
atom
EXPON 5
SYN | HEAD verb
,
atom
EXPON 6
SYN | HEAD noun
⟩
Lexical sharing allows the lexicon to create en-tries which instantiate more than one pretermi-nal node – each preterminal is a syntactic atom(Wescoat, 2002). The entry in (6) shows that oneword instantiates two atoms, intuitively, a verb anda noun.
Beyond this, the syntactic component of the lan-guage remains essentially unchanged, and in partic-ular, the incorporated noun may head an NP with in-ternal postnominal modifiers. The verb atom com-bines by the head-argument schema (Schema 3 ofPollard and Sag (1994)) and the postnominal mod-ifers combine by the head-modifier schema (Schema5 of Pollard and Sag (1994)), and structures like (7)on the following page result.
Such structures account for the configurationalproperties of noun incorporation in Tongan, but thisanalysis has yet to deal with the absolutive casemarking in noun incorporation. First, let us recog-nize three types of nominal expression in Tongan:one that has both CASE and DET features, a type Iwill call canonical; one that just has DET features,a type I will call determined; and one that lacksboth CASE and DET features, which I will call bare.These correspond to the phrase types KP (for ‘casephrase’), DP, and NP, respectively, in the analysis ofincorporation proposed by Massam (2001) for Ni-uean, a closely-related language.
Given this typology, and the general patterns ofcase marking of Tongan, it seems reasonable to as-sume that Tongan has a case constraint, where, ifthere are two canonical NPs, ergative case is re-quired of the less oblique and absolutive of the moreoblique, as in (8):
2

(7)
S
5 V NP NP
6 N A syntax
t o-manioke kano-lelei ‘a Sione phonology‘plant-cassava’ ‘good’ (name)
(8)2
4ARG-ST
*
NPcanonicalh
CASE ergi
,NPcanonicalh
CASE absi
+
3
5
If there are not two canonical NPs on the ARG-ST,then the first NP is constrained to be in the absolu-tive.
As the lexical sharing analysis is predicated on thelexical status of the verb-noun combination, it fol-lows that no syntactic atoms may intervene in thesyntactic structure between them. In other words,lexical sharing predicts that any prenominal atoms –such as case markers, determiners, and prenominaladjectives – must be absent. This accounts for theproperties seen in examples (1)–(4) above withoutstipulation. As the NP in the syntax cannot host acase marker or determiner (such as the first NP in(7)), it is of type bare.
So, while the ARG-ST of transitive verbs is nor-mally instantiated as in (9) below, in noun incorpo-ration structures, this requirement for the second ar-gument to be bare causes the default type canon-ical to be overridden and the ARG-ST to be as in(10).
(9)[
ARG-ST⟨
NPcanonical, NP/canonical
⟩
]
(10)[
ARG-ST⟨
NPcanonical, NPbare
⟩
]
With an ARG-ST like (10), incorporating verbs donot meet the case constraint given in (8), and thusmust take their first argument in the absolutive. So,on this analysis, noun incorporation does not reducethe number of arguments that combine with the verb,but does reduce their case-marking status.
Further support from this view of case-markingcomes from so-called middle objects – objects of
verbs with low transitivity. These verbs have theirexternal argument marked in the absolutive caseand their second argument – the middle object – ismarked only with a determiner, with no prenominalcase marker at all, as shown below in (11):
(11) Na‘ePAST
hekaride
‘aABS
Mele(name)
heDET
hoosi.horse
‘Mary rode on the horse.’
Examples like (11) show that middle object verbshave ARG-STs as in (12).
(12)[
ARG-ST⟨
NPcanonical, NPdetermined
⟩
]
These structures also do not meet the case con-straint in (8), so their ARG-ST initial argument alsomust be in the absolutive case, as (11) shows it tobe.
A critical claim made by previous analyses ofthis kind of phenomenon in Tongan and related lan-guages (Gerdts, 1998; Massam, 2001) is that theadjacency between the verb and incorporated noun(and its phrase) is coincidental. As the above para-graphs outlined, the Lexical Sharing analysis, incontrast, claims that it is not. Rather, the analy-sis claims that the lexicon enforces the adjacency,and constrains the syntactic properties (including thecase marking) of the construction. Thus, a lexicalistanalysis is a superior account of these data, sinceit offers better predictions about the configurationand the case-marking in noun incorporation in Ton-gan.
References
C. Maxwell Churchward. 1953. Tongan Grammar. Ox-ford University Press, London.
3

Donna B. Gerdts. 1998. Incorporation. In AndrewSpencer and Arnold M. Zwicky, editors, The Hand-book of Morphology, pages 84–100. Blackwell, Ox-ford.
Jong-Bok Kim, Peter Sells, and Michael T. Wescoat.2004. Korean copular constructions: A lexical shar-ing approach. In M. Endo Hudson, Sun-Ah Jun,and Peter Sells, editors, Proceedings of the 13thJapanese/Korean Linguistics Conference, Stanford,California. CSLI Publications.
Diane Massam. 2001. Pseudo noun incorporation inNiuean. Natural Language and Linguistic Theory,19:153–197.
Carl Pollard and Ivan A. Sag. 1994. Head-driven PhraseStructure Grammar. University of Chicago Press,Chicago.
Sara Thomas Rosen. 1989. Two types of noun incorpo-ration: A lexical analysis. Language, 65:294–317.
Jeffrey T. Runner and Raul Aranovich. 2003.Noun incorporation and rule interaction in the lex-icon. In Stefan Muller, editor, Proceedings of theHPSG-2003 Conference, Michigan State University,East Lansing, pages 359–379. CSLI Publications.http://cslipublications.stanford.edu/HPSG/4/.
Michael T. Wescoat. 2002. On Lexical Sharing. Ph.D.thesis, Stanford University.
4

Towards A Semantic Analysis of Argument/Oblique Alternations in HPSG
John BeaversDepartment of Linguistics
Stanford UniversityStanford, CA, 94305-2150
In this paper I outline a semantic analysis of ar-gument/oblique alternations. I argue that when suchalternations exhibit semantic contrasts it is alwaysin terms of the relative number of entailments as-sociated with the alternating participant. I sketch aframework for capturing these contrasts in HPSG,using the locative alternation as a case study:1
(1) a. John loaded the hay onto the wagon.
b. John loaded the wagon with the hay.
In (1a) the locatum is realized as a direct argu-ment and in (1b) as an oblique, and vice versa forthe location participant. The classic semantic obser-vation (Anderson 1971) is that whichever participantis realized as direct object receives a “holistically af-fected” interpretation (all moved or all loaded up):
(2) a. John loaded the hay onto the wagon,leaving enough space for the grain.
b. #John loaded the wagon with the hay,leaving enough space for the grain.
(3) a. John loaded the wagon with the hay,with enough left over to fill the pick-up.
b. #John loaded the hay onto the wagon,with enough left over to fill the pick-up.
Only the oblique realizations are acceptable ina context where they are not holistically affected.
1This is part of a larger study based on a theory of thematicroles as sets of entailments, following primarily Dowty (1991).I use the term “entailment” in the sense of Dowty’s (1989) “lex-ical entailments”, i.e. properties a verb ascribes to an argumentdue to its role in the event, ignoring their ontological status ase.g. entailments vs. implicatures. See Beavers (to appear) formore details on the English data motivating this analysis andprevious literature on the semantic basis of alternations.
Thus they are underspecified for holistic affect-edness (i.e. they neither entail nor contradict it).Other properties, however, are invariant, e.g. oneparticipant is always a location, the other a loca-tum, and both are always at least partially affected(loaded/moved). Other realization patterns that aremorphosyntactically similar to (1) involve relatedbut distinct differences in interpretation, as in (4).
(4) a. John cut his hand on the rock. (hand af-fected; rock not necessarily affected)
b. John cut the rock with his hand. (rockaffected; hand not necessarily affected)
While the variants in (1) differ in holistic affected-ness, (4) exhibits a contrast in simple affectedness.Otherwise, the morphosyntactic and semantic sim-ilarities suggest that (1) and (4) are two manifesta-tions of one alternation where the exact contrasts areverb-specific (cf. Fillmore 1977, Dowty 1991).
While the locative alternation has been well stud-ied (see Levin and Rappaport 1988, inter alia), fewauthors have observed that there is a general contrastbetween alternating direct arguments and obliques interms of underspecificity (though see Ackerman andMoore 2001, which I discuss further below). Forexample, in the dative alternation (e.g. Rich threwBarry the ball/the ball to Barry) the recipient isinvariably a goal (which the theme is intended toreach), but when it is realized as first object it isalso an intended possessor, giving rise to the fact thatinanimate locations realized as first objects must beconstrued of as capable of possession (e.g. the Lon-don office in John sent London a package; Green1974). Likewise for the reciprocal alternation The
5

car and the truck collided/The car collided with thetruck, when both entities are realized as a conjoinedsubject both must be in motion but when one is re-alized as an oblique it is underspecified for motion.Thus an adequate analysis of alternations must cap-ture the following generalization:
(5) Direct argument variants entail more aboutthe alternating participant than oblique vari-ants.
Previous HPSG analyses have generally failed tocapture this, typically by not providing a rich enoughsemantics to capture the contrasts and not char-acterizing the argument/oblique contrast in a gen-eral way. For example, Koenig and Davis (2004)analyze English locative alternations in terms ofUND(ERGOER) assignment. The entity linked toUND is always direct object, and the alternationarises from different choices of UND (resulting fromdifferent choices of KEY relations; see Kordoni2002 for related HPSG work on Greek and Van Valin2002 for a similar approach in Role and ReferenceGrammar). However, this does not directly capturethe semantics of locative alternations since no spe-cific entailments are associated with either variant.One could stipulate that the entity linked to UNDmust be associated with more entailments. However,this does not explain what those entailments are on averb-by-verb basis, and also fails to generalize sincerecipients in the dative alternation are not necessar-ily linked to UND (e.g. Kordoni 2004 posits an ad-ditional macrorole) and in the reciprocal alternationthere is not necessarily an UND feature at all (seealso Beavers to appear for discussion of why analy-ses based on structured semantic representations aregenerally ill-suited to capture (5)).
Instead, I encode (5) in terms of thematic rolesdefined as sets of entailments as in Dowty (1989,1991). For a verb
�describing situation � , the role
a participant � plays in � is defined as a set of verb-specific entailments � , which I refer to as an indi-vidual thematic role (following Dowty 1989). Thus� is the set of all things, from the very general tothe quite specific, that
�says about � ’s role in � .
Individual thematic roles are related to one anotherin terms of specificity. For two individual thematicroles � and � , � is more specific than � if ����� .I characterize (5) in terms of thematic roles as in (6).
(6) Morphosyntactic Alignment Principle(MAP): When participant � may be realizedas either a direct or oblique argument ofverb�
, it bears role � as a direct argumentand role � as an oblique where ����� .
However, (6) fails to explain which roles � and��� will bear for a given verb and alternation, i.e. itmisses the generalization that the verb-specific con-trasts cross-classify into more general types basedon very general notions like degrees of affectedness.For instance, (1) exhibits a contrast in terms of holis-tic affectedness (however manifested for a givenverb, e.g. completely loaded/moved for load, com-pletely sprayed/covered for spray), whereas (4) ex-hibits a contrast in simple affectedness (manifestedin different ways e.g. for cut vs. break).
A better solution would derive the contrasts foreach verb in terms of a more limited and general no-tion of possible contrasts. Following Dowty (1989),I propose to do this in terms of smaller, more gen-eral sets of entailments called thematic role types.Thematic role types are universal sets of non-verb-specific entailments that cross-classify individualthematic roles in terms of properties such as affect-edness, possession, motion, etc., relevant for argu-ment linking.2 For instance, for the alternations in(1) and (4) I propose the thematic role types in Table1 on the following page (which are also relevant forother object alternations; see Beavers to appear).
Thematic role types form specificity contrasts justas individual thematic roles do, forming general hi-erarchies reflecting decreasing specificity:
(7) HOL. AFFECTED AFFECTED PARTICIPANT
The alternations of individual thematic roles in (1)and (4) can be described as minimal contrasts intheir thematic role types along (7):
(8) Role Type load/spray cut/break
HOL. AFFECTED DOAFFECTED OBL DOPARTICIPANT OBL
2The thematic role types I propose here are L-thematic rolesin the sense of Dowty (1989), defined as linguistically signifi-cant intersections of individual thematic roles, i.e. subsets thatmany individual thematic roles share in common. In light ofDowty (1991) these could be defined instead as sets of proto-role entailments as in Beavers (to appear), though I ignoreproto-roles here. Note that the term “type” here is not related tothe HPSG notion of “type”.
6

Thematic Role Type Example Individual Thematic Roles of this TypeHOLISTICALLY AFFECTED Completely loaded or moved entity (DO � ����� )AFFECTED Loaded, moved entity (oblique � ����� ), or cut entity (DO ��� )PARTICIPANT Entity not known to be affected (oblique ���� )
Table 1: Example Thematic Role Types
This can be characterized via a function from in-dividual thematic roles to individual thematic rolesas in (9), by which we can reformulate (6) as in (10).
(9) For thematic role types �� and �� , ����� �� ,forming a minimal thematic role type con-trast, and for individual thematic role � oftype �� , the role ����������� �! is the maxi-mal subset of � of type � .
(10) MAP (Revised): When participant � maybe realized as either a direct or oblique ar-gument of verb
�, it bears role � as a direct
argument and role ������� �! as an oblique.
For example, if the wagon in (1) has individualthematic role LOCATION "$#&%' of type HOLISTICALLY
AFFECTED as direct object, its role as an obliqueis ������� LOCATION "(#�%') of type AFFECTED, whichincludes all the entailments in LOCATION "$#&%' savethose that make it type HOLISTICALLY AFFECTED
rather than AFFECTED. To capture (10) in HPSG Ifirst assume a feature ROLES in each verb’s CONTvalue (assuming the MRS semantics of Copestake etal. 2003 but ignoring scoping-related features):
(11) verb-mrs * mrs & + ROLES set(set(entailments)) ,ROLES defines the set of maximal individual the-
matic roles a verb licenses, i.e. the roles a verb willassign to its direct arguments. Each verb specifieson its RELS lists elementary predications of typerole-rel, which attribute an individual thematic rolein ROLES to a participant:
(12) role-rel *elementary-predication & - ARG1 i
ROLE set(entailments(i)) .We can capture (10) as constraints on v-lxm,
which for expository purposes I present in two parts.First is the linking of direct arguments to maximalroles, done simply by associating each NP argumentdirectly with a role on the verb’s ROLES list:3
3For the remainder of the document I ignore irrelevant fea-tures such as SS and LOC in the paths to the features of interest.
(13) v-lxm /011111111112ARG-ST 3 NP 465 , ..., NP 4(798;: list < non-NP =CONT
01111112 ROLES > ? 5 , ..., ? 7 @BA set
RELS C 012 role-rel
ARG1 i DROLE ? 5 E FG , ...,
012role-rel
ARG1 i 7ROLE ? 7 E FGIH : list
E FFFFFFGE FFFFFFFFFFG
The roles assigned to obliques are more com-plicated. Ideally, they are the output of ����� forsome role on ROLES. However, we also want torestrict which oblique markers occur in which al-ternations. Following Gawron (1986), Markanto-natou and Sadler (1995), and Wechsler (1995) I as-sume that oblique markers are semantically content-ful, contributing individual thematic roles that mustbe compatible with the role assigned by the verb. Forexample, the PPs relevant for (1) are given in (14).
(14) a. 011111112 ORTH 3 onto, the, wagon 8CONT
01112 ROLES > LOCATION JLKLMON @RELS C - wagon-rel
ARG1 i . H E FFFG E FFFFFFFGb. 011111112 ORTH 3 with, the, hay 8
CONT
01112 ROLES > CAUSALLY-INTERMEDIATE @RELS C - hay-rel
ARG1 i . H E FFFG E FFFFFFFGThe PPs in (14) correspond to two potential ar-
guments of load, where the individual thematicroles supplied by each preposition represent theirinherent semantics. For locative prepositions theLOCATION P#&%" role is the general set of entailmentsthat define a participant as a locational goal (whereI assume specific choices of locational preposi-tions, e.g. on(to), in(to), are pragmatically deter-mined and not part of the thematic role per se). Fol-lowing Croft (1991), I assume with assigns a roleCAUSALLY-INTERMEDIATE, representing an entitythat is causally intermediate in the event’s force-dynamic structure, i.e. acted upon by the agent butforce-dynamically antecedent to other participants.
7

This role encompasses both locatums and instru-ments (see Levin and Rappaport 1988 on with as a“displaced theme” marker).
To ensure compatibility between the preposition’sand verb’s individual thematic roles, the latter mustbe a superset of the former. I encode this via a func-tion ����� , where ����� ���� � � � if �� � and � if�� �� .4 The linking constraints are:5
(15) v-lxm //0111111111111111111111111111112
ARG-ST C PP �L5�� ROLES > � 5 @�� ,...,
PP ��� � ROLES > � � @ � H : list < non-PP =
CONT
011111111111111112ROLES > � 5 , ..., � � @;A set
RELS C012role-rel
ARG1 j DROLE min(sup( � 5 , � 5 )) E FG ,
...,012role-rel
ARG1 j �ROLE min(sup( � � , � � )) E FG
H : list
E FFFFFFFFFFFFFFFFG
E FFFFFFFFFFFFFFFFFFFFFFFFFFFFFGThus for each PP in (15), its role is a subset of
some role Q in the ROLES set of that verb (corre-sponding to a decrease in thematic role type) and asuperset of the role P determined by the preposition:
(16) Role ������� Actual Role Role �� � �! #"%$�&('*)+$#�-,�.0/1/ 2 .All load need specify is its ARG-ST and a list of
maximal roles (including a locatum and locationalgoal, both holistically affected). No explicit linkingneeds to be stated (though I stipulate subject linkingsince I am primarily concerned here with objects):
(17) 011111111111112ORTH 3 load 8ARG-ST 3 NP 4 , NP, PP 8CONT
0111112 ROLES > D LOADER, LOCATUM N K�M43 , LOCATION N K�M43 @RELS C 012 role-rel
ARG1 i
ROLE D E FG , ... H E FFFFFGE FFFFFFFFFFFFFG
4The function&('*)
is only for presentational convenience.It simply serves to coidentify every entailment of the preposi-tion’s role with an entailment in the verb’s role. Spelling thisout explicitly reduces the readability of the AVMs.
5This constraint is English specific. For a language likeFinnish with more elaborate case morphology (13) and (15)could be trivially elaborated by including a distinction betweenNPs which have a CASE feature with a structural case valuevs. those with an oblique case value (which pattern like PPs).Note that the constraints in (15) are defaults; a particular verbcan override the general linking of obliques to certain classes ofroles if it idiosyncratically selects a particular oblique marker.
Although (17) stipulates few constraints, its out-put is restricted by the preposition inventory of En-glish, yielding only two classes of head-complementstructures, exemplified by (18) and (19):
(18) 01111111111111112ORTH 3 loaded, the wagon, with the hay 8DTRS C V, NP � , PP 5*� ROLES > D CAUSALLY-INTERMED. @ � HCONT
0111112 ROLES > ..., 6 LOCATUM N K�M43 , 7 LOCATION N K�M83 @RELS C ...,
012role-rel
ARG1 j
ROLE 7 E FG ,
012role-rel
ARG1 k
ROLE min(sup( D , 6 )) E FG H E FFFFFGE FFFFFFFFFFFFFFFG
(19) 01111111111111112ORTH 3 loaded, the hay, onto the wagon 8DTRS C V, NP � , PP 5*� ROLES > D LOCATION JLK�M�N @�� HCONT
0111112 ROLES > ..., 6 LOCATUM N K�M43 , 7 LOCATION N K�M83 @RELS C ...,
012role-rel
ARG1 j
ROLE 6 E FG ,
012role-rel
ARG1 k
ROLE min(sup( D , 7 )) E FG H E FFFFFGE FFFFFFFFFFFFFFFG
Acceptable structures similar to (19) could also bebuilt with other acceptable locational goal markers(e.g. in(to)), while presumably with is the only gen-eral CAUSALLY-INTERMEDIATE marker in English(by, via, etc. mark more specific means/manner rolesthat are not subsets of load’s LOCATUM "(#�%�' role).Any other prepositions, or different linking with thesame prepositions, would result in a unification fail-ure. Note that (following Markantonatou and Sadler1995) no polysemy of the verb is required. Differentvariants arise from the thematic roles licensed by theverb and the inherent roles of the oblique markers,maintaining the (implicit or explicit) assumption ofmuch recent work cited above that alternations aredetermined by the lexical semantics of the verbs andthe relevant oblique markers.
This approach has two advantages over previ-ous work discussed above. First, the semantics-to-morphosyntax mapping is encoded without interme-diate levels of semantic structure such as predicatedecompositions or structured elementary predica-tions as in Koenig and Davis (2004) (see Beavers toappear for more discussion). Second, by basing therelevant generalizations on verb-specific individualthematic roles organized by types, it directly linksthe idiosyncratic semantics of each verb to the moregeneral contrasts alternations exhibits across verbs.
Note that the generalization in (5) differs fromthe LFG approach in Ackerman and Moore (2001).
8

Ackerman and Moore propose that obliques devi-ate more than direct arguments from Dowty’s (1991)proto-agent/patient roles (“less prototypical” in theirPARADIGMATIC ARGUMENT SELECTION PRINCI-PLE). On the approach outlined here, “less proto-typical” is given a more specific interpretation as un-derspecificity of thematic role entailments, making astronger claim. Furthermore, my approach, thoughdefining thematic roles as sets of entailments, isnot wedded to proto-roles and thus may capture abroader set of generalizations. For example, it is nota priori obvious that recipient realization in generalneeds to be modeled using proto-roles, even if thegeneral principle in (5) nonetheless governs the se-mantic contrasts the dative alternation exhibits.
However, the analysis presented here is by nomeans complete; it is instead intended as a proof-of-concept for an entailment-based approach to alter-nations in HPSG. I have ignored several issues here,for instance verbs that do not undergo alternations(e.g. put and fill are non-alternating locative verbs)and alternations that exhibit no semantic contrast(e.g. John blamed Mary for his problems/blamedhis problems on Mary). Likewise I largely ig-nore Dowty’s proto-role theory, which could pro-vide a more principled view of subject/object selec-tion within which this framework could be situated(though see Davis 2001 for a critique of Dowty’s ap-proach). For more on these issues, see Beavers toappear. Finally, I make no predictions about whichargument structures a given verb may have (havingassumed that all locative verbs take one PP and twoNP arguments). Presumably this is derivable fromsome of the same semantic factors discussed above,an issue I leave to future investigation.
References
Farrell Ackerman and John Moore. 2001. Proto-Properties and Grammatical Encoding. CSLI Publi-cations, Stanford, CA.
Stephen R. Anderson. 1971. On the role of deep struc-ture in semantic interpretation. Foundations of Lan-guage, 7(3):387–396.
John Beavers. To appear. Thematic role specificity andargument/oblique alternations in English. In Proceed-ings of WECOL 2004, University of Southern Califor-nia, Los Angeles.
Ann Copestake, Dan Flickinger, Ivan Sag,and Carl Pollard. 2003. Minimal re-cursion semantics: An introduction.http://www.cl.cam.ac.uk/˜acc10/papers/newmrs.ps.
William Croft. 1991. Syntactic Categories and Gram-matical Relations: The Cognitive Organization of In-formation. University of Chicago Press, Chicago.
Anthony Davis. 2001. Linking by Types in the Hierar-chical Lexicon. CSLI Publications, Stanford, CA.
David Dowty. 1989. On the semantic content of thenotion ‘thematic role’. In Gennaro Chierchia, Bar-bara H. Partee, and Raymond Turner, editors, Prop-erties, Types, and Meaning. Kluwer, Dordrecht.
David Dowty. 1991. Thematic proto-roles and argumentselection. Language, 67(3):547–619.
Charles J. Fillmore. 1977. The case for case reopened.In Peter Cole and Jerrold M. Sadock, editors, Gram-matical Relations, pages 59–82. Academic Press, NewYork.
Jean Mark Gawron. 1986. Situations and prepositions.Linguistics and Philosophy, 9:327–382.
Georgia Green. 1974. Semantic and Syntactic Regular-ity. Indiana University Press, Bloomington, IN.
Jean-Pierre Koenig and Anthony Davis. 2004. The KEYto lexical semantic representations. Unpublished ms.,the State University of New York at Buffalo.
Valia Kordoni. 2002. Valence alternations in Greek: anMRS analysis. In Jong-Bok Kim and Stephen Wech-sler, editors, Proceedings of the HPSG 2002 Confer-ence, pages 129–146, CSLI Publications, Stanford,CA.
Valia Kordoni. 2004. Between shifts and alternations:Ditransitive constructions. In Sefan Muller, editor,Proceedings of the HPSG 2004 Conference, pages151–167, Stanford, CA. CSLI Publications.
Beth Levin and Malka Rappaport. 1988. What to dowith � -roles. In Wendy Wilkins, editor, Thematic Re-lations. Academic Press, San Diego, CA.
Stella Markantonatou and Louisa Sadler. 1995. Linkingindirect arguments and verb alternations in English.In Francis Corblin, Daniele Godard, and Jean-MarieMarandin, editors, Empirical Issues in Formal Syntaxand Semantics, pages 103–125. Peter Lang, Berne.
Robert D. Van Valin. 2002. The role and reference gram-mar analysis of three-place predicates. Unpublishedms., The State University of New York at Buffalo.
Stephen Wechsler. 1995. The Semantic Basis of Argu-ment Structure. CSLI Publications, Stanford, CA.
9

10

Integrating Discourse Information in Grammar
Nuria BertomeuDepartment of Computational Linguistics
Saarland UniversityGermany
Valia KordoniDepartment of Computational Linguistics
Saarland UniversityGermany
1 Introduction
The grammar of a language stipulates what canbe uttered and what not. Fragments are felicitousonly within a certain context, that is, it is the sur-rounding context which makes an stand-alone con-stituent grammatical or ungrammatical. The gram-mar should, thus, contain contextual constraints, asthese are crucial for constituents to be consideredroot sentences.
In Schlangen’s approach (Schlangen, 2003) to theresolution of elliptical fragments, however, it is thecontext within the discourse model which decideswhether a fragment is felicitous, and there is nocontextual information in the construction type li-censing the fragment. Cooper and Ginzburg (2003),on the other hand, not only include contextual con-straints in the type accounting for fragments, butalso stipulate in it how the full meaning of the frag-ment should be recovered from the source.
But there is sometimes some degree of uncer-tainty about how a fragment should be resolved,especially in the cases where there is no explicitsource, like in (1), or in the cases where some in-formation from the source is implicitely overriddenby the fragment and it is knowledge which tells usthis, like in (2).
(1) > Has Anastacia released any new CDs in thelast year?- Yes, ”Left outside alone”.> Any prizes? / > Prizes.
(2) > What is planned for the opening ceremonyof the Olympic Games in Beijing?
- Lots of concerts.> And for the Football World Championship?
Departing from the underspecified semantics offragments proposed by Schlangen (2003), the mainaim of this paper is to constrain the types licens-ing fragments with information from the preced-ing discourse. This information must, however, beminimal, since in the resolution process sometimesother extra-linguistic sources of information comeinto play. Thus, we consider the resolution processto be dependent not only on the grammar, but arguefor the need that the grammar ensures that utterancescan only be uttered/interpreted given a certain con-text.
On the other hand, current approaches to the syn-tax of fragments consider them to be headed, that is,the constituent provided by the fragment is the head-daughter of the sentence. This constituent is raisedto a sentence and the GHFP (Ginzburg and Sag,2001) is, thus, overridden. We will also argue, con-sidering cases of gapping like the one shown in (3),in favour of treating the remnant constituents as non-head-daughters and propose an alternative analysis.
(3) > When did 2-Pac release “All eyez on me”?> (And) Michael Jackson “Thriller”?
2 Contextual Information in the Grammar
The interpretation of fragments is bound to the con-text. Sometimes the context is just the situation ofutterance, like when uttering the following sentencein a restaurant:
(4) A coffee, please.
11

But more often the contextual information neededfor the interpretation of the fragment is in the pre-ceding discourse. This information can be a clause,in which case the resolution involves substitution ofa constituents from the sentence by the constituentsprovided in the fragment, or extension of the sen-tence by a modifier contributed by the fragment. Wewill call this type antecedent ellipsis. But the anchorwithin the context can also be some salient entitiessomehow related to the content contributed by thefragment, like in (1). We will call this type anchorellipsis. To resolve it one has to identify the anchorwithin the context and infer the relation holding be-tween it and the remnant. Finally, there is one typeof ellipsis with a partial linguistic antecedent, likein (5), where the fragment is to be interpreted as amodifier of the antecedent. However, we only knowthat ‘homework’ is a reason for not coming but notexactly why1.
(5) I cannot come. Homework.
Taking into account short answers, clarification re-quests and sluices, Ginzburg and Cooper (2003)identify the antecedent of the ellipsis with the Maxi-mal Question under Discussion, that is, the questionwhich is currently being discussed. If we take intoconsideration elliptical questions like in the previ-ous examples we will see that the antecedent cannotbe the Maximal Question under Discussion, sincethe second question opens a new issue which is notdependent on the previous one. At least in thoseexamples, this means that the DP (dialogue partici-pant) has accepted the previous answer, downdatingit, thus, from QUD.
In Bertomeu (work in progress) a discourse modelis presented which combines a discourse-recordcontaining different level representations of the pre-vious utterances, and their degrees of activation inmemory, with plans about actions. Those utteranceswhose syntactic structure is still available in memoryare still accessible as antecedents, as well as thoseissues which remain open in the conversation. Ac-cess to the latter is regulated by the action plan. Thismodel also makes use of a salience ranking to findentities in the context to which the remnant stands
1See (Alcantara and Bertomeu, 2005) for a corpus study ofellipsis in spontaneous spoken language supporting this classi-fication and providing quantitative distributional data.
in some relation for the cases of anchor ellipsis, andof scriptal knowledge for cases of total absence oflinguistic source. In this model a fragment can haveas antecedent what in (Cooper and Ginzburg, 2003)is called the Maximal Question under Discussion ifit is an answer to the question, or a correction, orsubquestion of it. Otherwise the fragment can reusesyntactic structure in memory from some previousutterance 2 .
However, sometimes it is not straightforward todecide what counts as an antecedent or anchor, andit may be that a fragment can be resolved upon sev-eral of them, resulting in ambiguity. It may also bethat there is ambiguity with respect to parallelism,that is, when the fragment shares syntactic and se-mantic features with more than one element in thesource and there is uncertainty about which role itis intended to fill. Finally, adjuncts may not be re-tained in the resolution as shown in (2). We believethat taking this kind of decisions is the task of apragmatic module rather than that of grammar, sinceother sources of information like inferences aboutgoals, knowledge of the world, etc., may play a cru-cial role. That is why we reject the view that thegrammar contains information about how the frag-ment must be resolved. However, the grammar caninclude information about the preceding discourse.This permits to restrict well-formed fragments tothose which are somehow bound to the precedingdiscourse context. Without such a constraint everyconstituent could be raised to a sentence.
Schlangen (2003) assigns an underspecified se-mantics to fragments using the MRS formalism(Copestake et al., 2001). Fragments have as con-tent a subtype of the type message. That is, theyhave the semantics of a main clause, but the rela-tion instantiating the main event is unknown andthe only information available is that the stand-aloneconstituent instantiates an argument of this relation,which one that argument is remains unknown. Wewill adopt the semantics proposed by Schlangen(2003), but will introduce another element: contex-tual constraints, for the reasons argued above. Inorder to do this, we will introduce the feature AN-TECEDENT, a subfeature of CONTEXT, which takes
2See (Alcantara and Bertomeu, 2005) for data regarding theavailability as antecedents of issues not currently under discus-sion.
12

as value an object of type MRS. Our notion of an-tecedent is a very general one and embraces all pos-sible sources independently of the relation in whichthey stand to the fragment, i.e. Maximal Questionunder Discussion, a recently mentioned fact, etc.In section 4 we explain how to constrain by meansof this feature the well-formedness of fragments ofthe both kinds explained above. But first let’s turnbriefly to speak about the syntax of fragments.
3 The Syntax of Fragments.
Regarding the syntax of fragments, both Cooper andGinzburg (2003) and Schlangen (2003) make thetype head-frag(ment)-phrase inherit from h(eade)d-ph(rase). They also consider that the stand-aloneconstituent which constitutes the fragment is thehead-daughter of it. The GHFP, which states thatmother and daughter must share values for the fea-ture HEAD by default, is, thus, overridden. This is,however, problematic when we want to account forfragments formed by more than one constituent in-dependent from each other, like those shown in (3).Upon which reasons can we decide here which con-stituent is the head-daughter?
Gregory and Lappin (1997), on the other hand,propose an analysis of intrasentential gapping ashaving a phonetically-null head-daughter. The rem-nants are, thus, non-head daughters.
A lot of data from German and English suggeststhat in elliptical constructions it is namely the headthat falls away. For example:
(6) My flat is 30 m2 and the neighbour’s 40.
Also in the psycholinguistic literature it has beenclaimed that the most psychologically plausibleparsing mechanism is left-corner parsing (Crocker,1999). This implies that the human parser alreadybegins to build structure as soon as it encounters anew item. For fragments this would mean that theparser analyses remnants as arguments or adjunctsand posits an empty head which is then semanti-cally filled when resolving the fragment. This is lesscostly than analysing the constituent provided in thefragment as the head and then reanalysing when asister or the real semantic head is encountered. Fromthe point of view of the syntax-semantics interface itis also desirable that there is parallelism betwen the
syntactic and semantic structures, that is, that the se-mantic heads correspond to the syntactic heads.
For the reasons just mentioned, we argue here fortreating remnants of fragments as non-head daugh-ters. However, it remains here an open researchquestion whether the type accounting for fragmentsshould inherit from the type non-h(eade)d-ph(rase)in the type hierarchy which states that the phrasedoesn’t have a head-daughter, but does have non-head-daugthers, or, whether it should inherit fromh(eade)d-ph(rase) and the head-daughter be phonet-ically empty.
4 Integrating Discourse Information.
We will depart from Schlangen’s type hierar-chy of fragments but will add two new dimen-sions: one to account for contextual dependency,res(olution)-type, and one to account for ad-junct fragments, frag(ment)-adj(unct)-type. Bothdimensions inherit from the most general typefrag(ment). The res-type dimension has two sub-types, the ant(ecedent)-frag(ment) type and theanchor-frag(ment) type. In Figure 1 the represen-tation of ant-frag is shown. The type states thatone or more constituents, non-head-daughters, areraised to a sentence. The value for the featureHEAD is a finite verb. The value for the featureM(AIN-)C(LAUSE) is positive. The mother gets theREL(ATION)S and H(ANDLE)-CONSTRAINTS fromthe construction constraints and from the daughters.The G(LOBAL-)TOP has the same value as the labelof the elementary predicate containing the messagetype and this, in turn, has as value for the featureSOA a handle which is geq3 with the label of a soa.The soa’s index, in turn, is the main index of the sen-tence. For the moment we only say that there is atleast a non-head-daugther, leaving for the other di-mensions to specify its category and function in thesentence. Our contribution at this point is to statethat the feature C(ON)T(E)XT contains a subfeatureANTECEDENT which has as value a semantic objectof type mrs containing at least one elementary predi-cate. We use the feature REL(ATIO)N as in (Sag andPolard, 1994) and coindex the values of it for thesoa-relation and the elementary predicate in the an-tecedent. We choose to represent the relation with
3Greater or equal. See (Schlangen, 2003).
13

ant-frag
SYNSEM.LOCAL
CAT
HEAD
[fin-verbMC +
]
SUBCAT
SUBJ <>
SPEC <>
COMPS <>
SPR <>
CONT
mrsINDEX 0 eventGTOP 2 handleLTOP 2
RELS A ⊕ B
H-CONS C ⊕ D
C-CONT
mrsLTOP 2
RELS A <
msgLBL 2
SOA 3
,
soaLBL 4 handleRELN 5 soa-relationARG0 0
,...>
H-CONS C <
geqSC-ARG 3
OUSCPD 4
>
CTXT
ANTECEDENT
mrs
RELS<
[soaRELN 5
],...>
NON-HEAD-DTRS <
sign
CONT
[RELS B
H-CONS D
],...>
Figure 1: General type for fragments with an-tecedent
a feature instead of the type of the elementary pred-icate because this allows to say that both relationsare of the same type, without claiming that they arethe same event and have the same arguments. In-formally, what this type states is that there must bean elementary predicate in the discourse record uponwhich the fragment is resolved. However, it can bethe same event (understood as index) or not. Wedon’t say anything about the arguments because ofthe possible ambiguity mentioned above.
In Figure 2 the type anchor-nm-np-int-fragis shown which inherits constraints from thetypes anchor-frag(ment), n(on)m(odified)-frag,n(ominal)p(hrase)-frag and int(errogative)-frag.This type accounts for fragments like the one in(1), where the entity provided by the fragment is
anchor-nm-np-arg-int-frag
C-CONT
mrsLTOP 2
RELS A <
msgLBL 2
RELN intSOA 3
,
soaLBL 4 handleRELN unknown-relARG0 0
ARGA 6
ARGB 7
,...>
H-CONS C <
geqSC-ARG 3
OUSCPD 4
>
CTXT
ANTECEDENT
mrs
RELS <
[nom-objHOOK.INDEX 6
],...>
NON-HEAD-DTRS <
CAT
HEAD nominal
SUBCAT
[COMPS <>
SPR <>
]
CONT.HOOK.INDEX 7
,...>
Figure 2: Non-modified interrogative fragmentwithout antecedent (anchor)5
related to some salient entity in the discourse recordby a relation which must be inferred. Again ourcontribution to this type is to state that the contextprovides an entity which, as the one provided by thefragment, is an argument of an unknown relation,leaving underspecified which one. The main charac-teristic of the dimension adj(unct)-frag(ment)-typeis that the fragment modifies the soa-relation. Thisis expressed by the adjunct taking as value for ARG1the index of the soa-relation. Scopal adverbs willhave as value for ARG1 a handle, allowing, thus,modals to scope over them. However, there arecases where the fragments do not modify directlythe soa-relation like in (5), where the NP providedby the fragment is contained in a modifying PPor subordinated clause. This can be accountedfor with the type ant(ecedent)-n(on)m(odified)-n(oun)p(hrase)-adj(unct)-decl(arative)-cl(ause),which is shown in Figure 3. A new semantic object,undersp(ecified)-mod(ifier) is added to the type hier-achy to account for modifieres in an underspecifiedway.
14

ant-nm-np-adj-decl
C-CONT
mrsLTOP 2
RELS A <
msgLBL 2
RELN prpstnSOA 3
,
soaLBL 4 handleRELN 5 soa-relARG0 0
,
undersp-modLBL handleARG1 0
ARG 7
...>
H-CONS C <
geqSC-ARG 3
OUSCPD 4
>
CTXT
ANTECEDENT
mrs
RELS <
[soaRELN 5
],...>
NON-HEAD-DTRS <
CAT
HEAD nominal
SUBCAT
[COMPS <>
SPR <>
]
CONT.HOOK.INDEX 7
,...>
Figure 3: Non-modified adjunct fragment clause with partial antecedent
5 Conclusion
In this paper we have proposed a way of integratingdiscourse information in the grammar. This is animportant issue for a theory like HPSG where therepresentation of a sign contains information fromall linguistic levels, assuming, thus, a wider notionof grammar which includes pragmatics.
A very general notion of antecedent is usedto constrain the well-formedness of fragments.This approach has advantages over Cooper andGinzburg’s approach (Cooper and Ginzburg, 2003)because the notion of antecedent is wider than theone of Maximal Question under Discussion, and be-cause no constraints fully determine how the frag-ment must be resolved. Consequently, it covers amuch wider range of fragment types. It also hasadvantages over Schlangen’s approach (Schlangen,2003) in that it reduces felicitous fragments to thosewhich are somehow bound to the context and thishappens already in the grammar.
We also have proposed to analyse the rem-nants of fragments as non-head-daughters, follow-ing Howard and Lappin’s analysis of intrasententialgapping (Gregory and Lappin, 1997). We believethis is in accordance with psycholinguistically moreplausible parsing techniques.
ReferencesManuel Alcantara and Nuria Bertomeu. 2005. Ellip-
sis in Spontaneous Spoken Language. In Workshopon Cross-Modular Approaches to Ellipsis at ESSLLI2005.
Robin Cooper and Jonathan Ginzburg. 2003. Clarifica-tion, ellipsis, and the nature of contextual updates indialogue. Linguistics and Philosophy, 27(3).
Dan Flickinger, Carl Pollard, Ivan A. Sag and AnnCopestake. 2001. Minimal Recursion Semantics: Anintroduction. Language and Computation, 1(3):1–47.
Matthew W. Crocker. 1999. Mechanisms for sentenceprocessing. In Garrod and Pickering, editors, Lan-guage Processing. Psychology Press.
Jonathan Ginzburg and Ivan A. Sag. 2001. Interrogativeinvestigations, the form meaning and use of Englishinterrogatives. CSLI publications.
Howard Gregory and Shalom Lappin. 1997. A compu-tational model of ellipsis. In Proceedings of the Con-ference on Formal Grammar, ESSLLI 1997, Aix-en-Provence.
Ivan A. Sag and Carl Polard. 1994. Head-driven PhraseStructure Grammar. University Chicago Press.
David Schlangen. 2003. A Coherence-Based Approachto the Interpretation of Non-Sentential Utterances inDialogue. Ph.D. thesis, Institute for Communica-tion and Collaborative Systems, School of Informatics,University of Edinburgh.
15

16

The dual nature of Tswana infinitive forms
Denis Creissels Danièle Godard Départment de linguistique CNRS, Laboratoire de Linguistique Formelle
Université Lyon-2 Louis Lumière Université Paris 7, UFRL Lyon, France Paris 05, France
[email protected] [email protected]
1 Introduction
The infinitive in Tswana (a Bantu language) has two types of occurrences, verbal (1) and nominal (2) as shown by the presence of the genitive:1 (1) Mosadi o apere mosese 1-woman S3:1-put.on-PFT-V 3-dress o montle [go ya moletlong] 3.LK 3-pretty INF-go-V 3-fair ‘The woman has put on a pretty dress to go to the fair’ (2) Ga ke rate [go nwa bojalwa NEG-S1S-like-V INF-drink-V 14-beer ga ba sadi] 15-GEN-2-woman ‘I don't like the fact that women drink beer’
We show that the hybrid nature of the Tswana infinitive can be captured nicely in the mixed cate-gory approach proposed in Malouf (2000), in spite of a clear incompatibility between most environ-ments in which the two types occur. In fact, we claim that, with its hybrid morphology, the Tswana infinitive bears witness to the (grammatical) reality of mixed categories.
1 We use the accepted orthography; the glosses make it clear what the linguistic segmentation is. The following abbreviations are used: APPL=applicative; CAUS= causative; DEM= demonstrative; FUT=future; GEN= genitive; INF=infinitive; LK= linker; LOC= locative; NEG=negative; O1S= 1pSg object agreeement index, etc. O3:X= 3rdp index agreeing with NCLASS X; PFT= perfect; POT= potential; PRO1S= 1stpSg pronoun, etc.; PRO3:X= 3rdp pro-noun, agreeing with NCLASS X; S1S= 1stp subject agreement index, etc.; S3:X= 3rdp subject index, agreeing with NCLASS X; V= final vowel.
2 Common properties of the two occur-rence types
The two uses of the infinitive share the following properties:
(i) the infinitive has the same morphological variations as a non infinitive V, in both of its oc-currence types; it bears tense-aspect markers (TAM), which encompass (a) a VFORM value (which is, leaving aside the infinitive, a choice in {indicative, subjunctive, imperative, relative, cir-cumstantial, sequential1, sequential2}, (b) a TENSE value ({present, perfect, fut., potential, continuative} relevant for indic., circ., relative, inf.), (c) a POLarity (with two values, see NEG in (2)). The infinitive, which is incompatible with the above VFORM values, has the same tense and po-larity variations as a finite indic. verb (except for a few combinations). In addition, the final vowel (noted V) depends on the TAM value, as it does with other V forms. (3)a. [Go kasebale lokwalo lo] INF-POT-NEG-read-V 11-letter 11.DEM gago monate NEG-S3:15 3-pleasant-thing ‘It is not pleasant to be unable to read this letter’ b. Ke gakgamalela [go kasebue S1S-wonder-APPL-V INF-POT-NEG-speak-V Setswana gabone] 7-tswana 15.GEN-PRO3:2 ‘I wonder at their inability to speak Tswana’
(ii) the infinitive bears the prefix go- , which is the noun class prefix 15. In nominal uses, the de-pendents show class agreement with this prefix, in
17

the same way as they do with common nouns (see (5)).
(iii) the subject cannot be realized; the infinitive does not contain the personal subject agreement index which is present on finite forms. (4)a. O roga batho jalo S2S-insult-V 2-person this way ‘You insult people this way’ b. [Go roga batho jalo] INF-insult-V 2-person this-way go tlaa tshwarisa mapodisi S3:15-FUT-O2S-catch-CAUS-V 6-policeman ‘Insulting people this way will make the police arrest you’ c.*[Go o roga batho jalo] INF-2S2-insult-V 2-person this-way
(iv) the complements of the infinitival are the same as those of the corresponding finite forms. Thus, it can have an object NP (or an adverb such as jalo) in both uses (2), (4b).
The last property is usual with hybrid forms such as (verbal) gerunds, but the combination of the other ones is noteworthy. It is not expected that a fully tensed form fails to combine with a subject. In fact, it goes against the universal deverbalization hierarchy proposed by Croft (1991), cited in Ma-louf (2000, 96). We make the hypothesis that there is a clash between the obligatory presence of a sub-ject agreement index on the verb whose subject is realized, and the fact that go- occupies this slot.
3 The contrast between nominal and ver-bal infinitive
The properties of the two occurrence types are or-ganized in two different sets. We have the follow-ing correlations.
3.1 Nominal infinitive
(i) the infinitive can take a number of depend-ents characterizing nominals (demonstrative, geni-tive, adjective, relative clause), in addition to the same complements as the corresponding finite verb. They show class agreement with the infini-tive, as do dependents on the noun. The genitive bears the N class 15 in (5b), just as the genitive in (5a) bears the N class 6.
(5)a. madi a basadi 6-money 6.GEN-2-woman ‘the women's money’ b. [go bua Setswana ga Lekgoa le] INF-speak-V 7-tswana 15. GEN-5-euro. 5.DEM ‘the fact that this European speaks Tswana’
(ii) an applicative verb has one more comple-ment than the corresponding intransitive verb. If a psychological V such as ‘to wonder’ takes as its complement an infinitive phrase containing a nominal dependent denoting the source, the appli-cative morpheme (-el-) is obligatory: (6)a. O gakgamalela bopelokgale S3:1-wonder-APPL-V 14-courage jwa mosimanee / *O gakgamala ... 14.GEN-1-boy ‘He marvels at the boy's courage’ b. O gakgamalela [go bua Setswana S3:1-wonder-APPL-V INF-speak-V 7-tswana ga Lekgoa le] / * O gakgamala ... 15.GEN-5-european 5.DEM ‘He marvels at the fact that this European speaks Tswana’
(iii) the argument corresponding to the subject of the fin V is unrealized or realized as a genitive.
(iv) the object NP cannot be separated from the V by an adverb in Tswana, nor can the infinitive in its nominal use. (7)a. Ke itse monna yo sentle S1S-know-V 1-man 1.DEM 7-good / *Ke itse sentle monna yo ‘I know this man well’ b. O rata [go letsa 3S:1-like-V INF-weep.CAUS-V katara mo ga gago] 9.guitar 15.DEM 15.GEN-PRO2S c. *O rata thata [go letsa katara mo ga gago] ‘He likes (a lot) for you to play the guitar’
(v) they have all the functions of NP (e.g. they can be locative).
(vi) they can be anaphorized like NP; they can co-occur with an object agreement on the V.
3.2 Verbal infinitive
(i’) there is no nominal dependent.
18

(ii’) an intransitive psychological verb can add an infinitive complement with a source interpreta-tion without being applicative: (8) O gakgamala [go utlwa Lakgoa S3:1-wonder-V INF-hear-V 5-european le mmuisa ka Setswana] S3:5-O3:1-speak-CAUS-V prep 7-tswana ‘He marvels at hearing this Euro. speak T’
(iii’) the subject is controlled by, or identified with (raising predicates are common) an NP in the main sentence.
(iv’) the infinitive can be separated from the V by an adverb. (9) O rata thata [go letsa katara] 3S:1-like-V a-lot INF-weep.CAUS-V 9.guitar ‘He likes a lot to play the guitar’
(v’) in some environments, they alternate with full CP (introduced by comprs such as gore).
(vi’) they are not anaphorized by pronominals (only by an adverb such as jalo ‘thus’), and do not give rise to object agreement on the V.
4 An analysis in the mixed category ap-proach
4.1 Why not a lexical rule (LR)?
Given the clear contrast between the two uses, it is tempting to propose a LR that changes the category of the word, keeping its morphological skeleton, and its argument structure (10). There are at least two morphologically related problems with this analysis. First, the LR is word-to-lexeme, since the output is a lexeme, and the input is a word (it is fully inflected), which would be an isolated case in Tswana. Second, it cannot account for the presence on the verb (the verbal use of the inf) of the N class prefix. Since the Tswana infinitive bears on its morphological sleeve the evidence that such cate-gories exist, we turn to a mixed category analysis.
4.2 The lexicon
(i) HEAD value: following Malouf (2000), we propose a mixed category. The partial hierarchy of HEAD values is as follows:
head
nominal verbal
p-noun c-noun infinitive verb (11) verbal =>
(12) nominal => [HEAD|NCLASS noun-class] Hence, the Tswana infinitive has both a VFORM value and a NCLASS value.
(ii) lexeme and word: the lexeme is defined as being [HEAD verbal]; this underspecified value is resolved in the word either as infinitive, or as verb. Words whose HEAD is infinitive also inherit the feature [NCLASS 15] from nominal. They inherit the content (relation) as well as the argument struc-ture from the verbal lexeme.
(iii) morphology: nothing prevents a realiza-tional approach to the sequence given in the de-scription of the LR above (in favor of it, note the dependency of the final vowel on the tam value, and the morphological alternation between the sub-ject index and the nclass prefix go-). We use ‘base’ rather than ‘root’, since the base, but not the root, can include derivational morphemes (at least in certain traditions), passive, applicative and causa-tive morphemes, in this case. The I-FORM values must take the argument structure into account in order to integrate the possible agreement indices for the complements. See (13).
4.3 The constructions
This infinitive can head two constructions, differ-entiated by their semantics. This accounts for the fact that they do not always alternate, even in the absence of a constraint coming from the environ-ment; this is the case in (1), the verbal infve goal phrase, where one has to use a CP if the subject is realized: the required semantics (presumably ‘out-come’, a subtype of ‘message’, Ginzburg and Sag 2000) is incompatible with the presence of nominal dependents. It also accounts for speakers' intuition that, if we have an applicative instead of an intran-sitive verb in (8), the interpretation is different (glossed by ‘the fact that’).
The internal structure of the InfveP in all its uses is ‘flat’: (i) there is no specifier (an N with its nclass prefix is a full NP); (ii) apart from the adja-
19

cency of the object with the head which is a gen-eral property in Tswana (7), the complements in-herited from the lexeme and the nominal dependents can scramble (14), although there is at least a tendency for the nominal dependents to be ordered among themselves (dem< gen< adj< RC). Such ‘scrambling’ clearly argues against an NP-over-VP analysis, proposed by Mugane (2003) for the related language Kikuyu. (14) [Go tsena gagwe mo ofising] INF-enter-V 15-GEN-PRO3:1 in 9.office-LOC ‘Her entrance into the office’
We assume that nominal dependents (including the genitive) are [MOD 1 , 1 ≥ nominal ] (see the above hierarchy of heads, and Sag 2003 for the use of the lattice hierarchy in the formulation of the constraint). Since the infinitive inherits the argu-ments of the verbal lexeme, we can have, for in-stance, both an object NP and a genitive (2), or an object NP and an adjective (go letsa katara mo gontle, lit. a nice playing the guitar).
We transpose on the head-comps-cx the distinc-tion proposed for words in Bouma et al. (2001) between the argument structure defined on the lex-eme, and an extended list of dependents. In addi-tion, the two more specific infve-head-comp-cx (coalesced here using an alternative content value) specify the content, relying on the following (par-tial) hierarchy of sem-objects (where ‘message’ and ‘soa’ are as in Ginzburg and Sag 2000):
abstract-obj nom-obj
message soa property eventuality phys-obj info-obj ...
sem-obj
Fore the constraints on the infinitive-head-complements-cx, see (15) and (16).
While an infveP with no nominal dependent is free to have either an abstract-obj or a nom-obj content, the others must have a content of type nom-obj. The relation which is the content of the verbal lexeme is a building block for two different content types at the level of the construction. ‘eventuality’ is the primary nom-obj compatible with this relation (this implies that, if an eventual-ity is associated with the verb-word in an event-based semantics for the S, it may not denote ex-
actly the same object, see Asher 1993). However, the interpretation of the nominal infveP seems to be able to shift towards ‘manner of doing sth’, as do IE nominalizations. Only nom-objects seem to be anaphorized, or represented by an agreement index on the verb.
Predicates select the so-called verbal or nomi-nal InfveP on a semantic basis. Control and raising verbs select an InfveP with an abstract-obj content, and let one of their argument NP control or be identified with the unrealized subject of the InfveP. Psychological verbs (in our ex., ‘to like’, ‘to mar-vel at’), which are known not to constrain their source argument, can precisely accept both types. Locative prepositions select a nom-obj, etc. The subject of nominal InfveP is not controlled, since it does not combine with a control predicate. It re-mains to be seen whether the subject of a (verbal) goal InfveP (1) is syntactically controlled or prag-matically interpreted.
References Bouma, G., R. Malouf and I.A. Sag. 2001. Satisfying
constraints on extraction and adjunction. Natural Language and Linguistic Theory, 19: 1-65.
Cole, D.T. 1955. An Introduction to Tswana grammar. Longman, Cape Town.
Creissels, D. 2003. Présentation du tswana. Lalies, 23: 5-128.
du Plessis, J.A. 1982. Sentential infinitives and nominal infinitives. South African J.of African Languages, 2/1.
du Plessis, J.A. and M. Visser. 1992. Xhosa Syntax. Via Africa, Pretoria.
Ginzburg, J. and I.A. Sag. 2000. Interrogative Investi-gations. CSLI Publ., Stanford.
Malouf, R. 2000. Mixed categories in the hierarchical lexicon. CSLI Publ., Stanford.
Mugane, J. 2003. Hybrid Constructions in Gikuyu: Agentive Nominalizations and infinitive-Gerund constructions. Butt, M. and T. Holloway King (eds), Nominals inside and out, CSLI Publ.., Stanford, 235-265.
Sag, I.A. 2003. Coordination and underspecification. HPSG Conference (CSLI Publ. web site).
Visser, M. 1989. The Syntax of infinitive in Xhosa. South African J. of African Languages 9/4.
20
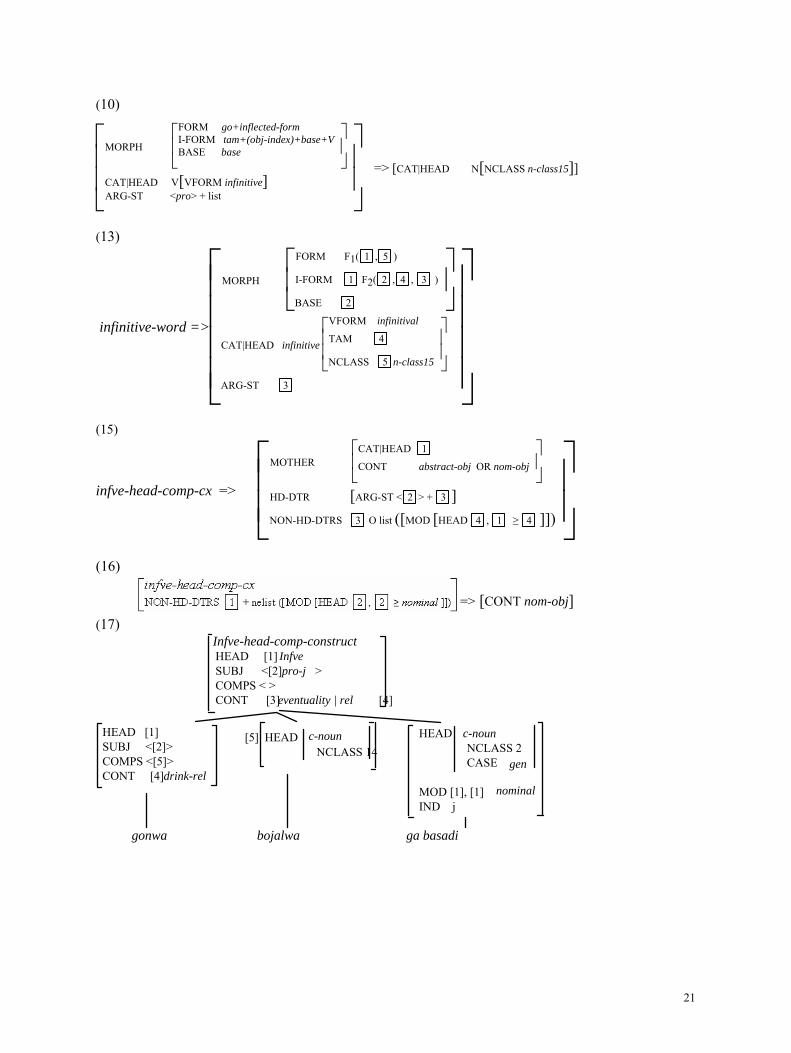
(10)
⎣⎢⎢⎡
⎦⎥⎥⎤MORPH
⎣⎢⎡
⎦⎥⎤FORM go+inflected-form
I-FORM tam+(obj-index)+base+VBASE base
CAT|HEAD V[VFORM infinitive]ARG-ST <pro> + list
=> [CAT|HEAD N[NCLASS n-class15]]
(13)
infinitive-word =>
⎣⎢⎢⎢⎢⎡
⎦⎥⎥⎥⎥⎤MORPH
⎣⎢⎡
⎦⎥⎤FORM F1( 1 , 5 )
I-FORM 1 F2( 2 , 4 , 3 )
BASE 2
CAT|HEAD infinitive
⎣⎢⎢⎡
⎦⎥⎥⎤VFORM infinitival
TAM 4
NCLASS 5 n-class15
ARG-ST 3
(15)
infve-head-comp-cx =>
⎣⎢⎢⎡
⎦⎥⎥⎤
MOTHER ⎣⎢⎡
⎦⎥⎤CAT|HEAD 1
CONT abstract-obj OR nom-obj
HD-DTR [ARG-ST < 2 > + 3 ]NON-HD-DTRS 3 O list ([MOD [HEAD 4 , 1 ≥ 4 ]])
(16)
(17) Infve-head-comp-constructHEAD [1] SUBJ <[2] > COMPS < > CONT [3] [4]
Infvepro-j
eventuality | rel
HEAD [1] SUBJ <[2]> COMPS <[5]> CONT [4]drink-rel
[5] HEAD NCLASS 14
c-noun HEAD NCLASS 2 CASE MOD [1], [1] � IND j
c-noun
gen
nominal
gonwa bojalwa ga basadi
=> [CONT nom-obj]
21

22

Syncretism in German: a unified approach to underspecification,indeterminacy, and likeness of case
Berthold CrysmannDFKI GmbH & Saarland University
Saarbrücken, Germany
Nouns, adjectives and determiners in Germaninflect for case, number and gender. However,as is typical for inflectional languages, thesemorphosyntactic feature dimensions are not ex-pressed by discrete, individually identifiable af-fixes. Rather, affixes realise complex featurecombinations. Although four case, three genderand two number specifications can clearly be dis-tinguished, the morphological paradigms of thelanguage are also characterised by heavy syn-cretism. Often, syncretism cannot be resolvedto disjunctive specification or underspecificationwithin a single feature, but it cuts across thethree inflectional dimensions: a German definitedeterminer, such as der can be nominative singu-lar masculine, genitive or dative plural, as well asgenitive or dative singular feminine. In the past,this property of German paradigms has providedsome motivation for the notion of distributeddisjunctions (Krieger, 1996; Netter, 1998). How-ever, since disjunctions are in general muchharder to process than type inference, type-based underspecification of case/number/genderspecifications appears to be the key towards anefficient and concise treatment of syncretism.
Ambiguous nominal forms in German are alsosubject to indeterminacy. Again, indeterminacyis not restricted to individual inflectional dimen-sions, but rather follows the patterns of syn-cretism. Although the notions of ambiguity andindeterminacy are intimately related, there iscurrently no analysis at hand that is capable ofcombining the machinery necessary to cover fea-ture indeterminacy with the benefits of under-specification.
In this paper I will propose an entirely type-based approach to syncretism that will success-
fully reconcile Daniels (2001)’s approach to fea-ture indeterminacy with morphosyntactic under-specification across features. Furthermore, I willshow how list types can be fruitfully put to use toabstract out individual featural dimensions fromcombined case/number/gender type hierarchies,permitting the expression of likeness constraintsin coordinate structures. As a result, the currentproposal presents an entirely disjunction-free ap-proach to syncretism, addressing indeterminacy,underspecification and likeness constraints.
1 Feature neutrality
It has been argued by Ingria (1990) that the phe-nomenon of feature neutrality in coordinationconstitutes a severe challenge for unification-based approaches to feature resolution and con-cludes that unification should rather be sup-planted by feature compatibility checks.
(1) Erhe
findetfinds.A
undand
hilfthelps.D
Frauen.women.A/D
‘He finds and helps women.’
(2) * Erhe
findetfinds.A
undand
hilfthelps.D
Kindern.children.D
(3) * Erhe
findetfinds.A
undand
hilfthelps.D
Kinder.children.A
Unification-based frameworks such as LFG orHPSG have taken up the challenge, refining therepresentation of feature constraints in such away that neutrality can be modelled without anysubstantial changes to the underlying formalism.For HPSG, Daniels (2001) proposed to addressthese problems by means of enriching the typehierarchy to include neutral types, an idea orig-inally due to Levine et al. (2001).
23

Daniels (2001) has also discussed cases wherethe potential for feature indeterminacy does notonly involve the values of a single feature: as il-lustrated in (4), a masculine noun like Dozen-ten can express any cell of the case/numberparadigm except nominative singular. Accord-ingly, one and the same form can be subjectto feature indeterminacy regarding number, gen-der, or even case.
(4) derthe
Antragpetition
desDef.G.Sg
oderor
derDef.G.Pl
Dozentenlecturer.G/D/A+N.Pl
‘the petition of the lecturer(s)’
(5) derDef.N.M.Sg
oderor
dieDef.N.F.Sg
Abgeordneterepresentative.N.Sg.M/F
‘the male or female representative’
(6) Erhe
findetfinds.A
undand
hilfthelps.D
Dozenten.lecturers.A/D
‘He finds and helps lecturers.’
A determiner like der is neutral between nom-inative singular masculine and genitive/dativeplural. However, indeterminacy with respect tonumber is not independent of case, as illustratedby (7), where the unavailability of a nominativesingular reading for Dozenten is responsible forthe illformedness of the sentence.
(7) * derthe.N.Sg.M+G/D.Sg.F+G.PlDozentenlecturer.G/D/A+N.Pl
istis
hierhere
To incorporate the issue of neutrality acrossfeatures, Daniels suggests to combine values ofdifferent inflectional features into an overarchingtype hierarchy, the nodes of which are essentiallyderived by building the Cartesian product of thetypes within each inflectional dimension.
2 Underspecification
Combined type hierarchies across different in-flectional feature dimensions have also beenfruitfully put to use in the context of effi-cient grammar engineering. In the LinGO ERG(Flickinger, 2000), person and number are rep-resented as values of a single feature PNG, per-mitting the expression of, e.g., non-3rd-singular
agreement without the use of negation or dis-junction.
In the context of more strongly inflecting lan-guages, such as German, where syncretism is thenorm rather than the exception, underspecifica-tion of inflectional features across different di-mensions is even more pressing: a typical nounsuch as Computer can express any case/numbercombination, except genitive singular and da-tive plural, i.e. 6 in total. Using combinedcase/number/gender hierarchies, the syncretismbetween nominative/dative/accusative singularand nominative/genitive/accusative plural canbe represented compactly as one entry. The verysame holds for German determiners and adjec-tives. Intuitively, it would make perfect sense totry and exploit the combined type hierarchies re-quired for the treatment of neutrality in order toarrive at a more concise and efficient representa-tion of syncretism.
3 The Problem
Although both feature indeterminacy and am-biguity do call for type hierarchies combin-ing different inflectional dimensions, these twoapproaches have not yet received a unifiedtreatment to date: it has been recognised asearly as Zaenen and Karttunnen (1984) that inunification-based formalisms feature neutralitycannot be reduced to underspecification. The ap-parent incompatibility of neutrality and under-specification is even more surprising, as thesetwo notions are intimately related: i.e., the ambi-guity of a form between two values is a necessaryprerequisite for this form to be embeddable in aneutral context.
(8)
acc-dat
acc dat
p-acc acc&dat p-dat
p-acc&dat
Taking as starting point the case hierar-chy proposed by Daniels (2001), one might betempted to assign a case-ambiguous form like‘Frauen’ a supertype of both acc and dat, e.g.acc-dat, which can be resolved to p-acc (‘dieFrauen’) or p-dat (‘den Frauen’), depending on
24

context. However, to include feature-neutrality,it must also be possible to resolve it to the neu-tral type acc&dat. Suppose now that a form likedie ‘the’ is itself ambiguous, i.e. between nom-inative and accusative, representable by a typenom-acc, again a supertype of acc. Unification ofthe case values of die ‘the’ and Frauen ‘women’will yield acc, which will still be a supertype ofthe neutral type acc&dat, erroneously licensingthe unambiguously non-dative die Frauen ‘thewomen’ in the neutral accusative/dative contextof findet und hilft ‘finds and helps’.
(9) * Erhe
findetfinds.A
undand
hilfthelps.D
[die[the
Frauen]women].A
Thus, under Daniels’s account, lexical itemsare explicitly assigned leaf type values, so-called“pure types”. While successful at resolving theissue of indeterminacy, this approach in factdrastically increases the amount of lexical am-biguity, having to postulate distinct entries fortype-resolved pure accusative, pure dative, purenominative, pure genitive, as well as all pair-wise case-neutral variants of a single form likeFrauen ‘women’. Ideally, all these different read-ings should be representable by a single lexicalentry, if only underspecification could be madeto work together with indeterminacy.
4 A Solution
The reason for the apparent incompatibilityof underspecification and feature neutrality lieswith the attempt to address both aspects withina single type hierarchy. Instead, I shall argue todraw a principled distinction between inherentinflectional feature values, where unification spe-cialises from underspecified or ambiguous typesto unambiguous types, and external or subcate-gorised feature values where unification proceedsfrom non-neutral, though generally unambigu-ous to neutral types. As a result we will have twopartially independent hierarchies, one for ambi-guity (i-case) and an inverse one for neutrality(e-case).
In order to permit satisfaction of any subcat-egorised case by some inherent case, all we needto do is define the greatest lower bound for anypair of internal and external case specification.
Thus, underspecified internal cases will unifywith a corresponding neutral case, whereas spe-
cific internal cases will only unify with theircorresponding non-neutral cases. As depictedabove, more specific types in one hierarchy willbe compatible with less specific types in theother, and vice versa. Thus, disambiguation ofi-case values will always reduce the potentialfor neutrality, as required. On a more concep-tual level, these cross-classifications between thetwo hierarchies embody the logical link betweenunderspecification and neutrality.
(10)
case
e-case
i-case
e-da
te-acc
i-da
t-acc
i-no
m-acc
...
e-da
t-acc
i-da
ti-acc
i-no
m...
s-da
ts-da
t-acc
s-acc
5 Likeness constraints incoordination
It has been argued by Müller (p.c.) that one ofthe main obstacles for exploiting combined case-number-gender hierarchies to provide an entirelydisjunction-free representation of German syn-cretism surfaces in certain coordinate structures.It is a well-known fact about German that like-ness of category in coordinate structures includeslikeness of case specification, but excludes, as arule, requirements concerning the likeness of gen-der or number specifications in the conjuncts,a pattern which is quite neatly predicted byHPSG’s segregation of head features and indexfeatures. However, in free word order languageslike German, case arguably serves not only a cat-egorial function, but also a semantic one, thereby
25

supporting the originally morphological motiva-tion towards organising all agreement featuresinto a single hierarchy (see also Kathol (1999)for a similar proposal). Moreover, the mere ex-istence of indeterminacy across case and indexfeatures makes combined hierarchies almost in-evitable.
Müller discusses syncretive pronominals inGerman, such as der, which is ambiguous, in-ter alia, between nominative singular masculine,as shown in (11), and dative singular feminine,as illustrated in (12).
(11) Derthe.N.S.M
schläft.sleeps
‘That one sleeps.’
(12) IchI
helfehelp
der.the.D.S.F
‘I help that one.’
This ambiguity could be represented by a typen-s-m+d-s-f. Subcategorisation for nominativesingular (type n-s-g) or dative (type d-n-g) willdisambiguate these forms accordingly.1
In coordinate structures, however, we observethat likeness of case equally eliminates one ofthe possible gender specifications for der, as wit-nessed by the disambiguation (13). Thus, wemust be able to distribute the case requirementover the two conjuncts in such a way that it canexert its disambiguatory potential, without ac-tually unifying the entire case/number/genderspecifications of the two conjuncts.
(13) IchI
helfehelp
derthe.D.S.F
undand
demthe.D.S.M
Mann.man
‘I help this one and the man.’
In Daniels (2001), this problem was partly an-ticipated: he suggests to address the issue oflikeness of case by means of a relational con-straint same-case/2, which restricts the two ar-guments to satify identical type requirements.This type equality is essentially imposed by dis-junctive enumeration of the four possible sub-categorised case values. In typed feature for-malisms without relational constraints, his so-lution may be mimicked by means of unfolding
1For ease of exposition, I am abstracting away fromthe internal/external distinction, which is immaterialhere, since we are only dealing with underspecification,not indeterminacy.
the relevant phrase structure schemata into case-specified variants. In both cases, a greater partof the efficiency gains achieved by underspecifi-cation may get eaten up by this disjunctive ap-proach to case similarity.
An alternative, though not fully satisfactorysolutiuon would involve retaining a head fea-ture case along-side the combined agr feature.While this move will be at least effective in rulingout unacceptable surface strings, it will fail toimpose the disambiguation potential of the sub-categorising head onto the individual conjuncts.
What is really needed here is a data structurethat may serve to both express the appropriatecase-requirements in terms of a combined hier-archy, and permit arbitrarily many specific in-stantiations of the case constraint. Fortunately,typed feature formalisms do provide for such adata structure, namely typed lists.
To start with, we will set up a hierarchy of caselist types, as depicted in figure (14)2, where eachlist type immediately subsumes at least one sub-type representing a non-empty list of the samecase type.
(14)
case-list
ngd-listngd-cons ng-cons
n-cons
g-cons
nd-cons
d-cons
gd-cons
ng-list
n-list
g-list
nd-list
d-list
gd-listnga-list
nga-cons
na-cons
a-cons
ga-cons
na-list
a-list
ga-list
nda-list
nda-cons
da-cons
da-list
gda-list
gda-conscase-cons
Types in the combined case-number-genderhierarchy will now restrict their case value toan appropriate list type, as given in (15).
(15) nda-n-g →[case nda-list
]Non-empty case lists bear a type constraint
restricting the first value to the correspond-ing agreement type in the combined case/num-ber/gender hierarchy. Actually, thanks to typeinference in the hierarchy of case lists, we onlyneed to do this for the 4 immediate subtypesof case-cons, namely ngd-cons, nga-cons, nda-cons, and gda-cons. In order to propagate thecase specification onto all elements of the openlist, the tail is constrained to the correspondinglist type (see (16)).
2The type hierarchy has been exported from the LKB:supertypes are on the left, subtypes are on the right.
26

(16) nda-cons →⟨nda-n-g | nda-list
⟩Now that we have a data structure that en-
ables us to encode likeness of case for arbitraryinstances of case/number/gender types, all weneed to do is refine our existing coordinationschemata to distribute the case restriction im-posed on the coordinate structure onto the in-dividual conjuncts. In the implemented Germangrammar we are using, coordinate structures arelicensed by binary phrase structure schemata.Thus, all we have to do is to constrain the agrfeature of the left conjunct daughter to be token-identical to the first element on the mother’sagr|case list, and percolate the rest of this listonto the (recursive) righthand conjunct daugh-ter’s agr|case value:
(17) coord-phr →ss | l |agr |case
⟨1 | 2
⟩coord-dtrs
⟨[ss | l |agr 1
],[
ss | l |agr |case 2]⟩
Coordinating conjunctions, which combine
with a conjunct by way of a head-complementrule, will equate their own agr|case|firstvalue with the agr value of their complement,percolating the case constraint onto the last con-junct.
(18)
ss | l[agr |case
⟨1 , ...
⟩]val |comps
⟨[l |agr 1
]⟩
The case of correlative coordinations can betreated exactly analogously.
6 Conclusion
In this paper we have argued for an extensionto Daniels (2001) original approach to featureindeterminacy in HPSG which makes it possi-ble to combine the empirical virtues of his type-based approach to the phenomenon with theadvantages of underspecified representation ofsyncretism across features, namely generality ofspecification and efficiency in processing.
We have further shown how likeness con-straints abstracting out a particular inflectionaldimension from a combined inflectional type hi-erarchy can still be expressed concisely by meansof typed lists.
ReferencesS. Bayer and M. Johnson. 1995. Features and agree-
ment. In Proceedings of the 33rd Annual Meetingof the ACL, pages 70–76.
Ann Copestake. 2001. Implementing Typed FeatureStructure Grammars. CSLI Publications, Stan-ford.
Michael Daniels. 2001. On a type-based analysis offeature neutrality and the coordination of unlikes.In Proceedings of the 8th International Confer-ence on Head-Driven Phrase Structure Grammar,CSLI Online Proceedings, pages 137–147, Stan-ford. CSLI Publications.
Daniel P. Flickinger. 2000. On building a more effi-cient grammar by exploiting types. Natural Lan-guage Engineering, 6(1):15–28.
R. J. P. Ingria. 1990. The limits of unification.In Proceedings of the 28th Annual Meeting of theACL, pages 194–204.
Andreas Kathol. 1999. Agreement and the syntax-morphology interface in HPSG. In Robert Levineand Georgia Green, editors, Studies in Contempo-rary Phrase Structure Grammar, pages 209–260.Cambridge University Press, Cambridge and NewYork.
Hans-Ulrich Krieger. 1996. TDL — A Type Descrip-tion Language for Constraint-Based Grammars,volume 2 of Saarbrücken Dissertations in Com-putational Linguistics and Language Technology.DFKI GmbH, Saarbrücken.
Robert Levine, Thomas Hukari, and MichaelCalcagno. 2001. Prasitic gaps in English: Someoverlooked cases and their theoretical implica-tions. In Peter Culicover and Paul Postal, editors,Parasitic Gaps, pages 181–222. MIT Press, Cam-bridge, MA.
Klaus Netter. 1998. Functional Categories in anHPSG for German. Number 3 in Saarbrücken Dis-sertations in Computational Linguistics and Lan-guage Technology. German Research Center forArtificial Intelligence (DFKI) and University ofthe Saarland, Saarbrücken.
Annie Zaenen and Lauri Karttunnen. 1984. Mor-phological non-distinctiveness and coordination.In Proceedings of the First Eastern States Con-ference on Linguistics (ESCOL), pages 309–320.
27

28

Coordination Modules for a Crosslinguistic Grammar Resource
Scott DrellishakUniversity of Washington
Emily M. BenderUniversity of Washington
1 Background
The Grammar Matrix (Bender et al., 2002) is pre-sented as an attempt to distill the wisdom of exist-ing broad-coverage grammars and document it in aform that can be used as the basis for new gram-mars. The main goals of the project are: (i) todevelop in detail semantic representations and inparticular the syntax-semantics interface, consistentwith other work in HPSG; (ii) to represent gener-alizations across linguistic objects and across lan-guages; and (iii) to allow for very quick start-up asthe Matrix is applied to new languages. The currentGrammar Matrix release includes types defining thebasic feature geometry and technical devices (e.g.,for list manipulation), types associated with Mini-mal Recursion Semantics (see, e.g., (Copestake etal., 2003)), types for lexical and syntactic rules, anda hierarchy of lexical types for creating language-specific lexical entries, and links to theLKB gram-mar development environment (Copestake, 2002). Itis, however, completely silent on the topic of coor-dination.
The next step in Matrix development is the cre-ation of ‘modules’ to represent analyses of gram-matical phenomena which differ from language tolanguage, but nonetheless show recurring patterns.In this paper, we propose a design for a set of mod-ules pertaining to coordination. Coordination is anespecially important area to cover early on as co-ordinated phrases have a relatively high text fre-quency and thus could pose an important imped-iment to coverage in the development of Matrix-based grammars. In addition, while the world’s lan-guages evince a wide variety of coordination strate-gies, many of the challenges of providing grammat-
ical analyses of coordination constructions are con-stant across all of the different strategies. Thus a rel-atively compact statement of the full set of possiblemodules is possible and the insights gained in ex-isting work on coordination in the English ResourceGrammar (version of 10/04, http://delph-in.net/erg;(Flickinger, 2000)) can be reasonably directly ap-plied to other languages.
In this paper, we restrict our attention toand co-ordination but consider how coordination works fordifferent phrase types as well as both 2-way and n-way coordination.1 §2 provides a typological sketchof coordination strategies found in the world’s lan-guages.§3 motivates design decisions we have takenin this analysis. §4 presents a sample analysis ofcoordination in Ono.§5 discusses how we encodethe information which can be compiled to create thetypes and instances needed for a particular grammar.Finally, in §6 we discuss further extensions to thegrammatical analysis and issues of the user inter-face.
2 Typological Sketch
Across the world’s languages, and across the phrasetypes within those languages, we find a wide varietyof coordination strategies. These strategies can beclassified along several dimensions; among these arethe manner of marking, the location of the marking,and the etymological meaning of the mark.
The manner of marking coordination varieswidely, and includes lexical, morphological, andphonological marking, as well as simple juxta-position. The strategy most familiar from Indo-
1We leave for future work issues such as non-constituentcoordination or the interaction of syncretism and coordination(e.g., (Beavers and Sag, 2004; Dalrymple and Kaplan, 2000)).
29

European languages is the use of a separate lexicalitem (e.g. Englishand). In some languages, coor-dination is not marked at all: the coordinands aremerely juxtaposed. This occurs, for example, in thecoordination of noun phrases in Abelam, a Sepik-Ramu language of Papua New Guinea:
(1) w2ny bal@ w2ny ac2 wary2.b@rthat dog that pig fight‘that dog and that pig fight’ (Laylock, 1965, 56)
Morphological marking generally involves in-flecting one or more of the coordinands into somekind of conjunctive or continuative form. For ex-ample, in Kanuri (Nilo-Saharan) VPs can be coor-dinated by placing the earlier one in ‘conjunctiveform’:
(2) k@raz@ mal@mro walwono.studied.CONJmalam became‘He studied and became a malam.’(Hutchison, 1981, 322)
In a few languages, coordination is marked bywhat appears to be a phonological alteration of thecoordinands. For example, in Telugu (Dravidian),adjective phrases and noun phrases are coordinatedby lengthening the final vowels in the coordinands:
(3) kamalaa wimalaa poDugu.Kamala Vimala tall‘Kamala and Vimala are tall.’(Krishnamurti and Gwynn, 1985, 325)
Languages which require a special intonationcontour to accompany coordination by juxtapositionare arguably using a phonological marking strategyas well. While ideally it would be very interesting toincorporate a model of prosody into grammar imple-mentations, this is currently not feasible. Therefore,for present purposes, we will treat the juxtapositionstrategy as though it had no overt marking.
Coordination strategies can also be classified bythe location of the marking. In the simple caseof two-way coordination, there are three positionswhere the marking may occur: before the first coor-dinand (initial), between the coordinands (medial),or after the second coordinand (final). In fact, themedial position is often more clearly associated witheither the first or second coordinand, as a postfix orprefix respectively. In addition, languages vary inthe number of marks used. If zero marks are used,we have the juxtaposition strategy, also referred to
asasyndeton; if one mark is used, this is referred toasmonosyndeton; if each coordinand is marked, thisis referred to aspolysyndeton (Haspelmath, 2000).
Finally, coordination strategies vary in the ety-mology of the marker. Some languages use an el-ement related to the comitative marker and others anelement not clearly related to anything else (Stassen,2000). Rarer etymological sources include numberwords (Huanuco Quechua) and pronouns (Sedang).
Our intention with the coordination modules is toprovide syntactic and semantic scaffolding powerfulenough to deal with most or all of these structures,and flexible enough to be enhanced to cover otheresoteric strategies that might be discovered.
3 Design Decisions
3.1 Category-specific Rules
It may seem desirable at first to have a single rulethat covers the coordination of all phrase types.However, experience with detailed work on English(as represented by the English Resource Grammar)suggests that this is not practical, given our formal-ism and current assumptions about feature geometry.The core generalization2 is that phrases of the samecategory can be coordinated to make a larger phraseof that category. Thus a common first-pass attemptat modeling coordination involves a rule that iden-tifies HEAD andVAL values across the coordinandsand the mother (see e.g., (Sag et al., 2003)). How-ever, there are features which have been placed in-sideHEAD for independent reasons which need notbe identified across coordinands, such asAUX :
(4) Kim slept and will keep on sleeping.
Further, there are differences in the semantic ef-fects of coordination for individuals and events. Inparticular, nominal indices must be bound by quan-tifiers in MRS, leading NP and NOM coordinationrules to introduce additional quantifiers. No suchconstraint holds for event indices.
Finally, there are idiosyncrasies to coordination incertain phrase types. A prime example here is theagreement features on coordinated NPs in English.For NPs coordinated withand, at least, the number
2This generalization is subject to several well known excep-tions, which tend to have low text frequency.
30

of the conjoined phrase is always plural, and the per-son is the lesser of the person values of other co-ordinands (first person and second person give firstperson, etc.). In the context of our cross-linguisticanalysis, we also find languages where the coordina-tion strategy is different for different phrase types.
In light of these facts, the analysis is considerablysimplified by positing separate rules for the coordi-nation of different phrase types. These rules stipu-late matchingHEAD values, rather than identifyingthem. These rules are, of course, arranged into a hi-erarchy in which supertypes capture generalizationsacross all of the different coordination constructions.
3.2 Binary branching structure
Whether coordination involves binary branching orflat structure is a matter of much theoretical debate(see e.g., (Abeille, 2003)). Rather than review thosearguments here, we present two engineering consid-erations which support a binary branching analysis.
First, while theLKB allows rules with any givennumber of daughters, it does not permit rules withan underspecified number of daughters. This meansthat a rule like (5a) would have to be approximatedvia some number of rules with a specific arity (5b):
(5) a. NP→ NP+ and NP
b. NP→ NP and NPNP→ NP NP and NPNP→ NP NP NP and NP. . .
With binary branching, in contrast, three rulesproduce an unlimited number of coordinands:
(6) NP-CJ → and NP (bottom coord rule)NP-CJ → NP NP-CJ (mid coord rule)NP → NP NP-CJ (top coord rule)
(7) NP
NP NP-CJ
NP NP-CJ
and NP
Second, there is the issue of ‘promotion’ of agree-ment features in coordinated NPs (and potentiallyother phrase types). In French, for example, the gen-der value of a coordinated NP is masculine iff at least
one of the coordinands is. In order to state this con-straint in this system, we’ll need separate rule sub-types which posit [GEND masc] on the mother andon one daughter, leaving the other daughter unspec-ified.3 In either system, this means doubling thenumber of rules, but the binary branching systemstarts out with fewer rules (and in fact, only the topand mid coordination rules need to be doubled, notthe bottom coord rule). The flat structure system, onthe other hand, potentially has a very large numberof rules to start with. When we also consider promo-tion of person values, the number of rules involvedgets larger, and the gain from the binary branchingsystem becomes even clearer.
4 Sample Analysis
In this section, we provide a sketch of an analysisof coordination of verb phrases and noun phrases inOno, a Trans-New Guinea language. As describedby Phinnemore (1988), Ono verb phrases are coor-dinated by inflecting non-final verbs into a “medial”form, as in (8), while noun phrases are coordinatedwith the medial monosyndetonso, as in (9).
(8) mat-ine gelig-e taun-go arivillage-his leave-MED town-to go-MED
more zoma ka-ki so ea seu-kethen sickness see-him-3sDS and there die-fp.-3s‘He left his village, went to town, and got sick and diedthere.’ (Phinnemore, 1988, 109)
(9) koya so kezong-no numa len-girain and clouds-ERG way block-3sDS‘Rain and clouds block the way...’(Phinnemore, 1988, 100)
We handle these structures with six rules:vp top coord rule, vp mid coord rule, vp bottomcoord rule, np top coord rule, np mid coord rule,and np bottom coord rule. The mid and top co-ord rules are non-headed rules with two daugh-ters, one for each coordinand, calledLCONJ-DTR and RCONJ-DTR. We assume additionalboolean HEAD features COORD and (for verbs)MEDIAL . vp bottom coord rule simply marks a[MEDIAL −] VP as coordinated (i.e.COORD +).Thevp mid coord rule will look something like thefollowing:
3Dalrymple and Kaplan’s (2000) set-based system for suc-cinctly handling such facts is not currently available in the LKB .
31

SYNSEM..CAT
HEAD
verb
VFORM 1
TAM 2
COORD +
VAL 3
[
COMPS 〈 〉]
LCONJ-DTR..CAT
HEAD
verb
VFORM 1
TAM 2
MEDIAL +
COORD −
VAL 3
RCONJ-DTR..CAT
HEAD
verb
VFORM 1
TAM 2
COORD +
VAL
This rule identifies several features of the coor-dinated VPs, marks the resulting phrase as coordi-nated, and takes a medial-form, noncoordinate leftcoordinand. This use of theCOORD feature will en-force right-branching structure, so it is not necessaryto specifyMEDIAL on the mother node, which canonly serve as theRCONJ-DTR of any further highercoordination. The Onovp top coord rule differs se-mantically from the mid rule in how it combinesthe semantic contributions of the coordinands, anddiffers syntactically from it only in that the mothernode is [COORD−]. The structure assigned the co-ordination of three VPs, the first two of which are inmedial form, is shown in (10), where VP-CJ is a VPmarked [COORD+].
(10) VP
VP VP-CJ
VP VP-CJ
VP
For noun phrases, we will need an additionallexical item so of HEAD type conj, and thenp bottom coord rule will combine so with an NPinto a COORD-marked NP. Thenp mid coord rulewill look something like the following:
SYNSEM..CAT
HEAD
noun
CASE 1
AGR
[
PER 2
NUM pl
]
COORD +
VAL 3
[
SPR 〈 〉
COMPS 〈 〉
]
LCONJ-DTR..CAT
HEAD
noun
CASE 1
AGR.PER 2
COORD −
VAL 3
RCONJ-DTR..CAT
HEAD
noun
CASE 1
AGR.PER 2
COORD +
VAL 3
This rule identifies several features of the coordi-nated noun phrases, and constrains the mother to beplural, the mother and theRCONJ-DTR to be coor-dinated and theLCONJ-DTR to be not coordinated.The np top coord rule will be similar, except thatit combine the semantic contributions of all coor-dinands slightly differently, and will also mark themother node [COORD−]. Based on these rules,the structure of a coordinated noun phrase madeup of three NPs conjoined with a singleso willlook like (7) above, where NP-CJ is an NP marked[COORD+].
For languages with polysyndeton, the only modi-fication to the rules in (6) is the omission of the midrule, which results in the marking of coordination oneach coordinand, because each additional NP willrequire one more bottom (and top) node:
(11) NP-CJ → and NP (bottom coord rule)NP → NP-CJ NP-CJ (top coord rule)
5 Modularization
The intended goal of the coordination modules is toprovide a basis for formal analyses for as wide avariety of languages as possible. However, we ex-pect that we will be able to capture this variationbased on a more limited set of semantic and syn-tactic rules. While it is not the case that all lan-guages have the same number of or divisions be-tween word classes, we expect to be able to capture
32

the semantics of various phrase types in a language-independent way. The Matrix will provide coordina-tion rules for phrases whose semantic contributionconsists of individuals (e.g. noun phrases), events(e.g. verb phrases), modification of individuals (e.g.adjectives), modification of events (e.g. adverbs),and so forth.
In addition, we expect to find commonalitiesamong the syntactic rules that can be factored out.For example, the parts of the VP and NP rulesfor Ono above that deal with the featureCOORD
can be adapted to deal with general asyndeton,monosyndeton, and polysyndeton coordination. Allthree strategies will have bottom and top coordi-nation rules (with the mid rule only needed formonosyndeton), but the rules will vary slightly. Themonosyndeton rules will look like the rules in (6)above; the polysyndeton rules will look like the rulesin (11); and the asyndeton rules will look like (12).
(12) NP-CJ → NP (bottom coord rule)NP → NP NP-CJ (top coord rule)
Different manners of marking coordination can becaptured by varying the bottom rule. It can be eithera rule that combines a separate lexical coordinatorwith the lowest coordinand, or else a non-branchingrule triggered by a morphological feature.
Based on the answers to questions posed to theuser about the facts of the language being ana-lyzed, the semantic coordination rules and syntac-tic/morphological coordination rules will be cross-classified to produce a set of language-specific rulesappropriate to the language at hand.
6 Conclusion and Outlook
We have presented an overview of an initial set ofcoordination modules for the Grammar Matrix. Webelieve that they are suited to providing syntacticallyand semantically valid analyses of the diverse coor-dination strategies in the world’s languages. Further-more, the factored representation given to the under-lying types used to create language-specific coordi-nation systems provides a means formalizing gener-alizations across languages.
The next steps for this project include: 1. Testingthe coverage of the modules by deploying them inimplemented grammars for a diverse range of lan-guages. 2. Expanding the coverage to include other
types of coordination (in the first instance, coordina-tion with or, but, etc.). 3. Working out the user inter-face and in particular a set of questions and a proto-col for presenting them to the linguist which coversthe ground necessary to handle any given languagewhile avoiding redundancy in any particular case.
ReferencesAnne Abeille. 2003. A lexicalist and construction-base ap-
proach to coordinations. In Stefan Muller, editor,Proceed-ings of HPSG03. CSLI, Stanford.
John Beavers and Ivan A. Sag. 2004. Ellipsis and apparentnon-constituent coordination. In Stefan Muller, editor,Pro-ceedings of HPSG04, pages 48–69. CSLI, Stanford.
Emily M. Bender, Dan Flickinger, and Stephan Oepen. 2002.The grammar matrix.Proceedings of COLING 2002 Work-shop on Grammar Engineering and Evaluation.
Ann Copestake, Daniel P. Flickinger, and Carl Pollard Ivan A.Sag. 2003. Minimal Recursion Semantics. An introduction.
Ann Copestake. 2002.Implementing Typed Feature StructureGrammars. CSLI, Stanford.
Mary Dalrymple and Ronald M. Kaplan. 2000. Feature inde-terminacy and feature resolution.Language, 76:759–798.
Dan Flickinger. 2000. On building a more efficient grammarby exploiting types.NLE, 6 (1):15 – 28.
Martin Haspelmath. 2000. Coordination. In Timothy Shopen,editor, Language typology and linguistic description, 2ndedition. Cambridge University Press, Cambridge.
John P. Hutchison. 1981.A reference grammar of the Kanurilanguage. University of Wisconsin - Madison, Madison, WI.
BH. Krishnamurti and J. P. L. Gwynn. 1985.A grammar ofmodern Telugu. Oxford University Press, Delhi.
D. C. Laylock. 1965.The Ndu language family (Sepik district,New Guinea). Linguistic Circle of Canberra, Series C, No 1.The Australian National Library, Canberra.
Penny Phinnemore. 1988. Coordination in Ono.Language andLinguistics in Melanesia, 19:97–123.
Ivan A. Sag, Thomas Wasow, and Emily M. Bender. 2003.Syn-actic Theory: A Formal Introduction. CSLI, Stanford.
Leon Stassen. 2000. And-languages and with-languages.Lin-guistic Typology, 4:1–54.
33

34

A new well-formedness criterion for semantics debugging
Dan FlickingerCSLI
Stanford UniversityStanford, CA
Alexander Koller and Stefan ThaterDepartment of Computational Linguistics
Universität des SaarlandesSaarbrücken, Germany
{koller,stth}@coli.uni-sb.de
Abstract
We present a novel well-formedness con-dition for underspecified semantic repre-sentations which requires that every cor-rect MRS representation must be anet.We apply this condition to identify a setof eleven rules in the English ResourceGrammar (ERG) with bugs in their seman-tics component, and thus demonstrate thatthe net test is useful in grammar debug-ging. In addition, we show that a partlycorrected ERG derives 3 % less non-netson the Rondane treebank and we expectthat after completing the correction of theERG, only 5.5 % non-nets are derived,which we take as support for our initial hy-pothesis.
1 Introduction
A very exciting recent development in (compu-tational) linguistics is that large-scale grammarswhich compute semantic representations for their in-put sentences are becoming available. For instance,the English Resource Grammar (Copestake andFlickinger, 2000) is a large-scale HPSG grammarfor English which computes underspecified seman-tic representations in the MRS formalism (Copes-take et al., 2004). It is standard to use underspeci-fication to deal with scope ambiguities; apart fromMRS, there is a number of other underspecificationformalisms, such as dominance constraints (Egg etal., 2001) and Hole Semantics (Bos, 1996).
However, the increased power of the new gram-mars comes with a new challenge for grammar engi-neering: How can we be sure that all semantic out-puts the grammar computes (through any combina-tion of semantic construction rules) are correct, andhow can we find and fix bugs? This problem ofse-mantics debuggingis an important factor in the 90%
of grammar development time that is spent on thesyntax-semantics interface (Copestake et al., 2001).
Grammar development systems such as the LKBimplement some semantic sanity checks, which arepractically useful, but rather shallow, and thereforelimited in their power. On the theoretical side, thereare attempts to formalise “best practices” of gram-mar development in asemantic algebra(Copestakeet al., 2001), but this is quite a far-reaching projectthat is not yet fully implemented.
One potential alternative method for semanticsdebugging comes from Fuchss et al.’s recent workon nets(Fuchss et al., 2004). They claim that everyunderspecified description (written in MRS or as adominance constraint) that is actually used in prac-tice is anet, i.e. it belongs to a restricted class of de-scriptions with certain useful structural properties,and they substantiate their claim through an empir-ical evaluation on a treebank. If this “Net Hypoth-esis” is true, we can recognise a grammar rule (orcombination of rules) as problematic if it producesonly non-nets on a variety of inputs.
In this paper, we show that such a use of nets is in-deed possible. We use the ERG to derive MRS rep-resentations for all sentences in the Rondane tree-bank (distributed with the ERG) and the Verbmo-bil sections of the Redwoods treebank (Oepen etal., 2002). Our first result is a small set of elevenrules which systematically cause the MRS represen-tations to be non-nets for every sentence in whichthey are used. These rules all have faulty seman-tics components, i.e. we have identified semanticallybuggy rules. We are currently correcting the gram-mar by hand. The partly corrected grammar pro-duces 89.5 % nets and only 8 % non-nets for the syn-tactic analyses in the Rondane corpus, and we expectthat after completing the correction of the problem-atic rules, only 5.5 % non-nets are derived, which wetake as further support of the Net Hypothesis.
35

h7
l0:proposition
l8:eachz
l13:sectionz
l2:udefx
l14:suitablez & also & asy
h3 h4
h6
h1
h9 h10
l5:ay
l12:tourx & compoundx,y
l11:singlex & dayx
Figure 1: Graphical representation of the MRS for“Each section is also suitable as s single day tour.”
2 Minimal Recursion Semantics
We start with a brief overview of Minimal Recur-sion Semantics (MRS). MRS (Copestake et al.,2004) is the standard scope underspecification for-malism used in current HPSG grammars, such asthe English Resource Grammar (ERG; (Copestakeand Flickinger, 2000)) or grammars derived from theGrammar Matrix (Bender et al., 2002). Its purpose isto separate the problem of resolving scope ambigui-ties from semantics construction.
Fig. 1 shows a graphical representation of the(slightly simplified) MRS which the ERG derivesfor the sentence “Each section is also suitable asa single day tour” from the Rondane treebank.It consists ofelementary predications(EPs) suchasl2:udef(x,h3,h4), l5:a(y,h6,h7), l12:tour(x,y), andl12:compound(x,y), and ofhandle constraintssuchas h6 =q l12. Elementary predications specify theparts that a semantic representation must be madeup of, and handle constraintsh=q l specify, approx-imately, thath must outscopel . Termsl i on the left-hand side of EPs are calledlabels, termshi are called(argument) handles, and termsx, y, etc. are ordinaryfirst-order variables. Notice that there are two EPsfor the labell12; this is called anEP conjunction,and interpreted as conjunction of the two formulaslabelled byl12.
The graph in Fig. 1 can be given an explicit in-terpretation as a representation of an MRS struc-ture (Fuchss et al., 2004). The nodes correspond tothe labels and handles in the MRS, and the solidedges correspond to the EPs. We call the subgraphsthat are connected by solid edges thefragmentsof
l0h1 = l8
h9 = l13 h10 = l5h6 = l2
h3 = l11 h4 = l12
h7 = l13
Figure 2: Configuration of the MRS in Fig. 1.
the graph. The dasheddominance edgesare usedto represent handle constraints, the outscoping re-quirement between a variable and its binder (suchas between the quantifier atl2 and the variable inl12), and the implicit constraint that the “top” labell0 must outscope all other EPs. Note that we assumethat the graph does not contain transitively redun-dant edges; for instance there is no binding edge be-tweenl2 andl11. EP conjunctions are represented byexplicit conjunction at the graph nodes.
An underspecified MRS structure describes a setof configurations, orscope-resolvedMRS struc-tures. The scope-resolved MRS structures can becomputed by arranging all the fragments of an MRSstructure into a tree, in such a way that every la-bel except for the one at the root is identified witha handle, and all the outscoping requirements are re-spected. One of the five scope-resolved MRSs forthe MRS in Fig. 1 is shown in Fig. 2 (we omit EPsfor clarity). Note that in general it is possible thatmore than one label is assigned to the same handle,and that the scope-resolved MRS structure can con-tain more EP conjunctions than the original MRSstructure. In such a case, we call the scope-resolvedMRS structure amerging configuration.
3 MRS-Nets
We say that an MRS structure is anet if all the frag-ments in its graph are of one of the three formsshown in Fig. 3. In astrong fragment, every leaf(argument handle) and no other node has exactlyone outgoing dominance edge. For example, the nu-clear fragmentsl11 andl14 in Fig. 1 are strong frag-ments. In aweakfragment, every leaf but one has ex-actly one outgoing dominance edge, and the root ofthe fragment has one outgoing dominance edge too.Weak fragments correspond to quantifiers (such asl2 andl8 in Fig. 1) where the dominance edge from
36

... ... ...
... ...
(a) strong (b) weak (c) island
Figure 3: Fragment Schemata of Nets
the root represents the implicit variable binding. Fi-nally, island fragments may have leaves with mul-tiple outgoing dominance edges, but then all domi-nance children must be connected byhypernormalpaths. A hypernormal path is an undirected pathwhich doesn’t use two dominance edges that comeout of the same node. An example for an island frag-ment is the topmost fragment in Fig. 1. Its dom-inance children are the three quantifier fragments,and there is a hypernormal path between each pairof these fragments – for instance,l2, l12,h6, l5 andl5, l14, l8.
Because all fragments in Fig. 1 are strong, weak,or island, the MRS it represents is a net. By con-trast, Fig. 5 shows two MRS structures which arenot nets. Both structures violate theislandconditionbecause the topmost fragment has outgoing edges toquantifier fragments (e.g. in the left-hand graph, thefragments for “a bit” and “two young Norwegians”)which are only connected via the top fragment it-self, and not by an additional hypernormal path. Theleft-hand graph also contains a quantifier fragment(“a bit”) which violates theweakcondition, as thereis an open argument handle without a correspondingdominance edge out of the root of the fragment.
Nets were introduced in (Niehren and Thater,2003; Fuchss et al., 2004) as a technical restriction;the key theorem about nets is that they can be trans-lated into normal dominance constraints (Egg et al.,2001) and Hole Semantics (Bos, 1996). This meansthat nets can be solved efficiently using the solversfor normal dominance constraints (Bodirsky et al.,2004). Nets have other useful properties: For exam-ple, nets have no merging configurations, so all EPconjunctions can be resolved to true conjunctions ina preprocessing step.
The crucial restriction that nets impose is thatthe dominance children of island fragments mustbe hypernormally connected. Intuitively, hypernor-
mal connectedness means that nets must be “down-wards” connected: In the example in Fig. 1,l2 andl8 are “tied together” by the zig-zag path throughl12 and l14, whereas “a bit” and “two young Nor-wegians” in Fig. 5 have no such connection. A lin-guistic intuition for this is that quantifiers that aresyntactic arguments of the same verb remain hyper-normally connected because their variables occur asarguments of this verb.
4 Nets in Semantics Debugging
Now we show that nets can indeed be used to iden-tify grammar rules with incomplete semantics com-ponents, and that non-nets are so infrequent in prac-tice that it is reasonable to assume that all correctMRS structures are indeed nets.
4.1 Previous Work
Recently, Fuchss et al. (Fuchss et al., 2004) pre-sented a first evaluation of whether the MRS struc-tures that can be derived using the ERG are netsor not. They found that about 83% of the MRSstructures derived for all syntactic readings of allthe sentences in the Redwoods treebank (Copestakeand Flickinger, 2000) are in fact nets. Their impres-sion from inspecting some non-nets was that non-nets seemed to be systematically incomplete. Theytook this as suggestive of what they call theNet Hy-pothesis: that all MRS structures needed in practice(i.e. for the parses of a treebank according to a large-scale grammar) are nets.
4.2 Experiment
If the Net Hypothesis is true, the 17% non-nets mustbe the results of errors in the annotation or the gram-mar rules, and every MRS that is not a net can betaken as an indicator that the grammar rules used inproducing it might be candidates for debugging.
In order to analyse this in more detail, we re-ran Fuchss et al.’s evaluation, using the October2004 version of the ERG. As test corpora, we usedthe Verbmobil sections of the Redwoods 5 Tree-bank (Jan. 2005) which contains 10503 sentences,and the Rondane Treebank (1034 sentences) dis-tributed with the ERG. Both corpora are annotatedwith HPSG syntactic structures, for each of which aunique MRS structure can be extracted.
37

Treebank #Sents. Ill-formed Non-Nets NetsVerbmobil 10503 11 % 17 % 72 %
Rondane 1034 8 % 11 % 81 %
Figure 4: Classification of the sentences in the tree-banks.
The table in Fig. 4 shows the results of the ex-periment. Each sentence in the treebanks was classi-fied into one of three categories: (1) sentences whoseMRS structure was not well-formed according tothe shallow tests in the LKB system (e.g., structurescontaining variables that aren’t bound by any quan-tifier, or structures with cycles); (2) sentences whoseMRS structures were okay according to the LKBchecks, but were not nets, and (3) sentences whoseMRS structures were nets. Of all the MRSs thatare well-formed according to the test in the LKB,81 % (Redwoods) and 88 % (Rondane) are nets, and19 % (Redwoods) and 12 % (Rondane) aren’t. Inter-estingly, the ratio of nets to non-nets is much smallerif we look not only at the annotated syntactic analy-ses, but atall possible analyses (as Fuchss et al. did).
4.3 Semantic Debugging
Then we checked which rules were “responsible” forthe introduction of non-net structures. We found thatthere is a group of eleven rules which systematicallyderive only non-nets for all syntactic analyses of allsentences in the treebanks; these rules account forapprox. 55% of the non-nets:
1. Measure noun phrases like “2–3 hours”(MEASURE_NP, BARE_MEASURE_NP)
2. Coordinations of more than two conjuncts like“train, bus or car”(P_COORD_MID, N_COORD_MID)
3. Sentence fragmens like “Delicious!”(rules FRAG_PP_S, FRAG_R_MOD_I_PP,FRAG_ADJ, and FRAG_R_MOD_AP)
4. Other rules: VPELLIPSIS_EXPL_LR,NUM_SEQ, TAGLR.
Indeed, the semantics components of all elevenrules are buggy, in that the MRS graphs that theycompute have too few dominance edges or uncon-nected fragments that should constitute an single
Treebank #Sents. Ill-formed Non-Nets NetsRondane 961 2.5 % 8 % 89.5 %
Figure 7: Classification of the sentences in the Ron-dane treebank for the partly corrected version of theERG
fragment (e.g., by forming an EP-conjunction). Thisis illustrated by the structures shown in Fig. 5. Thestructure on the left is derived by the ERG for thesentence “a bit further on we meet two young Nor-wegians”. In this structure, the quantifier “a bit”(whose analysis uses the MEASURE_NP rule) in-troduces a bound variablex that is used only in itsrestriction, but in none of the predicates in its scope(“meet further on”). This is obviously not intended.Because the missing variable binding also relaxesthe constraints on how fragments can be plugged to-gether, the underspecified description admits struc-turally wrong readings, e.g. by plugging “youngNorwegian” into the scope of “a bit” (see Fig. 6). Ifwe fix the structure by usingx in the EPs for “furtheron”, this introduces an additional dominance edge inthe graph which makes the structure a net.
A similar bug occurs in the right-hand MRSstructure. The EPs “and” and “implicit_conj” aretwo different components of the same collective“tea, milk, and coffee”, and should therefore be con-nected. Because they aren’t, the structure has mean-ingless scopings such as the one shown in Fig. 6(and almost 1000 further scopings) where “and” and“drink” have been merged into the same argumenthandle. If we connect “and” and “drink” either bycollecting them into a single EP-conjunction, or byintroducing additional material (e.g., an qauntifierfragment) that connects the two nodes, the MRSstructure again becomes a net.
4.4 Re-Evaluating the Net Hypothesis
We are currently working on correcting the seman-tics components of the eleven faulty rules by hand. Ifall problematic rules are corrected in a way that onlynets are derived, we expect that of the well-formedMRS structures 94.5 % (Rondane) and 91.5 % (Red-woods) of the syntactic structures as annotated inthe treebanks derive nets. A first experiment showsthat with our partly corrected version of the ERG,almost 92 % of the derivations annoted with well-
38

proposition
udefx
bitx & cardx & degree
pronounzudefy
pronznorwegiany & youngy & cardy
meetz,y & on & further
proposition
udefx
andx,y
udefy
teax coffeey drinku
udefz udefw udefu
beu,w
implicit_conjz,wmilkz
Figure 5: MRS expressions for the annotated derivation for “a bit further on we meet two young Norwe-gians” (left) and “Drink is tea, milk and coffee” (right) in the Rondane treebank
proposition
udefx
bitx & cardx & degree
pronounz
udefy
pronznorwy & youngy &
cardy
meetz,y & on &
further
udefx
proposition
& andx,y
udefyteax
coffeey
drinku
udefz
udefw
udefu
beu,wicz,wmilkz
Figure 6: Example solutions for the MRS structures in Fig. 5
formed MRS structures (89.5% of all sentences) inthe Rondane treebank produce nets (Fig. 7).1 It isimportant to note that in particular measure nounphrases with degree modifications, which are rela-tively often used, are not yet fully corrected. Notealso that the number of ill-formed MRS structureshas been considerably reduced.
It is important to note that at least some applica-tions of each of the eleven rules above passed thewell-formedness checks in the LKB, which showsthat nets can allow us to identify semantically prob-lematic rules which shallower checks can’t find. Inaddition, non-nets make up a larger portion of theMRS structures in the original grammar than theill-formed structures; so they are likely to captureclasses of errors that are at least as prevalent as thosethat the existing checks do.
1For technical reasons, the treebank for the partly correctedgrammar contains slightly fewer sentences. Note that if we re-move the missing sentences from the classification for the orig-inal treebank, we obtain results similar to the ones shown inFig. 4.
5 Conclusion
We have shown that nets can be a useful tool for de-bugging the semantics component of a large-scalegrammar. All eleven rules in the ERG that com-puted only non-nets turned out to be semanticallyproblematic, typically in that they were missinga variable name coindexation, or some fragments(EPs) were unconnected; also, none of these ruleswould have been easily found by the existing well-formedness tests in the LKB. A partly corrected ver-sion of the ERG derived 89.5 % nets on the Rondanecorpus.
In order to make the net criterion practically use-ful, we have developed an efficient algorithm thatchecks whether a given MRS is a net in linear time.A portable open source implementation of this algo-rithm is publically available fromhttp://utool.sourceforge.net.
There are various ways in which the work we re-port here could be extended. On the one hand, itwould be interesting to see whether a similar debug-ging methodology would yield problem rules basedon the LKB’s well-formedness tests, and it wouldbe natural to look not just for problematicrules, but
39

also for problematiclexicon entriesthis way. On theother hand, we suspect that some semantically prob-lematic MRS structures are derived not by a sin-gle rule, but by a combination of rules. One way offinding such rule combinations would be to analysethe MRSs for a corpus with a decision tree learner,which would try to derive rules that capture suchcombinations.
References
Emily M. Bender, Dan Flickinger, and Stephan Oepen.2002. The grammar matrix: An open-source starter-kitfor the rapid development of cross-linguistically con-sistent broad-coverage precision grammars. In JohnCarroll, Nelleke Oostdijk, and Richard Sutcliffe, edi-tors,Procedings of the Workshop on Grammar Engi-neering and Evaluation at the 19th International Con-ference on Computational Linguistics., Taipei, Taiwan.
M. Bodirsky, D. Duchier, J. Niehren, and S. Miele. 2004.A new algorithm for normal dominance constraints. InProc. SODA.
J. Bos. 1996. Predicate logic unplugged. InProc. 10thAmsterdam Colloquium, pages 133–143.
A. Copestake and D. Flickinger. 2000. An open-source grammar development environment and broad-coverage english grammar using HPSG. InProc.LREC.
A. Copestake, A. Lascarides, and D. Flickinger. 2001.An algebra for semantic construction in constraint-based grammars. InProc. 39th ACL, Toulouse.
A. Copestake, D. Flickinger, C. Pollard, and I. Sag. 2004.Minimal recursion semantics: An introduction.Jour-nal of Language and Computation. To appear.
M. Egg, A. Koller, and J. Niehren. 2001. The constraintlanguage for lambda structures.Journal of Logic, Lan-guage, and Information, 10:457–485.
R. Fuchss, A. Koller, J. Niehren, and S. Thater. 2004.Minimal Recursion Semantics as dominance con-straints: Translation, evaluation, and analysis. InProc.42nd ACL, Barcelona.
J. Niehren and S. Thater. 2003. Bridging the gap be-tween underspecification formalisms: Minimal recur-sion semantics as dominance constraints. InProc. 41stACL, Sapporo.
S. Oepen, K. Toutanova, S. Shieber, C. Manning,D. Flickinger, and T. Brants. 2002. The LinGO Red-woods treebank: Motivation and preliminary applica-tions. InProc. 19th COLING.
40

Object-to-Subject Raising: An Analysis of the Dutch Passive
Frederik Fouvry and Valia KordoniDepartment of
Computational Linguistics and PhoneticsSaarland University
Saarbrucken, Germany{fouvry,kordoni }@coli.uni-sb.de
Gertjan van NoordCenter for Language and Cognition
University of GroningenGroningen, The [email protected]
1 Introduction
This paper focuses on passive constructions inDutch. Specifically, we focus onworden, as wellas krijgen passives in Dutch, for which we pro-pose a uniform, raising analysis inHPSG. We alsoshow that such an analysis can be carried over to ac-count for passives cross-linguistically. Specifically,we look at corresponding structures in German andshow that there is no need for a dual raising andcontrol analysis for the German “agentive” (werden)and the German “dative” (kriegen) passives, respec-tively, as has been proposed in Muller (2002) andMuller (2003).
2 The data
The following are examples of the main passives inDutch.1,2
(1) a. PeterPeter.subj
kustkisses
haar.her.obj1
“Peter kisses her.”
b. Zijshe.subj
wordtis
gekustkissed
(door Peter).(by Peter)
“She is kissed (by Peter).”
(2) Het raamthe window.subj
isis
geopend.opened
“The window is open.”
Dutch also exhibits a special kind of passiveswhich are formed with the auxiliarykrijgen (“toget”; henceforth,krijgen passive). Thekrijgen pas-sive is formed from ditransitive verbs in Dutch,
1The zijn (“stative”) passives in (2) above are beyond thescope of this paper.
2In the glosses subj = subject, obj1 = object1 (primary ob-ject), obj2 = object2 (secondary object).
which subcategorise for aprimary (obj1) and asec-ondary (obj2) object. Thesecondaryobject of theditransitive verb surfaces as the subject of thekrij-genpassive:
(3) a. IkI.subj
stuursend
hemhim.obj2
het boekthe book.obj1
toe.to
“I send him the book.”
b. Hijhe.subj
krijgtgets
het boekthe book.obj1
toegestuurd.sent-to
“He gets the book sent.”
(4) a. Wewe.subj
betalenpay
hemhim.obj2
zijn salarishis wages.obj1
door.through
“We continue to pay him his wages.”
b. Hijhe.subj
krijgtgets
zijnhis
salariswages.obj1
doorbetaald.paid-through
“He is being paid his wages.”
In contrast, when theprimaryobject of the ditran-sitive verb surfaces as the subject of the passive formof Dutch ditransitives, like the one in (3a), for in-stance, then this passive is formed with the auxiliaryworden, like the passive form of regular transitiveverbs in Dutch (see example (1) above):
(5) a. IkI.subj
stuursend
hemhim.obj2
hetthe
boekbook.obj1
toe.to
“I send him the book.”
b. Hetthe
boekbook.subj
wordtis
hemhim.obj2
toegestuurd.sent-to
“The book is sent to him.”
c. *Hijhe.subj
wordtis
hetthe
boekbook.obj1
toegestuurd.sent-to
“He is sent the book.”
As can be observed in examples (3) and (4) above,the primary objects of the active forms in (3a) and(4a) (het boekandzijn salaris, respectively) retain
41

their grammatical function (obj1) in the passive sen-tences in (3b) and (4b). Actually, the absence of theprimary object of the ditransitive active form fromthe correspondingkrijgen passive renders the latterungrammatical:
(6) *Hijhe.subj
krijgtgets
toegestuurd.sent-to
“*He was sent.”
2.1 Some interesting exceptions
The only exception in the passive patterns in Dutchpresented in section 2 is observed with the verbbe-talen (to pay) and its derivatives (doorbetalen(tocontinue payment),uitbetalen(to pay out),terugbe-talen(to pay back), etc).
As shown from examples (5a)–(5c) above, in gen-eralsecondaryobjects (obj2s) in Dutch ditransitivescan never passivise with the auxiliaryworden. Thatis, thesecondaryobject of Dutch ditransitives, likegevenandbetalen, can never surface as the subjectof awordenpassive:
(7) *Hijhe.subj
wordtis
hetthe
boekbook.obj1
gegeven.given
“He is given the book.”
(8) *Hijhe.subj
wordtis
zijnhis
salariswages.obj1
doorbetaald.paid-through
“He is being paid his wages.”
An exception to this pattern is observed in struc-tures like the one in example (9) below. Moreover,when in active sentences headed by the verbbetalen(to pay) theprimary object (obj1) is not phonolog-ically realised, thenkrijgen passive structures arealso possible (see example (9b) below), in contrastto the behaviour of the rest of the Dutch ditransitivesas presented in (6) in the previous section. This lastpattern is also to be observed with the verbuitkeren(to pay out benefits; see example (10)).
(9) a. Hijhe.subj
wordtis
doorbetaald.paid-through
“He is being paid.”
b. Hijhe.subj
krijgtgets
doorbetaald.paid-through
“He is getting paid.”
(10) a. Hijhe.subj
krijgtgets
uitgekeerd.paid-out
“He is getting paid out benefits.”
b. Hijhe.subj
wordtis
uitgekeerd.paid-out
“He is being paid out benefits.”
But whereas (9a) and (9b) have the same mean-ing, (10b) does not entail the same as the sentencein (10a). Specifically,hij is the secondary object in(9a), (9b) and (10a), whereas it is the primary ob-ject in (10b). We will return to examples (9)–(10) insection 5.
3 Cross-linguistic evidence and previousanalyses
German also exhibits similar passive structures tothe Dutch ones we have presented in section 2. In-teresting for our purposes here are the passives ofGerman ditransitives shown in the following exam-ples (from Muller (2003)):
(11) a. Der Mannthe man.Nom
hathas
den Ballthe ball.Acc
dem Jungenthe boy.Dat
geschenkt.given
“The man gave the ball to the boy.”
b. Der Ballthe ball.Nom
wurdewas
dem Jungenthe boy.Dat
geschenkt.given
“The ball was given to the boy.”
c. Der Jungethe boy.Nom
bekam/kriegtegot
den Ballthe ball.Acc
geschenkt.given
“The boy got the ball as a present.”
Muller (2002), adapting Heinz and Matiasek’s(1994) account of, among others, passivisation inGerman, proposes a raising analysis for the Ger-man werden passives (see example (11b) above)and a control-like analysis for the Germanbekom-men/kriegenpassives, like the one in example (11c)above. The lexical entry for the auxiliarybekom-menin (12) below is (slightly modified) from Muller(2002, p. 149) and captures the gist of his analysisfor the dativebekommen/kriegenpassives in Ger-man.
(12) bekomm-(dative passive auxiliary)
42

SUBCAT⟨
1 NP[str
]2
⟩⊕ 3 ⊕ 4
XCOMP
⟨V
pppLEX +
SUBCAT 3 ⊕⟨
NP[ldat
]2
⟩⊕ 4
XCOMP 〈〉
⟩
The control-like part of the account he proposeslies on the subject of the dative passive auxiliary be-ing coindexed with the dative element of the em-bedded participle. As mentioned in Muller (2002,p. 149) “all elements from theSUBCAT list of theembedded verb are raised to theSUBCAT list ofbekommenexcept for the dative object”.
The analysis in (12) above for the Germanbekom-men/kriegenpassives is somewhat surprising giventhe fact that passive structures in German headed bybekommen/kriegendo not entail that somebody getssomething, as the following examples from Muller(2002, p. 132) also aim at showing:
(13) Erhe
bekamgot
zwei Zahnetwo teeth
ausgeschlagen.PART(out).knocked
“He got two teeth knocked out.”
(14) a. Der Bubthe lad
bekommt/kriegtgets
das Spielzeugthe toy
weggenommen.PART(away).taken
“The boy has the toy taken away from him.”
b. Der Betrunkenethe drunk
bekam/kriegtegot
die Fahrerlaubnisthe driving allowance
entzogen.withdrawn
“The drunk had his driving license taken away.”
As Muller (2002, p. 132) also proposes “themeaning ofbekommenand kriegen is bleached inthese constructions. Therefore it is not justifiedto assume that the subject in such dative passiveconstructions is a receiver and gets a thematic rolefrom bekommen/erhalten/kriegen”. In other words,Muller (2002) also disfavours a control analysis forthe Germanbekommen/kriegen“dative” passives.
The only reason imposing an analysis like the onepresented in (12) we can think of is the realistic tech-nical difficulty to have the lexically case marked da-tive secondary object (NP
[ldat
]) of the SUBCAT list
of the passive participle getting raised to the sub-ject NP of the auxiliarybekommen/kriegen, whichshould bear a structural nominative case. Thus, the
analysis in (12) only denotes an index sharing be-tween the structurally case marked subject NP of theauxiliary bekommen/kriegenand the lexically casemarked secondary object NP of the passive partici-ple, in the spirit of a control analysis, instead ofan entire synsem object sharing between these twoNPs, which would have been expected under a rais-ing analysis, as would have also, apparently, beenfavoured by Muller (2002).
4 Motivation for a raising analysis ofpassives in Dutch
The analysis we propose and formalise in the nextsection for the Dutch passives we have presented insection 2 is a uniform raising analysis. The motiva-tion in favour of such an analysis, especially for thekrijgenpassives, in contrast to a control analysis likethe one proposed in (12) in section 3, is based on thegeneral treatment of raising and control phenomenapresented in Pollard and Sag (1994).
Specifically, following Jacobson (1990), Pollardand Sag (1994, p. 141) show that whereas equi verbsallow NPs (or PPs) instead of their VP complement,this is never true for raising verbs (the examples arefrom Pollard and Sag (1994, pp. 141–142)):
(15) Leslie tried/attempted/wants something/it/to win.
(16) *Whitney seems/happens something/it.
Such contrasts between equi and raising verbs,Pollard and Sag (1994, p. 142) comment,“follow di-rectly from the Raising Principle.3 Since the raisingverbs in (16) assign no semantic role to their subjectargument, there must be an unsaturated complementon the sameSUBCAT list. But NPs likesomethingorit are saturated, and hence theSUBCAT list requiredfor examples like those in (16) is systematically ex-cluded.”
krijgen-headed structures in Dutch behave in asimilar way to raising structures like the one in ex-ample (16) above:
3Raising Principle (Pollard and Sag, 1994, p. 140): Let Ebe a lexical entry whoseSUBCAT list L contains an element Xnot specified as expletive. Then X is lexically assigned no se-mantic role in the content of E if and only if L also contains a
(nonsubject) Y[
SUBCAT⟨
X⟩]
.
43

(17) ?Hijhe
krijgtgets
het boekthe book
toegestuurdsent
enand
zijn buurmanhis neighbour
krijgtgets
datthat
ook.too
“*He is sent the book and his neighbour is that too.”
(18) *Hijhe
krijgtgets
uitbetaaldpaid
enand
PietPeter
krijgtgets
datthat
ook.too
“*He gets paid and Peter gets that too.”
krijgen does not introduce a semantic role (likethe auxiliariesworden(passive) andhebben(perfecttenses)).
5 Formalisation of the analysis
Based on the motivation presented in section 4, weformalise our analysis for the Dutchwordenpassivein the lexical entry in (19) below and our analysisfor the Dutchkrijgen passive in the lexical entry in(20) below. Both lexical entries use the functionraise to nominative()(Figure 1).4
This function takes a noun synsem, and preservesall values in the output, except for theCASE value,which is set tonominative.
As aimed at and expected, in both lexical entriesbelow all the elements of theSUBCAT list of the em-bedded participle are raised to theSUBCAT list ofwordenandkrijgen, respectively. In the case ofwor-den, the accusative primary object of the embeddedparticiple surfaces as the nominative subject of theauxiliary after raising. In the case ofkrijgen, it is thedative secondary object which surfaces as the nomi-native subject of the auxiliary after raising.5
(19) worden(passive auxiliary)
SUBCAT
⟨raiseto nominative
(1
)⟩⊕ 2 ⊕ 3
XCOMP
⟨V
pppLEX +
SUBCAT 2 ⊕⟨
1 NP[
CASE acc]⟩⊕ 3
XCOMP 〈〉
⟩
(20) krijgen (dative passive auxiliary)
4There are other ways in which the same effect can beobtained in a formalism. We chose a function because it iscompact and easy to understand. Specifically, the functionraise to nominative()(Figure 1) is really only an abbreviatorydevice, since it only consists of simple unifications. The sameeffect could be obtained, more verbosely, without functions.
5In our analysis, primary objects (obj1) bear accusative case,and secondary objects (obj2) dative case.
SUBCAT
⟨raiseto nominative
(1
)⟩⊕ 2 ⊕ 3
XCOMP
⟨V
pppLEX +
SUBCAT 2 ⊕⟨
1 NP[
CASE dat]⟩⊕ 3
XCOMP 〈〉
⟩
The lexical entry in (19) accounts for the exam-
ples in (1b) and (5b) in section 2. In the case ofexample (1b) the value of2 in (19) is the empty list,since the verbkussen(to kiss) is transitive, and notditransitive. 3 may contain PP denoting the logicalsubject (door Peterin example (1b)).
The lexical entry in (20) accounts for the exam-ples in (3b) and (4b) in section 2, where the ditran-sitive verbs have a primary object. For most ditran-sitive verbs, the primary object is compulsory, whilefor uitkerenand thebetalen-family, it is optional.Example (6) demonstrates the former: the primaryobject is missing, while in (3b) and (4b) it is present(i.e. 2 in (20) is a list containing the primary object).In examples (9b) and (10a) on the other hand,2 isthe empty list: the primary object is absent.
This variation is a lexical property of the verbs,and not limited to the passive mood, as the followingexamples show.
(21) *IkI.subj
stuursend
hemhim.obj2
toe.to
“*I send him.”
(22) WeWe.subj
betalenpay
hemhim.obj2
door.through
“We continue to pay him.”
(23) Zethey.subj
kerenpay
hetit.
uit.out
“They pay it out benefits.”
(21) is (3) without (compulsory) primary object,(22) (4a) without (optional) primary object, and (23)(10) also without (optional) primary object.
As far as example (9) is concerned, we assumethat the verbbetalen(to pay), as well as its deriva-tives doorbetalen, uitbetalen, terugbetalen, etc.,may also have a purely transitive use:
(24) a. IkI.subj
betaalpay
de tuinman.the gardener.obj1
b. De tuinmanthe gardener.subj
wordtis
betaald.paid
44

raiseto nominative
LOC
CAT
HEAD
[CASE case
]SUBCAT 1
LEX 2
CONTENT 3
CONTEXT 4
NONLOC 5
−→
LOC
CAT
HEAD
[CASE nom
]SUBCAT 1
LEX 2
CONTENT 3
CONTEXT 4
NONLOC 5
Figure 1: Definition of the function raiseto nominative()
In such cases, the sole object of the active form ofthebetalen-family verbs is considered to be their pri-mary object, which may, therefore, be accounted forby the auxiliarywordenin (19). Then the value of2 in (19) is the empty list, since the verbbetalen(topay) is considered to function as transitive, and notditransitive.
6 Conclusion
We have motivated and formalised a uniform rais-ing analysis for thewordenandkrijgen passives inDutch. The analysis accounts for the Dutch data pre-sented in section 2, without needing to find refugeto ad hoc theoretical and technical resorts, like theanalysis of Muller (2002) (cf., the control-like anal-ysis of the Germanbekommen/kriegenpassives), aspresented in section 3. The formalisation of the anal-ysis in section 5 is essentially based on the fact thatthe information shared in raising constructions mayleave out some paths from theSYNSEM information,while still remaining a raising analysis. In the caseat hand, theSYNSEM value of the primary object ofthe embedded participle of thewordenpassive, aswell as theSYNSEMvalue of the secondary object ofthe embedded participle of thekrijgen passive, areraised to the subject of their respective auxiliaries,with only their CASE value changing to the nomi-native case required by the subject. Such a formal-isation does not only account in a straightforwardway for the behaviour of the Dutch data at hand (seesection 2), but it can also offer a solution to the anal-ysis presented in (12) in section 3 for the Germanbekommen/kriegenpassives. Finally, such a formali-sation also amends naturally the shortcomings of theintended raising analyses of German passives pro-posed in Kathol (1994) and Pollard (1994), whichsuggest that what should be raised to the subject ofthe werdenand bekommen/kriegenpassives is notthe entire argument NP, but only its INDEX speci-
fication, since indices do not contain a specificationfor CASE, and they can, thus, belong to NPs withdifferentcase values without giving rise to a conflict.But as was also mentioned in section 3, structure-sharing only among indices points to a control anal-ysis of passivisation in German. Thus, our analysis,which formally captures the fact that passivisation isbased on structure-sharing of entire synsem objects,is the most straightforward analysis.
ReferencesWolfgang Heinz and Johannes Matiasek. 1994. Argu-
ment structure and case assignment in German. InJohn Nerbonne, Klaus Netter, and Carl Pollard, edi-tors,German in Head-Driven Phrase Structure Gram-mar, pages 199–236. CSLI Publications. No. 46 inCSLI Lecture Notes.
Pauline Jacobson. 1990. Raising as function composi-tion. Linguistics and Philosophy, 13:423–475.
Andreas Kathol. 1994. Passives without Lexical Rules.In John Nerbonne, Klaus Netter, and Carl Pollard, edi-tors,German in Head-Driven Phrase Structure Gram-mar, pages 237–272. CSLI Publications. No. 46 inCSLI Lecture Notes.
Stefan Muller. 2002.Complex Predicates: Verbal Com-plexes, Resultative Constructions, and Particle Verbsin German. Number 13 in Studies in Constraint-BasedLexicalism. Center for the Study of Language and In-formation, Stanford.
Stefan Muller. 2003. Object-to-subject-raising and lexi-cal rule: An analysis of the German passive. In StefanMuller, editor,Proceedings of the HPSG-2003 Confer-ence, Michigan State University, East Lansing, pages278–297. CSLI Publications.
Carl Pollard and Ivan A. Sag. 1994.Head-Driven PhraseStructure Grammar. University of Chicago Press.
Carl Pollard. 1994. Toward a Unified Account of Pas-sive in German. In John Nerbonne, Klaus Netter, andCarl Pollard, editors,German in Head-Driven PhraseStructure Grammar, pages 273–296. CSLI Publica-tions. No. 46 in CSLI Lecture Notes.
45

46

A Computational Treatment of V-V Compounds in Japanese
Chikara HashimotoDepartment of Infomatics
Kyoto UniversityJapan, 606-8501, Kyoto
Francis BondMachine Translation Research Group
NTT Communication Science LaboratoriesJapan, 619-0237, Kyoto
1 Introduction
In this study, we examine how a large-scale compu-tational grammar can account for the complex natureof Japanese verbal compounds (V1-V2 compounds,hereafter), such as yomi-owaru (read-finish) ‘finishto read’. It is necessary to develop a linguisticallyaccurate and computationally tractable analysis forV1-V2 compounds, since they are common in writ-ten documents and spontaneous speech, and, despitetheir surface simplicity, they show various complex-ities. To date, several computational Japanese gram-mars have been developed, but little attention hasbeen paid to V1-V2 compounds. In fact, their ap-proaches are either enumerating all V1-V2s in thelexicon as if they were single words without inter-nal structures (the exhaustive listing approach) orsimply concatenating the V1 and V2 of any kindof V1-V2 without taking into account the differ-ences in their syntactic and semantic composition(the simple concatenation approach). The formersuffers from undergeneration since some patternsare very productive and moreover a V1-V2 can em-bed another one: [[[nade-mawasi]-tuzuke]-sobire]-kakeru ([[[stroke-slue]-continue]-fail]-be.about.to).The latter approach leads to overgeneration since notall combinations of two verbs are allowed: *waki-ageru (boil-raise) (cf. waki-agaru (boil-go.up)).
We develop the analysis of V1-V2s that is com-patible with the linguistic analyses and observationsmade by Kageyama (1993) and Matsumoto (1996)while being computationally tractable. The analysisis implemented in JACY (Siegel & Bender, 2002)using the LKB system (Copestake, 2002) and evalu-ated with the Hinoki corpus (Bond et al., 2004) and
the [incr tsdb()] system (Oepen & Carroll, 2000).
2 DataV1-V2s show differences in terms of how productivethey are, how their transitivity and case-marking aredetermined, whether or not they are compositional,and what semantic composition they undergo if theyare compositional. First, as for their productivity,some V1-V2s are very productive and allow even aphrase in the V1 position. In (2), for example, theV1-V2 headed by sobireru (fail) allows the phrasalV1, nade-te age (stroke-TE give), while the V1-V2
headed by mawasu (caress) does not.
(1) a. nade-sobireru (stroke-fail) ‘fail to stroke’
b. nade-mawasu (stroke-caress) ‘fondle’
(2) a. nade-te age-sobireru (stroke-TE give-fail)‘fail to stroke for someone’
b.*nade-te age-mawasu (stroke-TE give-caress) ‘?’
Second, some V1-V2s inherit V2’s transitivity andcase-marking (3), while others are given those ofV1’s (4).
(3) a. Ken-ga huku-o kiru (Ken-NOM clothes-ACC wear) ‘Ken wears clothes.’
b. huku-ga kuzureru (clothes-NOM
get.out.of.shape) ‘Clothes get out ofthe shape.’
c. huku-ga ki-kuzureru (clothes-NOM wear-get.out.of.shape) ‘Clothes get out of theshape by someone’s wearing.’
47

(4) a. Ken-ga siai-ni katu (Ken-NOM game-DAT
win) ‘Ken wins games.’
b. Ken-ga siai-o tuzukeru (Ken-NOM game-ACC continue) ‘Ken continues games.’
c. Ken-ga siai-ni kati-tuzukeru (Ken-NOM
game-DAT win-continue) ‘Ken continuesto win games.’
Third, some V1-V2s show semantic composition-ality (5), but others are highly lexicalized (6).
(5) a. kaki-hazimeru (write-begin) ‘begin towrite’
b. naki-sakebu (cry-shout) ‘cry and shout’
(6) a. uti-kiru (hit-cut) ‘abort’
b. tori-simaru (take-fasten) ‘police’
Finally, compositional V1-V2s are composed indiverse ways. (7a)–(7b) correspond to (5a)–(5b), re-spectively.
(7) a. ∃x ∃y begin(x, write(x, y))b. ∃x and(cry(x), shout(x))
3 Analysis3.1 Linguistic AnalysesKageyama (1993)’s insightful analysis claims thatdifferent behaviors of different V1-V2s are mostlypredictable from how they are composed. He dis-tinguishes two major types: syntactic V1-V2 com-pounds and lexical V1-V2 compounds. The twocomponent verbs of syntactic V1-V2 compounds arecombined in the syntax, while lexical V1-V2 com-pounds are formed in the lexicon. Accordingly, syn-tactic V1-V2s are generally as productive and com-positional as ordinary phrases, but lexical V1-V2sare often irregular and idiomatic. Table 1 summa-rizes the characteristics of the two types in more de-tail.
Kageyama further divides syntactic V1-V2s intothree types: Raising (e.g. V1-kakeru (V1-be.about.to) ‘be about to V1’), Control (e.g. V1-sobireru (V1-fail) ‘fail to V1’), and V complemen-tation types (e.g. V1-tukusu (V1-exhaust) ‘work outto V1’). This is supported by, among other things,a contrast in passivizability; Raising and Controltypes do not allow passivization of V1-V2, as op-posed to the V complementation type.
(8) hon-gabook-NOM
Ken-niKen-DAT
yomi-{*kake/*sobire/tukus}-rare-taread-{*be.about.to/*fail/exhaust}-PASS-PAST
Also, the three kinds show differences in whetherV2s thematically restrict their subjects and objects.
(9) a. ame-garain-NOM
huku-oclothes-acc
nurasi-{kake/*sobire/*tukusi}-tahumidify-{be.about.to/*fail/*exhaust}-PAST
‘The rain {was about/failed/worked out} towet the clothes.’
b. Ken-gaKen-NOM
atama-ohead-ACC
hiyasi-{kake/sobire/*tukusi}-tacool-{be.about.to/fail/*exhaust}-PAST
‘Ken {was about/failed/worked out} to cooloff.’
Since V2s of Control (-sobireru) and V (-tukusu)types put a thematic restriction on a subject, whichthe subject, ame (rain) in (9a), cannot satisfy, onlythe Raising type (-kakeru) is grammatical in the ex-ample. In (9b), only the V type is ruled out sinceit restricts an object to something that can be ex-hausted, but the object, atama, which is a part ofthe idiom, atama-o hiyasu ‘cool off,’ cannot meetthe restriction.
Matsumoto (1996) classifies lexical V1-V2s intoseven subtypes according to the semantic relationsbetween V1 and V2. Each subtype, its example anda tentative semantics of the example are depicted in(10).
(10) PAIR V1-V2S: naki-sakebu (cry-shout)→ and(shout(x), cry(x))
CAUSE V1-V2S: yake-sinu (burn-die)→ cause(burn(x), die(x))
MANNER V1-V2S: kake-yoru (run-come)→ in.manner.of(come(x), run(x))
MEANS V1-V2S: tataki-kowasu (hit-break)→ by.means.of(break(x, y), hit(x, y))
V1-V2S WITH DEVERBALIZED V1:sasi-semaru (thrust-close)
→ emphasized.by(close(x), thrust)
48

Table 1: Syntactic V1-V2s vs. Lexical V1-V2s
Syntactic Lexical
ProductivityVery productive; the V2s allow al-most any V1.
Not so productive; the combination of V1 andV2 is more restricted.
TransitivityThe V1’s transitivity and case-marking are passed to the V1-V2.
Either V1 or V2 or both participate in the de-termination of transitivity and case-marking.
Compositionality Compositional.Some of them show varying degrees of com-positionality, but others are highly lexical-ized.
SemanticsThe semantics of V2 consistentlyembeds V1’s semantics.
There are various kinds of semantic composi-tion.
V1-V2S WITH DEVERBALIZED V2:hare-wataru (clear.up-cross)
→ modified.by(clear.up(x), cross)
Matsumoto notes how the semantic relation deter-mines the transitivity and the semantic compositionof V1-V2 and posits a semantic analysis to deal withthe phenomena. Although Matsumoto presents aprecise and comprehensive analysis, it assumes fine-grained semantic notions and a complicating map-ping theory. To implement this, the grammar wouldhave to recognize which semantic relation holds be-tween the two component verbs. But this dependsheavily on world knowledge and pragmatic infer-ence, and hence is not currently computationallytractable.
In sum, Kageyama (1993) and Matsumoto (1996)present useful analyses, but these must be revised tomake them computationally tractable.
3.2 Computational Analysis — Proposal
Our analysis of syntactic V1-V2s is mostly compat-ible with Kageyama (1993) but, as an HPSG analy-sis, assumes neither PRO nor government. (11) il-lustrates the analysis. (the V-embedding type corre-sponds to Kageyama’s V complementation type.)
(11) a. Raising‘Ken is about to read a book.’
S
PP
Ken-ga-NOM
VP
VP
PP
hon-obook-ACC
V1
yomiread
V2
-kakerube.about.to
be.about.to(read(Ken, book))
b. Control‘Ken fails to read a book.’
S
PP
Ken-ga-NOM
VP
VP
PP
hon-obook-ACC
V1
yomiread
V2
-sobirerufail
fail(Ken, read(Ken, book))
c. V-embedding‘Ken reads a book thoroughly.’
49

S
PP
Ken-ga-NOM
VP
PP
hon-obook-ACC
V
V1
yomiread
V2
-tukusuexhaust
exhaust(Ken, book, read(Ken, book))
The Raising and Control structures are almost thesame as those of Sag et al. (2003); the subject ofRaising type V2 is “raised” from the V1, and the sub-ject of Control type V2 controls that of the V1. TheV-embedding type has a structure where the sub-ject and object of the V2 control the subject and ob-ject of the V1, respectively. These characteristics ofthe three are reflected in their semantic representa-tions in (11). That is, the Raising type V2, kakeru(be.about.to) in (11a), does not thematically restrictits subject, Ken, and object, hon (book), while theControl type V2, sobireru (fail), puts a thematic re-striction on its subject, Ken. The V-embedding typeV2 assigns thematic roles to both the subject and ob-ject. Clearly, these differences account for (9). Note,in addition, that the Raising and Control types havea VP embedding structure, while the V-embeddingtype does not. The contrast in (8) is accounted for bythe difference; only the object of the V-embeddingtype is selected by both the V1 and V2, thus onlythis structure allows the passivization of V1-V2 as awhole. Other things to notice are that it is the V1
that determines the V1-V2’s transitivity and, in mostcases, case-marking, and that their semantic struc-tures are consistently embedding structures.
One of the divergences from Kageyama (1993) in-volves the V1 passivization. Kageyama (1993) al-ways accepts the V1 passivization of Control typebut necessarily rules out that of his V complementa-tion type, based on the difference in their syntacticconfigurations: the VP complement vs. the V com-plement. But this is incorrect as shown in (12).
(12) a.*hon-gabook-NOM
yom-are-sobireruread-PASS-fail
‘A book fails to be read.’
b. Ken-gaKen-NOM
nagur-are-tukusupunch-PASS-exhaust
‘Ken endures the successive punches.’
We basically allow all V1 passivizations but seman-tically restrict them. In (12a), for example, the sub-ject, hon (book), cannot be construed as FAILER. In(12b), on the other hand, Ken can be interpreted asthe one who exhausts himself by being punched alot.
As for lexical V1-V2s, we classify them into fivesubtypes roughly following Matsumoto (1996).
(13) a. Right-headed V1-V2s
b. Argument mixing V1-V2s
c. V1-V2s with deverbalized V1
d. V1-V2s with deverbalized V2
e. Non-compositional V1-V2s
The Right-headed and Argument mixing typesjointly cover most of Matsumoto’s Pair, Cause,Manner and Means compounds. The Non-compositional type is introduced to distinguish com-positional and non-compositional V1-V2s. Un-like Matsumoto’s finer grained semantic analysis,our analysis leaves the exact semantic relationshipunder-specified. The constraints on compositioncome from an extended ARG-ST. As illustrated in(14), the ARG-ST consists of one EXTernal argumentand two INTernal arguments and is classified into sixtypes, following Imaizumi and Gunji (2000).
(14) a.
arg-st
EXT indexINT1 indexINT2 index
b.arg-st
nonagentive
argless unaccusative
monounac diunac
agentive
unergative transitive
monotrans ditrans
50

c.EXT INT1 INT2
argless × × ×
monounac × © ×
diunac × © ©
unergative © × ×
monotrans © © ×
ditrans © © ©
First, the Right-headed V1-V2 obeys the SharedParticipant Condition (Matsumoto, 1996), which re-quires that the two component verbs share at leastone argument that is co-indexed with an argumentof the other component verb. Any two argumentscan be co-indexed between V1 and V2 if the argu-ments agree in the EXT/INT distinction. The transi-tivity and case-marking of the V1-V2 are inheritedfrom the V2 (hence Right-headed). The semanticsis totally compositional; the two semantic represen-tations of the V1 and V2 are predicated by an un-derspecified semantic relation, which can be spec-ified as Pair, Cause, Manner or Means by a com-ponent outside the grammar. For example, the se-mantic representations of the first two V1-V2s in(10) can be glossed as unspec rel(shout(x),cry(x))and unspec rel(burn(x),die(x)). The semantic rela-tion cannot be fully specified in a purely syntacticaccount since it is affected by contexts, pragmat-ics, and world knowledge, as these become avail-able, the relation can be constrained further. Further,the underspecification greatly simplifies the imple-mentation. The Right-headed V1-V2, formulated inthis way, covers most of the lexical V1-V2s (Mat-sumoto’s Pair, Cause, Manner and Means) withoutmaking the grammar complicated.
Second, the Argument mixing V1-V2 has a pe-culiarity; it is ambiguous in that they can take ar-guments from either the V1 or V2. nomi-aruku(drink-walk), for example, can take as the object ei-ther something to drink (V1’s argument) or a placeto walk (V2’s argument), according to Matsumoto(1996). To account for this, we underspecify thetransitivity and case-marking of the V1-V2 such thatthey can be inherited from either the V1 or V2. An-other peculiarity involves the fact that the V2 is re-stricted to a monotrans verb that expresses a spatialmotion,1 while the V1 is transitive and must not be
1In the JACY framework, a locative accusative argument isconsidered an object.
a spatial motion verb. As for the semantics, it is thesame as that of the Right-headed V1-V2 except thatthe semantic relation is alway construed as Manner.
Third, the V1-V2 with deverbalized V1 includesa V1 that is deverbalized and only emphasizes thecontent of V2 in some way (Kageyama, 1993; Mat-sumoto, 1996). For instance, sasi-semaru (thrust-close), in our analysis, represents something like em-phasize(close(x)). In the sense that the V1 is dever-balized, the V1-V2 is considered not fully composi-tional. Naturally, as the V1 is deverbalized, it is theV2 that determines the transitivity and case-markingof the V1-V2. As Kageyama (1993) notes, there isno restriction on the possible combinations of the V1
and V2 in terms of ARG-ST.Fourth, the V1-V2 with deverbalized V2, as the
name implies, includes a V2 that loses its originalverbal meaning and takes on an adverbial meaningthat modifies the V1 (Kageyama, 1993; Matsumoto,1996). For instance, hare-wataru (clear.up-cross)ican be glossed as cross(clear.up(x)) in our analy-sis. Similarly to the V1-V2 mentioned in the lastparagraph, this type of V1-V2 is also considered notfully compositional, since the V2 has lost its origi-nal verbal meaning. Regarding the transitivity andcase-marking of the V1-V2, the V1 determines themsince the V2 is deverbalized. In addition, accord-ing to Kageyama (1993), the V1 and V2 of this typemust agree in agentivity, unlike the V1-V2 with se-mantically deverbalized V1.
The two types with a deverbalized componentverb lexically encode an embedding semantic struc-ture, similarly to the lexical treatment of the ‘bi-clausal’ nature of Japanese causatives proposed byManning et al. (1996).
As for productivity, the first two types are moreproductive than the last two. Actually, we can freelycoin a V1-V2 that belongs to the first one, the Right-headed V1-V2, as long as it is semantically and prag-matically plausible. On the other hand, the Non-compositional V1-V2 is absolutely not productiveand literally non-compositional; the V1-V2 is totallylexicalized and should be analyzed as a single word.
All in all, even though our analysis might becoarser than Kageyama (1993) and Matsumoto(1996), it is sufficient to account for V1-V2’s com-plex characteristics summarized in §2 and Table 1and, what is more, is computationally tractable.
51

4 Evaluation
To see if our implementation works well in practice,we conducted a corpus-based evaluation and exam-ined its coverage, the amount of ambiguity, and ef-ficiency. First, we extracted a small evaluation cor-pus from the Hinoki corpus (Bond et al., 2004). Theevaluation corpus consists of 219 sentences, whereeach sentence contains at least one V1-V2. In addi-tion, we prepared two versions of JACY: JACY-plainand JACY-vv. JACY-plain is given no V1-V2 imple-mentation but contains 1,325 lexical entries in thelexicon, which were added by the developers overthe course of its development. In contrast, JACY-vvis equipped with all the V1-V2 implementations butwithout any compositional V1-V2 entries in the lex-icon. Table 2 shows the results of the experiment.We find that JACY-vv gains more coverage and less
Table 2: Experimental results
JACY-plain JACY-vv
Coverage (%) 52.1 63.5Ambiguity (φ) 53.41 50.78time (φ) 4.85 6.43space (φ) 816779 995681
ambiguity than JACY-plain. The increased coverageis due to the remarkable productivity of the Rightheaded type. The reduction in ambiguity involvesthe more restricted nature of our approach to thefree word order of Japanese. The table also showsthe two versions’ processing efficiency: time andspace.2 Adding the rules and lexical types for V1-V2s slightly degrades JACY-vv’s efficiency. How-ever, JACY-vv still works fast enough for practicalNLP applications.
Acknowledgement
We appreciate many people for helping this re-search. We especially thank Takao Gunji, MelanieSiegel, Dan Flickinger, Sato Satoshi and NTT Ma-chine Translation Research Group.
2time shows how long the grammar needs to parse one sen-tence, and space shows how much memory the grammar con-sumes to parse one sentence.
ReferencesBond, F., Fujita, S., Hashimoto, C., Nariyama, S.,
Nichols, E., Ohtani, A., Tanaka, T., & Amano,S. (2004). The Hinoki Treebank — A Tree-bank for Text Understanding. In Proceedingsof the First International Joint Conference ofNatural Language Processing, pp. 554–559.
Copestake, A. (2002). Implementing Typed FeatureStructure Grammars. CSLI Publications.
Imaizumi, S., & Gunji, T. (2000). Complex Eventsin Lexical Compounds. In Itou, T., & Yatabe,S. (Eds.), Lexicon and Syntax (in Japanese),pp. 33–59. Hitsuji Shobou.
Kageyama, T. (1993). Grammar and Word Forma-tion (in Japanese). Hitsuji Shobou.
Manning, C. D., Sag, I. A., & Iida, M. (1996). TheLexical Integrity of Japanese Causatives. InGunji, T. (Ed.), Studies in the Universalityof Constraint-Based Structure Grammars, pp.9–37. Osaka University.
Matsumoto, Y. (1996). Complex Predicates inJapanese: A Syntactic and Semantic Study ofthe Notion ‘Word’. CSLI Publications.
Oepen, S., & Carroll, J. (2000). Performance pro-filing for grammar engineering. Natural Lan-guage Engineering, 81–97.
Sag, I. A., Wasow, T., & Bender, E. M. (2003). Syn-tactic Theory: A Formal Introduction (2 edi-tion). CSLI Publications, Stanford.
Siegel, M., & Bender, E. M. (2002). Efficient DeepProcessing of Japanese. In Proceedings of the3rd Workshop on Asian Language Resourcesand International Standardization Taipei, Tai-wan.
52

On Non-Canonical Clause Linkage
Anke HollerDepartment of Computational Linguistics
Institute of General and Applied LinguisticsUniversity of Heidelberg
69117 Heidelberg, [email protected]
1 Introduction
In generative grammar, it is commonly assumedthat clauses that can stand alone as complete sen-tences differ grammatically from ones that are de-pendent on a matrix clause and are in this respectsubordinated. This difference is often expressedby a boolean feature called ROOT (or alike), andby analysing +ROOT-clauses as syntactically highestclauses. The stipulation of a ROOT feature has beenmotivated by an observation going back to Emonds(1970) whereby clauses vary in admitting of so-called root phenomena. Whereas +ROOT clausessupport these phenomena, -ROOT clauses disallowthem.1
Contrary to this assumption, Green (1996) arguesthat the best explanation of the acceptability of rootphenomena in embedded clauses is not a syntac-tic, but a pragmatic one, and thus distinguishingdependent clauses from independent utterances canbe done ROOT-less. Working within construction-based HPSG, Green (1996) suggests to introducea new dimension of clauses, called DEPENDENCY,with three partitions subordinate, main and indiffer-ent with most subtypes of clauses being indifferentas to whether they act as main clauses or subordinateclauses. While Green (1996) is correct in assumingthat a binary feature is not justified for the distinctionof main and subordinate clauses, her approach mustbe revised to cover dependent clauses that simulta-neously behave like main and subordinate clauseswith respect to their syntactic form, their interpreta-tion, and their functional usage, and therefore indi-
1For a listing of these phenomena see among many othersHooper und Thompson (1973), Green (1996), Heycock (2002).As for German, an initial position of the finite verb is usallytaken as a typical root property.
cate that a pure pragmatic account is not adequate.The paper is structured as follows: In the next
section, several non-canonical clause linkage phe-nomena occuring in German will be discussed whichchallenge any approach implementing a twofold dif-ferentiation between main and subordinate clausetypes. Recent HPSG seems well equipped to han-dle the presented data as will be shown in sec. 3.There, a constraint-based analysis will be sketchedthat makes use of the idea that feature structures de-scribing clause types can be organized according tothe way the respective clause is linked to its syntac-tic surrounding. Sec. 4 provides some concludingremarks.
2 The Data
In German, a typical SOV language, canonical sub-ordinated clauses differ from canonical main clausesby the position of the finite verb. Whereas the finiteverb in main clauses is fronted (henceforth called‘V2’), it occurs in clause-final position (hence-forth called ‘VF’) in subordinated clauses. Thiswell-known fact forms the basis of previous HPS-Gian work on the classification of German clausetypes, cf. Uszkoreit (1987), Kathol (1995) and Net-ter (1998), in which the position of the finite verb(i.e. V2 versus VF) is ‘hard-wired’ to the type or thefeature representing main and subordinate clauses,resp. For instance, Kathol (1995) introduces twosubtypes of the type clause, called root and sub-ordinate, and partitiones root by v1 and v2. Trac-ing the traditional descriptive model of Topologi-cal Fields, cf. Drach (1937), he formulates a set ofconstraints on constituent order domains, cf. Reape(1994), such that the finite verb is restricted to a par-
53

ticular topological field in dependence of the respec-tive clause type. Thus, for any clause of type subor-dinate the finite verb has to be in clause final posi-tion whereas the finite verb of clauses of type rootalways stands in clause initial position. Addition-ally, Kathol (1995) assumes that clauses of type rootbear a PHON feature but not clauses of type subor-dinate arguing that root clauses only can be utteredindependently.2
Splitting clause types into root and subordinatedepending on the position of the finite verb and thepresence of PHON, as Kathol (1995) does it, yieldsan approach that classifies dependent V2 clausessuch as (1a) as root but independent VF clauses suchas (1b) as subordinate, predicting contrary to thefacts that the respective V2 clause is uttered inde-pendently but not the VF one.
(1) a. IchI
glaube,think
erhe
hathas
recht.right
‘I think that he is right.’
b. ObWhether
erhe
nochstill
kommt?comes
‘I wonder whether he will still come?’
Reis (1997), however, has demonstrated that de-pendent V2 clauses like (1a) similarly show prop-erties of clear subordinate clauses and clear rootclauses, and thus can be assigned to either of them.As evidence she gives inter alia that dependent V2clauses (i) are information-structurally integratedinto their matrix clause signaled by a rising tone atthe end of the matrix predicate, (ii) admit variablebinding from the matrix clause, (iii) are restrictedto a final position within the matrix clause, whichmeans that they must not occur initially or in theso-called middle field, (iv) disallow correlates andund zwar-supplements, and (v) disallow extraction.3
If dependent V2 clauses were the single clausalclass exhibiting the listed properties, one might seek
2Netter (1998) combines verbal position and the root-subordinate distinction by stipulating types of the followingkind: V-2 Declarative Main, V-Final Declarative Subordinate,V-2 Interrogative Main, V-Final Interrogative Subordinate, etc.Uszkoreit (1987) formulates restrictions relating the value of theboolean feature M(AIN)C(LAUSE) to the value of the booleanfeature INV(ERTED) which represents the finite verb’s clausalposition.
3(i) and (ii) are typical properties of subordinate clauseswhereas (iii) to (v) usually substantiate root clauses.
for an idiosyncratic explanation closely related tothe properties of their matrix clauses. In German,however, there exist several types of clauses show-ing similar mixed properties in terms of a root-subordinate distinction, albeit occuring in miscel-laneous syntactic environments. Reis (1997) pro-vides evidence that the so-called free dass-clauses,cf. (2a), have the properties (i) to (v), Gartner (2001)observes them with a certain class of restrictive rel-ative clauses dubbed V2 relatives, cf. (2b).
(2) a. ErHe
mussmust
imin the
Gartenbackyard
sein,be
dassthat
erhe
nichtnot
aufmacht.opens
‘He must be in the backyard since he doesnot open.’
b. DasThe
Blattsheet
hathas
eineone
Seite,side
diethat
istis
ganzcompletely
schwarz.black
‘The sheet has one side that is completelyblack.’
Reis (1997) and Gartner (2001) further show thatthese clauses are in semantic respects different fromtheir canonical counterparts: In contrast to ordinarycomplement clauses, dependent V2 clauses and freedass-clauses do not realize an argument of the ma-trix predicate. Also, V2 relatives are interpreted re-strictively but differ from restrictive relative clausesin that they are limited to indefinite noun phrases.Thus, the three types of clauses behave all about thesame in terms of a restricted licensing by the matrixclause. In addition, dependent V2 clauses share withfree dass-clauses that they cannot be interpreted inthe scope of negation or negative predicates. Sim-ilarly, V2 relatives cannot attach to a negated nounphrase, neither.
Pragmatically, the aforementioned clauses haveone property in common: They all have illocu-tionary force. Even though their illocutionaryassociation somehow seems to be related to thematrix clause, cf. Boettcher (1972), Reis (1997),Gartner (2002) and Meinunger (2004), the fact itselfshows that the clauses cannot be ordinary embeddedclauses, cf. Green (2000b).
The grammatical properties of the clauses just
54

considered indicate that their relation to a poten-tial matrix clause is not canonical inasmuch theyare not clear-cut subordinated (embedded) clauses.4
Interestingly, there exists yet another class of de-pendent clauses that are not canonically linked totheir syntactic surrounding in German. This classcomprises at least the so-called weil-V2 adverbialclauses, cf. (3a), and non-restrictive relative clausesof any kind, in particular wh-relatives, cf. (3b).5
(3) a. PeterPeter
kommtcomes
zutoo
spat,late
weilbecause
erhe
hathas
keinenno
Parkplatzparking lot
gefunden.found
‘Peter is late because he could not find aparking lot.’
b. MaxMax
spieltplays
Orgel,organ
waswhich
gutgood
klingt.sounds
‘Max is playing the organ, which soundsgood.’
It can be shown that the clauses in (3) introducedby weil and was respectively are prosodically andpragmatically independent from their matrix clause,which is indicated by an independent focus domainand an autonomous illocutionary force. In addition,these clauses are syntactically dispensable, disallowvariable binding from outside and occur only at thevery end of a complex sentence. Moreover, their se-mantic interpretation is peculiar. Weil-V2 adverbialclauses, for instance, behave differently from canon-ical weil-clauses in that they are able to give rea-sons for a speaker’s attitude.6 Wh-relatives are intro-duced by an anaphoric pronoun and denote proposi-tions, which is certainly a consequence of their non-restrictiveness and contrasts with restrictive relativeclauses which are usally analyzed as denoting prop-erties. Finally, negation does not scope over theseclauses, neither.
Looking at the data given so far reveals that threeclasses of dependent clauses can be distinguished
4On the other hand, they do not show properties of well-defined main (root) clauses, neither.
5Weil-V2 adverbial clauses are mainly attested for collo-quial German, but can be observed in written German as well,cf. Uhmann (1998), who extensively describes this clausal class.Holler (2003) provides a comprehensive analysis of the gram-mar of wh-relatives.
6See Haegeman (1984) for a discussion of similar phenom-ena in English.
dependending on the way of being linked to theirlinguistic surrounding. Besides the canonical de-pendent clauses including all clauses that form di-rectly or indirectly a component part of their matrixclause (such as complement clauses of all kinds, or-dinary adverbial clauses, restrictive relative clauses,etc.), two classes of dependent, but non-canonicallylinked clauses can be identified by means of thegrammatical properties afore described. Table 1gives an overall picture of these facts.7
Clausal Class I II IIITypical example a (VF) d (V2) g (VF)
b (VF) e (V2) h (VF)c (VF) f (VF) i (V2)
Prosodically integrated yes yes noSyntactically attached yes yes noSemantically peculiar no yes yesIndependent information struct. no no yesIndependent illocutionary force no yes yes
Table 1: Grammatical properties of three empiri-cally identified clausal classes
It strikes that the position of the finite verb isnot appropriate to differentiate between these clausalclasses. Rather, the data suggest that the clauses dif-fer in the degree to which they are integrated into apotential matrix clause.
3 Accounting for the Data
The sign-based monostratal architecture of HPSGqualifies very well to account for the presented data.The core of the analysis advocated here is the obser-vation that clauses vary with respect to the way theyare linked to their linguistic surrounding. Becausethis originates from syntactic, semantic and prag-matic properties of the clauses involved, it seemsto be natural to encode it in grammar. In HPSG,the type hierarchy lends itself to reconstruct the ob-served distinction. For this reason, it is proposedto partition the type phrase in terms of a dimen-sion LINKAGE, and to distinguish between un-linked and linked objects. The type unlinked com-prises all independently uttered sentences includ-
7For reasons of space, the following abbreviations are used:a = complement clause, b = restrictive relative clause, c = stan-dard adverbial clause, d= dependent V2 clause, e = restrictiveV2 relative clause, f = free dass-clause, g = non-restrictive d-relative clause, h = non-restrictive wh-relative clause, i = weilV2 adverbial clause.
55

ing VF-clauses as given by (1b). The type linkedwhich describes all objects somehow combined withthe linguistic surrounding is further partitioned bythe types integr(ated), semi-integr(ated) and non-integr(ated), which represent clausal objects that arefully, partly or not integrated into a potential matrixclause.8 It is assumed that the newly defined typesare cross-classified with subtypes of phrase comingfrom other dimensions such as CLAUSALITY andHEADEDNESS, cf. Sag (1997).
phrase
unlinked linked
integr semi-integr non-integr
Figure 1: Partition of phrase w.r.t. the dimensionLINKAGE
Nothing in particular shall be said here aboutclauses of type integrated, since they are analyzed ina standard way. The two remaining clausal classes oftype linked, i.e. semi-integrated and non-integratedclauses, are certainly more instructive. Next, ananalysis will be sketched which formulates restric-tions on these two types and, thus, captures thesyntactic, semantic and pragmatic properties of theclauses discussed in sec. 2.
Clauses of type semi-integrated: Although semi-integrated clauses are less tightly connected to theirmatrix clause as they show the properties (iii) to (v)presented in sec. 2, it is obvious that they are syn-tactically attached to it. Thus, they are analyzed asmodifiers of a saturated verbal projection. By fol-lowing Engdahl und Vallduvı (1996) in stipulatingan INFO-STRUCT attribute that enriches CONTEXT,it can be required that semi-integrated clauses iden-tify their INFO-STRUCT value with that of the ma-trix clause, which easily copes with property (i). Inaddition, an psoa object of type intend, cf. Green(2000a), is contained in the BACKGROUND set of asemi-integrated clause, thereby accounting for the
8Unfortunately, it cannot be discussed here to which extentthis distinction can be used for constituents other than clauses.At least, there is evidence from German and English that nomi-nal left-peripheral elements also need to be classified regardingtheir degree of (non-)integrateness into a clause, cf. Shaer undFrey (2004).
empirical fact that these clauses have illocutionaryforce.9 The constraint on objects of type semi-integrated shown in fig. 2 expresses these restric-tions.
semi-integrated →
SS | LOC
CAT | HD | MOD
LOC
CAT
[HD verbSUBCAT 〈〉
]
CXT | INFO-STR 1
CXT
[INFO-STR 1
BACKGR{[
intend], . . .
}]
Figure 2: Restricting semi-integrated clauses
Clauses of type non-integrated: Adapting theapproach to peripheral adverbials of Haegeman(1991), it is assumed that clauses of type non-integrated are orphan constituents which are syn-tactically unattached.10 By providing additionalbackground information, orphaned clauses serve toform the discourse frame against which the propo-sition expressed in the matrix clause is evaluated.Hence, the modification relation is not establishedin syntax, but rather at the level of utterance in-terpretation. This can easily be implemented intothe grammar by introducing phrases of type head-orphan-phrase as subtype of headed-phrase, cf. Sag(1997), and requiring that the CONTENT value ofthe orphan is unified with the BACKGROUND setof the head as illustrated in fig. 3. The fact thatan orphan is not included into the host’s infor-mation structure and has illocutionary force of itsown is again grasped by manipulating the INFO-STRUCT and BACKGROUND values of phrases oftype head-orphan-phrase. Since it is assumed thatnon-integrated clauses are cross-classified as a sub-type of head-orphan-phrase, they have to obey therestrictions for orphans. This analysis provides avanilla account of the properties of non-integratedclauses as described in sec. 2.11
9Of course, any other analysis of illocutionary force couldhave been implemented here.
10Haegeman (1991) points out that this does not mean thatorphans would be syntactically unconstrained.
11The fact that negation neither takes scope over semi-integrated clauses nor over non-integrated ones can easily beimplemented in the lexicon by restricting the negation andthe negative verbs to clauses of type integrated. Further, LPrules are defined which limit clauses of types semi-integratedand non-integrated to final positions in a complex sentencestructure.
56

head-orphan-phrase →
HD-DTR | SS | LOC
CAT | HD verb
CXT
[INFO-STR 1
BKGR{
3 , 4[intend
], . . .
}]
ORPHAN-DTR | SS | LOC
CONT 3
CXT
[INFO-STR 2
BKGR{
5[intend
], . . .
}]
Figure 3: Restricting orphan constituents such asnon-integrated clauses
4 Conclusion
Considering as example German, the present pa-per has investigated a certain subset of clause link-age phenomena and has developed a constraint-based analysis accounting for the empirical fact thatclauses need to be distinguished w.r.t. their degree ofintegratedness into a potential matrix clause. It hasbeen shown that the generally assumed twofold dis-tinction between main and subordinate clauses (orroot and embedded clauses) does not suffice to dealwith the presented data. Moreover, it has been ar-gued that the discussed linkage phenomena origi-nate from syntactic, semantic and pragmatic prop-erties of the clauses involved, and should hence beencoded in grammar. By partitioning objects oftype phrase in terms of a LINKAGE dimension andby constraining the CONTEXT value of these ob-jects, the data are covered without any reference tothe position of the finite verb. Additionally, non-integrated clauses are considered as ‘orphan’ con-stituents which are unattached in syntax, but pro-vide the context for the interpretation of the ma-trix clause. Such an approach explains the empiri-cal facts assembled in a straightforward way. Fur-ther research must show to what extent the proposedanalysis can cope with similar phenomena in otherlanguages.
References
Boettcher, W. (1972). Studien zum zusammengeset-zten Satz. Frankfurt/M.: Athenaum.
Drach, E. (1937). Grundgedanken der deutschenSatzlehre. Frankfurt: Diesterweg.
Emonds, J. (1970). Root and Structure-PreservingTransformations. Doktorarbeit, MIT, Cambridge.
Engdahl, E. und E. Vallduvı (1996, May). Infor-mation Packaging in HPSG. In C. Grover undE. Vallduvı (Hrsg.), Edinburgh Working Papersin Cognitive Science, Vol. 12: Studies in HPSG,Chapter 1, 1–32. Scotland: Centre for CognitiveScience, University of Edinburgh.
Green, G. (1996). Distinguishing main and subordi-nate clause: The root of the problem. unpl. Ms.,University of Illinois.
Green, G. M. (2000a). The Nature of Pragmatic In-formation. In R. Cann, C. Grover, und P. Miller(Hrsg.), Grammatical Interfaces in HPSG, Num-mer 8 von Studies in Constraint-Based Lexical-ism, 113–138. Stanford: CSLI Publications.
Green, M. (2000b). Illocutionary Force and Seman-tic Content. Linguistics and Philosophy 23, 435–473.
Gartner, H.-M. (2001). Are there V2-RelativeClauses in German? Journal of Comparative Ger-manic Linguistics 3(2), 97–141.
Gartner, H.-M. (2002). On the Force of V2 Declar-atives. Theoretical Linguistics.
Haegeman, L. (1984). Remarks on AdverbialClauses And Definite NP-Anaphora. LinguisticInquiry 15, 712–715.
Haegeman, L. (1991). Parenthetical Adverbials:The Radical Orphanage Approach. In S. Chiba,A. Ogawa, Y. Fuiwara, N. Yamada, O. Koma, undT. Yagi (Hrsg.), Aspects of Modern English Lin-guistics, 232–254. Tokyo: Kaitakusha.
Heycock, C. (2002). Embedded root phenomena.unpl. Ms., University of Edinburgh.
Holler, A. (2003). An HPSG Analysis of the Non-Integrated Wh-Relative Clauses in German. InS. Muller (Hrsg.), Proceedings of the HPSG-2003 Conference, Michigan State University, EastLansing, Stanford, 163–180. CSLI Publications.
Hooper, J. und S. Thompson (1973). On the ap-plicability of root transformations. Linguistic In-quiry 4, 465–497.
Kathol, A. (1995). Linearization-Based GermanSyntax. Doktorarbeit, Ohio State University.
Meinunger, A. (2004). Verb position, verbal moodand the anchoring (potential) of sentences. In
57

H. L. und Susanne Trissler (Hrsg.), The syntaxand semantics of the left periphery, 313–341.Mouton de Gruyter.
Netter, K. (1998). Functional Categories in anHPSG for German. Nummer 3 von Saarbruk-ken Dissertations in Computational Linguisticsand Language Technology. Saarbrucken: GermanResearch Center for Artificial Intelligence (DFKI)and University of the Saarland.
Reape, M. (1994). Domain Union and Word OrderVariation in German. In J. Nerbonne, K. Netter,und C. J. Pollard (Hrsg.), German in Head-DrivenPhrase Structure Grammar, 151–197. StanfordUniversity: CSLI Publications.
Reis, M. (1997). Zum syntaktischen Status un-selbstandiger Verbzweit-Satze. In C. Durscheid,K. H. Ramers, und M. Schwarz (Hrsg.), Syntaxim Fokus. Festschrift fur Heinz Vater. Tubingen:Niemeyer.
Sag, I. A. (1997). English Relative Clause Construc-tions. Journal of Linguistics 33(2), 431–484.
Shaer, B. und W. Frey (2004). Integrated andNon-Integrated Leftperipheral Elements in Ger-man and English. In W. F. Benjamin Shaer undC. Maienborn (Hrsg.), Proceedings of the Dis-located Elements Workshop, ZAS Berlin 2003,Band 2 of ZAS Papers in Linguistics 35, 465–502.
Uhmann, S. (1998). Verbstellungsvariation in weil-Satzen. Zeitschrift fur Sprachwissenschaft 17(1),92–139.
Uszkoreit, H. (1987). Word Order and ConstituentStructure in German. Chicago University Press.
58

Gradience and Parametric Variation
Frank KellerSchool of Informatics
University of Edinburgh2 Buccleuch Place
Edinburgh EH8 9LW, [email protected]
Dora AlexopoulouDepartment of LinguisticsUniversity of Cambridge
Sidgwick AvenueCambridge CB4 9DA, UK
1 Introduction
Gradient grammaticality has received renewed at-tention in recent years, which is partly due to a aninnovation in experimental methodology, viz., theintroduction of the magnitude estimation paradigm(Bard et al., 1996; Cowart, 1997) that allows the elic-itation of reliable gradient acceptability judgments.The application of this methodology to crosslinguis-tic variation has revealed a number of interesting re-sults, but these results also pose an important chal-lenge for a parametric approach to variation: of-ten, variation is confined to quantitative differencesin the magnitude of otherwise identical principles.Here we approach the issue with particular refer-ence to crosslinguistic studies focusing on superior-ity and locality violations involved in weak islands(whether-islands).
2 Experimental Results on Superiority andRelativized Minimality
Two important experimental investigations of gra-dience and crosslinguistic variation are Feather-ston’s (2005) comparative study of superiority ef-fects and d-linking in English and German, andMeyer’s (2003) study of superiority effects in Rus-sian, Polish, and Czech. The main results can besummarized as follows:
• A clear (statistically significant) dispreferencefor in-situ subjects (English, German, Russian,Polish, Czech, modulo a “reverse animacy” ef-fect in Polish).
• A clear crosslinguistic effect of discourse-linking, where in-situ d-linked subjects are es-sentially as acceptable as other in-situ phrases.
• Crosslinguistically, the d-linking status of theobject is irrelevant (English, German, Polish,Czech).
• No clear interactions between arguments andadjuncts are detected (English, German, Polish,Czech, Russian).
• Not only in-situ subjects are dispreferred, butinitial subjects are preferred (marginal effect inGerman, significant in English).
These studies therefore show that crosslinguisticvariation is confined to quantitative differences inotherwise crosslinguistically stable preferences. Forexample, while initial subjects are clearly preferredin English, only a marginal preference was detectedin German.
Our own experimental investigation of the in-teraction between islands and resumption in En-glish, Greek, and German (Alexopoulou and Keller,2002, 2003; Keller and Alexopoulou, 2005) showsa pattern of variation consistent with Featherston’s(2005) and Meyer’s (2003) findings. The results canbe summarized as follows:
• A clear crosslinguistic effect of weak island vi-olations (resembling, in all languages a similardrop in the acceptability in that-clauses).
• A strong contrast between weak and strong is-land violations.
• Resumption is unacceptable in questions in allthree languages.
• The acceptability of resumption does im-prove in embedded whether-questions andthat-clauses in all three languages.
59

Again, crosslinguistic variation is confined toquantitative variation in the magnitude of the ef-fects. For example, resumption in questions is moreacceptable in Greek than in German and English,which is evident from the fact that questions withresumptives are more acceptable than strong islandviolations in Greek, but as bad as strong islands inEnglish and German. Furthermore, weak islands in-cur a stronger violation in German (as does ordinaryembedding under dass).
3 Universals and Parameters
The most important aspect of these studies isthat they indicate that effects relating to superior-ity and relativized minimality are present crosslin-guistically. This confirms the existence of univer-sals where their status has either been disputed(e.g., superiority in German, Polish, Czech, andRussian, whether-islands in Greek and German) orwhere their existence was not properly acknowl-edged (e.g., the fact that resumption improves weakislands in English even though such resumptives areless acceptable than gaps). Furthermore, it is proba-bly no accident that such crosslinguistic similaritiesrelate to locality principles.1
However, it is not straightforward to account forthe type of crosslinguistic variation indicated bythese studies, namely quantitative variation in themagnitude of universal principles. An initial re-sponse would be to discard such variation as sur-face noise, of no theoretical interest. However, atthe same time it is important to acknowledge thatsuch differences can be responsible for surface con-trasts between languages. For example, unlike En-glish, in German and Greek pronominals are accept-able as gaps when embedded in a whether-island.Intuitively, this appears to be related to the fact thatin Greek pronominals are better in ordinary ques-tions in the first instance, while in German, gapsare much worse in the same structure. Similarly, thestronger preference for initial subjects in Englishvs. German questions ought to relate to the statusof subjects in the two languages. Of course, suchfacts can be attributed to structural/parametric differ-
1But note that Featherston (2005) takes the fact that it is re-ally only subjects that exhibit superiority to corroborate ECPanalyses and as counterevidence to economy/locality driven ac-counts.
ences between languages. Indeed, in Alexopoulouand Keller (2003), we attribute the relative toleranceof pronominals in Greek questions to the clitic sta-tus of the Greek pronominal and its PF realizationas an affix. Similarly, we assume that operations as-sociated with V2 in German incur extra processingcosts in both dass- and ob-clauses that are responsi-ble for the extra drop in acceptability (compared tothe reduction in the acceptability of that-clauses inEnglish and Greek). If this line of reasoning provescorrect, then quantitative differences can indeed bereduced to parametric variation.
4 Hard vs. Soft Constraints andParameters
If we assume that quantitative differences can be re-duced to parametric variation, then this means thatnew questions arise with regard to the status ofparameters. When is a given crosslinguistic differ-ence, e.g. the optionality of resumption in Greek andGerman indirect questions, to be accounted for asthe consequence of quantitative differences of inter-acting principles (related to parameters) and whenshould a straightforward parametric account be at-tempted? The literature draws a distinction betweenhard and soft constraints. In particular, magnitudeestimation studies applied to a variety of phenom-ena (e.g., agreement, auxiliary selection, binding, in-formation structure, word order) from various lan-guages indicate the existence of these two types ofconstraints (Sorace and Keller, 2005; Keller, 2000).Hard constraints induce categorical judgments whenviolated and their acceptability cannot be improvedby context (e.g., agreement, case violations); softconstraints induce mild ungrammaticality and theyappear to interact with context.
Building on this distinction we hypothesize thatthe locality principles underlying superiority andweak island effects are governed by soft constraints.They only induce mild ungrammaticality, while fac-tors such as d-linking may improve both superior-ity and relativized minimality violations (Feather-ston (2005) has demonstrated the effect of d-linkingexperimentally for English and German). The con-sequence of this hypothesis is the admission of twotypes of “universals”. Those that are not directly re-lated to parametric variation and tend to be con-
60

stant across languages, inducing only gradient un-acceptability, and those that are related to paramet-ric variation and give rise to categorical judgments.Further evidence for this hypothesis is provided bymagnitude estimation studies focusing on informa-tion structure, binding, and auxiliary selection (seeSorace and Keller 2005 for an overview).
References
Alexopoulou, Theodora and Frank Keller. 2002. Re-sumption and locality: A crosslinguistic experi-mental study. In Papers from the 38th Meeting ofthe Chicago Linguistic Society. Chicago, volume1: The Main Session, pages 1–14.
Alexopoulou, Theodora and Frank Keller. 2003.Linguistic complexity, locality and resumption.In Proceedings of the 22nd West Coast Con-ference on Formal Linguistics. Cascadilla Press,Somerville, MA, pages 15–28.
Bard, Ellen Gurman, Dan Robertson, and AntonellaSorace. 1996. Magnitude estimation of linguisticacceptability. Language 72(1):32–68.
Cowart, Wayne. 1997. Experimental Syntax: Ap-plying Objective Methods to Sentence Judgments.Sage Publications, Thousand Oaks, CA.
Featherston, Sam. 2005. Magnitude estimationand what it can do for your syntax: Some wh-constraints in German. Lingua 115(22):1525–1550.
Keller, Frank. 2000. Gradience in Grammar: Exper-imental and Computational Aspects of Degrees ofGrammaticality. Ph.D. thesis, University of Edin-burgh.
Keller, Frank and Theodora Alexopoulou. 2005. Acrosslinguistic, experimental study of resumptivepronouns and that-trace effects. In Proceedingsof the 27th Annual Conference of the CognitiveScience Society. Stresa.
Meyer, Roland. 2003. Superiority effects in Russian,Polish and Czech: Comparative evidence fromstudies on linguistic acceptability. In Proceedingsof the 12th Conference on Formal Approaches toSlavic Linguistics. Ottawa.
Sorace, Antonella and Frank Keller. 2005. Gradi-ence in linguistic data. Lingua 115(11):1497–1524.
61

62

The syntax and semantics of multiple degree modification in English
Christopher KennedyDepartment of Linguistics
University of Chicago1010 E 59th Street
Chicago, IL 60637 [email protected]
Louise McNallyDept. Traduccio i FilologiaUniversitat Pompeu Fabra
La Rambla, 30-3208002 Barcelona Spain
1 Multiple degree modification in English
In this paper we offer an integrated syntactic and se-mantic analysis of various cases of multiple degreemodification in English, some examples of whichappear in (1).
(1) a. a new tower 10 feet taller than the Em-pire State Building
b. an old department store a lot less tallerthan the city hall building than is thenew company headquarters
c. a structural engineer very much moreafraid of heights than the architect
To our knowledge, no such integrated proposal ex-ists for this kind of modification in the HPSG lit-erature. Pollard and Sag (1994) broadly sketch asyntactic analysis of multiple degree modification.However, because it lacks a semantics, their anal-ysis does not make very specific predictions aboutthe restrictions on various combinations of multipledegree modifiers. Although we show that some ofthese restrictions are matters of pragmatic or lexi-cal semantic detail, others turn out to involve fun-damental aspects of the syntax and semantics of de-gree modification. In contrast, Abeille and Godard(2003) present a detailed syntax and semantics forFrench degree adverbs, but their analysis is situatedmore in the context of a general analysis of adver-bial modification, rather than within the context ofa complete treatment of degree modification. As aresult, their analysis does not address multiple de-gree modification or differences in the distributionsof different subclasses of degree expressions; on the
other hand, nothing in our analysis will conflict inimportant ways with their proposal.
As the syntax of multiple degree modification istightly bound up with the semantics of the expres-sions involved, we begin by presenting our seman-tic assumptions. We follow Kennedy (1999) in an-alyzing gradable adjectives and related experssions(such as the vague determinersmany and few) asmeasure functions, which map individuals to de-grees on a scale (type〈e, d〉). Measure functionsare converted to properties of individuals by degreemorphology; in Kennedy’s analysis, the category ofdegree expressions includes measure phrases (e.g.10 feet), comparative morphemes (e.g.-er/more,less, as), intensifiers (e.g.very), and the phonolog-ically null positive degree morphemepos (for the‘positive’, unmarked form of a gradable adjective,e.g., (is) tall). Such expressions take a measure-function and return a property of individuals that isexpressed as a relation between two degrees: onedetermined by applying the measure function to theargument of the predicate; the other introduced bythe degree morpheme (the ‘standard value’).
For example, the comparative morphememorehas the denotation in (2) in Kennedy’s analyis.
(2) [[more]] = λg ∈ D〈e,d〉λdλx.g(x) ≻ d
The degree argument is expressed by the compar-ative clause (the constituent introduced bythan),which denotes a maximal degree (von Stechow,1984). A simple comparative predicate like (3a) isassigned the denotation in (3b): it is true of an objectif it has a degree of height that exceeds the maximal
63

degree to which the Empire State Building is tall.1
(3) a. [[more tall] [than the Empire StateBuilding is tall]]
b. λx.tall (x) ≻ max{d′ | tall (the ESB)
� d′}
A problem with this approach is that multiple de-gree modification facts such as those illustrated in(1) and other data strongly suggest that neither com-parative morphemes nor intensifers really belong inthe category of degree morphology as defined above.For example, (1b) shows that a comparative canmodify another comparative, which is unexpectedon Kennedy’s analysis, since he treats degree mor-phemes as type-changing: he would be forced tohypothesize that e.g.less can combine not onlywith measure function-denoting expressions (whenit takes a simple adjective) but also with property-denoting ones (when it combines with a compara-tive+adjective complex). This is not a typical caseof type polymorphism.
Similar comments apply to intensifiers. Althoughit is sometimes claimed to the contrary, a number ofcombinations of multiple intensifiers are possible (aseven a simple Google search will demonstrate):
(4) a. very much aloneb. rather very goodc. rather quite interesting
Again, Kennedy’s treatment of intensifiers as typechanging forces one to adopt a rather ad hoc typepolymorphism to account for the fact that these ex-pressions modify both adjectives and other intensi-fiers.
In contrast to the comparative morphemes and in-tensifiers stand a group of degree expressions that‘close off’ the predicate they combine with; theseinclude (at least) measure phrases, degreethis/that,proportional modifiers likecompletelyandhalf, andthe wh-degree morphemehow. These expressionscan combine with an unmodified adjective or witha comparative (provided a system of measurementis defined for the adjective in the case of measure
1We assume for simplicity here that the comparative clauseis an ellipsis structure; this issue is orthogonal to the main con-cerns of this paper. See (Kennedy, 2002) for a compositionalanalysis. Likewise, we abstract away from the morphologicalalternation betweenmoreand-er.
phrases), as shown in (5) for the measure phrase2metersand degreethat.
(5) a. 2 meters/that tallb. 2 meters/that{taller, less tall, too tall}
However, they do not accept further modification(6a), nor can they further modify an intensifier (6b)(we assume themuchin (5b) is a dummy element;see (Corver, 1997)):
(6) a. *rather 2 meters/that longb. *2 meters/that very long
2 Three classes of degree expressions andone lexical rule
In this paper, we develop an analyis in which de-gree expressions are divided into three subclasses:(true) DEGREE MORPHEMES, which map gradableadjectives into properties of individuals;INTENSI-FIERS, which affect the computation of the standardof comparison for the positive form; andSCALE AD-JUSTERS, which modify the measure function ex-pressed by the adjective. In addition, we assume alexical rule to handle the interpretation of the un-marked positive form.
2.1 The positive form
As noted above, Kennedy (1999) assumes that thepositive form involvues a null degree morphemepos, which maps a gradable adjective to a prop-erty of individuals that expresses a relation to acontext-dependent standard of comparison (see also(Bartsch and Vennemann, 1972), (Cresswell, 1977),(Klein, 1980), (von Stechow, 1984), (Kennedy,1999), (Kennedy and McNally, 2005)). The posi-tive form of an adjective liketall is thus analyzed asthe predicate [AP postall], which denotes the prop-erty of having a degree of length that exceeds a stan-dard of length whose value is determined based onfeatures of the context of utterance (what is beingtalked about, the interests/expectations of the par-ticipants in the discourse, etc.; see (Lewis, 1970),(Bogusławski, 1975), (Graff, 2000), (Barker, 2002),(Kennedy and McNally, 2005)). Here we take the(possibly universal) absence of overt morphologyin the positive form at face value and instead as-sume a lexical rule that maps measure functions to
64

properties of individuals in the absence of overt de-gree morphology. This rule (whose particular imple-mentation is not crucial for our purposes) is statedin (7), wherestnd is a context-dependent functionfrom a measure function (a ‘basic’ gradable adjec-tive meaning) to a degree in the range of the mea-sure function (its scale) that represents an appropri-ate standard of comparison for the gradable propertymeasured by the adjective in the context of utter-ance. (Compare Lewis’ (1970) and Barker’s (2002)DELINEATION FUNCTION.)
(7)
cat A
cont| rest
reln 1 g〈e,d〉
arg1 2 x
⇒
cat AP
cont| rest
reln ≻
arg1 1
arg2 2
arg3 stnd( 1 )
With this as our starting point, we now turn to theanalysis of degree morphology.
2.2 True degree morphemes
This category contains expressions of type〈〈e, d〉, 〈e, t〉〉; in English: how, that, and mea-sure phrases. These behave as in (Kennedy, 1999),mapping a measure function onto a property ofindividuals expressed as a relation between degrees:the degree derived by applying the measure functionto the individual argument of the predicate, and astandard degree specified by the degree morphemeitself. For example, in the case of measure phrases,this is the correponding degree of measurement, asillustrated by our analysis of the measure phrase2meters(8).
(8)
2 meters
cat Deg
cont| rest
reln �
arg1 g
arg2 x
arg3 2 meters
2.3 Intensifiers
We analyze intensifiers as traditional predicate mod-ifiers (type〈〈e, t〉, 〈e, t〉〉), which are restricted to ap-ply only to gradable predicates in the positive form.We derive this restriction from their semantics, treat-ing them as expressions that modify thestnd func-tion introduced by the positive form rule in (7)(cf. (Wheeler, 1972), (Klein, 1980)). This proposalis based on two observations. First, the semantic ef-fect of intensification is to ‘adjust’ the contextuallydetermined standard of comparison. Second, thedistribution of degree modifiers is highly sensitive tothe type of standard of comparison associated withparticularpos+adjective combinations (whether thestandard is context dependent or lexically deter-mined by the adjectival head; see Kennedy and Mc-Nally’s (2005) analysis ofveryvs.much).
Consider for example the case ofvery. Both tallandvery tall require an object to exceed a contextualstandard of height, but the standard of comparisonintroduced by the latter is greater than that used bythe former. Following Wheeler (1972) and (1980),we derive this result by assuming thatverymodifiesthe stnd function associated with its argument (anadjective to which the lexical rule in (7) has applied)so that it computes a standard of comparison basedon just the heights of those objects that its argumentis true of. That is, [AP very tall] is (syntacticallyand semantically) just like [AP tall], except that thestandard of comparison for the former is computedby considering only those objects that count as tallin the context of utterance. General principles of in-formativity ensure that the modifiedstnd functionwill select a new standard of comparison partitionsthe domain of [AP very tall] into things it is trueof and things it is false of, effectively boosting thebase standard associated with [AP tall] (i.e., sometall objects will not count as very tall).
This proposal is made explicit in (10) (after theReferences section). For the puposes of illustration,we adopt Kasper’s (1997) treatment of nonintersec-tive modification, where the MOD feature is split upinto information about the ARGument of the modi-fier (including its internal content) vs. the (External)CONTent of the resulting phrase.
Our analysis explains why measure phrases (orrather, measure phrase + adjective combinations)
65

cannot be intensifed, even though their semantic(and syntactic) type should in principle allow for it.The difference between [AP MP A] (a type 〈e, t〉predicate consisting of a measure phrase plus grad-able adjective) and [AP A] (a positive form gradableadjective to which the rule in (7) has applied) is thatthe latter is evaluated with respect to thestnd func-tion but the former is not. As a result, there is novalue for an intensifier to manipulate, so the addi-tion of an intensifier has no semantic effect.
2.4 Scale adjusters
This category includes comparatives andtoo/enough, after they have been saturated bytheir internal (clausal) arguments; their seman-tic type is that of gradable adjective modifiers(〈〈e, d〉, 〈e, d〉〉). Specifically, we claim that theseexpressions modify the measure function theytake as input by resetting the maximal or minimalvalue (depending on the morpheme) to the degreeintroduced by the comparative clause. For example,more than CP(where CP is the comparative clause)takes a measure function and assigns it a new scalewhose minimal value is the degree denoted by CP.Thus if tall is a function that maps an individualonto whatever part of the height scale correspondsto its height,taller than the Empire State Buildingmaps an individual onto whatever region of theheight scale represents its ‘taller-than-the-ESB-ness’: an object whose height is less than or equal tothe maximal degree of the Empire State Building’sheight is mapped onto the zero element of thederived scale, and all others are mapped onto theiractual height value. This is made explicit in (11)(after References).
The result of this analysis is that expressions con-sisting of an adjective plus comparative morphol-ogy must ultimately either undergo the positive formrule in (7) or combine with a true degree morpheme(e.g. a measure phrase) in order to derive a propertyof individuals. Assuming that the positive form of anadjective that uses a scale with a minimal element istrue of an object as long as it has a non-minimal de-gree of the relevant property (Kennedy and McNally,2005), the result is thattaller than CPis true of anobject if its height exceeds the degree denoted bythe CP (the minimal element of the derived scale).In other words,taller than the Empire State Build-
ing is true of an object just in case its height exceedsthat of the Empire State Building, which is exactlywhat we want.
3 Predictions of the analysis
In our presentation, we go through the analysis ofcomplex modification structures like those in (1) indetail; here we outline the predictions about possi-ble combinations of degree expressions made by ourproposals:
1. Iteration of comparative expressions and inten-sifiers should be possible.
2. Iteration of true degree morphemes should notbe possible.
3. Measure phrases should be external to all com-parative morphology.
4. Under the assumption that intensifiers and scaleadjusters are not reanalyzable as intersective(unlike, e.g., what is the case with many ad-jectives or adverbs), iterations both of compar-atives and of intensifiers must be interpreted ina nested right-branching fashion, rather than ina left branching fashion, as predicted on Pollardand Sag’s Specifier analysis.
The data presented above illustrate 1-3; 4 is diffi-cult to test because of the rarity of sequences of morethan 2 intensifiers, but appears to be borne out by thefact that the interpretation of the string in (9a) cor-responds on our intuitions to the bracketing in (9b)rather than that in (9c).
(9) a. Becca was rather very slightly drunklast night(www.elvislovers.fanspace.com/fsguestbook.html)
b. (rather (very (slightly)))c. *((rather (very))(slightly))
4 Concluding remarks
Our HPSG implementation of degree modifierscombines intensifiers and scale adjusters with theirsemantic arguments in Head-Adjunct structures,while true degree morphemes combine with their ar-guments in a Head-Specifier structure. Our analysis
66

thus resembles Abeille and Godard’s insofar as theyargue for a Head-Adjunct analysis of French degreeadverbs. It refines their proposal in allowing (atleast in English) for two types of degree Adjuncts:those that operate on ‘bare adjectives’ (measurefunctions), and those that operate on gradable APs(i.e., on thestnd function introduced by the positiveform). Kennedy and McNally’s (2005) commentsconcerning the semantics of the degree modifierwellindicate that these two types are clearly justified.
Nonetheless, the analysis also preserves theessence of the insight behind Pollard and Sag’s pro-posal, on which degree expressions are treated asspecifiers of adjectives, adverbs or other gradablepredicates in a Head-Specifier configuration. It sim-ply reduces the class of expressions that have thisspecifying function, as a result of having refined thesemantics of degree modification.
A question of broader theoretical interest is whythe set of degree expressions should be divided upin the way we have proposed here. We claim thatthis is a natural result of our initial assumptions thatgradable adjectives have basic meanings as measurefunctions, and ‘derived’ meanings (in the positiveform) as context-dependent properties of individu-als (where context dependence comes from thestndfunction). If the basic semantic type of a gradableadjective is〈e, d〉 (a measure function), then thereshould exist overt morphology (in addition to ourpositive form lexical rule) that converts a gradableadjective to a property of individuals: this is ourclass of true degree morphemes. Furthermore, if nat-ural language quite generally allows expressions oftype 〈τ, τ〉, there should also exist a class of mod-ifiers of measure functions: these are our scale ad-justers. By the same token, we also expect to findmodifiers of the type〈e, t〉 variant of a gradable ad-jective (the positive form): this is our class of inten-sifiers.
References
Anne Abeille and Daniele Godard. 2003. The syn-tactic flexibility of French degree adverbs. In StefanMuller, editor,Proceedings of the 10th InternationalConference on Head-Driven Phrase Structure Gram-mar, pages 26–46, Stanford, CA. CSLI Publications.
Chris Barker. 2002. The dynamics of vagueness.Lin-guistics and Philosophy, 25(1):1–36.
Renate Bartsch and Theo Vennemann. 1972. The gram-mar of relative adjectives and comparison.Linguistis-che Berichte, 20:19–32.
Andrzej Bogusławski. 1975. Measures are measures: Indefence of the diversity of comparatives and positives.Linguistiche Berichte, 36:1–9.
Norbert Corver. 1997. Much-support as a last resort.Linguistic Inquiry, 28:119–164.
M. J. Cresswell. 1977. The semantics of degree. In Bar-bara Partee, editor,Montague Grammar, pages 261–292. Academic Press, New York.
Delia Graff. 2000. Shifting sands: An interest-relativetheory of vagueness.Philosophical Topics, 20:45–81.
Robert T. Kasper. 1997. The semantics of recursive mod-ification. Ms., Ohio State University.
Christopher Kennedy and Louise McNally. 2005. Scalestructure and the semantic typology of gradable predi-cates.Language, 81(2):1–37.
Christopher Kennedy. 1999.Projecting the Adjective:The Syntax and Semantics of Gradability and Compar-ison. Garland, New York. (1997 UCSC Ph.D thesis).
Christopher Kennedy. 2002. Comparative deletion andoptimality in syntax.Natural Language & LinguisticTheory, 20.3:553–621.
Ewan Klein. 1980. A semantics for positive and compar-ative adjectives.Linguistics and Philosophy, 4:1–45.
David K. Lewis. 1970. General semantics.Synthese,22:18–67.
Carl Pollard and Ivan Sag. 1994.Head-Driven PhraseStructure Grammar. University of Chicago Press,Chicago.
Arnim von Stechow. 1984. Comparing semantic theoriesof comparison.Journal of Semantics, 3:1–77.
Samuel Wheeler. 1972. Attributives and their modifiers.Nous, 6(4):310–334.
67

(10)
very
cat|head
mod
arg
cat AP
cont 1
reln ≻
arg1 g
arg2 x
2 arg3 stnd(g)
econt 3
(1
)
cont 3
[reln recompute-stndvery
arg1 1
]
(11)
more than
cat|head
mod
arg[cont
[index 1 g
]]
econt 2
(1 ,d
)
val[comps
⟨CPd
⟩]
2 cont
reln more-thanarg1 g
arg2 d
68

It-Extraposition in English: A Constraint-Based Approach
Jong-Bok KimSchool of English
Kyung Hee UniversitySeoul, 130-701, Korea
Ivan A. SagDepartment of Linguistics
Stanford UniversityStanford, 94305
1 Basic Issues
According to the Projection Principle (Chomsky1981), expletives have no semantic content and thuscannot occur in theta-marked positions. However,there seem to exist overt cases where the expletiveit appears in the object position as in (1) (Postal &Pullum 1988):
(1) a. I dislike it that he is so cruel.b. They never mentioned it to the candidate thatthe job was poorly paid.c. We may depend upon it that we won’t aban-don him.d. I should resent it greatly that you did not call.
Many attempts (e.g. the case-based analysis byAuthier (1991), the predication analysis by Roth-stein (1995), the Spec analysis by Stroik (1996))have been made to account for such examples, withthe common postulation of the expletive in the Specof CP position and various movement processes. Forexample, to generate cases like (1d), Stroik (1996)claims that the object expletiveit is generated inthe Spec of CP at base argument structure and thenmoved into the Spec of an AGR projection to sat-isfy case checking, together with several movementoperations as shown in the following:
(2) [...[PredP resenti [AGRoP itj [AGRo′ ti [V P
greatly [V P [V ′ ti [CP tj [C′ that you did notcall]]]]]]]]]
Such analyses may be able to generate cases like(1d) or similar examples, but they still fail to accountfor the fact that the expletive is obligatory in (3a),optional in (3b), and prohibited in (3c):
(3) a. Type I: I blame *(it) on you [that we can’tgo].b. Type II: Nobody expected (it) of you [thatyou could be so cruel].c. Type III: John said (*it) to his friends [thatwe had betrayed him].
2 A Proposal
This paper argues that such contrasts, in addition tothe distribution possibilities ofit in the object posi-tion, follow naturally from a lexical analysis basedon tight interactions between lexical and English-independent constraints, rather than otherwise un-motivated movement operations.
2.1 Lexically Controlled Extraposition
The first property of English object extrapositionwe need to consider is that the overt expletive indirect object position is possible only with certainverbs taking clausal complements, and not with oth-ers (Authier 1991). It appears that the verbs takingclausal complements can also take an NP object orallows the expletive object:
(4) a. They didn’t even mention his latest promo-tion/that he was promoted recently.b. They demanded justice/that he should leave.
(5) a. They never mentioned it to the candidate thatthe job was poorly paid.b. They demand it of our employees that theywear a tie.
However, verbs taking either a CP or an NP onlydisallow object extraposition:
69

(6) a. I think *(of) you all the time.b. I wonder *(about) that.
(7) a. I think (*it) that John had an accident.b. I wondered (*it) how he did on the test.
Another general observation we can make is thatmany verbs select a complement that can be realizedeither as an NP or a CP:
(8) a. Tom proved the independence of the hypoth-esis/the hypothesis was independent.b. Tom forgot our invitations/that we neededinvitations.
As suggested in Sag et al. (2003), one simple way ofspecifying such a lexical property is to introduce anew part-of-speech typenominalthat subsumes bothnounandcomp. In accordance with the basic prop-erties of type hierarchy, this system then means thatif an element is specified with [HEADnominal], itcan be realized either as [HEADnoun] or as [HEADcomp]. English will thus have at least the three lex-ical types: v-np-tr for verbs selecting just NP (de-vour, like, pinch, elude,...), v-s-tr for verbs selectingonly CPs (hope, hint, wonder,...), andv-nominal-trfor verbs selecting both NPs and CPs (prove, forget,see,...). These three types will basically have the fol-lowing ARG-ST value:
(9)a.
[v-np-trARG-ST〈X, NP,...〉
]b.
[v-s-trARG-ST〈X, CP,...〉
]c.
[v-nominal-trARG-ST〈X, [HEAD nominal],..〉
]Because of the status of the typenominal, thepresent system allows a lexical element with the in-formation (9c) to be realized either as in (9a) or asin (9b).
2.2 Some Theoretical Apparatus
As is well-known, there is a systematic alternationbetween non-extraposed and extraposed sentencesas shown in the following pair:
(10) a. That Chris knew the answer occurred to Pat.b. It occurred to Pat that Chris knew the answer.
Pollard and Sag (1997) and Sag et al. (2003) cap-ture this relationship with a lexical rule that turns the
sentential subject (in (10a)) into a sentential ‘com-plement’ of the verb (in (10b)). However, this com-plement approach, as pointed out by Keller (1995),Bouma (1996), and van Frank (1996), suffers fromproblems for cases like the following:
(11) a. They regret it [very much] [that we couldnot hire Mosconi].b. It struck a grammarian last month, [who an-alyzed it], [that this clause is grammatical].
If the extraposedthat-clause is the complement ofregret, we would not expect the intervention of theadverbial elementsvery muchor the relative clausein (11). Departing from the traditional complementapproach (and following Bouma 1996, among oth-ers), we take English extraposition to be a nonlocaldependency and introduce the nonlocal feature EX-TRA together with the following lexical rule:1
(12) Extraposition Lexical Rule:[ARG-ST A ⊕ 〈 1 [nominal]〉 ⊕ B
SEM fact
]⇒
[ARG-ST A ⊕ 〈NP[NFORM it]〉 ⊕ B
EXTRA 〈 1 [HEAD comp]〉
]This rule basically turns av-nominal-tr into a wordthat selects an expletive NP with the CP as its EX-TRA value.2 The input element also has a semanticrestriction requiring that the message type of the se-mantic content befact. As noted by Bolinger (1976),nonfactives or suppositions do not allow object ex-traposition.
(13) a. *I resent it that she did that, if indeed shedid.b. I resent it that she did that.
The feature EXTRA is discharged when a head com-bines with the extraposed phrase, in accordance withthe Head-Extra Rule:
(14) Head-Extra Phrase:[EXTRA 〈 〉
]→ H
[EXTRA 〈 1 〉
], 1
1This rule can be applied to subject extraposition, too. Thus,in our analysis, unlike that of Sag et al. (2003), thethat-clausein (10b) is not the complement ofoccurred, but rather an extra-posed element.
2One basic constraint that works in the grammar is the Ar-gument Realization Constraint which ensures the ARG-ST ele-ments will be realized as SUBJ and COMPS in syntax.
70

One additional language-independent constraintrelevant in extraposition is that the langauge inde-pendently prohibits a CP from having any elementto its right (cf. Kuno’s (1987) Ban on Non-sentenceFinal Clause (BNFC)):
(15) a. I believe strongly that the world is round.b. *I believe [that the world is round] strongly.
This BNFC constraint (an LP rule) basically barsany argument from appearing after a sentential ar-gument. In the present context this means that thereexists no word whose COMPS list contains some-thing to its CP complement.
3 Explaining the Three Types
Given these independently motivated assumptions,facts concerning English object extraposition theneasily follow.
Type I: As noted earlier, verbs likeblamerequirethe obligatory presence of the expletiveit in the ob-ject position:
(16) a. I blame the case on you.b. *I blame that we can’t go.c. *I blame [that we can’t go] on you.d. I blame it on you that we can’t go.e. *I blame on you that we can’t go.
The data imply thatblamewill have the followinglexical entry:3
(17)[
v-nominal-trARG-ST〈 1 NP, 2 [HEAD nominal], 3 PP[FORMon]〉
]The verbblameselects anominaland a PP as its ar-guments. If thenominalcomplement is resolved asan NP (as in (18)a), we generate (16a). If it insteadis realized as a CP (as in (18b)) then it cannot berealized before the PP, because of the BNFC, thusaccounting for the deviance of (16c).
(18)a.
[v-nominal-trARG-ST〈 1 NP, 2 NP, 3 PP[FORMon] 〉
]b. *
[v-nominal-trARG-ST〈 1 NP, 2 CP, 3 PP[on] 〉
]3The boxed integer here is introduced to show the relation-
ships with related lexical entries as in (17) or (18).
The deviance of (16e) is explained by appeal to a fur-ther LP Constraint requiring controllers to precedethe phrases (whose subject) they control:
(19) 1 ≺ [SUBJ〈 1 〉]
Note that we know theon-phrase here is predicativebecause of examples like the following:
(20) a. They put the blame on Lee.b. The blame was on us.
One way that (18b) can give rise to a legitimateword is to apply the Extraposition Lexical Rule, asshown in the following:
(21) [extraposed-wARG-ST〈 1 , NP[NFORMit], 3 PP〉EXTRA 〈 2 [HEAD comp]〉
]
The output in (21) can then give rise to sentenceslike (16d) with the following (simplified) structure:
(22) VP[hd-extra-ph
EXTRA 〈 〉
]nnnnnnn
TTTTTTTTTTTTT
VP[EXTRA 〈 2 〉
]nnnnnnn
BBBB
BBBB
B
PPPPPPPPPPPPPP
2 CP
��������
****
****
V[ARG-ST〈NP, NP[it] PP〉EXTRA 〈 2 〉
]NP
������
######
PP[on]
1111
111 that...
blame it on you
Type II: In the Type II examples, the expletiveitis optional, as noted earlier:
(23) a. Nobody expected that of you.b. Nobody expected that you could be so cruel.c. *Nobody expected [that you could be socruel] of you.d. Nobody expected it of you [that you couldbe so cruel].e. Nobody expected of you [that you could beso cruel].
The data lead us to assume the following lexical en-try for verbs likeexpect:
71

(24)[
v-nominal-tr
ARG-ST〈 1 NP, 2[HEAD nominal
], 3 (PP[FORMof])〉
]According to the lexical entry in (24), the verbex-pect takes anominaland an optional case-marking(i.e. nonpredicative) PP. Depending on the instantia-tion of the HEAD value, we will have the followingtwo realizations.
(25)a.
[v-nominal-trARG-ST〈 1 NP, 2 NP, (3 PP[FORMof])〉
]b.
[v-nominal-trARG-ST〈 1 NP, 2 CP, 3 (PP[FORMof])〉
](25a) will be able to generate sentences like (23a).When the PP complement does not appear, we willhave sentences like (23b). However, with the PP ar-gument, the instantiation (25b) cannot give rise tothe ungrammatical (23c), because of the BNFC con-straint. But because the PP is non-predicative, ex-amples like (23e) are predicted to be well-formed,as no violation of the LP Constraint in (19) is en-gendered. Extraposition is also possible, generatinga word that selects an expletive object and turns theargument CP into the value of the nonlocal featureEXTRA. The output lexical entry will allow sen-tences like (23d) with the following structure:
(26) VP[hd-extra-ph
EXTRA 〈 〉
]nnnnnnn
TTTTTTTTTTTTT
VP[EXTRA 〈 2 〉
]nnnnnnn
BBBB
BBBB
B
PPPPPPPPPPPPPP
2 CP
��������
****
****
V[ARG-ST〈NP, NP[it] PP〉EXTRA 〈 2 〉
]NP
������
######
PP[of]
�������
0000
000 that...
expected it of you
Type III: Unlike the other two types, this type ofverb appears not to allow object extraposition. Thatis, it seems that no expletive is possible in such acase even though this type of verb could have a CPcomplement:
(27) a. John thought (to himself) that Mary wascoming.b. ?*John thought it to himself that Mary wascoming.
This fact could be simply be accounted for viaan appropriate lexical entry, but, as we will show,there are in fact ample attested examples like (27b)and hence some reason to believe that the entire lit-erature on English object extraposition has made amistaken assumption about the data in question. Weultimately explore the idea that all CP-compatiblecomplements can in principle give rise to extraposi-tion.
4 Conclusion
The analysis presented here implies that lexicalspecifications — both general constraints on verbclasses and individual lexical constraints — play acrucial role in English object extraposition. Thesespecifications interact with one lexical rule and twoLP rules to predict that observed patterns of varia-tion.
Selected ReferencesAuthier, J.-Marc . 1991. V-Governed Expletives, Case Theory,
and the Projection PrincipleLinguistic Inquiry 22, no.4,721-740.
Bouma, Gosse. 1996. Complement Clauses and Expletives.Papers from the sixth CLIN Meeting.
Iwakura, Kunihiro. 1994. The Distribution of CP-Trace and theExpletiveIt. Linguistic Analysis24, no. 1-2, 122-141.
Keller, Frank. 1995. Towards an Account of Extraposition inHPSG.Proceedings of the EACL.
Kuno, Susumo. 1987.Functional Syntax. Chicago: The Uni-versity of Chicago Press.
Postal, Paul, and Geoffrey Pullum. 1988. Expletive NounPhrases in Subcategorized PositionsLinguistic Inquiry19,no. 4, 635-670.
Rothstein,Susan D. 1995. Pleonastics and the Interpretation ofPronounsLinguistic Inquiry26, no.3, 499-529.
Sag, Ivan, Tomas Wasow, and Emily Bender. 2003.SyntacticTheory: A Formal Approach. CSLI Publications.
Stroik, Thomas S. 1996. Extraposition and Expletive-Movement: A Minimalist Account.Lingua: InternationalReview of General Linguistics99, no. 4, 237-251.
van Eynde, Frank. 1996. A monostratal treatment of it extra-position without lexical rules.Papers from the sixth CLINMeeting 1995.
72

Copy Constructions and their Interaction with the Copula in Korean
Jong-Bok KimSchool of English
Kyung Hee UniversitySeoul, 130-701, [email protected]
Peter SellsDepartment of Linguistics
Stanford UniversityStanford, 94305
1. The Copula
The Korean copula-i- forms a phonological wordwith its preceding N host (see Oh (1991)), and hasbeen treated by some linguists as a syntactic Vwhich happens to be a clitic on a preceding NP com-plement (in particular Yoon (2003)). (1)a-b illustratesome basic properties:
(1) a. ku salam-i haksayng-i-tathat person-NOM student-COP-DECL
‘That person is a student.’
b. ku salam-i [mikwuk-eysethat person-NOM America-atkongpwu ha-n] haksayng-i-tastudy do-PAST student-COP-DECL
‘That person is a student who studied inAmerica.’
In this paper we add to a growing body of evidencewhich shows that N+i- is a lexically-formed verb.An apparent problem for this approach is that the Nhosting the copula can head a fully-formed syntac-tic NP (see (1)b). The facts with the copula can beaccounted for in HPSG through the adoption of theLexical Sharing approach of Wescoat (2002). Infor-mally, Lexical Sharing allows words to instantiateone or morelexical-category nodes; thus, alongsidefamiliar one-word-to-one-phrase instantiation, ex-emplified bysalam-i ‘person-NOM’, the theory alsopositsportmanteau words, which instantiate two ormore adjacent lexical-category nodes. This allowsus to accept the lexicality ofhaysayng-i-‘student-COP’, a form which may receive verbal inflectionalaffixation in the lexicon (see Kim et al. (2004)).
2. Evidence from the Echo Construction
Our new evidence comes from the ‘Echo ContrastiveConstruction (ECC)’, which involves the doublingof Vs, but none of their phrasal arguments and ad-juncts. The function of the ECC, whose basic formis V-ki-nunV-ta as in (2), is to set up a negative im-plicature in the interpretation of the whole sentence(see Choi (2003), Cho et al. (2004), Kim (2002)).(2)b shows a related construction, what we call the‘Ha Contrastive Construction (HCC)’. In either ex-ample, the event is presented against the backgroundof the negative implicature, indicated by the ‘but. . . ’ in our translations.
(2) a. John-i Tom-ul [manna-ki-nunJohn-NOM Tom-ACC meet-Nmlz-TOP
manna-ss-ta]meet-PAST-DECL
‘John met Tom, but . . . .’
b. John-i Tom-ul [manna-ki-nunJohn-NOM Tom-ACC meet-Nmlz-TOP
hay-ss-ta]do-PAST-DECL
‘John met Tom, but . . . .’
The interaction of the ECC with the copula providesstrong support for our claim. The only grammaticalform of an ECC with the positive copulai-ta alsoinvolves doubling the N host of the copula, as in (3)a(see Oh (1991), Kim and Chung (2002)).
(3) a. ku salam-i [mikwuk-eysethat person-NOM America-atkongpwu ha-n] haksayng-i-ki-nunstudy do-PAST student-COP-NMLZ-TOP
73

haksayng-i-tastudent-COP-DECL
‘That person is a student who studied inAmerica (but he still doesn’t speak En-glish well).’
b. *ku salam-i [mikwuk-eysethat person-NOM America-atkongpwu ha-n] haksayng-i-ki-nunstudy do-PAST student-COP-NMLZ-TOP
i-taCOP-DECL
Under the clitic analysis, the copula never forms asyntactic unit with its NP complement: thus thereis no easy way to make the copied part in (3)a aconstituent; it would be the head of the complementNP and the following V selecting for that NP. How-ever, we see clearly that the ECC treats N+Copulaas a syntactic constituent, and that the copula cannotfunction as a pure V in the syntax, from the contrastin (3)a and (3)b. The copula verb alone cannot becopied, as it has no syntactic status by itself.
The facts in (3) contrast directly with the ECCfacts with the negative copulaani-ta, which takes anominative-marked complement (see (8)a): theani-ta verbal part can be doubled by itself, as in (4)b,just like a regular verb (cf. (2)a). And while the dou-bling of N + negative copula as in (4)a is grammati-cal, this example does not have the ‘negative impli-cature’ interpretation typical of the ECC, but ratherhas a VP-topic interpretation – along the lines of ‘asfor not being a fool, that person is not a fool’.1 Thisasymmetry shows that the ECC targets a verb in thesyntax and intuitively copies it, meaning that there isa lexical formhaksayng-i-for (3)a alongsideani-tafor (4)b.2
(4) a. ku salam-i papo-kathat person-nom fool-NOM
ani-ki-nun papo-ka ani-taNCOP-NMLZ-TOP fool-NOM NCOP-DECL
‘It is true that that person is not a fool.’(VP-topic)
1A caveat: prosodic prominence on the marker-nuncan alsotrigger the negative implicature due to its contrastive properties.
2The positive copula is one of a class of verbal elements in-cluding-tap-ta‘is.every.bit’ and-kath-ta‘seem’ (noted by Yoon(2003)), which behave in the same way, including in the ECC.
b. ku salam-i papo-kathat person-NOM fool-NOM
ani-ki-nun ani-taNCOP-NMLZ-TOP NCOP-DECL
‘That person is not a fool (but he is notso smart).’
Although the details will come later, the structure weassign to (3)a is given in (5) (next page).
3. Further Issues with the Copula
Jo (2004) discusses pairs of examples apparently in-volving the ECC and the copula, based on the simpleexample in (6)a:
(6) a. chelswu-ka pwuca-i-ess-echelswu-NOM rich-COP-PAST-DECL
‘Chelswu was rich (a rich man).’
b. chelswu-ka pwuca-nunchelswu-NOM rich-TOP
pwuca-i-ess-erich-COP-PAST-DECL
c. chelswu-ka pwuca-i-ki-nunchelswu-NOM rich-COP-NMLZ-TOP
pwuca-i-ess-erich-COP-PAST-DECL
Jo argues that the relation between (6)b and (6)cshows that what is copied is either the N before thecopula, for b, or a larger constituent consisting of Nand the copula, for c, both coming from the samesource in a transformational derivation.
However, there are several types of evidencewhich show that though (6)c is an instance of theECC, (6)b is not, and is rather an ‘N-Copy Con-struction’ (we will call it ‘NCC’), which reinforcesthe meaning of the N, and we translate it (roughly)as ‘truly’. As mentioned above, the pragmatic hall-mark of the ECC is that it sets up a negative implica-ture, without any assistance from other morphemesin the clause which may have adversitive or conces-sive meanings. This distinguishes (6)b from (6)c,and identifies only c as the ECC. While they both in-volve copying constructions (which will be related,but not identical, in our analysis), the key differenceis that (6)b involves copying Ns, while (6)c involvescopying Vs, and only the latter type has the negativeimplicature. One clear difference can be observed
74

(5) VP
NP V
syntaxRelS N V V
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
lexiconmikwuk-eyse kongpwu ha-n haksayng-i-ki-nun haksayng-i-ta
from the alternation with the HCC. With noun andcopula, the ECC alternates with the HCC (see (2)b),while the NCC does not:
(7) a. chelswu-ka pwuca-nunchelswu-NOM rich-TOP
pwuca-i-ess-e/*hay-ss-erich-COP-PAST-DECL/*do-PAST-DECL
‘Chelswu is a truly rich man.’
b. chelswu-ka pwuca-i-ki-nunchelswu-NOM rich-COP-NMLZ-TOP
pwuca-i-ess-e/hay-ss-erich-COP-PAST-DECL/do-PAST-DECL
‘Chelswu is a rich man, but . . . .’
The HCC is clearly a V-V complex predicate, so itsfailure to work with an N first part in a is expected.
Next, the interaction with the negative copula istelling. From the simple example in (8)a, we mightexpect the following alternatives to be acceptable:
(8) a. chelswu-ka pwuca-ka ani-tachelswu-NOM rich-NOM NCOP-DECL
‘Chelswu is not a rich man.’
b. chelswu-ka pwuca-kachelswu-NOM rich-NOM
ani-ki-nun ani-taNCOP-NMLZ-TOP NCOP-DECL
‘Chelswu is not a rich man (but he is verygenerous).’ (negative ECC)
c. chelswu-ka pwuca-kachelswu-NOM rich-NOM
ani-ki-nun pwuca-ka ani-taNCOP-NMLZ-TOPrich-NOM NCOP-DECL
‘As for not being rich, Chelswu is notrich.’ (negative VP-topic)
d. ??chelswu-ka pwuca-nun pwuca-kachelswu-NOM rich-TOP rich-NOM
ani-ta (negative NCC)NCOP-DECL
However, the last example is essentially unaccept-able, showing that while the ECC sets up a negativeimplicature, the NCC involves N copying and rein-forces the positive property of the N. This explainswhy d is strange – the N-copy part sets up a strongpositive assertion, but then the verb negates it.3
4. Lexical Sharing HPSG Analysis
Wescoat (2002) argues that the atomic units ofphrase structure are neither words, as claimed byDi Sciullo and Williams (1987), nor morphemes,as assumed in Autolexical Syntax (see Sadock(1991)), but rather lexical-category-bearingatomicconstituents, each of which maps into alexical ex-ponent, i.e. a word which is said toinstantiatetheatomic constituent. The basic idea of lexical shar-ing is then that two or more atomic constituents may‘share’ the same exponent, or equivalently, that asingle word may instantiate multiple atomic con-stituents. This scheme provides a straightforwardmodel of words that appear to straddle a phraseboundary. Lexical sharing may be simply imple-mented using the basic machinery of HPSG, inwhich there is a basic sort ofsign. Two subtypesof sign, namelyphraseandword, have been tradi-tionally employed for representing phrase-structureconstituents; thus, standard HPSG is among those
3Further differences exist between the ECC and the NCC.Delimiters like -man can be used in the ECC but not in theNCC as inchelswu-ka pwuca-i-ki-man pwuca-ya/*chelswu-kapwuca-man pwuca-ya. In addition, a proper noun cannot oc-cur in the NCC as inku salam-i John-i-ki-nun John-i-ya/?*kusalam-i John-un John-i-ya.
75

theories that regard words as the atoms of phrasestructure. In the lexical sharing approach we divorcethe typeword from this role, and have a new, prop-erly syntactic type to represent atomic constituentsin phrase-structure, namelyatom. The modifiedsignhierarchy is shown in (9).(9) sign
lex(ical)-sign syn(tactic)-sign
stem sub-word word atom phrase
The type (initalics) of an AVM determines whatattributes (inSMALL CAPS) and what types of val-ues the AVM may contain. The principal new typedeclarations are given in (10).
(10) a.[
lex-signPHON(OLOGY) list(form)INST(ANTIATE)S non-empty-list(atom)
]
b.[
syn-signSYNSEM synsem
]
c.[
atomEXPON(ENT) wordARG-ST list(synsem)
]
d.[
phraseD(AUGH)T(E)RS non-empty-list(syn-sign)
]
The new attributesEXPON andINSTS in (10) imple-ment lexical sharing: eachatomis linked viaEXPON
to a lexical exponent of typeword; additionally, ev-eryword contains, as the value ofINSTS, an orderedlist enumerating eachatom that theword instanti-ates. We ensure reciprocal linkage betweenwordandatomwith the constraints in (11).
(11) a.atom ⇒ 1
[
EXPON
[
word
INSTS⟨
. . . , 1 , . . .⟩
]]
b.
word ⇒ 1
[
INSTS
⟨[
atomEXPON 1
]
, . . . ,
[
atomEXPON 1
]⟩]
The effect of (11) is illustrated by the schematizationin (12) of an instance of lexical sharing (comparewith thehaksayng-i-ki-nunpart of (5)).
(12)1
[
atomEXPON 3
]
2
[
atomEXPON 3
]
3
[
word
INSTS⟨
1 , 2
⟩
]
The tags1 , 2 , and 3 reveal the interpenetration ofthe AVMs which they index: bothatom 1 andatom2 have the sameword 3 as value ofEXPON, givingrise to lexical sharing; moreover,word 3 containsboth atom 1 andatom 2 in its INSTS list, therebyenabling theword to determine individually the syn-tactic features of eachatom. When there is no actuallexical ‘sharing’, i.e. when aword is exponent of asingleatom, the INSTS list is simply of length one.
Different from the negative copula verb which se-lects two nominative arguments, the positive copula-i does not exist as a word itself. In morphology, itcombines with a nounsub-wordas input, and returnsa verb-root. This new lexical item can instantiatetwo syntactic atoms, the first of which is the nounthat was input to the rule, and the second is a two-place predicate which expresses thebe-rel; see (13)(next page).
This morphological process applies to an N sub-word and creates a form of typeverb-root. Thatnew form instantiates two atoms in the syntax, anN (which heads NP) and a V (which heads VP),and may be input to further lexical rules. Hence,this is appropriate for the formhaksayng-i-ki-nunin(5). The lexical rule puts the relevant syntax and se-mantics of the host N as information about the sec-ond argument of the V that the output form instan-tiates. Nevertheless, this is still a two-place V, anatom which will eventually combine in syntax witha complement NP and then a subject NP.
The first element in INSTS is optional, to cap-ture true incorporation: in one option, the wordhaksayng-i-(the final word in (5)) only instantiatesone atom, V, andhaksayngis truly incorporated.
5. Copying HPSG Analysis (ECC andNCC)
The similarities and differences of the two construc-tions can be generalized by the constructional con-straint in (14); the two constructions both involvecopying the V or N stem (intuitively, within VP orNP, respectively). We specify the stem as the exactinflectional forms of the two ‘copies’ usually differ,due to other properties of the constructions.
(14) copy-ph:
[ ] →[
MORPH|STEM 1
]
, H[
MORPH|STEM 1
]
76

(13) Positive Copularization:
1
sub-wordPHON φ
INSTS
⟨
2
atomEXPON 1
SYNSEM|LOC
[
CAT|HEAD 3
[
noun]
CONT 4
[
INDEX j]
]
⟩
⇒
5
verb-rootPHON φ-i-
INSTS
⟨
( 2 ),
atomEXPON 5
SYNSEM|LOC
CAT|HEAD[
verb]
CONT
be-relARG1 i
ARG2 j
ARG-ST
⟨
NPi,
[
CAT|HEAD 3
CONT 4
[
INDEX j]
]⟩
⟩
The ECC would inherit from (14) and from a se-mantic constraint setting up the negative implicature(for details, see Cho et al. (2004). The NCC wouldalso inherit from (14) and but from a semantic con-straint expressing a reinforced positive assertion ofthe property denoted by the (copied) N. The firstcopy in the NCC is marked with-nun, while a verbin the ECC must be first nominalized with-ki (whichwe treat via a FORM feature) before hosting-nun, orsome other particle (see footnote 3).
In conclusion, the Korean positive copula displaysintriguing properties. Closer examination of the rel-evant data supports our lexical sharing treatment ofthe precopular element and the copula as a lexicalunit. We have shown how a constructional approachcan begin to address the similarities and differencesof the ECC and the NCC.
References
Sae-Youn Cho, Jong-Bok Kim, and Peter Sells. 2004.Contrastive verb constructions in Korean. In S. Kunoet al., editor,Harvard Studies in Korean Linguistics,volume 10, pages 360–371. Dept. of Linguistics, Har-vard University.
Kiyong Choi. 2003. The echoed verb construction in Ko-rean: Evidence for V-raising. In Patricia M. Clancy,editor,Japanese/Korean Linguistics, volume 11, pages457–470. CSLI, Stanford Linguistics Association.
Anna-Maria Di Sciullo and Edwin Williams. 1987.Onthe Definition of Word. MIT Press, Cambridge.
Jung-Min Jo. 2004. Variation in predicate cleft construc-tions in Korean: Epiphenomena at the Syntax-PF in-terface. In S. Kuno et al., editor,Harvard Studies inKorean Linguistics, volume 10, pages 424–437. Dept.of Linguistics, Harvard University.
Jong-Bok Kim and Chan Chung. 2002. Korean copulaconstructions: A construction and linearization per-spective.Ene, 27:171–193.
Jong-Bok Kim, Peter Sells, and Michael T. Wescoat.2004. Korean copular constructions: A lexical sharingapproach. In M. E. Hudson, S.-A. Jun, and P. Sells, ed-itors, Japanese/Korean Linguistics, volume 13. CSLI,Stanford Linguistics Association.
Youngsun Kim. 2002. The syntax of Korean verbal fo-cus constructions. InProceedings of the 2002 LSK In-ternational Summer Conference, pages 333–344. TheLinguistic Society of Korea.
Mira Oh. 1991. The Korean copula and palatalization.Language Research, 27:701–724.
Jerrold M. Sadock. 1991.Autolexical Syntax: A Theoryof Parallel Grammatical Representations. Universityof Chicago Press, Chicago.
Michael T. Wescoat. 2002.On Lexical Sharing. Ph.D.thesis, Stanford University.
James Hye-Suk Yoon. 2003. What the Korean copulareveals about the interaction of morphology and syn-tax. In Patricia M. Clancy, editor,Japanese/KoreanLinguistics, volume 11, pages 34–49. CSLI, StanfordLinguistics Association.
77

78

The scope interpretation of the light verb construction in Japanese
Yusuke KubotaDepartment of LinguisticsThe Ohio State University
222 Oxley Hall1712 Neil Avenue
Columbus, OH 43210, [email protected]
1 The syntax and semantics of the lightverb construction in Japanese
In the light verb construction (LVC) in Japanese, anargument of a verbal noun (VN) subcategorized forby a light verb (LV) can sometimes be syntacticallyrealized as an argument of the LV, as was first no-ticed by Grimshaw and Mester (1988); in (1a), thegoal argumentTookyoo e no ‘to Tokyo’ of the VNyusoo ‘transport’ appears with the genitive markerno, indicating its status as an argument of a noun,whereas in (1b), the same goal argument appears asan argument of the LV without the genitive marker:
(1) a. KareraThey
waTOP
[TookyooTokyo
eGOAL
noGEN
bussigoods
noGEN
yusoo]transport
oACC
si-ta.do-PAST
‘They transported goods to Tokyo.’
b. Karera wa Tookyoo e [bussi no yusoo] osi-ta.
This phenomenon was termed ‘argument transfer’by Grimshaw and Mester (1988). Matsumoto (1996)later discovered that the range of verbs that triggerargument transfer in Japanese is not limited to theprima facie LVsuru ‘do’; a lot of raising and controlverbs exhibit patterns of argument realization analo-gous to that in (1b). In (2), the goal argument of theVN is transferred to the raising verbhazimeru:
(2) KareraThey
waTOP
TookyooTokyo
eGOAL
bussigoods
noGEN
yusootransport
oACC
hazime-ta.begin-PAST
‘They began transporting goods to Tokyo.’(1996, 77)
The following is a partial list of verbs that triggerargument transfer taken from Matsumoto (1996):1
• aspectual verbs:kurikaesu ‘repeat’, tuzukeru‘continue’,kaisi suru ‘begin’, etc.
• verbs of thinking/planning: kuwadateru ‘at-tempt’, wasureru ‘forget’, kangaeru ‘think’,etc.
• verbs/nominal adjectives with possibilitymeaning: dekiru ‘can’, ari-uru ‘be possible’,etc.
• directive and permissive verbs:meiziru ‘order’,motomeru ‘ask’, mitomeru ‘permit’ etc.
Matsumoto (1996) further claimed that not onlyarguments but also adjuncts can be transferred fromthe VN to the LV. As convincingly demonstrated byYokota (1999), however, this assumption is empir-ically wrong; syntactic dependents of the LV thatare unequivocally adjuncts can never allow an inter-pretation in which it has been ‘transferred’ from theVN, as shown by the following data:
(3) a. BussyuBush
waTOP
KoizumiKoizumi
niDAT
tyokusetudirect
noGEN
hoobeivisit-US
oACC
mitome-ta.permit-PAST
‘Bush permitted Koizumi to visit US di-rectly.’
1In this paper, I will use the term ‘light verb’ as a cover termfor verbs that trigger argument transfer.
79

b. BussyuBush
waTOP
KoizumiKoizumi
niDAT
tyokusetudirectly
hoobeivisit-US
oACC
mitome-ta.permit-PAST
‘Bush permitted Koizumi to visit US inperson.’
Tyokusetu no ‘direct’ in (3a) has the form of a nomi-nal modifier whereastyokusetu ‘directly’ in (3b) hasthe form of a verbal modifier. If adjuncts could betransferred from the VN to the LV, (3b) should havea reading in which the adjuncttyokusetu semanti-cally modifies the embedded VN, from which it hasbeen transferred (i.e. a reading which entails that thevisit to US was supposed to be performed in a di-rect manner). As Yokota correctly points out, how-ever, such an interpretation is only appropriate forsentences like (3a) and not available for sentenceslike (3b). The only reading available for (3b) isone which the adjunct modifies the LV. This fact iscompletely unexpected under Matsumoto’s (1996)analysis.2 Thus, the correct generalization is thatonly arguments can be transferred in the LVC inJapanese.
An important fact that has hitherto been unnoticedin the literature is that quantifiers behave in the sameway as adjuncts with respect to the possibilities ofscope interpretation in the LVC. As demonstratedby the following data, a quantificational argumentof the VN cannot take scope lower than the LV if ithas been transferred from the VN to the LV:
(4) a. Zeikancustoms
waTOP
gyoosyatrader
niDAT
HuransuFrance
karafrom
noGEN
wainwin
dakeonly
noGEN
yunyuuimport
oACC
mitome-ta.permit-PAST‘The customs permitted the trader to im-port wine alone from France.’ (permit>only)
2Moreover, as I will discuss in detail in the full paper, thealleged cases of adjunct transfer raised by Matsumoto (1996)are dubious in the following two respects: (i) as argued byYokota (1999), it is doubtful whether what Matsumoto claimsto be adjuncts that have been transferred are really adjuncts; (ii)Matsumoto’s argument crucially relies on the assumption thatthe ‘transferred’ adjuncts semantically modify the VN and notthe LV, for which he does not give convincing evidence.
b. Zeikancustoms
waTOP
gyoosyatrader
niDAT
HuransuFrance
karafrom
wainwine
dakeonly
yunyuuimport
oACC
mitome-ta.permit-PAST‘Only as for wine, did the customs permitthe trader to import from France.’ (only>permit)
In (4a), where the quantified NPwain dake ‘onlywine’ syntactically appears as an argument of theembedded VN, the quantifier takes scope lower thanthe LV mitomeru ‘permit’. By contrast, in (4b),where the same quantified NP is transferred from theVN to the LV and syntactically realized as an argu-ment of the latter, it has to take scope over the LV.3
What the data in (3) and (4) show is that the be-haviors of adverbs and quantifiers with respect to theLVC is essentially the same in that their semanticscope is determined simply by their syntactic posi-tions: if they appear as a dependent of the VN, theytake scope higher than the VN and lower than theLV; if they appear as a dependent of the LV, theytake scope over the LV. As we will see in section3, this is in contrast with some complex predicateslike causatives, for which adverbs and quantifierscan sometimes take scope lower than the positionsthey syntactically appear.
2 Previous analyses and their problems
Matsumoto (1996) employs the mechanism of func-tional uncertainty (Kaplan and Zaenen, 1989) inLFG to formulate an analysis of the LVC. In hisanalysis, sentence (2) is assigned the c-structure andf-structure in Figure 1. In the c-structure, the ver-bally case-marked goal PPTookyoo ni ‘to Tokyo’syntactically appears as a sister to the LV. In the f-structure that corresponds to the top S node of thisc-structure, this goal argument fulfills the grammat-ical function OBLgo of the embedded f-structure ofthe VN. The discrepancy between syntactic sister-hood and semantic head-dependent relation is medi-ated by functional uncertainty.
3The readings for (4a) and (4b) are clearly distinct from eachother with different truth conditions; only the former is compat-ible with a situation where the customs permitted the trader toimport other goods than wine from France.
80

S
(↑ SUBJ) =↓NP
karera wa
(↑ XCOMP OBLgo) = ↓PP
Tookyoo ni
(↑ XCOMP) =↓NP
(↑ OBJ) =↓NP
bussi no
↑ = ↓N
yusoo o
↑ = ↓VP
hazime-ta
PRED ‘begin〈XCOMP〉SUBJ’
SUBJ [PRED ‘they’]
XCOMP
PRED ‘transport〈SUBJ,OBJ,OBLgo〉’
SUBJ
OBJ [PRED ‘goods’]
OBLgo
PRED ‘to〈OBJ〉’
CASE GOAL
OBJ [PRED ‘Tokyo’ ]
Figure 1: Matsumoto’s (1996) analysis of LVC
While this is a simple and elegant analysis, anobvious problem is that it wrongly admits adjuncttransfer, since functional uncertainty does not dis-tinguish arguments from adjuncts. Given the ob-servation that adjunct transfer is really impossi-ble, Yokota (1999) proposes an alternative to Mat-sumoto’s analysis in which an explicit stipulation onthe function uncertainty schema rules out the pos-sibility of adjunct transfer. Although this modifica-tion serves the desired purpose as far as the adjunctdata in (3) are concerned, it is implausible in the firstplace in that it avoids overgeneration by a mere stip-ulation. More seriously, it is not clear how such ananalysis could be extended to account for the fact ofquantifier scope. Given the parallelism between ad-junct scope and quantifier scope data, what is calledfor is a mechanism that accounts for these two phe-nomena in a uniform manner. However, it is un-likely that such an analysis could be developed byextending the proposals of Matsumoto (1996) andYokota (1999).4
3 A uniform analysis of the scopeinterpretation of the light verbconstruction
Cipollone (2001) recently proposed an analysisof the semantics of the causative construction inJapanese in terms of structured semantic represen-tation, which can potentially account for adverb andquantifier scope phenomena in a uniform manner. I
4This point may not be immediately clear given that Mat-sumoto’s (1996) and Yokota’s (1999) analyses are not equippedwith a mechanism of quantifier scope to begin with. As will bedemonstrated in the full paper, however, analyses along the linesof their proposals cannot capture the parallelism between ad-junct scope and quantifier scope phenomena straightforwardly,even extended with a suitable mechanism of quantifier scope.
will show in this section that, by extending the pro-posal of Cipollone, a straightforward analysis of thesemantics of the LVC can be constructed, where theparallelism between adjunct and quantifier scope inthe LVC is systematically predicted.
The syntax-semantics mismatch in the causativeconstruction in Japanese is well-known at least asearly as Shibatani (1976). In the causative con-struction in Japanese, the sequence of the verb rootand the causative suffix behaves as one word, con-stituting an inseparable syntactic unit. An adverbor quantifier that combines with this complex verb,however, can either take scope over the whole com-plex predicate or ‘inside’ the complex predicate,higher than the verb root but lower than the causativepredicate. The basic idea of Cipollone (2001) in ac-counting for this scope ambiguity phenomenon is toallow for slight noncompositionality in the domainof semantics. By doing so, it becomes possible forquantifiers and adverbs to ‘look inside’ the semanticrepresentation of the phrase they syntactically com-bine with to pick up the portion they semanticallyscope over.
Figure 2 illustrates Cipollone’s (2001) analysisfor one of the readings for the sentenceGakkoo dehasir-ase-ta ‘(I) made (him) run at school’, in whichthe modifiergakkoo-de ‘at school’, which syntacti-cally combines with the whole causative verbhasir-ase ‘cause to run’, semantically modifies only theverb root (i.e. a reading in which what took place atschool is the running event). Notice first of all thatthe CONT feature is list-valued, unlike the standardnotation in HPSG (Pollard and Sag, 1994). This list-valued semantic representation can be thought of asa chain of lambda-abstraction, where the value ofthe LAMBDA feature is a variable index bound by
81

VP
CONT 4
⟨
6
LAMBDA 3
PSOA|NUC
cause-relCAUSER 1
CAUSEE 2
EFFECT 3
,
LAMBDA 8 none
PSOA|NUC
location-relLOCATION school
EVENT 7
[
NUC
[
run-relRUNNER 2
]
]
⟩
PP
[
MOD 5
CONT 4
]
gakkoo de
5 VP
CONT
⟨
6 ,
[
LAMBDA 8
PSOA 7
]
⟩
hasir-ase-ta
Figure 2: Cipollone’s (2001) analysis of narrow scope reading for an adverb in causative
the lambda operator. The semantic interpretation ofa phrase is obtained by applying lambda-conversionsuccessively to this list-valued CONT value, whereeach element of the list is given as an argument to anelement immediately to its left. The structure in Fig-ure 2 is licensed by the head-adjunct schema. Thus,the CONT value of the upper VP comes from theCONT value of the adjunct daughter. The adverb,in turn, is specified in the lexicon in such a waythat its semantic contribution can be integrated withwhichever portion of the list-valued CONT value ofthe head daughter it combines with; this is formallyrealized by the constraint in Figure 3. In Figure
MOD
CONT 1 ⊕
⟨
[
LAMBDA 2
PSOA 3
]
⟩
⊕ 4
CONT 1 ⊕
⟨
[
LAMBDA 2
PSOAmodify( 3 )
]
⟩
⊕ 4
Figure 3: Cipollone’s (2001) adjunct schema
2, this constraint is satisfied in such a way that thesemantic contribution of the adverb is integrated tothe second element of the CONT value of the headdaughter, which corresponds to the semantics of theverb root. Thus, the narrow scope reading results.If the semantic contribution of the adverb is insteadintegrated to the first element of the CONT valueof the head daughter, the wide scope reading is ob-tained, which entails that what took place at schoolis the causing event.
The system proposed by Cipollone (2001) opensup a way to account for the parallelism of adjunct
and quantifier scope phenomena in a uniform man-ner, since it becomes possible to make the form ofthe semantic representation of the complex predicateresponsible for the availability of scope ambiguity.More specifically, under this scenario, the causativeconstruction exhibits scope ambiguity for adverbsand quantifiers alike since it has a partially transpar-ent semantic representation like the one in Figure 2.By contrast, the LVC does not exhibit scope ambigu-ity either for adverbs or quantifiers since the internalsemantic structure is made invisible to phrases at-taching from outside.5
The opacity of the semantic representation for theLVC can be guaranteed by lexical specifications onthe LV. I propose the lexical entry for the LVmito-meru ‘permit’ in Figure 4.6,7
What is crucial here is that the value of the CONTfeature is specified as a singleton list. In otherwords, in the LVC, lambda-conversion of the com-plex semantic representation, in which the meaningof the VN (tagged as3 in Figure 4) is embedded un-der the meaning of the LV, is forced by the lexical
5The possibility of accounting for the variability of allow-able scope interpretations for different verbs by positingβ-reduced and non-β-reduced semantic representations is alreadynoted in Cipollone (2001). However, his actual formulation(particularly of the quantifier scope mechanism) would fail tocapture the correlation of adverb scope and quantifier scopewith respect to different types of complex predicates observedabove.
6Following Ryu (1993), I model argument transfer in theLVC in terms of the mechanism of argument composition inHPSG (Hinrichs and Nakazawa, 1994), by which unsaturatedarguments of an embedded predicate are inherited to the higherpredicate by means of structure sharing in the COMPS list.
7β-reduce is a function that produces apsoa object from achain of lambda-abstractedpsoa objects by lambda-conversion.
82

CAT
HEAD verb
VAL
SUBJ 〈NPi〉
COMPS 〈NPj 〉 ⊕ 2 ⊕
⟨
N
CAT
HEAD |CASEacc
VAL
[
SUBJ〈NPj 〉
COMPS 2
]
CONT 3
⟩
CONT
⟨
LAMBDA none
PSOA|NCL
permit-rel
AGT i
PT j
TH β-reduce( 3 )
⟩
Figure 4: Lexical entry fortyokusetu ‘directly’
V
CONT 5
⟨
LAMBDA none
PSOA|NCL
[
direct-rel
ARG 1
]
⟩
Adv
[
HEAD |MOD 2
CONT 5
]
tyokusetu 2 V
CONT 4
⟨
LAMBDA none
PSOA 1
NCL
permit-rel
AGT i
PT j
TH β-reduce( 3 )
⟩
N
CONT 3
⟨
LAMBDA none
PSOA|NCL
[
visit-us-rel
AGT i
]
⟩
hoobei o
V[
CONT 4
]
mitome-ta
Figure 5: Tree for (3b)
specification of the LV. As a consequence, the inter-nal structure of the complex predicate is no longervisible from outside. Under the present analysis, thestructure in Figure 5 is assigned to (3b). It is cor-rectly predicted that the only reading available forthis sentence is one in which the adverb semanticallymodifies the LV. Although the adverb is specified bythe constraint in Figure 3 in such a way that it canincorporate its semantic contribution to whicheverportion of the list-valued semantic representation ofthe head daughter it combines with, only one optionis available here since the CONT value of the headdaughter is made into a singleton list by virtue of thelexical specification of the LV in Figure 4.
Cipollone (2001) accounts for quantifier scopeambiguity of causatives by means of the word-internal quantification mechanism originally pro-posed by Manning et al. (1999), which is indepen-dent of the novel semantic representation he advo-cates. However, it is trivially easy to revise his anal-ysis in such a way that it crucially makes use of thepartially structured semantic representation in deter-mining quantifier scope. By revising his analysis inthis way, it becomes possible to capture the paral-lelism of adverb scope and quantifier scope with re-spect to different types of complex predicates in astraightforward manner.
In our revised system, quantifier scope is deter-
83

V
CONT
⟨
4
LAMBDA 2
PSOA
QUA 〈 〉
NCL
cause-relCAUSERi
CAUSEEj
CAUSED 2
,
LAMBDA none
PSOA
QUA 〈3-books〉
NCL
read-relREADERj
READ k
⟩
NP[
QS{
3-books} ]
san-satu no hon o V
CONT
⟨
4 ,
LAMBDA none
PSOA
QUA 〈 〉
NCL
read-relREADERj
READ k
⟩
yom-ase-ta
Figure 7: Narrow scope reading for a quantifier in causative
mined in much the same way as adverb scope; quan-tifiers are allowed to pick up whichever portion ofthe list-valued semantic representation of the headdaughter to scope over. Following Pollard and Sag(1994), I assume that a quantifier takes scope overthe psoa object to whose QUANTS value it is dis-charged from QSTORE. The Quantifier Scope Prin-ciple in Figure 6 takes care of the determination ofquantifier scope along the lines described above.8
The quantifier inherited via QSTORE is discharged
CONT 1 ⊕
⟨
[
PSOA
[
QUA list( 5 ) ⊕ 2
NCL 3
] ]
⟩
⊕ 4
→ H
CONT 1 ⊕
⟨
[
PSOA
[
QUA 2
NCL 3
] ]
⟩
⊕ 4
,[
QS 5
]
Figure 6: Quantifier Scope Principle
into the QUANTS list of one of the elements of thelist-valued CONT value of the head daughter. Figure7 illustrates an analysis for the narrow scope read-ing for the sentenceSan-satu no hon o yom-ase-ta‘(I) made (him) read three books’.9 In this tree,
8QUA and QS abbreviate QUANTS and QSTORE,respectively.
9The narrow scope reading and the wide scope reading forthis sentence are distinct from each other: in the narrow scopereading, what the causer did was just to bring about a situationin which the number of books read by the causee amounted tothree, where the causer is noncommittal about the choice of spe-cific books; by contrast, in the wide scope reading, the sentenceentails that there were three books for which the causer broughtabout a situation in which the causee read them, in which case
the quantifiersan-satu no hon ‘three books’ is dis-charged into the QUANTS list of the second elementof the CONT value of the head daughter, which cor-responds to the semantics of the verb root. Thus, thenarrow scope reading is obtained. If the quantifier isinstead discharged into the QUANTS list of the firstelement of the CONT value of the head daughter, thewide scope reading results. Thus, quantifier scopeambiguity for causatives is correctly predicted.
What is crucial in the present analysis is that ad-verb scope and quantifier scope are determined withrespect to the same information: the (potentially)partially transparent semantic representation of thehead daughter. Thus, it is straightforwardly pre-dicted that the narrow scope reading for a quanti-fier syntactically appearing as an argument of theLV is unavailable in the LVC because of the se-mantic opacity induced by the LV. Though I omitan analysis here for an LVC sentence involving aquantifier, it should be clear from the discussion sofar that quantifier scope is determined uniquely for(4b) in much the same way as adverb scope is de-termined uniquely as in Figure 5 for (3b). Thus,the fact that quantifier scope ambiguity is unavail-able for the LVC is also correctly predicted underthe present analysis.
4 Conclusion
In the Japanese LVC, adverbs and quantifiers thatsyntactically appear as dependents of the LV can-
the causer knows for sure which books were read by the causee.
84

not take scope lower than the LV, in sharp contrastto some other complex predicates like causatives,which exhibit the so-called narrow scope readingsfor adverb and quantifiers. This was first noticedfor the case of adverbs by Yokota (1999). However,Yokota’s analysis misses the generalization that thesame phenomenon is observed for quantifier scope.It was shown in this paper that a theory of seman-tic interpretation of complex predicates that system-atically predicts this parallelism can be constructedby extending the analysis of causatives by Cipol-lone (2001). The proposed analysis crucially makesuse of the partially structured semantic representa-tion introduced by Cipollone in accounting for theavailability of adverb and quantifier scope ambigu-ity for different types of complex predicates in a uni-form manner.
References
Domenic Cipollone. 2001. Morphologically com-plex predicates in Japanese and what they tellus about grammar architecture.Ohio State Uni-versity Working Papers in Linguistics, 56:1–52.http://ling.osu.edu/osu wpl/osuwpl56/.
Jane Grimshaw and Armin Mester. 1988. Light verbsandθ-marking.Linguistic Inquiry, 19:205–232.
Erhard W. Hinrichs and Tsuneko Nakazawa. 1994. Lin-earizing AUXs in German verbal complexes. In JohnNerbonne, Klaus Netter, and Carl J. Pollard, editors,German in Head-Driven Phrase Structure Grammar,number 46 in CSLI Lecture Notes, pages 11–38. CSLIPublications, Stanford.
Ronald Kaplan and Annie Zaenen. 1989. Long-distancedependencies, constituent structure, and functional un-certainty. In Mark Baltin and Anthony Kroch, editors,Alternative Conceptions of Phrase Structure, pages17–42. The University of Chicago Press, Chicago.
Yo Matsumoto. 1996. Complex Predicates inJapanese. CSLI Publications/Kurosio Publishers,Stanford/Tokyo.
Carl J. Pollard and Ivan A. Sag. 1994.Head-DrivenPhrase Structure Grammar. Studies in ContemporaryLinguistics. University of Chicago Press, Chicago,London.
Byong-Rae Ryu. 1993. Structure sharing and argumenttransfer: An HPSG approach to verbal noun construc-tions. SfS-Report 04-93, Department of Linguistics,The University of Tubingen, Tubingen, Germany.
Masayoshi Shibatani. 1976. Causativization. InMasayoshi Shibatani, editor,Syntax and Semantics,volume 5, pages 239–294. Academic Press, New Yorkand Tokyo.
Kenji Yokota. 1999. Light verb constructionsin Japanese and functional uncertainty. InMiriam Butt and Tracy Holloway King, edi-tors, Proceedings of the LFG99 Conference,Stanford. CSLI Publications. http://www-csli.stanford.edu/publications/LFG/lfg4.html.
85

86

A New HPSG Approach to Polish Auxiliary Constructions
Anna KupscCNRS, Loria (Langue et Dialogue)and Polish Academy of Sciences
Institute of Computer Science21, Ordona, 01-237 Warsaw, Poland
Jesse TsengCNRS, Loria (Langue et Dialogue)
Campus Scientifique – BP 23954506 Vandœuvre-lès-Nancy, France
The “l-participle” form of the verb in Polish (forshort: l-form, so called because it ends in l or ł, usu-ally followed by a vowel) agrees with the subjectin number and gender and is principally associatedwith the past tense. In this use, it takes personalendings in the 1st and 2nd persons1 but these end-ings can also “float” to a position left of the verb—compare (1a) and (1b).
(1) a. Tyyou
widziałessee � -2sg
tenthis
film.film
‘You saw this film.’
b. Tysyou-2sg
widziałsee �
tenthis
film.film
The l-form is also used in conditional construc-tions, in combination with the element by. In thiscase, it is by that takes the personal endings, and theinflected forms of by either appear immediately afterthe l-form (2a), or they float to its left (2b).
(2) a. Tyyou
widziałbyssee � .cond-2sg
tenthis
film.film
‘You would see this film.’
b. Tyyou
byscond-2sg
widziałsee �
tenthis
film.film
And finally, the l-form can be used to form the fu-ture tense, in combination with future forms of theauxiliary byc ‘be’. In this use, the l-form agreeswith the subject in gender and number, as usual,but we do not find the 1st and 2nd person endingsthat characterize the past tense and the conditional.
1The full inventory of forms is: 1sg -m, 2sg - s, 1pl - smy, and2pl - scie.
The relative order of the future auxiliary and the l-form verb is also much freer than in the other twoconstructions—see (3).
(3) a. Tyyou
bedzieszfut-2sg
widziałsee �
tenthis
film.film
‘You will see this film.’
b. Tyyou
widziałsee �
bedzieszfut-2sg
tenthis
film.film
c. Tyyou
widziałsee �
tenthis
filmfilm
bedziesz.fut-2sg
Some previous accounts of Polish verbal con-structions, e.g., Borsley and Rivero (1994), Bors-ley (1999), Kupsc (2000), have attempted to providea unified analysis of all three uses of l-form verbs,although in fact their properties are quite divergent.We will focus on the past tense and the conditionalconstructions, motivating distinct analyses that ac-count for their particularities more adequately.
1 Empirical Observations
There are a number of crucial differences betweenthe conditional particle by and the past tense mark-ings that suggest strongly that they do not have thesame grammatical status.
First, the forms of conditional by can be foundafter words ending in any segment (i.e., any of thevowels and consonants that appear word-finally inPolish); this is the same behavior we observe forweak (clitic) pronouns. On the other hand, the pasttense markings are more particular about the phono-logical properties of their host, and the differentforms have specific constraints (subject to wide vari-ation), as discussed in Banski (2000):
87

� the 1sg marking (-m) can only be attached toa word ending in a non-nasal vowel (i.e., note or a);
� the 2sg marking (-s) can additionally (butsomewhat marginally) follow a nasal vowel orthe glide j;
� the 1-2pl forms (-smy and -scie) can addition-ally (but quite marginally) follow l, r, ł in a sim-ple coda (e.g., wór ‘sack’ but not wiatr ‘wind’).
Second, the presence of conditional by has nomorphophonological effect on the preceding mate-rial (again, as in the case of pronominal clitics, e.g.,Dłuska (1974), Rappaport (1988)). Past tense mark-ings, on the other hand, do induce changes whenthey follow an l-form verb. With a masculine singu-lar subject, the l-form ends in ł, and so an epentheticvowel e must be inserted before the markings -m(4a) and -s (1a). This creates an additional sylla-ble, which results in stress shift, and, with certainverbs, leads to a vowel shift ó to o (4a).2 In the plu-ral, the addition of the markings -smy, and -scie can,for some speakers or in fast speech, shift the stressone syllable to the right (4b).
(4) a. POmógłhelp.3sg
� poMOgłemhelp.1sg
b. poMOglihelp.3pl
� ?pomogLIsmyhelp.2pl
These observations suggest that the past tenseendings are much more closely bound to the preced-ing word than the conditional particle. In fact, theirbehavior is more typical of morphological suffixesthan of independent syntactic items.
Another interesting difference, discussed inBanski (2000), is the interaction of the conditionaland past tense markings with coordination. The con-ditional particle can take wide scope over a coordi-nation of VPs in both preverbal (5a) and postver-bal (5b) position. With singular past tense mark-ings, wide scope is possible only in preverbal posi-tion (6a) (Banski (2000) overlooks this possibility).The personal ending has to be repeated on all con-juncts if it is realized to the right of the l-verb (6b).(For some speakers this requirement is relaxed in theplural).
2Capital letters mark lexical stress.
(5) a. Czestooften
bymcond-1sg
[czytałread
iand
pisał].write
‘I would often read and write.’
b. Czestooften
[czytałbymread.cond-1sg
iand
pisał(bym)].write(.cond-1sg)
(6) a. Czestomoften.1sg
[czytałread
iand
pisał].write
‘I was often reading and writing.’
b. Czestooften
[czytałemread.1sg
iand
pisał*(em)].write*(.1sg)
According to the criteria of Miller (1992), the oblig-atory repetition of past tense markings in coordina-tion as in (6b) speaks in favor of their affix statusin postverbal positions, whereas optional repetitionof the conditional particle in (5b) excludes an affixanalysis. On the other hand, the wide scope overcoordination in preverbal positions, (5a) and (6a),cannot distinguish between affix and syntactic cliticstatus.
Finally, there is an important difference in theparadigms of the past tense and conditional mark-ings as there is no 3rd person past tense marking(singular or plural). Compare (7a) and (7b):
(7) a. TomekTom
czytałread
ksiazke.book
‘Tom read a book.’
b. TomekTom
bycond.3sg
czytałread
ksiazke.book
‘Tom would read a book.’
This contrast makes it difficult to maintain a paralleltreatment of conditional and past tense particles asauxiliaries, because 3rd person past tense construc-tions would be left strangely ‘auxiliary-less’.
The data presented above highlight distinct prop-erties of conditional and past tense constructionsand indicate that, despite certain similarities, thetwo constructions should be analyzed independently.The rest of the paper presents a proposal along theselines.
88

���������������
word
SS
������������clitic
HEAD
�� verbVFORM condNEG � ��
ARG-ST � � , VP
��� HEAD � VFORM l-form
SUBJ � COMPS � �
������� ������������ ��������������
Figure 1: Lexical entry of the conditional clitic
2 Proposed Analysis
2.1 Conditional Auxiliary by
We follow Borsley (1999) and Kupsc (2000) intreating all forms of by appearing to the left ofthe l-form verb as clitic auxiliaries. They satisfythe lexical description in Fig. 1. As observed inKupsc (2000), there is no direct evidence for theflat structure of conditional auxiliary constructionspostulated in Borsley (1999) and we assume VP-complementation here. The resulting entry is that ofan ordinary raising verb; the various inflected formsof by can make reference to the INDEX of the raisedSUBJ element.
The placement of by in the sentence field3 tothe left of the l-form verb is determined primarilyby prosodic structure (see for example Mikos andMoravcsik (1986) and Banski (2000)). We believethat a DOMAIN-based analysis (cf. Reape (1992))is the best way to handle the linearization possi-bilities, although we do not offer a full accounthere. We simply introduce a shorthand booleanfeature CL(ITIC)-HOST to identify words that sat-isfy (marked [ � CL-HOST]) or do not satisfy ([ � CL-HOST]) the prosodic and other conditions for hostinga clitic immediately to the right. Non-prosodic con-ditions on CL-HOST are most apparent in the post-verbal sentence field. All verbs can be [ � CL-HOST],so clitics (including conditional by and pronominalclitics4) can appear immediately to their right. Butall (non-clitic) words to the right of the rightmost
3We use the term “field” in a purely descriptive way, withoutsuggesting that any version of the topological fields approach,as used for the analysis of German word order, would be appli-cable to Polish.
4As argued in Kupsc (2000), Polish pronominal clitics aresyntactic items.
verb in a clause must be [ � CL-HOST] because cli-tics cannot appear in this field. This is a constraintdetermined simply by linear order, and one that can-not be overridden by prosodic or syntactic consider-ations. To account for clitic clusters (including thoseimmediately to the right of the l-form verb), we as-sume that clitics can be [ � CL-HOST] and license cl-itics to their right. As noted in Witkos (1997), therelative order of pronominal and conditional cliticsis very constrained as pronominal clitics tend to fol-low rather than precede the conditional auxiliary, (8)vs. (9). The same constraint will account for theungrammaticality of (10) and ensure the correctnessof (11).
(8) Tyyou
byscond-2sg
gohim.cl
widział.see
(9) ?*Tyyou
gohim.cl
byscond-2sg
widział.see
(10) *Tyyou
widziałsee
gohim.cl
bys.cond-2sg
(11) Tyyou
widziałbyssee.cond-2sg
go.him.cl
‘You would have seen him.’
We do not, therefore, adopt the morphologicalcompound approach of Borsley (1999) for the com-bination of an l-form verb followed by by. In our ac-count, by is always a clitic, whether it appears some-where to the left of the l-form or immediately to itsright. There is no evidence (stress shift or vowelquality alternations, for example) to motivate twodistinct types of combination.
2.2 Past Tense Agreement Markings
Our analysis of the “floating” past tense elements-m, -s, -smy, and -scie is motivated by the obser-vation that these elements do not function as aux-iliary verbs in modern Polish. In fact, as discussedin section 1, the past tense personal markings areno longer independent syntactic items at all, but suf-fixes. We take the l-form to be the head of a simplepast tense construction, requiring the presence of anagreement marking in the 1st and 2nd persons.
Unlike ordinary suffixes, the past tense agreementmarkings can attach to a variety of hosts, and they donot always appear on the lexical head of a phrase, orin any particular linear position in the phrase (e.g., at
89

the left or right edge). A special affixation and prop-agation mechanism is needed to handle this kind ofbehavior. The realization of the agreement mark-ing is subject to a surface order constraint: it mustappear exactly once, somewhere to the left of thel-form verb (or on the verb itself). And unlike inordinary cases of agreement, there are no syntac-tic restrictions on the constituent that receives themarking: it can be a complement, an adjunct, ora filler, an NP or a PP, or even a complementizer(see, e.g., Borsley and Rivero (1994) for some ex-amples). A special mechanism is also required tohandle this aspect of the phenomenon.
Agreement markers appearing to the left of the l-form are introduced by the inflectional rule in (12).
(12)
��������wordPHON �SS
���� synsemLOC � CAT � HEAD � verbCL-HOST
�AGR-MARK � �
��������������
�� �PHON Fagr-nonvb � � � � �SS � AGR-MARK � index
The input cannot be a verb, but there are no othercategorial restrictions on the host. The output ofthe rule is the same word with the appropriate suffix(identified by its index), with a phonological formdetermined by the function Fagr-nonvb. For incompat-ible combinations (e.g., a word ending in a nasalvowel cannot take the 1st person singular suffix,a word ending in a consonant cannot take any suffix,there are no 3rd person suffixes) no output form canbe constructed and the rule fails. When suffixationis possible, the corresponding index element appearson the suffixed word’s AGR(EEMENT)-MARK(ING)list. The empty AGR-MARK list in the input preventsiteration of the rule. We assume that the AGR-MARK
value is introduced lexically, i.e., it is specified ineach lexical entry. The only words in Polish witha non-empty AGR-MARK list are those that have un-dergone rule (12) and, as we will discuss below insec. 2.3, the 1st and 2nd person forms of the condi-tional and future auxiliaries.
The suffixed word that introduces the AGR-MARK
element participates normally in syntactic combina-tions, with all possible grammatical functions (head,complement, modifier, etc.). The presence of the
agreement affix has no influence on the syntacticproperties of the host. The affix does influence thelinearization potential of its host: the output of (12)remains [ � CL-HOST], so the suffixed word must endup in a surface position that is compatible with thisfeature. But its exact location within a phrase cannotbe specified: it can be the first word, the last word, orsomewhere in the middle. But in all cases, informa-tion about the affix must be projected. This meansthat the value of AGR-MARK is amalgamated fromall daughters in every phrasal combination. The for-malization of this constraint is given in Fig. 2, butfirst we need to explain the role of the verb in pasttense constructions.
The agreement marker is required by the l-form verb. We encode this using the featureAGR(EEMENT)-TRIG(GER), which takes a list of in-dex objects as its value. For past tense verbs, AGR-TRIG is specified lexically: for l-verbs with 1st or2nd person subject, AGR-TRIG contains the appro-priate index (structure-shared with the INDEX valueof the subject), whereas l-verbs with 3rd person sub-jects have an empty AGR-TRIG list. All other wordshave an empty AGR-TRIG list:
(13)
�word
SS � L � C � H ��� VFORM l-form � � SS � AGR-TRIG � � An element on AGR-TRIG can be discharged by ap-plying a suffixation rule to the verb itself:
(14)
�������wordPHON �SS
��� L � C � H � VFORM l-formCL-HOST
�AGR-TRIG �
� �� � ���������� PHON Fagr-vb � � � � �
SS � AGR-TRIG � � �This rule must be distinct from (12) above, becausethe morphophonological aspects of agreement suf-fixation (encoded in the function Fagr-vb) are differ-ent for verbal hosts. For example, Fagr-vb handles e-epenthesis and the ó to o alternation in masculinepast tense forms—recall (1a) and (4a). Moreover,the grammatical effect of the rule is to empty theverb’s AGR-TRIG list.
In other cases, AGR-TRIG must be discharged ata distance, by interaction with an AGR-MARK ele-ment introduced earlier in the clause. The overall
90

������phrase
HD-DTR � SS� AGR-MARK �AGR-TRIG � �
NON-HD-DTRS
� � SS � AGR-MARK � , . . . , � SS � AGR-MARK � ��� �����
� � � � � � . . . � �� �� SS
�� AGR-MARK� �� � �� index �
AGR-TRIG � �� ��� ��
��� SS � AGR-MARK � �
AGR-TRIG � � �HD-DTR � SS � AGR-TRIG
�����
Figure 2: Amalgamation of AGR-MARK from dependents
constraint on phrasal combinations is given in Fig. 2.All the daughters’ AGR-MARK elements are amal-gamated (to yield the list � ). If this list does notcorrespond to the head daughter’s AGR-TRIG value,then the first disjunct on the right-hand side is sat-isfied: the mother’s AGR-MARK value is the (maxi-mally singleton) amalgamated list � , and the valueof AGR-TRIG is taken from the head daughter. But ifthe amalgamation � of the daughters’ AGR-MARK
lists does unify with the head’s AGR-TRIG list, thenthey “cancel each other out” and both lists are emptyin the phrasal description (second disjunct).5
The agreement marking cannot appear to the rightof the verb that selects it. To block such structures,we formulate the following linear precedence rule:
(15) � SS � AGR-MARK� � � ��� HD-DTR� SS � AGR-TRIG
� � � �At the clausal level, there can be no unlicensedagreement markers (AGR-MARK elements) and nounsatisfied agreement requirements (AGR-TRIG ele-ments):
(16) clause �
�� SS
�AGR-MARK ���AGR-TRIG ���
��2.3 Conditional (revisited) and Future
In addition to the lexical description given in Fig. 1,we assume that the 1st and 2nd person forms of the
5The second disjunct covers the interesting case where thehead’s non-empty AGR-TRIG requirement is discharged by pres-ence of the corresponding AGR-MARK element on anotherdaughter, and the less interesting (but much more frequent) casewhere the daughters’ AGR-MARK lists and the head’s AGR-TRIGlist are all simply empty, and both values remain empty on themother.
conditional clitic by (bym, bys, bysmy, byscie) havea non-empty AGR-MARK list, containing the indexof their subject. The 3rd person form by has anempty AGR-MARK list. This means that the samel-form verb appears in past tense and in conditionalconstructions; we do not need to assume distinct “fi-nite” and “participial” variants. This analysis ac-counts for the fact that the conditional auxiliary mustcombine with a “bare” (unsuffixed) l-form (17a),and the fact that no other word can carry the agree-ment marking (17b, 17c). Also, note that the LPrule (15) does not prevent the conditional auxiliary(with non-empty AGR-MARK) from appearing to theright of the l-form (with corresponding AGR-TRIG),because in this case the l-projection is not the head(17d).
(17) a. *Ty bys widziałes ten film. (undischargedAGR-MARK)
b. *Tys bys widział ten film. (undischargedAGR-MARK)
c. *Tys by widział ten film. (by selects a 3rdperson subject)
d. Ty widziałbys ten film.
Recall that the conditional auxiliary cannot appearany further to the right because it is a clitic, and allwords in this part of the clause are [ � CL-HOST].
The same analysis applies to the forms of the fu-ture tense auxiliary—recall examples in (3).6 This
6Forms of the future tense auxiliary:
SG PL
1st bede bedziemy2nd bedziesz bedziecie3rd bedzie beda
91

auxiliary, however, is quite different from the condi-tional in other ways: it is an independent word (nota clitic), and it may require a flat structure as pro-posed for French auxiliary constructions in Abeilléand Godard (2002) (to allow “clitic climbing”, cf.discussion in Kupsc (2000)).
3 Conclusion
We have presented two separate analyses of Polishpast tense and conditional constructions based ontheir distinct morphophonological, inflectional andsyntactic properties. As in Borsley (1999), we treatthe conditional particle as an auxiliary clitic verb butwe do not adopt his morphological compound analy-sis and explain all positions of the weak auxiliary bylinear order. On the other hand, in our analysis thepast tense marking is neither a syntactic item nor anauxiliary. We treat it as an agreement suffix which isrequired by the l-verb but can be realized in differentplaces in the sentence.
The past tense in Polish is an interesting case ofgrammaticalization where competing analyses areavailable. We have presented an alternative to ear-lier approaches but a fully adequate analysis wouldneed to be able to model the transition between dif-ferent grammatical structures which is currently tak-ing place in the grammar of Polish past tense forms.
References
Abeillé, A. and Godard, D. (2002). The syntac-tic structure of French auxiliaries. Language, 78,404–452.
Banski, P. (2000). Morphological and ProsodicAnalysis of Auxiliary Clitics in Polish and En-glish. Ph.D. thesis, Uniwersytet Warszawski,Warsaw.
Borsley, R. D. (1999). Weak auxiliaries, complexverbs and inflected complementizers. In R. D.Borsley and A. Przepiórkowski, editors, Slavic inHead-Driven Phrase Structure Grammar, pages29–59. CSLI Publications, Stanford, CA.
Borsley, R. D. and Rivero, M. L. (1994). Clitic aux-iliaries and incorporation in Polish. Natural Lan-guage and Linguistic Theory, 12, 373–422.
Dłuska, M. (1974). Prozodia Jezyka Polskiego.Panstwowe Wydawnictwo Naukowe, Warsaw.
Kupsc, A. (2000). An HPSG Grammar of PolishClitics. Ph. D. dissertation, Polish Academy ofSciences and Université Paris 7.
Mikos, M. and Moravcsik, E. (1986). Moving Cli-tics in Polish and Some Cross Linguistic General-izations. Studia Slavica, pages 327–336.
Miller, P. H. (1992). Clitics and Constituents inPhrase Structure Grammar. Garland, New York.
Rappaport, G. C. (1988). On the relationship be-tween prosodic and syntactic properties of pro-nouns in the Slavic languages. In A. M. Schenker,editor, American Contribution to the Tenth In-ternational Congress of Slavists, pages 301–327.Slavica Publishers, Columbus, Ohio.
Reape, M. (1992). A Formal Theory of Word Order:A Case Study in West Germanic. Ph. D. disserta-tion, University of Edinburgh.
Witkos, J. (1997). Polish inflectional auxiliaries re-visited. Paper presented at the 30th Poznan Lin-guistic Meeting, Adam Mickiewicz University,Poznan, Poland, May 1–3, 1997.
92

A Trace Analysis of Korean UDCs
Sun-Hee LeeDepartment of Computer Engineering and Science
Ohio State UniversityColumbus, OH 43210, USA
1 Introduction
In Korean, there are various grammatical constructionsthat involve a long-distance dependency between a gapand some constituent that is coreferential with that gap.The dependency is in principle unbounded and can becaptured by a feature percolation mechanism withinHPSG. However, c ertain properties of gaps in Koreanunbounded dependency constructions (hereafter UDCs)raise questions as to whether a syntactic approach to thislong-distance dependency is appropriate. In fact, someprevious researchers, including (Kang, 1986) and Yoon[1993] have argued that this dependency needs to be han-dled at the level of semantics, not syntax. In such a se-mantic approach, UDC gaps are treated as null resump-tive pronouns ( so-called pros in GB terms), and syntacticbinding between a gap and its antecedent is not required.However, UDC gaps and pros in Korean show differentproperties with respect to Strong Crossover and Coordi-nation facts. Furthermore, we examine putative resump-tive pronouns (RPs), and the resumptive reflexive (RR)caki that appear in the same positions of UDC gaps, andargue that these resumptive elements are audible traces.This argument is compatible with resumptive pronounanalyses of (Georgopoulos, 1991) in Palauan and (Vail-lette, 2001) in Hebrew. In this paper, we claim that thefiller-gap linkage in Korean UDCs needs to be handled atthe level of syntax and that unbounded dependencies inKorean can be captured by a feature percolation mecha-nism within HPSG. We also investigate some controver-sial issues of island constraints and strong crossover withrespect to filler-gap linkage in Korean UDCs.
This paper shows that unbounded dependencies rep-resented by traces, RPs, and the RR caki can be sim-ply captured - without posing any extra mechanisms - inthe traditional HPSG analysis of UDCs following (Pol-lard and Sag, 1994). It is because in HPSG tracesare not all required to have the same feature, unlikein other movement-basedapproaches including the min-
imalist program and GB theory. In addition, we concludethat the three kinds of Korean UDC elements appearing ingap positions do not form separate categories from theircorresponding forms appearing in non-UDCs based onthe same semantic and pragmatic properties such as lo-gophoricity and contrastiveness.
2 A Null Pronominal Analysis and ItsProblems
Korean has been standardly considered to be a pro-droplanguage. This is a language where a contextually iden-tifiable element or some element introduced in the pre-ceding context can be dropped. (Huang, 1984) arguesthat “cool” languages, including Chinese and Korean, aredifferent from “hot” languages, like English, in that coollanguages license a zero topic that binds a null element.While Huang argues that the phonologically null elementpro appears only in the subject position in cool languages,it has been argued that there is no subject-object asymme-try in Korean((Cole, 1987)). Since Korean is classifiedas a pro-drop language, it is possible to argue that gapsin UDCs are null resumptive pronouns or pros, and thatcorrespondingly, the long-distance dependencies are notsyntactic relations but rather semantic binding relations.The following examples show that a gap can be replacedby an overt pronoun or the long-distance reflexive caki,which appears to support the semantic binding analysis.
(1) a. kuthat
namcai-nunman-TOP
[ sacang-ipresident-NOM
eps-umyeon,absent-if
ei motunevery
il-ulwork-ACC
ttemath-ayatook care
haysstahad to
].
‘As for that mani, if the president were absent, (hei)had to take care of everything.’
93

b. kuthat
namcai-nunman-TOP
[ sacang-ipresident-NOM
eps-umyeon,absent-if
kui/cakii-kahe/self
motunall
il-ulwork-ACC
ttmath-ayatook care
haysstadid
].
‘As for that mani, if the president were absent, hei
had to take care of everything.’
As for English Cinque [1990] and (Postal, 1994) pro-pose transformational analyses with null pronominals forEnglish tough gaps and parasitic gaps. In Korean, (Chae,1998) and (Kang, 1986) assumed that tough construc-tions, topicalization, and relativization in Korean licensepros, which are phonologically null elements in the gapposition. However, in this study we treat those pronounsand the long-distance (LD) caki as audible traces and ar-gue that the filler-gap linkages in Korean UDCs need tobe captured by a syntactic mechanism of binding and notjust by semantic coreference. Three different kinds oftraces show the same phenomenon with respect to StrongCrossover and Coordination. This suggests that they be-long to the same category of trace.
3 Properties of Korean UDC GapsA UDC gap needs to have a coreferential element withinthe given sentence. While the syntactic and semanticconnectivity between a gap and its antecedent in KoreanUDCs is similar to the corresponding English sentences,Korean UDC gaps are known to be less sensitive toisland constraints. The following properties have beenpointed out by general properties of Korean UDC gaps.
[1] Syntactic ConnectivityThere are two natural classies of Korean UDCs: strongUDCs and weak UDCs. In the case of strong UDCs, thefiller is accompanied by the morphosyntactic case markerthat originated from the gapped position, thus the fillershows a strong syntactic association with its gap. StrongUDCs in Korean include the following topic sentence.
(2) a. Mary-kaMary-NOM
John-eykeyJohn-to
senmwul-ulpresent-ACC
cwuessta.gave‘Mary gave a present to John.’
b. Johni-eykey-nunJohn-to-TOP
[ Mary-kaMary-NOM
ei senmwul-ulpresent-ACC
cwuessta].gave‘As for Johni, Mary gave a present (to himi)
The case markers of the topic element in (2) show thatit is syntactically connected to the gap; the dative case
eykey (to) is required by the verb cwuta (give).
[2] Sentence-Internal BindingA UDC gap must have a coreferential element withinthe same sentence. This property distinguishes UDCgaps from pros, which are licensed by various syntactic,semantic, and pragmatic factors. For example, discoursefactors allow a repeated or already-known element tobe dropped from a sentence in languages like Korean.When this happens, the missing element can be retrievedfrom the context. However, a UDC gap requires itscoreferential element to be present in the given sentence;it cannot be licensed only by context.
[3] Island ConstraintsWith respect to Korean UDCs, it has been argued thatsome examples of topicalization and relativization aresubject to three island constraints: the Complex NP con-straint (CNPC), the Sentential Subject constraint, and theAdjunct constraint. This evidence has been used to sup-port the claim that topicalization and relativization in-volve NP movement out of gap positions in Korean. Incontrast, it has been also pointed out that topic and rel-ative clauses in Korean frequently do violate island con-straints ((Kang, 1986)). Inconsistency of data with re-spect to island constraints suggests that unlike most pre-vious analyses in GB theory, island constraints cannot beused as a crucial test for determining whether a particularconstruction is a UDC or not.
However, some crosslinguistic studies have pointed outthat sensitivity to island constraints cannot be used as evi-dence for the existence of a filler-gap linkage. When deal-ing with English adjunct extractions, (Hukari and Levine,1995) argued that island effects are substantially irrel-evant to the issue of whether or not adjunct extractionrepresents a genuine syntactic filler-gap construction. In-stead, they argued that adjunct extraction belongs to thesame category of UDCs as argument extraction. Theybased their conclusion on parallel patterns of crossovereffects and on cross-linguistic evidence of syntactic bind-ing domain effects. (Szabolcsi and den Dikken, 1999)also argued that some island constraint effects are rele-vant to the semantic scope that an expression takes overcertain operators.
Considering that island constraint violations are drivenby semantic and pragmatic factors but not by a syntac-tic operation like movement, inconsistency of island con-straints in Korean UDCs cannot be supporting evidencefor semantic binding approaches to Korean. In additionto syntactic connectivity, semantic binding relations be-tween a UDC gap and a constituent are tighter than otherbinding relations between a pronoun and its antecedent.In the next section, we will examine strong crossover andcoordination facts that distinguish the filler-gap linkage
94

of Korean UDC gaps from semantic binding. Then, laterin this paper we will provide a syntactic representationof unbounded dependencies with a simple syntactic tool,which avoids all the problems of island constraint viola-tions that the movement approaches have confronted.
4 Characterizing Properties of KoreanUDC Gaps
4.1 Strong CrossoverThe Strong Crossover (SCO) Constraint does not applyto pros in general, as we see in (3).
(3) [ Johni-unJohn-TOP
[ ei [ Mary-kaMary-NOM
kui-eykeyhe-to
[ proi
kayahanta-ko]must go-COMP
malhayssta-ko]told-COMP
kiekhanta].remember
‘As for Johni, (hei) remembers that Maryj told himi
that (ei) must go.’
In(3), ei represents a gap directly linked to its antecedentin the position of topic. It contrast with a pro that appearsin the most deeply embedded clause. In general, prosin Korean occur when their coreferential elements (an-tecedents) are introduced in the previous context or whentheir coreferential elements syntactically precede. Theproi takes the preceding pronoun kui as its antecedent andrefers to John in (3). This violates the SCO constraint.In contrast with pros, UDC gaps observe the SCO con-straint, as in the following example.
(4) * kuthat
aii-nunchild-TOP
Mary-kaMary-NOM
kuthat
papoi-eykeyidiot-to
[ei/kui/cakii-lul/he-/selfACC
calwell
tolpokessta-ko]take care-COMP
yaksokhayssta.promised‘As for the childi, Mary promised that idioti to take careof himi well.’
The example (4) shows that SCO is observed for UDCs.Instead of a pronoun an epithet has been used in (4). Itis because the use of pronoun ku may allow a resumptivepronoun analysis of the intervening pronoun, which fol-lows (Vaillette, 2001). In order to examine the applica-bility of crossover to Hebrew RPs, (Vaillette, 2001) re-places the upper pronoun by an epithet. The epithet hasthe same index value as the antecedent, while it retains anindependent lexical meaning. Although (what looks like)pronouns and reflexives can be audible (SLASH-bearing)traces, epithets cannot be. Thus, the same strategy can beapplied to Korean.
A notable point is that resumptive pronominal ele-ments in Korean UDCs observe the SCO constraint as
do inaudible traces. This fact is problematic because pre-vious literature has assumed that SCO violations are trig-gered by the status of UDC gaps; in general UDC gapsare nonpronominal elements or R(eferring)-expressions.However, RPs in Korean UDCs show the same SCO ef-fects as nonpronominal gaps in spite of their pronominalstatus. Within Chomskyan approaches, the SCO effectsare accounted for by Principle C that requires so-called R-expressions to be unbound. Similarly, within the frame-work of HPSG, the SCO phenomenon has been explainedby the binding condition C that specifies that a nonpro-noun must be o-free. However, (Postal, 2004) argues thatthe SCO phenomenon in English cannot be accounted forby Chomsky’s Principle C, and based on his arguemnts itis hard to argue that SCO effects are attributed to the sta-tus of UDC gaps as nonpronominal elements.1 The SCOeffects in Korean UDCs are not associated with PrincipleC (or condition C in HPSG). This argument is supportedby the following examples.
(5) a. kuthe
aii-nunkid-TOP
wuli-kawe-NOM
[ADV P Johnk-ulJohn-ACC
thonghay-se]mediate-by
[S ei iphakentrance
sihem-eyexam-at
hapkyekhayss-um-ul]pass-NML-ACC
alkeyknow
toyessta.became
(lit.)‘As for the kidi, we got to know via John that(hei) passed the entrance exam.’
b. * kuthe
aii-nunkid-TOP
wuli-kawuli-NOM
[ADV P kuthat
papoi-lulidiot-ACC
thonghay-se]mediate-by
[S ei iphakentrance
sihem-eyexam-at
hapkyekhayss-um-ul]pass-NML-ACC
alkeyknow
toyessta.became
(lit.)‘As for the kidi, we got to know via that idiotithat (hei) passed the university exam.’
c. * kuthat
aii-nunchild-TOP
wuli-kawe-NOM
[ADV P kuthat
papoi-lulidiot-ACC
thonghay-se]mediate-by
[S kui-kahe-NOM
iphakentrance
sihem-eyexam-at
hapkyekhayss-um-ul]pass-NML-ACC
alkeyknow
1(Postal, 2004) points out that the SCO effect cannot be re-duced to Chomsky’s Principle C that bars anaphoric linkage be-tween pronoun and the nonpronominal trace based on (i) exis-tence of SCO effects in non-NP extraction, (ii) the secondarystrong effect, (iii) the Asymmetry Property and (iv) failure ofthe c-command condition required for Principle C. He claimsthat even though the Principle C account of the SCO effect isoften considered to be supporting evidence of traces as non-promoninal R-expressions,there is no empirical evidence forany trace-like objects connected with extraction.
95

toyessta.became
(lit.) ‘As for the kidi, we got to know via that idiotithat hei passed the entrance exam.’
In the given examples, the intervening epithets are lo-cated in adjunct phrases that do not c-command (or o-command) the gaps in the embedded phrases. Althoughno violation of Principle C (or condition C) can be in-duced in (5), anaphoric linkage between a filler and a gapis as impossible as in (5b) and (5c). Moreover, whena gap appears in an adverbial phrase of the embeddedclause, the SCO effects appear in spite of the failureof c-command between a pronoun or an epithet and itsanaphoric gap. Specifically, the backward linking of apronoun or an epithet to an antecedent in an adjunct canbe licensed as shown in (6a).2 In contrast, the antecedentin an adjunct cannot be topicalized as in (6b) and (6c).
(6) a. Nay-kaI-NOM
kyay/kuhe/that
papoj-hantheyidiot-to
[[ Johnj-iJohn-NOM
ttena-camaca]leave-soon
Mary-kaMary-NOM
tochakhayssta-ko]arrived-COMP
cenhaysse.told
‘I told himj /that idiotj that Mary arrived right afterhej(John)left.’
b. ?* Johnj-unJohn-TOP
nay-kaI-NOM
kyay/kuhe/that
papoj-hantheyidiot-to
[[
ej ttena-camaca]leave-soon
Mary-kaMary-NOM
tochakhayssta-ko]arrived-COMP
cenhaysse.told
‘As for Johnj , Ii told himj /that idiotj that Mary ar-rived right after hej left.
c. ?* Johnj-unJohnTOP
nayi-kaI-NOM
kyay/kuhe/that
papoj-hantheyidiot-to
[[
kuj-kahe-NOM
ttena-camaca]left-soon
Mary-kaMary-NOM
tochakhayssta-ko]arrived-COMP
cenhaysse.told
‘As for Johnj , Ii told himj /that idiotj that Mary ar-rived right after hej left.’
2In general, backward linking between a pronoun and its an-tecedents is often allowed. Postal points out that ungrammaticalextractions out of islands can be still used to test binding hy-pothesis because of the following principle. This principle canbe used for examples in (6).
(i) Mere extraction from an island, even when yielding severeill-formedness, does not inherently block anaphoric link-age if such are licit in the pre-extraction structure itself.
Based on the fact that a pronoun and its anaphoric ele-ment do not hold a c-command (or o-command) relation,we conclude that SCO effects in Korean UDCs cannot bereduced to Principle C in GB theory or condition C inHPSG. Thus, there is no factual support for the status oftraces as nonpronominal elements, which is why the SCOconstraint is observed by both RPs and inaudible traces inKorean UDCs. This accords with SCO effects in Englishas shown in (Postal, 2004). An RP can be represented inHPSG via the propagation of a non-local feature. In ad-dition to an RP, the long distance reflexive caki ‘self’ canalso appear in the position of the trace.
4.2 Coordination
In general, it has been argued that the Coordinate Struc-ture Constraint (CSC) is observed in Korean coordinatestructures. The constraint disallows asymmetric extrac-tion out of one conjunct. For example, (7b) and (7c) areungrammatical because only one conjunct has a missingelement. However, (7a) is grammatical because the top-icalized element is connected to the missing elements inboth conjuncts.
(7) a. ithis
chaykj-unbook-TOP
[ aitul-ikids-NOM
ej cohaha-kolike-CONJ
eluntul-toadults-also
ej chohahay].like
‘As for this bookj , kids like (itj) and adults also like(itj).’
b. * ithis
chaykj-unbook-TOP
[ aitul-ikids-NOM
ej cohaha-kolike-CONJ
eluntul-iadults-NOM
manhwachayk-ulcomic book-ACC
silehay].like
‘As for this bookj , kids like (itj) and adults dislikescomic books.’
c. * ithis
chaykj-unbook-TOP
[ aitul-ikids-NOM
manhwachayk-ulcomic books-ACC
cohaha-kolike-CONJ
elun-iadults-NOM
ej cohahay].like
‘As for this bookj , kids like comic books and adultsdislike (itj).’
Another fact related to coordination is that a gap in aconjunct is allowed when there is a gap in the other con-junct,or a pronoun, as in (8a) and (8b).
(8) a. ithis
chaykj-unbook-NOM
[aitul-ikids-NOM
kukesj-ulit-ACC
acwuvery
cohaha-kolike-CONJ
nointul-toold people-also
ej congcongoften
chassnunta]ask for‘As for this bookj , kids like itj very much and oldpeople also buy (itj) often.’
96

b. ithis
chaykj-unbook-NOM
[aitul-ikids-NOM
ei acwuvery
cohaha-kolike-CONJ
nointul-toold people-also
kukesj-ulit-ACC
congcongoften
chassnunta]ask for
‘As for this bookj , kids like (itj) very much and oldpeople also ask for (itj).’
In particular, the example (8b) shows that the gap in thefirst conjunct is a trace but not a pro. It is supported by thegeneral fact that in Korean a pro is not allowed to appearin the first conjunct of coordinated structures.
Given that the CSC operates in Korean UDCs to re-quire a gap in each conjunct and given that the pronomi-nal kukes in a conjunct does not cause a violation of theCSC, as in (8a) and (8b), we can argue that those pro-nouns are RPs and that they behave in the same way astraces. Thus, this favors the UDC approach to RPs.
In summary, we argue that the pronouns appearing inthe gap positions are not pros. Instead, we argue that RPsin the gap position work as audible traces. Accordingto the trace approach, RPs and gaps arise from a singlemechanism. This argument is crosslinguistically compat-ible with (Georgopoulos, 1991) and (Vaillette, 2001) withrespect to Palauan and Hebrew. The terms for UDC gapsand non-UDC correspondents in Korean are summarizedin the following chart. The UDC elements in the left-hand column all triggers a nonzero SLASH feature whilethe right-hand column cannot.
(9)UDCs non-UDCs
zero trace proovert resumptive prn (ordinary) prncaki resumptive refl (ordinary) refl
5 The Analysis of RPs and RR caki
Korean UDCs always involve the presence of one ofthree elements that give rise to a nonlocal SLASH fea-ture: trace, resumptive pronoun, and resumptive reflex-ive. These three elements have certain properties withrespect to the SCO constraint and coordination. Each ofthem shares certain information with a filler that appearsin a possibly distant higher node. Furthermore, they sharecertain properties in common with their correspondingforms in non-UDCs. The occurrences of the reflexivecaki are associated with semantic and pragmatic prop-erties of logophoricity and constrastiveness, in contrastwith neutral occurrences of pronouns.3 Thus, we claim
3According to (Sells, 1987), logophoricity refers to sub-ject of consciousness (SELF), the source of reported speech(SOURCE), and deictic perspective (PIVOT)
that RPs and the RR caki in UDCs are respectively thesame elements of pronouns and the LD reflexive caki innon-UDCs. This approach is reminiscent of (Pollard andXue, 1998) who pointed out that a distinction betweenstructural and discourse binding should not be treated aslexical ambiguity.
Our UDC approach is different from accounts ofChomsky’s minimalist program and GB theory, where alltraces are considered to be the same category.4 Chom-sky’s binding theory requires that fillers be reconstructedto the trace position before binding conditions are ap-plied. Within this kind of approach, it is hard to cap-ture the fact that RPs and RR caki work as traces. TheHPSG system makes three different kinds of traces pos-sible and captures the fact that traces, RPs, and the RRcaki in UDCs belong respectively to the subset of pros,pronouns, the LD reflexive caki in non-UDCs. In addi-tion, our trace analysis of resumptive elements casts somedoubt on traceless approaches proposed by (Sag, 1997)and (Kim, 1998). According to their traceless analyses,gap information is encoded in the lexical entry of a pred-icate without involving a structural position for an emptycategory. However, resumptive elements that trigger theSLASH feature need to appear in syntactic structures.Thus, the existence of audible correspondents of tracessupports the traditional HPSG analysis of (Pollard andSag, 1994), which assumes an empty category in a givensyntactic structure. One way that a non-local dependencycan be bound off is for a local tree to instantiate the filler-gap schema. In line with (Levine et al., 2001)’s unitaryanalysis of English parasitic gaps, we argue that the non-local feature specification can be used to account for dif-ferent kinds of Korean UDCs.
ReferencesHee-Rahk Chae. 1998. A comparative analysis of tough-
and comparative constructions in English and Korean.Language Research, 34-1:33–71.
Peter Cole. 1987. Null objects in universal grammar.Linguistic Inquiry, 18-4:597–612.
Carol Georgopoulos. 1991. Syntactic Variables:resumptive pronouns and A’ binding in Palauan.Kluwer, Dordrecht.
Cheng-Teh James Huang. 1984. On the distribution andreference of empty pronouns. Linguistic Inquiry, 15-4:531–574.
Thomas Hukari and Robert Levine. 1995. Adjunct ex-traction. Journal of Linguistics, 31:195–226.
4Within GB theory, noun phrases are classified by the twobinary features, a(naphoric) and p(ronominal), and all traces areassumed to be R-expressions with -a and -p features.
97

Young-Se Kang. 1986. Korean Syntax and UniversalGrammar. Ph.D. thesis, Harvard University, Cam-bridge, MA.
Jong-Bok Kim. 1998. A head-driven and constraint-based analysis of Korean relative clause constructions.Language Research, 34.4:1–41.
Robert Levine, Thomas Hukari, and Michael Calcagno.2001. Parasitic gaps in English: Some overlookedcases and their theoretical implications. In Peter Culi-cover and Paul Postal, editors, Parastic Gaps, pages181–222. MIT Press, Cambridge, MA.
Carl Pollard and Ivan A. Sag. 1994. Head-driven PhraseStructure Grammar. The University of Chicago Press,Chicago.
Carl Pollard and Ping Xue. 1998. Chinese reflex-ive ziji:syntactic reflexive vs. nonsyntactic reflexives.Journal of East Asian Linguitics, 7:287–318.
Paul M. Postal. 1994. Contrasting extraction types.Journal of Linguistics, 30:159–186.
Paul M. Postal. 2004. Skeptical Linguistic Essays. Ox-ford University Press, New York, NY.
Ivan Sag. 1997. English relative constructions. Journalof Linguistics, 33:431–494.
Peter Sells. 1987. Aspects of logophoricity. LinguisticInquiry, 18:445–479.
Anna Szabolcsi and Marcel den Dikken. 1999. Islands.GLOT International, 4-6:3–9.
Nathan Vaillette. 2001. Hebrew relative clauses inHPSG. In D. Flickinger and A. Kathol, editors, TheProceedings of the 7th International Conference onHead-Driven Phrase Structure Grammar. CSLI.
98

An HPSG approach to the who/whom puzzle
Takafumi Maekawa
Department of Language and Linguistics
University of Essex
Wivenhoe Park
Colchester
CO4 3SQ, UK
1 Introduction
Numerous attempts have been made to elucidate
properties of the case systems of human
language.1 In the case of the example in (1), most
of the previous studies on case marking would
argue that the English interrogative/relative
pronoun who manifests nominative case, while
accusative case is realized in the form of whom.
(1) a. Who saw whom?
b. someone whom you rely on
c. someone who relies on you
In this paper, we will first observe that the
distribution of who and whom poses a challenge to
any theory of the above sort. Second, we will
discuss the analysis by Lasnik and Sobin (2000).
Then we will propose an analysis, in which the
interaction of small of number of constraints can
accommodate the seemingly complex body of data.
Section 5 is the conclusion.
2 The who/whom puzzle
The assumption that who is nominative and whom
is accusative is apparently justified by (2), where
who in the subject position does not alternate with
whom, which indicates that whom is not
nominative.
(2) a. Who/*whom wrote the editorial?
b. the man who/*whom came to dinner
1 For HPSG literature on case, see Heinz and Matiasek 1994; Meurers 2000;
Pollard 1994; Przepiórkowski 1999, etc.
However, whom is not the only option in non-
subject positions. In (3)–(5) whom alternates with
who as object of a verb or preposition in main
clauses (3), embedded clauses (4), and in situ (5).
(3) a. those whom/who we consulted.
b. someone whom/who we can rely on
c. He didn’t say whom/who he had invited.
(4) a. Whom/who did you meet?
b. Whom/who are you referring to?
(5) a. Who is going to marry whom/who?
b. Who is buying a gift for whom/who?
Any theory that assumes that who is nominative
and whom accusative would predict that only
whom is allowed in (3). One might say that this
alternation would be predictable if we assumed
that who can be accusative as well as nominative.
(6) shows, however, that the situation is not so
simple.
(6) a. To whom/*who are you referring?
b. someone on whom/*who we can rely
A noun phrase as a prepositional complement in a
fronted PP take the accusative form, as in about
him/*he. This is unexpected if who can be
accusative.
Another complication about the who/whom
distinction is that whom can appear in the
syntactic environments where the nominative case
is normally expected.
(7) a. We feed children who/whom we think
are hungry.
b. The man who/whom I believe has left.
99

c. The man who/whom it was believed
had left.
Any theory that assumes that who is nominative
and whom accusative would only predict the
occurrence of who in (7); but in fact whom is
allowed. The above data poses a challenge to any
theory of syntax which deals with the who/whom
distinction in parallel to other English pronominal
distinctions, such as they/them.
It is clear that there is a complex body of data
here, but the distribution of who and whom in the
above data can be summarized in the following
way.
(8) Distribution of who and whom Environments forms
Embedded
clause
who/whom
Main clause who/whom
In-situ who/whom
Subject who
Pied-piping whom
This summary reveals that who and whom
alternate in all the syntactic environments except
for subject of the nearest following finite verb and
object of the fronted preposition (pied-piping).
3 Lasnik and Sobin’s (2000) approach
A recent attempt to provide a theoretical account
to the who/whom distinction is Lasnik and Sobin’s
(2000).2 They argue that who is the basic form of
the wh-pronoun, which can check either
nominative (NOM) or accusative (ACC) case.
The suffix -m of whom is assumed to be associated
with an additional ACC feature and has to be
checked independently of the ACC feature
associated with the stem who. This additional
ACC feature carried by the suffix is checked by
the following rules with the status of ‘grammatical
viruses’, which serve to license prestige forms.
(9) The Basic ‘whom’ Rule
(Lasnik and Sobin 2000: 354)
If: [V/P] who- -m
[ACC] [ACC]
1 2 3
then: check ACC on 3
2 See also Kayne (1984) and Radford (1988). For descriptive work, see
Jespersen (1924; 1927), Quirk et al (1985), Huddleston and Pullum (2002), etc.
(10) The Extended ‘whom’ Rule
(Lasnik and Sobin 2000: 359)
If: who- -m … NP, where
[ACC]
1 2 3
a) 3 is the nearest subject NP to 2, and
b) ‘…’ does not contain a V which has
1–2 (a single word whom) as its
subject,
then: check ACC on 2.
Rule (9) licenses the occurrence of whom as object
of a verb or preposition, as in (3f), (3g), (6a) and
(6b). Rule (10) accounts for the occurrence of
initial whom in any type of wh-construction where
the wh-pronoun functions as the object of a verb
(3a, b, d) or stranded preposition (3c, e), or the
subject of an embedded clause (7). The
unacceptable occurrences of whom in (2) are ruled
out by the fact that they are not compatible with
the sequential arrangement of (9) nor (10).
However, their approach involves a
questionable assumption: it is not clear whether
the who/whom distinction should be treated as a
matter of case. Two different forms of a lexeme
should not necessarily be seen as two different
cases of the lexeme. If they are not realisations of
case, it will not be necessary to assume that the
stem who- and the affix -m have two different
cases. Other things being equal, it would be
preferable not to have such a counter-intuitive
assumption.
There are other problems. First, Lasnik and
Sobin’s (2000) rules are characterised as extra-
grammatical devices within Virus Theory. Other
things being equal, a theory without such extra
devices is preferable to that with them.
Second, the analysis deals with all instances
of left-dislocated whom in terms of rule (10). This
would lead us to expect that whom licensed by
(10) has the identical distribution in any syntactic
environments. Huddleston and Pullum (2002:
465) point out, however, that ‘[t]he formal feel of
whom is most apparent in main clause
interrogatives’. The following examples from
Huddleston and Pullum (2002: 465) illustrate that
relative whom is not confined to formal style.
(11) a. Hugh wasn’t impressed with this
ingratiating barman whom Roddy had
raked up.
100

b. Award-winning journalist Nelson
Keece (Gary Busey) is coldly detached
from his chosen subject, serial killer
Stefan (Arnold Vosloo), whom he
catches in the act of murder.
A satisfactory analysis of the who/whom
distinction should be able to say something about
this fact, but it seems that Lasnik and Sobin’s
(2000) consideration of register is not fine-grained
enough to do it.
4 An HPSG analysis
A satisfactory analysis of the who/whom
distinction should be able to ensure that there is a
position where only whom is available (i.e., (6)), a
position where only who is available (i.e., (2)),
and positions where who and whom alternate (i.e.,
(3)–(5) and (7)). It should be noted here that
whom is perceived as formal in style whereas who
as less formal or informal, so non-existence of
who in pied-piping will be able to be attributed to
the fact that pied piping is confined to formal style
(See below for details). Therefore, the apparent
complexity of the data is reducible to the
following rather simple generalization.
(12) a. Informal style employs who in every
syntactic environment.
b. In formal style, whom is employed in
all syntactic environments except when
it is subject of the nearest following
verb; in the latter cases, who is used, as
in (2).
Following Wilcock (1999), we represent register
variation in terms of the feature REGISTER,
which is appropriate for CONTEXT. The
REGISTER feature takes a value of sort register,
which has two subsorts, formal and informal. The
style difference between who and whom can be
formalized in the following lexical constraints of
these word forms (cf. Wilcock 1999).
(13) a. [ ]who PHON REGISTER
who LME→
informal
b. [ ]whom PHON / REGISTER
who LME→
formal
We further assume that a word has the feature
L(EXE)ME, which represents the lexeme which
the word form instantiates (Ackerman and
Webelhuth 1998). (13a) indicates that the lexeme
<who> is phonologically realised as <who> in an
informal register, while (13b) states that it is
realised as <whom> by default in a formal register.
These constraints determine the distribution
of who and whom observed in (3)–(7). The
alternation observed in (3)–(5) and (7) is attributed
to the difference in register specified in the above
constraints: who is employed in an informal style
while whom is employed in a formal style, no
matter what syntactic environment they appear in
and what sort of semantic role they have. As has
been stated earlier, non-existence of who in pied-
piping in (6) is due to the fact that formal status of
pied-piping conflicts with the [REGISTER
informal] specification of who (See Wilcock 1999;
cf. Paolillo 2000).
We saw above that who appears in a formal
register as well as in an informal register when it
is a subject of the nearest following verb, as in (2).
This means that (13b) should be overridden by a
constraint licensing the occurrence of who in a
formal register. We propose the following
constraint.
(14)
[ ]who PHON[1]
REGISTER
,
[2]] [LOC SUBJ
] verb[HEAD
,who LME
[2] LOC]1[
DOM
→
formal
fin
phrase
L
The value of the attribute DOM(AIN) represents
linear order of a clause (see, e.g., Pollard et al.
1993; Reape 1994; and Kathol 2000). (14)
involves the assumption that a filler is in the same
domain as the following VP. This constraint
states that the lexeme <who> takes the
phonological form <who> in a formal register if it
is subject of the nearest following finite verb
phrase. (14) overrides the default constraint (13b),
which accounts for ungrammaticality of whom,
and licences who in (2).
We argued above that whom is more
acceptable in a less formal register in embedded
clauses than in main clauses, as illustrated by the
not formal but not fully informal examples in (11).
To deal with these cases, we need to have a more
fine-grained classification of register than that
101

given earlier. We assume that the type formal has
two subsorts, fully-formal and semi-formal. We
can formulate the new classification in the
following hierarchy.
(15) register
formal informal
fully-formal semi-formal
There are thus three maximal subtypes for
register: fully-formal, semi-formal and informal.
We introduce a further constraint in (16).
(16)
[ ][ ]formal-fully
cl-int-wh-ns
REGISTER[1]
whom PHON]1[ DTR-H-NON
IC
→
+
(16) states that the REGISTER value of whom,
specified as formal by constraint (13b), is resolved
to fully-formal if it is the non-head daughter of
independent clauses ([IC +]) of the type
nonsubject-wh-interrogative-clause (Ginzburg and
Sag 2000). This captures the considerably more
formal status of whom in main clauses. Since
constraint (16) does not apply for [IC −] clauses, the REGISTER value of whom remains formal in
embedded clauses. This entails that whom can
appear in a semi-formal as well as fully-formal
register, which accounts for the occurrence of
whom in less formal style sentences in (11). This contrast between main clause interrogatives
and relatives matches Huddleston and Pullum’s
(2002) description cited earlier: ‘[t]he formal feel
of whom is most apparent in main clause
interrogatives’.
5 Conclusion
In this paper, we have investigated the who/whom
distinction in English, and provided an alternative
analysis to that by Lasnik and Sobin (2000) within
HPSG. The register specification via the
REGISTER feature and the register hierarchy in
(15) allow us a more fine-grained analysis with
wider empirical coverage. Another advantage of
the present analysis is that constraints are stated in
a general formalism available in HPSG, rather
than given with extra grammatical devices.
References Ackerman, F. and Webelhuth, G. 1998. A Theory of
Predicates. Stanford: CSLI Publications. Ginzburg, J., and Sag, I. A. Interrogative Investigations.
Stanford: CSLI Publications. Heinz, W. and Matiasek, J. 1994. Argument structure
and case assignment in German. In Nerbonne, J., et al (eds.), 199–236.
Huddleston, R. and Pullum, G. K. 2002. The Cambridge Grammar of the English Language. Cambridge: Cambridge University Press.
Jespersen, O. 1924. The Philosophy of Grammar. Chicago: University of Chicago Press.
Jespersen, O. 1927. A Modern English Grammar on Historical Principles, Part III. London: Allen & Unwin.
Kathol, K. 2000. Linear Syntax. Oxford: Oxford University Press.
Kayne, R. S. 1984. Connectedness and Binary Branching. Dordrecht: Foris Publications.
Lasnik, H. and Sobin, N. 2000. The who/whom puzzle: on the preservation of an archaic feature. Natural Language and Linguistic Theory 18, 343–371.
Meurers, W. D. 2000. Raising spirits (and assigning them case). Groninger Arbeiten zur Germanistischen Linguistik 43, 173–226.
Nerbonne, J., Netter, K., and Pollard, C. (eds.). 1994. German in Head-Driven Phrase Structure Grammar. Stanford: CSLI Publications.
Paolillo, J. Formalizing formality: an analysis of register variation in Sinhala. Journal of Linguitics 36, 215–259.
Pollard, C. 1994. Toward a unified account of passive in German. In Nerbonne, J., et al (eds.).
Pollard, C., Kasper, R., and Levine, R. 1994. Studies in constituent ordering: Towards a theory of linearization in Head-Driven Phrase Structure Grammar. Research Proposal to the National Science Foundation, Ohio State University.
Przepiórkowski, A. 1999. On case assignment and “adjuncts as complements”. In Webelhuth, G., et al (eds.), 231–245.
Quirk, R.,. Greenbaum, S., Leech, G., and Svartvik, J. 1985. A Comprehensive Grammar of the English Language. London: Longman.
Radford, A. 1988. Transformational grammar. Cambridge : Cambridge University Press.
Reape, M. 1994. Domain union and word order variation in German. In Nerbonne, J., et al (eds.), 151–98.
Wilcock, G. 1999. ‘Lexicalization of context’. In Webelhuth, G., et al (eds.), 373–387. Webelhuth, G., Koenig, J-P. and Kathol, A. (eds.).
1999. Lexical and Constructional Aspects of Linguistic Explanation. Stanford: CSLI Publications.
102

From “hand-written” to computationally implemented HPSG theories
Nurit Melnik ∗
Caesarea Rothschild Institutefor Interdisciplinary Applications of Computer Science
Haifa UniversityHaifa, Israel 31905
1 Overview
HPSG has logical and mathematical foundationswhich make it amenable to computational imple-mentation. Yet it is seldom the case that this po-tential is in fact fulfilled, although there exist a num-ber of platforms for implementing HPSG grammars.Thus, most descriptions and analyses of linguisticphenomena in the literature are not substantiated bya working computational grammar.
Two leading implementation platforms are avail-able for implementing HPSG grammars. The Lin-guistic Knowledge Building (LKB) system (Copes-take, 2002) is the primary engineering environmentof the LinGo English Resource Grammar (ERG) atStanford. LKB is developed not particularly for im-plementing HPSG grammars, but rather, as a frame-work independent environment for typed featurestructures grammar. TRALE, an extension of theAttribute Logic Engine (ALE) system, is a grammarimplementation platform that was developed as partof the MiLCA project (Meurers et al., 2002), specif-ically for the implementation of theoretical HPSGgrammars that were not explicitly written for lan-guage processing.1 The two platforms are basedon different approaches, distinct in their underlyinglogics and implementation details.
This paper adopts the perspective of a computa-tional linguist whose goal is to implement an HPSG
∗This research was supported by the Israel Science Founda-tion (grant no. 136/01) and by The Caesarea Edmond Benjaminde Rothschild Foundation Institute for Interdisciplinary Appli-cations of Computer Science.
1See http://milca.sfs.nphil.uni-tuebingen.de/A4/HomePage/English/beschr.html
theory. It is based on the implementation of a “hand-written” grammar proposed by Melnik (2002) to ac-count for verb initial constructions in Modern He-brew. A representative subset of the grammar, in-cluding word order, agreement, and valence alterna-tion phenomena, serves as a test case.
The paper focuses on different dimensions, rele-vant to HPSG grammar implementation: type defi-nition, grammar principles, lexical rules, exhaustivetyping, definite relations, non-binary grammar rules,semantic representation, grammar evaluation, anduser-interface. It examines, compares, and evaluatesthe different means which the two approaches pro-vide for implementation, by referring to examplesfrom a “hand-written” grammar fragment that wasimplemented in the two systems. The paper con-cludes that the approaches occupy diametrically op-posed positions on two axes:FAITHFULNESS to the“hand-written’ theory andCOMPUTATIONAL AC-CESSIBILITY. The findings of this paper are valu-able to linguists who are interested in implementingtheir grammar, as well as to those who develop im-plementation platforms.
2 Type Definition
Types in a typed feature-structure framework are de-fined by determining (i) the type’s hierarchical rela-tion to other types, (ii) appropriateness conditions,(iii) constraints on the values of embedded features,and (iv) path equations.
TRALE separates theSIGNATURE, where the firsttwo properties are defined, from theTHEORY, inwhich the latter are stated. In the signature file, typesare entered in a list format, where subtypes appear
103

indented under their respective supertype(s). Fea-tures and values are introduced following the type.Constraints on embedded features and path equa-tions are entered separately from the signature in thetheory file as implicational constraints in which thetype is the antecedent.
LKB, on the other hand, takes a centralizedbottom-up approach, where all the information re-lated to a type is defined in one location, in theTYPES file. The definition of each type, then, in-cludes a list of its immediate supertype(s) and intro-duced features, as well as all other type-related con-straints. This approach facilitates the task of defin-ing the type inventory and accessing this informationwhile developing the grammar.
Although the hierarchies are defined differentlyin the two systems, they are both subject to theglb condition, which requires that the hierarchy bea bounded complete partial order (BCPO). Thus,when a non-BCPO hierarchy is defined, TRALE en-forces the condition by producing an error messageduring compilation. LKB, on the other hand, auto-matically creates a glb type in each case of violationand restructures the hierarchy accordingly.
On the one hand, by automatically fixing the vi-olation, LKB enables the grammar writer to main-tain ignorance regarding a potentially confusing is-sue. This ignorance, however, turns into confusiononce the grammar writer views the type hierarchydiagram. The automatic restructuring of the hier-archy, including the addition of generically namedtypes, may be incomprehensible to the naive gram-mar writer. Moreover, the resulting hierarchy isreflected only in the display and not in the actualdefinitions, rendering the automatically created glbtypes, along with their generic names, inaccessible.A possible solution is to modify the hierarchy defini-tion to reflect the corrected hierarchy, thus allowingthe grammar writer to give the glb types more mean-ingful labels.
Multi-dimensional type hierarchies arewidely used in the HPSG literature, yet multi-dimensionality is not a part of the formal typesystem itself (Penn and Hoetmer, 2003). NeitherLKB nor TRALE provide the grammar writerwith a way to define partitions (or dimensions)in the hierarchy. Consequently, if partition labelsare implemented as types in the hierarchy, they
are not distinguished formally from other types,nor do LKB and TRALE prevent the grammarwriter from defining types that inherit from twosubtypes under one pseudo-partition. Moreover, amulti-dimensional inheritance hierarchy in whichpartitions are defined as types does not respectthe glb condition, and is therefore subjected tothe systems’ distinct treatments, described above.Although this omission does not prevent grammarwriters from implementing their grammars, theresult clearly does not reflect the source and theintention of the grammar writer.
3 Principles
Principles in HPSG are often defined as implica-tional constraints. Thus, for example, the Head Fea-ture Principle (HFP), which states that the value ofthe HEAD feature of the headed-phrase is structure-shared with that of its head-daughter, is defined as atype constraint on thehd-phtype.
hd-ph→[
HEAD 1
HD-DTR[
HEAD 1]]
In LKB principles are necessarily linked to typesand are stated as part of the type definition. Thus, theHFP is implemented as part of the definition of thetypehd-ph. In TRALE, on the other hand, principlessuch as the HFP are stated as part of the theory, inthe form of implicational constraints where the typeis the antecedent, similarly to the definition above.TRALE, however, extends implicational constraintsto express principles which do not target a partic-ular type. More specifically, the antecedent of im-plicational constraints can be arbitrary function-free,inequation-free feature structures .
Consider, for example, the followingcomplex-antecedent principle (Meurers, 2001).
word
SYNSEM| LOC |CAT
HEAD
[verb
VFORM finite
]
VAL |SUBJ⟨
LOC |CAT |HEAD noun⟩
→[SYNSEM| LOC | ... |SUBJ
⟨[LOC |CAT |HEAD |CASEnominative
]⟩]
The principle expresses the generalization that NPsubjects of finite verbs are assigned nominative
104

case. The complex antecedent singles out therelevant class of verbs without requiring there to bea corresponding type.
The ability to use implicational constraints withcomplex antecedents provides the grammar writerwith additional means to express generalizations.When the given dimensions in the type hierarchydo not group together a particular set of objects towhich a certain generalization applies, the grammarwriter can choose not to expand the hierarchy, butrather to use a complex feature structure as an an-tecedent to an implicational constraint expressingthe generalization. This solution can cut down onthe size of the type hierarchy and its complexity.
4 Lexical Rules
The main issue that is pertinent to the implementa-tion of lexical rules (LRs) is the “carrying over” ofinformation from the input to the output of the rule.The descriptions of the input and output of lexicalrules generally include only the features and valuesthat are relevant for the particular rule; either thosewhich constrain the types of objects on which toapply the rule or those which provide “informationhandles” (Meurers, 1994). All information whichis not changed by the lexical rule is assumed to becopied over from the input to the output. An im-plementation platform thus has to implement the ex-plicit as well as implicit copying of values.
LKB views lexical rules as unary grammar ruleswhich relate a mother structure (the output) to itsdaughter (the input). Similarly to grammar rules, thedescription of the daughter is included in theARGS
feature of the mother. This provides a partial solu-tion to the “carrying over” problem — the descrip-tions of both the mother and daughter are a part of asingle feature structure. Nevertheless, the grammarwriter is required to explicitly specify by structure-sharing the information that is copied over. Asidefrom deviating from HPSG conventions, this solu-tion may result in a loss of generality.
TRALE provides two mechanisms for imple-menting lexical rules: the traditional ALE mecha-nism and a mechanism referred to as ‘description-level lexical rules’ (DLRs) which encodes the treat-ment proposed in Meurers & Minnen (1997). Unlikethe format of the rules in LKB, the TRALE syntax
for both types of LRs is similar to the familiar ‘X⇒Y’ notation. More importantly, from the perspectiveof the grammar writer, the main distinction betweenthe two approaches is in the “carrying over” mech-anism. ALE LRs, similarly to the LKB mechanism,require explicit specification of “carried over” infor-mation. The DLR version provides an automatic“carrying over” mechanism which implements theintuitions behind the “hand-written” version of lex-ical rules. This is a clear advantage in terms of ap-proximating written theories and maintaining gener-ality.
5 Exhaustive Typing and SubtypeCovering
‘Exhaustive typing’ refers to a particular interpre-tation of the signature according to which subtypesexhaustively cover their supertypes. Consequently,if an object is of a certain non-maximal typet then itis also of some more specific subtype subsumed byt.2
A simple example is the HPSG analysis ofsubject-auxiliary inversion in English. In order torestrict the licensing of inversion to auxiliary verbs,verbs are defined as having two features:INV andAUX . Furthermore, the general typeverbis assumedto have two subtypes:main-verbandaux-verb.
[verbAUX boolINV bool
]
[main-verbAUX −INV −
] [aux-verbAUX +
INV bool
]
Under an exhaustive typing interpretation, objectsof type verb which are not compatible with eithermain-verbor aux-verb (e.g., verbs specified with[AUX −]
and[INV +
]) are rejected. This is the in-
terpretation which TRALE employs. In LKB suchfeature structures are accepted.
In addition, TRALE employs a subtype coveringstrategy whereby if the system recognizes that thevalues of a feature structure of a non-maximal type
2This interpretation is also referred to in the literature as‘closed world’. However, as one reviewer pointed out, the terms‘closed/open world’ have a different meaning in the study ofprogramming languages and should therefore be avoided.
105

are consistent with the values of only one of its sub-types, it will promote those values to the values ofthe compatible subtype. This is justified only underan exhaustive typing interpretation, and is thereforenot a part of the LKB system.
One advantage to TRALE’s approach is thatit implements an implicit assumption in “stan-dard” HPSG (e.g., (Pollard and Sag, 1994)) and isthus appropriate if the goal is to narrow the gapbetween “hand-written” theories and their imple-mented counterparts. Second, Meurers (1994) notesthat “while both interpretations allow the inferencethat appropriateness information present on a typegets inherited to its subtypes, we can now addi-tionally infer the appropriateness specifications on atype from the information present on its subtypes”.Moreover, in addition to increasing the expressivepower, such a system facilitates syntactic detec-tion of errors and increased efficiency in processing(Meurers, 1994).
The main reasons that are given for adoptingthe alternative approach, often referred to as ‘open-world reasoning’, are not theoretical, but rather, mo-tivated by engineering considerations. This typeof reasoning allows the grammar writer to be non-committal regarding the complete inventory of typesneeded to account for the language. This is partic-ularly helpful during incremental grammar/lexicondevelopment.
6 Definite Relations
“Hand-written” HPSG makes use of various rela-tions which are external to the description language,many of which apply to lists and sets. One such re-lation isAPPEND. LKB and TRALE differ greatly inthe solutions that they offer for implementing “hand-written” analyses which make use of definite rela-tions. LKB takes a conservative stance and adheresto the description language, while TRALE augmentsthe description language with a programming lan-guage for implementing definite relations and incor-porating them into type constraints and rules.
Programming definite relations in the TRALE en-vironment is very similar to programming in Prolog,with the exception that first-order terms in Prologare replaced with descriptions of feature structures.Thus, a list in this case is not a list of terms, but
rather a list of descriptions of feature structures.A thorough discussion of the benefits of adding
recursive relations to the description language ofimplementation platforms for HPSG grammars isfound in Meurerset al. (2003), which comparesthe treatment of unbounded dependencies and op-tional arguments in the ERG, implemented in LKB,with that of TRALE. They conclude that the abilityto express relational goals increases the grammar’smodularity and its ability to express generalizations,and reduces the gap between “hand-written” theo-ries and their implemented counterparts. This con-clusion is echoed in the following section.
7 Non-binary Grammar Rules
Grammar rules in the HPSG literature are not re-stricted to binary rules. A prime example is thehead-complement phrase, one of the most basicphrase structures in the grammar. In addition to be-ing non-binary, the head-complement phrase rule isdesigned to account for phrases with a varying num-ber of daughters. Implementing a rule for such aphrase type poses a number of challenges for a com-putational system, challenges which are handled dif-ferently by the two systems.
The assumption in LKB is that the number ofdaughters associated with each rule is fixed. Thus,for grammars which are not restricted to binarybranching trees the grammar writer needs to de-fine phrase types and grammar rules for each arity.TRALE provides a specialcats> operator to ex-press rules with daughters lists of unspecified length.This, combined with the ability to incorporate def-inite recursive relations into the grammar providesthe grammar writer with a way to implement non-binary grammar rules, such as the head-complementrule, in a concise and elegant manner, which closelyapproximates “hand-written” grammars. This, how-ever, does require from the grammar writer the pro-gramming skills needed to be able to code using thedefinite logic programming language.
8 Semantic Representation
LKB contains a module for processing MinimalRecursive Semantics (MRS) representations. Themodule is independent from the rest of the LKBand provides tools for manipulating MRS structures
106

in feature structure representations (Copestake andFlickinger, 2000). TRALE provides an alternativemodule which is an implementation of Lexical Re-source Semantics (Penn and Richter, 2004). A com-parison and evaluation of the two systems will begiven in the full paper.
9 Evaluating Competence andPerformance
Implemented grammars can be evaluated accordingto two dimensions: competence and performance.The competence of a grammar refers to its coverageand accuracy, that is the ability to account for alland nothing but sentences which are assumed to begrammatical. Performance relates to the resources— mainly processor time and memory space — thatare used during processing.
Both LKB and TRALE provide a way for defin-ing a test suite which can be used as a benchmark-ing facility. A batch parse returns for each sentencein the test suite the number of parses and passiveedges. In terms of performance, TRALE indicatesfor each sentence the CPU time in seconds that ittook to process the sentence. In LKB only a totalfigure for all sentences is given. More sophisticatedtools for evaluating competence and performance ofgrammars are available in both systems through the[incr tsdb()] package (Oepen, 2001).
10 User-Interface Issues and Features
Aside from major design differences between thetwo systems, LKB and TRALE are distinguished byother more superficial user-interface type of differ-ences.• LKB provides an interactive display of the gram-mar’s type hierarchy. The user can click on typesand examine their immediate and expanded defini-tions. TRALE produces static images of the hierar-chy.• Both systems provide ways for displaying andinspecting feature structures and syntactic trees.TRALE’s Grisu graphical interface displays fea-ture structures in AVMs that are identical to thoseof “hand-written” HPSG. The LKB display is lesscompact and more difficult to navigate.• Parametric macros in TRALE are used as ashorthand for descriptions that are used frequently.
Macros are especially useful for defining the lexiconwhen it is structured to minimize lexeme-specific in-formation.• LKB is a graphic-user-interface system wherecommands are invoked through drop-down menus.In TRALE the user interacts with the program byusing commands entered at the Prolog prompt.• LKB uses the same syntax to define types, lexicalrules, grammar rules, and words in the lexicon. InTRALE distinct formats, similar to “hand-written”HPSG, are used for each of the grammar compo-nents.• LKB comes with the Matrix (Bender et al., 2002),an open-source starter-kit for rapid prototyping ofprecision broad-coverage grammars. TRALE gram-mars need to be implemented from scratch, or basedon existing grammars.
11 Conclusion
Generally speaking, the characterization of HPSGas an implementable grammatical theory is justified,due to the computational effort that was put intodesigning and developing the two implementationplatforms discussed in this paper. The major gapthat was identified between “hand-written” HPSGand its implemented counterpart was in the multi-dimensional inheritance mechanism, which is not in-corporated into neither implementation platforms.
LKB and TRALE can be compared and evaluatedalong two different axes:FAITHFULNESS and AC-CESSIBILITY. Faithfulness is the extent to whichthe implemented grammar resembles the original“hand-written” one. Accessibility, on the otherhand, is the degree of computational skills that is re-quired from a linguist in order to implement a gram-mar.
In some way, LKB can be viewed as a simpli-fied TRALE. Thus, when implicational constraintswith complex antecedents, DLR lexical rules, thecats> operator, definite clauses, and macros areeliminated, one can implement an LKB-like gram-mar in TRALE. Of course, one LKB feature thatcannot be assimilated is the automatic correction ofglb condition violations.
The gap between the LKB-like TRALE gram-mar and a grammar implemented using the entirecollection of tools provided by TRALE character-
107

izes the differences between the systems. The ‘true’TRALE grammar is positioned much higher on thefaithfulness axis than the LKB-like TRALE gram-mar. The TRALE tools needed in order to elevate theLKB-like grammar on this axis require from the lin-guist more computational skills. This is especiallytrue when writing (and debugging) Prolog definiteclauses to express relational constraints.
In terms of accessibility, the menu-driven user in-terface of LKB is more user-friendly than TRALE’scommand-line interface, making LKB more attrac-tive to the less computationally savvy linguist. How-ever, tipping the balance a little on the accessibilityscale towards TRALE is its AVM display, which ismuch easier to process than LKB’s. Consequently,a computational linguist interested in implementingan HPSG theory must consider these dimensionswhen choosing an implementation platform.
References
Emily M. Bender, Daniel P. Flickinger, and StephanOepen. 2002. The grammar matrix: An open-source starter-kit for the rapid development ofcross-linguistically consistent broad-coverage preci-sion grammars. In John Carroll, Nelleke Oostdijk, andRichard Sutcliffe, editors,Proceedings of the Work-shop on Grammar Engineering and Evaluation at the19th International Conference on Computational Lin-guistics, pages 8–14, Taipei, Taiwan.
Ann Copestake and Dan Flickinger. 2000. An opensource grammar development environment and broad-coverage English grammar using HPSG. InProceed-ings of the 2nd International Conference on LanguageResources and Evaluation, Athens, Greece.
Ann Copestake. 2002. Implementing Typed FeatureStructure Grammars. CSLI publications, Stanford,CA.
Nurit Melnik. 2002. Verb-Initial Constructions in Mod-ern Hebrew. Ph.D. thesis, University of California atBerkeley.
Detmar Meurers and Guido Minnen. 1997. A compu-tational treatment of lexical rules in HPSG as covari-ation in lexical entries. Computational Linguistics,23(4):543–568.
W. Detmar Meurers, Gerald Penn, and Frank Richter.2002. A web-based instructional platform forconstraint-based grammar formalisms and parsing. InDragomir Radev and Chris Brew, editors,EffectiveTools and Methodologies for Teaching NLP and CL,
pages 18 – 25, New Brunswick, NJ. The Associationfor Computational Linguistics.
Detmar Meurers, Kordula De Kuthy, and Vanessa Met-calf. 2003. Modularity of grammatical constraints inHPSG-based grammar implementations. InProceed-ings of the ESSLLI ’03 workshop “Ideas and Strate-gies for Multilingual Grammar Development”, Vi-enna, Austria.
Detmar Meurers. 1994. On implementing an HPSGtheory – Aspects of the logical architecture, the for-malization, and the implementation of head-drivenphrase structure grammars. In Erhard W. Hinrichs,Detmar Meurers, and Tsuneko Nakazawa, editors,Partial-VP and Split-NP Topicalization in German –An HPSG Analysis and its Implementation, pages 47–155. Eberhard-Karls-Universitat Tubingen, Tubingen,Germany.
Detmar Meurers. 2001. On expressing lexical gener-alizations in HPSG. Nordic Journal of Linguistics,24(2):161–217. Special issue on ‘The Lexicon in Lin-guistic Theory’.
Stephan Oepen. 2001.[incr tsdb()] — competence andperformance laboratory. User manual. Technical re-port, Computational Linguistics, Saarland University,Saarbrucken, Germany. in preparation.
Gerald Penn and Kenneth Hoetmer. 2003. In search ofepistemic primitives in the English Resource Gram-mar. In Proceedings of the 10th International Con-ference on Head-Driven Phrase Structure Grammar,East Lansing, Michigan.
Gerald Penn and Frank Richter. 2004. Lexical re-source semantics: From theory to implementation.In Stefan Muller, editor, Proceedings of the HPSG-2004 Conference, Center for Computational Linguis-tics, Katholieke Universiteit Leuven, pages 423–443.CSLI Publications, Stanford.
Carl Pollard and Ivan A. Sag. 1994.Head-Driven PhraseStructure Grammar. CSLI Publications and Univer-sity of Chicago Press.
108

Phrasal or Lexical Resultative Constructions?
Stefan MullerTheoretische Linguistik/Computerlinguistik
Universitt Bremen/Fachbereich 10Postfach 33 04 40D-28334 Bremen
Abstract
Goldberg and Jackendoff (2004) arguethat a phrase structure rule like (1a) is notsufficient to account for resultative con-structions like (1b) and suggest a familyof related constructions that make explicitthe idiosyncratic properties of resultativesecondary predications.
(1) a. VP→ V NP AP/PP
b. They drank the pub dry.
In my talk I show that the data discussedby Goldberg and Jackendoff can be cap-tured in a lexicon-oriented analysis andthat syntactic structures may be even moreabstract than (1a).
Furthermore, I show that it is difficult orimpossible to capture the interaction be-tween other phenomena and resultativeconstructions in an insightful way andthat it is not obvious how a phrasal ap-proach can capture cross-linguistic gener-alizations.
The paper will be published elsewhere and there-fore cannot be included here. If you are interested inthe paper, please contact the author.
References
Adele E. Goldberg and Ray S. Jackendoff. 2004. TheEnglish resultative as a family of constructions.Lan-guage, 80(3):532–568.
Adele E. Goldberg. 1995.Constructions. A Construc-tion Grammar Approach to Argument Structure. Cog-nitive Theory of Language and Culture. University ofChicago Press, Chicago/London.
109

110

Adverbial Extraction: A defense of tracelessness
Ivan A. SagDepartment of Linguistics
Stanford UniversityStanford, 94305
1 Introduction
Ever since the ‘adverbs-as-complements’ [A-as-C]analysis was first proposed by Bouma and van No-ord, it has been controversial. Even though a num-ber of people have offered extensive motivation forthis view in various languages (e.g. Przepiorkowski1999, Manning et al. 1999), there are various issuesof adequacy that have been raised by researchersin the HPSG research community. Specifically, ina penetrating study, Levine (2002) raises importantquestions about how the A-as-C analysis developedby Bouma et al. (2001) [BMS] can be reconciledwith examples like (1):
(1) In how many seconds flat did Robin find achair, sit down, and whip off her logging boots?
Because in BMS’s analysis, an adverb selected bya verb identifies its MOD value’s KEY value withthe verb’s KEY value, (1) poses a dilemma: if theextracted adverb is associated with a dependent ofeach verb (find, sit, and whip), then three contradic-tory KEY values must be equated. Intuitively, (1)requires that the adverb modify the coordinate struc-ture (since this sentence has a cumulative readingand its meaning is a question about the duration of atripartite event), yet BMS’s analysis assumes that allpostverbal adverbials are complements, and hencelacks any way to associate the adverb with the ap-propriate modifier position and no way to assign itthe correct scope. On the other hand, Levine argues,if there are adverbial traces that can appear whereveradverbs can appear, then these examples are unprob-lematic – the adverbial trace is in a position adjoined
to the coordinate structure, and hence outscopes theconjunction.
In this paper, I explore a small modification ofthe BMS analysis that resolves this problem with-out introducing traces of the sort that Levine argueswould provide an alternative account of data like (1).The goal of saving the BMS analysis is worthwhile,it should be noted, as it is the only extant HPSGextraction analysis which is immediately consistentwith the extensive evidence cited for A-as-C andwhich also provides a straightforward account of thefact, documented extensively by Hukari and Levine(1995), that adverb extraction triggers the same mor-phosyntactic repercussions as complement extrac-tion in languages (e.g. Chamorro, Palauan, Thomp-son River Salish, Irish,...) that register extraction de-pendencies locally. Under BMS’s proposal, all verbsand complementizers within an extraction domainare distinguished by having a nonempty SLASHvalue. Under an approach where adverbial traces ter-minate filler-gap dependencies, there is no motiva-tion for extraction information (a nonempty SLASHvalue) to be registered on the verb modified by anadverbial trace.
2 Analysis
In unpublished work, Bouma et al. (1998) ob-serve that the BMS analysis requires a stip-ulation based on a binary relation they callsuccessively-out-modify in order to en-sure that the linear order of postverbal modifiers de-termines their relative scope:
111

(2) a. Robin reboots the Mac [frequently] [inten-tionally]. intnl(freq(reboot..))
b. Robin reboots the Mac [intentionally] [fre-quently]. freq(intnl(reboot..))
This stipulation can be eliminated by returning toa lexical-rule (LR)-based analysis like that origi-nally proposed by van Noord and Bouma(see alsoPrzepiorkowski 1999). For convenience, I will for-mulate this as lexical rule as a unary schema thatsimply extends a verb’s ARG-ST list, i.e. as in (3),where the daughter is the ‘LR input’ and the motheris the ‘LR output’:1
(3) Adverb Addition Schema (AAS):Mother:�������������
PHON �SS �LOC �CONT
�� LTOP �HCONS � �� � � RELS � ��
ARG-ST � �� �� LTOP �MOD � LOC � CAT �HEAD verb
CONT � LTOP � ��� ������������������
Dtr:��������PHON �SS �LOC
���� CAT �HEAD verb
CONT
�� LTOP HCONS �RELS � ��
� ���ARG-ST �
� �������The AAS requires that the local top ( � ) of the se-lected adverb is also the verb’s local top. It also en-sures that the local top ( � ) of the daughter verb isless than or equal to the adverb’s MOD value’s localtop ( � ). This means that when a verb combines witha scopal adverbial complement, the verb’s predica-tion will always be within the scope of that adver-bial, as shown in (4). In addition, selected adverbialsmust be able to modify verbal expressions (hence the[HEAD verb] specification in the adverbial’s MOD
1I am aware that by eliminating DEPS, I raise controversialissues about the role of binding theory in the treatment of Prin-ciple C effects, but these are orthogonal to the matters at hand.I follow Copestake et al.’s presentation of MRS throughout. Inparticular, lexical constraints are assumed to ensure that the lo-cal top (a handle) of a verb or a scopal adverb is equal to that ofits predication, modulo quantifiers ( ��� ).
value2):
(4)�����������������
PHON � found SS �LOC �CONT
��������LTOP �RELS
� ��� find-relLBL ARG1 !ARG2 "
���� �HCONS �# � �$ � , � � �
���������ARG-ST
�NP % , NP& , �� LTOP �
MOD � ...HEAD verb...LTOP � � ��'�
������������������Here the selected adverb, if scopal, will have to in-clude the verb’s local top, and hence the verb’s pred-ication, within its scope. The use of ( , rather than)+* , is crucial to my analysis.
Notice that the mother in (3) (the ‘LR output’)says nothing about the KEY value of the verb or thatof the MOD value. In addition, when a verb selectstwo adverbials, the first adverbial’s local top entersinto an ( relation with the local top of the second ad-verbial’s MOD value. This ensures that subsequentscopal adverbials will always outscope prior adver-bials (and that all such adverbials will include theverb’s predication in their scope).
The only two resolved mrs-s that satisfy the con-straints imposed by (4) for an example like (5a) areshown in (5b,c):
(5) a. Kim found a chair in 30 seconds.
b. , LTOP .-RELS �# :found(k,y), � :a(y, ./ , ), / :chair(y), .- :in-30-secs( � ) 10
in-30-secs(a (y, chair(y), found(k,y)))
c. , LTOP -RELS �# � :found(k,y) , - :a(y, ./ , ), / :chair(y) , :in-30-secs( � ) 10
a (y, chair(y), in-30-secs( found(k,y)))
The handle ( 243 ) of the quantifer a is within thepreposition’s scope in (5b), but outside it in (5c).
It is important to understand that the adverbialcomplement’s scope remains ‘clause-bounded’ un-der this proposal. A verb like believe or try selects averbal phrase as complement and lexically identifiesthe local top of the relevant complement with the ap-propriate semantic argument (the second argument
2Note that no further LOC, CAT, SUBCAT or HEAD iden-tity is enforced.
112

of believe-rel or try-rel). Since a VP’s local top willbe identified with that of the rightmost adverbial inan example like (6), all of the adverbs must be withinthe scope of the embedding handle-embedding rela-tion:
(6)VP5
...RELS �# - :try(x, .6 ) 17V5
...LTOP 687 ADV 5...LTOP 7 ...
ADV 65...LTOP 697
In short, this proposal entails that the scope inter-actions of selected scopal adverbials parallel thatof true modifiers, but in the opposite order. (seeCopestake et al. (to appear) discussion of Kim ap-parently almost succeeded. (has only an appar-ently(almost(succeeded(k))) reading).
3 Extracted Adverbials Scope overConjunctions
In head-filler constructions of all sorts, it is rea-sonable to assume that the filler daughter’s CATand INDEX values are identified with those of thehead daughter’s SLASH member.3 Now reconsiderLevine’s example in (1) above. In this case, theCAT and INDEX values of the adverbial filler (thePP in how many minutes flat) will be identified withthose of the SLASH member, which will in turn(via standard HPSG principles governing the inher-itance of SLASH specifications) be identified withthe SLASH members of the selected adverbials, assketched in (7):
(7)
3Given MRS, it would be an unwanted complication to iden-tify the entire CONT value of filler and the gap in a UDC. Iden-tifying the LTOP of the filler daughter with that of the SLASHvalue would also impose unwanted scope restrictions when thefiller is scopal.
�� PH � in,how,many,secs,flat,did,Robin,find,a,chair,sit,down,and,whip,off,hr,lgng,boots
..SLASH :<; ��� PH � in.. ..CAT PP � � PH � did,R.,find..,sit..,and,whip..
..SL : - [CAT ] ; �� PH � did,R. .. � � PH � find..,sit..,and,whip..
..SL : - ; �� PH � find.. ..SL : - ; � � PH � sit..
..SL : - ; � � PH � and,whip.. ..SL : - ; �
The SLASH values also make their way down to theverbs find, sit, and whip, where they are ‘amalga-mated’ from the selected adverbial, as in the BMSanalysis. Making normal assumptions about gaps,the CAT value of each selected adverbial is identi-fied with the CAT value of its SLASH value. SinceMOD is within CAT, it follows that the filler’s MODvalue must outscope each verbal predication.
Following Copestake et al. (to appear), I assumethat conjunctions embed the local tops of the con-juncts as their arguments, roughly as in (8):
(8)
������ PH � find,a,chair,sit,down,and,whip,off,hr,lgng,bts ..RELS
� ��� and-relLBL -ARGS � , � , / ���� ,..
� �������� PH � find.. ..LTOP � � PH � sit..
..LTOP � � � PH � and,whip.. ..LTOP / �
Since each conjunct’s local top is embedded as anargument of the conjunction, the only way the filleradverbial can simultaneously outscope find-rel, sit-rel, and whip-rel) is for that adverbial to outscopethe and-rel (since, given the nature of MRS, the ad-verbial’s relation can only appear once in a resolvedmrs structure). The correct result thus results fromthe resource-sensitive nature of MRS. Assuming avariant of and-rel that provides the appropriate cu-mulative event interpretation discussed by Levine,his example (1) is properly analyzed, as sketched in(9):
113

(9) ������ LTOP -RELS �. .- :how-many(x, , � ), :second(x), � :in( ./ ,x), h / :and(h � ,h = ,h > ), � :a(y, #? , .@ ), #? :chair(y), @ :found(k,y) , = :sit-down(k), A> :whip-off-h-l-boots(k)
� �����Note that the use of ( , rather than )B* (as in Copes-take et al. to appear), is crucial, as this is what allowsthe and-rel to ‘slip in’ to the resolved mrs structure.
4 Further Issues
The question remains of how to deal with other ex-amples involving adverbs that follow a coordinate-structure, e.g. (10)[from Levine 2002]. Exactly thesame analysis developed above extends to these ex-amples if they are analyzed in terms of a rightwardextraction scheme of the sort that would also treatexamples like (11a), where a left-adjoined (true)modifier is within the scope of the right adjoined PPmodifier:
(10) Robin [found a chair, sat down, and whippedoff her logging boots] [in twenty seconds flat].
(11) a. Sandy [[rarely visited a friend] because ofillness].
b. Sandy [rarely [visited a friend because ofillness]].
The because(rarely...) reading associated with(11a) involves rightward extraction of the because-phrase. This should be contrasted with therarely(because...) reading associated with (11b),where the because-phrase is directly realized as acomplement of visited, with rarely modifying the re-sultant VP.
5 Conclusion
The traceless adverb-as-complement analysis isalive and well. It gives a principled answer to theimportant questions raised by Levine about the in-teraction of adverbial extraction and cumulative con-junction, while at the same time providing a coher-ent, unified approach for systematizing the massiveevidence for the A-as-C approach provided by vanNoord and Bouma (1994), Przepiorkowski 1999,
Manning et al., and others. Although I have mod-ified the BMS analysis in three ways, by eliminat-ing DEPS, returning to van Noord and Bouma’s lex-ical rule analysis of adverb addition, and introduc-ing ( constraints, I preserve the elegant account thatBMS provide of the Hukari/Levine (1995) observa-tion that adverb and complement extraction are bothmorphosyntactically registered in all languages thatlocally register extraction dependencies. No analy-sis with ‘wh-traces’ has achieved a comparable re-sult.
References
Bouma, Gosse, Robert Malouf, and Ivan A. Sag.1998. Adjunct Scope and Complex Predicates.Paper presented at the 20th Annual Meetingof the DGfS. Section 8: The Syntax of Ad-verbials – Theoretical and Cross-linguistic As-pects. Halle, Germany.
Bouma, Gosse, Robert Malouf, and Ivan A. Sag.2001. Satisfying Constraints on Extraction andAdjunction. Natural Language and LinguisticTheory. 19.1: 1–65.
van Noord, Gertjan, and Gosse Bouma. 1994.The Scope of Adjuncts and the Processing ofLexical Rules. Proceedings of Coling: Kyoto,Japan.
Copestake, Ann, Dan Flickinger, Carl Pollard, andIvan A. Sag. To appear. Minimal RecursionSemantics: an Introduction. To appear in Re-search on Language and Computation.
Hukari, Thomas E., and Robert D. Levine. 1995.Adjunct Extraction. Journal of Linguistics 31:195–226.
Levine, Robert D. 2002. Adjunct valents: Cu-mulative scoping adverbial constructionsand impossible descriptions. In J. Kim andS. Wechsler, eds., Proceedings of the 9thInternational Conference on Head-DrivenPhrase Structure Grammar, Kyung-Hee Uni-versity, Seoul. Stanford: CSLI Publications.http://cslipublications.stanford.edu/HPSG/3/.Pp. 209–232.
114

Manning, Christopher, Ivan A. Sag, and MasayoIida. 1999. The Lexical Integrity of JapaneseCausatives. In R. D. Levine and G. Green, eds.,Readings in Modern Phrase Structure Gram-mar. Cambridge University Press. Pp. 39–79.
Przepiorkowski, Adam. 1999. Case Assign-ment and the Complement-Adjunct Dichotomy:A Non-Configurational Constraint-Based Ap-proach. Doctoral dissertation, University ofTubingen.
115

116

Selectional Restrictions in HPSG: I’ll eat my hat!
Jan-Philipp SoehnDepartment of German Linguistics, University of Jena
Fürstengraben 28, D-07743 Jena, [email protected]
1 Introduction
The phenomenon of selectional restrictions, first de-scribed by Chomsky (1965, pp. 114ff), is part of almostevery introduction to linguistics. A violation of selec-tional restrictions is the explanation for the oddity of thefollowing examples:1
(1) !Kim ate a motor-bike.
(2) !There is an apple bathing in the water.
The verbeat requires anedible object and the action ofbathingcan be fulfilled only by ananimateactor. Eventhough the view about the role of selectional restrictionsis rather diversified, there is general agreement about thecentral point of compatibility between verbs and their ar-guments.2
Implemented in a natural language processing system,selectional restrictions help with parsing, word-sense dis-ambiguation and the resolving of anaphora. The wordstar in the sentence “The astrologer married a star”is ambiguous between “famous person” and “celestialbody”. However, the example can be disambiguated be-cause we know that the object ofmarry must behuman.
A characteristic of selectional restrictions is that theyare language-specific. This can be illustrated by the verbsdrive andride and their German counterpartsfahrenandreiten. Consider the following data:3
(3) a1) Kim drives a truck/car/!motor-bike/!bike/ !horse
a2) Kim rides a!truck/ !car/motor-bike/bike/horse
b1) Ute fährt ein(en) Lastwagen/Auto/Motorrad/Fahrrad/!Pferd
1A superscript exclamation mark indicates a violation of se-lectional restrictions.
2Selectional restrictions play a role with adjectives andnouns, too. In this contribution we will confine ourselves withthe discussion of verbs.
3The German examples are a nearly word-by-word transla-tion, therefore they are not glossed.
b2) Ute reitet ein(en)!Lastwagen/!Auto/!Motorrad/ !Fahrrad/Pferd
Whereas in Englishdrivemeans a locomotion by operat-ing a motorized vehicle having more than three wheels,the Germanfahren is not sensitive to the number ofwheels of the vehicle. The English wordride denotesa locomotion while sitting on a saddle or seat like on ahorse, the German counterpartreitencan be said only forriding on the back of an animal. Thus, selectional restric-tions are part of language-dependent lexical information.
Does violation of selectional restrictions always resultin an ungrammatical utterance? The answer is no. Inmetonymic, metaphoric or idiomatic utterances, selec-tional restrictions may be violated:
(4) She puts the wine on the table, right next to theglasses.
A metonymy can be found in example (4), for the objectof put is the container (e. g. a bottle), rather than the sub-stance.As abookis notedible, violating the selectional restric-tion of devour, we understand (5) as being metaphoric:
(5) He devoured the book in one single night.
Thus, the violation of selectional restrictions allow us torecognize a nonliteral meaning.
Information from selectional restrictions mark sen-tences as odd only if one has in mind the lexical meaningof the words and a “normal” context of utterance. Thismeans that there is nothing inherently wrong with a sen-tence such as (1), because the reader only has to imaginea suitable context (e. g. eating chocolate motor-bikes). Inaddition, there are certain contextual features that renderexpressions likeate a motor-bikeperfectly grammatical.These “repairing contexts” (cf. Chomsky, 1965, p. 158and Androutsopoulos and Dale, 2000, p. 1) neutralizeviolations of selectional restrictions and the sentence isfully interpretable:
(6) a) !Kim ate a motor-bike.
117

b) Kim did not eat a motor-bike.
c) One cannot eat motor-bikes.
d) Kim tries to eat a motor-bike./Kim be-lieves/dreames that she can eat motor-bikes.
e) I’ll eat my hat if Kim ate a motor-bike.
f) Did Kim really eat a motor-bike?
The repairing contexts are negation (6 b), modals andnegation (c), epistemic verbs asbelieve, try, etc. whosearguments introduce a state-of-affairs in a possible – notthe actual – world (d), conditionals (e) and questions(f).4 Thus, a violation of selectional restrictions is highlycontext sensitive. Therefore, Androutsopoulos and Daleargue that selectional restrictions are a pragmatic phe-nomenon.
To sum up, we have so far seen that, on the one hand,selectional restrictions are part of the lexical informa-tion. On the other hand, a violation of selectional re-strictions does not mean that the expression becomes to-tally uninterpretable, but some context features may re-pair the violation or a suitable context-of-utterance evenrenders the expression perfectly inconspicuous. In ourview, one can account for these facts best when regardingthe phenomenon of selectional restrictions as part of thesemantics-pragmatics-interface.
2 Selectional Restrictions in HPSG
2.1 Previous Approaches
There are not many publications about selectional restric-tions in HPSG. We only know about those of Nerbonne(1996) and Androutsopoulos and Dale (2000).
In his article, Nerbonne focuses on topics which arerelated to the processing of semantic information. In or-der to disambiguate the sense ofchair in the example“The chair decided on Mary” he introduces a new fea-tureM-AGT for “mental agent” within the semantics mod-ule. Thus one can distinguish between the two meanings“piece of furniture” and “head of organization”. How-ever, the author does not make clear what other featureswould be necessary and a worked-out concept of selec-tional or sortal constraints is far beyond the focus of Ner-bonne’s contribution.
A more concrete proposal for handling selectionalrestrictions is described by Androutsopoulos and Dale(op. cit.). The authors describe two alternative ap-proaches. In their first proposal Androutsopoulos andDale adopt a pragmatic point of view, putting all relevantinformation about a verb’s selectional restrictions on theBACKGROUND set of the verb. They argue that selec-tional restrictions belong to the non-literal information,which is always situated inCONTEXT BACKGROUND, in
4Chomsky (1965, p. 158) also mentions meta-linguistic ex-pressions likeIt is not a good idea to eat motor-bikes.
contrast to literal information, which is to be handled inthe CONTENT. For this approach the authors need an in-ferencing component which compares the relevant psoasto rule out signs corresponding to readings that violate aselectional restriction. This “constraint-satisfactionrea-soning” would have to be pipe-lined after the parser ofa natural language processor, because the informationcomes from a semantic hierarchy and has to be comparedwith the arguments present.
In their alternative approach Androutsopoulos andDale treat selectional restrictions exclusively withinCONTENT. They introduce a sortal hierarchy belowindex. So theINDEX value of the object ofeat can beconstrained to be of sortedible. This approach is moreefficient for NLP applications. However, it yields an im-mediate failure of analysis when there is a violation ofselectional restrictions and so does Nerbonne’s proposal.Neither approach takes into account the effect of a repair-ing context. Only the first alternative by Androutsopoulosand Dale seems to be capable of being sensitive to con-textual effects but, regrettably, the authors do not explainhow this might work.
2.2 Our Proposal
As we have argued above, the phenomenon of selectionalrestrictions can be best accounted for by regarding it aspart of the semantics-pragmatics-interface. The idea isto put the relevant information into theBACKGROUND
set (BGR) of the CONTEXT of a sign and use structure-sharing with respective semantic indices. Contrary to thefirst proposal by Androutsopoulos and Dale (op. cit.) weintroduce a semantic hierarchy with new sorts and rela-tions as part of everyunembedded-sign. Thus, we avoidthe need for a separate inferencing component.
Unembedded signs are potential stand-alone utter-ances. According to Richter (2004, ch. 2.1.2), theyare empirical objects and central to linguistic research.Richter argues already in (1997, ch. 5.2) that a more fine-grained distinction ofsigns is necessary. In the signaturewhich he develops, every subsort ofsigncan occur as anembedded and as an unembedded version. Major differ-ences between embedded and unembedded signs are thatthe latter do not contain any unbound traces (if one as-sumes that traces exist) and that they have illocutionaryforce.
As a first step, we define two new elements to figure onthe BGR set. These are, following standard assumptions,subsorts ofpsoa.[
sel-restr-impARG indexMUST-SATISFY selection-sort
][sel-restr-stfARG indexSATISFIES selection-sort
]
The first psoa can be introduced toBGR by signs whichimpose a selectional restriction.5 A verb, e. g. eat, can
5sel-restr-impfor imposed
118

subcategorize for a noun with a certain restriction. Nounssuch asapplesatisfy this restriction.6 They have also in-cluded this information in theirBGR set.
The phrase„. . . eats apples“is sketched in Fig. 1. Thecollection of all elements in allBGR sets is guaranteedby theCONTEXTUAL-CONSISTENCY-PRINCIPLE, whichexists independently of our proposal.
As a second step we introduce a principle which en-sures that the values ofMUST-SATISFY (M-STF) andSATISFIES(STF) in theCTXT BGR set are compatible. Tobe compatible means that theSTF value of the argumentof eat is either identical to theM-STF value of the verbitself, or that theSTFvalue is a sub-element of theM-STF
value in a semantic ontology. In other terms, the verbonly requires an edible object, whereas the object itselfcan be more concrete – a pancake or a banana.
The principle should license only phrases which havecompatible values ofM-STF andSTF – but only if the ar-gument or the whole proposition is outside the scope of anegational, a conditional or a question-operator. As statedabove, these contexts “repair” the effect of a violation ofselectional restrictions.
(7) VALIDITY -PRINCIPLE OFSELECTIONAL
RESTRICTIONS(VPSR, preliminary version):If in a phrasex there is a signs, a verbv (s is anargument ofv) and a propositionp, which is formedby v and its arguments, andif neither the meaning associated withs nor themeaning associated withp are within the scope ofa negational operator, a conditional operator or aquestion-operator or an epistemic verb,then theSTF value of asel-rest-stfelement in theCTXT BGR set of x and the M-STF value of asel-restr-impelement that shares theARG value withsel-rest-stfmust be compatible.
How can we capture this compatibility formally? Thevalues ofM-STF and STF are a subsort of the newly-introducedselection-sort, cf. Fig. 2. This sort has a finitenumber of subsorts such asabstract, physical, artifact,animate, edible,. . . which correspond to units of a seman-tic ontology as in WordNet7 or GermaNet8. In Fig. 3, weroughly sketch such a semantic ontology, including mul-tiple inheritance (subunits inherit from more than one su-perunit). In such an ontology the units are related to eachother, indicated by the tree-structure. We want to estab-lish such relations between the subsorts ofselection-sort,too.
A sort hierarchy, as used for the normal HPSG sort in-ventory, cannot be adopted here. An HPSG formalism
6sel-restr-stffor satisfies7cf. Christiane Fellbaum, ed. (1998):Wordnet: An Elec-
tronic Lexical Database. Bradford Books, The MIT Press.8cf. http://www.sfs.nphil.uni-tuebingen.de/lsd/
for Pollard/Sag-style grammars (as RSRL e.g. Richteret al., 1999) requires that objects be sort-resolved. Thisallows us to talk about objects having maximally spe-cific sorts on the one hand and about underspecified de-scriptions (among them lexical entries) on the other. Ifwe had a sort hierarchy forselection-sortanalogous tothe one in Fig. 3, we could not capture generalizationssuch as, e. g., thateat takes somethingedibleas its ob-ject, for edibleis not maximally specific. To clarify thispoint, we still take our example ofeat which the lexi-cal constraint to have anedible object. Consider a con-crete utterance “She eats pancakes.” where there is anoun-object with
[STF pancake
], which is the argument of
a verbal objecteatwith an arbitrary, maximally specificvalue
[M-STF banana
]. Even thoughbananais a subsort
of edible (the constraint in the lexical entry of the verbthus is fulfilled), the two sortsbananaandpancakearestill incompatible and the selectional restriction seems tobe violated. This shows that we need sorts such asedible,which are somewhere in the middle of the hierarchy, asvalues in sort-resolved objects.
Thus we insert the subsorts ofselection-sortinto thesignature as depicted in Fig. 2. The relations have to bedefined separately, e. g. they can be collected in a list.This list is the value of a new attributeHIERARCHY,which we define for all unembedded signs. It containspairs of subsorts ofselection-sortbeing in an “is a”-relation. Formally this is a partial order of the elementsbelow selection-sort. The following principle describesthe list and defines it as the value ofHIERARCHY for ev-ery unembedded sign.
(8) SELECTION-HIERARCHY-PRINCIPLE (outlined):unembedded-sign→HIERARCHY
⟨[
is_aARG1 animateARG2 animate
],
[is_aARG1 animateARG2 person
],
[is_aARG1 animateARG2 animal
],...
⟩
We do not mean that theHIERARCHY, which can eas-ily get quite big, is a genuine “linguistic” part of ev-ery unembedded sign. We only want to express the factthat every speaker has access to this kind of knowledgewhen formulating or hearing an utterance. Technicallybut not conceptually, this amounts to the same. Defin-ing HIERARCHY as a feature ofunembedded-signallowsus to determine the grammaticality of each unembeddedsign without additional context. Thus we do not have topostpone the treatment of selectional restrictions to a sep-arate inferencing component but we can recognize the se-mantical ill-formedness immediately for each unembed-ded sign.
Returning back to our selectional restriction approach,we recapitulate: compatibility ofselection-sorts means
119

that there is an “is-a”-relation between the values ofMUST-SATISFY andSATISFIES. This relation can containone or more intermediate sorts; it is transitive.
(9) She drank a sip of the Cabernet Sauvignon 2001.
This example is about a special kind of wine.CabernetSauvignonis wine, whichis an alcoholic beverage, whichis a beverage, whichis drinkable. The example showsthat such an ontology becomes remarkably complex. Atthis point we have to admit that it is very easy to postulateand outline such ontologies. However, the implementionrequires a lot of work, particularly when accounting forall the theoretical and empirical problems such a projectraises (for a successful project cf. the one mentioned infootnote 7).
Having formalized the notion of compatibility, we cannow reformulate the VPSR in the following way.
(10) VALIDITY -PRINCIPLE OFSELECTIONAL
RESTRICTIONS(VPSR, final version):If in an unembedded signx there is a signs, a verbv (s is an argument ofv) and a propositionp, whichis formed byv and its arguments, andif neither the meaning associated withs nor themeaning associated withp are within the scope ofa negational operator, a conditional operator or aquestion-operator or an epistemic verb,then theSTF value of asel-rest-stfelement in theCTXT BGR set of x and the M-STF value of asel-restr-impelement that shares theARG value withsel-rest-stfmust be in a relation on theHIERARCHY
list of x.
3 Summary
We have proposed a way to integrate selectional restric-tions into HPSG which includes the effects of repairingcontexts. Restrictions are imposed by the verbs in theirlexical entries and have to be satisfied by the verbs’ argu-ments. If the argument is within the scope of a repairingoperator, the whole sign is not ungrammatical – it is li-censed by the VPSR.9
A further application of our approach might be thehandling of metonymy (see e. g. Egg, 2004). It requiresa certain amount of world knowledge to understand ametonymic utterance. For example, one has to know thatwine, like every other drinkable liquid, is normally stored
9One argument we have disregarded is that a violation ofselectional restrictions gets repaired by a certain kind ofcon-texts like fairy tales of science fiction stories. To accountforthis kind of contextual shift one would have to assume a morefine-grained structure in theCONTEXT and distinguish betweena standard context and an active context. Moreover, one wouldneed relations which can take over standard assumptions (foot-balls are not edible) to the actual context or which can introducenew scenarios (starships can travel faster than light).
in a container, which can be placed on a table, cf. (4).Thus, for a metonymic utterance to be felicitous, a cer-tain relation must hold between an element in the utter-ance and another object, as e. g.in_container, has_partor consists_of. These relations could be defined for allsorts in theHIERARCHY list. As we have already imple-mented theis_a-relation there, some generalizations canbe captured in an elegant way.
Acknowledgements
The research to the paper was funded by theDeutscheForschungsgemeinschaft. I am grateful to Frank Richter,Manfred Sailer, Janina Radó, Adrian Simpson and the re-viewers of HPSG’05 for comments and Michelle Wilbra-ham for help with English.
References
Androutsopoulos, Ion and Dale, Robert (2000). Selec-tional Restrictions in HPSG. InProceedings of COL-ING 2000, Saarbrücken, pp. 15–20.
Chomsky, Noam (1965).Aspects of the Theory of Syntax.MIT Press, Cambridge, MA.
Egg, Markus (2004). Metonymie als Phänomender Semantik-Pragmatik-Schnittstelle.metaphorik.de(Online-Journal), ISSN 1618-2006 6, 36–53.
Nerbonne, John (1996). Computational Semantics – Lin-guistics and Processing. In S. Lappin (Ed.),Hand-book of Contemporary Semantic Theory, pp. 459–482.Blackwell Publishers, London.
Richter, Frank (1997). Die Satzstruktur des Deutschenund die Behandlung langer Abhängigkeiten in einerLinearisierungsgrammatik. Formale Grundlagen undImplementierung in einem HPSG-Fragment. InE. Hinrichs, D. Meurers, F. Richter, M. Sailer,and H. Winhart (Eds.),Ein HPSG-Fragment desDeutschen, Teil 1: Theorie, Number 95 in Arbeitspa-piere des SFB 340, pp. 13–187. Universität Tübingen.
Richter, Frank (2004).Foundations of Lexical ResourceSemantics. Professorial dissertation (version of 09-24-2004), Eberhard-Karls-Universität Tübingen.
Richter, Frank, Sailer, Manfred, and Penn, Gerald (1999).A Formal Interpretation of Relations and Quantifica-tion in HPSG. In G. Bouma, E. Hinrichs, G.-J. M.Kruijff, and R. Oehrle (Eds.),Constraints and Re-sources in Natural Language Syntax and Semantics,pp. 281–298. Stanford: CSLI Publications.
120

PHON⟨eats apples
⟩
SS
LOC
CAT
[HEAD 1
SUBCAT⟨
2⟩]
CTXT[
BGR{
..., 4 , 5 ,...}]
DTRS
H-DTR
PHON⟨eats
⟩
SS LOC
CAT
[HEAD 1 verb
SUBCAT⟨
2 NP, 6⟩]
CONT
[INDEX
[PERSON 3rdNUMBER sing
]]
CTXT
BGR
..., 4
sel-restr-imp
ARG 3
MUST-SATISFY edible
,...
C-DTRS
⟨
PHON⟨apples
⟩
SS 6 LOC
CAT[
HEAD noun]
CONT[
INDEX 3 NUMBER plural]
CTXT
BGR
..., 5
sel-restr-stf
ARG 3
SATISFIESapple
,...
⟩
Figure 1: Phrase including selectional restrictions
abstract physical animate inanimate edible person . . .
selection-sort(belowobject)
Figure 2: The sortselection-sort
top
abstract physical
animate edible inanimate . . .
person animal n_artfct artifact
. . . man teacher . . . edible_animal edible_n_artfct . . . motor-bike
. . . man_teach . . . chicken . . . . . . apple
Figure 3: A semantic ontology
121

122

Projecting RMRS from TIGER Dependencies
Kathrin SpreyerComputational Linguistics Department
Saarland UniversityD-66041 Saarbrucken, Germany
Anette FrankLanguage Technology Lab
DFKI GmbHD-66123 Saarbrucken, Germany
1 Introduction
Since the successful exploitation of treebanks fortraining stochastic parsers, treebanks are under de-velopment for many languages. Treebanks furtherenable evaluation and benchmarking of competitiveparsing and grammar models. While parser evalua-tion against treebanks is most natural for treebank-derived grammars, it is extremely difficult for hand-crafted grammars that represent higher-level func-tional or semantic information, such as LFG, HPSG,or CCG grammars (cf. Carroll et al., 2002).
In a recent joint initiative, the TIGER project pro-vides dependency-based treebank representationsfor German, on the basis of the TIGER treebank(Brants et al., 2002). Forst (2003) applied tree-bank conversion methods to the TIGER treebank,to derive an f-structure bank for stochastic trainingand evaluation of a German LFG parser. A moregeneral, theory-neutral dependency representation iscurrently derived from this TIGER-LFG treebank,to enable cross-framework parser evaluation (Forstet al., 2004). However, while Penn-treebank stylegrammars and LFG analyses are relatively close todependency representations (cf. Crouch et al., 2002;Kaplan et al., 2004), the situation is different forgrammar formalisms that deliver deeper semanticrepresentations, such as HPSG or CCG.
In order to provide a closer evaluation standardand appropriate training material for German HPSGgrammars, we propose a method for the semi-automatic construction of an RMRS treebank forGerman on the basis of the LFG- resp. TIGER-Dependency Bank. In contrast to treebanks con-
structed from analyses of hand-crafted grammars,the RMRS treebank constitutes a standard for com-parative parser evaluation where the upper boundfor coverage is defined by the corpus (here, Germannewspaper text), not by the grammar.
Our treebank conversion method effectively im-plements RMRS semantics construction from de-pendency structures, and can be further developed toa general method for RMRS construction from LFGf-structures, similar to recent work in the LOGONproject.1
2 The TIGER Dependency Bank
The input to our treebank conversion process con-sists of dependency representations of the TIGERDependency Bank (TIGER-DB). The TIGER-DBis derived from (a subset of) the TIGER treebank.It abstracts away from constituency in order to re-main as theory-neutral as possible. The TIGER-DBis derived semi-automatically from the TIGER-LFGBank of Forst (2003), by defining various normalisa-tions. The dependency format is similar to the Parc700 Dependency Bank (King et al., 2003). So-calleddependency triples are sets of two-place predicatesthat encode grammatical relations. The argumentsrepresent the head of the dependency and the depen-dent, respectively. The triples further retain a num-ber of morphological features from the LFG repre-sentations, such as agreement information for nom-inals and adjectives, or tense information. Figure 1displays a sample dependency representation.
1See the online demo for LFG-based MRS semantics con-struction for Norwegian, as currently used in the LOGONproject: http://decentius.aksis.uib.no:8010/logon/xle-mrs.xml
123

sb(m ussen ~0, Museum ~1)case(Museum ~1, nom)gend(Museum ~1, neut)num(Museum~1, sg)mod(Museum~1, privat ~1001)cmpd lemma(Museum~1, Privatmuseum)oc inf(m ussen ~0, weichen ~3)mood(mussen ~0, ind)tense(m ussen ~0, pres)sb(weichen ~3, Museum ~1)
Figure 1: TIGER-DB structure forPrivatmuseummuss weichen– Private museum deemed to vanish.
However, dependency structures are difficult tomatch against the output of HPSG parsing. HPSGanalyses do not come with an explicit representationof functional structure, but directly encode semanticstructures, in terms of MRS (Copestake et al., 2005)or RMRS (Copestake, 2003). This leaves a gap to bebridged in terms of normalisation of diathesis, theencoding of arguments vs. adjuncts, the represen-tation of constructions like relative clauses, and therepresentation of quantifiers and their scoping rela-tions.
In order to provide a gold standard that can bematched against the output of HPSG parsing forevaluation, and further, for training stochastic gram-mar models, we propose a method for treebank con-version that essentially performs RMRS construc-tion from LFG-based dependency representations.
For the purpose of semantics construction, thetriples format has both advantages and disadvan-tages. On the one hand, the LFG-derived dependen-cies offer all the advantages of a functional as op-posed to a constituency-based representation. Thisrepresentation already filters out the semantically in-appropriate status of auxiliaries as heads; their con-tribution is encoded by features such asperf orfut , which can be directly translated into featuresof semantic event variables. Most importantly, thetriples localize dependencies which are not locallyrealized in terms of phrase structure (as e. g. in con-trol structures, coordination, or long-distance con-structions), so that when constructing the semanticsfrom the dependency format, we do not need ad-ditional mechanisms to identify the arguments of agoverning predicate.
The challenges we face mainly concern the lackof constituency information in the dependency rep-
resentations. While standard definitions of the prin-ciples for (R)MRS construction refer to constituencyinformation, we now have to define RMRS compo-sition on the basis of dependency relations.
3 RMRS Construction from TIGERDependency Structures
3.1 Treebank Conversion by Term Rewriting
Similar to Forst (2003) we are using the term rewrit-ing system of Crouch (2005) for treebank conver-sion. Originally designed for Machine Translation,the system is a powerful tool for structure rewrit-ing that is also applied to other areas of NLP, suchas induction of knowledge representations (Crouch,2005).
The input to the system consists of a set of factsin a prolog-like term representation. The rewriterules refer to these facts in the left-hand side (LHS),either conjunctively (expressed by separating con-juncts with a comma ‘, ’) or disjunctively (expressedby ‘|’). Expressions on the LHS may be negated bya prefixed ‘- ’, thereby encoding negative constraintsfor matching. A rule applies if and only if all factsspecified on the LHS are satisfied by the input set offacts. The right-hand side (RHS) of a rewrite ruledefines a conjunction of facts which are added to theinput set of facts if the rule applies. The system fur-ther allows the user to specify whether a matchedfact will be consumed (i. e., removed from the setof facts) or whether it will be retained in the rule’soutput set of facts (marked by the prefix ‘+’).
The processing of rules isstrictly ordered. Therules are applied in the order of textual appearance.Each rule is tested against the current input set offacts and, if it matches, produces an output set offacts that provides the input for the next rule in se-quence. Each rule applies concurrently to all distinctsets of matching facts, i.e. it performs parallel appli-cation in case of alternative matching facts.
The system offers powerful rule encoding facili-ties: Macros are parameterized patterns of (possiblydisjunctive) facts; templates are parameterized ab-stractions over entire (disjunctive) rule applications.These abstraction means help the user to define rulesin a perspicious and modular way.
124

3.2 RMRS Construction
Within the formal framework of HPSG, every lexicalitem defines a complete RMRS structure. Seman-tics composition rules are defined in parallel withsyntactic composition. In each composition step,the RMRSs of the daughters are combined accord-ing to strict semantic composition rules, to yield theRMRS representation of the phrase (cf. Copestakeet al., 2001). Following the scaffolding of the syn-tactic structure in this way finally yields the semanticrepresentation of the sentence.
For our task, the input to semantics construction isa dependency structure. As established by work onGlue Semantics (Dalrymple, 1999), semantics con-struction from dependency structures can in similarways proceed recursively, to deliver a semantic pro-jection of the sentence. However, the resource-basedconstruction mechanism of Glue Semantics leads toalternative derivations in case of scope ambiguities.
In contrast to Glue, we target an underspeci-fied semantic representation. Although defined onphrasal configurations, the algebra for (R)MRS con-truction as defined in Copestake et al. (2001) canbe transposed to composition on the basis of depen-dency relations, much alike the Glue framework.
Yet, the rewriting system we are using is notsuited for a recursive application scheme: the rulesare strictly ordered, and each rule simultaneouslyapplies to all facts that satisfy the constraints. Thatis, the RMRS composition cannot recursively fol-low the composition of dependents in a given inputstructure.
The RMRS Skeleton. RMRS construction is thusdesigned around oneglobal RMRS, featuring a TOP
label, a RELS set containing theelementary pred-ications (EPs), a set HCONS of handle constraintswhich state restrictions on possible scopes, and a setof ING constraints that represent thein-group rela-tion.2
Instead of projecting and accumulating RMRSconstraints step-wise by recursive phrasal composi-tion rules from the lexical items to the top level ofthe sentence, we directly insert all EPS, ING and
2Whenever two handles are related via an ing constraint,they can be understood to be conjoined. This is relevant, e.g.,for intersective modification, since a quantifier that outscopesthe modified noun must also take scope over the modifier.
HCONS constraints into the global RMRS, i.e. theRMRS with the top handle. The semantics compo-sition rules are thus reduced to the inherent semanticoperations of the algebra of Copestake et al. (2001):the binding of argument variables and the encodingof scope constraints. These basic semantic opera-tions are defined by appropriate definitions and op-erations on the HOOK features in the compositionrules.
Lexical RMRSs. The notion oflexical RMRSsasit is defined here slightly differs from the standardone. If semantic composition proceeds along a treestructure, lexical RMRSs are constructed at the leafnodes. In our scenario, a lexical RMRS is projectedfrom the PRED features in the dependency struc-tures, irrespective of any arguments, which are con-sidered by subsequent composition rules.
We define the lexical RMRSs in two steps: First,the hook label is (freely) instantiated and thus avail-able for reference to this RMRS by other rules. Sec-ond, the hook variable and the basic semantics (EPsfor the relation and the ARG0, at least) are intro-duced on the basis of the predicate’s category. Thiscategory information is not explicit in the depen-dencies, but it can be induced from the grammaticalfunction borne by the predicate, as well as the pres-ence or absence of certain morphological features.
Figure 2 shows a sample lexical RMRS and therule that yields it: The rule applies to predicates, i.e.to pred features, with a valuePred and a hook la-belLb . In the RHS, one EP is added for the relationrepresented byPred , and one for the ARG0, whichis identified with the hook variable.3
Composition. The semantic composition of argu-ments and functors makes use of an attributearg()which encodes the argument structure of the predi-cates.4 Given a predicatearg(Fctor,N,Arg) ,
3In fact, for modifiers and specifiers we define lexicalRMRSs in a special way, in that we immediately bind the se-mantic argument. The motivation for this is that whenever oneof the dependency relationsmo or spec are encountered, nomatter what their exactPred value may be, the semantics con-tributed by the head of this dependency can be unambiguouslyrelated to the semantic head, and is thus recorded already atthe“lexical” level.
4As explained below, the information about subcategorizedarguments is reconstructed from the triples, in the predicatearg(Fctor,N,Arg) , whereN encodes the argument posi-tion, Fctor andArg are indices of functor and argument, re-
125

(a) add ep(Lb,Type,Feat,Val) ::+rels( ,Rels)
==> ep(Rels,EP), type(EP,Type), lb(EP,Lb),complex term(Feat,EP,Val).
(b) +pred(X,Pred), -mo( ,X), -spec( ,X),+’s::’(X,SemX), +hook(SemX,Hook), +lb(Hook,Lb)
==> var(Hook,Var)&& add ep(Lb,ep rel,rel,Pred)&& add ep(Lb,ep arg0,arg0,Var).
(c)
TOP handle
RELS
{. . .,
[Riese n
LB h
ARG0 x
], . . .
}
HCONS{
. . .
}I NG
{. . .
}
Figure 2: (a) Expansion ofadd ep template, (b) a rule with a template call, (c) the output lexical RMRS.
(a) +arg(X,2,Arg), +g f(Arg,’oc fin’), sort(Lb,h), sort(LbPrpstn,h)get lb(X,LbX), get lb(Arg,LbArg), == > && add ep(LbX,ep arg2,argx,LbPrpstn)+comp form(Arg,dass) && add ep(LbPrpstn,ep rel,rel,’prpstn mrel’)
&& add ep(LbPrpstn,ep arg0,arg0,Lb)&& add qeq(Lb,LbArg).
(b)
TOP handle
RELS
. . .,
hoffenv
LB 1
ARG0 e
ARG1 x
ARG2 2
,
[prpstnm rel
LB 2
ARG0 3
],
entlassenv
LB 4
ARG0 e
ARG1 u
ARG2 x
ARG3 x
, . . .
HCONS{
. . ., 3 qeq 4 , . . .
}
Figure 3: (a) Sample argument binding rule and (b) output RMRS.
the binding of the argument to the functor is steeredby the previously defined hooks of the two semanticentities in that the matching rule attaches an EP withan attribute ARGN to the externalized label in thefunctor’s hook. The value of the attribute ARGN isthe hook variable of the argument. A slightly morecomplicated example is shown in Figure 3, it fea-tures the introduction of an additional propositionand a scope constraint. This rule binds a declarative(marked by the complementizerdass) finite clausalobject (oc fin ) to the verb it is an argument of.To achieve this binding, a proposition relation is as-signed as the value of the verb’s ARG2, and thisproposition in turn has an ARG0, which takes scopeover the hook label of the matrix verb in the objectclause (for the definition of the templateadd ep ,see Figure 2; the templateadd qeq works simi-larly: It adds a qeq constraint to the set of handleconstraints). In general, the binding of argumentsdoes not depend on the order of rule applications.That is, the fact that the system performs concur-rent rule applications in a cascaded rule set is notproblematic for semantics construction. Though, we
spectively.
have to make sure that every partial structure is as-signed a hook, prior to the application of composi-tion rules. This is ensured by stating the rules forlexical RMRSs first.
Scope constraints. In having the rules introducehandle constraints, we define restrictions on the pos-sible scoped readings. These are defined maximallyrestrictive in the sense that they must allow for alland only the admissible scopes. This is achieved bygradually adding qeq relations to the global HCONS
set. Typically, this constraint relates a handle argu-ment of a scopal element, e. g. a quantifier, and thelabel of the outscoped element. However, we cannotalways fully predict the interaction among severalscoping elements. This is the case, inter alia, for themodification of verbs by more than one scopal ad-verb. This type of ambiguity is modeled by meansof a UDRT-style underspecification, that is, we leavethe scope among the modifiers unspecified, but re-strict each to outscope the verb handle.5
5This is in accordance with the German HPSG grammar, andwill also be adapted in the ERG (p.c. D. Flickinger).
126

3.3 Challenges
Some aspects of semantic composition crucially de-pend on lexical and phrase structural informationwhich is not available from the dependencies. Herewe briefly point out the problems and how we solvedthem.
Argument Structure. Although LFG grammarsexplicitly encode argument structure in the seman-tic form of the predicate, the derived dependencytriples only record the atomic PRED value. We re-cover the missing information by way of prepro-cessing rules. The rules make reference to the lo-cal grammatical functions of a predicate, and testfor features typically borne by non-arguments, forinstance, expletives can be identified via the featurepron type( ,expl) . In the composition step,the resultingarg predicates will be interpreted astheslotsthat a functor needs to fill.
The TIGER-DB does not provide informationabout control properties of equi-verbs, nor do theymark scopal modifiers. We extracted lexical entriesfrom the broad-coverage German HPSG, and inter-leave them with the rules for semantics construction,to ensure their proper representation.
Constituency. It is often assumed that there isa crucial difference between the semantics of VP-modification and that of S-modification. Thus, weare faced with the problem that no distinction what-soever is drawn between heads and their projectionsin the dependency structures. Hence, we restrictscope with respect to the verb, but do not excludethe proposition-modifying reading.
Similarly, coordination is represented as a setof conjuncts in the triples, but to meet the binarybranching coordination analysis of HPSG, we mustconstruct a recursive semantic embedding of partialcoordinations. The rules process the conjuncts in aright-to-left manner, each time combining the par-tial coordination to the right with the conjunct on theleft, thereby building a left-branching coordination.
3.4 Treebank Construction and QualityControl
TIGER 700 RMRS Treebank. Our aim is to con-struct a treebank of 700 sentences from the TIGERdependency bank. Instead of selecting a random
sample of sentences, we opt for a block of consecu-tive sentences. In this way, the treebank can be fur-ther extended by annotations for intersentential phe-nomena, such as co-reference relations, or discourserelations.
However, we have to accommodate for gaps, dueto sentences for which there are reasonable func-tional syntactic, but (currently) no sound semanticanalyses. This problem arises for sentences involv-ing, e.g., elliptical constructions, or else ungrammat-ical or fragmented sentences. We will include, butexplicitly mark such sentences for which we can ob-tain partial, but no fully sound semantic analyses.We will correspondingly extend the annotation setto yield a total of 700 correctly annotated sentences.
Automatic Conversion and Quality Control.Currently, we have covered the main body ofrewrite rules for converting dependency structuresto RMRSs. The grammar comprises about 70 rules,15 macros and templates. In the next step we willimplement a cascaded approach for quality control,with an initial feedback loop between (i) and (ii):
(i) Manual phenomenon-based error-detection. Inthe construction process, we mark the application ofconstruction rules by inserting phenomenon-specificidentifiers, and use these to select sample RMRSsfor phenomenon-based inspection, both in the de-velopment phase and for final quality control.
(ii) Investigation of detected errors can result inthe improvement of automatic RMRS construction(feedback loop to (i)). Errors that cannot be coveredby general rules need to be adjusted manually.
(iii) Manual control. Finally, we need to performmanual control and correction of errors that couldnot be covered by automatic RMRS construction. Inthis phase, we will mark and separate the structuresor phenomena that are not covered by the state-of-the-art in RMRS-based semantic theory.
4 Conclusion
We have presented a method for semantics con-struction which converts dependency structures to(R)MRSs as they are output by HPSG grammars.This approach allows cross-framework parser evalu-ation on a broad-coverage basis, and can be appliedto existing dependency banks for English (e. g. Kinget al. (2003)).
127

References
Brants, S., Dipper, S., Hansen, S., Lezius, W., andSmith, G. (2002). The TIGER Treebank. InPro-ceedings of the Workshop on Treebanks and Lin-guistic Theories, Sozopol, Bulgaria.
Carroll, J., Frank, A., Lin, D., Prescher, D., andUszkoreit, H., editors (2002).Beyond PARSE-VAL – Towards Improved Evaluation Measuresfor Parsing Systems, Workshop Proceedings ofthe Third International Conference on LanguageResources and Evaluation, LREC 2002 Confer-ence, Las Palmas, Gran Canaria.
Copestake, A. (2003). Report on the Design ofRMRS. Technical Report D1.1a, University ofCambridge, University of Cambridge, UK. 23pages.
Copestake, A., Flickinger, D., Sag, I., and Pollard,C. (2005). Minimal Recursion Semantics. to ap-pear.
Copestake, A., Lascarides, A., and Flickinger, D.(2001). An Algebra for Semantic Constructionin Constraint-based Grammars. InProceedings ofthe ACL 2001, Toulouse, France.
Crouch, R. (2005). Packed Rewriting for MappingSemantics to KR. InProceedings of the Sixth In-ternational Workshop on Computational Seman-tics, IWCS-06, Tilburg, The Netherlands.
Crouch, R., Kaplan, R., King, T., and Riezler, S.(2002). A comparison of evaluation metrics fora broad coverage parser. InBeyond PARSEVAL.Workshop at the LREC 2002 Conference, Las Pal-mas.
Dalrymple, M., editor (1999).Semantics and Syntaxin Lexical Functional Grammar: The ResourceLogic Approach. MIT Press.
Forst, M. (2003). Treebank Conversion – Establish-ing a testsuite for a broad-coverage LFG from theTIGER treebank. InProceedings of LINC’03, Bu-dapest, Hungary.
Forst, M., Bertomeu, N., Crysmann, B., Fouvry,F., Hansen-Schirra, S., and Kordoni, V. (2004).Towards a Dependency-Based Gold Standard forGerman Parsers: The Tiger Dependency Bank.In Hansen-Schirra, S., Oepen, S., and Uszkoreit,
H., editors,Proceedings of LINC 2004, Geneva,Switzerland.
Kaplan, R., Riezler, S., King, T., Maxwell, J.,Vasserman, A., and Crouch, R. (2004). Speed andaccuracy in shallow and deep stochastic parsing.In Proceedings of HLT-NAACL’04, Boston, MA.
King, T., Crouch, R., Riezler, S., Dalrymple, M., andKaplan, R. (2003). The PARC 700 DependencyBank. InProceedings of LINC 2003, Budapest.
128

Free Relatives in Persian
Mehran Taghvaipour Department of Language and Linguistics
University of Essex Colchester CO4 3SQ
1 Data
Like in English, free relatives (FRs) in Persian are Unbounded Dependency Constructions (UDCs). Persian FRs may contain a gap or a resumptive pronoun (RP) which is linked to and licensed by the FR word. Example (1) shows a Persian FR in brackets1. (1) Yasmin [hærči Amy ____ xærideh.bud] Yasmin whatever Amy ____ had.bought ra2 bærdašt. RA took-3sg ‘Yasmin took whatever Amy had bought.’ Example (2) shows a Persian FR with a RP. (2) [hærki beš pul dadim] umæd. whoever to-him money gave-1sg came-3sg ‘Whoever we gave money to came.’ The structure of FRs is bipartite, containing a phrasal part (‘relative phrase’) and a sentential part. This is illustrated in (3). 1 The FR in (1) is nominal. Other types of FRs, such as adjec-tival or adverbial, are also possible in Persian; however, I shall focus on nominal FRs here. 2 This particle (whose colloquial form is ro or simply -o) is a specificity marker (Karimi, 1989). It comes after an NP when the NP is specific and is not in the position of subject of object of preposition.
(3)
NP (free relative)
NP (relative phrase) S hærči Amy ____ xærideh.bud whatever Amy ____ had.bought Persian FRs come only in non-specific form. That is, the relative phrase always contains a word which is accompanied by the prefix hær, ‘-ever’. Also, as in most languages (e.g., English) the range of wh-words that can appear in Persian FRs is re-stricted. However, what is more interesting in Per-sian is that free relative words are not restricted to wh-words. For example, for hærki, ‘whoever’, we can have ‘hærkæs’, which is a combination of hær, ‘-ever’, and the noun kæs, ‘person’. Therefore, what is always present in a Persian FR word is the prefix hær-, ‘ever’. The sentential part of a Persian FR is an incom-plete finite sentence that contains either a gap or a RP. The pattern of distribution of RPs in Persian FRs is different from that of the ordinary relative clauses (RCs) in this language. While in ordinary RCs, it is possible to have gaps in object position, in FRs this is not possible. Examples in (4) illus-trate.
129

(4) a. zæn-i ke mæn u Woman-RES3 COMP I her
ra dust.daræm injast. RA love-1sg here-is
‘The woman that I love is here.’
b. [hærki-o mæn (*u) whoever-RA I (her) dust.daræm] injast love-1sg here-is ‘Whoever I love is here.’
Moreover, the complementizer ke which is obliga-tory in ordinary RCs is optional in FRs. While the examples in (1), (2) and (4b) above show that we do not need ke in FRs, example (5) shows that it is possible to have ke in a FR. It is indeed possible to have ke in any of the abovementioned above ex-amples. (5) hærkæs (ke) ___ pirhæn every/any + person COMP ___ shirt pušide tu tim-e mast. wear-3sg in team-EZ we+be-1pl ‘Whoever is wearing a shirt is in our team.’ Another property of Persian FRs is that they allow pied piping. Examples in (6) illustrate. (6) a. hærki mæn baš hærf+zædæm æz
Whoever I with-he tak-1sg from I
mæn bištær midunest. more knew-3sg ‘Whoever I talked to knew more than me.’
3 Particle –i attaches to the NPs modified by restrictive relative clauses. I will show it by –RES in gloss.
b. ba hærki mæn hærf+zædæm
with whoever I talk-1sg æz mæn bištær midunest. from I more knew-3sg ‘To whoever I talked knew more than me.’
Persian data also show that FRs in this language are subject to categorial matching. Examples in (7) illustrate. (7) a. Yasmin [æz hærči] Setareh Yasmin from whatever Setareh
bædeš.miyad xošeš.miyad.
dislike-3sg like-3sg
‘Yasmin dislikes whatever Setareh likes.’ b. Yasmin [æz hærči] Setareh Yasmin from whatever Setareh
bædeš.miyad dust.dareh.
dislike-3sg like-3sg
‘Yasmin dislikes whatever Setareh likes.’ The matrix verb in (7a) is the compound verb xošeš.miyad, ‘like’ which subcategorizes for a PP, starting with the preposition æz, ‘from’. The rela-tive verb in this sentence is bædeš. miyad, ‘dis-likes’, which also subcategorizes for a PP, starting with the preposition æz, ‘from’. Both requirements are met and the result is grammatical. However, (7b) is ungrammatical as the categorial matching is not observed. The matrix verb in (7b) is the com-pound verb dust.dareh, ‘likes’, which subcatego-rizes for an NP. The relative verb in (7b) is the compound verb bædeš.miyad, ‘dislikes’, which subcategorizes for a PP, starting with the preposi-tion æz, ‘from’. The requirements of the two verbs are not satisfied and the sentence is, therefore, un-grammatical.
2 An HPSG Analysis
I shall provide a unified HPSG approach to take care of the dependency between the relative phrase
130

and the gap or the RP with a truly single mecha-nism, using only the SLASH feature. A variety of evidence from coordination, parasitic gaps, cross-over, and island constraints shows that Persian gaps and RPs are strikingly similar. A coordination example is given in (8) below. One conjunct con-tains a gap whereas the other conjunct contains a RP. The gap and the RP are both licensed by and linked to hærki, ‘whoever’. (8) [hærki umæd va beš whoever came-3sg and to-him pul dadim] ræqsid. money gave-1sg dance-3sg ‘[Whoever ___ came and we gave money to ____(*him)] danced.’
To capture the similarities of RPs and gaps, I sug-gest that gaps and RPs should be treated similarly (unlike Vaillette’s (2001) analysis). If gaps are treated as traces4 (as in Pollard and Sag’s (1994), Levine and Hukari (2003), and Lee (2004)), then RPs will be similar to traces except in two respects. Firstly, RPs will have phonological content whereas traces will not. Secondly, the value of their GAPTYPE features is different. GAPTYPE is a feature that I have introduced in order to capture the distributional properties of RPs and traces. GAPTYPE is a non-local feature whose value can be either trace or rp, for traces and RPs, respec-tively. The reason for distinguishing traces and RPs with a NONLOCAL feature is that this is not reflected within the value of SLASH and hence it is possible for a single unbounded dependency to be associated with a trace and an RP. This makes the inheritance of the nonlocal feature easy and possible in the middle of those UDCs which in-volve coordination of two NPs where one contains a RP and the other a gap. Other analyses (e.g., Vaillette (2001)) which utilise more than one nonlocal feature (SLASH and RESUMP) do not seem to be able to handle the inheritance of the features in such coordinate structures that contain
4 It is also possible to develop a traceless approach by, for instance, treating synsems of RPs (rp-ss) a mixed category: a subtype of gap-ss and canon-ss at the same time. I shall not follow this approach here.
gap in one conjunct and RP in the other. The lexi-cal entry for trace is shown in (9). (9) PHONOLOGY < >
LOCAL 1
SYNSEM SLASH 1
NONLOC GAPTYPE trace In addition, the impossibility of RPs in object posi-tions in FRs requires a more complex value for SLASH. By doing so, the encoded information in SLASH will show the type of the unbounded de-pendency (e.g., wh-interrogative, relative clause, free relative, etc.) as well; therefore, making it ac-cessible not only at the bottom of the dependency but also at the top. I shall assume that the value of SLASH is a set of ud-object elements, for which two features are appropriate: LOCAL and UD-TYPE. The value of LOCAL is a set of local struc-tures, and the value of UD-TYPE is ud-type, which can be for instance rc (for relative clauses), fr (for free relatives), or wh (for wh-interrogatives). The complex value of SLASH is shown in (10). The hierarchy in (11) shows three of the possible in-stances of ud-type. (10) ud-object LOCAL local
SLASH UD-TYPE ud-type
(11) ud-type rc fr wh … We noted above that RPs are not allowed in object positions. To prevent RPs from appearing in object positions, I shall propose the following constraint.
131

(12) RESUMPTIVE OBJECT CONSTRAINT HEAD verb
GAPTYPE rp COMPS <…, , …> ~ [1] = fr SLASH {[UD-TYPE [1]]} The effect of this constraint is that if a complement of a verb is a resumptive pronoun, then the value of its UD-TYPE cannot be fr. In other words, a pronoun which is resumptive by having a rp value for its GAPTYPE feature cannot be used in un-bounded dependencies of the type free relative (fr), if it is going to be a verbal complement. At the top of the dependency, the SLASH feature needs to be bound off at an appropriate point. Similar to Wright and Kathol’s (2003) analysis, I assume that this appropriate point is the relative phrase which acts as the filler. However, if the relative phrase is the filler, then naturally, we ex-pect to have the sentential part as the head. Persian data do not support this idea and suggest that it is the relative phrase that acts as the head in deter-mining the external distribution of the phrase. For example, categorical matching comes from the relative phrase (see example 7 above). Therefore, I am assuming that the relative phrase in Persian FRs is the head and the filler at the same time. I propose the following constraint on Persian FRs. (13) Free Relatives Constraint free-relative
>
<
]1[ DTR-HD[2]]} {[LOC SLASH
HEAD ,[2] LOC
{[]} REL-F]1[ DTRS
{} SLASH
verbalphrase
There are two points noteworthy here. Firstly, the filler is the head daughter in this constraint. Sec-ondly, the value of HEAD is verbal and not v. Fol-lowing Sag (1997), I will assume that verbal is a supertype of both verb (v) and complementizers
(c). This assumption will allow me to handle the optionality of complementizer ke in Persian FRs. The standard HPSG constraints that operate on headed phrases will suffice for the inheritance of SLASH. There is also another nonlocal feature which is originated at the relative phrase: the F-REL feature. We noted earlier that not all wh-words can come in relative phrases. Likewise, not all words with the prefix hær- are allowed to ap-pear in FR constructions. In order to differentiate phrases that are eligible to occur as fillers in the FR constructions, I will use, following Kim’s (2001), the nonlocal feature F-REL which takes a set of referential indices as its value (Jacobson (1977), Kim and Park (1997) as cited in Kim (2001: 42)). FR words will have a nonempty specification for this feature. Other instances of hær- combinations or wh-words in any context other than the FR will have empty F-REL features. The F-REL generated from a lexical entry is subject to two constraints: Lexical Amalgamation of F-REL (Kim 2001: 43) and Ginzburg and Sag’s (2000) Generalised Head Feature Principle (GHFP). Selected References Ginzburg J. and I. Sag, 2000. Interrogative Inves-
tigations: The Form, Meaning, and Use of English Interrogatives. CSLI Publications, Stanford, California.
Lee, S-H. (2004) A Lexical Analysis of Select Ko-rean Unbounded Dependency Construc-tions. Doctoral dissertation in Ohio State University, USA.
Levine, R. D. and T. Hukari. 2003. The Unity of Unbounded Dependency Constructions. University of Chicago Press. USA.
Karimi, S. 1990. "Obliqueness, Specificity, and Discourse Functions: râ in Persian," Lin-guistic Analysis, Vol. 3&4. PP 139-191
Kim. J.B. 2001. Constructional Constraints in Eng-lish Free Relative constructions. Korean Society for Language and Information 5(1): 35-53.
Pollard C., and I. Sag, 1994. Head-Driven Phrase Structure Grammar. The University of Chicago Press, USA.
Sag, I., 1997. English Relative Clause Construc-tions. Journal of Linguistics 33:431-474.
132

Vaillette, N. 2001. Hebrew Relative Clauses in HPSG. Proceedings of the 7th International Conference on Head-Driven Phrase Struc-ture Grammar, CSLI Publications.
Wright, A. and A. Kathol. 2003. When a Head is not a Head: A Constructional Approach to Exocentricity in English. In Jong-Bok Kim and Steve Wechsler (eds.) Proceedings of the Ninth International Conference on Head-Driven Phrase Structure Grammar. Pages: 370-387.
133

134

Plural Comitative Constructions in Polish
Beata TrawinskiEberhard-Karls-Universität Tübingen
Sonderforschungsbereich 441Nauklerstraße 35
D-72074 Tü[email protected]
1 Introduction
This paper deals with Polish comitative construc-tions (CCs) involving the preposition z ‘with’, as ap-pears in (1).
(1) JanJan.NOM
zwith
MariaMaria.INSTR
odjechali.left.PLUR
‘Jan and Maria left.’
The CC in (1) consists of the nominative singularNP Jan and the z-PP, and combines with the pluralpredicate. Because of the plural agreement, we willrefer to this type of CC as the plural comitative con-struction (PCC).1
PCCs have previously been treated by linguists interms of coordination2 (cf. (Vassilieva and Larson,2001) for corresponding Russian expressions and(Dyła, 1988) and Dyła and Feldman (to appear) forPolish), complementation (cf. (Feldman, 2002) andDyła and Feldman (to appear) for Russian) and ad-junction (cf. (McNally, 1993) and (Ionin and Ma-tushansky, 2002) for Russian). However, most ofthese analyses remain problematic in some respects.For example, the analysis of (Vassilieva and Larson,2001) fails to explain the case assignment on the sec-ond NP, cannot rule out the ungrammatical inversionof the first and the second NPs and cannot account
1Note that CCs in Polish, as well as in many other languages,can also involve singular agreement on the verb. The treatmentof CCs with singular agreement on the verb seems relativelystraightforward. However, this is not the case for PCCs. There-fore, PPCs will be the exclusive focus of this paper.
2Note, however, that there has been no uniform treatmentof coordination. Thus, coordination might correspond to othersyntactic structures, such as adjunction, depending on the anal-ysis used.
for grammatical structures involving a conjunction.The approach of (Dyła, 1988) and Dyła and Feldman(to appear) cannot prohibit the inversion of the firstand the second NPs, nor ungrammatical iteration. Inaddition, it is both conceptually and formally incom-patible with HPSG, which provides the underlyinggrammatical framework. (Feldman, 2002) analyzesthe Russian comitative preposition s ‘with’ as a nounwhich selects two complements. However, by treat-ing s ‘with’ as a noun, neither the vocality alterna-tion (cf. s vs. so), which is typical for prepositionsbut not for nouns, nor the modification by the adverbvmeste ‘together’, can be explained.
This paper offers an HPSG adjunction-based anal-ysis of PCCs that accounts for their syntactic, se-mantic and pragmatic properties by providing a spe-cial lexical entry for the preposition z. Conse-quently, no additional constraints on phrase struc-ture or semantic constraints will be needed in orderto license PCC.
In the following section we will present the re-sults of an examination of PCCs with respect to var-ious linguistic phenomena such as number and gen-der resolution, control phenomena, distributivity, ex-traction, case assignment, iteration, recursion andpro-drop phenomena. The aim of our tests was toprovide an empirical basis for generalizations aboutthe syntactic and semantic properties of PCCs. Atthe same time, we have investigated coordinate, ad-junct and complement structures with respect to thesame phenomena. The objective was to determinewhich of these structures shares the most syntactic
135

��������������������������������
wordPHON � z �
SYNS
�����������������������������LOC
����������������������������
CAT
��������������������HEAD
�������prepPFORM z
MOD:
���� LOC
���� CAT � HEAD nounVAL � COMPS ����
CONT nom-objINDEX 1
RESTR 2 ���� INSTANCE 1 ����� 3 �������� �����
��������VAL � COMPS �
�������� LOC
�������� CAT
��� HEAD nounCASE instr
VAL � SPR ���SUBJ ���COMPS ����
����CONT npro
INDEX 4
RESTR 5 ���� INSTANCE 4 ����� 6 � �� �������� ������� �
���������������������CONT
���� npro
INDEX � PERSON 3rdNUMBER plur �
RESTR 2 � 5 �! � conjoin-rel
CONJUNCTS � 1 , 4 � �#"�����
� ���������������������������
� ����������������������������
���������������������������������
$
� 6 neset % 3 neset � $ � 6 eset % 3 eset �Figure 1: The relevant part of the lexical entry of the preposition z ‘with’
and semantic properties with the PPC.3
2 Results of the Empirical Observations
Based on a number of linguistic tests, we have beenable to observe that PCCs behave in the same way asdoes ordinary coordination with regard to numberresolution, gender resolution, control of pronouns,PRO subjects and distributive interpretation. How-ever, with respect to case assignment and the gram-matical category of the constituents involved, PCCsshare its properties with both NP-adjuncts and NP-complements. Since PCCs also show the same be-havior as NP-adjuncts with respect to the control ofpronouns within z-PPs, the occurrence of pronounswithin PCCs, iteration, and recursion, we considerit plausible to analyze PPCs syntactically as an in-stance of adjunction.
Based on these empirical observations, two gener-alizations can be made: (1) PCCs share their seman-tic properties with ordinary coordination, (2) PCCsshare their syntactic properties NP-adjunction. Fur-thermore, PCCs show several idiosyncratic features,e.g., with respect to the distribution of pronounswithin PCCs, or concerning requirements for def-
3In the full version of the paper, we will provide appropriateexamples for each of the tests.
initeness, number or restrictiveness of the NPs in-volved.
In the next section we will provide our HPSGanalysis for PCC in Polish.
3 The Analysis
We have adopted the proposal by (McNally, 1993),thereby treating PCCs as adjunct-structures.4 Thecore component of our analysis is the lexical entryfor the preposition z in Figure 1.
The lexical entry in Figure 1 licenses the prepo-sition z ‘with’, which selects one non-pronominalcomplement and modifies an NP. In this respect, thedescription in Figure 1 does not differ from descrip-tions of other modifying prepositions. However, theCONTENT value in Figure 1 differs from that of or-dinary modifying prepositions. The value of the at-tribute CONTENT is a nominal object of the usualform. Note that the NUMBER value is assumed tobe plural. The GENDER value depends on the GEN-DER values of the selected NP and the modified NP.Since PCCs show the same gender resolution patternas coordination, we assume that PCCs are subject of
4Note that (McNally, 1993) has not provided a descriptionof gender and number resolution, or of any control-related phe-nomena.
136

� PHON & Jan 'SYNS 4 � LOC � CAT | HEAD 1 noun
CONT | INDEX 3 | GENDER virile �(� ���������
PHON & z 'SYNS
������� LOC
������� CAT HEAD 5 prep
MOD: 4
VAL | COMPS ) 6 * �CONT 2
�� INDEX � NUM plurPER 3rdGEND virile �
RESTR + � conjoin-rel
CONJUNCTS � 3 , 7 � �-, ���������������������������
PHON & Maria 'SYNS 6 � LOC � CAT HEAD noun
CASE instr �CONT | INDEX 7 | GENDER fem
� � �. /
�� PHON & z, Maria 'SYNS LOC CAT � HEAD 5
MOD: 4
VAL | COMPS & ' �CONT 2
�0� ��. 1� PHON & Jan, z, Maria '
SYNS � LOC � CAT | HEAD 1
CONT 2 �(� �
Figure 2: The structure of the PCC Jan z Maria ‘Jan and Mary’
general constraints on gender resolution.The RESTR feature of the preposition z ‘with’ pro-
vides information on the relation between the objectdenoted by the selected NP and the object denotedby the modified NP. This involves a conjoin relation.The value of the CONJUNCTS feature, which is ap-propriate for the sort conjoin-rel, is a set of indexobjects identified as the INDEX values of the modi-fied and the selected NPs. Note that the proposed ar-chitecture of the CONTENT value of the prepositionz ‘with’ which occurs in PCCs makes it possible toaccount for a distributive and collective reading ofPCCs.5
The last two conjuncts of the description in Fig-ure 1 ensure that the selected NP and the modifiedNP are either both modified or both not modified.PCCs require the same level of modification fromboth constituents. However, an additional constraintis needed which will ensure that the complement NPand the modified NP agree with respect to definite-ness.
The structure in Figure 2 describes the PCC Janz Maria ‘Jan and Mary’, using the lexical entry inFigure 1.
By virtue of the description in Figure 1, the prepo-sition z selects first the non-pronominal NP Maria asits complement, assigning to it the instrumental case.Then z combines with the NP Jan. The CONJUNCTS
5For more details on a collective and distributive reading as-sociated with (Russian) comitative constructions see (Dalrym-ple et al., 1998).
set in the semantic representation of the prepositionz ‘with’ contains the index values of the selected andthe modified NPs. This reflects the fact that the bothNPs are interpreted as conjuncts.
Note that z provides its own INDEX value, whichpercolates to the mother node according to the com-mon semantics principle of HPSG in the tradition of(Pollard and Sag, 1994). Thus, the entire PCC cancontrol third person plural virile pronouns as well asPRO subjects.
4 Summary and Outlook
We have provided a lexicalist analysis of PolishPCCs assuming PCCs are head-adjunct-structures.In our future work, we will examine whether othertypes of CCs in Polish involving the preposition z,such as plural pronoun CCs (cf. (2) with the pluralpronoun my ‘we’) and verb-coded CCs (cf. (2) withpro), can be described in a similar way.6
6As indicated by R1-R3, the CC in (2) has three possible in-terpretations. According to the first interpretation (see the trans-lation R1), the first person plural pronoun my (‘we’) and pro de-note a set of individuals including the speaker but not includingthe individual denoted by the NP selected by the prepositionz, that is, Maria. In contrast, the meaning of the pronoun my(‘we’) and pro according to the interpretation indicated by thetranslation R2, includes both the denotation of Maria and thespeaker. It does not include any further individuals, and thuscarries the meaning Maria and I. Finally, the pronoun my (‘we’)and pro according to the third interpretation (see the translationR3) refer to a set of individuals including the speaker, the in-dividual denoted by the argument of z, i.e., Maria, and somefurther individuals.
137

(2) Mywe
//
propro
zwith
MariaMaria
odjechalismy.left
R1: ‘We left with Maria.’R2: ‘Maria and I left.’R3: ‘Maria and the rest of us left.’
We will attempt to provide a uniform treatment ofall CC types in Polish that can license each of theinterpretations indicated in R1-R3 and that accountsfor the idiosyncratic properties of CCs.
ReferencesMary Dalrymple, Irene Hayrapetian, and Tracy Holloway
King. 1998. The Semantics of the Russian ComitativeConstruction. Natural Language and Linguistic The-ory, 16:597–631.
Stefan Dyła and Anna Feldman. to appear. On Comi-tative Constructions in Polish and Russian. In Pro-ceedings of the Fifth European Conference on FormalDescription of Slavic Languages, Lepizig.
Stefan Dyła. 1988. Quasi-Comitative Coordination inPolish. Linguistics, 26:383–414.
Anna Feldman. 2002. On NP-Coordination. InMaaike Schoorlemmer Sergio Baauw, Mike Huiskes,editor, Yearbook 2002, pages 39–67. Utrecht Instituteof Linguistics OTS.
Tania Ionin and Ora Matushansky. 2002. DPs with aTwist: A Unified Analysis of Russian Comitatives. InProceedings of FASL 11, Amherst, MA.
Louise McNally. 1993. Comitative Coordination: ACase Study in Group Formation. Natural Languageand Linguistic Theory, 11:347–379.
Carl J. Pollard and Ivan A. Sag. 1994. Head-Driven Phrase Structure Grammar. The University ofChicago Press, Chicago.
Maria B. Vassilieva and Richard K. Larson. 2001. TheSemantics of the Plural Pronoun Construction. InR. Hastings, B. Jackson, and Z. Zvolenszky, edi-tors, Proceedings of Semantics and Linguistic Theory(SALT) XI, Ithaca. CLC Publications, Dept. of Linguis-tics, Cornell University.
138

Phrasal prenominals with peculiar properties
Frank Van EyndeCentre for Computational Linguistics
University of Leuven – [email protected]
Abstract
Drawing on data from Dutch I willdemonstate that there are phrasal prenom-inals which cannot plausibly be analysedin terms of any of the usual subtypes ofheaded-phrase. To model them I pro-pose a new type, called head-independent-phrase. Its properties are spelled out informal detail and its range of application isillustrated with various examples, includ-ing cases of asymmetric coordination.
1 Introduction
In many languages, the prenominals show morpho-syntactic agreement with the nouns they modify. InDutch, for instance, the adjectival prenominals takethe nondeclined (or base) form if the noun is singularneuter and in standard case,1 as in elk zwart paard‘each black horse’. Otherwise, they take the de-clined form, as in the singular nonneuter elke zwarteezel ‘each-DCL black-DCL donkey’.2 If the prenom-inal is a phrase, rather than a single word, then itis the adjectival head of the prenominal which hoststhe declension affix, as in the plural zeer snelle paar-den ‘very fast-DCL horses’ and the singular non-neuter een van Rusland afhankelijke staat ‘a fromRussia dependent-DCL state’.
Given this generalization it is somewhat unex-pected that the declension affix in the singular non-neuter een zo groot mogelijke winst ‘an as large
1Standard case is either nominative or accusative.2The distinction is neutralized in NPs with a definite deter-
miner. In such NPs, the adjectives are also declined if the nounis singular neuter, as in het zwarte paard ‘the black-DCL horse’.
(as) possible-DCL profit’ is not hosted by the ad-jective which is intuitively the head of the AP(groot), but by a word which is intuitively its de-pendent (mogelijke). The same phenomenon canbe illustrated with superlative and comparative ad-jectives, as in de grootst mogelijke verwarring ‘thelargest possible-DCL confusion’ and de lager danverwachte beurskoers ‘the lower than expected-DCL
rating’.The objective of the paper is to find out how such
prenominals can best be modeled in terms of theHPSG framework.
2 Adjectival and participial prenominals
To pave the way I first spell out a general formatfor the treatment of prenominals. Following (Al-legranza, 1998) and (Van Eynde, 2003), I treat theprenominals as functors. Functors are non-headdaughters which select their head sister.3 The selec-tion is modeled in terms of a synsem valued featureSELECT, which is part of the functor’s HEAD value.4���
� head-functor-phr
DTRS ��� SYNSEM � LOC � CAT � HEAD � SELECT � � , HEAD-DTR � SYNSEM � synsem �
� ���
As demonstrated in (Van Eynde, 2003), the SE-LECT feature can be used to model NP-internal
3The notion ‘functor’ is also used in a broader sense. In(Reape, 1994, 154), for instance, it covers all kinds of selectors,i.e. adjuncts, specifiers and complementizers as well as headsin head-complement combinations. In my use the term coversadjuncts, specifiers and markers, but not heads.
4The HEAD � SELECT feature is a generalization of theHEAD � MOD and HEAD � SPEC features of (Pollard and Sag,1994). Non-head daughters which do not select their head sis-ter have the SELECT value none. Predicative adjectives, forinstance, are complements, rather than functors, and thereforehave the SELECT value none.
139

agreement. The Dutch nondeclined prenominal ad-jectives, for instance, can be treated as functorswhich select a singular neuter nominal in standardcase. Since the SELECT feature is part of the HEAD
value, it is shared between the mother and its headdaughter. The prenominal zeer snel ‘very fast’, forinstance, selects a singular neuter noun, since itshead snel ‘fast’ selects a singular neuter noun.5
NP
AP[SELECT � ]
Adv
zeer
A[SELECT � ]
snel
� N[sg, ntr]
paard
The internal structure of the AP can be modeledalong the same lines: the degree marker zeer ‘very’is an adverbial functor which selects an adjectivalhead.
2.1 A new type of headed phrases
Turning now to the exceptional AP in een zogroot mogelijke winst ‘an as large (as) possible-DCL
profit’, we can apply the same approach and treat thedeclined AP as a functor selecting a singular non-neuter or plural noun. Moreover, since it is the right-most word of the AP which hosts the affix, it is thatdaughter which is the syntactic head of the AP.
NP
AP[SELECT � ]
AP
Adv
zo
A
groot
A[SELECT � ]
mogelijke
� N[sg, nonntr]
winst
The rightmost daughter cannot only be a word,but also a phrase, as in een lager dan verwachteopkomst ‘a lower than expected-DCL turn-out’. Inthis phrase, the participle is the syntactic head of aprenominal VP[ptc].
NP
VP[SELECT � ]
A
lager
VP[SELECT � ]
Comp
dan
V[SELECT � ]
verwachte
� N[sg, nonntr]
opkomst
5I use the notation XP for all phrasal signs, no matterwhether they are fully saturated or not.
Having granted head status to the rightmostdaughter, we are now left with the problem of iden-tifying the role of the leftmost daughter. For a start,notice that we cannot plausibly treat it as selectedby the head: lager, for instance, is clearly not acomplement or a specifier of verwachte. More plau-sible would be a functor treatment, as in the caseof zeer snel ‘very fast’. The comparatives, for in-stance, could be treated as functors which select adan phrase as their head. The problem with thistreatment, though, is its lack of generality. The samecomparative would be treated as selecting a nominalin een lager rendement ‘a lower return’ and as se-lecting a dan phrase in een lager dan verwachte op-komst ‘a lower than expected-DCL turn-out’. Sim-ilarly, in the prenominal een lager dan verwachtrendement ‘a lower than expected return’, the danphrase would be the head of the comparative, whilein the predicative AP of het rendement is lagerdan verwacht ‘the return is lower than expected’, itwould be a dependent of the comparative. This sug-gests that the functor treatment is not very appropri-ate either.
For the development of a more plausible alter-native, I start from a proposal, originally made in(Van Eynde, 1998), to postulate a separate type forheaded phrases in which neither daughter syntacti-cally selects the other. As a name for the phrasesof that type, I employed the term head-independent-phrase, but its properties were not spelled out in anydetail. At this point, I will keep the name, but add adefinition.��� head-independent-phr
DTRS ��� SYNSEM � LOC � CAT � HEAD � SELECT none � , HEAD-DTR
� ��
The rightmost daughter is the head and, hence,shares its HEAD value with the mother. Given thefeature geometry this includes the SELECT value. Asa consequence, if the phrase as a whole is a prenomi-nal AP which selects a plural or a singular nonneuternoun, then it follows that its rightmost daughter mustbe declined, and this is only possible if that daughteris a word which can host the declension affix. Thisimplies that it can be an adjective or a participle, butnot an adverb or a pronoun. Combinations, such as* de grootst ooite winst ‘the largest ever-DCL profit’and * een groot genoege keuken ‘a large enough-DCL
140

kitchen’ are, hence, correctly excluded.The leftmost daughter is required to have the SE-
LECT value none. This constraint not only capturesthe difference with the functors, it also accounts forthe fact that the leftmost daughter must be nonde-clined. This follows from the fact that Dutch ad-jectives and participles are invariably nondeclinedwhen their SELECT value is none. Adjectives inpredicative position, for instance, never take the de-clension affix.
As pointed out in the introduction, the combina-tions which this new phrase type is intended to han-dle are unusual, in the sense that the syntactic headdoes not coincide with what is intuitively taken tobe the semantic head. This discrepancy, though, isnot included in the general definition of the type.The reason for this omission is that it would in-advertently exclude its application to a number ofconstructions which are, syntactically speaking, ofthe same type. The prenominal AP in een meerdan behoorlijke opbrengst ‘a more than decent-DCL
yield’, for instance, has the same syntactic structureas the one in een lager dan verwachte beurskoers‘a lower than expected-DCL rating’, but its syntactichead does coincide with what is intuitively taken tobe the semantic head. Similarly, the syntactic struc-ture of the prenominal AP in een zo goed als nieuwekeuken ‘an as good as new-DCL kitchen’ is nearlyidentical to the one of een zo groot mogelijke winst‘an as large as possible-DCL profit’, but in the for-mer the declined adjective is also the semantic head;its meaning can be paraphrased as ‘an almost newkitchen’. It would, hence, be overly restrictive to re-quire the nonhead daughter to be the semantic head.Further evidence against such a move is provided inthe next paragraph.
2.2 Asymmetric coordination
When prenominal adjectives are coordinated theycanonically take the same form. In witte en zwartetruien ‘white-DCL and black-DCL sweaters’, forinstance, both conjuncts are declined. This fol-lows from the strong version of the CoordinationPrinciple, which requires the conjunct daughters toshare the CATEGORY value of the mother (Pollardand Sag, 1994, 202). Given this requirement, onewould expect the combination in wit en zwarte tru-ien ‘white and black-DCL sweaters’ to be ill-formed,
but it is not. Apparently, it is possible to limit the de-clension to the rightmost conjunct. Limiting it to theleftmost conjunct, however, is not possible: * witteen zwart truien ‘white-DCL and black sweaters’ isplainly ungrammatical.
What distinguishes the asymmetric coordinationfrom the canonical symmetric coordination, is notonly its form, but also its meaning. While the phrasewith the symmetric coordination denotes a set ofsweaters which includes both white exemplars andblack ones, the phrase with the asymmetric coor-dination denotes a set of bi-colored sweaters. Inmore general terms, the symmetric coordination isdistributive, whereas the asymmetric one is not. Tomodel the latter’s syntactic properties, we need aphrase type which is right-headed. Moreover, sinceconjuncts do not select one another, it should be aphrase type in which neither daughter syntacticallyselects the other. Finally, since none of the conjunctscan be claimed to be the semantic head, we need aphrase type without constraints on semantic headed-ness. In sum, what we need is exactly what is pro-vided by the type head-independent-phrase. Apply-ing it to the example yields the following structure:
NP
AP[SELECT � ]
A
wit
AP[SELECT � ]
Conj
en
A[SELECT � ]
zwarte
� N[plural]
truien
Another example of this kind is een of anderekerel ‘one or other-DCL guy’. Also here, the firstconjunct lacks the affix, even though it does have adeclined counterpart (ene ‘one-DCL’), and also herethe coordination is not distributive.
3 Summing up
To model the unusual prenominals I have intro-duced a new type of headed phrases, called head-independent-phrase. In such phrases the rightmostdaughter is the head and neither daughter syntacti-cally selects the other; the syntactic head may butneed not coincide with what is intuitively the seman-tic head. The examples given so far all concern APsand nonfinite VPs, but they can also be NPs, as willbe demonstrated in the next section.
141

4 Genitive and numeral prenominals
NPs in prenominal position often take a genitiveaffix, as in wiens hoed ‘who-GEN hat’ and Petersvrienden ‘Peter-GEN friends’. In contrast to the ad-jectives and the participles, the genitive (pro)nounsdo not show morpho-syntactic agreement with thenouns they modify: Peters, for instance, is singu-lar and genitive, whereas its head vrienden ‘friends’is plural and in standard case. If the genitive is aphrase, the case is marked on the head noun. Inmijn vaders vrienden ‘my father-GEN friends’, forinstance, the genitive affix is hosted by the noun.This is just what one expects, since CASE is a HEAD
feature of nominal signs.What is less expected, though, is that the geni-
tive affix is sometimes hosted by a word which isintuitively not the head of the NP. Some relevant ex-ample are the prenominals in met ons aller instem-ming ‘with us all-GEN consent’ and in u beider vo-ordeel ‘in you both-GEN advantage’. In these com-binations, the personal pronoun and the quantifierform a phrase which modifies the common noun.6
The pronoun is intuitively the semantic head of thephrase, but it is the quantifier which has the geni-tive affix, while the pronoun is in the unmarked ac-cusative case. To model this, we need a phrase typein which the rightmost daughter is the syntactic, butnot necessarily the semantic, head. Moreover, sincethe relation between the pronoun and the quanti-fier is of a rather loose quasi-appositional kind, itshould be a type of phrase in which neither daugh-ter syntactically selects the other. In sum, what weneed is again what is provided by the type head-independent-phrase.
NP
NP[CASE � genitive]
N[CASE accusative]
ons
N[CASE � ]
aller
N
instemming
Interestingly, the general constraint that the SE-LECT value of the leftmost daughter be none has anontrivial consequence, for since it is typical of gen-itive (pro)nouns that they select a nominal head and
6The modifier can also be realized as a postnominal PP, asin met de instemming van ons allen ‘with the consent of us all-PL’ and in het voordeel van u beiden ‘in the advantage of youboth-PL’.
that their SELECT value is, hence, of type synsem,the constraint accounts for the fact that the personalpronoun cannot host the genitive affix.
Prenominal NPs are often genitive, but not al-ways. Let us, for instance, take the numeral in eengoede dertig pagina’s ‘a good-DCL thirty pages’. Asall numerals, different from een ‘one’, dertig se-lects a plural count noun. At the same time, the nu-meral is itself a singular noun, as demonstrated by itscompatibility with the indefinite article.7 The lackof number agreement between the numeral and thenoun it modifies is not exceptional: it simply followsfrom the fact, already illustrated above, that prenom-inal NPs are not subject to morpho-syntactic agree-ment. Employing the functor treatment the structureof the NP can be spelled out as follows.
NP
NP[SELECT � ]
Art
een
NP[SELECT � ]
A
goede
N[SELECT � ]
dertig
� N[pl, count]
pagina’s
The article and the adjective select the singularnumeral as their head, and the latter in turn selects aplural count noun as the head of the prenominal. Thecombinations in this example are, hence, all three ofthe head-functor type. More complex, though, is theprenominal in een stuk of dertig pagina’s ‘a piece orthirty pages’. This prenominal, meaning somethinglike ‘around thirty’, is headed by the numeral andselects a plural count noun, but cannot plausibly beanalysed in terms of the head-functor type of com-bination: it would, for instance, make little sense totreat the numeral as selected by een stuk. Instead,the prenominal is a typical instance of asymmetriccoordination and, hence, a candidate for treatmentin terms of the head-independent phrase type.
NP
NP[SELECT � ]
NP
een stuk
NP[SELECT � ]
Conj
of
N[SELECT � ]
dertig
� N[pl, count]
pagina’s
7For arguments that also the English numerals are nouns,see (Jackendoff, 1977).
142

The asymmetry is clear a.o. from the fact that thenumeral selects a plural count noun, whereas the in-definite NP in the left conjunct is not even compat-ible with plural count nouns, as illustrated by theungrammaticality of * een stuk pagina’s ‘a piecepages’. Further evidence for the head-independentanalysis is provided by the fact that the coordinationis not distributive.
5 An extension
So far, I have only made use of prenominal phrasesto motivate and illustrate the use of the head-independent-phrase type. This limitation, though, isonly due to presentational considerations. Since theprenominals tend to show more inflectional variationand to impose more detailed syntactic restrictionson their heads than most other phrases, they pro-vide more salient and striking evidence for or againstcertain possible treatments; in the absence of affixa-tion and syntactic selection restrictions, the evidencewould be less direct and, therefore, less convincing.
At this point, though, where a treatment hasemerged that fits the facts, we can leave the safeshore of the prenominals, venture into the open seaof clausal syntax, and discover that also there thephrases of type head-independent abound. Let us,for instance, take the frequency adverbial in zo goedals nooit lachen ‘as good as never laugh’. The ad-verbial has the same internal structure and the sameapproximating sense as the prenominal AP in eenzo goed als nieuwe keuken ‘an as good as new-DCL
kitchen’. The relation between the AP zo goed andthe adverb nooit is, hence, of the same type (head-independent) as in the case of the prenominal:
VP
AdvP[SELECT � ]
AP
zo goed
AdvP[SELECT � ]
Conj
als
Adv[SELECT � ]
nooit
� V
lachen
Notice that it is the adverb, and not the AP, whichselects the verb. XPs of type head-independent can,hence, select a verbal projection, as well as a nomi-nal one. Moreover, they can also be used as comple-ments. The predicative AP in die keuken is zo goedals nieuw ‘that kitchen is as good as new’, for in-
stance, is a complement of the copula, and has thesame internal structure as the adverbial above.
In sum, the phrases of type head-independent canbelong to any of the usual categories (AP, VP, NP,AdvP, ...) and can have any kind of syntactic func-tion.
6 Conclusion
Some prenominals, such as the AP in de grootstmogelijke verwarring ‘the largest possible-DCL con-fusion’, pose a challenge for a head-driven frame-work, since their syntactic head does not coincidewith what is intuitively taken to be the semantichead. To model such combinations, I have employeda type of headed phrases, called head-independent-phrase, building on a proposal in (Van Eynde, 1998).Typical of head-independent phrases is that they areright-headed and that neither daughter syntacticallyselects the other.
References
V. Allegranza. 1998. Determiners as functors: NP struc-ture in Italian. In S. Balari and L. Dini, editors, Ro-mance in HPSG, pages 55–107. CSLI Publications,Stanford.
R. Jackendoff. 1977. X-bar syntax: a study of phrasestructure. MIT Press.
C. Pollard and I. Sag. 1994. Head-driven Phrase Struc-ture Grammar. CSLI Publications and University ofChicago Press, Stanford/Chicago.
M. Reape. 1994. Domain union and word order variationin German. In J. Nerbonne, K. Netter, and C. Pollard,editors, German in HPSG, pages 151–197. CSLI Pub-lications, Stanford.
F. Van Eynde. 1998. The immediate dominanceschemata of HPSG. In P.-A. Coppen, H. van Halteren,and L. Teunissen, editors, Computational Linguisticsin the Netherlands 1997, pages 119–133. Rodopi, Am-sterdam/Atlanta.
F. Van Eynde. 2003. Prenominals in Dutch. In J.-B.Kim and S. Wechsler, editors, On-line Proceedings ofHPSG 2002, pages 333–356. CSLI Publications, Stan-ford University.
143

144

An HPSG Account of Closest Conjunct Agreement in NP Coordination inPortuguese
Aline VillavicencioDepartment of Language and Linguistics
University of EssexWivenhoe Park
Colchester, CO4 3SQ, [email protected]
Louisa SadlerDepartment of Language and Linguistics
University of EssexWivenhoe Park
Colchester, CO4 3SQ, [email protected]
1 Introduction
This paper discusses agreement strategies insidethe Noun Phrase observed in an empirical studyof Portuguese. Agreement phenomena in generalhave received considerable attention in recent yearsfrom the HPSG community (Pollard and Sag, 1994;Wechsler and Zlatic, 2003), among others. Pollardand Sag (1994) propose what can be thought of asa multilayered theory of agreement that allows dif-ferent agreement relations to hold between differentobjects simultaneously. This proposal, further de-veloped by Wechsler and Zlatic (2003) is centred onthe notions of CONCORD and INDEX agreement at-tributes. CONCORD, is closely related to the noun’sinflected form and includes information about case,number, and gender, which are relevant for agree-ment between e.g. determiners and nouns. INDEX,is related to semantic characteristics of the noun likemale or female, aggregate or non-aggregate and aredefined in features such as number, gender and per-son, for agreement between e.g. subjects and verbs.Languages vary as to which features are used forwhich agreement processes. Using this framework itis possible to account for many agreement phenom-ena, as for example, hybrid nouns (Corbett, 1991),which can be exemplified by titles like Majesty inlanguages like Spanish and French, since they trig-ger different agreements on different targets withinthe same clause, as in sentence (1) in Spanish, wherethe noun, which refers to a male referent, triggersfeminine agreement on the attributive adjective andmasculine in the predicative adjective. They can beanalysed in terms of a mismatch of INDEX and CON-
CORD values by specifying that a title like Majestadhas a feminine CONCORD and a masculine INDEX
and assuming that in Spanish predicate adjectivesshow INDEX agreement while NP-internal attribu-tive adjective shows CONCORD agreement.
(1) Suhis
Majestadi
majestysupremasupreme.F
estais
contento.happy.M.
EliHe
...
...
’His supreme majesty is happy. He ...’
A somewhat similar situation can be found inNP (and plural noun) coordination in Portuguese,where a mixed gender coordinate structure can trig-ger different agreement patterns in different targetsin the NP. For example, in (2), a masculine noun anda feminine noun are coordinated, and they triggermasculine agreement with the determiner and femi-nine with the postnominal adjective.1
(2) EstaThis
cancaosong
animaanimate
osthe.MPL
coracoesheart.MPL
eand
mentesmind.FPL
brasileiras.Brazilian.FPL
‘This song animates Brazilian hearts andminds.’
(3) EstaThis
cancaosong
animaanimates
osthe.MPL
coracoesheart.MPL
eand
mentesmind.FPL
brasileiros.Brazilian.MPL
(4) EstaThis
cancaosong
animaanimate
as/*osthe.FPL/MPL
mentesmind.FPL
eand
coracoesheart.MPL
*brasileiras/brasileiros.Brazilian.FPLMPL
1In these examples the adjectives and the determiners scopeover the coordinate structure as a whole.
145

One problem with this kind of construction lies indeciding which gender the coordinate structure as awhole should have. If one decides for a given genderfor the coordination, e.g. masculine, this would cap-ture the agreement with the determiner, but not withthe adjective (even though it would also account forsentences like (3) where the adjective is resolved tomasculine). Therefore a second problem is how toaccount for the agreement with the adjective in (2),given that is has a strong correlation with the genderof the closest noun, so that sentence (4) would beungrammatical.
These are examples of closest conjunct agree-ment (CCA) in noun coordinations, where a mod-ifier/specifier of a coordinate structure agrees withonly one conjunct: the one that is closest to it. Clos-est conjunct agreement has been discussed by Cor-bett (1991), Sadler (1999), Moosally (1999), Abeille(2004) and Yatabe (2004) inter alia, and it is a strat-egy of partial agreement that can be found in manylanguages such as Ndebele (Moosally, 1999) andWelsh (Sadler, 1999). Moosally (1999) proposesan HPSG formalisation for capturing partial agree-ment in Ndebele, where agreement constraints aredefined in a multiple inheritance hierarchy, and theCCA constraint is defined as:
2
6
6
6
6
4
CONT.INDEX.GENDER : 1
CONJ-DTRS : < ...
»
INDEX.GENDER : 1
–
>
3
7
7
7
7
5
capturing agreement with the last conjunct. Yatabe(2004) formalises CCA as part of a unified treat-ment which also deals with coordination of unlikecategories. However, in order to capture cases likethat in (2), it is essential to take into account infor-mation about the conjuncts in both extremities. Inthis paper we discuss a possible formalisation forcapturing agreement patterns found in NP coordi-nations in Portuguese. The discussion is based onan empirical study of different agreement strategiesand the requirements they pose for an HPSG treat-ment. Portuguese presents an interesting case study,since a number of different agreement strategies trig-gered by a given source can be employed at the sametime, such as those in (2), where a coordination canhave closest conjunct agreement between the deter-miner and the first coordinated noun and betweenthe last noun and the postnominal adjective. In or-
der to cover these cases, we propose an HPSG anal-ysis that has access to the agreement features of thefirst and last conjuncts. To present that we start witha discussion of nominal agreement patterns foundin NP (and noun) coordinations in Portuguese, sec-tion 2. We then look at an empirical study of closestconjunct agreement, in section 3. Finally, the ac-count proposed in HPSG that captures these cases ispresented, and the implications of adopting this ap-proach are discussed.
2 Agreement in Portuguese
In Portuguese determiners and adjectives straight-forwardly agree in gender and number with the nounthey scope over:
(5) a/*asthe.FS/the.FPL
paredewall.FS
colorida/*vermelhascoloured.FSG/red.FPL
the coloured/red wall
On the other hand coordinate structures present amuch wider range of agreement patterns, since co-ordinated nouns often jointly control agreement ondeterminers, adjectives and other dependents withinthe NP. A crosslinguistically very common patternin a two gender system involves the syntactic princi-ples of resolution summarized as:
(6) If all conjuncts are GEN = FEM, resolve to FEM
else, resolve to MASC
Although valid, this generalisation fails to addresscases of CCA. A more complete picture is givenby Moosally (1999), where agreement strategies incoordinations in Ndebele are classified in 3 types,which can also be applied to Portuguese. The firstone, Regular Agreement, is adopted when all thecoordinated NPs have the same gender, and speci-fiers and modifiers of the coordinate structure fol-low that gender (7). Resolution Agreement can beadopted for a conjunction of mixed gender nouns,whereby agreement is triggered by a specific featurein one of the conjuncts. For Portuguese, if there is atleast one masculine noun in the coordinate structure,it can trigger agreement with a postnominal adjec-tive, regardless of the gender of the other conjuncts(sentence 3). The third agreement strategy is thatof Closest Conjunct Agreement, when agreementwith dependents like determiners and adjectives is
146

triggered by the conjunct that is closest to each ofthem (sentences 2 and 8).
(7) athe.FS
paredewall.FS
eand
athe.FS
janelawindow.FS
coloridas/vermelhas/*vermelhoscoloured.FPL/red.FPL/red.MPL
the coloured/red wall and window
(8) ......
quethat
othe
professorteacher
possamay
recontextualizarrecontextualise
othe.MS
aprendizadolearning.MS
eand
athe.FS
experienciaexperience.FS
vividaslived.FP
duranteduring
athe
suahis
formacaotraining
...
...
from www.seed.pr.gov.br/evento fust/
Sentence (8) in particular raises a number of in-teresting issues because it is a clear case where num-ber resolution is also involved: despite the fact thatthe postnominal adjective scopes over the NP coor-dination as a whole, the feminine gender on the ad-jective indicates gender agreement with the closestconjunct, while plurality on the adjective indicates aresolved feature, since each NP is actually singular.
Determiners and adjectives differ as to which ofthese strategies they employ for agreement withNP/noun coordinations. Both determiners andprenominal adjectives scoping over all coordinatednouns, follow CCA, e.g. sentences (4) and (9), re-spectively. For a postnominal adjective modifyinga coordination of mixed gender, agreement can ei-ther follow a resolution strategy, with the adjectivein the masculine form (3) or it can agree with theclosest conjunct (2 and 8).
(9) ...as...theFPL
assustadorasfrightening.FPL
colinasmounds.FPL
eand
morroshills.MPL
deof
argilaclay
doof the
ParqueNational
Nacional...Park...
from www.nationalgeographic.pt/revista/0404/wallpaper.asp
A complex picture emerges in which the threesorts of agreement coexist in the NP, triggered bydifferent targets: determiners, prenominal adjectivesand postnominal adjectives. In many cases coordi-nated nouns trigger agreement between the deter-miner and the leftmost conjunct and the postnominal
adjective and the rightmost conjunct (2). This pic-ture is confirmed in a corpus based investigation ofNP internal agreement patterns in Portuguese, dis-cussed in the next section.
3 A Corpus Study
To estimate the approximate frequency with whichthe agreement strategies are used in coordinate NPsmodified by postnominal adjectives, a corpus-basedinvestigation was performed. Of particular interestare cases that combine agreement strategies (closestconjunct agreement of gender, but semantic resolu-tion of number).
In order to perform this analysis we searched theWeb (using Google) for occurrences of coordinatedNPs followed by plural adjectives. The searchesused the following pattern: “<ART> * e <ART> *<ADJ>”, where ART refers to Portuguese (definiteand indefinite) articles, and ADJ to adjectives, whichwere extracted from the 1,528,590 entry NILC Lex-icon (http://www.nilc.icmc.usp.br/nilc/index.html).As we want to test the correlation between the gen-der of each of the NPs and the gender of the adjec-tive, only adjectives that overtly reflect gender dis-tinction were used (9,915 masculine and 9,811 fem-inine adjectives). The results found are displayed intables 1 and 2, where Frequency indicates the num-ber of pages returned by Google for the searches,and NP1, NP2 and Adj refer to the gender of thefirst conjunct, second conjunct, and adjective, re-spectively. The number of the NP conjuncts is in-dicated in each table, but the adjective is plural inboth cases.
Table 1: Frequency of Adjective modifying an NPConjunction - Conjunction of Plural NPs
Case Frequency NP1 NP2 Adjective
(a) 0 FEM MASC FEM(b) 489 FEM MASC MASC(c) 468 MASC FEM FEM(d) 2317 MASC FEM MASC
These results give an indication of howwidespread the adoption of the closest con-junct agreement strategy is, in cases (b) and (c).Case (c), in particular, provides clear evidence forCCA, where the adjective scopes over both nouns,
147

Table 2: Frequency of Adjective modifying an NPConjunction - Conjunction of Singular NPs
Case Frequency N1 N2 Adjective
(a) 0 FEM MASC FEM(b) 137 FEM MASC MASC(c) 90 MASC FEM FEM(d) 1737 MASC FEM MASC
but agrees in gender with the closest. SimultaneousCCA of gender and number resolution are shownin table 2, case (c) . These constitute unambiguouscases of number resolution, as both NPs are singularand the adjective is plural (8). Such data providesempirical evidence for the complex interrelationof agreement strategies in NP coordinate struc-tures that need to be accounted for in a theory ofagreement.
4 An HPSG Formalisation
To account for these cases we propose an analysesthat stores agreement information about the leftmostand rightmost noun conjuncts, introducing two addi-tional agreement attributes: LAGR, for the leftmostconjunct, and RAGR for the rightmost conjunct.
For non-coordinated nouns LAGR, RAGR andCONCORD share the same values.
2
6
6
6
6
6
6
6
6
6
6
4
VAL.SPR.HEAD.CONCORD : 1
HEAD :
2
6
6
6
6
4
LAGR : 1 /p 2
RAGR : /p 2
CONCORD : /p 2
3
7
7
7
7
5
3
7
7
7
7
7
7
7
7
7
7
5
Determiners and prenominal adjectives agreewith nouns via LAGR, while postnominal adjectivesagree with nouns via RAGR, all having the samevalue but via different attributes. For a coordi-nate structure, the values of LAGR, RAGR and CON-CORD may differ. As these reentrancies betweenthem are defined as persistent default specifications(Lascarides and Copestake, 1999), noun coordinatestructures override these defaults and instead definethat LAGR values are reentrant with those of the left-most conjunct and RAGR with those of the rightmostconjunct.
We assume that the CONCORD of the coordinatestructure reflects the resolved gender for the wholeconjunct, adopting a resolution approach like that of
Wechsler and Zlatic (2003) or of Dalrymple and Ka-plan (2000). Kaplan and Dalrymple, for example,use marker sets to represent gender information andthis approach gives the desired result that, if there isat least a masculine noun in the coordinate structure,CONCORD.GENDER is masculine. As determinersand prenominal adjectives in Portuguese agree withthe leftmost noun closest to them, the agreementis by coindexation with LAGR. Postnominal adjec-tives, on the other hand, agree with the rightmostnoun closest to them (via RAGR), or adopt a resolvedagreement (via CONCORD).
For sentences like (2 and 3), both LAGR and CON-CORD are masculine and RAGR is feminine and thecorrect agreement values are observed, since the ad-jective can either agree with RAGR or CONCORD, butit will correctly rule out sentence (4) as ungrammat-ical. This formalisation can also capture a sentencelike (8), which has CCA for gender, but resolvednumber agreement for the postnominal adjective.
The coordination of mixed gender singular nounssharing a determiner seems to be much more con-strained. However, acceptable occurrences can befound as the sentence below, from one of the clas-sic exponents of Brazilian literature, O Guarani byMachado de Assis, exemplifies, where the relevantparts are in bold font:
D. Antonio tinha ajuntado fortuna durante osprimeiros anos de sua vida aventureira; e nao so porcapricho de fidalguia, mas em atencao a sua famılia,procurava dar a essa habitacao construıda no meiode um sertao, todo o luxo e comodidade possıveis.
The principles that allow cases like this need tobe further investigated, and will not be addressed inthis paper.
5 Conclusions
In this paper we discussed agreement processesfound in NP/noun coordinations in Portuguese, fur-ther investigated through an extensive empiricalstudy. Although we concentrated on gender andnumber agreement between nouns and their depen-dents in Portuguese, some similar strategies can alsobe found in other languages like Spanish and Ara-bic (Camacho, 2003), and this proposal could beused as the basis for a cross-linguistic formalisa-tion of these agreement processes. In order to cap-
148

2
6
6
6
6
6
6
6
6
6
6
6
4
SYNSEM.CAT.HEAD :
2
6
6
6
6
4
LAGR : 1 / 3
RAGR : 2 / 3
CONCORD : 3
3
7
7
7
7
5
CONJ-DTRS : <
»
SYNSEM.CAT.HEAD.CONCORD : 1
–
...
»
SYNSEM.CAT.HEAD.CONCORD : 2
–
>
3
7
7
7
7
7
7
7
7
7
7
7
5
2
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
4
SYNSEM.CAT.HEAD :
2
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
6
4
MOD :
2
6
6
6
6
6
6
6
6
6
6
4
SYNSEM.CAT.HEAD :
2
6
6
6
6
6
6
6
6
6
4
RAGR :
2
6
4
GENDER : 1
NUMBER : 2
3
7
5
CONCORD :
2
6
4
GENDER : 3
NUMBER : 4
3
7
5
3
7
7
7
7
7
7
7
7
7
5
3
7
7
7
7
7
7
7
7
7
7
5
CONCORD :
2
6
4
GENDER : 1 ∨ 3
NUMBER : 2 ∨ 4
3
7
5
3
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
5
3
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
5
ture these cases, we proposed an HPSG formalisa-tion that stores information about the leftmost andthe rightmost conjuncts, which, together with theresolved CONCORD feature, control agreement be-tween nouns, prenominal (determiners and adjec-tives) and postnominal (adjectives) dependents. Thisformalisation successfully captures the cases foundin the empirical study, and correctly rules out un-grammatical combinations.
Acknowledgements
This research was supported by the Noun PhraseAgreement and Coordination AHRB Project MRG-AN10939/APN17606.
References
Abeille, A., 2004. A lexicalist and construction-based approach to coordinations. In: Muller, S.(Ed.), Proceedings of the HPSG04 Conference.CSLI Publications, Katholieke Universiteit Leu-ven.
Camacho, J., 2003. The Structure of Coordination:Conjunction and Agreement Phenomena in Span-ish and Other Languages. Kluwer Academic Pub-lishers, Dordrecht.
Corbett, G. G., 1991. Gender. Cambridge UniversityPress, Cambridge, UK.
Dalrymple, M., Kaplan, R. M., 2000. Feature in-determinacy and feature resolution. Language76 (4), 759–798.
Lascarides, A., Copestake, A., 1999. Default repre-sentation in constraint-based frameworks. Com-putational Linguistics 25 (1), 55–105.
Moosally, M. J., 1999. Subject and object coordi-nation in Ndebele: and HPSG analysis. In: Bird,S., Carnie, A., Haugen, J. D., Norquest, P. (Eds.),Proceedings of the WCCFL 18 Conference. Cas-cadilla Press.
Pollard, C., Sag, I. A., 1994. Head-Driven PhraseStructure Grammar. The University of ChicagoPress, Chicago, IL.
Sadler, L., 1999. Non-distributive features and co-ordination in Welsh. In: Butt, M., King, T. H.(Eds.), On-line Proceedings of the LFG99 Con-ference.
Wechsler, S., Zlatic, L., 2003. The Many Faces ofAgreement. CSLI Publications, Stanford, CA.
Yatabe, S., 2004. A comprehensive theory of coor-dination of unlikes. In: Muller, S. (Ed.), Proceed-ings of the HPSG04 Conference. CSLI Publica-tions, Katholieke Universiteit Leuven, pp. 335–355.
149


















