
Faceted Metadata in Image Search & Browsing Using Words to Browse a Thousand Images
Upload
keelie-lancasterCategory
view
33download
2description

Faceted Searching and Browsing Over Large Collections
Wisam Dakka, Columbia University

Search Beyond Navigational Queries Data grows as user needs become more
complex, go from just navigation to discovery [Digital video camera], [energy-efficient cars]
Challenges for major search engines Discovery or research queries
Limited user activity Several dimensions of relevance in results but no
structure Prices, stores, reviews, locations, and recent news
Google Views: Faceted search with structure for discovery queries

xRank: Pushing Structure for Special Queries
Search Learn Explore Relate Scan Track

[Digital Video Camera] on Yahoo!

Large Collections and Lengthy Results
Most users examine only first or second page of query results Relevant results not only on first page, but on subsequent pages

Weaknesses of “Plain’’ Search Search often unsatisfactory
Poor ranking Large number of relevant items Broad-scope queries
Search sometimes insufficient Why do we go to movie rental store or bookstore? Not effective for curious users and users with little
knowledge of collections
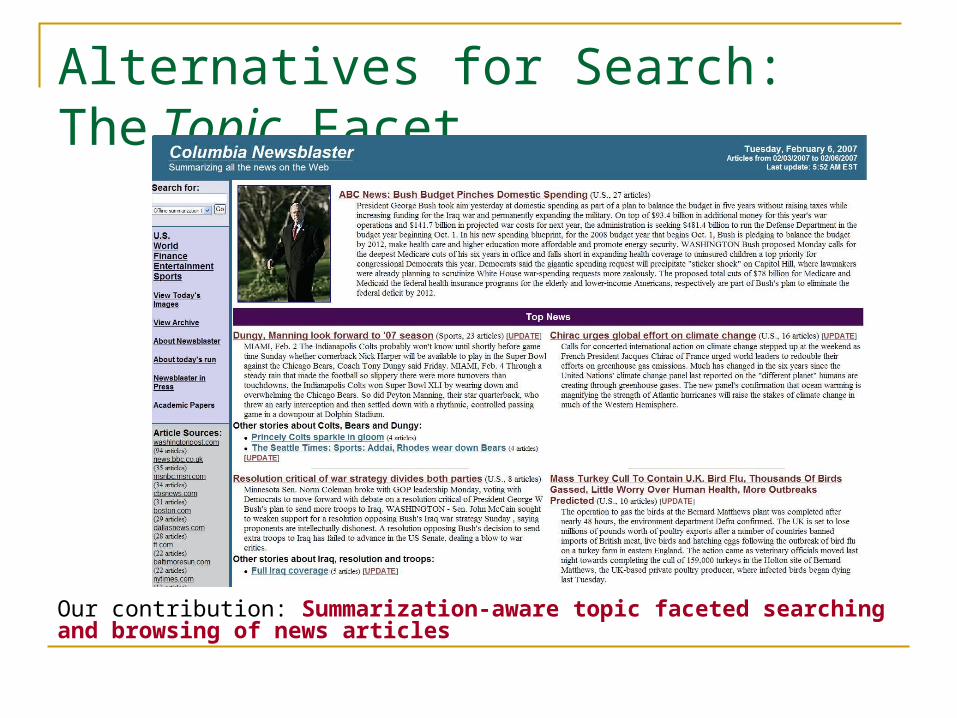
Alternatives for Search: The Topic Facet
Our contribution: Summarization-aware topic faceted searching and browsing of news articles

Alternatives for Search: The Time Facet
Our contribution: General strategy to naturally impose time in the retrieval task

Alternatives for Search: Multiple Facets
Our contribution: Automatically building faceted hierarchies

Agenda: Alternatives Alongside Search Searching and browsing with the topic facet
Searching and browsing with the time facet
Searching and browsing with multiple facets Extracting useful facets Automatically constructing faceted hierarchies
Conclusion and future work
[Barak Obama] [Google IPO]

Part 2: The Time Facet
Time-Faceted Searching and Browsing
[Barak Obama] [Google IPO]

Time in News Archives Topic-relevance ranking may not be sufficiently powerful Consider query [Madrid bombing]
[Madrid bombing prefer:03/11/2004−04/30/2004]
Searchers often do not know exact time or date a given event occurred

What to Do When Relevant Time Periods are Unknown?
Identify relevant time periods using query terms Restrict query results to these time periods Diversify the top-10 results
Alternatively, redefine relevance of a document as a combination of topic relevance and time relevance
Improve query reformulations using relevant time periods

General Time-Sensitive Queries
Time-sensitive results Prioritizing relevant documents from relevant time periods Ranking those documents first
Temporal relevance or The likelihood that day is relevant to query using distribution
of relevant documents in archive
[Mad Cow] [Abu Ghraib][Hurricane Florida]
[American beheading] [Barak Obama] [Google IPO]
)|( qtpt q

Temporal Relevance or Given [Madrid Bombing], what is the probability that today is relevant vs. 04/13/2004? Simple to compute if relevant documents known
Use estimation when relevant documents unknown
)|( qtp
)(
)()|()|(
qp
tptqpqtp
documentsrelevantallof
ttimeatdocumentsrelevantoftqp
#
#)|(
The probability that we see relevant documents at time t
# R
el
Do
cs
)|( qtp
t

Estimating Techniques for )|04/13/2004( qp
Top-k matching documents
SUM: Compute value as a normalized weighted sum of the relevance scores of documents published on 04/13/2004 [Diaz and Jones]
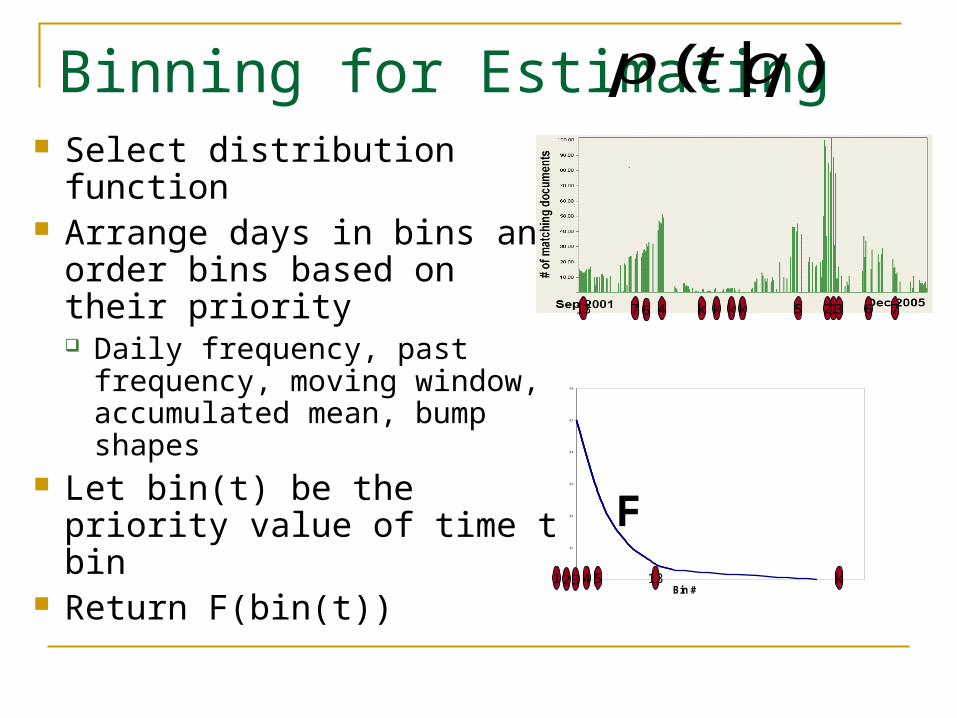
BINNING: Compute value as F(bin(04/13/2004)) Choose a distribution function F Arrange days in bins and order bins based on their priority Let bin(04/13/2004) be the priority value of 04/13/2004 bin
WORD: Compute value using frequency of query words on 04/13/2004 Keep track of word frequency for each day in a special index
Smoothing is applied
0
0.1
0.2
0.3
0.4
0.5
0.6
Bin #
Binning for Estimating )|( qtp Select distribution function Arrange days in bins and
order bins based on their priority Daily frequency, past
frequency, moving window, accumulated mean, bump shapes
Let bin(t) be the priority value of time t bin
Return F(bin(t))
12 34 567 6 713 kkkk
F1 2 3 4 5 13 k

Answering Queries: Background
To answer q, score each d based on d and q content
LM: Rank based on likelihood of generating q from d
BM25: Rank d based on the odds of d being observed in R
)()|()|( dpdqpqdp
),|(
),|(log
),|(
),|(log),|(
qRdp
qRdp
qdRp
qdRpqdRp
q=[Madrid Bombing] d= a document in the collection
R= documents relevant to [Madrid Bombing]

Answering Time-Sensitive Queries Related Work: Answering recency queries
[Barak Obama Speech] or [Myanmar cyclone] “Boost” topic relevance scores of most recent
documents, to promote recent articles Modify prior in language models
Does not work for other time-sensitive queries Goal: General framework for all queries
A document has two components: content and time Combine traditional relevance (content) with temporal
relevance

)()|( dpdqp d
Time
LM for Time-Sensitive Queries
)|( qdpqq
ContentThis is the content of the document This is the content of the document This is the content of
the document This is the content of the document This is the content of the
documentThis is the content of the document This is the content of the document This is the content of
the document This is the content of the document This is the content of the document This is the content of the document This is the content of the document This is the content of
the document
)|,( qtcp dd)|()|( qtpqcp dd
)|()()|( qtpcpcqp ddd
Implemented as part of Indri
Developed analogous integration with BM25 (also implemented as part of Lemur)
d
Time
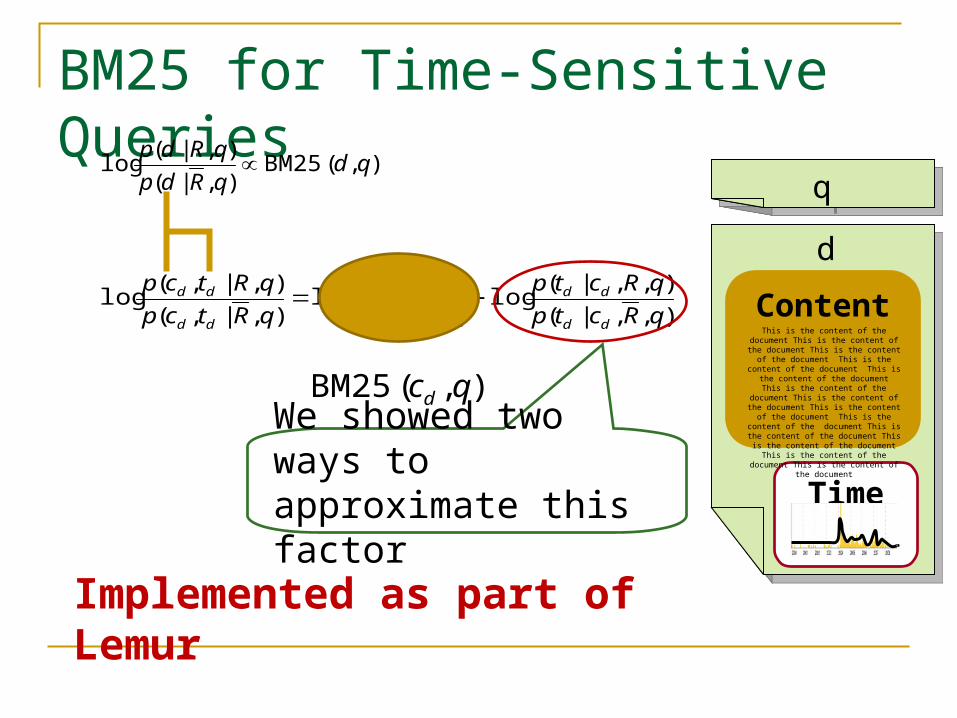
BM25 for Time-Sensitive Queries
ContentThis is the content of the document This is the content of the document This is the content of
the document This is the content of the document This is the content of the
documentThis is the content of the document This is the content of the document This is the content of
the document This is the content of the document This is the content of the document This is the content of the document This is the content of the document This is the content of
the document
Implemented as part of Lemur
),(BM25),|(
),|(log qd
qRdp
qRdp
),,|(
),,|(log
),|(
),|(log
),|,(
),|,(log
qRctp
qRctp
qRcp
qRcp
qRtcp
qRtcp
dd
dd
d
d
dd
dd
),(BM25 qcd
We showed two ways to approximate this factor

Evaluating LM and BM25 Data collections and queries
TREC News Archive Portion of TREC volumes 4 and 5, 1991-94 Three sets of time-sensitive queries with relevance judgments
Newsblaster Archive Six years of news crawled daily from multiple sources Amazon Mechanical Turk relevance judgments for 76 queries
LM and BM25 with temporal relevance SUM, BINNING, and WORD
TREC evaluation metrics P@k and MAP

Performance Over Newsblaster
BUMP and SUM-based improve precision at top recall cutoff levels significantly precision of our techniques drops for higher recall cutoff levels

Contributions Identify “most important” time period(s) for queries
without user input
Estimate temporal relevance using different techniques
Combine temporal relevance and topic relevance for all time-sensitive queries using several state-of-the-art retrieval models
Evaluate extensively our proposed methods to investigate the implications of adding time into retrieval task

Part 3: Searching and Browsing with Multiple Facets*
A. Extracting Useful Facets
B. Automatic Construction of Hierarchies
* Work published in CIKM05, SIGIR06 Workshop, ICDE07 Demo, and ICDE08

YouTubeFlickr
Useful facets for large collections
Facets for Searching and Browsing
Location People Time Topic Actor Animal
New York Times
A facet is a “clearly defined, mutually exclusive, and collectively exhaustive aspect, property, or characteristic of a class or specific subject” [S. R. Ranganathan]
Corbis

Beyond Topic and Time Facets Objective
Automatically generate a faceted interface over a large collection e.g., The New York Times or YouTube
Challenges We do not know what facets appear in the collection We need to build the hierarchy for each facet We need to associate items with facets
e.g., what terms describe the facet in a picture (dog->animal)
Approaches Supervised and unsupervised extraction of facet terms Hierarchy construction algorithm for each facet

Extraction of Facet Terms Goal: For each new item in the collection, extract descriptive
terms and extract a set of useful facets
feline, carnivore, mammal, animal, living being, object, entityorange, fish, tail, cute
Cat
Dog
General idea:
1. Identify important terms within each item• Corbis and YouTube user-provided tags
2. Derive context for each important term from external resources
• e.g., Wikipedia, WordNet, …
3. Associate terms with facets Supervised: Group terms with predefined
facet like in Corbis Unsupervised: Cluster terms

29
Supervised Extraction: Results Using SVM and Ripper
Baseline 10% (F1) slightly above random
classification Adding hypernyms 71% (F1) Adding associated keywords Ripper
Investigate whether rule-based assignments are sufficient High-level WordNet hypernyms
55% (F1), significantly worse than SVM Some classes (facets) work well with
simple, rule-based assignment of terms to facets Generic Animals (93.3%) Action Process Activity (35.9%) SVM with hypernyms and
associated keywords
Class Precision Recall F1GTH 87.70% 83.00% 85.29%APA 75.80% 75.80% 75.80%ATT 78.20% 83.50% 80.76%ABC 85.20% 87.60% 86.38%GCF 74.70% 76.76% 75.72%NCF 82.40% 87.57% 84.91%GTF 86.70% 75.00% 80.43%GPL 81.70% 90.10% 85.69%ATY 80.00% 81.30% 80.64%GEV 79.40% 56.30% 65.88%GAN 92.90% 92.90% 92.90%RPS 85.60% 76.30% 80.68%NTF 82.40% 80.30% 81.34%NORG 75.40% 76.58% 75.99%Average 82.01% 80.22% 80.89%
* F1 = harmonic mean of Precision & Recall

Identifying Important Terms for News Named Entities using LingPipe named entity recognizer
Output: named entities (e.g., Elizabeth II) Wikipedia Terms using Wikipedia titles, redirects, and anchor text
Output: Wikipedia-listed entities Yahoo Terms using Yahoo term extractor
Output: significant words or phrases

Extracting Context for News Document terms too specific for facet hierarchies Solution: Expand terms by querying external resources
Wikipedia WordNet

Original Text
DB
Expanded Text
DB
Context expansion introduces many noisy terms However: Facet terms infrequent in original collection,
yet frequent in expanded one Frequency-based shifting Rank-based shifting Log-likelihood statistic
Use identified terms to build facet hierarchies
Comparative Term Frequency Analysis

Recall and Precision Single day of Newsblaster
Month and single day of NYT
Recall: 5 users per story Keep terms listed by >2 users Measure overlap
Precision: Is hierarchy term useful? Is it correctly placed? Term precise if >4 users say yes
Data Set: 24 sources (SNB)
Recall
Precision

34
Efficient Hierarchy Construction After identifying facets, need to navigate within each facet Subsumption algorithm (Croft and Sanderson,
SIGIR1999) Improved version of subsumption algorithm
For best parameter values three times faster than original subsumption algorithm
Good integration with relational databases Extensive experiments

35
Ranking Methods: Maximize Coverage Ranking categories is important and difficult
Important: limited cognitive ability to understand presented information
Difficult: lack of explicit user goals while browsing Frequency-based Ranking (Baseline)
Users see first categories with greatest wealth of information
Set-cover Ranking Maximizing cardinality of top-k ranked categories
Merit-based Ranking Ranks higher categories that enable users to access their
contents with smallest average cost

36
Evaluation Results Generation algorithm runs three times faster than
original subsumption algorithm
Merit-based performs well and offers fast access to contents of collection
Merit-based rankings efficient to implement on top of relational database systems, while set-cover rankings typically take longer to compute

Task-based User Study Over News Articles Five users, “locate news items of interest”
Search interface that was augmented with our facet hierarchies Repeat 5 times (different topics)
Initially, keyword search, then facet hierarchies “War in Iraq” then refinements
Then, used facet hierarchies directly, keywords later Keyword search was gradually reduced by up to 50% Time required to complete each task dropped by 25%
(compared to search only) Satisfaction remained statistically steady

Summary of Contributions Supervised extraction of facets for collection like Corbis
Unsupervised discovery of useful facet terms for news Identifying important terms in a document using Wikipedia Deriving important context, useful for facet navigation, using
multiple external resources Evaluating quality and usefulness of the generated facets using
extensive user studies with Amazon Mechanical Turk service
Efficient hierarchy construction algorithm Ranking alternatives Extensive evaluation Human evaluation to examine usefulness and effectiveness of
hierarchies for free-text collection

Conclusions Developed efficient summarization-aware search for
Newsblaster
Integrated time in state-of-the-art retrieval models Time-sensitive queries Temporal relevance
Developed extraction techniques for useful facets News collections Corbis
“Created” efficient hierarchy construction algorithm with ranking alternatives
Performed extensive evaluations

Future Work Complex user needs
Detecting discovery queries Introducing structure and facets into Web search results
for such queries Using structure data used for QA
Manually or automatically extracted Using informative and authoritative sources Integrating of smart views and hierarchies for data
representation Enhancing snippet generation
Temporal summaries Searching for less tech-savvy users
Elderly or newcomers

Part 1. The Topic Facet*
Summarization-Aware Search and Browsing
* Work published in JCDL 2007

Topical Hierarchy of News Events With Machine Summaries

What Makes Search Effective in Newsblaster? Informative snippets: Summaries highlight essence
of news to help users navigate Browsing ability: Users should be able to navigate
articles in a format similar to browsing Newsblaster Speed: Users should not have to wait 12 hours for
query results; they should not even wait 12 minutes! Quality: Users should get relevant results
Summarization-Aware Search and Browsing

Summarization-Aware Search and Browsing Offline summarization
Summaries are query-independent Irrelevant documents and relevant documents might be mixed Sensitive to summary quality and coverage/coherence
Online summarization Unacceptably high running time
Hybrid alternative Some offline clusters might be relevant (no summarization) Some documents in irrelevant clusters might be relevant

A Hybrid Search Alternative: Reusing Offline Summaries and Clusters When Possible1. Select an initial set of offline clusters
2. Identify relevant offline clusters using a supervised machine learning classifier (more details soon)
3. Build online clusters using relevant documents from irrelevant clusters
4. Rank offline and online clusters
5. Generate summaries for online clusters in the top-k clusters
6. Return the top-k clusters and their summaries

Identifying Relevant Offline Clusters Classification task: Given a query and a set of clusters,
identify clusters that are relevant to the query Cluster-level features:
(aggregate) Okapi similarity of cluster documents and query (aggregate) Okapi similarity of cluster document titles and query Okapi similarity of cluster summary and query “recall”: fraction of overall matching documents in cluster “precision”: fraction of cluster documents that match query …
Query-level features: number of “matching” documents in collection number of “retrieved” clusters average size of retrieved clusters (aggregate) Okapi similarity of query and summaries of retrieved clusters …
Further details are omitted from this talk

Step 3: Ranking All Clusters (New and Old)
Not specific to Hybrid Search, but an essential part of it Only top few clusters returned to users Need to summarize online only new clusters among top
clusters for query
Alternate ranking strategies: By average Okapi score of matching documents in cluster By maximum Okapi score of matching documents in cluster By distance of document with highest Okapi score to cluster
“centroid”

Evaluation Questions Result Quality: How accurate are documents and summaries?
Document P@k and Summary P@k
Usefulness: How helpful are summaries for leading readers to relevant documents? NDCG (Normalized Discounted Cumulative Gain)
Efficiency: How efficient are our techniques? Response time
Evaluation Settings Data set: Several days of Newsblaster Labeling: Amazon Mechanical Turk
A service for distributing small tasks to a large number of users, paying a few cents per micro-task

Quality of Documents and Summaries in Results
P@20 documents P@k summaries
HybridOkapi: At least as good as the state-of-the-art flat-list search Careful use of offline clusters does not damage overall accuracy
HybridOkapi or OnOKapi: On average, returned more relevant summaries than OffDocOkapi

Usefulness of Summaries in Results Can MTURK annotators use the summaries to
predict the perfect ranking?
HybridOkapi and OnOkapi summaries substantially outperform OffDocOkapi summaries OffDocOkapi summaries are computed in a query-independent
fashion
Top-3 summaries of each technique shown to 5 annotators
Use NDCG to measure quality of ranking NDCG=1 means perfect ranking

Efficiency of Producing Search Results
Offline summaries attractive when response time important Online summaries take too much time (>200 seconds) HybridOkapi: Results quality better than offline; almost as good as
online but in significantly less time Careful use of offline clusters does not damage overall result
accuracy and substantially reduces cost of summarization at query-execution time

Contributions Definition of search strategy
Defining a rich feature set for cluster classification Defining cluster-ranking strategies
Evaluation Collecting user relevance judgments for clusters
and documents Validating effectiveness of the cluster classifier Validating efficiency and accuracy of
summarization-aware strategies Validating summary-level result quality


















