
Feature Transfer and Knowledge Distillation in...
39
Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop Feature Transfer and Knowledge Distillation in Deep Neural Networks (Two Interesting Papers at NIPS 2014) LU Yangyang [email protected] KERE Seminar Dec. 31, 2014
Transcript of Feature Transfer and Knowledge Distillation in...

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Feature Transfer and Knowledge Distillationin Deep Neural Networks(Two Interesting Papers at NIPS 2014)
LU Yangyang
KERE SeminarDec. 31, 2014

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Deep Learning F4 (at NIPS1 2014)
From left to right:
∙ Yann Lecun (http://yann.lecun.com/)
∙ Geoffrey Hinton (http://www.cs.toronto.edu/˜hinton/)
∙ Yoshua Bengio (http://www.iro.umontreal.ca/˜bengioy)
∙ Andrew Ng (http://www-cs-faculty.stanford.edu/people/ang/)1Advances in Neural Information Processing Systems

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Outline
How transferable are features in deep neural networks? NIPS’14IntroductionGenerality vs. Specificity Measured as Transfer PerformanceExperiments and Discussion
Distilling the Knowledge in a Neural Network. NIPS’14 DL workshopIntroductionDistillationExperiments: Distilled Models and Specialist ModelsDiscussion

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Outline
How transferable are features in deep neural networks? NIPS’14IntroductionGenerality vs. Specificity Measured as Transfer PerformanceExperiments and Discussion
Distilling the Knowledge in a Neural Network. NIPS’14 DL workshop

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Authors
∙ How transferable are features in deep neural networks?
∙ NIPS’14
∙ Jason Yosinski1, Jeff Clune2, Yoshua Bengio3, and Hod Lipson4
1 Dept. Computer Science, Cornell University2 Dept. Computer Science, University of Wyoming3 Dept. Computer Science & Operations Research, University of Montreal4 Dept. Mechanical & Aerospace Engineering, Cornell University

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction
A common phenomenon in many deep neural networks trainedon natural images:
∙ on the first layer they learn features similar to Gaborfilters and color blobs.
∙ occurs not only for different datasets, but even with verydifferent training objectives.
A 2-dimensional Gabor filter
Features at different layers of a neural network:
∙ First-layer features:general- finding standard features on the first layer seems to occur regardless of the exactcost function and natural image dataset
∙ Last-layer features:specific- the features computed by the last layer of a trained network must depend greatlyon the chosen dataset and task
∙ If first-layer features are general and last-layer features are specific, then theremust be a transition from general to specific somewhere in the network.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction
A common phenomenon in many deep neural networks trainedon natural images:
∙ on the first layer they learn features similar to Gaborfilters and color blobs.
∙ occurs not only for different datasets, but even with verydifferent training objectives.
A 2-dimensional Gabor filter
Features at different layers of a neural network:
∙ First-layer features:general- finding standard features on the first layer seems to occur regardless of the exactcost function and natural image dataset
∙ Last-layer features:specific- the features computed by the last layer of a trained network must depend greatlyon the chosen dataset and task
∙ If first-layer features are general and last-layer features are specific, then theremust be a transition from general to specific somewhere in the network.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction(cont.)
First-layer features(General)→ TRANSITION →Last-layer Features(Specific)
∙ Can we quantify the degree to which a particular layer is general or specific?
∙ Does the transition occur suddenly at a single layer, or is it spread out over severallayers?
∙ Where does this transition take place: near the first, middle, or last layer of thenetwork?
We are interested in the answers to these questions because, to the extent that featureswithin a network are general, we will be able to use them for transfer learning.
Transfer Learning 2:
∙ first train a base network on a base dataset and task
∙ then repurpose or transfer the learned features to a second target network to betrained on a target dataset and task
∙ This process will tend to work if the features are general, meaning suitable to bothbase and target tasks, instead of specific to the base task.
2http://www1.i2r.a-star.edu.sg/˜jspan/SurveyTL.htm,http://www.cs.ust.hk/˜qyang/publications.html

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction(cont.)
First-layer features(General)→ TRANSITION →Last-layer Features(Specific)
∙ Can we quantify the degree to which a particular layer is general or specific?
∙ Does the transition occur suddenly at a single layer, or is it spread out over severallayers?
∙ Where does this transition take place: near the first, middle, or last layer of thenetwork?
We are interested in the answers to these questions because, to the extent that featureswithin a network are general, we will be able to use them for transfer learning.
Transfer Learning 2:
∙ first train a base network on a base dataset and task
∙ then repurpose or transfer the learned features to a second target network to betrained on a target dataset and task
∙ This process will tend to work if the features are general, meaning suitable to bothbase and target tasks, instead of specific to the base task.
2http://www1.i2r.a-star.edu.sg/˜jspan/SurveyTL.htm,http://www.cs.ust.hk/˜qyang/publications.html
Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
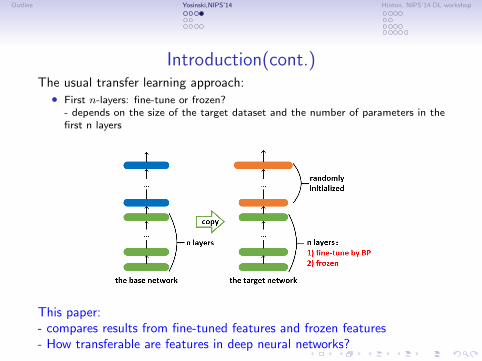
Introduction(cont.)The usual transfer learning approach:
∙ First 𝑛-layers: fine-tune or frozen?- depends on the size of the target dataset and the number of parameters in thefirst n layers
This paper:- compares results from fine-tuned features and frozen features- How transferable are features in deep neural networks?

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Generality vs. Specificity Measured as Transfer Performance
This paper: define the degree of generality of a set of features learned on task 𝐴 asthe extent to which the features can be used for another task 𝐵.
Task 𝐴 and Task 𝐵:
∙ Image Classification Task
∙ randomly spilt 1, 000 ImageNet classes → 500(Task 𝐴) + 500(Task 𝐵)
∙ train one 𝑁 -layer (𝑁 = 8 here) convolutional network on 𝐴 (𝑏𝑎𝑠𝑒𝐴) and anotheron 𝐵 (𝑏𝑎𝑠𝑒𝐵)
∙ define new networks: 𝑛 ∈ {1, 2, ..., 7}
∙ selffer networks 𝐵𝑛𝐵- first 𝑛 layers: copied from 𝑏𝑎𝑠𝑒𝐵 and frozen- higher (𝑁 − 𝑛) layers: randomly initialized
∙ transfer networks 𝐴𝑛𝐵∙ selffer networks 𝐵𝑛𝐵+: all layers are fine-tuned∙ transfer networks 𝐴𝑛𝐵+

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Overview of the experimental treatments and controlsCNN for image classification: using Caffe3
3Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C].Proceedings of the ACMInternational Conference on Multimedia. ACM, 2014: 675-678.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Three sets of ExperimentsHypothesis: If 𝐴 and 𝐵 are similar, authors expect that transferred features willperform better than when A and B are less similar.
Similar Datasets: Random 𝐴/𝐵 splits
∙ ImageNet contains clusters of similar classes, particularly dogs and cats.4
∙ On average, 𝐴 and 𝐵 will each contain approximately 6 or 7 of these felid classes,meaning that base networks trained on each dataset will have features at all levelsthat help classify some types of felids.
Dissimilar Datasets: Man-made/Natural splits
∙ ImageNet also provides a hierarchy of parent classes.
∙ create a special split of the dataset into two halves that are as semantically differentfrom each other as possible:- 𝐴: only man-made entities (551 classes)- 𝐵: only natural entities (449 classes)
Random Weights:
to ask whether or not the nearly optimal performance of random filters reported on
small networks5 carries over to a deeper network trained on a larger dataset
4{tabby cat, tiger cat, Persian cat, Siamese cat, Egyptian cat, mountain lion, lynx, leopard, snow leopard, jaguar, lion, tiger, cheetah}5Jarrett K, Kavukcuoglu K, Ranzato M, et al. What is the best multi-stage architecture for object recognition?[C]. Computer Vision,
2009 IEEE 12th International Conference on. IEEE, 2009: 2146-2153.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Three sets of ExperimentsHypothesis: If 𝐴 and 𝐵 are similar, authors expect that transferred features willperform better than when A and B are less similar.
Similar Datasets: Random 𝐴/𝐵 splits
∙ ImageNet contains clusters of similar classes, particularly dogs and cats.4
∙ On average, 𝐴 and 𝐵 will each contain approximately 6 or 7 of these felid classes,meaning that base networks trained on each dataset will have features at all levelsthat help classify some types of felids.
Dissimilar Datasets: Man-made/Natural splits
∙ ImageNet also provides a hierarchy of parent classes.
∙ create a special split of the dataset into two halves that are as semantically differentfrom each other as possible:- 𝐴: only man-made entities (551 classes)- 𝐵: only natural entities (449 classes)
Random Weights:
to ask whether or not the nearly optimal performance of random filters reported on
small networks5 carries over to a deeper network trained on a larger dataset
4{tabby cat, tiger cat, Persian cat, Siamese cat, Egyptian cat, mountain lion, lynx, leopard, snow leopard, jaguar, lion, tiger, cheetah}5Jarrett K, Kavukcuoglu K, Ranzato M, et al. What is the best multi-stage architecture for object recognition?[C]. Computer Vision,
2009 IEEE 12th International Conference on. IEEE, 2009: 2146-2153.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Similar Datasets (Random A/B splits)
∙ 𝐵𝑛𝐵: performance drop when 𝑛 = 4, 5- the original network contained fragile co-adapted features on successive layers- features that interact with each other in a complex or fragile way such that thisco-adaptation could not be relearned by the upper layers alone.
∙ 𝐵𝑛𝐵+: fine-tuning thus prevents the performance drop (𝐵𝑛𝐵)
∙ 𝐴𝑛𝐵: the combination of the drop from lost co-adaptation and the drop fromfeatures that are less and less general
∙ 𝐴𝑛𝐵+: transferring features + fine-tuning: generalize better than directly trainingon the target dataset
Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
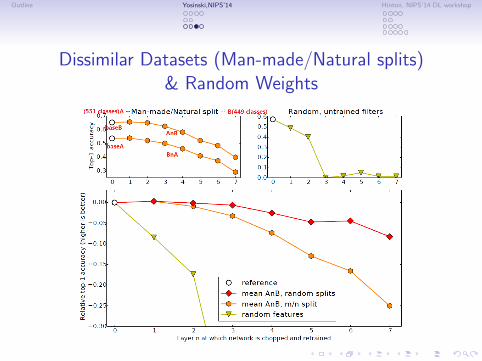
Dissimilar Datasets (Man-made/Natural splits)& Random Weights

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Summary
If first-layer features are general and last-layer features are specific, thenthere must be a transition from general to specific somewhere in thenetwork.
Experiments:fine-tuned v.s. frozen features on selffer and transfer networks
∙ on Similar Datasets (Random 𝐴/𝐵 splits):- performance degradation when using transferred features without fine-tuning:i) the specificity of the features themselvesii) the fragile co-adaption between neurons on neighboring layers
- initializing a network with transferred features from almost any number of layerscan produce a boost to generalization performance after fine-tuning to a newdataset
∙ on Dissimilar Datasets (Man-made/Natural splits):the more dissimilar the base task and target task are, the more performance drops
∙ on Random Weights:find lower performance on the relatively large ImageNet dataset than has been pre-viously reported for smaller datasets when using features computed from randomlower-layer weights vs. trained weights

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Summary
If first-layer features are general and last-layer features are specific, thenthere must be a transition from general to specific somewhere in thenetwork.
Experiments:fine-tuned v.s. frozen features on selffer and transfer networks
∙ on Similar Datasets (Random 𝐴/𝐵 splits):- performance degradation when using transferred features without fine-tuning:i) the specificity of the features themselvesii) the fragile co-adaption between neurons on neighboring layers
- initializing a network with transferred features from almost any number of layerscan produce a boost to generalization performance after fine-tuning to a newdataset
∙ on Dissimilar Datasets (Man-made/Natural splits):the more dissimilar the base task and target task are, the more performance drops
∙ on Random Weights:find lower performance on the relatively large ImageNet dataset than has been pre-viously reported for smaller datasets when using features computed from randomlower-layer weights vs. trained weights

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Outline
How transferable are features in deep neural networks? NIPS’14
Distilling the Knowledge in a Neural Network. NIPS’14 DL workshopIntroductionDistillationExperiments: Distilled Models and Specialist ModelsDiscussion

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Authors
∙ Distilling the Knowledge in a Neural Network
∙ NIPS’14 Deep Learning and Representation Learning Workshop6
∙ Geoffrey Hinton1,2†, Oriol Vinyals1†, Jeff Dean1
1 Google Inc.(Mountain View)2 University of Toronto and the Canadian Institute for Advanced Research† Equal contribution
6http://www.dlworkshop.org/

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction
The Story for Analogy:
∙ insects – a larval form: optimized for extracting energy and nutrientsfrom the environment
∙ insects – an adult form: optimized for the very different requirementsof traveling and reproduction
In large-scale machine learning (e.g. speech and object recognition)
∙ the training stage: extract structure from very large, highly redun-dant datasets; not in real time; can use a huge amount of computation
∙ the deployment stage: has much more stringent requirements onlatency and computational resources
We should be willing to train very cumbersome models if that makes iteasier to extract structure from the data.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction
The Story for Analogy:
∙ insects – a larval form: optimized for extracting energy and nutrientsfrom the environment
∙ insects – an adult form: optimized for the very different requirementsof traveling and reproduction
In large-scale machine learning (e.g. speech and object recognition)
∙ the training stage: extract structure from very large, highly redun-dant datasets; not in real time; can use a huge amount of computation
∙ the deployment stage: has much more stringent requirements onlatency and computational resources
We should be willing to train very cumbersome models if that makes iteasier to extract structure from the data.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction(cont.)
Cumbersome models:
∙ an ensemble of separately trained models
∙ a single very large model trained with a very strong regularizer
Distillation:
∙ Once the cumbersome model has been trained: using a different kindof training to transfer the knowledge from the cumbersome model toa small model that is more suitable for deployment.
∙ previous work7: demonstrate convincingly that the knowledge ac-quired by a large ensemble of models can be transferred to a singlesmall model
“knowledge” in a trained model:a learned mapping from input vectors to output vectors
7Bucilua C, Caruana R, Niculescu-Mizil A. Model compression[C].Proceedings of the 12th ACM SIGKDD international conference onKnowledge discovery and data mining. ACM, 2006: 535-541.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction(cont.)
Cumbersome models:
∙ an ensemble of separately trained models
∙ a single very large model trained with a very strong regularizer
Distillation:
∙ Once the cumbersome model has been trained: using a different kindof training to transfer the knowledge from the cumbersome model toa small model that is more suitable for deployment.
∙ previous work7: demonstrate convincingly that the knowledge ac-quired by a large ensemble of models can be transferred to a singlesmall model
“knowledge” in a trained model:a learned mapping from input vectors to output vectors
7Bucilua C, Caruana R, Niculescu-Mizil A. Model compression[C].Proceedings of the 12th ACM SIGKDD international conference onKnowledge discovery and data mining. ACM, 2006: 535-541.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Introduction(cont.)∙ Models are usually trained to optimize performance on the training data when the
real objective is to generalize well to new data.
∙ Information about the correct way to generalize is not normally available.
Distillation:transfer the generalization ability of the cumbersome model to a small model
∙ use the class probabilities produced by the cumbersome model as “soft targets”for training the small model8
∙ use the same training set or a separate “transfer” set for the transfer stage
8Caruana et al., SIGKDD’06: using the using the logits (the inputs to the final softmax) for transferring

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Distillation
Neural networks for multi-class classification: a “softmax”output layer
𝑞𝑖 =exp(𝑧𝑖/𝑇 )∑︀𝑗 exp(𝑧𝑗/𝑇 )
𝑧𝑖 : the logit, i.e. the input to the softmax layer
𝑞𝑖 : the class probability computed by the softmax layer
𝑇 : a temperature that is normally set to 1
Cumbersome models → the distilled model:
∙ training the distilled model on a transfer set
∙ using a soft target distribution for each case in the transfer set thatis produced by using the cumbersome model with a high temperaturein its softmax
∙ The same high temperature is used when training the distilled model,but after it has been trained it uses a temperature of 1.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Distillation(cont.)
When the correct labels are known for all or some of the transfer set, this method canbe significantly improved by also training the distilled model to produce the correctlabels.
∙ use the correct labels (hard targets) to modify the soft targets
∙ simply use a weighted average of two different objective functions
∙ Objective 1: the cross entropy with the soft targets(cumbersome and distilled models: using same high temperature)
∙ Objective 2: the cross entropy with the correct labels(using exactly the same logits in softmax of the distilled model but at atemperature of 1)
Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
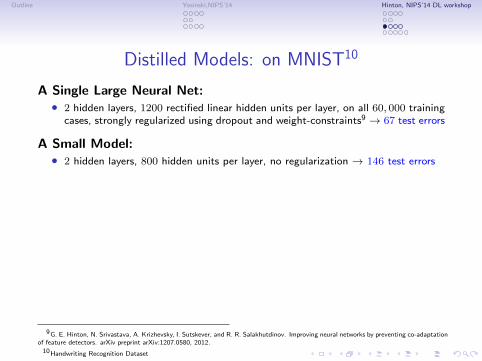
Distilled Models: on MNIST10
A Single Large Neural Net:∙ 2 hidden layers, 1200 rectified linear hidden units per layer, on all 60, 000 training
cases, strongly regularized using dropout and weight-constraints9 → 67 test errors
A Small Model:∙ 2 hidden layers, 800 hidden units per layer, no regularization → 146 test errors
∙ additionally matching the soft targets of the large net at 𝑇 = 20 → 74 test errors- 300 or more units per hidden layer: 𝑇 > 8, fairly similar results- 30 units per hidden layer: 𝑇 ∈ [2.5, 4], significantly better than higher or lowertemperatures
∙ omitting all examples of the digit 3 from the transfer set → 206 test errors(133/1010 threes)- fine-tune bias for the 3 class → 109 test errors (14/1010 threes)
∙ in the transfer set only containing the digit 7 and 8 from the training set: 47.3%test errors- fine-tune bias for the 7 and 8 class:13.2% test errors
9G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptationof feature detectors. arXiv preprint arXiv:1207.0580, 2012.
10Handwriting Recognition Dataset

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Distilled Models: on MNIST10
A Single Large Neural Net:∙ 2 hidden layers, 1200 rectified linear hidden units per layer, on all 60, 000 training
cases, strongly regularized using dropout and weight-constraints9 → 67 test errors
A Small Model:∙ 2 hidden layers, 800 hidden units per layer, no regularization → 146 test errors
∙ additionally matching the soft targets of the large net at 𝑇 = 20 → 74 test errors- 300 or more units per hidden layer: 𝑇 > 8, fairly similar results- 30 units per hidden layer: 𝑇 ∈ [2.5, 4], significantly better than higher or lowertemperatures
∙ omitting all examples of the digit 3 from the transfer set → 206 test errors(133/1010 threes)- fine-tune bias for the 3 class → 109 test errors (14/1010 threes)
∙ in the transfer set only containing the digit 7 and 8 from the training set: 47.3%test errors- fine-tune bias for the 7 and 8 class:13.2% test errors
9G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptationof feature detectors. arXiv preprint arXiv:1207.0580, 2012.
10Handwriting Recognition Dataset

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Distilled Models: on MNIST10
A Single Large Neural Net:∙ 2 hidden layers, 1200 rectified linear hidden units per layer, on all 60, 000 training
cases, strongly regularized using dropout and weight-constraints9 → 67 test errors
A Small Model:∙ 2 hidden layers, 800 hidden units per layer, no regularization → 146 test errors
∙ additionally matching the soft targets of the large net at 𝑇 = 20 → 74 test errors- 300 or more units per hidden layer: 𝑇 > 8, fairly similar results- 30 units per hidden layer: 𝑇 ∈ [2.5, 4], significantly better than higher or lowertemperatures
∙ omitting all examples of the digit 3 from the transfer set → 206 test errors(133/1010 threes)- fine-tune bias for the 3 class → 109 test errors (14/1010 threes)
∙ in the transfer set only containing the digit 7 and 8 from the training set: 47.3%test errors- fine-tune bias for the 7 and 8 class:13.2% test errors
9G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptationof feature detectors. arXiv preprint arXiv:1207.0580, 2012.
10Handwriting Recognition Dataset

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Distilled Models: on Speech RecognitionThe Objective of Automatic Speech Recognition (ASR):11
A Single Large Neural Net:
∙ 8 hidden layers, 2560 rectified linear units per layer
∙ a final softmax layer with 14, 000 labels (HMM targets ℎ𝑡)
∙ the total number of parameters: about 85𝑀
∙ training set: 2000 hours of spoken English data, about 700𝑀 training examples
Distilled Models:
∙ distilled under different temperatures:{1,2, 5, 10}∙ using a relative weight of 0.5 on the cross-entropy for the hard targets
A single model distilled from an ensemble of models works significantly better than amodel of the same size that is learned directly from the same training data.
11map a (short) temporal context of features derived from the waveform to a probability distribution over the discrete states of a HiddenMarkov Model (HMM)

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Specialist Models: on Image Annotation
Training an ensemble of models:
∙ An ensemble requires too much computation at test time can be dealtwith by using distillation.
∙ If the individual models are large neural networks and the dataset isvery large, the amount of computation required at training time isexcessive, even though it is easy to parallelize.
Learning specialist models:
∙ to show how learning specialist models that each focus on a differ-ent confusable subset of the classes can reduce the total amount ofcomputation required to learn an ensemble
∙ to show how the overfitting of training specialist models may be pre-vented by using soft targets

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Specialist Models: on Image Annotation(cont.)JFT: an internal Google dataset, 100 million labeled images, 15, 000 labels
A Generalist Model:
∙ Google’s baseline model for JFT – a deep CNN
∙ had been trained for about six months using asynchronous stochastic gradientdescent on a large number of cores
∙ used two types of parallelism
Specialist Models:
∙ trained on data that is highly enriched in examples from a very confusable subsetof the classes (e.g different types of mushroom)
∙ The softmax of this type of specialist can be made much smaller by combining allof the classes it does not care about into a single dustbin class.
∙ To reduce overfitting and share the work of learning lower level feature detectors:- each specialist model is initialized with the weights of the generalist model- training examples: 1/2 from its special subset, 1/2 sampled randomly from theremainder of the training set

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Soft Targets as RegularizersUsing soft targets instead of hard targets:
∙ A lot of helpful information can be carried in soft targets that couldnot possibly be encoded with a single hard target.
∙ Using far less data to fit the 85M parameters of the baseline speechmodel: Soft targets allow a new model to generalize well from only3% of the training set.
Using soft targets to prevent specialists from overfitting:
∙ If using a full softmax over all classes for specialists: soft targets may be a muchbetter way to prevent them overfitting than using early stopping
∙ If a specialist is initialized with the weights of the generalist, we can make it retainnearly all of its knowledge about the non-special classes by training it with softtargets for the non-special classes in addition to training it with hard targets.

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Summary
The training stage and the deployment stage have different requirements.
Distillation:Cumbersome models → transferring knowledge by matching soft targets(and hard targets) → A small, distilled model
∙ On MNIST:- works well even when the transfer set that is used to train the distilled modellacks any examples of one or more of the classes
∙ On Speech Recognition:- nearly all of the improvement that is achieved by training an ensemble of deepneural nets can be distilled into a single neural net of the same size which is fareasier to deploy.
∙ On Image Annotation: Specialist Models- the performance of a single really big net that has been trained for a very longtime can be significantly improved by learning a large number of specialist nets.- Have not yet shown that this method can distill the knowledge in the specialistsback into the single large net.
Distillation v.s. Mixture of Experts, Transfer Learning

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Summary
The training stage and the deployment stage have different requirements.
Distillation:Cumbersome models → transferring knowledge by matching soft targets(and hard targets) → A small, distilled model
∙ On MNIST:- works well even when the transfer set that is used to train the distilled modellacks any examples of one or more of the classes
∙ On Speech Recognition:- nearly all of the improvement that is achieved by training an ensemble of deepneural nets can be distilled into a single neural net of the same size which is fareasier to deploy.
∙ On Image Annotation: Specialist Models- the performance of a single really big net that has been trained for a very longtime can be significantly improved by learning a large number of specialist nets.- Have not yet shown that this method can distill the knowledge in the specialistsback into the single large net.
Distillation v.s. Mixture of Experts, Transfer Learning

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Appendix12
12http://www1.i2r.a-star.edu.sg/˜jspan/SurveyTL.htm

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Appendix (cont.)

Outline Yosinski,NIPS’14 Hinton, NIPS’14 DL workshop
Appendix (cont.)


















