
Gliederung - · 2 Hashing (Streuspeicherung) • Verfahren, die allgemein auf Bäume basieren...
31
Gliederung 5. Compiler 1. Struktur eines Compilers 2. Syntaxanalyse durch rekursiven Abstieg 3. Ausnahmebehandlung 4. Arrays und Strings 6. Sortieren und Suchen 1. Grundlegende Datenstrukturen 2. Bäume 3. Hashing (Streuspeicherung) 7. Graphen 1. Darstellung und Topologisches Sortieren 2. Kürzeste Wege 3. Fluß- und Zuordnungsprobleme
Transcript of Gliederung - · 2 Hashing (Streuspeicherung) • Verfahren, die allgemein auf Bäume basieren...

Gliederung
5. Compiler1. Struktur eines Compilers2. Syntaxanalyse durch rekursiven Abstieg3. Ausnahmebehandlung4. Arrays und Strings
6. Sortieren und Suchen1. Grundlegende Datenstrukturen2. Bäume3. Hashing (Streuspeicherung)
7. Graphen1. Darstellung und Topologisches Sortieren2. Kürzeste Wege3. Fluß- und Zuordnungsprobleme

2
Hashing (Streuspeicherung)
• Verfahren, die allgemein auf Bäume basieren garantieren einen logarithmischen Aufwand beim Datenzugriff (Suche, einfügen, löschen)
• Motivation für Hashverfahren– Voraussetzung für Binäre Suchbäume: (totale) Ordnung auf der
Nutzinformation – Ordnung nicht immer verfügbar: z.B. Einträge in einer Datenbank
(Kundendaten etc.)
• Grundidee der Hashverfahren– Datensätze werden in einem normalen Feld mit direktem Zugriff
gespeichert– Die Hash-Funktion ermöglicht für jeden gespeicherten Wert den
direkten Zugriff auf den Datensatz

3
Hashing (1)
• Hashing (engl.: to hash=zerhacken) beschreibt eine spezielle Art der Speicherung der Elemente einer Menge durch Zerlegung des Schlüssel-Universums
• Die Position des Daten-Elements im Speicher ergibt sich (zunächst) durchBerechnung direkt aus dem Schlüssel
• Die Menge aller möglichen Schlüssel (der Wertebereich) sei D (Domain)• Der Speicher wird ebenfalls zerlegt in m gleich große Behälter (Buckets)• Es ist |D| sehr viel größer als m• Eine Hash-Funktion h kann nun für jeden Schlüssel s die Nummer des
Buckets berechnen• Ideal wäre eine eindeutige Speicher-Zuordnung eines Datums mit
Schlüssel s zum Bucket mit Nummer h(s): Einfügen und Suchen könnten in konstanter Zeit (O(1)) erfolgen.
• Tatsächlich treten natürlich Kollisionen auf: Mehrere Elemente können auf die gleiche Hash-Adresse abgebildet werden. Kollisionen müssen (auf eine von verschiedenen Arten) behandelt werden.
}1,...,1,0{)( −∈ msh

4
Hashing: Prinzip• Schlüssel werden in einen zweiten, endlichen Bereich, mit dem eine
Reihung angesteuert wird, abgebildet• Suche wird mit speziellen Verfahren durchgeführt (z.B.
Reihungsindizierung, Kollisionsauflösung)
SucheSchlüssel Objekt
Hashfunktion H(Bereichs-Transformation)
HashwertReihungsindex oder Kollisionswert
Reihungsindizierungoder Kollisionsauflösung

5
Hashing: Beispiel
• Daten werden in einem Feld von 0 bis 9 gespeichert• Elemente 42 und 119 werden gespeichert• Hashfunktion: h= i mod 10
8
4
5
6
422
3
7
1199
1
0
EintragIndex
Kollision für die Werte 69 und 119:69 mod 10 -> 9119 mod 10 -> 9

6
Hash-FunktionenDef.: Es sei D ein Wertebereich von Schlüsseln und m dieAnzahl der Behälter Bo , ... , Bm-1 zum Speichern einer gegebenen Menge {e1, .. en} von Elementen (Datensätzen)Eine Hash-Funktion h ist eine (totale) Abbildung
h: D → {0, .. m-1},die jedem Schlüsselwert w ∈ D eine Nummer h(w) und damit einen Behälter Bh(w) zuordnet. Die Nummern der Behälter werden auch als Hash-Adressenund die Menge der Behälter als Hash-Tabelle bezeichnet.
WertebereichD
Bo
B1
...
...Bm-1
01......m-1
Hash-Adressen Hash-Tabelle
h(w)

7
Probleme beim Hashing
• Menge der möglichen Schlüssel (hier: alle Wörter) sehr viel größer als die endliche Menge der Tabellenindizes– Kollisionen, d.h. zwei oder mehrere Schlüssel werden auf dieselbe
Adresse abgebildet; müssen behandelt werden– Jede Strategie der Kollisionsbehandlung hat Vor- und Nachteile
• Hash-Funktion h sollte die Schlüssel möglichst gleichmäßig auf den Bereich der Tabellenindizes verteilen (gute Streuung)
• h soll effizient berechenbar sein (O(log M) oder O(1)).

8
Anforderungen an Hash-Funktionen
• Eine Kollision tritt dann auf, wenn bei Einfügen eines Elementes mit Schlüssel s der Bucket Bh(s) schon belegt ist. Nach einer Kollision werden Operationen zur Kollisionsbehandlung durchgeführt
• Eine Hash-Funktion h heißt perfekt für eine Menge von Schlüsseln S, falls keine Kollisionen für S auftreten.
• Ist h perfekt und |S| = n, dann gilt: n ≤ m. • Das Verhältnis
BF = # Gespeicherte Schlüssel/Größe der Hash-Tabelle = n/mbezeichnet man als Belegungsfaktor der Hash-Tabelle
• Eine Hash-Funktion ist gut gewählt, wenn– der Belegungsfaktor möglichst hoch ist,– für viele Schlüssel-Mengen die Anzahl der Kollisionen möglichst klein
ist,– sie leicht und effizient zu berechnen ist.

9
Hashing (2)
Beispiel: Hash-Funktion für Stringspublic static int h (String s){
int k = 0, m = 13;for (int i=0; i < s.length(); i++)
k += (int)s.charAt (i);return ( k%m );
}
Folgende Hash-Adressen werden generiert für m = 13.Schlüssel h(s)Test 0Hallo 2SE 9Algo 10
h wird perfekter, je größer m gewählt wird.

10
Grundoperationen auf Hash-Tabellen
• Einfügen eines Datenelements– Wende Hash-Funktion h auf den Schlüssel des Datenelements an:
Einfügeposition ∈ {1, ,,, m-1} in der Hash-Tabelle– Ist der Platz in der Hash-Tabelle noch frei, Datensatz dort speichern,
ansonsten Kollisionsbehandlung
• Löschen eines Datenelements– Wende h auf den Schlüssel des Datenelements an:
Position ∈ {1, ,,, m-1} in der Hash-Tabelle– Falls Datensatz an dieser Position gefunden, Datensatz löschen, sonst
je nach Kollisionsbehandlung weiter
• Suchen eines Datenelements– Wende h auf den Schlüssel des Datenelements an:
Position ∈ {1, ,,, m-1} in der Hash-Tabelle– Steht der Datensatz nicht auf dieser Tabellenposition, erfolgen je
nach Kollisionsbehandlung Zusatzoperationen (z.B. weitere Suche)

11
Wahl der Hash-Funktion
• Die Anforderungen hoher Belegungsfaktor und Kollisionsfreiheit stehen in Konflikt zueinander. Es ist ein geeigneter Kompromiss zu finden.
• Für die Schlüssel-Menge S mit |S| = n und Behälter B0, . . . , Bm-1 gilt:– für n > m sind Konflikte unausweichlich– für n < m gibt es eine (Rest-) Wahrscheinlichkeit PK(n,m) für das Auftreten
mindestens einer Kollision.
• Abschätzung für die Wahrscheinlichkeit einer Kollision PK(n,m)– Für beliebigen Schlüssel s ist die Wahrscheinlichkeit dafür, dass h(s) = j mit
j ∈ {0, . . . ,m - 1}: P[ h(s) = j ] = 1/m, falls Gleichverteilung gilt– Es gilt PK(n,m) = 1 - P¬K(n,m), wobei P¬K(n,m) die Wahrscheinlichkeit
dafür ist, dass es beim Speichern von n Elementen in m Behälter zu keinen Kollisionen kommt.

12
Wahrscheinlichkeit von Kollisionen
• Werden n Schlüssel nacheinander auf die Behälter B0, . . . , Bm-1 verteilt (bei Gleichverteilung), gilt jedes malP [ h(s) = j ] = 1/m
• Es sei P(i) die Wahrscheinlichkeit, dass beim Einfügen des i-ten Datensatzes in m Sektoren keine Kollision auftritt
• Dann gilt: P(1) = 1P(2) = (m-1) / m
...P(i) = (m-i+1) / m
• Damit ist
Für m = 365 etwa ist P(23) > 50% und P (50) ≈ 97% (Geburtstagsparadoxon)
nK mnmmmnPPPmnP )1)...(1(1)(*...*)2(*)1(1),( +−−
−=−=

13
Hash-Funktionen in der Praxis
In der Praxis verwendete Hash-Funktionen (Siehe D.E. Knuth: The Art of Computer Programming)• Sei W = integer, d.h. die Schlüsselwerte sind ganze Zahlen. Dann liefert
die sog. Divisions-Rest-Methode gute Hash-Funktionen: – h(w) = (a * w) mod m (a ≠ 0, a ≠ m und m Primzahl)
• Sei M eine Menge von Zeichenreihen der Form s = [s1, ... , sq] . Dann ist (neben der oben bereits genannten einfachen Funktion)
eine gute Hash-FunktionFür die Wahl von B wird der Wert 131 empfohlen – w ist die Wortbreite des Computers (also w = 32, w = 64)
msBsh wk
ii
i mod2mod)(1
0
= ∑
−
=

14
Behandlung von Kollisionen
• Die Behandlung von Kollisionen erfolgt bei verschiedenen Verfahren unterschiedlich.
• Ein Datensatz mit Schlüssel s ist ein Überläufer, wenn der Behälter h(s) schon durch einen anderen Satz belegt ist.
• Strategien zur Kollisionsbehandlung– Verkettung der Überläufer (Offenes Hashing): Es wird eine
Liste mit den Elementen aufgebaut, die dieselbe Position belegen– Sondieren (Geschlossenes Hashing): Es wird eine alternative
Position im Fall einer Kollision gesucht

15
Verkettung der Überläufer
• Überläufer außerhalb der Hash-Tabelle ablegen– Z.B. als verkettete lineare Liste– Liste wird an den Hash-Tabelleneintrag angehängt, der sich durch
Anwendung der Hash-Funktion auf die Schlüssel ergibt
• Separate Verkettung der Überläufer– die Hash-Tabelle enthält je einen Datensatz und einen Listen-Kopf pro
Behälter. – Weitere Datensätze (= Überläufer) werden in je einer Liste an den
betreffenden Behälter angehängt
• Direkte Verkettung der Überläufer– Die Hash-Tabelle enthält nichts als die Listen-Köpfe, alle Datensätze
befinden sich in den Listen– Alle Datensätze werden in den Überlaufketten gespeichert

16
Direkte Verkettung: Beispiel
• Verwendete Hash-Funktion : h(s) = (ord(s[1]) + ord(s[2]) + ord(s[3])) mod 4
• Zeichenkette: ‘‘Almodovar“h ('Almodovar') = (65+108+109) mod 4
= (1+0+1) mod 4 = 2
0 Allen Jarmusch1
Almodovar2 Wenders Kurosawa
3 Herzog Fellini

17
Separate Verkettung
• Im Gegensatz zum Speichern durch direkte Verkettung wird pro Behälter ein Datensatz direkt in der Hash-Tabelle gespeichert.
• Fallen in einem Behälter Überläufer an, so wird dafür eine Überlauf-Liste angelegt.
• Vergleich mit dem Speichern durch direkte Verkettung:– Überlauf-Listen werden nur bei Auftreten von Kollisionen benötigt. – enthält ein Behälter keinen Datensatz, so wird trotzdem Speicher
dafür vorgehalten.
Wenders Kurosawa Almodovar
Allen Jarmusch
0
1
2
3 Herzog Fellini
18
Separate Verkettung der Überläufer: Implementierung
• Die Hash-Tabelle ist ein Array (der Länge m) von Listen. D.h. jeder Behälter der Hash-Tabelle wird durch eine Liste implementiert
class hashTable {Liste [] ht;hashTable (int m){
ht = new Liste[m]; for (int i = 0; i < m; i++)
ht[i] = new Liste();}
...}
Konstruktor konstruiert Array mit m listen
19
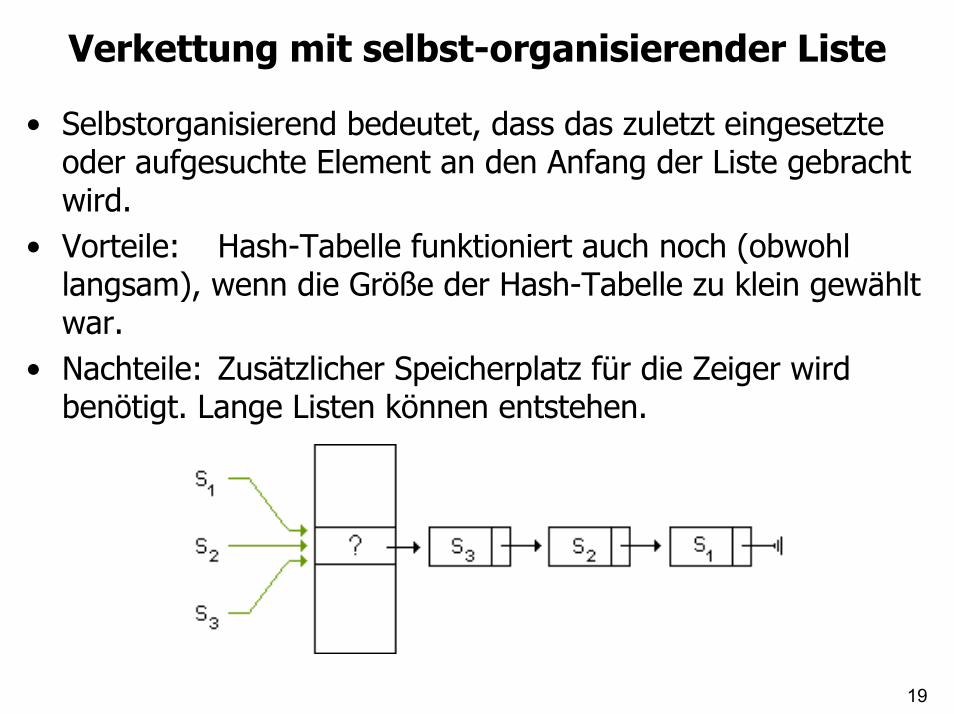
Verkettung mit selbst-organisierender Liste
• Selbstorganisierend bedeutet, dass das zuletzt eingesetzte oder aufgesuchte Element an den Anfang der Liste gebracht wird.
• Vorteile: Hash-Tabelle funktioniert auch noch (obwohl langsam), wenn die Größe der Hash-Tabelle zu klein gewählt war.
• Nachteile: Zusätzlicher Speicherplatz für die Zeiger wird benötigt. Lange Listen können entstehen.

20
Aufwand des offenen Hashing
• worst caseh(s) liefert immer den gleichen Wert, alle Datensätze sind in einer Liste: Verhalten wie bei Linearer Liste.
• average case– bei erfolgreicher Suche (und damit auch für den Fall des Entfernens eines
Datensatzes) gilt: Aufwand ≈ 1 + 0.5 * BF– bei erfolgloser Suche (und damit auch für den Fall des Einfügens eines
Datensatzes) gilt: Aufwand ≈ BF
• best caseDie Suche führt unmittelbar zum Erfolg: Aufwand ist O(1)

21
Geschlossene Hash-Verfahren
• Geschlossenes Hashing bedeutet, dass Überläufer nicht in separaten Listen, sondern in noch freien Bereichen der Hash-Tabelle selbst gespeichert werden.
• Der Prozess der Suche nach einer geeigneten Position bezeichnet man als Sondieren
• Vorgehensweise zum Speichern eines Datensatzes mit Schlüssel s:1. Speichere an Position h(s), wenn dort frei2. Sonst speichere an der nächsten freien Position, die durch
Sondieren ermittelt wird3. Ist kein Platz mehr frei, kann nicht gespeichert werden.

22
Sondierverfahren (1)
• Beim linearen Sondieren (linear probing) wird linear und zyklisch nach dem nächsten freien Platz in der Hash-Tabelle gesucht.
• Sekundärkollision: Schlüssel mit unterschiedlicher Streuadresse kollidieren
• Quadratisches Sondieren– Mit quadratisch wachsendem Abstand wird nach einem freien Platz
gesucht.

23
Sondierverfahren
• Lineares Sondieren: Falls die Position h(e) in der Hash-Tabelle besetzt ist, prüft das Verfahren der Reihe nach die Positionen:(h(w)+1) mod m, (h(w)+2) mod m, ...
• Quadratisches Sondieren: Lineares Sondieren neigt zur Clusterbildung: „Klumpen“ in denen alle Positionen bereits besetzt sind und sich dadurch lange Sondierfolgen bilden. Um dies zu vermeiden, wird die Folge der Quadratzahlen für die Sondierabstände verwendet(h(w)+1) mod m, (h(w)+4) mod m, ...,(h(w)+i 2) mod m
• Double Hashing (Doppelte Streuadressierung): Die doppelte Streuadressierung soll Sekundärkollisionen verhindernh(w) - h2(w) mod m, h(w) - 2*h2(w) mod m, ..., h(w) - (m-1)*h2(w) mod m(wobei h2(w)≠ 0 und h2(w) teilerfremd zu m)
Optimierungsmöglichkeit: Sondierung in beide Richtungen• Lineares Sondieren: (h(w)+1) mod m, (h(w)-1) mod m,(h(w)+21) mod m, ..• Quadratisches Sondieren: (h(w)+1) mod m, (h(w)-1) mod m, (h(w)+4) mod, (h(w)-4) mod
m

24
Löschen bei geschlossenen Hash-Verfahren
• Geschlossenes Hashing erfordert eine besondere Behandlung der Lösch-Operationen: Soll ein Datensatz gelöscht werden, so kann ein anderer Datensatz unerreichbar werden
• Zu löschende Datensätze dürfen also nicht physisch gelöscht, sondern nur als gelöscht markiert werden. Jeder Behälter muss als "frei", "belegt" oder "gelöscht" markiert sein.
• Beim Sondieren werden Behälter mit gelöschten Datensätzen wie belegte Sektoren zum "Weiterhangeln" benutzt.

25
Löschen bei geschlossenen Hash-Verfahren: Beispiel
D = Integer, h(w) = w mod 7, (absteigend) lineares Sondieren
1. Einfügen von: 78, 57, 80, 16, 21Beachte: (78 % 7 == 1), (57 % 7 == 1), (80 % 7 == 3),
(16 % 7 == 2), (21 % 7 == 0), (29 % 7 == 1)
57 78 16 80 21
Das Löschen von "57" würde "21" und "29" unerreichbar machen, falls nicht markiert!
frei
belegt
gelöscht
2. Einfügen von: 29
3. Löschen von: 57
57 78 16 80 29 21
57 78 16 80 29 21

26
Aufwand bei geschlossenen Hash-Verfahren
• Abschätzung nur über Wahrscheinlichkeiten• Wahrscheinlichkeit einer Kollision hängt vom Füllungsgrad ab
– Sei α der Anteil der belegten Buckets– Aufwand einer erfolglosen Suche: 1+ α + α2+.......=1/1-α
• Beispiele– Bei einer halbgefüllten Hash-Tabelle werden im Mittel 1/1-0,5=2
Zugriffe benötigt– Bei einem Belegungsfaktor von 90% sind bereits 10 Zugriffe
notwendig
• Faustregel: Beim geschlossenen Hashing sollte der Belegungsfaktor nicht größer als 80% werden

27
Hybride Hash-Verfahren (1)
Eine Analyse der bisher betrachteten Verfahren zeigt: • Die offenen Verfahren sind wesentlich schneller als die
geschlossenen, Sondieren ist zeitaufwendig (vor allem bei hohem Belegungsfaktor)
• Bei den offenen Verfahren wird Speicherplatz für die nicht belegten Sektoren verschwendet (umso mehr, je niedriger der Belegungsfaktor ist)
• Das hybride hashing (engl. auch: "Coalesced hashing") versucht Vorteile beider Verfahren miteinander zu verbinden– Überläufer werden wie beim geschlossenen Verfahren innerhalb der
Hash-Tabelle gespeichert, aber durch Referenzen miteinander verkettet.
– Jeder Sektor enthält (potentiell) einen Datensatz und eine Hash-Adresse, die auf einen anderen Sektor verweist, in dem nach einem "Überläufer" zu suchen ist.

28
Hybride Hash-Verfahren (2)
Die Hash-Tabelle ist jetzt ein doppeltes Array (der Länge m) (a) für die Datensätze, (b) für die Position eines möglichen "Überläufers".
class hashTable {Elem [] ht;int [] next; ...
}
Datensätze wie bei separater Verkettung.
Zusatz-Array für Sondierziel bei Überlauf.
21 78 16 80 57Einfügen von: 78, 57, 80, 16, 21
Beispiel: W = Integer, h(w) = w mod 7, Sondierziel: höchster freier Behälter:
6
ht
next
21 78 16 80 57Einfügen von: 69 (hash-Adresse 6 ist bereits belegt!)
6
ht
next69
5

29
Dynamische hashverfahren (1)
• Alle bisher betrachteten Verfahren hängen wesentlich vom Belegungsfaktor BF und damit von der (bisher als fest angenommenen) Länge der Hash-Tabelle ab. – Ist BF klein (etwa BF < 0.5), so wird Speicherplatz verschwendet. – Ist BF groß (etwa BF < 0.8), so werden das Einfügen und Suchen
(zeit-) ineffizient.• Zeigt die Hash-Tabelle insgesamt ein stark anwachsendes
Verhalten, so verschlechtert sich ihre Leistung mit wachsendem Belegungsfaktor
• Dieses grundsätzliche Problem kann auf zwei Arten gelöst werden: – Globale Reorganisation der Hash-Tabelle: Wahl einer neuen Hash-
Funktion und Umspeichern der Datensätze. (sehr aufwendig, Sperrung während der Reorganisation notwendig!)
– Dynamisches Hashing: Die Hash-Tabelle wird durch kleine lokale Reorganisationen ständig an die Anzahl der Datensätze angepaßt.

30
Dynamische hashverfahren (2)
• Grundidee: Beim Überschreiten eines vorgegebenen Schwellenwerts für den Belegungsfaktor BF wird ein neuerBehälter in der Hash-Tabelle (mit Hash-Adresse m) angelegt und die Datensätze des am meisten belegten Behälters werden möglichst gleichmäßig auf den bisherigen und auf den neuen Behälter aufgeteilt
• Die einzelnen Verfahren unterscheiden sich im Wesentlichen darin, wie die Hash-Funktion h zu adaptieren ist– Beim sog. linearen hashing wird die Hash-Tabelle durch die Aufspaltung eines
Sektors schrittweise expandiert, eine neue Expansionsstufe ist erreicht, wenn alle Sektoren aufgespalten sind und sich damit die Größe der Tabelle verdoppelt hat. Die Menge der hash-Adressen läßt sich z.B. erweitern, wenn man eine hash-Funktion h = w mod m zu h = w mod 2*m modifiziert.
– Beim sog. virtuellen hashing wird der Übergang auf eine neue Expansionsstufe in einem Schritt vollzogen.

31
Hashing: Zusammenfassung
• Hash-Tabellen sind in der Praxis die schnellsten Verfahren für Suchen/Einsetzen (vorausgesetzt sind natürlich gute Streufunktion und eine Tabelle, die nicht mehr als ca. 80%-90% voll ist).
• Hash-Tabellen liefern keine sortierte Reihenfolge oder das Minimum oder Maximum. Es ist auch nicht möglich, den größten Schlüssel <= k oder einen Schlüssel zwischen k1 und k2 zu finden
• Eine Hash-Tabelle hat i.d.R. eine feste Größe, die anders als bei den Suchbäumen nicht mit den Datenmengen wächst. Eine dynamische Mengenanpassung wird dadurch erreicht, dass ein Schwellenwert festgelegt wird, bei dem neue Behälter in die Hash-Tabelle angelegt werden (z.B. bei einer 90%-iger Füllung)
• obere Schranke für Aufwand ist O(m) (im Durchschnitt nahezu konst.)


















