
Experiences with Multigrid on 300K Processor Cores … · Experiences with Multigrid on 300K...
35
Experiences with Multigrid on 300K Processor Cores Lehrstuhl für Informatik 10 (Systemsimulation) Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de 15 th Copper Mountain Multigrid Conference March 31, 2011 B. Gmeiner U. Rüde (LSS Erlangen, [email protected]) T. Gradl 1
Transcript of Experiences with Multigrid on 300K Processor Cores … · Experiences with Multigrid on 300K...

Experiences with Multigrid on300K Processor Cores
Lehrstuhl für Informatik 10 (Systemsimulation)Universität Erlangen-Nürnberg
www10.informatik.uni-erlangen.de
15th Copper Mountain Multigrid ConferenceMarch 31, 2011
B. GmeinerU. Rüde (LSS Erlangen, [email protected])
T. Gradl
1

Motivation: How fast are computers today (and tomorrow)Performance of Solvers: Theory vs PracticeScalable Parallel Multigrid Algorithms for PDE
Matrix-Free FE solver: Hierarchical Hybrid GridsConclusions
Overview
2

Motivation
3

Example Peta-Scale System:Jugene @ Jülich
PetaFlops = 1015
operations/secondIBM Blue GeneTheoretical peak performance: 1.0027 Petaflop/s294 912 cores144 TBytes = 1.44 1014 #9 on TOP 500 List in Nov. 2010
4
For comparison: Current fast desktop PC is ∼ 20.000 times slower> 1 000 000 cores expected 2011Exa-Scale System expected by 2018/19
Extreme Scaling Workshop 2010 at Jülich Supercomputing Center

5
What are the consequences?For the application developers “the free lunch is over”
Need explicitly parallel algorithms, to get the performance potential of all future architectures
For HPCCPUs will have 2, 4, 8, 16, ..., 128, ..., ??? cores - maybe sooner than we are ready for thisWe will have to deal with systems with many millions of cores
The memory wall grows higherAn Exa-Scale system with 1018 Flops/sec and 10 MWatt power intake will have 10 PicoJoule available for each Flop - not enough to touch (main) memory

What‘s the problem? Would you want to propel a Super Jumbo
with four strong jet engines(not those of Rolls-Royce of course)
or with 300,000 blow dryer fans?
6

How fast are our algorithms (multigrid) on current CPUsAssumptions:
Multigrid requires 27.5 Ops/unknown to solve an elliptic PDE (Griebel ´89 for 2-D Poisson)A modern laptop CPU delivers >10 GFlops peak
Consequence:We should solve one million unknowns in 0.00275 seconds (364 MUpS) ~ 3 ns per unknown
7
Revised Assumptions:Multigrid takes 500 Ops/unknown to solve your favorite PDE you can get 5% of 10 Gflops performance
Consequence: On your laptop you shouldsolve one million unknowns in 1.0 second (1 MUpS)~ 1 microsecond per unknown
Consider Banded Gaussian Elimination on the Play Station (Cell Processor), single Prec. 250 GFlops, for 1000 x 1000 grid unknowns
~2 Tera-Operations for factorization - will need about 10 seconds to factor the system requires 8 GB Mem.Forward-backward substitution should run in about 0.01 second, except for bandwidth limitations

Ideal vs. Real PerformanceMaybe better to consider memory bandwidth rather than Flops as performance metric:
10 GByte/sec: we can read 1250 times 106 unknowns/secEven when assuming that the complete solution must be read 30 times, we should solve 106 unknowns in 0.025 sec.
State of the art (on Peta-Scale): ~1012 unknownsHeidelberg group (M. Blatt‘s talk, groundwater flow)HHG (this talk, tetrahedral FE, scalar elliptic PDE with piecewise const coeff.)waLBerla (H. Köstler‘s talk, Laplace on structured grids)Livermore group (pers. communication)
8

What can we do with 1012 unknowns?
9
10 000 points in each of 3Ddiscretizing the volume of earth uniformly with less than 1 km meshdiscretizing the volume of the atmosphere uniformly (wrt mass) with less than 200m grid.With Exa-Scale: Even if we wantto simulate a billion objects (particles): we can do a billion operations for each of them in each seconda trillion finite elements (finite volumes) to resolve a PDE, we can do a million operations for each of them in each second
Fluidized Bed(movie: thanks to K.E. Wirth)

10
Towards Scalable FE Software
Scalable Algorithmsand Data Structures
11
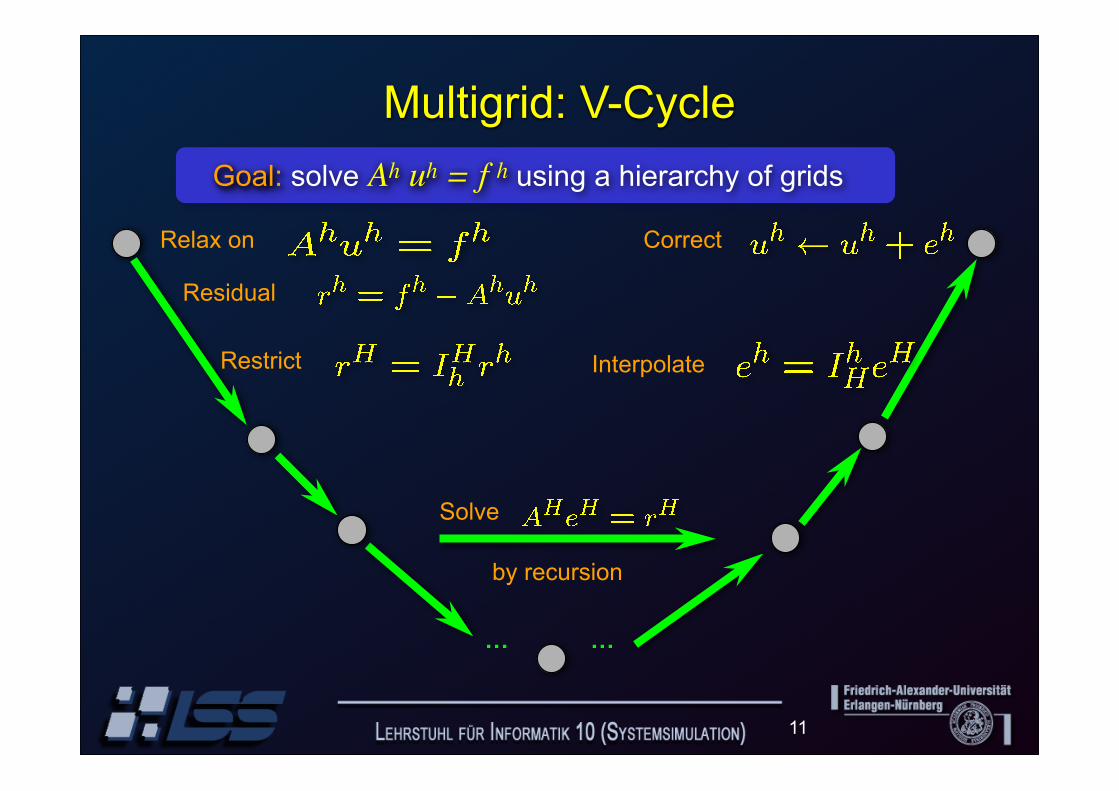
Multigrid: V-Cycle
Relax on
Residual
Restrict
Correct
Solve
Interpolate
by recursion
… …
Goal: solve Ah uh = f h using a hierarchy of grids

12
Parallel High Performance FE MultigridParallelize „plain vanilla“ multigrid
partition domainparallelize all operations on all gridsuse clever data structures
Do not worry (so much) about Coarse Grids
idle processors?short messages?sequential dependency in grid hierarchy?
Elliptic problems always require global communication. This cannot be accomplished by
local relaxation orKrylov space acceleration ordomain decomposition without coarse grid
Bey‘s Tetrahedral Refinement

13
Hierarchical Hybrid Grids (HHG)Joint work withFrank Hülsemann (now EDF, Paris), Ben Bergen (now Los Alamos), T. Gradl (Erlangen), B. Gmeiner (Erlangen)
HHG Goal: Ultimate Parallel FE Performance!unstructured adaptive refinement grids with
regular substructures for efficiencysuperconvergence effectstau-extrapolation for higher order FEmatrix-free implementation

14
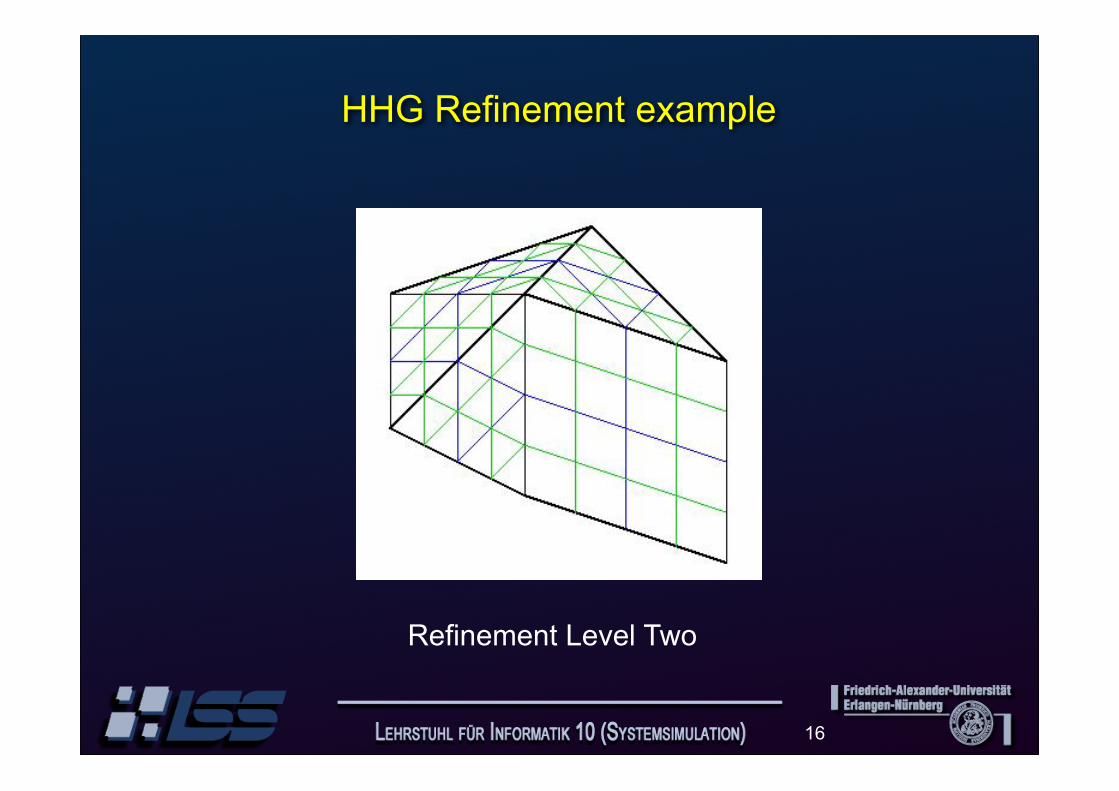
HHG refinement example
Input Grid

15
HHG Refinement example
Refinement Level one
16
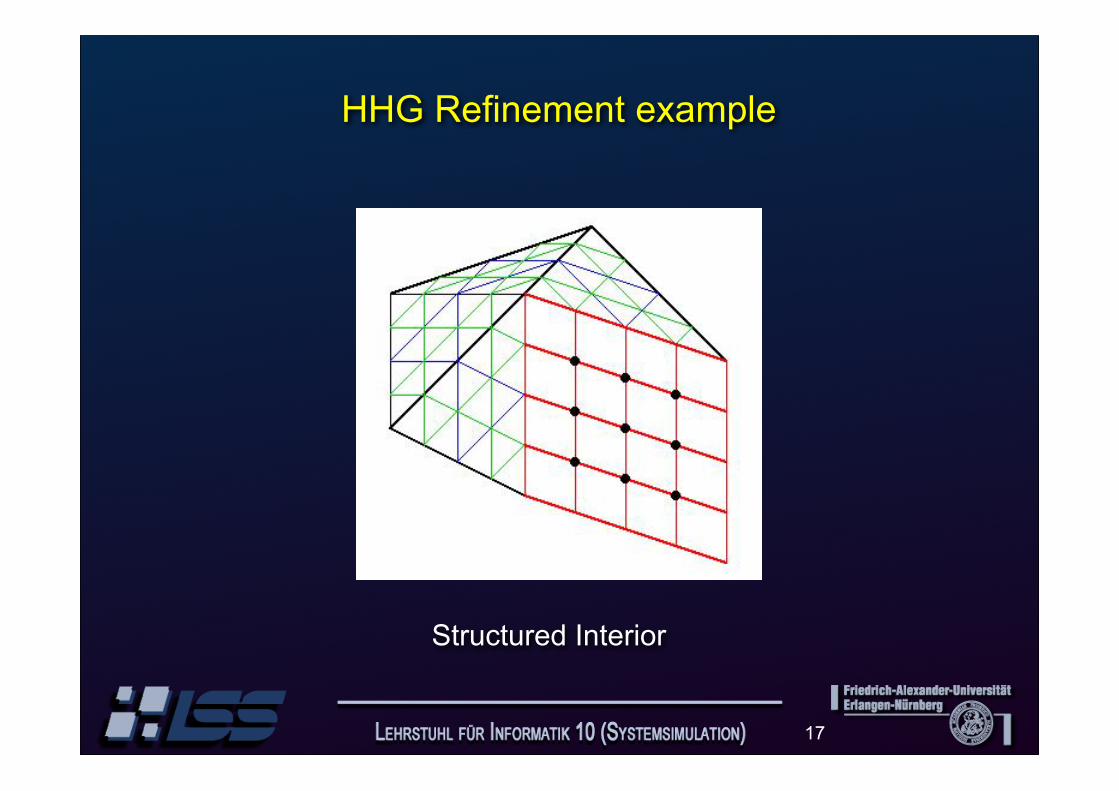
HHG Refinement example
Refinement Level Two
17
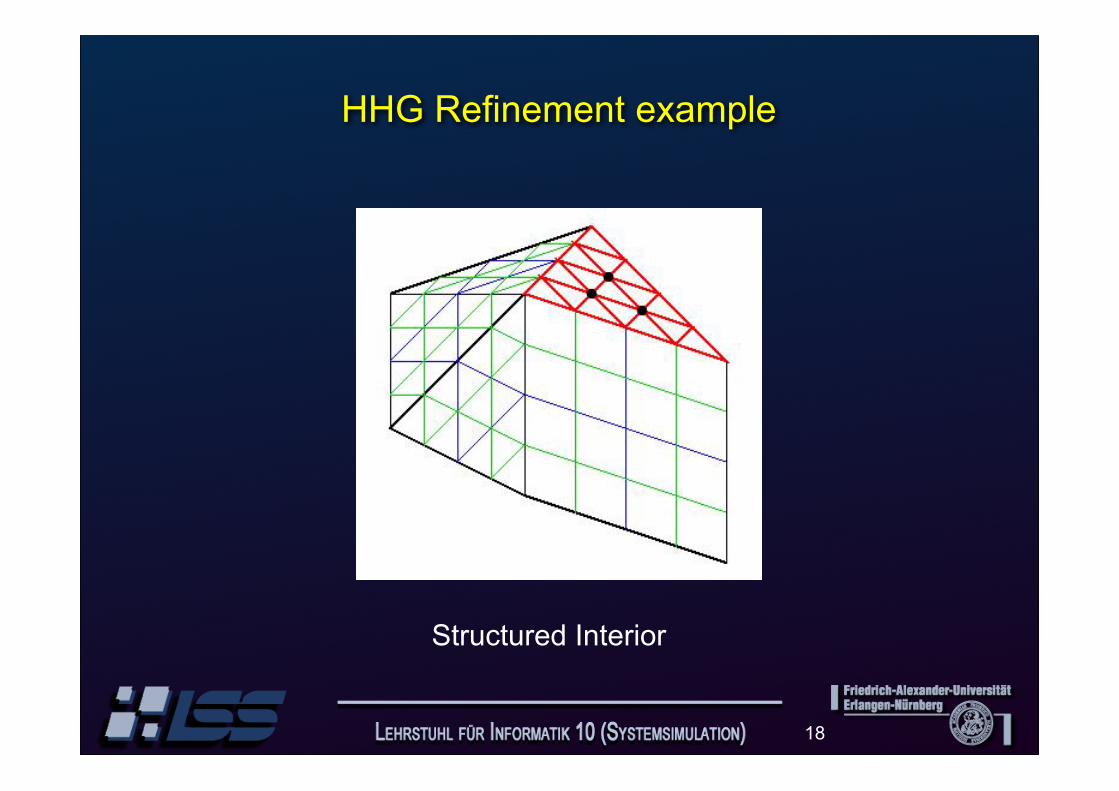
HHG Refinement example
Structured Interior
18
HHG Refinement example
Structured Interior
19
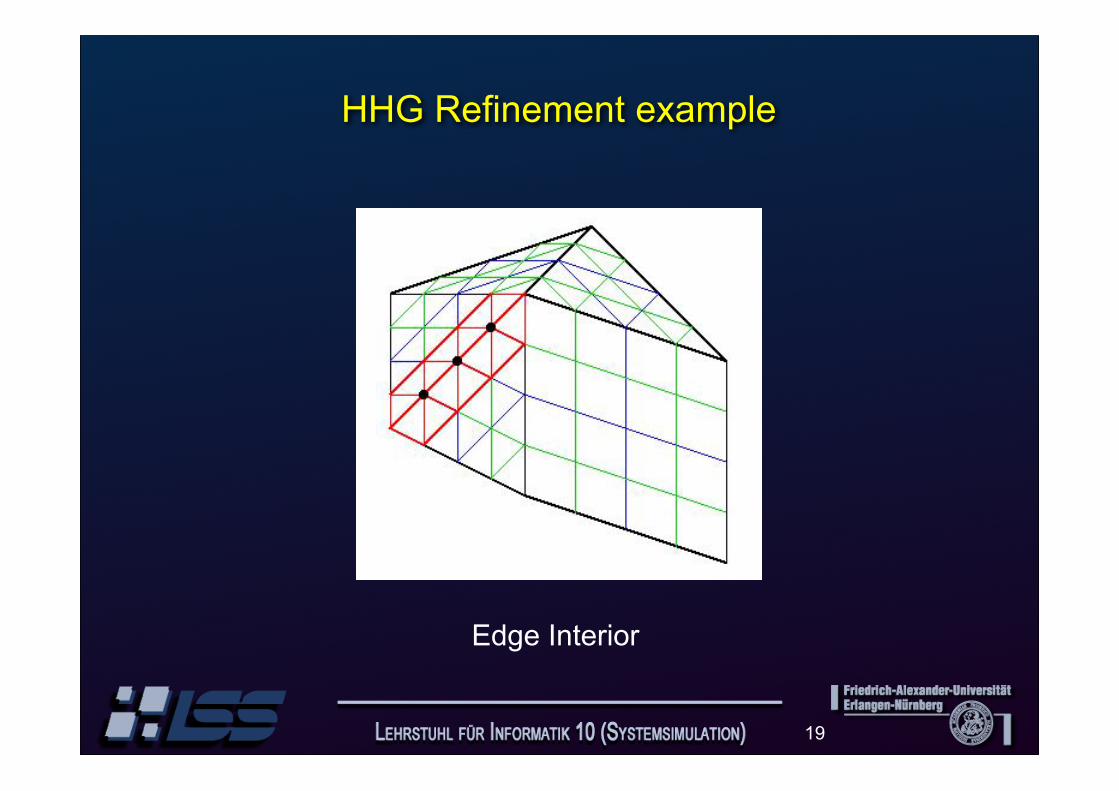
HHG Refinement example
Edge Interior

20
HHG Refinement example
Edge Interior

Special smoothers for tetrahedra with large or small angles
21
Joint work withF. Gaspar and C. Rodrigo, Zaragoza

22
Adaptivity in HHG (with conforming meshes)

Refinement with Hanging Nodes in HHG
23
Coarse grid
Fine Grid
Adaptive Grid with Hanging Nodes
Smoothing operation
Residual computation
Restriction Computation
Treating Hanging Nodes as in FAC: see e.g.McCormick: Multilevel Adaptive Methods for PDE, SIAM, 1989UR: Mathematical and Computational Techniques for Multilevel Adaptive Methods, SIAM, 1993See also Daniel Ritter‘s talk

24
HHG for ParallelizationUse regular HHG patches for partitioning the domain

25
HHG Parallel Update Algorithmfor each vertex do apply operation to vertexend for for each edge do copy from vertex interior apply operation to edge copy to vertex haloend for
for each element do copy from edge/vertex interiors apply operation to element copy to edge/vertex halosend for
update vertex primary dependencies
update edge primary dependencies
update secondary dependencies

26
12
The HHG Framework BlueGene/P Single-Core Performance Strong Scalability Weak Scalability
Scalability of HHG on Blue Gene/P (Jugene)
!"#$%&$'%()*+*,$%-./
0102
012
2
2020
34#5$'%67%86'$.
0 209000 :09000 ;09000 <09000 =09000
Figure: Strong Scaling behavior of HHG on PowerPC 450 cores. Thistest case was performed starting from 512 cores, solving 2.14 · 109 DoF.
Department for Computer Science 10 (System Simulation)
Strong Scaling

27
13
The HHG Framework BlueGene/P Single-Core Performance Strong Scalability Weak Scalability
Towards Realtime
Is it possible to add an implicit time stepping for parabolic orhyperbolic equations and achieve real-time performance with onetime step per frame?
Example:
• V(1,1) cycle
• 40 CG steps on the coarsest mesh
• 2.14 · 109 unknowns
• 5 Multigrid levels
• Utilized number of cores: 49 152
Time per cycle: 0.08 seconds
Department for Computer Science 10 (System Simulation)
28
#Proc #unkn. x 106 Ph.1: sec Ph. 2: sec Time to sol.
4 134.2 3.16 6.38* 37.98 268.4 3.27 6.67* 39.3
16 536.9 3.35 6.75* 40.332 1,073.7 3.38 6.80* 40.6
64 2,147.5 3.53 4.92 42.3128 4,295.0 3.60 7.06* 43.2
252 8,455.7 3.87 7.39* 46.4504 16,911.4 3.96 5.44 47.6
2040 68,451.0 4.92 5.60 59.0
3825 128,345.7 6.90 82.84080 136,902.0 5.68
6102 205,353.1 6.338152 273,535.7 7.43*
9170 307,694.1 7.75*
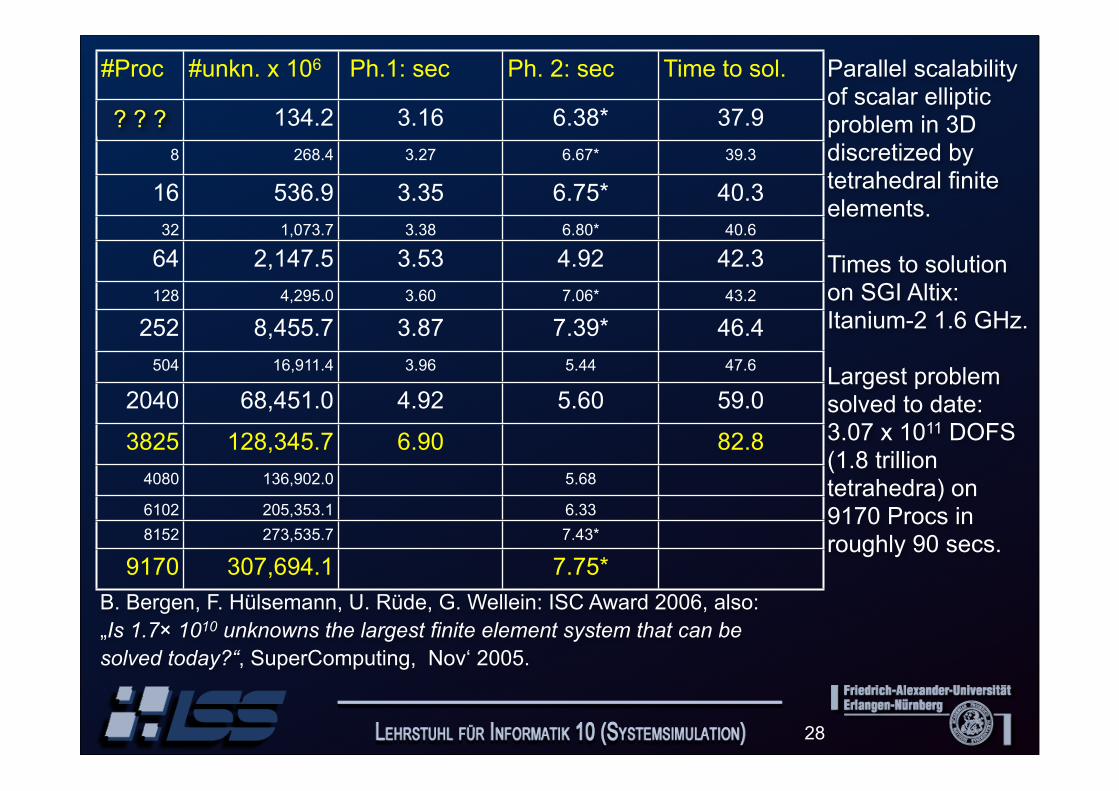
Parallel scalability of scalar elliptic problem in 3Ddiscretized by tetrahedral finite elements.
Times to solution on SGI Altix: Itanium-2 1.6 GHz.
Largest problem solved to date:3.07 x 1011 DOFS (1.8 trillion tetrahedra) on 9170 Procs in roughly 90 secs.
B. Bergen, F. Hülsemann, U. Rüde, G. Wellein: ISC Award 2006, also: „Is 1.7× 1010 unknowns the largest finite element system that can be solved today?“, SuperComputing, Nov‘ 2005.
? ? ?

Weak HHG Scalability on Jugene
29
2
Cores Struct. Regions Unknowns CG Time128 1 536 534 776 319 15 5.64256 3 072 1 070 599 167 20 5.66512 6 144 2 142 244 863 25 5.69
1024 12 288 4 286 583 807 30 5.712048 24 576 8 577 357 823 45 5.754096 49 152 17 158 905 855 60 5.928192 98 304 34 326 194 175 70 5.8616384 196 608 68 669 157 375 90 5.9132768 393 216 137 355 083 775 105 6.1765536 786 432 274 743 709 695 115 6.41
131072 1 572 864 549 554 511 871 145 6.42262144 3 145 728 1 099 176 116 223 180 6.81294912 294 912 824 365 314 047 110 3.80

Conclusions
30

31
Conclusions
Exa-Scale will be Easy!If parallel efficiency is bad, choose a slower serial algorithm
it is probably easier to parallelizeand will make your speedups look much more impressive
Introduce the “CrunchMe” variable for getting high Flops ratesadvanced method: disguise CrunchMe by using an inefficient (but compute-intensive!) algorithm from the start
Introduce the “HitMe” variable to get good cache hit ratesadvanced version: Implement HitMe in the „Hash-Brown Lookaside Table for the Multi-Threatened Cash-Filling Cloud-Tree“ data structure ... impressing yourself and others
Never cite “time-to-solution”who cares whether you solve a real-life problem anywayit is the MachoFlops that interest the people who pay for your research
Never waste your time by trying to use a complicated algorithm in parallel Use Primitive Algorithm => Easy to Maximize your MachoFlopsA few million CPU hours can easily save you days of reading in boring math books

Is Math Research Adressingthe Real Problems?
Performance?h-independent convergence is not the holy grailparallel efficiency is not the holy grailWe need theory that predicts the constants O(N) algorithms vs. „time to solution“ or „accuracy per MWh“
We will be drowned by the Tsunami of ParallelismValidation?
rigorous theory vs. experimental validation
„abstract“ numerical algorithms vs. high quality softwareWhere is the math?
32

SIAM J. Scientific Computingeditor-in-chief: Hans Petter Langtangen, Oslo
(Uli Ruede until 12-2010)
SISC papers are classified into three categories:Methods and Algorithms for Scientific Computing. Papers in this category may include theoretical analysis, provided that the relevance to applications in science and engineering is demonstrated. They should contain meaningful computational results and theoretical results or strong heuristics supporting the performance of new algorithms. (section editor: Jan Hesthaven)Computational Methods in Science and Engineering. Papers in this section will typically describe novel methodologies for solving a specific problem in computational science or engineering. They should contain enough information about the application to orient other computational scientists but should omit details of interest mainly to the applications specialist. (section editor: Irad Yavneh)Software and High-Performance Computing. Papers in this category should concern the development of high-quality computational software, high-performance computing issues, novel architectures, data analysis, or visualization. The primary focus should be on computational methods that have potentially large impact for an important class of scientific or engineering problems. (section editor: Tamara Kolda)
33

Acknowledgements
Dissertationen ProjectsN. Thürey, T. Pohl, S. Donath, S. Bogner (LBM, free surfaces, 2-phase flows)M. Mohr, B. Bergen, U. Fabricius, H. Köstler, C. Freundl, T. Gradl, B. Gmeiner (Massively parallel PDE-solvers)M. Kowarschik, J. Treibig, M. Stürmer, J. Habich (architecture aware algorithms)K. Iglberger, T. Preclik, K. Pickel (rigid body dynamics)J. Götz, C. Feichtinger, F. Schornbaum (Massively parallel LBM software, suspensions)C. Mihoubi, D. Bartuschat (Complex geometries, parallel LBM)
30+ Diplom- /Master- Thesis, 35+ Bachelor ThesisFunding by KONWIHR, DFG, BMBF, EU, Elitenetzwerk Bayern
34

Thank you for your attention!
Questions?
Slides, reports, thesis, animations available for download at:www10.informatik.uni-erlangen.de
35


















