
Homogenisierung von Massendaten im Kontext von Geodaten ... · The second part of this paper...
13
Zusammenfassung Der Beitrag beschreibt zunächst das geodätische Verfahren der Homogenisierung, das seinen Ursprung in der Datenauf- bereitung im Zuge der Digitalisierung analoger Karten hat. Der Zusammenhang zu den aus der Geoinformatik stammen- den Ansätzen der Integration und Verschmelzung hetero- gener räumlicher Datenquellen wird aufgezeigt. Es folgt eine Diskussion des Begriffs der geometrischen Heterogenität als Folge der Fragmentierung von Geodatenbeständen. Zuletzt wird gezeigt, dass das Verfahren der Homogenisierung die In- tegration geometrisch heterogener Datenquellen ermöglicht und dadurch einen Beitrag zur Herstellung geometrischer Interoperabilität in Geodaten-Infrastrukturen leisten kann. Der zweite Teil des Beitrags stellt das Modell der Homo- genisierung und seine Umsetzung in dem Programmsystem KATHOM vor. Die Lösung eines Normalgleichungssystems, dessen Dimension durch die Anzahl der nicht-inzidenten Ko- ordinaten der zu integrierenden Geometrien (Neupunkte) de- terminiert ist, bildet den Flaschenhals der Homogenisierung von Massendaten. Es folgt eine Untersuchung verschiedener Ansätze zur Überwindung des Flaschenhalses und deren Ver- gleich anhand realer Datensätze. Praktische Beispiele zeigen, dass ein Fill-In minimierendes Sortierverfahren, das einen Multilevel Nested Dissection Algorithmus (MLND) verwendet, zu einer Verbesserung der Performanz der Homogenisierung von Massendaten bis zum Faktor 80 gegenüber den bisher in KATHOM verwendeten Ansätzen führt. Summary This paper describes the geodetical procedure of homogenisa- tion, that has its origin in the processing of digitised analo- gous maps. The link to the geoinformation-science problem of integration and conflation of heterogeneous data sources is established. We discuss geometrical heterogeneity as a con- sequence of the fragmentation of spatial datasets. It is shown, that the procedure of homogenisation enables the integration of spatially heterogeneous data sources, and may thereby contribute to geometrical interoperability in spatial data infrastructures (SDI). The second part of this paper presents the functional model of homogenisation and its implementation in the program KATHOM. The solution of a system of normal-equations is identified as the bottleneck of the problem. The number of unknown parameters is determined by the number of non- incident coordinates of the geoobjects that have to be in- tegrated. Multiple approaches to overcome this bottleneck are investigated and compared using real data sets. Practical examples show, that a fill-in minimising ordering procedure, that uses a multi-level nested dissection approach, improves the performance of the homogenisation of large data sets up to the factor 80 compared to the approaches that have been used before in KATHOM. 1 Einleitung Der Begriff der Homogenisierung umschreibt die Verket- tung nichtlinearer topologischer Transformationen (auch: Gummituch oder rubber-sheet Transformation), mittels derer heterogene Mengen von Punkten, Linien und Flä- chen 1 aus unterschiedlichen Quellen nachbarschaftstreu und unter Beibehaltung datenimmanenter geometrischer Beziehungen in ein gemeinsames homogenes Zielsystem transformiert werden. Die Zusammenführung heterogener Objekte aus un- terschiedlichen Datenquellen zu einem konsistenten Gan- zen bezeichnet man gemeinhin als (Daten-)Integration (Kampshoff und Benning 2002). Die Homogenisierung ist ein Sonderfall dieser allgemeinen Integration; sie ist beschränkt auf die Geometrien raumbezogener Objekte. Die Homogenisierung wird daher – in Abgrenzung zu semantischer, schematischer und syntaktischer Integra- tion – auch als geometrische Integration bezeichnet (Wal- ter 1997, Hake et al. 2002). Die Homogenisierung stellt somit ein Verfahren zur geometrischen Integration dar, das der Herstellung geo- metrischer Interoperabilität zwischen räumlichen Daten- quellen dient. Das klassische Anwendungsgebiet der Homogenisie- rung liegt in der Datenaufbereitung bei der Erfassung großmaßstäbiger digitaler Datenbestände aus analogem Kartenmaterial (Benning und Scholz 1990, Gielsdorf et al. 2003, Hake et al. 2002, Hampp 1992, Morgenstern et al. 1988, Rose 1988, Wiens 1984). Das Ziel besteht dabei in der Einpassung und verketteten Transformation digitali- sierter Karten (Startsysteme) in das übergeordnete Landes- system (Zielsystem). Dabei entstehen Startsysteme von der Größe etwa eines Blattschnitts oder einer Inselkarte. In der Fortführungspraxis digitaler Geodatenbestände ermöglicht die Homogenisierung die permanente nach- barschaftstreue Anpassung bestehender räumlicher Objek- te an verbesserte Anschlusskoordinaten (Benning 1996, Liesen 1998). Die bei der Fortführungshomogenisierung auftretenden Datenmengen sind durch den Umfang der Transaktionen begrenzt auf einige hundert, in seltenen Fällen auch einige tausend Objekte. Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten … 130. Jg. 3/2005 zfv 133 Homogenisierung von Massendaten im Kontext von Geodaten-Infrastrukturen Stefan Kampshoff und Wilhelm Benning 1 Für den dreidimensionalen Fall ist die Definition um Volu- men zu erweitern, siehe z. B. Müller 1999.
Transcript of Homogenisierung von Massendaten im Kontext von Geodaten ... · The second part of this paper...

ZusammenfassungDer Beitrag beschreibt zunächst das geodätische Verfahrender Homogenisierung, das seinen Ursprung in der Datenauf-bereitung im Zuge der Digitalisierung analoger Karten hat.Der Zusammenhang zu den aus der Geoinformatik stammen-den Ansätzen der Integration und Verschmelzung hetero-gener räumlicher Datenquellen wird aufgezeigt. Es folgt eineDiskussion des Begriffs der geometrischen Heterogenität alsFolge der Fragmentierung von Geodatenbeständen. Zuletztwird gezeigt, dass das Verfahren der Homogenisierung die In-tegration geometrisch heterogener Datenquellen ermöglichtund dadurch einen Beitrag zur Herstellung geometrischerInteroperabilität in Geodaten-Infrastrukturen leisten kann.
Der zweite Teil des Beitrags stellt das Modell der Homo-genisierung und seine Umsetzung in dem ProgrammsystemKATHOM vor. Die Lösung eines Normalgleichungssystems,dessen Dimension durch die Anzahl der nicht-inzidenten Ko-ordinaten der zu integrierenden Geometrien (Neupunkte) de-terminiert ist, bildet den Flaschenhals der Homogenisierungvon Massendaten. Es folgt eine Untersuchung verschiedenerAnsätze zur Überwindung des Flaschenhalses und deren Ver-gleich anhand realer Datensätze. Praktische Beispiele zeigen,dass ein Fill-In minimierendes Sortierverfahren, das einenMultilevel Nested Dissection Algorithmus (MLND) verwendet,zu einer Verbesserung der Performanz der Homogenisierungvon Massendaten bis zum Faktor 80 gegenüber den bisher inKATHOM verwendeten Ansätzen führt.
SummaryThis paper describes the geodetical procedure of homogenisa-tion, that has its origin in the processing of digitised analo-gous maps. The link to the geoinformation-science problem ofintegration and conflation of heterogeneous data sources isestablished. We discuss geometrical heterogeneity as a con-sequence of the fragmentation of spatial datasets. It is shown,that the procedure of homogenisation enables the integrationof spatially heterogeneous data sources, and may therebycontribute to geometrical interoperability in spatial datainfrastructures (SDI).
The second part of this paper presents the functional modelof homogenisation and its implementation in the programKATHOM. The solution of a system of normal-equations isidentified as the bottleneck of the problem. The number ofunknown parameters is determined by the number of non-incident coordinates of the geoobjects that have to be in-tegrated. Multiple approaches to overcome this bottleneck areinvestigated and compared using real data sets. Practicalexamples show, that a fill-in minimising ordering procedure,that uses a multi-level nested dissection approach, improvesthe performance of the homogenisation of large data sets up
to the factor 80 compared to the approaches that have beenused before in KATHOM.
1 Einleitung
Der Begriff der Homogenisierung umschreibt die Verket-tung nichtlinearer topologischer Transformationen (auch:Gummituch oder rubber-sheet Transformation), mittelsderer heterogene Mengen von Punkten, Linien und Flä-chen1 aus unterschiedlichen Quellen nachbarschaftstreuund unter Beibehaltung datenimmanenter geometrischerBeziehungen in ein gemeinsames homogenes Zielsystemtransformiert werden.
Die Zusammenführung heterogener Objekte aus un-terschiedlichen Datenquellen zu einem konsistenten Gan-zen bezeichnet man gemeinhin als (Daten-)Integration(Kampshoff und Benning 2002). Die Homogenisierungist ein Sonderfall dieser allgemeinen Integration; sie istbeschränkt auf die Geometrien raumbezogener Objekte.Die Homogenisierung wird daher – in Abgrenzung zusemantischer, schematischer und syntaktischer Integra-tion – auch als geometrische Integration bezeichnet (Wal-ter 1997, Hake et al. 2002).
Die Homogenisierung stellt somit ein Verfahren zurgeometrischen Integration dar, das der Herstellung geo-metrischer Interoperabilität zwischen räumlichen Daten-quellen dient.
Das klassische Anwendungsgebiet der Homogenisie-rung liegt in der Datenaufbereitung bei der Erfassunggroßmaßstäbiger digitaler Datenbestände aus analogemKartenmaterial (Benning und Scholz 1990, Gielsdorf et al.2003, Hake et al. 2002, Hampp 1992, Morgenstern et al.1988, Rose 1988, Wiens 1984). Das Ziel besteht dabei inder Einpassung und verketteten Transformation digitali-sierter Karten (Startsysteme) in das übergeordnete Landes-system (Zielsystem). Dabei entstehen Startsysteme vonder Größe etwa eines Blattschnitts oder einer Inselkarte.
In der Fortführungspraxis digitaler Geodatenbeständeermöglicht die Homogenisierung die permanente nach-barschaftstreue Anpassung bestehender räumlicher Objek-te an verbesserte Anschlusskoordinaten (Benning 1996,Liesen 1998). Die bei der Fortführungshomogenisierungauftretenden Datenmengen sind durch den Umfang derTransaktionen begrenzt auf einige hundert, in seltenenFällen auch einige tausend Objekte.
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 133
Homogenisierung von Massendaten im Kontext vonGeodaten-Infrastrukturen
Stefan Kampshoff und Wilhelm Benning
1 Für den dreidimensionalen Fall ist die Definition um Volu-men zu erweitern, siehe z. B. Müller 1999.

Die Umstellung des Lagebezugssytems in großen Geo-basisdatenbeständen (Netztransformation bzw. Lagestatus-wechsel) stellt besondere Anforderungen an die Skalier-barkeit der Homogenisierung (Kampshoff und Benning2002).
Dem Wechsel des Lagebezugssystems in Primärdaten-beständen folgt eine Aktualisierung der Sekundärdaten-bestände auf der Seite der Nutzer von Geobasisdaten (z. B.Energieversorger, Kommunen). Das betrifft insbesonderesolche Nutzer amtlicher Geobasisdaten, die über eine Do-kumentation ihrer Vermögenswerte und Betriebsmittelauf der Grundlage amtlicher Geobasisdaten verfügen(Gielsdorf et al. 2004, Liesen 1998, Scheu et al. 2000,Stockwald 2000). Die Änderungen an den Geobasisdatenzerstören die (impliziten) geometrischen Relationen zwi-schen Basiskarte und Benutzerobjekten (Assoziativitäts-problem) (Wan und Williamson 1994a, Wan und William-son 1994b). Die Aufgabe der Homogenisierung bestehtdarin, die Konsistenz zwischen Geobasisdaten und Be-nutzerdaten wiederherzustellen.
Die Herausforderung für die Homogenisierung beigroßflächigen Netzänderungen liegt in der Bewältigungder anfallenden Massendaten, die leicht zu einer Größen-ordnung von einigen Millionen Punkten führen können.
2 Geometrische Interoperabilität in Geodaten-Infrastrukturen
Innerhalb von Geodaten-Infrastrukturen ermöglichenDienste und Formate wie WFS (Web Feature Service) undGML (Geography Markup Language) den Zugriff auf syn-taktisch heterogene Datenquellen. Die gemeinsame Nut-zung integrierter Datenbestände erfordert neben der syn-taktischen Interoperabilität die Überwindung geometri-scher Heterogenität (Gröger und Kolbe 2003). Es bestehtdaher Bedarf nach einem Dienst für die geometrische In-tegration, dessen Implementierung auf der Basis des geo-dätischen Verfahrens der Homogenisierung erfolgen kann.
Im Unterschied zu dem klassischen Einsatzgebiet derHomogenisierung handelt es sich dabei um ein online-Verfahren, bei dem die Entscheidung über zu integrie-rende Datenbestände und -modelle ad hoc getroffen wer-den kann (Bernard et al. 2003). Der Dienst erfordert übereine hohe Flexibilität und Konfigurierbarkeit für Datenaus unterschiedlichen Modellen hinaus ein hohes Maß anPerformanz und Skalierbarkeit, um als server-seitige Lö-sung in einem online-Verfahren in Betracht zu kommen.
Riedemann und Timm formulieren in diesem Zusam-menhang das ehrgeizige Ziel einer automatischen Echt-zeit-Integration (automated just-in-time integration) aufder Basis einer System-Architektur verteilter Daten undDienste (Riedemann und Timm 2003). Zur Integrationsoll in einem ersten Schritt die Definition eines gemein-samen Modells (common model) erfolgen, auf das sämt-liche Datenbestände abgebildet werden, vergleichbar mit
der Definition eines globalen Schemas in föderiertenDBMS (Conrad 1997, Kampshoff und Benning 2002). Ineinem zweiten Schritt findet eine Korrespondenzanalyseder Datensätze, sowohl auf der Modellebene (Schema-transformation) als auch auf der Instanzebene, statt.
Die Suche nach korrespondierenden Instanzen führt,soweit keine anderen identifizierenden Merkmale vorhan-den sind, zu einem geometrischen Zuordnungsproblem.Im Anschluss an die Zuordnung hat eine nachbarschafts-treue Anpassung der integrierten Datenbestände zu erfol-gen (Laurini 1994).
Die klassischen Homogenisierungsverfahren auf demGebiet der Datenaufbereitung umfassen sowohl geometri-sche Zuordnungsalgorithmen als auch Techniken zurnachbarschaftstreuen Transformation und Anpassung.Die Verwendung der bestehenden Ansätze als Processing-Service einer Dienste-Architektur für die Datenintegra-tion innerhalb von Geodaten-Infrastrukturen liegt dahernahe (OGC 2003). Die genannten Anforderungen zur Fle-xibilität und Konfigurierbarkeit könnten ein Hindernisbei der Wiederverwendung bestehender Homogenisie-rungslösungen darstellen, da diese oftmals eng an dieStrukturen proprietärer GIS gekoppelt sind. Eine Standar-disierung von Dienste-Schnittstellen in diesem Bereichist hilfreich, denn obgleich schon in Kottman (2000) dieNotwendigkeit von Diensten zur Geodaten-Integration(data fusion services) aufgezeigt wurde, ist dieser Bereichin der internationalen Standardisierung (ISO, OGC etc.)bisher wenig fortgeschritten.
Ein Dienst zur Echtzeit-Homogenisierung verteilterGeodatenbestände war bis vor wenigen Jahren allein auf-grund der benötigten Rechenzeiten undenkbar. Aufgrundder allgemeinen Leistungssteigerung im Bereich derHardware, vor allem aber aufgrund der rasanten Weiter-entwicklung der relevanten Verfahren der numerischenMathematik, die in Abschnitt 4 dieses Beitrags vorgestelltwird, ist sie jedoch in greifbare Nähe gerückt.
2.1 Abstraktionsebenen der geometrischenHeterogenität
Semantische, schematische und syntaktische Heteroge-nität, wie sie in Bishr definiert werden, sind strukturellerArt und betreffen die Ebene des konzeptuellen Modells(Gröger und Kolbe 2003, Bishr 1998). Die Ausprägungengeometrischer Heterogenität hingegen können unterteiltwerden in global-systematische, lokal-systematische undzufällige Effekte.
Die geometrische Heterogenität mit global-systemati-scher Natur betrifft sämtliche Instanzen einer Datenquel-le in gleicher systematischer Weise. Sie kann somit derModellebene zugeordnet werden. Ein Beispiel ist die sys-tematische Abweichung, die aus der fehlerhaften Einpas-sung gescannter Karten in das Landessystem resultiert.Räumliche Objekte, die aus dieser Datenquelle gebildetwerden, sind in gleicher Weise systematisch verfälscht.
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.134

Neben den global-systematischen Abwei-chungen existieren lokal-systematische undzufällige Abweichungen auf der Ebene ein-zelner Instanzen bzw. Geometrien. Ein Bei-spiel ist die lokal begrenzte Verzerrung einesDatenbestandes, die beispielsweise durch denAnschluss einer lokalen Vermessung an ei-nen fehlerhaft koordinierten Aufnahme-punkt oder durch einen lokalen Papierverzugbei der Digitalisierung analoger Karten ver-ursacht sein kann.
Im Ergebnis ist festzuhalten, dass geomet-rische Heterogenität räumlicher Objekte so-wohl auf der lokalen Ebene einzelner Instan-zen oder Cliquen benachbarter Instanzen alsauch auf der globalen Modellebene auftritt.
2.2 Ausprägung geometrischer Heterogenität
Die Heterogenität der Geometrien aus unterschiedlichenQuellen zeigt sich auf der Ebene einzelner Punkte darin,dass die Koordinaten homologer Punkte aus unterschied-lichen Datensätzen voneinander abweichen. Des Weite-ren können Inkonsistenzen hinsichtlich der geometrischenund topologischen Relationen der Geometrien unter-schiedlicher Systeme auftreten. Dabei unterscheidet manzwischen formalen Inkonsistenzen, die durch eine Über-prüfung der inneren logischen Struktur der Daten auf-gedeckt werden können (Gröger 2000), und Abbildungs-fehlern, bei denen zwar eine formal korrekte Instantiie-rung des Datenmodells vorliegt, die jedoch den erfasstenZustand der realen Welt nicht korrekt widergibt.
Da es sich bei der Homogenisierung ausschließlich umein geometrisches Verfahren handelt, spielen Abweichun-gen in der Granularität des Objektmodells und der Objekt-bildung eine untergeordnete Rolle, solange die Geo-metrien der Datenbestände strukturelle Ähnlichkeiten auf-weisen. Maßstabsunterschiede, die zu unterschiedlichenDetaillierungsgraden der räumlichen Objekte führen, sindhingegen problematisch für die geometrische Integration.Bei kleineren Unterschieden kann oftmals eine Anpassungmit einfachen Generalisierungsalgorithmen erfolgen, so-dass eine Integration der Objekte auf gleicher Detaillie-rungsstufe stattfinden kann. In dem Beispiel aus Abb. 1 isteine Vereinfachung des Gebäudeumrings im Zielsystemerforderlich, um eine konsistente Anpassung der Benut-zerdaten (hier: Topographie/Zaun) an die Objekte des Ziel-systems zur gewährleisten. Zunächst existieren zu denGebäudeeckpunkten des Startsystems keine homologenObjekte im Zielsystem, so dass die Topographie fehlerhafthomogenisiert wird (linke Seite der Abb. 1). Im vorliegen-den Fall kann der Gebäudeumring im Zielsystem durchGeneralisierung so angepasst werden, dass die Topogra-phie korrekt homogenisiert wird (rechte Seite der Abb. 1).
Bei starken Maßstabsdifferenzen, die beispielsweise zueinem Wechsel des Geometrietyps homologer Objekte
führen können, kommt eine Anpassung mittels Homoge-nisierung nicht in Betracht, da sich keine topologischeTransformation angeben lässt, die beispielsweise Flächenin Punkte überführt.
2.3 Ursache geometrischer Heterogenität: Fragmentierung von Geodaten
Die Ursache geometrischer Heterogenität liegt in der or-ganisatorisch und physisch getrennten Erfassung, Fort-führung und Haltung von Geodaten, die zu einer Zer-splitterung von Information geführt hat. Grundsätzlichunterscheidet man zwei Ausprägungen der Zersplitte-rung, die Layer-Fragmentierung und die zonale Fragmen-tierung (Laurini 1998, Gröger und Kolbe 2003):� Layer-Fragmentierung tritt zwischen Objekten unter-
schiedlicher Klassen aus Datenbeständen mit kon-gruenter oder stark überlappender räumlicher Ausdeh-nung auf, beispielsweise bei der Kombination vonGas- und Wasserdaten, die auf der Grundlage unter-schiedlicher Geobasisdaten referenziert wurden.Nahezu jede Aktualisierung der Geometrie von Geo-basisdaten führt auf der Seite der Datennutzer zu einerLayer-Fragmentierung. Integrierte Nutzerdatenbestän-de enthalten neben den Geobasisdaten weitere Layervon Objekten. So zieht die Aktualisierung der Geo-basisdaten in Netzinformationssystemen eine Layer-Fragmentierung zwischen den aktualisierten Geobasis-objekten und den Objekten der Netzsparten nach sich(Scheu et al. 2000, Stockwald 2000).Die Layer-Fragmentierung wird auch als thematischePartitionierung und im Kontext relationaler DBMS alsvertikale Fragmentierung bezeichnet (Worboys undDuckham 2004, S. 276).
� Als zonale Fragmentierung bezeichnet man die Auf-teilung der Objekte einer Klasse in Datenbestände, dieräumlich benachbarte weitestgehend disjunkte Gebieteumfassen. Ein klassisches Beispiel zonaler Fragmentie-rung stellen die geometrischen Abweichungen benach-barter Inselkarten dar, die beim Aufbau digitaler Geo-datenbestände zusammengeschlossen werden müssen.
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 135
Abb. 1: Geometrische Integration bei heterogenem Detaillierungsgrad ohne(links) und mit (rechts) Generalisierung

Eine ähnliche Aufgabe stellt sich bei der Kombina-tion von Geobasisdaten verschiedener administrativerGebietseinheiten (Kreise, Bundesländer oder Staaten)(Illert 1995). Sie können ebenfalls zonal fragmentierteInformationen enthalten, deren Widersprüche durchgeometrische Integration beseitigt werden müssen.Die zonale Fragmentierung nennt man auch räumlichePartitionierung und im Kontext relationaler DBMShorizontale Fragmentierung.
2.4 Homogenisierung: Beseitigung von Fragmentie-rung als Transformationsproblem
Der Zusammenhang zwischen den Geometrien fragmen-tierter Datenbestände ergibt sich aus den Koordinatenhomologer Punkte und aus Datenbestand übergreifendengeometrischen Relationen.
In der Homogenisierung werdendie Geometrien der einzelnen Daten-bestände jeweils einem Koordinaten-system zugeordnet. Dabei könnenmultiple Startsysteme auftreten, de-nen die Geometrien fragmentierterDatenquellen entstammen. Danebenexistiert in der Regel ein ausgezeich-netes Zielsystem. Für Anschluss-punkte (auch: Passpunkte) liegenKoordinaten zugleich im Start- undZielsystem vor. Punkte, deren Koor-dinaten in mehreren benachbartenStartsystemen vorliegen, werden alsRand- oder Verknüpfungspunkte be-zeichnet. Die dritte Gruppe vonPunkten bilden die Neupunkte, derenKoordinaten in nur einem der Start-systeme vorliegen. Darüber hinauskönnen sich aus geometrischen Be-ziehungen implizite Zusammenhän-ge zwischen den Systemen ergeben,
beispielsweise in Form von Geradheits- oder Abstands-relationen, an denen Punkte mit Koordinaten aus unter-schiedlichen Systemen beteiligt sind.
Die beschriebenen Zusammenhänge lassen sich in einobjektorientiertes Datenmodell umsetzen, das in Abb. 3als statische UML-Struktur dargestellt ist. Jeder Daten-bestand-Referenz ist ein Startsystem zugeordnet. Dabeikönnen multiple Datenbestände einem Startsystem ange-hören, wenn sie geometrisch zueinander konsistent sind(z. B. geometrisch konsistente Sparten eines Netzinforma-tionssystems). Ein Punkt kann aus einer Startkoordinate(Neupunkt), multiplen Startkoordinaten (Verknüpfungs-punkt) oder einer Zielkoordinate und beliebig vielenStartkoordinaten (Anschlusspunkt) bestehen. Es gibt ei-nige Nebenbedingungen, die in der Darstellung nichtenthalten sind. Beispielsweise sind die Instanzen der Ko-ordinaten-Klassen innerhalb eines Systems durch ihreKoordinatenwerte eindeutig identifiziert und Punkte mitmultiplen Startkoordinaten aus einem Startsystem sindunzulässig.
Das zentrale Ziel der Homogenisierung ist die Integra-tion fragmentierter räumlicher Datenbestände durch Be-seitigung der geometrischen Heterogenität zwischen denGeometrien unterschiedlicher Systeme. Übertragen aufdas Datenmodell der Abb. 3, liegt die Aufgabe der Homo-genisierung darin, Zielkoordinaten für sämtliche Instan-zen der Klasse Punkt zu ermitteln.
Dazu wird für jedes Startsystem Si eine topologischeTransformation von dem Startsystem in dasZielsystem ermittelt, wobei die Beziehungen benachbar-ter Startsysteme berücksichtigt werden. Das kann durcheine gemeinsame Bestimmung aller Transformationen
in einem Ausgleichungsprozess geschehen,wobei die Verkettung der Transformationen durch Ver-knüpfungspunkte und geometrische Bedingungen erfolgt.
T TSZ
SZn1
, ,…
T S ZSZ
ii: →
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.136
Abb. 2: Layer-Fragmentierung zwischen Geobasisdatenund Netzdaten
Abb. 3: Statisches Modell der Homogenisierung

3 Das Ausgleichungs-Modell derHomogenisierung
Das funktionale Modell der Homogenisierung im Pro-grammsystem KATHOM ist in Benning (1995), Benning(1996), Hettwer und Benning (2000), Hettwer (2003) be-schrieben. An dieser Stelle wird es daher ausschließlich inden Grundzügen dargestellt.
3.1 Die Beobachtungsgleichungen derHomogenisierung
Die Homogenisierung wird als Parameterschätzung imGauß-Markoff-Modell formuliert (Koch 1997), dessen uunbekannte feste Parameter β sich zusammensetzen aus� βz, den k unbekannten Zielsystem-Koordinaten der
Neupunkte, und� βt, den l unbekannten Transformationsparametern ei-
ner oder mehrerer (o. B. d. A.) 5-Parameter Transfor-mationen der Startsysteme in das Zielsystem.
Die n Beobachtungen des Gauß-Markoff-Modells der Ho-mogenisierung entstammen drei verschiedenen Gruppen,die hier zusammengefasst sind in den Vektoren� ys, der m Koordinaten der Punkte in einem oder meh-
reren Startsystemen (Hettwer 2003, S. 40),� yb, der o Beobachtungen zum Zwecke der Realisierung
geometrischer Bedingungen (Hettwer 2003, S. 45), und� yn, der q fingierten Beobachtungen zwischen benach-
barten Punkten nach dem hybriden Ansatz (Benning1995; Hettwer 2003, S. 55), die eine nachbarschafts-treue Transformation der Punkte gewährleisten.
Die zugehörigen Beobachtungsgleichungen yi + ei = hi(β)sind zu großen Teilen nicht-linear, sodass für den Über-gang in das lineare Gauß-Markoff-Modell eine Lineari-sierung der Beobachtungsgleichungen mit geeignetenNäherungswerten β(0) der unbekannten Parameter er-folgt.
In Blockmatrizen-Schreibweise erhält man das lineareGauß-Markoff-Modell der Homogenisierung bei Annah-me unabhängiger Beobachtungen zu
(1)
(2)
Das Modell (1) lässt sich durch Transformation mit derMatrix in ein Modell mit Ein-
heits-Gewichtsmatrix überführen. Dabei entstehen auf-grund der diagonalen Struktur von G keine zusätzlichenvon Null verschiedenen Einträge in der transformiertenKoeffizientenmatrix G'X. Nachfolgend wird von einemtransformierten Modell mit D(y) = σ 2I ausgegangen.
3.2 Schätzung der unbekannten Parameter
Die Bestimmung der unbekannten Parameter erfolgtdurch ein gedämpftes Gauß-Newton-Verfahren (Hettwerund Benning 2001). In jeder Iteration des Verfahrens wirdeine Lösung der Normalgleichungen des linearen Gauß-Markoff-Modells vorgenommen, wobei die mit einemDämpfungsfaktor λ(k) (0 < λ(k) < 1) multiplizierten Unbe-kannten-Zuschläge λ(k)β(k) der k-ten Iteration als Nähe-rungswerte für die (k + 1)-te Newton-Iteration benutztwerden.
(3)
(4)
(5)
(6)
Mit den direkten und den iterativen Gleichungslösernexistieren zwei grundlegend verschiedene Ansätze zurLösung des linearen Normalgleichungssytems (3) (Opfer1993).
Direkte Verfahren basieren für allgemeine Matrizenauf einer Gauß-Faktorisierung, im Falle positiv-definiter,symmetrischer Matrizen kann das Cholesky-Verfahrenzum Einsatz kommen. Liegt eine Faktorisierung der Nor-malgleichungsmatrix vor, kann mittels Vorwärts-Rück-wärtseinsetzen der Lösungsvektor bestimmt werden.
Bei der Verwendung voll besetzter Matrizen wächstder Aufwand zur Lösung des Normalgleichungssystemsbei dem direkten Verfahren mit O(u3), d. h. kubisch mitder Anzahl der unbekannten Parameter. Dabei dominiertdie rechnerische Komplexität der Cholesky-Faktorisie-rung mit u3/6 wesentlichen Operationen (Multiplikatio-nen und Divisionen), wohingegen das Vorwärts-Rück-wärtseinsetzen u2 wesentliche Operationen erfordert. DerSpeicherplatzbedarf wächst im Allgemeinen quadratischmit der Anzahl der Unbekannten.
Bei der Homogenisierung von Massendaten entstehenNormalgleichungen mit mehr als 106 Unbekannten, diejedoch nur schwach miteinander verknüpft sind. Eine Lö-sung kann nach heutigen Maßstäben allein aufgrund desSpeicherbedarfs nicht mit den Standardverfahren für vollbesetzte Matrizen durchgeführt werden.
Spezielle Verfahren für die Lösung und Inversion li-nearer Gleichungssysteme, deren Koeffizientenmatrix
∆y( )ki i
ky h+ = − ( )( )1 β 1+
X ( )k i
j
hk
+ =∂ ( )
∂
+( )
1
1
ββ β
β β β( ) ( ) ( ) ( )k k k k+ =1 λ ∆
X X X y’ k k k k k( ) ( ) ( ) ( ) ( )∆ ∆β = ′
G diag p pn= …( )1 , ,
D diag p p p p
p p
s
b
n
m m m o
m o m o q
( ) ( , , , , , ,
, , ) .
y
y
y
= … …
…
+ +
+ + + +−
σ 21 1
11
Es
b
n
z
t
( )y
y
y
X
X
X
X
=11
21
31
12
0
0
ββ
mit
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 137

nur zu einem geringen Anteil mit von Null verschiedenenElementen besetzt ist, heißen Sparse-Matrix Techniken.Wie gezeigt wird, hängt die rechnerische Komplexität derverschiedenen Sparse-Matrix Techniken wesentlich vonder Anzahl und der Verteilung der von Null verschie-denen Nebendiagonalelemente der Normalgleichungs-matrix ab. Bevor die Sparse-Matrix Techniken genauererläutert werden, erfolgt eine Analyse der Struktur derNormalgleichungsmatrix der Homogenisierung.
3.3 Struktur der Normalgleichungsmatrix
Die Dimension des Normalgleichungssystems ist iden-tisch mit der Anzahl der unbekannten Parameter u = k + l,deren Größenordnung im Wesentlichen durch die Anzahlder Koordinaten der Neupunkte k bestimmt ist.
Im vorliegenden Fall unkorrelierter Beobachtungensetzt sich die Normalgleichungsmatrix additiv aus denBeiträgen der einzelnen Beobachtungsgleichungen x'i mitX = |x1, … , xn|' zusammen zu
. (7)
Aus (7) ist ersichtlich, dass von Null verschiedene Neben-diagonalelemente nur dort entstehen, wo mehrere unbe-kannte Parameter an einer Beobachtungsgleichung betei-ligt sind.� Die Beobachtungsgleichungen der Startsystem-Koor-
dinaten der Neupunkte führen zu Verknüpfungen zwi-schen den unbekannten Koordinaten des Neupunktesund den fünf Transformationsparametern des Systems(14 Einträge je Neupunkt, 10 je Anschlusspunkt in X).Die Parameter der Transformation eines Systems sinddaher mit sämtlichen Koordinaten-Unbekannten derPunkte des Systems verknüpft.
� Die Beobachtungsgleichungen für die verschiedenenTypen geometrischer Bedingungen werden auf ele-mentare Bedingungen für zwei bis vier Punkte zurück-geführt und führen daher zu Verknüpfungen zwischenden Unbekannten von maximal zwei bis vier Punkten(vier bis acht Einträge in X).
� Die Beobachtungen zum Erhalt der Nachbarschaftwerden beim hybriden Ansatz als Differenz-Beobach-tungen zwischen den x und y Koordinaten benach-barter Punkte aufgebaut. Die Definition der Nachbar-schaft erfolgt mit dem Natural-Neighbour Kriterium.Die Nachbarschaftsbeobachtungen führen zu Ver-knüpfungen der Koordinaten-Unbekannten solcherPunkte, die innerhalb der Delaunay-Triangulation derPunkte eines Startsystems durch eine Kante verbundensind (vier Einträge in X je Kante zwischen zwei Neu-punkten).Die Delaunay-Triangulation ist ein planarer Graph mitn Knoten und besitzt folglich maximal 3n – 6 Kanten.Durch die Nachbarschaftsbeobachtungen werden dieUnbekannten eines Neupunktes mit durchschnittlich
maximal 2(3n – 6)/n ≈ 6 Unbekannten benachbarterPunkte verknüpft.
In Abb. 4 ist die Struktur der Normalgleichungsmatrix fürein praktisches Homogenisierungsproblem mit ca. 800Punkten und 160 geometrischen Bedingungen darge-stellt. Gut erkennbar sind die dicht besetzten Spalten derTransformationsparameter und die unregelmäßige Ver-teilung der Nebendiagonalelemente aufgrund der Nach-barschaftsbeobachtungen und der geometrischen Bedin-gungen.
4 Sparse-Matrix Techniken zur Lösung undInversion des Normalgleichungssystems
Verschiedene Verfahren für die direkte und iterative Lö-sung und Inversion sparser Normalgleichungssystemesind seit Jahrzehnten bekannt (Björck 1996, Duff et al.1986, George und Liu 1981, Schwarz et al. 1968) undkommen seit längerem in vielen geodätischen Anwen-
X X x x x x’ n n= +…+1 1’ ’
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.138
Abb. 5: Homogenisierungsverfahren für die Bestands-datenaktualisierung eines Netzinformationssystems(hier: Sparte Wasser)
Abb. 4: Nicht-nullelementeder Normal-gleichungs-matrix des Bei-spiels ausAbb. 5

dungen zum Einsatz (z. B. Ackermann et al. 1970, Ben-ning 1986, Gründig 1976, Stark 1984). Es existieren zahl-reiche, zum Teil frei verfügbare Software-Bibliotheken,auf die bei der Implementierung zurückgegriffen werdenkann (z. B. Arantes 2004).
Trotz der langjährigen Forschung auf diesem Gebietergeben sich fortlaufend neue Erkenntnisse, die zu wei-teren Verbesserungen der Verfahren führen. Ein Beispielhierfür ist das System METIS, das auf einem MultilevelAlgorithmus zur Partitionierung unregelmäßiger Graphenbasiert (Karypis und Kumar 1998a, Karypis und Kumar1998b). METIS lässt sich vorzüglich zur Fill-In reduzie-renden Sortierung der Normalgleichungsmatrix verwen-den. METIS liefert in vielen Fällen, so auch in der Homo-genisierung, bessere Ergebnisse als der Generalised Mul-tiple Minimum Degree Algorithmus, der Mitte der 80er-Jahre von Liu entwickelt wurde und aufgrund seiner sehrschnellen Laufzeit weit verbreitet ist (Liu 1985).
Da bereits umfangreiche Literatur zu den klassischenSparse-Matrix Techniken existiert, ist deren Darstellunghier auf das Wesentliche beschränkt; eine umfangreiche-re Einführung in die Thematik bieten Schenk und van derVorst (2004).
4.1 Speicherstrukturen für Sparse-Matrizen
Die speziellen Speicherstrukturen für Sparse-Matrizensind dahingehend optimiert, dass möglichst wenige Null-elemente gespeichert werden müssen. Die interne Indizie-rung sparser Strukturen weicht in der Regel ab von derexternen Indizierung (Zeile/Spalte) der Matrix; zusätz-liche Felder für die Lokalisierung der Elemente müssenvorgehalten werden.
Die Koordinatenspeichertechnik und die Profilspeicher-technik sind die am meisten verbreiteten Klassen vonSpeicherstrukturen für Sparse-Matrizen. Bei der Koordi-natenspeichertechnik werden ausschließlich von Nullverschiedene Elemente und deren Koordinaten (Indices)gespeichert, wohingegen bei der Profilspeichertechnikjeweils die Vektoren von der Diagonale bis zum letztenvon Null verschiedenen Element, die auch als Profil oderEnvelope der Matrix bezeichnet werden, vorgehaltenwerden. Die Profilspeichertechnik kommt im Vergleichzur Koordinatenspeichertechnik mit einfacheren Loka-lisierungsstrukturen aus. Dafür kann das Profil einerMatrix eine erhebliche Anzahl von Nullelementen ent-halten, sodass sich ein erhöhter Speicherbedarf der Koor-dinatenspeichertechnik ergeben kann.
4.2 Direkte Lösungsverfahren
Die Koeffizientenmatrix der Homogenisierung besitzt vol-len Spaltenrang. Die Normalgleichungsmatrix X’X derHomogenisierung ist somit positiv-definit. Im Folgendenwerden direkte Lösungsverfahren für symmetrische, posi-
tiv-definite sparse Systeme linearer Gleichungen be-trachtet, die prinzipiell in den drei Phasen Analyse, Fak-torisierung und Lösung ablaufen (Duff et al. 1986).1. Analyse der Normalgleichungsmatrix mit dem Ergeb-
nis einer Fill-In reduzierenden Sortierung der Unbe-kannten und anschließende symbolische Faktorisie-rung.
2. Numerische Faktorisierung der Normalgleichungs-matrix X’X = GG' in eine obere und untere Dreiecks-matrix mit Hilfe des Cholesky-Algorithmus für posi-tiv-definite Matrizen.
3. Vorwärts-Rückwärtseinsetzen zur Lösung des Unbe-kanntenvektors β.
4.2.1 Sortierung der Unbekannten zur Reduzierung derFill-In Elemente
Die Cholesky-Faktorisierung einer Sparse-Matrix X’Xführt in der Regel zur Entstehung zusätzlicher Nichtnull-elemente in der Faktormatrix G, deren Gesamtheit alsFill-In bezeichnet wird. Die Größe des Fill-Ins ist abhän-gig von der Reihenfolge der Unbekannten, sodass durcheine Umsortierung der Unbekannten das Fill-In reduziertwerden kann (vgl. Abb. 6). Eine Reduzierung des Fill-Insführt schließlich zu einer Verringerung des Speicher-bedarfs und der Anzahl der notwendigen wesentlichenOperationen.
Das Problem der Fill-In reduzierenden Sortierung derDiagonalelemente einer Sparse-Matrix ist NP-vollstän-dig. Nach heutigem Kenntnisstand existiert kein in poly-nomieller Zeit ablaufender Algorithmus zur Ermittlungeiner optimalen Sortierung (Yannakakis 1981). Es gibteine Reihe heuristischer Verfahren zur Fill-In Reduktion,die jedenfalls für die Praxis brauchbare Ergebnisse inkürzerer Zeit liefern.
Im Rahmen dieser Untersuchung wurden drei ver-schiedene Gruppen von Sortieralgorithmen miteinanderverglichen.
Banker-SortierungDie Banker-Sortierung wird im Zusammenhang mit derProfilspeichertechnik eingesetzt. Sie führt zu einer Ver-kürzung der Profilvektoren und somit zu einer Reduktiondes benötigten Speicherplatzes (Snay 1976), da Fill-In
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 139
Abb. 6: Effekt derUnbekannten-Sortierung(links) auf dieFaktormatrix(rechts) (Duffet al. 1986)

Elemente ausschließlich innerhalb des Profils entstehen(Björck 1996, S. 218). Das Verfahren ist in geodätischenAnwendungen weit verbreitet und wird beispielsweisein den Programmsystemen KAFKA und FLASH des Geo-dätischen Instituts der RWTH Aachen verwendet.
Minimum Degree AlgorithmusDer Minimum Degree Algorithmus verfolgt einen intuiti-ven Ansatz zur Minimierung des Fill-Ins. Aus dem Bei-spiel in Abb. 6 wird ersichtlich, dass Unbekannte miteiner hohen Zahl von Verknüpfungen zu anderen Unbe-kannten (man spricht auch vom Grad (degree) einer Un-bekannten) tendenziell weniger Fill-In Elemente erzeu-gen, wenn sie an das Ende des Unbekanntenvektors sor-tiert werden. Die Elimination einer Unbekannten βi führtzu einer paarweisen Verknüpfung aller mit βi verknüpf-ten Unbekannten durch Fill-In Elemente, soweit diesenicht schon vor der Elimination von βi verknüpft waren.Der Minimum Degree Algorithmus wählt nun in jedemEliminationsschritt die Unbekannte mit minimalem Gradzur folgenden Elimination aus.
Der Hauptaufwand des Minimum Degree Algorithmusliegt in der Aktualisierung des Grades der Nachbarn eli-minierter Unbekannter. Weiterentwicklungen setzen andieser Schwachstelle an. Zu nennen sind Lius GeneralisedMultiple Minimum Degree Algorithmus (MMD), der je-weils eine Menge von Unbekannten in einem Schritt eli-miniert, sowie der Approximate Minimum Degree Algo-rithmus (AMD), bei dem eine rechnerisch günstige Nähe-rung des Grades der Unbekannten ermittelt wird (Liu1985, Davis et al. 1996).
Besondere Schwierigkeiten bereiten Unbekannte mitsehr hohem Verknüpfungsgrad, wie z. B. die Transfor-mationsparameter βt, die mit sämtlichen anderen Unbe-kannten eines Systems verknüpft sind. Sie verursachenbei den Minimum Degree Ansätzen hohen Rechenauf-wand, da der Grad dieser Unbekannten bei jedem Elimi-nationsschritt neu bestimmt werden muss. Unbekanntemit überdurchschnittlich hohem Verknüpfungsgrad sollteman daher vorab von der Sortierung ausschließen und andas Ende der Diagonalen der Normalgleichungsmatrixpositionieren. Eine entsprechende Modifikation des AMDAlgorithmus ist der AMDpre Algorithmus nach (Carmen1997), der a priori eine Unterteilung des Normalglei-chungssystems (3) in ein sparses Teilsystem für βz undein dicht besetztes System für βt vornimmt.
(8)
Im Rahmen dieser Untersuchung wurde Carmens Prä-prozessor zur Berücksichtigung dicht besetzter Spaltenkombiniert mit Lius MMD Algorithmus, das Resultat nen-nen wir MMDpre.
Unabhängig von der Sortierung kann die Aufteilungdes Systems (8) auch für den gesamten Lösungsprozess
vollzogen werden. Mit Nij = X'iX erhält man durch Elimi-nation von βz aus (8) die Gleichungen
(9)
. (10)
Anstelle der Inversen der (k × k) Sparse-Matrix N11 in (9)ermittelt man das Produkt als Lösung desGleichungssystems
(11)
mit l rechten Seiten. Die Faktorisierung von N11 wirdauch zur Lösung von (10) benötigt, sodass der zusätzlicheAufwand zur Lösung von (11) in dem l-fachen Vorwärts-Rückwärtseinsetzen mit jeweils k2 wesentlichen Operatio-nen besteht.
Nested Dissection AlgorithmusDie Nested Dissection Algorithmen basieren auf der Se-parierung der Unbekannten durch Auswahl einer kleinenTeilmenge von Unbekannten βs (Separator), die den Un-bekanntenvektor β in zwei unverknüpfte Komponentenβ1 und β2 partitioniert. Die Partitionierung wird inner-halb der Komponenten rekursiv fortgesetzt, bis eine vor-gegebene Mindestgröße erreicht wird.
Die Anwendung des Nested Dissection Verfahrens aufdie Ausgleichung geodätischer Punktnetze entsprichtder Helmert'schen Blockmethode (Helmert 1880, S. 556;Björck 1996, S. 240; Wolf 1975, S. 99). Die Unbekanntenβs des Separators werden in dem Zusammenhang Ver-bindungsunbekannte genannt, die verbleibenden Unbe-kannten heißen Innenunbekannte.
Das Nested Dissection Verfahren führt auf eine Nor-malgleichungsmatrix mit Block-Diagonal-Struktur, wo-bei die Größe des Randes (Puffersystem) abhängig ist vonder Größe der Separatoren. Die Block-Diagonal-Strukturist invariant bzgl. der Cholesky-Faktorisierung (Björck1996, S. 225); somit hängt die Fill-In Reduktion desNested Dissection Verfahrens direkt von der Größe derSeparatoren ab.
Das Problem der Separierung einer Menge von Unbe-kannten in zwei unverknüpfte Komponenten kann auchals Partitionierung des Adjazenzgraphen der Matrix in-terpretiert werden (Friedrich 1930). Die Knotenmenge Vmit |V| = n des Adjazenzgraphen G = (V, E) ist gegebendurch die Elemente des Unbekanntenvektors β; die Kan-ten E von G sind definiert durch die von Null verschie-denen Nebendiagonalelemente (Verknüpfungselemente)der Normalgleichungsmatrix X'X.
Das Problem der Graphenpartitionierung bestehtdarin, zwei Teilmengen V1 und V2 gleicher Größe|V1| = |V2| = n/2 mit leerer Schnittmenge V1 ∩ V2 = ∅und vollständiger Vereinigung V1 ∪ V2 = V zu finden, so-dass die Menge der Kanten aus E, deren Knoten zugleichV1 und V2 angehören, minimiert wird. Die Graphenparti-
N B N11 12=
B N N= −11
112
N X y N11 1 12β βz = ′ − t
N N N N X N N X y22 21 111
12 2 21 111
1−( ) = ′ − ′( )− βt−
′ ′′ ′
=′′
X X X X
X X X X
X y
X y1 1 1 2
2 1 2 2
1
2
ββ
z
t
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.140

tionierung ist offenbar äquivalent zur Suche eines gutenSeparators für das Nested Dissection Verfahren.
Eine effiziente Heuristik zur Lösung des Graph-Parti-tionierungs-Problems im Kontext der Matrix-Sortierungist durch den Kernighan-Lin Algorithmus gegeben (Ker-nighan und Lin 1970). Ausgehend von initialen Partitio-nierungen des Adjazenzgraphen sucht man Teilmengenvon Knoten, deren Vertauschung zwischen den Partitio-nen zu einer Verkleinerung des Separators führt. Das Ver-fahren wird iterativ fortgesetzt bis ein lokales Minimumerreicht wird und keine entsprechenden Teilmengen vonKnoten mehr gefunden werden.
Eine weitere Beschleunigung der Graphenpartitionie-rung gewährleistet die Multilevel Technik, die auf denMultilevel Nested Dissection (MLND) Algorithmus führt.Der MLND Algorithmus verläuft in drei Phasen, der Zu-sammenfassungsphase (coarsening phase), der Partitionie-rungsphase und der Verfeinerungsphase (uncoarseningphase) (vgl. Abb. 7). Wie bei Multilevel Algorithmen üb-lich, wird zunächst eine stufenweise Vereinfachung der
Problemstellung, hier durch Reduktion der Dimensiondes Graphen G0 durch eine Zusammenfassung von Kno-ten zu Hyperknoten in mehreren Stufen G1, … , Gm
durchgeführt. Es folgt eine Partitionierung Pm des maxi-mal vereinfachten Graphen Gm und schließlich wird diePartitionierung Pm von Gm zurückprojiziert bis zum Gra-phen G0. Dabei werden die zwischenliegenden Partitio-nen Pm–1, … , P0 sukzessive durchschritten und es erfolgtjeweils eine lokale Verbesserung der projizierten Partitio-nen mit dem Kernighan-Lin-Algorithmus (Karypis undKumar 1998a).
Die Unbekannten mit hohem Verknüpfungsgrad soll-ten beim MLND Algorithmus getrennt behandelt werden,um eine optimale Performanz zu erzielen.
Implementierung im Programm KATHOMSämtliche der beschriebenen Verfahren sind in das Pro-grammsystem KATHOM integriert worden. Die Banker-Sortierung wurde aus dem Vorgängerprogramm FLASHübernommen (Benning und Scholz 1990). Der Sortier-algorithmus DSS_REORDER aus der Compaq ExtendedMath Library, dessen theoretischer Hintergrund nichtpubliziert ist, wurde von Hettwer integriert (Compaq Com-puter Corporation 2001, Hettwer 2003).
Neu sind der Generalised Multiple Minimum DegreeAlgorithmus, der Approximate Minimum Degree Algo-rithmus und das Multilevel Nested Dissection Verfahrenaus METIS. Dabei wurden jeweils Algorithmen zur Be-rücksichtigung der Unbekannten mit hohem Verknüp-fungsgrad vorgeschaltet.
4.2.2 Faktorisierung und Lösung sparser Normal-gleichungssysteme
Die Fill-In reduzierende Sortierung der Unbekannten, dieallein aufgrund der Verknüpfungsinformation der Nor-malgleichungsmatrix durchgeführt wird, liefert einenPermutationsvektor der eine neue Sortierung der Unbe-kannten vorgibt. Auf der Grundlage dieser Informationerfolgt im nächsten Schritt die Faktorisierung der Matrix,wobei zunächst eine symbolische Faktorisierung der per-mutierten Matrix durchgeführt wird. Auf deren Grund-lage werden die Positionen der Fill-In Elemente berech-net und die Felder der Koordinatenspeichertechnik auf-gebaut. Im Anschluss daran erfolgt die numerische Fak-torisierung, für die sich der left-looking Algorithmus unddie multifrontal Methode anbieten (Schenk und van derVorst 2004). Weiterhin existieren einige Ansätze zur Op-timierung der numerischen Faktorisierungsverfahren, dieder hierarchischen Speicherstruktur moderner Rechnerangepasst sind.
Die Anwendung des Nested Dissection Verfahrens führtoffenbar auf ein Normalgleichungssystem mit Block-Dia-gonal-Struktur, für dessen parallelisierte Lösung sich diegruppenweise Ausgleichung nach dem Zusammenschlie-ßungstyp unter Anwendung von Helmerts Additions-theorem für reduzierte Normalgleichungen anbietet (Wolf1975, S. 100, 114).
Implementierung im Programm KATHOMIm Programm KATHOM wurden die Algorithmen aus Ge-orge und Liu (1981) zur symbolischen und numerischenFaktorisierung und für das Vorwärts-Rückwärtseinsetzenverwendet, die den left-looking Ansatz verwenden undkeine numerischen Pivot-Strategien enthalten. Die Nor-malgleichungsmatrix der Homogenisierung ist stets posi-tiv-definit, sodass keine singulären führenden Haupt-untermatrizen auftreten. Eine Pivotisierung oder dazualternative Vorgehensweise ist nicht erforderlich (Koch1997, S. 28, 66, 202). Eine Parallelisierung der Lösungwurde testweise vorgenommen.
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 141
Abb. 7: Vorgehensweise bei traditioneller (a) und Multi-level Partitionierung (b) [Karypis und Kumar 1998b]

4.2.3 Partielle Berechnung der Kovarianzmatrix derunbekannten Parameter
Zur Berechnung des Parametervektors β aus den Normal-gleichungen (3) ist eine Inversion der Normalgleichungs-matrix nicht erforderlich. Allerdings werden die Elemen-te der Inversen (X'X)–1 zur Berechnung der Kovarianz-matrix benötigt, deren Ermittlung bei-spielsweise zur Durchführung von Hypothesentests erfor-derlich ist.
Die Inverse einer Sparse-Matrix ist im Allgemeinenvoll besetzt, sodass eine vollständige Berechnung allerElemente der Inversen bei der vorliegenden Problemstel-lung nicht in Frage kommt. Allerdings werden zur Anga-be der a posteriori Varianz einzelner Parameter sowie zurDurchführung von Hypothesentests nur ausgewählte Ele-mente der Inversen-Matrix benötigt.
Ein effizienter Algorithmus zur partiellen Inversionvon Sparse-Matrizen wurde Anfang der 70er-Jahre vonTakahashi angegeben (Takahashi et al. 1973, Erismanund Tinney 1975). Das Verfahren basiert auf der Gauß-Zerlegung einer hier symmetrischen n × n MatrixA = LDL', für deren Inverse Z = A–1 die folgende Bezie-hung gilt:
.
Aus der Beziehung (14) lässt sich eine Rekursionsvor-schrift für die Elemente der Inversen Z = (zij) ableiten.Ausgehend vom Element erhält man die weite-ren Elemente von Z aus den Zusammenhängen
(15)
(16)
Eine für die Inversion von Sparse-Matrizen besondersgünstige Eigenschaft des Algorithmus besteht darin, dassdie Berechnung der Elemente zij mit lij ≠ 0 ohne vorherigeBerechnung der Elemente zij mit lij = 0 erfolgen kann.Werden ausschließlich solche Elemente der Inversen be-nötigt, die bereits in A von Null verschieden sind oder alsFill-In Elemente in der Faktorisierung hinzugekommensind, kann die Berechnung der Inversen A–1 ohne zusätz-lichen Speicherbedarf geschlossen innerhalb der Sparse-Matrix Struktur der Faktormatrix erfolgen.
Implementierung im Programm KATHOMDer Takahashi-Algorithmus zur Berechnung der partiel-len Inversen ist in das Programm KATHOM integriertworden, wobei nur die in der Struktur der Cholesky-Fak-
torisierung enthaltenen Elemente berechnet werden. Wei-tere Elemente der Inversen werden nicht benötigt, denndie im weiteren Verlauf zur Durchführung der Ausreißer-tests benötigten Elemente sind bereits in den Normalglei-chungen von Null verschieden.
5 Anwendungsbeispiele
In den Abb. 8 und 9 sind die Ergebnisse der verschie-denen Sortierverfahren für das Testbeispiel aus Abb. 5dargestellt, die Ergebnisse des AMD sind aufgrund derÄhnlichkeit zum MMD nicht dargestellt. Bei dem MultiLevel Nested Dissection Ansatz ist die Partitionierung desProblems in jeweils (200 × 200)/2 Elemente große Blöckeerkennbar, die abgesehen von den Separatoren und derenFill-In auch in der Faktormatrix erhalten bleibt. DieseStruktur macht sich bei Verwendung des left-lookingAlgorithmus zur numerischen Faktorisierung der Matrixpositiv bemerkbar, da innerhalb eines lokal zusammen-hängenden Abschnitts des Elementvektors gearbeitetwerden kann, der vollständig in den Cache-Speicher derCPU passt. So ist zu erklären, dass die Faktorisierung undLösung der mit MLND sortierten Matrizen schneller ab-läuft als die Faktorisierung der MMD- und AMD-Matri-zen, obwohl diese zum Teil ein kleineres Fill-In besitzen.
Die Laufzeiten und die Größe des Fill-Ins der verschie-denen Sortieralgorithmen sind für einige Datensätze aus
′ = ′G DL
z d l z
i n j i
ii nn ki kik i
n
= −
= − … >
−
= +∑1
1
1 1mit und ., ,
z l zij ki kjk i
n
= −= +∑
1
z dnn nn= −1
(12)
(13)
(14)
Z L D L
L D L D L D L
D L
= ′
= ′ + −
= +
− − −
− − − − − − −
− −
1 1 1
1 1 1 1 1 1 1
0
1 1
( )
(
� ���� ����
II L Z− ′)
ˆ ( ˆ) ˆ ( )D β = ′σ 2 X X
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.142
Abb. 8: Ergeb-nisse des MLNDAlgorithmus(METIS)
Abb. 9: Ergeb-nisse des MMDAlgorithmus

realen Homogenisierungsproblemen (vgl. Tab. 1) in denAbb. 10 und 11 dargestellt. Die Rechenzeiten wurden aufeinem AMD Athlon 2800+ mit 1 Gb RAM ermittelt. DerMLND Algorithmus ist geringfügig langsamer als derMMDpre Algorithmus. Die vergleichsweise hohen Lauf-zeiten der DSS-CXML Unbekannten-Sortierung sind aufeine Unzulänglichkeit bei der Behandlung von Unbe-kannten mit hohem Verknüpfungsgrad zurückzuführen,die man beispielsweise mit der Vorgehensweise nachGleichung (9)–(11) umgehen kann.
Misst man die Qualität eines Sortierverfahrens anhandder Laufzeit der anschließenden numerischen Faktorisie-rung, so ist aus Abb. 12 erkennbar, dass MLND (METIS)den anderen Verfahren aufgrund des schnelleren Spei-cherzugriffs auch dann überlegen ist, wenn bei größerem
Fill-In eine größere Zahl von wesentlichen Operationenbenötigt wird. Für einige Datensätze fehlen Angaben zurLaufzeit der numerischen Faktorisierung nach Banker-Sortierung und DSS-CXML, da die 2Gb-Schranke für Be-nutzerprozesse in 32-bit Windows-Systemen überschrit-ten wurde.
In Kombination mit MLND ist eine Steigerung derRechenleistung durch den Einsatz parallelisierter Fakto-risierungs- und Lösungsverfahren auf Multiprozessor-Rechnern erzielbar (vgl. 4.2.2) (Gupta et al. 1997, Karypisund Kumar 1998a, Schenk 2000). Vielversprechende Test-läufe mit den Datensätzen aus Tab. 1 wurden mit dem pa-rallelen direkten Gleichungslöser PARDISO (Version 1.2.2)auf einem IBM Power 4 mit vier 1.3 GHz CPUs der UniBasel durchgeführt. Die Parallelisierung auf vier Pro-zessoren bewirkt für Datensatz 4 eine Beschleunigungder numerischen Faktorisierung um den Faktor 3,5 von15,5 s auf 4,4 s.
Die partielle Inversion der Normalgleichungsmatrixerfordert in den Datenbeispielen näherungsweise doppeltso viele wesentliche Operationen wie die numerischeFaktorisierung und Lösung der Normalgleichungen. DieInverse wird nur einmal am Ende der Gauß-Newton-Ite-rationen berechnet, sodass sie nur unwesentlich zur Ge-samtrechenzeit der Homogenisierung beiträgt. Zur Qua-litätsbeurteilung und Durchführung statistischer Testssollte die partielle Inverse (Kovarianzmatrix) daher im-mer berechnet werden.
In Abb. 13 sind die Gesamtlaufzeiten der ProgrammeKATHOM 1.10 (Banker-Algorithmus), KATHOM 1.18(DSS-CXML) und KATHOM 2.0 (MLND) aufgeführt. DerDatensatz 4 konnte aufgrund des erhöhten Speicher-bedarfs der anderen Verfahren nur mit der Version 2 desProgramms berechnet werden. Bei der Bewertung derLaufzeiten ist zu berücksichtigen, dass die in Version 1verwendeten Algorithmen zur Delaunay-Triangulationund Natural Neighbour Interpolation eine Punkt-in-Um-kreis-Suche mit linearem Aufwand verwenden, wodurchein insgesamt quadratisches Laufzeitverhalten vorliegt(Hettwer 2003, S. 95). In der Version 2 wird ein räum-licher Index benutzt, der zumindest für zufällig gleich-
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 143
Abb. 10: Rechenzeiten der Unbekannten-Sortierung
Abb. 11: Anzahl der Fill-In Elemente (bei DSS-CXML nichtzugänglich)
Abb. 12: Rechenzeiten der numerischen Faktorisierungund Lösung
Tab. 1: Testdatensätze mit bis zu 1,16 MillionenUnbekannten
Neup. Sollp. Geom. Bed. Nebendiag. (%)
1 18002 14284 20780 430663 (0,069)
2 143392 14863 27715 2517627 (0,006)
3 493088 115413 80057 8562485 (0,002)
4 578727 115286 199335 10779796 (0,002)
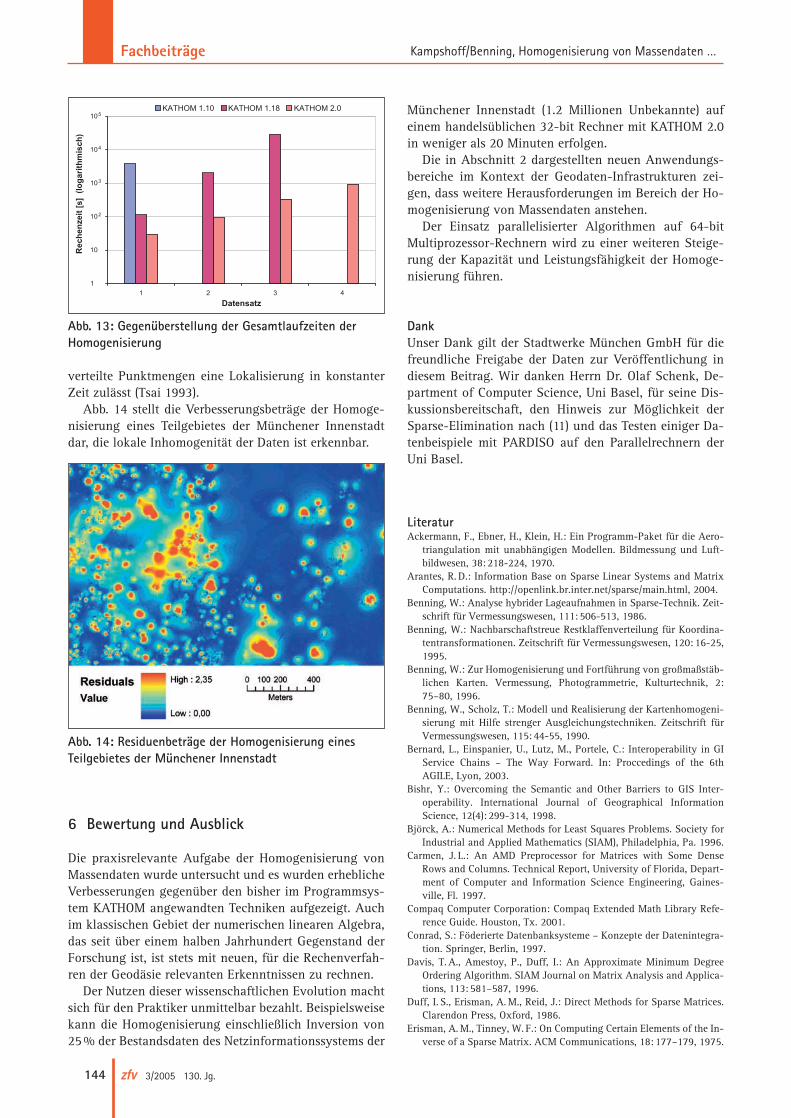
verteilte Punktmengen eine Lokalisierung in konstanterZeit zulässt (Tsai 1993).
Abb. 14 stellt die Verbesserungsbeträge der Homoge-nisierung eines Teilgebietes der Münchener Innenstadtdar, die lokale Inhomogenität der Daten ist erkennbar.
6 Bewertung und Ausblick
Die praxisrelevante Aufgabe der Homogenisierung vonMassendaten wurde untersucht und es wurden erheblicheVerbesserungen gegenüber den bisher im Programmsys-tem KATHOM angewandten Techniken aufgezeigt. Auchim klassischen Gebiet der numerischen linearen Algebra,das seit über einem halben Jahrhundert Gegenstand derForschung ist, ist stets mit neuen, für die Rechenverfah-ren der Geodäsie relevanten Erkenntnissen zu rechnen.
Der Nutzen dieser wissenschaftlichen Evolution machtsich für den Praktiker unmittelbar bezahlt. Beispielsweisekann die Homogenisierung einschließlich Inversion von25 % der Bestandsdaten des Netzinformationssystems der
Münchener Innenstadt (1.2 Millionen Unbekannte) aufeinem handelsüblichen 32-bit Rechner mit KATHOM 2.0in weniger als 20 Minuten erfolgen.
Die in Abschnitt 2 dargestellten neuen Anwendungs-bereiche im Kontext der Geodaten-Infrastrukturen zei-gen, dass weitere Herausforderungen im Bereich der Ho-mogenisierung von Massendaten anstehen.
Der Einsatz parallelisierter Algorithmen auf 64-bitMultiprozessor-Rechnern wird zu einer weiteren Steige-rung der Kapazität und Leistungsfähigkeit der Homoge-nisierung führen.
DankUnser Dank gilt der Stadtwerke München GmbH für diefreundliche Freigabe der Daten zur Veröffentlichung indiesem Beitrag. Wir danken Herrn Dr. Olaf Schenk, De-partment of Computer Science, Uni Basel, für seine Dis-kussionsbereitschaft, den Hinweis zur Möglichkeit derSparse-Elimination nach (11) und das Testen einiger Da-tenbeispiele mit PARDISO auf den Parallelrechnern derUni Basel.
LiteraturAckermann, F., Ebner, H., Klein, H.: Ein Programm-Paket für die Aero-
triangulation mit unabhängigen Modellen. Bildmessung und Luft-bildwesen, 38: 218-224, 1970.
Arantes, R. D.: Information Base on Sparse Linear Systems and MatrixComputations. http://openlink.br.inter.net/sparse/main.html, 2004.
Benning, W.: Analyse hybrider Lageaufnahmen in Sparse-Technik. Zeit-schrift für Vermessungswesen, 111: 506-513, 1986.
Benning, W.: Nachbarschaftstreue Restklaffenverteilung für Koordina-tentransformationen. Zeitschrift für Vermessungswesen, 120: 16-25,1995.
Benning, W.: Zur Homogenisierung und Fortführung von großmaßstäb-lichen Karten. Vermessung, Photogrammetrie, Kulturtechnik, 2:75–80, 1996.
Benning, W., Scholz, T.: Modell und Realisierung der Kartenhomogeni-sierung mit Hilfe strenger Ausgleichungstechniken. Zeitschrift fürVermessungswesen, 115: 44-55, 1990.
Bernard, L., Einspanier, U., Lutz, M., Portele, C.: Interoperability in GIService Chains – The Way Forward. In: Proccedings of the 6thAGILE, Lyon, 2003.
Bishr, Y.: Overcoming the Semantic and Other Barriers to GIS Inter-operability. International Journal of Geographical InformationScience, 12(4): 299-314, 1998.
Björck, A.: Numerical Methods for Least Squares Problems. Society forIndustrial and Applied Mathematics (SIAM), Philadelphia, Pa. 1996.
Carmen, J. L.: An AMD Preprocessor for Matrices with Some DenseRows and Columns. Technical Report, University of Florida, Depart-ment of Computer and Information Science Engineering, Gaines-ville, Fl. 1997.
Compaq Computer Corporation: Compaq Extended Math Library Refe-rence Guide. Houston, Tx. 2001.
Conrad, S.: Föderierte Datenbanksysteme – Konzepte der Datenintegra-tion. Springer, Berlin, 1997.
Davis, T. A., Amestoy, P., Duff, I.: An Approximate Minimum DegreeOrdering Algorithm. SIAM Journal on Matrix Analysis and Applica-tions, 113: 581–587, 1996.
Duff, I. S., Erisman, A. M., Reid, J.: Direct Methods for Sparse Matrices.Clarendon Press, Oxford, 1986.
Erisman, A. M., Tinney, W. F.: On Computing Certain Elements of the In-verse of a Sparse Matrix. ACM Communications, 18: 177–179, 1975.
Fachbeiträge Kampshoff/Benning, Homogenisierung von Massendaten …
zzffvv 3/2005 130. Jg.144
Abb. 14: Residuenbeträge der Homogenisierung einesTeilgebietes der Münchener Innenstadt
Abb. 13: Gegenüberstellung der Gesamtlaufzeiten derHomogenisierung

Friedrich, K.: Beiträge zur direkten und indirekten Auflösung der Nor-malgleichungen. Zeitschrift für Vermessungswesen, 59: 525–539,1930.
George, A., Liu, J.: Computer Solution of Large Sparse Positive DefiniteSystems. Prentice-Hall, Englewood Cliffs, 1981.
Gielsdorf, F., Gründig, L., Aschoff, B.: Geo-Referencing of AnalogueMaps with Special Emphasis on Positional Accuracy ImprovementUpdates. In: FIG Working Week 2003. International Federation ofSurveyors, Paris, France, 2003.
Gielsdorf, F., Gründig, L., Aschoff, B.: Positional Accuracy Improve-ment – A Necessary Tool for Updating and Integration of GIS Data.In: FIG Working Week 2004. International Federation of Surveyors,Athens, Greece, 2004.
Gröger, G.: Modellierung raumbezogener Objekte und Datenintegritätin GIS. Wichmann, Karlsruhe, 2000.
Gröger, G., Kolbe, T. H.: Interoperabilität in einer 3D-Geodateninfra-struktur. In: Bernard, L., Sliwinski, A., Senkler, K. (Hrsg.): IfGI Prints:Beiträge zu den Münsteraner GI-Tagen 2003, Heft Nummer 18. In-stitut für Geoinformatik, Uni Münster, 325–343, 2003.
Gründig, L.: Berechnung vorgespannter Seil- und Hängenetze unter Be-rücksichtigung ihrer topologischen und physikalischen Eigenschaf-ten und der Ausgleichungsrechnung. Reihe C, Heft Nummer 216,DGK, München. 1976.
Gupta, A., Karypis, G., Kumar, V.: Highly Scalable Parallel Algorithmsfor Sparse Matrix Factorization. IEEE Transactions on Parallel andDistributed Systems, 8 (5): 502–520, 1997.
Hake, G., Grünreich, D., Meng, L.: Kartographie. de Gruyter, Berlin,8. Ausgabe, 2002.
Hampp, D.: Digitalisierung, Homogenisierung und numerische Fortfüh-rung – ein schneller Weg zur aktuellen Digitalen Flurkarte. Mittei-lungsblatt DVW Bayern, (3): 239–252. 1. Digitalisierung und Homo-genisierung. 1992.
Helmert, F. R.: Die mathematischen und physikalischen Theorien derhöheren Geodäsie, Band 1, Teubner, Leipzig, 1880.
Hettwer, J.: Numerische Methoden zur Homogenisierung großer Geo-datenbestände. Veröffentlichungen des Geodätischen Instituts derRWTH Aachen, Heft Nummer 60, Geodätisches Institut der RWTHAachen, 2003.
Hettwer, J., Benning. W.: Nachbarschaftstreue Koordinatenberechnungin der Kartenhomogenisierung. Allgemeine Vermessungs-Nachrich-ten, 107: 194–197, 2000.
Hettwer, J., Benning. W.: Erweiterung des Konvergenzbereichs bei nicht-linearen Ausgleichungsaufgaben. Allgemeine Vermessungs-Nach-richten, 108: 254–259, 2001.
Illert, A.: Aspekte der Zusammenführung digitaler Datensätze unter-schiedlicher Quellen. In: Nachrichten aus dem Karten- und Vermes-sungswesen, Heft Nummer 113 der Reihe I. Verlag des Instituts fürAngewandte Geodäsie, Frankfurt am Main, 1995.
Kampshoff, S., Benning, W.: Integrierte Verarbeitung der Daten desLiegenschaftskatasters einschließlich Homogenisierung. zfv – Zeit-schrift für Geodäsie, Geoinformation und Landmanagement, 127:9–18, 2002.
Karypis, G., Kumar, V.: A Fast and High Quality Multilevel Scheme forPartitioning irregular Graphs. SIAM Journal on Scientific Compu-ting, 20: 359–392, 1998a.
Karypis, G., Kumar, V.: Multilevel Algorithms for Multi-Constraint GraphPartitioning. Technical Report MN 98-019, University of Minnesota,Department of Computer Science, Minneapolis, Mn. 1998b.
Kernighan, B. W., Lin, S.: An Efficient Heuristic Procedure for Partitio-ning Graphs. The Bell System Technical Journal, 1970.
Koch, K.-R.: Parameterschätzung und Hypothesentests in linearen Mo-dellen. Dümmler, Bonn, 1997.
Kottman, C.: White Paper on Data Fusion. Technischer Bericht, OpenGIS Consortium. http://www.opengis.org, 2000.
Laurini, R.: Multi-Source Updating and Fusion of Geographic Data-bases. Computers, Environment and Urban Systems, 18 (4): 243–256,1994.
Laurini, R.: Spatial Multi-database Topological Continuity and Indexing:a Step Towards Seamless GIS Data Interoperability. InternationalJournal of Geographical Information Science, 12 (4): 373–402, 1998.
Liesen, L.: ALK- und Netzhomogenisierung mit Homage. Vermessungs-ingenieur, 4: 199-204, 1998.
Liu, J.: Modification of the Minimum Degree Algorithm by Multiple Eli-mination. ACM Transactions on Mathematical Software, 11: 141–153,1985.
Müller, J.: Homogenisierung dreidimensionaler Szenarien nach der Me-thode der kleinsten Quadrate. Veröffentlichungen des GeodätischenInstituts der RWTH Aachen, Heft Nummer 56, Geodätisches Institutder RWTH Aachen, 1999.
Morgenstern, D., Prell, K.-M., Riemer, H.-G.: Digitalisierung, Aufberei-tung und Verbesserung inhomogener Katasterkarten. AllgemeineVermessungs-Nachrichten, 95 (8–9): 314–324, 1988.
OGC: OpenGIS Reference Model. http://www.opengis.org. 2003.Opfer, G.: Numerische Mathematik für Anfänger. Vieweg, Braun-
schweig, 1993.Riedemann, K., Timm, C.: Services for Data Integration (Special Section
on Spatial Data Usability). Data Science Journal, 2: 90–99, 2003.Rose, A.: Geraden- und Rechtwinkelausgleichung bei der Digitali-
sierung von Katasterkarten. Zeitschrift für Vermessungswesen,113: 581–587, 1988.
Schenk, O.: Scalable Parallel Sparse LU Factorisation Methods onShared Memory Multiprocessors. Dissertation, ETH Zürich, 2000.
Schenk, O., van der Vorst, H. A.: Solution of linear Systems. Erscheintin: Handbook of Numerical Analysis, Elsevier Science Publishers,The Netherlands, 2004.
Scheu, M., Effenberg, W., Williamson, I.: Incremental Update and Up-grade of Spatial Data. Zeitschrift für Vermessungswesen, 4: 115–120,2000.
Schwarz, H. R., Rutishauser, H., Stiefel, E.: Numerik symmetrischerMatrizen. Teubner, Stuttgart, 1968.
Snay, R. A.: Reducing the profile of sparse symmetric matrices. NOOATechnical Memorandum NOS NGS 4, National Geodetic Survey,Rockville, Md. 1976.
Stark, W.: Untersuchungen zur Lösung und Inversion schwach besetztergroßer geodätischer Normalgleichungen. Reihe C, Heft Nummer 301,DGK, München, 1984.
Stockwald, M.: Aktualisierung hybrider geographischer Informations-systeme bei Energieversorgungsunternehmen durch amtliche Geo-basisdaten. Reihe C, Heft Nummer 529, Deutsche Geodätische Kom-mission, München, 2000.
Takahashi, K., Fagan, J., Chen, M. S.: Formation of a Sparse Bus Impe-dance Matrix and its Application to Short Circuit Study. In: PowerIndustry Computer Applications Conference, 63–69, 1973.
Tsai, V. J. D.: Delaunay Triangulations in TIN Creation: an Overview anda Linear-Time Algorithm. International Journal of Geographical In-formation Systems, 7: 501–524, 1993.
Walter, V.: Zuordnung von raumbezogenen Daten – am Beispiel der Da-tenmodelle ATKIS und GDF. Reihe C, Heft Nummer 480, DeutscheGeodätische Kommission, München, 1997.
Wan, W. Y., Williamson, I.: Problems in Maintaining Associativity in LISwith Particular Reference to the Needs of the Utility Industry. TheAustrailian Surveyor, 39 (3): 187–193, 1994a.
Wan, W. Y., Williamson, I.: Solutions to Maintaining Associativity inLIS with Particular Reference to the Needs of the Utility Industry.The Austrailian Surveyor, 39 (4): 290–296, 1994b.
Wiens, H.: Flurkartenerneuerung mittels Digitalisierung und numeri-scher Bearbeitung unter besonderer Berücksichtigung des Zusam-menschlusses von Inselkarten zu einem homogenen Rahmenkarten-werk. Schriftenreihe des Instituts für Kartographie und Topographieder Universität Bonn, Heft Nummer 17, Kirschbaum, Bonn, 1984.
Wolf, H.: Ausgleichungsrechnung, Formeln zur praktischen Anwen-dung. Dümmler, Bonn, 1975.
Worboys, M. F., Duckham, M.: GIS: A Computing Perspective. CRCPress, Boca Raton, Fl, 2. Ausgabe, 2004.
Yannakakis, M.: Computing the Minimum Fill-In is NP-Complete. SIAMJournal on Algebraic Discrete Methods, 2: 77–79, 1981.
Anschrift der AutorenDr.-Ing. Stefan Kampshoff / Univ.-Prof. Dr.-Ing. Wilhelm BenningRheinisch-Westfälische Technische Hochschule AachenGeodätisches InstitutTemplergraben 55, 52056 [email protected] / [email protected]
FachbeiträgeKampshoff/Benning, Homogenisierung von Massendaten …
130. Jg. 3/2005 zzffvv 145


















