
HPC - HIGH PERFORMANCE COMPUTING (SUPERCOMPUTING… · HPC - HIGH PERFORMANCE COMPUTING...
142
Hermann Härtig HPC - HIGH PERFORMANCE COMPUTING (SUPERCOMPUTING) DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2014
Transcript of HPC - HIGH PERFORMANCE COMPUTING (SUPERCOMPUTING… · HPC - HIGH PERFORMANCE COMPUTING...

Hermann Härtig
HPC - HIGH PERFORMANCE COMPUTING (SUPERCOMPUTING) !DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2014

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
Understand
■ Systems Software for “High Performance Computing” (HPC), today & expected
■ MPI as a common programming model
■ What is “noise”?
■ How to use incomplete information for informed decisions
■ Advanced Load Balancing techniques (heuristics)
2

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
CLUSTERS & MPPCharacteristics of MPP Systems:
■ Highly optimised interconnect networks
■ Distributed memory
■ Size today: few 100000 CPUs (cores) + XXL GPU
!
Successful Applications:
■ CPU intensive computation, massively parallel Applications, small execution/communication ratios, weak and strong scaling
■ Cloud ?
Not used for:
■ Transaction-management systems
■ Unix-Workstation + Servers
3

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
CLUSTERS & MPPCharacteristics of Cluster Systems:
■ Use COTS (common off the shelf) PCs/Servers and COTS networks
■ Size: No principle limits
!
Successful Applications:
■ CPU intensive computation, massively parallel Applications, larger execution/communication ratios, weak scaling
■ Data Centers, google apps
■ Cloud, Virtual Machines
!
Not used for:
■ Transaction-management system
4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
PROGRAMMING MODEL: SPMD
■ Michael Flynn (1966): SISD, SIMD, MIMD, (MISD)SIMD
■ SPMD: Single Program Multiple DataSame program runs on “all” nodesworks on split-up dataasynchronously but with explicit synch pointsimplementations: message passing/shared memory/...paradigms: “map/reduce” (google) / GCD (apple) / task queues / ...
■ often: while (true) { work; exchange data (barrier)}
5

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1
problem

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1part 1
part 2
part 3
part 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1part 1
part 2
part 3
part 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1result 1
result 2
result 3
result 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1result 1
result 2
result 3
result 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
6
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1
result
Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
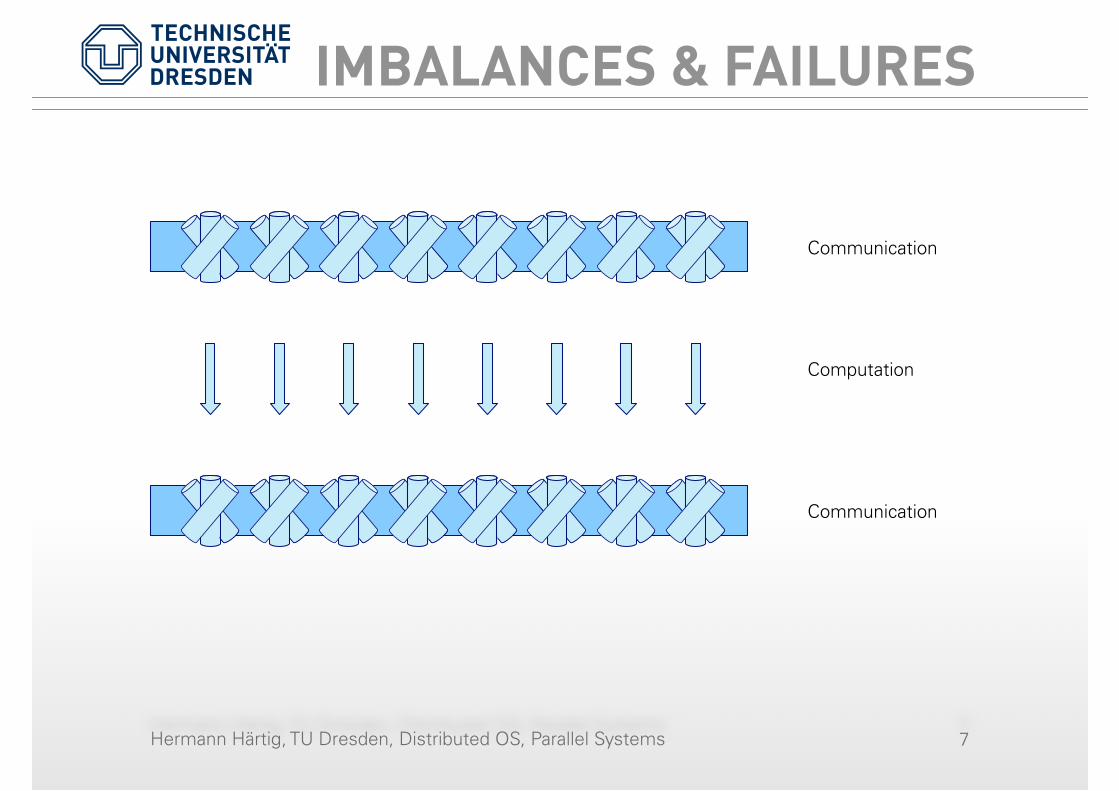
IMBALANCES & FAILURES
7
Communication
Computation
Communication

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
IMBALANCES & FAILURES
8
Communication
Computation
Communication

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
IMBALANCES & FAILURES
9
Communication
Computation
Communication

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
AMDAHL’S LAWCompute; communicate; compute; …
■ Examples (idealized, take with grain of salt !!!):
■ Compute: 10 micro, 100 micro, 1 ms
■ Communicate: 5 micro, 10 micro, 100 micro, 1ms assuming here: communication cannot be sped up
!
Amdahl's law: 1 / (1-P+P/N)
■ P: section that can be parallelized
■ 1-P: serial section
■ N: number of CPUs10

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
AMDAHL’S LAW
Compute( = parallel section),communicate( = serial section) →possible speedup for N=∞
■ 1ms, 100 μs: 1/0.1 → 10
■ 1ms, 1 μs: 1/0.001 → 1000
■ 10 μs, 1 μs: 0.01/0.001 → 10
■ ...
11

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
WEAK VS. STRONG SCALING
Strong:
■ accelerate same problem size
!
Weak:
■ extend to larger problem size
12

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
AMDAHL’S LAWJitter, “Noise”, “micro scrabblers":
■ Occasional addition to computation/communication time in one or more processes
■ Holds up all other processes
!
Compute( = parallel section), jitter ( → add to serial section), communicate( = serial section): possible speedup for N=∞
■ 1ms, 100μs, 100 μs: 1/0.2 → 5 (10)
■ 1ms, 100μs, 1 μs: 1/0.101 → 10 (1000)
■ 10 μs, 10μs, 1 μs: 0.01/0.011 → 1 (10)13

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
STATE OF THE ART IN HPC
14
Many-core Node
Application
Application

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
STATE OF THE ART IN HPC■ dedicate full partition to application
(variant: “gang scheduling”)
■ load balancing done (tried) by applications or user-level runtime (Charm++)
■ avoid OS calls
■ “scheduler”: manages queue of application processesassigns partitions to applicationssupervises run-time
■ applications run from checkpoint to checkpoint15

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
STATE OF THE ART IN HPC: RDMA
■ nodes access remote memory via load/store operations
■ busy waiting across nodes (within partition)
■ barrier ops supported by network
■ compare&exchange on remote memory operation
■ no OS calls for message ops (busy waiting)
16

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI BRIEF OVERVIEW
■ Library for message-oriented parallel programming
■ Programming model:
■ Multiple instances of same program
■ Independent calculation
■ Communication, synchronization
17

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1
problem

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1part 1
part 2
part 3
part 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1part 1
part 2
part 3
part 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1result 1
result 2
result 3
result 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1result 1
result 2
result 3
result 4

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DIVIDE AND CONQUER
18
node 1
CPU #2
CPU #1
node 2
CPU #2
CPU #1
result

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI STARTUP & TEARDOWN
■ MPI program is started on all processors
■ MPI_Init(), MPI_Finalize()
■ Communicators (e.g., MPI_COMM_WORLD)
■ MPI_Comm_size()
■ MPI_Comm_rank(): “Rank” of process within this set
■ Typed messages
■ Dynamically create and spread processes using MPI_Spawn() (since MPI-2)
19

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
20

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
20

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
20
MPI_Send( void* buf, int count, MPI_Datatype, int dest, int tag, MPI_Comm comm )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
20
MPI_Recv( void* buf, int count, MPI_Datatype, int source, int tag, MPI_Comm comm, MPI_Status *status )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
20
MPI_Bcast( void* buffer, int count, MPI_Datatype, int root, MPI_Comm comm )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
20
MPI_Reduce( void* sendbuf, void *recvbuf, int count MPI_Datatype, MPI_Op op, int root, MPI_Comm comm )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
■ Synchronization
20

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
■ Synchronization
■ Test
20
MPI_Test( MPI_Request* request, int *flag, MPI_Status *status )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
■ Synchronization
■ Test
■ Wait
20
MPI_Wait( MPI_Request* request, MPI_Status *status )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MPI EXECUTION
■ Communication
■ Point-to-point
■ Collectives
■ Synchronization
■ Test
■ Wait
■ Barrier
20
MPI_Barrier( MPI_Comm comm )

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
BLOCK AND SYNC
21
blocking call non-blocking call
synchronous communication
asynchronous communication

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
BLOCK AND SYNC
21
blocking call non-blocking call
synchronous communication
asynchronous communication
returns when message has been delivered

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
BLOCK AND SYNC
21
blocking call non-blocking call
synchronous communication
asynchronous communication
returns when message has been delivered
returns when send buffer can be reused

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
BLOCK AND SYNC
21
blocking call non-blocking call
synchronous communication
asynchronous communication
returns when message has been delivered
returns immediately, following test/wait checks for delivery
returns when send buffer can be reused

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
BLOCK AND SYNC
21
blocking call non-blocking call
synchronous communication
asynchronous communication
returns when message has been delivered
returns immediately, following test/wait checks for delivery
returns when send buffer can be reused
returns immediately, following test/wait
checks for send buffer

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
EXAMPLE
22
int rank, total; MPI_Init(); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &total); !MPI_Bcast(...); /* work on own part, determined by rank */ !if (id == 0) { for (int rr = 1; rr < total; ++rr) MPI_Recv(...); /* Generate final result */ } else { MPI_Send(...); } MPI_Finalize();

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
PMPI■ Interposition layer between library and
application
■ Originally designed for profiling
23
MPI Library
Send
Application

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
PMPI■ Interposition layer between library and
application
■ Originally designed for profiling
23
Profiler
SendMPI
Library
Send
Application

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
EXA-SCALE: HW+SW ASSUMPTIONS
■ Large number of nodes:
■ Many compute cores
■ 1 or 2 service cores
■ Failure rate exceeds checkpoint rate
■ Fast local persistent storage on each node
■ Not all cores available all the time (dark silicon due to heat/energy issues)
■ Compute + communication heavy applications, may not be balanced
■ short term changes of frequency ?24

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
ROLE OF OPERATING SYSTEM
■ for applications with extreme (bad) computation/communications ratio: NOT MUCH, but -> avoid “noise”, use common sense
■ all others: handle faultsuse dark silicon balance load gossipover decomposition & over subscription predict execution times use scheduling tricks optimise for network/memory topology
25

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
OPERATING SYSTEM “NOISE”Use common sense to avoid:
■ OS usually not directly on the critical path, BUT OS controls: interference via interrupts, caches, network, memory bus, (RTS techniques)
■ avoid or encapsulate side activities
■ small critical sections (if any)
■ partition networks to isolate traffic of different applications (HW: Blue Gene)
■ do not run Python scripts or printer daemons in parallel
26

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
FFMK@TU-DRESDEN +
+ Hebrew Uni (Mosix team) + ZIB (FS team)Fast and Fault-Tolerant Microkernel-based OS
■ get rid of partitions
■ use a micro-kernel (L4)
■ OS supported load balancing
■ use RAID for fast checkpoints
DFG-supported
27

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
4 TECHNOLOGIES
Microkernels, virtualization, split architectures
MOSIX-style online system management (gossip)
Distributed in-memory (on-node) checkpointing
MPI + applications
28

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
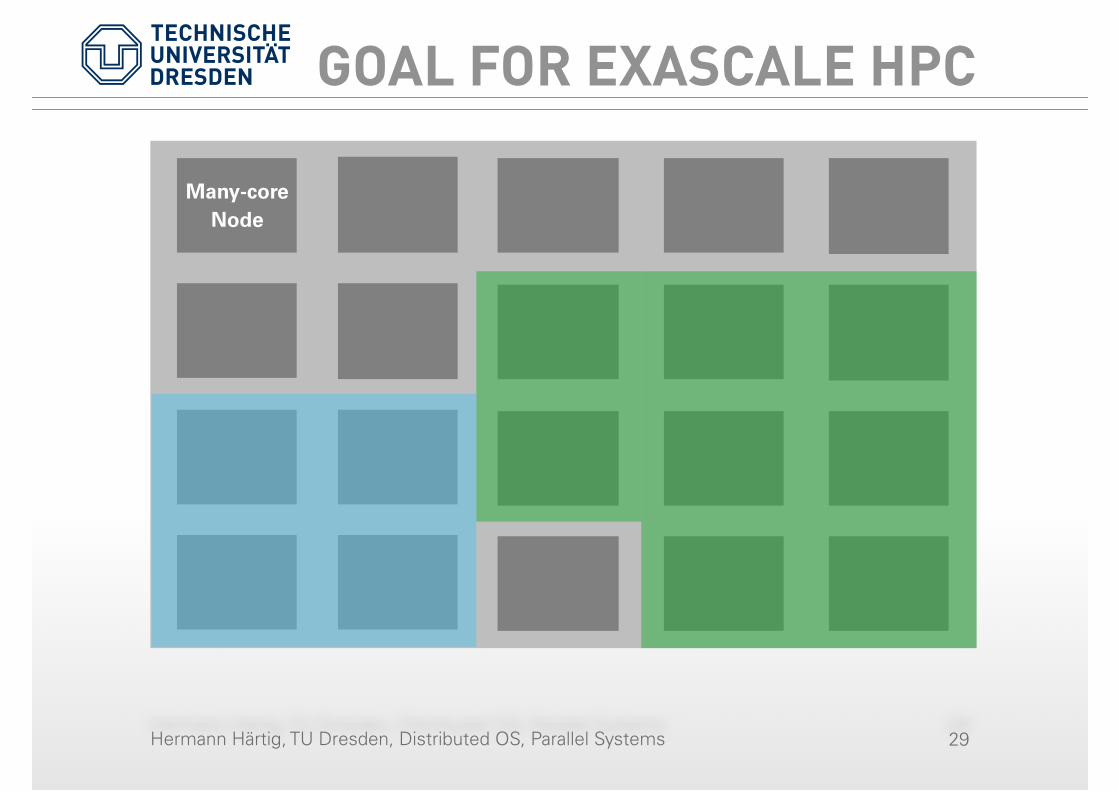
GOAL FOR EXASCALE HPC
29
Many-core Node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
GOAL FOR EXASCALE HPC
29
Many-core Node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
GOAL FOR EXASCALE HPC
29
Many-core Node
Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
GOAL FOR EXASCALE HPC
29
Many-core Node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
THIN COMMON SUBSTRATE
30
FFMK-OSFFMK-OSFFMK-OS FFMK-OS FFMK-OS
FFMK-OSFFMK-OSFFMK-OS FFMK-OS FFMK-OS
FFMK-OSFFMK-OSFFMK-OS FFMK-OS FFMK-OS
FFMK-OSFFMK-OSFFMK-OS FFMK-OS FFMK-OS

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
SMALL? PREDICTABLE?
31

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
SMALL? PREDICTABLE?
31

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: LOAD BALANCING
32

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: LOAD BALANCING
33

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: LOAD BALANCING
34

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: LOAD BALANCING
34

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
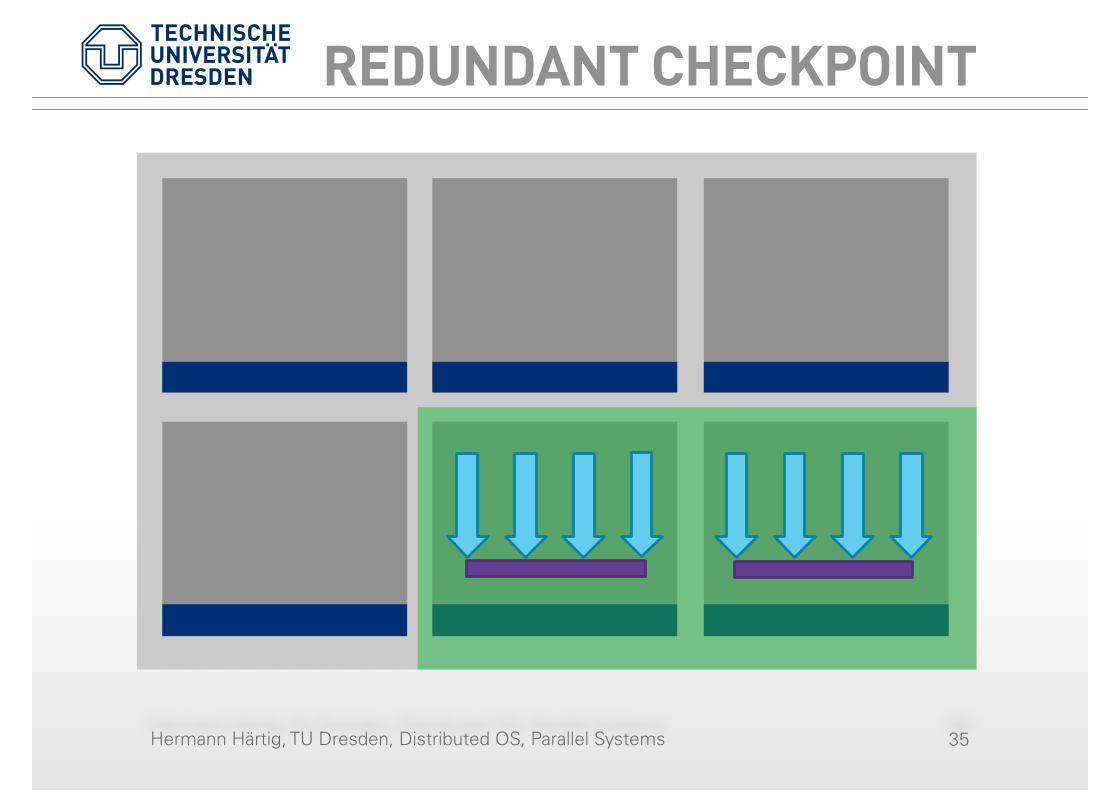
REDUNDANT CHECKPOINT
35
Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
35

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
36

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
36

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
37

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
37

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
37

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
38

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
38

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
38

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
39

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
REDUNDANT CHECKPOINT
39

TU Dresden Dealing with Load Imbalances
EXPERIMENTS: IMBALANCES, OVERDECOMPOSITION AND OVERSUBSCRIPTION
40

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
TOWARDS BALANCING
41
MPI ranks
time
Barrier

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
“MESSY” HPC
42
MPI ranks
time
Barrier
Imbalance in application workload

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
FAILURES
43
MPI ranks
time
Barrier
Reassign work to react to node failure

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
SPLITTING BIG JOBS
44
compute jobs
time
Barrier
overdecomposition & “oversubscription”

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
SMALL JOBS (NO DEPS)
45
compute jobs
time
Barrier
Execute small jobs in parallel (if possible)

TU Dresden Dealing with Load Imbalances
IMBALANCES
46
Unbalanced compute times of ranks per time step
Balanced compute times of ranks per time step
Application: COSMO-SPECS+FD4
Application: COSMO-SPECS+FD4

TU Dresden Dealing with Load Imbalances
IMBALANCES
47
-20
0
20
40
60
80
100
120
140
-20 0 20 40 60 80 100 120 140 160 180
Pro
cess ID
Timestep
0128_1x1
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Co
mp
utatio
n tim
e (fraction
)
Unbalanced compute times of ranks per time step
Application: COSMO-SPECS+FD4

TU Dresden Dealing with Load Imbalances
IMBALANCES
48
Application: COSMO-SPECS+FD4
Balanced compute times of ranks per time step
-20
0
20
40
60
80
100
120
140
-20 0 20 40 60 80 100 120 140 160 180
Pro
cess ID
Timestep
0128_1x1_lb
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Co
mp
utatio
n tim
e (fraction
)

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
49
0 s
500 s
1.000 s
1.500 s
2.000 s
2.500 s
Oversubscription factor (more ranks)
1x 2x 4x 8x
Non-blocking Blocking
Application: COSMO-SPECS+FD4 (no load balancing)
• Taurus 16 nodes w/ 16 Xeon E5-2690 (Sandy Bridge) @ 2.90GHz • 1x - 8x oversubscription (256 - 2048 MPI ranks, same problem size)

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
49
0 s
500 s
1.000 s
1.500 s
2.000 s
2.500 s
Oversubscription factor (more ranks)
1x 2x 4x 8x
Non-blocking Blocking
Application: COSMO-SPECS+FD4 (no load balancing)
• Taurus 16 nodes w/ 16 Xeon E5-2690 (Sandy Bridge) @ 2.90GHz • 1x - 8x oversubscription (256 - 2048 MPI ranks, same problem size)

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
49
0 s
500 s
1.000 s
1.500 s
2.000 s
2.500 s
Oversubscription factor (more ranks)
1x 2x 4x 8x
Non-blocking Blocking
Application: COSMO-SPECS+FD4 (no load balancing)
• Taurus 16 nodes w/ 16 Xeon E5-2690 (Sandy Bridge) @ 2.90GHz • 1x - 8x oversubscription (256 - 2048 MPI ranks, same problem size)

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
50
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
2.000 s
4.000 s
6.000 s
8.000 s
10.000 s
12.000 s
Oversubscription factor (fewer cores)
1x 2x 4x 8x 16x
64 Ranks, 1 node, 16-64 coresApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
50
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
2.000 s
4.000 s
6.000 s
8.000 s
10.000 s
12.000 s
Oversubscription factor (fewer cores)
1x 2x 4x 8x 16x
64 Ranks, 1 node, 16-64 coresApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
50
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
2.000 s
4.000 s
6.000 s
8.000 s
10.000 s
12.000 s
Oversubscription factor (fewer cores)
1x 2x 4x 8x 16x
64 Ranks, 1 node, 16-64 coresApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
51
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
200 s
400 s
600 s
800 s
1.000 s
Oversubscription factor (fewer cores)
1x 2x 4x
256 Ranks, 1-4 nodes, orig256 Ranks, 1-4 nodes, patchedApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
51
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
200 s
400 s
600 s
800 s
1.000 s
Oversubscription factor (fewer cores)
1x 2x 4x
256 Ranks, 1-4 nodes, orig256 Ranks, 1-4 nodes, patchedApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
51
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
200 s
400 s
600 s
800 s
1.000 s
Oversubscription factor (fewer cores)
1x 2x 4x
256 Ranks, 1-4 nodes, orig256 Ranks, 1-4 nodes, patchedApproximate linear scale

TU Dresden Dealing with Load Imbalances
OVERSUBSCRIPTION
51
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0 s
200 s
400 s
600 s
800 s
1.000 s
Oversubscription factor (fewer cores)
1x 2x 4x
256 Ranks, 1-4 nodes, orig256 Ranks, 1-4 nodes, patchedApproximate linear scale

TU Dresden Dealing with Load Imbalances
PATCHED: STEP TIME
52
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
0,5 s
1,0 s
1,5 s
2,0 s
2,5 s
3,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
PATCHED: STEP TIME
52
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
0,5 s
1,0 s
1,5 s
2,0 s
2,5 s
3,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
PATCHED: STEP TIME
52
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
0,5 s
1,0 s
1,5 s
2,0 s
2,5 s
3,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
PATCHED: STEP TIME
52
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
0,5 s
1,0 s
1,5 s
2,0 s
2,5 s
3,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
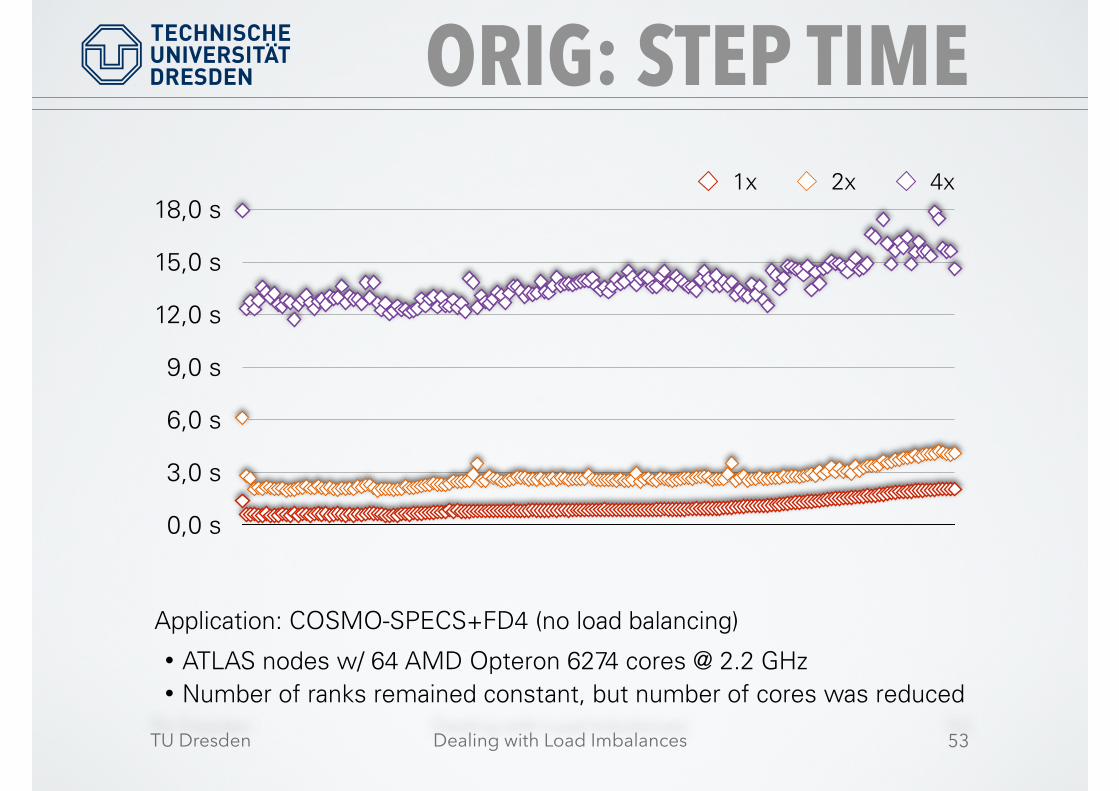
ORIG: STEP TIME
53
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
3,0 s
6,0 s
9,0 s
12,0 s
15,0 s
18,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
ORIG: STEP TIME
53
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
3,0 s
6,0 s
9,0 s
12,0 s
15,0 s
18,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
ORIG: STEP TIME
53
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
3,0 s
6,0 s
9,0 s
12,0 s
15,0 s
18,0 s1x 2x 4x
TU Dresden Dealing with Load Imbalances
ORIG: STEP TIME
53
Application: COSMO-SPECS+FD4 (no load balancing)
• ATLAS nodes w/ 64 AMD Opteron 6274 cores @ 2.2 GHz • Number of ranks remained constant, but number of cores was reduced
0,0 s
3,0 s
6,0 s
9,0 s
12,0 s
15,0 s
18,0 s1x 2x 4x

TU Dresden Dealing with Load Imbalances
EXPERIMENTS: GOSSIP SCALABILITY
54

TU Dresden Dealing with Load Imbalances
RANDOM GOSSIP
55
Distributed Bulletin Board
• Each node keeps vector with per-node info (own + info received from others)
• Once per time step, each node sends to 1 other randomly selected node a subset of its own vector entries (called “window”)
• Node merges received window entries into local vector (if newer)

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
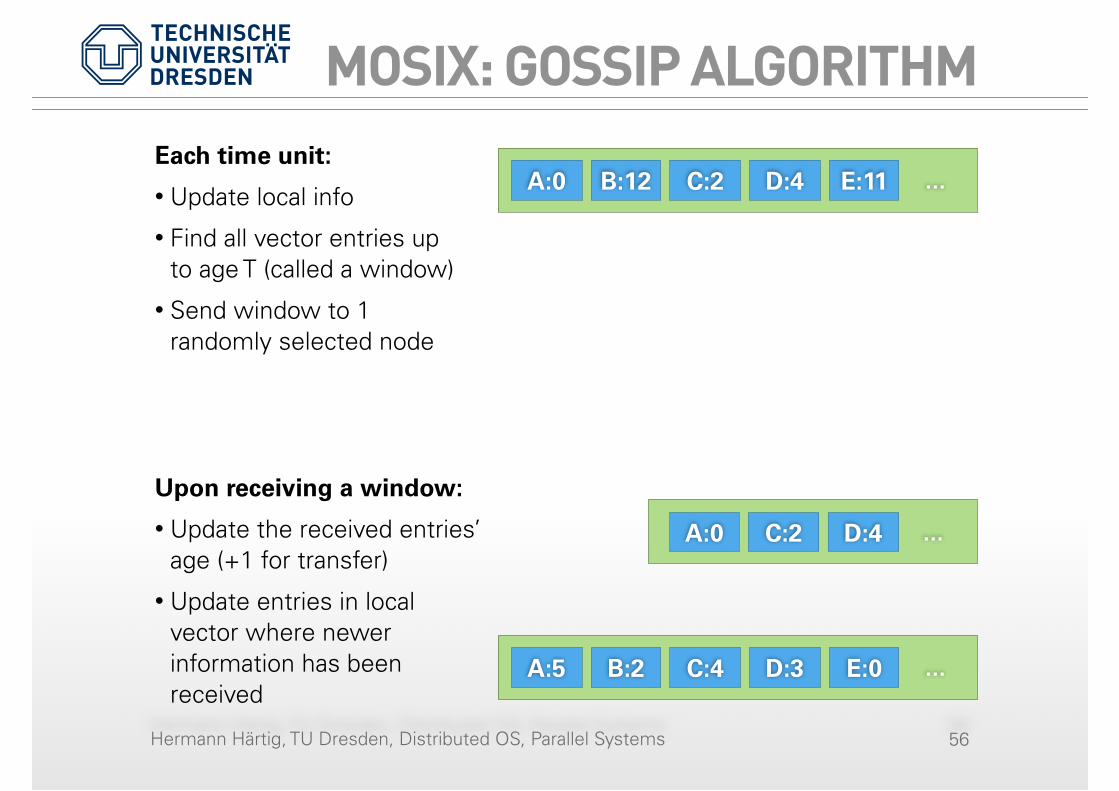
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...
Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...
A:1 C:3 ...D:5C:3A:1

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
56
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...
A:1 C:3 ...D:5
C:3A:1

TU Dresden Dealing with Load Imbalances
WINDOW SIZE
57
Gossip Algorithm:
At a fixed point during each unit of time, each node:
• Updates its own entry in the locally stored vectorwith the current state of the local resources andsets the age of this information to 0;
• For the remaining vector entries, updates thecurrent age to the age at arrival plus the timepassed since;
• Immediately sends a fixed-size window with themost recent vector entries to another node,which is chosen randomly with a uniform dis-tribution.
When a node receives a window, it:
• Registers the window’s arrival time in all the re-ceived entries using the local clock;
• Updates each of its vector’s entries with the cor-responding window entry, if the latter is newer.
Figure 1: The gossip algorithm with fixed windowsizes.
Technologies such as MOSIX are known to perform wellfor UNIX clusters. However, the overhead caused byMOSIX-like gossip algorithms on large-scale HPC machinesis not well understood, as these systems are much more sus-ceptible to network jitter. Menon and Kale evaluated theperformance of GrapevineLB [11], a load balancer exploitinggossip algorithms on top of the Charm++ runtime system.Their paper showed that the overall performance is improvedsubstantially, but they do not discuss the overhead caused bygossip-related messages being exchanged among the nodes.Soltero et. al. evaluated the suitability of gossip-based infor-mation dissemination for system services of exascale clus-ters [12]. Their simulations showed that good accuracy canbe achieved for power management services with up to amillion nodes. However, experiments using their prototypewere emulating only 1000 nodes and did not include mea-surements of network or gossip overhead on the applications.
Bhatele et al. [13] identify the contention for shared net-work resources between jobs as the primary reason for run-time variability of batch jobs in a large Cray system. OnBlueGene systems, however, each job is assigned a privatecontiguous partition of the torus network, so that contentionis avoided. In our measurements, we combined two appli-cations (a gossip program and an application benchmark)in a single batch job on a BlueGene/Q system, such thatnetwork contention becomes a critical concern. We thenmeasured the slowdown of the application due to the gossipactivities.
3. THE GOSSIP ALGORITHMConsider a cluster with a large number of active nodes.
Assume that each node regularly monitors the state of itsrelevant resources and also maintains an information vec-tor with entries about the state of the resources in all theother nodes. Each such vector entry includes the state ofthe resources of the corresponding node and the age of that
0 5 10 15
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1024 Nodes
14.21
9.77
8.46
7.83
7.49
7.29
7.18
7.09
7.03
7.01
Win
dow
size (rel. to n
ode co
unt)
0 5 10 15
2048 Nodes
14.86
10.46
9.15
8.53
8.19
7.99
7.87
7.78
7.73
7.71
Figure 2: Average vector age (relative to the unit oftime) for window sizes ranging from 10% to 100%of the number of nodes.
information. The gossip algorithm disseminates this infor-mation among nodes.The algorithm that is used in this paper was developed
in [1]. Figure 1 shows the pseudo code. Briefly, in thisalgorithm, every unit of time, each node monitors the stateof its resources and records it in its vector entry. Each of thenodes then exchanges a window containing a fixed amount ofthe newest information in its vector with another randomlychosen node. Thus, each node receives, on average, in everyunit of time information about other nodes and each of themeventually learns about the state of all nodes. Note thatthe nodes are not synchronized, i. e. all the nodes use thesame unit of time but run independently using their ownlocal clocks. One relevant parameter for the algorithm’sperformance is the size of the window, i. e., the amount ofinformation sent by each node. Another parameter that isstudied in this paper is the unit of time, which determinesthe rate of the information dissemination.
4. BENCHMARK SETUPIn a preliminary study, we measured the average age of
the vector vs. the size of the circulated window, for di↵er-ent cluster sizes. The results are depicted in Figure 2 for1024 and 2048 nodes. Configurations with 4096 and 8192nodes show similar behavior. From the figure it can be seenthat the steepest decrease in the average age of the vector iswhen increasing the window size from 10% to 20%, whereaslarger windows provide only marginal benefit at the cost oftransmitting significantly more data. As we will show inSection 5.2, circulating larger gossip messages causes higheroverhead than increasing the gossip rate. We therefore de-cided to run all experiments with a window size of 20% ofthe vector size.
4.1 BlueGene/Q HardwareWe performed measurements on the IBM BlueGene/Q
system JUQUEEN installed at Julich Supercomputing Cen-tre, Germany, which is ranked number 8 in the Novem-ber 2013 Top500 list of the largest supercomputers. TheJUQUEEN system has 28 672 nodes, each equipped withone 16-core PowerPC A2 1.6GHz processor, resulting in atotal of 458 752 cores. The 5D torus network has a peakbandwidth of 2GB/s per link, which can send and receiveat that rate simultaneously [14]. Since each node has 10

TU Dresden Dealing with Load Imbalances
NODES: VECTOR AGE
58
16-core PowerPC A2 1.6GHz processor, connected by a 5D Torus network. The network has a
duplex, peak bandwidth of 2GB/s per link [18] with a worst-case latency of 2.6µs per message.
Initially, the program allocated one gossip process to each node using MPI [15]. The unit of
time, i.e., the rate of the gossip was set to 100ms. We note that other than the gossip processes,
no other processes were running in the nodes.
For each colony size, the third row in Table 1 shows the average window size obtained by 5
runs, each lasted 100 units of time after reaching a steady state.
3.2 Average vector age
To approximate the average age of the vectors when colonies circulate windows with entries not
exceeding age T , we first find the average window age and then the average age of the whole vector.
Let Aw(T ) denote the average age of the window, which includes all the entries not exceeding
age T . Let Ag(T ) denote the average of all the vector entries whose age is greater than T and let
Av(T ) denote the average age of the whole vector. Then in Appendix B it is shown that:
Av(T ) =W (T )Aw(T ) + (n−W (T ))Ag(T )
n= Aw(T ) +
!
1−W (T )
n
"
(Ag(T )−Aw(T )) , (2)
where W (T ) is defined in Equation (1) and Aw(T ) =n ln(W (T ))−T (n−W (T ))
W (T )−1 .
Note that when circulating the whole vector, i.e., W (T ) = n, then Av(∞) = Aw(∞) = nn−1 lnn.
For each colony size and values of T , the top row in Table 2 shows the approximations of the
average age of the whole vector using Equation (2). Note that the right most column shows the
average age when circulating the whole vector. The corresponding averages from 5 simulations and
5 cluster measurements are shown in the second and third rows respectively.
Table 2: Average age of the whole vector.Circulating among colony nodes
Colony Method windows not exceeding age wholenodes 2 4 6 8 10 vector
Approx. 19.15 6.00 4.93 4.89 4.89 4.89128 Simulation 18.87 6.04 4.97 4.92 4.95
Measured 18.75 5.99 4.94 4.88 4.90Approx. 36.49 8.49 5.70 5.57 5.57 5.57
256 Simulation 36.33 8.57 5.77 5.63 5.62Measured 36.06 8.55 5.77 5.60 5.60Approx. 71.15 13.27 6.70 6.26 6.25 6.25
512 Simulation 71.01 13.34 6.81 6.34 6.32Measured 70.85 13.37 6.78 6.31 6.28Approx. 140.44 22.69 8.21 6.99 6.94 6.94
1K Simulation 139.76 22.73 8.33 7.06 7.01Measured 140.14 22.83 8.32 7.04 6.98Approx. 279.03 41.47 10.90 7.79 7.63 7.63
2K Simulation 267.82 41.58 11.08 7.89 7.71Measured 278.94 41.66 11.03 7.84 7.66Approx. 556.20 78.99 16.06 8.83 8.34 8.32
4K Simulation 479.96 79.10 16.23 8.95 8.42Measured 556.20 79.39 16.24 8.87 8.33Approx. 1,110.53 154.02 26.26 10.44 9.07 9.01
8K Simulation 798.97 153.80 26.48 10.59 9.43Measured 1,102.99 155.16 26.51 10.44 8.98
1M Approx. 141,911 19,209 2,605 360 58 13.861G Approx. 145M 19M 2M 360K 48K 20.79
8

TU Dresden Dealing with Load Imbalances
NODES: VECTOR AGE
58
16-core PowerPC A2 1.6GHz processor, connected by a 5D Torus network. The network has a
duplex, peak bandwidth of 2GB/s per link [18] with a worst-case latency of 2.6µs per message.
Initially, the program allocated one gossip process to each node using MPI [15]. The unit of
time, i.e., the rate of the gossip was set to 100ms. We note that other than the gossip processes,
no other processes were running in the nodes.
For each colony size, the third row in Table 1 shows the average window size obtained by 5
runs, each lasted 100 units of time after reaching a steady state.
3.2 Average vector age
To approximate the average age of the vectors when colonies circulate windows with entries not
exceeding age T , we first find the average window age and then the average age of the whole vector.
Let Aw(T ) denote the average age of the window, which includes all the entries not exceeding
age T . Let Ag(T ) denote the average of all the vector entries whose age is greater than T and let
Av(T ) denote the average age of the whole vector. Then in Appendix B it is shown that:
Av(T ) =W (T )Aw(T ) + (n−W (T ))Ag(T )
n= Aw(T ) +
!
1−W (T )
n
"
(Ag(T )−Aw(T )) , (2)
where W (T ) is defined in Equation (1) and Aw(T ) =n ln(W (T ))−T (n−W (T ))
W (T )−1 .
Note that when circulating the whole vector, i.e., W (T ) = n, then Av(∞) = Aw(∞) = nn−1 lnn.
For each colony size and values of T , the top row in Table 2 shows the approximations of the
average age of the whole vector using Equation (2). Note that the right most column shows the
average age when circulating the whole vector. The corresponding averages from 5 simulations and
5 cluster measurements are shown in the second and third rows respectively.
Table 2: Average age of the whole vector.Circulating among colony nodes
Colony Method windows not exceeding age wholenodes 2 4 6 8 10 vector
Approx. 19.15 6.00 4.93 4.89 4.89 4.89128 Simulation 18.87 6.04 4.97 4.92 4.95
Measured 18.75 5.99 4.94 4.88 4.90Approx. 36.49 8.49 5.70 5.57 5.57 5.57
256 Simulation 36.33 8.57 5.77 5.63 5.62Measured 36.06 8.55 5.77 5.60 5.60Approx. 71.15 13.27 6.70 6.26 6.25 6.25
512 Simulation 71.01 13.34 6.81 6.34 6.32Measured 70.85 13.37 6.78 6.31 6.28Approx. 140.44 22.69 8.21 6.99 6.94 6.94
1K Simulation 139.76 22.73 8.33 7.06 7.01Measured 140.14 22.83 8.32 7.04 6.98Approx. 279.03 41.47 10.90 7.79 7.63 7.63
2K Simulation 267.82 41.58 11.08 7.89 7.71Measured 278.94 41.66 11.03 7.84 7.66Approx. 556.20 78.99 16.06 8.83 8.34 8.32
4K Simulation 479.96 79.10 16.23 8.95 8.42Measured 556.20 79.39 16.24 8.87 8.33Approx. 1,110.53 154.02 26.26 10.44 9.07 9.01
8K Simulation 798.97 153.80 26.48 10.59 9.43Measured 1,102.99 155.16 26.51 10.44 8.98
1M Approx. 141,911 19,209 2,605 360 58 13.861G Approx. 145M 19M 2M 360K 48K 20.79
8

TU Dresden Dealing with Load Imbalances
SCALABILITY LIMITS
59
Problem: average age or window sizes too big for extreme numbers of nodes

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MASTER: GLOBAL VIEW
60

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MASTER: GLOBAL VIEW
60

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MASTER: GLOBAL VIEW
60

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MASTER: GLOBAL VIEW
60

TU Dresden Dealing with Load Imbalances
SYSTEM ARCHITECTURE
61

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsHermann Härtig, TU Dresden
L4 MICRO KERNELS
62
apps
commodity OS
L4
displa
L4/Re
critical application
Auth IO

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden HyoCore
SIMKO 3
63

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden HyoCore
SIMKO 3
63
“ Merkel!Phone “

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden FFMK 64
Linux Kernel !!!
!!!L4
TCB
App
Secure File System

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden FFMK 64
Linux Kernel !!!
!!!L4
TCB
App
Secure File System

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
App (local)
MOSIX MIGRATION
65
OS Virtualization Layer
Linux Kernel
Home Node Remote Node
App (Guest)
OS Virtualization Layer
Linux Kernel
MOSIX system call rerouting

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
RANDOMIZED GOSSIP
66
Distributed Bulletin Board
• Each node keeps vector with per-node info (own + info received from others)
• Once per time step, each node sends to 1 other randomly selected node a subset of its own vector entries (called “window”)
• Node merges received window entries into local vector (if newer)

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
RANDOMIZED GOSSIP
66
Distributed Bulletin Board
• Each node keeps vector with per-node info (own + info received from others)
• Once per time step, each node sends to 1 other randomly selected node a subset of its own vector entries (called “window”)
• Node merges received window entries into local vector (if newer)

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...
A:1 C:3 ...D:5C:3A:1

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
MOSIX: GOSSIP ALGORITHM
67
A:0 B:12 C:2 D:4 E:11 ...
A:0 C:2 ...D:4
Each time unit:
• Update local info
• Find all vector entries up to age T (called a window)
• Send window to 1 randomly selected node
Upon receiving a window:
• Update the received entries’ age (+1 for transfer)
• Update entries in local vector where newer information has been received
A:5 B:2 C:4 D:3 E:0 ...
A:1 C:3 ...D:5
C:3A:1

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
XTREEMFS ARCHITECTURE
68
����������� �
��������������������������������������������������������������������
MRC
������������������
������������������
objects
metadata
file content
OSD1
OSD2
...
OSDn
������������������������
�����������������������
���������������� !"�#
�������$%$��&�����'�(�
)*�+�,�� ��
��!-����&'$
�� ����.���������.#
��������������
�� !"#
��� ��
��.����
�����.#
/������0��
���
����
�������0��
���#
�$����� (�$$
client
1������
1������
2������
Figure 2: File access with XtreemFS
3.2 SecuritySecurity is of paramount importance for storage systems, as it protects the privacyof individual users and keeps data safe from unauthorized manipulation in the face ofshared resources and inherently insecure environments. Relevant aspects of the securityarchitecture include the authentication of users, the authorization of accesses and theencryption of messages and data.
3.2.1 Authentication
XtreemFS clients and servers are not required to run in a trusted environment. Clientsrunning on any machine may access any XtreemFS installation that is reachable overthe network. Consequently, servers cannot assume that clients are inherently trustwor-thy, nor can clients assume that servers are trustworthy.
To solve the problem, XtreemFS supports SSL connections between all clients andservers. When establishing a new server connection, e.g., in the course of mountinga volume or initially writing a file, clients and servers exchange X.509 certificates toensure a mutual authentication. The distinguished name of a client certificate reflectsthe identity of the user on behalf of whom subsequent operations are executed. Userand group IDs are thus unforgeable and allow for a secure authentication of individualusers.
3.2.2 Authorization
A complementary issue is the assignment and evaluation of access rights. XtreemFSoffers a common POSIX authorization model with different access flags for the owninguser, the owning group and all other users. An optional extension are POSIX accesscontrol lists (ACLs), which allow the definition of access rights at the granularity ofindividual users and groups.
File system calls with path names are directed to the MRC, where they can be au-thorized locally, as the MRC stores all relevant metadata to perform access control.

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
ARCHITECTURE
69
MPI Application
MPI Library
L4 Microkernel
Linux
Linux XtreemFS
Linux MPI-RT
MosiX Module
L4 XtreemFS
L4 MPI-RT
MPI Application
MPI Library
MPI Application
MPI Library

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
ARCHITECTURE
70
Node
Service Core
Service Core
Compute Core
Compute Core
Compute Core
MPI Application
MPI Library
L4 Microkernel
Linux
Linux XtreemFS
Linux MPI-RT
MosiX Module
L4 XtreemFS
L4 MPI-RT
MPI Application
MPI Library
MPI Application
MPI Library

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
XTREEMFS: FAST PATH
71
Client Node
XtreemFS Client
L4 XtreemFS
Checkpoint Node
XtreemFS OSD
Checkpoint Store
L4 XtreemFS
Hig
h-P
erfo
rman
ce
Inte
rco
nn
ect
Establish fast connection
WriteOpen
MPI App
LinuxLinux
Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden FFMK
NodeNodeCompute Node
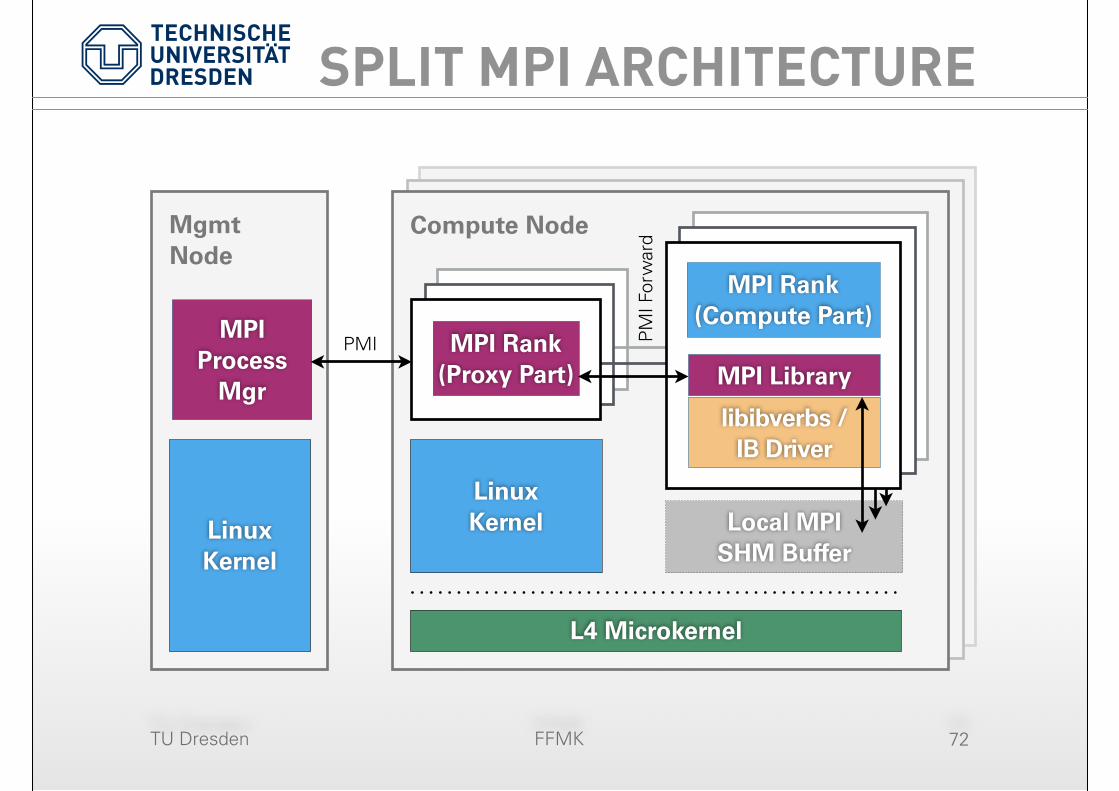
SPLIT MPI ARCHITECTURE
72
L4 Microkernel
MPI Rank (Proxy Part)
Linux Kernel
PM
I For
war
d
Mgmt Node
MPI Process
Mgr
Linux Kernel
Local MPI SHM Buffer
MPI Rank (Compute Part)
MPI Library
libibverbs / IB Driver
PMI

Hermann Härtig, TU Dresden, Distributed OS, Parallel SystemsTU Dresden FFMK
Compute Node
SPLIT MPI ARCHITECTURE
73
L4 Microkernel
MPI Process
Mgr
Local MPI SHM Buffer
MPI Rank (Compute Part)
MPI Library
PMI

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
DESIGN CHALLENGES
74

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
CHALLENGES
75
Fine-grained work splitting for system-supported load balancing?
How to synchronize? RDMA + polling ./. Block?
Gossip + Heuristics for EXASCALE ?
Application / system interface? “Yell” for help?
Compute processes, how and where to migrate / reroute communication?
Replication instead of / in addition to checkpoint/restart?
Reuse Linux (device drivers)?

Hermann Härtig, TU Dresden, Distributed OS, Parallel Systems
HARDWARE-WISHES
■ Perf counters for Network
■ fast redirection of messages
■ flash on node circumventing FTL
■ quick activation of threads without polling
76


















