
How to Win a Chinese Chess Game Reinforcement Learning Cheng, Wen Ju.
32
How to Win a Chinese Chess Game Reinforcement Learning Cheng, Wen Ju
-
Upload
braiden-parmentier -
Category
Documents
-
view
246 -
download
0
Transcript of How to Win a Chinese Chess Game Reinforcement Learning Cheng, Wen Ju.

How to Win a Chinese Chess Game
Reinforcement Learning
Cheng, Wen Ju
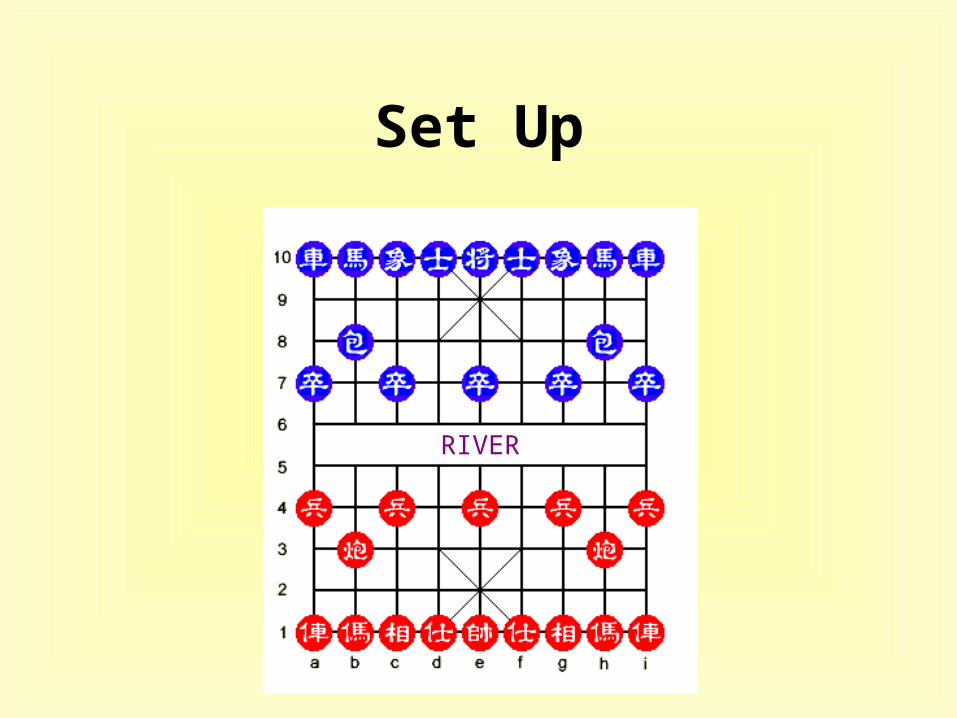
Set Up
RIVER
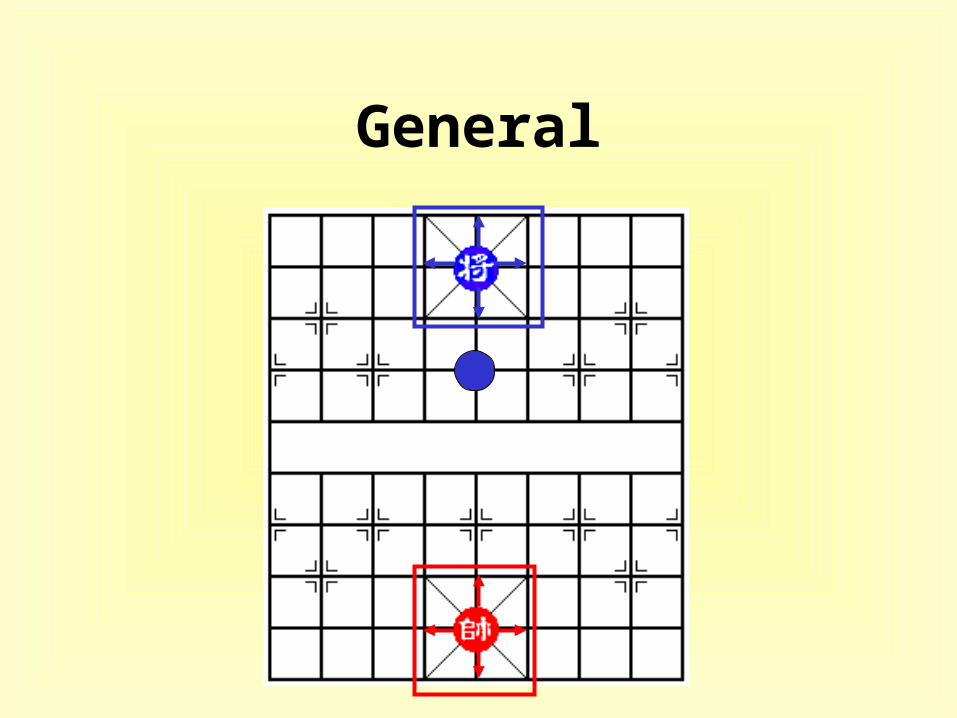
General
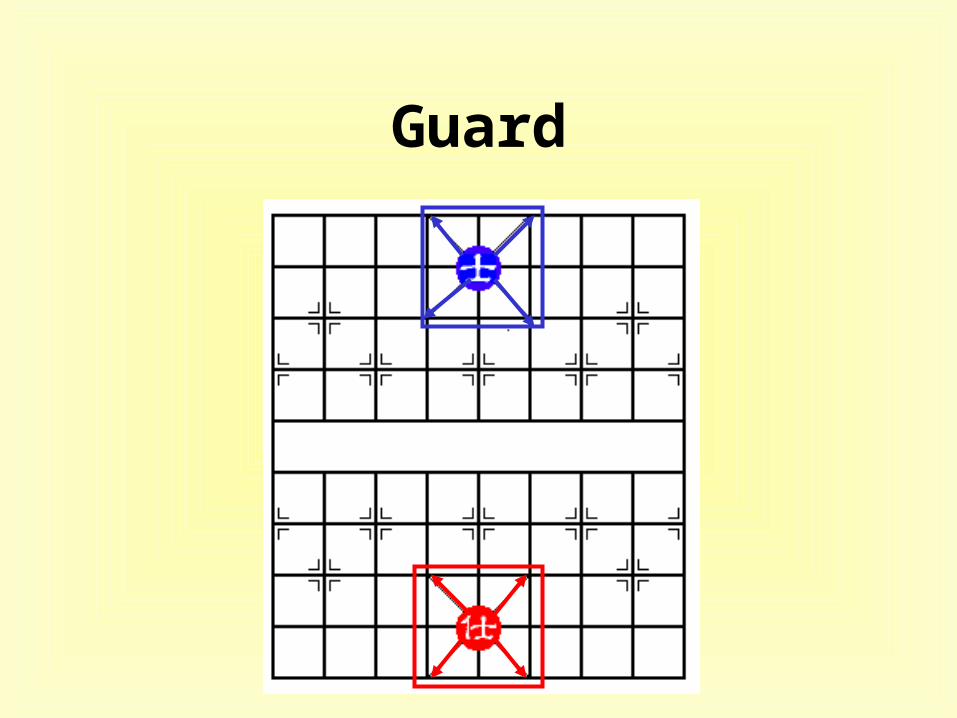
Guard
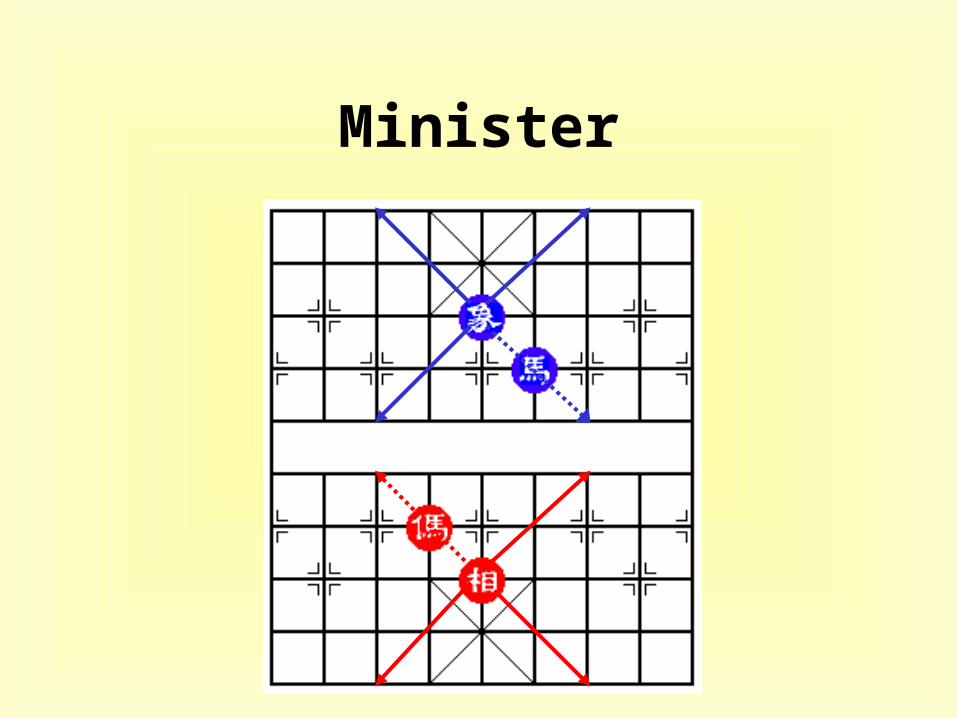
Minister
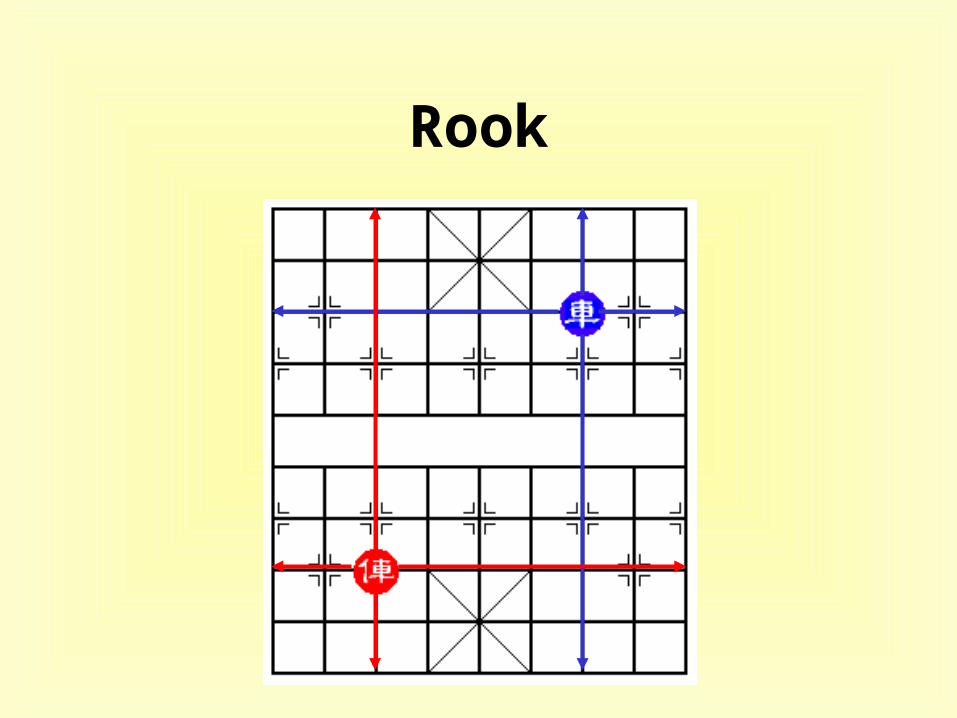
Rook
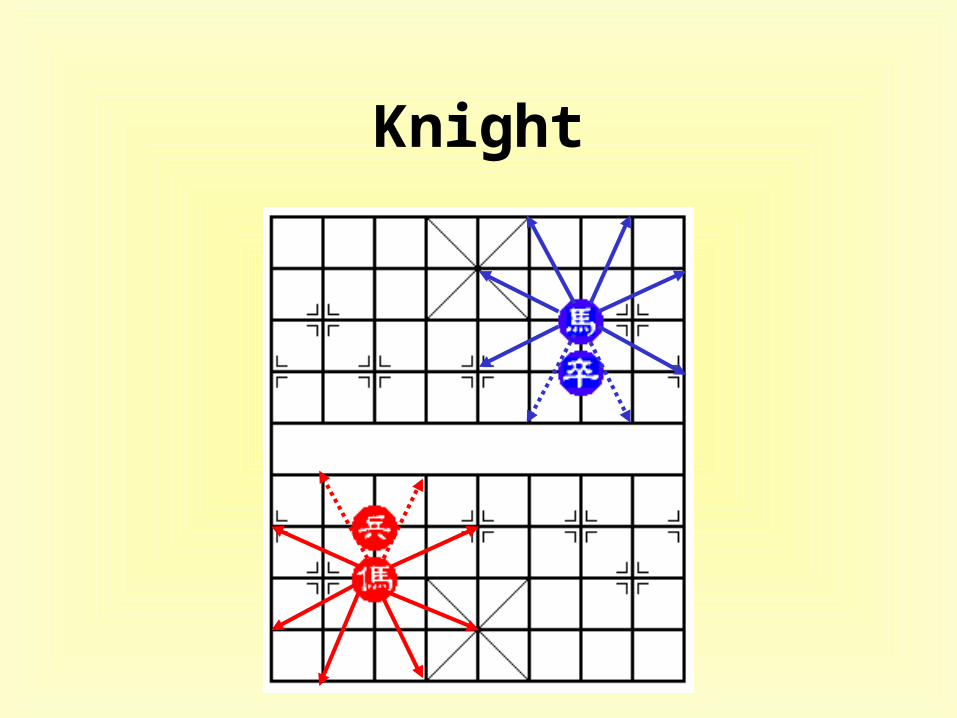
Knight
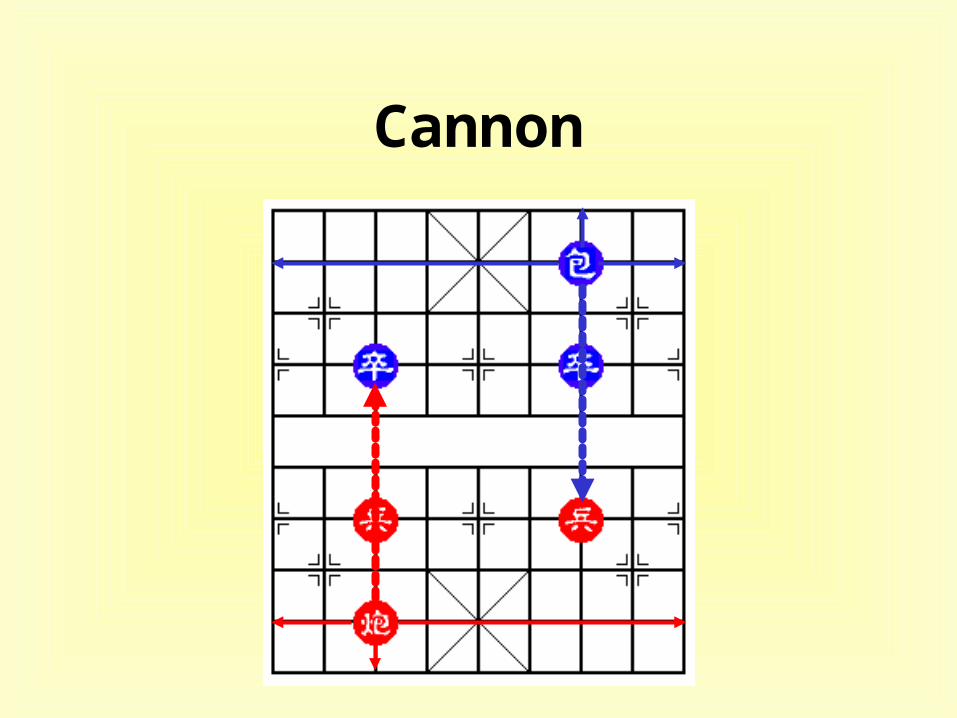
Cannon
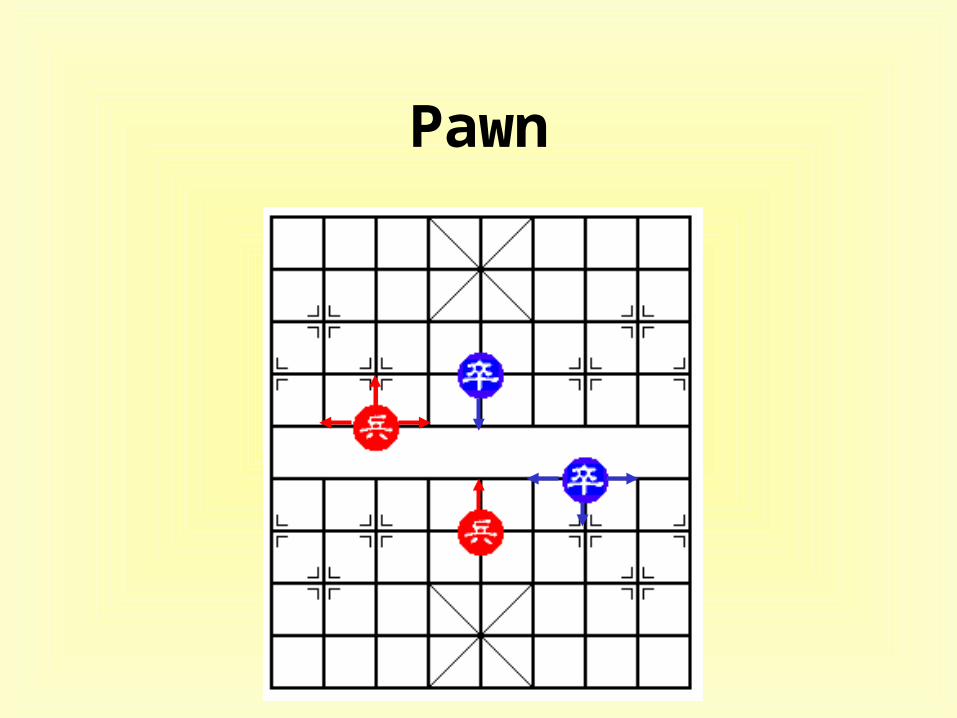
Pawn

Training
• how long does it to take for a human?• how long does it to take for a computer?• Chess program, “KnightCap”, used TD to learn its
evaluation function while playing on the Free Internet Chess Server (FICS, fics.onenet.net), improved from a 1650 rating to a 2100 rating (the level of US Master, world champion are rating around 2900) in just 308 games and 3 days of play.

Training
• to play a series of games in a self-play learning mode using temporal difference learning
• The goal is to learn some simple strategies– piece values or weights

Why Temporal Difference Learning
• the average branching factor for the game tree is usually around 30
• the average game lasts around 100 ply
• the size of a game tree is 30100

Searching
• alpha-beta search
• 3 ply search vs 4 ply search
• horizon effect
• quiescence cutoff search
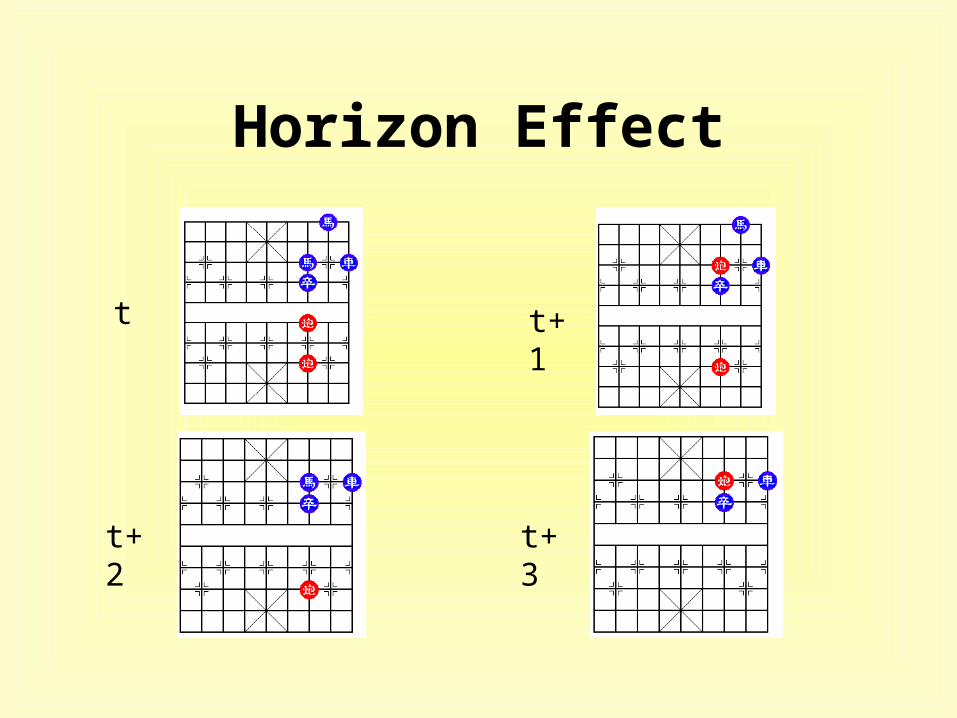
Horizon Effect
t t+1
t+2 t+3

Evaluation Function
• feature– property of the game
• feature evaluators– Rook, Knight, Cannon , Minister, Guard, and Pawn
• weight:– the value of a specific piece type
• feature function: f– return the current player’s piece advantage on a scale
from -1 to 1• evaluation function: Y
Y = ∑k=1 to 7 wk * fk

TD(λ) and Updating the Weights
wi, t+1 = wi, t + (Yt+1 – Yt) k=1 to t t-k∆ wiYk
= wi, t + (Yt+1 – Yt)(fi, t + fi, t-1 + 2fi, t-2 + … +
t-1fi, 1)
learning rate
–how quickly the weights can change
0.01
feedback coefficient
-how much to discount past values
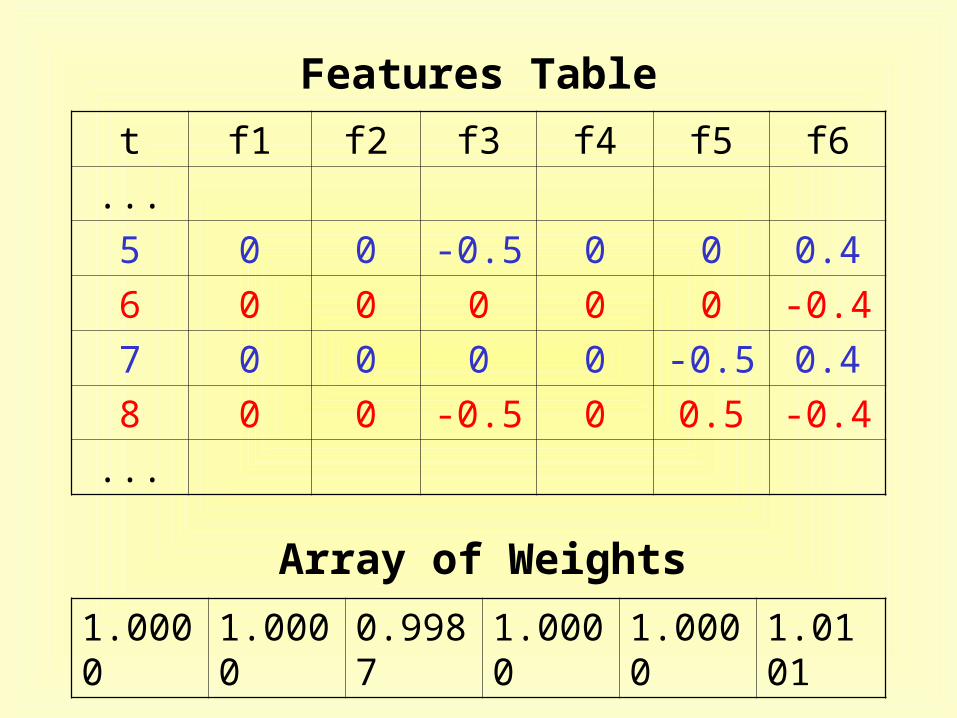
Features Table
t f1 f2 f3 f4 f5 f6
...
5 0 0 -0.5 0 0 0.4
6 0 0 0 0 0 -0.4
7 0 0 0 0 -0.5 0.4
8 0 0 -0.5 0 0.5 -0.4
...
Array of Weights
1.0000 1.0000 0.9987 1.0000 1.0000 1.0101
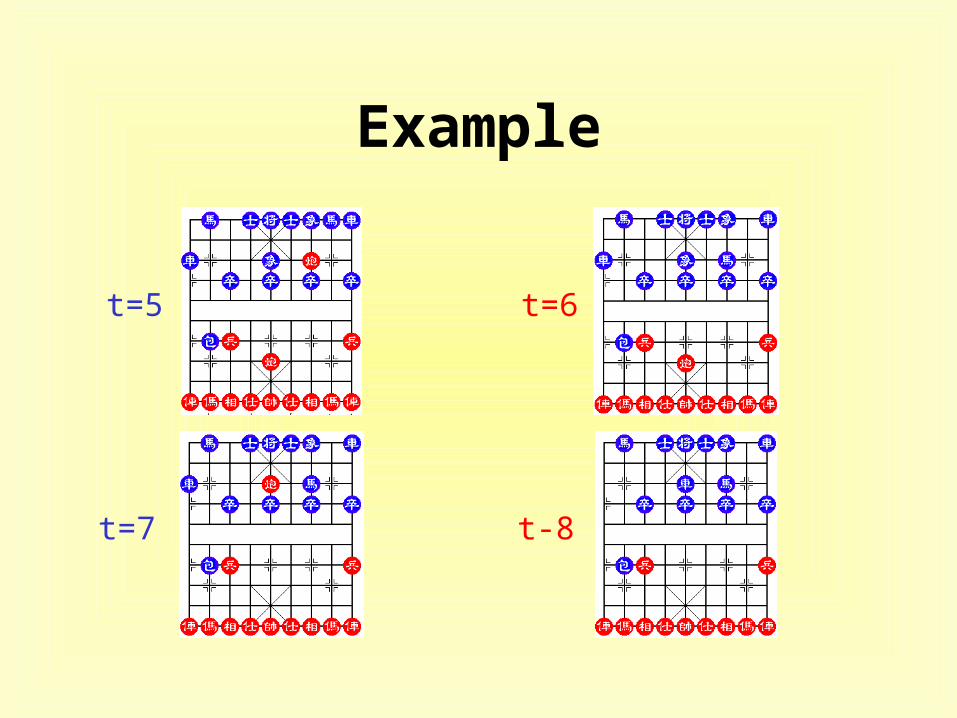
Example
t=5 t=6
t=7 t-8

Final Reward• loser
– if is a draw, the final reward is 0
– if the board evaluation is negative, then the final reward is twice the board
– if the board evaluation is positive, then the final reward is -2 times the board evaluation
• winner– if is a draw, the final reward is 0
– if the board evaluation is negative, then the final reward is -2 times the board evaluation
– if the board evaluation is positive, then the final reward is twice the board evaluation

Final Reward
• the weights are normalized by dividing by the greatest weight
• any negative weights are set to zero
• the most valuable piece has weight 1

Summary of Main Events
1. Red’s turn
2. Update weights for Red using TD(λ)
3. Red does alpha-beta search.
4. Red executes the best move found
5. Blue’s turn
6. Update weights for Blue using TD(λ)
7. Blue does alpha-beta search
8. Blue executes the best move found (go to 1)

After the Game Ends
1. Calculate and assign final reward for losing player
2. Calculate and assign final reward for winning player
3. Normalize the weights between 0 and 1

Results
• 10 games series• 100 games series• learned weights are carried over into the
next series• began with all weights initialized to 1• The goal is to learn the different the piece
values that is close to the default values defined by H.T. Lau or even better

Observed Behavior
• the early stages– played pretty randomly
• after 20 games– had identified the most valuable piece – Rook
• after 250 games– played better– protecting the valuable pieces, and trying to
capture a valuable piece
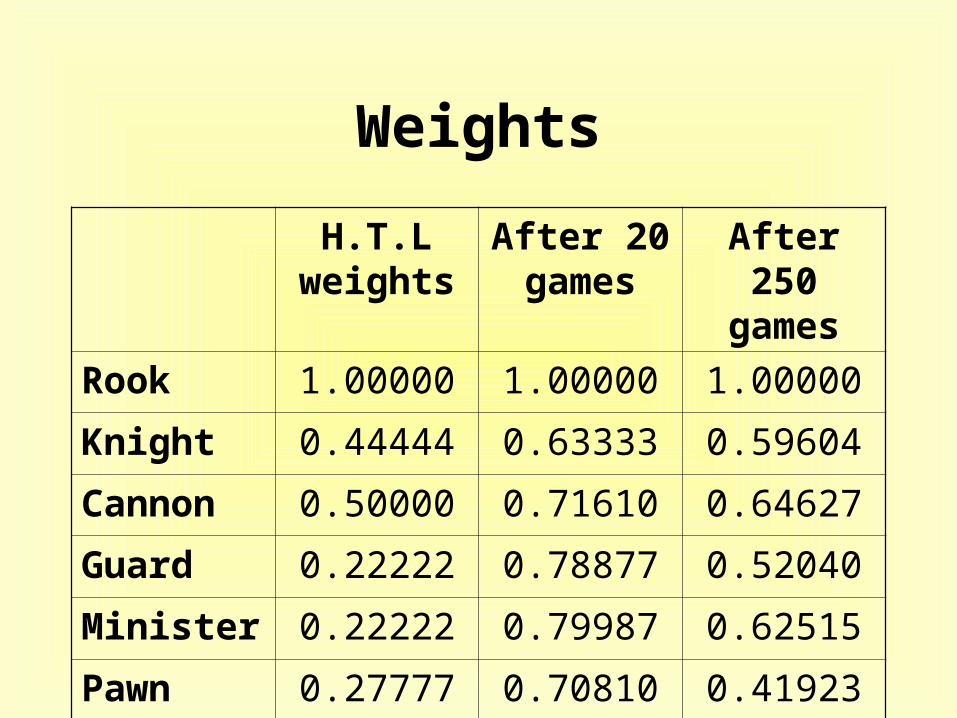
Weights
H.T.L weights
After 20 games
After 250 games
Rook 1.00000 1.00000 1.00000
Knight 0.44444 0.63333 0.59604
Cannon 0.50000 0.71610 0.64627
Guard 0.22222 0.78877 0.52040
Minister 0.22222 0.79987 0.62515
Pawn 0.27777 0.70810 0.41923

Testing
• self-play games– Red played using the learned weights after 250
games – Blue used H.T. Lau’s equivalent of the weights
• 5 games– red won 3– blue won once– one draw

Future Works
8 different types or "categories" of features:
1. Piece Values 2. Comparative Piece Advantage 3. Mobility 4. Board Position 5. Piece Proximity 6. Time Value of Pieces 7. Piece Combinations 8. Piece Configurations
Examples
Cannon behind Knight

Conclusion
• Computer Chinese chess has been studied for more than twenty years. Recently, due to the advancement of AI researches and enhancement of computer hardware in both efficiency and capacity, some Chinese chess programs with grand-master level (about 6-dan in Taiwan) have been successfully developed.
• Professor Shun-Chin Hsu of Chang-Jung University (CJU), who has involved in the development of computer Chinese chess programs for a long time of period, points out that “the strength of Chinese chess programs increase 1-dan every three years.” He also predicts that a computer program will beat the “world champion of Chinese chess” before 2012.

When and What
• 2004 World Computer Chinese Chess Championship
• Competition Dates :– June 25-26, 2004
• Prizes :(1) First Place USD 1,500 A gold medal(2) Second Place USD 900 A silver medal(3) Third Place USD 600 A bronze medal(4) Fourth Place USD 300

References
C. Szeto. Chinese Chess and Temporal Difference Learning
J. Baxter. KnightCap: A chess program that learns by combining TD(λ) with minimax search
T. Trinh. Temporal Difference Learning in Chinese Chess
http://chess.ncku.edu.tw/index.html


















