
Formal Semantics for an Abstract Agent Programming Language K.V. Hindriks, Ch. Mayer et al. Lecture...
40
Formal Semantics for an Abstract Agent Programming Language K.V. Hindriks, Ch. Mayer et al. Lecture Notes In Computer Science, Vol. 1365, 1997 http://www.nue.ci.i.u-tokyo.ac.jp/~duc/ppt/abstract-a pl.ppt M1. Nguyen Tuan Duc (duc@nue)
-
Upload
gannon-weedman -
Category
Documents
-
view
214 -
download
1
Transcript of Formal Semantics for an Abstract Agent Programming Language K.V. Hindriks, Ch. Mayer et al. Lecture...

Formal Semantics for an Abstract Agent Programming Language
K.V. Hindriks, Ch. Mayer et al.
Lecture Notes In Computer Science, Vol. 1365, 1997
http://www.nue.ci.i.u-tokyo.ac.jp/~duc/ppt/abstract-apl.ppt
M1. Nguyen Tuan Duc (duc@nue)

Source
Formal Semantics for an Abstract Agent Programming Language
Authors: K.V.Hindriks, F.S. de Boer, W. van der Hock, J.Ch. Mayer (Dept. of Computer Science, Utrecht Univ., the Netherlands)
Lecture Notes In Computer Science; Vol. 1365, 1997, pp 215 – 229
Proceedings of the 4th International Workshop on Intelligent Agents IV, Agent Theories, Architectures, and Languages

1.Introduction
There exist many agent programming languages AGENT-0, AgentSpeak(L) Lack a clear and formally defined semantics, difficult to for
malize the design, specification and verification
Need for an agent programming model based on existing programming concepts Logic programming, imperative programming Operational semantics

Agenda
Introduction Programming BDI-agents Abstract agent programming language Operational semantics Comparison with existing APLs Conclusions

2.Programming BDI-agents
BDI-agents: agents have Explicit goals (Desires) A set of plans to achieve a goal (Intensions) Information about the environment (Belief) Based on Human practical reasoning theory (Michael Brat
man) Many agent programming languages (APLs) based
on this model AGENT-0, AgentSpeak(L), …
However, APL is still disconnected from theory

Characteristics of BDI-agents
Complex internal mental state changes over time Beliefs, Desires, Plans, Intentions
Pro-active and reactive Goal-directed (proactive) Respond to changes in environment in a timely manner
(reactive) Reflective
Meta-level reasoning capabilities (e.g. goal revision)
Agent = goal-directed, belief-transforming entity

Requirement for APL
Theoretically, APL must have features for Belief updating (for newly observed,
communicated data, …) Goal updating (for goal revision) Practical reasoning (for finding the means to
achieve a goal) Practically, APL should contain all the familiar
constructs from imperative programming Sequential composition, tests, parallel execution,
etc.

3. An abstract agent programming language (3APL) An APL provides mechanism for
Belief updating Goal updating (goal revision) Practical reasoning (rule / plan to achieve a goal)

Belief
Beliefs are represented as First-order logic formulae from a language L.
P, F, C, A P: set of predicate symbols F: set of function symbols C: set of constant A: set of action symbols (not used in Belief)
Basic elements of L are given by a signature (Σ) Σ = <P, C, F, A> Term T ::= x | f(t, t,..., t) (x TVar, variable; f F)∈ ∈ Formulae B::= P(t, t,..., t) | not B | B B | B B | x.P(x)∧ ∨ ∃ At = the set of atoms ( constants, primitive predicates, …)

Example 1: robot Greedy Robot & Diamond
Diamond may randomly appear / disappear
Rocks are obstacles Basic predicates
diam( d, x, y ) : diamond d at (x, y) robot( r, x, y ): robot r at (x, y) rock( x, y ) : rock at (x, y)
Basic functions xc( x, y ) = x of nearest diamond from
(x, y) yc( x, y )
Perfect knowledge

Goals and actions
Goal: set of objectives agent tries to achieve Goal to do some action Goal to achieve some state of affairs
Signature Σ= <P, F, C, A>, Gvar: global variables, set of goal Lg A L⊆ g (basic actions) At L⊆ g
Φ L φ? L∈ ⇒ ∈ g
Gvar L⊆ g
π1, π2 ⊆ Lg π1; π2, π1 + π2, π1 || π2 L⇒ ∈ g
Rule for composition of goal Basic goals: basic actions, achievement goals (P(t) At), test goa∈
l (φ?) Basic actions are update operators on belief base
pickup( Greedy, d ) delete diam( d, x, y ) from σ (belief base)⇒

Goal variables
The language contains variables range over Goals Reflective reasoning Communication (parameter passing)
Receive request to establish some goal in a goal variable

Example 2: Actions and goal of Greedy west, east, north, south: move a step pickup( r, d ) : robot r pickup diamond d Goal: max_diam
User defined predicate Usually given in a procedure definition

Practical reasoning rules
To achieve its goals, agent has to Find the means for achieving them Revise its goal (in case of failure…)
⇒ Practical reasoning Practical reasoning rules Lp
φ L, π,π’ L∈ ∈ g π ← φ| π’ L⇒ ∈ p
π: head of the rule π’: body of the rule φ: guard Global variables of the rule = Free variables in π Local variables = variables in the rule except global one
Practical reasoning rule (PR) serves two functions Mean, recipe to achieve a goal (plan rule) Goal revision
-Φrepresents condition to apply the rule- Or used to retrieve data from B (by unifying predicates)

Plan rules: procedural knowledge Plan rules: rules with head is a basic goal P(t)
P(t) may be viewed as procedure calls to plans to achieve the goal
Plan rules encode procedural knowledge of an agent

Example 3: plan rules
max_diam ← robot( Greedy, x0, y0 ) x = xc∧( x0, y0 ) y = yc( x0, y0 ) | robot( Greedy, x, ∧y ); diam( z, x, y )?; pickup( Greedy, z ); max_diam Implementing greedy algorithm: repeat the followi
ng action: go to nearest diamond, take it
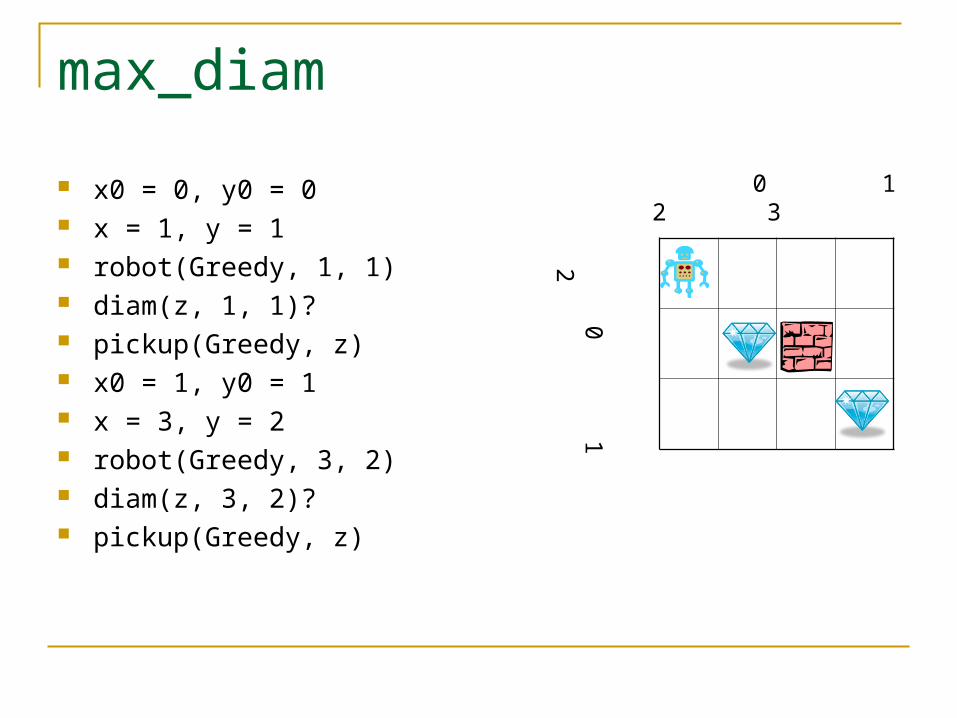
max_diam
x0 = 0, y0 = 0 x = 1, y = 1 robot(Greedy, 1, 1) diam(z, 1, 1)? pickup(Greedy, z) x0 = 1, y0 = 1 x = 3, y = 2 robot(Greedy, 3, 2) diam(z, 3, 2)? pickup(Greedy, z)
0 1 2 3
0 1 2

robot( r, x, y )
robot( r, x, y ) ← robot( r, x0, y0 ) |
(x = x0 y = y0 )? + [(x < x0)? west + (x0 < ∧x)? east + (y > y0)? south + (y0 > y)? north]; robot( r, x, y) robot( r, x0, y0 ) : to retrieve current position robot( r, x, y ) (in body): sub-goal
0 1 2 3 0 1 2

Revision of goals: reflective rules Rules with head contains an arbitrary
programs (including goal variables) Goal revise in case
Found a more optimal strategy Failure

Example 4: More optimal strategy Diamond suddenly appeared as nearer positi
on X; robot( r, x, y ) ← robot( r, x0, y0 ) not( x = ∧
xc( x0, y0 ) y = yc(x0, y0) ) | robot( r, xc( x∧0, y0 ), yc( x0, y0) )

Example 5: Failure
rock as (x0-1, y0) west; robot( r, x, y ) ← robot( r, x0, y0 ) ∧
rock( x0 – 1, y0 ) | [(y<=y0)?; north + (y0 <= y)?; south]; robot( r, x, y )

Three levels of agent programming Action Goal execution Goal revision (self-modifying program)

Agent programs
Agent = goal directed, belief transforming entity
Beliefs are updated by Actions Goals are updated by execution and revision An agent changes its beliefs and goals (PR
and basic actions are fixed)

Mental state
Mental state = <Π, σ>, where Π L∈ g is a goal base (set of goals) σ L is a belief base (set of beliefs)∈ Thus, the changing components in previous slide Denote: B: set of belief bases, Γ: PR-base
The behavior of an agent is fully specified if The semantics of basic actions is given The mechanism for executing goals and applying rules are
defined

Some definitions
Free vs. bounded variables P(x, d) x. Q(∧∃ y, x) z. G(a, b, ∧ ∀ z) Alpha conversion: P(x, d) x1. Q(y, x1) z. G(a,b,z)∧∃ ∧∀
Free(e) = { x | x is free in e } Substitution: [x/5] f(x) ≡ f(5) Unifier: if t1, t2, … are terms then unifier of t1, t2,…,
tn is a substitution θsuch that θ(t1) ≡ θ(t2) ≡…≡θ(tn)Ex: f(x, x) and f(y, z) θ = [x/z, y/z]⇒
Most general unifier (MGU) ξ ∀θ unifier∈ 、∃ ψ: θ = ψξ In the above example: [x/c, y/c] = [z/c][x/z, y/z]

Basic action transitions
Semantics of basic actions A is given by a transition function T: B x B → P(A) P(A) is variant of A If a T(σ,σ’) then denoted by <σ,σ’>a∈
<{…, robot(Greedy, n, m), not(rock(n-1,m)),…}, {…, robot(Greedy, n-1, m), not(rock(n-1, m))}> west;
<{…, diam(d,n,m), robot(Greedy, n, m), …}, {…, robot(Greedy, n, m), not(diam(d, n, m), …}> pickup(Greedy, d)
By observing the environment, agent knows action has succeeded or failed

Agent program
An agent program is a quadruple <T, Π0, σ0, Γ> T : a basic transition function (specifying the effect of basic
actions) Π0 : initial goal base σ0 : initial belief base Γ : PR-base
Thus, to program an agent is to specify its initial mental state define semantics of basic actions write a set of PR

Example 6: Agent program for Greedy Basic actions:
<{…, robot(Greedy, n, m), not(rock(n-1,m)),…}, {…, robot(Greedy, n-1, m), not(rock(n-1, m))}> west;
north, south, east <{…, diam(d,n,m), robot(Greedy, n, m), …}, {…, robot(Gree
dy, n, m), not(diam(d, n, m), …}> pickup(Greedy, d) Π0 = {max_diam} σ0 = { robot(Greedy, 0, 0), rock(1,5), rock(3,3), rock
(2,1), diam(d, 2, 2) } PR-base in example 4, 5

4. Operational semantics
Operational semantics Specify how a program can transform the system
state A transition system is a deductive system whi
ch allows to derive the transition of a program. Transition rules specify the meaning of each progr
amming construct. Transition rules transform configuration
In APL, configuration is mental state <Π,σ>

4.1. Practical reasoning rule
V = set of global variables in goal base PR-rule application
π’ ← φ| π’’ ’ Γ σ∈ ∧ |= (φθγ) ∀____________________________________ <π, σ> V → θγ <π’’θγ, σ> Where,
θ(π’) = θ(π), π Π ∈ A ’ Γmeans A is a variant of a PR-rule (alpha conversion)∈ γis a substitution such that no variable x: γ(x) V (retrieves par∈
ameter values from σ) ⇒ Perform alpha-conversion to avoid interference of local and global parameters
→ followed by θγ to record the substitution process

Example 7: goal revision
Suppose that Π = {east; robot( Greedy, 3, 2 )}, σ = {robot(Greedy, 0, 0), diam(d’, 3, 2), diam(d,2,2) }
Apply rule: X; robot( r, x, y ) ← robot( r, x0, y0 ) not( x = xc( x0, y0 ) y = yc(x0, y0) ) | ∧ ∧robot( r, xc( x0, y0 ), yc( x0, y0) )
θ = { X/east, r/Greedy, x/3, y/2 } ⇒ φθ≡ robot(Greedy, x0, y0) not( 3 = xc(x∧
0, y0) 2 = yc(x0, y0) )∧ γ= {x0/0, y0/0} π’’θγ ≡ robot(Greedy, xc(0, 0), yc(0, 0))
≡ robot(Greedy, 2, 2)
0 1 2 3

4.2. Execution rules
E denotes termination E ; π ≡ π E + π ≡ π ….
Execution rule 1: basic actions <σ, σ’>a
____________________________ <a, σ>V →Φ <E, σ’>
Φ is an identity substitution Thus, basic action means changing the state according
to transition function and stop execution

First-order tests
Check if some condition follows from σ
σ |= (φθ)∀ ____________________
<φ?, σ>V →θ <E, σ> Ex: diam(z, x, y)?; pickup(Greedy, z)
θ = {z/d, x/2, y/2} After first-order test, goal becomes pickup(Greed
y, d)

Sequential composition
<π1, σ>V →θ <π’1, σ’>
________________________________
<π1;π2, σ>V → θ <π’1; π2θ, σ’> Ex: in previous slide:
π1 = diam(z, x, y)?, π’1 = E θ = {z/d, x/2, y/2} π2 = pickup(Greedy, z) π1;π2θ ≡ E; pickup(Greedy, d) ≡ pickup(Gree
dy, d)

Non-deterministic choice
<π1, σ>V →θ <π’1, σ>
_____________________________
<π1 + π2, σ>V →θ <π’1, σ’>
<π2, σ>V →θ <π’2, σ>
_____________________________
<π1 + π2, σ>V →θ <π’2, σ’>

Parallel composition
<π1, σ>V →θ <π’1, σ>
____________________________________
<π1 || π2, σ>V →θ <π’1 || π2θ, σ’>
(similar rule for π2)

Goal execution
Let Π = {π0, …, πi, πi+1, …} L⊆ g, V = Free(Π) Goal execution
<πi, σ>V →θ <π’i, σ’>
__________________________________________________
< {π0, …, πi, πi+1, …}, σ>V → < {π0, …, π’i, πi+1, …}, σ’> There is no θ in the consequence This is because the mental state is the top level of execution. At t
his level, various goal are executed in a parallel fashion without communication

Computations of an agent program A computation of an agent program is a finite
or infinite sequence of configurations <Π0, σ0>, <Π1, σ1>, <Π2, σ2>, … such that, for each i: <Πi, σi> → <Πi+1, σi+1>

5. Comparison with existing APLs
AGENT-0: Only executes basic, primitive actions or skills of a
gent Goal revision is restricted to removing infeasible c
ommitments and uses built-in mechanism 3APL allows much more general revision rule
AgentSpeak(L): Quite similar to the proposed language 3APL provides more general and high-level progr
amming construct then AgentSpeak(L)

6. Conclusions
A transition system is a suitable formalism for specifying the operational semantics of APL
An abstract APL is proposed Includes all the regular programming constructs from
imperative programming and logic-programming Future work
Extensions to multi-agent systems with communication Mechanism for failure recovery Apply notions of standard concurrency theory (π-calculus) …


















