GPU, CUDA, OpenCL and OpenACC for Parallel Applications
60
GPU, CUDA e OpenCL for parallel Applications Ms. Eng. Marcos Amar´ ıs Gonz´ alez Dr. Alfredo Goldman vel Lejbman University of S˜ ao Paulo Institute of Mathematics an Statistics Department of Science Computing April, 2014 (gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 0 / 52
-
Upload
marcos-gonzalez -
Category
Software
-
view
121 -
download
0
Transcript of GPU, CUDA, OpenCL and OpenACC for Parallel Applications

GPU, CUDA e OpenCL for parallel Applications
Ms. Eng. Marcos Amarıs GonzalezDr. Alfredo Goldman vel Lejbman
University of Sao PauloInstitute of Mathematics an Statistics
Department of Science Computing
April, 2014
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 0 / 52

Timeline
1 GPUs e GPGPU
2 CUDAProfiling e Optimizacoes
3 OpenCL e OpenACC
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 0 / 52

GPUs
GPU, CUDA e OpenCL for parallel Applications
1 GPUs e GPGPU
2 CUDA
3 OpenCL e OpenACC
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 0 / 52

GPUs
Introducao
80’ primeiro controlador de vıdeo.
Evolucao dos jogos 3D.
Maior poder computacional.
Alem de gerar o cenario 3D, e precisoaplicar texturas, iluminacao, som-bras, reflexoes, etc.
Para tal, as placas graficas pas-saram a ser cada vez mais flexıveise poderosas
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 1 / 52

GPUs
Introducao
O termo GPU foi popularizado pela Nvidia em1999, que inventou a GeForce 256 como aprimeira GPU no mundo.
No 2002 fou lancada a primeira GPU paraproposito geral.
O termo GPGPU foi cunhado por Mark Harris.
Os principais fabricantes de GPUs sao a NVIDIAe a AMD.
2005 NVIDIA lancou CUDA, 2008 grupoKhronos lancou OpenCL, 2011 foi anunciadoOpenACC.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 2 / 52

GPUs
GPU de Proposito Geral
GPGPU (GPU de Proposito Geral).GPGPU podem atuar em conjunto com CPUs Intel ou AMD.Paralelismo do tipo SIMD.Programa principal executa na CPU (host) e e o responsavel por iniciar as threadsna GPU (device).Tem sua propria hierarquia de memoria e os dados devem ser transferidos atravesde um barramento PCI Express.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 3 / 52

GPUs
Lei de Amdahl e Taxonomia de Flynn
Lei de Amdahl - 1967
A Lei de Amdahl e a lei que governa o speedup na utilizacao de proces-sadores paralelos em relacao ao uso de apenas um processador.
Speedup:S = Speed-upP = Number of ProcessorsT = Time
Sp =T1
Tp(1)
Taxonomia de Flynn - 1966
Single Instruction Multiple InstructionSingle Data SISD - Sequential MISD
Multiple Data SIMD [SIMT] - GPU MIMD - Multicore
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 4 / 52

GPUs
Medidas de desempenho: FLOPS
FLOPS - FLoating-point Operations Per Second
Operacoes de ponto flutuante por segundo
Forma simples: medir o numero de instrucoes por unidade de tempo.No caso, instrucoes de ponto flutuante.
Linpack (sistemas densos de equacoes lineares)Melhor relacao desempenho/custo (Gflops/ $$);Melhor relacao desempenho/consumo (Gflops/Watts);Melhor relacao desempenho/volume (Gflops/Volume).
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 5 / 52

GPUs
GPU Versus CPU
Hoje em dia elas sao capaz de realizar a computacao paralela mais eficientedo que CPUs multicore.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 6 / 52

GPUs
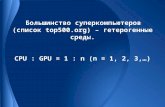
Top 500 Supercomputers
Intel Core i7 990X: 6 nucleos, US$ 1000 Desempenho teorico maximo de 0.4 TFLOP
GTX680: 1500 nucleos e 2GB, preco US$500 Desempenho teorico maximo de 3.0 TFLOP
Aceleradores e co-processadores no ranking dos 500 Supercomputadores mais rapidos do mundo.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 7 / 52

GPUs
Top 500 Green Supercomputers ≫ $$$$$$
Ranking dos supercomputadores mais eficientes no mundo em termos deenergia.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 8 / 52

GPUs
RoadMap de Arquiteturas de GPU NVIDIA
Em GPUs modernas o consumo de energia e uma restricao importante.Projetos de GPU sao geralmente altamente escalavel.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 9 / 52

GPUs
RoadMap de Arquiteturas de GPU NVIDIA
Em GPUs modernas o consumo de energia e uma restricao importante.Projetos de GPU sao geralmente altamente escalavel.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 9 / 52

GPUs
RoadMap de Arquiteturas de GPU NVIDIA
Compute Capability e uma diferenciacao entre arquiteturas e modelos deGPUs da NVIDIA, para certas especificacoes de hardware e software emelas.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 10 / 52

GPUs
Arquitetura de uma GPU NVIDIA
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 11 / 52

GPUs
Arquitetura Tesla
Arquitetura Tesla, ela e umas das primeiras com suporte a CUDA. Seu mul-tiprocessador tem 8 processadores e ate 16 Kb de memoria compartilhada.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 12 / 52

GPUs
Arquitetura Fermi
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 13 / 52

GPUs
Escalonador de WarpsOcultar latencia
1 escalonador de Warps em arquiteturas Tesla, 2 na arquitetura Fermi eKepler tem 4 escalonadores de Warp.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 14 / 52

GPUs
Escalonador de WarpsOcultar latencia
1 escalonador de Warps em arquiteturas Tesla, 2 na arquitetura Fermi eKepler tem 4 escalonadores de Warp.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 14 / 52

GPUs
Arquitetura Kepler
Arquitetura Kepler tem um multiprocessador (SMX) de 192 processadores,32 SFU, 32 unidades de escrita e leitura, arquivo de 64 kb de registradores,etc...
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 15 / 52

GPUs
Arquitetura Kepler
Arquitetura Kepler tem um multiprocessador (SMX) de 192 processadores,32 SFU, 32 unidades de escrita e leitura, arquivo de 64 kb de registradores,etc...
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 15 / 52

CUDA
GPU, CUDA e OpenCL for parallel Applications
1 GPUs e GPGPU
2 CUDA
3 OpenCL e OpenACC
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 15 / 52

CUDA
Compute Unified Device Architecture
CUDA - Compute Unified Device Architecture
CUDA e uma linguagem proprietaria para programacao em GPUs desenvolvida pelaNVIDIA.O CUDA esta na versao 7.0 atualmente, avanca tambem segundo o ComputeCapability das GPUs.Ela e uma extensao da linguagem C, e permite controlar a execucao de threads naGPU e gerenciar sua memoria.
Ambiente CUDA
CUDA Driver
CUDA Toolkit
CUDA SKD
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 16 / 52

CUDA
Compute Capability
As GPUs com compute capability 3.5 podem fazer uso do paralelismodinamico e Hyper-Q.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 17 / 52

CUDA
Paralelismo dinamico
Permite que segmentos de processamento da GPU gerem dinamicamentenovos segmentos, possibilitando que a GPU se adapte de modo dinamicoaos dados
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 18 / 52

CUDA
Hyper-Q
Permite que ate 32 processos MPI sejam lancados simultaneamente em umaGPU. O Hyper-Q e ideal para aplicacoes de cluster que usam MPI.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 19 / 52

CUDA
Funcoes Kernel
Threads executam o codigo definido em uma funcao kernel. A chamada da funcaokernel, dispara a execucao de N instancias paralelas para N threads.
Executado sobre So e chamada desdedevice float deviceFunction() device device.global float KernelFunction() device device/host.
host float hostFunction() host host.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 20 / 52

CUDA
Funcoes de Transferencia e Manipulacao de dados
Se declaram e alocam as variaveis no host e no device.
* cudaMalloc(void **pointer, size_t nbytes)
* cudaMemcpy(void *dst, const void *src, size_t count, enum
cudaMemcpyKind kind)
* cudaFree(void *pointer)
cudaMemcpyKind
cudaMemcpyHostToHost I Host ⇒ Host
cudaMemcpyHostToDevice I Host ⇒ Device
cudaMemcpyDeviceToHost IDevice ⇒ Host
cudaMemcpyDeviceToDevice I Device ⇒ Device
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 21 / 52

CUDA
Exemplo: Soma de Vetores
Processo de Transferencia de dados para a GPU, execucao do kernel daSoma de Vetores e transferencia da solucao de cada bloco de threads.
// allocate the memory on the GPU
cudaMalloc( (void **)& dev_a , N*sizeof(float ));
cudaMalloc( (void **)& dev_b , N*sizeof(float ));
cudaMalloc( (void **)& dev_partial_c , GridSize*sizeof(float ));
// copy the arrays ’a’ and ’b’ to the GPU
cudaMemcpy( dev_a , host_a , N*sizeof(float), cudaMemcpyHostToDevice );
cudaMemcpy( dev_b , host_b , N*sizeof(float), cudaMemcpyHostToDevice );
VecAdd <<<GridSize ,BlockSize >>>( dev_a , dev_b , dev_partial_c , N );
// copy the array ’c’ back from the GPU to the CPU
cudaMemcpy( host_partial_c , dev_partial_c , GridSize*sizeof(float),
cudaMemcpyDeviceToHost );
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 22 / 52

CUDA
Organizacao da Execucao
Uma chamada a uma funcao kernel cria um grid de blocos de threads, asquais executam o codigo.
Um SM, SMX ou SMM executa um ou mais blocos de threads e os cores eoutras unidades de execucao no multiprocessador executam as instrucoes decada thread.
Variaveis e palavras reservadas sao identificadores de cada thread dentro deum bloco.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 23 / 52

CUDA
Modelo de Programacao
Organizado em grids, blocos e threads. Threads sao agrupadas em blocos e estessao agrupados em um grid.Traducao para enderecamento linear para saber o id de uma thread em um grid.
Para saber a posicao de uma thread usamos as palavras reservadas:
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 24 / 52

CUDA
Espacos de Memoria sobre um dispositivo CUDA
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 25 / 52

CUDA
Espacos de Memoria sobre um dispositivo CUDA
A latencia de acesso a memoria global e 100x que da memoria com-partilhada.
Tem palavras reservadas para a declaracao das variaveis a ser alocadasem cada nıvel de memoria.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 26 / 52

CUDA
./devicequery
Device 0: "GeForce GTX 295"
CUDA Driver Version / Runtime Version 6.0 / 5.5
CUDA Capability Major/Minor version number: 1.3
Total amount of global memory: 896 MBytes (939327488 bytes)
(30) Multiprocessors, ( 8) CUDA Cores/MP: 240 CUDA Cores
GPU Clock rate: 1242 MHz (1.24 GHz)
Memory Clock rate: 1000 Mhz
Memory Bus Width: 448-bit
Maximum Texture Dimension Size (x,y,z) 1D=(8192), 2D=(65536, 32768), 3D=(2048, 2048, 2048)
Maximum Layered 1D Texture Size, (num) layers 1D=(8192), 512 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(8192, 8192), 512 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes
Total number of registers available per block: 16384
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 512
Max dimension size of a thread block (x,y,z): (512, 512, 64)
Max dimension size of a grid size (x,y,z): (65535, 65535, 1)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 256 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): No
Device PCI Bus ID / PCI location ID: 4 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 27 / 52

CUDA
./devicequery
Device 1: "GeForce GT 630"
CUDA Driver Version / Runtime Version 5.5 / 5.5
CUDA Capability Major/Minor version number: 2.1
Total amount of global memory: 2048 MBytes (2147155968 bytes)
( 2) Multiprocessors, ( 48) CUDA Cores/MP: 96 CUDA Cores
GPU Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 667 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 131072 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65535), 3D=(2048, 2048, 2048)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 32768
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (65535, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from GeForce GTX 660 (GPU0) -> GeForce GT 630 (GPU1) : No
> Peer access from GeForce GT 630 (GPU1) -> GeForce GTX 660 (GPU0) : No
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 5.5, CUDA Runtime Version = 5.5, NumDevs = 2, Device0 = GeForce GTX 660, Device1 = GeForce GT 630
Result = PASS
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 28 / 52

CUDA
./deviceQuery Starting...
Device 0: "Tesla K40c"
CUDA Driver Version / Runtime Version 6.5 / 5.5
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 11520 MBytes (12079136768 bytes)
(15) Multiprocessors, (192) CUDA Cores/MP: 2880 CUDA Cores
GPU Clock rate: 745 MHz (0.75 GHz)
Memory Clock rate: 3004 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Version = 5.5, NumDevs = 1,
Device0 = Tesla K40c Result = PASS
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 29 / 52

CUDA
Multiplicacao de Matrizes em CUDA - I
Esquema de paralelizacao e kernel da multiplicacao de matrizes por padraocom CUDA.
__global__ void matMul(float* Pd, float* Md,
float* Nd , int N) {
float Pvalue = 0.0;
int j = blockIdx.x * tWidth + threadIdx.x;
int i = blockIdx.y * tWidth + threadIdx.y;
for (int k = 0; k < N; ++k)
Pvalue += Md[j * N + k] * Nd[k * N + i];
Pd[j * N + i] = Pvalue;
}
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 30 / 52

CUDA
Multiplicacao de Matrizes em CUDA - II
Esquema da Multiplicacao de Matrizes usando memoria compartilhada emCUDA:
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 31 / 52

CUDA
Kernel da Multiplicacao de Matrizes usando memoria compartilhada emCUDA:__global__ void matMul(float* Pd, float* Md,
float* Nd , int N){
__shared__ float Mds[tWidth ][ tWidth ];
__shared__ float Nds[tWidth ][ tWidth ];
int tx = threadIdx.x;
int ty = threadIdx.y;
int Col = blockIdx.x * tWidth + tx;
int Row = blockIdx.y * tWidth + ty;
float Pvalue = 0;
for (int m = 0; m < N/tWidth; ++m) {
Mds[ty][tx] = Md[Row*N + (m*tWidth + tx)];
Nds[ty][tx] = Nd[Col + (m*tWidth + ty)*N];
__syncthreads ();
for (int k = 0; k < Tile_Width; ++k)
Pvalue += Mds[ty][k] * Nds[k][tx];
__syncthreads ();
}
Pd[Row * N + Col] = Pvalue;
}
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 32 / 52

CUDA Profiling e Optimizacoes
Ferramentas de Profiling
Ferramentas de Profiling oferecidas pela NVIDIA
Figura : Profiling Tools provided by NVIDIA
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 33 / 52

CUDA Profiling e Optimizacoes
NVIDIA Visual Profiling
Figura : Profile Discrete Cosine Transform(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 34 / 52

CUDA Profiling e Optimizacoes
Acessos Agrupados a Memoria
? A partir de GPUs de CC superior a 1.2.? Acessos agrupados realmente melhora o desempenho da aplicacao.? Se o endereco de base de um bloco e n, entao qualquer thread i dentro desse bloco deve acessaro endereco: (n+ i) ∗ typeOfRead.
Acessos Agrupados Acessos No Agrupados
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 35 / 52

CUDA Profiling e Optimizacoes
Conflito de Bancos na Memoria Compartilhada
A memoria compartilhada e dividida em modulos (tambem chamados debancos). Se duas posicoes de memoria ocorrem no mesmo banco, entaotemos um conflito de banco.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 36 / 52

CUDA Profiling e Optimizacoes
Figura : Achieved Occupancy metric in GTX-Titan
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 37 / 52

CUDA Profiling e Optimizacoes
Figura : Global Load Transactions metric in GTX-Titan
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 38 / 52

CUDA Profiling e Optimizacoes
Figura : Global Store Transactions metric in GTX-Titan
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 39 / 52

OpenCL
GPU, CUDA e OpenCL for parallel Applications
1 GPUs e GPGPU
2 CUDA
3 OpenCL e OpenACC
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 39 / 52

OpenCL
Open Computing LanguageModelo de plataforma
A linguagem serve como uma camada de abstracao ao hardware heterogeneo.
E composto por um host e um ou mais dispositivos OpenCL (OpenCL devices).
Cada dispositivo possui uma ou mais unidades de computacao (compute units).
Estes sao compostos por um conjunto de elementos de processamento (processing ele-ments).
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 40 / 52

OpenCL
Open Computing LanguageAplicacao e Funcoes Kernel em OpenCL
Uma aplicacao OpenCL deve seguir os seguintes passos:
1 Descobrir os componentes heterogeneos;
2 Detectar suas caracterısticas;
3 Criar os blocos de instrucoes (kernels) que irao executar na plataformaheterogenea;
4 Iniciar e manipular objetos de memoria;
5 Executar os kernels na ordem correta e nos dispositivos adequados pre-sentes no sistema;
6 Coletar os resultados finais.
( (gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 41 / 52

OpenCL
Contexto
Define o ambiente de execucao no qual os kernels sao definidos e executam.Assim, um contexto e todo o conjunto de recursos que um kernel vaiutilizar durante sua execucao.
// Get platform and device information
cl_platform_id platform_id = NULL;
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret = clGetPlatformIDs (1, &platform_id , &ret_num_platforms );
ret = clGetDeviceIDs( platform_id , CL_DEVICE_TYPE_DEFAULT , 1,
&device_id , &ret_num_devices );
// Create an OpenCL context
cl_context context = clCreateContext( NULL , 1, &device_id , NULL , NULL , &ret);
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 42 / 52

OpenCL
Fila de Comandos
Os comandos sao colocados nesta fila e aguardam seu momento de executar.Esta fila aceita tres tipos de comandos:
1 Execucao de kernel,
2 Transferencia de dados (objetos de memoria)
3 Sincronizacao, se e necessaria.
// Create a command queue
cl_command_queue command_queue = clCreateCommandQueue(context , device_id , 0, &ret);
// Create memory buffers on the device for each vector
cl_mem a_mem_obj = clCreateBuffer(context , CL_MEM_READ_ONLY ,
LIST_SIZE * sizeof(int), NULL , &ret);
cl_mem b_mem_obj = clCreateBuffer(context , CL_MEM_READ_ONLY ,
LIST_SIZE * sizeof(int), NULL , &ret);
cl_mem c_mem_obj = clCreateBuffer(context , CL_MEM_WRITE_ONLY ,
LIST_SIZE * sizeof(int), NULL , &ret);
// Copy the lists A and B to their respective memory buffers
ret = clEnqueueWriteBuffer(command_queue , a_mem_obj , CL_TRUE , 0,
LIST_SIZE * sizeof(int), A, 0, NULL , NULL);
ret = clEnqueueWriteBuffer(command_queue , b_mem_obj , CL_TRUE , 0,
LIST_SIZE * sizeof(int), B, 0, NULL , NULL);
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 43 / 52

OpenCL
Execute the OpenCL kernel// Create a program from the kernel source
cl_program program = clCreateProgramWithSource(context , 1,
(const char **)& source_str , (const size_t *)& source_size , &ret);
// Build the program
ret = clBuildProgram(program , 1, &device_id , NULL , NULL , NULL);
// Create the OpenCL kernel
cl_kernel kernel = clCreateKernel(program , "vector_add", &ret);
// Set the arguments of the kernel
ret = clSetKernelArg(kernel , 0, sizeof(cl_mem), (void *)& a_mem_obj );
ret = clSetKernelArg(kernel , 1, sizeof(cl_mem), (void *)& b_mem_obj );
ret = clSetKernelArg(kernel , 2, sizeof(cl_mem), (void *)& c_mem_obj );
// Execute the OpenCL kernel on the list
size_t global_item_size = LIST_SIZE; // Process the entire lists
size_t local_item_size = 64; // Divide work items into groups of 64
ret = clEnqueueNDRangeKernel(command_queue , kernel , 1, NULL ,
&global_item_size , &local_item_size , 0, NULL , NULL);
Kernel de Soma de Vetores.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 44 / 52

OpenCL
OpenCL - Tipos de Execucao de Kernels
2 tipos de execucao: Dara Parallel e TaskParallel. A hierarquia de execucao deOpenCL e tambem parecida que em CUDA.
N-Dimensional RangeCUDA OpenCLgrid NDRangeblock threads work groupthread work item
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 45 / 52

OpenCL
OpenCL - Modelo de Memoria
Parecido que em CUDA, em OpenCL existem 4 locais diferentes para amemoria que e enviada para o device:
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 46 / 52

OpenCL
CUDA - OpenCL
Semelhancas
O host inicia o ambiente de execucao na GPU.
As threads sao identificadas por ındices.
As threads sao agrupadas.
O host aloca e preenche dados na memoria do device
A execucao dos kernels pode ser sıncrona ou assıncrona.
Existem 4 diferentes tipos de memoria no device: Global, constante, local(shared), private.
Diferencas
No OpenCL existem 2 tipos de execucao diferentes:
1 Data Parallel
2 Task Parallel
O CUDA implementa so o modelo SIMT(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 47 / 52

OpenCL
OpenACC
Anunciado em novembro de 2011 na conferencia SuperComputing.E um padrao para programacao paralela.O padrao tem como base o compilador PGI (Portland Group)Colecao de diretivas para especificar lacos e regioes de codigo paralelizaveisem aceleradores.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 48 / 52

OpenCL
Modelo de execucao de OpenACC
O modelo de execucao do OpenACC tem tres nıveis: gang, worker e vector.Em GPU pode ser mapeado como:
gang → bloco de threads
worker → warp
vector → threads em um warp
As Diretivas em C/C++ sao especificadas usando #pragma.Se o compilador nao utilizar pre-processamento, as anotacoes sao ignoradasna compilacao.
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 49 / 52

OpenCL
Exemplo
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 50 / 52

OpenCL
Compilacao com PGI usando acc
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 51 / 52

OpenCL
So isso... Obrigado.
O EP 2 sobre GPUs, deve estar pronto para a sexta 17 de abrilcom data de entrega 1 de maio!
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 52 / 52