
Hochschule Wismarcleve/vorl/projects/da/wahnschaff.pdf · Hochschule Wismar Fachbereich Wirtschaft...
123
Hochschule Wismar Fachbereich Wirtschaft Diplomarbeit Web Log Mining - Analyse der Eignung von Data Mining-Verfahren zur Auswertung von internetbasierten Nutzungsdaten und Unterstützung von unternehmerischen Entscheidungen bei der Optimierung von Internetangeboten Diplomarbeit zur Erlangung des Grades eines Diplom-Wirtschaftsinformatiker (FH) der Hochschule Wismar eingereicht von: Norman Wahnschaff geboren am 18. März 1979 in Magdeburg Studiengang Wirtschaftsinformatik, WI 1998 Betreuer Prof. Dr. rer. nat. Jürgen Cleve weitere Gutachter Prof. Dr. oec. Erhard Alde Schwerin, d. 21. Januar 2003
Transcript of Hochschule Wismarcleve/vorl/projects/da/wahnschaff.pdf · Hochschule Wismar Fachbereich Wirtschaft...

Hochschule Wismar
Fachbereich Wirtschaft
Diplomarbeit
Web Log Mining - Analyse der Eignung von Data Mining-Verfahren zurAuswertung von internetbasierten Nutzungsdaten und Unterstützung von
unternehmerischen Entscheidungen bei der Optimierung von Internetangeboten
Diplomarbeit zur Erlangung des Grades eines
Diplom-Wirtschaftsinformatiker (FH)
der Hochschule Wismar
eingereicht von: Norman Wahnschaffgeboren am 18. März 1979 in MagdeburgStudiengang Wirtschaftsinformatik, WI 1998
Betreuer Prof. Dr. rer. nat. Jürgen Cleve
weitere Gutachter Prof. Dr. oec. Erhard Alde
Schwerin, d. 21. Januar 2003

II

Kurzreferat
In dieser Arbeit wird die Anwendbarkeit von Data Mining-Verfahren zur Untersuchung desVerhaltens der Besucher von Webpräsenzen, anhand ihrer internetbasierten Nutzungsda-ten, analysiert und auf ihre unterstützende Wirkung auf betriebswirtschaftliche Entscheidun-gen im Kontext der Optimierung der Webpräsenz geprüft. Die Auswertung dieser Daten wirdunter dem Einsatz von Data Mining-Konzepten vorgenommen. Diese Konzepte werden theo-retisch fundiert und auf ihre Übertragbarkeit auf praktische Problemfälle geprüft. In diesemRahmen werden Softwareprodukte vorgestellt, die die Auswertung der Besuchernutzungs-daten unterstützen. Die Analyseergebnisse sollen die Grundlage für eine Optimierung desInternetangebotes in wirtschaftlicher und ergonomischer Hinsicht bilden.
III

IV

Inhaltsverzeichnis
1. Einleitung 11.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. Inhaltsübersicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. Knowledge Discovery in Databases und Data Mining 52.1. Begriffsdefinitionen und -abgrenzung . . . . . . . . . . . . . . . . . . . . . . . 52.2. KDD-Prozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1. Datenselektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2.2. Datenvorbereitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2.3. Datentransformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.4. Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.5. Evaluation und Interpretation . . . . . . . . . . . . . . . . . . . . . . . 11
3. Web Log Mining 133.1. Begriffsdefinitionen und -abgrenzung . . . . . . . . . . . . . . . . . . . . . . . 133.2. Datenschutz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4. Datenkomponenten 194.1. Server-Logdateien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1.1. Access-Logdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.1.2. Error-Logdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.1.3. Referrer-Logdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.1.4. Agent-Logdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.1.5. Extended Logfile-Format . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2. Cookies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2.1. Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2.2. Anwendungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3. Technische Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.3.1. Caching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.3.2. Proxy-Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.3.3. Dynamische Internetadressen . . . . . . . . . . . . . . . . . . . . . . 30
4.4. Messgrößen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5. Prozess des Web Log Mining 335.1. Datengenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2. Datenselektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.3. Transaktionsidentikation und Datentransformation . . . . . . . . . . . . . . . 37
5.3.1. Transaktionsidentikation . . . . . . . . . . . . . . . . . . . . . . . . . . 37
V

Inhaltsverzeichnis
5.3.2. Datentransformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.4. Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.4.1. Aufgaben des Data Mining . . . . . . . . . . . . . . . . . . . . . . . . 445.4.2. Verfahren des Data Mining . . . . . . . . . . . . . . . . . . . . . . . . 45
5.4.2.1. Clusteranalyse . . . . . . . . . . . . . . . . . . . . . . . . . . 465.4.2.2. Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . . . 485.4.2.3. Entscheidungsbauminduktion . . . . . . . . . . . . . . . . . 515.4.2.4. Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . . . 525.4.2.5. Pfad- und Sequenzanalyse . . . . . . . . . . . . . . . . . . . 545.4.2.6. Deskriptive Statistik . . . . . . . . . . . . . . . . . . . . . . . 56
5.5. Evaluation und Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6. Vorstellen von Data Mining-Programmen im Kontext des Web Log Mining 596.1. Websuxess 4.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 596.2. XAffinity 3.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.3. KnowledgeStudio 3.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
7. Web Log Mining der PLANET internet commerce GmbH-Homepage 657.1. Datengenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 667.2. Datenselektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 677.3. Transaktionsidentifikation und Datentransformation . . . . . . . . . . . . . . . 68
7.3.1. Transaktionsidentifikation . . . . . . . . . . . . . . . . . . . . . . . . . 687.3.2. Datentransformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7.4. Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 767.4.1. Clusteranalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 767.4.2. Entscheidungsbauminduktion . . . . . . . . . . . . . . . . . . . . . . . 777.4.3. Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 827.4.4. Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 837.4.5. Pfadanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 847.4.6. Deskriptive Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
7.5. Evaluation und Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . 877.5.1. Clusteranalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 887.5.2. Entscheidungsbauminduktion . . . . . . . . . . . . . . . . . . . . . . . 887.5.3. Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 937.5.4. Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 947.5.5. Pfadanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 977.5.6. Deskriptive Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
7.6. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
8. Fazit und Ausblick 105
A. Thesen 111
VI

Tabellenverzeichnis
3.1. Vergleich der KDD-Definition mit der Web Log Mining-Definition . . . . . . . . 143.2. Web Log Mining-Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1. Wichtige Statuscodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.2. Überblick der Logdatei-Informationen . . . . . . . . . . . . . . . . . . . . . . . 25
5.1. Logdateieintrag eines Seitenabrufs . . . . . . . . . . . . . . . . . . . . . . . . 345.2. Logdateieintrag eines Seitenabrufs mit eingebetteten Elementen . . . . . . . 355.3. Logdateieinträge mit unterschiedlichen Übertragungsmethoden . . . . . . . . 355.4. Fehlerhafter Ressourcenabruf . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.5. Verfälschende Elemente in Logdateien . . . . . . . . . . . . . . . . . . . . . . 365.6. Aufspaltung zusammengesetzter in einzelne Attribute . . . . . . . . . . . . . 375.7. Transaktionsidentifikation mittels Vergleich von Internetadresse und Agentfeld 385.8. Transaktionen mittels Vergleich von Internetadresse und Agentfeld . . . . . . 385.9. Exemplarische Logdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405.10.Transaktionsidentifikation mit einem Zeitfenster . . . . . . . . . . . . . . . . . 415.11.Datenmatrix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.12.Kodierung des Transaktionsfeldes . . . . . . . . . . . . . . . . . . . . . . . . 425.13.Ermittlung der Referenzdauer . . . . . . . . . . . . . . . . . . . . . . . . . . . 435.14.Diskretisierung der Verweildauer . . . . . . . . . . . . . . . . . . . . . . . . . 43
7.1. Bereiche der PLANET GmbH-Homepage . . . . . . . . . . . . . . . . . . . . 667.2. Umfang der PLANET GmbH-Logdateien . . . . . . . . . . . . . . . . . . . . . 677.3. Doppelte Logdateieinträge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 687.4. Unangereicherte Transaktionsdaten . . . . . . . . . . . . . . . . . . . . . . . 707.5. Angereicherte Transaktionsdaten . . . . . . . . . . . . . . . . . . . . . . . . . 747.6. Zusätzliche Attribute mit Hilfe von Identifizierungsmechanismen . . . . . . . . 757.7. Datenbasis für die Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . 767.8. Ergebnisse der Clusteranalyse . . . . . . . . . . . . . . . . . . . . . . . . . . 777.9. Verteilung der Ausprägungen des Attributs „Besucherverhalten“ . . . . . . . . 787.10.Ausprägungsverteilung in Trainings- und Validierungsmenge (Verhältnis 50/50) 807.11.Vorhersageergebnisse der Entscheidungsbauminduktion (Verhältnis 50/50) . 817.12.Ausprägungsverteilung in Trainings- und Validierungsmenge (Verhältnis 70/30) 817.13.Vorhersageergebnisse der Entscheidungsbauminduktion (Verhältnis 70/30) . 827.14.Vorhersageergebnisse der Neuronalen Netze . . . . . . . . . . . . . . . . . . 837.15.Häufigste Assoziationsregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . 847.16.Häufigste Pfade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 857.17.Traffic nach Wochentagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
VII

Tabellenverzeichnis
7.18.Die beliebtesten Ressourcen . . . . . . . . . . . . . . . . . . . . . . . . . . . 877.19.Vorhergesagte und tatsächliche Gruppenverteilung mit der Entscheidungs-
baumvorhersage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 937.20.Vorhergesagte und tatsächliche Gruppenverteilung mit Neuronalen Netzen . 947.21.Interessante Assoziationsregeln . . . . . . . . . . . . . . . . . . . . . . . . . 947.22.Dokumente, die die Besucher zum Anklicken des Kontaktformulars animiert
haben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
VIII

Abbildungsverzeichnis
2.1. KDD-Prozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1. Taxonomie des Web Log Mining . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1. Konzept der serverseitigen Protokollaufzeichnung . . . . . . . . . . . . . . . 204.2. Ausschnitt einer typischen Logdatei im CLF-Format . . . . . . . . . . . . . . 204.3. Ausschnitt einer typischen Logdatei im ELF-Format . . . . . . . . . . . . . . 244.4. Ausschnitt einer Logdatei im ELF-Format mit Kennungsfeld . . . . . . . . . . 284.5. Caching-Mechanismus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.6. Funktionsweise eines Proxy-Servers . . . . . . . . . . . . . . . . . . . . . . . 294.7. Hierarchie der Messgrößen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.1. Web Log Mining-Prozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2. Data Mining-Ziele und Data Mining-Aufgaben . . . . . . . . . . . . . . . . . . 445.3. Data Mining-Aufgaben und Data Mining-Verfahren . . . . . . . . . . . . . . . 465.4. Clusteranalyse von Besuchern . . . . . . . . . . . . . . . . . . . . . . . . . . 475.5. Schema eines Neurons . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485.6. Darstellung eines Neuronalen Netzes . . . . . . . . . . . . . . . . . . . . . . 495.7. Neuronales Netz für die Vorhersage des Besucherverhaltens . . . . . . . . . 505.8. Ergebnisnetz für die Vorhersage des Besucherverhaltens . . . . . . . . . . . 505.9. Exemplarischer Entscheidungsbaum . . . . . . . . . . . . . . . . . . . . . . . 525.10.Navigationspfad einer Transaktion . . . . . . . . . . . . . . . . . . . . . . . . 555.11.Beispielchart von täglichen Page Views . . . . . . . . . . . . . . . . . . . . . 57
6.1. Oberfläche von Websuxess 4.0 . . . . . . . . . . . . . . . . . . . . . . . . . . 606.2. Oberfläche von XAffinity 3.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.3. Segmentansicht einer Datenmenge mit KnowledgeStudio 3.0 . . . . . . . . . 636.4. Entscheidungsbaum des KnowledgeStudios . . . . . . . . . . . . . . . . . . . 64
7.1. Homepage der PLANET internet commerce GmbH . . . . . . . . . . . . . . . 657.2. Traffic nach Stunden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 867.3. Beziehungen zwischen HTML-Dokumenten . . . . . . . . . . . . . . . . . . . 957.4. Beziehungen zwischen HTML-Dokumenten . . . . . . . . . . . . . . . . . . . 957.5. Beziehungen zwischen HTML-Dokumenten . . . . . . . . . . . . . . . . . . . 967.6. Häufigste Klickpfade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 987.7. Aufrufmöglichkeit des Kontaktformulars aus einem Produktbereich . . . . . . 99
IX

Abbildungsverzeichnis
X

Abkürzungsverzeichnis
Abb. AbbildungAbs. AbsatzAG AktiengesellschaftAOL America OnlineArt. ArtikelASCII American Standard Code for Information InterchangeBd. BandBDSG BundesdatenschutzgesetzBit Binary Digitbzw. beziehungsweiseca. circaCD Compact DiscCERN Conseil Europeén pour la Recherche NucléaireCGI Common Gateway InterfaceCHAID Chi-Squared Automatic Interaction DetectionCART Classification and Regression TreesCLF Common LogfileCMS Content-Management-SystemCSS Cascading StylesheetsCSV Comma Separated Valuesd.h. das heißtDIN Deutsches Institut für NormungDNS Domain Name SystemDSL Digital Subscriber Linee.V. eingetragener VereinE-Commerce Electronic CommerceELF Extended LogfileE-Mail Electronic MailGIF Graphic Interchange FormatGmbH Gesellschaft mit beschränkter HaftungGMT Greenwich Meridian TimeHrsg. HerausgeberHTML Hypertext Markup LanguageHTTP Hypertext Transfer ProtocolHTTPS Hypertext Transfer Protocol Securei.a. im allgemeinenICANN The Internet Corporation for Assigned Names and Numbers
XI

Abbildungsverzeichnis
i.d.R. in der RegelID IdentiferID3 Interactive Dichotomiser 3IIS Internet Information ServerIP Internet ProtocollISP Internet Service ProviderIuK Information und KommunikationIuKDG Informations- und KommunikationsdienstegesetzIVW Informationsgemeinschaft zur Feststellung der Verbreitung von
Werbeträgern e.V.Jg. JahrgangJPG Joint Photographic Expert GroupKB KilobyteKDD Knowledge Discovery in DatabasesKI Künstliche IntelligenzLAN Local Area NetworkMB MegabyteMin. MinutenNCSA National Center for Supercomputing ApplicationsNr. Nummero.V. ohne VerfasserODBC Open Database ConncetivityPDF Portable Document FormatPNG Portable Network GraphicROI Return on InvestmentRFC Request for CommentS. SeiteSQL Structured Query LanguageSSL Secure Sockets LayerTab. TabelleTDDSG TeledienstdatenschutzgesetzTDG Teledienstgesetzu.a. unter anderemu.U. unter Umständenu. undüberarb. überarbeiteteURL Uniform Resource LocatorVD Verweildauervgl. vergleicheW3C World Wide Web ConsortiumWI WirtschaftsinformatikWin WindowsWWW World Wide Webz.B. zum Beispielz.T. zum Teil
XII

1. Einleitung
1.1. Motivation
Das Internet hat sich in den letzten Jahren zu einem bedeutenden Medium für die Abwick-
lung geschäftlicher Prozesse entwickelt. Da die Webpräsenz eines Unternehmens immer
häufiger den ersten Kontakt zwischen einem potentiellen Kunden und dem Unternehmen
herstellt, hat sie stark an Bedeutung gewonnen. Gerade in einem so stark umkämpften
Markt wie dem Internet, ist es von immenser Bedeutung sich Wettbewerbsvorteile gegen-
über der Konkurrenz zu verschaffen, denn der Kunde ist nur einen Mausklick von dem näch-
sten Angebot entfernt. Unternehmungen, die über eigeneWebpräsenzen verfügen, sammeln
automatisch Nutzungsdaten in sogenannten Logdateien über die virtuellen Besuche ihrer
(potentiellen) Kunden. Die hierbei anfallenden Daten werden aber häufig nur unzureichend
verwertet. Da sich die Nutzungsdaten aus wirtschaftlichem Hintergrund auf das Verhalten
von Marktpartnern beziehen, sind sie zur Unterstützung wirtschaftlicher Entscheidungen von
großer Bedeutung. Das Management muss wissen, wer die Website besucht und, was noch
wichtiger ist, wer etwas kauft bzw. warum nichts gekauft wird. Websites werden heute als
Investition gesehen und müssen ihre Notwendigkeit, wie jede andere Marketinginvestition,
begründen. Je mehr man darüber weiß, wie viele Kunden die Website besuchen, wer sie
sind und für welche Bereiche sie sich interessieren, desto mehr wird die Website davon pro-
fitieren. Werden diese Informationen zur Optimierung der Website genutzt und mit anderen
gängigen Marketingaktivitäten verbunden, kann der gesamte Internetauftritt stark verbessert
werden. Einen Ansatzpunkt, um diese Nutzungsdaten effektiv verwenden zu können, liefern
dabei die Konzepte des Knowledge Discovery in Databases und Data Mining. Vor dem in-
ternetbasierten Hintergrund der Datenanalyse wird dieser Sachverhalt als Web Log Mining
bezeichnet.
Diese Arbeit beschäftigt sich mit der Untersuchung von Data Mining-Verfahren zur Auswer-
tung von internetbasierten Nutzungsdaten (Logdateien) und deren Nutzen zur Unterstützung
unternehmerischer Entscheidungen im Kontext der Optimierung von Internetangeboten. In
diesem Rahmen werden zunächst die konzeptionellen Grundlagen für die Datenanalyse un-
tersucht. Darauf aufbauend wird geprüft, ob diese Konzepte wirksam auf das Gebiet des
1

Kapitel 1. Einleitung
Web Log Mining anwendbar sind. In diesem Zusammenhang werden Softwareprodukte vor-
gestellt, die bei der Lösung der Analyseprobleme Anwendung finden. Abschließend wird die
Übertragbarkeit dieser Konzepte auf praktische Problemstellungen und deren Nutzen zur
Unterstützung unternehmerischer Entscheidungen bezüglich der Verbesserung des Interne-
tangebotes analysiert. Die Untersuchungsergebnisse sollen die Grundlage für eine Optimie-
rung von Internetangeboten in wirtschaftlicher und ergonomischer Hinsicht bilden.
1.2. Inhaltsübersicht
Zunächst werden die konzeptionellen Grundlagen für die Datenanalyse untersucht. In die-
sem Rahmen wird im zweiten Kapitel, Knowledge Discovery in Databases und Data Mining,
ein inhaltlicher Bezugsrahmen, mit der Definition von Knowledge Discovery in Databases
und Data Mining, für das Web Log Mining geschaffen.
Auf dieser Basis erfolgt im dritten Kapitel, Web Log Mining, die Definition und prozessorien-
tierte Darstellung des Web Log Mining. Dabei werden auch die rechtlichen Rahmenbedin-
gungen betrachtet.
Im vierten Kapitel, Datenkomponenten, wird auf die Datenkomponenten, die die Datenbasis
des Web Log Mining bilden, eingegangen. In diesem Zusammenhang werden technische
Probleme aufgezeigt und die Messgrößen vorgestellt.
Im Rahmen des fünften Kapitels, Prozess des Web Log Mining, erfolgt die detaillierte Defini-
tion und prozessorientierte Darstellung der einzelnen Phasen des Web Log Mining. Hierbei
werden Data Mining-Verfahren dargestellt, die im weiteren Verlauf der Arbeit Anwendung
finden.
Im sechsten Kapitel, Vorstellen von Data Mining-Programmen im Kontext des Web Log Mi-
ning, werden Data Mining-Produkte vorgestellt, die im Rahmen dieser Arbeit eingesetzt wer-
den.
Der praxisorientierte Teil der Arbeit folgt in Kapitel sieben, Web Log Mining der PLANET
internet commerce GmbH-Homepage. Dabei wird das in Kapitel drei und fünf theoretisch
fundierte Web Log Mining-Konzept auf seine praktische Anwendbarkeit geprüft. In diesem
Zusammenhang wird die in Kapitel sechs vorgestellte Data Mining-Software, mit den in-
ternetbasierten Nutzungsdaten der Internetpräsenz der Planet internet commerce GmbH,
eingesetzt. Am Ende des siebten Kapitels erfolgt eine Zusammenfassung der Analyseer-
gebnisse und eine Beurteilung der praktischen Bedeutung dieser Resultate.
Das achte Kapitel, Fazit und Ausblick, gibt eine abschließende Zusammenfassung der Unter-
suchungsergebnisse der Arbeit. Es erfolgt eine Bewertung des Web Log Mining-Konzeptes
und deren Nutzen zur Unterstützung unternehmerischer Entscheidungen bezüglich der Ver-
2

1.2. Inhaltsübersicht
besserung des Internetangebotes. Dabei werden auch Möglichkeiten aufgezeigt, wie die
Analyseergebnisse des Web Log Mining bei zukünftigen Projekten Anwendung finden kön-
nen.
Anhang A, Thesen, rundet die Arbeit, mit abschließenden Feststellungen bezüglich zur Ana-
lyse der Eignung von Data Mining-Verfahren zur Auswertung von internetbasierten Nut-
zungsdaten und Unterstützung von unternehmerischen Entscheidungen bei der Optimierung
von Internetangeboten, ab.
3

Kapitel 1. Einleitung
4

2. Knowledge Discovery in Databases undData Mining
2.1. Begriffsdefinitionen und -abgrenzung
Die Anzahl und Größe der weltweit routinemäßig anfallenden Datensammlungen und Daten-
banken nimmt ständig zu. Es wird geschätzt, dass sich die weltweit vorhandene Datenmenge
alle 20 Monate verdoppelt - bei Datenbanken ist die Rate wahrscheinlich noch höher1. Vie-
le dieser Datenbanken speichern riesige Datenmengen mit Tausenden oder Millionen von
Datensätzen. Die Daten werden ursprünglich meist für andere Zwecke als die Verwendung
in Data Mining-Systemen erfasst und routinemäßig archiviert. Sie resultieren aus verschie-
denen Erfassungsprozessen, und oft ist der Grund für ihre Speicherung, die ausreichend
zur Verfügung stehende, preisgünstige Speicherkapazität. Ausgangspunkt für die Entwick-
lung der Konzepte des Data Mining und des Knowledge Discovery in Databases (KDD) ist
diese Informationsflut. Wie oft bei jungen Forschungsrichtungen, ist das Begriffsverständnis
zu Beginn recht uneinheitlich. Während sich in der englischsprachigen Literatur bspw. eine
deutliche Abgrenzung der Begriffe Knowledge Discovery in Databases und Data Mining fin-
det, werden beide aufgrund einer inhaltlichen Deckungsgleichheit im Deutschen oft synonym
gebraucht2. Im Folgenden soll versucht werden beide Begriffe voneinander zu differenzie-
ren und zu definieren. Der Begriff Data Mining wurde vorwiegend von Statistikern, Daten-
analysten und der Management-Informationssystem-Gemeinde, KDD von den Vertretern für
Künstliche Intelligenz und dem Maschinellen Lernen verwendet3. Fayyad schlug 1996 eine
heute weithin anerkannte Definition vor, in der die beiden Begriffe getrennt wurden4:
„Knowledge Discovery in databases is the non-trivial process of identifying valid,
novel, potentially useful, and ultimately understandable patterns in data.“
1 [MENA00] S. 63 ff.2 [WIED01] S. 193 Vgl. [KÜPP99] S. 234 [FAYY96] S. 6 und S. 9
5

Kapitel 2. Knowledge Discovery in Databases und Data Mining
„Data Mining is a step in the KDD-Process consisting of particular data mining
algorithms that, under some acceptable computational efficiency limitations, pro-
duce a particular enumeration of patterns.“
Knowledge Discovery in Databases ist eine interdisziplinäre Forschungsrichtung, zu deren
Entstehung und Entwicklung insbesondere die Forschungsgebiete Maschinelles Lernen, Da-
tenbanksysteme und Statistische Datenanalyse beigetragen haben5. Dieser in der Literatur
auch als „Knowledge Extraction“ oder „Data Analysis“ bezeichnete Prozess ist darauf aus-
gerichtet, in umfangreichen Datenbeständen implizit vorhandenes Wissen zu entdecken und
explizit zu machen. Der Prozessbegriff beinhaltet mehrere iterative Schritte wie Datenvorver-
arbeitung, Mustererkennung und Evaluation, die notwendig sind, um verwertbare Ergebnisse
zu erhalten, was im nächsten Abschnitt noch einmal verdeutlicht wird. KDD bezeichnet also
den gesamten Prozess der Wissensentdeckung in großen Datenbeständen, während Da-
ta Mining die Anwendung verschiedener Algorithmen zur Musterextraktion zum Inhalt hat.
Die gefundenen Muster müssen für einen möglichst großen Teil der Daten Geltung haben
und bislang unbekannte, potentiell nützliche und leicht verständliche Zusammenhänge in
den Daten zum Ausdruck bringen. Aus den ermittelten Beziehungsmustern wird schließlich
durch Interpretation und Evaluation explizites Wissen abgeleitet6.
2.2. KDD-Prozess
Im Vorfeld des KDD-Prozesses wird relevantes und bereits vorhandenes Wissen über den
gewünschten Anwendungsbereich gesammelt sowie die Zielsetzung der Anwendung fest-
gelegt. Die Analyse von Rahmenbedingungen bildet einen weiteren Bestandteil der Vorbe-
reitung. Diese lassen sich mit Hilfe eines Lösungsszenarios herauskristallisieren. Dabei wird
festgestellt, welche Optionen der KDD-Prozess beinhalten kann und welche aus finanziellen,
organisatorischen oder politischen Gründen nicht in Frage kommen7. Die Abbildung 2.1 zeigt
die Schritte, die bei dem KDD-Prozess iterativ durchlaufen werden. Im Folgenden werden die
einzelnen Phasen des KDD-Prozesses erläutert.
2.2.1. Datenselektion
In der ersten Phase des KDD- Prozesses sind die Daten, die für die vom Anwender angefor-
derte Analyse benötigt werden oder geeignet erscheinen, zu bestimmen und aus den gege-
benen Datenquellen zu extrahieren. Neben dem Basisdatenbestand können auch externe
5 [DÜSI98] S. 291 f., [BENS01a] S. 61 f.6 [KIMM00] S. 127 [DAST00] S. 1
6

2.2. KDD-Prozess
Abbildung 2.1.: KDD-Prozess, Vgl. [FAYY96] S. 10
Daten für die Analyse herangezogen werden. So bieten bspw. Adressbroker8 Informationen
an, mit denen Kunden oder Interessenten zusätzlich qualifiziert werden können. In der Pha-
se der Datenselektion wird geprüft, welche Daten notwendig und verfügbar sind, um das
gesetzte Ziel zu erreichen. Können die selektierten Daten aufgrund technischer oder recht-
licher Restriktionen nicht in einen Zieldatenbestand überführt werden, ist die Datenselektion
erneut vorzunehmen9. Technische Restriktionen, die die Überführung in einen Zieldatenbe-
stand verhindern, sind z.B. Kapazitäts- und Datentypbeschränkungen des Zielsystems oder
fehlende Zugriffsrechte des Anwenders. Eine Möglichkeit diese Probleme zu umgehen, ist
die Beschränkung der Auswahl auf eine repräsentative Teildatenmenge des Gesamtdaten-
bestands. Jedoch können in diesem Zusammenhang verfälschte Analyseergenisse hervor-
gerufen werden. Bei der Verarbeitung personenbezogener Daten sind in Deutschland die
rechtlichen Bestimmungen10 des Bundesdatenschutzgesetzes zu beachten.
2.2.2. Datenvorbereitung
Da die Zieldaten aus den Datenquellen lediglich extrahiert wurden, ist im Rahmen der Daten-
vorbereitung die Datenqualität des Zieldatenbestands festzustellen und, sofern notwendig,
8 Einen umfangreichen Überblick bietet [MENA00] S. 314 ff.9 [BENS01a] S. 7410 Vgl. Abschnitt 3.2
7

Kapitel 2. Knowledge Discovery in Databases und Data Mining
durch den Einsatz geeigneter Verfahren zu steigern11. Aufgrund technischer oder mensch-
licher Fehler können die Daten operativer Systeme fehlerhafte Elemente enthalten. In der
Praxis wird damit gerechnet, das ein bis fünf Prozent der Felder des Datenbestands falsche
Angaben aufweisen12. Die Kenntnis der Schwächen der Analysedaten ist elementar für die
Qualität der Untersuchungsergebnisse. Die Anwender der Analysewerkzeuge müssen auf
die Zuverlässigkeit und Korrektheit der Daten vertrauen können. Fehlerhafte Daten verfäl-
schen möglicherweise die Resultate, ohne dass der Anwender von diesen Mängeln Kenntnis
erlangt, und fehlende Informationen verhindern eventuell die Berechnung wichtiger Kennzah-
len. Die zunehmende Durchführung (teil-) automatisierter Datenanalysen hat eine erhöhte
Anfälligkeit gegenüber Datenmängeln zur Folge, der durch geeignete Mechanismen zur Er-
kennung und Beseitigung solcher Schwächen zu begegnen ist13. Eine häufige, leicht zu
identifizierende Fehlerart besteht in fehlenden Werten. Zur Behandlung von fehlenden Wer-
ten stehen unterschiedliche Techniken zur Verfügung. Gängige Ersetzungsstrategien für nu-
merische Attributausprägungen sind das Einsetzen eines Nullwertes, eines Mittel-, Maximal-
oder Minimalwertes oder des Medians von Attributwerten innerhalb der Grundgesamtheit,
einer repräsentativen Teilmenge oder einer Klasse. Bei nichtnumerischen Attributausprä-
gungen kann es dagegen sinnvoll sein, die häufigste Attributausprägung einzusetzen14. Ei-
ne weitere Möglichkeit Attribute zu ersetzen, ist die nachträgliche manuelle Erhebung der
fehlenden Daten, das kann aber zu einem unverhältnismäßig hohen Aufwand führen. Eine
weitere potentielle Fehlerart wird durch Ausreißer15 hervorgerufen. Dabei handelt es sich
um Wertausprägungen, die deutlich vom Niveau der übrigen Werte abweichen. Bei diesen
Ausprägungen kann es sich um korrekt erfasste Daten handeln, die damit Eingang in die
Analyse finden oder aber um falsche Angaben, die nicht berücksichtigt werden dürfen und
daher aus dem Datenbestand zu löschen sind. Die Erkenntnisse, die der Nutzer eines Data-
Mining-Systems in dieser Phase über den Datenbestand gewinnt, können Hinweise auf die
Verbesserung der Datenqualität der operativen Systeme geben16. Mithilfe von geeigneten
Dienstprogrammen17 ist es möglich, ein grundlegendes Verständnis dieser Daten zu erlan-
gen und eventuell schon neues Wissen zu ermitteln.
11 [BENS01a] S. 7412 [GROB99]S. 813 [KNOB00] S. 90 f.14 [BENS01a] S. 7515 Umfassendere Informationen bietet [RUNK00] S. 17 ff.16 [GROB99] S. 817 [MENA00] S. 188 f. stellt in diesem Zusammenhang die leistungsstarken Editoren UltraEdit-32 und DataJunction vor.
8

2.2. KDD-Prozess
2.2.3. Datentransformation
Die im Unternehmen verfügbaren Rohdatenbestände erweisen sich häufig in ihrer Ursprungs-
form nicht für Data-Mining-Analysen geeignet oder als fehlerhaft. In der Phase der Daten-
transformation wird der analyserelevante Zieldatenbestand in ein Datenbankschema trans-
formiert, das von dem verwendeten Data-Mining-System verarbeitet werden kann. Dabei
werden neue Attribute oder Datensätze generiert bzw. vorhandene Attribute transformiert.
Dieser Schritt ist notwendig, da Analyseverfahren spezifische Anforderungen an die Daten-
struktur der Eingangsdaten stellen. Ziel der Transformation ist insbesondere die Gewährlei-
stung invarianter Datendarstellungsformen (z.B. durch Übersetzung textueller Informationen
in eindeutige Schlüssel oder Kodierungen) sowie die Einschränkung von Wertebereichen
zur Verringerung der Anzahl zu betrachtender Ausprägungen (Dimensionsreduktion). Letz-
teres kann durch Verallgemeinerung von Attributwerten auf eine höhere Aggregationsstufe,
z.B. durch Nutzung von Taxonomien oder durch Bildung von Wertintervallen geschehen,
wodurch sich die Granularität der Daten ändert18.
Die Transformation der Attribute wird unter Verwendung von Kodierungsverfahren durchge-
führt. Dabei können neue Attribute durch Anwendung logischer oder mathematischer Ope-
ratoren auf eines oder mehrere Attribute des Zieldatenbestandes erzeugt werden. Gängi-
ge Kodierungsverfahren sind z.B. Normalisierung, Binärkodierung oder Diskretisierung, die
nachfolgend kurz erläutert werden sollen:
• Die Binärkodierung erzeugt aus Attributen mit einer bestimmten Anzahl Merkmals-ausprägungen eine Menge binärer Attribute. Jeder Merkmalsausprägung wird ein bi-
näres Merkmal zugeordnet, das den Wert 1 annimmt, wenn die Ausprägung in einem
einzelnen Datensatz vorkommt und sonst den Wert 0 besitzt19. Dieses Verfahren kann
z.B. das Attribut Kaufverhalten mit den Ausprägungen Käufer und Nichtkäufer so ko-
diert, das alle Käufer den Wert 1 annehmen und alle Nichtkäufer den Wert 0. Auf diese
Weise kann ein qualitatives Attribut in mehrere binärkodierte Attribute überführt wer-
den. Das Binärkodierungsverfahren bereitet qualitative Attribute für Algorithmen vor,
die quantitative Eingabefolgen erfordern. Bei der Anwendung der Binärkodierung ist
zu beachten, dass die Performanz der Mustererkennung durch die steigende Attribu-
tanzahl beeinträchtigt werden kann20.
• Die Normalisierung ist ein Kodierungsverfahren, bei der sämtliche Merkmalsausprä-gungen eines Attributs auf die Werte einer stetigen, numerischen Skala (z.B. [0;1])
transformiert werden. Dabei werden alle Werte durch den ermittelten Maximalwert di-
vidiert oder mit dem Minimalwert subtrahiert und mit dem Bereich zwischen Maximal-18 Vgl. [KNOB00] S. 91 ff.19 Vgl. [GRIM98] S. 11420 Vgl. [BENS01a] S. 78
9

Kapitel 2. Knowledge Discovery in Databases und Data Mining
und Minimalwert dividiert. Eine andere Normalisierungstechnik bestünde darin, den
statistischen Mittelwert und die Standardabweichung der Attributwerte zu berechnen,
den Mittelwert von jedem Wert zu subtrahieren und das Ergebnis durch die Standard-
abweichung zu dividieren. Das Verfahren der Normalisierung kann dann angewendet
werden, wenn Minimum und Maximum eines Attributes gegeben sind21. Die Normali-
sierung kann z.B. zur Kodierung des Alters eingesetzt werden. Der Minimalwert hierbei
sind 0 Jahre und der Maximalwert bspw. 100 Jahre. Ein Alter von 40 Jahren würden
dann, auf einer Skala von 0 bis 1, mit 0,4 kodiert werden.
• Das Kodierungsverfahren Diskretisierung wird angewendet, um den Wertebereich
von quantitativen Attributausprägungen in endlich viele Teilmengen zusammenzufas-
sen. Die Diskretisierung kann z.B. bei der Verallgemeinerung des Alters sinnvoll sein,
da auf diese Weise die Altersinformationen zu Altersgruppen zusammengefasst wer-
den können und so eine Reduzierung der Attributausprägungen erreicht wird22.
Die bisher dargestellten Aktivitäten der Datenselektion, Datenvorbereitung und Datentrans-
formation verbrauchen einen erheblichen Teil der Gesamtressourcen des KDD-Prozesses.
In der Praxis kann nach Expertenschätzungen die Datenvorbereitung ca. 80 Prozent der Zeit
und Kosten des gesamten KDD-Prozesses beanspruchen23.
2.2.4. Data Mining
Liegen geeignete Datenbestände in befriedigender Qualität vor, können die Analysen durch-
geführt werden. In dieser Phase erfolgt die Verfahrensauswahl und deren Einsatz zur Identifi-
kation von Mustern auf der Basis des vorbereiteten Datenbestandes. In einem ersten Schritt
wird zunächst entschieden, welche grundlegende Data Mining-Operation24 (z.B. Klassifizie-
rung oder Segmentierung ) eingesetzt werden soll. Daran schließt sich die Auswahl eines
geeigneten Data Mining-Verfahrens25 (z.B. Clusteranalyse oder Neuronale Netze) an. Nach
der Auswahl eines für die konkrete Problemstellung geeigneten Verfahrens muss diese konfi-
guriert werden. Diese Parametrisierung bezieht sich auf die Vorgabe bestimmter methoden-
spezifischer Werte, wie z.B. die Festlegung minimaler relativer Häufigkeiten zur Realisierung
eines Interessantheitsfilters, die Auswahl der bei der Musterbildung oder -beschreibung zu
berücksichtigenden Attribute oder die Einstellung von Gewichtungsfaktoren für einzelne Ein-
gabevariablen26. Wenn eine zufriedenstellende Konfiguration gefunden wurde, kann mit der
Suche nach interessanten Mustern in den Daten begonnen werden.21 [WITT01] S. 56, [PYLE99] S. 251 ff.22 [SCHM00a] S. 19 f., [BÖHM00] S. 1 ff.23 [ALPR00a] S. 38 f.24 Vgl. Abschnitt 5.4.125 Vgl. Abschnitt 5.4.226 [KNOB00] S. 97 ff.
10

2.2. KDD-Prozess
2.2.5. Evaluation und Interpretation
In dieser Phase des KDD-Prozesses werden die entdeckten Muster und Beziehungen be-
wertet und interpretiert. Diese Muster sollen den Anforderungen der Gültigkeit, Neuartigkeit,
Nützlichkeit und Verständlichkeit genügen, um neues Wissen zu repräsentieren und einer
Interpretation zugänglich zu sein. Letztere ist Voraussetzung für die Umsetzung der gewon-
nenen Erkenntnisse im Rahmen konkreter Handlungsmaßnahmen. Bei Weitem nicht alle der
aufgedeckten Muster erfüllen jedoch diese Kriterien. Die Analyseverfahren fördern vielmehr
eine Vielzahl von Regelmäßigkeiten zutage, die irrelevant, trivial, bedeutungslos, bereits be-
kannt waren, aus denen dem Unternehmen kein ökonomischer Nutzen erwachsen kann oder
die unverständlich und nicht nachvollziehbar sind. Die Bewertung von Mustern kann anhand
des Kriteriums der Interessantheit vollzogen werden. Im Folgenden werden Dimensionen
der Interessantheit dargestellt27:
• Die Validität eines Musters ist ein objektives Maß dafür, mit welcher Sicherheit einMuster auch in Bezug auf neue Daten gültig ist.
• Das Kriterium der Neuartigkeit erfasst, inwieweit ein Muster das bisherige Wissen
ergänzt oder im Widerspruch zu diesem steht.
• Die Verständlichkeit misst, wie gut eine Aussage von einem Anwender verstanden
werden kann.
• Das Kriterium der Nützlichkeit eines Musters erfasst die praktische Anwendbarkeit für
den Anwender.
Die korrekte Interpretation von Data-Mining-Ergebnissen erfordert ein hohes Maß an Domä-
nenkenntnissen. Die Interpretation soll dazu dienen, das Domänenwissen des Anwenders
effektiv zu verändern. Im Idealfall sollte ein Team von Experten aus unterschiedlichen Berei-
chen gebildet werden, um sicherzustellen, dass die Bewertung korrekt ist und die gewonne-
nen Informationen der bestmöglichen Nutzung zugeführt werden. Die Interpretationsphase
lässt sich durch geeignete Präsentationswerkzeuge sowie durch die Verfügbarkeit zusätz-
licher Informationen über die Anwendungsdomäne unterstützen. Typischerweise erfolgt in
dieser Phase ein Rücksprung in eine der vorherigen Phasen. So ist meist eine Anpassung
der Parameter notwendig oder die Auswahl einer anderen Data Mining-Technik erforderlich.
Es kann auch nötig sein, zu der Datenselektionsphase zurückzukehren, wenn festgestellt
wird, dass sich die gewünschten Ergebnisse nicht mit der genutzten Datenbasis erreichen
lassen28.
27 Vgl. [KÜPP99] S. 88 ff., [KNOB00] S. 99 ff., [BENS01a] S. 88 f.28 Vgl. [KNOB00] S. 99
11

Kapitel 2. Knowledge Discovery in Databases und Data Mining
12

3. Web Log Mining
3.1. Begriffsdefinitionen und -abgrenzung
Ansätze des Data Mining, die das Internet als Datenquelle für die Mustererkennung her-
anziehen, werden unter dem Themengebiet des Web Mining zusammengefasst. In Abhän-
gigkeit von der inhalts- oder nutzungsorientierten Analyse des World Wide Web (WWW)
lassen sich die Teilgebiete des Web Content Mining und des Web Usage Mining vonein-
ander abgrenzen1. Web Content Mining befasst sich mit der Analyse von den im WWW
befindlichen Daten. Dazu gehören textuelle und multimediale Informationen jeglichen For-
mats und auch die Verbindungen (Links) zu den Nachbarseiten. Diese Richtung des Web
Mining trägt nicht dazu bei, Informationen über Online-Kunden zu gewinnen und soll daher
hier nicht näher betrachtet werden. Web Usage Mining dagegen beschäftigt sich mit dem
Verhalten von Internet-Nutzern. Bei dieser Ausprägungsform des Web Mining werden Da-
ta Mining-Methoden auf die Protokolldateien2 des Webservers angewandt, um Aufschlüsse
über Verhaltensmuster und Interessen der Online-Kunden zu erhalten3. Eine Ausprägungs-
form des Web Usage Mining, bei der sich die Analyse ausschließlich auf die Protokolldateien
des Web-Servers beschränkt, wird als Web Log Mining bezeichnet. Sofern neben den Pro-
tokolldateien noch weitere Datenbestände in den Mustererkennungsprozess einfließen, wird
diese Ausprägung als Integrated Web Usage Mining bezeichnet. Die Taxonomie des Web
Log Mining wird in der Abbildung 3.1 dargestellt.
1 Vgl. [BENS99a] S. 426, [COOL97] S. 1 f.2 Vgl. Abschnitt 4.13 Vgl. [HIPP02] S. 89 f.
13

Kapitel 3. Web Log Mining
Abbildung 3.1.: Taxonomie des Web Log Mining, [BENS99a] S. 427, [COOL97] S. 1
Die Definitionsgrundlage des Web Log Mining bilden die in den Abschnitten 2.1 und 2.2
dargestellten Definitionen des Data Mining und des KDD-Prozesses. Die sprachliche Ähn-
lichkeit der Begriffe Data Mining und Web Log Mining legt eine definitorische Ableitung des
Web Log Mining aus den Begriffsinhalten nahe. Bensberg definiert das Web Log Mining, auf
Basis des im Abschnitt 2.2 dargestellten KDD-Prozess, als einen4:
„... informationstechnologisch und methodisch integrierten Prozess, der durch
Anwendung von Methoden auf Protokolldaten Muster entdeckt und anwenderori-
entiert aufbereitet.“
Für die Definition desWeb Log Mining modifiziert Bensberg5 das Modell des KDD-Prozesses.
Die Tabelle 3.1 zeigt zusammenfassend die Phasen des KDD-Prozesses nach Fayyad6 und
das modifizierte Modell nach Bensberg.
Tabelle 3.1.: Vergleich der KDD-Definition mit der Web Log Mining-Definition
4 Vgl. [BENS01a] S. 1325 [BENS01a] S. 70 f. und S. 133 ff.6 [FAYY96] S.10
14

3.1. Begriffsdefinitionen und -abgrenzung
Als erste Abänderung des KDD-Prozesses nach Fayyad führt Bensberg die Phase der Da-
tengenerierung ein, in dieser Phase erfolgt die Aufzeichnung der Protokolldaten. Durch die
Integration dieser Phase als Teil des Web Log Mining-Prozesses wird sichergestellt, das die
internetbasierte Anwendung in den Prozess der Datenanalyse eingegliedert wird und so ein
kontinuierlicher Entwicklungsprozess sichergestellt werden kann7. Weiterhin führt Bensberg
die Phasen Datenvorbereitung und Datentransformation zu der Phase zusammen. Diese
Zusammenführung begründet er damit, das eine eindeutige Differenzierung zwischen der
Datenvorbereitung und der Datentransformation nicht immer sinnvoll oder möglich ist. So ist
unter dem Begriff der Transformation im engeren Sinne die Schemakonversion der Daten
zu verstehen. Da dieser Vorgang automatisch erfolgen kann, ist keine Benutzerinteraktion
notwendig8. Unter Transformation kann aber auch die Änderung der Datenbankstruktur und
der Datenbankinhalte verstanden werden. Diese Aktivitäten sind, nach Bensberg, Gegen-
stand der Datenvorbereitung, so das die Zusammenfassung beider Phasen möglich ist. Die
letzte Modifikation die Bensberg durchführt, betrifft die Phase der Evaluation und Interpre-
tation. Diese Phase gliedert er in drei einzelne Teilprozesse: Evaluation, Präsentation und
Interpretation. Bensberg legt besonderen Wert auf die Organisation der entdeckten Hypo-
thesen, sodass er die Phase der Evaluation explizit in den Web Log Mining-Prozess einglie-
dert. Der Präsentation der Ergebnisse der Mustererkennung widmet er eine eigene Phase,
um die Wichtigkeit dieser Aktivität im Wissensentdeckungsprozess hervorzuheben, denn nur
durch eine geeignete Visualisierung der Ergebnisse der Mustererkennung bzw. des Web Log
Mining-Prozesses wird eine effektive Wissensveränderung des Anwenders gewährleistet9.
Die meisten Analyseprogramme bieten bereits umfassende und skalierbare Präsentations-
bzw. Visualisierungsmöglichkeiten, die eine effektive Evaluation und Interpretation der Ana-
lyseergebnisse, mit entsprechendem Domänenwissen seitens des Anwenders oder geeig-
neter Experten, ermöglicht. Da die Visualisierungsergebnisse der Analyseprogramme meist
automatisch generiert werden, wird Bensbergs Aufspaltung der Evaluations- und Interpre-
tationsphase nach Fayyad für nicht notwendig erachtet. Weiterhin wird Bensbergs Phase
der Datenvorbereitung und Datentransformation nachfolgend Transaktionsidentifikation und
Datentransformation genannt, weil im Kontext des Web Log Mining die Datenvorbereitung
vorrangig im Zeichen der Identifikation von Transaktionen steht. Im weiteren Verlauf der Ar-
beit wird dem in Tabelle 3.2 dargestellten Web Log Mining-Prozess gefolgt.
7 Vgl. [BENS01a] S. 1328 [BENS01a] S. 719 [BENS01a] S. 70 f.
15

Kapitel 3. Web Log Mining
Tabelle 3.2.:Web Log Mining-Definition
Mit Hilfe von Web Log Mining lässt sich das Verhalten der Online-Besucher detailliert do-
kumentieren und analysieren. Auch können die Ergebnisse des Web Log Mining zur op-
timalen Konfiguration des Internetauftrittes sowie zur optimalen Werbeplatzierung genutzt
werden. Beispielsweise sollte die Seitenstruktur an häufigen Bewegungspfaden ausgerich-
tet sein, um die Navigation zu erleichtern. Außerdem bietet es sich an, wichtige Seiteninhal-
te (Werbung, Produktinformationen) auf diesen Pfaden zu platzieren. Für die Strategische
Planung spielen die Ergebnisse des Web Log Mining auch eine wichtige Rolle. Beispiels-
weise können strategische Partnerschaften mit anderen Websites, Bannerschaltungen und
Einträge in Suchmaschinen hinsichtlich ihrer Effizienz bewertet werden, da sich detailliert
feststellen lässt, über welche externen Links die meisten Besucher auf die Website gelang-
ten. Die Einsatzmöglichkeiten für das Web Log Mining werden nachfolgend aufgezeigt10:
Dokumentation:
• Dokumentation des Nutzerverhaltens
• Erstellung von umfangreichen skalierbaren Statistiken
Erfolgskontrolle:
• Erfolgskontrolle der Website
• Werbeerfolgskontrolle
Layout-Planung:
• Verbesserung der Websitestruktur
• Gruppierung der Websiteinhalte und Struktur für unterschiedliche Nutzergruppen
• Optimale Werbe- und Produktplatzierung10 Vgl. [HIPP02] S. 101
16

3.2. Datenschutz
Personalisierung:
• Personalisierte Seiteninhalte
• Zielgruppenspezifische Marketingkampagnen
Verkaufsmuster entdecken:
• Warenkorbanalyse
• Cross Selling-Angebote
Da im Rahmen des Web Log Mining-Prozesses personenbezogene Daten verarbeitet und
analysiert werden, sind auch datenschutzrechtliche Aspekte dieses Prozesses zu betrach-
ten.
3.2. Datenschutz
Die Nutzung personenbezogener Daten durch privatwirtschaftliche Unternehmen unterliegt
dem Gültigkeitsbereich des Bundesdatenschutzgesetzes (BDSG). Das Internet birgt viele
Risiken, die das Recht auf informelle Selbstbestimmung beschneiden. Deshalb hat der bun-
desdeutsche Gesetzgeber in Form des Informations- und Kommunikationsdienste-Gesetzes
(IuKDG) bereichsspezifische Datenschutzvorschriften für die Anbieter und Nutzer von Te-
lediensten11 erlassen, die die bestehenden Rechtsvorschriften des BDSG ergänzen. Da
diese Dienste im Rahmen internetbasierter Marktsysteme realisiert werden, sind die Da-
tenschutzvorschriften des IuKDG zur Prüfung der datenschutzrechtlichen Zulässigkeit der
Logdatei-Speicherung und Analyse anzuwenden12. Im Artikel 2 des IuKDG, dem Gesetz
über den Datenschutz bei Telediensten (Teledienstdatenschutzgesetz; TDDSG), werden fol-
gende Grundsätze definiert13:
• Keine Verarbeitung personenbezogener Daten ohne Notwendigkeit dazu
• Zweckbindung der Verarbeitung an die Erbringung von IuK-Diensten
• Transparente Darstellung der Datenverwendung
• Technische Sicherung der Nutzeranonymität11 Im Artikel 1 des IuKDG, dem Gesetz über die Nutzung von Telediensten (Teledienstgesetz; TDG), §2 Abs. 1werden „... Angebote von Waren und Dienstleistungen in elektronisch abrufbaren Datenbanken mit interakti-vem Zugriff und unmittelbarer Bestellmöglichkeit“ als Teledienst ausgewiesen.
12 Vgl. [BENS01a] S. 5313 [SCHW00] S. 16 f.
17

Kapitel 3. Web Log Mining
• Kontrolle durch eine unabhängige Instanz
Die Verwendung personenbezogener Daten zu Marketingzwecken oder für die Gestaltung
von Websites ist ausschließlich mit Einwilligung des Nutzers zulässig (§3 Abs. 1 TDDSG).
Verarbeitungsschritte, wie z.B. das Speichern, Ändern, Übermitteln und Nutzen der Daten
für andere Zwecke, sind laut §3 Abs. 2 TDDSG nur dann zulässig, wenn eine Rechtsvor-
schrift dies erlaubt oder die Einwilligung des Nutzers vorliegt. Um Nutzungsdaten in Log-
dateien verwenden zu dürfen, ist darauf zu achten, dass die Daten anonymisiert vorliegen
und keinen Personenbezug aufweisen. Andernfalls wären diese Nutzungsdaten sofort nach
Ende der Nutzung wieder zu löschen, es sei denn, sie werden für Abrechnungszwecke be-
nötigt. Zur technischen Wartung und Weiterentwicklung der Website sind Logdateien mit
anonymen Einträgen in den meisten Fällen ausreichend. Fehler, die bei der Nutzung auf-
treten oder benötigte Übertragungskapazitäten in einem bestimmten Zeitraum, lassen sich
auch unabhängig von der Zuordnung zu individuellen Nutzern erfassen. Die darauf basieren-
den Anpassungsmaßnahmen betreffen nur selten einzelne Nutzer, sondern eher allgemeine
Veränderungen der technischen Gestaltung einer Website. Im Marketingbereich ist hinge-
gen die Verbindung erhobener Nutzungsdaten mit vorliegenden Bestandsdaten von Kunden
von hohem Interesse. Gelingt die Verbindung von objektiven Verhaltensdaten und demogra-
phischen Daten entstehen detaillierte Persönlichkeitsprofile, die es erlauben, Kunden indi-
viduell anzusprechen und zu betreuen. Die Erstellung von Persönlichkeitsprofilen ist nach
dem Gesetz nur bei Verwendung von Pseudonymen erlaubt; eine Zusammenführung per-
sonenbezogener Daten ist unzulässig (§ 4 Abs. 4 TDDSG)14. Die gesetzlichen Vorschriften
kommen vor allem immer dann zum tragen, wenn Softwareprodukte aus anderen Ländern
eingesetzt werden. In diesem Zusammenhang muss geprüft werden, ob diese Produkte mit
den deutschen Gesetzesvorgaben konform sind.
14 [SCHW00] S. 17 f.
18

4. Datenkomponenten
Jeder Besuch auf einer Website erzeugt einen Datensatz, in dem sämtliche Vorgänge der
Sitzung aufgezeichnet werden. So wird eine beträchtliche Menge an Besucher- bzw. Kun-
dendaten erfasst und entweder in Server-Logdateien oder in einer anderen Art Datenbank
gespeichert. Da der Kontakt zwischen dem Unternehmen und den bestehenden bzw. poten-
tiellen Kunden immer häufiger über die Website stattfindet, kann eine umfassende Analyse
dieser webbasierten Daten zu einem wichtigen Unternehmensprozess werden. Das Unter-
nehmen wird vor allem wissen wollen, wer seine Website besucht, was ihn dorthin zieht und
wie er dorthin gelangt ist. Die Grundsteine für die Datenanalyse liegen in den Online-Daten.
Genauer gesagt, in den verschiedenen Komponenten, die für die Erzeugung der Server-
Logdateien und anderer webbasierter Datenbanken verwendet werden. In den folgenden
Abschnitten sollen die für den Web Log Mining-Prozess relevanten Datenkomponenten auf-
gezeigt werden1.
4.1. Server-Logdateien
WWW-Server haben die Aufgabe, auf Anfrage vonWWW-Clients Dateien (z.B. HTML-Dokumente)
zur Anzeige zur Verfügung zu stellen. Um die Zugriffe auf die bereitgestellten Dateien nach-
vollziehbar zu machen, führt der WWW-Server Logbücher über die Anfragen von Clients.
Diese Logbücher heißen Server-Logdateien. Die Einträge in diesen, von dem WWW-Server
erstellten, in der Regel ASCII-Textdateien, sind durch Kommata, Leerzeichen oder Tabstops
getrennt. Als Logdatei werden Dateien bezeichnet, in denen eingetretene Ereignisse auto-
matisch protokolliert werden. Dem Betreiber eines WWW-Servers liegen damit Protokolle
vor, die die Beanspruchung einer Website und von Websiteteilbereichen objektiv abbilden.
Der Aufruf einer Internet-Seite basiert auf dem Übertragungsverfahren Hypertext Transfer
Protocol (HTTP). Dabei gibt der Nutzer auf der Client-Seite in einem Internet-Browser die
Adresse (URL2) eines gewünschten Dokumentes an. Der Browser veranlasst die Herstel-
1 [MENA00] S. 266 f.2 Das URL-Format (Uniform Resource Locator) macht eine eindeutige Bezeichnung aller Dokumente im Inter-net möglich, es beschreibt die Adresse eines Dokuments oder Objekts, das von einem WWW-Client gelesenwerden kann.
19

Kapitel 4. Datenkomponenten
lung einer Verbindung zu demjenigen Web-Server, auf dem das Dokument vorliegt und
sendet eine Anfrage zur Übertragung. Der Server sendet das Dokument bzw. dessen In-
halte an die Adresse des Nutzers und protokolliert die Übertragung in der Logdatei3. Ein
WWW-Server erstellt in der Regel mindestens zwei Logdateien: für die Protokollierung der
Zugriffe (Access-Logdatei) und für die Fehlerprotokollierung (Error-Logdatei). Die meisten
Server unterstützen darüber hinaus zwei weitere Typen von Logdateien. Zum einen ist das
die Referrer-Logdatei für die Protokollierung der Herkunftsadressen und zum anderen die
Agent-Logdatei die protokolliert mit welchem Browser bzw. Betriebssystem auf die Website
zugegriffen wurde. Die Abbildung 4.1 soll diesen Sachverhalt verdeutlichen.
Abbildung 4.1.: Konzept der serverseitigen Protokollaufzeichnung, [BENS01a] S. 40
Logdateien treten in einer Vielzahl von Formaten auf, die sich nach Art und Reihenfolge
der enthaltenen Angaben unterscheiden. Trotz unterschiedlicher technischer Ansätze der
Webserverprodukte wird das ehemals von der NCSA (National Center for Supercompu-
ting Applications) entworfene Common Logfile-Format (CLF-Format) eingesetzt, das sich
als Standard für Protokolldaten etabliert hat. Die meisten WWW-Server unterstützten neben
proprietären auch dieses Format4. Einen Ausschnitt einer typischen Logdatei im CLF-Format
wird in der Abbildung 4.2 dargestellt. Im Folgenden sollen die unterschiedlichen Logdateiar-
ten aufgezeigt und erläutert werden.
Abbildung 4.2.: Ausschnitt einer typischen Logdatei im CLF-Format
3 [SCHW00] S. 8 f.4 Vgl. [MENA00] S.268
20

4.1. Server-Logdateien
4.1.1. Access-Logdatei
Eine der wichtigsten Informationsquellen, aus denen Daten über die Online-Besucher ge-
wonnen werden können, ist die Access-Logdatei5, die auch als Transfer-Logdatei bezeichnet
wird. Hier werden sämtliche Transaktionen zwischen dem Server und dem Browser aufge-
zeichnet. Eine Access-Logdatei im Common Logfile-Format enthält sieben Datenfelder. Ein
typischer Eintrag einer Access-Logdatei wird nachfolgend gezeigt.
Das Hostfeld ist das erste Feld des Common Log Formats. In der Regel ist das der Ser-
ver, der eine Anfrage an die Website stellt und als Wert entweder eine DNS-Adresse6 (z.B.
planet.de) oder eine IP-Adresse (z.B. 208.48.21.10) beinhaltet. Aus dem Hostfeld ist die Top
Level-Domain (Länderkennung: z.B. de oder Organisationstyp: z.B. edu) des anfragenden
Servers ersichtlich. Da Internetadressen eindeutig vergeben werden, kann dieses Feld als
Identifikationskriterium für Besucher der Website herangezogen werden. In der Praxis ist
dieses Identifikationskriterium aber mit Vorsicht zu genießen, denn die Identifizierung eines
Anwenders anhand seiner Internetadresse ist nicht immer eindeutig. Die meisten Anwen-
der wählen sich über einen Internet Service Provider (ISP; z.B. T-Online oder AOL) in das
Internet ein, d.h. jedes Mal, wenn sich der Anwender einwählt, bekommt er eine neue (dy-
namische) Internetadresse zugewiesen. Außerdem gibt es Fimennetzwerke, die sich über
einen Proxy-Server7 mit dem Internet verbinden und sich dabei mehrere Personen einen
Zugang teilen.
Das zweite Feld im Common Log Format ist das Identifikationsfeld. In diesem Feld wird die
Benutzerkennung des Anwenders protokolliert, mit der die Anmeldung am lokalen Netzwerk
erfolgt. Diese Kennung kann von dem WWW-Server jedoch nur dann aufgezeichnet werden,
wenn auf dem Rechnersystem des Besuchers der hierfür erforderliche Identifikationsdienst
aktiviert ist. Die Anwendung ist aber mit hohen Leistungseinbußen verbunden, so das die
Verfügbarkeit dieses Feldes in der Praxis kaum vorkommt8.
Das dritte Feld ist das Authuserfeld. Dieses enthält den authentifizierten Benutzernamen,
den ein Besucher benötigt, um Zugriff auf ein geschütztes Verzeichnis zu erhalten, das nur
mit Passwort zugänglich ist. Dieses Attribut besitzt nur dann einen Wert, wenn eine Zugriffs-
berechtigung für den Aufruf eines Dokuments erforderlich ist.
Als viertes Feld folgt der Zeitstempel. Dieses Feld gibt das Datum und die Uhrzeit des
Zugriffes sowie die Zeitzone des anfragenden Servers an. Das Format für das Datum lau-5 Vgl. [MENA00] S. 268 ff., [BROD00] S. 61 f.6 Das DNS (Domain Name System) ist ein verteilter Namensdienst des Internets, der symbolische Adressenauf numerische Adressen (IP-Adressen) abbildetet.
7 Vgl. Abschnitt 4.3.28 Vgl. [BENS01a] S. 42
21

Kapitel 4. Datenkomponenten
tet TT/MMM/JJJJ (im Beispiel: 29/Apr/2002) und für die Uhrzeit HH:MM:SS (im Beispiel:
10:25:52). Der letzte Eintrag des Zeitstempelfeldes zeigt die Abweichung der lokalen Ser-
verzeit von der Greenwich Meridian Time (GMT).
Das fünfte Feld ist das Transaktionsfeld. Es enthält meistens den GET-Befehl. Er meldet
dem Server, auf welches Dokument der ihn ansprechende WWW-Client zugreifen möch-
te (im Beispiel: /index_e.html). Es gibt zwei weitere Zugriffsmethoden: der POST- und der
HEAD-Befehl. Der POST-Befehl wird ausgeführt, wenn Daten vom Client zum Server über-
tragen werden, bspw. wenn in Formularen der Versenden-Button gedrückt wird. Der zwei-
te, weniger gebräuchliche Befehl ist der HEAD-Befehl. Er arbeitet wie der GET-Befehl, mit
dem Unterschied, dass der Server nur den <HEAD>-Abschnitt des angeforderten HTML-
Dokuments zurückgibt. Der letzte Bereich des Transaktionsfeldes ist der Name und die Ver-
sionsnummer des HTTP-Protokolls.
Das Statuscodefeld ist das sechste Feld im Common Log Format. Es beschreibt, mit wel-
chem Resultat die Transaktion verlaufen ist. In der Regel ist dies der Statuscode 200, was
bedeutet, dass der Server die durch den Client angeforderte Seite erfolgreich übertragen
hat. Es gibt mehrere Klassen des Statuscode, von denen die wichtigsten in Tabelle 4.1 auf-
gelistet werden9.
Tabelle 4.1.:Wichtige Statuscodes
Das siebte und letzte Feld ist das Transfervolumenfeld. Es zeigt die Gesamtzahl der wäh-
rend der Transaktion vom Server zum Client übertragenen Bytes an (im Beispiel: 1170 By-
tes).
9 Eine genauere Beschreibung der einzelnen Statuscodes bietet [o.V.01c] S. 1.
22

4.1. Server-Logdateien
4.1.2. Error-Logdatei
Die Error-Logdatei zeichnet Meldungen auf, die der Fehleranalyse und Administration des
WWW-Servers dienen. Dabei werden die aufgetretenen Fehler genauer protokolliert als in
der Access-Logdatei. Die folgenden Meldungen können erfasst werden:
• administrative Meldungen (z.B. beim Start eines WWW-Servers)
• Fehlermeldungen (z.B. bei Anforderung nicht vorhandener Ressourcen)
Der folgende Error-Logdatei-Eintrag zeigt einen Zugriffsfehler, der durch die Anforderung
einer auf dem Server nicht existierenden Ressource verursacht wurde.
In diesem Beispiel wird das HTML-Dokument index_e.html nicht gefunden. Werden solche
Fehlermeldungen öfter protokolliert, kann davon ausgegangen werden, dass sich in der Na-
vigation ein nicht-referenzierender Link befindet.
4.1.3. Referrer-Logdatei
Die Referrer-Logdatei enthält die URL, von der die Anfrage an die Website stammt. Die-
se Logdatei erfasst den Ort im Internet von dem aus ein Online-Besucher zu der Website
weitergeleitet wurde. Dies kann ein Link von einer anderen Seite oder das Ergebnis einer
Suchmaschine sein. Diese Logdatei kann auch aussagen, welche Suchbegriffe benutzt wur-
den, um das Online-Angebot zu finden. Ein Eintrag der Referrer-Logdatei kann wie folgt
aussehen:
Im Beispiel wurde im Webverzeichnis Yahoo nach den Begriffen „web“ und „mining“ gesucht.
Dies ist eine sehr aufschlussreiche Information, die großen Einfluss auf den Entwurf von
strategischen Marketingkampagnen haben kann. Die Aufzeichnung der URL des Referenten
stellt den Zusammenhang zwischen Einzelinteraktionen her und ermöglicht die Ermittlung
des Navigationspfades eines Besuchers10.
10 [MENA00] S. 273
23

Kapitel 4. Datenkomponenten
4.1.4. Agent-Logdatei
Im Agent-Log stehen Angaben zur Software-Ausstattung des WWW-Clients, darunter Typ
und Version von Browser und Betriebssystem. Aus diesen Angaben ergibt sich ein Bild
der technischen Ausstattung der Nutzer11. Die Website sollte dementsprechend so gestaltet
sein, dass der überwiegende Teil der Nutzer die Seite ohne Darstellungsprobleme aufrufen
kann. Mögliche Einträge einer Agent-Logdatei werden nachfolgend aufgezeigt:
MSIE ist die Abkürzung des Internet Explorers von Microsoft, dahinter wird die entspre-
chende Browserversion protokolliert. Weiterhin werden die verwendeten Betriebssysteme
gespeichert (z.B. Windows NT). Der WWW-Server speichert aber auch Anfragen von „nicht-
menschlichen“ Besuchern, wie die Zugriffe von Suchmaschinen-Robotern12 (z.B. Google-
bot).
4.1.5. Extended Logfile-Format
Die meisten Webserver können so konfiguriert werden, das die Access-, Referrer- und
Agentdaten in einer Logdatei gespeichert werden. Dabei werden die Informationen der Referrer-
und Agent-Logdatei an die Access -Logdatei angehängt. Dieses Format wird als Exten-
ded oder Combined Logfile-Format bezeichnet. Ein Ausschnitt einer Logdatei im Extended
Logfile-Format (ELF-Format) wird in Abbildung 4.3 gezeigt.
Abbildung 4.3.: Ausschnitt einer typischen Logdatei im ELF-Format
Abschließend sollen noch einmal alle Informationen, die aus den Feldern der Logdateien
gewonnen werden können, tabellarisch aufgezeigt werden (Tabelle 4.2). Dabei ist die Ex-
11 [SCHW00] S. 1012 Roboter, auch Crawler oder Spider genannt, sind Programme von Suchmaschinen die selbstständig nachDokumenten und Objekten im Internet suchen und für die Suchmaschinen indizieren.
24

4.2. Cookies
traktion von mehreren Informationen aus einem Feld möglich13. Bei der Darstellung wurde
auf die Einordnung der Error-Logdatei verzichtet, da diese Informationen nur für administra-
tive Zwecke (Websitewartung) relevant sind. Außerdem enthält das Statusfeld der Access-
Logdatei ausreichende Informationen über den Verlauf einer Transaktion.
Tabelle 4.2.: Überblick der Logdatei-Informationen
4.2. Cookies
Cookies sind kleine Textdateien, die von Servern auf der Festplatte das Besuchers erzeugt
werden können, wenn dessen Browser auf eine Seite zugreift. Jedes Mal, wenn ein Online-
Besucher zu der Website zurückkehrt, kann der Server, der den Cookie erzeugt hat, prüfen
und lesen, was zuvor in die Datei geschrieben wurde, z.B. welche Seiten also bei der letz-
ten Anwendersitzung aufgerufen wurden. Jeder Besuch eines Kunden auf einer Website
ist eigentlich ein einzelner, von vorherigen Besuchen losgelöster Vorgang. Cookies sind ei-
ne Möglichkeit, um diese voneinander unabhängigen Besuche miteinander in Beziehung zu
setzen und so eine realitätsnahe Verkaufssituation zu schaffen14. Sehr viele Internetseiten
setzen Cookies. Damit der Client-Rechner vor einer zu großen Cookieflut geschützt werden
kann, können Restriktionen auf der Client-Seite gesetzt werden. Die meisten WWW-Clients
stellen entsprechende Konfigurationsoptionen zur Verfügung.
4.2.1. Aufbau
Der Aufbau eines typischen15 Cookies soll anhand folgenden Beispiels erklärt werden:
13 In Abschnitt 5.2 wird genauer auf zusammengesetzte Felder eingegangen.14 Vgl. [MENA00] S. 280 ff.15 In dem Beispiel wird ein Netscape-Cookie gezeigt. Die Cookiedateien von anderen Browsern, wie dem Inter-net Explorer von Microsoft, sind ähnlich aufgebaut.
25

Kapitel 4. Datenkomponenten
Dieser Cookie enthält sieben Felder. Das erste Feld speichert den Hostnamen des Cookies
(im Beispiel: planet.de). Bei der Voreinstellung ist dies meist der Server, der den Cookie
erzeugt und an den Besucher geschickt hat. Nur der Server, der den Cookie speicherte,
kann ihn auch lesen. Dies bedeutet, dass planet.de nicht die gespeicherten Cookies von
z.B. google.de oder yahoo.de lesen kann.
Das folgende Feld zeigt an, ob der Cookie von allen Rechnern (TRUE) der Domain gele-
sen werden darf oder nur von einem (FALSE), d.h. das bei einem Eintrag „planet.de TRUE“
jeder Rechner der Domain planet auf den Cookie zugreifen darf, also auch die Rechner
wall.planet oder test.planet. Bei einem Eintrag „wall.planet.de FALSE“ darf nur von der Do-
main wall.planet.de auf den Cookie zugegriffen werden, test.planet.de hat keine Berechti-
gung.
Als nächstes folgt ein variabler Pfad (im Beispiel: /), von dem aus von jeder Seite der Website
(planet.de) auf diesen Cookie zugegriffen werden kann. Dabei ist der Zugriff auf den Cookie
auf diejenigen beschränkt, die ihn erzeugt haben. Cookies ohne eingestellten Pfad werden
nur temporär gespeichert, und wenn der Anwender den Browser schließt, gelöscht.
Die Verschlüsselung eines Cookies zeigt das nächste Feld. Ist dieser Parameter auf TRUE
gesetzt, wird die Information nur dann übertragen, wenn eine sichere Verbindung zwischen
Client und Server vorliegt, d.h. wenn HTTPS (Hypertext Transmission Protocol Secure) oder
SSL (Secure Sockets Layer) verwendet wird.
Als nächstes folgt das Datum, an dem der Cookie verfällt. Es wird in Sekunden seit dem 1.
Januar 1970, 0.00 Uhr GMT dargestellt (im Beispiel: 1054806622 Sekunden). Der Standard-
wert ist 0, d.h. der Cookie wird nicht auf der Festplatte des Besuchers gespeichert.
Das nächste Feld identifiziert den Cookie (im Beispiel: PLANET_Cookie). Der Cookiena-
me darf weder Kommata, noch Semikola oder Leerzeichen enthalten. Der neueste Cookie
ersetzt den älteren Cookie mit derselben Domain, demselben Pfad und demselben Namen.
Als letztes wird der Wert des Cookies gespeichert. In diesem Feld hinterlegt der Versender
des Cookies seine Informationen. Der Wert darf weder Kommata, noch Semikola oder Leer-
zeichen enthalten. Hier kann zum Beispiel die Anzahl der Besuche auf der Seite, aber auch
Benutzer-ID, Name oder Adresse des Besuchers gespeichert werden.
4.2.2. Anwendungen
In den Cookies können kurze Informationen von einem Kontakt mit einem WWW-Server bis
zum nächsten Kontakt mit demselben Server zwischengespeichert werden16. Die Verwen-16 Vgl. [OEBB00] S. 1
26

4.2. Cookies
dungsmöglichkeiten sind sehr variabel:
• Cookies wurden unter anderem für Warenkorb-Applikationen entwickelt. Mit einem
Warenkorb hat der Käufer die Möglichkeit, während eines Einkaufs in einem Super-
markt (Website) mehrere Produkte gleichzeitig zu kaufen und diese beim Verlassen
des Ladens an der Kasse (per Formular) zu bezahlen. Bei diesem Vorgang werden
wichtige Informationen festgehalten, zum Beispiel welche Produkte der Kunde beson-
ders mag und welche Zahlungsart er verwendet.
• Weiterhin werden Cookies zur Personalisierung von Websites eingesetzt. Da derWWW-Server durch die Cookies auf dem Rechner des Besuchers Informationen spei-
chern kann, besteht auch die Möglichkeit, Buch darüber zu führen, wie oft und wann
der Besucher das letzte Mal den jeweiligen Server besucht hat. Auch können persönli-
che Vorlieben, zum Beispiel ob in einer Online-Buchhandlung eher nach Fachbüchern
zum Thema Computer oder Kochen gesucht wird, erfasst und ausgewertet werden.
Beim nächsten Besuch dieses Nutzers auf der Website, wird er auf Neuerscheinungen
in dem bevorzugten Bereich hingewiesen.
• Ein wichtiges Einsatzgebiet für Cookies ist die Besucheridentifikation. Viele ISP ar-beiten mit dynamischen Internetadressen. Das bedeutet, dass der Besucher bei jeder
Internet-Verbindung eine neue anonyme Identität erhält. Der Server weiß, an welche
Adresse er die angeforderten Daten schicken soll, weiß aber nicht wirklich, welche
Person sich hinter dieser Internetadresse verbirgt. Mit Hilfe eines Cookies, der eine
eindeutige Benutzerkennung enthält und mit einer langen Lebensdauer versehen ist,
wird der Nutzer auch beim nächsten Besuch eindeutig identifiziert, obwohl er eine an-
dere Internetadresse erhalten hat.
Zur Besucheridentifikation bietet z.B. der Apache-Webserver ein entsprechendes Mo-
dul17 an. Dabei identifiziert der Server jeden neuen Besucher und gibt ihm eine ein-
deutige Kennung, die in Form eines Cookies auf dem Client-Rechner gespeichert wird.
Diese Kennung setzt sich aus der Internetadresse des Client-Rechners, der System-
zeit und der Server-Prozess-ID zusammen. Der Server kann so konfiguriert werden,
das er die Logdatei um ein weiteres Feld, das diese eindeutige Kennung beinhaltet, er-
gänzt. In der Abbildung 4.4 wird eine Logdatei im ELF-Format und diesem zusätzlichen
Kennungsfeld des Apache-Webservers gezeigt.
17 Der Apache-Webserver setzt zur Besucheridentifikation das Modul mod_usertrack ein. Nähere Informationenwerden im WWW unter http://httpd.apache.org/docs/mod/mod_usertrack.html gegeben.
27

Kapitel 4. Datenkomponenten
Abbildung 4.4.: Ausschnitt einer Logdatei im ELF-Format mit Kennungsfeld
4.3. Technische Probleme
Bedingt durch die einfache Konzeption von Logdateien und der Architektur des Internets
entstehen technische Probleme, welche die Qualität und Quantität des Datenbestandes be-
einflussen18. Eine Beurteilung von Informationen, die auf den Logdateien basieren, sollte die
nachfolgenden Fehlerquellen berücksichtigen.
4.3.1. Caching
Caches sind Speicher, die Daten temporär zwischenlagern, um den Zugriff bei einer er-
neuten Anforderung zu beschleunigen. Im Internet-Verkehr wird so die Auslastung der Ver-
bindungen reduziert. Dazu werden aus dem Internet abgerufene Webseiten und Grafiken
entweder lokal durch den WWW-Client oder auf einem speziellen Computer auf dem Weg
zwischen WWW-Client und WWW-Server (Proxy-Cache) abgespeichert. Erfolgt ein weiterer
Zugriff auf dieselbe Seite (entweder mit demselben WWW-Client oder durch einen anderen
den Proxy-Server19 nutzenden Besucher), wird diese nicht ein weiteres Mal vom WWW-
Server angefordert, wo diese Anforderung protokolliert werden könnte, sondern aus dem
Zwischenspeicher geladen. Die Folge ist, dass nicht mehr alle Seitenkontakte in den Log-
dateien verzeichnet werden. Die ausgewiesene Nutzung des Online-Angebotes ist potentiell
niedriger als die tatsächliche. Die Abbildung 4.5 stellt diesen Sachverhalt dar.
Ohne zusätzliche Maßnahmen führt eine Logdatei-Analyse zu verzerrten Ergebnissen. Das
Verfahren der Informationsgemeinschaft zur Feststellung der Verbreitung von Werbeträgern
e.V. (IVW)20 zur Reichweitenmessung von Online-Medien nutzt das Prinzip der Teildynami-
18 Vgl. [SCHW00] S. 12, [BROD00] S. 65 ff.19 Vgl. Abschnitt 4.3.220 Das Zählverfahren der IVW hat sich im deutschen Markt für Online-Werbung als Standard etabliert. Dabeiwird in jede HTML-Seite eine ein Pixel große, unsichtbare Grafik eingefügt, die bei jedem Seitenzugriff neu
28

4.3. Technische Probleme
Abbildung 4.5.: Caching-Mechanismus, [SCHW00] S. 13
sierung von Webseiten. Dies hat den Effekt, dass mindestens ein Element jeder Webseite
nicht von Caches gespeichert wird, so dass der Abruf einer Ressource vom WWW-Server
aufgezeichnet werden kann21.
4.3.2. Proxy-Server
Proxy-Server werden häufig als zentrale Schnittstelle zwischen dem Intranet einer Organisa-
tion und dem Internet eingesetzt22. Zum einen haben sie die Funktion eines großen Caches,
um die Netzwerklast und damit die Kosten der Internetanbindung einer Organisationseinheit
zu reduzieren. Die resultierenden Probleme wurden im vorangegangenen Abschnitt darge-
stellt. Zum anderen verbirgt ein Proxy-Server häufig ein gesamtes Netzwerk hinter seiner
eigenen Internetadresse. Dieser Zusammenhang wird in Abbildung 4.6 gezeigt.
Abbildung 4.6.: Funktionsweise eines Proxy-Servers
geladen und nicht in einem Cache zwischengespeichert wird. Durch die geringe Größe der Grafik von nur 43Byte entsteht nur eine geringe Mehrbelastung der Übertragungswege. Ein Eintrag in die Logdatei erfolgt beijedem Aufruf der Grafik. Ausführlichere Informationen werden im WWW unter http://www.ivw.de gegeben.
21 Vgl. [SCHW00] S. 1322 Vgl. [POHL99] S. 10
29

Kapitel 4. Datenkomponenten
In der Server-Logdatei erscheint stets die Adresse des Proxy-Servers, obwohl der Zugriff tat-
sächlich von verschiedenen Computern hinter diesem Proxy-Server erfolgte. Die Folge sind
eine zu geringe Besucherzahl, eine zu große Zahl an Seitenabrufen pro Besucher in der
Log-Analyse sowie eine verzerrte Verhaltensdarstellung. Um dieses Problem zu umgehen,
bedarf es einer anderen Art der Identifizierung eines Besuchers als dessen Internetadresse.
Ein möglicher Lösungsansatz wäre der Einsatz von Cookies23. Das sind kleine Dateien, wel-
che vom Browser auf der Festplatte gespeichert und später vom Server wieder ausgewertet
werden können. Nachteil dieser Vorgehensweise ist jedoch, dass viele Internetnutzer dem
Einsatz von Cookies kritisch gegenüberstehen, denn dieser Ansatz schränkt die Anonymität
von Nutzern in hohem Maße ein. Deshalb verfügen Browser über eine Option, die die Spei-
cherung von Cookies unterbinden kann. Die Wirksamkeit der Cookies hängt damit von der
Kooperationsbereitschaft des Besuchers ab24.
4.3.3. Dynamische Internetadressen
Eine weitere Quelle des Identifizierungsproblems stellt die dynamische Vergabe von Inter-
netadressen zahlreicher ISP dar. Da die Reservierung jeder einzelnen Internetadresse bei
der zuständigen Vergabestelle mit Kosten verbunden ist, gleichzeitig aber nie alle bei einem
ISP registrierten Kunden zum selben Zeitpunkt das Internet nutzen, halten die Provider in
der Regel nur eine relativ kleine Anzahl von Internetadressen bereit. Nur für die Dauer ei-
ner Einwahlverbindung wird dem Kunden dann eine jeweils gerade ungenutzte Adresse aus
diesem Pool zugewiesen. Zur Korrektur der Messfehler können entweder auch hier Cookies
eingesetzt werden oder der Besucher wird gezwungen, sich vor jeder Nutzung eines Online-
Angebotes am jeweiligen Webserver durch Eingabe eines Nutzernamens und Kennwortes
anzumelden. Letzteres Verfahren ermöglicht zwar eine exakte Zuordnung der Nutzung zu
einer Person, allerdings hält er auch zahlreiche Anwender davon ab, das Angebot überhaupt
in Anspruch zu nehmen25.
4.4. Messgrößen
Der Erfolg einer Internet-Präsenz wird oft an der Anzahl von Zugriffen auf die Website ge-
messen. Sowohl im Vergleich der Nutzungsintensität verschiedener Websites als auch zur
unternehmensinternen Bewertung der Website-Aktivität ist es notwendig, sich auf eindeutig
definierte Messgrößen zu einigen. Dabei ist zwischen objektiv messbaren und betriebswirt-
schaftlich interessanten Größen zu unterscheiden. Ein Unternehmen ist daran interessiert,
23 Vgl. Abschnitt 4.2.224 Vgl. [SCHW00] S. 14; Weitere Verfahren zur Besucheridentifikation werden in Abschnitt 5.3.1 vorgestellt.25 Vgl. [POHL99] S. 10
30

4.4. Messgrößen
aussagekräftige Zahlen wie die Anzahl der Nutzer festzustellen, verfügt aber in seinen Log-
dateien nur über eine Aufzeichnung abgerufener Dateien26. Den Zusammenhang zwischen
beiden Größen verdeutlicht eine hierarchische Gliederung der Website-Aktivität, die folgen-
de Kenngrößen definiert27:
• User (Besucher, Kunde)
• Visit (Session, Transaktion, Besuch)
• Page View (Page Impression, Sichtkontakt mit einer Seite)
• Hit (abgerufene Ressource)
User der Website sind Personen oder Maschinen (z.B. Suchmaschinen-Roboter), die sich
die Seiten im Internet angesehen haben. Ein Visit ist ein zeitlich zusammenhängender Nut-
zungsvorgang eines Users. Handelt es sich dabei um einen wiederkehrenden Nutzer, so
verursacht dieser im Zeitablauf mehrere Visits. Jeder Visit besteht wiederum aus einem oder
mehreren Page Views. Ein Page View wird gezählt, wenn ein Benutzer einen Sichtkontakt
mit einer Seite hat, wobei sich diese Seite physikalisch aus mehreren Dateien und Objek-
ten zusammensetzen kann, die als eigenständige Dateien auf dem Server vorliegen, z. B.
der Seitentext, Bilder oder Videodateien. Ein Page View kann sich also aus mehreren Hits
zusammensetzen. Jeder Aufruf einer einzelnen Datei wird als Hit bezeichnet und in einem
Eintrag der Logdatei protokolliert, so dass die Darstellung einer Seite im Browser mehrere
Hits verursachen kann. In der Abbildung 4.7 wird der Zusammenhang der definierten Größen
grafisch verdeutlicht.
Abbildung 4.7.: Hierarchie der Messgrößen
26 [SCHW00] S. 1127 Vgl. [KRAF00] S. 23 f., S. 27 und S. 36
31

Kapitel 4. Datenkomponenten
32

5. Prozess des Web Log Mining
In den nachfolgenden Abschnitten sollen die einzelnen Phasen desWeb Log Mining-Prozesses
erläutert werden. Die Voraussetzungen für diese Gliederung wurden in Abschnitt 3.1 ge-
schaffen. Die Abbildung 5.1 verdeutlicht noch einmal die Struktur des Web Log Mining-
Prozesses.
Abbildung 5.1.:Web Log Mining-Prozess, Aufbauend auf [BENS01a] S. 133
5.1. Datengenerierung
Diese Phase umfasst die Aufzeichnung der Logdateien durch den WWW-Server. In den
Logdateien werden sämtliche Aktivitäten der Besucher der Website protokolliert. Wie der
Inhalt oder das Schema der Protokollierung aussieht, ist von der Konfiguration des WWW-
Servers abhängig. Einen Überblick der Möglichkeiten des Informationsgewinns aus den Log-
33

Kapitel 5. Prozess des Web Log Mining
dateien wird in Abschnitt 4.1 gegeben. Der Konfigurationsaufwand ist von dem eingesetzten
WWW-Server abhängig. Bei diesen Produkten handelt es sich in erster Linie um den Open-
Source-Server Apache1, den Internet Information Server von Microsoft (IIS), Netscapes iPla-
net sowie Software von NCSA und CERN2. Wegen der Typvielfalt, der sich auf dem Markt
befindlichen WWW-Server, wird auf eine konkrete Konfigurationsbeschreibung verzichtet3.
Grundsätzlich ist die Phase der Datengenerierung nicht auf einen WWW-Server begrenzt.
In Abhängigkeit von der situativen Forschungsbestrebung können auch die Logdateien meh-
rerer WWW-Server simultan aufgezeichnet und in den Prozess des Web Log Mining einbe-
zogen werden. Hierbei ist zu beachten, das eine einheitliche Datenbasis geschaffen wird.
Dazu müssen die beteiligten WWW-Server gleichermaßen konfiguriert werden4.
5.2. Datenselektion
Die in der Phase Datengenerierung aufgezeichneten Logdateien bilden die Grundlage für
die Phase der Datenselektion. In dieser Phase werden die für die Analyse relevanten Daten
in einen Zieldatenbestand überführt. Alle für die Analyse uninteressanten Einträge werden
aus den aufgezeichneten Logdateien gefiltert. Interessant sind nur diejenigen Elemente, die
vom Benutzer explizit angefordert werden, nicht aber diejenigen, die automatisch vom Client-
Browser des Benutzers mitgeladen werden. Der WWW-Server erkennt hier keinen Unter-
schied. Dieser Sachverhalt soll anhand der Tabelle 5.1 und Tabelle 5.2 erläutert werden. Der
Aufruf einer Webseite könnte in der Logdatei5 folgendermaßen protokolliert worden sein:
Tabelle 5.1.: Logdateieintrag eines Seitenabrufs
Jeder Seitenabruf wird aber in Form von mehreren Hits aufgezeichnet, die abhängig von der
Anzahl der in das HTML-Dokument eingebetteten Elemente sind. Eine HTML-Seite wird in
der Regel aus verschiedenen Elementen konstruiert. Das können zum Beispiel das eigentli-
che HTML-Dokument, Bilddateien, Videodateien, Dateien zur Formatierung der HTML-Seite
oder Skripte sein. Das obige Beispiel könnte also in Wirklichkeit so aussehen:
1 Der Apache-Server ist mit ca. 60 Prozent, vor dem IIS mit 30 Prozent, der weltweite Marktführer.2 Im WWW unter http://www.netcraft.com/survey/ werden aktuelle Statistiken zu den Marktanteilen der einzel-nen WWW-Server veröffentlicht.
3 Einen Überblick für konkrete Konfigurationen liefert [MENA00] S. 274 ff.4 Vgl. [BENS01a] S. 133 ff.5 Die Auszüge der Logdateien in Kapitel 5 sind aus Verständnisgründen vereinfacht dargestellt wurden.
34
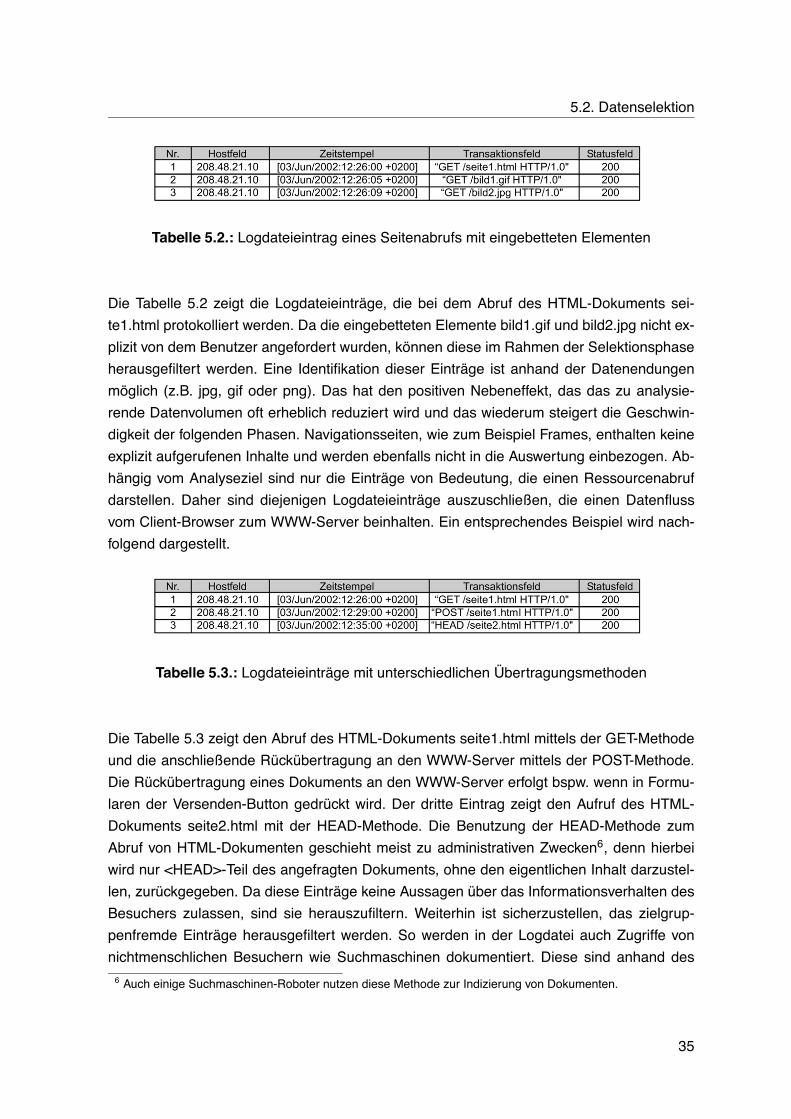
5.2. Datenselektion
Tabelle 5.2.: Logdateieintrag eines Seitenabrufs mit eingebetteten Elementen
Die Tabelle 5.2 zeigt die Logdateieinträge, die bei dem Abruf des HTML-Dokuments sei-
te1.html protokolliert werden. Da die eingebetteten Elemente bild1.gif und bild2.jpg nicht ex-
plizit von dem Benutzer angefordert wurden, können diese im Rahmen der Selektionsphase
herausgefiltert werden. Eine Identifikation dieser Einträge ist anhand der Datenendungen
möglich (z.B. jpg, gif oder png). Das hat den positiven Nebeneffekt, das das zu analysie-
rende Datenvolumen oft erheblich reduziert wird und das wiederum steigert die Geschwin-
digkeit der folgenden Phasen. Navigationsseiten, wie zum Beispiel Frames, enthalten keine
explizit aufgerufenen Inhalte und werden ebenfalls nicht in die Auswertung einbezogen. Ab-
hängig vom Analyseziel sind nur die Einträge von Bedeutung, die einen Ressourcenabruf
darstellen. Daher sind diejenigen Logdateieinträge auszuschließen, die einen Datenfluss
vom Client-Browser zum WWW-Server beinhalten. Ein entsprechendes Beispiel wird nach-
folgend dargestellt.
Tabelle 5.3.: Logdateieinträge mit unterschiedlichen Übertragungsmethoden
Die Tabelle 5.3 zeigt den Abruf des HTML-Dokuments seite1.html mittels der GET-Methode
und die anschließende Rückübertragung an den WWW-Server mittels der POST-Methode.
Die Rückübertragung eines Dokuments an den WWW-Server erfolgt bspw. wenn in Formu-
laren der Versenden-Button gedrückt wird. Der dritte Eintrag zeigt den Aufruf des HTML-
Dokuments seite2.html mit der HEAD-Methode. Die Benutzung der HEAD-Methode zum
Abruf von HTML-Dokumenten geschieht meist zu administrativen Zwecken6, denn hierbei
wird nur <HEAD>-Teil des angefragten Dokuments, ohne den eigentlichen Inhalt darzustel-
len, zurückgegeben. Da diese Einträge keine Aussagen über das Informationsverhalten des
Besuchers zulassen, sind sie herauszufiltern. Weiterhin ist sicherzustellen, das zielgrup-
penfremde Einträge herausgefiltert werden. So werden in der Logdatei auch Zugriffe von
nichtmenschlichen Besuchern wie Suchmaschinen dokumentiert. Diese sind anhand des6 Auch einige Suchmaschinen-Roboter nutzen diese Methode zur Indizierung von Dokumenten.
35
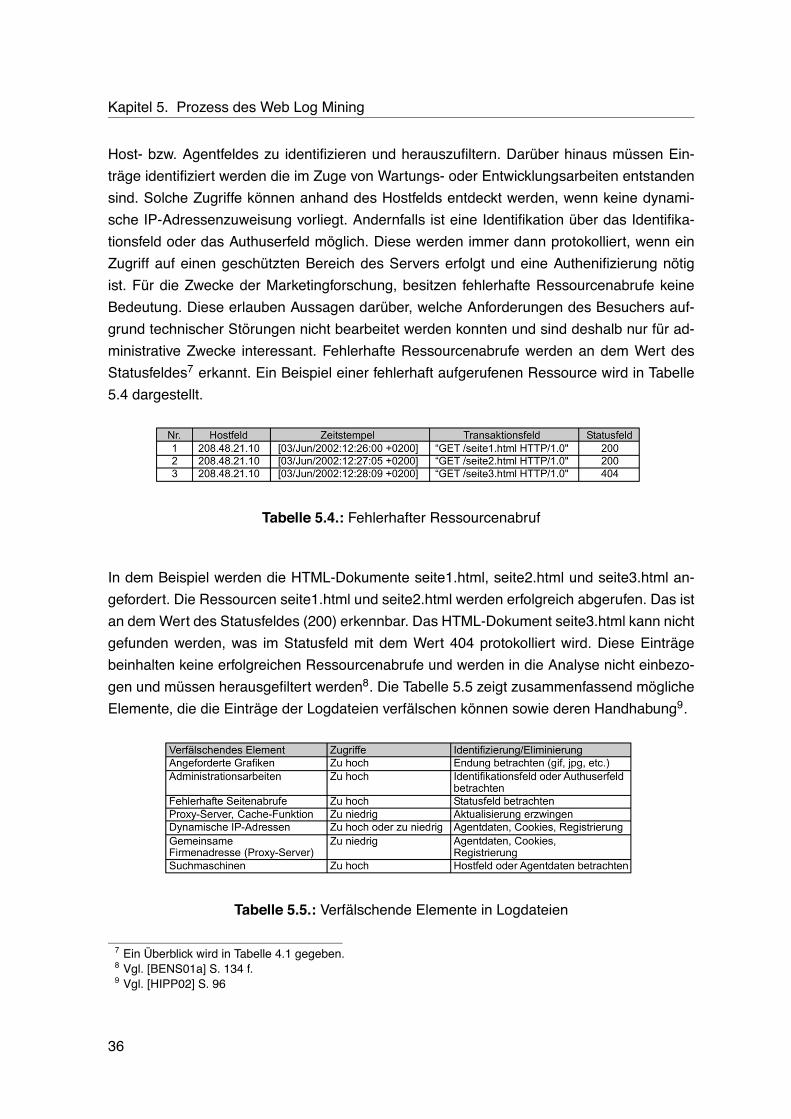
Kapitel 5. Prozess des Web Log Mining
Host- bzw. Agentfeldes zu identifizieren und herauszufiltern. Darüber hinaus müssen Ein-
träge identifiziert werden die im Zuge von Wartungs- oder Entwicklungsarbeiten entstanden
sind. Solche Zugriffe können anhand des Hostfelds entdeckt werden, wenn keine dynami-
sche IP-Adressenzuweisung vorliegt. Andernfalls ist eine Identifikation über das Identifika-
tionsfeld oder das Authuserfeld möglich. Diese werden immer dann protokolliert, wenn ein
Zugriff auf einen geschützten Bereich des Servers erfolgt und eine Authenifizierung nötig
ist. Für die Zwecke der Marketingforschung, besitzen fehlerhafte Ressourcenabrufe keine
Bedeutung. Diese erlauben Aussagen darüber, welche Anforderungen des Besuchers auf-
grund technischer Störungen nicht bearbeitet werden konnten und sind deshalb nur für ad-
ministrative Zwecke interessant. Fehlerhafte Ressourcenabrufe werden an dem Wert des
Statusfeldes7 erkannt. Ein Beispiel einer fehlerhaft aufgerufenen Ressource wird in Tabelle
5.4 dargestellt.
Tabelle 5.4.: Fehlerhafter Ressourcenabruf
In dem Beispiel werden die HTML-Dokumente seite1.html, seite2.html und seite3.html an-
gefordert. Die Ressourcen seite1.html und seite2.html werden erfolgreich abgerufen. Das ist
an demWert des Statusfeldes (200) erkennbar. Das HTML-Dokument seite3.html kann nicht
gefunden werden, was im Statusfeld mit dem Wert 404 protokolliert wird. Diese Einträge
beinhalten keine erfolgreichen Ressourcenabrufe und werden in die Analyse nicht einbezo-
gen und müssen herausgefiltert werden8. Die Tabelle 5.5 zeigt zusammenfassend mögliche
Elemente, die die Einträge der Logdateien verfälschen können sowie deren Handhabung9.
Tabelle 5.5.: Verfälschende Elemente in Logdateien
7 Ein Überblick wird in Tabelle 4.1 gegeben.8 Vgl. [BENS01a] S. 134 f.9 Vgl. [HIPP02] S. 96
36

5.3. Transaktionsidentikation und Datentransformation
Die Auswahl der für die Analyse relevanten Attribute der Logdatei ist von dem Analyseziel
des Anwenders abhängig. Interessiert sich der Anwender beispielsweise für die geographi-
sche Herkunft der Besucher, sind technische Informationen über Browsertyp oder Betriebs-
system irrelevant.
Für die nachfolgenden Phasen kann es wichtig sein, Informationen aus den zusammen-
gesetzten Attributen der Logdatei zu extrahieren. Sofern das Hostfeld in Form einer DNS-
Adresse vorliegt, kann daraus die Top Level-Domain und die Second Level-Damain10 her-
ausgefiltert werden. Weitere zusammengesetzte Attribute sind der Zeitstempel, das Trans-
aktionsfeld, das Referrerfeld und das Agentfeld. Wie diese Attribute aufgespalten werden
können, zeigt Tabelle 5.6.
Tabelle 5.6.: Aufspaltung zusammengesetzter in einzelne Attribute
5.3. Transaktionsidentikation und Datentransformation
5.3.1. Transaktionsidentikation
Im nächsten Schritt sind die analyserelevanten Daten der Datenbasis vom Anwender zu
selektieren und zu Transaktionen zusammenzufassen. Die Ableitung von Transaktionen ist
erforderlich, da der Gegenstand des Web Log Mining in der Analyse des Nutzungsverhal-
tens einzelner Anwender besteht. Eine Transaktion umfasst dabei alle Interaktionen eines
Besuchers mit der Webpräsenz, die sich in einem zeitlichen Zusammenhang befinden. In
Analogie zur Realwelt bildet eine Transaktion das virtuelle Äquivalent eines Kundenbesuchs
ab11. Auf der technischen Ebene erweist sich die Ableitung von Transaktionen als proble-
matisch, da das HTTP-Protokoll ein zustandsloses Übertragungsprotokoll ist. Das bedeutet,
dass es zwischen den Zugriffen auf Ressourcen des Webservers keinen Zusammenhang
gibt. Somit steht jeder Zugriff gleichberechtigt neben dem anderen und es ist keine triviale
Identifikation von Benutzersitzungen möglich.
10 Die Second Level-Domain ist der Abschnitt der Internetadresse, der vor der Top Level-Domain steht. Bei derInternetadresse wi.hs-wismar.de lautet die Second Level-Damain hs-wismar.
11 Vgl. [BENS99b] S. 5 f.
37
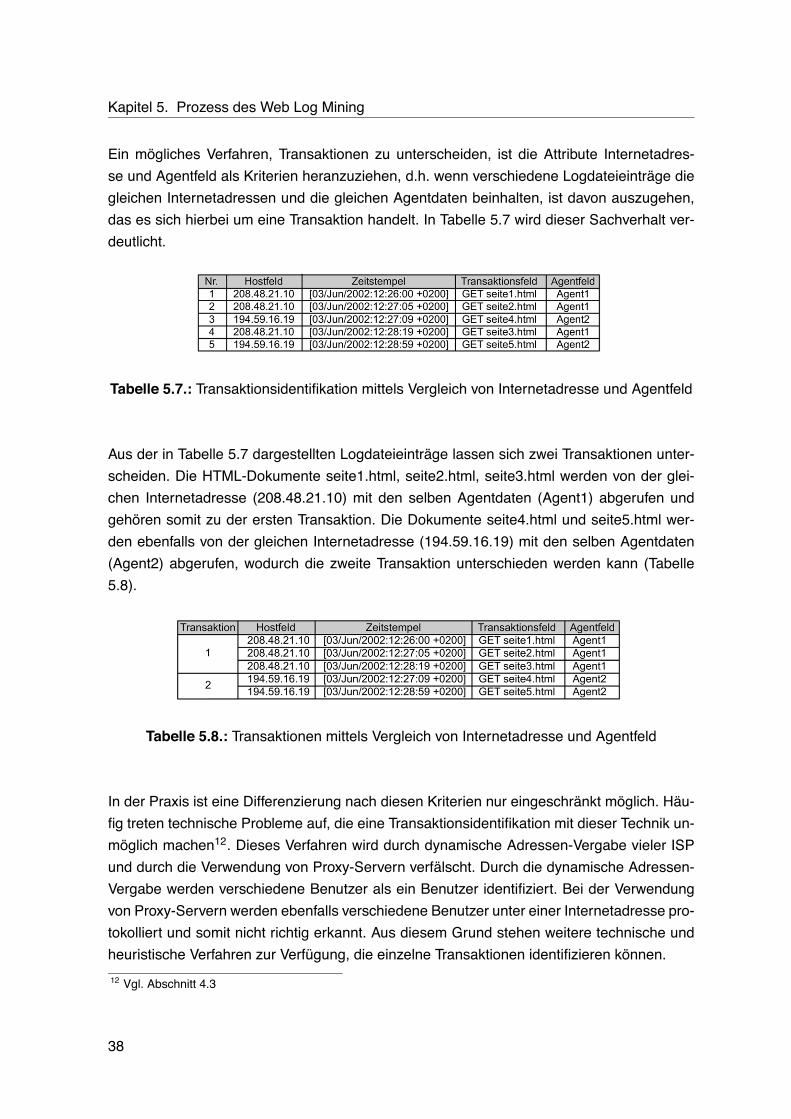
Kapitel 5. Prozess des Web Log Mining
Ein mögliches Verfahren, Transaktionen zu unterscheiden, ist die Attribute Internetadres-
se und Agentfeld als Kriterien heranzuziehen, d.h. wenn verschiedene Logdateieinträge die
gleichen Internetadressen und die gleichen Agentdaten beinhalten, ist davon auszugehen,
das es sich hierbei um eine Transaktion handelt. In Tabelle 5.7 wird dieser Sachverhalt ver-
deutlicht.
Tabelle 5.7.: Transaktionsidentifikation mittels Vergleich von Internetadresse und Agentfeld
Aus der in Tabelle 5.7 dargestellten Logdateieinträge lassen sich zwei Transaktionen unter-
scheiden. Die HTML-Dokumente seite1.html, seite2.html, seite3.html werden von der glei-
chen Internetadresse (208.48.21.10) mit den selben Agentdaten (Agent1) abgerufen und
gehören somit zu der ersten Transaktion. Die Dokumente seite4.html und seite5.html wer-
den ebenfalls von der gleichen Internetadresse (194.59.16.19) mit den selben Agentdaten
(Agent2) abgerufen, wodurch die zweite Transaktion unterschieden werden kann (Tabelle
5.8).
Tabelle 5.8.: Transaktionen mittels Vergleich von Internetadresse und Agentfeld
In der Praxis ist eine Differenzierung nach diesen Kriterien nur eingeschränkt möglich. Häu-
fig treten technische Probleme auf, die eine Transaktionsidentifikation mit dieser Technik un-
möglich machen12. Dieses Verfahren wird durch dynamische Adressen-Vergabe vieler ISP
und durch die Verwendung von Proxy-Servern verfälscht. Durch die dynamische Adressen-
Vergabe werden verschiedene Benutzer als ein Benutzer identifiziert. Bei der Verwendung
von Proxy-Servern werden ebenfalls verschiedene Benutzer unter einer Internetadresse pro-
tokolliert und somit nicht richtig erkannt. Aus diesem Grund stehen weitere technische und
heuristische Verfahren zur Verfügung, die einzelne Transaktionen identifizieren können.
12 Vgl. Abschnitt 4.3
38

5.3. Transaktionsidentikation und Datentransformation
Technische Verfahren ermöglichen durch zusätzliche Logdateieinträge die Identifikation
einzelner Transaktionen. Technische Verfahren sind zum Beispiel Cookies, Benutzerregi-
strierung, URL-Rewriting oder Hidden Form Fields.
Eine Möglichkeit, um unabhängig von der IP-Adresse festzustellen, ob sich hinter zwei ver-
schiedenen Kontakten derselbe anonyme Nutzer verbirgt, besteht in der Verwendung von
Cookies. Cookies sind Textdateien, die auf den Rechner des Besuchers einer Website ge-
schrieben werden, um diesen bei nachfolgenden Transaktionen zu identifizieren. In diesem
Fall erhalten Logdateien ein zusätzliches Feld, in dem eine nutzerspezifische Kennung fest-
gehalten wird13. Cookies können entweder für die Dauer einer Transaktion oder persistent,
zur Wiedererkennung des Nutzers bei erneuten Besuchen, vergeben werden. Allerdings be-
steht für den Nutzer immer die Möglichkeit, die Verwendung von Cookies auf dem eigenen
Rechner durch eine entsprechende Browserkonfiguration zu unterbinden bzw. die Cookies
manuell zu löschen. Selbst Cookies identifizieren lediglich einen bestimmten Rechner. Wird
dieser Rechner von mehreren Personen genutzt (z.B. Internetcafè), kann die Zuordnung von
Zugriffen zu einzelnen Transaktionen bzw. Personen nicht mehr gewährleistet werden. Erst
auf Basis einer eindeutigen Nutzeridentifikation, die einen Nutzer auch bei wiederholten Be-
suchen wiedererkennt, kann nach transaktionsübergreifenden Verhaltensmustern gesucht
werden.
Bei der Benutzerregistrierungmuss sich der Besucher, um mit der Website interagieren zu
können, registrieren lassen. In diesem Rahmen bekommt er ein entsprechendes Login und
Passwort zugewiesen, mit dem er sich in Zukunft authentifizieren muss. Auf diesem Wege
wird die Zusammenfassung der Logdateieinträge zu Transaktionen erzwungen. Allerdings
ist die Akzeptanz dieses Verfahrens bei den Anwendern nicht sehr hoch anzusiedeln.
Eine weitere Möglichkeit Besucher zu identifizieren ist das URL-Rewriting. Die Verwendung
von URL-Rewriting setzt die Möglichkeit zur Generierung dynamischer HTML-Seiten voraus,
da jede Seite, die vomWWW-Server an den Client versendet wird, eindeutige benutzerspezi-
fische Informationen beinhaltet. Bei diesem Mechanismus wird zunächst beim ersten Zugriff
eines Besuchers eine eindeutige Kennung erzeugt. Fordert der Besucher eine Ressource
von dem WWW-Server an, integriert der Server die Identifizierungsnummer des Besuchers
in die URL der angeforderten Seite. Ist einem Nutzer des Online-Angebotes z.B. die Kennung
142q78 zugeteilt, wird der URL der Parameter sessionid mit dem Wert 142q78 angehängt
(z.B. http://www.planet.de/shop.html?sessionid=142q78). URL-Rewriting ist eine Methode,
die sich vor allem dann anbietet, wenn der Client-Browser Cookies nicht unterstützt oder
der Benutzer Cookies deaktiviert hat. Ein Nachteil dieser Methode, ohne spezielle Mecha-
nismen14 ist die Sichtbarkeit der Identifizierungsnummer. Die Identifizierungsnummer lässt
13 Vgl. Abschnitt 4.2.214 Dabei werden temporär begrenzte Session-IDs eingesetzt, d.h. wenn über einen definierten Zeitraum hinwegkeine Aktion von dem Besucher auf der Website durchgeführt wurde, verfällt die entsprechende Session-ID.
39

Kapitel 5. Prozess des Web Log Mining
sich somit leicht manipulieren, so dass es möglich ist, dass ein Benutzer eine Seite mit der
Kennnummer eines anderen Benutzers aufruft15.
Eine Form der Benutzeridentifikation ohne Login und Passwort bieten die sogenannten Hid-
den Form Fields (versteckte Formularfelder). Hierzu muss jedes HTML-Dokument, das an
den Client gesandt wird, als Formular definiert werden. Diese spezielle HTML-Seite enthält
ein auf Clientseite nicht sichtbares, verstecktes Feld. In diesem Feld wird z.B. eine spe-
zifische Besucherkennung übertragen. Das Prinzip ist ähnlich dem URL-Rewriting, jedoch
wird die Besucherkennung hier nur einmal in den HTML-Quelltext kodiert, während sie bei
Verwendung von URL-Rewriting für jeden einzelnen Hyperlink vorliegt16.
Heuristische Verfahren verwenden ausschließlich die Attribute der Protokolldatei und Do-
mänenwissen über die Website, um Ressourcenabrufe von Besuchern zu Transaktionen
zusammenfassen zu können. Grundsätzlich differenzieren sich die verwendeten Verfahren
durch ihre Nutzung der verfügbaren Attribute zur Transaktionsableitung. Anhand der Tabelle
5.9 soll die Vorgehensweise heuristischer Verfahren verdeutlicht werden.
Tabelle 5.9.: Exemplarische Logdatei
Im dargestellten Beispiel erfolgen viele Ressourcenabrufe über einen Proxy-Server (proxy.
planet.de) mit dem gleichen Browser- und Betriebssystemtypen (Agent2). Die Möglichkeit
einer Identifizierung der Transaktionen anhand der Internetadresse oder dem Agentfeld ist
also nicht gegeben, da die Einträge in der Logdatei gleich sind. In diesem Zusammenhang
ist davon auszugehen, dass ein Besucher beim Abrufen der Seiten nicht den Browser oder
das Betriebssystem wechselt. Da diese beiden Attribute zur Ermittlung von Transaktionen
nur bedingt anwendbar sind, wird die Zeitkomponente für die Identifikation hinzugezogen.
Das Standardverfahren zur Identifizierung von Transaktionen anhand der Zeitkomponente
ist ein Zeitfensterverfahren. Sind zwei Zugriffe länger als das gegebene Zeitfenster vonein-
ander entfernt, werden sie verschiedenen Transaktionen zugeordnet. Liegen für eine Web-
site bereits identifizierte Transaktionen vor (eventuell mittels anfänglich gesetztem Zeitfen-
ster oder durch Beschränkung auf die unkritischen Transaktionen), kann die Verteilung der
15 Vgl. [RENN99] S. 2 f.16 Vgl. [SCHO] S. 1
40

5.3. Transaktionsidentikation und Datentransformation
Transaktions-Dauern geschätzt werden und daraus ein für die Website spezifisches Zeitin-
tervall bestimmt werden. Als Zeitfenster wird in der Praxis häufig ein Intervall von 30 Minuten
gewählt17. Erfolgt die Transaktionsabgrenzung auf Basis des Agentfeldes, des Hostfeldes
und mit einem Zeitfenster von 30 Minuten, so werden auf Grundlage der in Tabelle 5.9 ge-
zeigten Logdateieinträge die in Tabelle 5.10 dargestellten Transaktionen abgeleitet.
Tabelle 5.10.: Transaktionsidentifikation mit einem Zeitfenster
Wie dem Beispiel entnehmbar ist, wurde zunächst eine Differenzierung anhand des Agentfel-
des und des Hostfeldes vorgenommen. So können zwei Transaktionen identifiziert werden.
Die Unterscheidung zwischen der zweiten und dritten Transaktion wurde anhand eines Zeit-
fensters von 30 Minuten getroffen. Im Gegensatz zu den technischen Verfahren muss der
Anwender bei den heuristischen Verfahren Domänenwissen in den Transaktionsableitungs-
prozess einbringen18 (z.B. zur Schätzung der kritischen Referenzdauer). Damit übt er aber
auch erheblichen Einfluss auf die Ergebnisse aus. Um eine verzerrungsfreie Transaktions-
ableitung zu gewährleisten, ist in der Praxis die Datengrundlage dahingehend zu prüfen, ob
zumindest eine Teilmenge der Transaktionen durch Anwendung technischer Verfahren abge-
leitet werden kann. In diesem Fall steht eine valide Datengrundlage zur Verfügung, auf deren
Basis die Schätzung der kritischen Referenzdauer erfolgen kann. Ein großer Nachteil heu-
ristischer Verfahren besteht darin, dass potentiell falsch abgegrenzte Transaktionen erzeugt
werden, die in den Mustererkennungsprozess einfließen. Dies ist der Fall, wenn mehrere Be-
sucher zeitnah mit identischen Browser- und Betriebssystemtypen (Agentdaten) über einen
Proxy-Server auf eine Website zugreifen. Zur Zeit findet eine Marktbereinigung unter den
ISP und im Browsermarkt statt, was zur Folge hat, das weniger unterschiedliche Internet-
adressen und Browserdaten in den Logdateien protokolliert werden und dadurch eine Diffe-
renzierung der Transaktionen erschwert wird. In einer solchen Situation führen heuristische
Verfahren mehrere Nutzer zu einer Transaktion zusammen. Weiterhin sollte beachtet wer-
den, dass für die Transaktionsableitung je nach Umfang der Protokolldaten ein erheblicher
Rechenaufwand nötig ist. Das Ergebnis der Transaktionsableitung, die Transaktionsdaten,
bilden die Basis für die Datentransformationsphase.
17 Vgl. [BROG00] S. 94, [COOL99] S. 1318 Vgl. [BENS01a] S. 142 f.
41
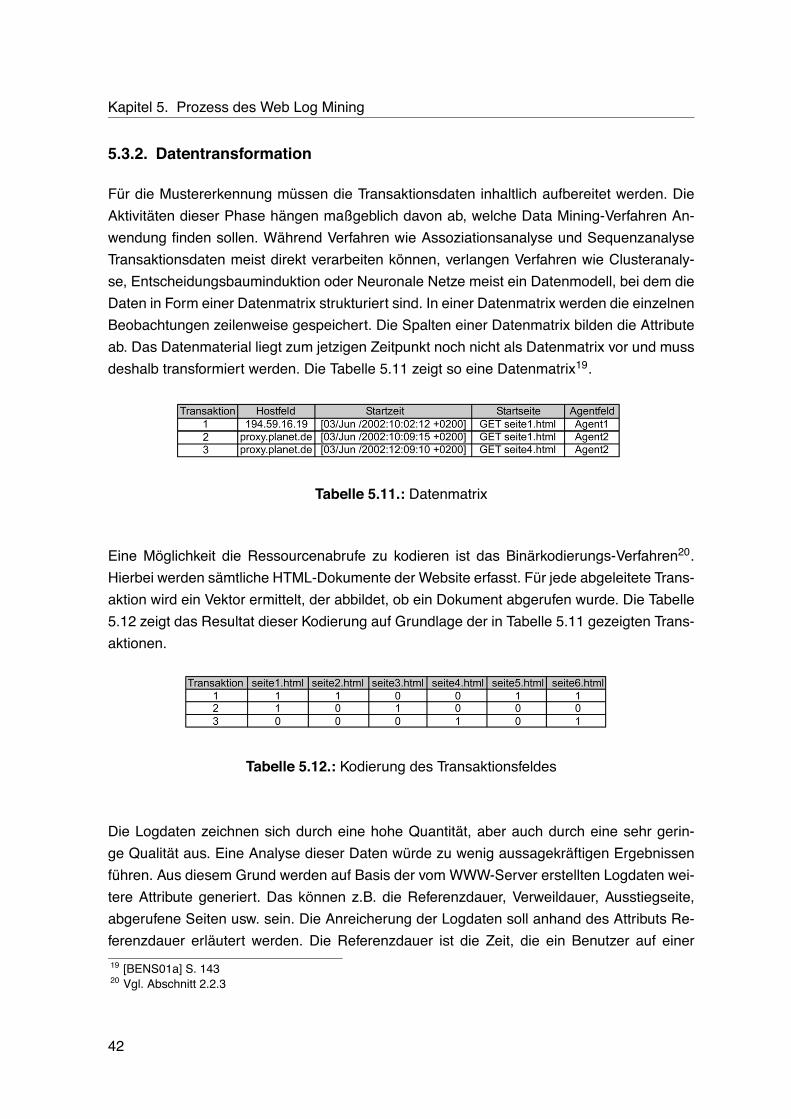
Kapitel 5. Prozess des Web Log Mining
5.3.2. Datentransformation
Für die Mustererkennung müssen die Transaktionsdaten inhaltlich aufbereitet werden. Die
Aktivitäten dieser Phase hängen maßgeblich davon ab, welche Data Mining-Verfahren An-
wendung finden sollen. Während Verfahren wie Assoziationsanalyse und Sequenzanalyse
Transaktionsdaten meist direkt verarbeiten können, verlangen Verfahren wie Clusteranaly-
se, Entscheidungsbauminduktion oder Neuronale Netze meist ein Datenmodell, bei dem die
Daten in Form einer Datenmatrix strukturiert sind. In einer Datenmatrix werden die einzelnen
Beobachtungen zeilenweise gespeichert. Die Spalten einer Datenmatrix bilden die Attribute
ab. Das Datenmaterial liegt zum jetzigen Zeitpunkt noch nicht als Datenmatrix vor und muss
deshalb transformiert werden. Die Tabelle 5.11 zeigt so eine Datenmatrix19.
Tabelle 5.11.: Datenmatrix
Eine Möglichkeit die Ressourcenabrufe zu kodieren ist das Binärkodierungs-Verfahren20.
Hierbei werden sämtliche HTML-Dokumente der Website erfasst. Für jede abgeleitete Trans-
aktion wird ein Vektor ermittelt, der abbildet, ob ein Dokument abgerufen wurde. Die Tabelle
5.12 zeigt das Resultat dieser Kodierung auf Grundlage der in Tabelle 5.11 gezeigten Trans-
aktionen.
Tabelle 5.12.: Kodierung des Transaktionsfeldes
Die Logdaten zeichnen sich durch eine hohe Quantität, aber auch durch eine sehr gerin-
ge Qualität aus. Eine Analyse dieser Daten würde zu wenig aussagekräftigen Ergebnissen
führen. Aus diesem Grund werden auf Basis der vom WWW-Server erstellten Logdaten wei-
tere Attribute generiert. Das können z.B. die Referenzdauer, Verweildauer, Ausstiegseite,
abgerufene Seiten usw. sein. Die Anreicherung der Logdaten soll anhand des Attributs Re-
ferenzdauer erläutert werden. Die Referenzdauer ist die Zeit, die ein Benutzer auf einer
19 [BENS01a] S. 14320 Vgl. Abschnitt 2.2.3
42
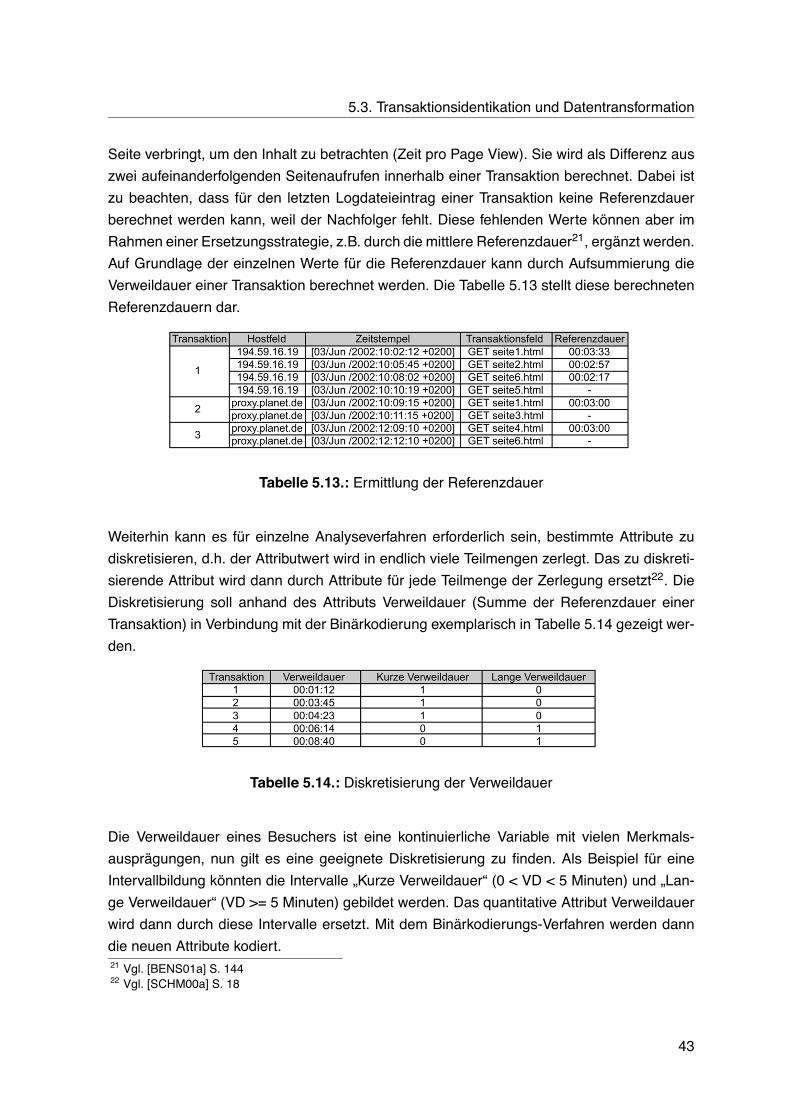
5.3. Transaktionsidentikation und Datentransformation
Seite verbringt, um den Inhalt zu betrachten (Zeit pro Page View). Sie wird als Differenz aus
zwei aufeinanderfolgenden Seitenaufrufen innerhalb einer Transaktion berechnet. Dabei ist
zu beachten, dass für den letzten Logdateieintrag einer Transaktion keine Referenzdauer
berechnet werden kann, weil der Nachfolger fehlt. Diese fehlenden Werte können aber im
Rahmen einer Ersetzungsstrategie, z.B. durch die mittlere Referenzdauer21, ergänzt werden.
Auf Grundlage der einzelnen Werte für die Referenzdauer kann durch Aufsummierung die
Verweildauer einer Transaktion berechnet werden. Die Tabelle 5.13 stellt diese berechneten
Referenzdauern dar.
Tabelle 5.13.: Ermittlung der Referenzdauer
Weiterhin kann es für einzelne Analyseverfahren erforderlich sein, bestimmte Attribute zu
diskretisieren, d.h. der Attributwert wird in endlich viele Teilmengen zerlegt. Das zu diskreti-
sierende Attribut wird dann durch Attribute für jede Teilmenge der Zerlegung ersetzt22. Die
Diskretisierung soll anhand des Attributs Verweildauer (Summe der Referenzdauer einer
Transaktion) in Verbindung mit der Binärkodierung exemplarisch in Tabelle 5.14 gezeigt wer-
den.
Tabelle 5.14.: Diskretisierung der Verweildauer
Die Verweildauer eines Besuchers ist eine kontinuierliche Variable mit vielen Merkmals-
ausprägungen, nun gilt es eine geeignete Diskretisierung zu finden. Als Beispiel für eine
Intervallbildung könnten die Intervalle „Kurze Verweildauer“ (0 < VD < 5 Minuten) und „Lan-
ge Verweildauer“ (VD >= 5 Minuten) gebildet werden. Das quantitative Attribut Verweildauer
wird dann durch diese Intervalle ersetzt. Mit dem Binärkodierungs-Verfahren werden dann
die neuen Attribute kodiert.21 Vgl. [BENS01a] S. 14422 Vgl. [SCHM00a] S. 18
43

Kapitel 5. Prozess des Web Log Mining
5.4. Data Mining
Auf der Grundlage der transformierten Transaktionsdaten erfolgt in der Phase des Data Mi-
ning die Mustererkennung. Im Rahmen dieses Abschnitts sollen Data Mining-Aufgaben und
Verfahren im Kontext des Web Log Mining betrachtet werden. Die Aufgabe des Data Mining
ist die automatische und nichttriviale Suche nach Wissen in großen Datenbeständen. Darauf
aufbauend können folgende Ziele definiert werden: die Vorhersage und die Beschreibung23.
Bei der Vorhersage wird versucht, auf Grund der Transaktionsdaten unbekannte und zukünf-
tige Ereignisse vorauszusagen. Die Beschreibung versucht, Daten(-gruppen) zu beschrei-
ben und sie, u.U. mit Hilfe von geeigneten Visualisierungsmethoden, gut interpretierbar dar-
zustellen. Die Unterscheidung zwischen beschreibenden und vorhersagenden Modellen ist
allerdings nicht sehr ausgeprägt, da vorhersagende Modelle einerseits einen beschreiben-
den Charakter haben, andererseits beschreibende Modelle ebenfalls zur Vorhersage genutzt
werden können.
5.4.1. Aufgaben des Data Mining
Die Aufgaben des Data Mining werden in der Literatur nicht einheitlich beschrieben24. Für
das Spezialgebiet Web Log Mining lassen sich insbesondere die Aufgaben Segmentierung,
Klassifikation, Abhängigkeitsentdeckung und Abweichungsentdeckung differenzieren, wel-
che nachfolgend erläutert werden sollen25.
Abbildung 5.2.: Data Mining-Ziele und Data Mining-Aufgaben, Vgl. [KIMM00] S. 17
Die Aufgabe der Segmentierung ist die Unterteilung der Daten in sinnvolle und interessante
Klassen (Segmente). Auf der Basis von Distanzmaßen soll dabei innerhalb eines Segments
23 [FAYY96] S. 1224 [KÜPP99] S. 7725 Vgl. [ALPR00b] S. 9 ff., [KIMM00] S. 15 ff., [NEEB99] S. 33 ff., [RUNK00] S. 64 ff.
44

5.4. Data Mining
eine höchstmögliche Homogenität, zwischen den Segmenten eine größtmögliche Heteroge-
nität erreicht werden. Der Grad der Homogenität und die Anzahl der Segmente kann vom
Benutzer über Parameter bestimmt werden. Die Segmentierung wird häufig zur Einteilung
von Kunden in Zielgruppen verwendet, um eine möglichst zielgruppenorientierte Marketing-
Aktivität zu realisieren. Dazu werden die Kundendaten und Transaktionen über einen gewis-
sen Zeitraum analysiert, wobei ähnliche Verhaltensmuster identifiziert werden.
Bei der Klassifikation liegen gegebene oder durch Segmentierung ermittelte Klassen vor,
die durch Regeln oder Funktionen beschrieben werden. Ergebnis ist einerseits die Ursa-
chenforschung von Ereignissen und anderseits die Prognosefähigkeit durch eine Abhängig-
keitsbeschreibung. Regeln sind häufig einfacher zu verstehen. Dafür ergeben Funktionen
meistens genauere Beschreibungen oder Prognosen. Der Unterschied zwischen der Klassi-
fikation und der Segmentierung liegt darin, dass bei der Klassifizierung vordefinierte Klassen
verwendet werden, während bei der Segmentierung diese erst generiert werden. Aus die-
sem Grund können mit der Klassifikation auch keine Klassen entdeckt werden, die zuvor
noch unbekannt oder nicht definiert wurden.
Ziel der Abhängigkeitsentdeckung ist es, ein Modell für aussagekräftige Abhängigkeiten
von Variablen zu finden. Dieses beschreibt dann einerseits auf einer strukturellen Ebene,
welche Variablen lokal voneinander abhängig sind, und andererseits auf einer quantitativen
Ebene, welche numerischen Werte der Stärke dieser Abhängigkeiten zugeordnet sind. Die
Abhängigkeiten werden in Form von Assoziationsregeln dargestellt.
Die Abweichungserkennung beschäftigt sich mit Objekten, die sich keinem Muster ein-
deutig zuordnen lassen. Bei diesen Ausreißern kann es sich um fehlerfreie, interessante
Merkmalsausprägungen handeln oder aber um fehlerhafte Daten, die keine realen Sach-
verhalte beschreiben. Die Zielsetzung der Abweichungsanalyse besteht darin, die Ursachen
für die untypischen Merkmalsausprägungen des Ausreißers aufzudecken. Auch signifikante
Änderungen in Bezug auf vorher definierte oder gemessene Werte sollen erkannt werden.
5.4.2. Verfahren des Data Mining
In diesem Abschnitt sollen Data Mining-Verfahren aufgezeigt und erläutert werden, die im
Kontext des Web Log Mining Anwendung finden können. In der Abbildung 5.3 werden die
im Abschnitt 5.4.1 erläuterten Data Mining-Aufgaben den nachfolgenden Verfahren zugeord-
net26.
26 Vgl. [KIMM00] S. 17, [BENS01b] S. 30, [ALPR00b] S. 13
45

Kapitel 5. Prozess des Web Log Mining
Abbildung 5.3.: Data Mining-Aufgaben und Data Mining-Verfahren, Vgl. [KIMM00] S. 17
Die Abbildung 5.3 erhebt keinen Anspruch auf Vollständigkeit. Einige dieser Verfahren kön-
nen für mehr als eine der hier aufgeführten Data Mining-Aufgaben verwendet werden, wobei
zur Lösung eines Problems oft eine Kombination von mehreren Verfahren verwendet wird.
Im Rahmen der folgenden Betrachtungen werden die Verfahren Clusteranalyse, Entschei-
dungsbauminduktion, Assoziationsanalyse, Pfad- und Sequenzanalyse, Neuronale Netze
und deskriptive Statistik vorgestellt.
5.4.2.1. Clusteranalyse
Mit Hilfe der Clusteranalyse sollen Elemente einer Eingabemenge gruppiert werden, indem
Daten mit ähnlichen Eigenschaften in einer Gruppe zusammengefasst werden. Die Grup-
penbildung erfolgt unter der Bedingung, dass die Wahrscheinlichkeit für das Vorhandensein
der tatsächlichen Struktur in den Daten maximiert wird27. Auch die Gruppen (Cluster), die
gebildet werden, sind (im Gegensatz zur Klassifikation) noch nicht definiert. Bei diesem Mu-
stererkennungsverfahren wird die Distanz genutzt, um innerhalb der Daten und Datensätze
Strukturen zu erkennen. Für die Clusteranalyse lassen sich zwei Schritte differenzieren28. In
dem ersten Schritt erfolgt die Auswahl und Anwendung eines Distanzmaßes29 zur Bestim-
mung der Ähnlichkeit von verschiedenen Objekten. Im zweiten Schritt werden die Objekte
auf der Basis ihrer Ähnlichkeitswerte durch einen Fusionierungsalgorithmus zusammenge-
fasst. Im Rahmen der Marketingforschung wird Clusteranalyse eingesetzt, um Konsumenten
mit gleichen bzw. ähnlichen Eigenschaften zu Gruppen zusammenzufassen. Die resultie-
rende Clusterbildung liefert dabei die Informationsgrundlage für eine zielgruppenspezifische
Marktbearbeitung. Die Clusteranalyse wird auch zum Identifizieren von Ausreißern einge-
setzt. Dabei werden z.B. Fehler oder Probleme erkannt, die vorher noch nicht aufgetreten
sind oder bekannt waren.
27 Vgl. [GROB99] S. 11, [RUNK00] S. 7228 Vgl. [BACK00] S. 26229 Einen Überblick liefert [GRIM98] S. 115 ff.
46

5.4. Data Mining
Die Abbildung 5.4 zeigt ein mögliches Ergebnis einer Clusteranalyse mit den Attributen Ver-
weildauer und Uhrzeit. Die identifizierten Transaktionsgruppen repräsentieren Kundenseg-
mente und können die Grundlage für eine segmentspezifische Marktanalyse bilden.
Abbildung 5.4.: Clusteranalyse von Besuchern
Bei der Modellierung von Clustern ist darauf zu achten, dass diese möglichst homogen sind
und eine minimale Anzahl von Clustern erreicht wird und damit eine maximale Genauigkeit.
Die nützliche oder relevante Anzahl der Cluster sollte der Anwender definieren, da er am
besten mit der Problemstellung vertraut ist. Eine Clusteranalyse einer Menge von WWW-
Seiten zu einer kleineren Anzahl homogener Cluster ist von Interesse, wenn eine größere
Website in kleinere Teil-Websites gegliedert werden soll. Das Ziel ist hierbei die anschlie-
ßende Klassifikation von Benutzern nach den Zugriffen auf die Teilbereiche der Website. Die
Ausgangsmenge der Website besteht in diesem Fall aus den Seiten der in Frage stehenden
Website. Die meisten Websites besitzen bereits eine natürliche Gliederung, so zum Beispiel
eine Gliederung der Unterseiten nach bestimmten inhaltlichen Aspekten, was die Einteilung
wesentlich erleichtern kann. Eine zweite Möglichkeit besteht in einem Rückgriff auf das durch
die URL der Ressourcen gegebene hierarchische Gliederungsschema der Website. Werden
für jede Ebene dieser Hierarchie alle Seiten zu einem Cluster zusammengefasst, deren URL
auf die obere Ebene verweisen, liefert dies eine hierarchische Klassifikation der Seiten. Eine
weitere Möglichkeit WWW-Seiten zu clustern ist, die Generierung geeigneter Daten in Form
von Eigenschaften von WWW-Seiten. Die Textgrundlage für die Generierung kann dabei von
der betreffenden Seite selbst stammen oder aus Seiten, die auf die entsprechende Seite ver-
weisen, extrahiert werden30. Diese Möglichkeit fällt aber mehr in den Definitionsbereich des
Web Content Mining und wird im Rahmen des Web Log Mining nicht näher betrachtet.
30 Vgl. [SCHM00b] S. 12 ff.
47

Kapitel 5. Prozess des Web Log Mining
5.4.2.2. Neuronale Netze
Neuronale Netze sind aus dem Wunsch heraus entstanden, das menschliche Gehirn mit-
samt seiner Lernfähigkeit nachzubilden. In Analogie zu einem Neuron im Gehirn ist das
Grundelement eines Neuronalen Netzes ein Verarbeitungselement, das mehrere gewichtete
Eingänge, eine Transfer- oder Aktivierungsfunktion und einen Ausgang besitzt. Die schema-
tische Darstellung eines Neurons ist in Abbildung 5.5 zu sehen.
Abbildung 5.5.: Schema eines Neurons, Vgl. [LUST02] S. 310
Die Lernfähigkeit besteht in der Anpassung der einzelnen Kantengewichte zwischen den ein-
zelnen Neuronen. Dabei wird die Informationsverarbeitung in zwei Schritten durchgeführt. Im
ersten Schritt werden die Eingabewerte (e1, e2, ..., en) mit den Faktoren (g1, g2, ..., gn) in-
dividuell gewichtet und aufsummiert (Kombinationsfunktion). Im zweiten Schritt geht das im
ersten Schritt ermittelte Ergebnis in die Transferfunktion ein, um den Ausgabewert zu berech-
nen. Die einzelnen Neuronen werden zu einem neuronalen Netz verbunden, das über eine
Eingabeschicht mit Eingabedaten versorgt wird und über eine Ausgabeschicht Ergebnisse
liefert. Darüber hinaus verfügen die meisten neuronalen Netze über eine oder mehrere ver-
borgene Verarbeitungsschichten31. Die Abbildung 5.6 zeigt eine schematische Darstellung
eines neuronalen Netzes.
Bevor ein neuronales Netz eingesetzt werden kann, muss es im Rahmen der Lernphase mit
Trainingsdaten konfiguriert werden. Dabei ist zwischen überwachtem und unüberwachtem
Lernen zu unterscheiden.
Überwachtes Lernen wird meist dazu verwendet, um Anwendungen zur Klassifizierung und
Vorhersage zu realisieren. Dazu werden in einer Lernphase mit Hilfe von Trainingsdaten die
Verknüpfungen zwischen den Verarbeitungseinheiten angepasst, so dass bei einem vorge-
gebenen Eingangssignal ein Soll-Ausgabemuster eintritt. Ein solches Netz zu trainieren ist
ein Prozess, in dem das Netz gleichzeitig Mengen von Ein- und Ausgabewerten zum Test be-
reit gestellt bekommt. Das Netz trainiert sich, indem es jedes Eingabe-Muster aufnimmt, ein
31 Vgl. [BENS01a] S. 122
48
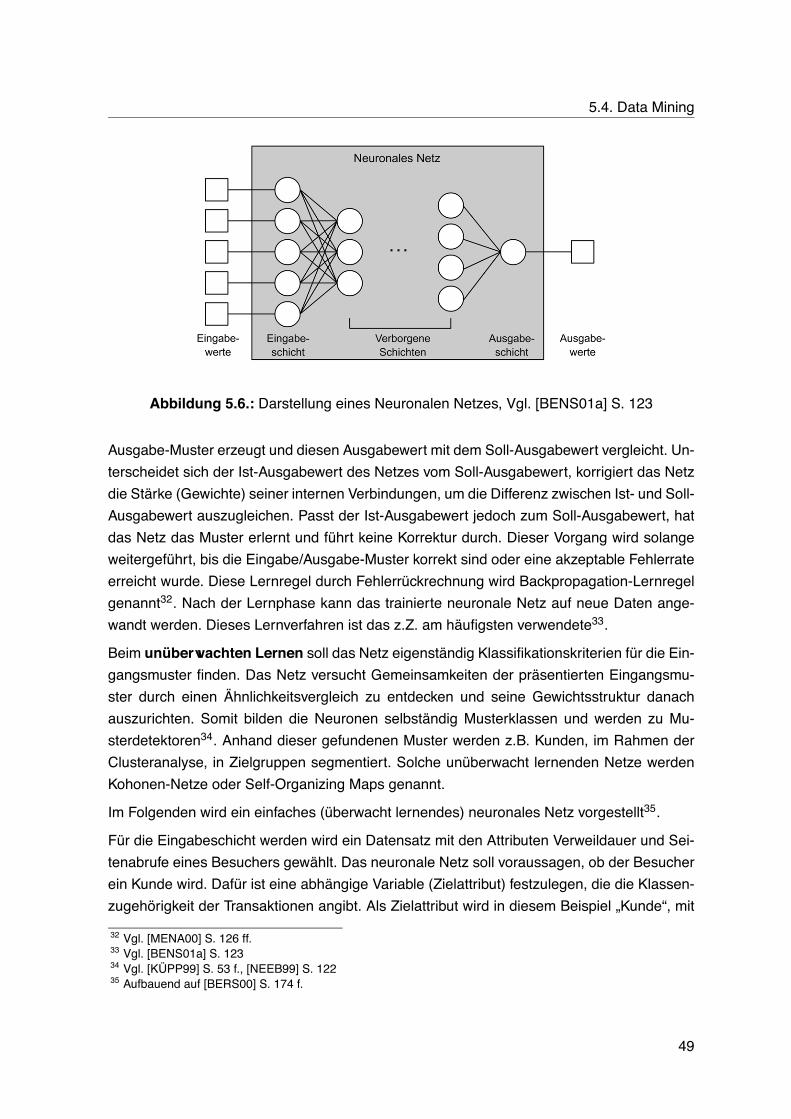
5.4. Data Mining
Abbildung 5.6.: Darstellung eines Neuronalen Netzes, Vgl. [BENS01a] S. 123
Ausgabe-Muster erzeugt und diesen Ausgabewert mit dem Soll-Ausgabewert vergleicht. Un-
terscheidet sich der Ist-Ausgabewert des Netzes vom Soll-Ausgabewert, korrigiert das Netz
die Stärke (Gewichte) seiner internen Verbindungen, um die Differenz zwischen Ist- und Soll-
Ausgabewert auszugleichen. Passt der Ist-Ausgabewert jedoch zum Soll-Ausgabewert, hat
das Netz das Muster erlernt und führt keine Korrektur durch. Dieser Vorgang wird solange
weitergeführt, bis die Eingabe/Ausgabe-Muster korrekt sind oder eine akzeptable Fehlerrate
erreicht wurde. Diese Lernregel durch Fehlerrückrechnung wird Backpropagation-Lernregel
genannt32. Nach der Lernphase kann das trainierte neuronale Netz auf neue Daten ange-
wandt werden. Dieses Lernverfahren ist das z.Z. am häufigsten verwendete33.
Beim unüberwachten Lernen soll das Netz eigenständig Klassifikationskriterien für die Ein-
gangsmuster finden. Das Netz versucht Gemeinsamkeiten der präsentierten Eingangsmu-
ster durch einen Ähnlichkeitsvergleich zu entdecken und seine Gewichtsstruktur danach
auszurichten. Somit bilden die Neuronen selbständig Musterklassen und werden zu Mu-
sterdetektoren34. Anhand dieser gefundenen Muster werden z.B. Kunden, im Rahmen der
Clusteranalyse, in Zielgruppen segmentiert. Solche unüberwacht lernenden Netze werden
Kohonen-Netze oder Self-Organizing Maps genannt.
Im Folgenden wird ein einfaches (überwacht lernendes) neuronales Netz vorgestellt35.
Für die Eingabeschicht werden wird ein Datensatz mit den Attributen Verweildauer und Sei-
tenabrufe eines Besuchers gewählt. Das neuronale Netz soll voraussagen, ob der Besucher
ein Kunde wird. Dafür ist eine abhängige Variable (Zielattribut) festzulegen, die die Klassen-
zugehörigkeit der Transaktionen angibt. Als Zielattribut wird in diesem Beispiel „Kunde“, mit
32 Vgl. [MENA00] S. 126 ff.33 Vgl. [BENS01a] S. 12334 Vgl. [KÜPP99] S. 53 f., [NEEB99] S. 12235 Aufbauend auf [BERS00] S. 174 f.
49

Kapitel 5. Prozess des Web Log Mining
Abbildung 5.7.: Neuronales Netz für die Vorhersage des Besucherverhaltens
den Ausprägungen „Ja“ oder „Nein“, gewählt. Üblicherweise akzeptieren Neuronale Netze
als Eingabewerte numerische Werte in den Intervallen [-1;+1] oder [0;1]. Die Eingabewer-
te bilden in diesem Beispiel für die Verweildauer 650 Sekunden und für die Seitenabrufe 9
abgerufene Ressourcen. Nach deren Normalisierung36 folgen die Werte 0,65 und 0,9 (Ab-
bildung 5.8). Danach werden normalisierten Eingangswerte mit ihren Gewichten multipliziert
und zu einem Ergebnis addiert. Es folgt (0,65∗0,7)+(0,9∗0,3)=0,725.
Abbildung 5.8.: Ergebnisnetz für die Vorhersage des Besucherverhaltens
Um eine Aussage über das Navigationsverhalten des Besuchers treffen zu können, wurde
das vorliegende Netz so trainiert, dass ein Wert von 0 einen Besucher indiziert, der kein
Kunde wird und ein Wert von 1 einen Kunden identifiziert, der Schwellwert liegt bei 0,5. Der
Ergebniswert von 0,725 liegt über dem Schwellwert, somit wird vermutet, dass der Besucher
ein Kunde wird.
Neuronale Netze stellen einen interessanten Ansatz bei der Gestaltung adaptiver Websites
dar. So könnte ein neuronales Netz etwa aus den bisherigen Bewegungen eines Besuchers
versuchen, seine künftigen Bewegungen abzuleiten und entsprechende Links anbieten. Die-
ser Ansatz wurde aber noch nicht weiterverfolgt37. Neuronale Netze werden in Bereichen
eingesetzt, wo eine Vorhersage und eine Suche nach zusammengehörigen Mustern nötig
36 Als Maximum wurde für die Verweildauer 1000 und für die Seitenabrufe 10 angenommen.37 Vgl. [SCHM00c] S. 24
50

5.4. Data Mining
ist. Beispiele für erfolgreiche Applikationen liegen in den Bereichen Evaluierung des Pfän-
dungsrisikos, Produktionskontrolle, Handschrift- und Zeichenerkennung38 und Kreditkarten-
betrug. Der Nachteil der neuronalen Netze besteht allerdings bei sehr großen Datenmengen
in einer sehr langen Rechenzeit. Für den Anwender präsentieren sich Neuronale Netze als
schwer interpretierbare Black Box-Systeme und sind deshalb für die Generierung verständ-
licher Hypothesen nur bedingt geeignet39.
5.4.2.3. Entscheidungsbauminduktion
Die Entscheidungsbauminduktion kann eingesetzt werden, um charakteristische, diskrimi-
nierende Merkmale für Transaktionsklassen zu identifizieren und die Klassenzugehörigkeit
von Transaktionen zu bestimmen. Zu diesem Zweck ist ein ein Zielattribut festzulegen, das
die Klassenzugehörigkeit der Transaktionen angibt40. Entscheidungsbäume helfen, auf ein-
zelne Datensätze auch in größeren Datenbanken effizient zuzugreifen, d.h. die Zugriffszeiten
sind unabhängig von der Größe der Datenbank konstant, da aus der Datenbank nur noch
die Daten geladen werden, die für die Beantwortung der vorliegenden Bereichsabfrage be-
nötigt werden41. Die Erstellung des Baumes erfolgt anhand der vorhandenen, historischen
Daten. Basierend auf der meist schon vorhandenen Einteilung der Daten in Klassen werden
weitere Untergruppen gebildet. Mathematisch gesehen ist ein Entscheidungsbaum ein ge-
richteter Graph mit Knoten und Kanten. Die Knoten stellen die unterschiedlichen Attribute
dar, die Kanten ihre möglichen Werte. Der Ursprungsknoten eines Entscheidungsbaumes
heißt Wurzelknoten. Der Wurzelknoten stellt das Attribut dar, das den Datensatz bezüglich
eines Informationskriteriums am besten klassifiziert. Dieses Informationskriterium ist die ei-
gentliche Basis der Klassifikation, denn es stellt ein Maß für den Informationsgewinn bei
einer Verzweigung bezüglich des Zielattributes dar. Ausgehend von diesem Wurzelknoten
teilt sich der Baum in weitere Zweige, die ihrerseits die entscheidenen Teilmengen nach die-
sem Informationskriterium am besten klassifizieren. Knoten, die sich nicht weiter aufspalten
lassen, heißen Blätter. Das Ziel ist, die Blätter des Baumes so homogen wie möglich zu ge-
stalten, d.h. die Daten sollten bezüglich des ausgewählten Merkmals relativ gleiche Werte
annehmen42.
In Abbildung 5.9 wird ein stark vereinfachtes Beispiel eines Entscheidungsbaumes darge-
stellt. Als Zielattribut wurde gewählt, ob ein Besucher etwas kauft oder nicht. Es wird ein
Entscheidungsbaum gesucht, der anhand der Merkmale Referrer und der Verweildauer mög-
lichst gut prognostiziert, ob ein Besucher etwas auf der Website kauft oder nicht. Mit Hilfe
38 Ein renommiertes Unternehmen in diesem Bereich ist die PLANET AG (http://www.planet.de).39 Vgl. [BENS01a] S. 12540 [BENS01a] S. 15441 [GROB99] S. 9 f.42 [DIED99] S. 63 f.
51

Kapitel 5. Prozess des Web Log Mining
Abbildung 5.9.: Exemplarischer Entscheidungsbaum
von Wenn-Dann-Abfragen können dann die geltenden Regeln innerhalb des Datensatzes
abgefragt werden. Aus dem Entscheidungsbaum lassen sich direkt die generierten Regeln
ablesen. Für das dargestellte Beispiel aus Abbildung 5.9 lässt sich z.B. folgende Regel ab-
lesen:
Wenn Referrer = Bannerwerbung und Verweildauer > 120 Sekunden dann Käufer
Insbesondere in den tieferen Verzweigungen des Baumes wird der Einfluss von zufälligen
Elementen (fehlende Werte, Ausreißer in den Daten) größer, was zu einer Übermodellierung
des Entscheidungsbaumes führen kann. Zur Umgehung des Problems bieten sich entspre-
chende Pruning-Verfahren43 an, die nur eine bestimmte maximale Tiefe der Bäume zulassen
oder eine Mindestanzahl der Objekte pro Knoten definieren.
5.4.2.4. Assoziationsanalyse
Das Ziel der Assoziationsanalyse ist die Entdeckung von Abhängigkeiten zwischen Teilmen-
gen von Daten44. Die Vorgabe eines Zielattributs, wie bei der Entscheidungsbauminduktion,
ist nicht notwendig, vielmehr wird die Suche auf statistisch auffällige Muster beschränkt45.
Ausgangspunkt ist eine Menge von Objekten, die durch binäre Attribute beschrieben werden
(liegt vor/liegt nicht vor). Die Objekte werden durch die Menge der vorliegenden Attribute be-
schrieben. Dabei werden Regeln folgender Form gesucht: Besitzt ein Objekt die Attribute
43 Das sind Beschneidungstechniken, die diejenigen Teilbäume entfernen, die nur eine geringe Bedeutung fürdas Klassifikationsergebnis besitzen.
44 [SCHM00a] S. 245 Vgl. [KÜPP99] S. 65
52

5.4. Data Mining
A, dann besitzt es auch die Attribute B (A ⇒ B). Die algorithmische Umsetzung der Analy-
severfahren zur Aufdeckung von Assoziationen basiert auf der Häufigkeitsbetrachtung von
Attributkombinationen. Dazu werden die Maße Konfidenz und Support definiert. Die Konfi-
denz einer Assoziationsregel A ⇒ B gibt an, wie oft bei Zutreffen von A auch tatsächlich B
zutrifft.
Konfidenz (Attribut A⇒ Attribut B) =Anzahl der Objekte die Attribut A und Attribut B enthaltenAnzahl der Objekte die Attribut A enthalten
Ein Anwendungsbeispiel könnte lauten: In 50 Prozent aller Fälle, bei denen ein Besucher
über ein Werbebanner bei yahoo.de auf die Website gelangte und die Website vorher drei
mal besucht hat, dann kauft er das Produkt A. Die Objekte sind hier Transaktionen von
Besuchern einer Website, die drei Attribute besitzen:
• der Referrer (über ein Werbebanner bei yahoo.de)
• die Anzahl der Besuche (Visits)
• die abgerufene Seite (der Kauf des Produkts A)
Der Support einer Attributmenge gibt an, wie häufig die Attribute gemeinsam innerhalb des
gesamten Datenbestandes vorkommen.
Support (Attribut A, Attribut B) =Anzahl der Objekte die Attribut A und Attribut B enthaltenAnzahl aller Objekte
Das Anwendungsbeispiel um den Support erweitert, lautet: In 50 Prozent aller Fälle, bei
denen ein Besucher über ein Werbebanner bei yahoo.de auf die Website gelangte und die
Website vorher drei mal besucht hat, dann kauft er das Produkt A, dies kommt bei insgesamt
5 Prozent aller Transaktionen vor.
Durch die Vorgabe einer Mindest-Konfidenz und einemMindest-Support kann gesteuert wer-
den, ab wann eine Assoziation als interessant anzusehen ist. Wenn keine Vorgaben gemacht
werden, können in einer umfangreichen Datenbasis fast beliebig viele Assoziationen auftre-
ten. Um die Regelmenge der Assoziationsanalyse zu begrenzen, kann ein zeitorientiertes
Kosumentenverhaltensmodell eingesetzt werden, das die Dauer der Referenzdauer berück-
sichtigt46. Dieses Konzept selektiert nur diejenigen Protokolleinträge, deren Referenzdauer
einen bestimmten Zeitraum überschreitet. Auf dieseWeise werden nur die Abrufe von HTML-
Dokumenten für die Assoziationsanalyse berücksichtigt, die von den Besuchern ausreichend
lang genug betrachtet wurden.
46 Vgl. [COOL99] S. 21 f.
53

Kapitel 5. Prozess des Web Log Mining
Eine Standardanwendung von Assoziationsregeln im Web Log Mining ist die Beschreibung
von Zugriffsmustern. Die Regel produktA.html⇒ produktB.html0,04; 0,5 besagt, dass 50 Pro-
zent aller Besucher, die die Seite produktA.html aufrufen, auch die Seite produktB.html
besuchen, dies kommt in 4 Prozent aller Transaktionen vor. Diese statistische Hypothese
kann vom Anwender nur sinnvoll interpretiert werden, wenn entsprechendes Domänenwis-
sen über die Inhalte der assoziierten Dokumente vorhanden ist. Sofern dieses Wissen nicht
vorhanden ist, können technische Verfahren eingesetzt werden, die das notwendige Wis-
sen über die Inhalte der referenzierten Dokumente bereitstellen. Die Bereitstellung dieses
Wissens kann im Anschluss an die Mustererkennung erfolgen, indem die Metadaten47 der
entsprechenden HTML-Dokumente ausgelesen werden48. Auf Basis der Ergebnisse der As-
soziationsanalyse können Webdesigner die HTML-Seiten anpassen oder ihre Anordnung
optimieren. Eine Verknüpfung entdeckter Seitenkombinationen durch entsprechende Ver-
weise kann dazu beitragen, die Benutzerfreundlichkeit der Website zu verbessern. Die Asso-
ziationsanalyse eignet sich, um diejenigen Seiten der Webpräsenz zu identifizieren, die am
häufigsten gemeinsam aufgerufen werden, jedoch können Assoziationsregeln keine Aus-
sage über die Reihenfolge der Aufrufe liefern. Damit Aussagen über die Reihenfolge der
Aufrufe getroffen werden können, wird die Pfad- und Sequenzanalyse eingesetzt49.
5.4.2.5. Pfad- und Sequenzanalyse
Für die Untersuchung von Navigationsreihenfolgen lassen sich zwei Analyseverfahren diffe-
renzieren: die Pfadanalyse und die Sequenzanalyse. Die Pfadanalyse erlaubt, auf der Basis
der abgeleiteten Transaktionen, die Identifikation der am häufigsten verwendeten Navigati-
onspfade (Klickpfade). Zu diesem Zweck wird für jede Transaktion die Menge der Teilpfade
ermittelt, auf denen Seiten erstmalig referenziert werden50. Ein Beispiel eines Navigations-
pfades einer Transaktion für eine gegebene Webpräsenz wird in der Abbildung 5.10 grafisch
dargestellt.
47 Metadaten sind standardisierte Informationen, die ein HTML-Dokument formal und inhaltlich beschreiben.48 [BENS01a] S. 146 f.49 [BENS99a] S. 1150 [BENS99a] S. 11
54

5.4. Data Mining
Abbildung 5.10.: Navigationspfad einer Transaktion
Die in der Abbildung 5.10 dargestellten Transaktion besucht ein Nutzer die HTML-Dokumente
in der Reihenfolge:
index.html→ produkte.html→ produktA.html→ produkte.html→ produktB.html→produkte.html→ index.html→ support.html
Auf der Basis dieses Navigationspfads werden diejenigen Pfade ermittelt, auf denen neue
Seiten abgerufen werden. Diese vorwärtsgerichteten Pfade lauten für das dargestellte Bei-
spiel folgender Maßen:
index.html→ produkte.html→ produktA.html
index.html→ produkte.html→ produktB.html
index.html→ support.html
Wird dieser Prozess für alle Transaktionen durchgeführt, können die am häufigsten besuch-
ten Teilpfade ermittelt werden. Die Ergebnisse der Pfadanalyse sind für einen Webmaster
sehr interessant, denn so erfährt er, über welche Wege die Besucher zu bestimmten Doku-
menten oder Bildern gelangt sind. Ein Designer könnte den Ergebnissen entnehmen, wie
der Besucher durch die Website navigierte und ob es Pfade oder Punkte gibt, über die viele
Besucher die Website verlassen51.
Sowohl die Assoziations- als auch die Pfadanalyse betrachten die Abhängigkeiten zwischen
den Attributen lediglich auf der Ebene einzelner Transaktionen. Für das Web Log Mining sind
jedoch auch Aussagen von Interesse, die sich auf alle Transaktionen eines Kunden beziehen
51 Vgl. [MENA00] S. 82
55

Kapitel 5. Prozess des Web Log Mining
und zeitliche Abhängigkeiten aufdecken. Im Zuge dieser Fragestellung sind intertransaktio-
nale Muster zu generieren, während bei der Assoziations- und Pfadanalyse lediglich intra-
transaktionale Muster gefunden werden können. Mit der Sequenzanalyse ist es möglich,
die zeitliche Abfolge der Transaktionen zu berücksichtigen. Mit ihrer Hilfe lassen sich typi-
sche Bewegungspfade der Besucher auf der Website analysieren. Unter der Voraussetzung
einer transaktionsübergreifenden Nutzeridentifikation kann auch die Abfolge verschiedener
Besuche eines Nutzers analysiert werden52. Ein möglicher Ansatz könnte das Setzen von
persistenten Cookies sein53. In diesem Fall können zusätzlich Aussagen über die zeitliche
Entwicklung des Besucherverhaltens getroffen werden. So lässt sich beispielsweise ermit-
teln, nach welcher Anzahl von Besuchen durchschnittlich eine Bestellung erfolgt oder in wel-
chem zeitlichen Abstand Wiederholungskäufe getätigt werden. Es können also Aussagen
folgender Art abgeleitet werden: 10 Prozent der Kunden, die auf der Seite produktA.html
eine Online-Bestellung durchführen, plazieren innerhalb von 15 Tagen auch eine Online-
Bestellung auf der Seite produktB.html. Zentrale Voraussetzung für die Durchführung von
Sequenzanalysen ist die transaktionsübergreifende Identifikation eines Benutzers. Da aus
Leistungs- und Sicherheitsgründen viele Internetzugänge mit Proxy-Servern ausgestattet
sind, ist die Benutzeridentifikation allerdings problematisch. Selbst wenn die Internetadres-
se des Benutzers protokolliert wird, ist dies keine Garantie dafür, dass auch wirklich dersel-
be Benutzer den Client-Browser bedient hat. Für sequenzanalytische Fragestellungen bietet
sich daher der Einsatz technischer Maßnahmen (z.B. Registierungsformulare) an, um die
Authentifizierung des Benutzers zu erzwingen54.
5.4.2.6. Deskriptive Statistik
Die am weit verbreitetste Analysemethode im Kontext des Web Log Mining stellen klassische
statistische Verfahren dar. Zahlreiche Analyseprogramme nutzen die deskriptive Statistik zur
Auswertung von Server-Logdateien. Deskriptive Statistik, auch beschreibende Statistik ge-
nannt, stellt Verfahren zur Verfügung, die das ungeordnet vorliegende Datenmaterial nach
Maßgabe definierter Kategorien ordnet, grafisch oder tabellarisch darstellt und die Gesamt-
heit der Dateninformation in einfachen Kennwerten etwa dem arithmetischen Mittel, Minima
oder Maxima verdichtet55. Website-Analyseprogramme importieren die Server-Logdateien
in eine integrierte Datenbank, die die Daten wiederum in zusammenfassende Berichte oder
Graphen umwandeln. Diese Daten können dann noch feiner skaliert werden, bis sie den dif-
ferenzierten Anforderungen des Anwenders genügen. So könnte es den Marketingmanager
interessieren, wie effektiv Werbekampagnen waren. Werbefachleute und Kooperationspart-
52 [BENS99a] S. 1253 Vgl. Abschnitt 4.2 und 5.3.154 [BENS99a] S. 1255 Vgl. [RAUH00] S. 2
56

5.5. Evaluation und Interpretation
ner möchten wissen, wie oft über ein Werbebanner zur Zielseite durchgeklickt wurde. Die
meisten dieser Analysetools liefern Statistiken wie die:
• beliebtesten Seiten
• Frequentation der Website
• Ein- und Ausstiegsseiten der Besucher
• durchschnittliche Verweildauer
• häufigsten Suchbegriffe
• Neugewinn von Besuchern pro Monat
• Herkunft der Besucher
• technische Ausstattung usw.
Die Abbildung 5.11 zeigt eine typische Ansicht eines Website-Analyseprogramms. Hier wird
die Anzahl der Page Views einer Website in Abhängigkeit der Tageszeit grafisch dargestellt.
Abbildung 5.11.: Beispielchart von täglichen Page Views
Website-Analyseprogramme stellen den Verkehr der Website nach verschiedenen Kriterien
grafisch dar und liefern umfangreiche skalierbare Gesamtansichten. Die Ausgabe dieser Be-
richte kann in verschiedenster Weise erfolgen, als Standard hat sich das Generieren von
HTML-Berichten etabliert, es werden aber auch verschiedene andere Dateiformate wie z.B.
für Adobe Acrobat, Microsoft Excel oder Word unterstützt.
5.5. Evaluation und Interpretation
Im Rahmen der Evaluation ist festzustellen, welche Bedeutung die Analyseergebnisse in
Bezug auf das Domänenwissen des Anwenders besitzen56. Im Zuge der Evaluation ist für56 Vgl. Abschnitt 2.2.5
57

Kapitel 5. Prozess des Web Log Mining
die entdeckten Muster festzustellen, ob es sich um einen bereits bekannten Zusammenhang
handelt, oder ob ein neuer Zusammenhang entdeckt wurde. Die Analyse einer Website be-
zieht Mitarbeiter aus verschiedenen Abteilungen wie IT, Marketing, Vertrieb, Einkauf usw. mit
ein. In jedem Fall werden sämtliche Personen, die für das Design und die Pflege der Web-
site verantwortlich sind, an dem Prozess beteiligt sein. Ist die Datenanalyse abgeschlossen,
sollten die erzielten Ergebnisse mit allen Beteiligten besprochen und analysiert werden. Ex-
perten, die auf bestimmte Bereiche im Unternehmen spezialisiert sind, sollten von den Er-
gebnissen der Analyse unterrichtet werden, um die Richtigkeit und Eignung der Ergebnisse
für die Erreichung der geschäftlichen Ziele zu bestätigen57. Aus managementorientierter
Perspektive wird mit dem Abschluss des Web Log Mining-Prozesses die informatorische
Grundlage für die Ausgestaltung internetbasierter Marketinginstrumente hergestellt. Bei der
Interpretation sind daher auch immer Effekte zu beachten, die aus der Umgestaltung der
Website resultieren, wie zum Beispiel Aktionen, die die Website in ihrer Struktur oder ihrem
Inhalt verbessern oder verändern.
57 Vgl. [MENA00] S. 207 f.
58

6. Vorstellen von Data Mining-Programmenim Kontext des Web Log Mining
In diesem Kapitel soll ein kurzer Überblick über die Software gegeben werden, die im Rah-
men des Web Log Mining-Prozesses in Kapitel 7 Anwendung findet. In diesem Zusammen-
hang werden drei kommerzielle Programme und ihre Data Mining Funktionalitäten vorge-
stellt1.
6.1. Websuxess 4.0
Der Markt für Logdatei-Analyseprogramme mit klassischen deskriptiven Auswertungsfunk-
tionen ist sehr groß. Der Marktführer im deutschsprachigen Raum ist Websuxess 4.0 von
Exody2. Dieses Programm implementiert zahlreiche deskriptive Analysefunktionen und die
Pfadanalyse. Ein großer Vorteil dieses Programms ist seine IVW-Konformität3. Damit ein
schneller Einstieg in die Handhabung des Programms gewährleistet ist, bietet Websuxess
eine umfangreiche deutschsprachige Hilfe, sowie Tutorials für unterschiedliche Anwender-
gruppen. Weiterhin wird Anfängern ein Assistent zur Seite gestellt, der die wichtigsten Pro-
grammfunktionalitäten leicht verständlich erklärt. Eine praktische Funktion ist, bestimmte
HTML-Seiten zu Gruppen zusammenzufassen, um bspw. nur bestimmte Bereiche der Web-
site zu analysieren. Auch bietet Websuxess Filterfunktionen die es erlauben, uninteressante
oder nichtrelevante Einträge der Logdatei4 auszuschließen.
Die Bedienoberfläche (Abbildung 6.1) von Websuxess ist übersichtlich aufgebaut. Auf der
1 In diesem Rahmen wurde auch das kostenlose Programm WEKA 3.2 (http://www.cs.waikato.ac.nz/∼ml/) ge-testet. Dieses Analyseprogramm wurde an der Universität von Waikato in Neuseeland entwickelt. Es stelltVerfahren zur Segmentierung, Klassifizierung und Abhängigkeitsentdeckung zur Verfügung. WEKA erfülltedie Anforderungen in puncto Qualität und Quantität bei der Verarbeitung großer und komplexer Datenmengennicht (sehr langsame Verarbeitung, viele Abstürze). Auch die grafische Aufbereitung der Analyseergebnisseist nicht bzw. nur sehr eingeschränkt vorhanden. Aus diesen Gründen kann WEKA für das Web Log Miningnur sehr begrenzt eingesetzt werden und wird deshalb in dieser Arbeit nicht genauer vorgestellt.
2 http://www.exody.de3 Vgl. Abschnitt 4.3.14 Vgl. Abschnitt 5.2
59
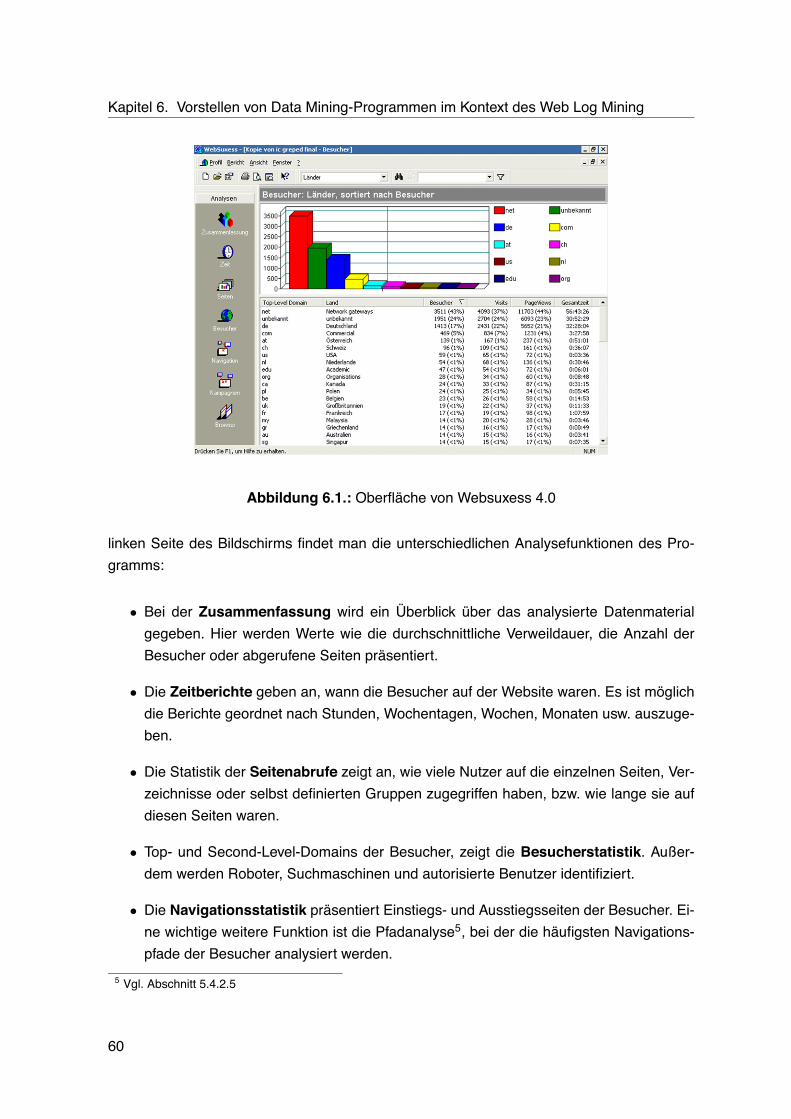
Kapitel 6. Vorstellen von Data Mining-Programmen im Kontext des Web Log Mining
Abbildung 6.1.: Oberfläche von Websuxess 4.0
linken Seite des Bildschirms findet man die unterschiedlichen Analysefunktionen des Pro-
gramms:
• Bei der Zusammenfassung wird ein Überblick über das analysierte Datenmaterialgegeben. Hier werden Werte wie die durchschnittliche Verweildauer, die Anzahl der
Besucher oder abgerufene Seiten präsentiert.
• Die Zeitberichte geben an, wann die Besucher auf der Website waren. Es ist möglichdie Berichte geordnet nach Stunden, Wochentagen, Wochen, Monaten usw. auszuge-
ben.
• Die Statistik der Seitenabrufe zeigt an, wie viele Nutzer auf die einzelnen Seiten, Ver-zeichnisse oder selbst definierten Gruppen zugegriffen haben, bzw. wie lange sie auf
diesen Seiten waren.
• Top- und Second-Level-Domains der Besucher, zeigt die Besucherstatistik. Außer-dem werden Roboter, Suchmaschinen und autorisierte Benutzer identifiziert.
• Die Navigationsstatistik präsentiert Einstiegs- und Ausstiegsseiten der Besucher. Ei-ne wichtige weitere Funktion ist die Pfadanalyse5, bei der die häufigsten Navigations-
pfade der Besucher analysiert werden.
5 Vgl. Abschnitt 5.4.2.5
60

6.2. XAffinity 3.0
• Die Kampagnenanalyse liefert einen Überblick der Seiten, über die die Besucher aufdie Website gelangt sind (Referrer). Weiterhin werden die genutzten Suchmaschinen
und Suchbegriffe der Nutzer dargestellt.
• Die Browserberichte liefern umfangreiche Informationen über die eingesetzte Brow-ser und Betriebssystemsoftware der Besucher. Außerdem werden die technischen Fä-
higkeiten (z.B. Cookies) der Browser erkannt.
Auf der rechten Bildschirmseite befindet sich der Arbeitsbereich. Hier werden die Analyse-
ergebnisse in vielfältiger Form grafisch und textuell gezeigt. Dabei können die Ergebnisse
nach unterschiedlichen Kriterien sortiert werden. Außerdem sind analysierte URLs mit Hy-
perlinks hinterlegt, sodass per Mausklick gleich auf die entsprechende Seite im Internet
gelangt werden kann. Damit die unterschiedlichen Analyseergebnisse spezifisch und über-
sichtlich dargestellt werden können, bietet Websuxess unterschiedliche Darstellungsmög-
lichkeiten (Balken-, 3D-, Tortendiagramme, usw.) der Analyseergebnisse. Die Ergebnisse
können als HTML-Bericht, ASCII- oder CSV-Datei exportiert werden.
6.2. XAffinity 3.0
XAffinity von der amerikanischen Firma Exclusive Ore6 ist ein Programm, das in erster Li-
nie für Warenkorbanalysen entwickelt wurde. Um eine Analyse mit XAffinity durchführen zu
können, wird zunächst ein neues Projekt angelegt. Dabei wird über ODBC7 oder OLE DB8
eine Verbindung zu einer Datenbank aufgebaut. XAffinity unterstützt die Datenbanksysteme
Microsoft SQL Server 6.5, Microsoft SQL Server 7.0, Microsoft Access, Oracle 8i, RedBrick
Warehouse und WhiteCross. In der geöffnenten Datenbank werden von XAffinity spezielle
Tabellen angelegt, in denen die Analyseergebnisse gespeichert werden. Wenn die zu ana-
lysierenden Daten nicht in den obengenannten Formaten vorliegen, besteht die Möglichkeit,
die gewünschten Daten zu importieren.
Diese Importmöglichkeit ist aber nur bei Nutzung der Microsoft Access-Datenbank gegeben.
Dabei werden ausschließlich CSV-Dateien unterstützt. Bevor die Analyse gestartet werden
kann, werden die entsprechenden Parameter (z.B. Konfidenz oder Support) definiert. Da-
nach kann eine Analysemethode gewählt werden. Da XAffinity für Warenkorbanalysen ent-
wickelt wurde, werden lediglich die Assoziations- und Sequenzanalyse unterstützt.
Nach der Analyse werden die gefundenen Regeln wahlweise in tabellarischer oder grafischer
Form (Abbildung 6.2) ausgegeben. Die grafische Darstellung der Assoziationsergebnisse6 http://www.xore.com7 ODBC (Open Database Connectivity) ist eine Datenbankschnittstelle, die eine Verbindung zwischen unter-schiedlichen Datenbanksystemen herstellen kann.
8 OLE DB ist, ähnlich wie ODBC, eine Datenbankschnittstelle von Microsoft.
61
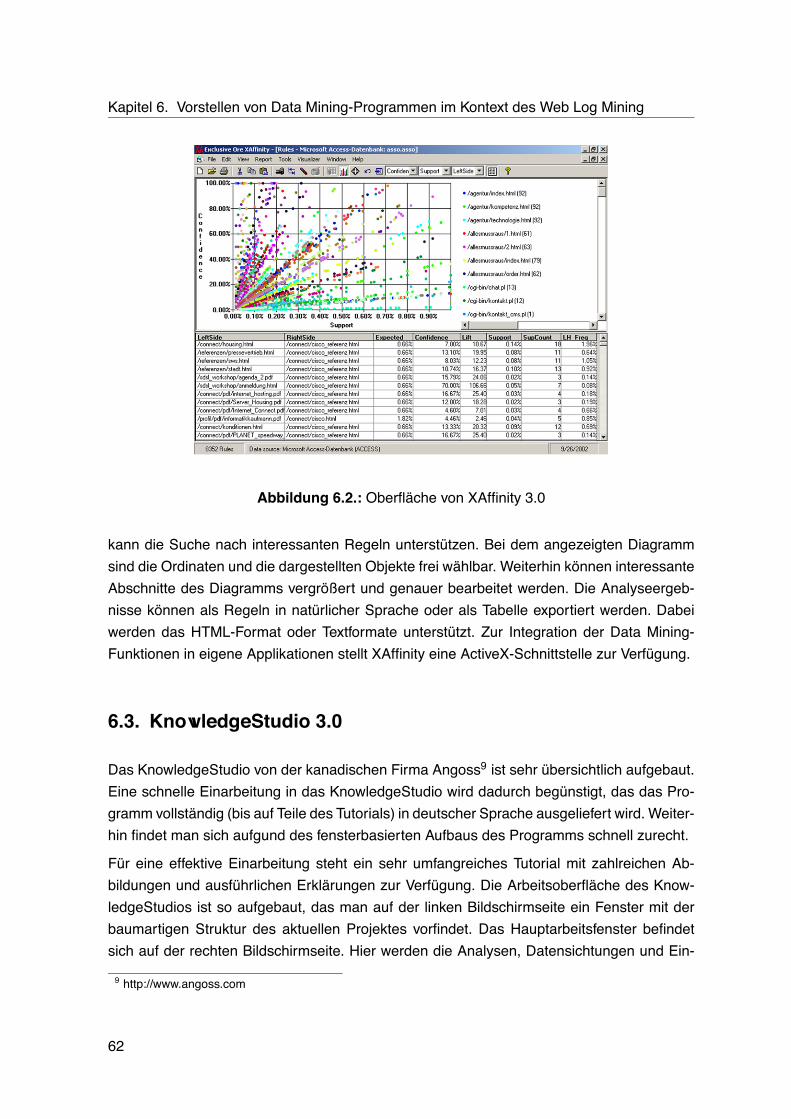
Kapitel 6. Vorstellen von Data Mining-Programmen im Kontext des Web Log Mining
Abbildung 6.2.: Oberfläche von XAffinity 3.0
kann die Suche nach interessanten Regeln unterstützen. Bei dem angezeigten Diagramm
sind die Ordinaten und die dargestellten Objekte frei wählbar. Weiterhin können interessante
Abschnitte des Diagramms vergrößert und genauer bearbeitet werden. Die Analyseergeb-
nisse können als Regeln in natürlicher Sprache oder als Tabelle exportiert werden. Dabei
werden das HTML-Format oder Textformate unterstützt. Zur Integration der Data Mining-
Funktionen in eigene Applikationen stellt XAffinity eine ActiveX-Schnittstelle zur Verfügung.
6.3. KnowledgeStudio 3.0
Das KnowledgeStudio von der kanadischen Firma Angoss9 ist sehr übersichtlich aufgebaut.
Eine schnelle Einarbeitung in das KnowledgeStudio wird dadurch begünstigt, das das Pro-
gramm vollständig (bis auf Teile des Tutorials) in deutscher Sprache ausgeliefert wird. Weiter-
hin findet man sich aufgund des fensterbasierten Aufbaus des Programms schnell zurecht.
Für eine effektive Einarbeitung steht ein sehr umfangreiches Tutorial mit zahlreichen Ab-
bildungen und ausführlichen Erklärungen zur Verfügung. Die Arbeitsoberfläche des Know-
ledgeStudios ist so aufgebaut, das man auf der linken Bildschirmseite ein Fenster mit der
baumartigen Struktur des aktuellen Projektes vorfindet. Das Hauptarbeitsfenster befindet
sich auf der rechten Bildschirmseite. Hier werden die Analysen, Datensichtungen und Ein-
9 http://www.angoss.com
62
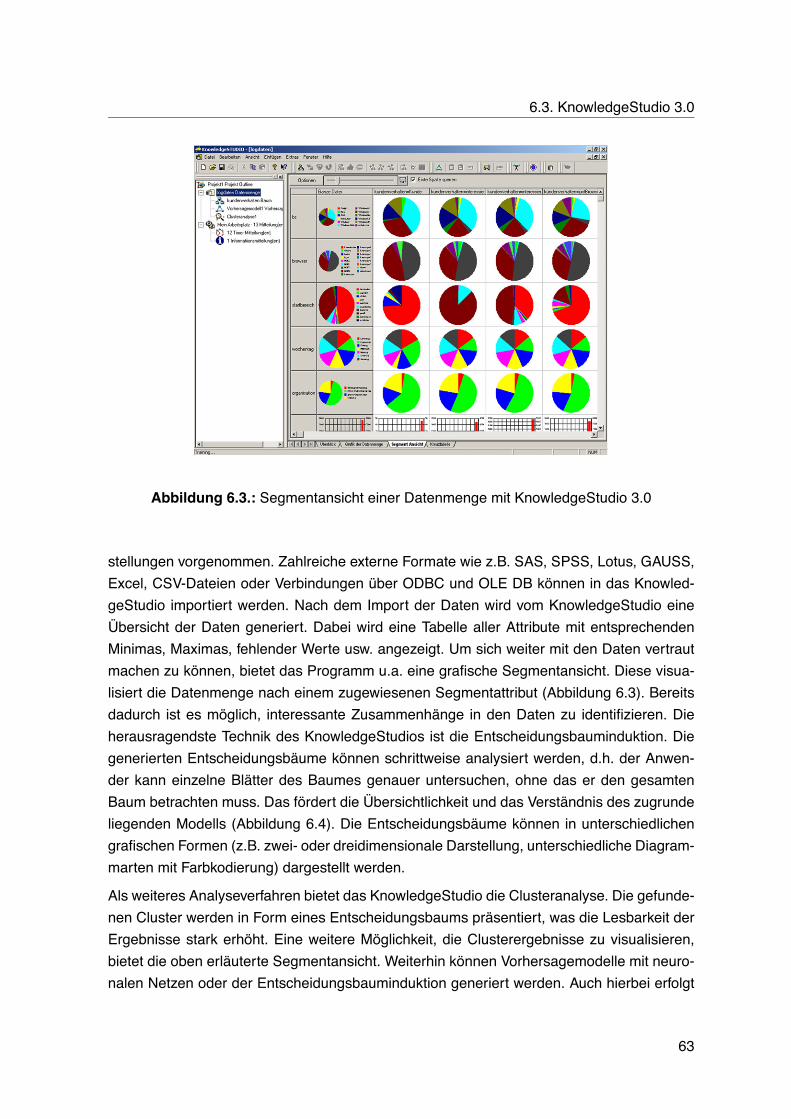
6.3. KnowledgeStudio 3.0
Abbildung 6.3.: Segmentansicht einer Datenmenge mit KnowledgeStudio 3.0
stellungen vorgenommen. Zahlreiche externe Formate wie z.B. SAS, SPSS, Lotus, GAUSS,
Excel, CSV-Dateien oder Verbindungen über ODBC und OLE DB können in das Knowled-
geStudio importiert werden. Nach dem Import der Daten wird vom KnowledgeStudio eine
Übersicht der Daten generiert. Dabei wird eine Tabelle aller Attribute mit entsprechenden
Minimas, Maximas, fehlender Werte usw. angezeigt. Um sich weiter mit den Daten vertraut
machen zu können, bietet das Programm u.a. eine grafische Segmentansicht. Diese visua-
lisiert die Datenmenge nach einem zugewiesenen Segmentattribut (Abbildung 6.3). Bereits
dadurch ist es möglich, interessante Zusammenhänge in den Daten zu identifizieren. Die
herausragendste Technik des KnowledgeStudios ist die Entscheidungsbauminduktion. Die
generierten Entscheidungsbäume können schrittweise analysiert werden, d.h. der Anwen-
der kann einzelne Blätter des Baumes genauer untersuchen, ohne das er den gesamten
Baum betrachten muss. Das fördert die Übersichtlichkeit und das Verständnis des zugrunde
liegenden Modells (Abbildung 6.4). Die Entscheidungsbäume können in unterschiedlichen
grafischen Formen (z.B. zwei- oder dreidimensionale Darstellung, unterschiedliche Diagram-
marten mit Farbkodierung) dargestellt werden.
Als weiteres Analyseverfahren bietet das KnowledgeStudio die Clusteranalyse. Die gefunde-
nen Cluster werden in Form eines Entscheidungsbaums präsentiert, was die Lesbarkeit der
Ergebnisse stark erhöht. Eine weitere Möglichkeit, die Clusterergebnisse zu visualisieren,
bietet die oben erläuterte Segmentansicht. Weiterhin können Vorhersagemodelle mit neuro-
nalen Netzen oder der Entscheidungsbauminduktion generiert werden. Auch hierbei erfolgt
63

Kapitel 6. Vorstellen von Data Mining-Programmen im Kontext des Web Log Mining
Abbildung 6.4.: Entscheidungsbaum des KnowledgeStudios
die Ausgabe der Prognoseergebnisse als Entscheidungsbaum. Die Regeln, die die Ana-
lyseverfahren identifiziert haben, können textuell in natürlicher Sprache ausgegeben oder
z.B. als SAS-, Excel- oder CSV-Format exportiert werden. Zur Integration der Data Mining-
Funktionen in eigene Anwendungen stellt Angoss eine ActiveX-Schnittstelle zur Verfügung.
64
7. Der Prozess des Web Log Mining -Anhand der Internetpräsenz der PLANETinternet commerce GmbH
In diesem Kapitel soll der Prozess des Web Log Mining, einschließlich der in Abschnitt 5.4.2
erläuterten Data Mining-Verfahren, anhand der Internetpräsenz der PLANET internet com-
merce GmbH1 (Abbildung 7.1) auf seine praktische Anwendbarkeit untersucht werden. Au-
ßerdem wird geprüft, inwieweit die vorgestellten Data Mining-Verfahren zur Unterstützung
unternehmerischer Entscheidungen im Kontext der Optimierung des Internetangebotes ein-
gesetzt werden können.
Abbildung 7.1.: Homepage der PLANET internet commerce GmbH
Die Internetpräsenz der PLANET internet commerce GmbH dient in erster Linie zur eigenen
1 http://www.planet-ic.de
65

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Imagepflege. Dabei werden die Firma, Referenzprojekte, Kompetenzen und Knowhow prä-
sentiert. In diesem Rahmen werden die vertriebenen Produkte vorgestellt bzw. eine Online-
Demonstration eines CMS2, des s.g. Satellite XL, angeboten. Weiterhin dient die Homepage
als eine Art Kommunikationsplattform mit den PLANET GmbH-Kunden, der Presse und Part-
nern. In diesem Zusammenhang werden PLANET interne Veranstaltungsinformationen und
aktuelle Informationen zur Verfügung gestellt. Im Downloadbereich können sich Besucher
fachliche Informationen zum Thema Internettechnologien bzw. Vorträge oder Präsentatio-
nen von vergangenen Veranstaltungen herunterladen. Die Homepage stellt auch einen Dis-
tributionskanal für die angebotene Produktpalette dar. Dabei handelt es sich aber nur um
ausschließlich zeitlich begrenzte Verkaufsaktionen. Bei auftretenden Personalbedarf kön-
nen über die Homepage, im Form von Stellenausschreibungen, neue Mitarbeiter akquiriert
werden. Die Homepage umfasst 7 Bereiche mit ca. 130 Dokumenten. Eine detaillierte Be-
schreibung der einzelnen Websitebereiche wird in Tabelle 7.1 gegeben.
Tabelle 7.1.: Bereiche der PLANET GmbH-Homepage
7.1. Datengenerierung
Für die Analyse der Homepage der PLANET GmbH wurden die Logdateien von Februar
2002 bis einschließlich September 2002 herangezogen. Die Logdaten umfassen insgesamt
73 Megabyte (MB) und beinhalten ca. 386000 Einträge. Die Logdateien wurden von einem
Apache-Webserver generiert und liegen im Extended Log File-Format (ELF-Format3) vor.
Ein genauerer Überblick des Umfangs der Protokolldateien wird in Tabelle 7.2 gegeben4.
2 Content-Management-System3 Vgl. Abschnitt 4.1.54 Die verwendeten Logdaten liegen der CD unter \skripte\log.txt bei.
66

7.2. Datenselektion
Tabelle 7.2.: Umfang der PLANET GmbH-Logdateien
Cookies oder ähnliche Mechanismen werden auf der Homepage nicht eingesetzt. Auch in
rechtlicher Beziehung erfüllt der Datenbestand die bundesdeutschen Bestimmungen, denn
die Protokolldaten werden nicht mit Kundenprofilen oder ähnlichen Daten verknüpft5.
7.2. Datenselektion
In dieser Phase des Web Log Mining-Prozesses werden alle für die Analyse nicht relevanten
Einträge aus den Logdateien entfernt6. Dies waren in dem vorliegenden Datenbestand vor
allem zielgruppenfremde und nicht explizit vom Besucher angeforderte Elemente. Weiterhin
wurden alle mit der HEAD-Methode angefragten Seiten, sowie fehlerhaft abgerufenen Res-
sourcen7 und Besuche von nichtmenschlichen Nutzern, sogenannte Roboter, Spider oder
Crawler, herausgefiltert. Zielgruppenfremde Einträge wurden durch interne Abrufe und durch
Testdateien verursacht. Als nicht vom Besucher explizit angeforderte Ressourcen wurden in
erster Linie Dateien mit den Endungen gif, jpg und css8 identifiziert. Für die Filterung der
Logdateieinträge von nichtmenschlichen Nutzern, wurde zunächst eine Liste9 mit aktuellen
Robotern, Spidern oder Crawlern erstellt10 und auf dieser Basis die Logdatei gefiltert. Auch
5 Vgl. Abschnitt 3.26 Die umfangreichen Filter- und Transformationsoperationen der ersten Phasen des Web Log Mining-Prozesseswurden mit unterschiedlichen PERL-Skripten vorgenommen. Die verwendeten Skripte wurden in dem Ver-zeichnis \skripte\ auf der mitgelieferten CD hinterlegt. Auf die Syntax der Skripte soll im Rahmen dieserArbeit nicht genauer eingegangen werden. Die Filteroperationen der Datenselektionsphase wurden mit denPERL-Skripten \skripte\grep.pl und grep2.pl vorgenommen.
7 Hierbei handelt es sich auch um die Zugriffe von Viren oder Trojanern, die z.B. versuchen Programme aufdem WWW-Server auszuführen. Der Trojaner Code Red versucht bspw. die Datei cmd.exe auf IIS-Servern(Windows-Betriebssysteme) zu starten. Dabei prüft er nicht, welches Betriebssystem bzw. welchen WWW-Server das angegriffene System verwendet. Die PLANET-GmbH nutzt den Apache-Server und ein Linux-System, weshalb diese Aufrufe in den Logdaten als fehlerhaft abgerufene Ressourcen protokolliert werden.
8 CSS (Cascading Stylesheets) ist eine HTML-Ergänzungssprache, mit der HTML-Elemente formatiert werdenkönnen.
9 Die vollständige Liste der Spider und aller anderen gefilteren Objekte liegt auf der CD unter \skripte\spiderGrep.txt vor.
10 Umfangreiche Listen stellen [o.V.01b] und [o.V.02a] zur Verfügung.
67

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
alle aufeinanderfolgenden doppelten Ressourcenabrufe innerhalb einer Transaktion wurden
herausgefiltert. Dieser Sachverhalt wird in Tabelle 7.3 gezeigt.
Tabelle 7.3.: Doppelte Logdateieinträge
Diese Ressourcenabrufe können immer dann entstehen, wenn ein Besucher den Aktualisieren-
Knopf im Browser drückt. Die doppelten Einträge sind für die Analyse uninteressant, sodass
jeweils einer dieser Abrufe gelöscht wurde. Der Umfang der Logdateien hat sich dabei von
anfänglich 385858 auf 30983 Einträge verringert, was einer Abnahme des Datenbestandes
um fast 92 Prozent entspricht. Die Ursache für die starke Verringerung der Datenmenge
liegt im Aufbau der Homepage. Jedes Mal, wenn der Nutzer eine HTML-Seite abruft, wer-
den mindestens (abhängig von der jeweiligen Seite) 16 weitere Ressourcen dazugeladen,
wobei es sich dabei um überwiegend Grafiken der Navigations- und Gestaltungselemente
handelt. Durch diese Gestaltungsweise wird die Anzahl der Logdateieinträge stark erhöht.
Da es sich bei diesen Elementen um nicht explizit abgerufene Ressourcen handelt, werden
sie im Rahmen dieser Phase herausgefiltert. Die starke Verringerung des Datenbestandes
hat sich sehr positiv auf die Performanz der nachfolgenden Phasen ausgewirkt.
7.3. Transaktionsidentifikation und Datentransformation
7.3.1. Transaktionsidentifikation
Bei diesem Schritt wird versucht, Ressourcenabrufe von Besuchern, die in einem zeitlichen
Zusammenhang stehen, zu Transaktionen zusammenzufassen. Dadurch soll ein Kundenbe-
such simuliert werden, um eine möglichst reale Verkaufssituation zu schaffen. Aufgrund der
technischen Rahmenbedingungen gestaltet sich die Schaffung dieser Situation sehr schwie-
rig. Auf der Homepage der PLANET GmbH werden derzeit keine technischen Mechanismen
(z.B. Cookies) eingesetzt, um Transaktionen abzuleiten. Deshalb ist es nötig, heuristische
Verfahren zu Transaktionsidentifizierung heranzuziehen. In diesem Zusammenhang wurde
das Zeitfensterverfahren angewandt11. Dabei wird das Hostfeld, das Agentfeld und ein Zeit-
fenster zur Transaktionsableitung genutzt., d.h. immer dann, wenn bei Zugriffen Hostfeld und
11 Vgl. Abschnitt 5.3.1
68

7.3. Transaktionsidentifikation und Datentransformation
Agentfeld gleich sind und zwei Ressourcenabrufe nicht länger als das gegebene Zeitfenster
voneinander entfernt sind, werden diese Einträge einer Transaktion zugeordnet. Als Dau-
er des Fensters werden, in Anlehnung an Cooley12, 30 Minuten gewählt. Aufgrund dieses
Verfahrens konnten 13518 Transaktionen in dem Datenbestand identifiziert werden13.
7.3.2. Datentransformation
Für die Anwendung von Data Mining-Methoden müssen die Transaktionsdaten inhaltlich und
strukturell aufbereitet und ergänzt werden. In dieser Phase wurde insbesondere darauf ge-
achtet, das der Datenbestand inhaltlich erweitert wird, um möglichst aussagekräftige Ana-
lyseergebnisse zu erzielen. Je nach eingesetztem Analyseprogramm können Assoziations-
und Sequenzanalyse die Transaktionsdaten meist direkt verarbeiten oder müssen durch das
Binärkodierungs-Verfahren in eine andere Form gebracht werden. Für die Entscheidungs-
bauminduktion, Clusteranalyse oder Neuronale Netze eignet sich der Datenbestand in nicht
erweiterter Form nur sehr eingeschränkt, denn die Transaktionsdaten sind zu diesem Zeit-
punkt zu wenig differenziert, um daraus aussagekräftige Muster identifizieren zu können.
Weiterhin ist es für den Einsatz dieser drei Analysemethoden nötig, die Transaktionsdaten
in eine Datenmatrix zu überführen. In Tabelle 7.4 wird der Transaktionsdatenbestand in der
Rohform gezeigt.
12 [COOL99]13 Für die Transaktionsidentifikation wurde das PERL-Skript \skripte\trans.pl eingesetzt.
69
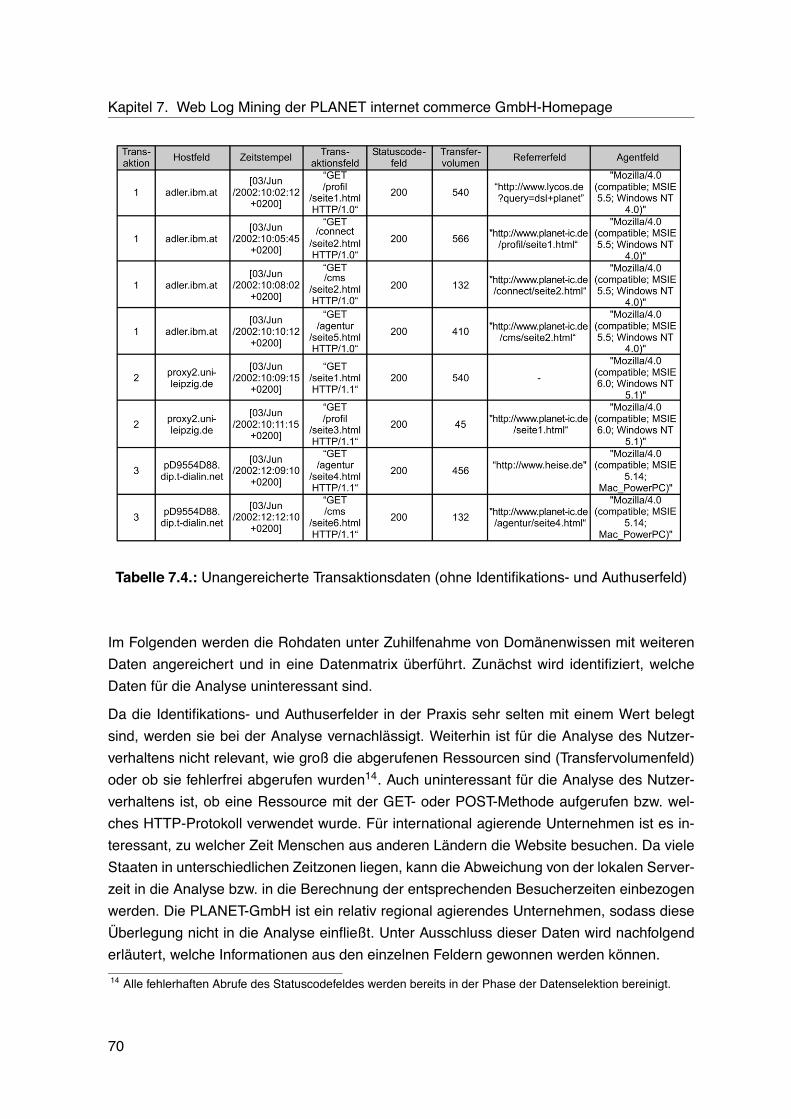
Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Tabelle 7.4.: Unangereicherte Transaktionsdaten (ohne Identifikations- und Authuserfeld)
Im Folgenden werden die Rohdaten unter Zuhilfenahme von Domänenwissen mit weiteren
Daten angereichert und in eine Datenmatrix überführt. Zunächst wird identifiziert, welche
Daten für die Analyse uninteressant sind.
Da die Identifikations- und Authuserfelder in der Praxis sehr selten mit einem Wert belegt
sind, werden sie bei der Analyse vernachlässigt. Weiterhin ist für die Analyse des Nutzer-
verhaltens nicht relevant, wie groß die abgerufenen Ressourcen sind (Transfervolumenfeld)
oder ob sie fehlerfrei abgerufen wurden14. Auch uninteressant für die Analyse des Nutzer-
verhaltens ist, ob eine Ressource mit der GET- oder POST-Methode aufgerufen bzw. wel-
ches HTTP-Protokoll verwendet wurde. Für international agierende Unternehmen ist es in-
teressant, zu welcher Zeit Menschen aus anderen Ländern die Website besuchen. Da viele
Staaten in unterschiedlichen Zeitzonen liegen, kann die Abweichung von der lokalen Server-
zeit in die Analyse bzw. in die Berechnung der entsprechenden Besucherzeiten einbezogen
werden. Die PLANET-GmbH ist ein relativ regional agierendes Unternehmen, sodass diese
Überlegung nicht in die Analyse einfließt. Unter Ausschluss dieser Daten wird nachfolgend
erläutert, welche Informationen aus den einzelnen Feldern gewonnen werden können.
14 Alle fehlerhaften Abrufe des Statuscodefeldes werden bereits in der Phase der Datenselektion bereinigt.
70

7.3. Transaktionsidentifikation und Datentransformation
Aus dem Hostfeld können zwei Informationen extrahiert werden: die Top- und die Second-
Level-Domain des anfragenden Besuchers. Die Top-Level-Domain gibt an, welche Länder-
kennung der Besucher aufweist bzw. von welcher Organisationform die Anfrage kam. Viele
Transaktionen beinhalten Top-Level-Domains aus denen nicht ersichtlich ist, aus welchem
Land der Besucher kam, das sind z.B. Domainendungen wie net, com, org, edu oder IP-
Adressen. Für die Identifikation des Herkunftslandes, auch in diesen speziellen Fällen, wird
das ProgrammGeoIP15 von der Firma Maxmind16 eingesetzt. GeoIP ermittelt dabei, mit Hilfe
interner und externer (im WWW) Datenbanken, das Herkunftsland des Besuchers. Außer-
dem wandelt GeoIP die gefundene Top-Level-Domain in den entsprechenden Ländernamen
um (de wird zu Germany usw.). Insgesamt können aus der Top-Level-Domain die Attribu-
te „Herkunft“ und „Land“ extrahiert werden. Die Differenzierung dieser Attribute ist deshalb
nötig, weil die „Herkunft“ neben den Länderkennungen (z.B. de oder at) auch Informationen
über die Organisationsform17 (z.B. net oder org) des Besuchers beinhaltet. Im Kontext des
Navigationsverhaltens der Besucher und den geographischen Gegebenheiten wurden die
Top-Level-Domains geclustert. So wurden bspw. alle nichtdeutschsprachigen Nachbarländer
zu einer Gruppe zusammengefasst. Das Attribut „Land“ gibt ausschließlich das Herkunfts-
land (z.B. Germany oder Austria) des Besuchers an.
Aus der Second-Level-Domain können nähere Informationen über den Organisationstyp des
anfragenden Nutzers ermittelt werden. Mit Organisationstyp ist hierbei, im Gegensatz zur
Top-Level-Domain, gemeint, ob sich der Besucher von einer großen Organisation, von einer
Bildungseinrichtung oder privat in das Internat eingewählt hat. Dabei werden die Namen von
Internet Service Providern bzw. ihre spezifischen Kennungen aus der Second-Level-Domain
extrahiert, z.B. kann aus pD9554D88.dip.t-dialin.net ermittelt werden, das der ISP, über den
sich der Besucher in das Internet eingewählt hat, T-Online mit seiner Kennung „t-dialin“ war.
Weiterhin kann festgestellt werden, ob sich ein Nutzer von einer Universität aus mit dem
Internet verbunden hat. Solche oder ähnliche Bildungseinrichtungen haben meist entspre-
chende Kennungen in ihren Second-Level-Domains, z.B. proxy2.uni-leipzig.de mit „uni“ für
die Universität Leipzig oder nawi.sf.hs-wismar.de mit „hs“ für die Hochschule Wismar. Für
die Gruppierung der Daten wird angenommen, das bei großen und mittelständischen Un-
ternehmen bzw. Organisationen (z.B. green.dresdnerbank.de) keine ISP-Kennungen wie „t-
dailin“ oder „aol“ in der Second-Level-Domain vorkommen. Aus diesem Grund wurde eine
Liste von regionalen und überregionalen ISP erstellt. Die Liste umfasst ca. 290 ISP, die
15 Das Programm ist auf der CD im Verzeichnis \skripte\GeoIPJava-1.1.0\ hinterlegt.16 http://www.maxmind.com17 Diese speziellen Top-Level-Domains stammen aus den Anfängen des WWW. So steht die Top-Level-Domainorg für eine nichtkommerzielle Organisation, das Pendant dazu ist com, net steht für Netzwerke aller Art, eduweißt Bildungseinrichtungen aus, mil steht für das US-Militär und gov für Regierungsinstitutionen. Dazuge-kommen sind neue Endungen wie z.B. biz für Showbiz oder info für Informationsseiten aller Art und weiteresind von der ICANN (The Internet Corporation for Assigned Names and Numbers; http://www.icann.org) ge-plant. Diese Organisationsstrukturen werden aber von vielen Organisationen zweckentfremdet, sodass nichtimmer eine eindeutige Zuordnung anhand der Top-Level-Domain möglich ist.
71

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
deutschland- oder weltweit operieren. Als Grundlage für die ISP-Liste diente das Provider-
verzeichnis von Heise Online18. Weiterhin wurde im Internet nach weiteren ISP recherchiert
und als Stichprobe, der vorliegende Logdatenbestand von zwei vollständigen Monaten nach
weiteren Providern durchsucht19. Auf Basis der Provieder-Liste wurden alle Besucher, die
einen ISP in ihrer Second-Level-Domain aufweisen, der Gruppe „Privater Besucher oder
kleine Organisation“ zugeordnet. Die Gruppe „Bildungseinrichtung“ wird anhand der spezi-
fischen Kennung in der Second-Level-Domain (uni, fh, tu usw.) oder der Top-Level-Domain
(edu oder ac20) gebildet. Alle verbleibenden Transaktionen wurden der Gruppe „Große Or-
ganisation und Unbekannte“ zugeordnet. Insgesamt wurden auf Basis des Hostfelds drei
neue Attribute gebildet: „Organisationstyp“, „Herkunft“ und „Land“.
Aus dem Zeitstempel der Logdateieinträge können drei Informationen entnommen werden:
Uhrzeit, Datum und Zeitzone des anfragenden Servers. Aus der Uhrzeit wurden nur die
Stundenangaben extrahiert, da eine feinere Gruppierung (Minuten und Sekunden) zu viele
und zu spezielle Analyseergebnisse liefern würde. Aus dem Datum wurden die Attribute Tag,
Wochentag und Monat gebildet. Die Zeitzone des anfragenden Servers ist für die Analyse
des Besucherverhaltens nicht relevant und wird deshalb nicht in die Analyse einbezogen.
Insgesamt konnten aus dem Zeitstempelfeld die Attribute „Stunde“, „Tag“, „Wochentag“ und
„Monat“ gewonnen werden.
Das Transaktionsfeld ist eines der wichtigsten Felder im Web Log Mining. Es gibt Auskunft
über die abgerufenen Ressourcen der Besucher. Die Logdaten wurden über einen Zeitraum
von Februar 2002 bis einschließlich September 2002 generiert. In dieser Zeit wurde die Web-
site aktualisiert, es wurden Dokumente hinzugefügt und gelöscht. Aufgrund dieses Sachver-
halts wurden die einzelnen Dokumente der Internetpräsenz zu Gruppen zusammengefasst.
Die Gruppierung orientiert sich dabei an der Hierarchie der Website, bspw. wurden alle Do-
kumente des Bereiches Web-Agentur der Gruppe „Agentur“ zugeordnet. Weiterhin wurden
die speziellen Bereiche „Aktion“ (spezielle Verkaufsaktionen), „Kontakt“ (wichtiger Teilbe-
reich von Profil) und „Satdemo“ (Dateien der Online-Demonstration des Programms Satellite
XL) angelegt. Durch diese globalere Betrachtung der Website werden Fluktuationen der ein-
zelnen Dokumente ausgeglichen. Mit Hilfe eines erweiterten Binärkodierungs-Verfahren21
wurde für jede Transaktion ein Vektor berechnet, der die Häufigkeiten der abgerufenen Do-
kumente auf die entsprechenden Bereiche abbildet.
Die Transaktionsidentifizierung schafft die Voraussetzung für die Bestimmung von Ein- und
Ausstiegsseiten der einzelnen Besucher. Darauf aufbauend werden die Attribute Einstiegs-
18 [UNGE02]19 Die vollständige ISP-Liste liegt der CD unter \skripte\provider.txt bei.20 Großbritannien und einige weitere Staaten nutzen ein eigenes Top-Level-System. So steht ac.uk für „acade-mic“, „United Kingdom“ oder co.uk für „commercial“.
21 Das Binärkodierungs-Verfahren wurde so erweitert, das nicht nur erfasst wird, ob ein Dokument abgerufenwurde, sondern auch wie oft.
72

7.3. Transaktionsidentifikation und Datentransformation
und Ausstiegsseite bzw. Einstiegs- und Ausstiegsbereich definiert. Für die Messung der wirt-
schaftlichen Bedeutung eines Besuchers für die Firma wurde das Attribut „Besucherverhal-
ten“ erzeugt. Das „Besucherverhalten“ wird durch die Gruppen „Kunde“, „Interessierter Nut-
zer“ und „Just Browsing“ definiert. Die Gruppe „Kunde“ umfasst alle Besucher die Produkte
kaufen, d.h. sie füllen Bestellformulare aus und schicken sie ab. Die PLANET GmbH ver-
treibt, bis auf wenige Verkaufsaktionen, nicht direkt Produkte über seine Homepage. Deshalb
wurde die Gruppe „Kunde“ um die Besucher, die Kontaktformulare abschicken oder sich für
die Satellite XL-Demo registrieren, erweitert. Die „Interessierten Nutzer“ sind Besucher, die
sich Produktblätter und Preislisten ansehen oder Bestell- bzw. Kontaktformulare anklicken,
aber nicht abschicken. Die Gruppe „Just Browsing“ umfasst alle Besucher, die den ande-
ren Gruppen nicht zugeordnet werden können. Aus dem Transaktionsfeld können insgesamt
die Attribute „Einstiegsseite“, „Einstiegsbereich“, „Ausstiegsseite“, „Ausstiegsbereich“, „Be-
sucherverhalten“ und die Abrufhäufigkeiten der einzelnen Bereiche extrahiert werden.
Das Referrerfeld gibt an, über welche URL die Besucher auf die Homepage gelangt sind.
Da im vorliegenden Datenmaterial sehr viele unterschiedliche Referrer auftraten, wurden
sie strukturiert und zu Gruppen zusammengefasst. Ist das Referrerfeld leer, wurde die URL
„von Hand“ in den Browser eingegeben und der Gruppe „Kein Referrer“ zugeordnet. Vie-
le Kunden der PLANET internet commerce GmbH haben im Impressum ihrer Homepage
einen Link auf die Website der PLANET GmbH. Diese Referrer wurden in der Gruppe „PLA-
NET Kunde“ zusammengefasst. Kamen die Nutzer über eine Presseanzeige, wurden sie der
Gruppe „Presse und PR“ zugeordnet.
Viele der Besucher fanden die Homepage mit Suchmaschinen. Für die Identifikation der
Suchmaschinen wurde eine Liste erarbeitet, die ca. 130 aktuelle Suchmaschinen umfasst22.
Die 15 häufigsten (deutschlandweit) genutzten Suchmaschinen23 werden bei der Gruppie-
rung differenziert, alle anderen wurden der Gruppe „Andere Suchmaschine“ zugeordnet.
Wenn der Referrer eine Suchmaschine ist, können aus dem Referrerfeld zusätzlich die Such-
begriffe extrahiert werden, durch die der Besucher die Website fand. Benutzten die Besucher
mehrere Suchbegriffe für eine Suchanfrage, wurde jeder einzelne Suchbegriff separat aus-
gewertet24. Durch diese Informationen können zwei neue Attribute definiert werden: „Refer-
rer“ und „Suchbegriff“.
Das Agentfeld gibt Auskunft zur Softwareausstattung des Besuchers. Aus diesem Feld
können Informationen über eingesetzte Betriebssysteme und Browser gewonnen werden.
22 Die vollständige Suchmaschinen-Liste liegt auf der CD unter \skripte\suchmaschinen.txt vor.23 Aktuelle Statistiken bietet [o.V.02c].24 Folgendes Beispiel soll dieses Vorgehen verdeutlichen: Wurden bei zwei Besuchen die Suchanfragen „pla-net+dsl“ und „dsl+highspeed+zugang“ verwendet, werden beide Suchanfragen dem Suchbegriff „dsl“ zuge-ordnet, weil dieser am häufigsten in dieser Datenmenge vorkommt. Dieser Mechanismus verhindert, dasdas Attribut „Suchbegriffe“ zu differenzierte Ausprägungen enthält. Ein Nachteil besteht aber auch darin, dasSuchbegriffe aus dem Zusammenhang gerissen werden.
73
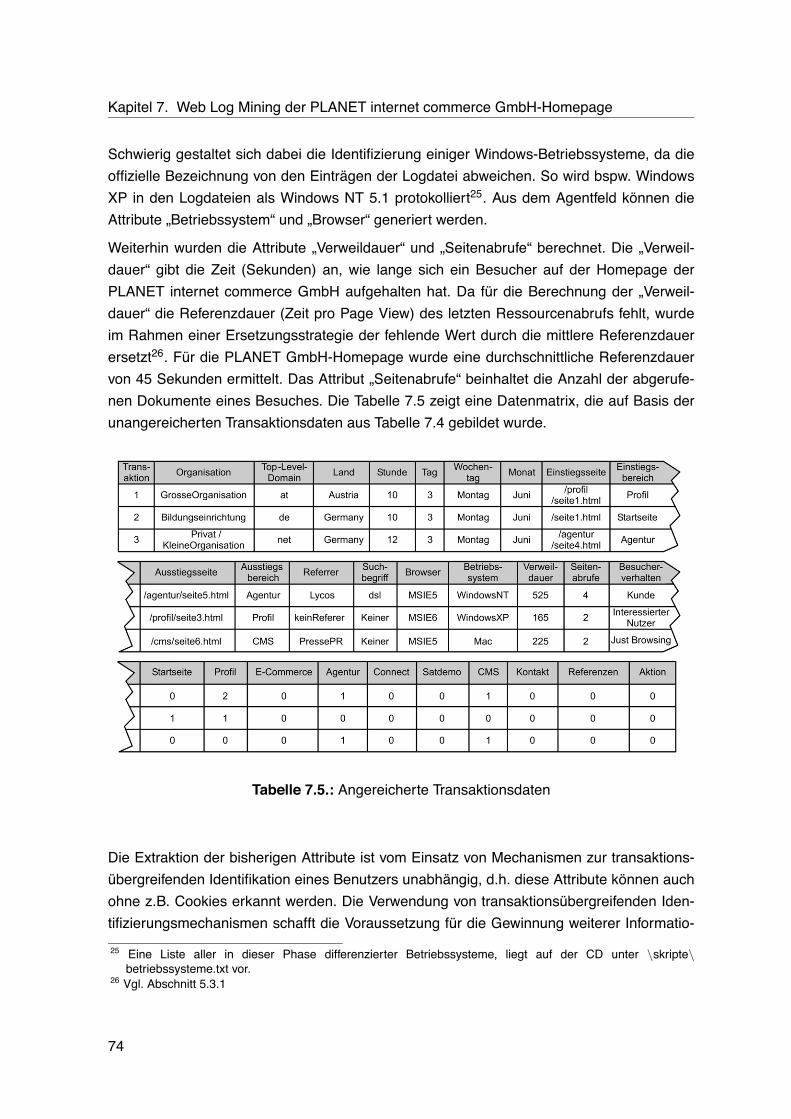
Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Schwierig gestaltet sich dabei die Identifizierung einiger Windows-Betriebssysteme, da die
offizielle Bezeichnung von den Einträgen der Logdatei abweichen. So wird bspw. Windows
XP in den Logdateien als Windows NT 5.1 protokolliert25. Aus dem Agentfeld können die
Attribute „Betriebssystem“ und „Browser“ generiert werden.
Weiterhin wurden die Attribute „Verweildauer“ und „Seitenabrufe“ berechnet. Die „Verweil-
dauer“ gibt die Zeit (Sekunden) an, wie lange sich ein Besucher auf der Homepage der
PLANET internet commerce GmbH aufgehalten hat. Da für die Berechnung der „Verweil-
dauer“ die Referenzdauer (Zeit pro Page View) des letzten Ressourcenabrufs fehlt, wurde
im Rahmen einer Ersetzungsstrategie der fehlende Wert durch die mittlere Referenzdauer
ersetzt26. Für die PLANET GmbH-Homepage wurde eine durchschnittliche Referenzdauer
von 45 Sekunden ermittelt. Das Attribut „Seitenabrufe“ beinhaltet die Anzahl der abgerufe-
nen Dokumente eines Besuches. Die Tabelle 7.5 zeigt eine Datenmatrix, die auf Basis der
unangereicherten Transaktionsdaten aus Tabelle 7.4 gebildet wurde.
Tabelle 7.5.: Angereicherte Transaktionsdaten
Die Extraktion der bisherigen Attribute ist vom Einsatz von Mechanismen zur transaktions-
übergreifenden Identifikation eines Benutzers unabhängig, d.h. diese Attribute können auch
ohne z.B. Cookies erkannt werden. Die Verwendung von transaktionsübergreifenden Iden-
tifizierungsmechanismen schafft die Voraussetzung für die Gewinnung weiterer Informatio-
25 Eine Liste aller in dieser Phase differenzierter Betriebssysteme, liegt auf der CD unter \skripte\betriebssysteme.txt vor.
26 Vgl. Abschnitt 5.3.1
74
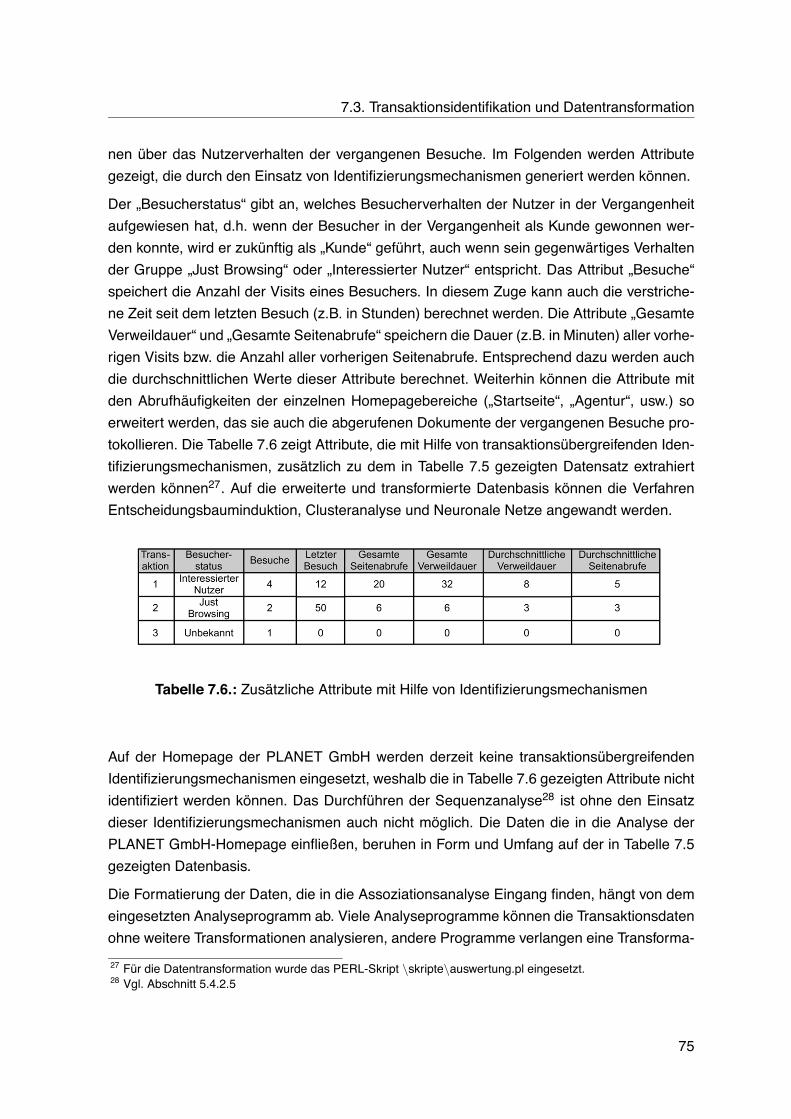
7.3. Transaktionsidentifikation und Datentransformation
nen über das Nutzerverhalten der vergangenen Besuche. Im Folgenden werden Attribute
gezeigt, die durch den Einsatz von Identifizierungsmechanismen generiert werden können.
Der „Besucherstatus“ gibt an, welches Besucherverhalten der Nutzer in der Vergangenheit
aufgewiesen hat, d.h. wenn der Besucher in der Vergangenheit als Kunde gewonnen wer-
den konnte, wird er zukünftig als „Kunde“ geführt, auch wenn sein gegenwärtiges Verhalten
der Gruppe „Just Browsing“ oder „Interessierter Nutzer“ entspricht. Das Attribut „Besuche“
speichert die Anzahl der Visits eines Besuchers. In diesem Zuge kann auch die verstriche-
ne Zeit seit dem letzten Besuch (z.B. in Stunden) berechnet werden. Die Attribute „Gesamte
Verweildauer“ und „Gesamte Seitenabrufe“ speichern die Dauer (z.B. in Minuten) aller vorhe-
rigen Visits bzw. die Anzahl aller vorherigen Seitenabrufe. Entsprechend dazu werden auch
die durchschnittlichen Werte dieser Attribute berechnet. Weiterhin können die Attribute mit
den Abrufhäufigkeiten der einzelnen Homepagebereiche („Startseite“, „Agentur“, usw.) so
erweitert werden, das sie auch die abgerufenen Dokumente der vergangenen Besuche pro-
tokollieren. Die Tabelle 7.6 zeigt Attribute, die mit Hilfe von transaktionsübergreifenden Iden-
tifizierungsmechanismen, zusätzlich zu dem in Tabelle 7.5 gezeigten Datensatz extrahiert
werden können27. Auf die erweiterte und transformierte Datenbasis können die Verfahren
Entscheidungsbauminduktion, Clusteranalyse und Neuronale Netze angewandt werden.
Tabelle 7.6.: Zusätzliche Attribute mit Hilfe von Identifizierungsmechanismen
Auf der Homepage der PLANET GmbH werden derzeit keine transaktionsübergreifenden
Identifizierungsmechanismen eingesetzt, weshalb die in Tabelle 7.6 gezeigten Attribute nicht
identifiziert werden können. Das Durchführen der Sequenzanalyse28 ist ohne den Einsatz
dieser Identifizierungsmechanismen auch nicht möglich. Die Daten die in die Analyse der
PLANET GmbH-Homepage einfließen, beruhen in Form und Umfang auf der in Tabelle 7.5
gezeigten Datenbasis.
Die Formatierung der Daten, die in die Assoziationsanalyse Eingang finden, hängt von dem
eingesetzten Analyseprogramm ab. Viele Analyseprogramme können die Transaktionsdaten
ohne weitere Transformationen analysieren, andere Programme verlangen eine Transforma-
27 Für die Datentransformation wurde das PERL-Skript \skripte\auswertung.pl eingesetzt.28 Vgl. Abschnitt 5.4.2.5
75

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
tion der Daten mit der Binärkodierung. Ein Beispiel einer exemplarischen Datenbasis (ohne
Binärkodierung) für die Assoziationsanalyse wird in Tabelle 7.7 gegeben.
Tabelle 7.7.: Datenbasis für die Assoziationsanalyse
Für deskriptive Analyseverfahren der Logdaten mit klassischen29 Website-Analyseprogrammen
ist keine Datentransformation nötig. Diese Programme sind für die Analyse von Logdateien
hoch spezialisiert und nehmen alle erforderlichen Transformationen selbst vor.
7.4. Data Mining
In diesem Abschnitt erfolgt auf Basis der transformierten Logdaten die Mustererkennung
mit ausgewählten Data Mining-Verfahren. Dabei werden die in Kapitel 6 vorgestellten Ana-
lyseprogramme eingesetzt30 Im Rahmen dieses Abschnitts werden nur die Ergebnisse der
Analysen vorgestellt, die Interpretation der Analyseergebnisse erfolgt im Abschnitt 7.5.
7.4.1. Clusteranalyse
Mit Hilfe der Clusteranalyse sollen Elemente einer Eingabemenge nach ihrer Ähnlichkeit
gruppiert werden. Die Clusteranalyse erfolgte mit dem KnowledgeStudio von Angoss. Die
Besucher31 der PLANET-Homepage wurden anhand ihres Navigationsverhaltens segmen-
tiert. Das Navigationsverhalten umfasst dabei alle Attribute, die mit dem Abruf von Ressour-
cen, bzw. dessen zeitlichen Rahmen, in Verbindung stehen. Die technische Ausstattung oder
Herkunft der Besucher ist hierbei nicht relevant. Als Eingangswerte in die Clusteranalyse
wurden die Attribute „Startseite“, „Startbereich“, „Ausstiegsseite", „Ausstiegsbereich“, „Sei-
tenabrufe“, „Verweildauer“, „Besucherverhalten“, „Uhrzeit“, „Wochentag“, „Tag“, „Monat“ und
29 Neben deskriptiver Statistik und Pfadanalyse werden i.A. keine weiteren Data Mining-Verfahren zur Analyseeingesetzt.
30 Die genauen Eingabeparameter für die einzelnen Verfahren werden in den entsprechenden Abschnitten auf-gezeigt. Alle Parameter die als Standardeinstellungen der jeweiligen Programme übernommen wurden, wer-den nicht explizit erläutert.
31 Für die Clusterung der Besucher wurde der gesamte Logdatenbestand herangezogen.
76

7.4. Data Mining
die Abrufhäufigkeiten der einzelnen Websitebereiche ausgewählt. Zur Clusterung dieser Da-
tenmenge32 wurde der K-Means-Algorithmus eingesetzt, dabei wird zunächst die Anzahl (k)
der Cluster vorgegeben. Die Anzahl der Cluster wird anfangs meist zufällig gewählt. In einem
zweiten Schritt werden die Datensätze demjenigen Cluster zugeordnet, zu dem die größte
Ähnlichkeit besteht. Problematisch ist die Bestimmung der optimalen Anzahl der Cluster,
dafür müssen mehrere Tests durchgeführt und deren Ergebnisse verglichen werden. Eine
aussagekräftige Segmentierung des Navigationsverhaltens wurde mit drei Clustern erreicht.
Das Resultat der Analyse war die Identifizierung zweier unterschiedlicher Navigationsweisen
innerhalb der Gruppe „Interessierter Nutzer“.
Tabelle 7.8.: Ergebnisse der Clusteranalyse
Wie aus der Abbildung 7.8 deutlich wird, weisen die „Interessierten Nutzer“ zwei unterschied-
liche Navigationsweisen auf. Sie werden sehr eindeutig auf den Cluster 1 und Cluster 3
verteilt. Diese neu entdeckten Gruppen wurden als „Interessierter Nutzer“ (Cluster 3) und
„Interessierter Kurzbesucher“ (Cluster 1) definiert. Die „Interessierten Kurzbesucher“ unter-
scheiden sich vor allem von den „Interessierter Nutzern“ durch Anzahl und Art der abgeru-
fenen Dokumente, denn diese Gruppe ruft ausschließlich nur ein PDF-Dokument ab. Eine
genauere Definition der einzelnen Gruppen wird im Rahmen der Entscheidungsbauminduk-
tion vorgenommen.
7.4.2. Entscheidungsbauminduktion
Die Entscheidungsbauminduktion wird eingesetzt, um Gruppen zu beschreiben oder ihr Ver-
halten in der Zukunft vorherzusagen. Die Einteilung dieser Gruppen kann entweder durch
den Anwender oder durch Clusterverfahren vorgenommen werden. Vor dem in erster Li-
nie betriebswirtschaftlichen Hintergrund der Optimierung der PLANET GmbH-Website, wird
das „Besucherverhalten“ als Zielattribut für die Entscheidungsbauminduktion herangezogen.
Basierend auf den Ergebnissen der Clusteranalyse aus Abschnitt 7.4.1 wurden die Ausprä-
gungen „Kunde“, „Interessierter Nutzer“, „Interessierter Kurzbesucher“ und „Just Browsing“
des Zielattributs generiert. Die genaue Verteilung dieser Ausprägungen wird in Tabelle 7.9
gezeigt.
32 Die für die Clusteranalyse verwendete Datenmatrix und das entsprechende KnowledgeStudio-Projekt, liegender CD unter \knowledgestudio\clusteranalyse\ bei.
77

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Tabelle 7.9.: Verteilung der Ausprägungen des Attributs „Besucherverhalten“
Als Eingangswerte in die Entscheidungsbauminduktion wurde der gesamte Datenbestand
sowie die Attribute „Startseite“, „Startbereich“, „Uhrzeit“, „Wochentag“, „Tag“, „Monat“, „Re-
ferrer“, „Suchbegriff“, „Organisationstyp“, „Herkunft“, „Land“, „Betriebssystem“, „Browser“,
„Ausstiegsseite“, „Ausstiegsbereich“, „Seitenabrufe“, „Verweildauer“ und die Abrufhäufigkei-
ten der einzelnenWebsitebereiche gewählt. Mit Hilfe der Entscheidungsbauminduktion33 des
Knowledge Studios wurden entsprechende Besucherprofile erstellt. Die einzelnen Gruppen
werden nachfolgend profiliert34.
Die typischen „Kunden“:
• kommen über die Startseite auf die Website,
• rufen durchschnittlich 12 Seiten auf,
• bleiben durchschnittlich 545 Sekunden auf der Website,
• bevorzugen die Wochentage Dienstag, Mittwoch, Donnerstag und Freitag zu den Zei-ten 7-16 und 17-23 Uhr,
• benutzen die Betriebssysteme Windows 2000, Windows 98 oder Windows NT mit denBrowsern Internet Explorer 5 oder 6,
• kommen aus Deutschland und ihre Top-Level-Domain ist de oder net,
• haben sich nicht über Bildungseinrichtungen in das WWW eingewählt,
• sind nicht über Suchmaschinen oder Presse und PR-Aktionen auf die Website gelangt,sondern über Websites der Kunden von PLANET oder ohne Referrer und
• verlassen die Homepage über die Bereiche Profil, nach Absenden eines Formularsoder der Satellite XL-Demo.
33 Für die Analyse wurde der s.g. KnowledgeSEEKER-Algorithmus eingesetzt, welcher die Verfahren ID3,CHAID und CART implementiert. Eine detailliertere Beschreibung bieten [MENA00] S. 150 f. und [o.V.02b]S.7. Als Genauigkeitsmaß wurde „Adjusted - P-value Bonferroni Adjustment Measure“ gewählt. Die für dieEntscheidungsbauminduktion verwendete Datenmatrix und das entsprechende KnowledgeStudio-Projekt,liegen der CD unter \knowledgestudio\entscheidungsbaum\tree\ bei.
34 Bei diesen Profilen handelt es sich um die typischen Ausprägungen der einzelnen Gruppen. Dabei werdennicht alle Objekte (Besucher) einer Gruppe berücksichtigt.
78

7.4. Data Mining
Die typischen „Interessierten Nutzer“:
• kommen über die Startseite auf die Website,
• benutzen die Betriebssysteme Windows 2000, Windows 98 oder Windows NT mit denBrowsern Internet Explorer 5 oder 6,
• kommen aus Deutschland und ihre Top-Level-Domain ist de oder net,
• bleiben durchschnittlich 293 Sekunden auf der Website,
• rufen durchschnittlich 8 Seiten auf,
• bevorzugen die Wochentage Montag, Dienstag, Mittwoch, Donnerstag und Freitag zuder Zeit 8-16 Uhr,
• kommen ohne Referrer, über Websites der Kunden von PLANET oder Suchmaschinen(Google) auf die Website,
• benutzten den Suchbegriff Planet und
• verlassen die Homepage über die Bereiche Kontakt, Profil oder Connect.
Die typischen „Interessierten Kurzbesucher“:
• kommen über die PDF-Dokumente auf die Website,
• benutzen die Betriebssysteme Windows 2000, Windows 98 oder Windows NT mit denBrowsern Internet Explorer 5 oder 6,
• kommen aus Deutschland oder dem deutschsprachigen Ausland und ihre Top-Level-
Domain ist de oder net,
• bleiben ca. 45 Sekunden35 auf der Website,
• rufen nur eine Seite auf,
• bevorzugen die Wochentage Montag, Dienstag, Mittwoch, Donnerstag und Freitag zuder Zeit 8-18 Uhr,
• kommen über eine Suchmaschine (Google) oder ohne Referrer auf die Website,
• benutzten die Suchbegriffe DSL, Taedose, Definition, Internet, Firewall, Internetsicher-heit oder LAN und
35 Da nur eine Ressource aufgerufen wurde, kann die Referenzdauer nicht direkt berechnet werden. Im Rahmeneiner Ersetzungsstrategie wurde die durchschnittliche Referenzdauer (45 Sekunden) als Wert herangezogen.
79

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
• verlassen die Homepage über die aktuelle PDF-Seite.
Die Gruppe „Just Browsing“:
• Alle anderen Besucher die nicht den oberen Gruppen angehören.
Neben der Beschreibung von Gruppen, kann mit Hilfe der Entscheidungsbauminduktion das
Verhalten künftiger Besucher prognostiziert werden. Das Vorhersagemodell36 soll dabei die
Besucher, die die Website betreten, den Ausprägungen „Kunde“, „Interessierter Nutzer“, „In-
teressierter Kurzbesucher“ und „Just Browsing“ zuordnen, d.h. das Verhalten der Besucher
soll nach ihrem Betreten der Homepage möglichst gut vorhergesagt werden. Für die Erstel-
lung des Modells wurden die Attribute zu Grunde gelegt, die beim Betreten einer Website
identifiziert werden können: „Startseite“, „Startbereich“, „Uhrzeit“, „Wochentag“, „Tag“, „Mo-
nat“, „Referrer“, „Suchbegriff“, „Organisationstyp“, „Herkunft“, „Land“, „Betriebssystem“ und
„Browser“. Die auf dieser Grundlage erstellte Datenmenge wurde zu gleichen Teilen (50
Prozent des Datensatzes werden als Trainings- und 50 Prozent als Validierungsmenge ge-
nutzt.) zufällig in Trainings- und Validierungsmenge gegliedert. Dabei wurde darauf geachtet,
das alle Attribute eine relativ ähnliche Ausprägungsverteilung in beiden Datenmengen auf-
weisen. Die Zusammensetzung des Zielattributs „Besucherverhalten“ in der Trainings- und
Validierungsmenge wird in Tabelle 7.10 gezeigt.
Tabelle 7.10.: Ausprägungsverteilung in Trainings- und Validierungsmenge (Verhältnis50/50)
Auf Basis dieser Datenmengen wurde ein Vorhersagemodell zunächst mit der Trainingsda-
tenmenge trainiert und seine Ergebnisse mit Hilfe der Validierungsdatenmenge auf seine
Gültigkeit geprüft. Die Vorhersageergebnisse der Entscheidungsbauminduktion werden in
Tabelle 7.11 aufgezeigt37.
36 Zunächst erfolgte die automatische Erstellung des Entscheidungsbaumes mit den Parametern: „Autoaufbau-Stopgröße“ = 30 und „Auto-Aufbau maximale Baumtiefe“ = 40. Der Algorithmus und das Genauigkeitsmaßwurden, wie oben beschieben, übernommen. Zur Entscheidungsbaumvorhersage mit dem KnowledgeStudiowurde das „KnowledgeTREE Decision Tree“-Modell und die Einstellung „Versteckte und sichtbare Verzwei-gungen beim Votieren verwenden“ gewählt.
37 Die für die Entscheidungsbaumvorhersage verwendeten Trainings- und Validierungsdaten und das ent-sprechende KnowledgeStudio-Projekt, liegen der CD unter \knowledgestudio\entscheidungsbaum\tree_vorhersage\ bei.
80
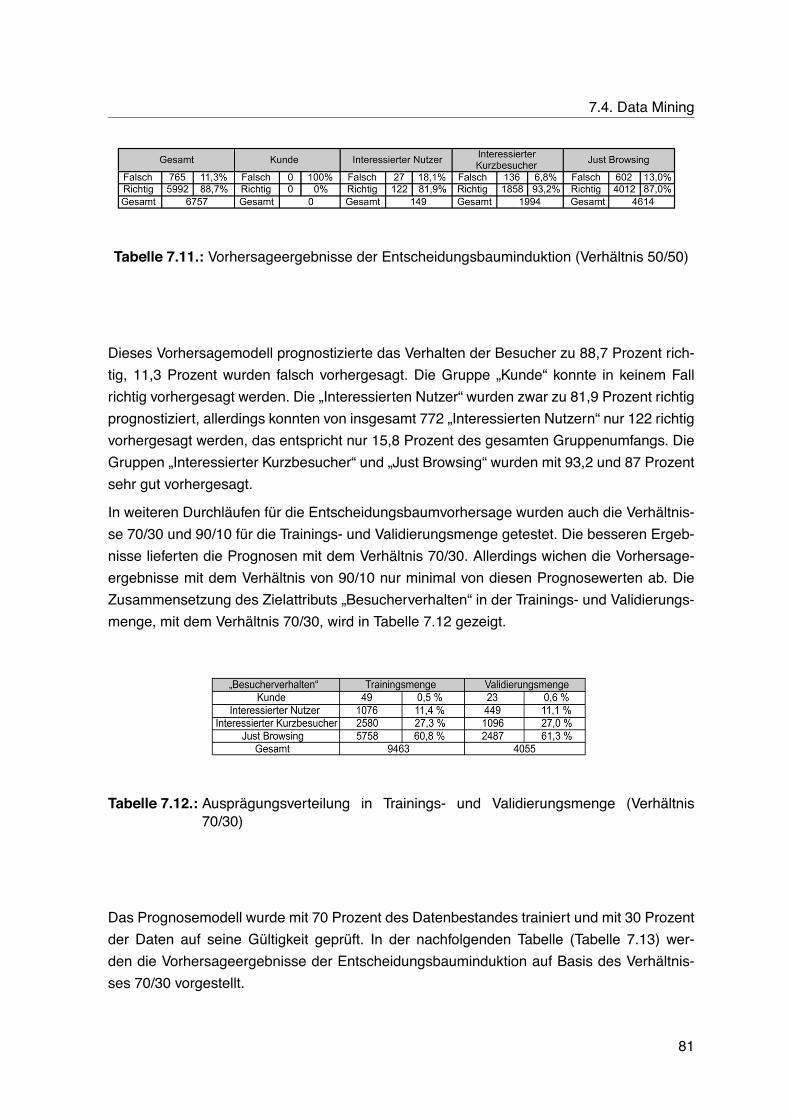
7.4. Data Mining
Tabelle 7.11.: Vorhersageergebnisse der Entscheidungsbauminduktion (Verhältnis 50/50)
Dieses Vorhersagemodell prognostizierte das Verhalten der Besucher zu 88,7 Prozent rich-
tig, 11,3 Prozent wurden falsch vorhergesagt. Die Gruppe „Kunde“ konnte in keinem Fall
richtig vorhergesagt werden. Die „Interessierten Nutzer“ wurden zwar zu 81,9 Prozent richtig
prognostiziert, allerdings konnten von insgesamt 772 „Interessierten Nutzern“ nur 122 richtig
vorhergesagt werden, das entspricht nur 15,8 Prozent des gesamten Gruppenumfangs. Die
Gruppen „Interessierter Kurzbesucher“ und „Just Browsing“ wurden mit 93,2 und 87 Prozent
sehr gut vorhergesagt.
In weiteren Durchläufen für die Entscheidungsbaumvorhersage wurden auch die Verhältnis-
se 70/30 und 90/10 für die Trainings- und Validierungsmenge getestet. Die besseren Ergeb-
nisse lieferten die Prognosen mit dem Verhältnis 70/30. Allerdings wichen die Vorhersage-
ergebnisse mit dem Verhältnis von 90/10 nur minimal von diesen Prognosewerten ab. Die
Zusammensetzung des Zielattributs „Besucherverhalten“ in der Trainings- und Validierungs-
menge, mit dem Verhältnis 70/30, wird in Tabelle 7.12 gezeigt.
Tabelle 7.12.: Ausprägungsverteilung in Trainings- und Validierungsmenge (Verhältnis70/30)
Das Prognosemodell wurde mit 70 Prozent des Datenbestandes trainiert und mit 30 Prozent
der Daten auf seine Gültigkeit geprüft. In der nachfolgenden Tabelle (Tabelle 7.13) wer-
den die Vorhersageergebnisse der Entscheidungsbauminduktion auf Basis des Verhältnis-
ses 70/30 vorgestellt.
81

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Tabelle 7.13.: Vorhersageergebnisse der Entscheidungsbauminduktion (Verhältnis 70/30)
Dieses Modell prognostizierte das Verhalten der Besucher zu 89 Prozent richtig, 11 Pro-
zent wurden falsch vorhergesagt. Das sind um 0,3 Prozent bessere Vorhersagen, als die
Ergebnisse mit dem 50/50 Verhältnis. Die Gruppe „Kunde“ konnte auch hier nicht vorher-
gesagt werden. Die „Interessierten Nutzer“ wurden mit 86,9 Prozent, um 5 Prozent besser
prognostiziert als bei dem ersten Vorhersagemodell. Allerdings konnten von insgesamt 449
„Interessierten Nutzern“ nur 73 richtig vorhergesagt werden, das entspricht nur 16,26 Pro-
zent des gesamten Gruppenumfangs, ist aber um 0,46 Prozent besser als das Prognose-
modell auf Basis des 50/50 Verhältnisses. Die Gruppen „Interessierter Kurzbesucher“ und
„Just Browsing“ wurden mit 92,2 und 87,4 Prozent ähnlich gut vorhergesagt. Die Ergebnisse
des Prognosemodells auf Basis des 70/30 Verhältnisses waren insgesamt minimal besser
als die Vorhersageergebnisse des 50/50 Modells.
7.4.3. Neuronale Netze
Ähnlich der Entscheidungsbauminduktion kann ein neuronales Netz Vorhersagen über das
Gruppenverhalten in der Zukunft treffen. Für diese Analyse setzt das KnowledgeStudio un-
überwacht lernende neuronale Netze (Backpropagation-Netze)38 ein. Unüberwacht lernende
neuronale Netze müssen zunächst trainiert werden39. Die Eingangswerte des Backpropagation-
Netzes sind, wie bei der Entscheidungsbaumvorhersage, die Attribute „Startseite“, „Startbe-
reich“, „Uhrzeit“, „Wochentag“, „Tag“, „Monat“, „Referrer“, „Suchbegriff“, „Organisationstyp“,
„Herkunft“, „Land“, „Betriebssystem“ und „Browser“. Das Zielattribut ist analog das „Besu-
cherverhalten“. Für Training und Validierung40 des Modells werden die gleichen Datenmen-
gen41 wie bei der Entscheidungsbauminduktion herangezogen. Die Tabelle 7.14 zeigt die38 Für die Erstellung der Vorhersagemodelle mit Neuronalen Netzen wurden die s.g. Multi-Layer Perceptronsdes KnowledgeStudios eingesetzt. Um einem Übertrainieren (Overfit) des Modells vorzubeugen, wurde ei-ne Test(validierungs)menge von 20 Prozent des Umfangs der Trainingsdaten gewählt. Die Anzahl der Ite-rationen wurde auf 2000 begrenzt. Das Neuronale Netz wurde mit diesen Parametern und einer „Anzahlversteckter Neuronen“ von 10, 11, 12, 13 und 14 fünf mal trainiert. Die für das Backpropagation-Netz ver-wendeten Trainings- und Validierungsdaten und das entsprechende KnowledgeStudio-Projekt, liegen der CDunter \knowledgestudio\neuronale_netze\ bei.
39 Vgl. Abschnitt 5.4.2.240 Die Neuronalen Netze wurden mit den gleichen drei Datenmengenverhältnissen wie bei Entscheidungsbaum-vorhersage trainiert und validiert. Dabei zeichnete sich der selbe Trend ab: die Analysen mit dem Verhältnis70/30 ergaben ist besten Ergebnisse. Aus diesem Grund werden nur die besten Vorhersageergebnisse vor-gestellt.
41 Vgl. Tabelle 7.12
82

7.4. Data Mining
Vorhersageergebnisse des Backpropagation-Netzes.
Tabelle 7.14.: Vorhersageergebnisse der Neuronalen Netze
Das Prognosemodell des Backpropagation-Netzes zeigt ähnliche Ergebnisse wie die Ent-
scheidungsbaumvorhersage. Es konnten 89,1 Prozent der Besucher richtig eingeordnet wer-
den, 10,9 Prozent wurden falsch prognostiziert. Die Gruppe „Kunde“ wurde in keinem Fall
richtig vorhergesagt und die Gruppen „Interessierter Kurzbesucher“ und „Just Browsing“ wur-
den mit 94 und 88 Prozent, analog zu der Entscheidungsbaumvorhersage, sehr gut progno-
stiziert. Lediglich die Vorhersageergebnisse der Gruppe „Interessierter Nutzer“ weichen mit
70,6 Prozent, um 16,3 Prozent von den Ergebnissen der Entscheidungsbaumvorhersage ab,
allerdings konnten mit 89 „Interessierten Nutzern“ 16 mehr prognostiziert werden, was 19,82
Prozent aller „Interessierten Nutzer“ entspricht.
7.4.4. Assoziationsanalyse
Das Ziel der Assoziationsanalyse ist die Entdeckung von interessanten Zusammenhängen
zwischen Teilmengen von Daten. Für dieses Analyseverfahren wurde Xaffinity von Exclusive
Ore eingesetzt. Xaffinity kann, ohne zusätzliche Transformationen, direkt auf die Transakti-
onsdaten angewandt werden42. Im Rahmen der Analyse der PLANET GmbH-Logdaten wird
versucht, interessante und aussagekräftige Zusammenhänge zwischen den einzelnen ab-
gerufenen Dokumenten der Homepage zu identifizieren. Für die Bestimmung des optimalen
Mindest-Supports wurden mehrere Testläufe durchgeführt. Wenn der Mindest-Support zu
hoch gewählt wird, werden relativ triviale Regeln generiert und eventuell interessante Regeln
nicht berechnet. Wird ein zu geringer Mindest-Support angesetzt, werden sehr viele Regeln
generiert und es kommt zu einer Informationsüberlastung des Anwenders. Für den Mindest-
Support für die Assoziationsanalyse der PLANET GmbH-Logdaten wurden 0,5 Prozent ge-
wählt, was 67 Besuchern entspricht. Um möglichst hochzusammenhängende Assoziations-
regeln zu erhalten, ist eine hohe Mindest-Konfidenz zu gewählen. Es ist aber auch interes-
sant zu untersuchen, warum bestimmte Seiten, die bei der Konzeptionierung der Homepage
strukturell zusammengefasst wurden, nicht zusammen aufgerufen werden. Für diese Unter-
suchungen ist eine niedrigere Mindest-Konfidenz zu wählen. Nachteilig bei der Wahl einer
42 Vgl. Tabelle 7.7
83
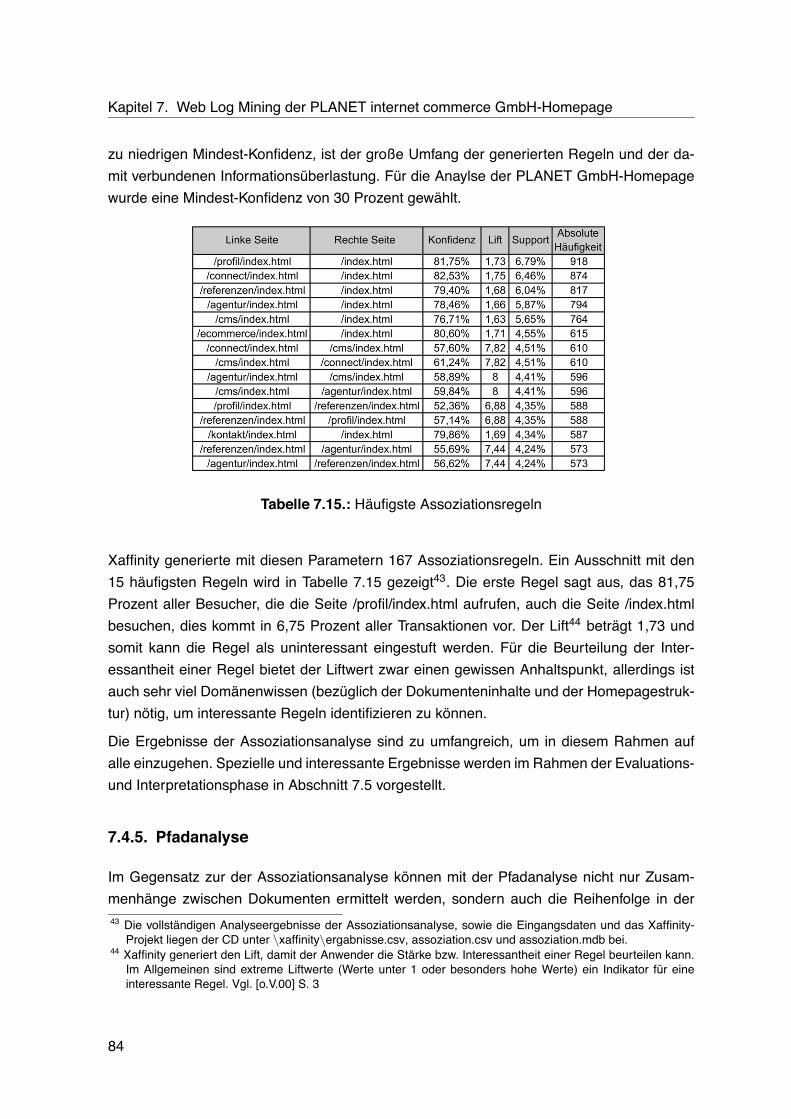
Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
zu niedrigen Mindest-Konfidenz, ist der große Umfang der generierten Regeln und der da-
mit verbundenen Informationsüberlastung. Für die Anaylse der PLANET GmbH-Homepage
wurde eine Mindest-Konfidenz von 30 Prozent gewählt.
Tabelle 7.15.: Häufigste Assoziationsregeln
Xaffinity generierte mit diesen Parametern 167 Assoziationsregeln. Ein Ausschnitt mit den
15 häufigsten Regeln wird in Tabelle 7.15 gezeigt43. Die erste Regel sagt aus, das 81,75
Prozent aller Besucher, die die Seite /profil/index.html aufrufen, auch die Seite /index.html
besuchen, dies kommt in 6,75 Prozent aller Transaktionen vor. Der Lift44 beträgt 1,73 und
somit kann die Regel als uninteressant eingestuft werden. Für die Beurteilung der Inter-
essantheit einer Regel bietet der Liftwert zwar einen gewissen Anhaltspunkt, allerdings ist
auch sehr viel Domänenwissen (bezüglich der Dokumenteninhalte und der Homepagestruk-
tur) nötig, um interessante Regeln identifizieren zu können.
Die Ergebnisse der Assoziationsanalyse sind zu umfangreich, um in diesem Rahmen auf
alle einzugehen. Spezielle und interessante Ergebnisse werden im Rahmen der Evaluations-
und Interpretationsphase in Abschnitt 7.5 vorgestellt.
7.4.5. Pfadanalyse
Im Gegensatz zur der Assoziationsanalyse können mit der Pfadanalyse nicht nur Zusam-
menhänge zwischen Dokumenten ermittelt werden, sondern auch die Reihenfolge in der43 Die vollständigen Analyseergebnisse der Assoziationsanalyse, sowie die Eingangsdaten und das Xaffinity-Projekt liegen der CD unter \xaffinity\ergabnisse.csv, assoziation.csv und assoziation.mdb bei.
44 Xaffinity generiert den Lift, damit der Anwender die Stärke bzw. Interessantheit einer Regel beurteilen kann.Im Allgemeinen sind extreme Liftwerte (Werte unter 1 oder besonders hohe Werte) ein Indikator für eineinteressante Regel. Vgl. [o.V.00] S. 3
84
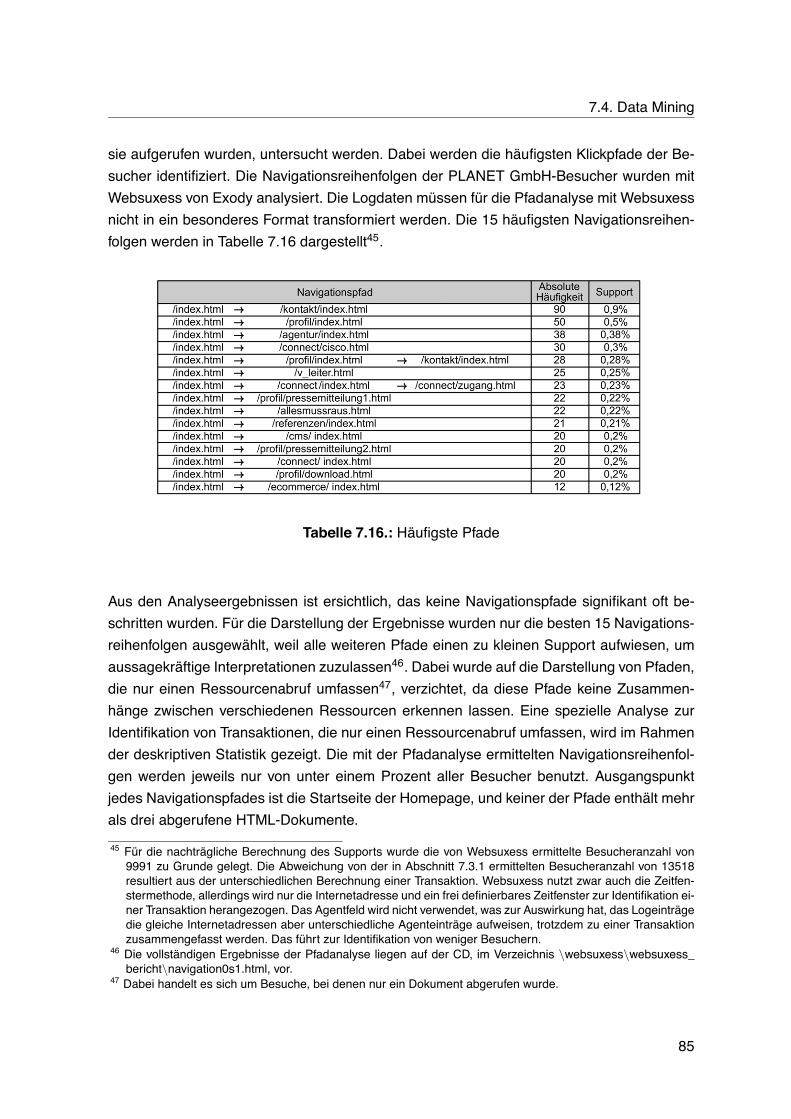
7.4. Data Mining
sie aufgerufen wurden, untersucht werden. Dabei werden die häufigsten Klickpfade der Be-
sucher identifiziert. Die Navigationsreihenfolgen der PLANET GmbH-Besucher wurden mit
Websuxess von Exody analysiert. Die Logdaten müssen für die Pfadanalyse mit Websuxess
nicht in ein besonderes Format transformiert werden. Die 15 häufigsten Navigationsreihen-
folgen werden in Tabelle 7.16 dargestellt45.
Tabelle 7.16.: Häufigste Pfade
Aus den Analyseergebnissen ist ersichtlich, das keine Navigationspfade signifikant oft be-
schritten wurden. Für die Darstellung der Ergebnisse wurden nur die besten 15 Navigations-
reihenfolgen ausgewählt, weil alle weiteren Pfade einen zu kleinen Support aufwiesen, um
aussagekräftige Interpretationen zuzulassen46. Dabei wurde auf die Darstellung von Pfaden,
die nur einen Ressourcenabruf umfassen47, verzichtet, da diese Pfade keine Zusammen-
hänge zwischen verschiedenen Ressourcen erkennen lassen. Eine spezielle Analyse zur
Identifikation von Transaktionen, die nur einen Ressourcenabruf umfassen, wird im Rahmen
der deskriptiven Statistik gezeigt. Die mit der Pfadanalyse ermittelten Navigationsreihenfol-
gen werden jeweils nur von unter einem Prozent aller Besucher benutzt. Ausgangspunkt
jedes Navigationspfades ist die Startseite der Homepage, und keiner der Pfade enthält mehr
als drei abgerufene HTML-Dokumente.
45 Für die nachträgliche Berechnung des Supports wurde die von Websuxess ermittelte Besucheranzahl von9991 zu Grunde gelegt. Die Abweichung von der in Abschnitt 7.3.1 ermittelten Besucheranzahl von 13518resultiert aus der unterschiedlichen Berechnung einer Transaktion. Websuxess nutzt zwar auch die Zeitfen-stermethode, allerdings wird nur die Internetadresse und ein frei definierbares Zeitfenster zur Identifikation ei-ner Transaktion herangezogen. Das Agentfeld wird nicht verwendet, was zur Auswirkung hat, das Logeinträgedie gleiche Internetadressen aber unterschiedliche Agenteinträge aufweisen, trotzdem zu einer Transaktionzusammengefasst werden. Das führt zur Identifikation von weniger Besuchern.
46 Die vollständigen Ergebnisse der Pfadanalyse liegen auf der CD, im Verzeichnis \websuxess\websuxess_bericht\navigation0s1.html, vor.
47 Dabei handelt es sich um Besuche, bei denen nur ein Dokument abgerufen wurde.
85

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
7.4.6. Deskriptive Statistik
Die klassische statistische Untersuchung der Planet Internet Commerce GmbH-Homepage
wurde mit Websuxess durchgeführt. Dabei können die Analysen nicht zielgruppenspezifisch,
wie bei der Entscheidungsbauminduktion sondern nur global für alle Besucher, durchgeführt
werden. Bei dieser klassischen Analyseform werden vor allem Minima, Maxima und Durch-
schnittswerte der in Abschnitt 6.1 vorgestellten Programmfunktionen generiert und darge-
stellt. Zunächst wurde eine Zusammenfassung mit folgenden Kennzahlen48 generiert. 9991
Nutzer besuchten die Webpräsenz und haben dabei 31276 Seiten aufgerufen. Diese Auf-
rufe führten insgesamt zu einem transferierten Datenvolumen (Traffic) von 4,27 Gigabyte.
Täglich konnten durchschnittlich 54,32 Besuche verzeichnet werden, die durchschnittlich 63
Sekunden dauerten und bei denen 2,4 weitere Seiten aufgerufen wurden. Pro Seite verweil-
te der Besucher durchschnittlich 26 Sekunden. Im Folgenden werden typische Ausschnitte
der Analyseergebnisse von Websuxess gezeigt.
Tabelle 7.17.: Traffic nach Wochentagen
Die Tabelle 7.17 zeigt die Auswertung des Traffics nach den Wochentagen. Deutlich wird,
dass sich die Anfragen im Zeitablauf ungleichmäßig verteilen. An den Wochenenden wird
der geringste und an den Montagen der meiste Traffic verzeichnet.
Abbildung 7.2.: Traffic nach Stunden
48 Wie schon bei der Pfadanalyse erklärt, können einige Werte, von den in den vergangenen Abschnitten ermit-telten Ergebnissen, abweichen.
86
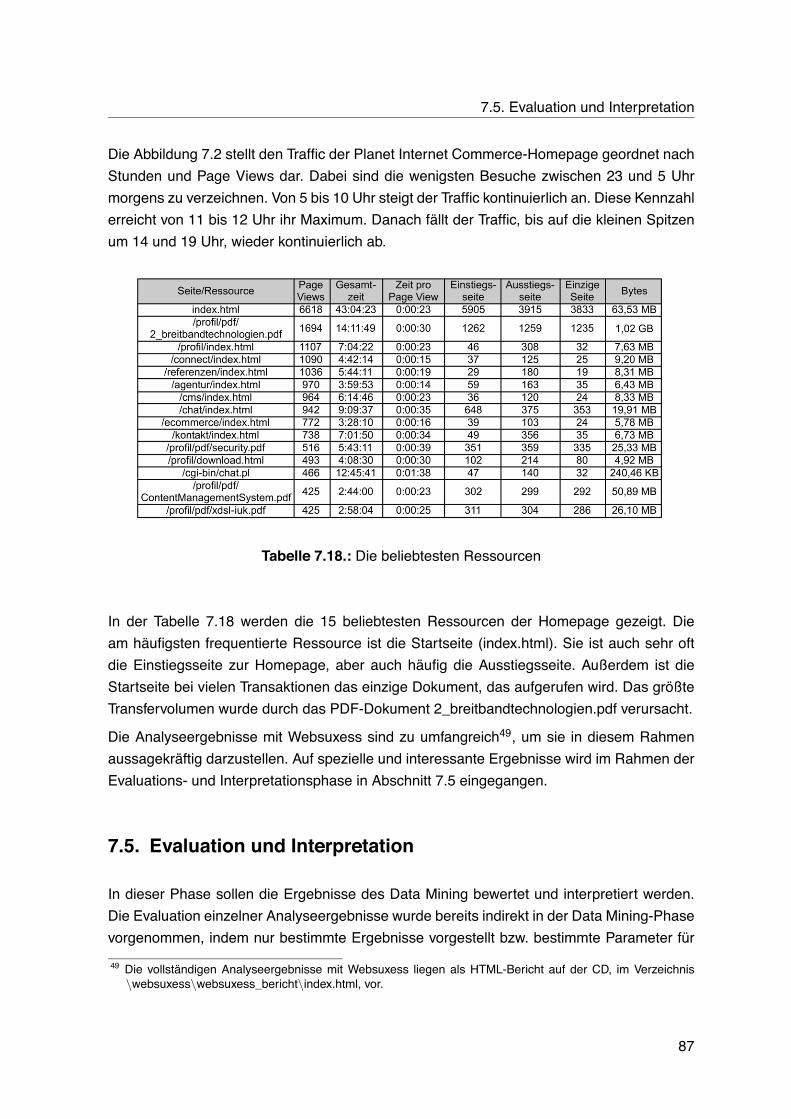
7.5. Evaluation und Interpretation
Die Abbildung 7.2 stellt den Traffic der Planet Internet Commerce-Homepage geordnet nach
Stunden und Page Views dar. Dabei sind die wenigsten Besuche zwischen 23 und 5 Uhr
morgens zu verzeichnen. Von 5 bis 10 Uhr steigt der Traffic kontinuierlich an. Diese Kennzahl
erreicht von 11 bis 12 Uhr ihr Maximum. Danach fällt der Traffic, bis auf die kleinen Spitzen
um 14 und 19 Uhr, wieder kontinuierlich ab.
Tabelle 7.18.: Die beliebtesten Ressourcen
In der Tabelle 7.18 werden die 15 beliebtesten Ressourcen der Homepage gezeigt. Die
am häufigsten frequentierte Ressource ist die Startseite (index.html). Sie ist auch sehr oft
die Einstiegsseite zur Homepage, aber auch häufig die Ausstiegsseite. Außerdem ist die
Startseite bei vielen Transaktionen das einzige Dokument, das aufgerufen wird. Das größte
Transfervolumen wurde durch das PDF-Dokument 2_breitbandtechnologien.pdf verursacht.
Die Analyseergebnisse mit Websuxess sind zu umfangreich49, um sie in diesem Rahmen
aussagekräftig darzustellen. Auf spezielle und interessante Ergebnisse wird im Rahmen der
Evaluations- und Interpretationsphase in Abschnitt 7.5 eingegangen.
7.5. Evaluation und Interpretation
In dieser Phase sollen die Ergebnisse des Data Mining bewertet und interpretiert werden.
Die Evaluation einzelner Analyseergebnisse wurde bereits indirekt in der Data Mining-Phase
vorgenommen, indem nur bestimmte Ergebnisse vorgestellt bzw. bestimmte Parameter für
49 Die vollständigen Analyseergebnisse mit Websuxess liegen als HTML-Bericht auf der CD, im Verzeichnis\websuxess\websuxess_bericht\index.html, vor.
87

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
die Analyseprogramme benutzt wurden. Zwischen dem Generieren von interessanten Er-
gebnissen und dem Anpassen der Eingabeparameter für die Programme besteht eine stän-
dige Wechselbeziehung. Die Data Mining-Ergebnisse der PLANET GmbH-Logdaten sollen
im Folgenden vorgestellt und auf ihren ökonomischen Nutzen geprüft werden.
7.5.1. Clusteranalyse
Die Clusteranalyse soll Gruppenstrukturen in großen Datenmengen entdecken. Im Rahmen
des Web Log Mining bietet dieses Verfahren die Möglichkeit, wertvolle Informationen über
das Navigationsverhalten der Besucher zu sammeln bzw. die Besucher anhand ihres Na-
vigationsverhaltens zu gruppieren. Die entdeckten Gruppen spiegeln ähnliche Verhaltens-
weisen wieder, strukturieren die Besucher jedoch nicht direkt nach ökonomischen Gesichts-
punkten. Für die betriebswirtschaftliche Betrachtung der Besucher empfiehlt sich daher ei-
ne Gruppierung nach den abgerufenen Ressourcen. So stellen Nutzer die eine Bestellung
aufgeben, z.B. durch den Aufruf der Ressource „bestellung.pl“, einen hohen betriebswirt-
schaftlichen Nutzen dar und werden der Gruppe „Kunde“ zugeordnet. Besucher, die sich
Produktseiten ansehen aber nichts bestellen, werden z.B. als „Interessierte Nutzer“ zusam-
mengefasst. Alle anderen Nutzer haben, zumindest für den direkten Vertrieb von Produkten,
keine ökonomische Bedeutung und werden der Gruppe „Just Browsing“ zugeordnet. Die
Clusteranalyse kann als Ergänzung zu dieser Einteilung eingesetzt werden, um bisher nicht
betrachtete bzw. entdeckte Gruppen in die weiteren Analysen einzubeziehen. So wurde für
die PLANET GmbH-Homepage die Gruppe „Interessierte Kurzbesucher“ entdeckt, die sich
ausschließlich PDF-Produktblätter ansehen. Diese vier Gruppen wurden durch das Attribut
„Besucherverhalten“ zusammengefasst. Im Rahmen des Web Log Mining kann die Cluster-
analyse als Unterstützung zur Generierung betriebswirtschaftlich relevanter Besuchergrup-
pen dienen.
7.5.2. Entscheidungsbauminduktion
Für eine möglichst wirkungsvolle und gezielte Ansprache (Werbung, spezielle Aktionen) der
zuvor definierten Gruppen werden mit Hilfe der Entscheidungsbauminduktion entsprechen-
de Gruppenprofile erstellt. Für die PLANET GmbH-Homepage wurde zur Beurteilung des
ökonomischen Nutzens eines Besuchers das Zielattribut „Besucherverhalten“ definiert. Da-
mit die Gruppenprofile möglichst detailliert erstellt werden können, fließen alle verfügbaren
Informationen in die Entscheidungsbauminduktion ein. In Abschnitt 7.5.2 wurden die Profile
der einzelnen Gruppen vorgestellt. Aus diesen Profilen können ökonomisch relevante und
gruppenspezifische Informationen extrahiert werden. Die für die PLANET GmbH-Homepage
erstellten Gruppenprofile werden nachfolgend analysiert und die Ergebnisse vorgestellt. Im
88

7.5. Evaluation und Interpretation
Rahmen dieser Auswertung wird jedoch nur auf die Ergebnisse eingegangen, die betriebs-
wirtschaftlich interessant sind oder zur Verbesserung der Website beitragen können. Die
Gruppe „Just Browsing“ wurde als vertriebstechnisch unbedeutend eingestuft und wird nicht
genauer betrachtet.
Die typischen „Kunden“ besuchen die Website teilweise zu anderen Zeiten als die anderen
Gruppen. Mit Hilfe der deskriptiven Statistik wurde ein Besuchermaximum für den Montag
ermittelt50. Dieses Ergebnis wird vor allem durch die Gruppen „Interessierter Nutzer“, „In-
teressierter Kurzbesucher“ und „Just Browsing“ beeinflusst. Die typischen „Kunden“ (ca. 82
Prozent) besuchen die Website aber vorrangig an den Tagen Dienstag, Mittwoch, Donners-
tag und Freitag, nicht am Montag. Weiterhin besuchen die „Kunden“, im Gegensatz zu den
anderen Gruppen51, die Website nicht nur tagsüber (7-16 Uhr, ca. 64 Prozent), sondern
auch abends (17-23 Uhr, ca. 29 Prozent). Mit diesen Informationen können gezielte Aktio-
nen oder entsprechende Werbung zu den Zeiten geschaltet werden, an denen die meisten
potentiellen Kunden die Homepage besuchen. So wäre bspw. denkbar, das Werbeplätze
auf anderen Websites von Dienstag bis Freitag in der Zeit von 7-16 oder 17 bis 23 Uhr ge-
mietet werden, um die Wahrscheinlichkeit, viele Kunden zu gewinnen, zu maximieren. Eine
andere Möglichkeit die potentiellen Kunden gezielter anzusprechen, ist der Einsatz von Ad-
Servern52 auf der eigenen Homepage. Mit Hilfe eines Ad-Servers ist es möglich, zu den
entsprechenden Zeiten spezielle Aktionen auf der Website anzubieten, um den Besucher
zum Kauf eines Produktes zu animieren. So können zum Beispiel, an den Wochentagen
Dienstag, Mittwoch, Donnerstag und Freitag in der Zeit von 7-16 oder 17-23 Uhr, potentielle
Kunden durch Schnupperangebote oder vergünstigte Konditionen angesprochen werden.
Die PLANET GmbH hat bereits in der Vergangenheit Werbung auf anderen Websites ein-
gesetzt, Sponsoring-Aktionen durchgeführt und sich in regionalen und überregionalen Pro-
viderverzeichnissen eingetragen. Mit Hilfe der Entscheidungsbauminduktion ist es möglich,
die Effizienz solcher Marketinginstrumente zu kontrollieren. Aus den Kundenprofilen ist er-
sichtlich, das die typischen „Kunden“ nicht über solche Aktionen (Referrer: Presse und PR)
auf die Homepage gelangt sind53. Was darauf schliessen lässt, das diese Instrumente nicht
effektiv waren, um direkt Kunden zu gewinnen. Es ist aber nicht auszuschliessen, das mit
den Marketingaktionen indirekt Kunden gewonnen werden konnten. Mit dem Einsatz von
transaktionsübergreifenden Identifikationsmechanismen (z.B. Cookies) könnten die Folge-
besuche eines Nutzers dokumentiert und so festgestellt werden, ob durch diese Marketingin-
strumente indirekt (zu einem späteren Zeitpunkt) ein Kunde akquiriert werden konnte. Durch
50 Vgl. Tabelle 7.1751 Vgl. Abbildung 7.252 Ad-Server sind spezielle Server, die parametergesteuert dynamische Inhalte und Werbung auf der ent-sprechenden Homepage anzeigen. Diese Parameter können z.B. Uhrzeit und Datum aber auch die Top-Level-Domain oder der verwendete Browser des Besuchers sein. Ein leistungsstarker Ad-Server ist dasOpensource-Produkt phpAdsNew (http://www.phpadsnew.com).
53 Insgesamt konnten in 8 Monaten von 72 „Kunden“ nur 2 direkt durch diese Aktionen gewonnen werden.
89

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
die Identifikationsmechanismen ist es möglich, die Effektivität von Online-Marketingkampagnen
besser beurteilen zu können und in diesem Zuge den Return on Investment (ROI) zu bestim-
men.
Über 22 Prozent der Gruppe „Kunde“ gelangen über die Websites von Kunden der PLANET
GmbH auf die Homepage der PLANET GmbH. Damit diese Möglichkeit, potentielle Kunden
zu gewinnen, weiter ausgeschöpft werden kann, könnten alle Kunden-Websites zukünftig
mit einem Impressum mit dem Verweis auf die PLANET GmbH-Homepage produziert bzw.
bestehende Kunden-Websites damit nachgerüstet werden.
Aus den Kundenprofilen ist ersichtlich, das viele „Kunden“ die Website nach dem Abschicken
eines Formulars verlassen (ca. 18 Prozent). Im Rahmen einer Cross-Selling-Strategie könn-
ten hier weitere Produkte angeboten bzw. andere Produkt(-bereiche) vorgestellt werden.
Viele der typischen „Interessierten Nutzer“ kommen über die Suchmaschine Google auf
die Homepage der PLANET GmbH (ca. 25 Prozent). Sie benutzten dabei häufig den Such-
begriff „Planet“54 (ca. 30 Prozent der Besucher die über Google kommen), was darauf hin-
deuten kann, das die Firma PLANET GmbH gezielt gesucht wurde. Mit diesen Informationen
ist es möglich, die Homepage so zu optimieren, das sie durch möglichst viele „Interessierte
Nutzer“ gefunden wird. Um das zu erreichen, müssen die Metadaten der Homepage opti-
miert werden. Suchmaschinen orientieren sich bei der Katalogisierung und Indizierung der
Websites in erster Linie55 an den Metadaten der einzelnen Seiten. Metadaten sind Infor-
mationen, die die Dokumente einer Website beschreiben. Dabei handelt es sich um be-
stimmte Befehle, die in die (HTML-)Dokumente integriert werden, wie z.B. „keywords“ in
dem Schlagworte gespeichert werden oder „description“ in dem der Inhalt des Dokuments
kurz beschrieben wird56. Wenn der Suchbegriff „Planet“ in die „keywords“ der Metadaten
der PLANET GmbH-Homepage aufgenommen wird, steigt die Wahrscheinlichkeit, das mehr
potentielle „Interessierte Nutzer“ die Homepage über Suchmaschinen finden.
Viele der „Interessierten Nutzer“ finden die Internetpräsenz der PLANET GmbH mit der
Suchmaschine Google. Deshalb bietet es sich an, die Homepage in erster Linie für diese
Suchmaschine zu optimieren bzw. Werbeplätze bei Google57 zu mieten, um die Chance der
Besuche durch potentielle „Interessierte Nutzer“ zu erhöhen.
Mehr als 17 Prozent der „Interessierten Nutzer“ gelangen über die Websites von Kunden der
54 Wie in Abschnitt 7.3.2 erläutert wurde, schließt der Suchbegriff „Planet“ auch Suchanfragen wie „pla-net+internet+commerce+dsl„ oder „internetzugang+planet“ ein.
55 Die Katalogisierung und Indizierung ist von den einzelnen Suchmaschinen abhängig. Viele Suchmaschinenziehen dabei, neben den Metadaten, auch die Inhalte der Website, wie z.B. den Text, heran.
56 Folgendes Beispiel zeigt die Syntax von HTML-Metadaten: <meta name=“keywords“ content=“e-commerce,cms, dsl“>, <meta name=“description“ content=“PLANET internet commerce, Technologien, Loesungen undKompetenzen“>.
57 Bei Google kann man z.B. s.g. AdWords (http://www.google.com/ads/) mieten, d.h. abhängig von dem Such-begriff des WWW-Nutzers wird Werbung neben den Suchergebnissen eingeblendet.
90

7.5. Evaluation und Interpretation
PLANET GmbH auf die Homepage der PLANET GmbH. Wie schon bei den „Kunden“ bietet
es sich auch für die potentiellen „Interessierten Nutzer“ an, das Impressum mit dem Verweis
auf die PLANET GmbH-Homepage in die Kunden-Websites zu integrieren.
Die „Interessierten Kurzbesucher“ rufen nur ein PDF-Dokument58 ab und verlassen die
Seite dann gleich wieder ohne weitere Ressourcen zu betrachten. Viele der „Interessierten
Kurzbesucher“ finden die PLANET GmbH-Homepage durch Suchmaschinen (über 77 Pro-
zent). Für die „Interessierten Kurzbesucher“ wird angenommen, das es sich hierbei vorrangig
um Personen handelt, für die in erster Linie die Beschaffung von Informationen und nicht der
Kauf von Produkten bzw. Dienstleistungen im Vordergrund steht. Diese Annahme wird auch
durch die Wahl der Suchbegriffe dieser Besucher (nicht „Planet“, sondern z.B. „Definition“)
gestützt. Auf der PLANET GmbH-Homepage werden viele PDF-Dokumente zum Download
angeboten. Das PDF-Format hat neben seinen darstellerischen und portabilitäts Vorzügen
auch einen psychologischen Vorteil. Viele WWW-Nutzer verbinden mit PDF-Dokumenten
inhaltliche Qualität. Suchmaschinen bieten entspechende Einstellungen an, die die Suche
explizit auf PDF-Dokumente begrenzen. Durch die PDF-Dokumente gewinnt die PLANET
GmbH-Homepage viele Besucher, die aber vertriebstechnisch relativ uninteressant sind.
Das liegt vor allem daran, dass die „Interessierten Kurzbesucher“ nur ein PDF-Dokument
aufrufen und dann die Homepage verlassen. Sie stellen somit keinen direkten betriebswirt-
schaftlichen Nutzen für die Firma dar. Es sollte mittels entsprechender Instrumente versucht
werden, die „Interessierten Kurzbesucher“ als „Interessierten Nutzer“ oder besser als „Kun-
den“ zu gewinnen. Die Voraussetzung dafür muss aber in den PDF-Dokumenten selbst ge-
schaffen werden. Denn immer, wenn ein WWW-Nutzer ein PDF-Dokument der PLANET-
GmbH in den Suchergebnissen der Suchmaschine findet und dieses aufruft, wird nur das
PDF-Dokument geladen, aber nicht die Navigation der Homepage. Dem Besucher wird so-
mit keine Möglichkeit gegeben, auf der Homepage zu navigieren. Auf den PDF-Dokumenten
könnten z.B. Links auf die Homepage der PLANET GmbH angeboten bzw. durch entspre-
chende Werbebotschaften der Besucher zum Weiterklicken animiert werden. Weiterhin ist
es auch möglich, durch die Integration bestimmter Befehle in die PDF-Dokumente, die Navi-
gationselemente der Homepage nachzuladen.
Eine andere Möglichkeit betriebswirtschaftlichen Nutzen aus den „Interessierten Kurzbesu-
chern“ zu ziehen, ist alle PDF-Dokumente zu schützen, die keine Produktinformationen ent-
halten. Damit soll verhindert werden, das jeder WWW-Nutzer diese fachlichen Informationen
abrufen kann, ohne das die Firma einen Nutzen davon hat. So könnte der Besucher dazu
gezwungen werden, z.B. seine E-Mail-Adresse zu hinterlassen, um das PDF-Dokument be-
trachten oder herunterladen zu dürfen. Mit den so gewonnenen Kundendaten können Inter-
essen (Inhalt des abgerufenden PDF-Dokuments) und Adresse (z.B. E-Mail) des Besuchers
58 Bei diesen Dokumenten handelt es sich um Produktblätter, aber vor allem auch um Vorträge oder anderefachliche Dokumente, die auf der Homepage zum kostenlosen Download angeboten werden.
91

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
festgestellt werden, welche die Basis für Mail-Kampagnen oder Newsletter-Aktionen bilden
können. Nachteilig bei dieser Vorgehensweise ist, dass die Akzeptanz, persönliche Daten im
Internet zu hinterlassen, nicht bei jedem Besucher gegeben ist.
Wie oben bei den „Interessierten Nutzern“ erklärt, könnte auch für die „Interessierten Kurz-
besucher“ durch eine Optimierung der Metadaten mit den entsprechenden Suchbegriffen ein
höheres Besucheraufkommen erzielt werden.
Grundsätzlich können auch Optimierungsmechanismen eingesetzt werden, die den ökono-
mischen Nutzen jeder Gruppe steigern können. Durch den Einsatz von transaktionsüber-
greifenden Identifizierungsmethoden, wie z.B. Cookies, bekommt jeder Besucher eine ein-
deutige Kennung (Besucher-ID) zugewiesen und kann bei seinen nachfolgenden Besuchen
auf der Homepage wiedererkannt werden. Dadurch wird ermöglicht, dass die Dokumente
oder Websitebereiche, die der Besucher bei seinen vergangenen Besuchen aufgerufen hat,
zu speichern und so seine Interessen zu identifizieren. Mit diesen Besucherdaten kann z.B.
die Startseite der Homepage, mit den besucherspezifischen (personalisierten) Produktbe-
reichen und entsprechender Werbung oder Aktionen, dynamisch generiert werden.
Wie hier gezeigt, können mit Hilfe der Entscheidungsbauminduktion Zielgruppenprofile er-
stellt und zielgruppenspezifisch Aktionen und Instrumente auf die einzelnen Gruppen an-
gewandt werden. Diese Möglichkeit schafft die Voraussetzung für differenzierte Marketing-
und Vertriebsstrategien, um den betriebswirtschaftlichen Nutzen der einzelnen Gruppen zu
maximieren.
Neben der Erstellung von Profilen können mit Hilfe der Entscheidungsbauminduktion auch
Prognosen gestellt werden. In diesem Rahmen wurde versucht, das Besucherverhalten auf
der PLANET GmbH-Homepage vorherzusagen. Die Ergebnisse der Entscheidungsbaum-
vorhersage wurden in Abschnitt 7.5.2 vorgestellt. Die besten Vorhersageergebnisse liefer-
ten die Modelle mit einem Verhältnis von Trainings- und Validierungsmenge von 70 zu 30
Prozent. Insgesamt konnte das Verhalten von 89 Prozent der Besucher richtig prognostiziert
werden. Jedoch konnten die betriebswirtschaftlich interessanteren Gruppen „Kunde“ und
„Interessierter Nutzer“ gar nicht bzw. nur relativ schlecht vorhergesagt werden. Als Ursache
für die schlechten Prognoseergebnisse bei den „Kunden“ wird angenommen, das zu wenige
Datensätze für ein effektives Training der Vorhersagemodelle zur Verfügung standen. Die
„Interessierten Nutzer“ konnten zwar mit einer Wahrscheinlichkeit von fast 87 Prozent richtig
vorhergesagt werden, jedoch wurden von 449 „Interessierten Nutzern“ in der Validierungs-
menge nur 73 vom Vorhersagemodell richtig eingestuft. Die anderen 376 „Interessierten
Nutzer“ wurden auf falsche Gruppen verteilt. Die nachfolgende Tabelle zeigt, wie die einzel-
nen Gruppen, die durch das Prognosemodell vorhergesagt bzw. auf die falschen Gruppen
verteilt wurden.
92
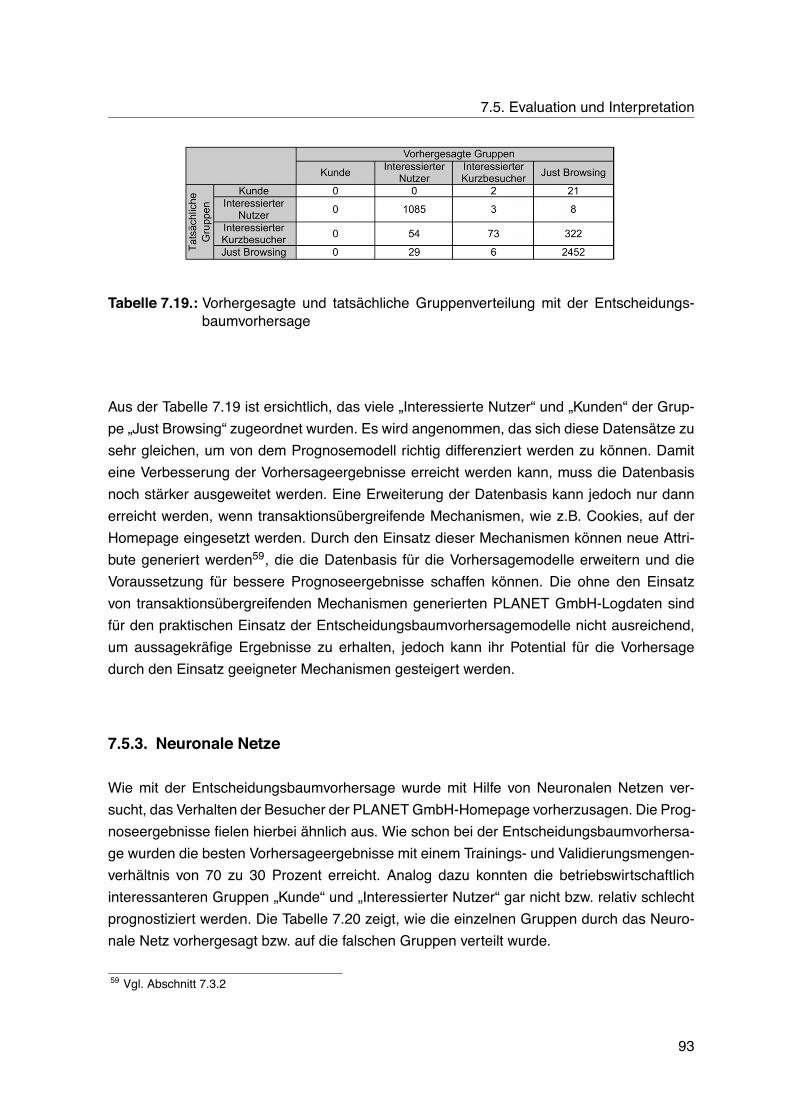
7.5. Evaluation und Interpretation
Tabelle 7.19.: Vorhergesagte und tatsächliche Gruppenverteilung mit der Entscheidungs-baumvorhersage
Aus der Tabelle 7.19 ist ersichtlich, das viele „Interessierte Nutzer“ und „Kunden“ der Grup-
pe „Just Browsing“ zugeordnet wurden. Es wird angenommen, das sich diese Datensätze zu
sehr gleichen, um von dem Prognosemodell richtig differenziert werden zu können. Damit
eine Verbesserung der Vorhersageergebnisse erreicht werden kann, muss die Datenbasis
noch stärker ausgeweitet werden. Eine Erweiterung der Datenbasis kann jedoch nur dann
erreicht werden, wenn transaktionsübergreifende Mechanismen, wie z.B. Cookies, auf der
Homepage eingesetzt werden. Durch den Einsatz dieser Mechanismen können neue Attri-
bute generiert werden59, die die Datenbasis für die Vorhersagemodelle erweitern und die
Voraussetzung für bessere Prognoseergebnisse schaffen können. Die ohne den Einsatz
von transaktionsübergreifenden Mechanismen generierten PLANET GmbH-Logdaten sind
für den praktischen Einsatz der Entscheidungsbaumvorhersagemodelle nicht ausreichend,
um aussagekräfige Ergebnisse zu erhalten, jedoch kann ihr Potential für die Vorhersage
durch den Einsatz geeigneter Mechanismen gesteigert werden.
7.5.3. Neuronale Netze
Wie mit der Entscheidungsbaumvorhersage wurde mit Hilfe von Neuronalen Netzen ver-
sucht, das Verhalten der Besucher der PLANET GmbH-Homepage vorherzusagen. Die Prog-
noseergebnisse fielen hierbei ähnlich aus. Wie schon bei der Entscheidungsbaumvorhersa-
ge wurden die besten Vorhersageergebnisse mit einem Trainings- und Validierungsmengen-
verhältnis von 70 zu 30 Prozent erreicht. Analog dazu konnten die betriebswirtschaftlich
interessanteren Gruppen „Kunde“ und „Interessierter Nutzer“ gar nicht bzw. relativ schlecht
prognostiziert werden. Die Tabelle 7.20 zeigt, wie die einzelnen Gruppen durch das Neuro-
nale Netz vorhergesagt bzw. auf die falschen Gruppen verteilt wurde.
59 Vgl. Abschnitt 7.3.2
93
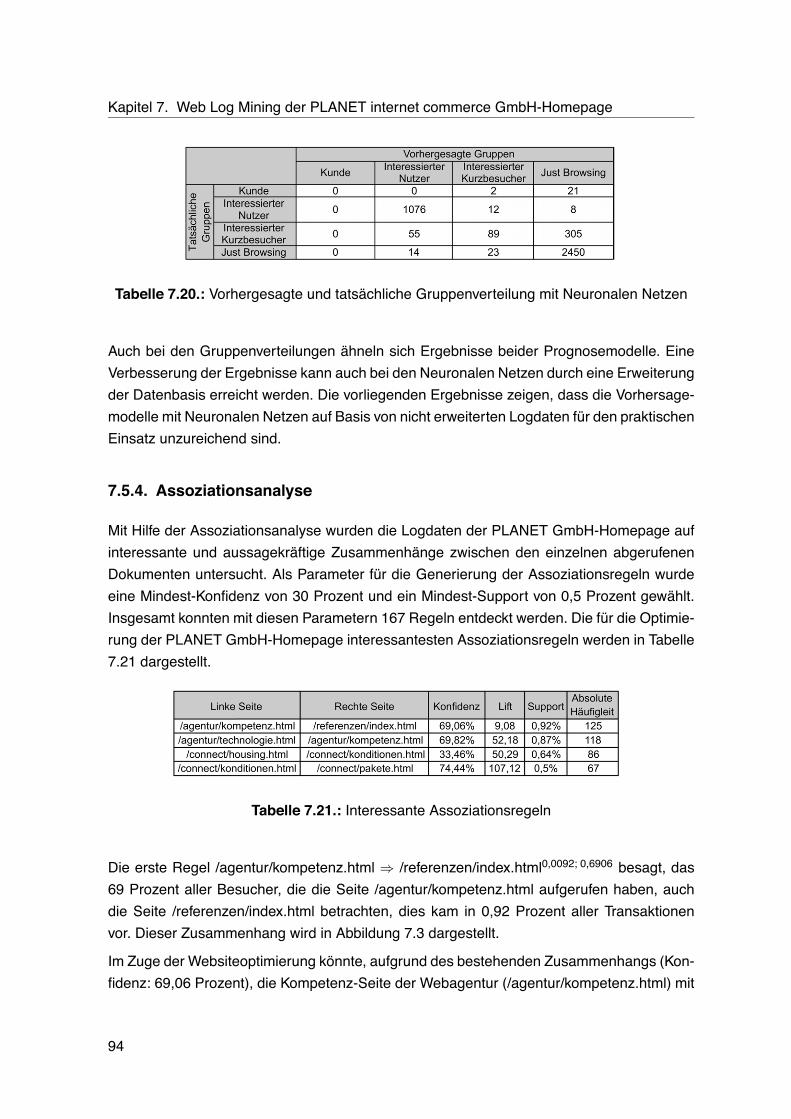
Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Tabelle 7.20.: Vorhergesagte und tatsächliche Gruppenverteilung mit Neuronalen Netzen
Auch bei den Gruppenverteilungen ähneln sich Ergebnisse beider Prognosemodelle. Eine
Verbesserung der Ergebnisse kann auch bei den Neuronalen Netzen durch eine Erweiterung
der Datenbasis erreicht werden. Die vorliegenden Ergebnisse zeigen, dass die Vorhersage-
modelle mit Neuronalen Netzen auf Basis von nicht erweiterten Logdaten für den praktischen
Einsatz unzureichend sind.
7.5.4. Assoziationsanalyse
Mit Hilfe der Assoziationsanalyse wurden die Logdaten der PLANET GmbH-Homepage auf
interessante und aussagekräftige Zusammenhänge zwischen den einzelnen abgerufenen
Dokumenten untersucht. Als Parameter für die Generierung der Assoziationsregeln wurde
eine Mindest-Konfidenz von 30 Prozent und ein Mindest-Support von 0,5 Prozent gewählt.
Insgesamt konnten mit diesen Parametern 167 Regeln entdeckt werden. Die für die Optimie-
rung der PLANET GmbH-Homepage interessantesten Assoziationsregeln werden in Tabelle
7.21 dargestellt.
Tabelle 7.21.: Interessante Assoziationsregeln
Die erste Regel /agentur/kompetenz.html ⇒ /referenzen/index.html0,0092; 0,6906 besagt, das
69 Prozent aller Besucher, die die Seite /agentur/kompetenz.html aufgerufen haben, auch
die Seite /referenzen/index.html betrachten, dies kam in 0,92 Prozent aller Transaktionen
vor. Dieser Zusammenhang wird in Abbildung 7.3 dargestellt.
Im Zuge der Websiteoptimierung könnte, aufgrund des bestehenden Zusammenhangs (Kon-
fidenz: 69,06 Prozent), die Kompetenz-Seite der Webagentur (/agentur/kompetenz.html) mit
94

7.5. Evaluation und Interpretation
Abbildung 7.3.: Beziehungen zwischen HTML-Dokumenten
dem Referenzenbereich (/referenzen/index.html) in Verbindung gebracht werden. Die Mög-
lichkeit der Zusammenlegung beider Dokumente ist aufgrund der unterschiedlichen Inhalte
nicht gegeben. Es könnte jedoch ein entsprechender Verweis (Link) von der Kompetenz-
Seite auf den Referenzenbereich gesetzt werden, damit die vorhandenen Kompetenzen der
Webagentur zusätzlich durch erfolgreiche Referenzprojekte unterstrichen werden. Die an-
deren Bereiche der Homepage beinhalten keine expliziten Kompetenz-Seiten, aber auch
hier könnten Verweise auf bereichsspezifische Referenzprojekte angeboten werden, um das
vorhandene Knowhow und dessen erfolgreiche praktische Anwendung zu präsentieren.
Abbildung 7.4.: Beziehungen zwischen HTML-Dokumenten
Die zweite Regel /agentur/technologie.html⇒ /agentur/kompetenz.html0,0087; 0,6982 zeigt, dass
die HTML-Dokumente /agentur/technologie.html und /agentur/kompetenz.html häufig in Zu-
sammenhang (Konfidenz: 69,82 Prozent) aufgerufen werden (Abbildung 7.4). Da es sich
hierbei um themenverwandte Dokumente handelt, könnte über eine Zusammenlegung bei-
der Inhalte nachgedacht werden, was in einem größeren Rahmen eine gewisse Vereinfa-
chung der Websitestruktur zur Folge hätte.
Aus der dritten Regel /connect/housing.html ⇒ /connect/konditionen.html0,0064; 0,3346 lässt
sich entnehmen, dass die Dokumente /connect/housing.html und /connect/konditionen.html
95

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Abbildung 7.5.: Beziehungen zwischen HTML-Dokumenten
nicht häufig in Zusammenhang aufgerufen wurden (Konfidenz: 33,46 Prozent). Auf der Seite
housing.html wird zur inhaltlichen Weiterführung ein Verweis auf die Seite konditionen.html
angeboten. Von der Seite konditionen.html führt ein Link zu der Seite pakete.html, auf der
die vertriebenen Webhosting-Produkte vorgestellt werden (Abbildung 7.5). Da der Verweis
von housing.html zu den vertriebenen Produkten bzw. Dienstleistungen im Bereich Web-
hosting offensichtlich nur selten genutzt wird, aber die erfolgreiche Präsentation der Pro-
dukte ökonomisch imense Bedeutung hat, muss die Struktur dieser Dokumente verbessert
werden, um mehr Besuchern die Produktübersicht zugänglich zu machen. Die vierte Regel
/connect/konditionen.html⇒ /connect/pakete.html0,005; 0,7444 zeigt, dass die Dokumente kon-
ditionen.html und pakete.html häufig zusammen aufgerufen werden, d.h. wenn der Besucher
ersteinmal die Seite konditionen.html angeklickt hat, ist die Wahrscheinlichkeit groß (Konfi-
denz: 74,44 Prozent), das auch die Seite pakete.html, mit der Produktübersicht, aufgerufen
wird. Auf Basis der Informationen, die der dritten und vierten Assoziationsregel entnommen
werden können, erfolgt eine Verbesserung der Struktur dieser Dokumente. Der Verweis von
der Seite housing.html auf konditionen.html ist sehr unscheinbar, was dazu beigetragen ha-
ben könnte, dass dieser Link relativ selten angeklickt wurde. Eine Verbesserungsmöglichkeit
wäre, diesen Verweis hervorzuheben und die Dokumente konditionen.html und pakete.html
zusammenzuführen. Eine andere Optimierung bestünde darin, konditionen.html ersatzlos zu
streichen, dafür aber die Seite housing.html inhaltlich zu erweitern und den Verweis auf die
Seite pakete.html hervorzuheben. Durch die Optimierungen könnte eine Erhöhung der Be-
sucherzahlen auf der Webhosting-Produktseite und somit eine Steigerung der Wahrschein-
lichkeit eines Kaufes erreicht werden.
Die Wahl der optimalen Eingabeparameter für die Generierung der Assoziationsregeln er-
weisst sich als sehr schwierig, denn werden die Mindest-Konfidenz und der Mindest-Support
96

7.5. Evaluation und Interpretation
zu klein gewählt, werden schon bei relativ kleinenWebsites, wie der PLANET GmbH-Homepage,
unüberschaubar viele Assoziationsregeln generiert und somit wird eine effektive Evaluation
und Interpretation unmöglich gemacht60.
Die Assoziationsanalyse kann im Rahmen des Web Log Mining sehr gut dazu eingesetzt
werden, um die Struktur einer Homepage zu optimieren. So können häufig in Zusammen-
hang aufgerufene Ressourcen mit Verweisen verbunden, gruppiert oder inhaltlich zusam-
mengeführt werden, was eine Vereinfachung der Websitestruktur nach sich zieht. Websites,
die in größerem Umfang Produkte oder Dienstleistungen anbieten, können im Rahmen einer
Cross-Selling-Strategie ihre Produktsortimente mit Hilfe der Assoziationsanalyse optimieren.
7.5.5. Pfadanalyse
Die häufigsten Navigationsreihenfolgen der Besucher auf der PLANET GmbH-Homepage
wurden mit der Pfadanalyse von Websuxess 4.0 identifiziert und in Abschnitt 7.4.5 vorge-
stellt (Tabelle 7.16). Als die beiden häufigsten Navigationsreihenfolgen konnten die Pfade
/index.html→ /kontakt/index.html (90 Besucher) und /index.html→ /profil/index.html (50 Be-
sucher) identifiziert werden. Einen weiteren interessanten Aspekt zeigt die fünf häufigste
Regel /index.html → /profil/index.html → /kontakt/index.html (28 Besucher). Die Abbildung
7.6 stellt den Zusammenhang, der zwischen diesen Navigationsreihenfolgen besteht dar.
Diese Regeln lassen den Trend erkennen, dass die Besucher der PLANET GmbH-Homepage
häufig zuerst Informationen über die Firma sammeln und sich vielleicht erst bei späteren Be-
suchen die vertriebenen Produkte ansehen. Eine weitere Ursache für diesen Trend könnte
die mangelnde Akzeptanz der Besucher sein, Kontakt zur Firma über das Internet herzustel-
len (per E-Mail) und sich stattdessen zunächst die Telefonnummer aus dem Kontaktbereich
beschaffen, um den zuständigen Mitarbeiter persönlich zu sprechen.
Keiner der Klickpfade wurde signifikant oft beschritten. Der relativ geringe Support der ein-
zelnen Navigationsreihenfolgen resultiert aus dem eingeschränkten Funktionsumfang der
Pfadanalyse von Websuxess 4.0. Denn Websuxess generiert nur vollständige Navigations-
pfade, so dass es immer unwahrscheinlicher wird gleiche Klickpfade zu erhalten, je mehr
Dokumente der Besucher aufruft. Teilpfade können mit Websuxess 4.0 nicht generiert wer-
den61.
Websuxess bietet jedoch die Möglichkeit, alle Verweise, die von einem Dokument oder zu
60 Wird bspw. eine Mindest-Konfidenz von 5 Prozent und ein Mindest-Support von 0,1 Prozent gewählt, wer-den 1603 Regeln generiert. Wenn keine Mindest-Konfidenz und kein Mindest-Support vorgegeben werden,werden bereits über 8500 Regeln erzeugt.
61 Je mehr Dokumente die Navigationspfade umfassen, desto unwahrscheinlicher ist eine Übereinstimmung mitanderen Pfaden. Die vom Anwender gesteuerte Generierung von interessanten Teilpfaden, ist mit Websu-xess 4.0 nicht möglich. So wäre bspw. interessant, über welche (Teil-)Pfade die Besucher zu bestimmtenProdukten gelangt sind und ob sie direkt oder über Umwege dorthin gelangten.
97

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
Abbildung 7.6.: Häufigste Klickpfade
einem bestimmten Dokument verfolgt wurden, darzustellen. So wurde untersucht, von wel-
chen Dokumenten aus die Besucher die Seite /kontakt/formular.html aufgerufen haben. Eine
genaue Analyse der Dokumente die die Besucher zu dem Kontaktformular geführt haben, ist
deshalb sehr interessant, weil von (fast) jeder Produktseite der PLANET GmbH-Homepage
die Möglichkeit zur Kontaktaufnahme per E-Mail (Abbildung 7.7)62 mit der Firma gegeben
ist. Somit kann z.B. identifiziert werden, von welcher Produktseite aus die meisten Aufru-
fe des Kontaktformulars kamen. Die zehn Dokumente, die die meisten Besucher zu dem
Kontaktformular geführt haben, werden in Tabelle 7.22 gezeigt.
62 Die Verweise führen zum Aufruf des Kontaktformulars /kontakt/formular.html.
98

7.5. Evaluation und Interpretation
Abbildung 7.7.: Aufrufmöglichkeit des Kontaktformulars aus einem Produktbereich
Tabelle 7.22.: Dokumente, die die Besucher zum Anklicken des Kontaktformulars animierthaben
Die meisten Besucher, die das Kontaktformular aufgerufen haben, sind über die Startseite
des Kontaktbereiches /kontakt/index.html dorthin gelangt (27 Prozent). Das Kontaktformular
diente bei 10 Prozent seiner Aufrufe als Einstiegsseite für den Besucher. Der Produktbe-
reich Content-Management-Systeme (CMS) hat von allen Produkt- bzw. Diestleistungsbe-
reichen die meisten Besucher zum Aufrufen des Kontaktformulars animiert (24 Prozent).
8 Prozent der Besucher kamen aus dem Bereich Connect (/connect/pakete.html). Wie be-
reits bei der Interpretation der Assoziationsregeln63 erläutert wurde, spielt das Dokument
/connect/pakete.html (Webhosting-Produktseite) eine wichtige Rolle für die Gewinnung von
potentiellen „Kunden“ bzw. „Interessierten Nutzern“ in dem Connect-Produktbereich. Es soll-
te versucht werden, dieses Dokument mehr Besuchern zugänglich zu machen, um den wirt-
schaftlichen Nutzen der Webhosting-Produktseite zu maximieren64. Der für die PLANET
GmbH wichtige Bereich CMS wird unter allen Produktbereichen am effektivsten von den
Besuchern genutzt, der zweite wichtige Bereich E-Commerce dagegen kaum. Damit auch
dieser Produktbereich effektiver genutzt wird, müssen die Produkte aus diesem Bereich bes-
ser präsentiert werden, das könnte z.B. durch entsprechende Hinweise auf der Startseite
geschehen.
Das Aufrufen des Kontaktformulars ist kein Indikator dafür, das es auch wirklich an die PLA-
NET GmbH abgesandt wurde, es spiegelt lediglich das Interesse des Besuchers wieder,
63 Vgl. Abschnitt 7.5.464 Konkrete Vorschläge wurden im vorherigen Abschnitt 7.5.4 gemacht.
99

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
mehr Informationen über ein Produkt zu erhalten und einen Kontakt, telefonisch oder per E-
Mail, zur Firma herzustellen. Von den 97 Aufrufen des Kontaktformulars wurde nur in 11 Fäl-
len das Formular auch abgeschickt, das entspricht einer Quote von ca. 11 Prozent65. Auch
hier ist der Trend zu erkennen, dass die Akzeptanz der Besucher im Internet persönliche
Daten zu hinterlassen sehr begrenzt ist. Daraus folgend, könnte in den Kopf des Kontakt-
formulars bzw. direkt in die Produktbereiche die Telefonnummer eines Ansprechpartners bei
der PLANET GmbH integriert werden, um den Anreiz zur Kontaktaufnahme mit der Firma
zu fördern. Für die wenigen Produktseiten, die noch keinen direkten Verweis auf das Kon-
taktformular besitzen, empfiehlt es sich, diese mit entsprechenden Verweisen nachzurüsten.
Das könnte die Motivation zu einer Kontaktaufnahme erhöhen und ist vor allem für zukünf-
tige Analysen der Website sehr hilfreich, um die Produkte zu identifizieren, die am meisten
Interesse bei den Besuchern hervorrufen.
Für die Optimierung einer Internetpräsenz ist die Pfadanalyse ein wichtiges Instrument. Mit
dieser Analysemethode lässt sich die Struktur und somit die Benutzerfreundlichkeit einer
Website verbessern. So können z.B. die Pfade zu bestimmten Ressourcen optimiert werden,
damit die Besucher direkt und nicht über Umwege zu den wichtigen Bereichen der Website
gelangen. Auch kann die Pfadanalyse die Voraussetzung für eine effektive Platzierung von
Produktinformationen oder Werbung schaffen. In diesem Fall werden auf besonders häufig
frequentierten Navigationspfaden die entsprechenden Botschaften platziert.
7.5.6. Deskriptive Statistik
Die Ergebnisse der klassischen Websiteanalyse sind ebenso wie die Besucheranalysen mit
der Assoziations- und Pfadanalyse nur vor einem globalen Hintergrund zu betrachten, ei-
ne Untersuchung von einzelnen Gruppen, wie bei der Entscheidungsbauminduktion oder
den Neuronalen Netzen, ist (mit den hier eingesetzten Programmen) nicht möglich. Dadurch
können nur Interpretationen und Maßnahmen getroffen werden, die alle Besucher der Web-
site betreffen, gruppenspezifische Instrumente können nicht direkt eingesetzt werden. Bei
der Interpretation der „Kunden“-Profile (Abschnitt 7.5.2) wurde ein entsprechendes Beispiel
gezeigt. Aus den Ergebnissen mit Websuxuess 4.0 konnte ein Besuchermaximum für den
Montag ermittelt werden. Eine gruppenspezifische Betrachtung dieses Ergebnisses (Ent-
scheidungsbauminduktion) zeigte jedoch, das die meisten „Kunden“ nicht am Montag die
PLANET GmbH-Homepage besuchen.
Beim Web Log Mining mit Websuxess 4.0 wurden die beliebtesten Dokumente der PLANET
GmbH-Homepage ermittelt (Tabelle 7.18). Aus der Tabelle geht hervor, das die Startseite
der Homepage (/index.html) mit 6618 Abrufen das am häufigsten besuchte Dokument ist.
65 Aus welchen Produktbereichen heraus die meisten Kontaktformulare an die Firma gesandt wurden, ist mitder Pfadanalyse (von Websuxess 4.0) nicht zu identifizieren.
100

7.5. Evaluation und Interpretation
Die zweitbeliebteste Ressource ist ein PDF-Dokument (/2_breitbandtechnologien.pdf) mit
1694 Abrufen. Dabei handelt es sich um einen Vortrag eines Firmenmitarbeiters zum sehr
aktuellen Thema Breitbandtechnologien (DSL, Wireless LAN, usw.). Für 1262 Besucher war
der Vortrag die Einstiegsseite zur Homepage. Das am dritthäufigsten besuchte Dokument
ist die Startseite des Bereiches Profil (/profil/index.html) mit 1107 Abrufen.
Websuxess 4.0 bietet Gruppierungsfunktionen mit denen Dokumente zu Gruppen zusam-
mengefasst und seperat ausgewertet werden können. So wurden alle Dokumente aus dem
Bereich Pressemitteilungen (/profil/pm) und Pressespiegel (/profil/ps) zu der Gruppe „Pres-
se“ zusammengefasst. Einzelne Pressemitteilungen wurden in der Statistik „Die beliebtesten
Ressourcen“ (Tabelle 7.18) aufgrund der relativ wenigen Abrufe nicht erfasst. Nach einer
erneuten Auswertung der Daten liegt die Gruppe „Presse“ an Platz drei der beliebtesten
Ressourcen mit insgesamt 1276 Abrufen nach der Startseite und dem PDF-Vortrag. Für 501
Besucher war eine Pressemitteilung die Einstiegsseite zur Homepage.
Diese Zahlen belegen, das aktuelle Meldungen/Themen bei den WWW-Nutzern sehr be-
liebt sind und ein Ausbau bzw. eine ständige Aktualisierung, je nach Marketingstrategie, als
Kundenservice oder zur Gewinnung von neuen Besuchern eingesetzt werden kann.
In diesem Zusammenhang wurden die Ergebnisse mit Hilfe der Entscheidungsbauminduk-
tion genauer geprüft. Die Dokumente aus dem Bereich „Presse“ und der PDF-Vortrag wur-
den zwar 1276 bzw. 1694 Mal abgerufen und animierten 501 bzw. 1262 WWW-Nutzer zum
Betreten der Homepage, jedoch sind die so gewonnenen Besucher betriebswirtschaftlich
relativ uninteressant. Ein „Kunde“ und 26 „Interessierte Nutzer“ konnten durch den Pres-
sebereich gewonnen werden, die verbleibenden 477 Besucher gehören der Gruppe „Just
Browsing“ an. Durch den PDF-Vortrag konnten 33 „Interessierte Nutzer“ akquiriert werden,
alle anderen sind „Interessierte Kurzbesucher“. Eine Strategie zur effektiveren Nutzung der
„Interessierten Kurzbesucher“ wurde in Abschnitt 7.5.2 vorgeschlagen. Eine Aufstockung
der Personalkapazitäten für die Ausweitung des Pressebereiches ist, nach diesen neuen Er-
gebnissen, als nicht mehr notwendig anzusehen. Das Beispiel zeigt, das den klassischen
Website-Analyseprogrammen, bei der gezielten Untersuchung bestimmter Ergebnisse, die
nötige Funktionalität fehlt, um dem Anwender die erforderlichen Informationen für aussage-
kräftige Interpretationen zu liefern.
Für 6112 Besucher war die Startseite der Homepage die Einstiegsseite zur Webpräsenz.
Von diesen Besuchern verließen 66 Prozent (4031) die Homepage dann gleich wieder, oh-
ne weitere Ressourcen aufzurufen. Das kann darauf hinweisen, das die Besucher etwas
Anderes oder Neues erwartet haben bzw. das die Inhalte der Startseite nicht ansprechend
sind66. Bei diesen WWW-Nutzern handelt es sich in erster Linie um Besucher, die die Ho-
66 Für die weitere Analyse dieses Sachverhaltes wurde, aufgrund der funktionellen Grenzen von Websuxess4.0, auch die Entscheidungsbauminduktion eingesetzt. Der Anstoß zu dieser Untersuchung ist auf die Ana-lyseergebnisse von Websuxess 4.0 zurückzuführen (Tabelle 7.18).
101

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
mepage der PLANET GmbH über Suchmaschinen gefunden (1702) und wahrscheinlich eine
andere Website erwartet haben. Diese Annahme wird durch die verwendeten Suchbegriffe
der Besucher gestützt. 1204 dieser Kurzbesucher verwendeten den Suchbegriff „planet“ und
327 „planets“. Für die Besucher, die keinen Referrer aufweisen67 (1112), wird angenommen,
das es sich dabei um Mitbewerber der PLANET GmbH handelt, die regelmäßig die Website
inspizieren oder um WWW-Nutzer die die Website, auf der Suche nach Neuigkeiten oder
Aktionen, besuchen. Eine Möglichkeit die Kurzbesucher, die ohne Referrer auf die Website
gelangen, zum längeren verweilen zu animieren, könnte eine häufigere Inhaltsänderung der
Homepage-Startseite sein. In diesem Zuge könnte z.B. die Rubrik Pressemitteilungen auf
der Startseite um weitere Einträge erweitert werden, ohne dass die Aktualität (und die damit
verbundenen Kosten), dieser Einträge in den Vordergrund zu stellen. Weiterhin könnte ein
dynamisches Anordnen68 der Startseitenelemente integriert werden, um eine Aktualisierung
der Website zu suggerieren.
Mit Hilfe von Programmen, die die klassische deskriptive Statistik zur Analyse von Web-
sites einsetzen, können schnell und effektiv übersichtliche Gesamtansichten des Website-
Traffics erstellt werden. Jedoch stoßen klassische Website-Analyseprogramme bei der Un-
tersuchung von Internetpräsenzen, wie an den Beispielen der Pressemitteilungen und des
Besuchermaximums gezeigt, schnell an ihre Grenzen. Die Festlegung einer Strategie zur
Optimierung der Website kann so, aufgrund der beschränkten Sichtweise und somit potenti-
ell falscher Interpretationen der Ergebnisse, zu uneffektiven Kampagnen und hohen Kosten
führen. Jedoch können die übersichtlichen und umfangreichen Statistiken von klassischen
Website-Analyseprogrammen wichtige Hinweise für genauere Analysen einzelner Sachver-
halte, mit den hier vorgestellten Data Mining-Verfahren, liefern und tragen somit zu einer
gezielteren Untersuchung und Optimierung der Website bei.
7.6. Zusammenfassung
Die Ergebnisse der Evaluations- und Interpretationsphase bilden die Basis für umfangreiche
Optimierungsaktivitäten der Internetpräsenz der PLANET GmbH. Die Website kann global
für alle Besucher mit den Ergebnissen der Assoziationsanalyse, der Pfadanalyse und der
deskriptiven Statistik optimiert werden aber auch zielgruppenspezifisch auf Grundlage der
Ergebnisse von Entscheidungsbauminduktion bzw. Vorhersage und den Neuronalen Netzen.
Die Assoziations- und Pfadanalyse und die Methoden der deskriptiven Statistik liefern in er-
67 Dabei handelt es sich um Besucher die die URL der PLANET GmbH-Homepage per Hand in den Browsereingaben oder die die Homepage mit einem Lesezeichen (Bookmark) gespeichert haben.
68 Dabei müssen nicht die Inhalte geändert werden, sondern nur deren Position auf der Seite. Bei dem Besucherkönnte so der Eindruck erweckt werden, das die Seite neu gestaltet bzw. neue Inhalte eingetragen wurdenund so sein Interesse erhöhen.
102

7.6. Zusammenfassung
ster Linie Ansätze zur strukturellen und ergonomischen Verbessung der Internetpräsenz. So
können Wege zu wichtigen Bereichen oder Produkten optimiert und häufig zusammen auf-
gerufene Ressourcen neu gruppiert werden. Die Umsetzung der Analyseergebnisse dieser
drei Data Mining-Verfahren würde eine Steigerung der Anwenderfreundlichkeit der Website
nach sich ziehen. Da die Optimierungsempfehlungen nur die Integration von neuen Verwei-
sen und die Zusammenlegung bzw. Verbesserung von bereits bestehenden Inhalten um-
fasst, ist der Umsetzungsaufwand, im Vergleich zu einer Neugestaltung, als überschaubar
einzustufen. Die Ergebnisse dieser Arbeit tragen zur Erstellung eines Relaunch-Konzeptes69
der Webpräsenz der PLANET GmbH bei. Im Zuge der Neugestaltung der Website können
strukturelle Änderungen, ohne großen Aufwand zu erzeugen, optimal einfließen.
Als Konsequenz einiger Analyseergebnisse wird die (Teil-)Dynamisierung der Startseite der
Internetpräsenz empfohlen. So wird bspw. im Rahmen der Interpretation der Zielgruppen-
profile, die gruppenspezifische Präsentation von Inhalten oder Marketing- bzw. Vertriebs-
strategien auf der Startseite favorisiert. Auch wird als Folge der hohen Ausstiegsrate auf der
Startseite eine Verbesserung bzw. Erweiterung des inhaltlichen Angebots dieses Dokuments
vorgeschlagen. Diese Empfehlungen können jedoch nur dann effektiv umgesetzt werden,
wenn entsprechende Instrumente eingesetzt werden. Ad-Server und Content-Management-
Systeme bieten die nötigen Funktionalitäten und das Potential, um die Startseite bzw. Websi-
te, auf Basis der Web Log Mining-Ergebnisse, erfolgreich zu optimieren. Für den Einsatz auf
der PLANET GmbH-Homepage empfehlen sich die Open Source-Produkte phpAdsNew70
als Ad-Server und OpenCms 571 als Content-Management-System. Durch phpAdsNew kön-
nen parametergesteuert Inhalte eines Dokuments dynamisch generiert werden. So können
z.B. verstärkt am Abend am Dienstag, Mittwoch, Donnerstag und Freitag, mit entsprechen-
den Angeboten auf der Startseite, um Kunden geworben werden, was in gewissem Maße zu
einer Personalisierung der Seite beitragen würde. Das CMS OpenCms 5 erleichtert die Ak-
tualisierung der Inhalte einer Seite erheblich, da mit einem speziellen Editor jedes Dokument
geändert werden kann, ohne das der Anwender Kenntnisse von der HTML-Programmierung
besitzen muss. Weiterhin bietet OpenCms 5 die technischen Voraussetzungen für eine Dy-
namisierung und Personalisierung von Inhalten. In diesem Zusammenhang können bspw.
die fünf neusten Meldungen aus dem Bereich Presse dynamisch in die Startseite integriert
werden. Der Einfügungsaufwand dieser Systeme wird dadurch reduziert, weil in der Firma
bereits Basis-Knowhow auf diesen Gebieten vorhanden ist und Forschungsarbeiten zu die-
sem Thema angefertigt wurden bzw. werden.
Der Einsatz von Prognosesystemen auf der Website ist zur Zeit nicht zu empfehlen. Die
Vorhersageergebnisse mit der Entscheidungsbaumvorhersage bzw. den Neuronalen Net-
69 Die Internetpräsenz der PLANET GmbH erhält in absehbarer Zeit, sowohl gestalterisch als auch inhaltlich,ein neues Erscheinungsbild.
70 http://www.phpadsnew.com71 http://www.opencms.org
103

Kapitel 7. Web Log Mining der PLANET internet commerce GmbH-Homepage
zen waren nicht ausreichend, um einen effektiven praktischen Einsatz zu garantieren. Da es
sich hierbei um ein sehr neues Forschungsgebiet handelt und noch keine entsprechenden
Softwareprodukte für den Internetbereich verfügbar sind, müsste eine firmeneigene Lösung
geschaffen werden. Der Einsatz von transaktionsübergreifenden Identifizierungsmechanis-
men kann die Ergebnisse von Prognosesystemen entscheidend verbessern. Jedoch muss,
um die Marktreife solcher Prognosesysteme zu erreichen, die Forschung auf diesem Gebiet,
mit den entsprechenden Personalkapazitäten, verstärkt werden. Die Basis dazu wurde mit
dieser Arbeit geschaffen. Transaktionsübergreifende Identifizierungsmechanismen schaffen
aber auch die Voraussetzung für den Einsatz der Sequenzanalyse und somit einer weiteren
Möglichkeit die Website zu optimieren. Auch können durch den Einsatz dieser Mechanismen
detaillierte Zielgruppenprofile erstellt werden, was eine noch genauere und somit effizientere
Planung von Marketing- und Vertriebsstrategien möglich macht.
Problematisch für zukünftige Analysen der PLANET GmbH-Homepage in diesem hier ge-
zeigten Umfang, sind die hohen Anschaffungs- bzw. Lizenzkosten der eingesetzten Data
Mining-Produkte. ... Eine zukünftige Analyse müsste aus wirtschaftlichen Gründen durch
einen externen Anbieter durchgeführt werden, denn die hohen Kosten für Personal und
Software-Lizenzen würden den Nutzen für diese relativ kleine Website übersteigen.
Der Nutzen dieser Arbeit für die PLANET GmbH kann, neben der Optimierung und Re-
launch der eigenen Internetpräsenz, die Schaffung einer Basis für die Etablierung eines neu-
en Tätigkeitsfeldes sein. Dieses Tätigkeitsfeld kann als Website-Optimierung zusammenge-
fasst werden. Dabei werden bestehende Internetpräsenzen optimiert bzw. im Rahmen einer
Cross-Selling-Strategie, auf Basis der Optimierungen, eine neue Internetpräsenz erstellt.
104

8. Fazit und Ausblick
Wie hier gezeigt wurde, stoßen klassische Web Log Mining-Programme bei der Analyse von
Internetpräsenzen immer häufiger an ihre Grenzen. Eine differenzierte Betrachtung, z.B. un-
ter ökonomischen Aspekten, der Besucher ist nicht bzw. nur sehr eingeschränkt möglich.
Klassische Web Log Mining-Programme untersuchen die Homepage-Besucher nur global,
die gezielte Analyse von speziellen Besuchergruppen sind nur sehr begrenzt möglich, die
Erstellung von Besucherprofilen, Verhaltensprognosen oder Assoziationsregeln sind derzeit
nicht möglich. Zur Erstellung von allgemeinen Gesamtansichten des Website-Traffics sind
diese Programme allerdings gut geeignet. Zudem bieten klassischeWebsite-Analyseprogramme
eine gute Performanz und sind, was Übersichtlichkeit der Ergebnisse und Anwenderfreund-
lichkeit betrifft, sehr ausgereift, so das umfangreiche Berichte schnell und unkompliziert er-
stellt werden können.
mit cookies wird alles besser
asso für shops
vorhersage
105

Kapitel 8. Fazit und Ausblick
106

Literaturverzeichnis
[ALPR00a] Alpar, Paul; Grob, Heinz Lothar; Weimann , Peter; Winter, Robert: Anwendungs-
orientierte Wirtschaftsinformatik - Eine Einführung in die strategische Planung, Ent-
wicklung und Nutzung von Informations- und Kommunikationssystemen, 2. überar-
beitete Auflage, Braunschweig/Wiesbaden, 2000
[ALPR00b] Alpar, Paul: Data Mining im praktischen Einsatz - Verfahren und Anwendungsfäl-
le für Marketing, Vertrieb, Controlling und Kundenunterstützung, Hrsg.: Niederreich-
holz, Joachim, Braunschweig/Wiesbaden, 2000
[BACK00] Backhaus, Klaus: Multivariate Analysemethoden - Eine anwendungsorientierte
Einführung, Berlin/Heidelberg, 2000
[BENS01a] Bensberg, Frank: Web Log Mining als Instrument der Marketingforschung: Ein
systemgestaltender Ansatz für internetbasierte Märkte, Wiesbaden, 2001
[BENS01b] Bensberg, Frank: Data Mining /Knowledge Discovery in Databases (KDD),
2001, im WWW unter http://www.wi.uni-muenster.de/aw/lehre/archiv/DMKDD.pdf
(01.10.2002)
[BENS99a] Bensberg, Frank; Weiß, Thorsten: Web Log Mining als Analyseinstrument des
World Wide Web, in Wirtschaftsinformatik, 41. Jg., Heft 5, 1999, S. 426-432
[BENS99b] Bensberg, Frank; Bieletzke, Stefan: Web Log Mining bei
cHL-Anwendungen, 1999, im WWW unter http://www.wi.uni-
muenster.de/aw/publikationen/CALCAT16.pdf (01.10.2002)
[BERS00] Berson, Alex; Smith, Stephen; Thearling, Kurt: Building Data Mining Applications
for CRM, New York, 2000
[BÖHM00] Böhm, Klemens: Data Warehousing and Mining, 2000, im WWW unter
http://www-dbs.inf.ethz.ch/ boehm/DD/dwm0102/quantAspects.pdf (01.10.2002)
[BROD00] Broder, Alan J.: Data Mining, the Internet, and Privacy, in: Web Usage Analysis
and User Profiling, Hrsg.: Masand, Brij, Spiliopoulou, Myra, Berlin/Heidelberg, 2000,
S. 56-73
107

Literaturverzeichnis
[BROG00] Broges, Jose; Levene, Mark: Data Mining of Navigation Patterns, in: Web
Usage Analysis and User Profiling, Hrsg.: Masand, Brij; Spiliopoulou, Myra, Ber-
lin/Heidelberg, 2000, S. 92-111
[COOL97] Cooley, Robert; Mobasher, Bamshad; Srivastava, Jaideep: Web Mi-
ning - Information and Pattern Discovery on the World Wide Web (A
Survey Paper), in: Proceedings of the 9th IEEE International Confe-
rence on Tools with Artificial Intelligence (ICTAI’97), 1997, im WWW unter
http://www.cs.umn.edu/research/websift/papers/tai97.ps (01.10.2002)
[COOL99] Cooley, Robert; Mobasher, Bamshad; Srivastava, Jaideep: Data
Preparation for Mining World Wide Web Browsing Patterns, in: Jour-
nal of Knowledge and Information Systems, 1999, im WWW unter
http://www.cs.umn.edu/research/websift/papers/kais99.ps (01.10.2002)
[DAST00] Dastani, Parsis: Data Mining Lösung in 10 Stufen, 2000, im WWW unter
http://www.database-marketing.de/miningstufen.htm (01.10.2002)
[DIED99] Diedrich, Holger: Theorie und betriebswirtschaftliche Einsatzmöglichkeiten von
neueren IT-basierten Verfahren des „Knowledge Discovery“, Diplomarbeit, Universität
Hamburg, 1999
[DÜSI98] Düsing, Roland: Knowledge Discovery in Databases und Data Mining; in: Analyti-
sche Informationssysteme, Springer-Verlag, Berlin, 1998, S. 291-299
[FAYY96] Fayyad, Usama; Piatetsky-Shapiro, Gregory; Smyth, Padhraic; Uthurusamy, Ra-
masamy: Advances in Knowledge Discovery and Data, Mining, Melo Park, California,
1996
[GRIM98] Grimmer, Udo; Mucha, Hans-Joachim: Skalierung als alternative Datentrans-
formation und deren Auswirkungen auf die Leistungsfähigkeit von Supervised Ler-
ning Algorithmen, in: Data Mining: Theoretische Aspekte und Anwendungen, Hrsg.:
Nakhaeizadeh, Gholamreza, Heidelberg, 1998, S. 109-141
[GROB99] Grob, Heinz Lothar; Bensberg, Frank: Das Data-Mining-Konzept, Ar-
beitsbericht Nr. 8, Münster 1999, im WWW unter http://www.wi.uni-
muenster.de/aw/publikationen/CGC8.pdf (01.10.2002)
[HIPP02] Hippner, Hajo; Merzenich, Melanie; Wilde, Klaus D.: E-CRM - mit Informations-
technologien Kundenpotenziale nutzen, Hrsg.: Schögel, Markus; Schmidt, Inga, Düs-
seldorf, 2002, S. 87-104
[KIMM00] Kimmerle, Joachim: Data Mining im Pharma-Großhandel, Diplomarbeit, Universi-
tät Stuttgart, 2000
108

Literaturverzeichnis
[KNOB00] Knobloch, Bernd: Der Data-Mining-Ansatz zur Analyse betriebswirtschaftlicher
Daten, Bamberger Beiträge zur Wirtschaftsinformatik Nr. 58, Bamberg, 2000
[KRAF00] Kraft, Marckus; Hartung, Stefan: Shop Suxess 4 Enterprise Edition Handbuch,
Eschborn, 2000
[KÜPP99] Küppers, Bertram: Data Mining in der Praxis - Ein Ansatz zur Nutzung der Poten-
tiale von Data Mining im betrieblichen Umfeld, Frankfurt am Main, 1999
[LUST02] Lusti, Markus: Data Warehousing und Data Mining - Eine Einführung in entschei-
dungsunterstützende Systeme, Berlin/Heidelberg, 2002
[MENA00] Mena, Jesus: Data Mining und E-Commerce: Wie Sie Ihre Online-Kunden besser
kennen lernen und gezielter ansprechen, Düsseldorf, 2000
[NEEB99] Neeb, Hans-Peter: Einsatzmöglichkeiten von ausgewählten Data Mining Verfah-
ren im Bereich Financial Services, Diplomarbeit Universität Karlsruhe, 1999
[OEBB00] Oebbeke, Alfons: Cookies im Internet, 2000, im WWW unter http://www.
glossar.de/glossar/1frame.htm?http%3A//www.glossar.de/glossar/z_cookies.htm
(01.10.2002)
[o.V.00] o.V.: XAffinity Whitepaper - Association and Sequencing Keys to successful Market
Basket, 2000, im WWW unter http://www.xore.com (01.10.2002)
[o.V.01a] o.V.: Glossar, 2001, im WWW unter http://medweb.uni-muenster.de/institute/imib/
lehre/skripte/biomathe/bio/glossar.html (01.10.2002)
[o.V.01b] o.V.: Spider List, 2001, im WWW unter http://www.spiderhunter.com/spiderlist/
(01.10.2002)
[o.V.01c] o.V.: SELFHTML: Diverse technische Ergänzungen - HTTP-Statuscodes, 2001, im
WWW unter http://selfhtml.teamone.de/diverses/httpstatuscodes.htm (13.12.2002)
[o.V.02a] o.V.: Search Engine Spider IP Addresses, 2002, im WWW unter http://www.
searchengineworld.com/spiders/spider_ips.htm (01.10.2002)
[o.V.02b] o.V.: KnowledgeSTUDIO Whitepaper Version 4, 2002
[o.V.02c] o.V.: European Search Engine Ratings, 2002, im WWW unter http://
searchenginewatch.com/reports/mmxi-europe.html (13.12.2002)
[PENZ00] Penzes, Adriana; Ungerer, Steffen: Servlets und andere ser-
verseitige Anwendungen, 2000, im WWW unter http://www.aifb.uni-
karlsruhe.de/CoM/teaching/seminars/computational-finance/servlets.pdf
(01.10.2002)
109

Literaturverzeichnis
[POHL99] Pohle, Carsten: Methoden der Werbeerfolgsplanung und -kontrolle imWorld Wide
Web: Theorie und Praxis, 1999, im WWW unter http://miro.wiwi.hu-berlin.de/∼cpohle/(01.10.2002)
[PYLE99] Pyle, Dorian: Data Preparation for Data Mining, San Francisco, 1999
[RAUH00] Rauh, Reinhold: Deskriptive Statistik und Inferenzstatistik, 2000, im WWW
unter http://cognition.iig.uni-freiburg.de/teaching/veranstaltungen/ws00/uebung1/
FolienSitz6.PDF (01.10.2002)
[RENN99] Rennekamp, Thorsten: Session-Tracking, 1999
[RUNK00] Runkler, Thomas A.: Information Mining - Methoden, Algorithmen und Anwen-
dungen intelligenter Datenanalyse, Braunschweig/Wiesbaden, 2000
[SCHO] Scholz, Michael: Technologien zur Realisierung von transaktions-resistenten
Speicherungen bei Electronic Commerce-Systemen, im WWW unter http://www.
competence-site.de/ecommerceshop.nsf/GrundlagenView
[SCHW00] Schwickert, Axel C.; Wendt, Peter: Web Site Monitoring - Teil 2: Datenquel-
len, Web-Logfile-Analyse, Logfile-Analyzer, in: Arbeitspapiere WI, Nr. 7/2000, Hrsg.:
Lehrstuhl für Allg. BWL und Wirtschaftsinformatik, Johannes Gutenberg-Universität:
Mainz 2000, imWWW unter http://wi.uni-giessen.de/gi/dl/det/Schwickert/1167/apap_
wi_2000_07.pdf (01.10.2002)
[SCHM00a] Schmidt-Thieme, Lars: Web Mining, 2000, im WWW unter http://viror.wiwi.uni-
karlsruhe.de/webmining.ws00/script/pdf/webmining-4.pdf (01.10.2002)
[SCHM00b] Schmidt-Thieme, Lars: Web Mining, 2000, im WWW unter http://viror.wiwi.uni-
karlsruhe.de/webmining.ws00/script/pdf/webmining-7.pdf (01.10.2002)
[SCHM00c] Schmidt-Thieme, Lars: Web Mining, 2000
[UNGE02] Ungerer, Bert: Internet-Provider, 2002, im WWW unter http://www.heise.de/ix/
provider/ (01.10.2002)
[WIED01] Wiedmann, Klaus-Peter: Neuronale Netze im Marketing Management: Praxis-
orientierte Einführung in modernes Data-Mining, Hrsg.: Buckler, Frank, Wiesbaden,
2001
[WITT01] Witten, Ian H.; Eibe, Frank: Data Mining - Praktische Werkzeuge und Techniken
für das maschinelle Lernen, München/Wien, 2001
[W3C] W3C: Logging Control In W3C httpd , im WWW unter http://www.w3.org/Daemon/
User/Config/Logging.html#common-logfile-format (01.10.2002)
110

A. Thesen
1. Prothese
2. Prothese
3. Prothese
111


















