

GPU Computingg in CAE Solutions - cadgraphics.co.kr · The direct equation solver is accelerate ......
25
Transcript of GPU Computingg in CAE Solutions - cadgraphics.co.kr · The direct equation solver is accelerate ......

GPUs AcceleraCA C i P CAE Uses Computing Power o
CPUCPUCPUCPU
ate Computingf GP f Si l iof GPUs for Faster Simulation
GPUGPUGPUGPU
S d U= Speed Up

Maximus Technology for t
NVIDIANVIDIA®® MAXIMUSMAXIMUS
Parallel Computing Parallel Computing
NVIDIANVIDIA®® MAXIMUSMAXIMUS
Visual Computing Visual Computing
CAD Operations
CAE Pre-Post
CAE Computation
Visualization
the Workstation
Intelligent GPU job Allocation
Unified Driver for Quadro + Tesla
ISV Application Certifications
HP D ll L l thHP, Dell, Lenovo, several others
New Kepler-based GPUs late 2012
Available Since November 2011

Major CAE solutions AMajor CAE solutions A
SIMULIA announced support for NVIDIA
DMP/Multi-GPUs supported in Abaqus 6.
ANSYS supports GPU since 13.0 and enpp
DMP/Multi-GPUs supported in Ansys Rel
MSC Nastran support since 2012.1 in NppAlpha
Impacts several solution sequences:High impact (SOL101 SOL108) MidHigh impact (SOL101, SOL108), Mid
With DMP> 1, multiple fronts are factorize
matrix domain
CST Studio Suite began to support GPUtoday
Accelerated by GPUAccelerated by GPU
GPU in Abaqus 6.11
.12
hanced for 14.5 Nov 2012
14.5
ov-2011 and enhanced in 2013
d (SOL103) Low (SOL111 SOL400)d (SOL103), Low (SOL111, SOL400)ed concurrently on multiple GPUs; 1 GPU per
in 2007, enhanced supports GPU

Abaqus/Standard GPU qSIMULIA announced support for CUDA a
NVIDIA GPU i l d T l 20 i dNVIDIA GPUs include Tesla 20-series and
The direct equation solver is accelerate
More of Abaqus will be moved to GPUs i
Explicit are not in GPU acceleration, un
Abaqus 6.12 supports multi-GPU, multi
Linux and Windows OS
Flexibility to run jobs on specific GPUs
Basic system recommendations
Large system memory (48GB) to avoid sc
Ratio of 1 GPU attached to 1 CPU socket
Computingp gand GPUs in Abaqus 6.11
d Q d 6000 K l K20 t ith h t fid Quadro 6000, Kepler K20 support with hot fix
ed on the GPU
n progressive stages
nsymmetric solve is in development in 6.13
-node DMP clusters
cratch I/O of system matrix
t (4-8 cores)

Multi-GPU Maximus workstatio(USA customer model)(USA customer model)
Abaqus 6.12-PR3 Elapsed time in Hours
Lower is
B tt
20
Elapsed time in Hours
Better
10
15
5
08c Baseline 4c2g 8c1g 8c2g 12c 12c1g 12c2g
Hardware: 2x Xeon X5670, 2.93 GHz CPUs, ~80GB of av
n w/ Abaqus 6.12
SIMULIA Abaqus Model: • 7.33M DOF (equations); ~52 TFLOPs( q );• Solid FEs• Nonlinear Static (3 Steps)• Direct Sparse solver
73GB t i i i IO
• 4 core + 2 gpu• Higher throughput
• ~73GB memory to minimize IO
Today Path Forward (High Perf)
Path Forward (Low Cost)• Higher throughput
• 0.5x time of single 8c job• Job completed in 8 to 10 hours
• No need to lock the system for 24 hrs;S h j b 6 d f
y ( g ) ( )
8 core 8 core + 2 GPU 4 core + 2GPU
Perf 1x 2.52x 1.9x• Start the job at 6pm; ready for post-
processing next morning at 8am$ 1x 1.15x 0.97x
Perf/$ 1x 2.2x 1.96x
$ k t ti + GPU + Ab t k
vailable memory, 2x Tesla C2070, Linux RHEL5.4
$ = workstation + GPUs + Abaqus tokens

Multi-GPU DMP Cluster Scaling (Aerospace Industry - Rolls-Royce plc)
40000
(Aerospace Industry Rolls Royce plc)
Lower
30000
ecs)
Lower is
Better1X
19 tokens
14 tokens
20000
psed
Tim
e (s
e
1.7X12 tokens
19 tokens
10000
Elap
3.1X 3.2X
4.6X6X
06c 12c 6c+2g 24c 24c+4g 36c 36c+6g 48c 48c+
7.6X 9.4X6X
11
Hardware: Each node with (2x Xeon X5670, 2.93 GHz CPUs, 48
Single node 2 nodes 3 nodes 4 node
w/ Abaqus 6.12
Abaqus Model: • 4.71M DOF (equations); ~77 TFLOPs
N li St ti (6 St )• Nonlinear Static (6 Steps)• Direct Sparse solver• ~92GB memory to minimize IO (1 node)
+8g
.2X
8-96GB memory, 2x Tesla M2090), Linux RHEL6.2, QDR IB
es

Abaqus 6.12 Multi-GPU, DMP clusters

HHHoHoLicLic
UnloUnlo
LicLic
Ab P f li LiAb P f li Li UnloUnlo(5 T(5 TAbaqus Portfolio LicenseAbaqus Portfolio License
1 ad1 ad1 ad1 adUnloUnloUnloUnlo((
Token SchemeToken Scheme
(sam(sam
ConConAbaqus 6.11 LicenseesAbaqus 6.11 Licensees
GPU GPU ow GPU ow GPU censing Workscensing Works
ocks a single CPU core ocks a single CPU core
censing Workscensing Works
ocks a single CPU core ocks a single CPU core Tokens)Tokens)
dditional token: dditional token: dditional token: dditional token: ocks 1 additional CPU core ocks 1 additional CPU core ––oror--ocks 1 entire GPUocks 1 entire GPU
k h f CPU & GPU) k h f CPU & GPU)e token scheme for CPU core & GPU)e token scheme for CPU core & GPU)
tact SIMULIA to enable GPUstact SIMULIA to enable GPUs

GPU Computing in GPU support since 13.0 and e
GPU-based Solvers: Sparse and P
Parallel Methods: Shared memo
Supported GPUs: Tesla 20XX, a
Model Suitability: Models > 500Model Suitability: Models > 500
Multi-GPU support: Multi-node in
l i GPU imulti-GPU in
Typical Speedup: More than 5x
cores + GPU
ANSYS Mechanicalenhanced for 14.5 Nov 2012
PCG/JCG (Linux and Win64)
ory (SMP) and Distributed ANSYSy ( )
and Quadro 6000, Kepler K5000/K20
0K DOF solid finite elements vs shells0K DOF, solid finite elements vs. shells
n 14,
14 5 14.5
x speedup using 8
vs. 2 core license

ANSYS Mechanical Solution
6
esul
ts
d
Platform: ANSYS Base License and Westm
4
5
Plat
form
Re
CPU Speed‐upGPU Speed‐upSolution Cost
2
3
Ove
r Bas
e
1.0 1.0
0
1
acto
rs G
ain
ANSYS Base License2 Cores
Fa
2 Cores
Results from Supermicro system, 2 x Xeon X5690 3.47GHz 96GB memory, CentOS 5.4 x64; Tesla C2075, CUDA 4.0.17
n Cost—Performance
Solution Cost Basis
ere CPUs
ANSYS base licenseANSYS HPC Pack$10K for workstation$ 2K for Tesla C2075
Performance BasisV14sp 5 Model
$ 2K for Tesla C2075
V14sp-5 Model
2,100K DOFSOLID187 FEsStatic nonlinearStatic, nonlinearOne iterationDistributed ANSYS 14Direct sparse solver

ANSYS Mechanical Solution
6
esul
ts
d
Platform: ANSYS HPC Pack and Westmere
4
5
Plat
form
Re
CPU Speed‐upGPU Speed‐upSolution Cost
Higheris
Better
2.42
3
Ove
r Bas
e
Go MoreParallel
1.0 1.01.35
0
1
acto
rs G
ain
ANSYS Base License2 Cores
ANSYS HPC Pack8 Cores
Fa
2 Cores 8 Cores
Results from Supermicro system, 2 x Xeon X5690 3.47GHz 96GB memory, CentOS 5.4 x64; Tesla C2075, CUDA 4.0.17
n Cost—Performance
Solution Cost Basis
CPUs
ANSYS base licenseANSYS HPC Pack$10K for workstation$ 2K for Tesla C2075
Performance BasisV14sp 5 Model
$ 2K for Tesla C2075
V14sp-5 Model
2,100K DOFSOLID187 FEsStatic nonlinearStatic, nonlinearOne iterationDistributed ANSYS 14Direct sparse solver

ANSYS Mechanical Solution
6
esul
ts
d
Platform: ANSYS HPC Pack and Westmere
4
5
Plat
form
Re
CPU Speed‐upGPU Speed‐upSolution Cost
Higheris
Better
2.42
3
Ove
r Bas
e
Go MoreParallel
1.0 1.01.35
0
1
acto
rs G
ain
ANSYS Base License2 Cores
ANSYS HPC Pack8 Cores
Fa
2 Cores 8 Cores
Results from Supermicro system, 2 x Xeon X5690 3.47GHz 96GB memory, CentOS 5.4 x64; Tesla C2075, CUDA 4.0.17
n Cost—Performance
Solution Cost BasisInvest 38% more over base license for > 5x !
CPUs + Tesla GPU
5.1
base license for > 5x ! ANSYS base licenseANSYS HPC Pack$10K for workstation$ 2K for Tesla C2075
Performance BasisV14sp 5 Model
$ 2K for Tesla C2075
1.38V14sp-5 Model
2,100K DOFSOLID187 FEsStatic nonlinear
ANSYS HPC Pack8 Cores + GPU
Static, nonlinearOne iterationDistributed ANSYS 14Direct sparse solver
8 Cores + GPU

NVIDIA Study on System Me
2000 Xeon 5560 2.8 GHz N
NOTE: Results Based on ANSYS Mechanical 13
L
15241500
Xeon 5560 2.8 GHz N
n Se
cond
s
Results from HP Z800CPUs, 48GB memory
Lower is
better
11551214
1000cal T
imes
in 1.3x
1 7x
682500
YS M
echa
nic
NOTE: Greatest benefit for CPU and CPU+GPU
1.7x
032 GB24 GB
ANSY
for CPU and CPU+GPU is in-memory solution
32 GBOut‐of‐memory
24 GBOut‐of‐memory
emory Requirements
Nehalem 4 Cores (Dual Socket)
.0 SMP Direct Solver Sep 2010
Nehalem 4 Cores + Tesla C2050
0 Workstation, 2 x Xeon X5560 2.8GHz y, MKL 10.25; Tesla C2050, CUDA 3.1 V12sp‐5 Model
8302.0x
‐ Turbine geometry
426
48 GB
‐ 2,100 K DOF‐ SOLID187 FEs‐ Static, nonlinear‐ One load step48 GB
In‐memory
34 GB required for in‐memory solution
One load step‐ Direct sparse

HoHoHoHoLicLic
ANSYS B LiANSYS B Li UnlUnlANSYS Base LicenseANSYS Base License
UnlUnl+ U+ U
ANSYS HPC PackANSYS HPC Pack
Multiple ANSYS HPC PacksMultiple ANSYS HPC Packs UnUnExaExa
* Academic custom
ow ANSYS ow ANSYS ow ANSYS ow ANSYS censing Workscensing Works
locks up to 2 CPU coreslocks up to 2 CPU cores
locks up to 8 CPU coreslocks up to 8 CPU coresUnlocks 1 GPUUnlocks 1 GPU
nlocks 1 GPU per every 8 coresnlocks 1 GPU per every 8 coresample: ample: 2 x ANSYS HPC Pack = 32 cores + 4 GPUs2 x ANSYS HPC Pack = 32 cores + 4 GPUs
mers: GPU feature is bundled with ANSYS Base License

ANSYS and NVIDIA Collabo
Release ANSYS Mechanica
13 0 SMP Si l GPU S13.0Dec 2010
SMP, Single GPU, SparsePCG/JCG Solvers
14 0 + Distributed ANSYS14.0Dec 2011
+ Distributed ANSYS+ Multi-node Suppor
14.5 + Multi-GPU Support.Oct 2012
Multi GPU Support+ Hybrid PCG;
+ Kepler GPU Suppor
15.0Mid-2013
CUDA 5 + Kepler Tunin
oration Roadmap
al ANSYS Fluent
d e and
S; Radiation Heat Transfer S;rt
Radiation Heat Transfer (beta)
t; + Radiation HT;t;
rt
Radiation HT;+ GPU AMG Solver (beta),
Single GPU
ng GPU Solver, Multi-GPU

ANSYS Mechanical 14.5 Mu
25
Dual Sockr D
ay
Results for Distributed ANSYS 14.5 Previe
20
Dual Sock
of
Jobs
Per
Higheris
Better
1210
15
al N
umbe
r
1.6x
8
5
10
S M
echa
nica
0AN
SYS
Xeon E5‐2687W 8 CoresT l C2075+ Tesla C2075
lti-GPU Performance
ket CPU + Tesla C2075V14sp‐5 Model
ew and Xeon 8-Core CPUs
19
ket CPU + Tesla C2075p
Turbine geometry
8
Turbine geometry2,100 K DOFSOLID187 FEsStatic, nonlinearOne iteration (total One iteration (total solution requires 25)Distributed ANSYS 14Direct sparse solver
Xeon E5‐2687W 8 Cores
Results from HP Z820; 2 x Xeons (16 Cores) 128GB, CentOS 6.2 x86_64; 2 x Tesla C2075, CUDA 4.2
+ 2 x Tesla C2075

ANSYS and NVIDIA Collabo
Release ANSYS Mechanica
13 0 SMP Si l GPU S13.0Dec 2010
SMP, Single GPU, SparsePCG/JCG Solvers
14 0 + Distributed ANSYS14.0Dec 2011
+ Distributed ANSYS+ Multi-node Suppor
14.5 + Multi-GPU Support.Oct 2012
Multi GPU Support+ Hybrid PCG;
+ Kepler GPU Suppor
15.0Mid-2013
CUDA 5 + Kepler Tunin
oration Roadmap
al ANSYS Fluent
d e and
S; Radiation Heat Transfer S;rt
Radiation Heat Transfer (beta)
t; + Radiation HT;t;
rt
Radiation HT;+ GPU AMG Solver (beta),
Single GPU
ng GPU Solver, Multi-GPU

ANSYS Fluent 14.5 NVAMGNVAMG Project – Preview of ANSYS F
1.0000E+00
1.0000E-02
1.0000E-01
als
1.0000E-04
1.0000E-03
r Res
idua
1 0000E-06
1.0000E-05Erro
r
1 0000E 08
1.0000E-07
1.0000E 06
1.0000E-081 11 21 31 41 51 61 71 81 9
Iteration Numb
G Solver for GPUsFluent Convergence Behavior
NVAMG-Cont Numerical ResultsNVAMG-X-mom
NVAMG-Y-mom
NVAMG-Z-mom
FLUENT-Cont
Mar 2012: Test for convergence at each iteration
FLUENT-X-mom
FLUENT-Y-mom
FLUENT-Z-mom
matches precise Fluent behavior
Model FL5S1:‐ Incompressible
‐ Flow in a Bend‐ Flow in a Bend
‐ 32K Hex Cells
‐ Coupled Solver
1 101 111 121 131 141
er

ANSYS Fluent 14.5 NVAMG
3000
D l S k t CPUec)
NVAMG Project – Preview of ANSYS F
2832
2000
Dual Socket CPU
er T
ime
(Se
2000
t A
MG
Sol
ve
5.5x
1000
NSY
S Fl
uent
517
0
AN
2 x Xeon X5650,Only 1 Core Used
G Solver for GPUs
D l S k t CPU T l C2075
Fluent Performance
Helix ModelDual Socket CPU + Tesla C2075
Loweris
B ttBetter
Helix geometry
933 1.8x
1.2M Hex cells
Unsteady, laminar
Coupled PBNS, DP
AMG F l CPU517
2 x Xeon X5650,
AMG F‐cycle on CPU
AMG V‐cycle on GPU
NOTE: All jobs All 12 Cores Used NOTE: All jobs solver time only

Titan: World’s Fast18 688 T l K218,688 Tesla K2
27 Petaflops Peak: 90% of
17.59 Petaflops Sustained
est Supercomputer20 A l20 Accelerators
f Performance from GPUs
d Performance on Linpack
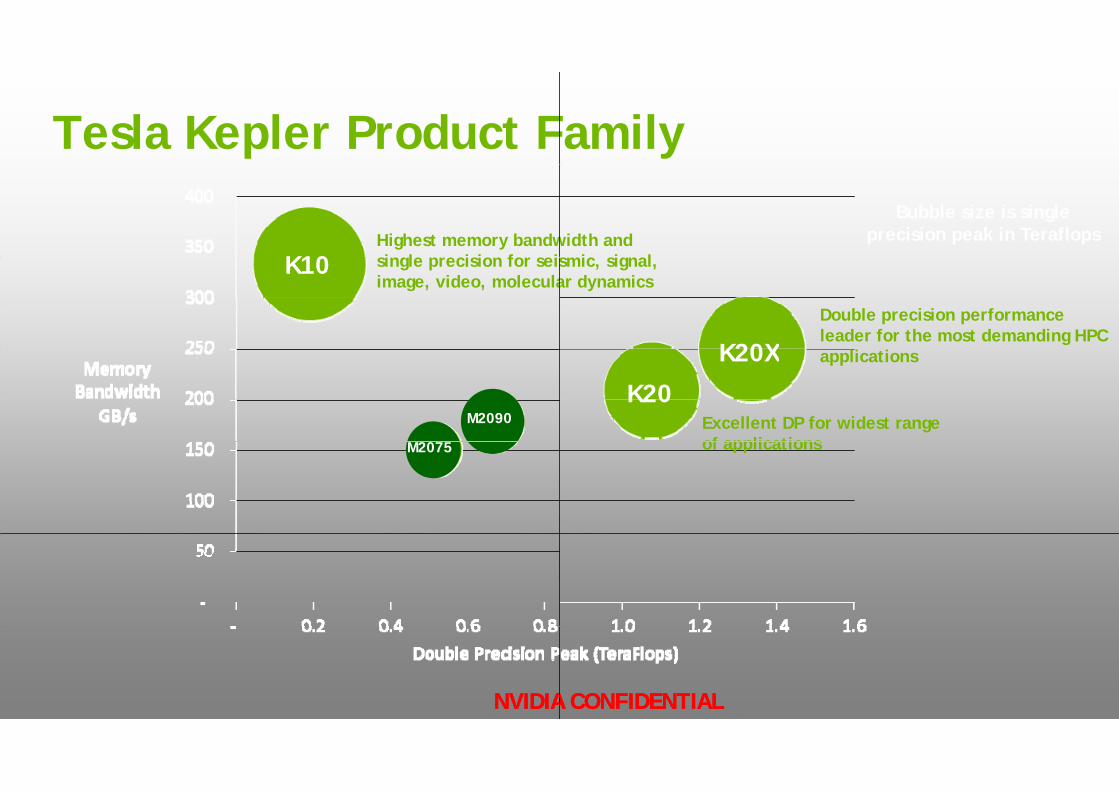
Tesla Kepler Product F
Highest memory bandwi gl i i f iK10 single precision for seis
image, video, moleculaK10
M2090
20M2075
NVIDIANVIDIA
Family
width and i ig l
Bubble size is single precision peak in Teraflops
Double precision performance leader for the most demanding HPC
l
smic, signal, ar dynamics
K20X
Excellent DP for widest range of applications
applicationsK20X
K20
of applications
A CONFIDENTIALA CONFIDENTIAL
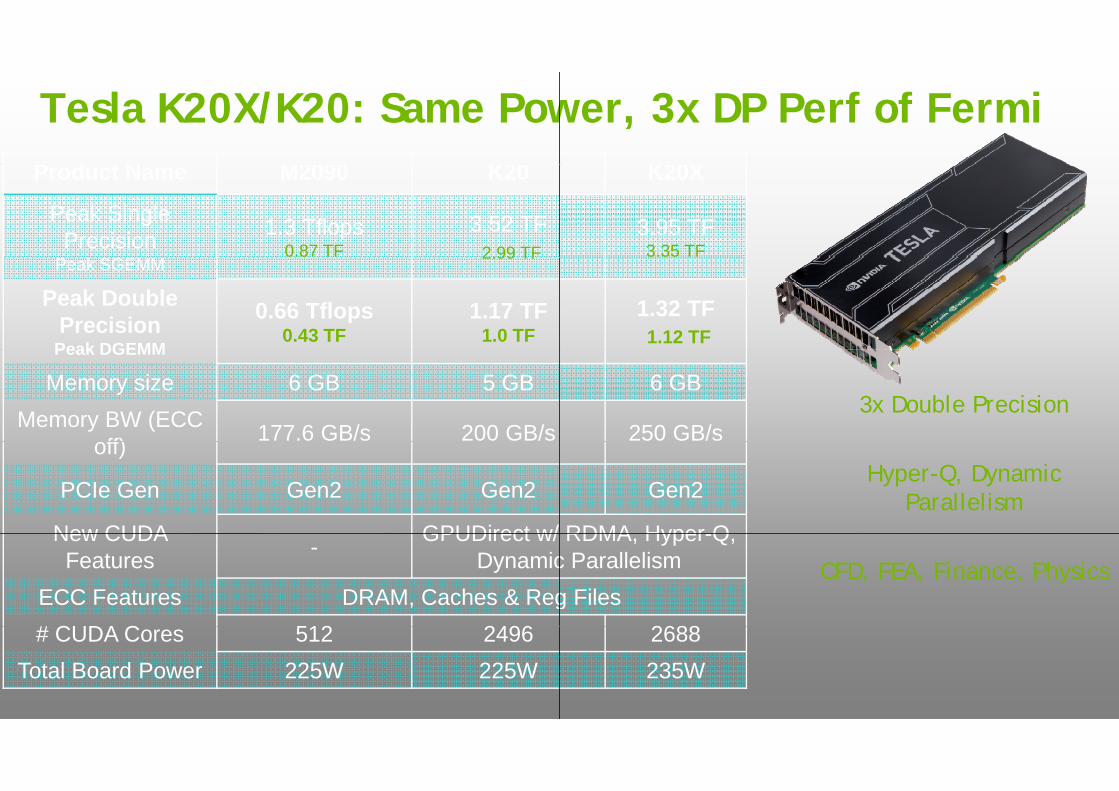
Tesla K20X/K20: Same PowP d t N M2090 K20Product Name M2090 K20
Peak Single Precision 1.3 Tflops
0.87 TF3.52 TF
2.99 TFPeak SGEMM
2.99 TF
Peak Double Precision
Peak DGEMM
0.66 Tflops0.43 TF
1.17 TF1.0 TF
Peak DGEMM
Memory size 6 GB 5 GBMemory BW (ECC
ff) 177.6 GB/s 200 GB/soff)
PCIe Gen Gen2 Gen2
New CUDA GPUDirect w/New CUDA Features - GPUDirect w/
DynamicECC Features DRAM, Caches & Reg# CUDA C 512 2496# CUDA Cores 512 2496
Total Board Power 225W 225W
wer, 3x DP Perf of FermiK20XK20X
3.95 TF3.35 TF
1.32 TF1.12 TF
6 GB
250 GB/s3x Double Precision
Gen2
RDMA Hyper Q
Hyper-Q, Dynamic Parallelism
RDMA, Hyper-Q, c Parallelismg Files
2688
CFD, FEA, Finance, Physics
2688235W

감사합니다

More info
More info at:http://www nvidia com/abaqushttp://www.nvidia.com/abaqus
• GPGPUs in the real world. The ABAQUS• Acceleration of SIMULIA’s Abaqus Solver
Read More About ANSYS and GPU ComputANSYS Unveils GPU Computing for AcceleratSpeed Up Simulations with a GPU Article in Speed Up Simulations with a GPU, Article in Speeding to a Solution, Article in ANSYS AdvHPC Delivers a 3-D View, Article in ANSYS Ad
For More Information on the NVIDIA and Awww.nvidia.com/ansys
S experience – SIMULIA Corp.on NVIDIA GPUs – Acceleware Inc.
tinged Engineering Simulations ANSYS Advantage Magazine ANSYS Advantage Magazine
vantage Magazinedvantage Magazine
ANSYS Solution


















