
How MapReduce part of Hadoop works (i.e. system's view) ?
287
Hadoop MapReduce - System’s View By Niketan Pansare ([email protected]) Rice University Wednesday, March 27, 13
-
Upload
niketan-pansare -
Category
Education
-
view
122 -
download
0
Transcript of How MapReduce part of Hadoop works (i.e. system's view) ?

Hadoop MapReduce -System’s View
By Niketan Pansare ([email protected])Rice University
Wednesday, March 27, 13
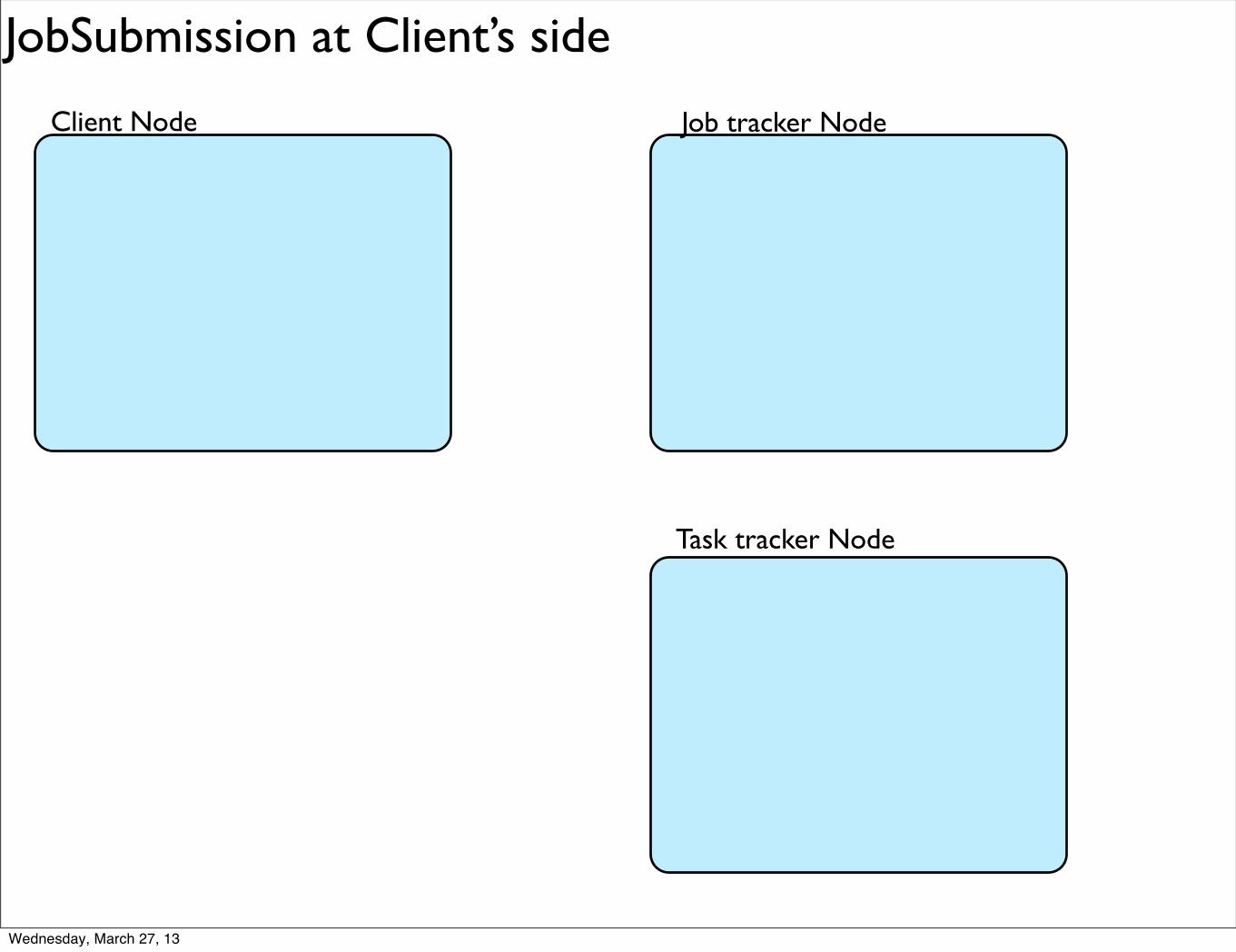
JobSubmission at Client’s side
Client Node Job tracker Node
Task tracker Node
Wednesday, March 27, 13

Client Node
Client pgm
Wednesday, March 27, 13

Client Node
Client pgm
Job
Wednesday, March 27, 13

Client Node
Client pgm
Job
Wednesday, March 27, 13
Client Node
Client pgm
Job
job.submit()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTrackerjobSubmissionClient.getNewJobID()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
jobSubmissionClient.getNewJobID()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
jobSubmissionClient.getNewJobID()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
jobSubmissionClient.getNewJobID()
RPC call
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
jobConf.getOutputFormat().checkOutputSpecs()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources
JobSubmissionFiles
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources
1. Get destination paths- Job staging area (getStagingArea())- Job submission area- Job config file path (getJobConfPath())- Job jar file path (getJobJar())- Information about splits: (a) split meta file (getJobSplitMetaFile()) (b) split file (getJobSplitFile())
JobSubmissionFiles
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (jar)
Shared FS (HDFS)
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (jar)
Shared FS (HDFS)
Wednesday, March 27, 13
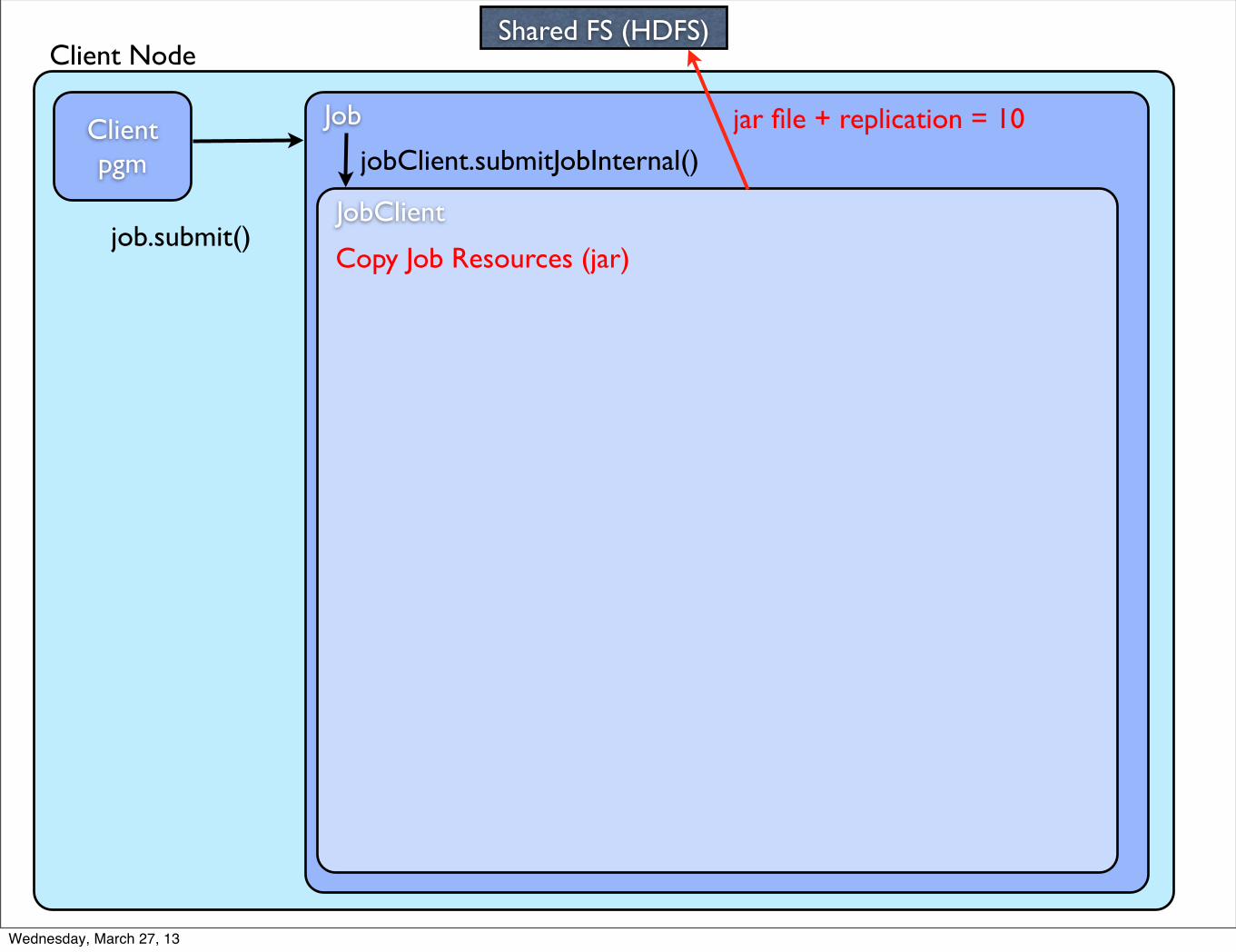
Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (jar)
Shared FS (HDFS)
jar file + replication = 10
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (jar)
Shared FS (HDFS)
jar file + replication = 10
replication = mapred.submit.replication = default: 10
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
Shared FS (HDFS)
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
Wednesday, March 27, 13
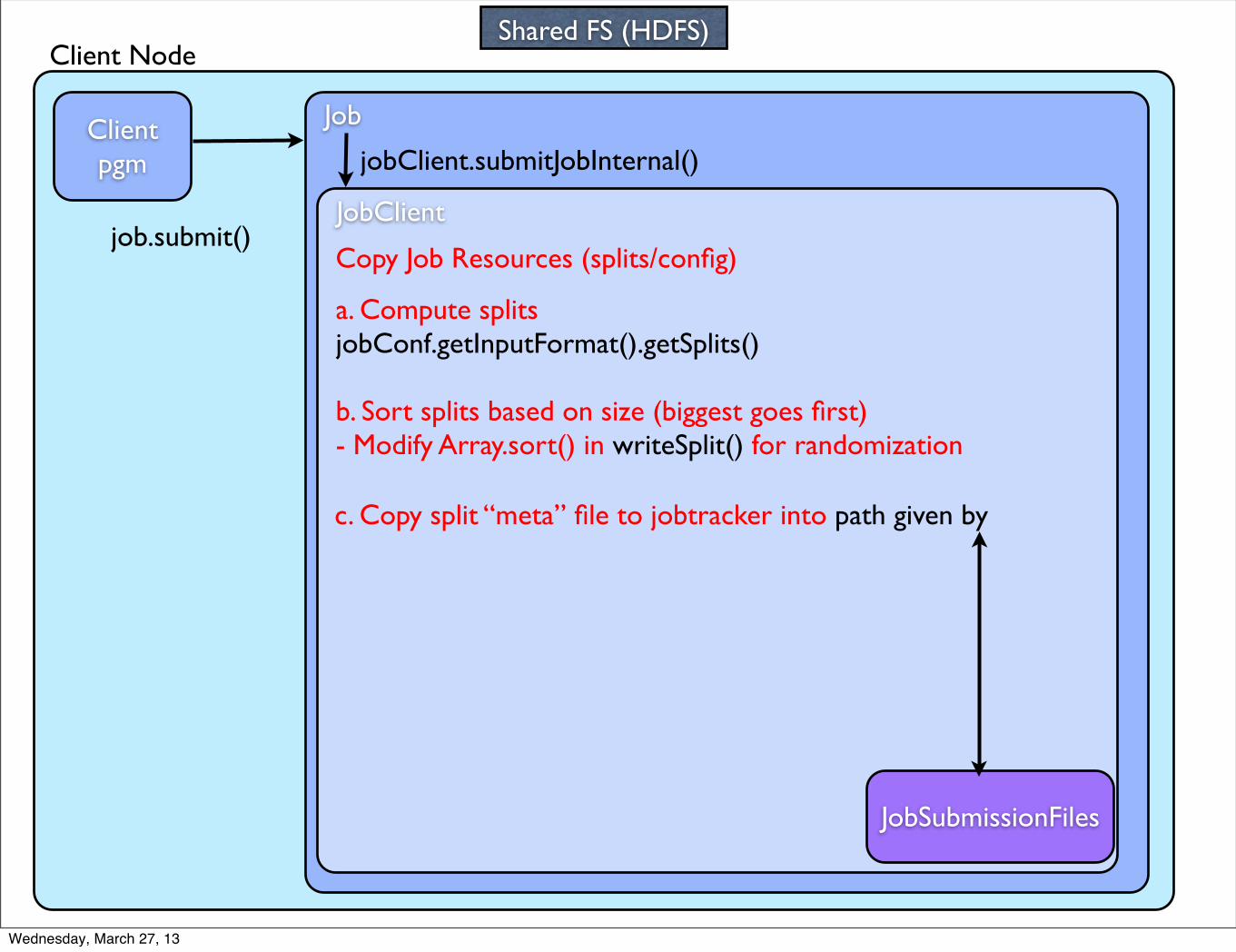
Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
Wednesday, March 27, 13
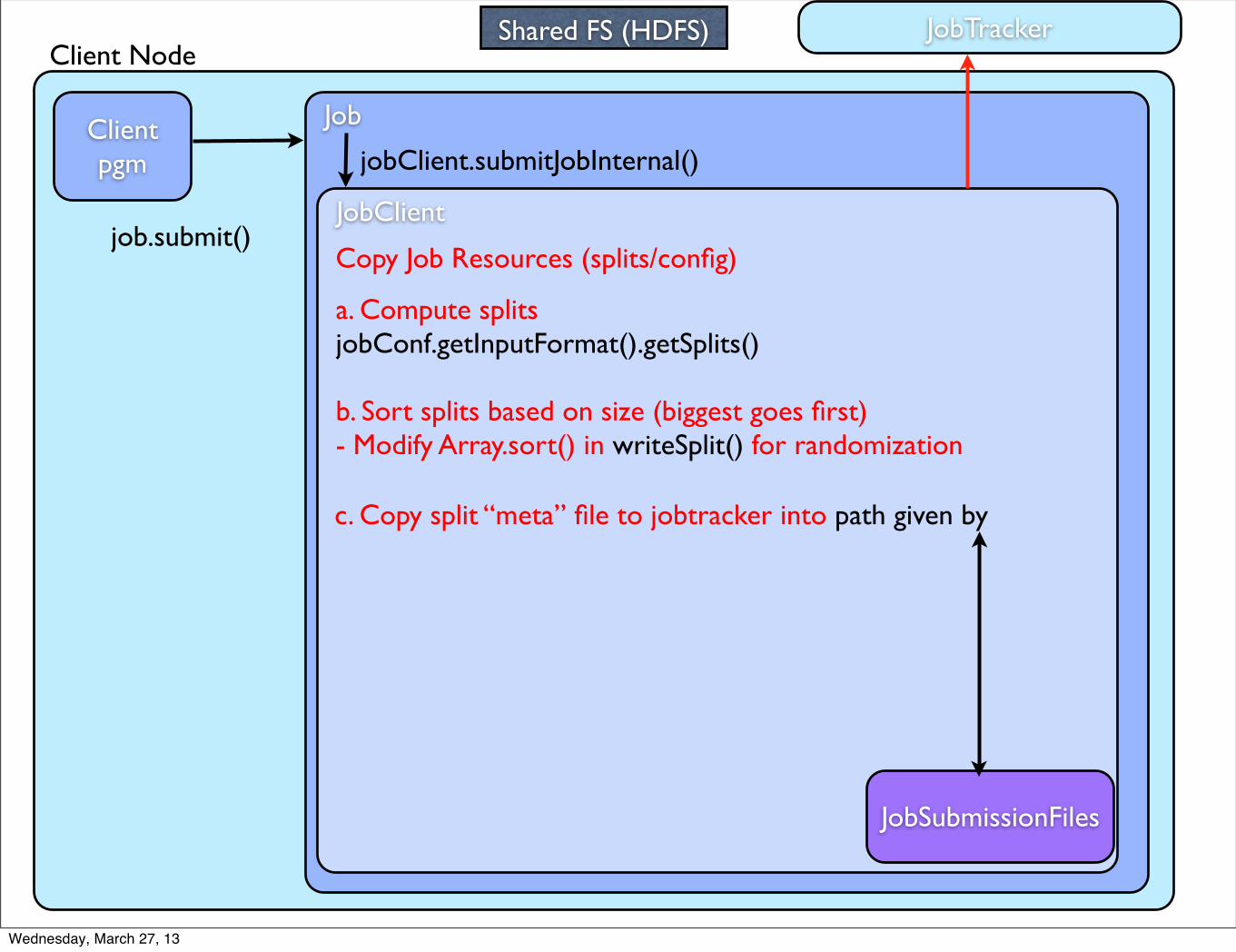
Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
Wednesday, March 27, 13
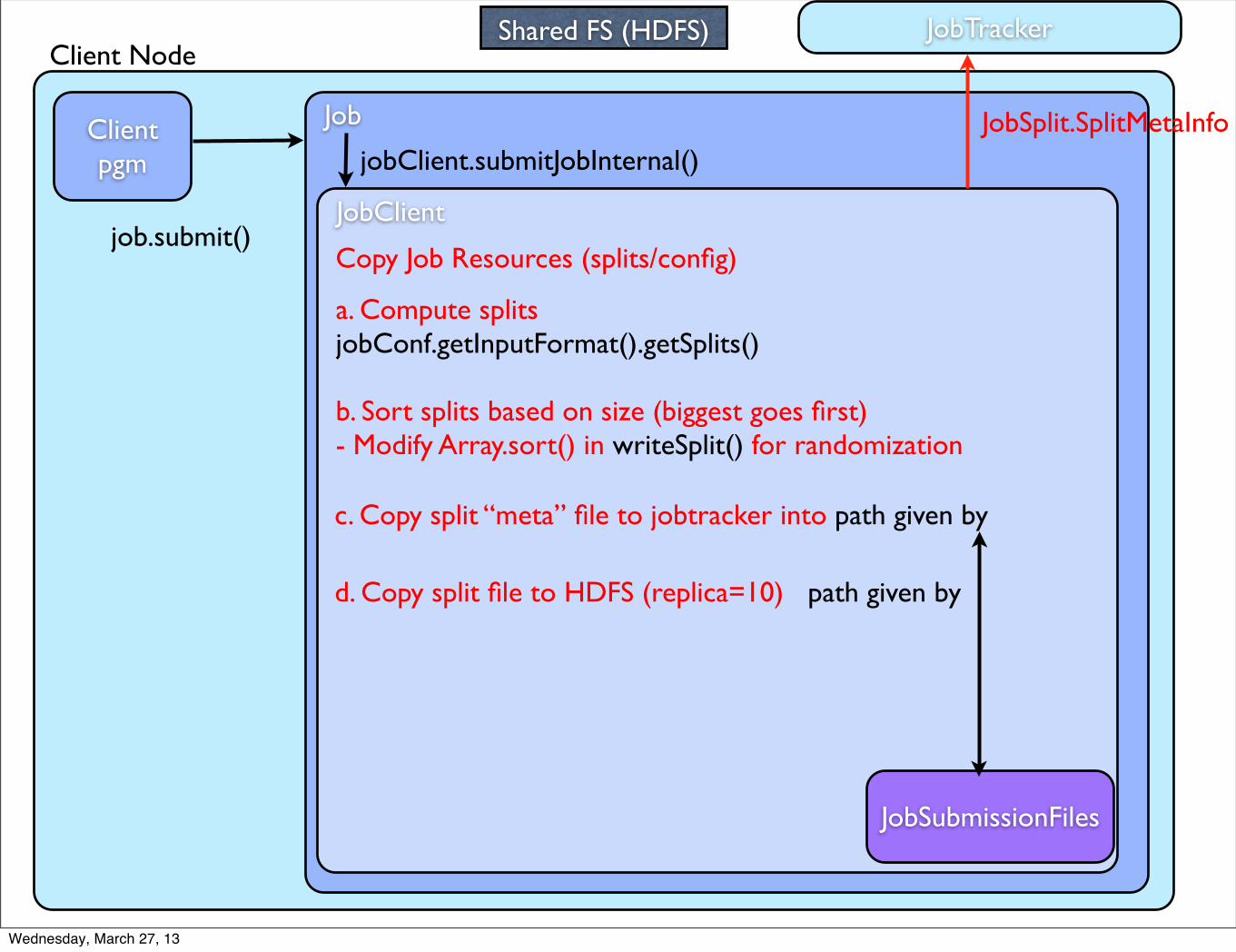
Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
d. Copy split file to HDFS (replica=10) path given by
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
d. Copy split file to HDFS (replica=10) path given by
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
d. Copy split file to HDFS (replica=10) path given by
JobSplit.TaskSplitIndex
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
d. Copy split file to HDFS (replica=10) path given by
JobSplit.TaskSplitIndex
e. Copy job config file to JobTracker path given by
Wednesday, March 27, 13
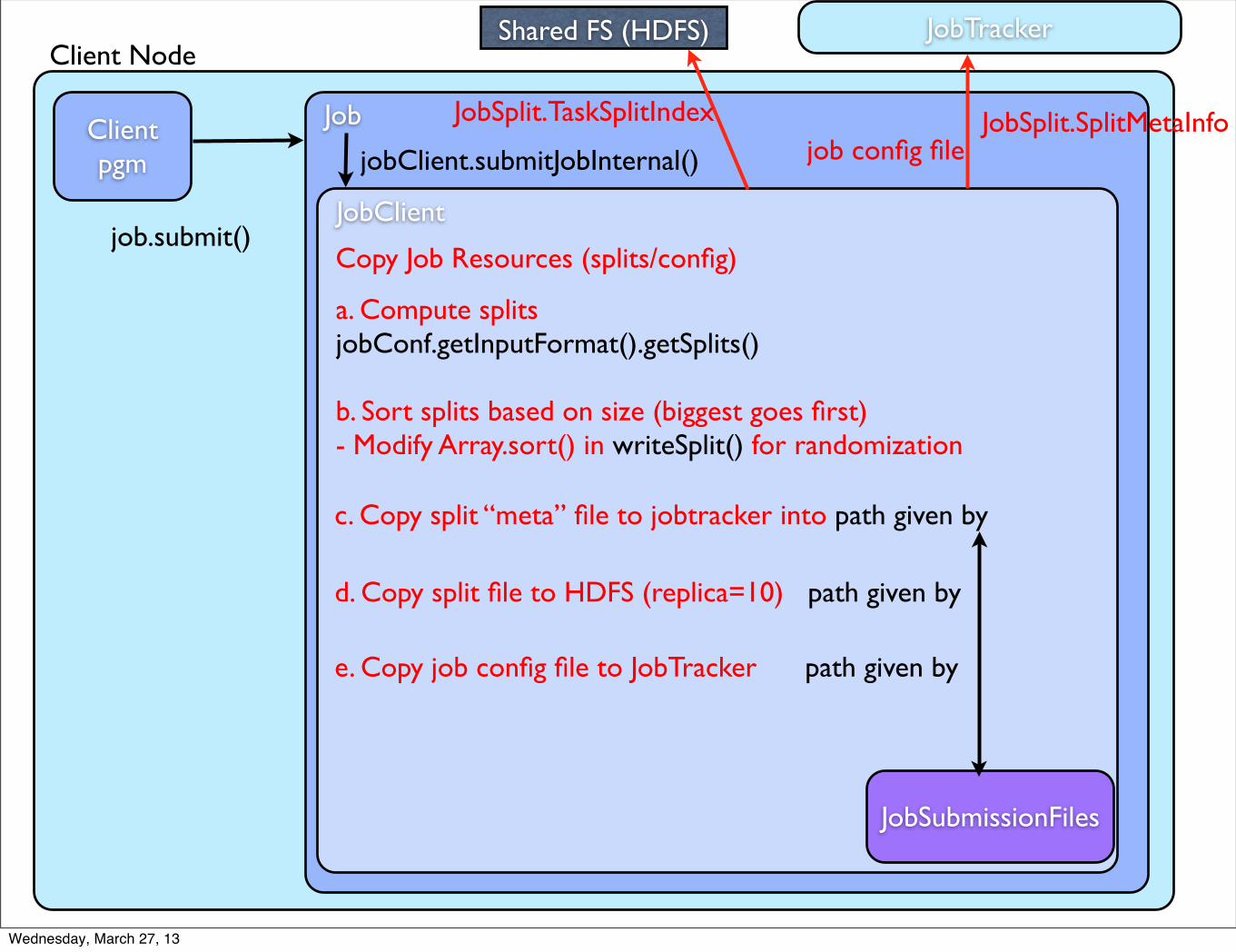
Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
JobTracker
Copy Job Resources (splits/config)
JobSubmissionFiles
Shared FS (HDFS)
a. Compute splits jobConf.getInputFormat().getSplits()
b. Sort splits based on size (biggest goes first)- Modify Array.sort() in writeSplit() for randomization
c. Copy split “meta” file to jobtracker into path given by
JobSplit.SplitMetaInfo
d. Copy split file to HDFS (replica=10) path given by
JobSplit.TaskSplitIndex
e. Copy job config file to JobTracker path given by
job config file
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
After copying job resources (jar, split files, config)
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
After copying job resources (jar, split files, config)
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
After copying job resources (jar, split files, config)
RPC submitJob()
Wednesday, March 27, 13

Client Node
Client pgm
Job
job.submit()JobClient
jobClient.submitJobInternal()
Client stub to JobTracker
JobTracker
After copying job resources (jar, split files, config)
RPC submitJob()
Done with Job Submission at Client side ....Now let’s look at JobTracker’s side.
Wednesday, March 27, 13

JobSubmission at Job tracker node
Client Node Job tracker Node
Task tracker Node
Client stub to JobTracker
JobTracker
Wednesday, March 27, 13

JobSubmission at Job tracker node
Client Node Job tracker Node
Task tracker Node
Client stub to JobTracker
RPC submitJob() JobTracker
Wednesday, March 27, 13
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
Read job config file
Wednesday, March 27, 13
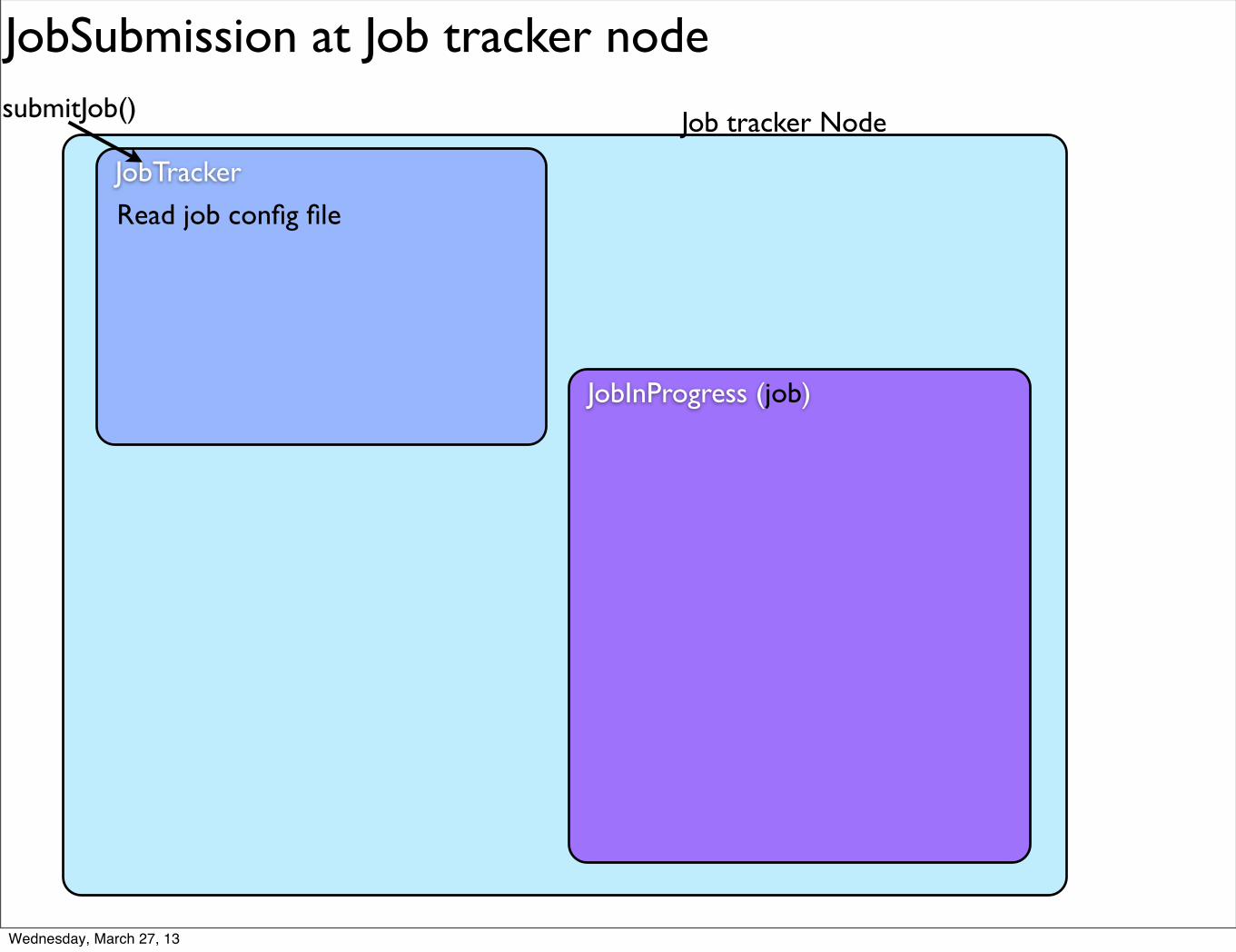
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
Read job config file
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
createSplits()
Wednesday, March 27, 13
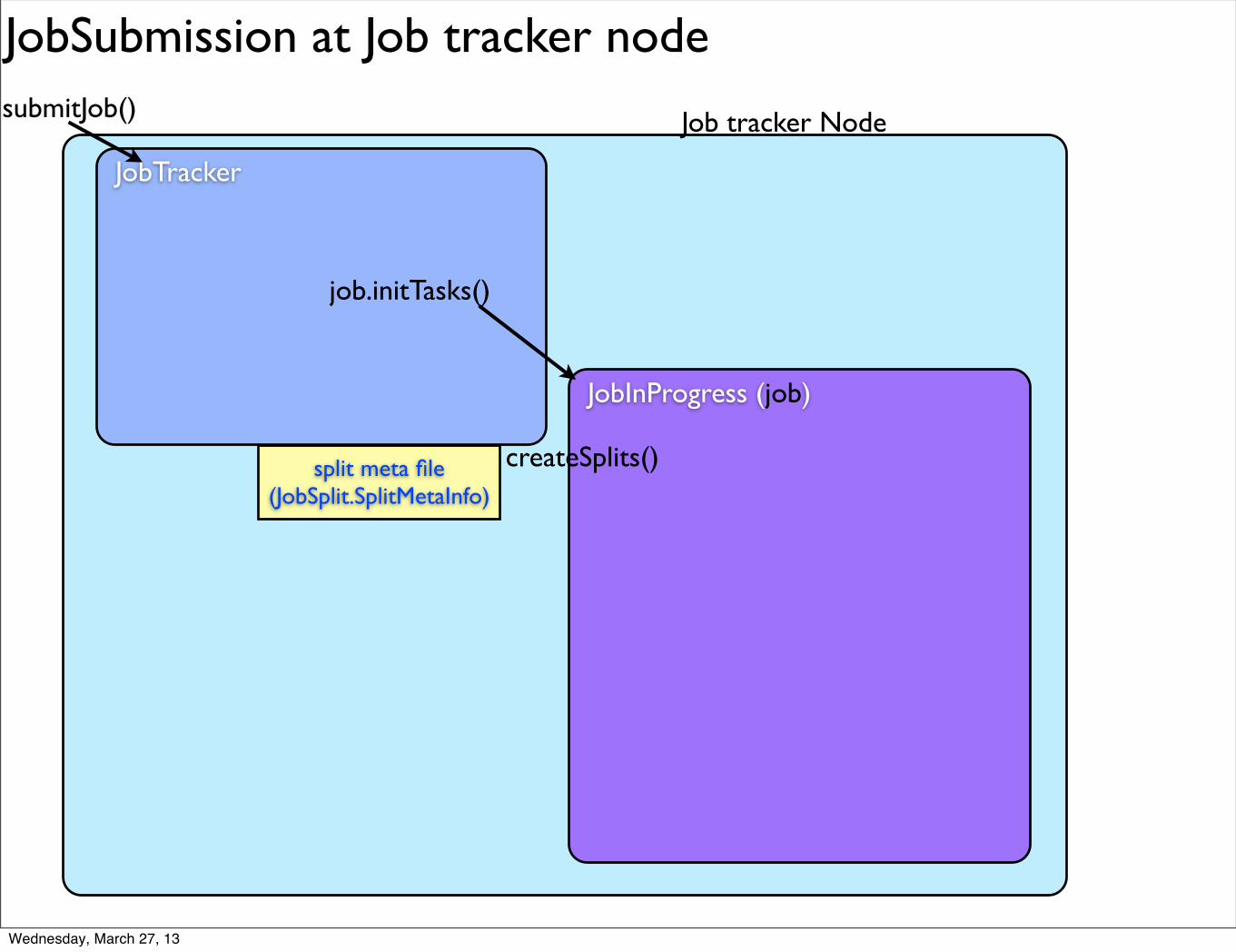
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
split meta file (JobSplit.SplitMetaInfo)
createSplits()
Wednesday, March 27, 13
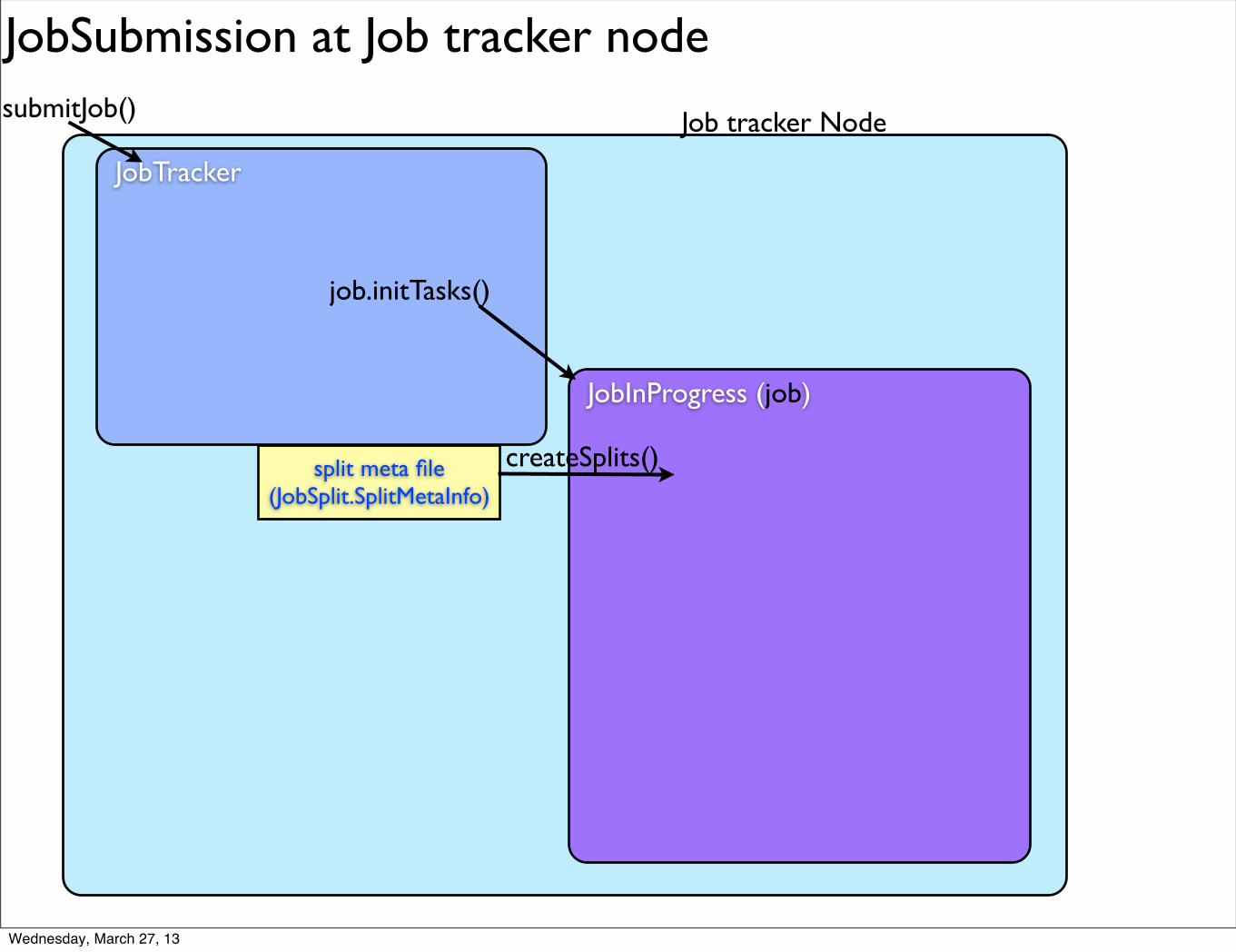
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
split meta file (JobSplit.SplitMetaInfo)
createSplits()
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
split meta file (JobSplit.SplitMetaInfo)
createSplits()JobSplit.TaskSplitMetaInfo[] splits
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
split meta file (JobSplit.SplitMetaInfo)
JobSplit.TaskSplitMetaInfo[] splits
Wednesday, March 27, 13
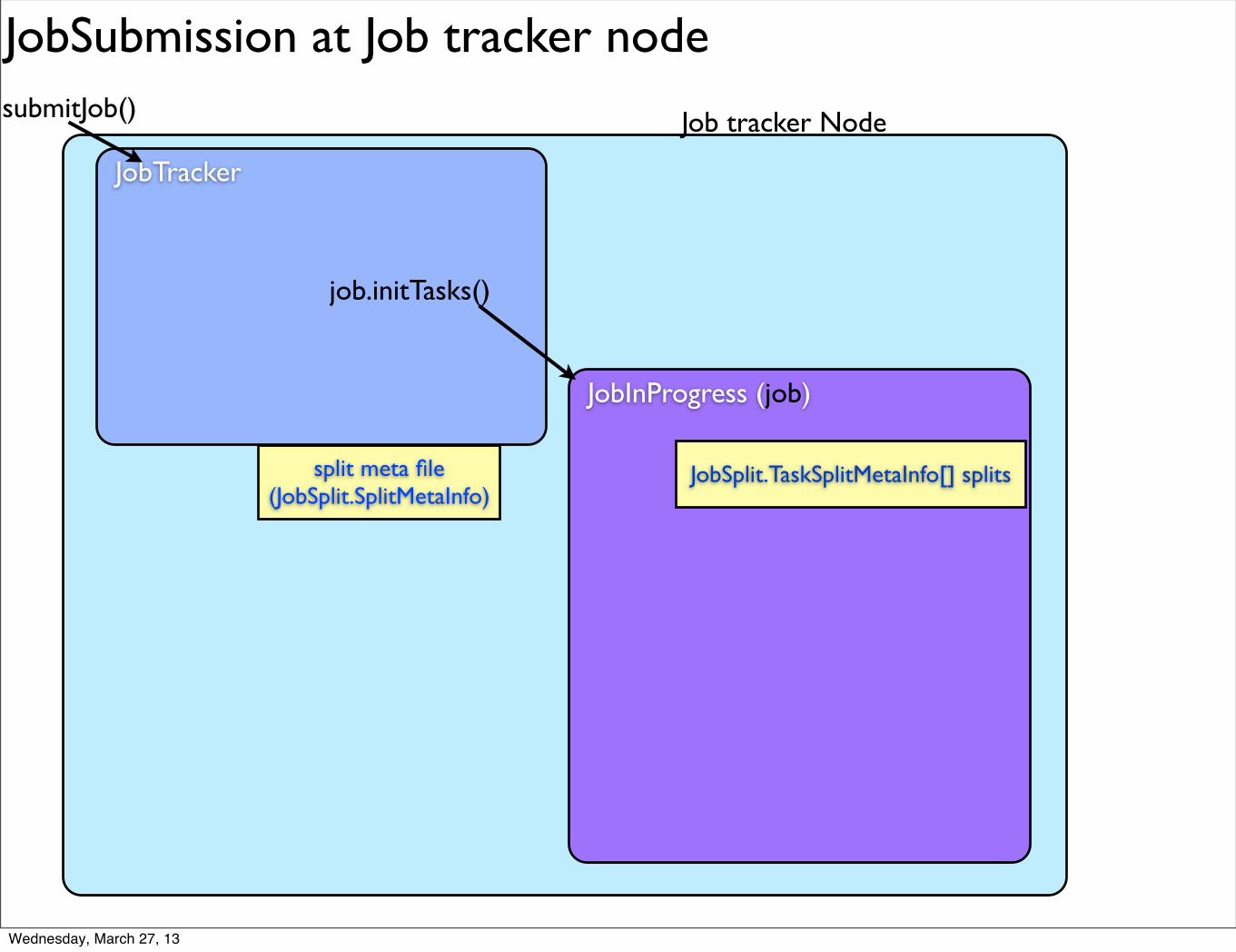
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
split meta file (JobSplit.SplitMetaInfo)
JobSplit.TaskSplitMetaInfo[] splits
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
1 map per split
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
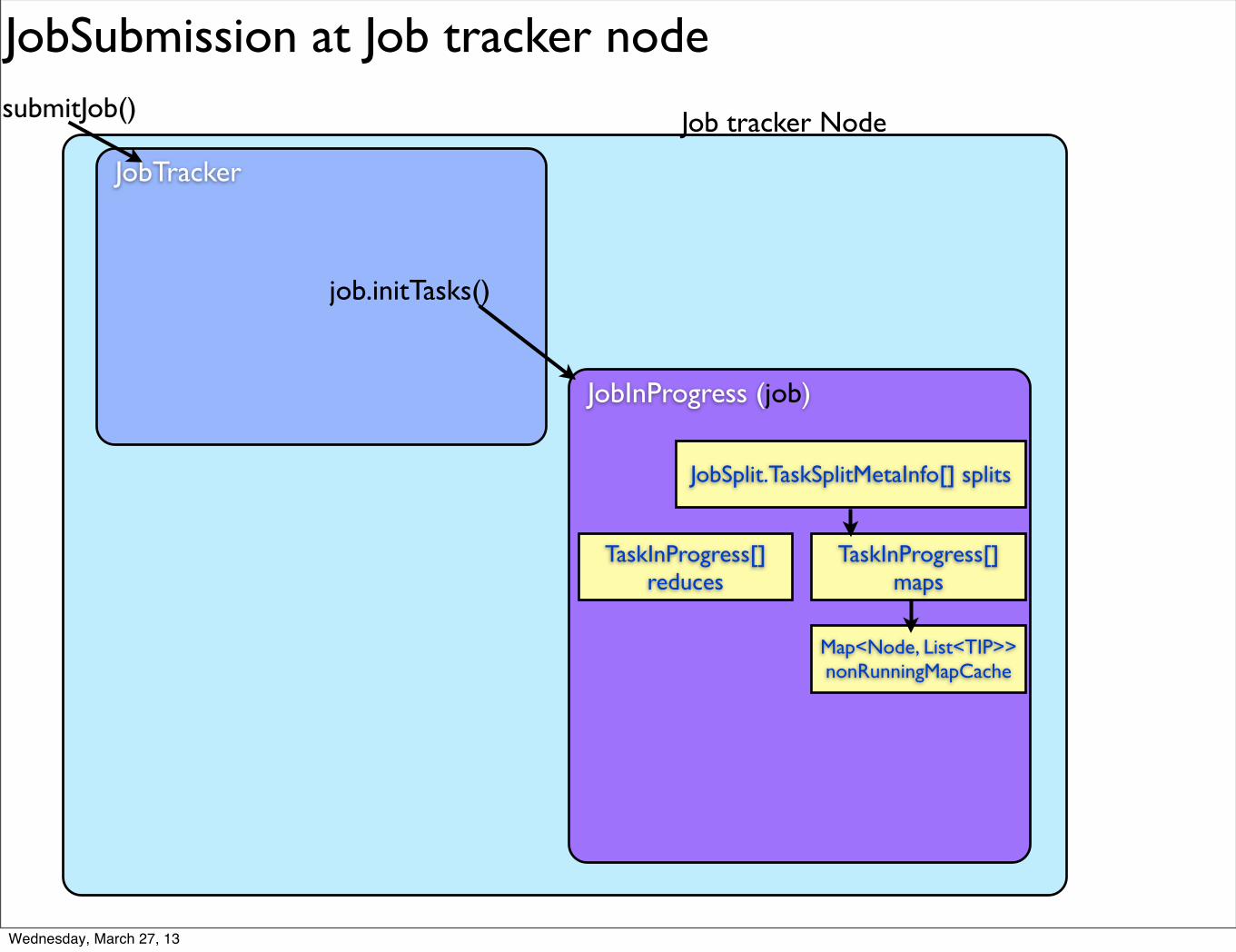
Map<Node, List<TIP>>nonRunningMapCache
Wednesday, March 27, 13
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
mapred.reduce.tasks
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Wednesday, March 27, 13
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
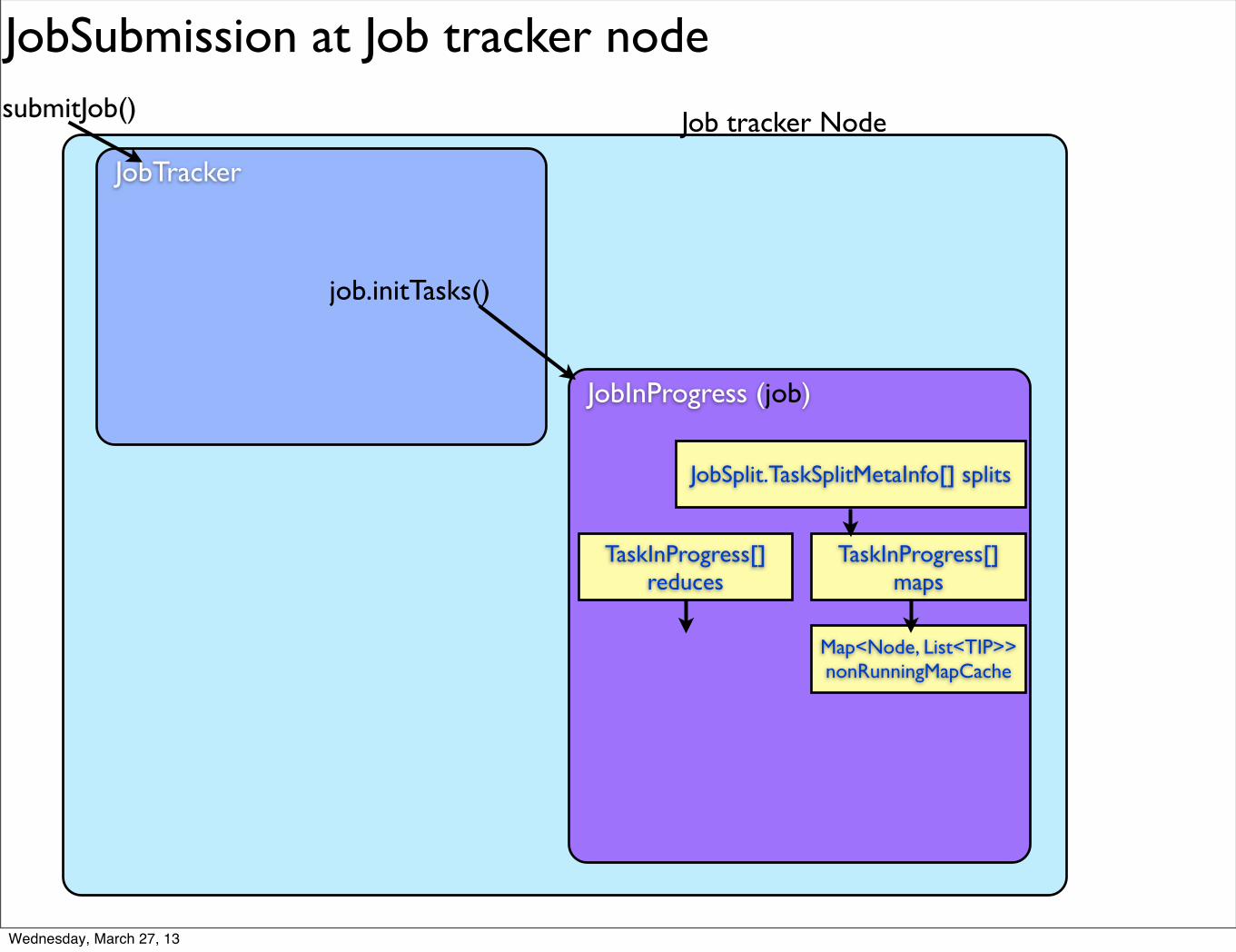
Set<TaskInProgress>nonRunningReduces
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
Other bookkeeping structures:
runningMapCache, nonLocalMaps, failedMaps, ...
+JobProfile, JobStatus
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
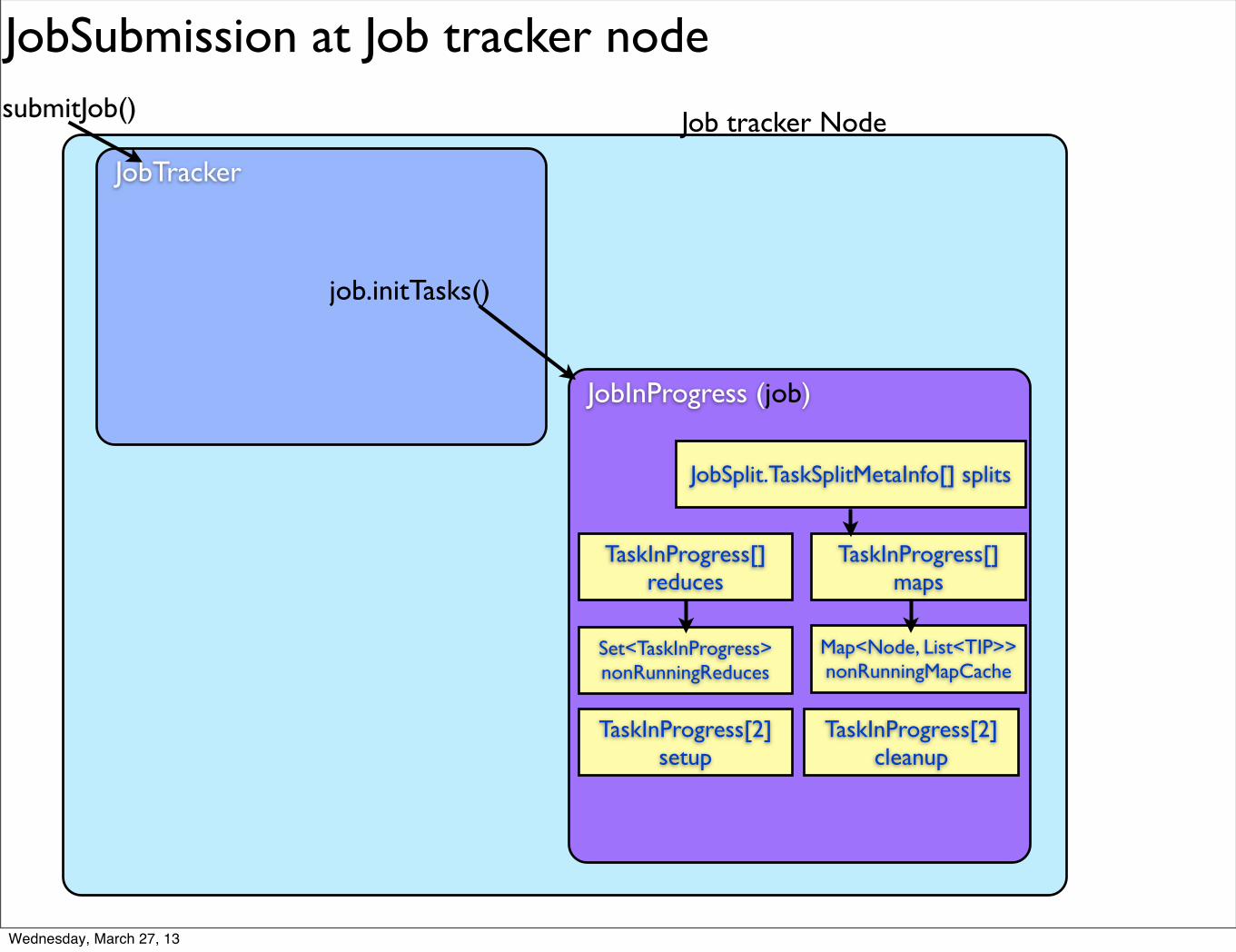
TaskInProgress[2]setup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Run by TaskTracker and are used to setup and to cleanup tasks
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
2 = One for map and other for reduce task
Wednesday, March 27, 13
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
What code to run by TaskInProgress ?
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
What code to run by TaskInProgress ?User-defined
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
What code to run by TaskInProgress ?
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
What code to run by TaskInProgress ?
For setup and cleanup, specified by mapred.output.committer.classDefault: FileOutputCommitter
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
What code to run by TaskInProgress ?
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
job.initTasks()
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
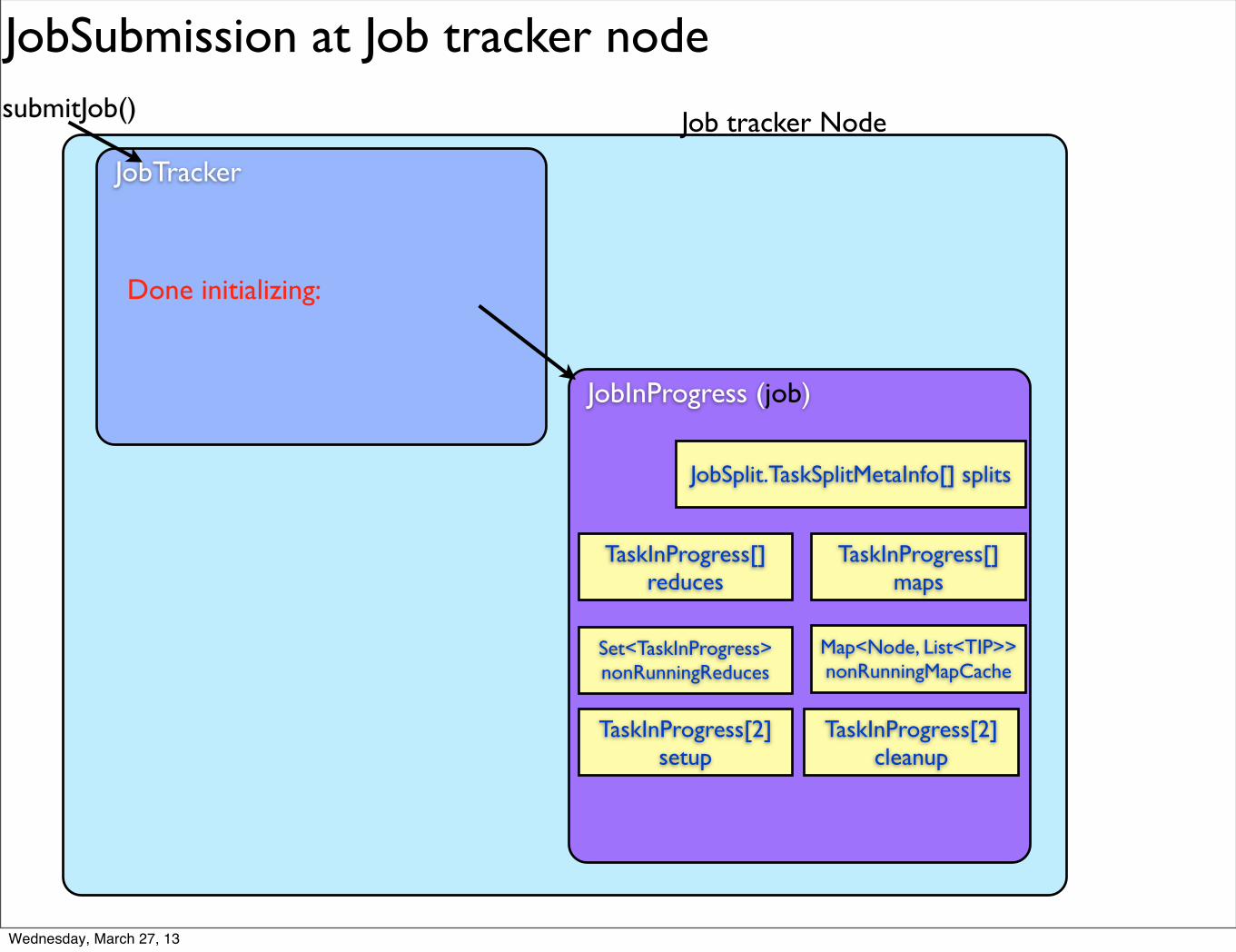
Done initializing:
Wednesday, March 27, 13
JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Done initializing:
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker Node
JobTracker
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Queue exists ? + User permissions
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
addJob()
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
addJob()
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
addJob()
Notify Listeners of the queue
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
addJob()
Wednesday, March 27, 13

JobSubmission at Job tracker node
Job tracker NodesubmitJob()
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
addJob()
Done submitting the job !!!
Wednesday, March 27, 13

TaskScheduler class
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
- Multiple queue, each with different priority (VERY_HIGH, HIGH, ....)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
- Multiple queue, each with different priority (VERY_HIGH, HIGH, ....)- User specifies job priority (mapred.job.priority)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
- Multiple queue, each with different priority (VERY_HIGH, HIGH, ....)- User specifies job priority (mapred.job.priority)- Logic:
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
- Multiple queue, each with different priority (VERY_HIGH, HIGH, ....)- User specifies job priority (mapred.job.priority)- Logic: First select queue with highest priority
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)
- Multiple queue, each with different priority (VERY_HIGH, HIGH, ....)- User specifies job priority (mapred.job.priority)- Logic: First select queue with highest priority Then FIFO within that queue
Wednesday, March 27, 13

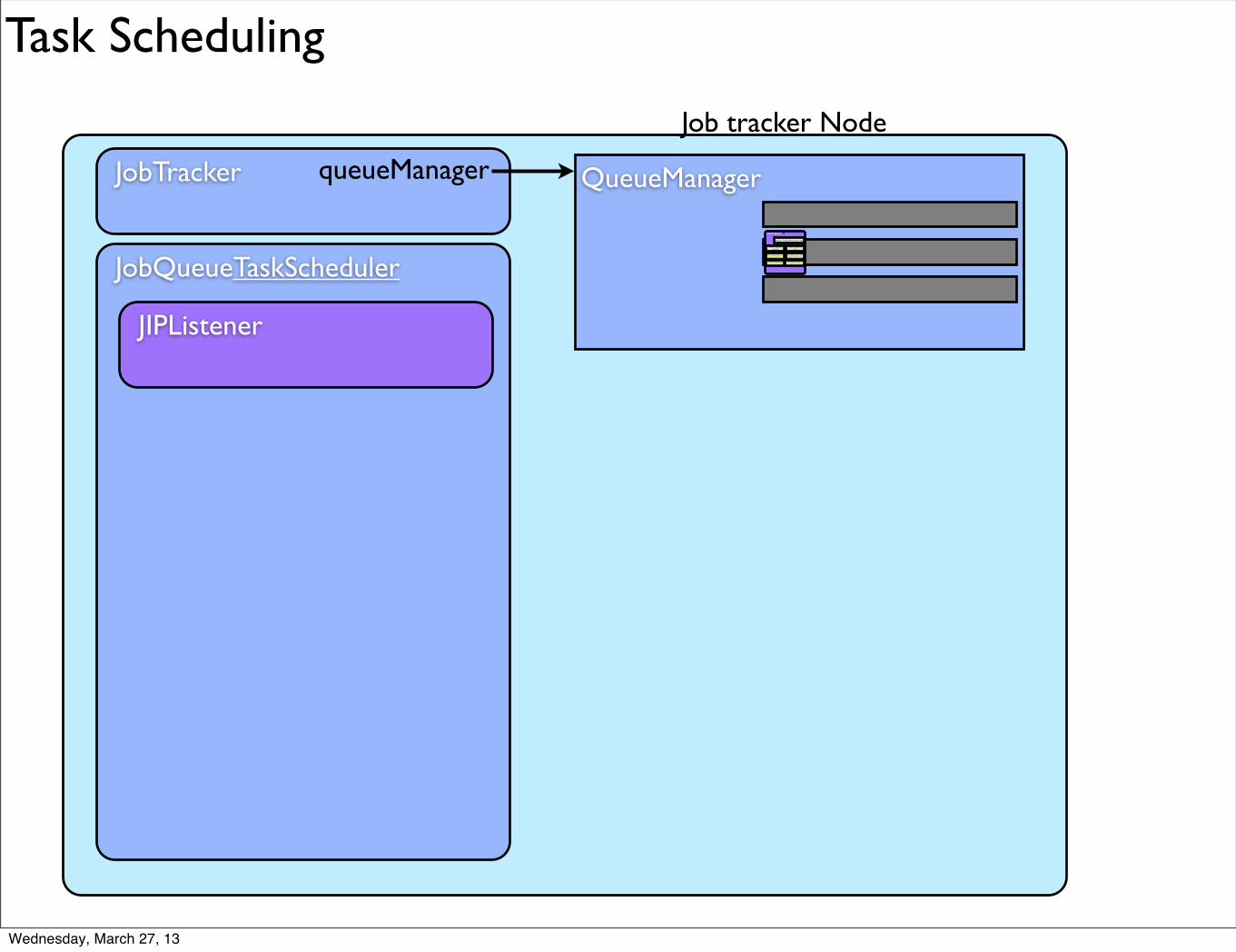
Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanupJobQueueTaskScheduler
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanupJobQueueTaskScheduler
JIPListener
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanupJobQueueTaskScheduler
JIPListener
Callback jobAdded(JIP)
Wednesday, March 27, 13
Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanupJobQueueTaskScheduler
JIPListener
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
1. Calculate availableMapSlots
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobQueueTaskScheduler
List<Task> assignTasks(TaskTracker)
1. Calculate availableMapSlots
JobTracker
availableMapSlots = trackerCurrentMapCapacity � trackerRunningMaps
= min(dmapLoadFactor ⇤ trackerMapCapacitye, trackerMapCapacity)
� trackerRunningMaps
where,
trackerMapCapacity = taskTrackerStatus.getMaxMapSlots()
trackerRunningMaps = taskTrackerStatus.countMapTasks()
mapLoadFactor =
X
8jobsJIP’s numMapTask � finishedMapTask
clusterStatus.getMaxMapTasks()
TaskTrackerStatus
ClusterStatusJIPListener
JobInProgress (JIP)
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener getJobQueue() usesMap<JobSchedulingInfo, JIP> +
FIFO_JOB_QUEUE comparator
Process jobs in higher priority queue first
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
Wednesday, March 27, 13

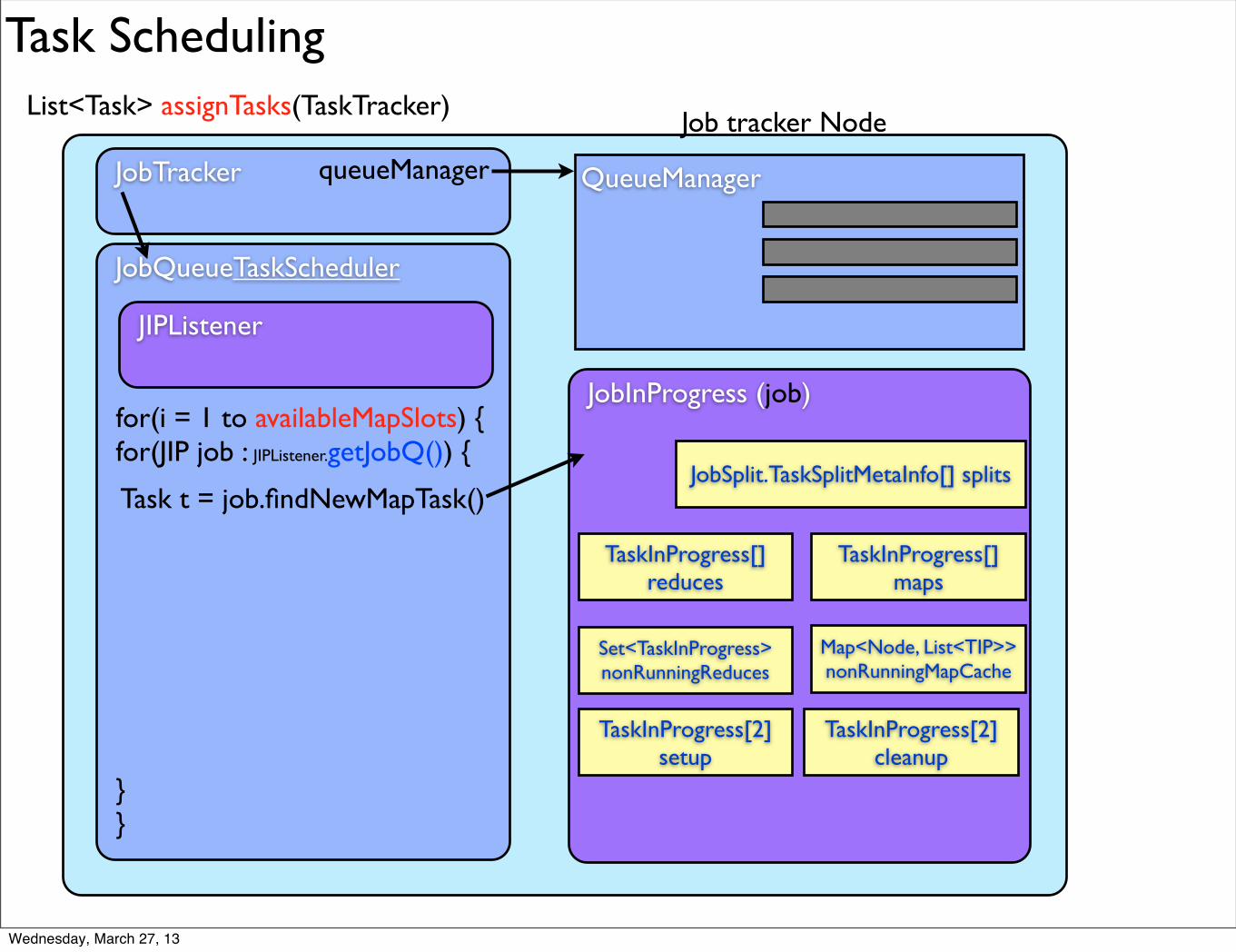
Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
- Return task with most failures (not on given m/c) w/o locality (JIP’s failedMaps) - Return non-running tasks using locality info (JIP’s nonRunningMapCache)- Return speculative task
Wednesday, March 27, 13
Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
assignedTasks.add(t)
// Also, make sure there are free slots in cluster for speculative tasks
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
assignedTasks.add(t)
// Also, make sure there are free slots in cluster for speculative tasks
Do same thing for reducer
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
assignedTasks.add(t)
// Also, make sure there are free slots in cluster for speculative tasks
Wednesday, March 27, 13
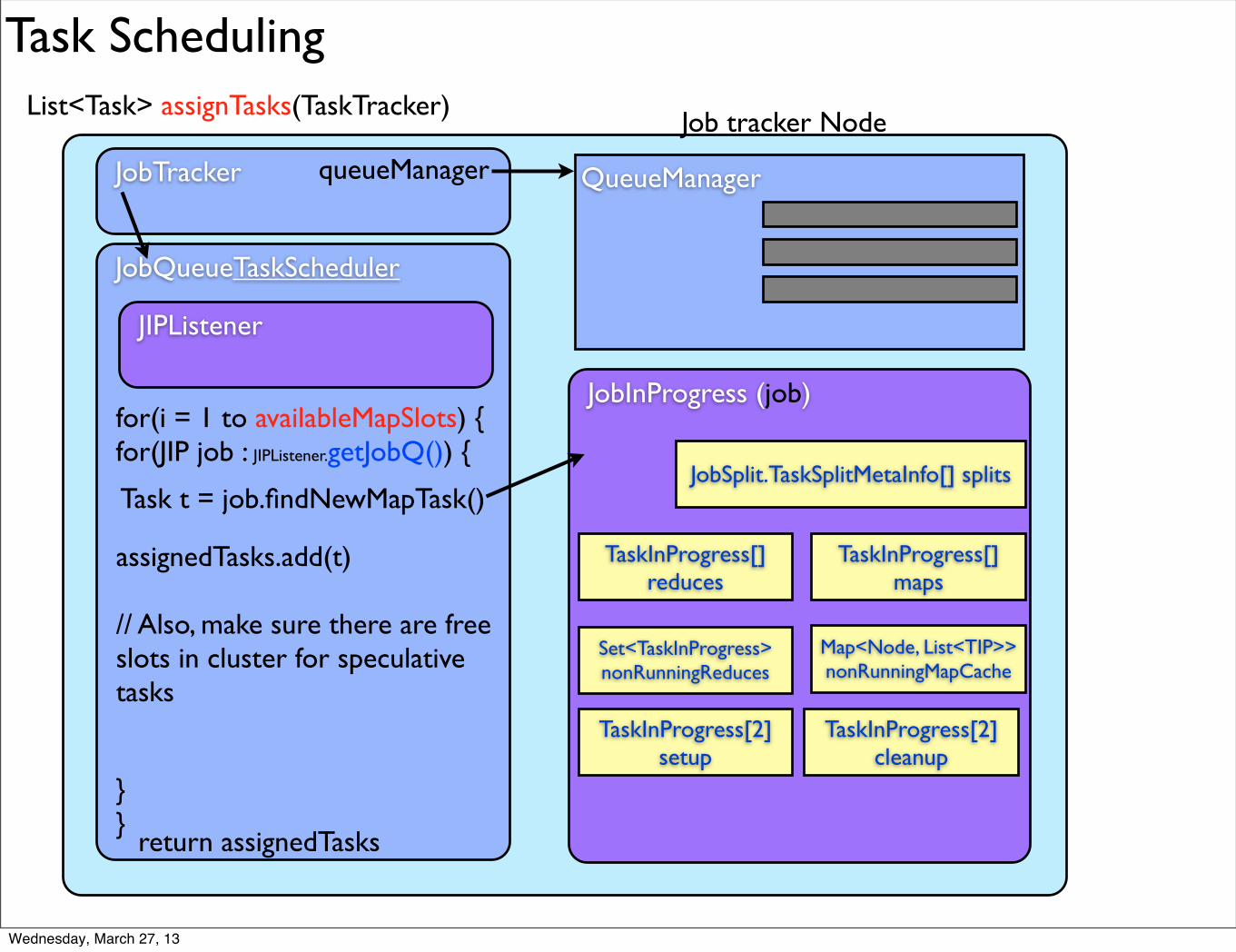
Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
List<Task> assignTasks(TaskTracker)
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
assignedTasks.add(t)
// Also, make sure there are free slots in cluster for speculative tasks
return assignedTasks
Wednesday, March 27, 13

Task Scheduling
Job tracker Node
JobTracker QueueManagerqueueManager
JobInProgress (job)
JobSplit.TaskSplitMetaInfo[] splits
TaskInProgress[] maps
TaskInProgress[] reduces
Map<Node, List<TIP>>nonRunningMapCache
Set<TaskInProgress>nonRunningReduces
TaskInProgress[2]setup
TaskInProgress[2]cleanup
JobQueueTaskScheduler
JIPListener
for(i = 1 to availableMapSlots) {for(JIP job : JIPListener.getJobQ()) {
}}
Task t = job.findNewMapTask()
assignedTasks.add(t)
// Also, make sure there are free slots in cluster for speculative tasks
return assignedTasks
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:
Min share: 30 slots 40 slots
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:
Min share: 30 slots 40 slots
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:Cluster: 100 slots available. Allocate them !
Min share: 30 slots 40 slots
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:Cluster: 100 slots available. Allocate them !
Min share: 30 slots 40 slots
40 slots30 slots30 slots
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:Cluster: 100 slots available. Allocate them !
Min share: 30 slots 40 slots
40 slots30 slots30 slots
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Pools:Cluster: 100 slots available. Allocate them !
Min share: 30 slots 40 slots
40 slots30 slots30 slots
15 15Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
Goal: Provide fast response time for small jobs and guaranteed service levels for productions jobs.
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Additional features: - Job weights for unequal sharing (based on priority or size) - Limits for #running jobs per user/pool
Usage:cp build/contrib/fairscheduler/*.jar libmapred.jobtracker.taskScheduler to o.a.h.m.FairSchedulermapred.fairscheduler.allocation.file to /path/pool.xml
Pools:Cluster: 100 slots available. Allocate them !
Min share: 30 slots 40 slots
40 slots30 slots30 slots
15 15Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
~ FairScheduler, queues instead of pools.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
~ FairScheduler, queues instead of pools.Queue share % of cluster. Queue can have jobs of different priorities
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
~ FairScheduler, queues instead of pools.Queue share % of cluster. Queue can have jobs of different priorities
FIFO scheduling within each queue. Scheduling more deterministic than FairScheduler.
Wednesday, March 27, 13

TaskScheduler class• Used by JobTracker to schedule Task on TaskTracker.• Uses one or more JobInProgressListener to receive notifications about the jobs.• Uses ClusterStatus to get info about the state of cluster. • Methods:• start(), terminate(), refresh()• Collection<JobInProgress> getJobs(String queueName)• List<Task> assignTasks(TaskTracker)
• Implementations:• Specified by mapred.jobtracker.taskScheduler • Default: FIFO scheduler (o.a.h.mapred.JobQueueTaskScheduler)• Facebook’s FairScheduler• Yahoo’s CapacityScheduler
- Doesnot support preemption- Bad for production cluster (high priority can be misused)
~ FairScheduler, queues instead of pools.Queue share % of cluster. Queue can have jobs of different priorities
FIFO scheduling within each queue. Scheduling more deterministic than FairScheduler.
Also, unlike other 2, provides support for memory-based scheduling and preemption.
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
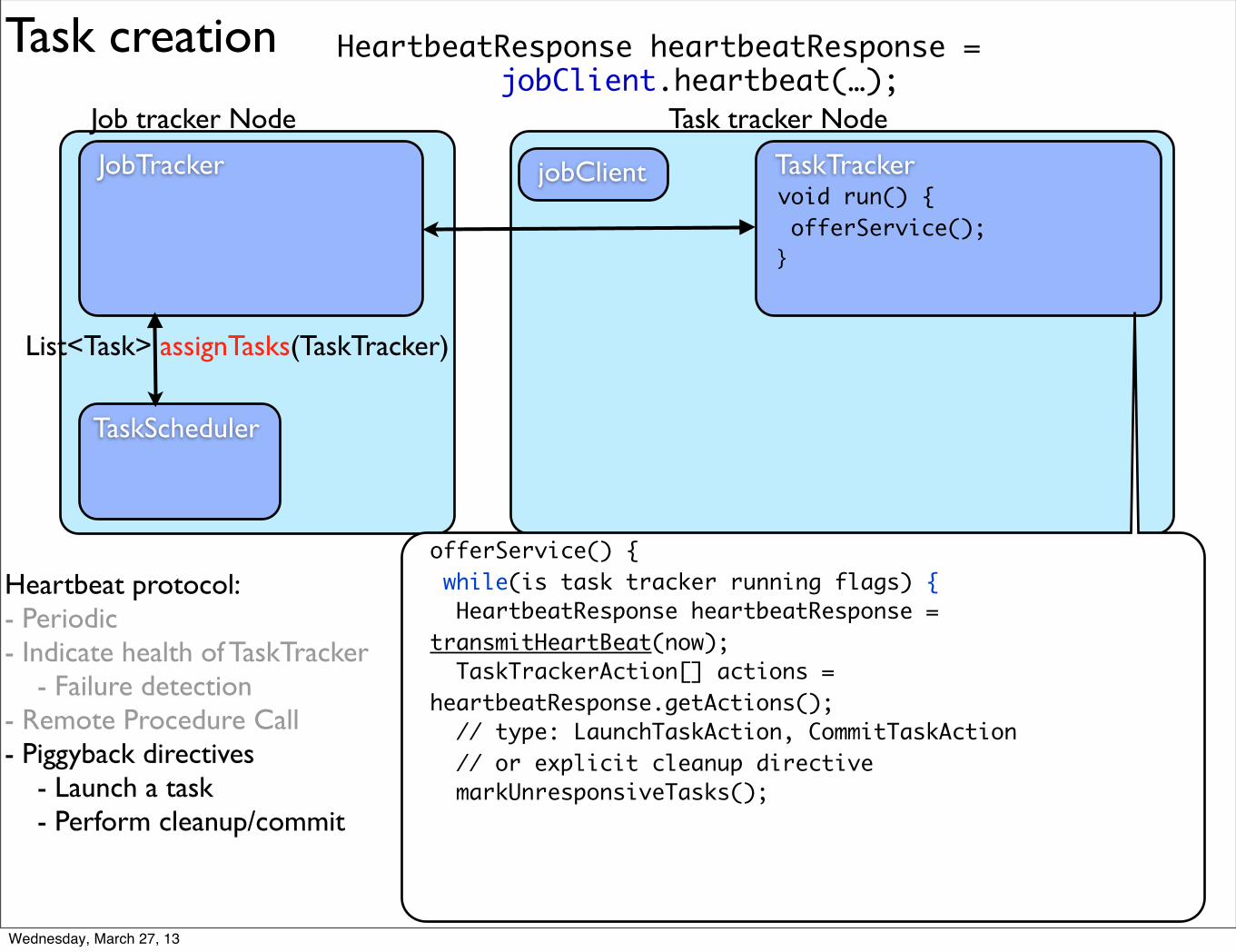
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTrackerjobClient
TaskScheduler
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTrackerjobClient
this.jobClient = (InterTrackerProtocol) UserGroupInformation.getLoginUser().doAs( new PrivilegedExceptionAction<Object>() { public Object run() throws IOException { return RPC.waitForProxy(InterTrackerProtocol.class, InterTrackerProtocol.versionID, jobTrackAddr, fConf); } });
TaskScheduler
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTrackerjobClient
jobClient.heartbeat(…);
this.jobClient = (InterTrackerProtocol) UserGroupInformation.getLoginUser().doAs( new PrivilegedExceptionAction<Object>() { public Object run() throws IOException { return RPC.waitForProxy(InterTrackerProtocol.class, InterTrackerProtocol.versionID, jobTrackAddr, fConf); } });
TaskScheduler
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTrackerjobClient
jobClient.heartbeat(…);
this.jobClient = (InterTrackerProtocol) UserGroupInformation.getLoginUser().doAs( new PrivilegedExceptionAction<Object>() { public Object run() throws IOException { return RPC.waitForProxy(InterTrackerProtocol.class, InterTrackerProtocol.versionID, jobTrackAddr, fConf); } });
TaskScheduler
List<Task> assignTasks(TaskTracker)
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13
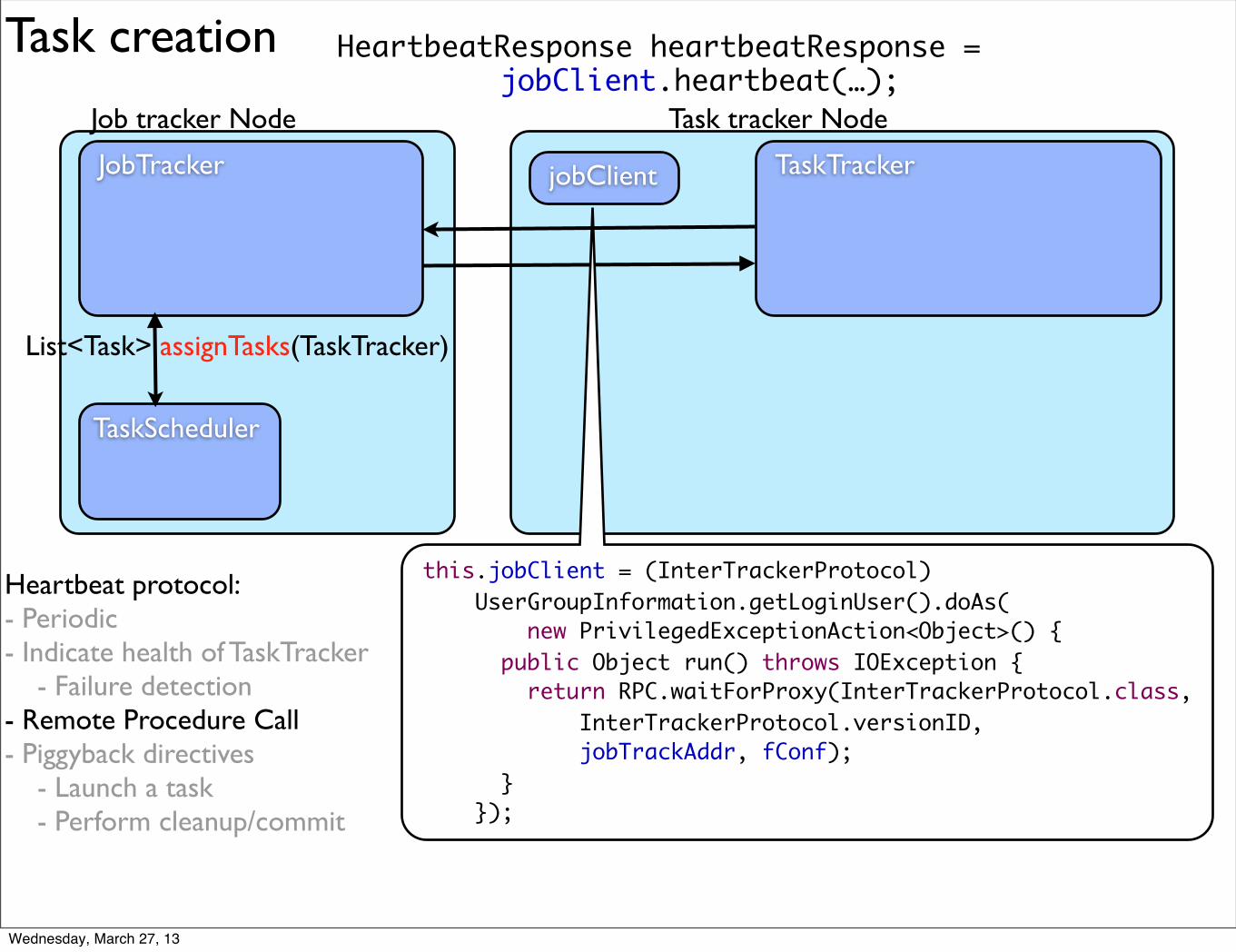
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTrackerjobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
this.jobClient = (InterTrackerProtocol) UserGroupInformation.getLoginUser().doAs( new PrivilegedExceptionAction<Object>() { public Object run() throws IOException { return RPC.waitForProxy(InterTrackerProtocol.class, InterTrackerProtocol.versionID, jobTrackAddr, fConf); } });
TaskScheduler
List<Task> assignTasks(TaskTracker)
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() {
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) {
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now);
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions();
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks();
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
Heartbeat protocol:- Periodic- Indicate health of TaskTracker
- Failure detection- Remote Procedure Call- Piggyback directives
- Launch a task- Perform cleanup/commit
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
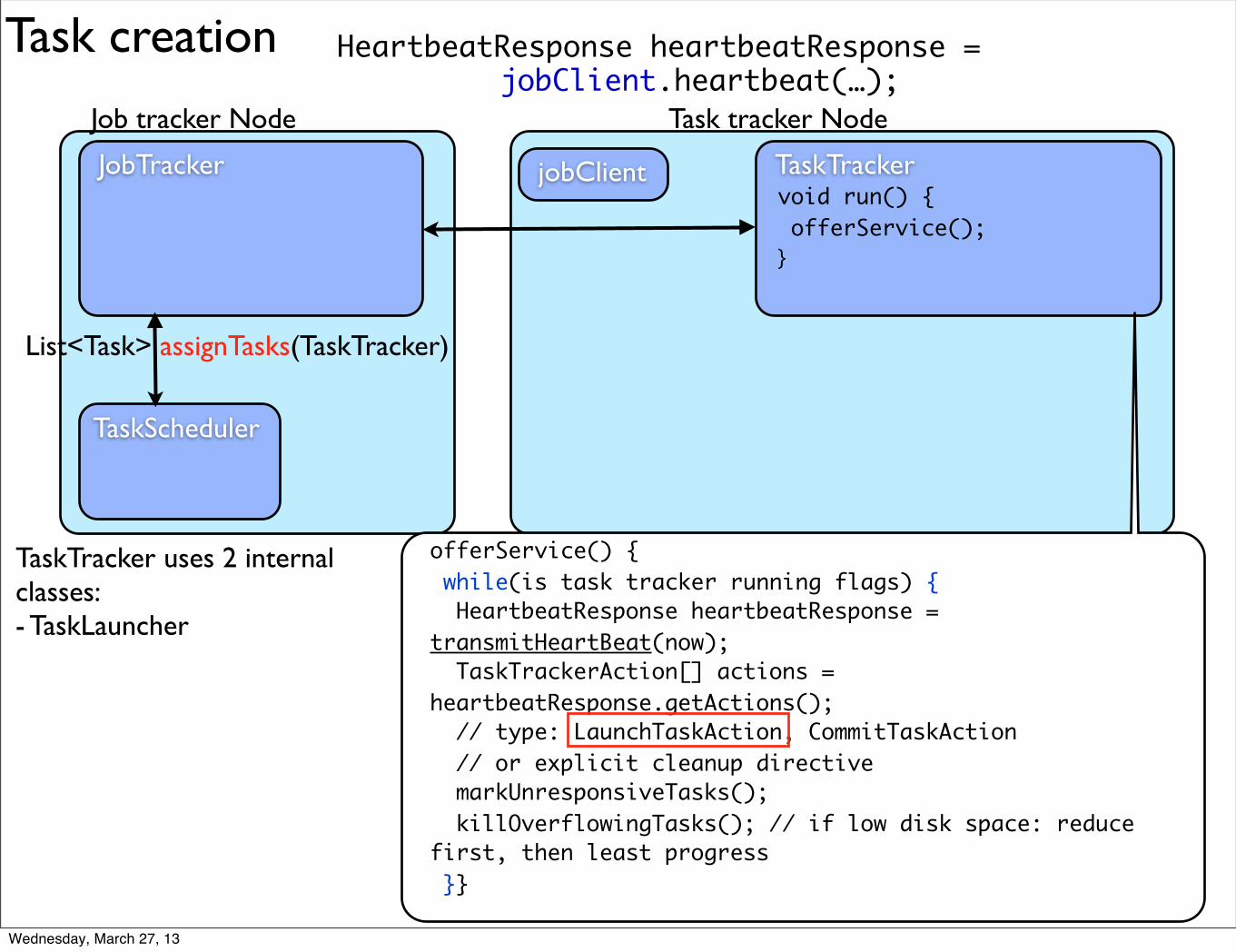
TaskTracker uses 2 internal
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes:
Wednesday, March 27, 13
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes: - TaskLauncher
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes: - TaskLauncher
mapLauncher,reduceLauncher
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes: - TaskLauncher
mapLauncher,reduceLauncher- TaskInProgress’s launchTask()
Wednesday, March 27, 13
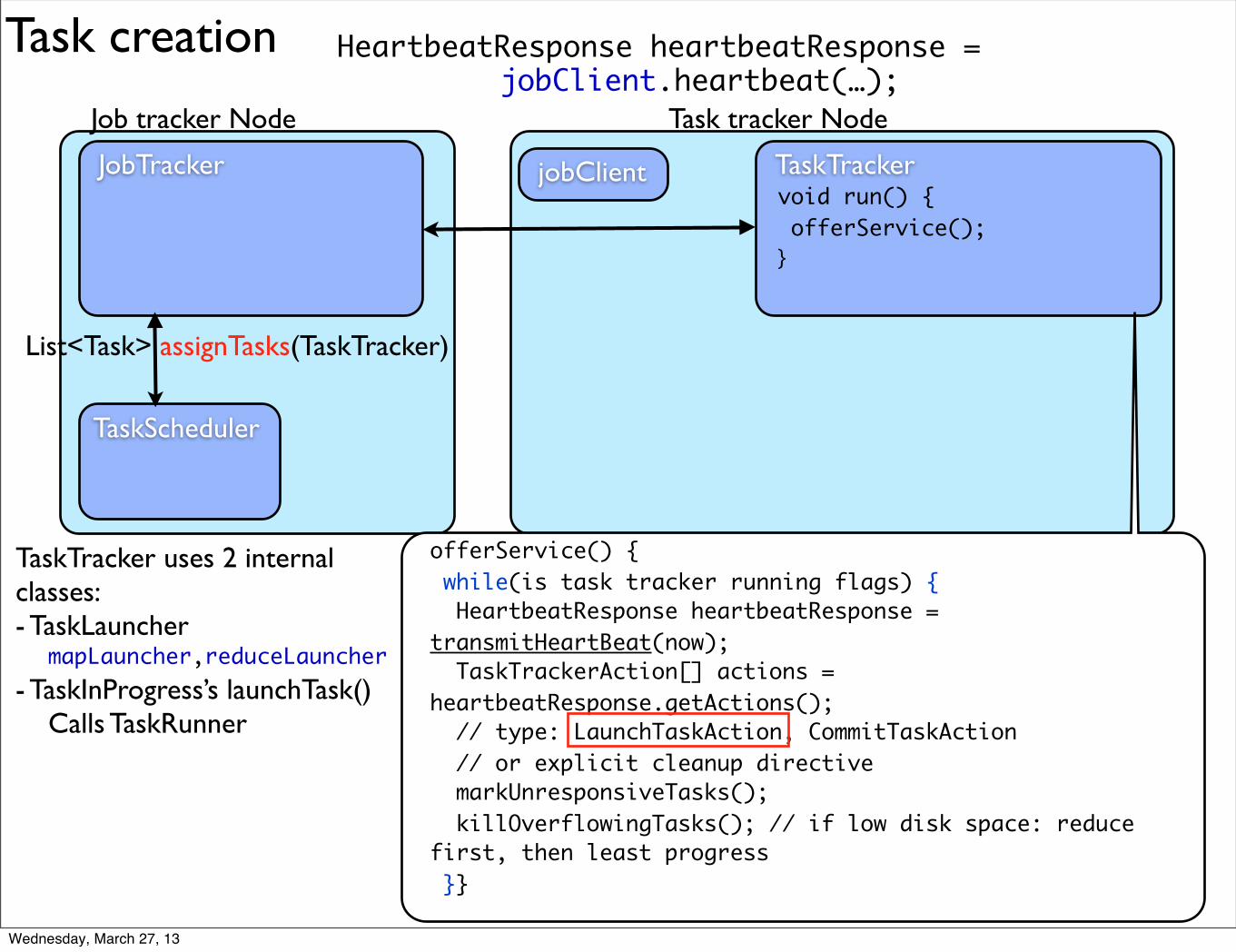
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes: - TaskLauncher
mapLauncher,reduceLauncher- TaskInProgress’s launchTask()
Calls TaskRunner
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(…);
List<Task> assignTasks(TaskTracker)
offerService() { while(is task tracker running flags) { HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); TaskTrackerAction[] actions = heartbeatResponse.getActions(); // type: LaunchTaskAction, CommitTaskAction // or explicit cleanup directive markUnresponsiveTasks(); killOverflowingTasks(); // if low disk space: reduce first, then least progress }}
void run() { offerService();}
TaskTracker uses 2 internal classes: - TaskLauncher
mapLauncher,reduceLauncher- TaskInProgress’s launchTask()
Calls TaskRunner
TaskRunner
start()
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
Wednesday, March 27, 13
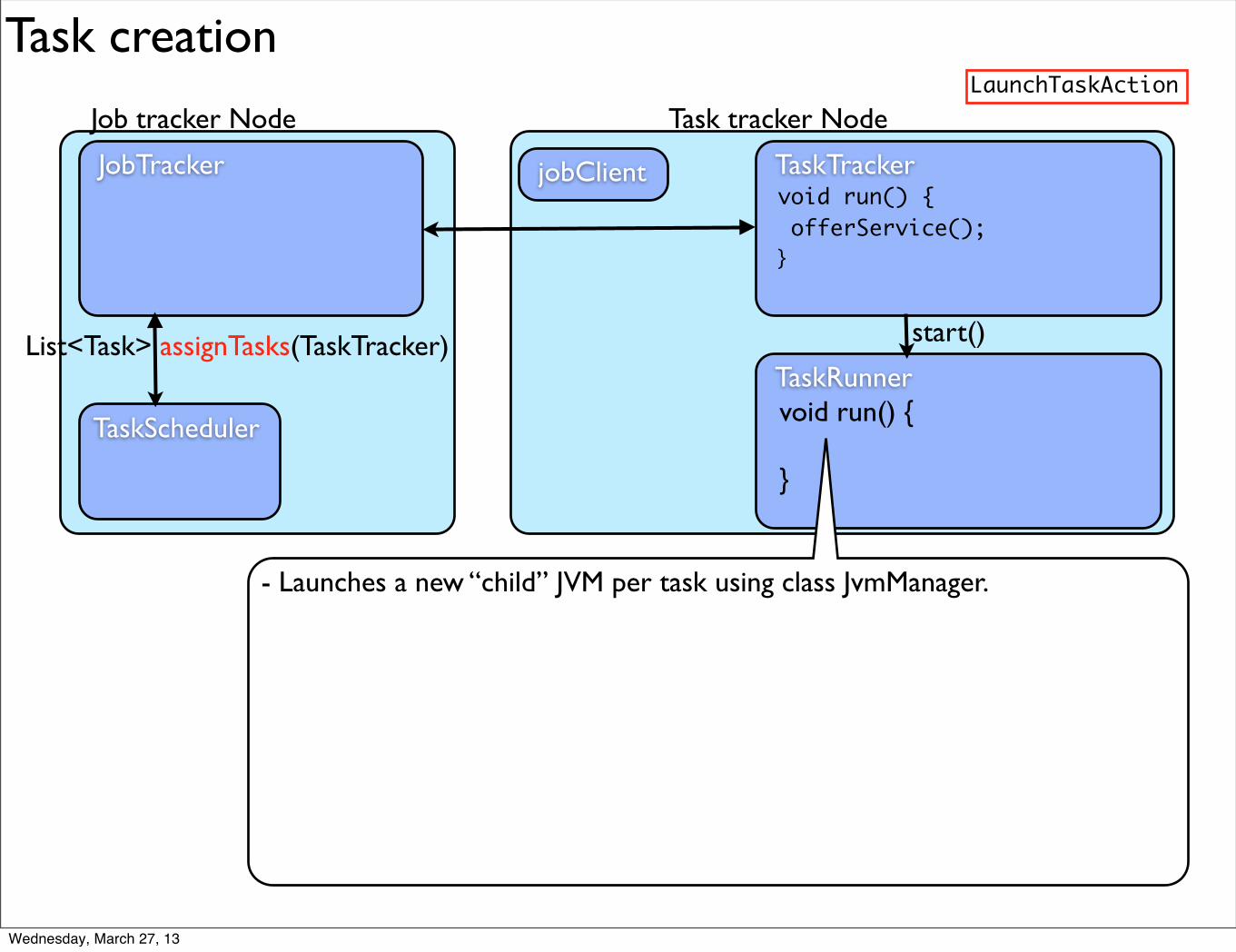
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager.
Wednesday, March 27, 13
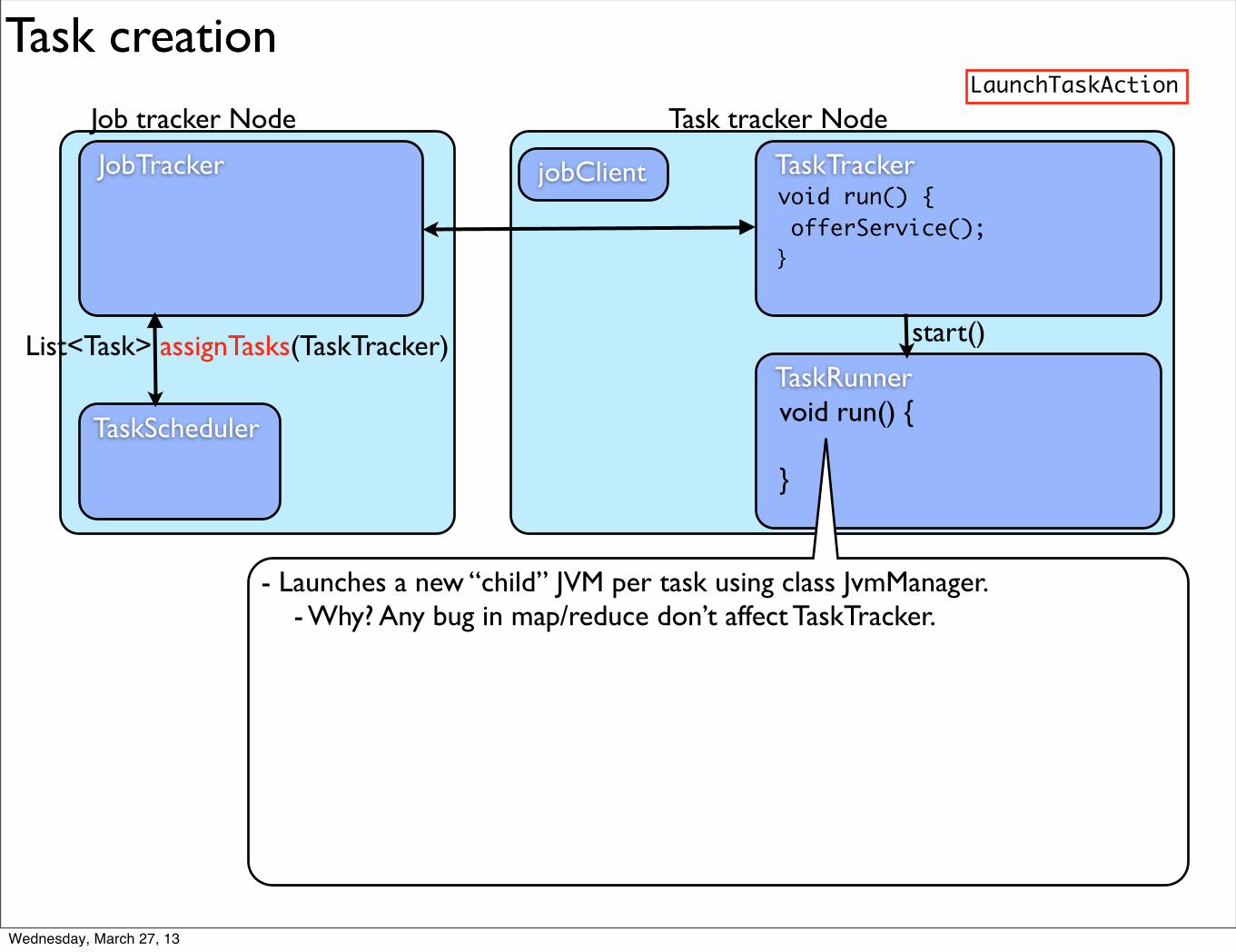
Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
Wednesday, March 27, 13

Task creation
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
Wednesday, March 27, 13

Task creation in little more detail
Job tracker Node Task tracker Node
JobTracker TaskTracker
TaskScheduler
jobClient
List<Task> assignTasks(TaskTracker)
void run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
Wednesday, March 27, 13
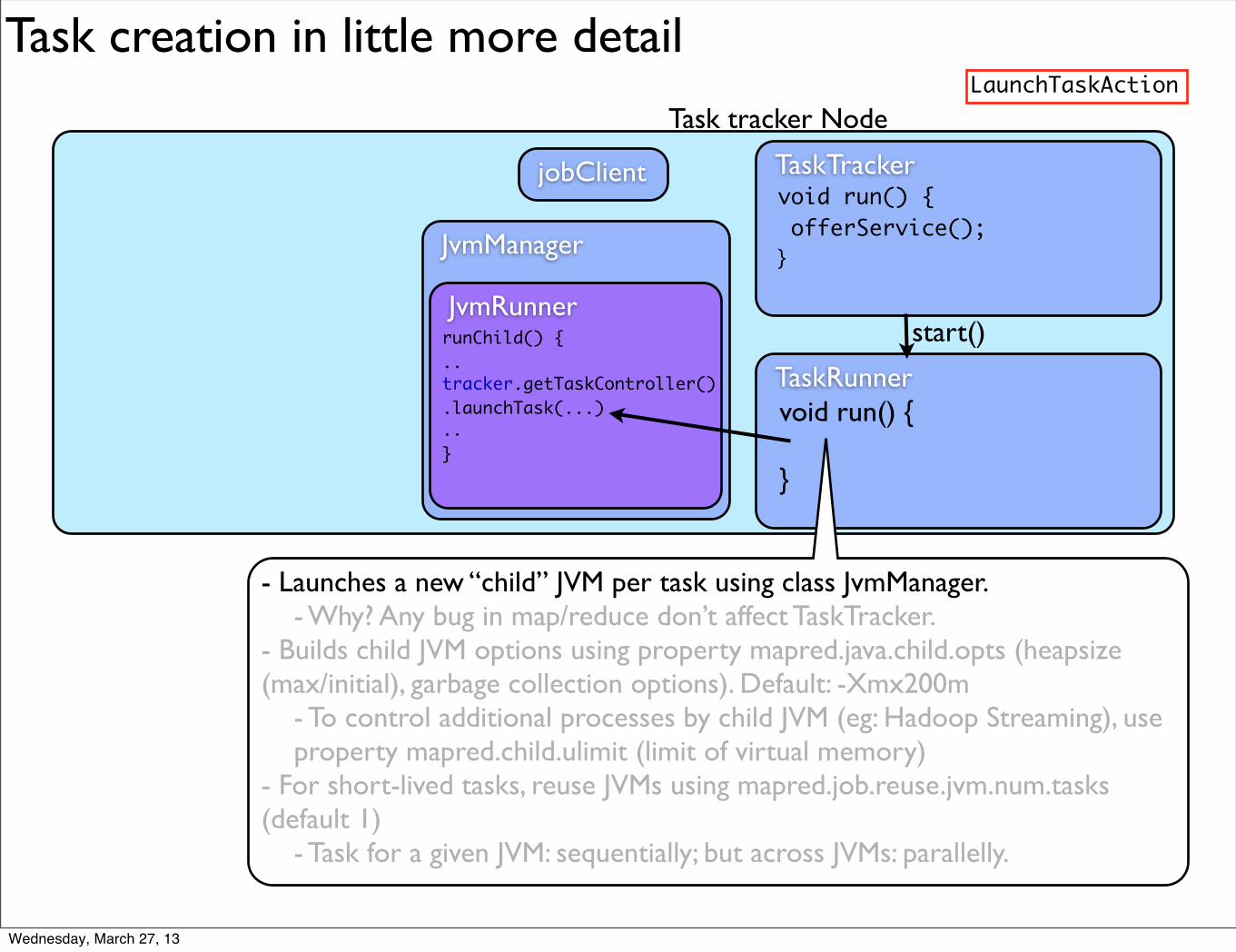
Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Different JVM
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Different JVM
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Different JVM
Childvoid main(..) { .... }
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Different JVM
umbilicalChildvoid main(..) { .... }
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
- Launches a new “child” JVM per task using class JvmManager. - Why? Any bug in map/reduce don’t affect TaskTracker.
- Builds child JVM options using property mapred.java.child.opts (heapsize (max/initial), garbage collection options). Default: -Xmx200m
- To control additional processes by child JVM (eg: Hadoop Streaming), use property mapred.child.ulimit (limit of virtual memory)
- For short-lived tasks, reuse JVMs using mapred.job.reuse.jvm.num.tasks (default 1)
- Task for a given JVM: sequentially; but across JVMs: parallelly.
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
- TaskController pluggable through mapred.task.tracker.task-controller (DefaultTaskController or LinuxTaskController)- Creates directories for task (attempt, working, log)- Pass JVM args and OS specific manipulations to TaskLog and then to o.a.h.util.Shell, which invokes JVM through java’s ProcessBuilder.
Note, args for JVM already set by TaskRunner’s getJVMArgs(...)- Default main class: Child.java
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
Wednesday, March 27, 13
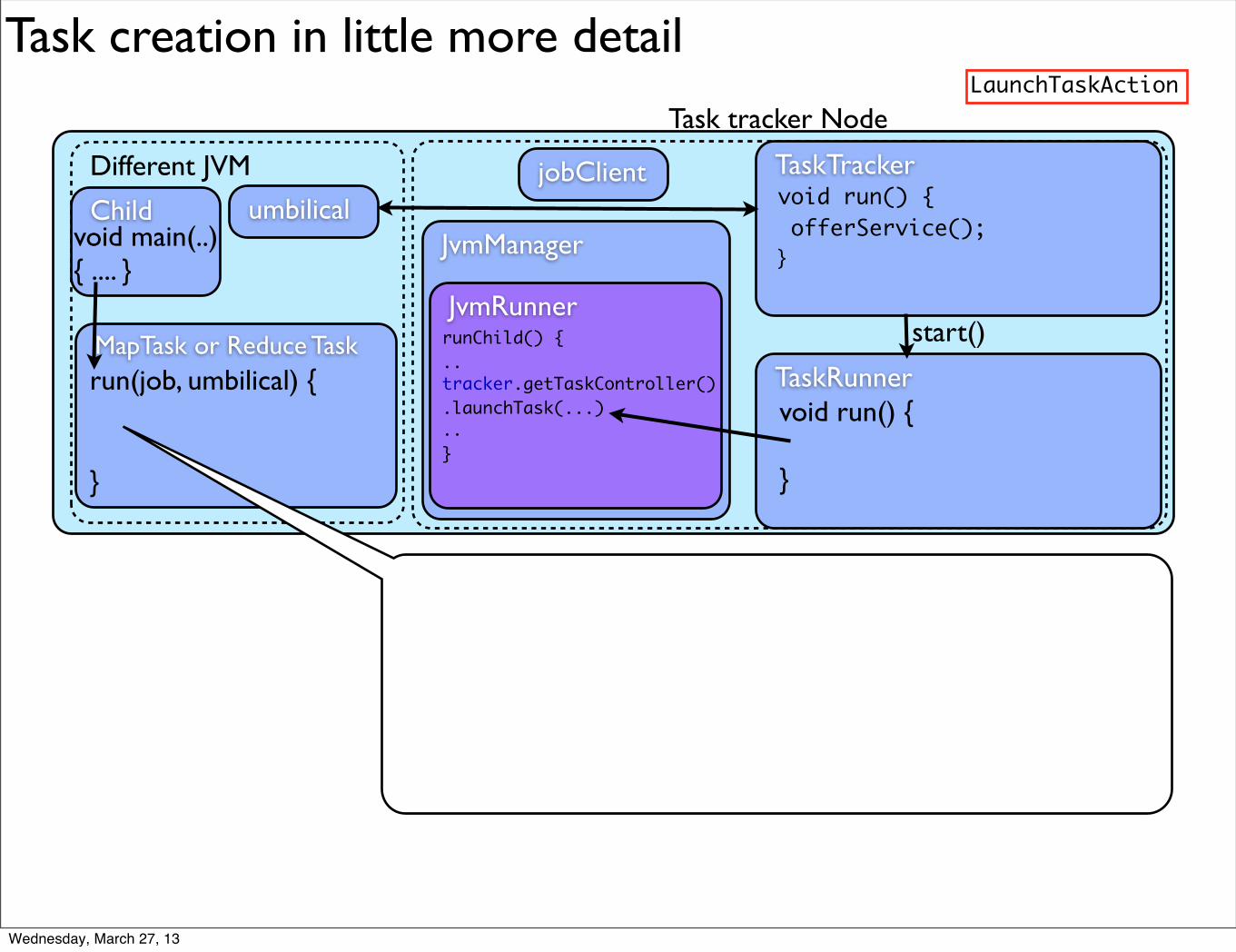
Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.- Check if it is job/task setup/cleanup task.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.- Check if it is job/task setup/cleanup task.
- If so, run their respective method and return.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.- Check if it is job/task setup/cleanup task.
- If so, run their respective method and return.- Else, do Map/Reduce specific actions !!!
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.- Check if it is job/task setup/cleanup task.
- If so, run their respective method and return.- Else, do Map/Reduce specific actions !!!
- Perform commit operation if it is required.
Wednesday, March 27, 13

Task creation in little more detail
Task tracker Node
TaskTrackerjobClientvoid run() { offerService();}
TaskRunner
start()
LaunchTaskAction
void run() {
}
JvmManager
JvmRunnerrunChild() {..tracker.getTaskController().launchTask(...)..}
Different JVM
umbilicalChildvoid main(..) { .... }
MapTask or Reduce Taskrun(job, umbilical) {
}
TaskReporter
- Create TaskReporter that also uses umbilical object.- Check if it is job/task setup/cleanup task.
- If so, run their respective method and return.- Else, do Map/Reduce specific actions !!!
- Perform commit operation if it is required.- If speculative task, ensure only one of the duplicate task is committed.
Wednesday, March 27, 13

Map-specific actions:
Wednesday, March 27, 13

Map-specific actions:
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.- When buffer reaches certain threshold, a background thread MapOutputBuffer’s inner class SpillThread will start spilling the buffer to the disk (mapred.local.dir).
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.- When buffer reaches certain threshold, a background thread MapOutputBuffer’s inner class SpillThread will start spilling the buffer to the disk (mapred.local.dir).
- If specified, run combiner if at least 3 spill files (min.num.spills.for.combine)
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.- When buffer reaches certain threshold, a background thread MapOutputBuffer’s inner class SpillThread will start spilling the buffer to the disk (mapred.local.dir).
- If specified, run combiner if at least 3 spill files (min.num.spills.for.combine)- Before writing to disk, compress if mapred.compress.map.output is true.
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.- When buffer reaches certain threshold, a background thread MapOutputBuffer’s inner class SpillThread will start spilling the buffer to the disk (mapred.local.dir).
- If specified, run combiner if at least 3 spill files (min.num.spills.for.combine)- Before writing to disk, compress if mapred.compress.map.output is true.- Sort uses user-defined Comparator and Partitioner.
Sort/Spill
Wednesday, March 27, 13

Map-specific actions:
map
map
map
MapperInputFormat
mapper & input using ReflectionUtils.newInstance(...)
split 1
split 2
split 3
split 4
split 5
Build split using MapTask’s getSplitDetails(splitIndex, ...) + Use FileSystem/Deserializer from JobConf
For each key-value read from the split (through context.nextKeyValue()), call user-defined map
Store output of map into in-memory circular buffer (MapOutputBuffer)- If no reducer, uses DirectMapOutputCollector instead, which writes immediately to disk.- When buffer reaches certain threshold, a background thread MapOutputBuffer’s inner class SpillThread will start spilling the buffer to the disk (mapred.local.dir).
- If specified, run combiner if at least 3 spill files (min.num.spills.for.combine)- Before writing to disk, compress if mapred.compress.map.output is true.- Sort uses user-defined Comparator and Partitioner.
Sort/SpillFinal output: One sorted
partitioned file
Wednesday, March 27, 13

In-memory circular buffer
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
<Partition, Key offset, Value offset>
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
Wednesday, March 27, 13
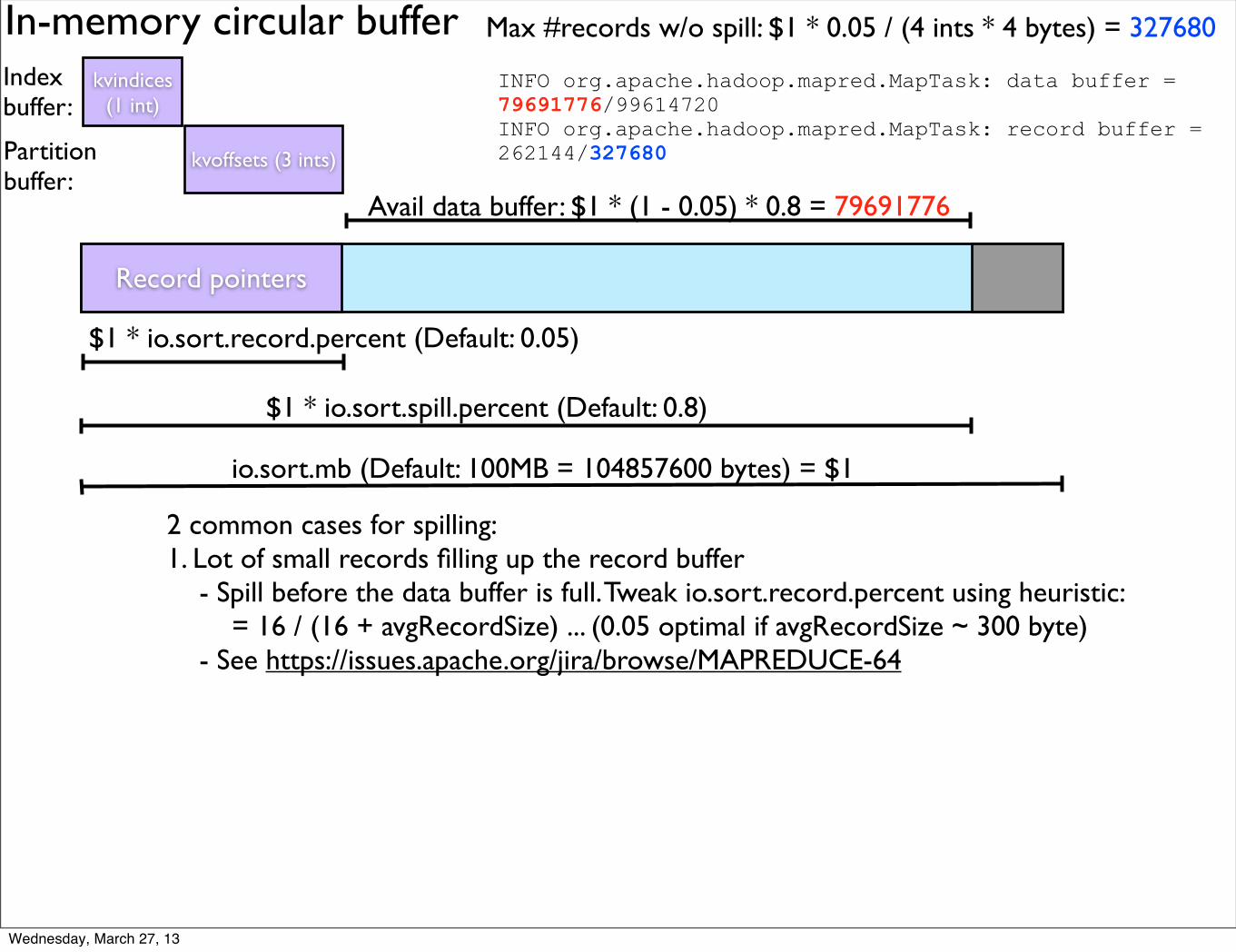
In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64
Wednesday, March 27, 13
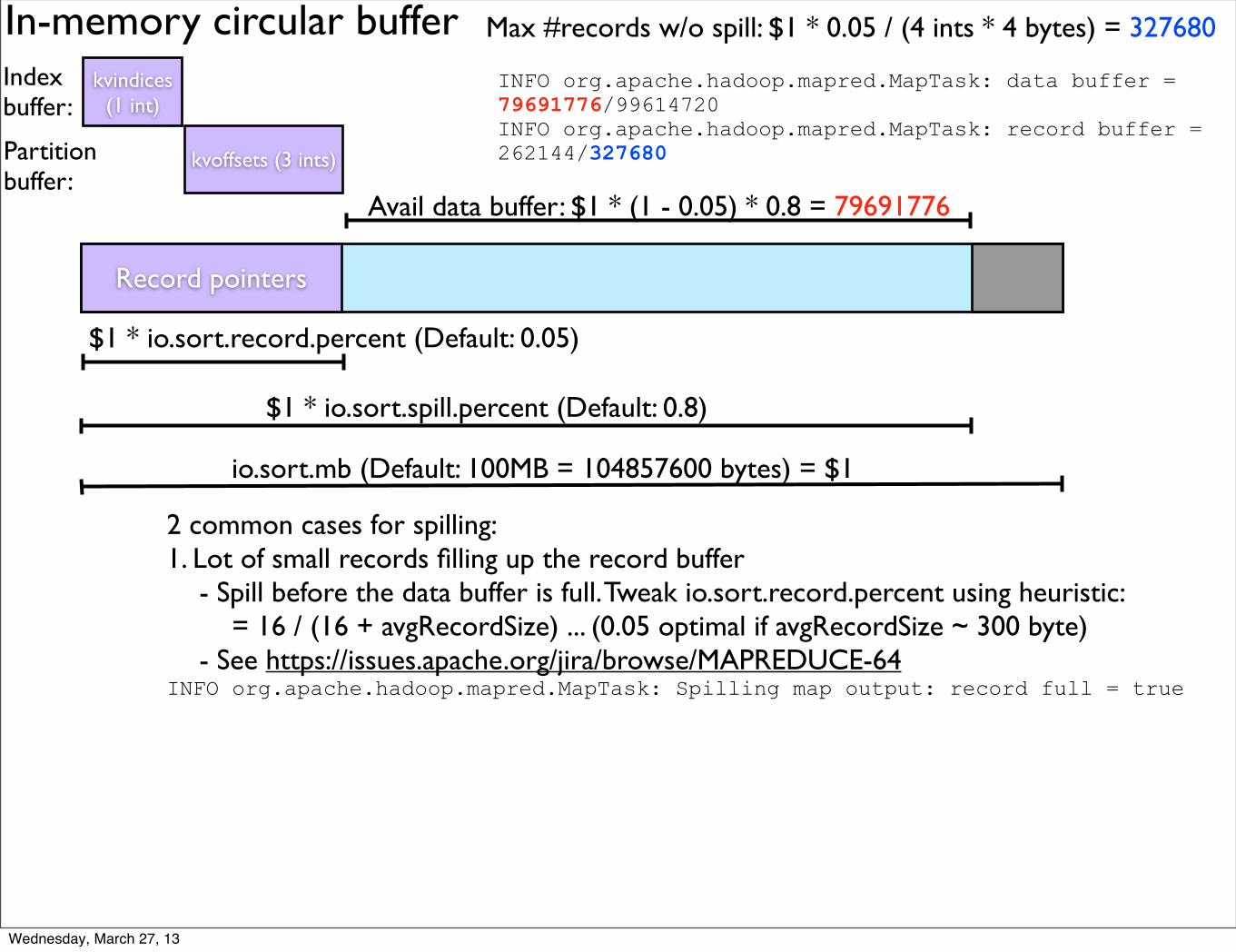
In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64INFO org.apache.hadoop.mapred.MapTask: Spilling map output: record full = true
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64INFO org.apache.hadoop.mapred.MapTask: Spilling map output: record full = true
2. Few but very large records filling up the data buffer
Wednesday, March 27, 13
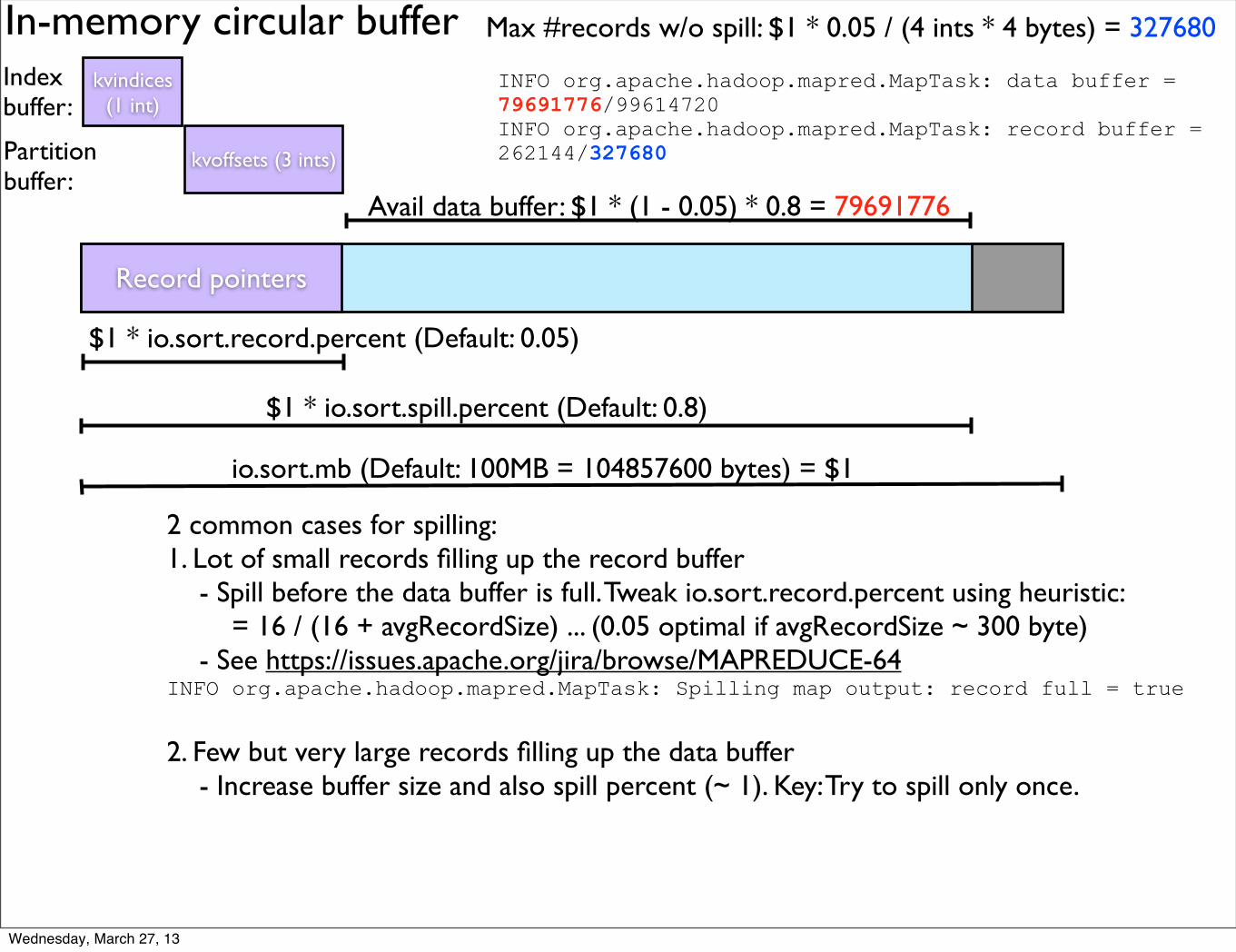
In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64INFO org.apache.hadoop.mapred.MapTask: Spilling map output: record full = true
2. Few but very large records filling up the data buffer- Increase buffer size and also spill percent (~ 1). Key: Try to spill only once.
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64INFO org.apache.hadoop.mapred.MapTask: Spilling map output: record full = true
2. Few but very large records filling up the data buffer- Increase buffer size and also spill percent (~ 1). Key: Try to spill only once.- Tradeoff: Buffer takes memory from JVM (i.e. from mapred.child.java.opts). Therefore, if Max JVM =1GB and $1=128MB, then user code gets only 896MB.
Wednesday, March 27, 13

In-memory circular buffer
io.sort.mb (Default: 100MB = 104857600 bytes) = $1
$1 * io.sort.spill.percent (Default: 0.8)
$1 * io.sort.record.percent (Default: 0.05)
Record pointers
kvindices(1 int)
kvoffsets (3 ints)
Index buffer:
Partition buffer:
Avail data buffer: $1 * (1 - 0.05) * 0.8 = 79691776
INFO org.apache.hadoop.mapred.MapTask: data buffer = 79691776/99614720INFO org.apache.hadoop.mapred.MapTask: record buffer = 262144/327680
Max #records w/o spill: $1 * 0.05 / (4 ints * 4 bytes) = 327680
2 common cases for spilling:1. Lot of small records filling up the record buffer
- Spill before the data buffer is full. Tweak io.sort.record.percent using heuristic:= 16 / (16 + avgRecordSize) ... (0.05 optimal if avgRecordSize ~ 300 byte)
- See https://issues.apache.org/jira/browse/MAPREDUCE-64INFO org.apache.hadoop.mapred.MapTask: Spilling map output: record full = true
2. Few but very large records filling up the data buffer- Increase buffer size and also spill percent (~ 1). Key: Try to spill only once.- Tradeoff: Buffer takes memory from JVM (i.e. from mapred.child.java.opts). Therefore, if Max JVM =1GB and $1=128MB, then user code gets only 896MB.
INFO org.apache.hadoop.mapred.MapTask: Spilling map output: buffer full = true
Wednesday, March 27, 13

Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
Wednesday, March 27, 13

Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
Wednesday, March 27, 13
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13

Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskTracker (map-side)
mapping info
TaskTracker (reduce-side)
TaskTracker (reduce-side)
JobTracker
thru heartbeat
Wednesday, March 27, 13

Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskTracker (map-side)
mapping info
TaskTracker (reduce-side)
TaskTracker (reduce-side)
JobTracker
thru heartbeat
Reducers know which machines to fetch data from.
Wednesday, March 27, 13

Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskTaskTracker (map-side)
mapping info
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
Wednesday, March 27, 13
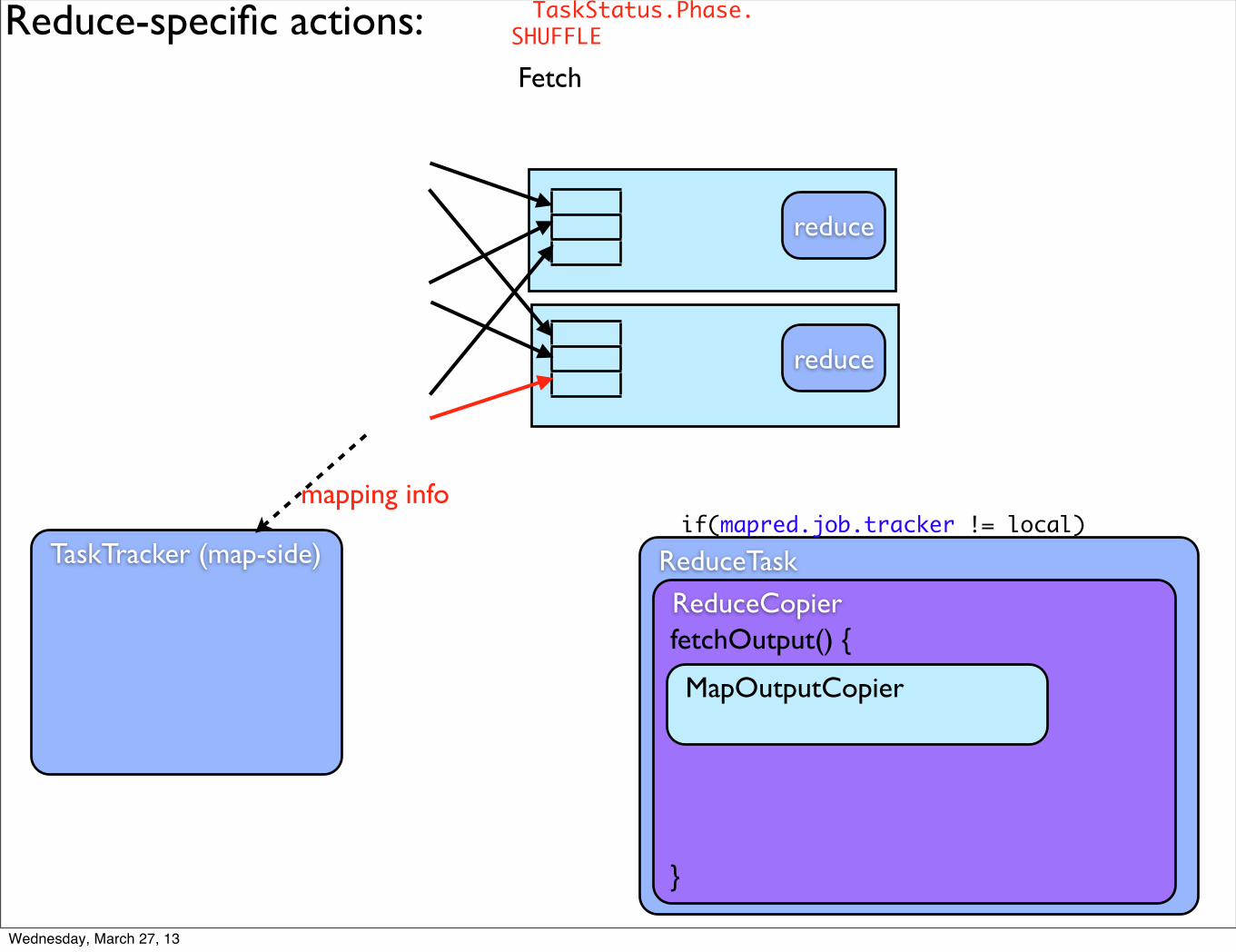
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
- mapred.reduce.parallel.copies: #MapOutputCopier threads (i.e. # fetches in parallel on each reduce task)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
- mapred.reduce.parallel.copies: #MapOutputCopier threads (i.e. # fetches in parallel on each reduce task)
- Default: 5
Wednesday, March 27, 13
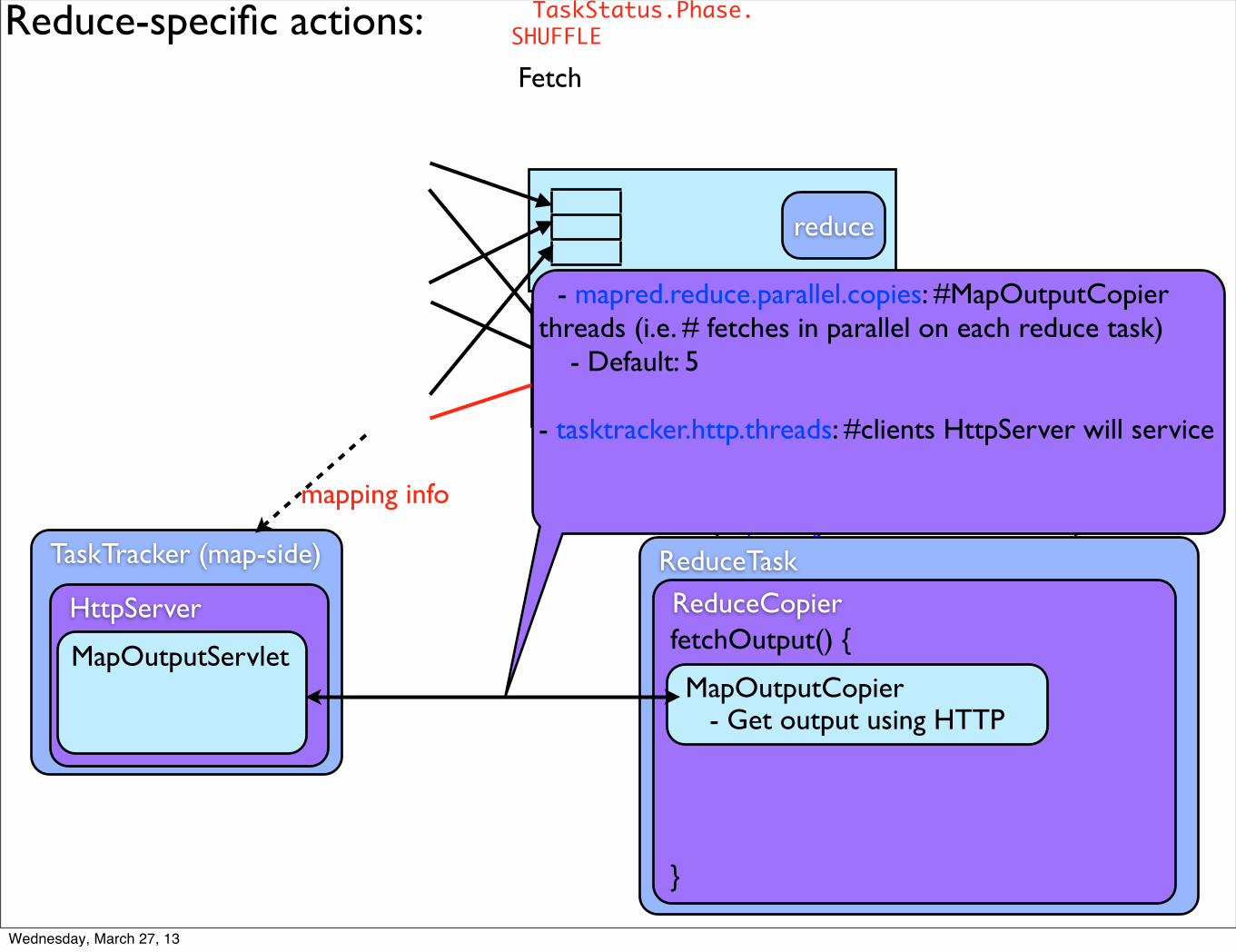
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
- mapred.reduce.parallel.copies: #MapOutputCopier threads (i.e. # fetches in parallel on each reduce task)
- Default: 5
- tasktracker.http.threads: #clients HttpServer will service
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
- mapred.reduce.parallel.copies: #MapOutputCopier threads (i.e. # fetches in parallel on each reduce task)
- Default: 5
- tasktracker.http.threads: #clients HttpServer will service- Default: 40
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
TaskTracker (map-side)
mapping info
ReduceCopierfetchOutput() {
}
MapOutputCopier
HttpServer
MapOutputServlet
- Get output using HTTP
- mapred.reduce.parallel.copies: #MapOutputCopier threads (i.e. # fetches in parallel on each reduce task)
- Default: 5
- tasktracker.http.threads: #clients HttpServer will service- Default: 40- Mapreduce2 will use Netty (2x #processors)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
TaskTracker (map-side)
mapping info
HttpServer
MapOutputServlet
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
TaskTracker (map-side)
mapping info
HttpServer
MapOutputServlet
Wednesday, March 27, 13
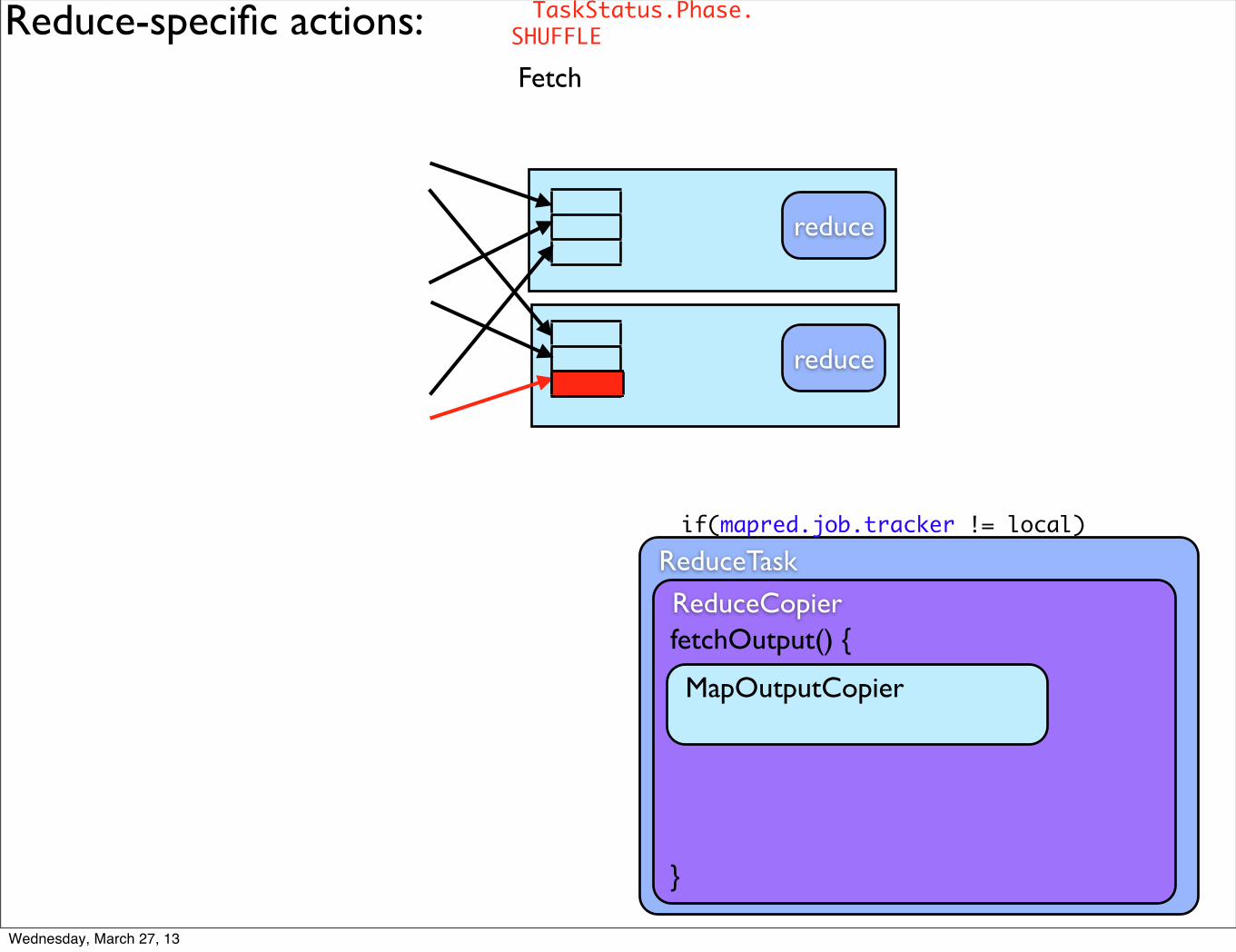
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?
Wednesday, March 27, 13
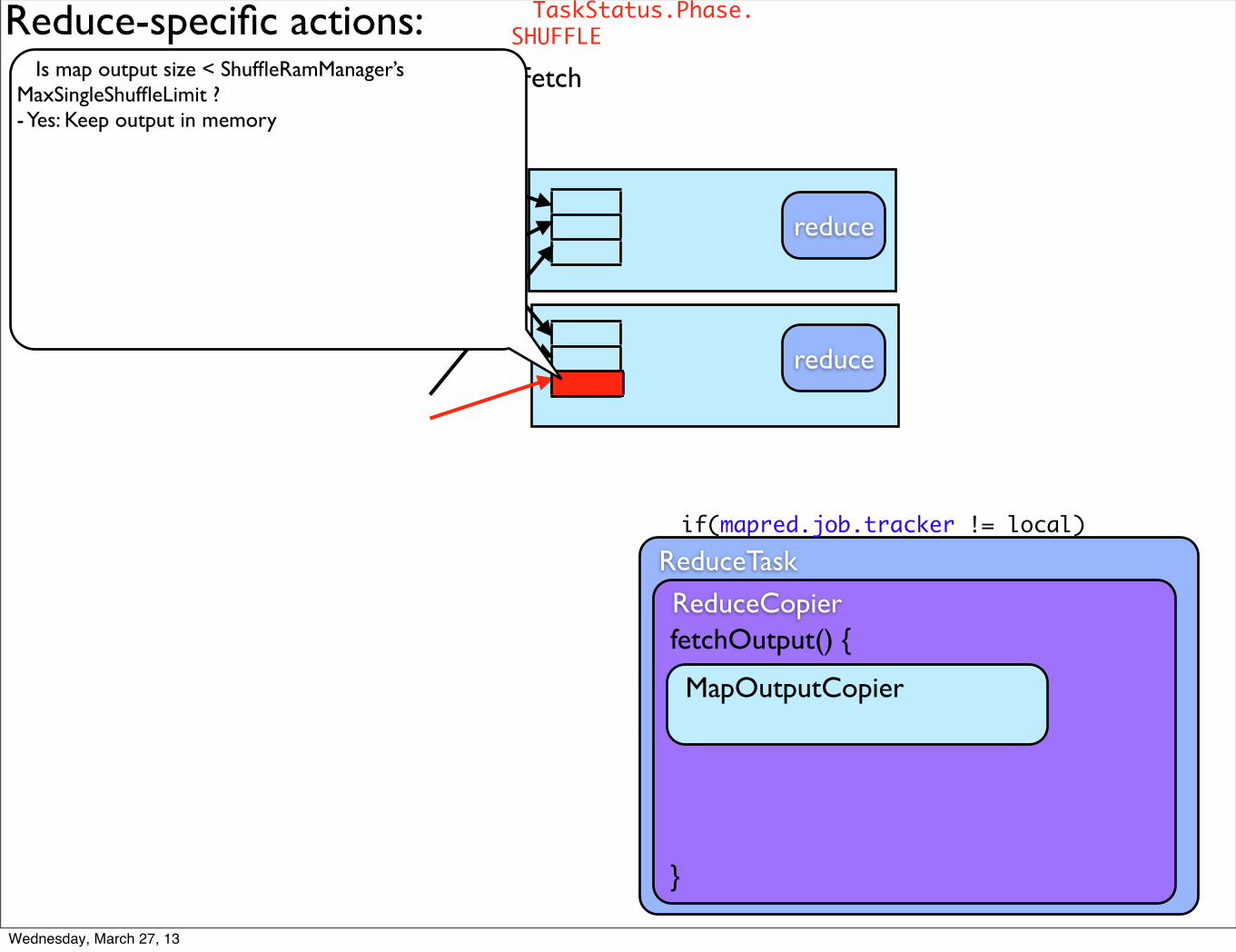
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform “in-memory merge” if
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13
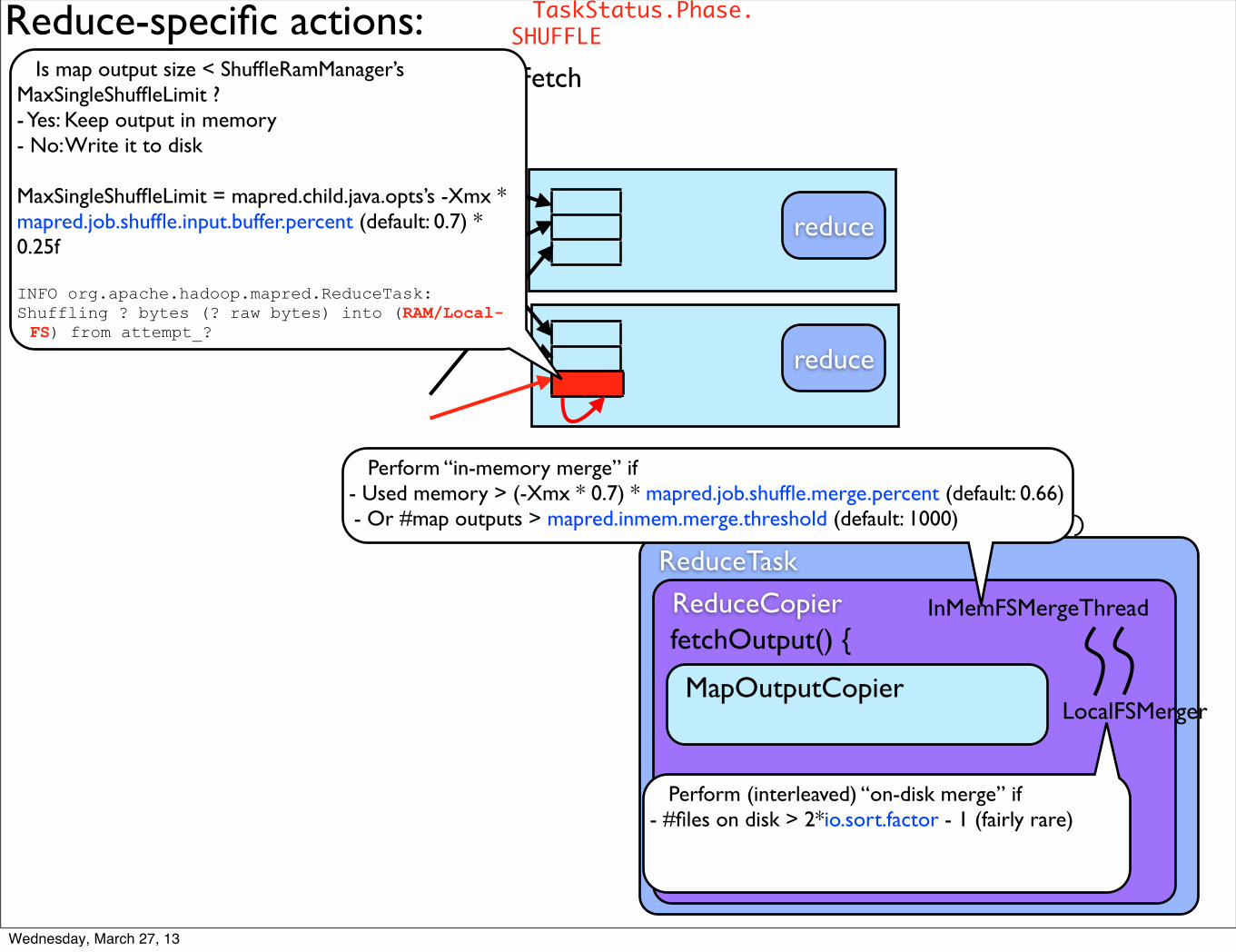
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 10
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13
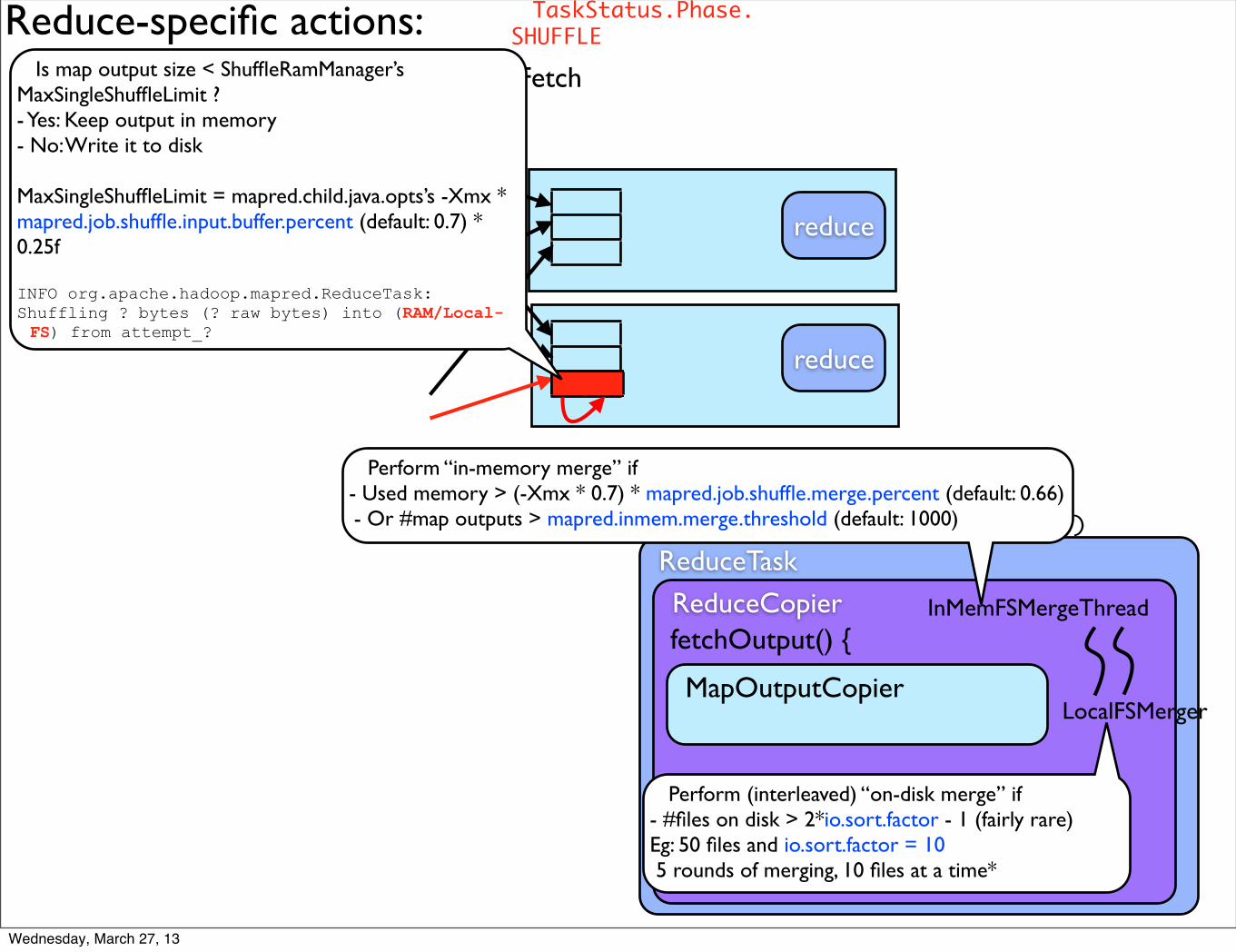
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 105 rounds of merging, 10 files at a time*
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 105 rounds of merging, 10 files at a time*
Merge
SORT
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Wednesday, March 27, 13
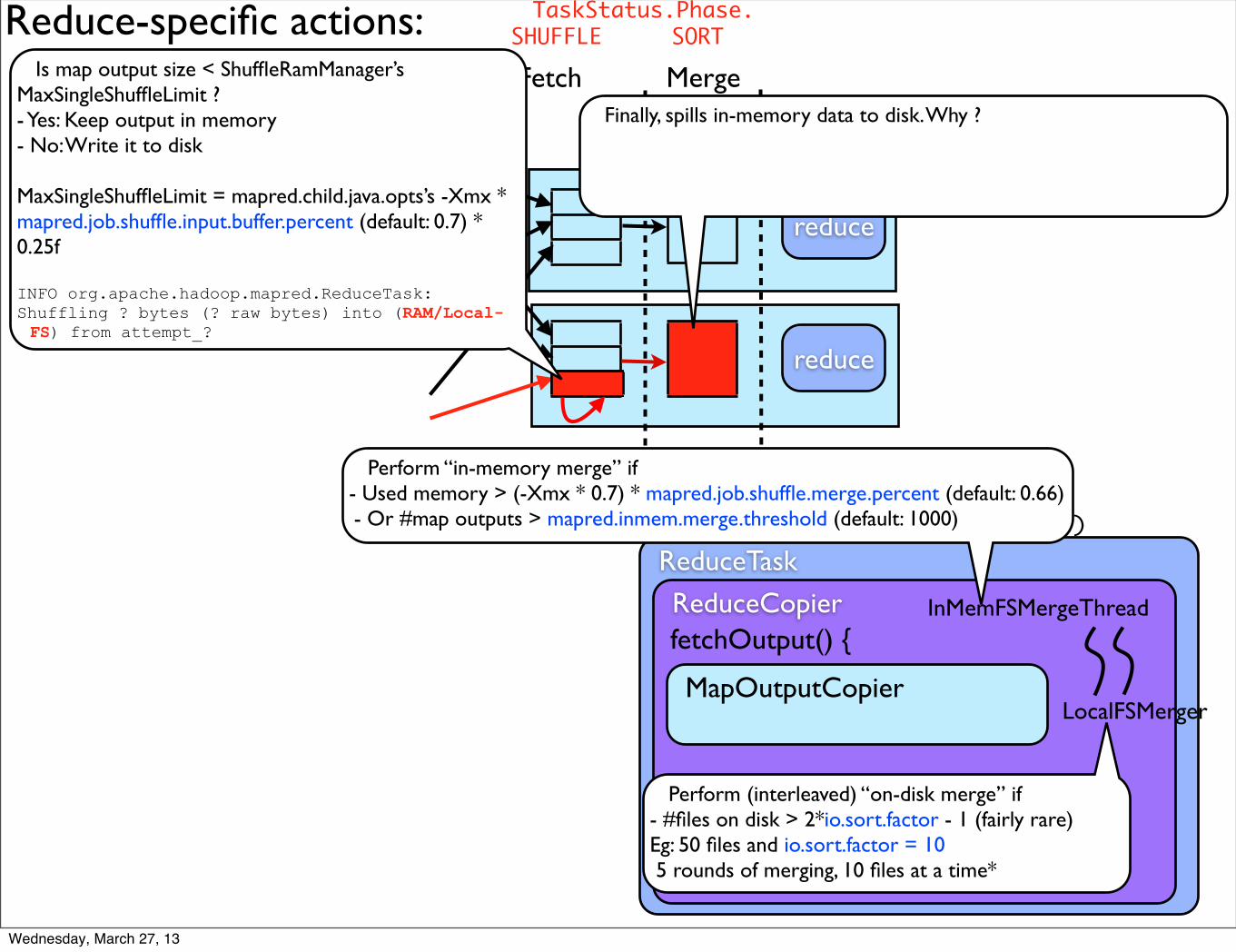
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 105 rounds of merging, 10 files at a time*
Merge
SORT
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Finally, spills in-memory data to disk. Why ?
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 105 rounds of merging, 10 files at a time*
Merge
SORT
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Finally, spills in-memory data to disk. Why ?- Assumes user reduce() needs all the RAM.
Wednesday, March 27, 13
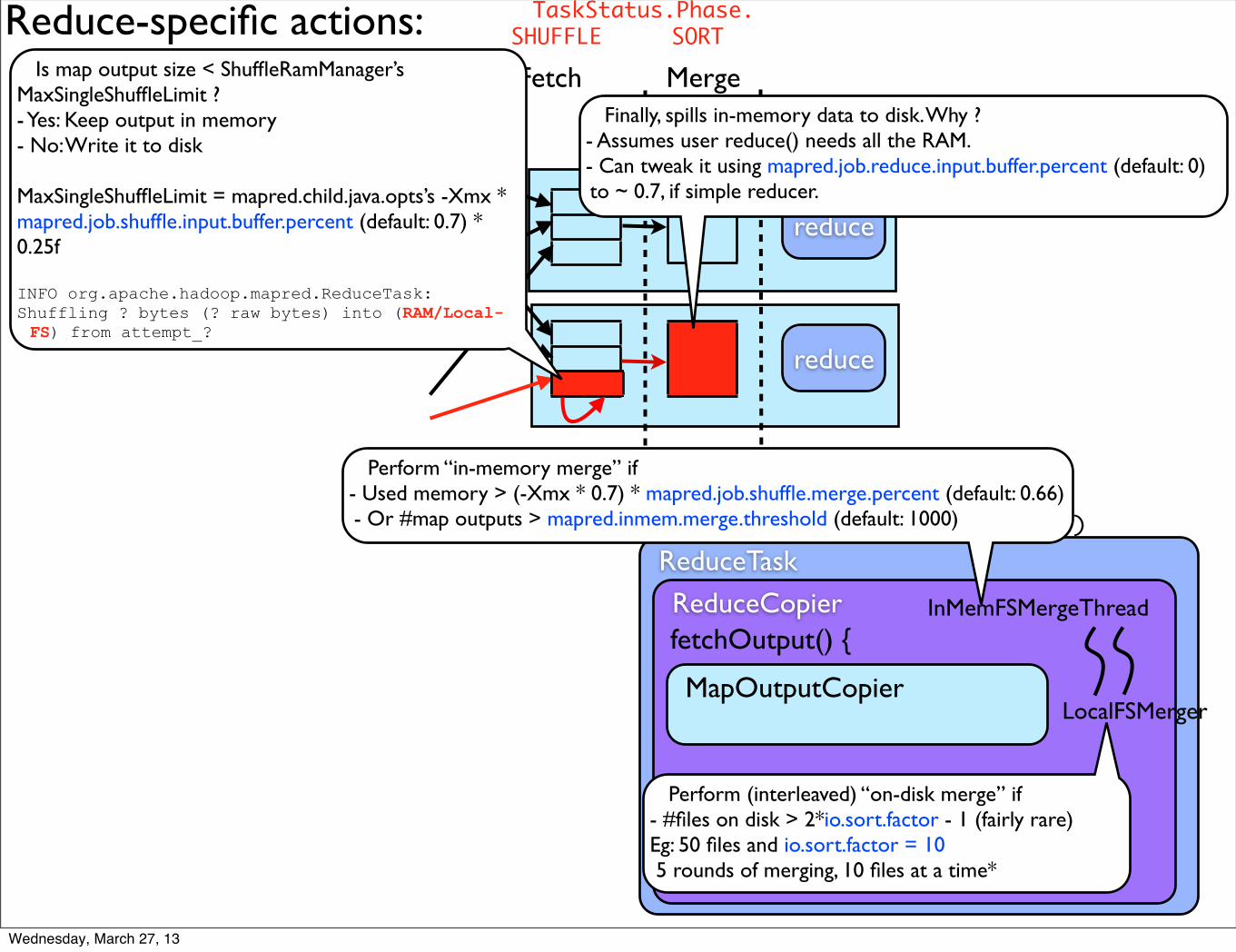
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTaskif(mapred.job.tracker != local)
ReduceCopierfetchOutput() {
}
MapOutputCopier
Is map output size < ShuffleRamManager’s MaxSingleShuffleLimit ?- Yes: Keep output in memory- No: Write it to disk
MaxSingleShuffleLimit = mapred.child.java.opts’s -Xmx * mapred.job.shuffle.input.buffer.percent (default: 0.7) * 0.25f
INFO org.apache.hadoop.mapred.ReduceTask: Shuffling ? bytes (? raw bytes) into (RAM/Local-FS) from attempt_?
LocalFSMerger
InMemFSMergeThread
Perform (interleaved) “on-disk merge” if- #files on disk > 2*io.sort.factor - 1 (fairly rare)Eg: 50 files and io.sort.factor = 105 rounds of merging, 10 files at a time*
Merge
SORT
Perform “in-memory merge” if- Used memory > (-Xmx * 0.7) * mapred.job.shuffle.merge.percent (default: 0.66)- Or #map outputs > mapred.inmem.merge.threshold (default: 1000)
Finally, spills in-memory data to disk. Why ?- Assumes user reduce() needs all the RAM.- Can tweak it using mapred.job.reduce.input.buffer.percent (default: 0) to ~ 0.7, if simple reducer.
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTask
Merge
SORT
Wednesday, March 27, 13
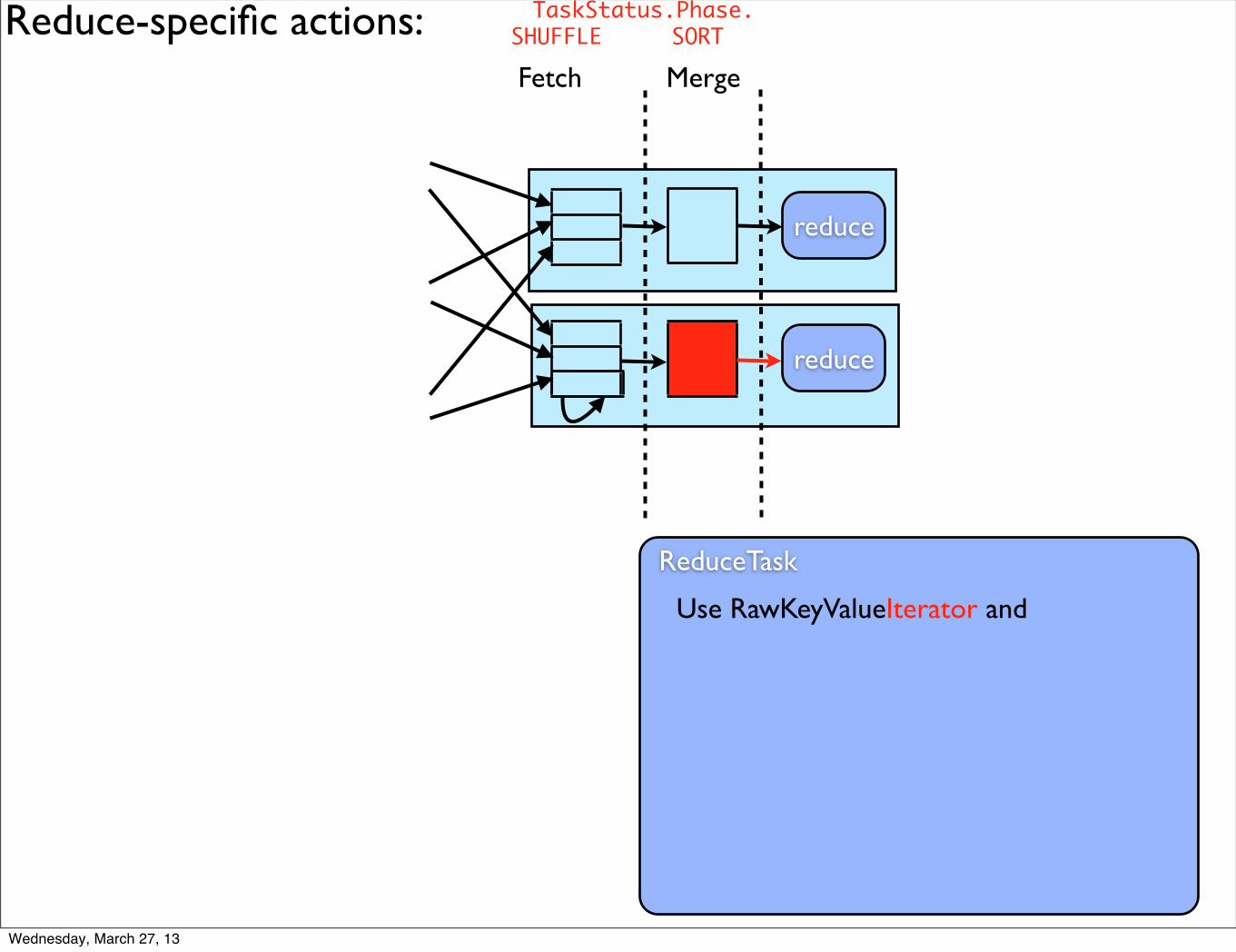
reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTask
Merge
SORT
Use RawKeyValueIterator and
Wednesday, March 27, 13

reduce
reduce
Sort/Spill
Reduce-specific actions:
map
map
map
MapperInputFormat
split 1
split 2
split 3
split 4
split 5
TaskStatus.Phase.
Fetch
SHUFFLE
ReduceTask
Merge
SORT
call user-defined Reducer class.
part-0
part-1
Reducer OutputFormat
REDUCE
Use RawKeyValueIterator and
Wednesday, March 27, 13

References- Hadoop - The definitive guide 3rd edition by Tom White.- Hadoop Operations by Eric Sammers.- Data-Intensive Text Processing by Jimmy Lin and Chris Dyers.- Mining of Massive Datasets by Rajaraman et al.- Online Aggregation for Large MapReduce Jobs by Pansare et al.- Distributed and Cloud Computing by Hwang et al.- http://developer.yahoo.com/hadoop/tutorial/- http://www.slideshare.net/cloudera/mr-perf- http://gbif.blogspot.com/2011/01/setting-up-hadoop-cluster-part-1-manual.html- http://www.cs.rice.edu/~fd2/pdf/hpdc106-dinu.pdf
Wednesday, March 27, 13

















![ApproxHadoop: Bringing Approximations to MapReduce Frameworkssantosh.nagarakatte/... · Hadoop. Hadoop is the best-known, publicly available im-plementation of MapReduce [1]. Hadoop](https://static.fdocuments.net/doc/165x107/5f0f6abb7e708231d4440e6d/approxhadoop-bringing-approximations-to-mapreduce-frameworks-santoshnagarakatte.jpg)
