
Hadoop Ecosystem Vorstellung der Komponenten · Open Source für Apache Hive and Cloudera Impala...
50
Hadoop Ecosystem Vorstellung der Komponenten Oracle/metafinanz Roadshow Februar 2014
Transcript of Hadoop Ecosystem Vorstellung der Komponenten · Open Source für Apache Hive and Cloudera Impala...

Hadoop Ecosystem
Vorstellung der Komponenten
Oracle/metafinanz Roadshow
Februar 2014

©
Wir fokussieren mit unseren Services die Herausforderungen des Marktes und verbinden
Mensch und IT.
Business Intelligence
Customer Intelligence
• Customer based Analytics & Processes
• Churn Prediction and
Management
• Segmentation and
Clustering
Insurance
Reporting
• Standard & Adhoc
Reporting
• Dashboarding
• BI Office Integration
• Mobile BI & InMemory
• SAS Trainings for Business
Analysts
Insurance Analytics
• Predictive Models, Data Mining & Statistics
• Scorecarding
• Social Media Analytics
• Fraud & AML
BI & Risk Risk
• Solvency II (Standard
& internal Model)
• Regulatory Reporting
• Compliance
• Risk Management
Enterprise DWH
• Data Modeling & Integration & ETL
• Architecture: DWH & Data Marts
• Hadoop & Columnar DBs
• Data Quality &
Data Masking
Themenbereiche Über metafinanz
metafinanz gehört seit 23 Jahren zu den erfahrensten
Software- und Beratungshäusern mit Fokus auf die
Versicherungsbranche.
Mit einem Jahresumsatz von 250 Mio. EUR und über
1.500 Mitarbeitern entwickeln wir für unsere Kunden
intelligente zukunftsorientierte Lösungen für
komplexe Herausforderungen
Referenten
Seite 2
Carsten
Herbe
Michael
Prost
mail: [email protected] phone: +49 89 360531 5039
Hadoop Ecosystem 10.02.2014
Slavomir
Nagy
Head
of
Data
Ware
ho
usin
g
DW
H P
rin
cip
al
Co
nsu
ltan
t
DW
H S
en
ior
Co
nsu
ltan
t

© ©
Inhalt
Einführung 1
Hive 2
Sentry 4
Sqoop 5
Mahout 8
HBASE 9
Oozie 12
Hadoop Ecosystem
Pig 6
Giraph 7
HUE 13
Zookeeper 14
Flume 11
10.02.2014 Seite 3
Impala 3 File Formats 10
Cloudera Manager 15
©
Einführung 1
©
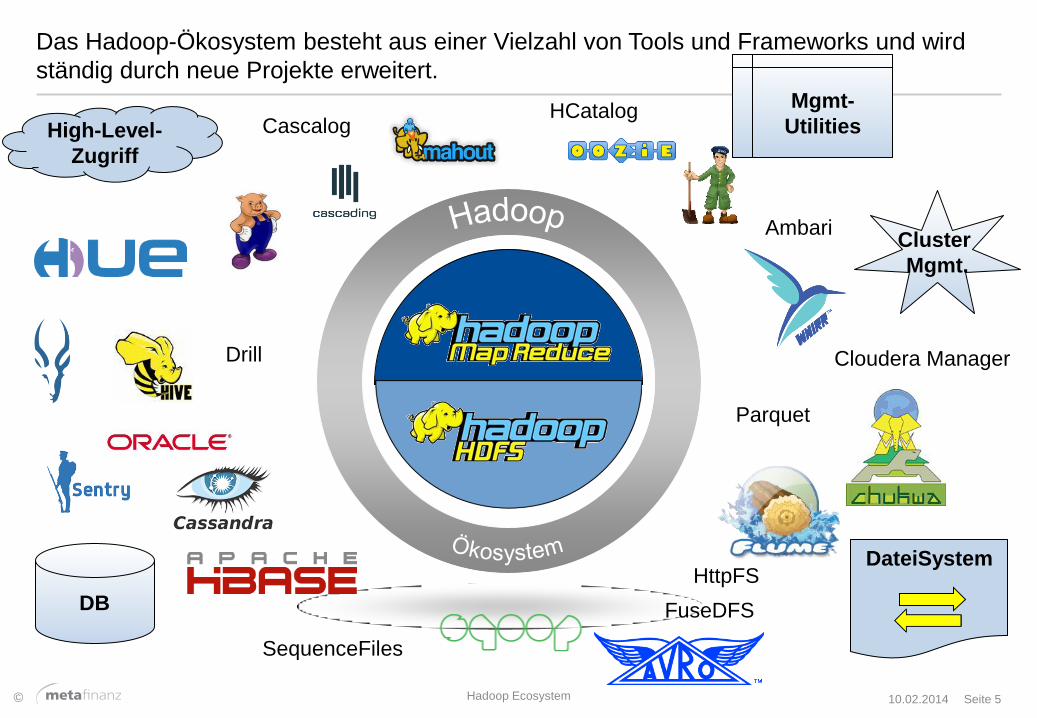
Das Hadoop-Ökosystem besteht aus einer Vielzahl von Tools und Frameworks und wird
ständig durch neue Projekte erweitert.
HttpFS
Drill
Ambari
HCatalog Cascalog
DB
DateiSystem
High-Level-
Zugriff
Mgmt-
Utilities
Cloudera Manager
Cluster
Mgmt.
FuseDFS
Hadoop Ecosystem
Parquet
SequenceFiles
10.02.2014 Seite 5

©
Hive 2
©
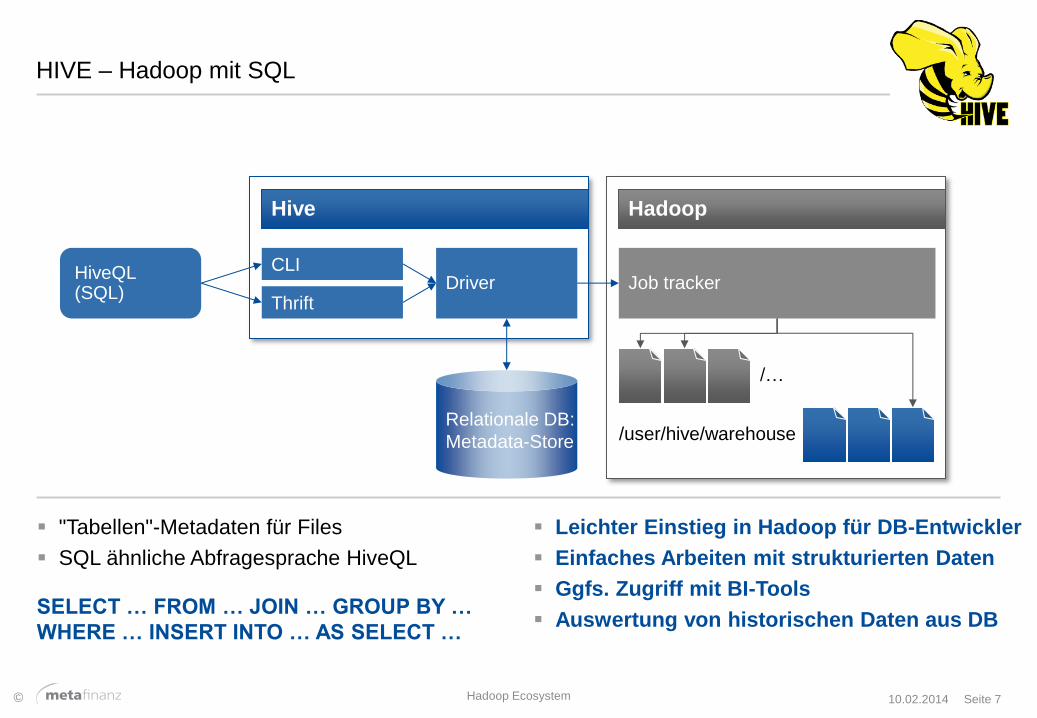
HIVE – Hadoop mit SQL
"Tabellen"-Metadaten für Files
SQL ähnliche Abfragesprache HiveQL
SELECT … FROM … JOIN … GROUP BY …
WHERE … INSERT INTO … AS SELECT …
Leichter Einstieg in Hadoop für DB-Entwickler
Einfaches Arbeiten mit strukturierten Daten
Ggfs. Zugriff mit BI-Tools
Auswertung von historischen Daten aus DB
HiveQL (SQL)
Hive
Driver CLI
Thrift
Relationale DB:
Metadata-Store
Hadoop
Job tracker
/user/hive/warehouse
/…
Hadoop Ecosystem 10.02.2014 Seite 7

©
Impala 3
©
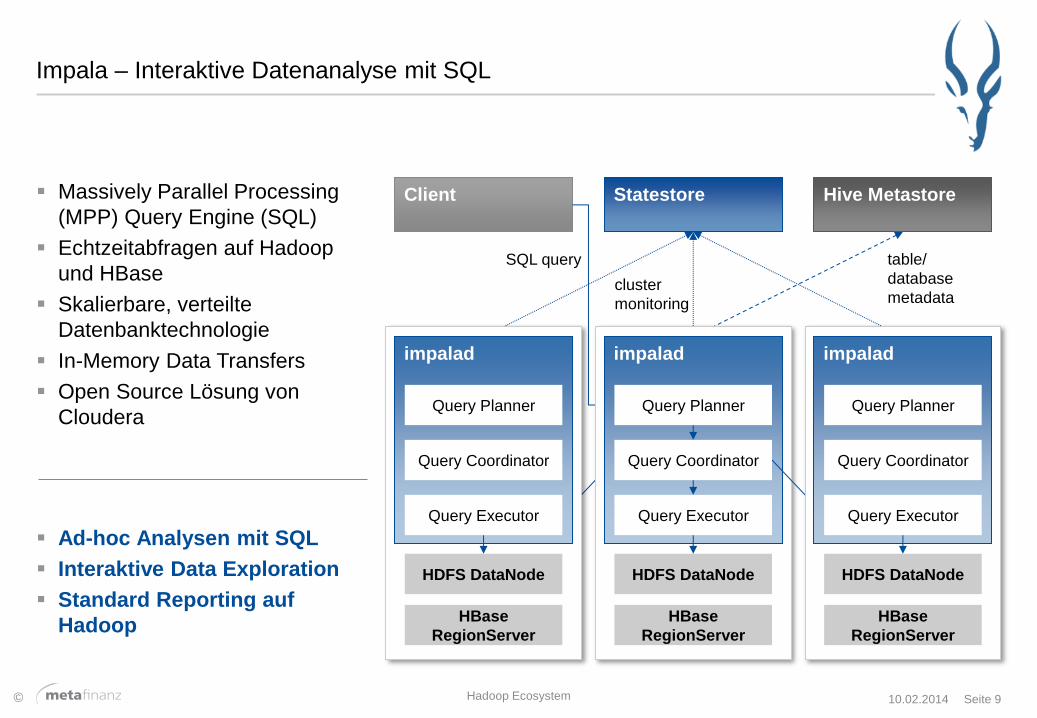
Impala – Interaktive Datenanalyse mit SQL
Massively Parallel Processing
(MPP) Query Engine (SQL)
Echtzeitabfragen auf Hadoop
und HBase
Skalierbare, verteilte
Datenbanktechnologie
In-Memory Data Transfers
Open Source Lösung von
Cloudera
Ad-hoc Analysen mit SQL
Interaktive Data Exploration
Standard Reporting auf
Hadoop
Statestore Hive Metastore Client
SQL query
cluster
monitoring
table/
database
metadata
impalad
HBase
RegionServer
HDFS DataNode
Query Executor
Query Coordinator
Query Planner
HBase
RegionServer
HDFS DataNode
impalad
Query Executor
Query Coordinator
Query Planner
impalad
HBase
RegionServer
HDFS DataNode
Query Executor
Query Coordinator
Query Planner
Hadoop Ecosystem 10.02.2014 Seite 9

©
Sentry 4
©
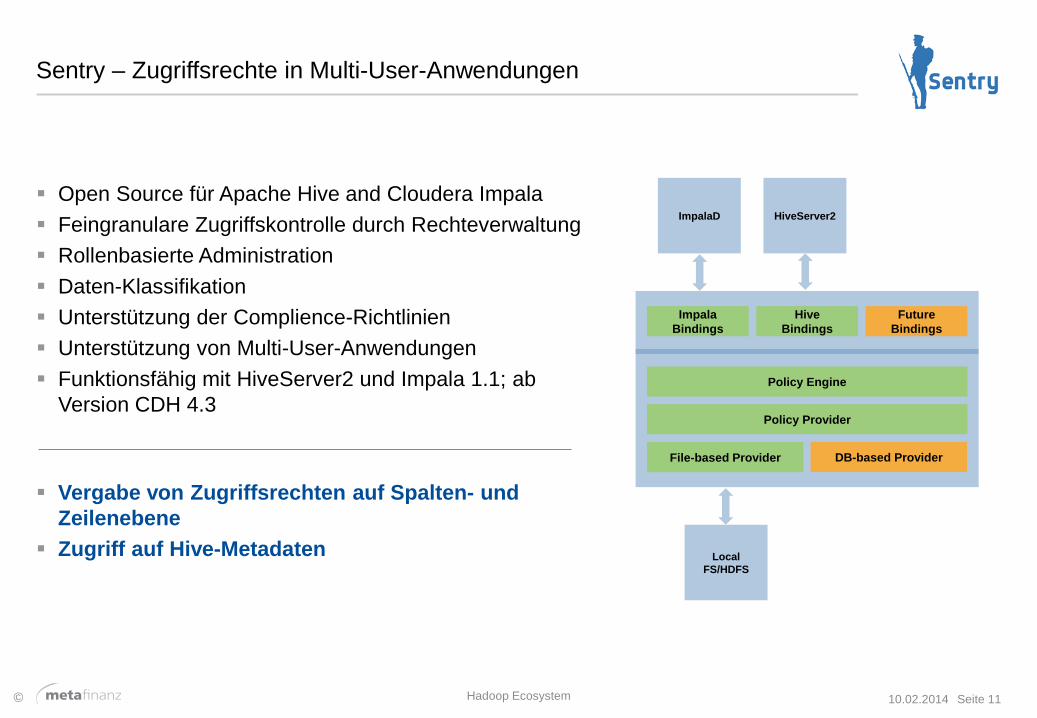
Sentry – Zugriffsrechte in Multi-User-Anwendungen
Open Source für Apache Hive and Cloudera Impala
Feingranulare Zugriffskontrolle durch Rechteverwaltung
Rollenbasierte Administration
Daten-Klassifikation
Unterstützung der Complience-Richtlinien
Unterstützung von Multi-User-Anwendungen
Funktionsfähig mit HiveServer2 und Impala 1.1; ab
Version CDH 4.3
Vergabe von Zugriffsrechten auf Spalten- und
Zeilenebene
Zugriff auf Hive-Metadaten
Hadoop Ecosystem 10.02.2014 Seite 11
Impala
Bindings
Hive
Bindings
Future
Bindings
Policy Engine
Policy Provider
File-based Provider DB-based Provider
ImpalaD HiveServer2
Local
FS/HDFS

©
Sentry – sentry-provider.ini
[databases]
db_test1 = /projects/db_test1-sentry-provider.ini
db_test2 = /projects/db_test2-sentry-provider.ini
[groups]
group_admin = admin_role
group_user_sales = user_sales_role
[roles]
admin_role = server=server1, \
server=server1->uri=hdfs://nameservice1/projects/
user_sales_role = server=server1, \
server=server1->uri=hdfs://nameservice1/projects/sales
Hadoop Ecosystem 10.02.2014 Seite 12

©
Sqoop 5
©
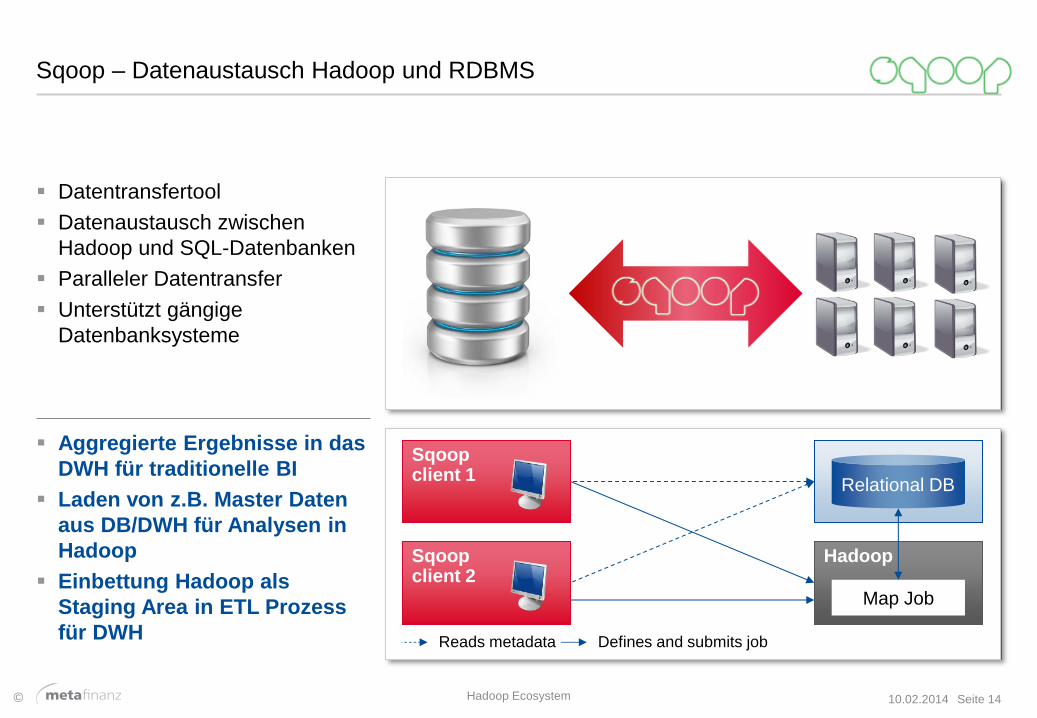
Sqoop – Datenaustausch Hadoop und RDBMS
Datentransfertool
Datenaustausch zwischen
Hadoop und SQL-Datenbanken
Paralleler Datentransfer
Unterstützt gängige
Datenbanksysteme
Aggregierte Ergebnisse in das
DWH für traditionelle BI
Laden von z.B. Master Daten
aus DB/DWH für Analysen in
Hadoop
Einbettung Hadoop als
Staging Area in ETL Prozess
für DWH
Hadoop
Relational DB
Map Job
Reads metadata Defines and submits job
Sqoop client 2
Sqoop client 1
Hadoop Ecosystem 10.02.2014 Seite 14

©
Pig 6
©
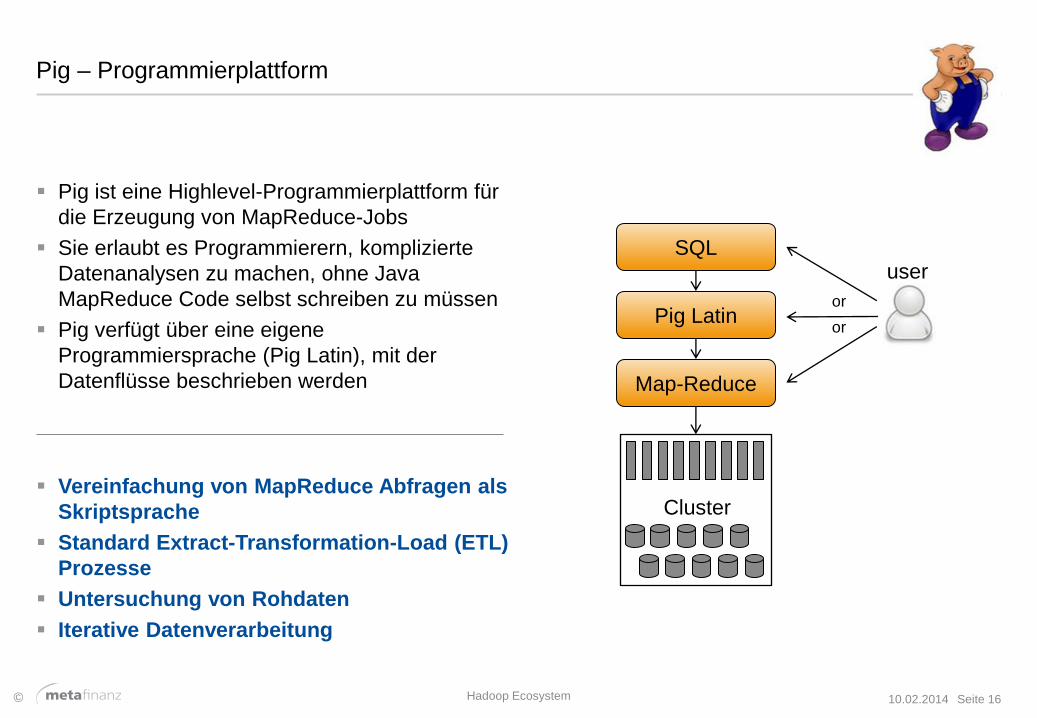
Pig – Programmierplattform
Pig ist eine Highlevel-Programmierplattform für
die Erzeugung von MapReduce-Jobs
Sie erlaubt es Programmierern, komplizierte
Datenanalysen zu machen, ohne Java
MapReduce Code selbst schreiben zu müssen
Pig verfügt über eine eigene
Programmiersprache (Pig Latin), mit der
Datenflüsse beschrieben werden
Vereinfachung von MapReduce Abfragen als
Skriptsprache
Standard Extract-Transformation-Load (ETL)
Prozesse
Untersuchung von Rohdaten
Iterative Datenverarbeitung
10.02.2014 Seite 16
user
or
or
SQL
Pig Latin
Map-Reduce
Cluster
Hadoop Ecosystem

©
Pig – Programmierplattform
Hadoop Ecosystem
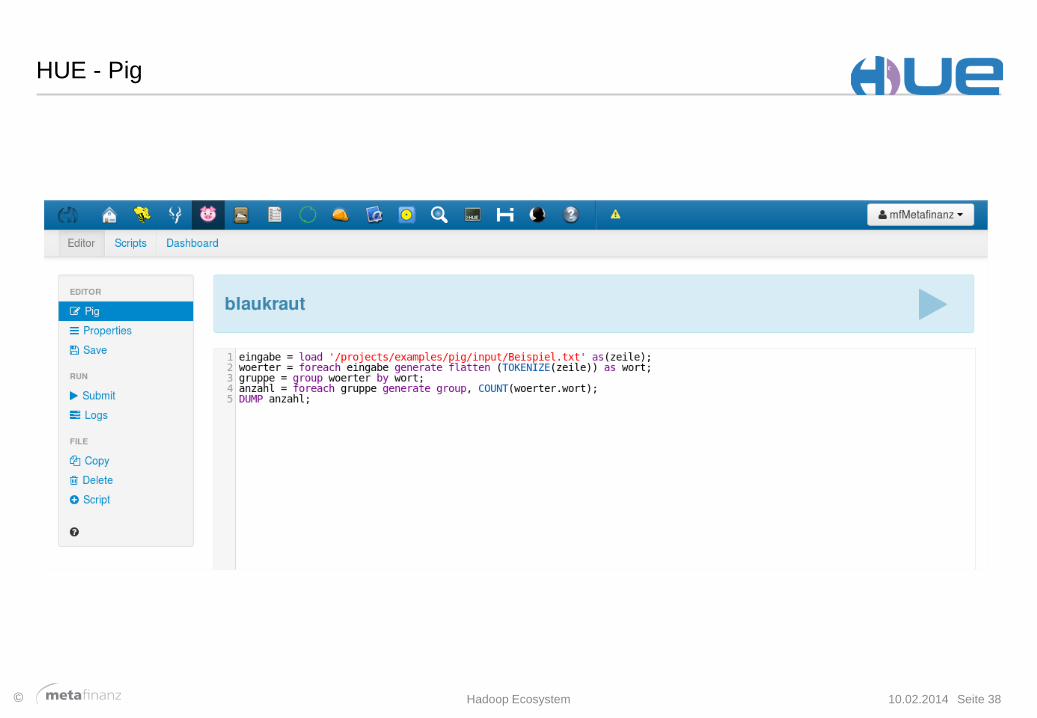
eingabe = load '/projects/examples/pig/input/Beispiel.txt' as(zeile);
woerter = foreach eingabe generate flatten (TOKENIZE(zeile)) as wort;
gruppe = group woerter by wort;
anzahl = foreach gruppe generate group, COUNT(woerter.wort);
DUMP anzahl;
(und,1)
(bleibt,2)
(Blaukraut,2)
(Brautkleid,2)
Blaukraut bleibt Blaukraut
und Brautkleid bleibt Brautkleid
Beispiel.txt
Beispiel WordCount
10.02.2014 Seite 17

©
Giraph 7
©
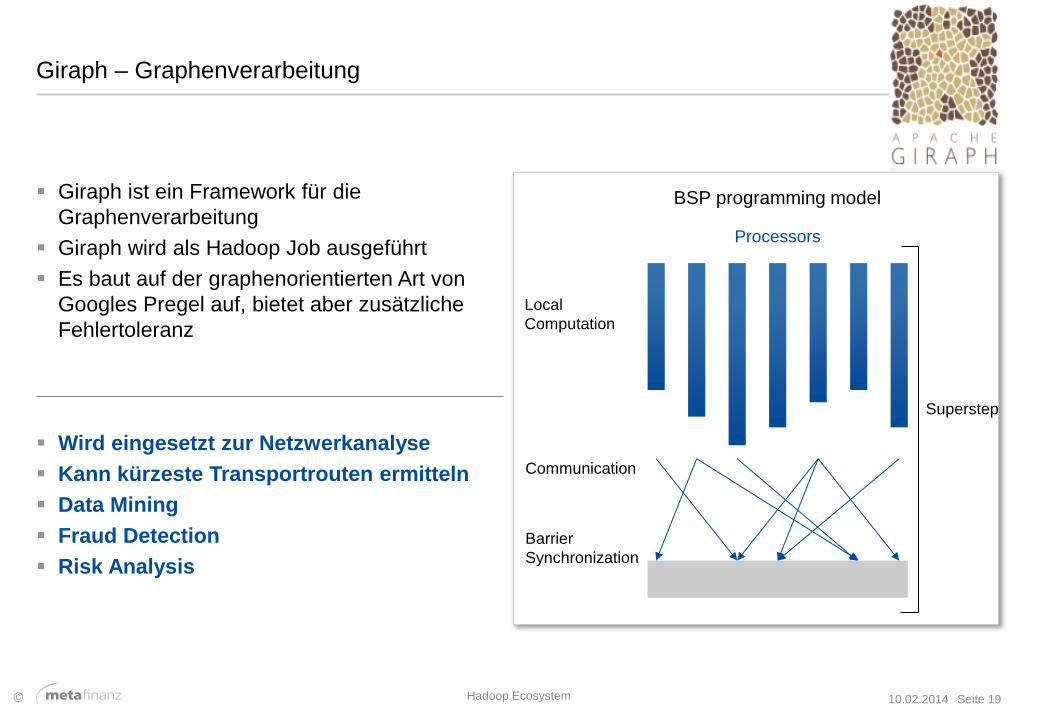
Giraph – Graphenverarbeitung
Giraph ist ein Framework für die
Graphenverarbeitung
Giraph wird als Hadoop Job ausgeführt
Es baut auf der graphenorientierten Art von
Googles Pregel auf, bietet aber zusätzliche
Fehlertoleranz
Wird eingesetzt zur Netzwerkanalyse
Kann kürzeste Transportrouten ermitteln
Data Mining
Fraud Detection
Risk Analysis
Local
Computation
Communication
Barrier
Synchronization
Processors
BSP programming model
Superstep
Hadoop Ecosystem 10.02.2014 Seite 19

©
Mahout 8
©
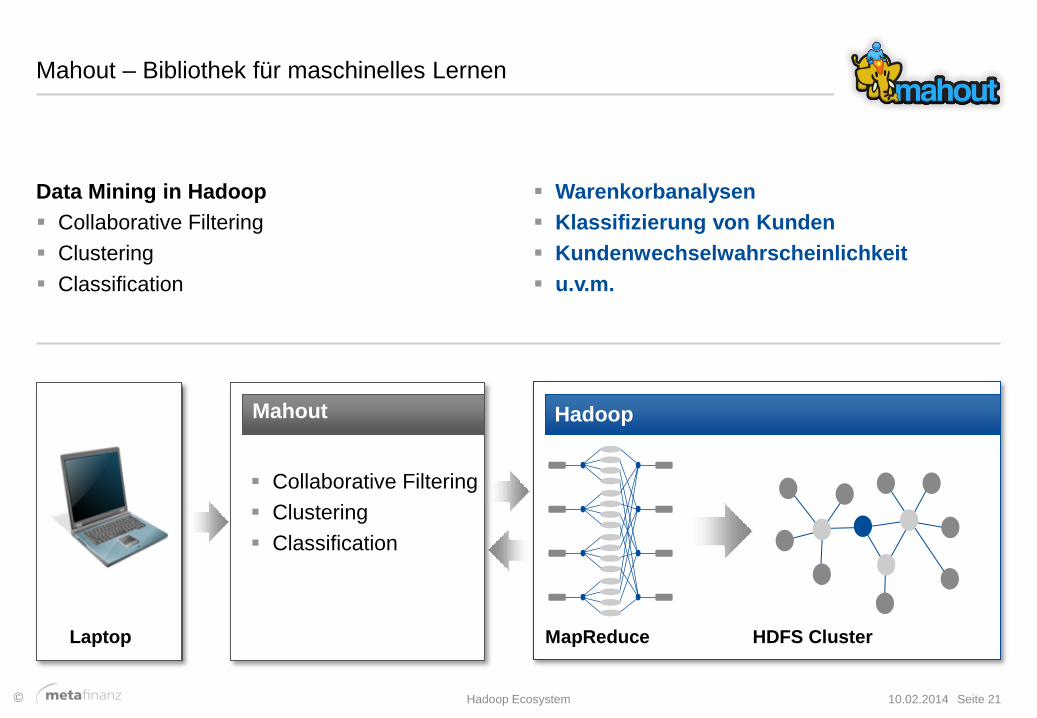
Mahout – Bibliothek für maschinelles Lernen
Warenkorbanalysen
Klassifizierung von Kunden
Kundenwechselwahrscheinlichkeit
u.v.m.
Data Mining in Hadoop
Collaborative Filtering
Clustering
Classification
Laptop
Mahout
Collaborative Filtering
Clustering
Classification
Hadoop
MapReduce HDFS Cluster
10.02.2014 Hadoop Ecosystem Seite 21

©
HBase 9

©
HBase - NoSQL Datenbank
Verteilte NoSQL- Datenbank
Multi-dimensional
Nur eine Spalte indiziert ("Key-Value")
Einzelsatzverarbeitung inkl. Updates
Schneller Zugriff auf Einzelsätze
Benutzerprofile für Web-Anwendungen
Warenkörbe
Analyseergebnisse aus HDFS
Client
HRegion-
Server
HRegion-
Server
HRegion-
Server
ZooKeeper
ZooKeeper
ZooKeeper
ZooKeeper
ZooKeeper
HMaster
HDFS HDFS
HDFS HDFS
Hadoop Ecosystem 10.02.2014 Seite 23

©
HBase - NoSQL Datenbank
Hadoop Ecosystem
create 'blogposts', 'post', 'image'
put 'blogposts', 'row1', 'post:title', 'Hello World'
put 'blogposts', 'row1', 'post:author', 'The Author'
put 'blogposts', 'row1', 'image:bodyimage', 'image.jpg'
get 'blogposts', 'row1'
COLUMN CELL
image:bodyimage timestamp=1390902504848, value=image.jpg
post:author timestamp=1390902473758, value=The Author
post:title timestamp=1390902453844, value=Hello World
3 row(s) in 0.0390 seconds
Anlegen der Tabelle
'blogposts' mit den
Spaltenfamilien 'post' und
'image'
Hinzufügen von Daten
Ausgabe einer einzelnen
Zeile: row1
Datensätze schreiben und lesen
10.02.2014 Seite 24

©
File Formats 10

©
Sequence Files sind Dateien, die vor allem für die performante Verarbeitung von Daten bei
MapReduce verwendet werden
Sequence Files
Dateien, die binär kodierte Schlüssel-Wert-Paare enthalten
Geeignet zur Verarbeitung aller Hadoop-Datentypen
Enthalten Metadaten, die den Datentyp des Schlüssels und des
dazugehörigen Wertes identifizieren
Angeboten werden drei verschiedene Dateiformate für Sequence Files:
Uncompressed key/value records.
Record compressed key/value records
Block compressed key/value records
10.02.2014 Hadoop Ecosystem Seite 26

©
Avro ist ein Datenserialisierungsframework, das einfach angewendet
werden kann und viele Möglichkeiten bietet.
Apache Avro
Apache Avro™ ist ein Datenserialisierungsframework.
Avro bietet:
reichhaltige Datenstrukturen
kompaktes, schnelles, binäres Datenformat
Container Datei zur persistenten Datenspeicherung
10.02.2014 Hadoop Ecosystem Seite 27

©
Parquet – spaltenbasiertes, binäres Speicherformat für Hadoop
Parquet
Verarbeitung der Daten mit Hive, Impala, Pig, MapReduce
Unterstützt die Speicherung geschachtelter Daten
Legt spaltenweise individuelle Kompressionsmodelle fest
Komprimierung erfolgt mit Snappy oder GZIP
10.02.2014 Hadoop Ecosystem Seite 28

©
Flume 11
©
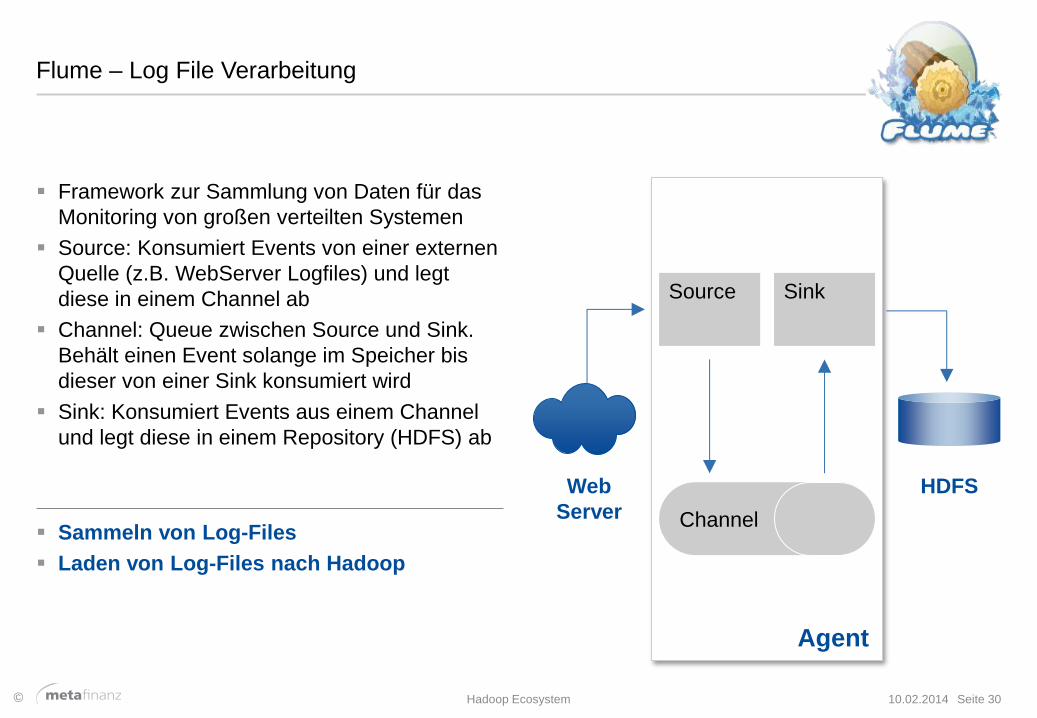
Flume – Log File Verarbeitung
Framework zur Sammlung von Daten für das
Monitoring von großen verteilten Systemen
Source: Konsumiert Events von einer externen
Quelle (z.B. WebServer Logfiles) und legt
diese in einem Channel ab
Channel: Queue zwischen Source und Sink.
Behält einen Event solange im Speicher bis
dieser von einer Sink konsumiert wird
Sink: Konsumiert Events aus einem Channel
und legt diese in einem Repository (HDFS) ab
Sammeln von Log-Files
Laden von Log-Files nach Hadoop
Agent
Source Sink
Channel
Web
Server
HDFS
10.02.2014 Hadoop Ecosystem Seite 30

©
Oozie 12
©
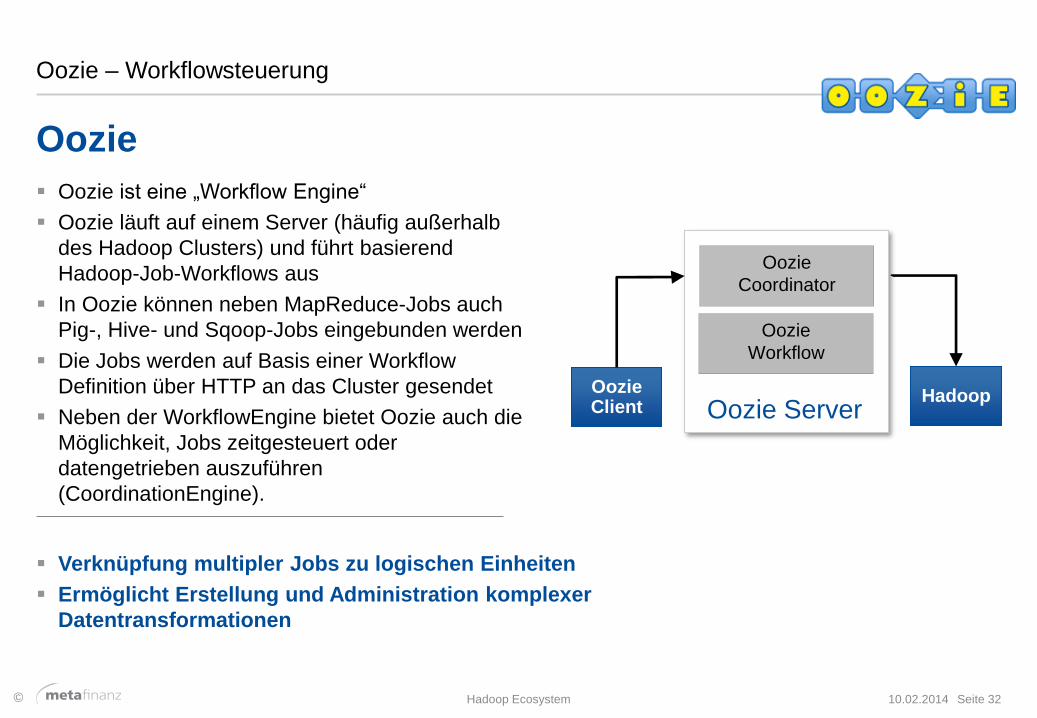
Oozie – Workflowsteuerung
Oozie ist eine „Workflow Engine“
Oozie läuft auf einem Server (häufig außerhalb
des Hadoop Clusters) und führt basierend
Hadoop-Job-Workflows aus
In Oozie können neben MapReduce-Jobs auch
Pig-, Hive- und Sqoop-Jobs eingebunden werden
Die Jobs werden auf Basis einer Workflow
Definition über HTTP an das Cluster gesendet
Neben der WorkflowEngine bietet Oozie auch die
Möglichkeit, Jobs zeitgesteuert oder
datengetrieben auszuführen
(CoordinationEngine).
Verknüpfung multipler Jobs zu logischen Einheiten
Ermöglicht Erstellung und Administration komplexer
Datentransformationen
Oozie
10.02.2014 Hadoop Ecosystem Seite 32
Oozie Client Oozie Server
Oozie
Coordinator
Oozie
Workflow
Hadoop
©
Oozie – Workflowsteuerung
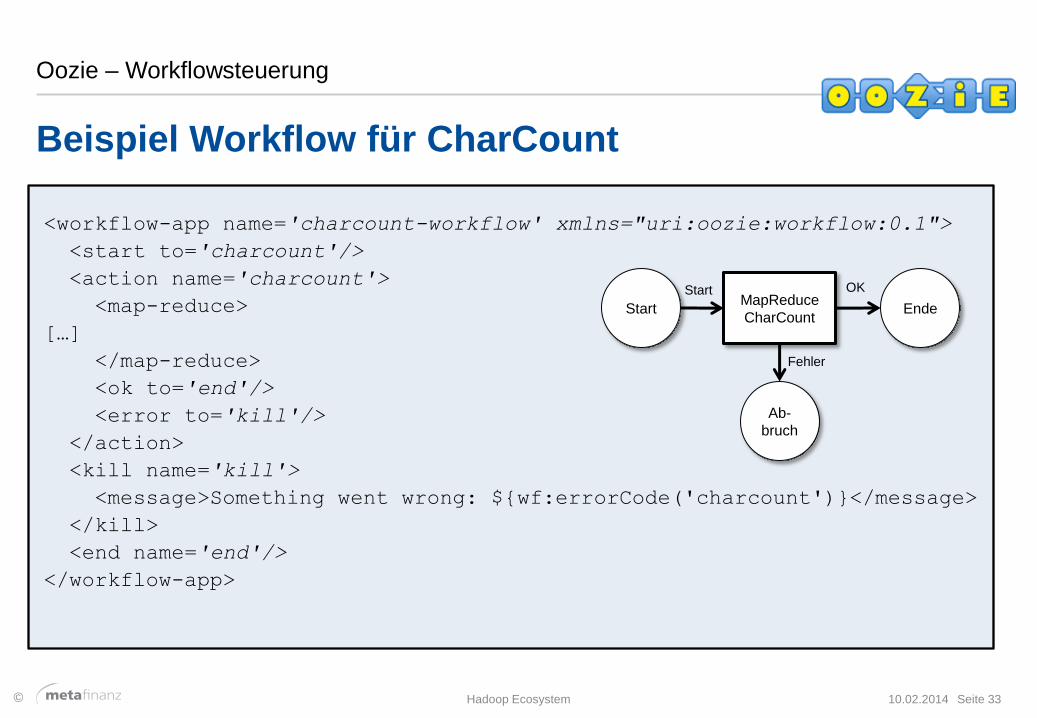
<workflow-app name='charcount-workflow' xmlns="uri:oozie:workflow:0.1">
<start to='charcount'/>
<action name='charcount'>
<map-reduce>
[…]
</map-reduce>
<ok to='end'/>
<error to='kill'/>
</action>
<kill name='kill'>
<message>Something went wrong: ${wf:errorCode('charcount')}</message>
</kill>
<end name='end'/>
</workflow-app>
Start Ende
Ab-
bruch
MapReduce
CharCount
Start OK
Fehler
Beispiel Workflow für CharCount
10.02.2014 Hadoop Ecosystem Seite 33

©
HUE 13
©
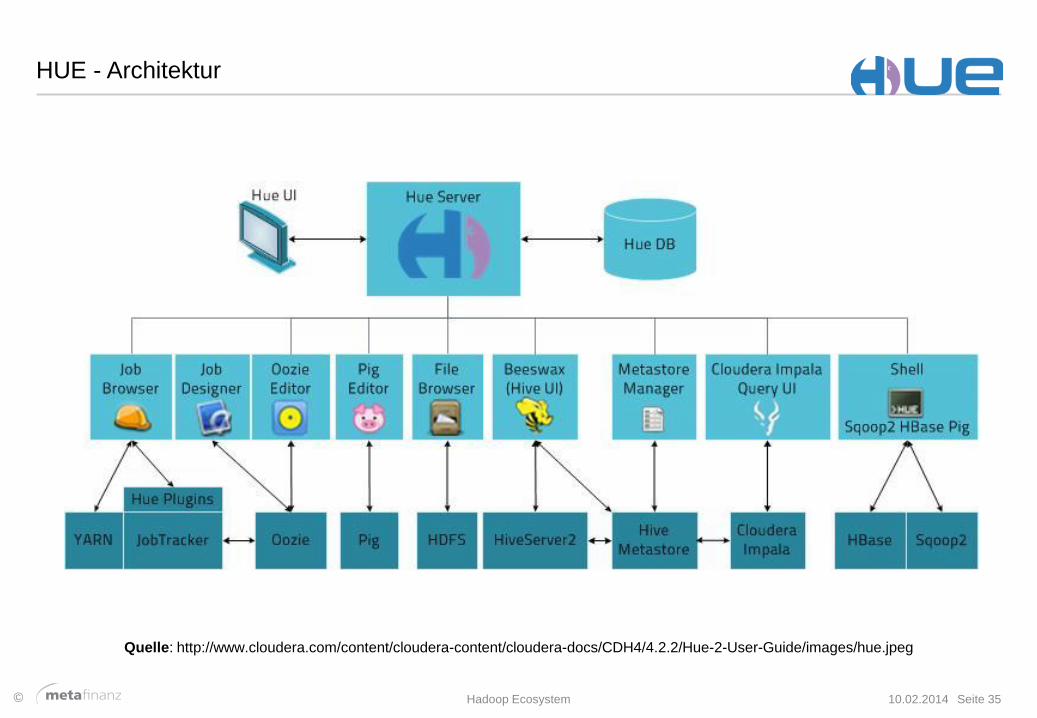
HUE - Architektur
10.02.2014 Hadoop Ecosystem Seite 35
Quelle: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/4.2.2/Hue-2-User-Guide/images/hue.jpeg
©
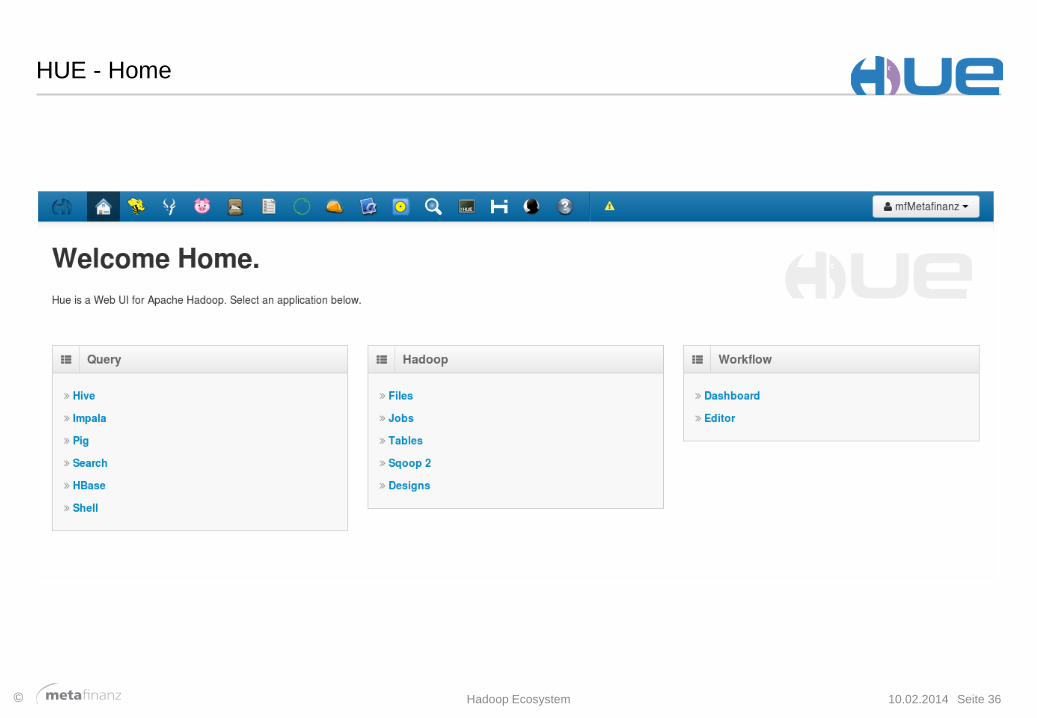
HUE - Home
10.02.2014 Hadoop Ecosystem Seite 36
©
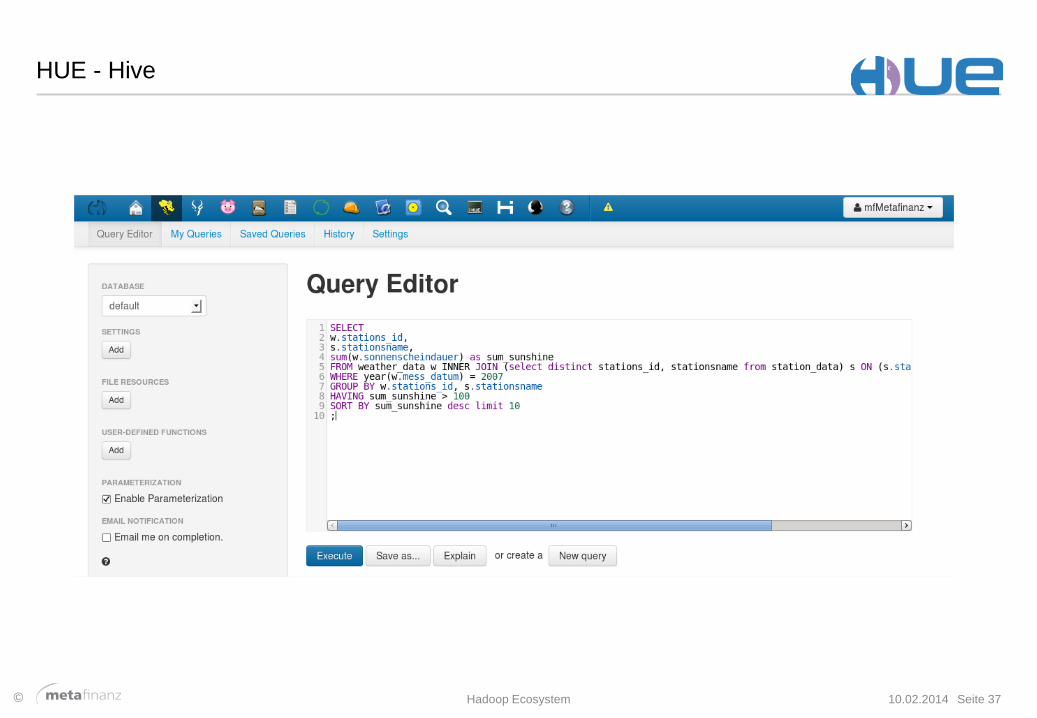
HUE - Hive
10.02.2014 Hadoop Ecosystem Seite 37
©
HUE - Pig
10.02.2014 Hadoop Ecosystem Seite 38
©
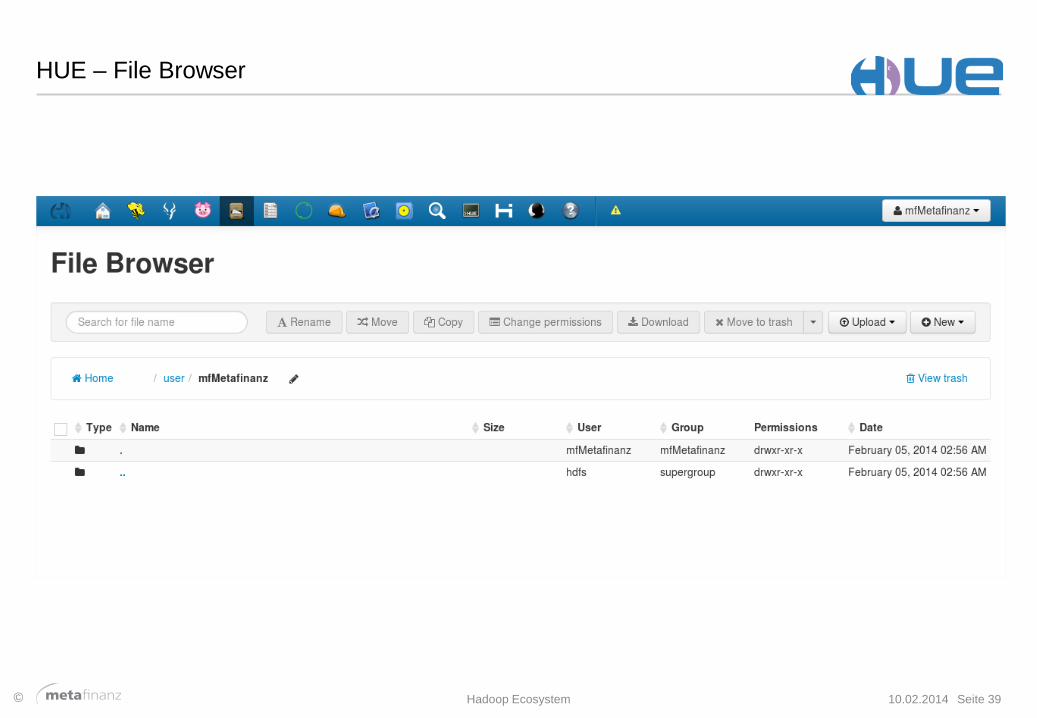
HUE – File Browser
10.02.2014 Hadoop Ecosystem Seite 39

©
ZooKeeper 14
©
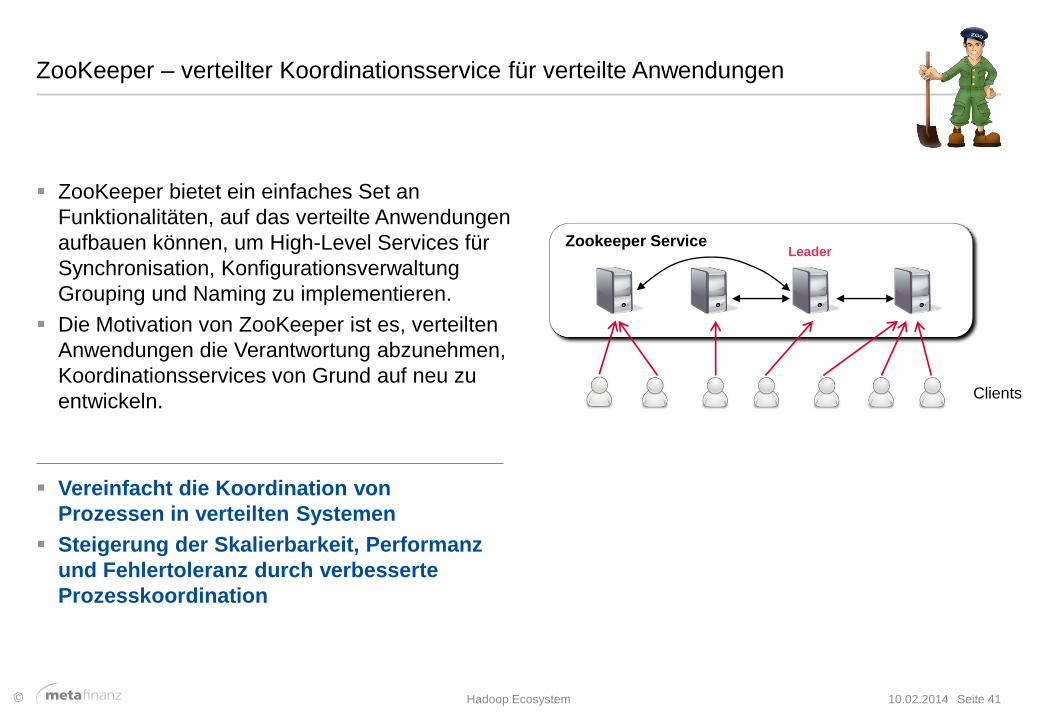
ZooKeeper – verteilter Koordinationsservice für verteilte Anwendungen
ZooKeeper bietet ein einfaches Set an
Funktionalitäten, auf das verteilte Anwendungen
aufbauen können, um High-Level Services für
Synchronisation, Konfigurationsverwaltung
Grouping und Naming zu implementieren.
Die Motivation von ZooKeeper ist es, verteilten
Anwendungen die Verantwortung abzunehmen,
Koordinationsservices von Grund auf neu zu
entwickeln.
Vereinfacht die Koordination von
Prozessen in verteilten Systemen
Steigerung der Skalierbarkeit, Performanz
und Fehlertoleranz durch verbesserte
Prozesskoordination
10.02.2014 Hadoop Ecosystem Seite 41
Clients
Zookeeper Service Leader

©
Cloudera Manager 15

©
Cloudera Manager – End-to-End Administration für Hadoop
Manage Einfache Installation, Konfiguration und Betrieb von
Hadoop-Clustern durch zentralgesteuerter, intuitiver
Administration für alle Services, Hosts und Workflows.
Monitor Zentrale Sicht auf alle Aktivitäten im Cluster durch
Heatmaps, proaktive Tests und Warnungen.
Diagnose Einfache Diagnose und Problemlösung durch Operational
Reports und Dashboards, Events, Intuitive Log Viewing,
Audit Trails und Integration mit dem Cloudera Support.
Cloudera Manager
10.02.2014 Hadoop Ecosystem Seite 43
©
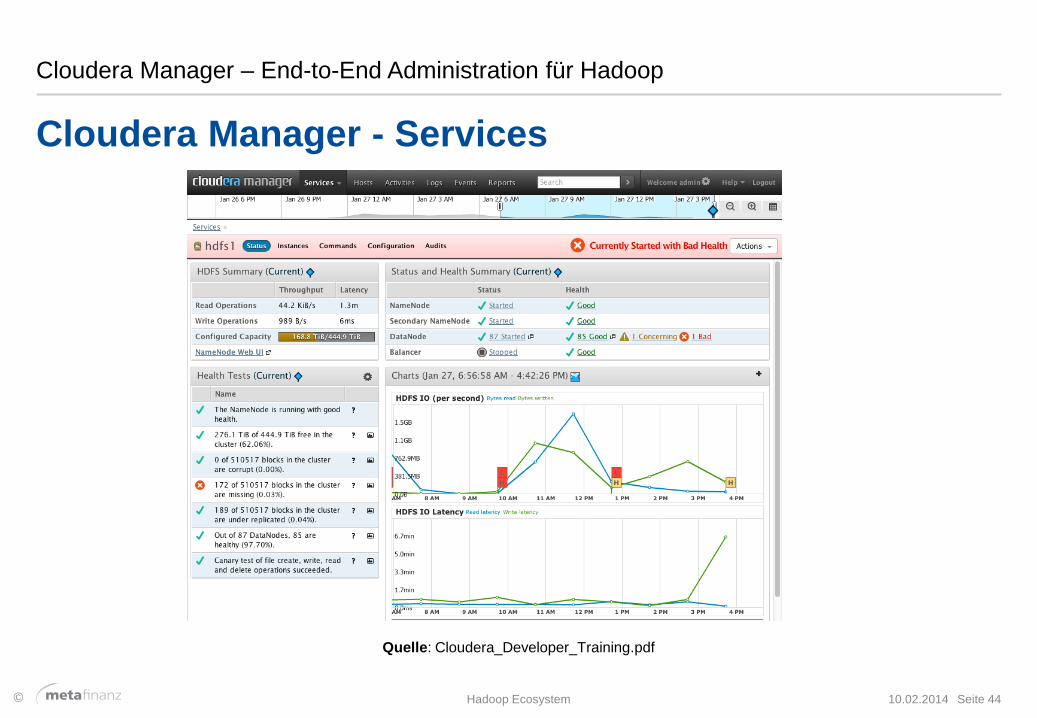
Cloudera Manager – End-to-End Administration für Hadoop
Cloudera Manager - Services
10.02.2014 Hadoop Ecosystem Seite 44
Quelle: Cloudera_Developer_Training.pdf

©
Cloudera Manager – End-to-End Administration für Hadoop
Cloudera Manager - Activities
10.02.2014 Hadoop Ecosystem Seite 45
Quelle: Cloudera_Developer_Training.pdf
©
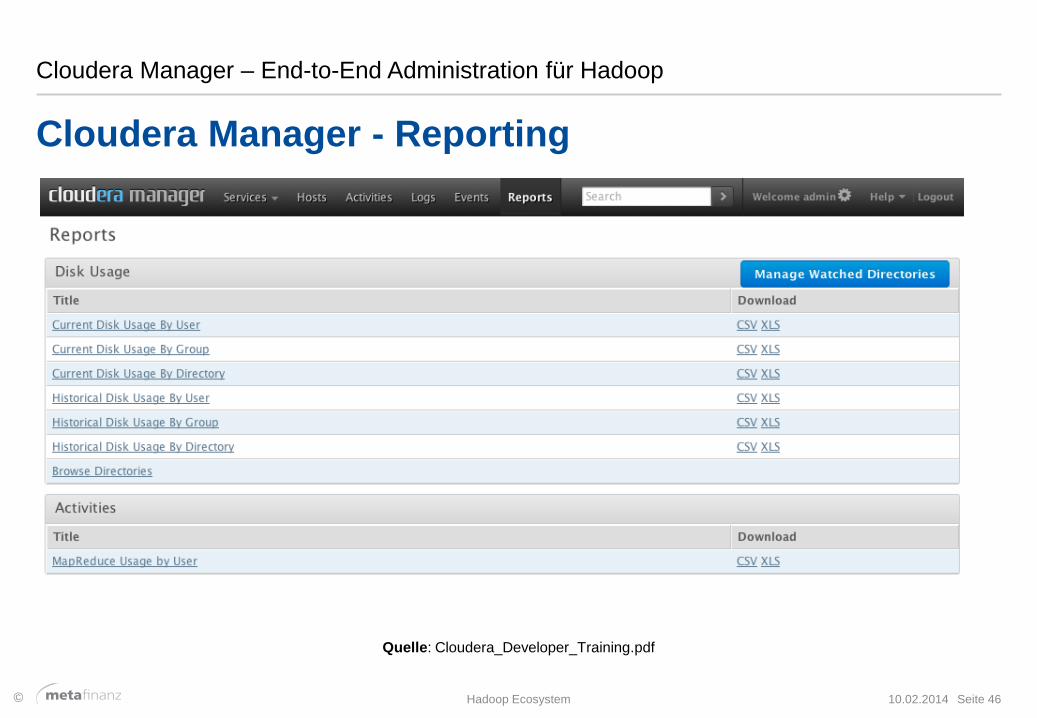
Cloudera Manager – End-to-End Administration für Hadoop
Cloudera Manager - Reporting
10.02.2014 Seite 46 Hadoop Ecosystem
Quelle: Cloudera_Developer_Training.pdf

©
Cloudera Manager – End-to-End Administration für Hadoop
Cloudera Manager – Authorization Manager
10.02.2014 Seite 47 Hadoop Ecosystem
Quelle: Cloudera_Developer_Training.pdf

©
Wir bieten offene Trainings an sowie maßgeschneiderte Trainings für individuelle Kunden.
metafinanz training
Einführung Hadoop (1 Tag)
Einführung Oracle in-memory Datenbank TimesTen
Data Warehousing & Dimensionale Modellierung
Oracle SQL Tuning
OWB Skripting mit OMB*Plus
Oracle Warehousebuilder 11.2 New Features
Einführung in Oracle: Architektur, SQL und PL/SQL
Mehr Information unter http://www.metafinanz.de/news/schulungen
All trainings are also available in English on request.
Hadoop Intensiv-Entwickler Training (3 Tage)
Seite 48 Hadoop Ecosystem 10.02.2014

©
Hadoop Ecosystem
Fragen? Jetzt …
Carsten Herbe
Head of Data Warehousing
mail [email protected]
phone +49 89 360531 5039
… oder später?
Hadoop Ecosystem
Downloads unter
dwh.metafinanz.de

DWH & Hadoop Expertise
http://dwh.metafinanz.de
Besuchen Sie uns auch auf:
metafinanz Informationssysteme GmbH
Leopoldstraße 146
D-80804 München
Phone: +49 89 360531 - 0
Fax: +49 89 350531 - 5015
Email: [email protected]
www.metafinanz.de
Vielen Dank für Ihre Aufmerksamkeit!


















