
Harnessing over a Million CPU Cores to Solve a Single...
29
Harnessing over a Million CPU Cores to Solve a Single Hard Mixed Integer Programming Problem on a Supercomputer Yuji Shinano Zuse Institute Berlin 1 06/07/2017 The 1st workshop on parallel constraint reasoning
Transcript of Harnessing over a Million CPU Cores to Solve a Single...

Harnessing over a Million CPU Cores to Solve a Single Hard Mixed Integer
Programming Problem on a Supercomputer
Yuji ShinanoZuse Institute Berlin
106/07/2017 The 1st workshop on parallel constraint reasoning

OutlineØ Background and Purpose
u State-of-the-art Mixed Integer Programming (MIP) solversu Parallelization of MIP solvers
ØUbiquity Generator (UG) framework and ParaSCIPØComputational results for solving previously unsolved MIP instances
on supercomputersØHow to harness over a million CPU coresØConcluding remarks
The 1st workshop on parallel constraint reasoning 2

Background and Purpose
The 1st workshop on parallel constraint reasoning 3
MIP (Mixed Integer Linear Programming)Ø minimizes or maximizes a linear functionØ is subject to linear constraintsØ has integer and continuous variables
The most general form of combinatorial optimization problemsMany applications
min{c
€x : Ax Æ b, l Æ x Æ u, xj œ Z, for all j œ I}
A œ Rm◊n, b œ Rm, c, l, u œ Rn, I ™ {1, . . . , n}

The 1st workshop on parallel constraint reasoning 4

Background and Purpose
The 1st workshop on parallel constraint reasoning 5
MIP (Mixed Integer Linear Programming)Ø minimizes or maximizes a linear functionØ is subject to linear constraintsØ has integer and continuous variables
The most general form of combinatorial optimization problemsMany applicationsMIP solvability has been improving
min{c
€x : Ax Æ b, l Æ x Æ u, xj œ Z, for all j œ I}
A œ Rm◊n, b œ Rm, c, l, u œ Rn, I ™ {1, . . . , n}

Progress in a state-of-the-art MIP solver
The 1st workshop on parallel constraint reasoning 6
Time limit:10000 sec.
Test set:3741 model
- 235 discarded due to inconsistent answers
- 934 discarded none of the version can solve
- speed-up measured on >100s bracket; 1205 models

Background and Purpose
The 1st workshop on parallel constraint reasoning 7
MIP (Mixed Integer Linear Programming)Ø minimizes or maximizes a linear functionØ is subject to linear constraintsØ has integer and continuous variables
The most general form of combinatorial optimization problemsMany applicationsMIP solvability has been improving
min{c
€x : Ax Æ b, l Æ x Æ u, xj œ Z, for all j œ I}
A œ Rm◊n, b œ Rm, c, l, u œ Rn, I ™ {1, . . . , n}
Development of a massively parallel MIP solver- can solve instances that cannot be solved by state-of-the-art MIP solvers- keeps catching up performance improvements of state-of-the-art MIP solvers
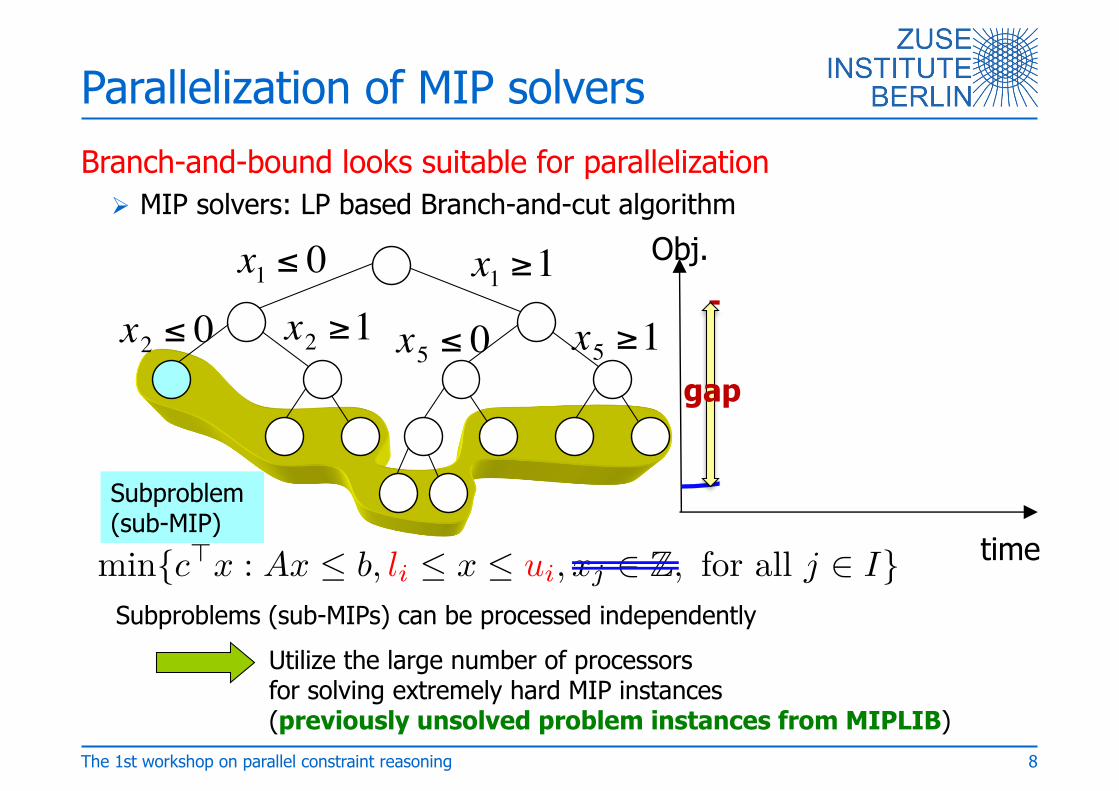
Parallelization of MIP solversBranch-and-bound looks suitable for parallelization
Ø MIP solvers: LP based Branch-and-cut algorithm
Subproblems (sub-MIPs) can be processed independentlyUtilize the large number of processors for solving extremely hard MIP instances(previously unsolved problem instances from MIPLIB)
€
x1 ≤ 0
€
x2 ≥1
€
x2 ≤ 0
€
x1 ≥1
€
x5 ≥1
€
x5 ≤ 0
Subproblem(sub-MIP)
8
min{c
€x : Ax Æ b, li Æ x Æ ui, xj œ Z, for all j œ I}
The 1st workshop on parallel constraint reasoning
time
Obj.
gap

Performance of state-of-the-art MIP Solvers
MIP solver benchmark (1 thread): Shifted geometric mean of results taken from the homepage of Hans Mittelmann (23/Mar/2014). Unsolved or failed instances are accounted for with the time limit of 1 hour.
Huge performancedifference!
9
As of14/April/2017
The 1st workshop on parallel constraint reasoning

Solving techniques involved in SCIP
The 1st workshop on parallel constraint reasoning 10
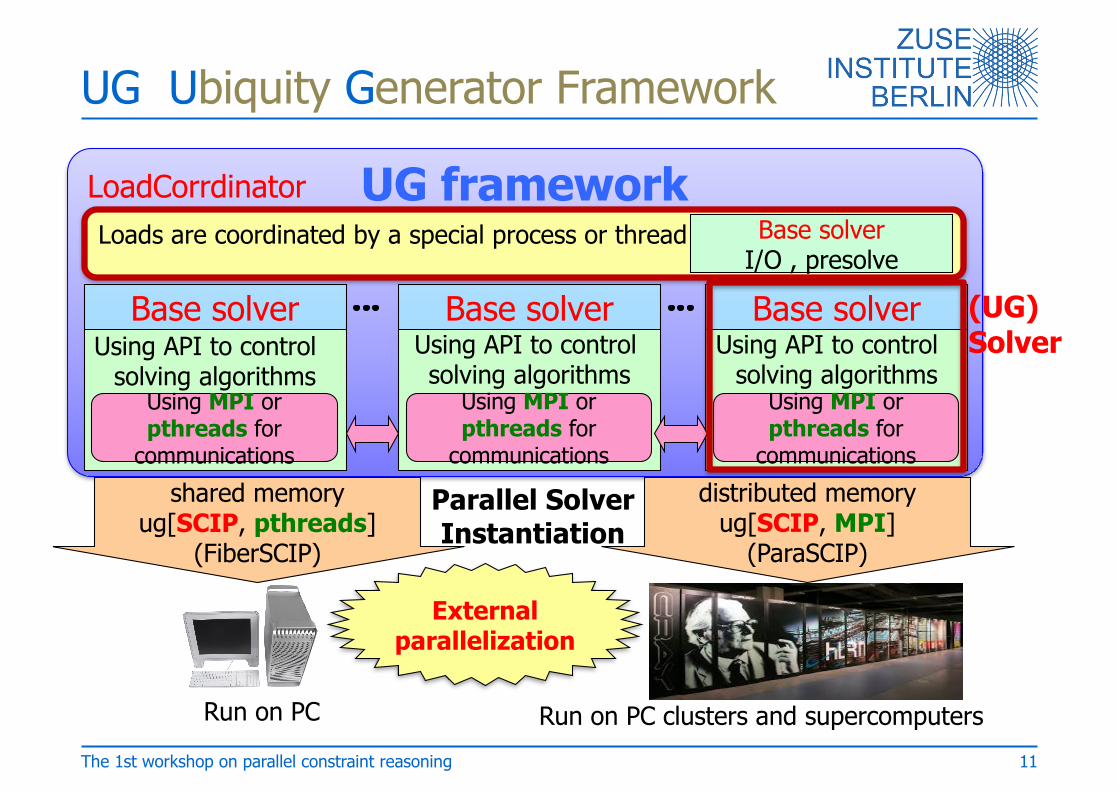
UG Ubiquity Generator Framework
UG framework
Using API to control solving algorithms
Using API to control solving algorithms
Using API to control solving algorithms
Base solver Base solver Base solver
Using MPI or pthreads for
communications
Using MPI or pthreads for
communications
Using MPI or pthreads for
communicationsshared memory
ug[SCIP, pthreads](FiberSCIP)
Loads are coordinated by a special process or thread Base solverI/O , presolve
distributed memoryug[SCIP, MPI]
(ParaSCIP)
Parallel SolverInstantiation
Run on PC clusters and supercomputersRun on PC
LoadCorrdinator
(UG)Solver
11
Externalparallelization
The 1st workshop on parallel constraint reasoning

Dynamic load balancing is neededp Highly unbalanced tree is generated
p Two types of irregularity can be handled well § Irregular # of nodes are generated by a sub-MIP
§ Irregular computing time for a node solving
1.5h0.001sec
1,297,605 Real observation for solving ds in parallel with 4095 solvers
1
12The 1st workshop on parallel constraint reasoning

GAMS and Condor: M.R.Bussieck and M.C.Ferris (2006)
13The 1st workshop on parallel constraint reasoning
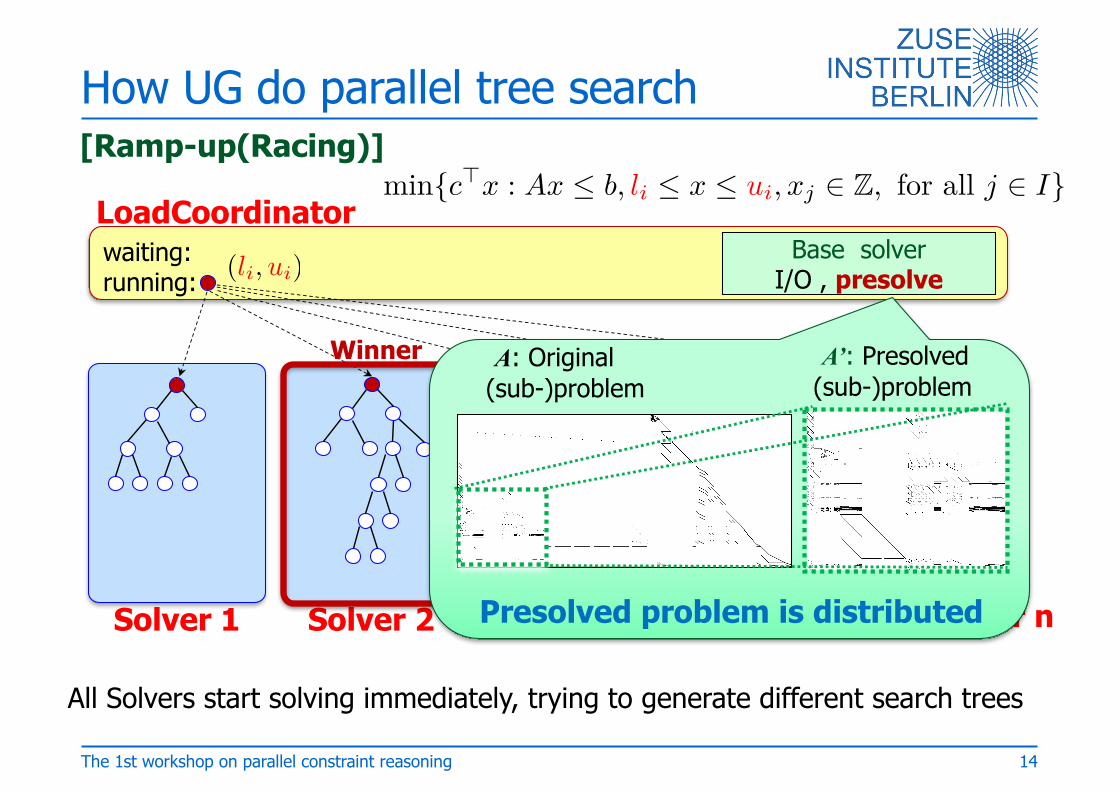
How UG do parallel tree search
waiting: running:
Base solverI/O , presolve
LoadCoordinator
Solver 1 Solver 2 Solver 3 Solver 4 Solver n
[Ramp-up(Racing)]
Winner
P
A: Original (sub-)problem
A’: Presolved(sub-)problem
All Solvers start solving immediately, trying to generate different search trees
14The 1st workshop on parallel constraint reasoning
min{c
€x : Ax Æ b, li Æ x Æ ui, xj œ Z, for all j œ I}
(li, ui)
Presolved problem is distributed

How UG do parallel tree search
waiting: running:
Base solverI/O , presolve
LoadCoordinator
Solver 1 Solver 2 Solver 3 Solver 4 Solver n
[Ramp-up(Racing)]
Winner
Winner is selected by taking into account dual bound, # nodes, etc.15The 1st workshop on parallel constraint reasoning

Dynamic load balancingLoadCoordinator
Solver 1
16The 1st workshop on parallel constraint reasoning
Solver 2 Solver 3 Solver 4 Solver 5 Solver n
Global view of tree search
- Send periodically and asynchronously- Interval is specified by a parameter
Notification message: best dual bound, # nodes remain, # nodes solved
Open nodes:p
Try to keep p open nodes in LoadCoordinator
LoadCoordinator makes selected Solvers in collecting mode
Expected to have heavy nodes:
large subtree underneath

Dynamic load balancingLoadCoordinator
Solver 1
17The 1st workshop on parallel constraint reasoning
1080
1100
1120
1140
1160
1180
1200
1220
1240
0 50 100 150 200 250 300 350 400
Obje
ctiv
e Fu
ncti
on V
alue
Computing Time (sec.)
"Incumbents""Optimal"
"GlobalLBs""Solver1"
"Solver10""Solver11""Solver12""Solver13""Solver14""Solver15""Solver16""Solver17""Solver18""Solver19"
"Solver2""Solver20""Solver21""Solver22""Solver23""Solver24""Solver25"
"Solver26""Solver27""Solver28""Solver29"
"Solver3""Solver30""Solver31""Solver32""Solver33""Solver34""Solver35""Solver36""Solver37""Solver38""Solver39"
"Solver4""Solver5""Solver6""Solver7""Solver8""Solver9"
Solver 2 Solver 3 Solver 4 Solver 5 Solver n
Open nodes:p
Solver which has best dual bound node
Collecting mode Solver
- Changes search strategy tobest dual bound first
- Sends requested number of nodes
p*mp

Why can it handle large scale?LoadCoordinator
Solver 1
18The 1st workshop on parallel constraint reasoning
1080
1100
1120
1140
1160
1180
1200
1220
1240
0 50 100 150 200 250 300 350 400
Obje
ctiv
e Fu
ncti
on V
alue
Computing Time (sec.)
"Incumbents""Optimal"
"GlobalLBs""Solver1"
"Solver10""Solver11""Solver12""Solver13""Solver14""Solver15""Solver16""Solver17""Solver18""Solver19"
"Solver2""Solver20""Solver21""Solver22""Solver23""Solver24""Solver25"
"Solver26""Solver27""Solver28""Solver29"
"Solver3""Solver30""Solver31""Solver32""Solver33""Solver34""Solver35""Solver36""Solver37""Solver38""Solver39"
"Solver4""Solver5""Solver6""Solver7""Solver8""Solver9"
Solver 2 Solver 3 Solver 4 Solver 5 Solver n
Open nodes:p
Solver which has best dual bound node
Collecting mode Solver
The # of solvers at a time is restricted
- The number is increased by at most 250 even if run with 80,000 Solvers
- Starts from 1- Dynamically switching

Layered presolving
The 1st workshop on parallel constraint reasoning
Global view of tree search
min{c
€x : Ax Æ b, li Æ x Æ ui, xj œ Z, for all j œ I}
A: Original (sub-)problem
A’: Presolved(sub-)problem
A’: Original (sub-)problem
A’’: Presolved(sub-)problem

Check pointing of UG
waiting: running:
Base solverI/O , presolve
LoadCoordinator
Solver 1 Solver 2 Solver 3 Solver 4 Solver n
n
p
Only essential root nodes of subproblems are savedIf a sub-tree has been solved, checkpoint file contains comp. statistics
20The 1st workshop on parallel constraint reasoning

Check pointing
The 1st workshop on parallel constraint reasoning
Only the essential nodes are saveddepending on run-time situation
21

Restarting
The 1st workshop on parallel constraint reasoning
Only the essential nodes are saveddepending on run-time situation
Huge trees might be thrown away,but the saved nodes’ dual bound values are calculated more precisely.
22

Main results for MIP solving by ParaSCIP
November 2015 triptim3 was solved with 864 cores in 9.5 hours December 2015 rmine10 was solved with 48 restarted jobs
23
Titan: Cray XK7, Opteron 6274 16C 2.2GHz, Cray Gemini interconnectISM: Fujitsu PRIMERGY RX200S5HLRN II: SGI Altix ICE 8200EX (Xeon QC E5472 3.0 GHz/X5570 2.93 GHz)HLRN III: Cray XC30 (Intel Xeon E5-2695v2 12C 2.400GHz, Aries interconnect)
The 1st workshop on parallel constraint reasoning

The biggest and the longest computationSolving rmine10: 48 restarted runs with 6,144 to 80,000 cores
The 1st workshop on parallel constraint reasoning 24
1
100
10000
1x106
1x108
1x1010
0 1x106 2x106 3x106 4x106 5x106 6x106 7x106 0 10000 20000 30000 40000 50000 60000 70000 80000 90000
Numb
er of
Node
s
Numb
er of
Active
Solve
rs + 1
Computing Time (sec.)
# nodes left# active solvers
# nodes in check-point file
-1916
-1915.5
-1915
-1914.5
-1914
-1913.5
-1913
-1912.5
-1912
0 1x106 2x106 3x106 4x106 5x106 6x106 7x106
Objec
tive F
uncti
on Va
lue
Computing Time (sec.)
IncumbentsGlobal LBs
How upper and lower bounds evolved
How open nodes and active solvers evolved
Titan with 80,000 coresThe others: HLRN III
It took about 75 days and 6,405 years of
CPU core hours!
UG can handle up to 80,000
MPI process

Combining with internal parallelizaion
The 1st workshop on parallel constraint reasoning 25
ug[Xpress,MPI] : ParaXpressu A powerful massively parallel MIP solver
u Can handle, hopefully efficiently, up to80,000 (MPI processes ) x 24 (threads) = 1,920,000 (cores)
Shared MemoryShared Memory
ParaXpressLoad-
Coordinator ProcessXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
Processing Element or Compute node
UG Solver processXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
UG Solver processXpress
threadthreadthreadthread
Processing Element or Compute node
Connection network
: CPU core

Solving open instances (ger50_17_trans)
The 1st workshop on parallel constraint reasoning 26
1
100
10000
1x106
1x108
1x1010
0 200000 400000 600000 800000 1x106 1.2x106 1.4x106 1.6x106 1.8x106 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
Numb
er of
Node
s
Numb
er of
Active
Solve
rs + 1
Computing Time (sec.)
# nodes left# active solvers
# nodes in check-point file
7300
7320
7340
7360
7380
7400
7420
0 200000 400000 600000 800000 1x106 1.2x106 1.4x106 1.6x106 1.8x106
Objec
tive F
uncti
on V
alue
Computing Time (sec.)
IncumbentsGlobal LBs
Depth first search
2 Xpress threads 4 Xpress threads
4 or 8 Xpressthreads
Using up to 43,344
on HLRN III(Cray XC30)
Rows: 499Cols: 22414Ints:18062

Combining with distributed MIP solver
The 1st workshop on parallel constraint reasoning 27
ug[PIPS-SBB,MPI]u PIPS-SBB: a specialized solver for two-stage Stochastic MIPs that
uses Branch & Bound to achieve finite convergence to optimality u Use PIPS-S: Backbone LP solver: PIPS-S (M. Lubin, et al. Parallel
distributed-memory simplex for large-scale stochastic LP problems, Computational Optimization and Applications, 2013.)
u One branch node is processed in parallel with distributed data structure
u 80,000 (MPI processes ) x 100 (PIPS-SBB MPI processes) = 8,000,000 (cores)
PIPS-SBB: Rank 0
PIPS-SBB: Rank 1
PIPS-SBB: Rank 2
PIPS-SBB: Rank 0
PIPS-SBB: Rank 1
PIPS-SBB: Rank 2
PIPS-SBB: Rank 0
PIPS-SBB: Rank 1
PIPS-SBB: Rank 2
Global incumbentsolution
LoadCoordinator: Rank 0
UG Solver 1:Rank 1
UG Solver 2:Rank 2
UG Solver 3:Rank 3
Red Rank: UG solver MPI rank

Run different solvers with different configurations in parallel UGS: UG synthesizer• Runs many different solvers in parallel
as MPMD(Multiple Program, Multiple Data) model MPI program
The 1st workshop on parallel constraint reasoning 28
UGS
Mediate solutionsharing
ugsXpressconfig1
ugsXpressconfig2
ugsGurobiconfig1
ugsCPLEXconfig1
ugsParaXpress
config1
ugsPAC_Xpress
config1: B&B solvers: Heuristic solvers
can be distributed memory solvers
…
The first job:Multiple ParaXpresses run with different configurations
with completely different solver implementations sharing incumbent solutions
The following jobs:Restarted from the most promising check pointing file

Concluding remarksØUG is a general framework to parallelize any kind of state-of-the-
art branch-and-bound based solversu ug[SCIP,*]
n Tool to develop parallel general branch-and-cut solvers.Customized SCIP solver can be parallelized with the least effort• ug[SCIP-Jack, *]: Solver for Steiner Tree Problems and its variants
- only the solver which can run on a distributed memory computing environment (solved three open benchmark instances)
u ug[Xpress, MPI]( = ParaXpress ), ug[PIPS-SBB, MPI]
ØUGS is another general framework to configure a parallel solver that can realize any combination of algorithm portfolio and racing
The 1st workshop on parallel constraint reasoning 29


















