
HiTune: Dataflow-Based Performance Analysis for Big · PDF fileHiTune: Dataflow-Based...
16
Intel Confidential HiTune: Dataflow-Based Performance Analysis for Big Data Cloud Bo Huang Principal Engineer Intel APAC R&D Ltd. Aug 16, 2011 USENIX ATC’11
Transcript of HiTune: Dataflow-Based Performance Analysis for Big · PDF fileHiTune: Dataflow-Based...

Intel Confidential
HiTune: Dataflow-Based Performance Analysis for Big Data Cloud
Bo Huang Principal Engineer
Intel APAC R&D Ltd. Aug 16, 2011
USENIX ATC’11

2
Big Data
• “Industrial Revolution of Data”
– The heartbeat of mobile, cloud and social computing
– Expanding faster than Moore’s law
• E.g., Internet of Things
• What is Big Data?
– Too large to work with using traditional tools
– Require a new architecture
• Massively parallel software running on 100s~1000s of servers
2011/8/23 3
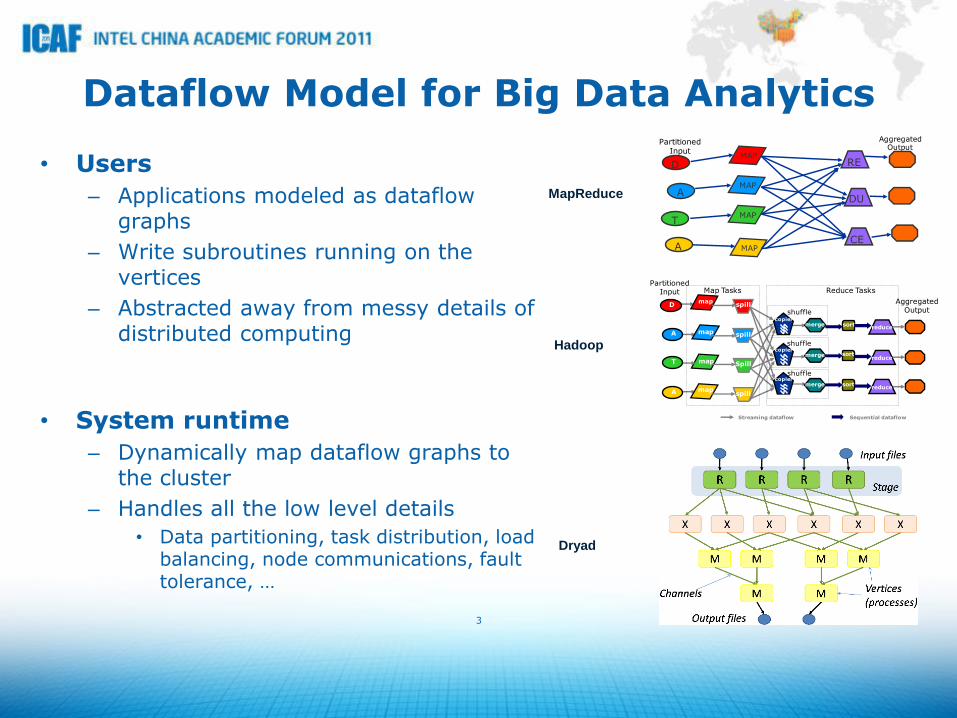
Dataflow Model for Big Data Analytics
• Users
– Applications modeled as dataflow graphs
– Write subroutines running on the vertices
– Abstracted away from messy details of distributed computing
• System runtime
– Dynamically map dataflow graphs to the cluster
– Handles all the low level details
• Data partitioning, task distribution, load balancing, node communications, fault tolerance, …
D
A
T
A
MAP
MAP
MAP
MAP
RE
DU
CE
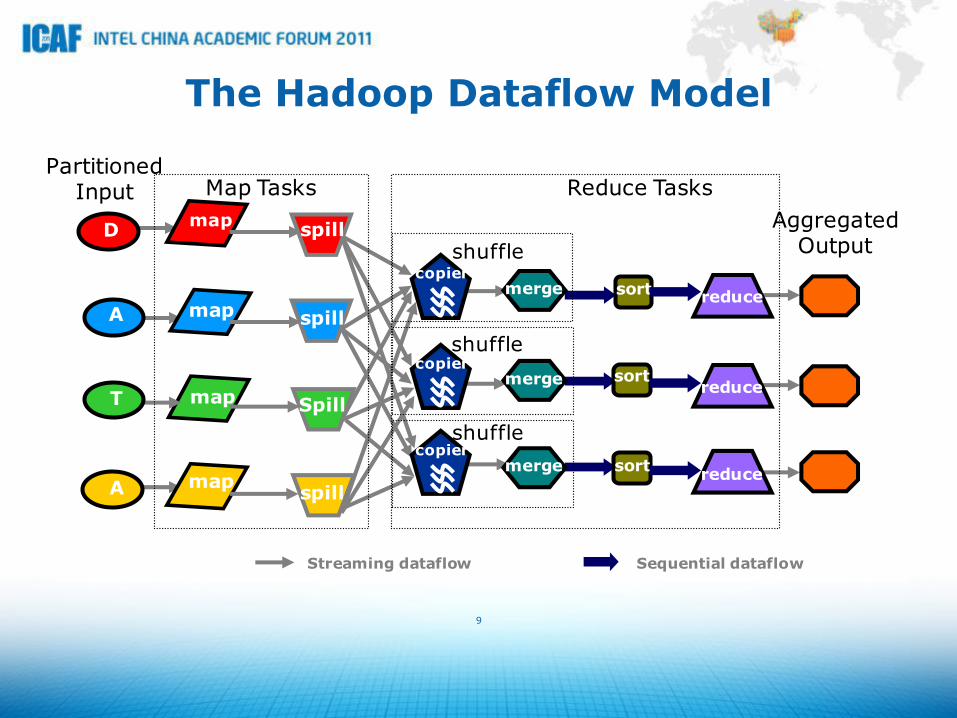
Partitioned Input
Aggregated Output
spill
Streaming dataflow
D
A
A
map
map
map
map
reduce
Aggregated Output
Partitioned Input
copier
copier
copiersort
sort
sortmerge
merge
merge
reduce
reduce
Sequential dataflow
shuffle
shuffle
shuffle
spill
Spill
spill
T
Map Tasks Reduce Tasks
MapReduce
Hadoop
Dryad

4
What Worked
• Parallel programming is hard
– Distributed programming is harder
– Dataflow model makes it a lot easier
• An appropriately high level of abstraction
– User required to consider data parallelisms exposed by the dataflow
– Runtime distributes executions of subroutines by exploiting data dependencies encoded in the dataflow
Nontrivial software written with threads,
semaphores, and mutexes are
incomprehensible to humans.
Edward A. Lee
CGO 2007, March 2007
Auto-Partitioning Compiler
for Intel Network Processor (IXP)

5
What Didn’t Work
• Dataflow abstraction makes Big Data system appear as a “black box”
– Very difficult for a user to understand runtime behaviors
– Performance analysis & tuning remains a big challenge
• Key challenges of performance analysis for Big Data
– Massively distributed system
• How to correlate concurrent performance activities (across 10000s of programs and machines)?
– High level dataflow abstraction
• How to relate low level performance activities to high level dataflow model?
6
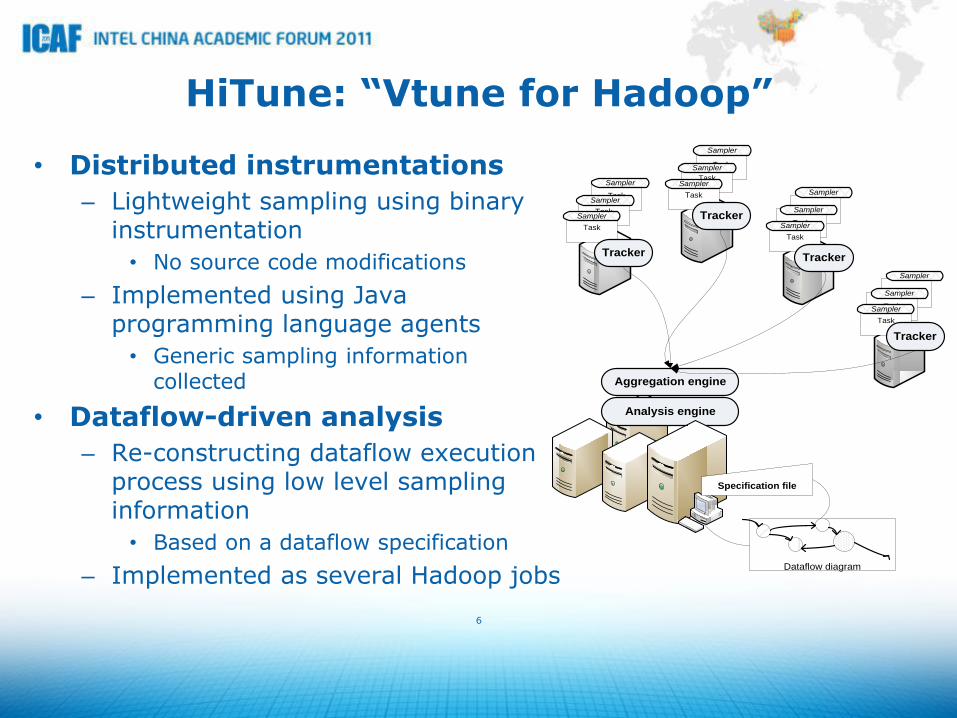
HiTune: “Vtune for Hadoop”
• Distributed instrumentations
– Lightweight sampling using binary instrumentation
• No source code modifications
– Implemented using Java programming language agents
• Generic sampling information collected
• Dataflow-driven analysis
– Re-constructing dataflow execution process using low level sampling information
• Based on a dataflow specification
– Implemented as several Hadoop jobs
Task
Task
Task
Task
Task
Task
Task
Task
Task
Sampler
Dataflow diagram
Sampler
Sampler
Task
Sampler
Sampler
Sampler
Task
Sampler
Sampler
Sampler
Task
Sampler
Sampler
Sampler
Aggregation engine
Tracker
Tracker
Tracker
Tracker
Analysis engine
Specification file
Adaptor
Adaptor
Adaptor
Chukwa
Agent
Adaptor
Adaptor
Adaptor
Chukwa
Collector
HDFS
Chukwa
Demux
Local HiTune
data
Local HiTune
data
Local HiTune
data
Local HiTune
data
Local HiTune
data
Local HiTune
data HiTune
Paser
HiTune
Paser
HiTune
Analyzer
Hadoop
Job
Hadoop
Job
HiTune Report (.csv)
Instrumentation
PostProcess
Analysis
Hive
HiveQL
Hive Query Excel Spreadsheet
Visual
Report Samples (.xlsm)
Chukwa
Agent
Chukwa
Collector
Chukwa
Collector
Aggregation
7
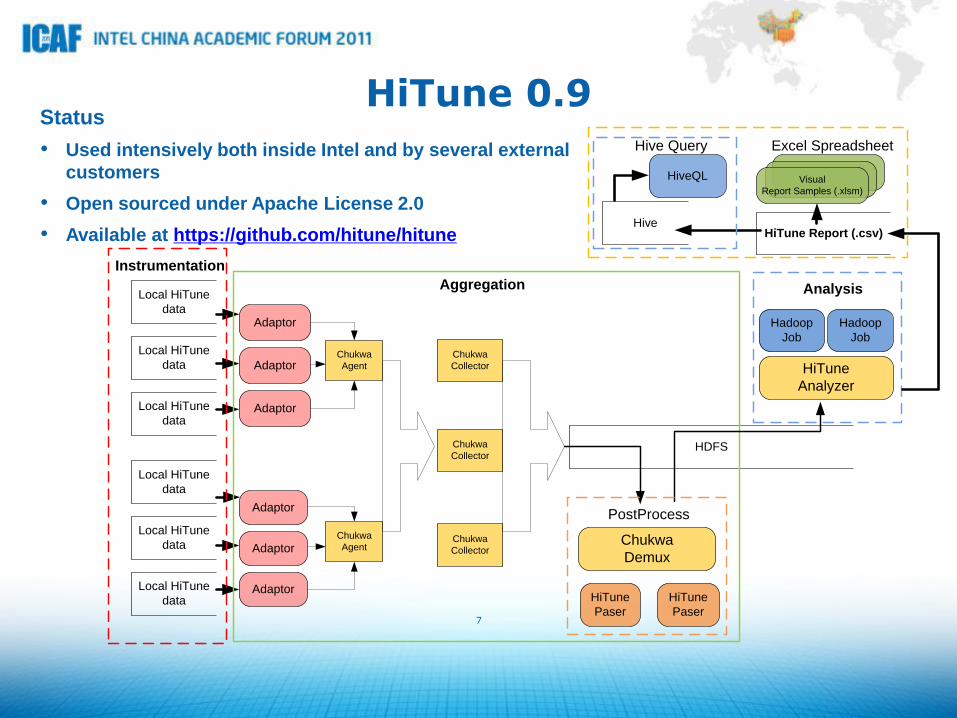
HiTune 0.9 Status
• Used intensively both inside Intel and by several external
customers
• Open sourced under Apache License 2.0
• Available at https://github.com/hitune/hitune
8
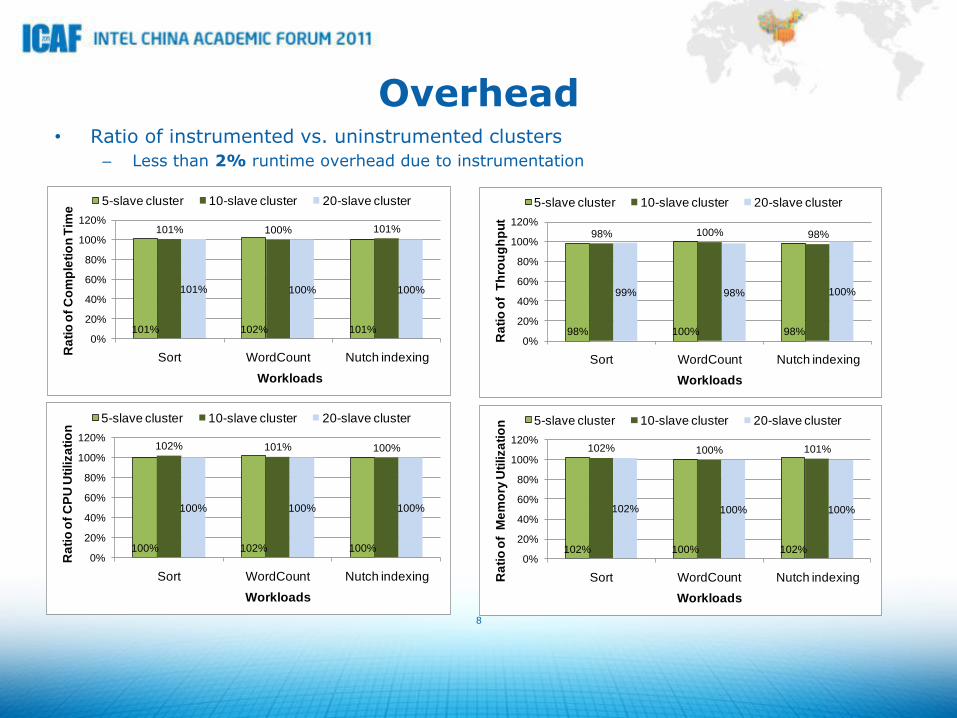
Overhead • Ratio of instrumented vs. uninstrumented clusters
– Less than 2% runtime overhead due to instrumentation
101% 102% 101%
101% 100% 101%
101% 100% 100%
0%
20%
40%
60%
80%
100%
120%
Sort WordCount Nutch indexing
Ra
tio
of
Co
mp
leti
on
Tim
e
Workloads
5-slave cluster 10-slave cluster 20-slave cluster
100% 102% 100%
102% 101% 100%
100% 100% 100%
0%
20%
40%
60%
80%
100%
120%
Sort WordCount Nutch indexing
Ra
tio
of
CP
U U
tiliza
tio
n
Workloads
5-slave cluster 10-slave cluster 20-slave cluster
102% 100% 102%
102% 100% 101%
102% 100% 100%
0%
20%
40%
60%
80%
100%
120%
Sort WordCount Nutch indexingRa
tio
of
Me
mo
ry U
tiliza
tio
n
Workloads
5-slave cluster 10-slave cluster 20-slave cluster
98% 100% 98%
98% 100% 98%
99% 98% 100%
0%
20%
40%
60%
80%
100%
120%
Sort WordCount Nutch indexing
Ra
tio
of
Th
rou
gh
pu
t
Workloads
5-slave cluster 10-slave cluster 20-slave cluster
9
The Hadoop Dataflow Model
spill
Streaming dataflow
D
A
A
map
map
map
map
reduce
Aggregated Output
Partitioned Input
copier
copier
copiersort
sort
sortmerge
merge
merge
reduce
reduce
Sequential dataflow
shuffle
shuffle
shuffle
spill
Spill
spill
T
Map Tasks Reduce Tasks

10
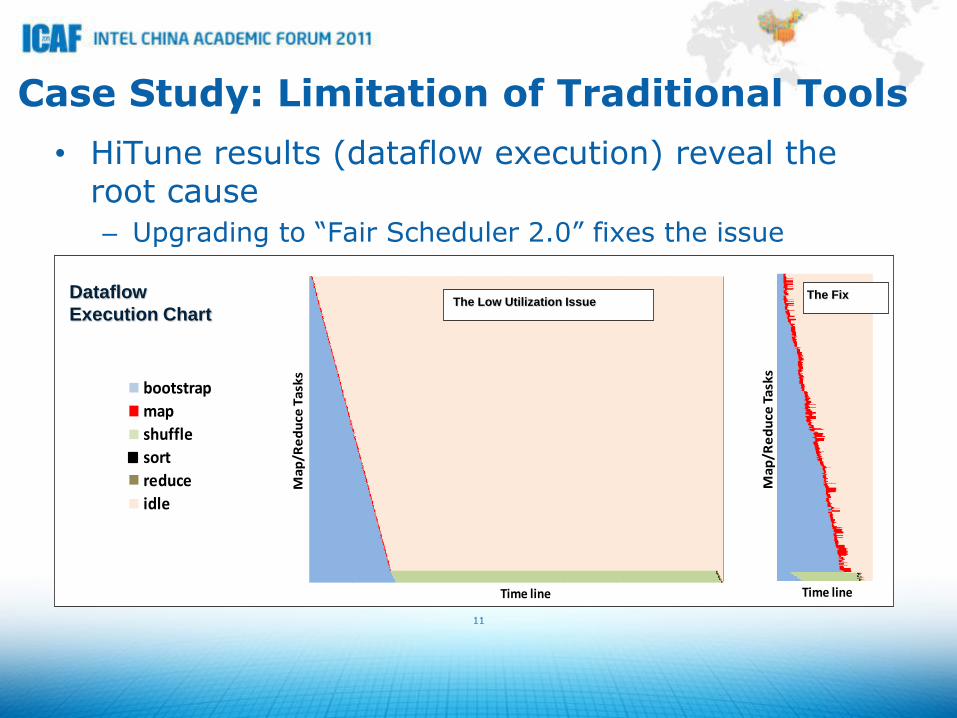
Case Study: Limitation of Traditional Tools
• Sorting many small files (3200 500KB-sized files) using Hadoop 0.20.1
– Cluster very lightly utilized (extremely low CPU, disk I/O and network utilization)
– No obvious bottlenecks or hotspots in the cluster
– Traditional tools (e.g., system monitors and program profilers) fail to reveal the root cause
11
Case Study: Limitation of Traditional Tools
• HiTune results (dataflow execution) reveal the root cause
– Upgrading to “Fair Scheduler 2.0” fixes the issue
Dataflow
Execution Chart
Time line
Ma
p/R
ed
uce
Ta
sks
Sorting small files
bootstrap map shuffle sort reduce idle
Ma
p/R
ed
uce
Ta
sks
0.20.1 0.19.1
Time line
Ma
p/R
ed
uce
Ta
sks
Sorting small files
bootstrap map shuffle sort reduce idle
Ma
p/R
ed
uce
Ta
sks
0.20.1 0.19.1
Time line
Ma
p/R
ed
uce
Ta
sks
Sorting small files
bootstrap map shuffle sort reduce idle
Ma
p/R
ed
uce
Ta
sks
0.20.1 0.19.1 The Fix
The Low Utilization Issue
Ma
p/R
ed
uce
Ta
sks bootstrap
map
shuffle
sort
reduce
idle
Time line
Ma
p/R
ed
uce
Ta
sks
Sorting small files
bootstrap map shuffle sort reduce idle
Map
/Re
du
ce T
asks
0.20.1 0.19.1
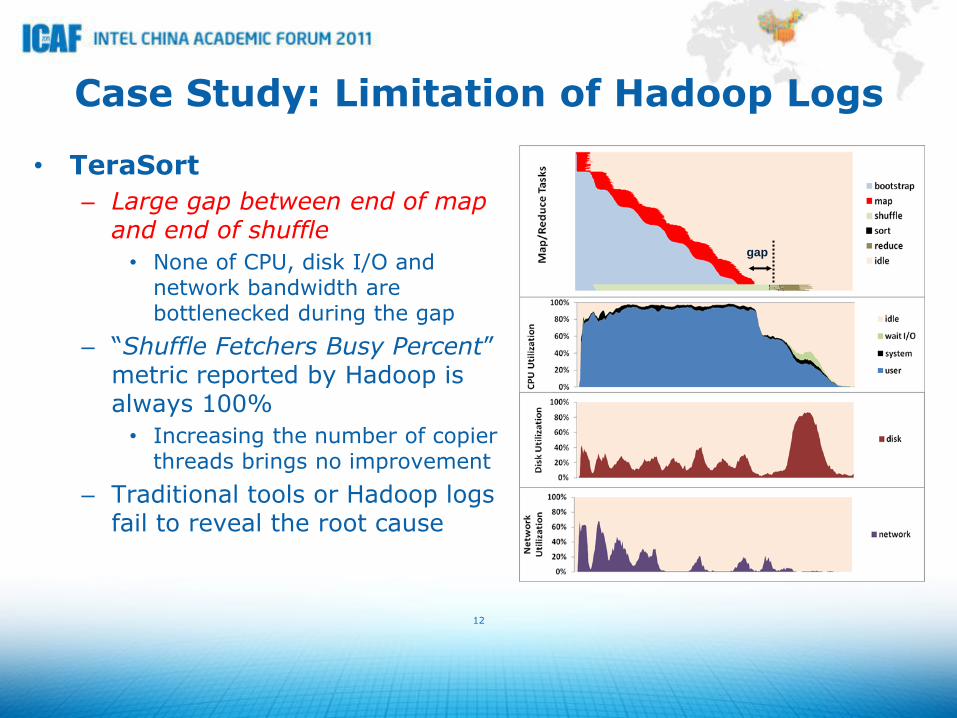
12
Case Study: Limitation of Hadoop Logs
• TeraSort
– Large gap between end of map and end of shuffle
• None of CPU, disk I/O and network bandwidth are bottlenecked during the gap
– “Shuffle Fetchers Busy Percent” metric reported by Hadoop is always 100%
• Increasing the number of copier threads brings no improvement
– Traditional tools or Hadoop logs fail to reveal the root cause
gap
13
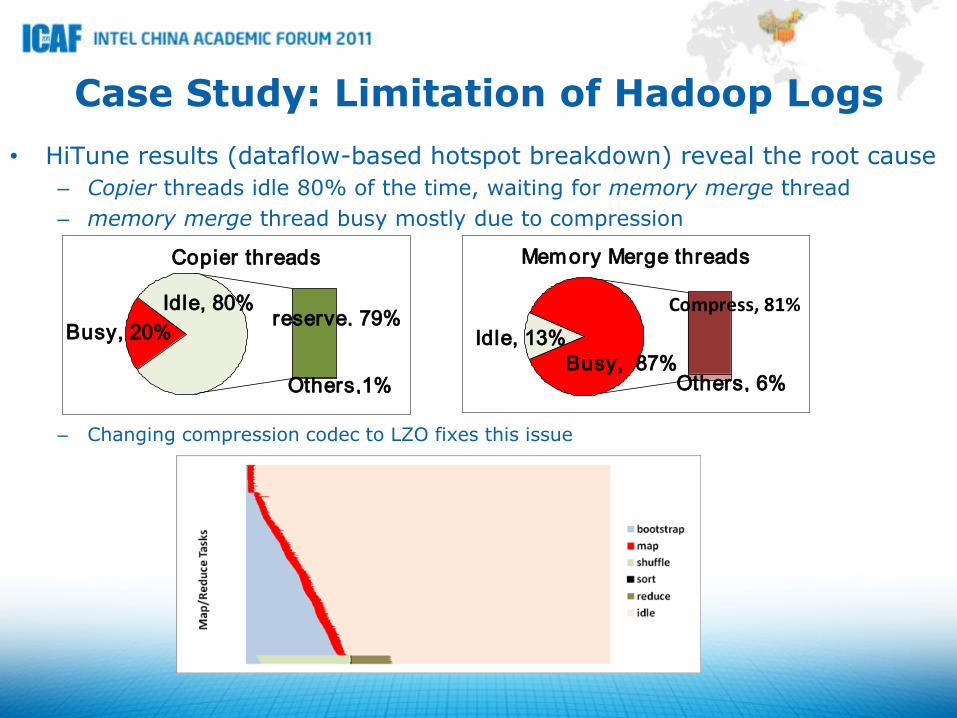
Case Study: Limitation of Hadoop Logs
• HiTune results (dataflow-based hotspot breakdown) reveal the root cause
– Copier threads idle 80% of the time, waiting for memory merge thread
– memory merge thread busy mostly due to compression
– Changing compression codec to LZO fixes this issue
Copier threads
Busy, 20%
Idle, 80%reserve, 79%
Others,1%
Compress, 81%
Memory Merge threads
Idle, 13%
Busy, 87%Others, 6%
14
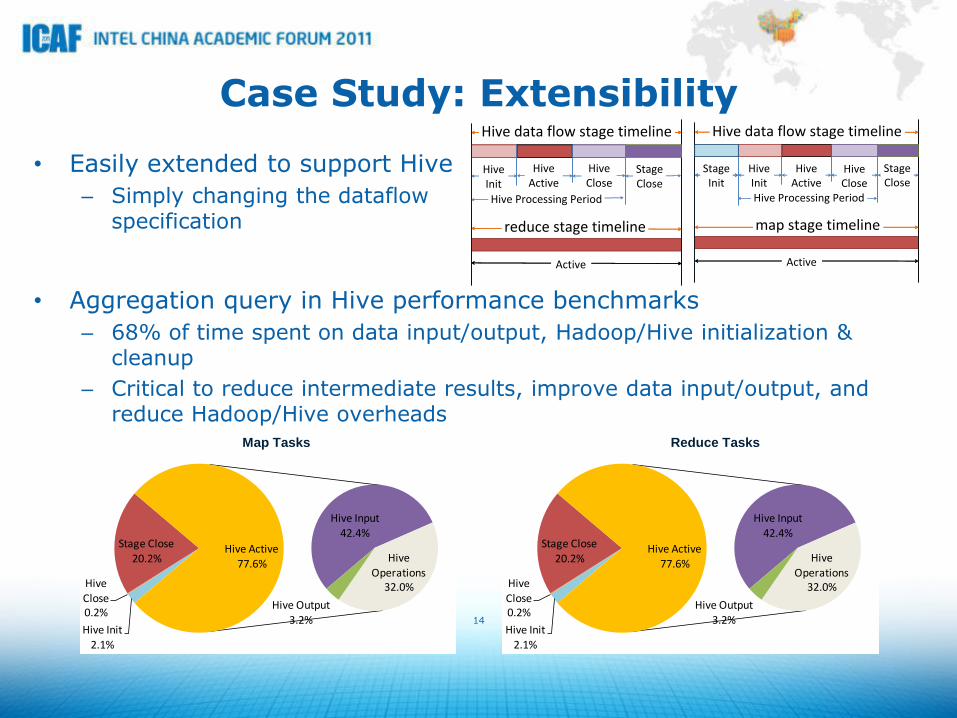
Case Study: Extensibility
• Easily extended to support Hive
– Simply changing the dataflow specification
• Aggregation query in Hive performance benchmarks
– 68% of time spent on data input/output, Hadoop/Hive initialization & cleanup
– Critical to reduce intermediate results, improve data input/output, and reduce Hadoop/Hive overheads
Hive Init
Hive Active
Hive Close
Hive Processing Period
Active
Hive data flow stage timeline
map stage timeline
Stage Init
Stage Close
Hive Init
Hive Active
Hive Close
Stage Init
Hive Init
Hive Active
Hive Close
Hive Processing Period
Active
Hive data flow stage timeline
map stage timeline
Stage Init
Stage Close
Hive Init
Hive Active
Hive Close
Stage Init
Hive Processing Period
Active
Hive data flow stage timeline
reduce stage timeline
Stage Close
Hive Init
Hive Active
Hive Close
Hive Processing Period
Active
Hive data flow stage timeline
reduce stage timeline
Stage Close
Hive Init
Hive Active
Hive Close
Hive Init
2.1%
Hive
Close0.2%
Stage Close
20.2%
Hive Input42.4%
Hive Operations
32.0%
Hive Output3.2%
Hive Active77.6%
Hive Init Hive Close Stage Close
Hive Input Hive Operations Hive Output
Hive Init
2.1%
Hive
Close0.2%
Stage Close
20.2%
Hive Input42.4%
Hive Operations
32.0%
Hive Output3.2%
Hive Active77.6%
Hive Init Hive Close Stage Close
Hive Input Hive Operations Hive OutputMap Tasks Reduce Tasks

15
Summary
• HiTune - “VTune for Hadoop”
– Better insights on Hadoop runtime behaviors
• Dataflow-based analysis
– Extremely low runtime overheads
– Very good scalability & extensibility
– v0.9 open sourced under Apache License 2.0
• See https://github.com/hitune/hitune
* Refer to our USENIX ATC’11 paper for more details

2011/8/23 16











![HiTune - Dataflow-Based Performance Analysis for Big Data ... · every day and 800TB compressed data scanned daily [1]. This type of “Big Data” phenomenon has led to the emergence](https://static.fdocuments.net/doc/165x107/5f05e89f7e708231d4155305/hitune-dataflow-based-performance-analysis-for-big-data-every-day-and-800tb.jpg)





