Handbook of Blind Source Separation, Independent Component...
65
Handbook of Blind Source Separation, Independent Component Analysis and Applications P. Comon and C. Jutten Eds October 8, 2009
Transcript of Handbook of Blind Source Separation, Independent Component...

Handbook of Blind Source Separation,
Independent Component Analysis
and Applications
P. Comon and C. Jutten Eds
October 8, 2009

2

Glossary
x vector of components xp, 1 ≤ p ≤ Ps, x, y sources, observations, separator outputsN number of sourcesP number of sensorsT number of observed samples? convolutionA matrix with components Aij
A, B mixing and separation matricesG, W, Q global, whitening, and separating unitary matricesg Fourier transform of gs estimate of quantity spx probability density of xψ joint score functionϕi marginal score function of source si
Φ first characteristic functionΨ second characteristic functionEx, E{x} mathematical expectation of xI{y} or I(py) mutual information of yK{x;y} or K(px; py) Kullback divergence between px and py
H{x} or H(px) Shannon entropy xL likelihoodA, B mixing, and separating (non linear) operatorscum{x1, . . . , xP } joint cumulant of variables {x1, . . . , xP }cumR{y} marginal cumulant of order R of variable yQT transpositionQH conjugate transpositionQ∗
complex conjugationQ† pseudo-inverse
3

4
Υ contrast functionR real fieldC complex fieldA estimator of mixing matrixdiag A vector whose components are the diagonal of matrix ADiag a diagonal matrix whose entries are those of vector atraceA trace of matrix AdetA determinant of matrix Ameana arithmetic average of component of vector as(ν) Fourier transform of process s(t)⊗ Kronecker product between matrices⊗⊗⊗ tensor product•j contraction over index jkrank{A} Kruskal’s k-rank of matrix A

Contents
Glossary 3
1 Sparse Component Analysis 71.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Sparse signal representations . . . . . . . . . . . . . . . . . . . . 10
1.2.1 Basic principles of sparsity . . . . . . . . . . . . . . . . . 111.2.2 Dictionaries . . . . . . . . . . . . . . . . . . . . . . . . . . 121.2.3 Linear transforms . . . . . . . . . . . . . . . . . . . . . . 131.2.4 Adaptive representations . . . . . . . . . . . . . . . . . . 14
1.3 Joint sparse representation of mixtures . . . . . . . . . . . . . . . 141.3.1 Principle . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.3.2 Linear transforms . . . . . . . . . . . . . . . . . . . . . . 151.3.3 Principle of `τ minimization . . . . . . . . . . . . . . . . . 171.3.4 Bayesian interpretation of `τ criteria . . . . . . . . . . . . 181.3.5 Effect of the chosen `τ criterion . . . . . . . . . . . . . . . 191.3.6 Optimization algorithms for `τ criteria . . . . . . . . . . . 211.3.7 Matching pursuit . . . . . . . . . . . . . . . . . . . . . . . 251.3.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.4 Estimating the mixing matrix by clustering . . . . . . . . . . . . 271.4.1 Global clustering algorithms . . . . . . . . . . . . . . . . . 281.4.2 Scatter plot selection in multiscale representations . . . . 301.4.3 Use of local scatter plots in the time-frequency plane . . . 33
1.5 Relative Newton method for square matrices . . . . . . . . . . . 361.5.1 Relative Optimization framework . . . . . . . . . . . . . . 371.5.2 Newton Method . . . . . . . . . . . . . . . . . . . . . . . 381.5.3 Gradient and Hessian evaluation . . . . . . . . . . . . . . 391.5.4 Sequential Optimization . . . . . . . . . . . . . . . . . . . 401.5.5 Numerical Illustrations . . . . . . . . . . . . . . . . . . . . 401.5.6 Extension of Relative Newton: blind deconvolution . . . . 43
1.6 Separation with a known mixing matrix . . . . . . . . . . . . . . 431.6.1 Linear separation of (over-)determined mixtures . . . . . 441.6.2 Binary masking assuming a single active source . . . . . . 441.6.3 Binary masking assuming M < P active sources . . . . . 451.6.4 Local separation by `τ minimization . . . . . . . . . . . . 46
5

6 CONTENTS
1.6.5 Principle of global separation by `τ minimization . . . . . 461.6.6 Formal links with single-channel traditional sparse ap-
proximation . . . . . . . . . . . . . . . . . . . . . . . . . . 471.6.7 Global separation algorithms using `τ minimization . . . 481.6.8 Iterative global separation: demixing pursuit . . . . . . . 49
1.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 501.8 Outlook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 511.9 Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . . . . 54Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54

Chapter 1
Sparse Component Analysis
R. Gribonval and M. Zibulevsky
1.1 Introduction
Sparse decomposition techniques for signals and images underwent considerabledevelopment during the flourishing of wavelet-based compression and denoisingmethods [75] in the early 1990s. Some ten years elapsed before these techniquesbegan to be fully exploited for blind source separation [72, 106, 66, 70, 116, 61,15, 111]. Their main impact is that they provide a relatively simple frameworkfor separating a number of sources exceeding the number of observed mixtures.Also they greatly improve quality of separation in the case of square mixingmatrix.
The underlying assumption is essentially geometrical [98], differing consid-erably from the traditional assumption of independent sources [19]. This canbe illustrated using the simplified model of speech discussed by Van Hulle [106].One wishes to identify the mixing matrix and extract the sources based on theobserved mixture:
x(t) = As(t) + b(t), 1 ≤ t ≤ T (1.1)
For this purpose, one assumes that at each point t (variable designating atime instant for temporal signals, a pixel coordinate for images, etc.), a singlesource is significantly more active than the others. If Λn ⊂ {1, . . . , T} denotesthe set of points where the source with index n is most active (we will referto the temporal support of source n), then for all t ∈ Λn one has by definition|sn(t)| À |sm(t)| for m 6= n, and therefore:
x(t) ≈ sn(t)An, t ∈ Λn (1.2)
where An = (Apn)1≤p≤P is the (unknown) n-th column of the mixing matrix.It follows that the set of points {x(t) ∈ CP , t ∈ Λn} is more or less aligned
7

8 CHAPTER 1. SPARSE COMPONENT ANALYSIS
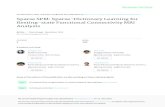
along the straight line passing through the origin and directed by vector An.As shown in Figure 1.1(a) for a stereophonic mixture (P = 2) of three audiosources (N = 3), this alignment can be observed in practice on the scatter plot{x(t) ∈ CP , 1 ≤ t ≤ T}. In this figure in dimension P = 2, the scatter plot isthe collection of points representing the pairs of values (x1(t), x2(t)) observedfor all T samples of the mixture signal.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−1
0
1
(a) Sources disjoint in time
t
s 1(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
s 2(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
s 3(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−1
0
1
(b) Musical sources
t
s 1(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
s 2(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
s 3(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−20
0
20
(c) MDCT of sources
k
c s 1(k)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−5
0
5
k
c s 2(k)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−20
0
20
k
c s 3(k)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−1
−0.5
0
0.5
1
Sources Mixture
t
x 1(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
x 2(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−1
−0.5
0
0.5
1
Sources Mixture
t
x 1(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−0.5
0
0.5
t
x 2(t)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−20
−10
0
10
20
MDCT of the sources mixture
k
c x 1(k)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 105
−20
−10
0
10
20
k
c x 2(k)
−0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
x1(t)
x 2(t)
Scatter plot
−0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
x1(t)
x 2(t)
Scatter plot
−20 −15 −10 −5 0 5 10 15 20−20
−15
−10
−5
0
5
10
15
20
cx
1
(k)
c x 2(k)
Scatter plot
Figure 1.1: “Geometric” principle of source separation by sparse decomposition.Sources (top), the corresponding mixtures (middle) and the resulting scatterplots (bottom). (a) – For sources with with disjoint temporal supports, the tem-poral scatter plot shows alignments along the columns of the mixing matrix. (b)– For more complex signals such as musical signals (centre), the temporal scatterplot is not legible. (c) – An appropriate orthogonal time-frequency transform(MDCT) applied to the same musical signals (right) results in a scatter plot inwhich the column directions of the mixing matrix are clearly visible.
It is thus conceivable to estimate the mixing matrix A using a clusteringalgorithm [110] – the scatter plot is separated into N clusters of points {x(t), t ∈Λn} – and to estimate the direction An of each cluster. If the mixture is (over)-determined (N ≤ P ), the sources can be estimated with the pseudo-inverse [47]of the estimated mixing matrix s(t) := A†x(t), but even in the case of an under-

1.1. INTRODUCTION 9
determined mixture (N > P ), by assuming the sources have disjoint supports,they can be estimated using least squares1 from the obtained clusters:
sn(t) :={〈x(t), An〉/‖An‖22 if t ∈ Λn,0 if not
Although simple and attractive, Van Hulle’s technique generally cannot beapplied in its original form, as illustrated in Figure 1.1(b), which shows the tem-poral scatter plot of a stereophonic mixture (P = 2) of N = 3 musical sources.It is clear that the sources cannot be considered to have disjoint temporal sup-ports, and the temporal scatter plot does not allow visually distinguishing thecolumn directions of the mixing matrix.
This is where sparse signal representations come into play. Figure 1.1(c)shows the coefficients csn(k) of an orthogonal time-frequency transform appliedto the sources (MDCT [87]), the coefficients cxp
(k) of the mixture, and finallythe time-frequency scatter plot of points (cx1(k), cx2(k)), 1 ≤ k ≤ T . On thetime-frequency scatter plot, one can once again observe the directions of columnsof the mixing matrix and apply the strategy described previously for estimatingA. The MDCT coefficients for the original sources on the same figure explainthis “miracle”: the coefficients of the MDCTs for the different sources have(almost) disjoint supports, given that for each source only a small number ofMDCT coefficients are of significant amplitude. The above-mentioned approachcan once again be used to estimate A and the coefficients of the time-frequencytransform applied to the sources. The sources themselves are estimated byapplying an inverse transform.
1
Mixture
x1(t)
x2(t)
xp(t)
Joint sparserepresentation
cx1(k)
cx2(k)
cxp(k)
Scatter plot
Mixing matrix
estimation
A
Separation in thetransformed domain
cs1(k)
cs2(k)
csN(k)
Reconstruction
s1(t)
s2(t)
sN(t)
Sources
Figure 1.2: Block diagram of sparsity-based source separation methods
Diagram 1.2 shows the structure of sparsity-based source separation meth-ods, for which we have just introduced the main ingredients:
1The notation 〈·, ·〉 is used for the scalar product between two vectors, e.g. for col-
umn vectors 〈x(t), An〉 := x(t)AHn =
∑Pp=1 xp(t)A
∗pn and for row vectors 〈sn, sn′ 〉 =∑T
t=1 sn(t)s∗n′ (t).

10 CHAPTER 1. SPARSE COMPONENT ANALYSIS
1. A step for changing the representation of the observed mixture, to makethe supports of the source coefficients in the new representation as disjointas possible. For this purpose, joint sparse representation techniques areused.
2. The column directions of the mixing matrix are estimated using the mix-ture representation. In addition to classical ICA algorithms, clusteringalgorithms can be applied to the scatter plot.
3. Finally, estimating the (sparse) source representations makes it possibleto reconstruct the sources.
Chapter outlineThe rest of this chapter provides a detailed discussion of the main approachesfor each step of sparse separation. Sparse signal representation and dictionariesare introduced in Section 1.2 with relevant examples. The formalism and mainalgorithms for calculating joint sparse representations of mixtures x(t) are de-scribed in Section 1.3, which concludes by reviewing the main characteristics,advantages and disadvantages of these algorithms, the scope of which extendswell beyond source separation. Section 1.4 examines actually using the spar-sity of joint mixture representations for the second step of source separation,in which the mixing matrix is estimated from scatter plots, while Section 1.5discusses the Relative Newton framework for the special case of a square mixingmatrix. Finally, Section 1.6 focuses on the algorithms for the actual separationstep in the “transform” domain, to estimate the sources once the mixing matrixhas been estimated. The possible choices for the different steps of sparse sourceseparation are summarized in Section 1.7, which also discusses the factors thatmay determine these choices. To conclude, in Section 1.8 we assess the newdirections and challenges opened up by sparse source separation, such as usingnew diversity factors between sources, blind estimation of suitable dictionariesand separation of under-determined convolutive mixtures.
1.2 Sparse signal representations
The basic assumption underlying all sparse source separation methods is thateach source can be (approximately) represented by a linear combination of fewelementary signals ϕk, known as atoms2 that are often assumed to be of unitenergy. Specifically it is assumed that each (unknown) source signal can bewritten:
s(t) =K∑
k=1
c(k) ϕk(t) (1.3)
2Although the notations ϕ (or ψ) and Φ (or Ψ) are used elsewhere in this book to denotethe marginal score functions (or the joint score function) of the sources and the first (orsecond) characteristic function, they will be used in this chapter to denote atoms with regardto signal synthesis and analysis and the corresponding dictionaries/matrices.

1.2. SPARSE SIGNAL REPRESENTATIONS 11
where only few entries c(k) of the vector c are significant, most of them beingnegligible. In the case of Van Hulle’s simplified speech model [106], the con-sidered atoms are simply Dirac functions, ϕk(t) = δ(t − k), i.e. time samples.Many audio signal processing applications involve the short-term Fourier trans-form (STFT, also called Gabor transform or spectrogram) [75] where the indexk = (n, f) denotes a time-frequency point, c(k) is the value of the STFT appliedto the signal s at this point, and (1.3) corresponds to the reconstruction formulafor s based on its STFT using the overlap-add (OLA) method [89]. It is possibleto use other families of atoms known as dictionaries, which are better suited torepresenting a given type of signal. In our context, the sparseness of a signal’srepresentation in a dictionary determines the dictionary’s relevance.
1.2.1 Basic principles of sparsity
Informally, a set of coefficients c(k) is considered sparse if most of the coefficientsare zero or very small and only a few of them are significant. In statistical (orprobabilistic) terms, coefficients c(k) are said to have a sparse or super-Gaussiandistribution if their histogram (or probability density) has a strong peak at theorigin with heavy tails, as shown in Figure 1.3.
−20 −15 −10 −5 0 5 10 15 200
10
20
30
40
c
Figure 1.3: Histogram of MDCT coefficients of the first source in the mixtureof musical signals in Figure 1.1(c)
The most common model of sparse distribution is the family of generalizedGaussian distributions:
pc(c) ∝ exp(−α |c|τ ) (1.4)
for 0 < τ ≤ 1, where the τ = 1 case corresponds to the Laplace distribution.Certain Bayesian source separation techniques that assume sparsity use Student-t distributions to exploit their analytical expression in terms of the GaussianMixture Model [40]. For the same reasons, the bi-Gaussian model, where oneGaussian distribution has low variance and the other high variance, is oftenused as well [30].

12 CHAPTER 1. SPARSE COMPONENT ANALYSIS
For the generalized Gaussian model, the set of coefficients c = {c(k)}Kk=1,
assumed statistically independent, has a distribution of pc(c) ∝ exp(−α‖c‖ττ )
where ‖c‖τ denotes the `τ “norm”3:
‖c‖τ :=
(K∑
k=1
|c(k)|τ)1/τ
(1.5)
The likelihood of a set of coefficients thus increases as its `τ norm decreases.The norm ‖c‖τ
τ can then be used to quantify the sparsity of a representation c,which is the approach taken in the rest of this chapter.
1.2.2 Dictionaries
In general, one considers complete dictionaries, that is to say dictionaries thatallow the reconstruction of any signal s ∈ CT ; in other words, the space gener-ated by the atoms of the dictionary is CT in its entirety. Limiting the approachpresented in this chapter to the case of real signals poses no particular prob-lems. With Φ denoting the K × T matrix whose K rows consist of atomsϕk(t), 1 ≤ t ≤ T , k = 1, . . . K, the sparse model (1.3) of sources can be writtenin matrix form4:
s = cs ·Φ (1.6)
where cs = (cs(k))Kk=1 is a row vector of K coefficients.
If the selected dictionary is a basis, K = T and a one-to-one correspondenceexists between the source signal s and its coefficients cs = s ·Φ−1 (cs = s ·ΦH
for an orthonormal basis). This is the case for a dictionary corresponding to anorthogonal basis of discrete wavelets, or the orthogonal discrete Fourier basis[75], or a MDCT (Modified Discrete Cosine Transform [87]) type basis.
By contrast, if the dictionary is redundant (K > T ), there is an infinitenumber of possible coefficient sets for reconstructing each source. This is thecase for a Gabor dictionary, comprising atoms expressed as:
ϕn,f (t) = w(t− nT ) exp(2jπft) (1.7)
– where w is called an analysis window – and used to compute the STFT of asignal as STFTs(n, f) = 〈s, ϕn,f 〉. The construction and study of redundantdictionaries for sparse signal representation is based on the idea that, amongthe infinitely many possibilities, one can choose a representation particularlywell suited to a given task.
3Strictly speaking, this is a norm only for 1 ≤ τ ≤ ∞, with the usual modification ‖c‖∞ =supk |c(k)|. We will also use the term “norm”, albeit improperly, for 0 < τ < 1. For τ = 0,with the convention c0 = 1 if c > 0 and 00 = 0, the `0 norm is the number of non-zerocoefficients of c.
4With the usual source separation notation, the mixing matrix A acts to the left on thematrix of source signals s, which is why the dictionary matrix Φ must act to the right on thecoefficients cs for signal synthesis. This notation will be used throughout this chapter.

1.2. SPARSE SIGNAL REPRESENTATIONS 13
Since the early 1990s, building dictionaries has been the focus of severalharmonic analysis studies, still being pursued today. This has led to the con-struction of several wavelet families as well as libraries of orthogonal waveletpacket bases or local trigonometric functions [75] and other more sophisticatedconstructions (curvelets, etc. [95]) too numerous to cite here. Sparse coding[41, 70, 69, 1] is closer to the source separation problem and also aims at thelearning of a dictionary (redundant or non-redundant) maximizing the sparserepresentation of a training data set.
1.2.3 Linear transforms
In a given dictionary Φ, the traditional approach for calculating a representationof s consists of calculating a linear transform:
cΨs := s ·Ψ, (1.8)
and the calculated coefficients are thus the values of the correlations
cΨs (k) = 〈s, ψk〉 (1.9)
of s with a set of dual atoms ψk(t), which form the columns of the matrix Ψ.One can thus consider the atoms ϕk(t) as related to signal synthesis, as opposedto the atoms related to signal analysis ψk(t).
For the transformation of a signal s (analysis, (1.8)), followed by its recon-struction (synthesis, (1.6)), the transform must satisfy s · ΨΦ = s for everysignal s to result in perfect reconstruction, i.e. ΨΦ = I (I is the identity ma-trix, here T ×T in size). For example, in the case of a Gabor dictionary (1.7), aset of dual atoms compatible with the reconstruction condition (1.8) takes theform:
ψn,f (t) = w′(t− nT ) exp(2jπft), (1.10)
where the analysis window w′(t) and the reconstruction window w(t) must sat-isfy the condition
∑n w′(t−nT )w(t−nT ) = 1 for every t. Therefore, analysing
a signal with the analysis atoms ψn,f is akin to calculating its STFT with thewindow w′, whereas reconstruction with the synthesis atoms ϕn,f correspondsto overlap-add reconstruction based on the STFT [89].
When the dictionary Φ is a basis for the signal space, as is the discreteorthonormal Fourier basis, or a bi-orthogonal wavelet basis [75], the only trans-form Ψ allowing perfect reconstruction is Ψ = Φ−1 (a fast Fourier transformor a fast wavelet transform correspondingly).
For these types of non-redundant dictionaries that correspond to “criticallysampled” transforms, the relation ΦΨ = I also holds; that is, synthesis of asignal based on a representation cs, followed by analysis of the signal, makes itpossible to find the exact coefficients used. This does not hold true in the caseof redundant linear transforms, such as the STFT or the continuous wavelettransform.
In the case of any redundant dictionary, there is an infinite number of “dual”matrices Ψ that satisfy the reconstruction condition ΨΦ = I, but none satisfy

14 CHAPTER 1. SPARSE COMPONENT ANALYSIS
the identity ΦΨ = I. The pseudo-inverse [47] Ψ = Φ† = (ΦHΦ)−1ΦH of Φoffers a specific choice of linear transform, providing the least squares solutionto the representation problem s = csΦ:
cֆ
s = arg mincs|csΦ=s
K∑
k=1
|cs(k)|2 . (1.11)
1.2.4 Adaptive representations
The reason for using a redundant dictionary is to find a particularly sparserepresentation from among the infinite possibilities for a given signal. Thedictionary’s redundancy is aimed at offering a broad range of atoms likely torepresent the typical signal structures in a suitable way, so that the signal canbe approximated by a linear combination of a small, carefully selected atom setfrom the dictionary.
Paradoxically, the more redundant the dictionary, the higher the numberof non-zero coefficients in a representation obtained by a linear transform.Thus, for the STFT associated with a Gabor dictionary, redundancy increaseswith overlap between adjacent windows (which increases the number of analysisframes) and with zero-padding (which increases the number of discrete analysisfrequencies), but since a given atom’s “neighbouring” atoms in time-frequencyare highly correlated to it, the number of non-negligible coefficients observedduring analysis of a Gabor atom (1.7) also increases with the transform’s re-dundancy.
To fully leverage the potential of redundant dictionaries and obtain truelysparse signal representation, linear transforms must be replaced by adaptivetechniques. The principle of these techniques, which emerged in the 1990s, is toselect a limited subset Λ of atoms from the dictionary based on the analysed sig-nal. Consequently, only the selected atoms are assigned a non-zero coefficient,resulting in a sparse representation or a sparse approximation of the signal. Themain techniques to obtain adaptive signal representation are described in thefollowing section, in the slightly more general context of joint sparse represen-tation of mixtures, which is the first step in sparse source separation.
1.3 Joint sparse representation of mixtures
The first step in a system of sparse source separation (see Figure 1.2) consists incalculating a joint sparse representation of the observed mixture x, to obtain arepresentation that facilitates both the estimation of the mixing matrix and thatof the sources by clustering algorithms. While this type of representation canbe obtained with linear transforms (STFT, wavelet transforms, etc.), greatersparsity may be achieved by using algorithms for joint adaptive decompositionof the mixture.

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 15
1.3.1 Principle
An approximate sparse representation of a mixture x takes the form x ≈ CxΦ,where:
Cx =
cx1
. . .cxP
=
[Cx(1) . . . Cx(K)
](1.12)
is a matrix of dimensions P × K in which each row cxpis a row vector of K
coefficients cxp(k) representing one of the P channels of the mixture. CalculatingCx for a mixture x ≈ As is aimed at reducing the problem to a separationproblem Cx ≈ ACs, which is expected to be easier to solve if Cs is sparse.
By combining the sparse model of sources (see (1.3) or (1.6)) with the noisyinstantaneous linear mixture model (1.1), one obtains a global sparse model ofthe mixture:
x = ACsΦ + b, where Cs =
cs1
. . .csN
=
[Cs(1) . . . Cs(K)
]
(1.13)is an N × K matrix in which each row csn is a sparse vector consisting of Kcoefficients csn(k) representing one of the N sources, and each column Cs(k),1 ≤ k ≤ K, indicates the degree of “activity” of the different sources for agiven atom. If a representation Cs of the sources exists where they have disjointsupports (each atom only activated for one source at most), then Cx := ACs isan admissible (approximate) representation of the (noisy) mixture x and shouldenable its separation via the scatter plot.
When Φ is an orthonormal basis such as the MDCT, a unique representationexists for the mixture (and the sources) and can thus be calculated simply byinverse linear transform, necessarily satisfying Cx ≈ ACs. We saw an exampleof this with the musical sources, where the scatter plot of the columns of therepresentation Cx obtained by linear transform with an orthonormal MDCT-type basis Φ clearly highlighted the column directions of the mixing matrix (seeFigure 1.1(c)), making it possible to pursue the separation. By contrast, whenΦ is a redundant dictionary, the calculated representation Cx depends on thechosen algorithm and does not necessarily satisfy the identity Cx ≈ ACs, whichis crucial for the subsequent steps of sparse separation.
Selecting a relevant joint sparse approximation algorithm for the mixturethus depends on the algorithm’s ability to provide a representation that satis-fies the approximation Cx ≈ ACs with sufficient accuracy, provided the sourcesallow a representation Cs with sufficiently disjoint supports. This importantpoint will be discussed for each of the joint sparse mixture approximation algo-rithms described in this section together with their main properties.
1.3.2 Linear transforms
The simplest joint representation of a mixture involves applying the same lineartransform (e.g. STFT) to all channels. Formally, by juxtaposing the transforms

16 CHAPTER 1. SPARSE COMPONENT ANALYSIS
cΨxp:= xpΨ of each of the mixture components xp, 1 ≤ p ≤ P , one obtains a
matrix:CΨ
x := xΨ (1.14)
called the transform of mixture x. Its numerical calculation is particularlysimple but, as discussed above, this type of transform does not necessarily takefull advantage of the dictionary’s redundancy to obtain representations withhigh sparseness.
Algorithms
The linear transforms Ψ applied to a mixture are often associated with fast algo-rithms: Fourier transform, STFT, orthogonal wavelet transform, etc. Anotherpossibility [29] is that the dictionary Φ consists in the union of a certain num-ber of orthonormal bases associated with fast transforms (wavelet, local cosine,etc.), Φ = [Φ1 . . .ΦJ ], in which case the pseudo-inverse Φ† = J−1ΦH providesa dual transform Ψ := Φ† that is simple and quick to apply by calculating eachof the component fast transforms and concatenating the coefficients obtained.It is also possible to simultaneously calculate two STFTs for the same mixture,one with a small analysis window and the other with a large window, to obtaina sort of multi-window transform [82].
Properties and limitations
By the linearity of the transform, the initial source separation problem (1.1) hasan exact analogue in the transform domain (see (1.8) and (1.14)):
CΨx = ACΨ
s + CΨb . (1.15)
Separation in the transform domain, to estimate the source transforms Cs
based on Cx and ultimately reconstruct s := CsΦ, is thus relevant if the supportsof the sources in the transform domain CΨ
s are reasonably disjoint.Despite the advantages of a simple, efficient numerical implementation,
transforms are far from ideal in terms of sparse representation when the dictio-nary is redundant. In particular, the least squares representation Cֆ
x := xֆ
is generally not as sparse as representations minimizing other criteria more ap-propriate to sparsity, such as `τ criteria, with 0 ≤ τ ≤ 1. This is why adaptiveapproaches based on minimizing the `τ norm where 0 ≤ τ ≤ 1 have elicited in-tense interest since the early 1990s [48, 23], in a context extending well beyondthat of source separation [83, 43, 90, 29, 96]. Most early efforts have focused onadaptive methods for sparse representation of a given signal or image; interestin equivalent methods for joint representation of several signals has developedsubsequently [49, 68, 50, 27, 104, 102, 57]. We will discuss joint representationbelow, first in the general case of `τ criteria where 0 ≤ τ ≤ ∞. We will thenlook more specifically at the corresponding algorithms for values of τ ≤ 2 whichcan be used to obtain sparse representations.

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 17
1.3.3 Principle of `τ minimization
Rather than using linear transforms, joint sparse representations can be definedthat minimize an `τ criterion, for 0 ≤ τ ≤ ∞. Before defining them in detail, wewill review the definition of the corresponding “single-channel” sparse represen-tations: among all the admissible representations of a signal x1 (i.e. satisfyingx1 = cx1Φ), the representation cτ
x1with the smallest `τ norm is selected, which
amounts to selecting the most likely representation in terms of an assumedgeneralized Gaussian distribution of the coefficients (1.4).
In the multi-channel case, the optimized criterion takes the form:
Cτx := arg min
Cx|CxΦ=x
K∑
k=1
(P∑
p=1
∣∣cxp(k)∣∣2
)τ/2
(1.16)
for 0 < τ < ∞, with an obvious modification for τ = ∞. For τ = 0, with theconvention c0 = 1 if c > 0 and 00 = 0, the `0 norm affecting the criteria (1.16)is the number of non-zero columns Cx(k), i.e. the number of atoms used in therepresentation. Minimizing the `0 norm is simply a means of representing themixture with as few atoms as possible, which intuitively corresponds to lookingfor a sparse representation.
This particular form of the optimized criterion defines a representation of xthat actually takes into account the joint properties of the different channels xp,in contrast to a criterion such as
∑k
∑p
∣∣cxp
∣∣τ , which may be more intuitivebut decouples optimization over the different channels. In Section 1.3.4, we willexamine a Bayesian interpretation explaining the form taken by the criterion(1.16).
Due to the intrinsic noise b of the mixing model (1.1) and the possibleinaccuracy of the sparse source model (1.6), it is often more useful to look for anapproximate sparse representation – also known as a joint sparse approximation– via the optimization of the criterion:
Cτ,λx := arg min
Cx
‖x− CxΦ‖2F + λ
K∑
k=1
(P∑
p=1
∣∣cxp(k)∣∣2
)τ/2 (1.17)
where ‖y‖2F :=∑
pt |yp(t)|2 is the Frobenius norm of the y matrix, i.e. the sumof the energies of its rows. The first term of the criterion is a data fidelity termthat uses least squares to measure the quality of the approximation obtained.The second term measures the “joint” sparsity of the multi-channel represen-tation Cx, relative to the criterion (1.16), and the λ parameter determines therespective importance attributed to the quality of the approximation and tosparsity. When λ tends to zero, the obtained solution, Cτ,λ
x , approaches Cτx ;
when λ is sufficiently large, Cτ,λx tends to zero.

18 CHAPTER 1. SPARSE COMPONENT ANALYSIS
1.3.4 Bayesian interpretation of `τ criteria
The specific form of the `τ criterion used to select a multi-channel joint represen-tation (1.16)-(1.17), which couples the selection of coefficients for the differentchannels, is not chosen arbitrarily. The following paragraphs aim to provide anoverview of its derivation in a Bayesian context. Readers more interested in thealgorithmic and practical aspects can skip to Section 1.3.6.
Whether an adaptive or transform approach is used, a Bayesian interpreta-tion is possible for optimizing the criteria in (1.11), (1.16) or (1.17): (1.11) cor-responds to calculating the most likely coefficients for reconstructing x = CxΦunder the assumption of an i.i.d. Gaussian distribution pCx(·) with variance σ2
x.Under this assumption, the distribution of Cx is expressed (see equation (1.4)for τ = 2):
pCx(Cx) ∝ exp(−‖Cx‖2F
2σ2x
)= exp
(−
∑Kk=1 ‖Cx(k)‖22
2σ2x
)(1.18)
In the specific context of source separation, the distribution pCx(Cx) ofCx = ACs depends on the distribution pCs(Cs) of the source coefficients Cs
and on the distribution pA(A) of the mixing matrix. In the absence of priorknowledge of the mixing matrix, for blind separation its distribution is natu-rally assumed invariant by arbitrary spatial rotations, i.e. pA(A) = pA(UA)for any unitary matrix U. This is the case if the columns An are normalized‖An‖2 = 1, independent and uniformly distributed over the unit sphere of CP .This assumption alone implies that the prior distribution of the coefficients Cx
of the noiseless mixture for any atom k is radial; that is, for any unitary matrixU:
p(Cx(k)) = p(UCx(k)) = rk (‖Cx(k)‖2) (1.19)
where rk(·) ≥ 0 is a function of the distributions pCs(k)(Cs(k)) and pA(A).If the coefficients Cs(k) are i.i.d. for different k, then the form of the prior
distribution of Cx can be deduced:
p(Cx) =K∏
k=1
r (‖Cx(k)‖2) . (1.20)
A maximum likelihood (ML) approach makes it possible to define a decom-position of the noiseless mixture as:
Crx := arg max
Cx|CxΦ=xp(Cx) = arg min
Cx|CxΦ=x
K∑
k=1
− log r (‖Cx(k)‖2) . (1.21)
In the noisy case, assuming the noise b is i.i.d. Gaussian of variance σ2b,
a maximum a posteriori (MAP) approach maximizes the posterior probability,i.e. it minimizes:
− log p(Cx|x) =1
2σ2b
‖x− CxΦ‖2F +K∑
k=1
− log r(‖Cx(k)‖2). (1.22)

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 19
The function r, which in theory can be calculated from the distributionspA(A) of the mixing matrix and pc(c) of the sparse source coefficients, is some-times difficult to use in solving the corresponding optimization problem. Sincethe distributions on which this function depends are not necessarily well un-derstood themselves, it is reasonable to solve the global optimization prob-lem (1.21) or (1.22) with an assumed specific form of the r function, such asr(z) := exp(−α |z|τ ) for an exponent 0 ≤ τ ≤ 2, similar to the adaptive ap-proaches (1.16)-(1.17).
1.3.5 Effect of the chosen `τ criterion
The choice of the `τ norm is important a priori, since it can considerably in-fluence the sparsity of the resulting solution. Figure 1.4 illustrates this pointschematically. Figures 1.4(a)-(b)-(c) show, in dimension 2, the contour linesof `τ norms for τ = 2, τ = 1 and τ = 0.5. In Figure 1.4(d), a continuousline represents the set of admissible representations (CxΦ = x) of a mixture x,which forms an affine sub-space of the space RK of all possible representations.The least `τ norm representation of x is the intersection of this line with the“smaller” contour line of the `τ norm that intersects it. These intersections havebeen indicated for τ = 2, τ = 1 and τ = 0 (for τ = 0 the intersections are withthe axes). One can see that none of the coordinates of the least squares solution(τ = 2) is non-zero, whereas the least `0 or `1 norm solutions are situated alongthe axes. Here, the least `1 norm solution, which is unique, also coincides withthe least `τ norm solutions for 0 < τ ≤ 1. Geometrically, this is explained bythe fact that the contour lines of the `τ norms, for 0 < τ ≤ 1 have “corners” onthe axes, in contrast to the contour lines of the `2 norm (and of the `τ normsfor 1 < τ ≤ 2), which are convex and rounded.
As a result, in the single-channel context, any representation Cτx ∈ RK (or
Cτ,λx ) that solves the optimization problem (1.16) (or (1.17)) for 0 ≤ τ ≤ 1,
is truly sparse insofar as it has no more than T non-zero coefficients, where Tis the dimension of the analysed signal x ∈ RT 5. This property is due to the“concavity“ of the `τ norm [64] for 0 ≤ τ ≤ 1, as shown in Figure 1.4(c). We willrefer to this property repeatedly throughout this chapter, for the multi-channelcase as well. It can be defined as follows:
Definition 1.1 The representation Cτx (or Cτ,λ
x ) is a truly sparse represen-tation if it implies no more than T atoms of the dictionary (where T is thedimension of the signals), i.e. if there are no more than T indices k wherebythe column Cx(k) is non-zero.
This definition is given here in the multi-channel case, but it generalizes anequivalent idea initially proposed for the single-channel case by Kreutz-Delgadoet al. [64].
5Here, the fact that we are considering real-valued signals and coefficients seems to beimportant, since examples with complex coefficients show that the `τ minimizer can be non”truly sparse” [108].

20 CHAPTER 1. SPARSE COMPONENT ANALYSIS
(a) contour line: l2 norm
cX
1
c X2
−20 −15 −10 −5 0 5 10 15 20−20
−15
−10
−5
0
5
10
15
20
(b) contour line: l1 norm
cX
1
c X2
−20 −15 −10 −5 0 5 10 15 20−20
−15
−10
−5
0
5
10
15
20(c) contour line: l1/2 norm
cX
1
c X2
−20 −15 −10 −5 0 5 10 15 20−20
−15
−10
−5
0
5
10
15
20
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
Set of all the solutions of x=CX Φ
least l2 norm solution
least l1 norm and least l0 norm solutions
least l0 norm solution
Figure 1.4: (a)-(b)-(c): contour lines of `τ norms for τ = 2, 1, 1/2. (d) Schematiccomparison of the sparsity of representations obtained using least squares (nonadaptive linear transform) and low-dimensional `1 or `0 norm minimization(adaptive representations). The continuous line symbolizes all the possible rep-resentations Cx = (cx1 , cx2) of a given mixture x. The intersection of this linewith the circle centred on the origin which is tangent to it provides the leastsquares solution. Its intersections with the x-axis (“+” symbol) and the y-axis(“x” symbol) correspond to two solutions with a unique non-zero coefficient,and thus a minimal `0 norm. The y-axis solution is also the unique intersectionbetween all the possible representations and the smallest “oblique” square cen-tred on the origin (dotted line) that intersects it, making it the least `1 normsolution as well. One can see that the least squares solution has more non-zerocoefficients than the least `0 or `1 norm solutions.

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 21
For τ > 1, since `τ is a real norm in the mathematical sense of the term,it is convex, and its minimization does not lead to truly sparse representations,as shown in Figure 1.4(a). However, the convexity of the corresponding criteriagreatly facilitates their optimization and can favour their practical use.
Intense theoretical work, initiated by the results of Donoho and Huo [33],has shown in the single-channel case that the specific choice of the `τ normoptimized with 0 ≤ τ ≤ 1 has little (or no) influence on the representationobtained [55, 54, 52] when the analysed signal x is adequately approximatedwith sufficiently sparse coefficients Cx. Similar results for the multi-channel case[102] show that, when the same assumptions are made, the `0 and `1 criteriaessentially lead to the same representations. Extending these results to the `τ
criteria, 0 ≤ τ ≤ 1, will undoubtedly point to the same conclusion.In light of these theoretical results, the choice of a specific `τ criterion to
optimize for 0 ≤ τ ≤ 1 depends primarily on the characteristics of the algorithmsavailable for optimization and their numerical properties. The description ofoptimization algorithms for the slightly broader range of 0 ≤ τ ≤ 2 is thesubject of the following section.
1.3.6 Optimization algorithms for `τ criteria
Adaptive representation algorithms that optimize a criterion (1.17) or (1.16) for0 ≤ τ ≤ 2 have received a great deal of attention, with regard to theoreticalanalysis as well as algorithms and applications.
For τ = 2, both (1.16) and (1.17) can be solved with simple linear alge-bra, but for τ = 0, the problem is a combinatorial one [31, 78] and a prioriuntractable. A body of theoretical work initiated by Donoho and Huo [33] sug-gests that its solution is often equal or similar to that of the correspondingproblems with 0 < τ ≤ 1 [55]. The algorithms able to optimize these criteriaare of particular interest, despite the specific difficulties of the non-convex op-timization of τ < 1, and in particular the risk of obtaining a local optimum.Finally, the algorithms for optimizing strictly convex `τ criteria with 1 < τ ≤ 2offer the advantage of simplicity, even though the theoretical elements linkingthe representations they provide to those obtained with `τ criteria for 0 ≤ τ ≤ 1are currently lacking. Their main advantage, owing to the strict convexity of theoptimized criterion, is the guaranteed convergence to the unique global optimumof the criterion.
For all the algorithms presented below, selecting an order of magnitude forthe regularization parameter λ is also a complex issue in blind mode. An ex-cessively high value for this parameter will over-emphasize the sparsity of theobtained representation Cτ,λ
x , compromising the quality of the reconstruction‖x−Cτ,λ
x Φ‖2. An excessively low value will amount to assuming that the sparsesource model is accurate and the mixture is noiseless, which could result in arte-facts. The selection of parameters τ and λ, which define the optimized criterion,should thus represent a compromise between the sparsity of the representationand the numerical complexity of the minimization. In typical applications, λwould be chosen to obtain a reconstruction error of the order of the noise, if the

22 CHAPTER 1. SPARSE COMPONENT ANALYSIS
magnitude of the latter is known.
Algorithm for τ = 2: regularized least squares
For τ = 2, the exact representation C2x solves the least squares problem
min ‖Cx‖2F under the constraint CxΦ = x and is obtained analytically by lineartransform, using the pseudo-inverse of the dictionary, i.e. C2
x = Cֆx = xֆ.
As shown in Figure 1.4, C2x is generally not a “truly sparse” representation.
The approximate representations C2,λx , which solve the regularized least squares
problem min ‖x − CxΦ‖2F + λ‖Cx‖2F for λ > 0, are also obtained linearly asC2,λ
x = xΨλ, where Ψλ has two equivalent expressions:
Ψλ := (ΦHΦ + λIT )−1ΦH = ΦH(ΦΦH + λIK)−1 (1.23)
with IM as the M × M identity matrix. When λ tends to zero, Ψλ tends tothe pseudo-inverse Φ† of the dictionary, and for any λ value the linearity of therepresentation guarantees that C2,λ
x = AC2,λs + C2,λ
b .
Algorithm for 0 < τ ≤ 2: M-FOCUSS
For 0 < τ ≤ 2 the M-FOCUSS algorithm [27] (an iterative reweighted leastsquares or IRLS algorithm) and its regularized version are iterative techniquesthat converge extremely quickly towards a local minimum of the criterion tobe optimized. This algorithm is derived from the FOCUSS algorithm initiallydefined for the single-channel case [48]. Given the non-convexity of the opti-mized criterion, it is difficult to predict whether the global optimum is reached,which in any case depends on the chosen initialization. It has not yet beendemonstrated (except in the P = 1 single-channel case) that the algorithm al-ways converges on a “truly sparse“ solution, although this is indeed the caseexperimentally [27]. Starting with an initialization C
(0)x , the value of which can
have a decisive impact on the algorithm’s point of convergence, a weighted meansquare criterion is minimized iteratively:
C(m)x := arg min
Cx
{‖x− CxΦ‖2F +
λ |τ |2‖Cx(W (m))−1‖2F
}(1.24)
where the diagonal weighting matrix:
W (m) := diag(‖C(m−1)
x (1)‖1−τ/22 , . . . , ‖C(m−1)
x (K)‖1−τ/22
)(1.25)
tends to drive to zero those columns whose energy ‖C(m−1)x (k)‖2 is low. In
practice, as we saw in Section 1.3.6, each iteration thus involves updating thediagonal weighting matrix W (m) and the weighted dictionary Φ(m) := W (m)Φto obtain:
C(m)x := x
((Φ(m))
HΦ(m) +
λ |τ |2
IT
)−1
(Φ(m))H
W (m). (1.26)

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 23
While the M-FOCUSS algorithm converges very rapidly towards a local mini-mum of the optimized criterion [27] and often produces very sparse represen-tations, it is difficult to determine when convergence to the global minimum isreached, depending on the chosen initialization. The initialization most oftenused, and which in practice gives satisfactory results, is the least squares repre-sentation, obtained using the pseudo-inverse Φ† of the dictionary. Even if thenumber of iterations necessary before convergence is low, each iteration can bequite costly numerically because of the inversion of a square matrix of size atleast T which is required, cf. (1.26).
Because the algorithm is globally non-linear, it is difficult a priori to de-termine whether its representation Cx of the mixture satisfies the identityCx ≈ ACs with reasonable accuracy. Theoretical results [52, 102] on optimiza-tion criteria similar to (1.17) suggest this to be true when the representations ofthe sources are sufficiently sparse and disjoint, but actual proof is still lackingfor the optimum Cτ,λ
x of the criterion (1.17), and for the approximate numericalsolution limm→∞ C
(m)x calculated with M-FOCUSS.
Algorithms for τ = 1 (single-channel case)
Optimizing (1.16) in the single-channel case (P = 1) for τ = 1 is known as BasisPursuit and optimizing (1.17) is known as Basis Pursuit Denoising [23]. Pro-posed by Donoho and his colleagues, Basis Pursuit and Basis Pursuit Denoisingare closer to principles than actual algorithms, since the optimization method isnot necessarily specified. Several experimental studies and the intense theoret-ical work initiated by Donoho and Huo [33] have shown the relevance of sparserepresentations obtained using the `1 criterion; for example, they guarantee theidentity Cx ≈ ACs when Cs is sufficiently sparse [102].
However, the generic numerical optimization methods of linear programming,quadratic programming, conic programming, etc. [12] for calculating them (inboth the real and complex cases and the single-channel and multi-channel cases)are often computationally costly. In order to reduce computations, TruncatedNewton strategy was used by [23] in the framework of Primal-Dual InteriorPoint method. Algorithms such as LARS (Least Angle Regression) [35] thattake more specific account of the optimization problem [105, 35, 74, 85, 45] areable to further simplify and accelerate the calculations. The next challenge isto adapt these efficient algorithms to the multi-channel case.
Algorithms for 1 ≤ τ ≤ 2: iterative thresholding (single-channel case)
For the values 1 ≤ τ ≤ 2, the criterion to optimize (1.17) is convex. Effi-cient iterative numerical methods were proposed [28, 36, 42] for calculating theoptimum cλ,τ
x , for the P = 1 single-channel case. Starting with an arbitraryinitialization c
(0)x (typically c
(0)x = 0), the principle is to iterate the following
thresholding step:
c(m)x (k) = Sλ,τ
(c(m−1)x (k) + 〈x− c(m−1)
x Φ, ϕk〉)
, 1 ≤ k ≤ K (1.27)

24 CHAPTER 1. SPARSE COMPONENT ANALYSIS
where Sλ,τ is a thresholding function, plotted in Figure 1.5 for λ = 1 and a fewvalues of 1 ≤ τ ≤ 2.
−1.5 −1 −0.5 0 0.5 1 1.5
−1
−0.5
0
0.5
1
Thresholding function for some values of τ
t
Sλ,
τ(t)
τ=2τ=1τ=0.5
Figure 1.5: Curves of the thresholding function Sλ,τ (t) over the interval t ∈[−1.5, 1.5] for λ = 1 and a few values of τ
For τ = 1, the soft thresholding function is used:
Sλ,1(t) :=
t + λ2 , if t ≤ −λ
2
0, if |t| < λ2
t− λ2 , if t ≥ λ
2
(1.28)
whereas for τ > 1:
Sλ,τ (t) := u, where u satisfies u +λ · τ
2· sign(u) · |u|τ−1 = t. (1.29)
This thresholding function comes from the optimization of criterion (1.17)when Φ is an orthonormal basis (recall that iterative thresholding is defined forthe P = 1 single-channel case), because each coordinate must then be optimizedindependently:
minc(k)
|〈x, ϕk〉 − c(k)|2 + λ |c(k)|τ
When the value of the optimum cλ,τx (k) is non-zero, the derivative of the
optimized criterion exists and cancels outs, which implies:
2(cλ,τx (k)− 〈x, ϕk〉) + λ · sign(cλ,τ
x (k)) · ∣∣cλ,τx (k)
∣∣τ−1= 0
that is, according to the expression of the thresholding function (1.29):
cλ,τx (k) = Sλ,τ (〈x, ϕk〉).
For 1 ≤ τ ≤ 2, Daubechies, DeFrise and De Mol proved [28, theorem 3.1] thatif the dictionary satisfies ‖Φc‖22 ≤ ‖c‖22 for all c, then c(m) converges stronglyto a minimizer cλ,τ
x of (1.17), regardless of the initialization. If Φ is also a basis

1.3. JOINT SPARSE REPRESENTATION OF MIXTURES 25
(not necessarily orthonormal), this minimizer is unique, and the same is true bystrict convexity if τ > 1. However, this minimizer is generally a “truly sparse”solution only for τ = 1. In addition, when the dictionary consists of atoms ofunit energy, then at best ‖Φc‖22 ≤ µ‖c‖22 for a certain number µ < ∞. Thealgorithm must then be slightly modified to ensure convergence, by iteratingthe thresholding step below:
c(m)x (k) = Sλ
µ ,τ
(c(m−1)x (k) +
〈x− c(m−1)x Φ, ϕk〉
µ
). (1.30)
While there is currently no known complexity analysis of this algorithm, itoften takes few iterations to obtain an excellent approximation of the solution.Additional significant acceleration can be achieved via sequential optimizationover subspaces spanned by the current thresholding direction and directions offew previous steps (SESOP) [37]. Many algorithmic variants exist and the ap-proach is intimately related to the notion of proximal algorithm. Each iterationis relatively low-cost given that matrix inversion is not necessary, unlike for thealgorithm M-FOCUSS which has been examined previously. These threshold-ing algorithms can be extended to the multi-channel case [44]. To use themfor sparse source separation, it remains to be verified whether they guaranteeapproximate identification Cx ≈ ACs.
1.3.7 Matching pursuit
Matching Pursuit proposes a solution to the problem of joint sparse approxima-tion x ≈ CxΦ not through the global optimization of a criterion, but through aniterative greedy algorithm . Each step of the algorithm involves finding the atomin the dictionary that, when added to the set of already selected atoms, will re-duce the approximation error to the largest extent. We assume here that theatoms in the dictionary are of unit energy. To approximate the multi-channelsignal x, a residual r(0) := x is initialized, then the following steps are repeated,starting at m = 1:
1. Selection of most correlated atom:
km := arg maxk
P∑p=1
|〈r(m−1)p , ϕk〉|2 (1.31)
2. Updating of residual:
r(m)p := r(m−1)
p − 〈r(m−1)p , ϕkm〉ϕkm , 1 ≤ p ≤ P. (1.32)
After M iterations, one obtains the decomposition:
x =M∑
m=1
c1(m)ϕkm
. . .cP (m)ϕkm
+ r(M) (1.33)

26 CHAPTER 1. SPARSE COMPONENT ANALYSIS
with cp(m) := 〈r(m−1)p , ϕkm
〉.This algorithm was initially introduced for single-channel processing by Mal-
lat and Zhang [76]. The generalization to the multi-channel case [49, 50, 27, 68]that we present here converges in the same manner as the original single-channelversion [49, 50] in that the residual norm tends to zero as the number of itera-tions tends to infinity. In contrast, the convergence rate, whether single-channelor multi-channel, is not fully understood [68]. In one of the variants of this al-gorithm, the residuals can be updated at each step by orthogonal projectionof the analysed signal on the linear span all the selected atoms (referred to asorthogonal matching pursuit). It is also possible to select the best atom at eachstep according to other criteria [68, 27, 104], or to select several atoms at atime [79, 14].
The matching pursuit presented here, which involves no matrix inversion, canbe implemented quite rapidly by using the structure of the dictionary and fastalgorithms for calculating and updating r(m)ΦH [53, 65]. The main parameteris the choice of the stopping criterion; the two main approaches set either thenumber of iterations or the targeted approximation error ‖r(m)‖F beforehand.A typical choice is to stop when the residual error is of the order of magnitudeof the noise level, if the latter is known.
Like the approaches based on `1 norm minimization [102], matching pursuithas been been the subject of several experimental and theoretical studies, whichhave shown [104] that it can guarantee the identity Cx ≈ ACs when Cs issufficiently sparse [56].
1.3.8 Summary
Table 1.1 summarizes the main numerical characteristics of the algorithms forjoint sparse signal representation presented in this section. Their field of appli-cation extends far beyond source separation, since the need to jointly representseveral signals exists in a number of areas. For example, colour images con-sist of three channels (red-green-blue) whose intensities are correlated, and theuse of joint sparse representation techniques (based on matching pursuit [43])has proven effective for low-bit rate image compression. Readers interestedin further details on these algorithms will find their original definitions in thebibliographic references and, in some cases, an analysis of certain theoreticalproperties that have been proven.
In practice, the joint sparse representation of a mixture implies two choices:
1. Selection of a dictionary Φ in which the mixture channels are likely toallow a sufficiently sparse joint representation;
2. Selection of an algorithm and its parameters for calculating a representa-tion.
For example, for audio signals, the Gabor dictionary (1.7) is often used totake account of the frequency components that may appear at different timesin the mixture, and the representation most often used is the STFT, a linear

1.4. ESTIMATING THE MIXING MATRIX BY CLUSTERING 27
Method Transform M-FOCUSS Basis Pursuit Iterative Matchingthresholding Pursuit
Criterion (1.17) (1.17) (1.17) (1.17) (1.31)-(1.32)Parameters τ = 2 0 ≤ τ ≤ 2 τ = 1 1 ≤ τ ≤ 2 M iterations
λ λ λ λ
Advantages -very fast -high -high -fast -fastsparsity (τ ≤ 1) sparsity -good -good
sparsity sparsityIssues -choice of λ -choice of λ -choice of λ -choice of λ -choice of Mand -limited -initialization -memory costdifficulties sparsity -memory cost -computing
-computing time time (linear,(inversion of quadratic,large matrices) conic progr.)
ReferencesP = 1 [48] [23] [28] [76]
[55] [33] [101][52] [103] [58]
P > 1 [27] [102] [44] [49][104]
Table 1.1: Comparative summary of algorithms for joint sparse mixture repre-sentation discussed in Section 1.3
transform. While we have attempted in this section to present useful informationfor selecting an algorithm, selecting the dictionary currently mostly depends onexpert knowledge of the analysed signals in most cases. One can also learn adictionary automatically from a set of signal realizations [70, 71, 80, 4, 92].
1.4 Estimating the mixing matrix by clustering
The algorithms discussed above can be used to analyze a mixture x in order tocalculate a joint sparse representation (or approximation) Cx, which is the firststep in a source separation system based on sparsity, as described in Figure 1.2.The second step of this system, for separating instantaneous linear mixtures,consists in estimating the mixing matrix A by means of the scatter plot of thecoefficients {Cx(k)}1≤k≤K .
For determined mixtures, it is of course possible to use any ICA method toestimate A, which means that the other techniques described in this book canbe employed as well. Here we concentrate on approaches specifically based onthe assumed sparsity of the sources.
The two main classes of approaches used make assumptions about the spar-sity of the sources but not about the type of mixture, i.e. determined or unde-termined. The first approach, based on Bayesian (or variational) interpretation,aims to maximize the likelihood of the estimated matrix and involves (approx-imate) optimization of the global criteria; the second is more geometric andrelies on clustering algorithms.

28 CHAPTER 1. SPARSE COMPONENT ANALYSIS
Variational approaches
Variational approaches [70, 115] generally involve joint iterative optimization ofthe matrix and the source representations. This task is very challenging compu-tationally, and the quality of solution may suffer from the presence of spuriouslocal minima. However, in the case of square mixing matrix, the problem isreduced to the optimization with respect to unmixing matrix only, which canbe treated efficiently the Relative Newton method [112, 112] as described in theSection 1.5.
Geometric approach: clustering from scatter plots
The geometric approach is very intuitive and capable of estimating the numberof sources [8]. In addition, certain clustering algorithm variants do not make thestrong sparsity assumption in order to estimate the mixing matrix using simplealgorithms, even when the source representations are almost non-disjoint [2, 8].
Most of the approaches presented below are applicable in theory, regardlessof the number of sensors P ≥ 2 [107, 98, 2, 8]. However, we will only explainthese approaches where P = 2, corresponding for example to stereophonic audiomixtures, because the geometric intuitiveness is simpler and more natural insuch cases. Since generalizing to the P ≥ 3 case poses no particular conceptualproblems, we leave this to the reader. However, the computing requirementsbecome excessive for certain methods, particularly those based on calculatinghistograms.
1.4.1 Global clustering algorithms
Figure 1.6(a), an enlargement of Figure 1.1(c), shows a typical scatter plot of thecoefficients {Cx(k)} ⊂ R2 for a stereophonic mixture (P = 2). Alignments of
−20 −15 −10 −5 0 5 10 15 20−20
−15
−10
−5
0
5
10
15
20
cx
1
(k)
c x 2(k)
(a) Scatter plot in Cartesian coordinates
θρ
0 0.5 1 1.50
2
4
6
8
10
12
14
16
18
Direction θDis
tanc
e fr
om th
e or
igin
e ρ
(b) Scatter plot in Polar coordinates
Figure 1.6: Scatter plot of MDCT coefficients for the mixture on the right ofFigure 1.1, with Cartesian coordinates (a) and polar coordinates (b). Accumu-lations of points, shown as dotted lines, are observed along the directions of thecolumns of the mixing matrix.

1.4. ESTIMATING THE MIXING MATRIX BY CLUSTERING 29
points are observed along the straight lines generated by the columns An of themixing matrix. In this example, each point Cx(k) = ρ(k) · [cos θ(k), sin θ(k)]T ∈R2 can also be shown with polar coordinates:
{ρ(k) := (−1)ε
√|cx1(k)|2 + |cx2(k)|2,
θ(k) := arctan(cx2(k)/cx1(k)) + επ,(1.34)
where ε ∈ {0, 1} is selected such that 0 ≤ θ(k) < π, as shown in Figure 1.6(b).The points then accumulate around the angles θn corresponding to the directionsof the columns An. A natural idea [100, 15] is to exploit the specific geometricstructure of the scatter plot in order to find the directions θn, making it possibleto estimate An := [cos θn sin θn]T .
Raw histogram
A naive approach consists of calculating a histogram of θ(k) angles, assumingthe accumulation of points corresponding to the directions of interest will resultin visible peaks. The resulting raw histogram, shown in Figure 1.7(a) andbased on points from Figure 1.6(b), does make it possible to see (and detectby thresholding) one of the directions of interest, but trying to find the otherdirections with it would be futile.
The scatter plot often contains a number of points of low amplitude ρ(k),whose direction θ(k) is not representative of the column directions of the mixingmatrix. These points, which correspond to the numerous atoms (time-frequencypoints in this example) where all the sources are approximately inactive, havea “flattening” effect on the histogram of directions, making it unsuitable fordetecting the direction of the sources.
Weighted histograms
A weighted histogram can be calculated in a more efficient manner, and may besmoothed with “potential functions”, also called Parzen windows. The weight-ing aims to obtain a histogram that depends on the small number of pointswith large amplitude rather than the majority of points with negligible ampli-tude. The following function is calculated (for a set of discrete angles on a gridθ` = `π/L, 0 ≤ ` ≤ L):
H(θ`) :=K∑
k=1
f(|ρ(k)|) · w(θ` − θ(k)) (1.35)
where f(ρ) is a weighting function that gives a different role to the scatterplot points depending on their distance from the origin |ρ(k)|, and w(·) is asmoothing window, also known as a potential function [15] or Parzen window.
Figure 1.7(b) illustrates the histogram thus obtained with a rectangularsmoothing window of size π/L (corresponding to a non-smoothed histogram)and respectively f(|ρ|) = |ρ|. Taking account of ρ to weight the histogram

30 CHAPTER 1. SPARSE COMPONENT ANALYSIS
proves to be critical in this example for the success of histogram-based tech-niques, since it highlights peaks in the histogram close to angles correspondingto the actual directions of the sources in the mixture. Weighting according tothe distance from the origin |ρ(k)| is more satisfactory here than using a rawhistogram, because it more effectively highlights these peaks. Other forms ofweighting are possible [111], but no theoretical or experimental comparativestudies were found examining the effect of the chosen smoothing window andweighting function on the quality of the estimation of A.
0 0.5 1 1.50
1000
2000
3000
4000
5000
6000
Direction θ
raw histogram
0 0.5 1 1.50
200
400
600
800
1000
1200
Direction θ
histogram weighted by |ρ|
Figure 1.7: Histograms based on the scatter plot with polar coordinates inFigure 1.6(b): (a) raw histogram measuring the frequencies of occurrence ata given θ angle; (b) histogram weighted by the distance from the origin |ρ|.Weighting based on distance from the origin results in strong peaks close to thedirections of the actual sources (indicated by dotted lines) whereas only onepeak is visible on the raw histogram.
1.4.2 Scatter plot selection in multiscale representations
In many cases, especially in wavelet-related decompositions, there are distinctgroups of coefficients, in which sources have different sparsity properties. Theidea is to select those groups of features (coefficients) which are best suited forseparation, with respect to the following criteria: (1) sparsity of coefficients (2)separability of sources’ features [117, 114, 62]. After the best groups are selected,one uses only these in the separation process, which can be accomplished by anyICA method, including the Relative Newton method (in case of square mixingmatrix), or by clustering.
1.4.2.1 Motivating example: random blocks in the Haar basis
Typical block functions are shown in Figure 1.8. They are piecewise constant,with random amplitude and duration of each constant piece. Let us take aclose look at the Haar wavelet coefficients at different resolutions. Wavelet

1.4. ESTIMATING THE MIXING MATRIX BY CLUSTERING 31
Sources Sensors (mixtures)
0 50 100 150 200 250 300 350 400 450 500−2
−1
0
1
2
3
0 50 100 150 200 250 300 350 400 450 500−2
−1
0
1
2
0 50 100 150 200 250 300 350 400 450 500−3
−2
−1
0
1
2
3
0 50 100 150 200 250 300 350 400 450 500−2
−1
0
1
2
Figure 1.8: Time plots of block signals
Raw All wavelet Hi resolutionsignals coefficients wavelet coefficients
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
−6 −4 −2 0 2 4 6−6
−4
−2
0
2
4
6
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
BS-Infomax 13.9% 4.2% 0.69%C-means clustering 13.3% 2.4% 0.41%
Figure 1.9: Separation of block signals: scatter plots of sensor signals and mean-squared separation errors (%)
basis functions at the finest resolution are obtained by translation of the Haarmother wavelet:
ϕj(t) =
−1 if t = 0
1 if t = 10 otherwise .
(1.36)
Taking a scalar product of a function s(t) with the wavelet ϕj(t − τ), oneproduces a finite differentiation of the function s(t) at the point t = τ . Thismeans that the number of non-zero coefficients at the finest resolution for a blockfunction will correspond roughly to the number of jumps it has. Proceeding tothe next, coarser resolution level
ϕj−1(t) =
−1 if t = −1,−2
1 if t = 0, 10 otherwise
(1.37)
the number of non-zero coefficients still corresponds to the number of jumps,but the total number of coefficients at this level is halved , and so is the sparsity.If we proceed further in this direction, we will achieve levels of resolution, wherethe typical width of a wavelet ϕj(t) is comparable to the typical distance betweenjumps in the function s(t). In this case, most of the coefficients are expected tobe nonzero, and, therefore, sparsity will fade-out.
To demonstrate how this influences the accuracy of blind source separation,two block-signal sources were randomly generated (Fig 1.8, left), and mixed by

32 CHAPTER 1. SPARSE COMPONENT ANALYSIS
the matrix
A =(
0.8321 0.6247−0.5547 0.7809
)(1.38)
The resulting mixtures, x1(t) and x2(t) are shown in Figure 1.8, right. Fig-ure 1.9, first column, shows the scatter plot of x1(t) versus x2(t), where thereare no visible distinct features. In contrast, the scatter plot of the wavelet coef-ficients at the highest resolution (Figure 1.9, third column) shows two distinctorientations, which correspond to the columns of the mixing matrix.
Results of separation of the block sources are presented in Figure 1.9. Thelargest error (13%) was obtained on the raw data, and the smallest (below 0.7%)– on the wavelet coefficients at the highest resolution, which have the best spar-sity. Use of all wavelet coefficients leads to intermediate sparsity and perfor-mance.
1.4.2.2 Adaptive wavelet packet selection
Multiresolution analysis. Our choice of a particular wavelet basis and of thesparsest subset of coefficients was obvious in the above example: it was basedon knowledge of the structure of piecewise constant signals. For sources havingoscillatory components (like sounds or images with textures), other systems ofbasis functions, for example, wavelet packets [26], or multiwavelets [109], mightbe more appropriate. The wavelet packets library consists of the triple-indexedfamily of functions:
ϕjnk(t) = 2j/2ϕn(2jt− k), j, k ∈ Z, n ∈ N. (1.39)
As in the case of the wavelet transform, j, k are the scale and shift parameters,respectively, and n is the frequency parameter, related to the number of oscil-lations of a particular generating function ϕn(t). The set of functions ϕjn(t)forms a (j, n) wavelet packet. This set of functions can be split into two parts ata coarser scale: ϕj−1,2n(t) and ϕj−1,2n+1(t). It follows that these two form anorthonormal basis of the subspace which spans {ϕjn(t)}. Thus, one arrives at afamily of wavelet packet functions on a binary tree (Figure 1.10). The nodes ofthis tree are numbered by two indices: the depth of the level j = 0, 1, .., J , andthe number of nodes n = 0, 1, 2, 3, ..., 2j–1 at the specified level. Using waveletpackets allows one to analyze given signals not only with a scale-oriented de-composition but also on frequency sub-bands. Naturally, the library containsthe wavelet basis.
The decomposition coefficients cjnk = 〈s, ϕjnk〉 also split into (j, n) setscorresponding to the nodes of the tree, and there is a fast way to compute themusing banks of conjugate mirror filters, as is implemented in the fast wavelettransform.
Choice of the best nodes in the tree. A typical example of scatter plotsof the wavelet packet coefficients at different nodes of the wavelet packet treeis shown in Figure 1.11 (frequency-modulated signals were used as a sources.)

1.4. ESTIMATING THE MIXING MATRIX BY CLUSTERING 33
(0,0)
(1,0) (1,1)
(2,0) (2,1) (2,2) (2,3)
(3,0) (3,1) (3,2) (3,3) (3,4) (3,5) (3,6) (3,7)
Figure 1.10: Wavelet packets tree
The upper left scatter plot, labeled “C”, corresponds to the set of coefficients atall nodes. The reminder are the scatter plots of sets of coefficients indexed in awavelet packet tree above. Generally speaking, the more distinct the directionsappearing on these plots, the more precise the estimation of the mixing matrix,and, therefore, the better the separation.
It is difficult to decide in advance which nodes contain the sparsest sets ofcoefficients. That is why one can use the following simple adaptive approach.
First, apply a clustering algorithm for every node of the tree and compute ameasure of clusters’ distortion (for example, the mean squared distance of datapoints to the centers of their own clusters. Here again, the weights of the datapoints can be incorporated. Second, choose a few best nodes with the minimaldistortion, combine their coefficients into one data set, and apply a separationalgorithm to these data.
More sophisticated techniques dealing with adaptive choice of best nodes, aswell as their number can be found in [63, 62].
1.4.3 Use of local scatter plots in the time-frequency plane
Despite the visible presence of alignments along the mixing matrix columnsin the global scatter plot, the most traditional clustering algorithms such asK-means [110] can prove difficult to use for estimating the matrix. While aK-means algorithm is particularly simple to implement, the results depend onproper initialization and correctly determining beforehand the number of sourcespresent. Using the global scatter plot is even more difficult when the mixedsources contribute with very diverse intensities to the mixture, or when theirrepresentations are not sufficiently disjoint, as when several musical instrumentsplay in time and in harmony, thereby producing simultaneous activity at certaintimes and frequencies.
Figure 1.12 illustrates this phenomenon, showing the time-frequency repre-sentations (MDCT) of each channel of a stereophonic mixture, as well as thelocal scatter plots {Cx(k)}k∈Λ where Λ corresponds to a subset of time-frequency

34 CHAPTER 1. SPARSE COMPONENT ANALYSIS
C C00 C10 C11
−4 −3 −2 −1 0 1 2 3 4
−4
−3
−2
−1
0
1
2
3
4
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
C20 C21 C22 C23
−4 −3 −2 −1 0 1 2 3 4−4
−3
−2
−1
0
1
2
3
4
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
−4 −3 −2 −1 0 1 2 3 4
−4
−3
−2
−1
0
1
2
3
4
C30 C31 C32 C33
−4 −3 −2 −1 0 1 2 3 4
−4
−3
−2
−1
0
1
2
3
4
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
C34 C35 C36 C37
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
−4 −3 −2 −1 0 1 2 3 4−4
−3
−2
−1
0
1
2
3
4
Figure 1.11: Scatter plots of the WP coefficients of the FM mixtures
atoms close to a central time and frequency. In the first local scatter plot, onecannot see any distinct alignment along a column of the underlying mixing ma-trix. In the second plot, on the contrary all the points are distinctly alignedaround a single mixture direction, that of the source whose activity is dominantthroughout the corresponding time-frequency zone. The direction of this sourcecan thus be identified using the local scatter plot.
If this type of zone can be detected, A can be estimated, which is theprinciple of the methods proposed by Deville et al. [3, 38, 2, 88]: the varianceof the ratio cx1(k)/cx2(k) is calculated for each region considered, then regionswith lower variance are selected to estimate the corresponding column directionsof A. A similar approach, but one where the different channels play a moresymmetrical role, consists in performing Principle Component Analysis (PCA)based on the local scatter plot and selecting the zones whose main directionis the most dominant relative to the others [8]. Techniques based on selecting“simple autoterms” of bilinear time-frequency transforms [39] are also very closeto this principle.

1.4. ESTIMATING THE MIXING MATRIX BY CLUSTERING 35
Zone A
Zone B
time in samples
freq
uenc
y in
dex
(a)MDCT of channel x
1
10 20 30 40 50 60
50
100
150
200
250
Zone A
Zone B
time in samples
freq
uenc
y in
dex
(b)MDCT of channel x
2
10 20 30 40 50 60
50
100
150
200
250
−2 0 2−2
−1
0
1
2
cx
1
c x 2
(c)Local scatter plot in Zone A
−2 0 2−2
−1
0
1
2
cx
1
c x 2
(d)Local scatter plot in Zone B
Figure 1.12: Top: MDCTs cx1 and cx2 of the two channels x1 and x2 of thenoiseless stereophonic mixture with three sources represented in Figure 1.1(c),with grey-level used to show intensity (from black for time-frequency zoneswith low energy to white for zones with higher energy). Two time-frequencyzones (Zone A and Zone B) are indicated. Bottom: corresponding local scatterplots: (a) Zone A, where several sources are simultaneously active; (b) Zone B,where one source is dominant. On average, Zone A points have higher energiesthan Zone B points, therefore contributing more to the weighted histograms.However, Zone B points provide a more reliable estimation of direction.

36 CHAPTER 1. SPARSE COMPONENT ANALYSIS
1.5 Square mixing matrix: Relative Newtonmethod for quasi-maximum likelihood sep-aration
When the mixing matrix is square non-degenerative, one can perform BSS byany of the methods presented in other chapters of this book. However useof sparsity prior can greatly improve separation quality in this case as well[115, 117]. We consider the model
Cx = ACs (1.40)
where the mixture coefficients Cx can be obtained via analysis transform of themixture signals (1.14) or, even better, by joint sparse approximation (1.17). Theequation above can be treated as a standard BSS problem with Cs, Cx and thecoefficient index k substituted by S, X and time index t:
X = AS (1.41)
Now we just say that the sources S are sparse themselves. We will use log-likelihood BSS model [81, 19] parameterized by the separating matrix B =A−1. If we assume the sources to be i.i.d, stationary and white, the normalizednegative-log-likelihood of the mixtures is
L(B; X) = − log |detB|+ 1T
∑
i,k
h(bix(t)
), (1.42)
where bi is i-th row of B, h(·) = − log f(·), and f(·) is the probability densityfunction (pdf) of the sources. A consistent estimator can be obtained by theminimization of (1.42), also when h(·) is not exactly equal to − log f(·) [84].Such quasi-ML estimation is practical when the source pdf is unknown, or isnot well-suited for optimization. For example, when the sources are sparse, theabsolute value function or its smooth approximation is a good choice for h(·)[23, 80, 71, 115, 117, 114]. Among other convex smooth approximations to theabsolute value, one can use
h1(c) = |c| − log(1 + |c|) (1.43)hλ(c) = λh1(c/λ) (1.44)
with λ a proximity parameter: hλ(c) → |c| as λ → 0+. Widely acceptednatural gradient method does not work well when the approximation of theabsolute value becomes too sharp. Below we describe the Relative Newtonmethod [112, 113], which overcomes this obstacle. The algorithm is similar inpart to the Newton method of Pham and Garat [84], while enriched by positivedefinite Hessian modification and line search, providing global convergence.

1.5. RELATIVE NEWTON METHOD FOR SQUARE MATRICES 37
1.5.1 Relative Optimization framework
Suppose one has some current estimate of the separating matrix Bk. One canthink about the current source estimate
Sk = BkX (1.45)
as a mixture in some new BSS problem
Sk = AkS
where S are the actual sources to be found. This new problem can be approx-imately solved by one or several steps of some separation method, leading tothe next BSS problem, so on... One uses such an idea for the minimization ofquasi-ML function (1.42):
• Start with an initial estimate B0 of the separation matrix;
• For k = 0, 1, 2, ..., Until convergence
1. Compute current source estimate Sk = BkX;2. For the new BSS problem Sk = AkS, decrease sufficiently its quasi-
ML function L(V ; Sk). Namely, get ”local” separation matrix Vk+1
by one or few steps of a conventional optimization method (startingwith V =I).
3. Update the overall separation matrix
Bk+1 = Vk+1Bk; (1.46)
The Relative (or Natural) Gradient method [25, 7, 22], described in this bookin chapters Likelihood and Iterative Algorithms, is a particular instance of thisapproach, when the standard gradient descent step is used in Item 2. Thefollowing remarkable invariance property of the Relative Gradient method isalso preserved in general:
Given current source estimate Sk, the trajectory of the method andthe final solution do not depend on the original mixing matrix.
This means that even ill-conditioned mixing matrix influences the convergence ofthe method no more than a starting point, and does not influence the final solu-tion at all. Therefore one can analyze local convergence of the method assumingthe mixing matrix to be close to the identity. In this case, when h(c) is smoothenough, the Hessian of (1.42) is well-conditioned, and high linear convergencerate can be achieved even with the Relative Gradient method. However, if weare interested in h(c) being less smooth (for example, using small λ in modulusapproximation (1.43)), use of a Newton step in item 2 of Relative Optimizationbecome rewarding.
A natural question arises: how can one be sure about the global convergencein terms of ”global” quasi-log-likelihood L(B;X) given by (1.42) just reducingthe ”local” function L(V ; Sk)? The answer is:

38 CHAPTER 1. SPARSE COMPONENT ANALYSIS
One-step reduction of the ”local” quasi-log-likelihood leads to theequal reduction of ”global” one:
L(Bk;X)− L(Bk+1;X) = L(I; Sk)− L(Vk+1;Sk)
This can be shown by subtracting the following equalities obtained from (1.42),(1.45) and (1.46)
L(Bk;X) = − log | detBk|+ L(I;Sk) (1.47)
L(Bk+1; X) = − log |detBk|+ L(Vk;Sk) (1.48)
1.5.2 Newton Method
Newton method is an efficient tool of unconstrained optimization. It convergesmuch faster than the gradient descent when the function has a narrow valley, andprovides quadratic rate of convergence. However, its iteration may be costly,because of the necessity to compute the Hessian matrix of the mixed secondderivatives and to solve the corresponding system of linear equations. In thenext subsection we will see how this difficulty can be overcome using the relativeNewton method, but first we describe the Modified Newton method in generalsetting.
Modified Newton method with a line search
Suppose that we minimize an arbitrary twice-differentiable function f(x) andxk is the current iterate with the gradient gk = ∇f(xk) and the Hessian matrixHk = ∇2f(xk). Newton step attempts to find a minimum of the second-orderTaylor expansion of f around xk
yk = arg miny
{q(xk + y) = f(xk) + gT
k y +12yT Hky
}
The minimum is provided by solution of the Newton system
Hkyk = −gk.
When f(x) is not convex, the Hessian matrix is not necessarily positive definite,therefore the direction yk is not necessarily a direction of descent. In this casewe use the Modified Cholesky factorization6 [46], which automatically finds adiagonal matrix R such that the matrix Hk + R is positive definite, providing asolution to the modified system
(Hk + R)yk = −gk (1.49)
After the direction yk is found, the new iterate xk+1 is given by
xk+1 = xk + αkyk (1.50)6MATLAB code of modified Cholesky factorization by Brian Borchers, available at
http://www.nmt.edu/˜borchers/ldlt.html

1.5. RELATIVE NEWTON METHOD FOR SQUARE MATRICES 39
where the step size αk is determined by exact line search
αk = arg minα
f(xk + αyk) (1.51)
or by a backtracking line search (see for example [46]):
α := 1; WHILE f(xk + αyk) > f(xk) + βαgTk yk, α := γα
where 0 < β < 1 and 0 < γ < 1. The use of line search guarantees monotonedecrease of the objective function at every Newton iteration. Our typical choiceof the line search constants is β = γ = 0.3. It may also be reasonable to give βa small value, like 0.01.
1.5.3 Gradient and Hessian evaluation
The likelihood L(B; X) given by (1.42) is a function of a matrix argument B.The corresponding gradient with respect to B is also a matrix
G(B) = ∇L(B;X) = −B−T +1T
h′(BX)XT , (1.52)
where h′(·) is used as an element-wise matrix function. The Hessian of L(B; X)is a linear mapping (4D tensor) H defined via the differential of the gradientdG = HdB. We can also express the Hessian in standard matrix form convertingB into a long vector b = vec(B) using row stacking. We will denote the reverseconversion B = mat(b). Denote
L(b,X) ≡ L(mat(b), X), (1.53)
with the gradientg(b) = ∇L(b;X) = vec(G(B)) (1.54)
The Hessian of − log | detmat(b)| is determined using i-th column Ai and j-throw Aj of A = B−1. Namely, the r-th column of H, r = (i− 1)N + j, containsthe matrix (AiAj)T stacked row-wise (see [112, 113]):
Hr = vec(AjTAT
i ). (1.55)
The Hessian of the second term in L(b,X) is a block-diagonal matrix with thefollowing N ×N blocks constructed using the rows Bm of B:
1T
∑t
h′′(Bmx(t))x(t)xT (t), m = 1, .., N (1.56)
Hessian simplifications in Relative Newton method
Relative Newton iteration k uses the Hessian of L(I, Sk). Hessian of− log | detB| given by (1.55), becomes very simple and sparse, when B = A = I.Each column of H contains only one non-zero element, which is equal to 1:
Hr = vec(ejeTi ), (1.57)

40 CHAPTER 1. SPARSE COMPONENT ANALYSIS
where ej is an N-element standard basis vector, containing 1 at j-th positionand zeros at others. The second block-diagonal term of the Hessian (1.56) alsosimplifies greatly when X = Sk → S. When we approach the solution, andthe sources are independent and zero mean, the off-diagonal elements in (1.56)converge to zero as sample size grows. As a result, we have only two non-zeroelements in every row of the Hessian: one from log|det(·)| and another from thediagonal of the second term. After reordering the variables
v = [V11, V12, V21, V13, V31, ..., V22, V23, V32, V24, V42, ...VNN ]T
we get the Hessian with diagonal 2x2 and 1x1 blocks, which can be invertedvery fast.
In order to guarantee a descent direction and avoid saddle points, we substi-tute the Hessian with a positive definite matrix: change the sign of the negativeeigenvalues (see for example [46]), and force the small eigenvalues to be abovesome threshold (say, 10−8 of the maximal one).
1.5.4 Sequential Optimization
When the sources are sparse, the quality of separation greatly improves withreduction of smoothing parameter λ in the modulus approximation (1.44). Onthe other hand, the optimization of the likelihood function becomes more diffi-cult for small λ. Therefore, we first optimize the likelihood with some moderateλ, then reduce λ by a constant factor (say, 10 or 100), and perform optimiza-tion again, so on... This Sequential Optimization approach reduces the overallcomputations considerably.
Smoothing Method of Multipliers (SMOM)
Even gradual reduction of the smoothing parameter may require significantnumber of Newton steps after each update of λ. More efficient way to achievean accurate solution of a problem involving a sum of absolute value functions isto use SMOM method, which is an extension of Augmented Lagrangian tech-nique [11, 86, 10] used in constrained optimization. It allows to obtain accuratesolution without forcing the smoothing parameter λ to go to zero. SMOM canbe efficiently combined with the Relative Optimization. We refer the reader to[113] for the exposition of this approach.
1.5.5 Numerical Illustrations
Two data sets were used. The first group of sources was random sparse data withGaussian distribution of non-zero samples, generated by the MATLAB functionSPRANDN. The second group of sources were four natural images from [24].The mixing matrix was generated randomly with uniform i.i.d. entries.

1.5. RELATIVE NEWTON METHOD FOR SQUARE MATRICES 41
Smoothing parameter λ = 1
0 20 40 60 8010
−10
10−5
100
105
Iteration
Norm of Gradient
Relative Newton Fast Relative NewtonNatural Gradient
0 5 10 15 20 2510
−10
10−5
100
105
Time, Sec
Nor
m o
f Gra
dien
t
Smoothing parameter λ = 0.01
0 20 40 60 8010
−10
10−5
100
105
Iteration
Nor
m o
f Gra
dien
t
0 10 20 30 40 5010
−10
10−5
100
105
Time, Sec
Nor
m o
f Gra
dien
t
Figure 1.13: Separation of artificial sparse data with 5 mixtures by 10k sam-ples: Relative Newton with exact Hessian (dashed line), Fast Relative Newton(continuous line), Natural Gradient in batch mode (squares).
Relative Newton method
Figure 1.13 shows the typical progress of different methods applied to the arti-ficial data with 5 mixtures of 10k samples. The Fast Relative Newton method(with 2x2 block-diagonal Hessian approximation) converges in about the samenumber of iterations as the Relative Newton with exact Hessian, but signifi-cantly outperforms it in time. Natural gradient in batch mode requires muchmore iterations, and has a difficulty to converge when the smoothing parameterλ in (1.44) becomes too small.
In the second experiment, we demonstrate the advantage of the batch-modequasi-ML separation, when dealing with sparse sources. We compared the FastRelative Newton method with stochastic natural gradient [25, 7, 22], Fast ICA[60] and JADE [20]. All three codes are available at public web sites [73, 59, 21].Stochastic natural gradient and Fast ICA used tanh nonlinearity. Figure 1.14shows separation of artificial stochastic sparse data: 5 sources of 500 samples,30 simulation trials. As we see, Fast Relative Newton significantly outperformsother methods, providing practically ideal separation with the smoothing pa-rameter λ = 10−6 (sequential update of the smoothing parameter was usedhere). Timing is of about the same order for all the methods, except of JADE,which is known to be much faster with relatively small matrices.

42 CHAPTER 1. SPARSE COMPONENT ANALYSIS
0 5 10 15 20 25 30
100
10−2
10−4
10−6
Simulation trial
Inte
rfer
ence
−to
−si
gnal
rat
io
Stochastic natural gradientFast ICAJADEFast relative Newton, λ=0.01Fast relative Newton, λ=0.000001
0 5 10 15 20 25 300
0.2
0.4
0.6
0.8
1
1.2
1.4
Simulation trial
CP
U ti
me,
sec
onds
Stochastic natural gradientFast ICAJADEFast relative Newton, λ=0.01Fast relative Newton, λ=0.000001
Figure 1.14: Separation of stochastic sparse data: 5 sources of 500 samples,30 simulation trials. Left – interference-to-signal ratio, right – CPU time.
0 5 10 150
1
2
3
4
5
6
7
8
Num
ber
of H
essi
ans
Outer iteration
Sequentialsmoothingmethod
Smoothing methodof multipliers
0 10 20 30 40 5010
−15
10−10
10−5
100
Time, Sec
ISR
Sequentialsmoothingmethod
Smoothing method ofmultipliers
Figure 1.15: Relative Newton method with frozen Hessian. Left - number ofHessian evaluations per outer iteration (the first data set); Right - interference-to-signal ratio. Dots correspond to outer iterations
Sequential Optimization vs Smoothing Method of Multipliers(SMOM)
In the third experiment we have used the first stochastic sparse data set: 5mixtures, 10k samples. Figure 1.15 demonstrates advantage of the SMOM com-bined with the frozen Hessian strategy [113]: the Hessian is computed once andthen used in several Newton steps, while they are effective enough. As we see,the last six outer iterations does not require new Hessian evaluations. At thesame time the Sequential Optimization method without Lagrange multipliers,requires 3 to 8 Hessian evaluations per outer iterations towards the end. As aconsequence the method of multipliers converges much faster.
In the fourth experiment, we separated four natural images [24], presentedin Figure 1.16. Sparseness of images can be achieved via various wavelet-typetransforms [115, 117, 114], but even simple differentiation can be used for thispurpose, since natural images often have sparse edges. Here we used the stackof horizontal and vertical derivatives of the mixture images as an input to theseparation algorithms. Figure 1.16 shows the separation quality achieved bystochastic natural gradient, Fast ICA, JADE, the fast relative Newton method

1.6. SEPARATION WITH A KNOWN MIXING MATRIX 43
1 2 3 4 50
0.02
0.04
0.06
0.08
0.1
0.12
Figure 1.16: Separation of images with preprocessing by differentiation. Left:top – sources, middle – mixtures, bottom – separated. Right: Interference-to-signal ratio (ISR) of image separation. 1 – stochastic natural gradient; 2 – FastICA; 3 – JADE; 4 – Relative Newton with λ = 10−2; 5 – SMOM (bar 5 is notvisible because of very small ISR, of order 10−12.)
with λ = 10−2 and the SMOM. Like in the previous experiments, SMOM pro-vides practically ideal separation with ISR of about 10−12. It outperforms theother methods by several orders of magnitude.
1.5.6 Extension of Relative Newton: blind deconvolution
We only mention two important extensions of the Relative Newton method.First, block-coordinate version of the method [16] has an improved convergencerate for large problems. Second, the method can be modified for blind decon-volution of signals and images [17, 18].
1.6 Separation with a known mixing matrix
The first two steps of a sparse source separation system (Figure 1.2) involvecalculating:
• a sparse representation/approximation Cx such that x ≈ CxΦ;
• an estimation of the mixing matrix A.
The sources are finally separated in the last step. According to the type ofmixture (determined or not), several approaches are possible, depending moreor less on the sparsity and disjointness of the source representations.

44 CHAPTER 1. SPARSE COMPONENT ANALYSIS
1.6.1 Linear separation of (over-)determined mixtures
When A is an invertible square matrix, its inverse B := A−1 can be appliedto the mixture x = As, assumed noisefree, to obtain s := A−1x = A−1As.An alternative consists in first estimating a representation of the sources Cs :=A−1Cx, then estimating the sources by reconstruction, s := CsΦ. In the over-determined case where the number of sensors exceeds the number of sources, thepseudo-inverse B := A† can be used. These two alternatives (separation of theinitial mixture or its representation) are strictly identical provided that Cx is anexact representation of the mixture x. This is not true when Cx is only a sparseapproximation of mixture x ≈ CxΦ; whereas the first approach guarantees thatx = As, the second approach only provides the approximation x ≈ CxΦ =ACsΦ = As. For (over-)determined separation problems, separation in thesparse domain is potentially interesting only when the mixture to separate isnoisy, in which case obtaining an approximation x ≈ As can effectively denoisethe mixture.
Sparse source separation can be particularly useful for separating under-determined mixtures where the number of sources N exceeds the number ofsensors P . In this case, it is often much more efficient than any of the linearseparation methods, which estimate the sources using a separation matrix Btaking the form s = Bx. Simple linear algebra arguments show that it is notpossible to perfectly separate the sources linearly in the under-determined case,and more specifically [51] that the estimation of at least one of the sourcesnecessarily undergoes a level of residual interference from the other sources ofaround 10 log10(N/P−1) decibels [51, Lemma 1]. In the following discussion, wefocus on sparse methods that can overcome the limits of linear separation. Theyall start by estimating a representation Cs of the sources before reconstructingthe estimated sources as s = CsΦ. Depending on the case, this representationis obtained directly from the initial mixture x and the estimated matrix A(Sections 1.6.5 to 1.6.8), or from A and the joint sparse representation Cx ofthe mixture (Sections 1.6.2 to 1.6.4), which assumes that the identity Cx ≈ ACs
is reasonably verified.
1.6.2 Binary masking assuming a single active source
The source model with disjoint support representations described in the intro-duction corresponds to estimating the representation of each source by meansof masking, based on the calculated representation of the mixture Cx:
csn(k) := χn(k) · A
HnCx(k)
‖An‖22(1.58)
where the mask χn(k) is defined as:
χn(k) :={
1 if n = n(k);0 if not. with n(k) := arg max
n
|AHnCx(k)|‖An‖22
;
(1.59)

1.6. SEPARATION WITH A KNOWN MIXING MATRIX 45
that is, only the most active source is attributed a non-zero coefficient, whereasthe coefficients of the other sources are set to zero, or “masked”. The degree ofa source’s activity, which determines the mask, is measured as the correlationbetween the corresponding column An of the estimated mixing matrix and thecomponent Cx(k) of the mixture.
Successful masking depends on the sources mainly having disjoint representa-tions, effectively resulting in the approximation Cx(k) ≈ An(k)csn
(k). Althougha strong assumption, this can be checked for many audiophonic mixtures [9] inthe time-frequency domain. It is the main reason for the good results obtainedwith the DUET algorithm [111], which performs a variant of masking in thetime-frequency domain where the mask χn(k) is applied to one of the channelscxp
of the mixture, rather than to the linear combination of all of the chan-nels AH
nCx. Inversely, masking AHnCx has the advantage of guaranteeing that
the source to be estimated is in fact present in the masked “virtual channel”,whereas a source not present in a given channel cannot be estimated by maskingthis channel.
1.6.3 Binary masking assuming M < P active sources
When the number of mixed sources N is high, the mean number of sourcessimultaneously active can exceed 1, despite the sparse representation of eachsource. Assuming the number of active sources does not exceed M , whereM < P , an approach [50, 6] generalizing the binary masking described aboveinvolves:
1. determining the set IM (k) ⊂ {1, . . . , N} of indices of M active sources inthe Cx(k) component;
2. using least squares to calculate the components of the active sources.
Denoting as AI the matrix composed of A columns with index k ∈ I, if theset of active sources is I, then the estimated components of the sources are:
csn(k) := 0, k /∈ I, (1.60)
(csn(k))k∈I := AI
†Cx. (1.61)
The set IM (k) of active sources is thus chosen to minimize the mean squareerror of reconstructing Cx:
IM (k) := arg minI|card(I)≤M
‖Cx − AIAI†Cx‖22 (1.62)
= arg maxI|card(I)≤M
‖AIAI†Cx‖22. (1.63)
When M = 1, the principle of binary masking applies exactly as describedabove.

46 CHAPTER 1. SPARSE COMPONENT ANALYSIS
1.6.4 Local separation by `τ minimization
When the number of sources assumed active can reach M = P , it is no longerpossible to define the set I(k) of active sources by mean square error min-imization since generically, with any subset I of P active sources, a perfectreconstruction is obtained, Cx = AIA−1
I Cx.An alternative is to exploit the sparsity of the sources by a maximum likeli-
hood approach that assumes a generalized Gaussian distribution of the sourcecoefficients:
Cs(k) := arg minCs(k)|ACs(k)=Cx(k)
N∑n=1
|csn(k)|τ . (1.64)
which for 0 ≤ τ ≤ 1 results in estimating a source representation where, foreach atom ϕk, no more than P sources are “active” [64]. In practice, ratherthan use the heavy artillery of iterative algorithms for `τ norm optimization(FOCUSS, etc.) to solve (1.64), a combinatorial approach can be employed inlow dimension, which involves selecting the best set of P active sources as:
I(k) := arg minI|card(I)=P
‖A−1I Cx‖τ . (1.65)
For greater numerical efficiency, the(NP
)possible inverse matrices A−1
I canbe pre-calculated as soon as the mixing matrix is estimated.
This approach is widely used, particularly for separating audio sources basedon their STFTs, and provides good results overall. For stereophonic audiomixtures, Bofill and Zibulevsky [15] proposed this sort of local optimization forτ = 1, and Saab et al. [93] experimentally studied how the choice of τ affects thequality of the results, for sound mixtures. For the examples they considered,their results are satisfactory in terms of separation quality, and do not varysubstantially with the chosen exponent τ .
For noisy mixtures, the separation criterion (1.68) can be replaced to advan-tage by the following, where the λ parameter adjusts the compromise betweenfaithful reconstruction of the mixture coefficients and sparsity of the estimatedsources:
Cs(k) := arg minCs(k)
{1
2σ2b
‖Cx(k)− ACs(k)‖2F + λ
N∑n=1
|csn(k)|τ}
(1.66)
Depending on the value of λ, the number of active estimated sources variesfrom zero to P . As the reader may have noticed, for an exponent τ = 0, thesystem of masking presented in Section 1.6.3 applies, but the number of activesources can vary for each component.
1.6.5 Principle of global separation by `τ minimization
When the Φ dictionary is an orthonormal basis and a simple orthogonal trans-form is used to calculate the joint mixture representation, the independent es-

1.6. SEPARATION WITH A KNOWN MIXING MATRIX 47
timation of source components according to the criterion (1.66) actually corre-sponds to optimizing a more global criterion:
Cs := arg minCs
{‖x− ACsΦ‖2F + λ
∑
nk
|csn(k)|τ
}(1.67)
This results in the equation:
‖x− ACsΦ‖2F = ‖xΦH − ACs‖2F = ‖CΦH
x − ACs‖2F
=K∑
k=1
‖CΦH
x (k)− ACs(k)‖22,
For an arbitrary dictionary, calculating sources via the criterion (1.67)amounts to a maximum a posteriori (MAP) estimation with the assumptionof a generalized Gaussian distribution of source coefficients (1.4). In the samevein, Zibulevsky and Pearlmutter [115] popularized the separation of under-determined mixtures by using a sparse source model and MAP estimation:
Cs := arg maxCs
p(Cs|x, A) = arg minCs
{1
2σ2b
‖x− ACsΦ‖2F +∑
nk
h(csn(k))
}
(1.68)with h(c) = − log pc(c) where pc(·) is the common distribution of source coeffi-cients, assumed independent. Note that the estimation of Cs does not involvethe representation Cx of the mixture, calculated in an initial step (see Fig-ure 1.2). Here this representation only serves to estimate the mixing matrix.Since optimization of a criterion such as (1.68) or (1.67) is only a principle, wewill now provide specific details on algorithms that apply it.
1.6.6 Formal links with single-channel traditional sparseapproximation
It may come as a surprise that optimization problems such as (1.67) are formallymore conventional than the problems of joint sparse mixture representation(1.16)-(1.17) mentioned in Section 1.3. This formal link, while not essentialfor understanding the definition of iterative thresholding or Matching Pursuitalgorithms for separation, is more critical for describing the FOCUSS algorithmin this context. Readers more interested in the description of algorithms thatare conceptually and numerically simpler can skip to Section 1.6.7.
Given that:ACsΦ =
∑
nk
csn(k)Anϕk,
the optimization (1.67) consists in approximating the mixture x (considered asa P × T matrix) with a sparse linear combination of P × T matrices taking theform {Anϕk}nk.

48 CHAPTER 1. SPARSE COMPONENT ANALYSIS
In the vector space of the P × T matrices, the problem is one of sparseapproximation of the “vector” x based on the dictionary Φ7 comprising N ×K “multi-channel atoms” {Anϕk}nk. Thus, the optimization algorithms forsparse representation of a one-dimensional signal do not require substantialmodification to their formal expressions: iterative thresholding techniques [28,36] for 1 ≤ τ ≤ 2, linear, quadratic or conic programming [23, 12] for τ = 1,and iterative reweighted least squares (such as FOCUSS) for 0 < τ ≤ 2. Thedetailed description of these algorithms makes use of the elements described inSection 1.3, considering the specific case of P = 1, i.e. where the representationsare no longer joint.
1.6.7 Global separation algorithms using `τ minimization
While things are simple on paper, the same is not necessarily true numeri-cally: the thresholding algorithms are feasible because they involve no matrixinversion, but minimizing the `1 norm (basis pursuit) or the `τ norm (FO-CUSS) quickly becomes impracticable because of the repeated inversions of(P × T ) × (P × T ) square matrices. By contrast, we will see that matchingpursuit is easy to apply, with an algorithm that is efficient in practice.
Algorithm for 0 < τ ≤ 2: FOCUSS and basis pursuit
The FOCUSS algorithm for minimizing the criterion (1.67) is iterative. Startingfrom an initialization C
(0)s , the value of which can decisively influence the algo-
rithm’s point of convergence, the weighted mean square criterion is iterativelyminimized:
C(m)s := arg min
Cs
{‖x− ACsΦ‖2F +
λ |τ |2
∑
nk
∣∣∣(w(m)nk )−1 csn(k)
∣∣∣2}
(1.69)
where w(m)nk := |c(m−1)
sn (k)|1−τ/2. Denoting asW(m) the (N×K)×(N×K) squareweighting matrix whose diagonal elements are the N×K coefficients w
(m)nk , each
iteration consists in updating W(m) as well as the weighted dictionary Φ(m) inwhich the N ×K atoms are the multi-channel signals w
(m)nk Anϕk, each of size
P ×T . Using the description of the M-FOCUSS algorithm in the single-channelcase, Section 1.3.6, we then calculate
C(m)s := X
((Φ(m))H Φ(m) +
λ |τ |2
IP×T
)−1
(Φ(m))H W(m) (1.70)
where X is none other than the P × T column vector obtained by reorganizingthe coefficients of x, and C is an N × K column vector whose reorganizationas a matrix is precisely C
(m)s . This algorithm, which requires prior inversion
7The italicized notation Φ is used here to distinguish between this dictionary of matricesand the dictionary of atoms Φ from which it is built. Whereas Φ is a K×T matrix, Φ shouldhereafter be considered as a (N ×K)× (P × T ) matrix.

1.6. SEPARATION WITH A KNOWN MIXING MATRIX 49
of a (P × T ) × (P × T ) square matrix at each iteration can only be used inpractice if the dictionary is sufficiently structured to permit blockwise inversion,which is the case when Φ is an orthonormal basis. The quadratic programmingalgorithms used for basis pursuit raise the same difficulties.
Algorithms for 1 ≤ τ ≤ 2: iterative thresholding
Given the estimated mixing matrix A and the dictionary Φ considered, thefirst step is to determine a real µ < ∞ such that, for any N × K matrix Cs,‖ACsΦ‖2F ≤ µ‖Cs‖2F . Based on some initialization C
(0)s (often chosen as zero),
this is followed by iteratively defining:
csn(k)(m) = Sλµ ,τ
(c(m−1)sn
(k) +〈AH
n(x− AC(m−1)s Φ), ϕk〉µ
)(1.71)
and the resulting sequence necessarily converges to a minimizer of (1.67) as soonas 1 ≤ τ ≤ 2 [28]. If τ > 1 or if Φ and A are both invertible square matrices,this minimizer is also unique [28].
1.6.8 Iterative global separation: demixing pursuit
Algorithms for solving global `τ optimization problems such as (1.67) for 0 <τ ≤ 1 are extremely time and memory hungry, especially if the data to beseparated are high-dimensional and the computing time or power requirementsare considerable. A much faster alternative approach is demixing pursuit [56, 67],a type of matching pursuit applied directly to the “vector” x with the atomdictionary {Anϕk}nk. The definition of this algorithm assumes that the atomsare of unit energy, which amounts to assuming the single-channel atoms ϕk areof unit energy and the columns An of the mixing matrix are also of unit norm.This last assumption is not restrictive since it is compatible with the naturalindeterminations of source separation [19]. Theoretical research [56] indicatesthat if (1.67) has a sufficiently sparse solution, then demixing pursuit as well as`1 norm minimization can be used to find it.
More explicitly, to decompose and separate a multi-channel mixture usingdemixing pursuit, the first step is to initialize a residual r(0) = x, followed byiteration of the following steps starting with m = 1:
1. Selection of the most correlated mixing matrix column and atom:
(nm, km) := arg maxnk
|〈AHn r(m−1)
p , ϕk〉| (1.72)
2. Updating of the residual:
r(m) := r(m−1) − 〈Anmr(m−1)p , ϕkm〉Anmϕkm (1.73)

50 CHAPTER 1. SPARSE COMPONENT ANALYSIS
The decomposition below is obtained after M iterations:
x =M∑
m=1
c(m)Anmϕkm
+ r(M) (1.74)
with c(m) := 〈Anmr(m−1), ϕkm〉.Variants similar to orthogonal matching pursuit are possible, and in terms of
numerical calculation, demixing pursuit can be implemented very efficiently byexploiting the dictionary’s structure and the rapid updates for finding the largestscalar product from one iteration to the next. An open, rapid implementationis available [53, 65].
1.7 Conclusion
In this chapter we have described the main steps of source separation methodsbased on sparsity. One of the primary advantages these methods offer is the pos-sibility to separate under-determined mixtures, which involves two independentsteps in most methods [99]: a) estimating the mixing matrix; b) separation usingthe known mixing matrix. In practice, as shown in Figure 1.2, these methodsusually involve four steps:
1. Joint sparse representation Cx of the channels of the mixture x;
2. Estimation of A based on the scatter plot {Cx(k)};3. Sparse separation in the transform domain;
4. Reconstruction of the sources.
Implementing a method of sparse source separation requires making a certainnumber of choices.
Choosing the dictionary Φ. This choice is essentially based on expert knowl-edge of the class of signals considered. A typical choice for audio mixtures orseismic signals is a Gabor time-frequency dictionary, or a wavelet time-scaledictionary; this is also true for biological signals such as cardiac or electro-encephalogram signals. For natural images, dictionaries of wavelets, curveletsor anisotropic Gabor atoms are generally used. Implementing methods to au-tomatically choose a dictionary remains an open problem, even if techniquesfor learning dictionaries based on reference data sets are now available. Thevery concept of matching a dictionary to a class of signals is in need of furtherclarification.
Choosing the algorithm for the joint sparse representation Cx of the mixture.This choice depends a priori on several factors. Available computing power canrule out certain algorithms such as M-FOCUSS or basis pursuit when the mix-ture is high-dimensional (many sensors P or samples/pixels/voxels/ etc. T ).In addition, depending on the level of noise b added to the mixture, the dis-tribution of source coefficients in the selected dictionary, etc., the parameters

1.8. OUTLOOK 51
for optimal algorithm performance (exponent τ , penalty factor λ, stop crite-rion for matching pursuit, etc.) can vary. How easy they are to adjust, via adevelopment data set, may then be taken into consideration.
Choosing the separation method. Separation methods do not all have thesame robustness in the case of an inaccurately estimated mixing matrix. Acomparison of several methods [67] based on time-frequency dictionaries andstereophonic audio mixtures (P = 2) showed that, while less effective thanwhen P active sources are assumed (Section 1.6.4) and the mixing matrix Ais perfectly known, binary masking separation assuming a single active source(Section 1.6.2) is more robust, and thus more effective, than when only animperfect estimation of A is available.
Choosing the algorithm for estimating A. This is undoubtedly the mostdifficult choice; while any “reasonable” choice for the dictionary, for the jointsparse mixture representation algorithm or for the separation method makes itpossible to separate the sources grosso modo when the mixing matrix, even ifunder-determined, is known, an excessive error in estimating the mixing matrixhas a catastrophic effect on the results, which become highly erratic. In particu-lar, if the number of sources is not known in advance, an algorithm that providesa very robust estimation is an absolute necessity. This tends to eliminate ap-proaches based on detecting peaks in a histogram in favour of those, like thealgorithm DEMIX [8], that exploit redundancies (e.g. temporal and frequen-tial persistence in an STFT) in the mixture representation to make estimatingthe column directions of A more robust (with measurement of reliability). Ifthe source supports are not disjoint enough, it becomes necessary to use theapproaches in Section 1.6.4, which are not very robust if A is not accuratelyestimated, making a robust estimation of the mixing matrix all the more critical.
1.8 Outlook
To date, most blind source separation techniques based on sparsity have reliedon a sparse model of all the sources in a common dictionary, making it possibleto exploit their spatial diversity in order to separate them. The principle ofthese techniques consists in decomposing the mixture into the basic components,grouping these components by the similarity of their spatial characteristics,and finally recombining them to reconstruct the sources. This principle maybe applied to more general decompositions [97], provided that an appropriatesimilarity criterion enables regrouping components from the same source. Belowwe discuss some of the possibilities that are starting to be explored.
Spatial diversity and morphological diversity: looking for diversity in sources.While sources have sparse decompositions in different dictionaries, sparsity canalso be exploited to separate them. This is a valid approach, including for theseparation of sources from a single channel, when no spatial diversity is available.This type of approach, called Morphological Component Analysis (MCA) [97]because it uses differences in the waveforms of the sources to separate them, hasbeen successfully applied to separating tonal and transient “layers” in musical

52 CHAPTER 1. SPARSE COMPONENT ANALYSIS
sounds [29] for compression, and for the separation of texture from smoothercontent in images [96]. It is also possible to jointly exploit the spatial diversityand the morphological diversity of sources [13], which amounts to looking for amixture decomposition with the form:
x =N∑
n=1
An · csn ·Φ(n) + b =N∑
n=1
K∑
k=1
csn(k)Anϕ(n)k + b (1.75)
where csn ·Φ(n) is a sparse approximation of sn in a specific dictionary Φ(n). Theestimated sources are then reconstructed as sn :=
∑k csn
(k)ϕ(n)k . The validity
of such an approach outside a purely academic context is based on the existenceof morphological diversity between sources. Beyond its implementation, thereal challenge of MCA lies in determining source-specific dictionaries (by expertknowledge or learning).
Separation of under-determined convolutive mixtures. So far, we have mainlydiscussed the separation of instantaneous mixtures, but sparsity also makes itpossible to process simple forms of convolutive mixtures as well as anechoic mix-tures (i.e. with a delay) [111, 88]. The analysis of real mixtures raises problemsof convolutive separation and possibly under-determination, x = A ? s + b. Toadapt and extend sparsity-based techniques to this context, the conditions ofmixture A must be identified, and separation must be performed when A isknown or estimated. The first task remains challenging, despite some interest-ing approaches [77], but the second is easier and should be addressed by anapproach similar to the deconvolution methods based on `1 norm minimization[94, 34]. Formally, once A is estimated, a decomposition of the mixture is soughtwith the form:
x =N∑
n=1
An ? (cn ·Φ(n)) + b =N∑
n=1
K∑
k=1
cn(k) ·An ? ϕ(n)k + b (1.76)
and the sources sn :=∑
k csn(k)ϕ(n)k are reconstructed. The success of such an
approach, still to be demonstrated in practice, depends on the global diversity(combined morphological and spatial diversity) of the multi-channel waveformsAn ? ϕ
(n)k .
Exploring the broad application potential of sparse source separation meth-ods remains substantially limited by the algorithmic complexity of the opti-mizations involved. It is thus critical to develop and implement new algorithmswhich ideally combine three crucial properties:
• propensity to guarantee or ensure high probability of good sparse approx-imations;
• high numerical efficiency, i.e. economic use of computing resources (mem-ory, arithmetic operations, etc.);
• robustness in case of approximate estimation of the mixing matrix.

1.8. OUTLOOK 53
Algorithms with “certifiable” performance. A number of sparse decomposi-tion algorithms have been proposed, and we have described the main examplesin this chapter. They include the iterative algorithms of the matching pursuitcategory and the techniques based on minimizing `1 criteria, studied exten-sively at the initiative of Donoho and Huo [33] (see for example [103, 56, 32, 52]and the references cited therein). These algorithms perform well – in a precisemathematical sense that makes it possible to “certify” their performance – pro-vided the sources are close enough to a sparse model. Non-convex techniquesfor `τ optimization, 0 < τ < 1, are currently being analysed [52], but some-what surprisingly, there is less interest in convex `τ optimization techniquesfor 1 < τ ≤ 2. “Certification” using theorems on the quality of results fromjoint approximation algorithms (see Section 1.3) or separation algorithms (seeSection 1.6) is thus an area in which numerous questions are still open.
In the single-channel case, Gribonval and Nielsen [54, 55] proved that whilea highly sparse representation exists (implying a sufficiently small number ofatoms), it is the only solution common to all the optimization problems (1.16)for 0 ≤ τ ≤ 1. Similar results [52] lead to the conclusion that all the single-channel sparse approximation problems (1.17) have very similar solutions for0 ≤ τ ≤ 1, provided that the analysed signal can be approximated effectively(in terms of mean square error) by combining a sufficiently small number ofatoms from the dictionary. Tropp et al. [104, 102] have shown that for τ = 1,these results extend to the noisy multi-channel case.
Numerically efficient algorithms. From a numerical point of view, we havediscussed the difficulties of solving the optimization problems (1.17) or (1.67) for0 ≤ τ ≤ 1, which can involve inverting large-size matrices. Other approaches,such as the matching pursuit family, offer an interesting alternative in termsof algorithmic complexity, both for joint approximation and separation with aknown mixing matrix. A fast implementation of complexity O(T log T ) calledMPTK (the matching pursuit toolkit) was proposed and is freely available [53,65]. With redundant dictionaries such as multi-scale Gabor dictionaries, it isthen possible to calculate good sparse approximations in a timeframe close tothe signal’s duration, even when very long. Other proposals such as iterativethresholding algorithms [28, 42, 36, 44] are also extremely promising in termsof numerical efficiency.
Estimating the mixing matrix... and the dictionary! When sparsity is as-sumed, the problem of identifiability (and identification) of the mixing matrix isnot a trivial one, given its direct link to the robustness of separation algorithmsas a function of the accuracy of mixing matrix estimation. While we are startingto understand how to analyse and “certify” the performance of sparse approx-imation algorithms, initial results from similar assessments of mixing matrixidentification algorithms [5], although encouraging, are only valid under restric-tive sparse models that cannot tolerate noise. The choice of dictionary(/ies)Φ/Φ(n) is to some extent a dual problem, whose impact on separation per-formance is yet to be understood. While current practice involves choosing theanalysis dictionary(/ies) from a library of traditional dictionaries, based on prioravailable knowledge of the sources, learning the dictionary based on the data to

54 CHAPTER 1. SPARSE COMPONENT ANALYSIS
separate, or sparse coding is formally equivalent to the problem of estimating A(aside from the transposition given that xH = ΦHCH
s AH +bH). The approachesmay differ considerably in practice because of the substantial difference in di-mension of the matrices to estimate (A is P × N , Φ is K × T , and generallyK ≥ T À N ≈ P ), which fundamentally changes the problem’s geometry andone’s intuitive grasp of it.
The idea of representing a mixture in a domain where it is sparse in order tofacilitate separation has made it possible to successfully tackle the problem ofseparating under-determined instantaneous linear mixtures. The methods mostfrequently used today [91] rely on traditional dictionaries (Gabor, wavelets)identical for all sources, and representations based on linear transforms (STFT,etc.). To go further and determine whether sparsity – promising a priori forhandling more complex and more realistic source separation problems – canmove beyond this stage in practice, it is clear that certain technical obstaclesidentified above must be overcome. But above all, a serious effort to compara-tively evaluate and analyse sparsity-based approaches is now more critical thanever.
1.9 Acknowledgements
R. Gribonval would like to warmly thank Simon Arberet for his precious helpin preparing many of the figures in this chapter, as well as Gilles Gonon, SachaKrsulovic, Sylvain Lesage and Prasad Sudhakar for carefully reading an initialdraft and offering many useful suggestions, comments and criticisms, whichenabled to substantially improve the organization of this chapter.
Bibliography
[1] S. Abdallah and M. Plumbley, If edges are the independent compo-nents of natural images, what are the independent components of naturalsounds?, in Proc. Int. Conf. Indep. Component Anal. and Blind SignalSeparation (ICA2001), San Diego, California, Dec. 2001, pp. 534–539.
[2] F. Abrard and Y. Deville, A time-frequency blind signal separationmethod applicable to underdetermined mixtures of dependent sources, Sig-nal Processing, 85 (2005), pp. 1389–1403.
[3] F. Abrard, Y. Deville, and P. White, From blind source separationto blind source cancellation in the underdetermined case: a new approachbased on time-frequency analysis, in Proc. Int. Workshop on IndependentComponent Analysis and Blind Signal Separation (ICA 2001), San Diego,California, Dec. 2001.
[4] M. Aharon, M. Elad, and A. Bruckstein, The K-SVD: An algorithmfor designing of overcomplete dictionaries for sparse representation, IEEETransactions on Signal Processing, 54 (2006), pp. 4311–4322.

BIBLIOGRAPHY 55
[5] M. Aharon, M. Elad, and A. Bruckstein, On the uniqueness ofovercomplete dictionaries, and a practical way to retrieve them, Journalof Linear Algebra and Applications., 416 (2006), pp. 48–67.
[6] A. Aıssa-El-Bey, K. Abed-Meraim, and Y. Grenier, Underdeter-mined blind source separation of audio sources in time-frequency domain,in Proc. First Workshop on Signal Processing with Sparse/StructuredRepresentations (SPARS’05), Rennes, France, Nov. 2005.
[7] S. Amari, A. Cichocki, and H. H. Yang, A new learning algorithmfor blind signal separation, in Advances in Neural Information ProcessingSystems 8, MIT Press, 1996.
[8] S. Arberet, R. Gribonval, and F. Bimbot, A robust method to countand locate audio sources in a stereophonic linear instantaneous mixture,in Proc. of the Int’l. Workshop on Independent Component Analysis andBlind Signal Separation (ICA 2006), J. P. J. Rosca, D. Erdogmus andS. Haykin, eds., vol. 3889 of LNCS Series, Charleston, South Carolina,USA, Mar. 2006, Springer, pp. 536–543.
[9] R. Balan and J. Rosca, Statistical properties of STFT ratios for twochannel systems and applications to blind source separation, in Proc. Int.Workshop on Independent Component Analysis and Blind Signal Separa-tion (ICA 2000), Helsinki, Finland, June 2000, pp. 429–434.
[10] A. Ben-Tal and M. Zibulevsky, Penalty/barrier multiplier methodsfor convex programming problems, SIAM Journal on Optimization, 7(1997), pp. 347–366.
[11] D. Bertsekas, Constrained Optimization and Lagrange Multiplier Meth-ods, Academic Press, New York, 1982.
[12] D. Bertsekas, Non-Linear Programming, Athena Scientific, Belmont,MA, 2nd ed., 1995.
[13] J. Bobin, Y. Moudden, J.-L. Starck, and M. Elad, Multichan-nel morphological component analysis, in Proc. First Workshop on SignalProcessing with Sparse/Structured Representations (SPARS’05), Rennes,France, Nov. 2005.
[14] J. Bobin, J.-L. Starc, J. Fadili, Y. Moudden, and D. L. Donoho,Morphological component analysis: an adaptative thresholding strategy,IEEE Transactions on Image Processing, 16 (2007), pp. 2675–2681.
[15] P. Bofill and M. Zibulevsky, Underdetermined blind source separa-tion using sparse representations, Signal Processing, 81 (2001), pp. 2353–2362.

56 CHAPTER 1. SPARSE COMPONENT ANALYSIS
[16] A. M. Bronstein, M. M. Bronstein, and M. Zibulevsky, Blindsource separation using block-coordinate relative Newton method, SignalProcessing, 84 (2004), pp. 1447–1459.
[17] , Relative optimization for blind deconvolution, IEEE Trans. SignalProcessing, 53 (2005), pp. 2018–2026.
[18] A. M. Bronstein, M. M. Bronstein, M. Zibulevsky, and Y. Y.Zeevi, Blind deconvolution of images using optimal sparse representa-tions, IEEE Trans. Image Processing, 14 (2005), pp. 726–736.
[19] J.-F. Cardoso, Blind signal separation: statistical principles, Proceed-ings of the IEEE. Special issue on blind identification and estimation, 9(1998), pp. 2009–2025.
[20] J.-F. Cardoso, High-order contrasts for independent component analy-sis, Neural Computation, 11 (1999), pp. 157–192.
[21] , JADE for real-valued data, tech. report, ENST, 1999.http://sig.enst.fr:80/~cardoso/guidesepsou.html.
[22] J.-F. Cardoso and B. Laheld, Equivariant adaptive source separation,IEEE Transactions on Signal Processing, 44 (1996), pp. 3017–3030.
[23] S. S. Chen, D. L. Donoho, and M. A. Saunders, Atomic decompo-sition by basis pursuit, SIAM J. Sci. Comput., 20 (1998), pp. 33–61.
[24] A. Cichocki, S. Amari, and K. Siwek, ICALAB toolbox for im-age processing – benchmarks, tech. report, The Laboratory for Ad-vanced Brain Signal Processing, RIKEN Brain Science Institute, 2002.http://www.bsp.brain.riken.go.jp/ICALAB/ICALABImageProc/benchmarks/.
[25] A. Cichocki, R. Unbehauen, and E. Rummert, Robust learning al-gorithm for blind separation of signals, Electronics Letters, 30 (1994),pp. 1386–1387.
[26] R. R. Coifman, Y. Meyer, and M. V. Wickerhauser, Wavelet anal-ysis and signal processing, in Wavelets and their applications, Jones andBarlett. Ruskai B. et al. eds., Boston, (1992).
[27] S. Cotter, B. Rao, K. Engan, and K. Kreutz-Delgado, Sparsesolutions to linear inverse problems with multiple measurement vectors,IEEE Trans. Signal Proc., 53 (2005), pp. 2477–2488.
[28] I. Daubechies, M. Defrise, and C. De Mol, An iterative thresholdingalgorithm for linear inverse problems with a sparsity constraint, Commu-nications on Pure and Applied Mathematics, 57 (2004), pp. 1413–1457.
[29] L. Daudet and B. Torresani, Hybrid representations for audiophonicsignal encoding, Signal Processing, special issue on Coding Beyond Stan-dards, 82 (2002), pp. 1595–1617.

BIBLIOGRAPHY 57
[30] M. Davies and N. Mitianoudis, A sparse mixture model for overcom-plete ica, IEE Proceedings - Vision Image and Signal Processing, 151(2004), pp. 35–43. special issue on Nonlinear and Non-Gaussian SignalProcessing.
[31] G. Davis, S. Mallat, and M. Avellaneda, Adaptive greedy approxi-mations, Constr. Approx., 13 (1997), pp. 57–98.
[32] D. Donoho, M. Elad, and V. Temlyakov, Stable recovery of sparseovercomplete representations in the presence of noise, IEEE Trans. Inf.Th., 52 (2006), pp. 6–18.
[33] D. Donoho and X. Huo, Uncertainty principles and ideal atomic de-compositions, IEEE Trans. Inform. Theory, 47 (2001), pp. 2845–2862.
[34] C. Dossal, Estimation de fonctions geometriques et deconvolution, PhDthesis, Ecole Polytechnique, Palaiseau, France, 2005.
[35] B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani, Least angleregression, Annals of Statistics, 32 (2004), pp. 407–499.
[36] M. Elad, Why simple shrinkage is still relevant for redundant represen-tations?, IEEE Trans. Information Theory, 52 (2006), pp. 5559–5569.
[37] M. Elad, B. Matalon, and M. Zibulevsky, Coordinate and sub-space optimization methods for linear least squares with non-quadraticregularization, Applied and Computational Harmonic Analysis, 23 (2007),pp. 346–367.
[38] Y. F.Abrard, Blind separation of dependent sources using the ”time-frequency ratio of mixtures” approach, in ISSPA 2003, Paris, France, July2003, IEEE.
[39] C. Fevotte and C. Doncarli, Two contributions to blind source sepa-ration using time-frequency distributions, IEEE Signal Processing Letters,11 (2004), pp. 386–389.
[40] C. Fevotte and G. S. J., A bayesian approach for blind separationof sparse sources, IEEE Trans. Speech and Audio Processing, (2006). toappear.
[41] D. Field and B. Olshausen, Emergence of simple-cell receptive fieldproperties by learning a sparse code for natural images, Nature, 381 (1996),pp. 607–609.
[42] M. Figueiredo and R. Nowak, An EM algorithm for wavelet-basedimage restoration, IEEE Trans. Image Process., 12 (2003), pp. 906–916.
[43] R. M. Figueras i Ventura, P. Vandergheynst, and P. Frossard,Low rate and flexible image coding with redundant representations., IEEETransactions on Image Processing, 15 (2006), pp. 726 – 739.

58 CHAPTER 1. SPARSE COMPONENT ANALYSIS
[44] M. Fornasier and H. Rauhut, Recovery algorithms for vector valueddata with joint sparsity constraints, Tech. Report 27, Johns Radon Insti-tute for Computational and Applied Mathematics, Austrian Academy ofSciences, 2006.
[45] J.-J. Fuchs, Some further results on the recovery algorithms, in Proc.First Workshop on Signal Processing with Sparse/Structured Representa-tions (SPARS’05), Rennes, France, Nov. 2005, pp. 67–70.
[46] P. E. Gill, W. Murray, and M. H. Wright, Practical Optimization,Academic Press, New York, 1981.
[47] G. H. Golub and C. Van Loan, Matrix Computations, The John Hop-kins University Press, Baltimore and London, 2nd ed., 1989.
[48] I. F. Gorodnitsky and B. D. Rao, Sparse signal reconstruction fromlimited data using focuss : a reweighted norm minimization algorithm,IEEE Trans. Signal Proc., 45 (1997), pp. 600–616.
[49] R. Gribonval, Sparse decomposition of stereo signals with matching pur-suit and application to blind separation of more than two sources froma stereo mixture, in Proc. Int. Conf. Acoust. Speech Signal Process.(ICASSP’02), vol. 3, Orlando, Florida, May 2002, IEEE, pp. III/3057– III/3060.
[50] , Piecewise linear source separation, in Proc. SPIE ’03, M. Unser,A. Aldroubi, and A. Laine, eds., vol. 5207 Wavelets: Applications in Signaland Image Processing X, San Diego, CA, Aug. 2003, pp. 297–310.
[51] R. Gribonval, L. Benaroya, E. Vincent, and C. Fevotte, Pro-posals for performance measurement in source separation, in Proc. 4thInt. Symp. on Independent Component Anal. and Blind Signal Separa-tion (ICA2003), Nara, Japan, Apr. 2003, pp. 763–768.
[52] R. Gribonval, R. M. Figueras i Ventura, and P. Van-dergheynst, A simple test to check the optimality of sparse signal ap-proximations, EURASIP Signal Processing, special issue on Sparse Ap-proximations in Signal and Image Processing, 86 (2006), pp. 496–510.
[53] R. Gribonval and S. Krstulovic, MPTK, The Matching PursuitToolkit, 2005.
[54] R. Gribonval and M. Nielsen, On the strong uniqueness of highlysparse expansions from redundant dictionaries, in Proc. Int Conf. Inde-pendent Component Analysis (ICA’04), LNCS, Granada, Spain, Sept.2004, Springer-Verlag.
[55] R. Gribonval and M. Nielsen, Highly sparse representations from dic-tionaries are unique and independent of the sparseness measure, Appl.Comput. Harm. Anal., 22 (2007), pp. 335–355.

BIBLIOGRAPHY 59
[56] , Beyond sparsity : recovering structured representations by `1-minimization and greedy algorithms., Advances in Computational Math-ematics, 28 (2008), pp. 23–41.
[57] R. Gribonval, H. Rauhut, K. Schnass, and P. Vandergheynst,Atoms of all channels, unite! Average case analysis of multi-channelsparse recovery using greedy algorithms, J. Fourier Anal. Appl., 14 (2008),pp. 655–687.
[58] R. Gribonval and P. Vandergheynst, On the exponential conver-gence of Matching Pursuits in quasi-incoherent dictionaries, IEEE Trans.Information Theory, 52 (2006), pp. 255–261.
[59] A. Hyvarinen, The Fast-ICA MATLAB package, tech. report, HUT,1998. http://www.cis.hut.fi/˜aapo/.
[60] , Fast and robust fixed-point algorithms for independent componentanalysis, IEEE Transactions on Neural Networks, 10 (1999), pp. 626–634.
[61] A. Jourjine, S. Rickard, and O. Yilmaz, Blind separation of disjointorthogonal signals: Demixing n sources from 2 mixtures, in Proc. IEEEConf. Acoustics Speech and Signal Proc. (ICASSP’00), vol. 5, Istanbul,Turkey, June 2000, pp. 2985–2988.
[62] P. Kisilev, M. Zibulevsky, and Y. Zeevi, A multiscale frameworkfor blind separation of linearly mixed signals, The Journal of MachineLearning Research, 4 (2003), pp. 1339–1363.
[63] P. Kisilev, M. Zibulevsky, Y. Y. Zeevi, and B. A. Pearlmutter,Multiresolution framework for sparse blind source separation, tech. re-port, Department of Electrical Engineering, Technion. Haifa, Israel, 2000.http://ie.technion.ac.il/˜mcib/.
[64] K. Kreutz-Delgado, B. Rao, K. Engan, T.-W. Lee, and T. Se-jnowski, Convex/schur-convex (csc) log-priors and sparse coding, in 6thJoint Symposium on Neural Computation, Institute for Neural Computa-tion, May 1999, pp. 65–71.
[65] S. Krstulovic and R. Gribonval, MPTK: Matching Pursuit madetractable, in Proc. Int. Conf. Acoust. Speech Signal Process. (ICASSP’06),vol. 3, Toulouse, France, May 2006, pp. III–496 – III–499.
[66] T.-W. Lee, M. S. Lewicki, M. Girolami, and T. J. Sejnowski,Blind source separation of more sources than mixtures using overcompleterepresentations, IEEE Signal Processing Letters, 6 (1999), pp. 87–90.
[67] S. Lesage, S. Krstulovic, and R. Gribonval, Under-determinedsource separation: comparison of two approaches based on sparse decom-positions, in Proc. of the Int’l. Workshop on Independent Component

60 CHAPTER 1. SPARSE COMPONENT ANALYSIS
Analysis and Blind Signal Separation (ICA 2006), J. P. J. Rosca, D. Er-dogmus and S. Haykin, eds., vol. 3889 of LNCS Series, Charleston, SouthCarolina, USA, Mar. 2006, Springer, pp. 633–640.
[68] D. Leviatan and V. Temlyakov, Simultaneous approximation bygreedy algorithms, Tech. Report 0302, IMI, Dept of Mathematics, Uni-versity of South Carolina, Columbia, SC 29208, 2003.
[69] M. Lewicki, Efficient coding of natural sounds, Nature Neurosci., 5(2002), pp. 356–363.
[70] M. Lewicki and T. Sejnowski, Learning overcomplete representations,Neural Computation, 12 (2000), pp. 337–365.
[71] M. S. Lewicki and B. A. Olshausen, A probabilistic framework for theadaptation and comparison of image codes, Journal of the Optical Societyof America, 16 (1999), pp. 1587–1601.
[72] J. Lin, D. Grier, and J. Cowan, Faithful representation of separabledistributions, Neural Computation, 9 (1997), pp. 1305–1320.
[73] S. Makeig, ICA toolbox for psychophysiological research. ComputationalNeurobiology Laboratory, the Salk Institute for Biological Studies, 1998.http://www.cnl.salk.edu/˜ ica.html.
[74] D. Malioutov, M. Cetin, and A. Willsky, Homotopy continuationfor sparse signal representation, in Proceedings of the IEEE InternationalConference on Acoustics, Speech, and Signal Processing, (ICASSP’05),vol. V, Mar. 2005, pp. 733–736.
[75] S. Mallat, A Wavelet Tour of Signal Processing, Academic Press, SanDiego, CA, 1998.
[76] S. Mallat and Z. Zhang, Matching pursuit with time-frequency dictio-naries, IEEE Trans. Signal Proc., 41 (1993), pp. 3397–3415.
[77] T. Melia and S. Rickard, Extending the DUET blind source sep-aration technique, in Proc. First Workshop on Signal Processing withSparse/Structured Representations (SPARS’05), Rennes, France, Nov.2005, pp. 67–70.
[78] B. Natarajan, Sparse approximate solutions to linear systems, SIAM J.Computing, 25 (1995), pp. 227–234.
[79] D. Needell and J. A. Tropp, Cosamp: Iterative signal recovery fromincomplete and inaccurate samples, tech. report, Caltech, 2008.
[80] B. A. Olshausen and D. J. Field, Sparse coding with an overcom-plete basis set: A strategy employed by v1?, Vision Research, 37 (1997),pp. 3311–3325.

BIBLIOGRAPHY 61
[81] B. A. Pearlmutter and L. C. Parra, Maximum likelihood blindsource separation: A context-sensitive generalization of ICA, in Advancesin Neural Information Processing Systems 9, MIT Press, 1997.
[82] E. Pearson, The Multiresolution Fourier Transform and its applicationto Polyphonic Audio Analysis, PhD thesis, University of Warwick, Sept.1991.
[83] G. L. Peotta L and V. P, Image compression using an edge adaptedredundant dictionary and wavelets, Signal Processing, 86 (2006), pp. 444–456.
[84] D. Pham and P. Garat, Blind separation of a mixture of independentsources through a quasi-maximum likelihood approach, IEEE Transactionson Signal Processing, 45 (1997), pp. 1712–1725.
[85] M. Plumbley, Geometry and homotopy for `1 sparse signal rep-resentations, in Proc. First Workshop on Signal Processing withSparse/Structured Representations (SPARS’05), Rennes, France, Nov.2005, pp. 67–70.
[86] R. Polyak, Modified barrier functions: Theory and methods, Math. Pro-gramming, 54 (1992), pp. 177–222.
[87] J. Princen and A. Bradley, Analysis/synthesis filter bank design baseson time domain aliasing cancellation, IEEE Trans. Acoustics, Speech andSignal Proc., ASSP-34 (1986), pp. 1153–1161.
[88] M. Puigt and Y. Deville, Time-frequency ratio-based blind separationmethods for attenuated and time-delayed sources, Mechanical Systems andSignal Processing, 19 (2005), pp. 1348–1379.
[89] L. Rabiner and R. Schafer, Digital Processing of Speech Signals, Pren-tice Hall, 1978.
[90] V. P. Rahmoune A and F. P, Flexible motion-adaptive video codingwith redundant expansions, IEEE Transactions on Circuits and Systemsfor Video Technology, 16 (2006), pp. 178–190.
[91] S. Rickard, R. Balan, and J. Rosca, Real-time time-frequency basedblind source separation, in 3rd International Conference on IndependentComponent Analysis and Blind Source Separation (ICA2001), San Diego,CA, Dec. 2001.
[92] R. Rubinstein, M. Zibulevsky, and M. Elad, Learning sparse dic-tionaries for sparse signal representation, IEEE Transactions on SignalProcessing, (2008). submitted.

62 CHAPTER 1. SPARSE COMPONENT ANALYSIS
[93] R. Saab, O. Yilmaz, M. McKeown, and R. Abugharbieh, Un-derdetermined sparse blind source separation with delays, in Proc. FirstWorkshop on Signal Processing with Sparse/Structured Representations(SPARS’05), Rennes, France, Nov. 2005, pp. 67–70.
[94] F. Santosa and W. Symes, Linear inversion of band-limited reflectionsismograms, SIAM J. Sci. Statistic. Comput., 7 (1986), pp. 1307–1330.
[95] J. L. Starck, E. J. Candes, and D. L. Donoho, The curvelet trans-form for image denoising, IEEE Transactions on Image Processing, 11(2000), pp. 670–684.
[96] J.-L. Starck, M. Elad, and D. Donoho, Image decomposition : Sepa-ration of textures from piecewise smooth content, in Wavelet: Applicationsin Signal and Image Processing X, Proc, SPIE ’03, M. Unser, A. Aldroubi,and A. Laine, eds., vol. 5207, San Diego, CA, Aug. 2003, SPIE (The In-ternational Society for Optical Engineering), pp. 571–582.
[97] J.-L. Starck, Y. Moudden, J. Bobin, M. Elad, and D. Donoho,Morphological component analysis, in Proceedings of the SPIE conferencewavelets, vol. 5914, July 2005.
[98] F. Theis, A. Jung, C. Puntonet, and E. Lang, Linear geomet-ric ICA: Fundamentals and algorithms, Neural Computation, 15 (2003),pp. 419–439.
[99] F. J. Theis and E. W. Lang, Formalization of the two-step approach toovercomplete BSS, in Proc. SIP 2002, Kauai, Hawaii, USA, 2002, pp. 207–212.
[100] F. J. Theis, C. Puntonet, and E. W. Lang, A histogram-based over-complete ICA algorithm, in Proc. 4th Int. Symp. on Independent Com-ponent Anal. and Blind Signal Separation (ICA2003), Nara, Japan, Apr.2003, pp. 1071–1076.
[101] J. Tropp, Greed is good : Algorithmic results for sparse approximation,IEEE Trans. Inform. Theory, 50 (2004), pp. 2231–2242.
[102] J. Tropp, Algorithms for simultaneous sparse approximation. part ii:Convex relaxation, Signal Processing, 86 (2006), pp. 589–602. specialissue on Sparse Approximations in Signal and Image Processing.
[103] J. Tropp, Just relax: Convex programming methods for identifying sparsesignals in noise, IEEE Trans. Information Theory, 52 (2006), pp. 1030–1051.
[104] J. Tropp, A. Gilbert, and M. Strauss, Algorithms for simultaneoussparse approximation. part i: Greedy pursuit, Signal Processing, 86 (2006),pp. 572–588. special issue on Sparse Approximations in Signal and ImageProcessing.

BIBLIOGRAPHY 63
[105] B. Turlach, On algorithms for solving least squares problems under an`1 pernalty or an `1 constraint, in 2004 Proc. of the American StatisticalAssociation, vol. Statistical Computing Section [CDROM], Alexandria,VA, 2005, American Statistical Association, pp. 2572–2577.
[106] M. Van Hulle, Clustering approach to square and non-square blindsource separation, in IEEE Workshop on Neural Networks for Signal Pro-cessing (NNSP99), Aug. 1999, pp. 315–323.
[107] L. Vielva, D. Erdogmus, and J. Principe, Underdetermined blindsource separation using a probabilistic source sparsity model, in Proc. Int.Conf. on ICA and BSS (ICA2001), San Diego, California, Dec. 2001,pp. 675–679.
[108] E. Vincent, Complex nonconvex lp norm minimization for underdeter-mined source separation, in Proc. Int. Conf. Indep. Component Anal. andBlind Signal Separation (ICA2001), Springer, 2007, pp. 430–437.
[109] D. Weitzer, D. Stanhill, and Y. Y. Zeevi, Nonseparable two-dimensional multiwavelet transform for image coding and compression,Proc. SPIE, 3309 (1997), pp. 944–954.
[110] R. Xu and D. W. II, Survey of clustering algorithms, IEEE Transactionson Neural Networks, 16 (2005), pp. 645–678.
[111] O. Yilmaz and S. Rickard, Blind separation of speech mixtures viatime-frequency masking, IEEE Transactions on Signal Processing, 52(2004), pp. 1830–1847.
[112] M. Zibulevsky, Blind source separation with Relative Newton method,Proceedings ICA-2003, (2003), pp. 897–902.
[113] M. Zibulevsky, Relative Newton and smoothing multiplier optimiza-tion methods for blind source separation, in Blind Speech Separation,S. Makino, T. Lee, and H. Sawada, eds., Springer Series: Signals andCommunication Technology XV, 2007.
[114] M. Zibulevsky, P. Kisilev, Y. Y. Zeevi, and B. A. Pearlmutter,Blind source separation via multinode sparse representation, in Advancesin Neural Information Processing Systems 12, MIT Press, 2002.
[115] M. Zibulevsky and B. A. Pearlmutter, Blind source separationby sparse decomposition in a signal dictionary, Neural Computation, 13(2001), pp. 863–882.
[116] , Blind source separation by sparse decomposition, Tech. ReportCS99-1, Univ. of New Mexico, July 1999.

64 CHAPTER 1. SPARSE COMPONENT ANALYSIS
[117] M. Zibulevsky, B. A. Pearlmutter, P. Bofill, and P. Kisilev,Blind source separation by sparse decomposition, in Independent Compo-nents Analysis: Principles and Practice, S. J. Roberts and R. M. Everson,eds., Cambridge University Press, 2001.

Index
Algorithmeglouton, 25
atoms, 10
Basis Pursuit, 23Basis Pursuit Denoising, 23
Cholesky factorization, 38clustering, 8complete, 12conic programming, 23
demixing pursuit, 49dictionaries, 11
Hessian, 39historique, 7
iterative reweighted least squares, 22iterative thresholding, 23
joint sparse approximation, 17
line search, 39linear programming, 23local scatter plots, 33log-likelihood, 36
M-FOCUSS, 22Matching Pursuit, 25maximum a posteriori, 18, 47morphological diversity, 52
natural gradient, 37Newton method, 38
quadratic programming, 23
relative gradient, 37
relative Newton, 36relative optimization, 37reprsentation
parcimonieuse conjointe, 17vraiment parcimonieuse, 19
scatter plot, 8smoothing method of multipliers
(SMOM), 40spatial diversity, 51
thresholding, 24
under-determined, 8
Vraisemblancemaximum de, 18
65