
Euclid’s Algorithm - Carnegie Mellon...
23
9/23/2014 1 BeiHang Short Course, Part 2: Operation Centric Hardware Operation‐Centric Hardware Description and Synthesis James C. Hoe J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s1 Department of ECE Carnegie Mellon University Collaborator: Arvind (MIT) James C. Hoe and Arvind, “Operation‐Centric Hardware Description and Synthesis,” IEEE Transactions on Computer‐Aided Design of Integrated Circuits and Systems, Volume 23, Number 9, pp 1277‐1288, September 2004. Rules Gcd(a, b) if a>b, b!=0 Gcd(a%b, b) (mod) Euclid’s Algorithm: Greatest Common Divisor Gcd(a, b) if a b, b! 0 Gcd(a%b, b) (mod) Gcd(a, b) if a>b, b!=0 Gcd(a‐b, b) (mod‐iter) Gcd(a, b) if a<b Gcd(b, a) (flip) Gcd(a, 0) a (done) Execution: flip J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s2 Gcd(2,4) Gcd(4,2) flip Gcd(0,2) mod‐iter Gcd(2,2) mod‐iter Gcd(2,0) flip
Transcript of Euclid’s Algorithm - Carnegie Mellon...

9/23/2014
1
BeiHang Short Course, Part 2: Operation Centric HardwareOperation‐Centric Hardware Description and Synthesis
James C. Hoe
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s1
Department of ECE
Carnegie Mellon University
Collaborator: Arvind (MIT)James C. Hoe and Arvind, “Operation‐Centric Hardware Description and Synthesis,” IEEE Transactions on Computer‐Aided
Design of Integrated Circuits and Systems, Volume 23, Number 9, pp 1277‐1288, September 2004.
Rules
Gcd(a, b) if a>b, b!=0 Gcd(a%b, b) (mod)
Euclid’s Algorithm: Greatest Common Divisor
Gcd(a, b) if a b, b! 0 Gcd(a%b, b) (mod)
Gcd(a, b) if a>b, b!=0 Gcd(a‐b, b) (mod‐iter)
Gcd(a, b) if a<b Gcd(b, a) (flip)
Gcd(a, 0) a (done)
Execution:flip
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s2
Gcd(2,4) Gcd(4,2)flip
Gcd(0,2)mod‐iter
Gcd(2,2)mod‐iter
Gcd(2,0)flip
9/23/2014
2
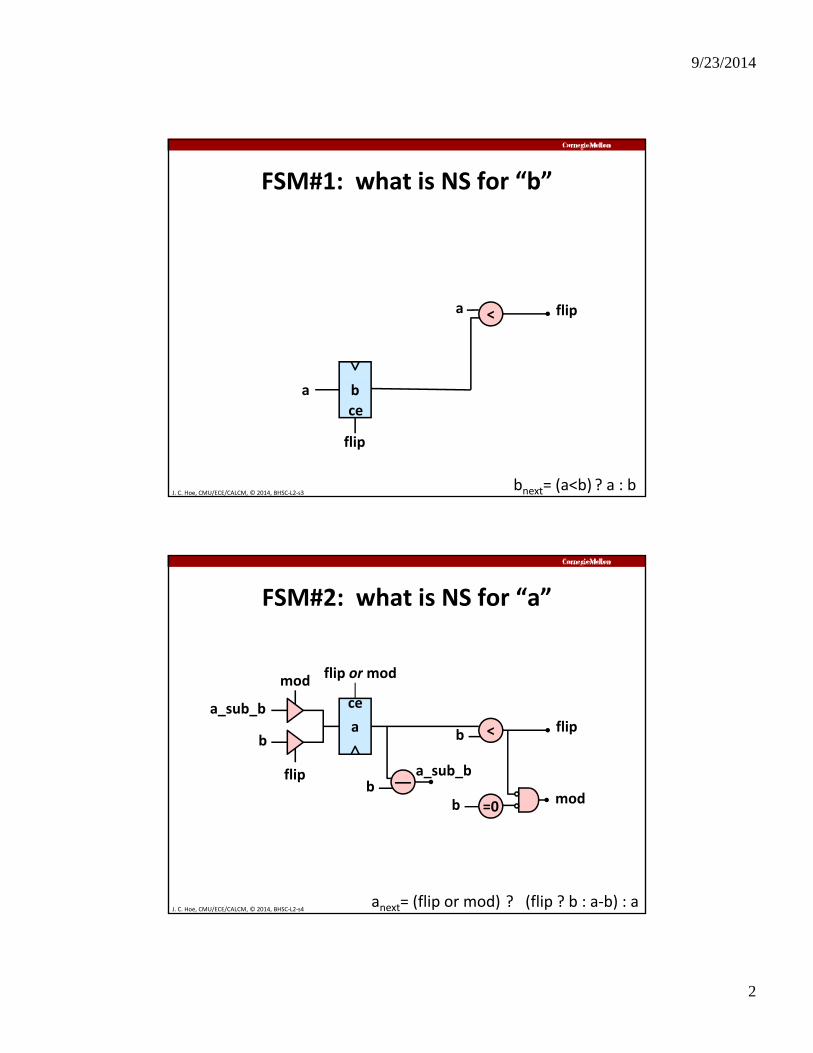
FSM#1: what is NS for “b”
a < flip
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s3
a b
flip
ce
bnext= (a<b) ? a : b
FSM#2: what is NS for “a”
flip ormod
b
b ––a_sub_b
< flipa
flip ormod
ce
flip
mod
a_sub_b
b
d
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s4
b =0mod
anext= (flip or mod) ? (flip ? b : a‐b) : a

9/23/2014
3
Mapping to Hardware
flip ormod
‐a_sub_b
< flipa
flip ormod
ce
flip
mod
a_sub_b
b
d
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s5
a b
flip
ce
=0mod
Is it clear that the two FSMs together implements GCD?
Cooperating FSM is “State‐centric”
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s6

9/23/2014
4
Operation‐Centric Decomposition
a
b
a
b
‐
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s7
when a < ba’ = bb’ = a
when a >= b && b!=0a’= a – bb’= b
Otherwise do nothing
A Very Complicated Real‐Life Example: Out‐of‐Order Speculative Processor
F h U iFetch Unit Decode Unit
RF ROB
status
BTB
PC
IntU
BPU
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s8
status
MemU
9/23/2014
5
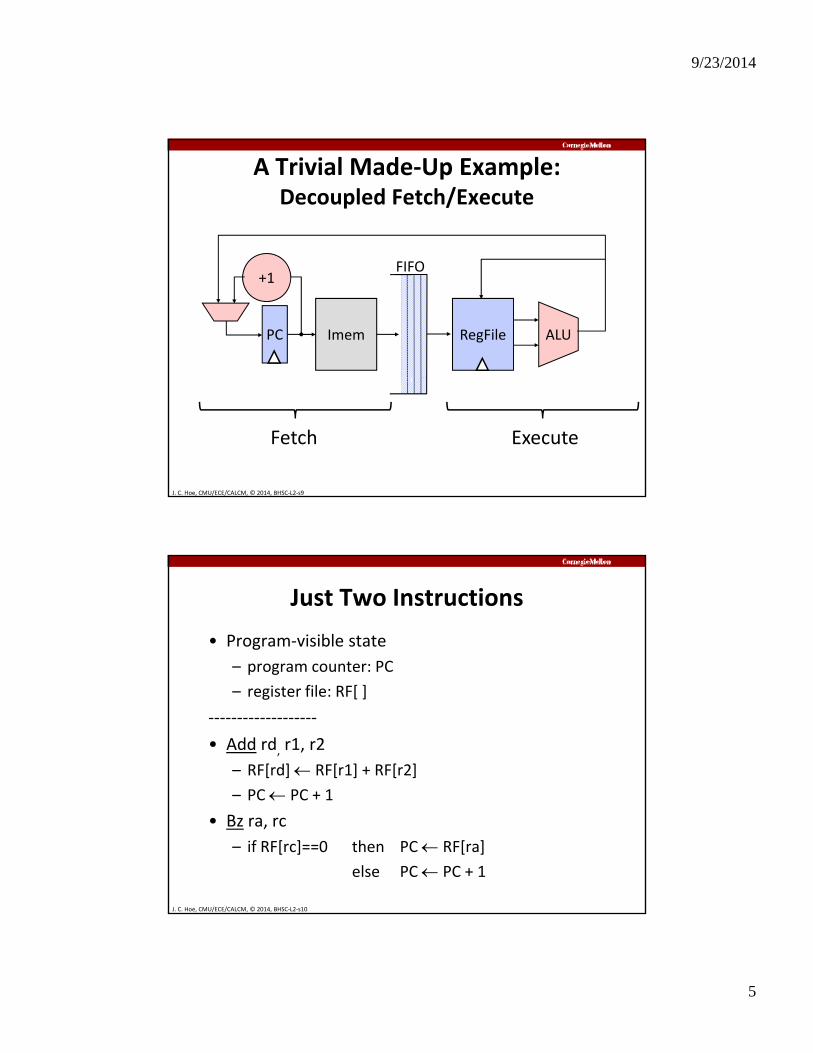
A Trivial Made‐Up Example: Decoupled Fetch/Execute
Imem
+1
RegFile ALUPC
FIFO
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s9
Fetch Execute
Just Two Instructions
• Program‐visible state
– program counter: PCp g
– register file: RF[ ]
‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐
• Add rd, r1, r2
– RF[rd] RF[r1] + RF[r2]
PC PC + 1
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s10
– PC PC + 1
• Bz ra, rc
– if RF[rc]==0 then PC RF[ra]
else PC PC + 1
9/23/2014
6
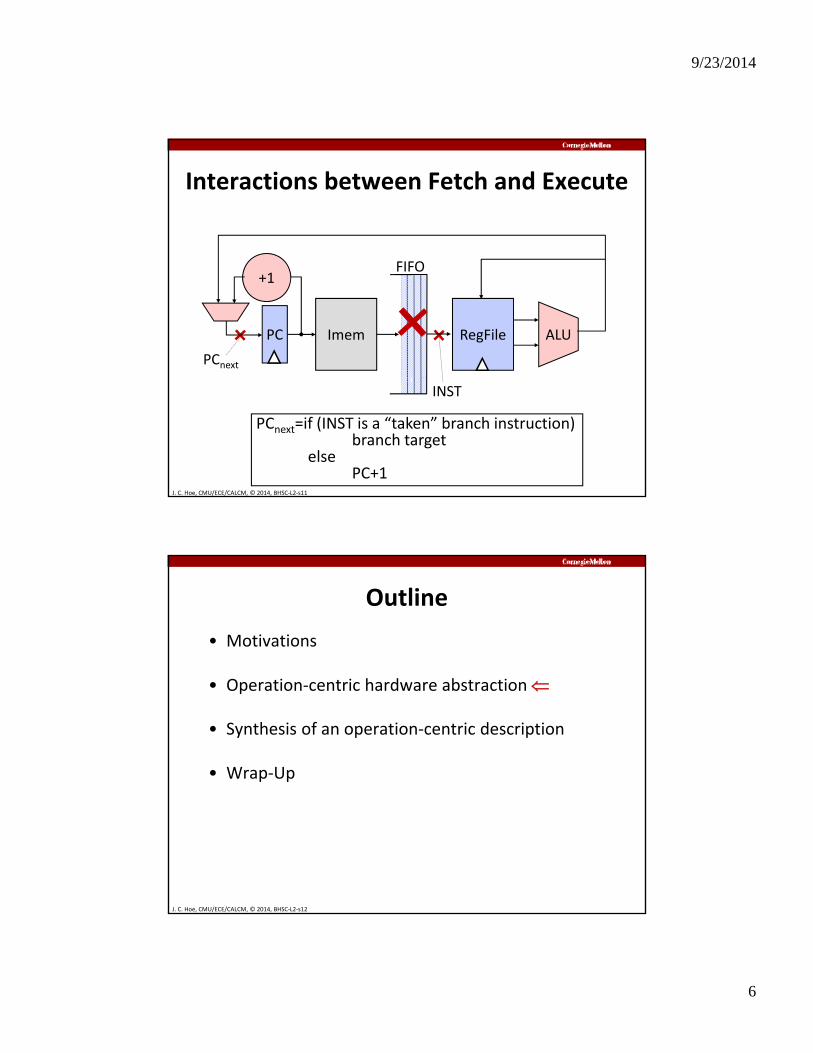
Interactions between Fetch and Execute
PCnext
Imem
+1
RegFile ALUPC
FIFO
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s11
INST
PCnext=if (INST is a “taken” branch instruction)branch target
elsePC+1
Outline
• Motivations
• Operation‐centric hardware abstraction
• Synthesis of an operation‐centric description
• Wrap‐Up
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s12

9/23/2014
7
Operation‐Centric Abstraction
regarray(ROM) FIFO array
IMEMPC RF
reg (ROM) FIFO array
BF
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s13
STATE = Proc( pc, imem, bf, rf )
Processor Model: Fetch Rule
Fetch Rule
Proc( pc, imem, bf, rf )
Proc( pc+1, imem, bf.enq(inst), rf)
let inst=imem[pc]
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s14
PC IMEM
+1
BF RF ALU

9/23/2014
8
TRSpec Rewrite Rules
• Takes notation from Term Rewriting Systems (TRS)
<left‐hand‐side pattern>when <predicate expression>
==> <right‐hand‐side rewrite expression>let
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s15
let<variables bindings>
Atomic Execution Semantics
Given a set of rules and an initial term s
While ( some rules are applicable to s )
{
choose an applicable rule
(non‐deterministic)
AtomicUpdateStep
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s16
apply the rule atomically to s
}
Note: after a rule fires, applicability of rules is re‐evaluated from scratch on the new state
Step

9/23/2014
9
Processor Model: Execute Rules
Add Rule
Proc( pc, imem, bf, rf )when bf.first( )=Add(rd, r1, r2)
Proc( pc, imem, bf.deq( ), rf[ rd:=(rf[r1]+rf[r2]) ] )
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s17
PC IMEM
+1
BF RF ALU
Processor Model: branch‐if‐zero
Bz Not‐Taken
Bz Taken
Proc( pc, imem, bf, rf ) if rf[rc]0 when bf.first( )=Bz(ra, rc)
Proc( pc, imem, bf.deq( ), rf )
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s18
Proc( pc, imem, bf, rf ) if rf[rc]==0
when bf.first( )=Bz(ra, rc)
Proc( rf[ra], imem, bf.clear( ), rf )
Is this (good) hardware description?

9/23/2014
10
Operation‐Centric Abstraction
• Explicit declaration of storage (same as RTL)
• Describes system behavior as a collection of guarded y gactions (a.k.a. rules); instead a collection of distributed state‐machine NS logic
– a rule is guarded by a predicate condition; if “condition” true then always correct to apply action
– rule application is atomic, i.e., if multiple rules
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s19
enabled, pick only one to proceed
– an execution corresponds to a sequence of rule applications
Excerpt from Superscalar Model:Dataflow‐Order Dispatch
Rule “Dispatch Instruction : Non‐Branch”
IntU( Queue(.. { entry }[i] ..), . . . . . . . )if ( op is a valid type && ALU is available )whereRsEntry(Valid, id, op, arg1, arg2) = entryArg(Valid, value1, ‐‐) = arg1Arg(Valid, value2, ‐‐) = arg2
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s20
==>IntU( Queue(.. { RsEntry(Invalid,‐,‐,‐,‐,‐,‐) }[i] .. ), . . .
. . . , Result(Valid, id, val), . . . . )whereval=Execute(op, value1, value2)

9/23/2014
11
Outline
• Motivations
• Operation‐centric hardware abstraction
• Synthesis of an operation‐centric description
• Wrap‐Up
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s21
Operations to Synchronous C‐FSM
Mapping
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s22
Mappingand
Scheduling

9/23/2014
12
Rule: A Functional Interpretation
• A rule may be decomposed into two parts (s) and (s) such that
rule = s. if (s) then (s) else s
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s23
Rule: As a State Transition Logic
Proc( pc, imem, bf, rf ) if rf[rc]==0 when bf.first( )=Bz(ra, rc)
PC
RF
PC’
RF
next
enable
when bf.first( ) Bz(ra, rc) Proc( rf[ra], imem, bf.clear( ), rf )
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s24
IM
BF
currentstate
IM
BF’
nextstate values

9/23/2014
13
Putting Them All Together
enables from01
next statenext
OR latch enable
enables fromdifferent rulesthat update PC
PC
n
selPC
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s25
next statevalues fromdifferent rulesthat update PC
statevalue
1,PC
nPC
Putting Them All Together
01enables from
next
OR latch enable
PC
n
selPC
next state
enables fromdifferent rulesthat update PC
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s26
statevalue
1,PC
nPC
next statevalues fromdifferent rulesthat update PC

9/23/2014
14
Putting Them All Together
01enables from
next
OR latch enable
PC
n
selPC
next state
enables fromdifferent rulesthat update PC
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s27
statevalue
1,PC
nPC
next statevalues fromdifferent rulesthat update PC
Single‐Rule‐per‐Cycle Scheduler
1 1
Scheduler:PriorityEncoder
2
n
2
n
1. i i
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s28
2. 1 2 .... n 1 2 .... n
3. one rule at a time i.e., at most one i is true
9/23/2014
15
Correctness
• Implementation is deterministic but the spec is not
– implementation’s state transitions must correspond to some legal execution of TRSpec
– implementation must maintain liveness
• Weak‐fairness can be achieved
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s29
– if a transition stays applicable, it will be selected within bounded number of steps
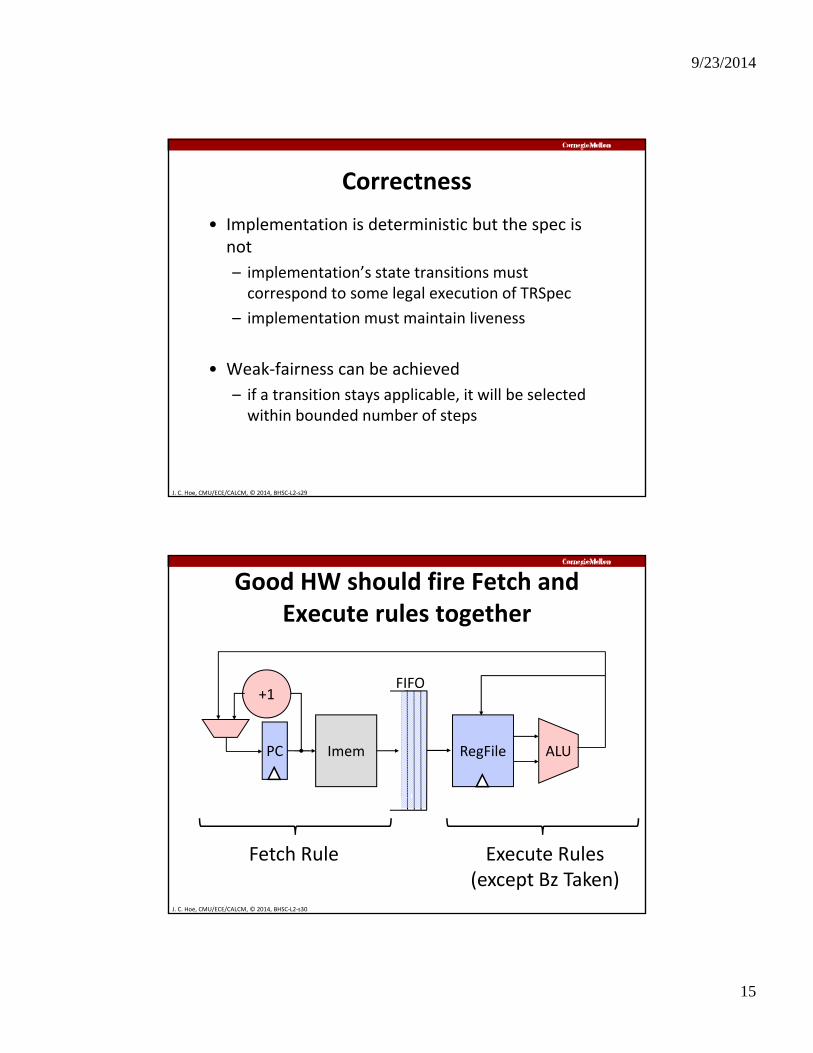
Good HW should fire Fetch and Execute rules together
Imem
+1
RegFile ALUPC
FIFO
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s30
Fetch Rule Execute Rules(except Bz Taken)

9/23/2014
16
Executing Rules Concurrently
• Applying Fetch and Add together on the same state when both are enabledwhen both are enabled
– does not produce conflicting updates
– gives the same results as if one after the other
– in particular, applying doesn’t invalidate the other
• Concurrent Execution
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s31
– statically determine which transitions can be safely executed concurrently (formalizing the above)
– generate a scheduler and update logic that allows as many concurrent transitions as possible
Conflict‐Free Rules
Ra and Rb are conflict‐free if
s . a(s) b(s) 1. a(b(s)) b(a(s))2. a(b(s)) == b(a(s)) 3. a(b(s)) == a(s)b(s)
updates do not overlap or conflict
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s32
You can fire any number of conflict‐free rules in a clock cycle as long as they are all
pairwise conflict‐free!!
or conflict
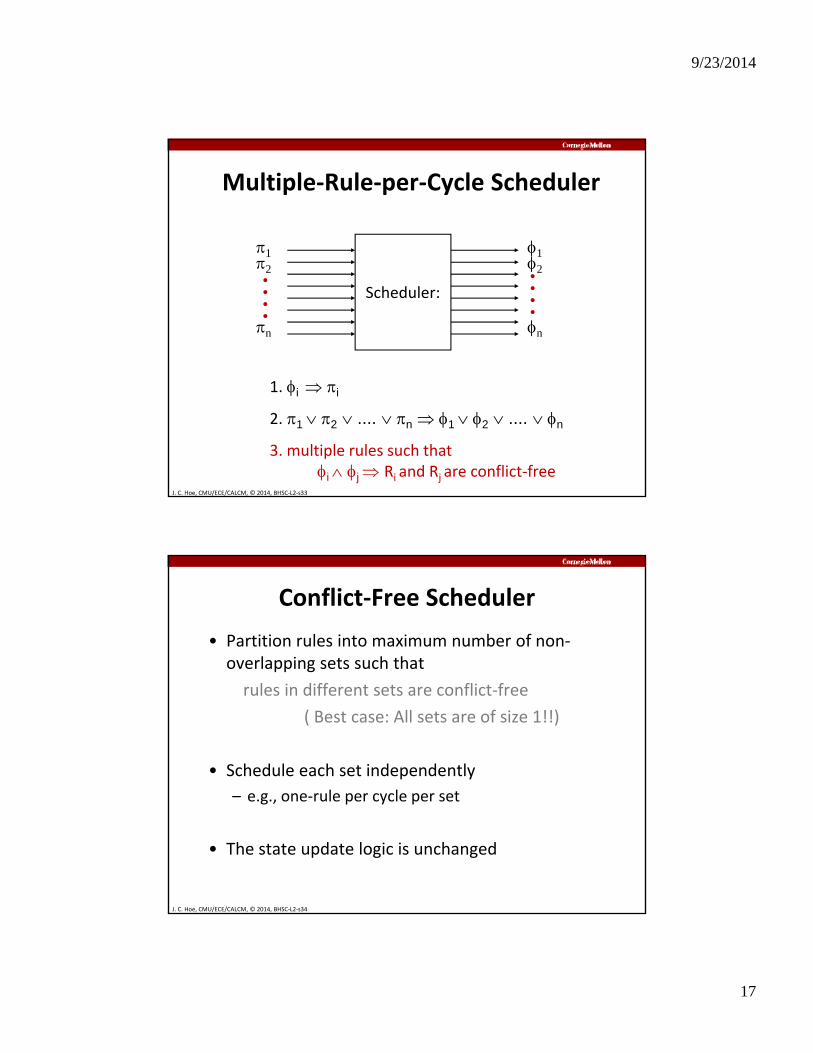
9/23/2014
17
Multiple‐Rule‐per‐Cycle Scheduler
1 1
Scheduler:
2
n
2
n
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s33
1. i i
2. 1 2 .... n 1 2 .... n
3. multiple rules such thati j Ri and Rj are conflict‐free
Conflict‐Free Scheduler
• Partition rules into maximum number of non‐overlapping sets such that
rules in different sets are conflict‐free
( Best case: All sets are of size 1!!)
• Schedule each set independently
e g one rule per cycle per set
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s34
– e.g., one‐rule per cycle per set
• The state update logic is unchanged

9/23/2014
18
CF Scheduling Example
T1 T2
T6 T3
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s35
Conflict GraphCF Graph
T5 T4
CF Scheduling Example
T1 T2 T1 T21 2
T6 T3
T1 T2
T6 T3
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s36
T5 T4 T5 T4
CF Graph Conflict Graph

9/23/2014
19
Multiple‐Rule‐per‐Cycle Scheduler
Scheduler12
122
n
2
n
Scheduler
Scheduler
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s37
1. i i
2. 1 2 .... n 1 2 .... n
3. multiple rules such thati j Ri and Rj are conflict‐free
Performance Gain
• Multiple rules per cycle p p y
But is this always optimal?
• CF scheduler does not increase critical path
– partitioned schedulers are smaller and faster than a single monolithic scheduler
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s38
a single monolithic scheduler
– distributed scheduler lowers wiring delay for ’s and ’s

9/23/2014
20
CF Schedule is too strict
Ra and Rb are sequentially‐composable (SC) if
s . a(s) b(s) 1. a(b(s)) b(a(s))2. a(b(s)) == b(a(s)) 3. a(b(s)) == a(s)b(s)
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s39
Applying a pair of SC rules concurrently to the same state produce the same outcome as only
one ordering, but that is all that is required
SC Scheduling
For each CF scheduling group in a given clock cycle,
a b c …. the transitive closure of Ra,Rb,Rc ….
on SC is ordered
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s40
For the sake of implementation, we further require the orderings to be consistent in all clock cycles

9/23/2014
21
TRSpec
TRSpec and TRAC(aka my PhD Thesis)
Design
RTL
Design
TRAC
Synopsys
RTL sim
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s41
TargetTech.
StdCell
GateArray
FPGA
Synopsys
U.S. Patent #6,597,664 and #6,901,055
TRSpec vs. Verilog
• 5‐stage pipelined, 32‐bit MIPS R2000 Integer Core
CBA tc6a LSI 10KArea
(cells)Clock Area
(gates)Clock
TRSpec 9059 10.3ns96 6MHz
34674 23.7ns41 9MHz
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s42
96.6MHz 41.9MHz
Hand-codedVerilog
RTL
7168 10.4ns96MHz
26543 23.8ns42.1MHz

9/23/2014
22
Recap the Last Hour
• Operation‐centric design abstracts away synchronous clock as the marker of progress
– designer thinks in terms of a sequence of atomic updates
– many correct mapping to synchronous FSM‐D
– let compiler pick a “good” one
• What if precise timing is a part of the design
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s43
p g p gspecification?
– need a way to mix abstractions smoothly
Bluespec: doing it for real
• A real commercial implementation
– operation‐centric “guarded atomic actions”p g
– full high‐level language with proper modular design support
– mix seamlessly with RTL‐like timing control when necessary
• Free academic license available
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s44
• Visit www.bluespec.com

9/23/2014
23
J. C. Hoe, CMU/ECE/CALCM, © 2014, BHSC‐L2‐s45
Computer Architecture Lab (CALCM)
Carnegie Mellon University
http://www.ece.cmu.edu/CALCM


















