
Foundations for Scaling ML in Apache Spark by Joseph Bradley at BigMine16
31
Foundations for Scaling ML in Apache Spark Joseph K. Bradley August 14, 2016 ® ™
-
Upload
bigmine -
Category
Data & Analytics
-
view
551 -
download
1
Transcript of Foundations for Scaling ML in Apache Spark by Joseph Bradley at BigMine16

Foundations for Scaling ML in Apache Spark
Joseph K. Bradley August 14, 2016
® ™

Who am I?
Apache Spark committer & PMC member Software Engineer @ Databricks Machine Learning Department @ Carnegie Mellon
2

• General engine for big data computing • Fast • Easy to use • APIs in Python, Scala, Java & R
3
Apache Spark
SparkSQL Streaming MLlib GraphXLargest cluster: 8000 Nodes (Tencent)
Open source • Apache Software Foundation • 1000+ contributors • 200+ companies & universities

NOTABLE USERS THAT PRESENTED AT SPARK SUMMIT 2015 SAN FRANCISCO
Source: Slide 5 of Spark Community Update
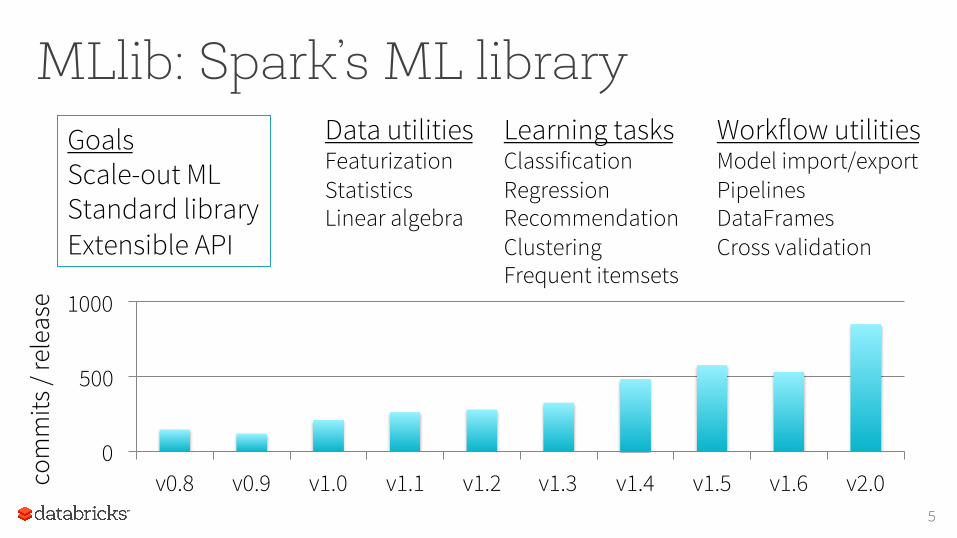
MLlib: Spark’s ML library
5
0
500
1000
v0.8 v0.9 v1.0 v1.1 v1.2 v1.3 v1.4 v1.5 v1.6 v2.0 com
mits
/ re
leas
e
Learning tasks Classification Regression Recommendation Clustering Frequent itemsets
Data utilities Featurization Statistics Linear algebra
Workflow utilities Model import/export Pipelines DataFrames Cross validation
Goals Scale-out ML Standard library Extensible API

MLlib: original design
RDDs Challenges for scalability
6
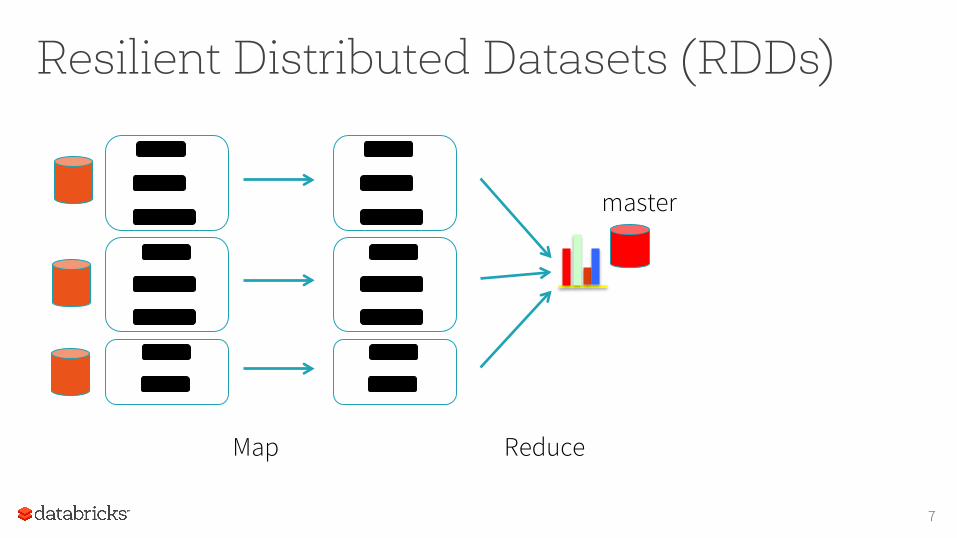
Resilient Distributed Datasets (RDDs)
7
Map Reduce
master
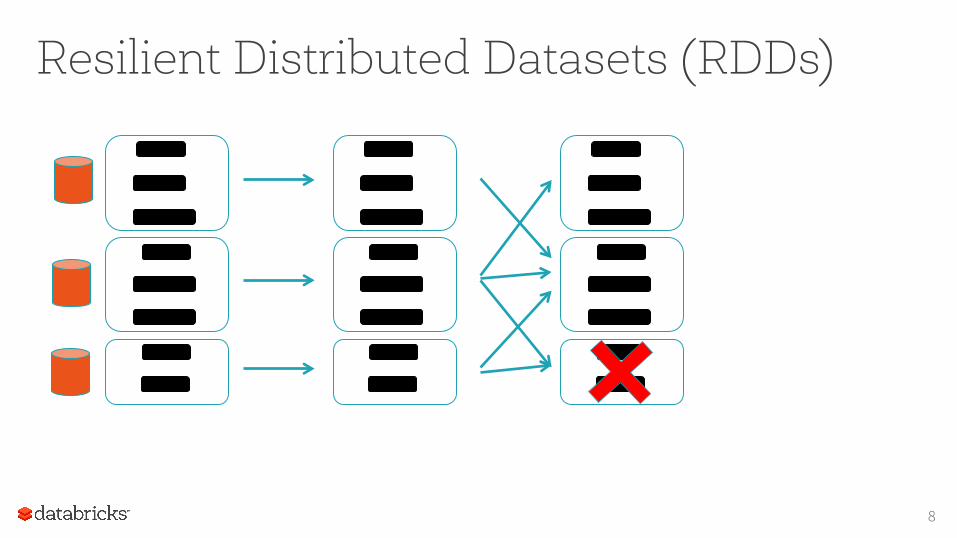
Resilient Distributed Datasets (RDDs)
8
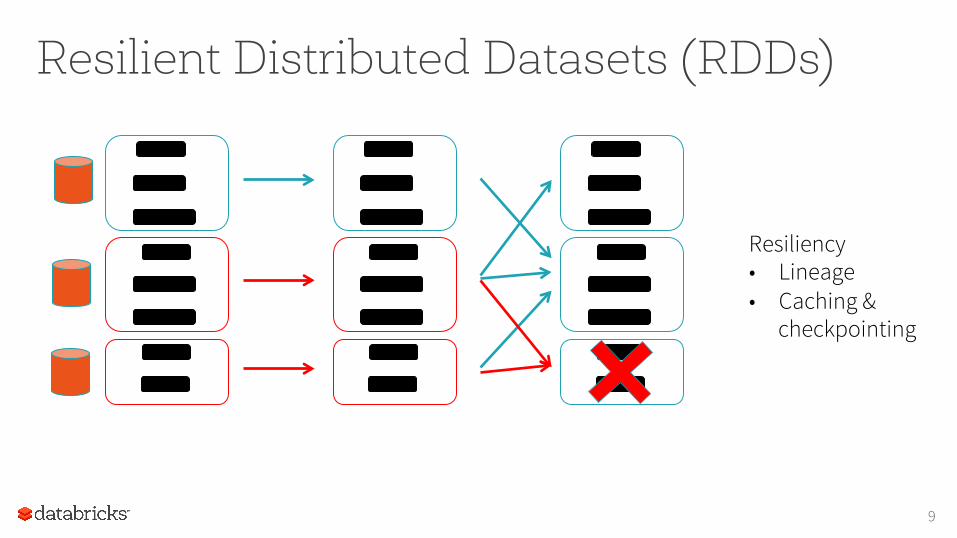
Resilient Distributed Datasets (RDDs)
9
Resiliency • Lineage • Caching &
checkpointing

ML on RDDs: the good
Flexible: GLMs, trees, matrix factorization, etc. Scalable: E.g., Alternating Least Squares on Spotify data • 50+ million users x 30+ million songs • 50 billion ratings Cost ~ $10 • 32 r3.8xlarge nodes (spot instances) • For rank 10 with 10 iterations, ~1 hour running time.
10

ML on RDDs: the challenges
Partitioning • Data partitioning impacts performance. • E.g., for Alternating Least Squares Lineage • Iterative algorithms à long RDD lineage • Solvable via careful caching and checkpointing JVM • Garbage collection (GC) • Boxed types
11

MLlib: current status
DataFrame & Dataset integration Pipelines API
12

Spark DataFrames & Datasets
13
dept age name
Bio 48 HSmith
CS 34 ATuring
Bio 43 BJones
Chem 61 MKennedy
Data grouped into named columns
DSL for common tasks • Project, filter, aggregate, join, … • 100+ functions available • User-Defined Functions (UDFs)
data.groupBy(“dept”).avg(“age”)
Datasets: Strongly typed DataFrames

DataFrame optimizations
Catalyst query optimizer Project Tungsten • Memory management • Code generation
14
Predicate pushdown Join selection …
Off-heap Avoid JVM GC Compressed format
Combine operations into single, efficient code blocks

ML Pipelines
• DataFrames: unified ML dataset API • Flexible types • Add & remove columns during Pipeline execution
15

Load data FeatureextracIon
Originaldataset
16
PredicIvemodel EvaluaIon
Text Label I bought the game... 4
Do NOT bother try... 1
this shirt is aweso... 5
never got it. Seller... 1
I ordered this to... 3
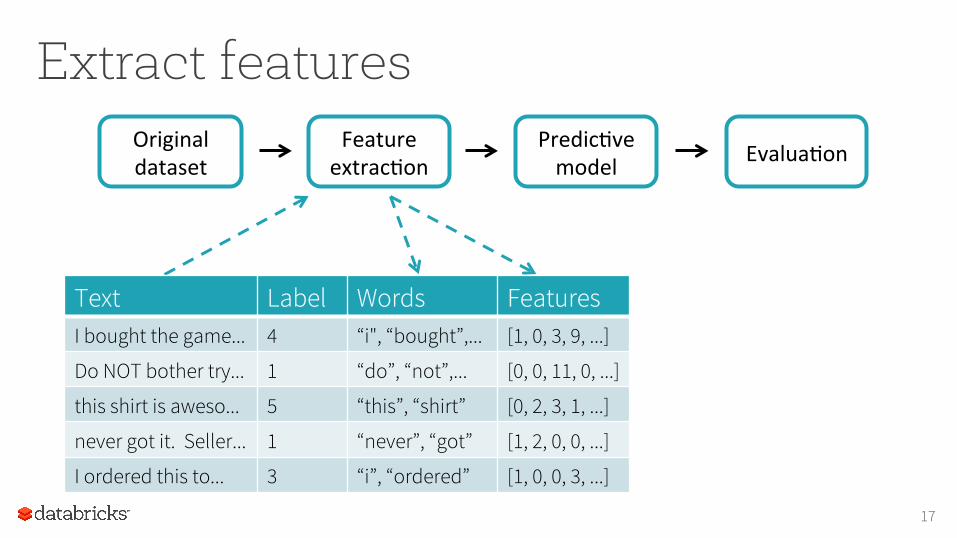
Extract features FeatureextracIon
Originaldataset
17
PredicIvemodel EvaluaIon
Text Label Words Features I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...]
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...]
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...]
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...]
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...]
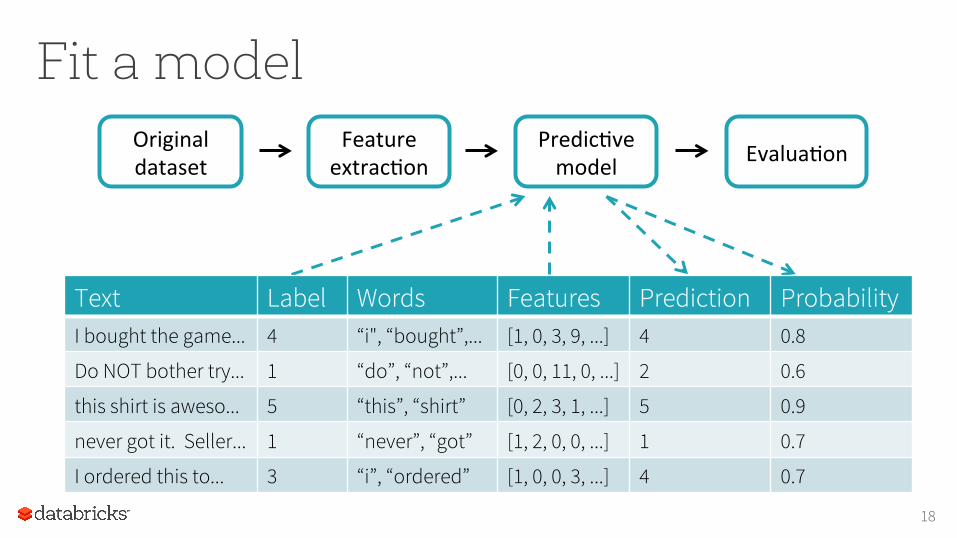
Fit a model FeatureextracIon
Originaldataset
18
PredicIvemodel EvaluaIon
Text Label Words Features Prediction Probability I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7
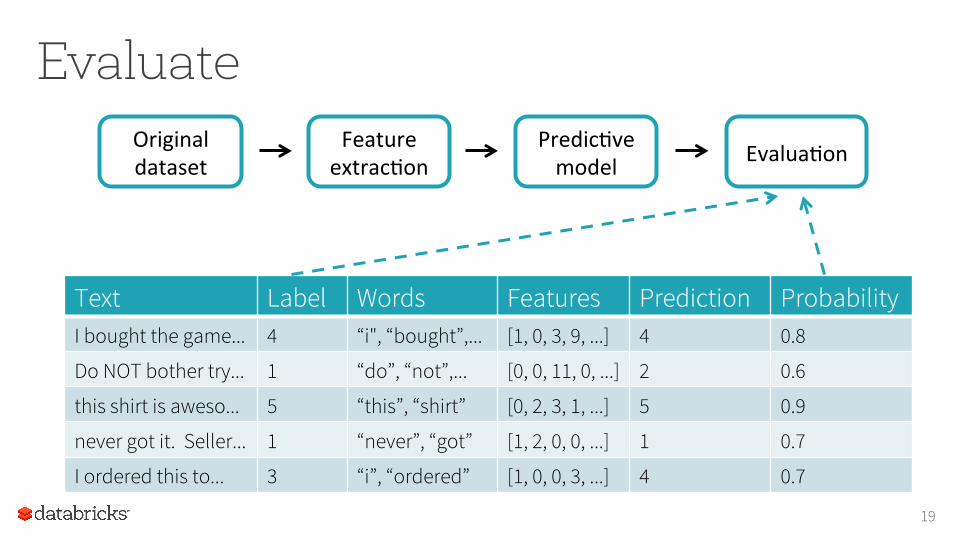
Evaluate FeatureextracIon
Originaldataset
19
PredicIvemodel EvaluaIon
Text Label Words Features Prediction Probability I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7

ML Pipelines
DataFrames: unified ML dataset API • Flexible types • Add & remove columns during Pipeline execution • Materialize columns lazily • Inspect intermediate results
20

Under the hood: optimizations
Current use of DataFrames • API • Transformations & predictions
21
Feature transformation & model prediction are phrased as User-Defined Functions (UDFs) à Catalyst query optimizer à Tungsten memory management
+ code generation

MLlib: future scaling
DataFrames for training Potential benefits • Spilling to disk • Catalyst • Tungsten Challenges remaining
22
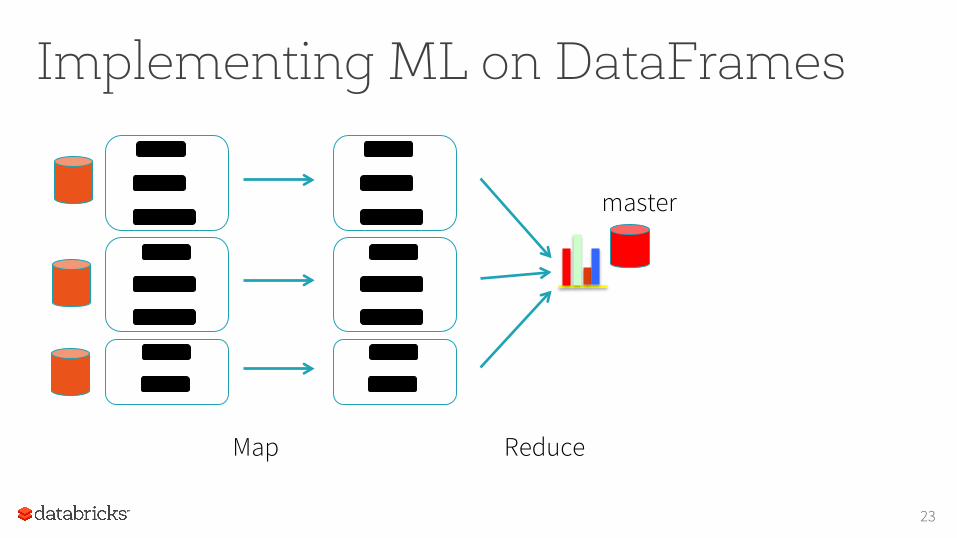
Implementing ML on DataFrames
23
Map Reduce
master

Scalability
DataFrames automatically spill to disk à Classic pain point of RDDs
24
java.lang.OutOfMemoryError
Goal: Smoothly scale, without custom per-algorithm optimizations

Catalyst in ML
Key idea: automatic query (ML algorithm) optimization • DataFrame operations are lazy. • Express entire algorithm as DataFrame operations. • Let Catalyst reorganize the algorithm, data, etc. à Fewer manual optimizations
25
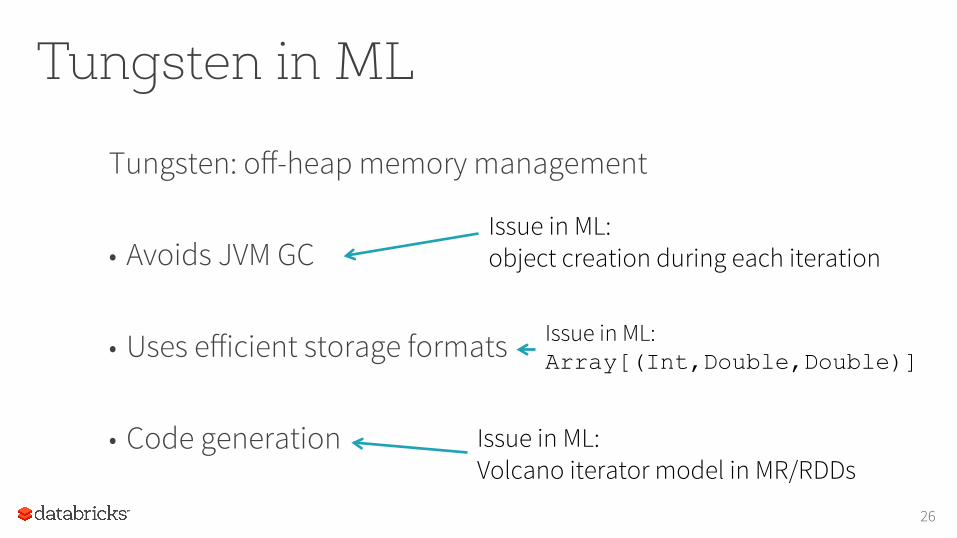
Tungsten in ML
Tungsten: off-heap memory management • Avoids JVM GC
• Uses efficient storage formats
• Code generation
26
Issue in ML: object creation during each iteration
Issue in ML: Array[(Int,Double,Double)]
Issue in ML: Volcano iterator model in MR/RDDs

Prototyping ML on DataFrames Currently: • Belief propagation • Connected components Current challenges: • DataFrame query plans do not have iteration as a top-level concept • ML/Graph-specific optimizations for Catalyst query planner Eventual goal: Port all ML algorithms to run on top of DataFrames à speed & scalability
27

To summarize... MLlib on RDDs • Required custom optimizations MLlib with a DataFrame-based API • Friendly API • Improvements for prediction MLlib on DataFrames • Potential for even greater scaling for training • Simpler for non-experts to write new algorithms
28

Get started Get involved • JIRA http://issues.apache.org • mailing lists http://spark.apache.org • Github http://github.com/apache/spark • Spark Packages http://spark-packages.org Learn more • New in Apache Spark 2.0
http://databricks.com/blog/2016/06/01 • MOOCs on EdX http://databricks.com/spark/training
29
Try out Apache Spark 2.0 in Databricks Community Edition http://databricks.com/ce
Many thanks to the community for contributions & support!

Databricks Founded by the creators of Apache Spark Offers hosted service • Spark on EC2 • Notebooks • Visualizations • Cluster management • Scheduled jobs
30
We’re hiring!

Thank you!
Twitter: @jkbatcmu


















