
Feedly & Cassandra at Fashiolista
31
Accidental scaling issues From a hobby project to one of the largest online fashion communities
-
Upload
thierry-schellenbach -
Category
Technology
-
view
1.581 -
download
1
Transcript of Feedly & Cassandra at Fashiolista

Accidental scaling issues From a hobby project to one of the largest online fashion communities

About Me
• Thierry Schellenbach
• Founder/ CTO Fashiolista
• Github/tschellenbach
• Feedly & Django Facebook
• Blog: mellowmorning.com
• @tschellenbach

Today
• Fashiolista’s growth
• Pre Cassandra feed systems
• Github/tschellenbach/Feedly
– Cassandra learnings
– Remaining challenges

A long time ago
Rick, Joost, Thierry & Thijs

Launched Fashiolista at TNW
Got a few hundred users
And went back to work

Brazil?!
• Blogs• Twitter• Capricho (Teen
magazine with 1.8M followers)

Growth
2nd largest fashion community
• 1.5M members
• 17M loves/month
• 94M pageviews (google analytics)

5.000.000+14.000.000+

The team

Global Fashion Discovery
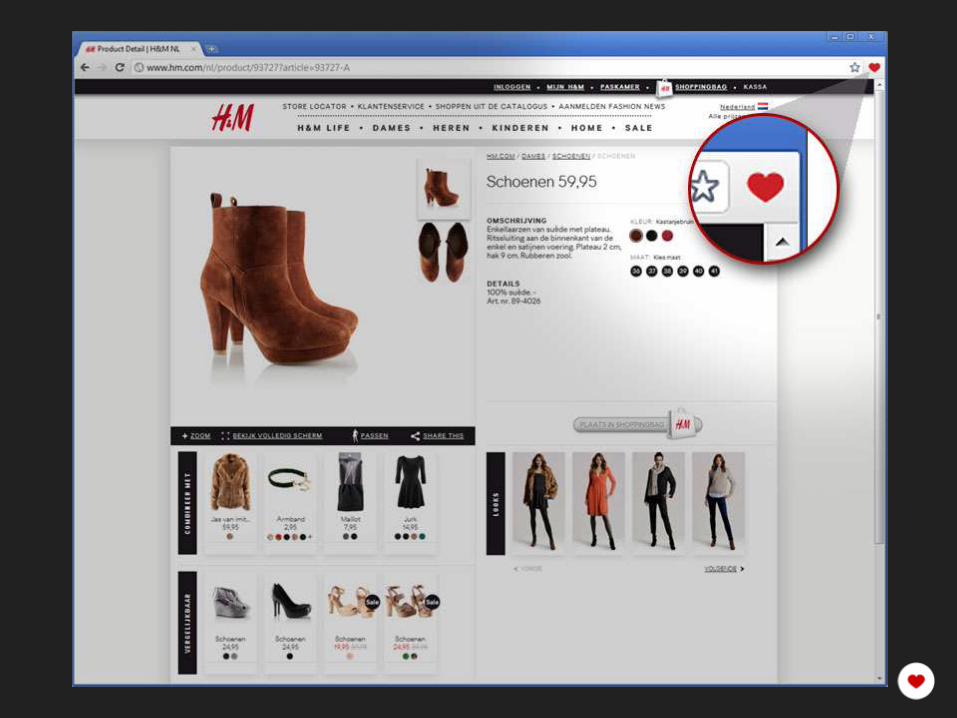
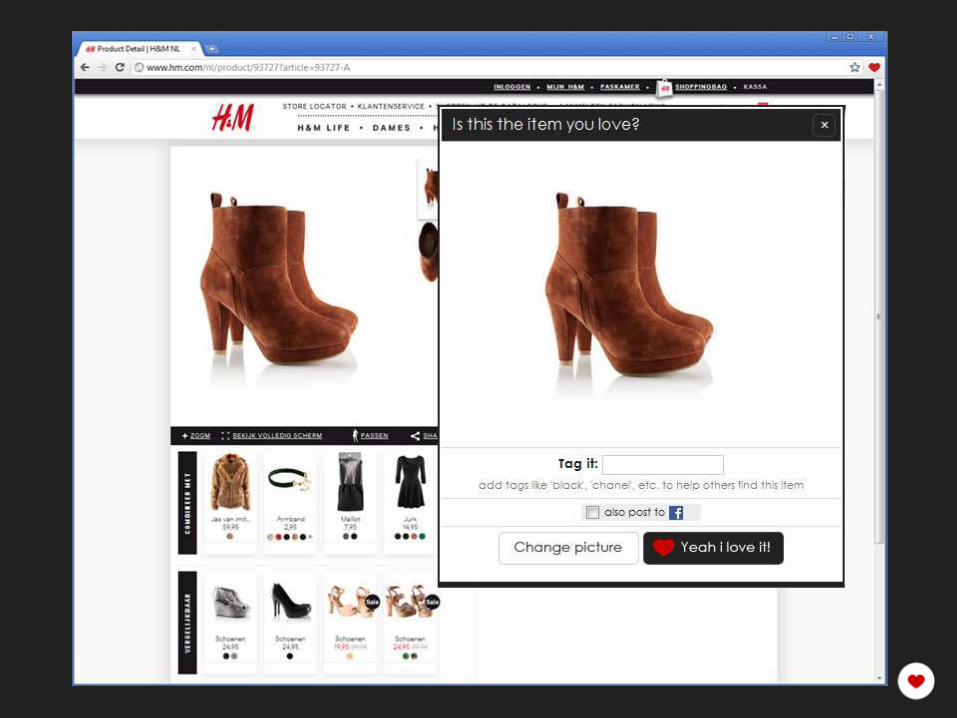
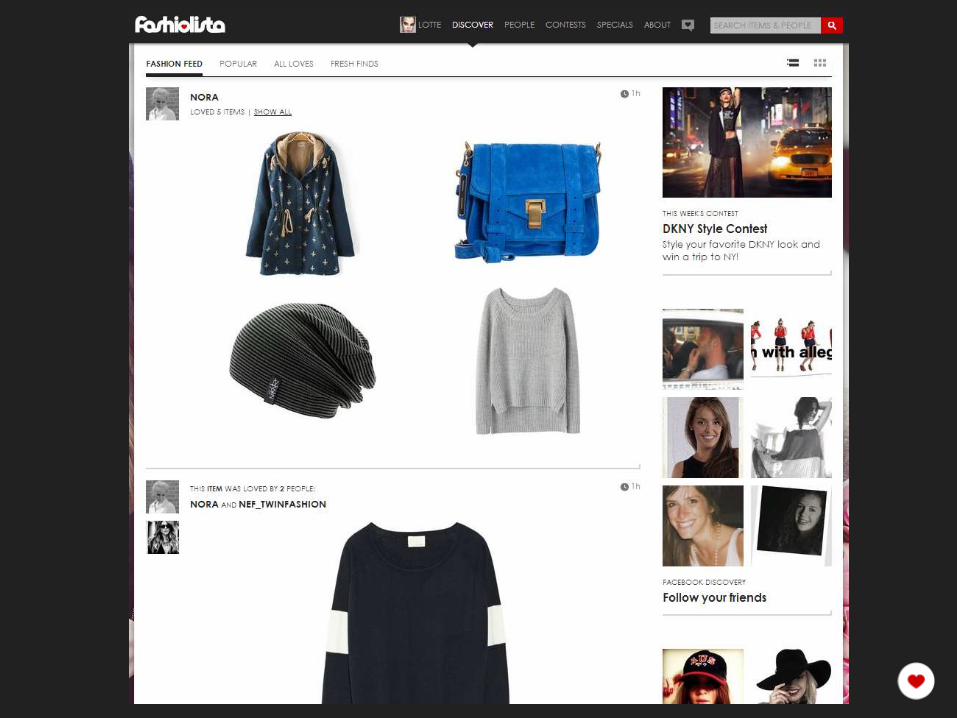

Our Stack
• Django/Python
• PostgreSQL/ Pgbouncer
• Cassandra
• Redis
• Solr
• Celery/ RabbitMQ
• AWS/ Ubuntu
• Nginx/ Gunicorn/ Supervisor
• Newrelic, Datadog & Sentry

Feed History
1. PostgreSQL
2. Redis – Feedly 0.1
3. Cassandra – Feedly 0.9
More details in this highscalability post:
http://bit.ly/hsfeedly

PostgreSQL - Pull
1. Smooth till we reached ~100M activities
2. Spikes in performance due to the query planner
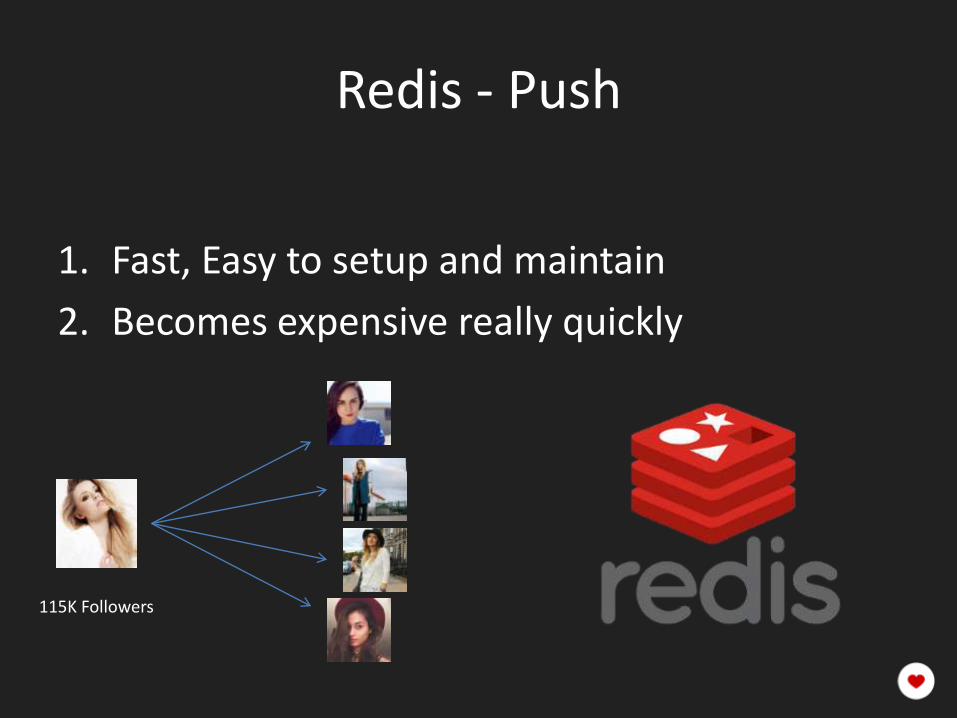
Redis - Push
1. Fast, Easy to setup and maintain
2. Becomes expensive really quickly
115K Followers

Cassandra - Feedly 0.9
1. Few moving components
2. Supported by Datastax
3. Instagram
4. Easy to add capacity
5. Cost effective

We open sourced Feedly!
• Github/tschellenbach/Feedly
• Python library, which allows you to build newsfeed and notification systems using Cassandra and/or Redis

Feedly – What can you build?
Newsfeeds Notification systems

Cassandra Challenges
1. Which Python library to chose?
• Pycassa
• CQLEngine (using the old CQL module)
• Python-Driver (beta)
• Fork CQLEngine to support Python-Driver
– Github/tbarbugli/cqlengine

Cassandra Challenges
2. Importing data(300M loves * 1000 followers = 300 billion activities)
• High CPU load
• Nodes going down
• Start with many nodes, scale down afterwards

Cassandra Challenges
3. Optimizing import speed (300M loves * 1000 followers = 300 billion activities)
• Python-Driver
• Batch queries
• Non-Atomic (unlogged) batch queries
• Prepared statements

Cassandra Challenges
4. Data model denormalization
CREATE TABLE fashiolista_feedly.timeline_flat (feed_id ascii, activity_id varint, actor int, extra_context blob, object int,target int, time timestamp, verb intPRIMARY KEY (feed_id, activity_id) ) WITH CLUSTERING ORDER BY (activity_id ASC)
AND bloom_filter_fp_chance=0.010000 AND caching='KEYS_ONLY' AND dclocal_read_repair_chance=0.000000 AND gc_grace_seconds=864000 AND read_repair_chance=0.100000 AND replicate_on_write='true' AND populate_io_cache_on_flush='false' AND compaction={'class': 'SizeTieredCompactionStrategy'} AND compression={'sstable_compression': 'LZ4Compressor'};

Opscenter is great
Opscenter & Datastax AMI are greatFor startups Enterprise is also Free

Evaluation
7 instances, m1.xlarge, 2.59 TBCassandra 2.0.0, CQL3, Python-driver(Would have been one expensive Redis cluster)
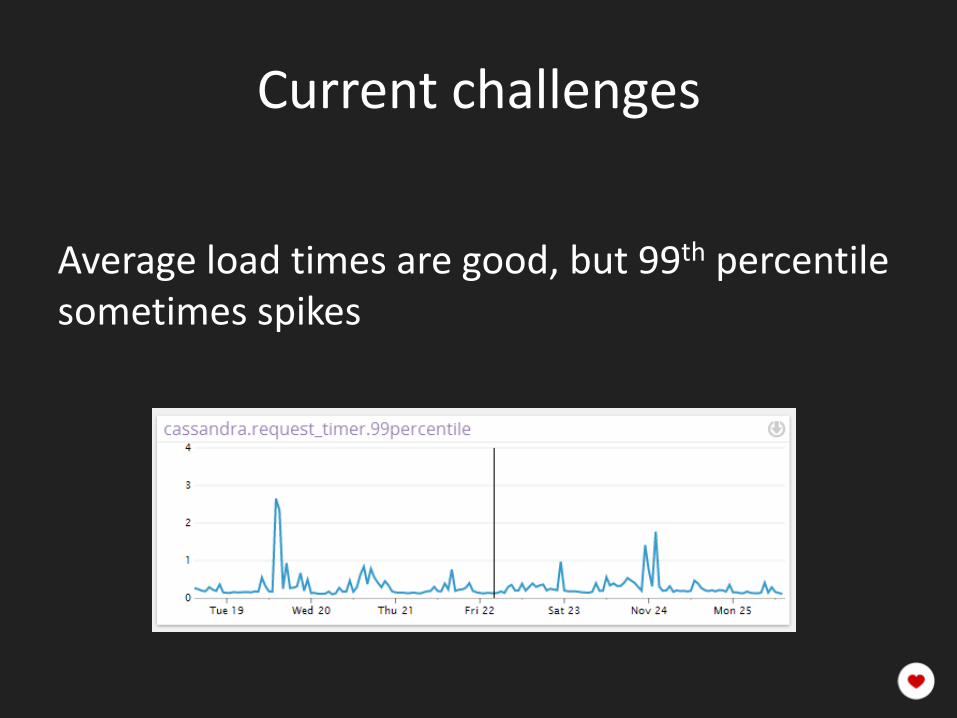
Current challenges
Average load times are good, but 99th percentile sometimes spikes

Current Challenges
How do we limit the storage for feeds?
Trimming?(Not supported)
DELETE from timeline_flat WHERE activity_id < 5000
Use a TTL on the rows?

Fork Feedly
This is our first time using Cassandra, let us know how we can further speedup our implementation:
http://bit.ly/feedlycassandra
Check out Feedly atGithub.com/tschellenbach/Feedly
Ask questions, Give tips to these guys:
Thierry Schellenbach Tommaso Barbugli Guyon Morée


















