
Hidden Markov Models -...
74
~
Transcript of Hidden Markov Models -...

Hidden Markov ModelsAdvances and applications
Diego Milone
d.milone~ieee.org
Tópicos Selectos en Aprendizaje Maquinal
Doctorado en Ingeniería, FICH-UNL
November 14, 2016

s inc
( )
i
Advances Applications
Hidden Markov Trees as Observation Densities(HMM-HMT)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 2 / 52

:
s inc
( )
i
Advances Applications
Motivation: Sequences of Trees
The main motivation for this section is:
to learn variable-length sequences
of tree-structured data
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 3 / 52

s inc
( )
i
Advances Applications
First: A Model for Just one Tree
Let be w = [w1, w2, . . . , wN ] a tree structured data with J levels(N = 2J − 1 for binary trees). The Hidden Markov Tree can be dened as
θ = 〈U ,R,κ, ε,F〉where
i) U = u ∈ [1 . . . N ] is the set of nodes in the tree,
ii) R = R ∈ [1 . . . NM ] is the set of states in all the nodes andRu = Ru ∈ [1 . . .M ] the set of states in the node u.
iii) ε =[εu,mn = Pr(Ru = m|Rρ(u) = n)
], is the conditional probability
of node u being in state m given that the state in its parent nodeρ(u) is n,
iv) κ = [κp = Pr(R1 = p)], ∀p ∈ R1 are the probabilities for the rootnode being on state p.
v) F = fu,m(wu) = Pr (Wu = wu|Ru = m) are the observationprobability distributions.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 4 / 52

s inc
( )
i
Advances Applications
First: A Model for Just one Tree
Let be w = [w1, w2, . . . , wN ] a tree structured data with J levels(N = 2J − 1 for binary trees). The Hidden Markov Tree can be dened as
θ = 〈U ,R,κ, ε,F〉where
i) U = u ∈ [1 . . . N ] is the set of nodes in the tree,
ii) R = R ∈ [1 . . . NM ] is the set of states in all the nodes andRu = Ru ∈ [1 . . .M ] the set of states in the node u.
iii) ε =[εu,mn = Pr(Ru = m|Rρ(u) = n)
], is the conditional probability
of node u being in state m given that the state in its parent nodeρ(u) is n,
iv) κ = [κp = Pr(R1 = p)], ∀p ∈ R1 are the probabilities for the rootnode being on state p.
v) F = fu,m(wu) = Pr (Wu = wu|Ru = m) are the observationprobability distributions.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 4 / 52

s inc
( )
i
Advances Applications
First: A Model for Just one Tree
Let be w = [w1, w2, . . . , wN ] a tree structured data with J levels(N = 2J − 1 for binary trees). The Hidden Markov Tree can be dened as
θ = 〈U ,R,κ, ε,F〉where
i) U = u ∈ [1 . . . N ] is the set of nodes in the tree,
ii) R = R ∈ [1 . . . NM ] is the set of states in all the nodes andRu = Ru ∈ [1 . . .M ] the set of states in the node u.
iii) ε =[εu,mn = Pr(Ru = m|Rρ(u) = n)
], is the conditional probability
of node u being in state m given that the state in its parent nodeρ(u) is n,
iv) κ = [κp = Pr(R1 = p)], ∀p ∈ R1 are the probabilities for the rootnode being on state p.
v) F = fu,m(wu) = Pr (Wu = wu|Ru = m) are the observationprobability distributions.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 4 / 52

s inc
( )
i
Advances Applications
HMT: Preliminars
Additional notation:
C(u) = c1(u), . . . , cNu(u) is the set of children of the node u.
Tu is the subtree observed from the node u (including all itsdescendants).
Turv is the subtree from node u but excluding node v and all itsdescendants.
Likelihood:
Lθ(w) , Pr(w|θ) =∑∀r
Pr(w, r|θ)
=∑∀r
∏u
εu,rurρ(u)fu,ru(wu) =∑∀rLθ(w, r)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 5 / 52

s inc
( )
i
Advances Applications
HMT: Preliminars
Additional notation:
C(u) = c1(u), . . . , cNu(u) is the set of children of the node u.
Tu is the subtree observed from the node u (including all itsdescendants).
Turv is the subtree from node u but excluding node v and all itsdescendants.
Likelihood:
Lθ(w) , Pr(w|θ) =∑∀r
Pr(w, r|θ)
=∑∀r
∏u
εu,rurρ(u)fu,ru(wu) =∑∀rLθ(w, r)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 5 / 52

s inc
( )
i
Advances Applications
Expectation Maximization for HMT
Expected values and counters (upward-downward algorithm):
βu(n) , Pr (Tu |ru = n, θ ) = fu,n(wu)∏
v∈C(u)
βu,v(n),
βρ(u),u(n) , Pr(Tu∣∣rρ(u) = n, θ
)=∑m
βu(m)εu,mn,
αu(n) , Pr (T1ru, ru = n |θ ) =∑m
εu,nmβρ(u)(m)αρ(u)(m)
βρ(u),u(m),
γu(m) , Pr(ru = m|w, θ) =αu(m)βu(m)∑n
αu(n)βu(n),
ξu(m,n) , Pr(ru = m, rρ(u) = n|w, θ)
=βu(m)εu,mnαρ(u)(n)βρ(u)(n)/βρ(u),u(n)∑
n
αu(n)βu(n).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 6 / 52

s inc
( )
i
Advances Applications
Expectation Maximization for HMT
Expected values and counters (upward-downward algorithm):
βu(n) , Pr (Tu |ru = n, θ ) = fu,n(wu)∏
v∈C(u)
βu,v(n),
βρ(u),u(n) , Pr(Tu∣∣rρ(u) = n, θ
)=∑m
βu(m)εu,mn,
αu(n) , Pr (T1ru, ru = n |θ ) =∑m
εu,nmβρ(u)(m)αρ(u)(m)
βρ(u),u(m),
γu(m) , Pr(ru = m|w, θ) =αu(m)βu(m)∑n
αu(n)βu(n),
ξu(m,n) , Pr(ru = m, rρ(u) = n|w, θ)
=βu(m)εu,mnαρ(u)(n)βρ(u)(n)/βρ(u),u(n)∑
n
αu(n)βu(n).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 6 / 52

s inc
( )
i
Advances Applications
EM for HMT: Reestimation Formulas
For multiple observations W =w1,w2, . . . ,wL
, and using
fu,ru(w`u) = N(w`u, µu,ru , σu,ru
), we have
εu,mn =
∑`
ξ`u(m,n)∑`
γ`ρ(u)(n), µu,m =
∑`
w`uγ`u(m)∑
`
γ`u(m),
and
σ2u,m =
∑`
(w`u − µu,m)2γ`u(m)∑`
γ`u(m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 7 / 52

s inc
( )
i
Advances Applications
EM for HMT: Reestimation Formulas
For multiple observations W =w1,w2, . . . ,wL
, and using
fu,ru(w`u) = N(w`u, µu,ru , σu,ru
), we have
εu,mn =
∑`
ξ`u(m,n)∑`
γ`ρ(u)(n), µu,m =
∑`
w`uγ`u(m)∑
`
γ`u(m),
and
σ2u,m =
∑`
(w`u − µu,m)2γ`u(m)∑`
γ`u(m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 7 / 52

s inc
( )
i
Advances Applications
EM for HMT: Reestimation Formulas
For multiple observations W =w1,w2, . . . ,wL
, and using
fu,ru(w`u) = N(w`u, µu,ru , σu,ru
), we have
εu,mn =
∑`
ξ`u(m,n)∑`
γ`ρ(u)(n), µu,m =
∑`
w`uγ`u(m)∑
`
γ`u(m),
and
σ2u,m =
∑`
(w`u − µu,m)2γ`u(m)∑`
γ`u(m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 7 / 52

s inc
( )
i
Advances Applications
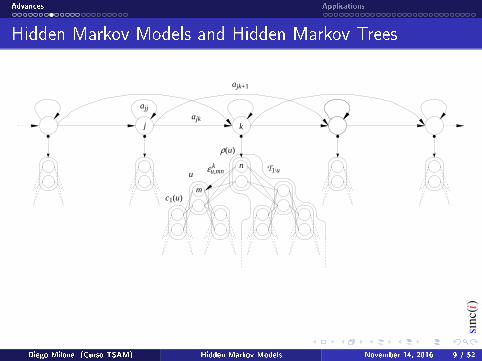
Hidden Markov Models and Hidden Markov Trees
To model a sequence W = w1,w2, . . . ,wT , where wt = [wt1, wt2, . . . , w
tN ]
is a tree structured data with J levels, the HMM-HMT model is dened asthe composite Θ , ϑ[θ].
That is, each state k ∈ Q in the external HMM has an HMTθk = 〈Uk,Rk,κk, εk,Fk〉.
Then, in Θ we have
bk(wt) , Pr(wt|θ) =
∑∀r
Pr(wt, r|θ) =∑∀r
∏∀uεku,rurρ(u)f
ku,ru(wtu).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 8 / 52

s inc
( )
i
Advances Applications
Hidden Markov Models and Hidden Markov Trees
To model a sequence W = w1,w2, . . . ,wT , where wt = [wt1, wt2, . . . , w
tN ]
is a tree structured data with J levels, the HMM-HMT model is dened asthe composite Θ , ϑ[θ].
That is, each state k ∈ Q in the external HMM has an HMTθk = 〈Uk,Rk,κk, εk,Fk〉.
Then, in Θ we have
bk(wt) , Pr(wt|θ) =
∑∀r
Pr(wt, r|θ) =∑∀r
∏∀uεku,rurρ(u)f
ku,ru(wtu).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 8 / 52
s inc
( )
i
Advances Applications
Hidden Markov Models and Hidden Markov Trees
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 9 / 52

s inc
( )
i
Advances Applications
HMM-HMT: Likelihood
The full-model likelihood for the composite model is
LΘ(W) =∑∀q
T∏t=1
(aqt−1qt
∑∀r
∏∀uεqt
u,rurρ(u)f q
t
u,ru(wtu)
)=
∑∀q
∑∀R
∏t
aqt−1qt
∏∀uεqt
u,rturtρ(u)
f qt
u,rtu(wtu)
=∑∀q
∑∀RLΘ(W,q,R)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 10 / 52

:
s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
In this case, the auxiliary function is dened as
D(Θ, Θ) ,∑∀q
∑∀RLΘ(W,q,R) log (LΘ(W,q,R))
...
D(Θ, Θ) =∑∀q
∑∀RLΘ(W,q,R) ·
[∑t
log(aqt−1qt) +
+∑t
∑∀u
log
(εqt
u,rturtρ(u)
)+ log
(f q
t
u,rtu(wtu)
)]
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 11 / 52

:
s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
In this case, the auxiliary function is dened as
D(Θ, Θ) ,∑∀q
∑∀RLΘ(W,q,R) log (LΘ(W,q,R))
...
D(Θ, Θ) =∑∀q
∑∀RLΘ(W,q,R) ·
[∑t
log(aqt−1qt) +
+∑t
∑∀u
log
(εqt
u,rturtρ(u)
)+ log
(f q
t
u,rtu(wtu)
)]
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 11 / 52
s inc
( )
i
Advances Applications
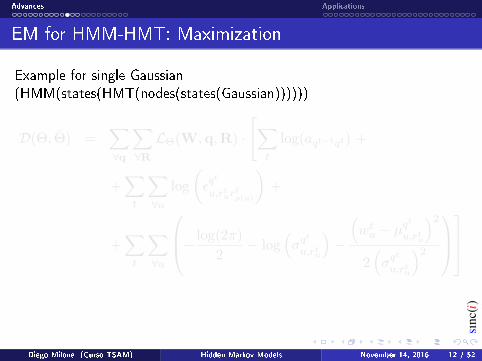
EM for HMM-HMT: Maximization
Example for single Gaussian(HMM(states(HMT(nodes(states(Gaussian))))))
D(Θ, Θ) =∑∀q
∑∀RLΘ(W,q,R) ·
[∑t
log(aqt−1qt) +
+∑t
∑∀u
log
(εqt
u,rturtρ(u)
)+
+∑t
∑∀u
− log(2π)
2− log
(σq
t
u,rtu
)−
(wtu − µ
qt
u,rtu
)2
2(σq
t
u,rtu
)2
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 12 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
Example for single Gaussian(HMM(states(HMT(nodes(states(Gaussian))))))
D(Θ, Θ) =∑∀q
∑∀RLΘ(W,q,R) ·
[∑t
log(aqt−1qt) +
+∑t
∑∀u
log
(εqt
u,rturtρ(u)
)+
+∑t
∑∀u
− log(2π)
2− log
(σq
t
u,rtu
)−
(wtu − µ
qt
u,rtu
)2
2(σq
t
u,rtu
)2
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 12 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
For εku,mn the restriction∑
m εku,mn $ 1 should be satised. If we use
D(Θ, Θ) , D(Θ, Θ) +∑n
λn
(∑m
εku,mn − 1
),
with ∇εku,mnD(Θ, Θ) = 0 the learning rule results
εku,mn =
∑t
γt(k)ξtku (m,n)∑t
γt(k)γtkρ(u)(n).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 13 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
For εku,mn the restriction∑
m εku,mn $ 1 should be satised. If we use
D(Θ, Θ) , D(Θ, Θ) +∑n
λn
(∑m
εku,mn − 1
),
with ∇εku,mnD(Θ, Θ) = 0 the learning rule results
εku,mn =
∑t
γt(k)ξtku (m,n)∑t
γt(k)γtkρ(u)(n).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 13 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
For εku,mn the restriction∑
m εku,mn $ 1 should be satised. If we use
D(Θ, Θ) , D(Θ, Θ) +∑n
λn
(∑m
εku,mn − 1
),
with ∇εku,mnD(Θ, Θ) = 0 the learning rule results
εku,mn =
∑t
γt(k)ξtku (m,n)∑t
γt(k)γtkρ(u)(n).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 13 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
From ∇µku,mD(Θ, Θ) = 0 we obtain
µku,m =
∑t
γt(k)γtku (m)wtu∑t
γt(k)γtku (m)
and, in a similar way,
(σku,m)2 =
∑t
γt(k)γtku (m)(wtu − µku,m
)2
∑t
γt(k)γtku (m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 14 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
From ∇µku,mD(Θ, Θ) = 0 we obtain
µku,m =
∑t
γt(k)γtku (m)wtu∑t
γt(k)γtku (m)
and, in a similar way,
(σku,m)2 =
∑t
γt(k)γtku (m)(wtu − µku,m
)2
∑t
γt(k)γtku (m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 14 / 52

s inc
( )
i
Advances Applications
EM for HMM-HMT: Maximization
From ∇µku,mD(Θ, Θ) = 0 we obtain
µku,m =
∑t
γt(k)γtku (m)wtu∑t
γt(k)γtku (m)
and, in a similar way,
(σku,m)2 =
∑t
γt(k)γtku (m)(wtu − µku,m
)2
∑t
γt(k)γtku (m).
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 14 / 52

s inc
( )
i
Advances Applications
Minimum Classication Error Approach for HMM-HMT
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 15 / 52

:
s inc
( )
i
Advances Applications
Some hidden requirements for ML training
Using ML for classication purposes:
Isolated training of models
Enough expression power in the model
Enough representative training data
Enough (innite?) reestimation steps
The Minimum Classication Error (MCE) approach:
1 Simulation of the classier decision
2 Soft approximation of the 0-1 loss
3 Minimization of the empirical classication risk
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 16 / 52

:
s inc
( )
i
Advances Applications
Some hidden requirements for ML training
Using ML for classication purposes:
Isolated training of models
Enough expression power in the model
Enough representative training data
Enough (innite?) reestimation steps
The Minimum Classication Error (MCE) approach:
1 Simulation of the classier decision
2 Soft approximation of the 0-1 loss
3 Minimization of the empirical classication risk
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 16 / 52

s inc
( )
i
Advances Applications
Minimum Classication Error Training
Let gj(W; Λ) be a set of discriminant functions, with Λ the wholeparameter set. For the MCE approach we can choose:
1 Simulation of the classier decision:
di(W; Λ) = −gi(W; Λ) + maxj 6=i
gj(W; Λ)
2 Soft approximation of the 0-1 loss:
`(di(W; Λ)) = `i(W; Λ) = (1 + exp (−γdi(W; Λ) + β))−1
3 Minimization of the empirical classication risk: The classication riskconditioned on W can be written as
`(W; Λ) =
M∑i=1
`i(W; Λ) I(W ∈ Ωi),
where I(·) is the indicator function and Ωi stands for the set ofpatterns which belong to class i.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 17 / 52

s inc
( )
i
Advances Applications
Minimum Classication Error Training
Let gj(W; Λ) be a set of discriminant functions, with Λ the wholeparameter set. For the MCE approach we can choose:
1 Simulation of the classier decision:
di(W; Λ) = −gi(W; Λ) + maxj 6=i
gj(W; Λ)
2 Soft approximation of the 0-1 loss:
`(di(W; Λ)) = `i(W; Λ) = (1 + exp (−γdi(W; Λ) + β))−1
3 Minimization of the empirical classication risk: The classication riskconditioned on W can be written as
`(W; Λ) =
M∑i=1
`i(W; Λ) I(W ∈ Ωi),
where I(·) is the indicator function and Ωi stands for the set ofpatterns which belong to class i.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 17 / 52

s inc
( )
i
Advances Applications
Minimum Classication Error Training
Let gj(W; Λ) be a set of discriminant functions, with Λ the wholeparameter set. For the MCE approach we can choose:
1 Simulation of the classier decision:
di(W; Λ) = −gi(W; Λ) + maxj 6=i
gj(W; Λ)
2 Soft approximation of the 0-1 loss:
`(di(W; Λ)) = `i(W; Λ) = (1 + exp (−γdi(W; Λ) + β))−1
3 Minimization of the empirical classication risk: The classication riskconditioned on W can be written as
`(W; Λ) =
M∑i=1
`i(W; Λ) I(W ∈ Ωi),
where I(·) is the indicator function and Ωi stands for the set ofpatterns which belong to class i.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 17 / 52

s inc
( )
i
Advances Applications
Minimum Classication Error Training
Let gj(W; Λ) be a set of discriminant functions, with Λ the wholeparameter set. For the MCE approach we can choose:
1 Simulation of the classier decision:
di(W; Λ) = −gi(W; Λ) + maxj 6=i
gj(W; Λ)
2 Soft approximation of the 0-1 loss:
`(di(W; Λ)) = `i(W; Λ) = (1 + exp (−γdi(W; Λ) + β))−1
3 Minimization of the empirical classication risk: The classication riskconditioned on W can be written as
`(W; Λ) =
M∑i=1
`i(W; Λ) I(W ∈ Ωi),
where I(·) is the indicator function and Ωi stands for the set ofpatterns which belong to class i.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 17 / 52

s inc
( )
i
Advances Applications
MCE training for HMM-HMT
For the HMM-HMT we propose a Viterbi-based discrimination function
−g(W|Λ) = log
(maxq,RLΘ(W,q,R)
)=
∑t
log aqt−1qt +∑t
∑∀u
log εqt
u,rturtρ(u)
+∑t
∑∀u
log f qt
u,rtu(wtu)
and the missclassication function dened as the inverse relation
di(W; Λ) = 1−
[1M−1
∑j 6=i gj(W; Λ)−η
]−1/η
gi(W; Λ)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 18 / 52

s inc
( )
i
Advances Applications
MCE training for HMM-HMT
For the HMM-HMT we propose a Viterbi-based discrimination function
−g(W|Λ) = log
(maxq,RLΘ(W,q,R)
)=
∑t
log aqt−1qt +∑t
∑∀u
log εqt
u,rturtρ(u)
+∑t
∑∀u
log f qt
u,rtu(wtu)
and the missclassication function dened as the inverse relation
di(W; Λ) = 1−
[1M−1
∑j 6=i gj(W; Λ)−η
]−1/η
gi(W; Λ)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 18 / 52

s inc
( )
i
Advances Applications
MCE training for HMM-HMT
Based in the Generalized Probabilistic Descent (GPD) method, thealgorithm can be summarized as:
Λ←− Λ− ατ∂`(Wτ ; Λ)
∂Λ
∣∣∣∣Λ=Λτ
.
Thus, the updating process that works upon the transformed means µ(j)ku,m
is given by
µ(j)ku,m ←− µ(j)k
u,m − ατ∂`i(Wτ ; Λ)
∂µ(j)ku,m
∣∣∣∣∣Λ=Λτ
(1)
and applying the chain rule of dierentiation we get...
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 19 / 52

s inc
( )
i
Advances Applications
MCE training for HMM-HMT
Based in the Generalized Probabilistic Descent (GPD) method, thealgorithm can be summarized as:
Λ←− Λ− ατ∂`(Wτ ; Λ)
∂Λ
∣∣∣∣Λ=Λτ
.
Thus, the updating process that works upon the transformed means µ(j)ku,m
is given by
µ(j)ku,m ←− µ(j)k
u,m − ατ∂`i(Wτ ; Λ)
∂µ(j)ku,m
∣∣∣∣∣Λ=Λτ
(1)
and applying the chain rule of dierentiation we get...
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 19 / 52

s inc
( )
i
Advances Applications
MCE training for HMM-HMT
Based in the Generalized Probabilistic Descent (GPD) method, thealgorithm can be summarized as:
Λ←− Λ− ατ∂`(Wτ ; Λ)
∂Λ
∣∣∣∣Λ=Λτ
.
Thus, the updating process that works upon the transformed means µ(j)ku,m
is given by
µ(j)ku,m ←− µ(j)k
u,m − ατ∂`i(Wτ ; Λ)
∂µ(j)ku,m
∣∣∣∣∣Λ=Λτ
(1)
and applying the chain rule of dierentiation we get...
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 19 / 52

s inc
( )
i
Advances Applications
MCE training for the Gaussian means
Ii i iiiiiii iii:...for j = i
µ(i)ku,m ←−µ(i)k
u,m − ατγ`i(1− `i)di − 1
gi×
×∑t
δ(qt − k, rtu −m)
[wtu − µ
(i)ku,m
σ(i)ku,m
]
...for j 6= i
µ(j)ku,m ←−µ(j)k
u,m − ατγ`i(1− `i)(1− di)g−η−1j∑k 6=i g
−ηk
×
×∑t
δ(qt − k, rtu −m)
[wtu − µ
(j)ku,m
σ(j)ku,m
]
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 20 / 52

s inc
( )
i
Advances Applications
MCE training for the Gaussian variances
In a similar way:...for j = i
σ(i)ku,m ←−σ(i)k
u,m − ατγ`i(1− `i)di − 1
gi×
×∑t
δ(qt − k, rtu −m)
(wtu − µ(i)ku,m
σ(i)ku,m
)2
− 1
...for j 6= i
σ(j)ku,m ←−σ(j)k
u,m − ατγ`i(1− `i)(1− di)g−η−1j∑k 6=i g
−ηk
×
×∑t
δ(qt − k, rtu −m)
(wtu − µ(j)ku,m
σ(j)ku,m
)2
− 1
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 21 / 52

s inc
( )
i
Advances Applications
MCE training for the transition probabilities in the HMT
...for j = i
ε(i)ku,mn ←−ε
(i)ku,mn − ατγ`i(1− `i)
di − 1
gi×
×∑
t
δ(qt − k, rtu −m, rtρ(u) − n)−
−∑t
∑p
δ(qt − k, rtu − p, rtρ(u) − n)ε(i)ku,mn
...for j 6= i
ε(j)ku,mn ←−ε
(j)ku,mn − ατγ`i(1− `i)(1− di)
g−η−1j∑k 6=i g
−ηk
×
×∑
t
δ(qt − k, rtu −m, rtρ(u) − n)−
−∑t
∑p
δ(qt − k, rtu − p, rtρ(u) − n)ε(j)ku,mn
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 22 / 52

s inc
( )
i
Advances Applications
MCE training for the transition probabilities in the HMM
...for j = i
a(i)sj ←−a
(i)sj − ατγ`i(1− `i)
di − 1
gi×
×
T∑t=1
δ(qt−1 − s, qt − j)−T∑t=1
δ(qt−1 − s)a(i)sj
...for j 6= i
a(j)sj ←−a
(j)sj − ατγ`i(1− `i)(1− di)
g−η−1j∑k 6=i g
−ηk
×
×
T∑t=1
δ(qt−1 − s, qt − j)−T∑t=1
δ(qt−1 − s)a(j)sj
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 23 / 52
s inc
( )
i
Advances Applications
Applications
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 24 / 52

:
s inc
( )
i
Advances Applications
The rst application: speech recognition
t “ en que ”
Speech signal Signal processing and analysis Pattern recognition
Text
ASR System
The problem complexities:
Speech continuity, context dependenceInter/intra speaker variabilityThe structures of speechNoise and other distortions
Types of speech recognizers:
Vocabulary size: small, medium, large, very large, unrestrictedSpeakers: mono- multi- independentSpeaking styles: isolated connected read uent spontaneousDistortions: robust/non-robust speech recognition
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 25 / 52

:
s inc
( )
i
Advances Applications
The rst application: speech recognition
t “ en que ”
Speech signal Signal processing and analysis Pattern recognition
Text
ASR System
The problem complexities:
Speech continuity, context dependenceInter/intra speaker variabilityThe structures of speechNoise and other distortions
Types of speech recognizers:
Vocabulary size: small, medium, large, very large, unrestrictedSpeakers: mono- multi- independentSpeaking styles: isolated connected read uent spontaneousDistortions: robust/non-robust speech recognition
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 25 / 52

:
s inc
( )
i
Advances Applications
The rst application: speech recognition
t “ en que ”
Speech signal Signal processing and analysis Pattern recognition
Text
ASR System
The problem complexities:
Speech continuity, context dependenceInter/intra speaker variabilityThe structures of speechNoise and other distortions
Types of speech recognizers:
Vocabulary size: small, medium, large, very large, unrestrictedSpeakers: mono- multi- independentSpeaking styles: isolated connected read uent spontaneousDistortions: robust/non-robust speech recognition
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 25 / 52
s inc
( )
i
Advances Applications
The speech recognition model
ASR System
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 26 / 52

s inc
( )
i
Advances Applications
The speech recognition model
s ( t ) s [ m , k ]
silencio el sótano silencio B E
e l s o t a n o
está en del comedor
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 27 / 52

s inc
( )
i
Advances Applications
Language model for speech recognition
sil
de
a
caudal
Jucar
veinte
y
E B
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 28 / 52

s inc
( )
i
Advances Applications
Language model and prosody
Layer N Layer 2
sil
de
a
caudal
Jucar
veinte
y
de
a
caudal
Jucar
veinte
y
de
a
caudal
Jucar
veinte
y
sil sil
Layer 1
E B
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 29 / 52

s inc
( )
i
Advances Applications
Speech recognition: conguration for similar tasks
Speaker recognition/identication
Word-spotting
Emotion recognition
Language recognition
Pronunciation quality evaluation (for teaching)
Automatic translation
Recognition of pathologies in voices
Multimodal speech recognition
...
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 30 / 52

s inc
( )
i
Advances Applications
Recognition of masticatory events in cows and sheep
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 31 / 52

s inc
( )
i
Advances Applications
Masticatory events in sheep
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 32 / 52

s inc
( )
i
Advances Applications
Model for classication of ruminant ingestive events
s1 s2 s3 s1 s2 s3s1 s2 s3
c1 c2 c3
Eventlevel
Sub-eventlevel
Acousticlevel
Languagemodel
Compoundlevel
chew chew-bite
bite sil
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 33 / 52

s inc
( )
i
Advances Applications
Language model for masticatory events in sheep/cows
S Esil sil
bite
chew
chew-bite
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 34 / 52
s inc
( )
i
Advances Applications
HMM in Computer Vision
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 35 / 52

s inc
( )
i
Advances Applications
HMM in Computer Vision: OCR
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 36 / 52

s inc
( )
i
Advances Applications
HMM in Computer Vision: OCR by frames
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 37 / 52

s inc
( )
i
Advances Applications
HMM in Computer Vision: OCR by grammars
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 38 / 52

s inc
( )
i
Advances Applications
HMM in Computer Vision: Cancer
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 39 / 52
s inc
( )
i
Advances Applications
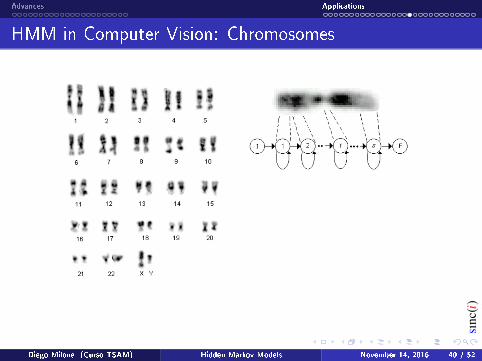
HMM in Computer Vision: Chromosomes
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 40 / 52

s inc
( )
i
Advances Applications
HMM for Denoising
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 41 / 52

s inc
( )
i
Advances Applications
HMM for Denoising
Denoising with HMM-HMT in the wavelet domain and re-synthesis
Nx: signal lengthNw : window widthNs: step of the analysisDWT: discrete wavelet transform (Daubechies-8)
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 42 / 52

s inc
( )
i
Advances Applications
Denoising: Doppler
a)-15
-10
-5
0
5
10
15
0 200 400 600 800 1000 b)-15
-10
-5
0
5
10
15
0 200 400 600 800 1000
c)-15
-10
-5
0
5
10
15
0 200 400 600 800 1000 d)-15
-10
-5
0
5
10
15
0 200 400 600 800 1000
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 43 / 52

s inc
( )
i
Advances Applications
Denoising: Heavisine
a)-15
-10
-5
0
5
10
0 200 400 600 800 1000 b)-15
-10
-5
0
5
10
0 200 400 600 800 1000
c)-15
-10
-5
0
5
10
0 200 400 600 800 1000 d)-15
-10
-5
0
5
10
0 200 400 600 800 1000
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 44 / 52
s inc
( )
i
Advances Applications
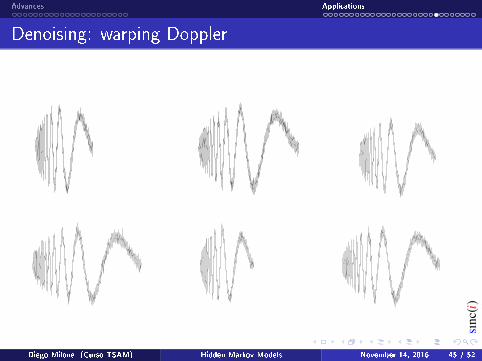
Denoising: warping Doppler
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 45 / 52
s inc
( )
i
Advances Applications
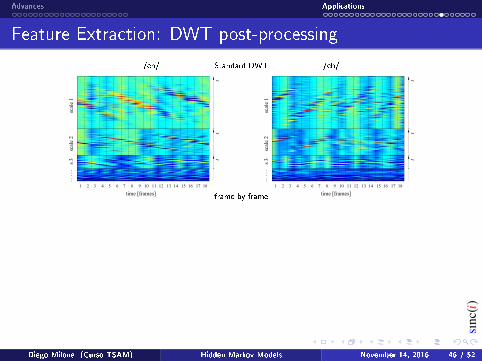
Feature Extraction: DWT post-processing
/eh/ Standard DWT /eh/
frame by frame
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 46 / 52

s inc
( )
i
Advances Applications
Feature Extraction: DWT post-processing
/eh/ Standard DWT /eh/
frame by frameSpectrum Modulus by Scale (SMS) DWT
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 47 / 52

s inc
( )
i
Advances Applications
HMM in Bioinformatics
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 48 / 52
s inc
( )
i
Advances Applications
HMM in Bioinformatics
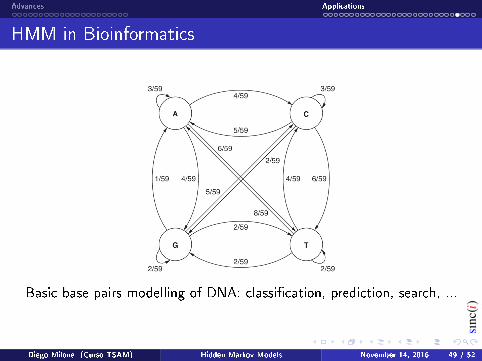
Basic base pairs modelling of DNA: classication, prediction, search, ...
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 49 / 52
s inc
( )
i
Advances Applications
HMM in Bioinformatics
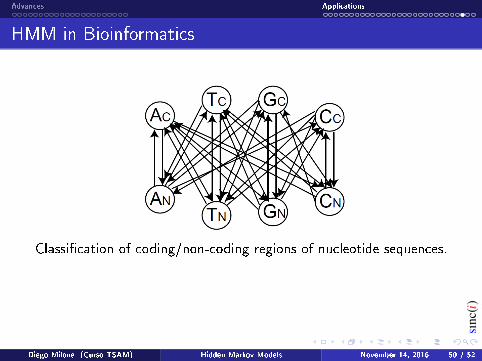
Classication of coding/non-coding regions of nucleotide sequences.
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 50 / 52

s inc
( )
i
Advances Applications
HMM in Bioinformatics
Alignment and prediction of exons using genomic DNA from two dierentorganisms
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 51 / 52
s inc
( )
i
Advances Applications
HMM in Bioinformatics
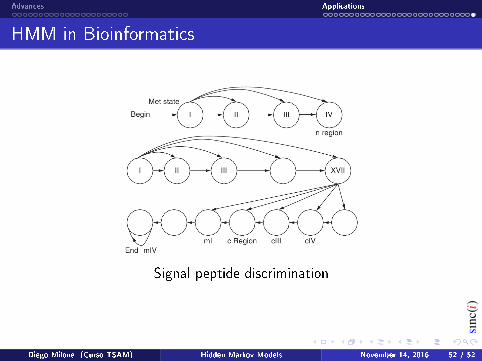
Signal peptide discrimination
Diego Milone (Curso TSAM) Hidden Markov Models November 14, 2016 52 / 52


















