
GPU Accelerated Tandem Traversal of Blocked...
13
GPU Accelerated Tandem Traversal of Blocked Bounding Volume Hierarchies Jesper Damkjær and Kenny Erleben {damkjaer,kenny}@diku.dk Department of Computer Science University of Copenhagen October 2009
Transcript of GPU Accelerated Tandem Traversal of Blocked...

GPU Accelerated Tandem Traversal of BlockedBounding Volume Hierarchies
Jesper Damkjær and Kenny Erleben{damkjaer,kenny}@diku.dk
Department of Computer ScienceUniversity of Copenhagen
October 2009

Traditional BVH Traversal
Two BVHs are traversed
Using either a stack or a queueUsing a descend rule descending either treeDescend both trees simultainiously
For each descend, the BVs in the nodes are compared foroverlap
2

Naive BVH on GPU
One pair of BVHs per Thread
Upper space bound for stack
k (c − 1) max (height(A),height(B)) ,
max. cardinality, c , and size of two BV node references, k .
Shared memory too small and global memory too slow
3

Use Blocks
1 Block ≡ Each node has 4 children
If overlap ⇒ 16 new overlaps
Less data to transfer and more work per thread
4

Use Double Buffered ListStack/Queue ⇒ Double buffered list
Swap input/output paris for next pass5
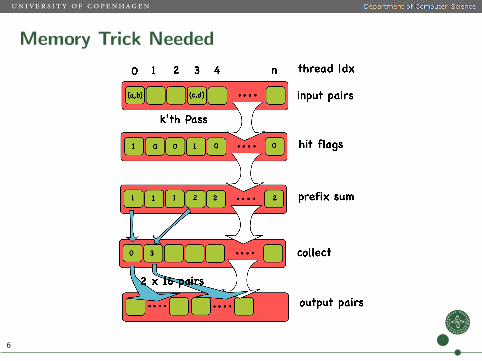
Memory Trick Needed
6

Need Imaginary Nodes
Less than 4 children ⇒ fill with imaginary nodes
Fills up space ⇒ part of calculation time ⇒ use sparesly
7

Blocks with Mixed Internal or Leaf Nodes
Not allowed ⇒ Simpler code
8

Internal Block versus Leaf Block
if collide (a, k) ⇒ push (e, k)if collide (a, l) collision ⇒ push (e, k)if collide (a,m) collision ⇒ push (e, k)if collide (a, n) collision ⇒ push (e, k)
Redundant results ⇒ add extra check to code
9

The Test Setup
Three different configuration types
Structured stack Unstructured Pile Rock Slide
10

The Test Setup (Cont’d)
For each configuration type
Increasing number of triangles in objectsIncreasing number of objects
Test against Rapid
Rapid uses OBBs we use AABBs
No optimization of imaginary nodes in BVHs (upto 33%)
11

Results
Rapid on Intel Quad CPU using one core
216343
512729
100019248
12
0
1
2
3
Number of objects
Stack: Rapid
Triangles per object
Tim
e in
sec
onds
216343
512729
1000240006000
1500
0
1
23
4
5
Number of objects
Pile: Rapid
Triangles per objectTi
me
in s
econ
ds
5001000
15002000
2500240006000
1500
0
0.1
0.2
0.3
Number of objects
Rockslide: Rapid
Triangles per object
Tim
e in
sec
onds
Cuda on ge9800 GX2 using one core
216343
512729
100019248
12
0
1
2
3
Number of objects
Stack: Cuda only
Triangles per object
Tim
e in
sec
onds
216343
512729
1000240006000
1500
0
1
23
4
5
Number of objects
Pile: Cuda only
Triangles per object
Tim
e in
sec
onds
5001000
15002000
2500240006000
1500
0
0.1
0.2
0.3
Number of objects
Rockslide: Cuda only
Triangles per object
Tim
e in
sec
onds
Stack (5-8) Pile (3-7) Slide (2)
12

Thanks
Questions?
13



![[ACM-ICPC] Traversal](https://static.fdocuments.net/doc/165x107/555602ded8b42a8a5f8b55a7/acm-icpc-traversal.jpg)














