
Redwood Needles Newsletter, February 2007 ~ Sierra Club, Redwood Chapter
Upload
makoto-yuiCategory
view
218download
2
Makoto YUI -‐ Research engineer, Treasure Datatwitter: @myui
Hivemall: Scalable Machine Learning Library for Apache Hive

➢2015/04 Joined Treasure Data, Inc.➢1st Research Engineer in Treasure Data➢My mission in TD is developing ML-as-a-Service
(MLaaS) ➢2010/04-2015/03 Senior Researcher at National Institute
of Advanced Industrial Science and Technology, Japan. ➢Worked on a large-scale Machine Learning project and
Parallel Databases ➢2009/03 Ph.D. in Computer Science from NAIST
➢XML native database and Parallel Database systems➢Super programmer award from the MITOU Foundation
(Government funded program for finding young and talented programmers)➢ Super creators in Treasure Data: Sada Furuhashi,
Keisuke Nishida2
Who am I ?

1. What is Hivemall (very short intro.)
2. Why Hivemall (motivations etc.)
3. Hivemall Internals
4. How to use Hivemall
3
Agenda
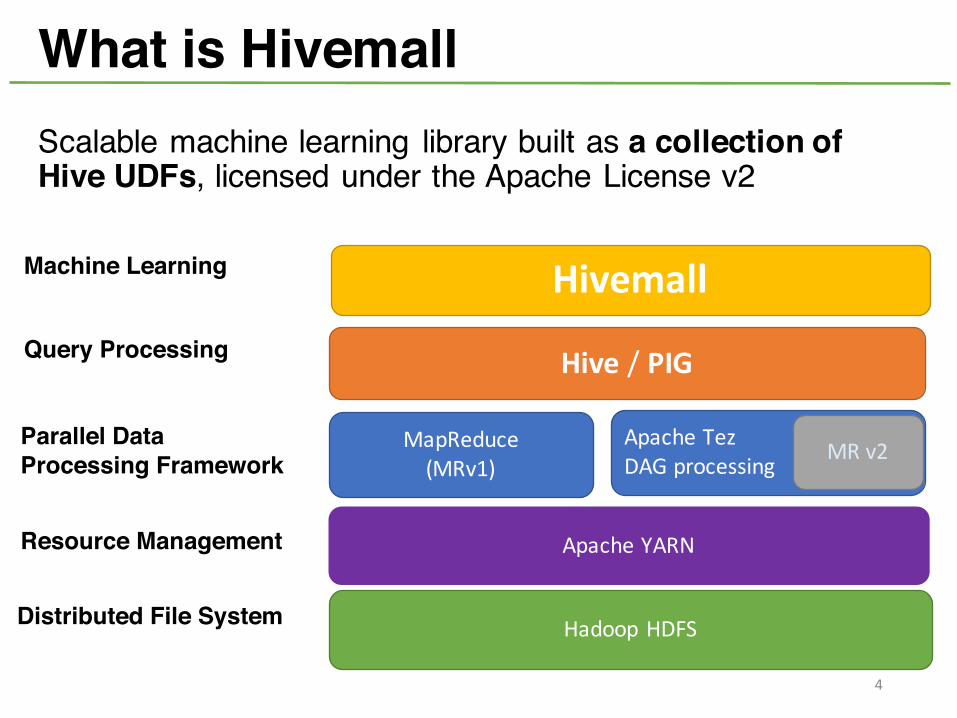
What is HivemallScalable machine learning library built as a collection of Hive UDFs, licensed under the Apache License v2
Hadoop HDFS
MapReduce(MRv1)
Hive / PIG
Hivemall
Apache YARN
Apache Tez DAG processing MR v2
Machine Learning
Query Processing
Parallel Data Processing Framework
Resource Management
Distributed File System
4
5
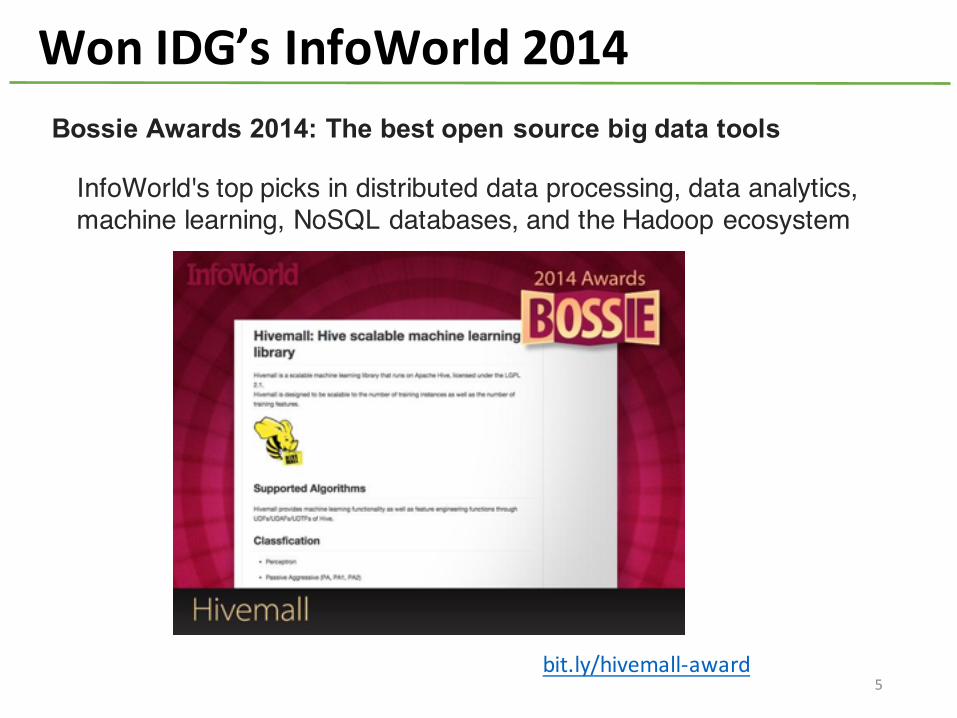
Won IDG’s InfoWorld 2014Bossie Awards 2014: The best open source big data tools
InfoWorld's top picks in distributed data processing, data analytics, machine learning, NoSQL databases, and the Hadoop ecosystem
bit.ly/hivemall-‐award

List of functions in Hivemall v0.3
• Classification (both binary-‐ and multi-‐class)✓ Perceptron✓ Passive Aggressive (PA)✓ Confidence Weighted (CW)✓ Adaptive Regularization of Weight Vectors (AROW)
✓ Soft Confidence Weighted (SCW)✓ AdaGrad+RDA
• Regression✓ Logistic Regression (SGD)✓ PA Regression✓ AROW Regression✓ AdaGrad✓ AdaDELTA
• kNN and Recommendation✓Minhash and b-‐Bit Minhash(LSH variant)
✓ Similarity Search using K-‐NN✓Matrix Factorization
• Feature engineering✓ Feature hashing✓ Feature scaling(normalization, z-‐score)
✓ TF-‐IDF vectorizer
6
Treasure Data support Hivemallv0.3 in the HDP2 environment

1. What is Hivemall (very short intro.)
2. Why Hivemall (motivations etc.)
3. Hivemall Internals
4. How to use Hivemall
7
Agenda

Why Hivemall
1. In my experience working on ML, I used Hive for preprocessing and Python (scikit-‐learn etc.) for ML. This was INEFFICIENT and ANNOYING. Also, Python is not as scalable as Hive.
2. Why not run ML algorithms inside Hive? Less components to manage and more scalable.
8
That’s why I build Hivemall.
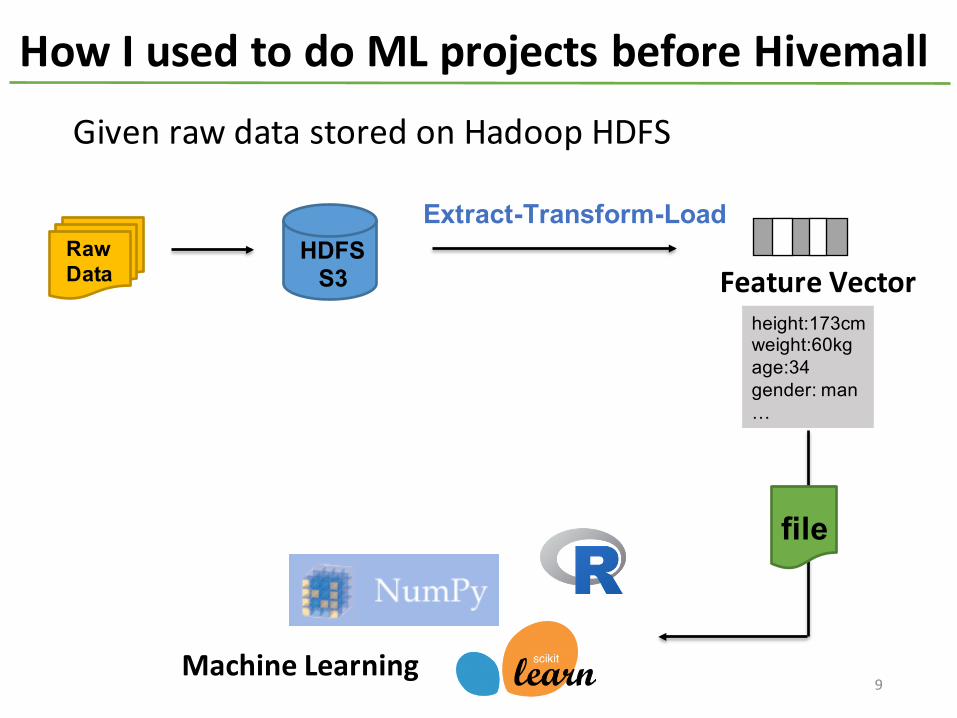
How I used to do ML projects before Hivemall
9
Given raw data stored on Hadoop HDFS
RawData
HDFSS3 Feature Vector
height:173cmweight:60kgage:34gender: man…
Extract-Transform-Load
Machine Learning
file
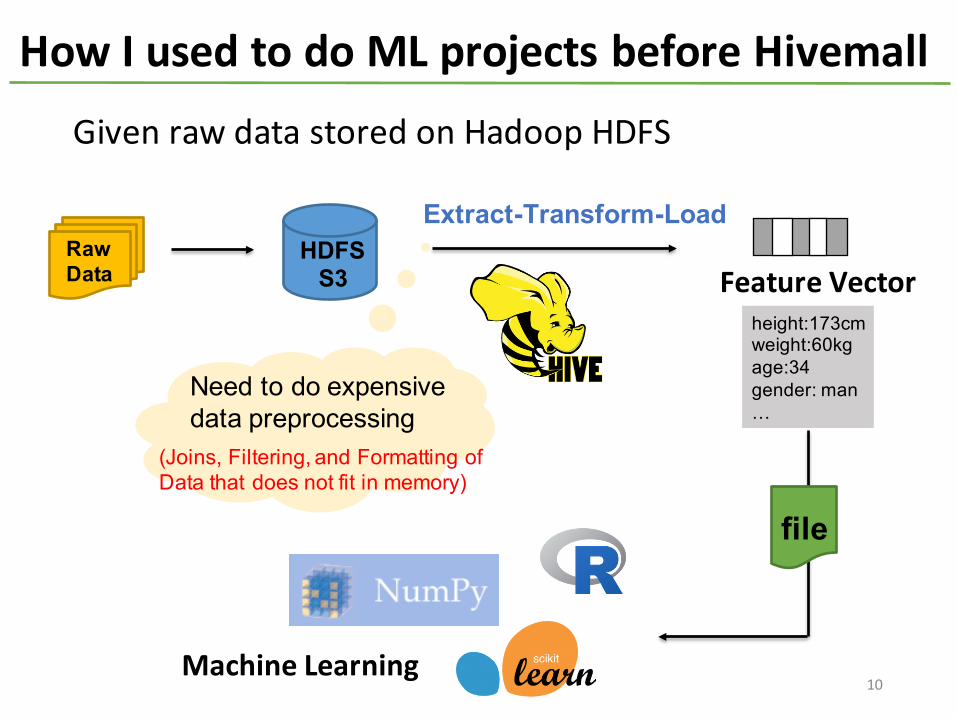
How I used to do ML projects before Hivemall
10
Given raw data stored on Hadoop HDFS
RawData
HDFSS3 Feature Vector
height:173cmweight:60kgage:34gender: man…
Extract-Transform-Load
file
Need to do expensive data preprocessing
(Joins, Filtering, and Formatting of Data that does not fit in memory)
Machine Learning
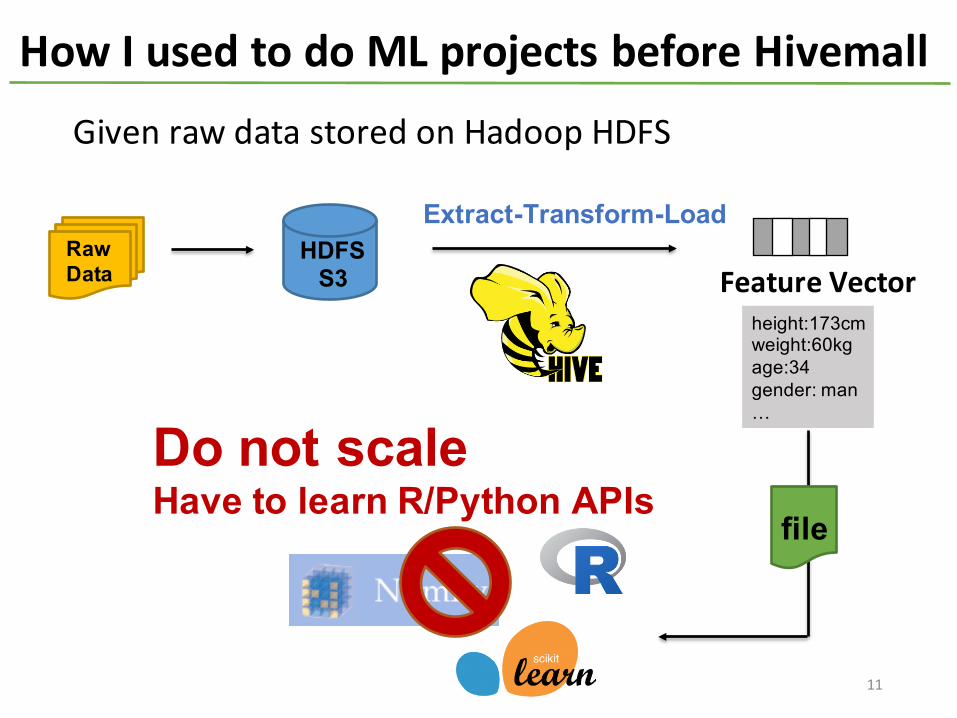
How I used to do ML projects before Hivemall
11
Given raw data stored on Hadoop HDFS
RawData
HDFSS3 Feature Vector
height:173cmweight:60kgage:34gender: man…
Extract-Transform-Load
file
Do not scaleHave to learn R/Python APIs
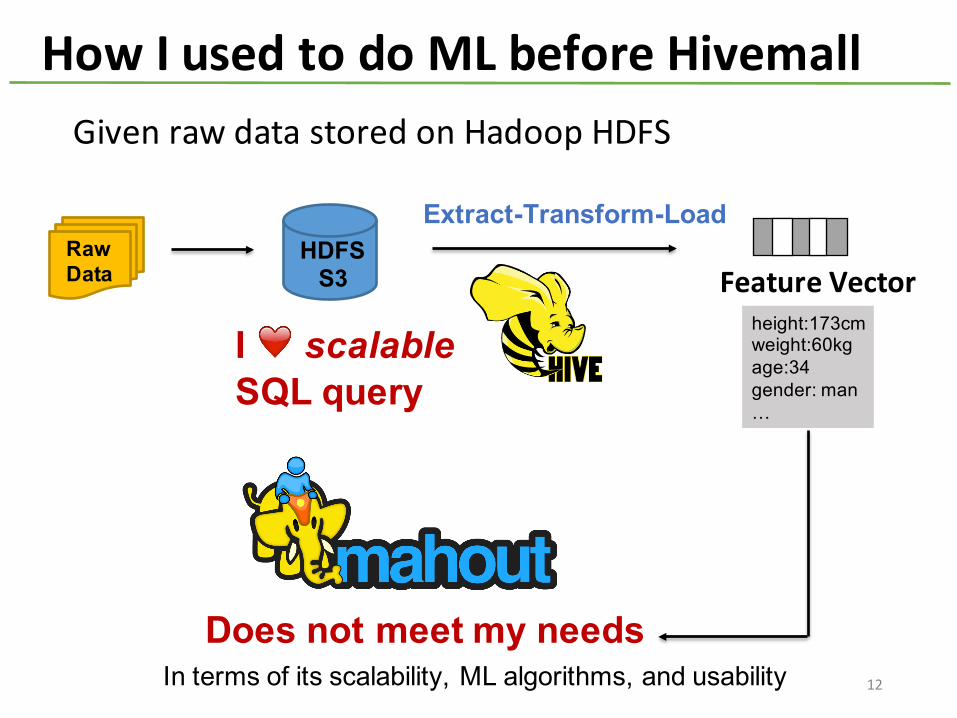
How I used to do ML before Hivemall
12
Given raw data stored on Hadoop HDFS
RawData
HDFSS3 Feature Vector
height:173cmweight:60kgage:34gender: man…
Extract-Transform-Load
Does not meet my needsIn terms of its scalability, ML algorithms, and usability
I ❤️ scalableSQL query

Framework User interfaceMahout Java API ProgrammingSpark MLlib/MLI Scala API programming
Scala Shell (REPL)H2O R programming
GUICloudera Oryx Http REST API programmingVowpal Wabbit(w/ Hadoop streaming)
C++ API programmingCommand Line
Survey on existing ML frameworks
Existing distributed machine learning frameworksare NOT easy to use
13

Hivemall’s Vision: ML on SQL
100+ lines
of code
Classification with Mahout
CREATE TABLE lr_model ASSELECTfeature, -‐-‐ reducers perform model averaging in parallelavg(weight) as weightFROM (SELECT logress(features,label,..) as (feature,weight)FROM train) t -‐-‐ map-‐only taskGROUP BY feature; -‐-‐ shuffled to reducers
✓Machine Learning made easy for SQL developers (ML for the rest of us)
✓ Interactive and Stable APIs w/ SQL abstraction
This SQL query automatically runs in parallel on Hadoop 14

1. What is Hivemall
2. Why Hivemall
3. Hivemall Internals
4. How to use Hivemall
15
Agenda
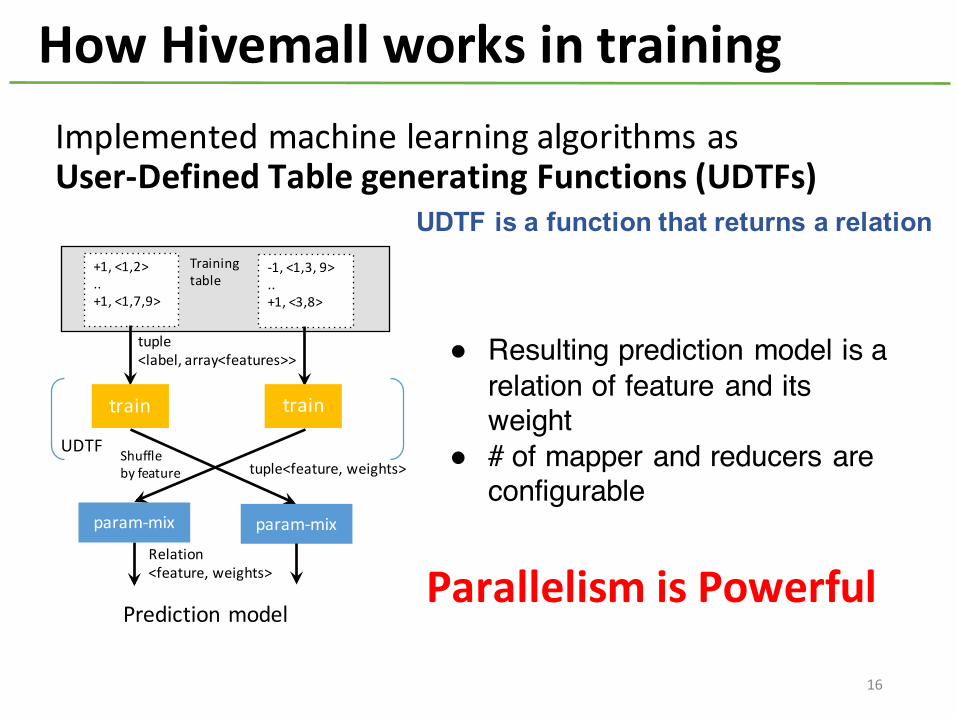
Implemented machine learning algorithms as User-‐Defined Table generating Functions (UDTFs)
How Hivemall works in training
+1, <1,2>..+1, <1,7,9>
-‐1, <1,3, 9>..+1, <3,8>
tuple<label, array<features>>
tuple<feature, weights>
Prediction model
UDTF
Relation<feature, weights>
param-‐mix param-‐mix
Training table
Shuffle by feature
train train
! Resulting prediction model is a relation of feature and its weight
! # of mapper and reducers are configurable
16
UDTF is a function that returns a relation
Parallelism is Powerful
train train
+1, <1,2>..+1, <1,7,9>
-‐1, <1,3, 9>..+1, <3,8>
merge
tuple<label, array<features >
array<weight>
array<sum of weight>, array<count>
Training table
Prediction model
-‐1, <2,7, 9>..+1, <3,8>
final merge
merge
-‐1, <2,7, 9>..+1, <3,8>
train train
array<weight>
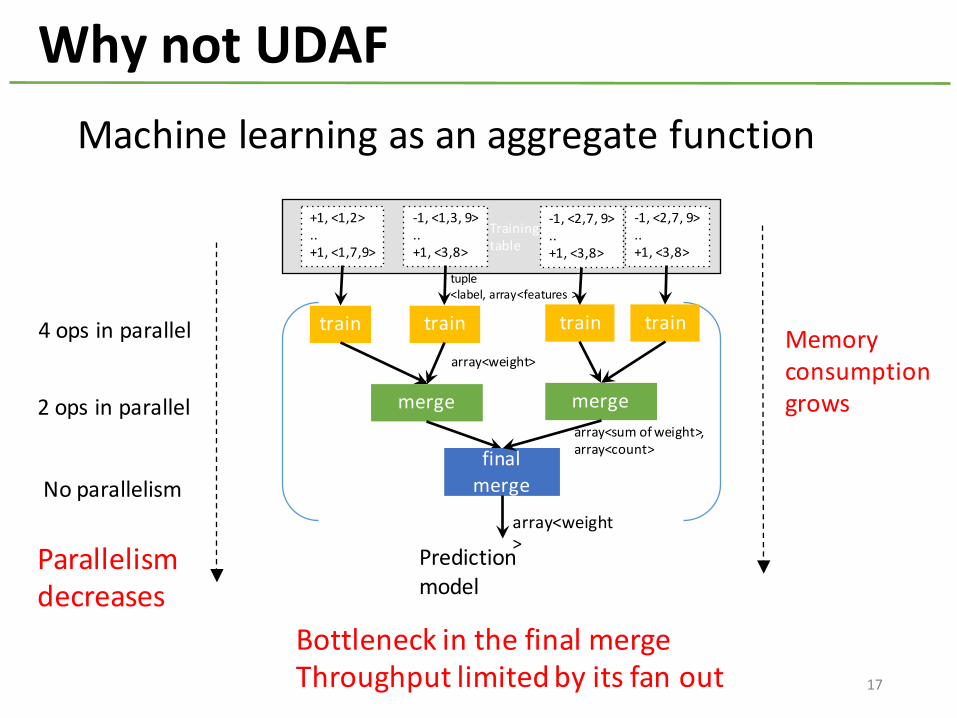
Why not UDAF
4 ops in parallel
2 ops in parallel
No parallelism
Machine learning as an aggregate function
Bottleneck in the final mergeThroughput limited by its fan out
Memory consumptiongrows
Parallelismdecreases
17
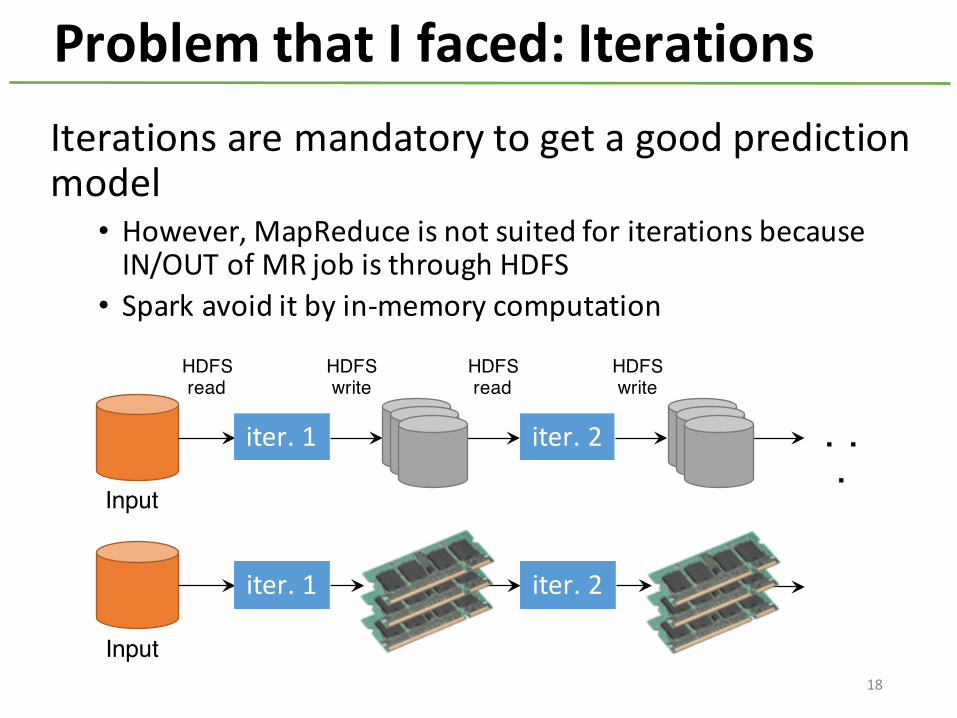
Problem that I faced: IterationsIterations are mandatory to get a good prediction model• However, MapReduce is not suited for iterations because IN/OUT of MR job is through HDFS• Spark avoid it by in-‐memory computation
iter. 1 iter. 2 . . .
Input
HDFSread
HDFSwrite
HDFSread
HDFSwrite
iter. 1 iter. 2
Input18

val data = spark.textFile(...).map(readPoint).cache()
for (i <- 1 to ITERATIONS) {val gradient = data.map(p =>(1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x
).reduce(_ + _)w -= gradient
}Repeated MapReduce steps
to do gradient descent
For each node, loads data in memory once
This is just a toy example! Why?
Training with Iterations in SparkLogistic Regression example of Spark
Input to the gradient computation should be shuffled for each iteration (without it, more iteration is required)
19

What MLlib actually do?
Val data = ..
for (i <- 1 to numIterations) {val sampled = val gradient =
w -= gradient}
Mini-‐batch Gradient Descent with Sampling
Iterations are mandatory for convergence because each iteration uses only small fraction of data
GradientDescent.scalabit.ly/spark-‐gd
sample subset of data (partitioned RDD)
averaging the subgradients over the sampled data using Spark MapReduce
20

Alternative Approach in HivemallHivemall provides the amplify UDTF to enumerate iteration effects in machine learning without several MapReduce steps
SET hivevar:xtimes=3;
CREATE VIEW training_x3asSELECT*
FROM (SELECTamplify(${xtimes}, *) as (rowid, label, features)FROMtraining
) tCLUSTER BY rand()
21

Map-‐only shuffling and amplifying
rand_amplify UDTF randomly shuffles the input rows for each Map task
CREATE VIEW training_x3asSELECT
rand_amplify(${xtimes}, ${shufflebuffersize}, *) as (rowid, label, features)
FROMtraining;
22
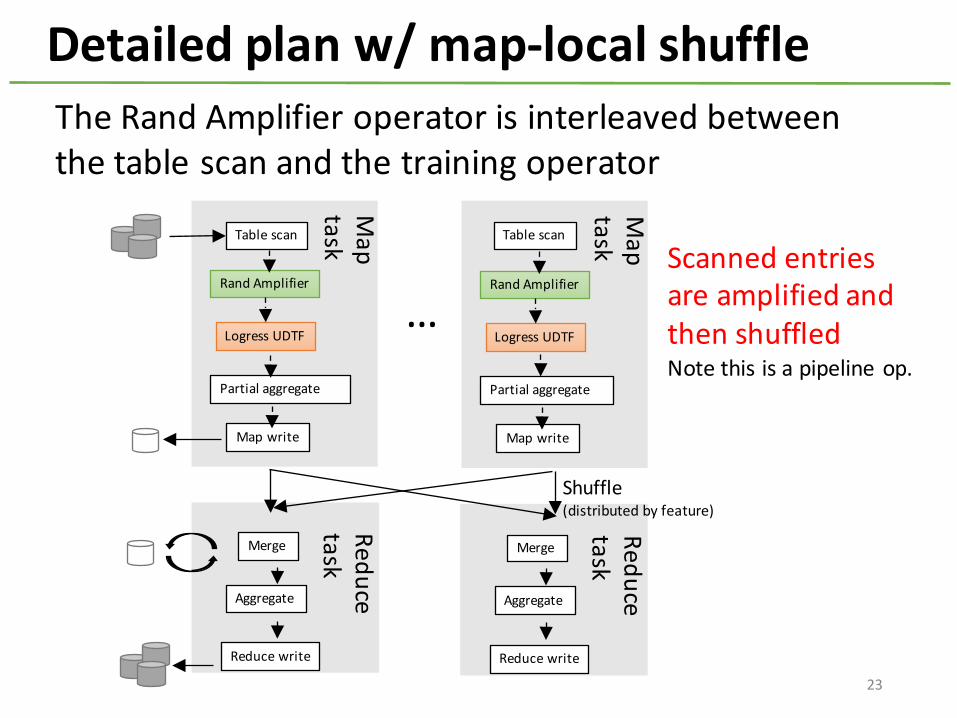
Detailed plan w/ map-‐local shuffle
…
Reduce taskMerge
Aggregate
Reduce write
Map
taskTable scan
Rand Amplifier
Map write
Logress UDTF
Partial aggregate
Map
taskTable scan
Rand Amplifier
Map write
Logress UDTF
Partial aggregate
Reduce taskMerge
Aggregate
Reduce write
Scanned entries are amplified and then shuffledNote this is a pipeline op.
The Rand Amplifier operator is interleaved between the table scan and the training operator
23
Shuffle (distributed by feature)

Method ELAPSED TIME (sec) AUC
Plain 89.718 0.734805
amplifier+clustered by(a.k.a. global shuffle)
479.855 0.746214
rand_amplifier (a.k.a. map-‐local shuffle)
116.424 0.743392
Performance effects of amplifiers
With the map-‐local shuffle, prediction accuracy got improved with an acceptable overhead
24

1. What is Hivemall
2. Why Hivemall
3. Hivemall Internals
4. How to use Hivemall
25
Agenda
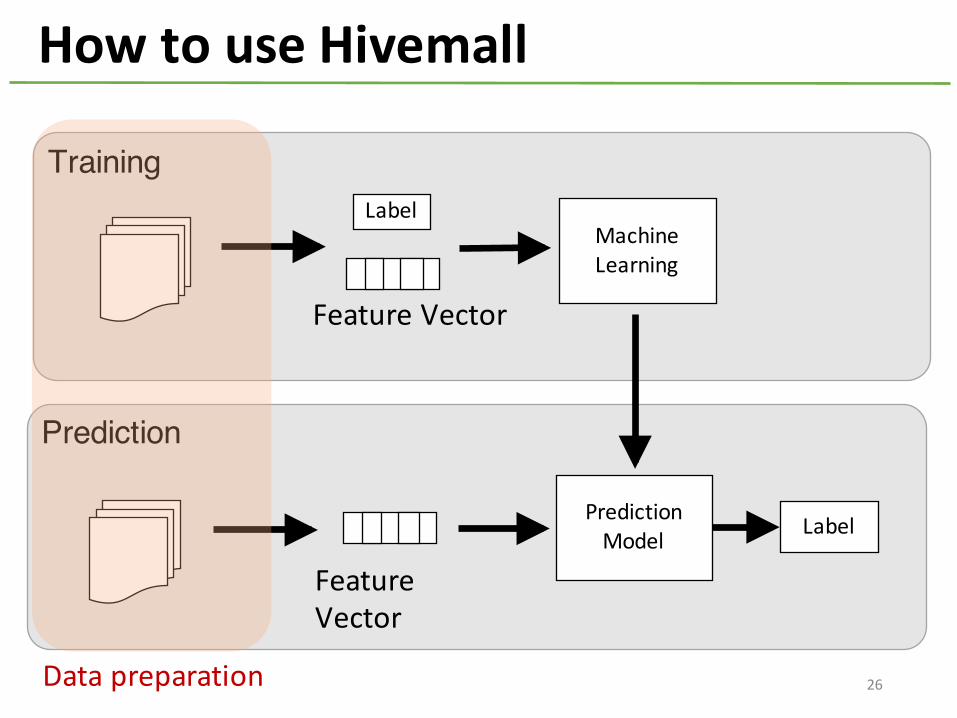
How to use Hivemall
MachineLearning
Training
Prediction
PredictionModel Label
Feature Vector
Feature Vector
Label
Data preparation 26

Create external table e2006tfidf_train (rowid int,label float,features ARRAY<STRING>
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '¥t' COLLECTION ITEMS TERMINATED BY ",“
STORED AS TEXTFILE LOCATION '/dataset/E2006-tfidf/train';
How to use Hivemall -‐ Data preparation
Define a Hive table for training/testing data
27
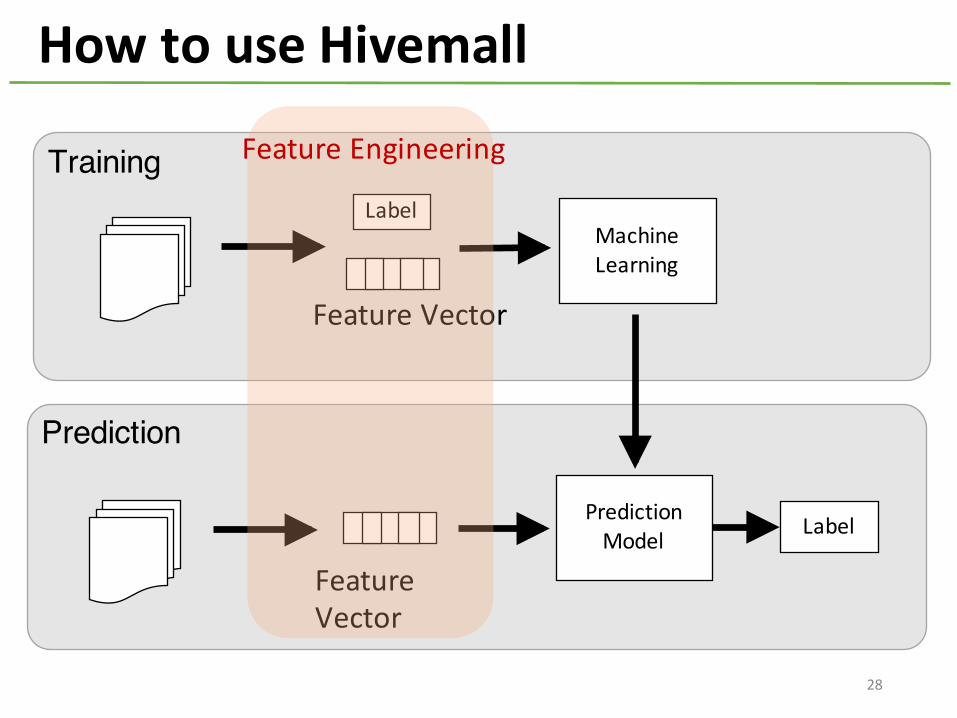
How to use Hivemall
MachineLearning
Training
Prediction
PredictionModel Label
Feature Vector
Feature Vector
Label
Feature Engineering
28

create view e2006tfidf_train_scaled asselect rowid,rescale(target,${min_label},${max_label})
as label, features
from e2006tfidf_train;
Applying a Min-Max Feature Normalization
How to use Hivemall -‐ Feature Engineering
Transforming a label value to a value between 0.0 and 1.0
29
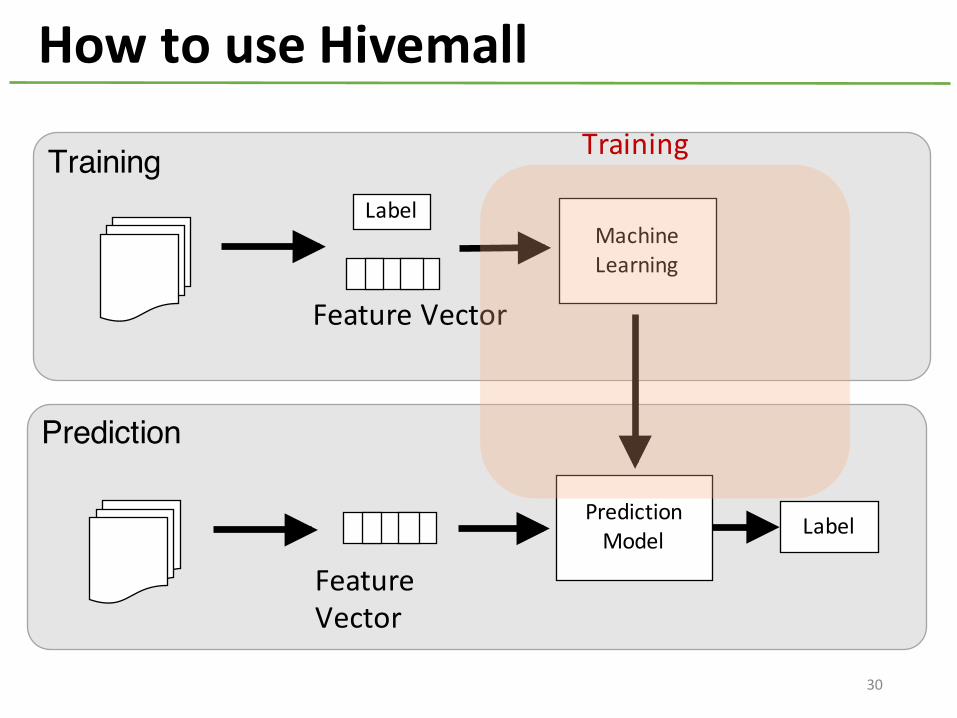
How to use Hivemall
MachineLearning
Training
Prediction
PredictionModel Label
Feature Vector
Feature Vector
Label
Training
30

How to use Hivemall -‐ Training
CREATE TABLE lr_model ASSELECTfeature,avg(weight) as weight
FROM (SELECT logress(features,label,..)
as (feature,weight)FROM train
) tGROUP BY feature
Training by logistic regression
map-‐only task to learn a prediction model
Shuffle map-‐outputs to reduces by feature
Reducers perform model averaging in parallel
31

How to use Hivemall -‐ Training
CREATE TABLE news20b_cw_model1 ASSELECT
feature,voted_avg(weight) as weight
FROM(SELECT
train_cw(features,label) as (feature,weight)
FROMnews20b_train
) t GROUP BY feature
Training of Confidence Weighted Classifier
Vote to use negative or positive weights for avg
+0.7, +0.3, +0.2, -‐0.1, +0.7
Training for the CW classifier
32
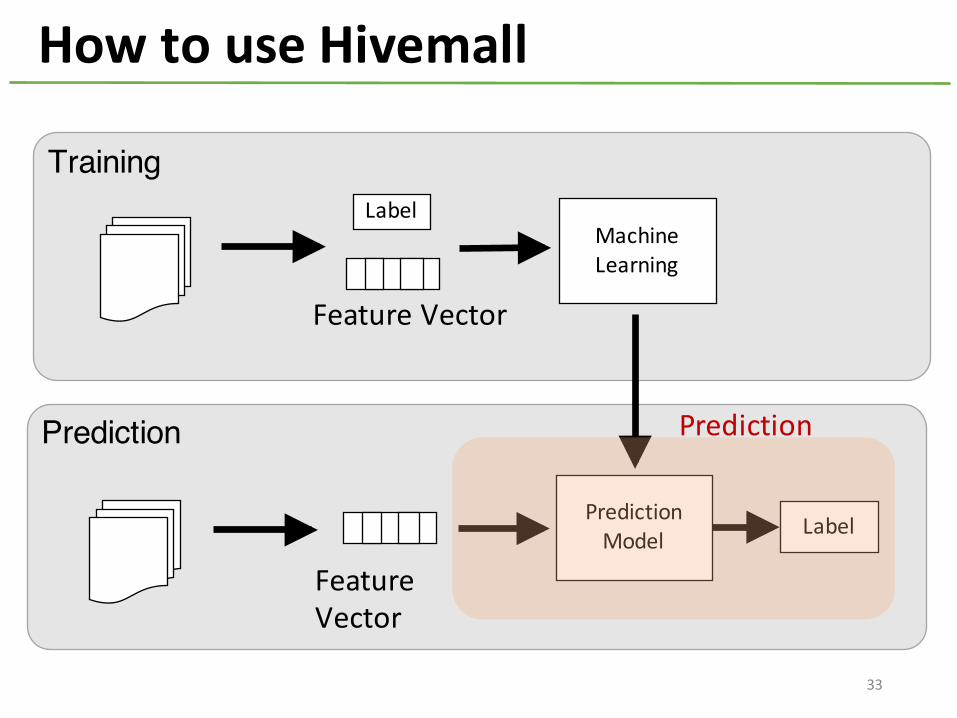
How to use Hivemall
MachineLearning
Training
Prediction
PredictionModel Label
Feature Vector
Feature Vector
Label
Prediction
33

How to use Hivemall -‐ Prediction
CREATE TABLE lr_predict asSELECTt.rowid, sigmoid(sum(m.weight)) as prob
FROMtesting_exploded t LEFT OUTER JOINlr_model m ON (t.feature = m.feature)
GROUP BY t.rowid
Prediction is done by LEFT OUTER JOINbetween test data and prediction model
No need to load the entire model into memory
34
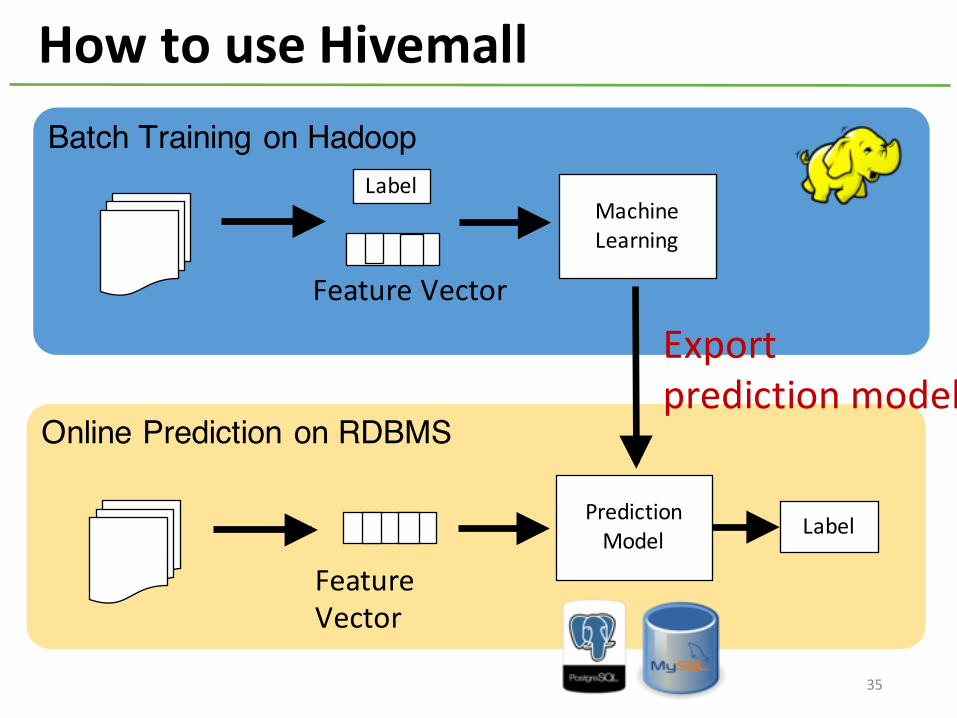
How to use Hivemall
MachineLearning
Batch Training on Hadoop
Online Prediction on RDBMS
PredictionModel Label
Feature Vector
Feature Vector
Label
Export prediction models
35
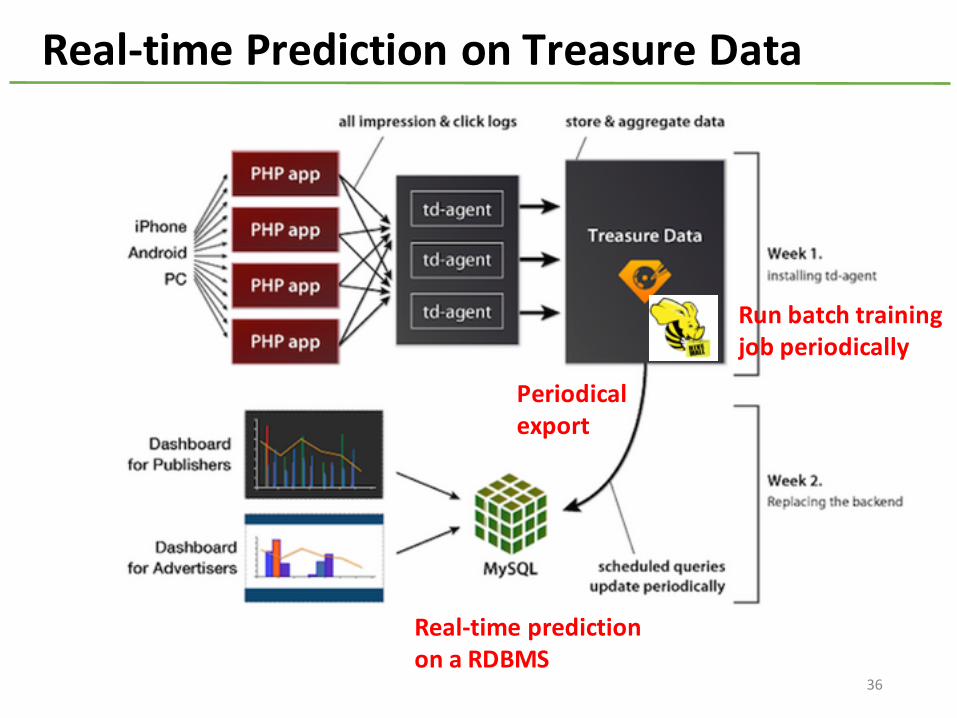
Real-‐time Prediction on Treasure Data
Run batch trainingjob periodically
Real-‐time predictionon a RDBMS
Periodicalexport
36

Conclusion
Hivemall provides a collection of machine learning algorithms as Hive UDFs/UDTFs
37
Ø For SQL users that need MLØ For whom already using HiveØ Easy-‐of-‐use and scalability in mindDo not require coding, packaging, compiling or introducing a new programming language or APIs.
Hivemall’s Positioning

Thank you!Makoto YUI -‐ Research engineer / Treasure Data
twitter: @myui
38
Download Hivemall from bit.ly/hivemall

example: #hivemall is really handsome
39
Q&A
Please Tweet Your Impression on Hivemall #hivemall


















