
VGate: контроль доступа к виртуальным машинам и серверам виртуализации. Презентация участников

chars2word2vec:Рекуррентный словарь
Тагирджанов Азат
Шенбин Илья
Руководитель: Алексеев Антон

ЗадачиИсследовать устойчивость Word2Vec к удалению из словаря случайного набора слов.
Построить модель, “восстанавливающую” word2vec из посимвольного представления слова.
2 / 13

Устойчивость Word2VecХотим моделировать разбиение обучающей выборки на train и test:
● Обучаем модель 1 на полном корпусе● Заменяем в корпусе n% слов из словаря уникальными токенами● Обучаем модель 2 на прореженном корпусе● Сравниваем получившиеся модели по некоторой метрике
3 / 13

1. Изменение окрестности слова
Как изменяется множество top_n ближайших векторов для каждого вектора после удаления части слов?
4 / 13
множество 20 наиболее близких слов

● Берем вектор, соответствующий удаленному слову из исходной модели
● Вставляем его в прореженную модель● Сравниваем множества top_n
ближайших векторов в исходной и прореженной моделях
5 / 13
2. Изменение окрестности удаленного слова
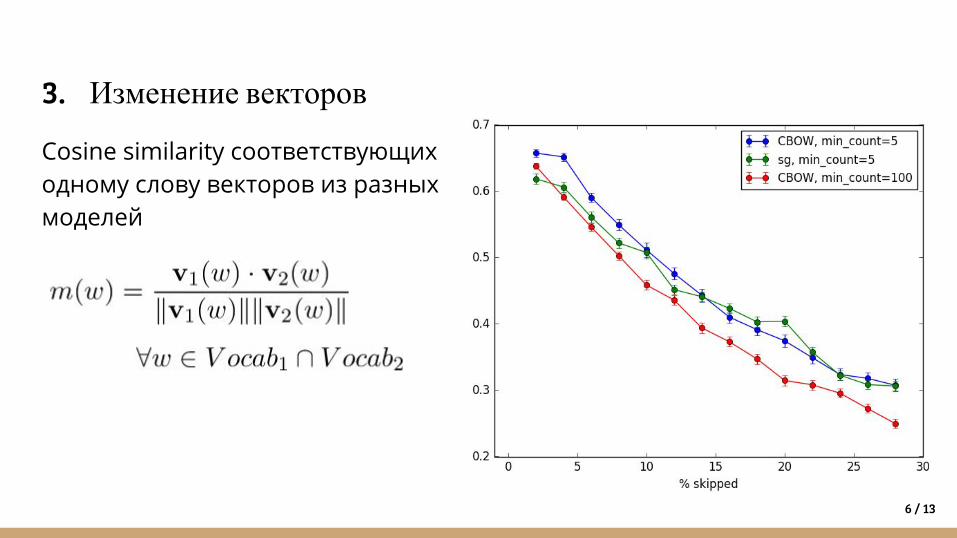
Cosine similarity соответствующих одному слову векторов из разных моделей
6 / 13
3. Изменение векторов

Архитектура сети● Вход: последовательность символов произвольной длины
Выход: соответствующий вектор из word2vec
● Первый слой: преобразование последовательности произвольной длины к вектору фиксированной размерности
○ LSTM / GRU○ CNN + Global maxpooling / weighted sum
● Полносвязные слои● Cosine proximity loss
7 / 13

Результаты базовой модели
8 / 13
красного петергургский иванова
огненногоплоскогомогучегоязыческогосеребряноготемногоживотворящеготалбандасвященногоблагодатногоморскогожелтогоионысинеговодного
канадскийпетербургскийстоличныйавстрийскийпрославленныйлитовскийбелорусскийобъединенныйалтайскийкиевскийнорвежскийастраханскийизраильскийбританскийфинский
власовасоловьевакарпенковоронцовагавриловалысенкозахаровалеоноваковаленкоосиповатихоновахаритоноваибрагимовамакароваандреева

Предобучение модели● Предлагается предсказывать, является ли пара слов похожими● Обучающая выборка состоит из пар слов с отрицательными или
положительными метками, генерируется следующим образом:○ (+) Для некоторого слова среди его топ-k берём наиболее посимвольно похожее○ (-) Для того же слова из k случайных слов из словаря выбираем посимвольно самое
похожее
● Расширение этой модели: по сгенерированному слову из положительного примера предсказываем word2vec
9 / 13

Предсказание кластеров● Для упрощения задачи предлагается предварительно выполнить
кластеризацию векторов● В качестве ответа будет использоваться центроид кластера,
предсказанного моделью
10 / 13

Результаты
11 / 13
top100 weighted top100
LSTM 0.0719 0.0136
CNN 0.0786 0.0066
LSTM + CNN 0.0874 0.0133
clusters 0.0331 0.0018
LSTM + clusters 0.0741 0.0130
CNN + clusters 0.0810 0.0067

Дальнейшие исследования● Использовать методы структурного машинного обучения● Сделать выход CNN/RNN-слоя разреженным● ...
12 / 13

Используемые технологии● Python● Keras (with TensorFlow backend)● Numpy● Sklearn● Gensim
● Github: https://github.com/ilya-shenbin/chars2word2vec
13 / 13


















