
EPSO
74
C C O O M M P P U U T T A A Ç Ç Ã Ã O O E E V V O O L L U U C C I I O O N N Á Á R R I I A A : : U U M M A A I I N N T T R R O O D D U U Ç Ç Ã Ã O O Versão 2.0 – Março 2005 Vladimiro Miranda Professor Catedrático da FEUP Investigador do INESC Porto, Portugal
-
Upload
victor-veloso -
Category
Documents
-
view
214 -
download
1
description
computação evolucionaria
Transcript of EPSO

CCOOMMPPUUTTAAÇÇÃÃOO EEVVOOLLUUCCIIOONNÁÁRRIIAA:: UUMMAA IINNTTRROODDUUÇÇÃÃOO VVeerrssããoo 22..00 –– MMaarrççoo 22000055
VVllaaddiimmiirroo MMiirraannddaa
PPrrooffeessssoorr CCaatteeddrrááttiiccoo ddaa FFEEUUPP IInnvveessttiiggaaddoorr ddoo IINNEESSCC PPoorrttoo,, PPoorrttuuggaall

NOTA INTRODUTÓRIA
O texto seguinte foi escrito com a intenção de proporcionar a alunos de pós-graduação em engenharia, particularmente interessados em sistemas de energia eléctrica, uma visão inicial sobre a computação
evolucionária e, em especial, os algoritmos em que a representação do problema se faz nas suas variáveis naturais. A esta representação atribuiu-se o nome de fenotípica, para evocar o conceito de fenótipo e
evidenciar o contraste com os algoritmos genéticos, que operam sobre uma representação das variáveis de um problema numa forma dita cromossómica que poderemos associar a um genótipo.
Para além da referência necessária às Estratégias de Evolução e à Programação Evolucionária, o texto inclui uma descrição de um modelo de Enxame Evolucionário de Partículas (EPSO), que é uma interessante
construção híbrida dos métodos evolucionários com os dos enxames de partículas.
O texto está dividido em 5 capítulos, sendo os dois primeiros de exposição de bases teóricas. O primeiro recolhe material de tutoriais dados pelo autor em congressos internacionais como o ISAP – Intelligent
Systems Application in Power Systems, e o IEEE Power Meeting. O segundo corresponde a trabalho de pesquisa do autor e publicações referenciadas. Os dois seguintes contêm matérias e exemplos didácticos,
usados de forma dispersa no Mestrado em Engenharia Electrotécnica e de Computadores da FEUP – Faculdade de Engenharia da Universidade do Porto, e exemplos de características reais, resultantes das
actividades de investigação científica e desenvolvimento tecnológico produzidas no âmbito da Unidade de Sistemas e Energia do INESC Porto – Instituto de Engenharia de Sistemas e Computadores do Porto,
Portugal. O último capítulo estabelece uma comparação entre os métodos que operam no fenótipo e os algoritmos genéticos, e apresenta um exemplo de aplicação real, ilustrativo de um verdadeiro algoritmo
genético
A motivação para a compilação deste material há-de encontrar-se na oportunidade oferecida pela Universidade Federal do Pará, Brasil, de cooperar na sua Pós-Graduação em Engenharia Elétrica, o que o autor reconhecidamente agradece, bem como à CAPES, pelo apoio prestado que permitiu consubstanciar
essa cooperação na forma de uma estadia como Professor Titular Visitante. A primeira versão constava apenas dois primeiros quatro capítulos e foi datada de 5 de Novembro de 2004.
Belém (PA), Brasil, 5 de Março de 2005
Vladimiro Miranda*
*O autor é, nesta data, Professor Catedrático da FEUP e Director do INESC Porto, Portugal. A sua especialização é em aplicação de
técnicas de inteligência computacional a sistemas de potência. Tem sido responsável de vários projectos em Portugal , na União Europeia e noutros países. Publicou mais de 200 trabalhos nos seus temas de especialidade.
1

CONTEÚDOS
CAPÍTULO I
AS ESTRATÉGIAS DE EVOLUÇÃO E A PROGRAMAÇÃO EVOLUCIONÁRIA
CAPÍTULO II
ENXAMES DE PARTÍCULAS (PSO) E ENXAMES EVOLUCIONÁRIOS (EPSO)
CAPÍTULO III
EXEMPLOS DIDÁCTICOS
CAPÍTULO IV
EXEMPLOS DE APLICAÇÃO REAL
CAPÍTULO V
OS ALGORITMOS GENÉTICOS
2

ÍNDICE
CAPÍTULO I ......................................................................................................................................................................5
AS ESTRATÉGIAS DE EVOLUÇÃO E A PROGRAMAÇÃO EVOLUCIONÁRIA..................................................5 1. INTRODUÇÃO ..............................................................................................................................................................5 2. ESTRATÉGIAS DE EVOLUÇÃO.................................................................................................................................7
2.1. O modelo canónico (μ,κ,λ,ρ) ES ............................................................................................................................8 2.2. Parâmetros objecto e estratégicos ............................................................................................................................8 2.3. Algoritmo geral ........................................................................................................................................................9 2.4. Mais alguns conceitos básicos..................................................................................................................................9 2.5. A primeira (1+1)ES e a regra do 1/5 ......................................................................................................................10 2.6. Focando em direcção ao óptimo.............................................................................................................................11 2.7. A estratégia auto-adaptativa σSA-(1,λ)ES.............................................................................................................12 2.8. Como escolher um bom valor para o factor de aprendizagem? .............................................................................13 2.9. Extensão de (1,λ)ES para (μ,λ)ES .........................................................................................................................15 2.10. Auto-adaptação em σSA(μ,λ)ES .........................................................................................................................15
3. PROGRAMAÇÃO EVOLUCIONÁRIA......................................................................................................................17 3.1. A ponte (μ+λ) para a ES ........................................................................................................................................17 3.2. Um esquema para a Programação Evolucionária...................................................................................................17 3.3. Outras variantes de Programação evolucionária ....................................................................................................18
4. ASPECTOS COMUNS DA EP E DAS ES ..................................................................................................................19 4.1. Potenciando os processos de mutação....................................................................................................................19 4.2. A recombinação como factor principal ..................................................................................................................20 4.3. Restrições...............................................................................................................................................................21 4.4. Arranque do processo.............................................................................................................................................22 4.5. Função de adaptação ..............................................................................................................................................22 4.6. Computação ...........................................................................................................................................................22
5. CONCLUSÕES ............................................................................................................................................................22 CAPÍTULO II ...................................................................................................................................................................24
ENXAMES DE PARTÍCULAS (PSO) E ENXAMES EVOLUCIONÁRIOS (EPSO)................................................24 6. INTRODUÇÃO ............................................................................................................................................................24 7. A OPTIMIZAÇÃO POR ENXAME DE PARTÍCULAS (PSO)..................................................................................25
7.1. O modelo simples...................................................................................................................................................25 7.2. Controlando a convergência...................................................................................................................................26
8. EPSO – ENXAME DE PARTÍCULAS EVOLUCIONÁRIO ......................................................................................27 8.1. Uma visão crítica da PSO sob o paradigma das estratégias de evolução ...............................................................27 8.2. Os Enxames Evolucionários como estratégia auto-adaptativa ...............................................................................27 8.3. Os méritos do EPSO ..............................................................................................................................................29
3

9. EXPERIÊNCIAS COM O EPSO..................................................................................................................................30 9.1. O modelo básico.....................................................................................................................................................30 9.2. O EPSO em funções teste ......................................................................................................................................30 9.3. Problemas com restrições.......................................................................................................................................34 9.4. Problemas com variáveis discretas ou inteiras .......................................................................................................34 9.5. Tamanho dos enxames ...........................................................................................................................................34 9.6. Comunicação entre partículas ................................................................................................................................34
10. CONCLUSÕES ..........................................................................................................................................................35 CAPÍTULO III..................................................................................................................................................................36
EXEMPLOS DIDÁCTICOS ........................................................................................................................................36 11. INTRODUÇÃO ..........................................................................................................................................................36 12. ESTRATÉGIAS DE EVOLUÇÃO NO PROBLEMA DE DESPACHO DE GERAÇÃO.........................................36
12.1. Um exemplo de problema clássico do despacho óptimo de geração....................................................................37 12.2. Uma ES não adaptativa ........................................................................................................................................38 12.3. Uma ES auto-adaptativa.......................................................................................................................................40 12.4. Um modelo de EPSO para o despacho económico clássico.................................................................................42 12.5. Comparação entre modelos ES não adaptativos, auto-adaptativos e EPSO.........................................................44
13. CONCLUSÕES ..........................................................................................................................................................45 CAPÍTULO IV..................................................................................................................................................................46
EXEMPLOS DE APLICAÇÃO REAL ........................................................................................................................46 14. INTRODUÇÃO ..........................................................................................................................................................46 15. DESPACHO ECONÓMICO ......................................................................................................................................46
15.1. Um modelo aplicado na União Europeia para redes isoladas ..............................................................................46 15.2. Outras propostas...................................................................................................................................................47
16. CONTROLO DE TENSÃO E ENERGIA REACTIVA .............................................................................................47 16.1. Controlo de tensão, energia reactiva e redução de perdas com EPSO .................................................................49 16.2. Sistema muito carregado e todos os controlos disponíveis ..................................................................................49 16.3. Sistema extremamente carregado e apenas com acção nas tomadas de transformadores ....................................52 16.4. EPSO na minimização de perdas de uma rede de distribuição de empresa europeia ...........................................53 16.5. Planeamento de energia reactiva – exemplo com ES...........................................................................................57
17. CONCLUSÕES ..........................................................................................................................................................60 CAPÍTULO V...................................................................................................................................................................61
OS ALGORITMOS GENÉTICOS ...............................................................................................................................61 18. INTRODUÇÃO ..........................................................................................................................................................61 19. CARACTERÍSTICAS PRÓPRIAS DOS ALGORITMOS GENÉTICOS .................................................................61 20. DISTINÇÃO ENTRE AG E ES/EP............................................................................................................................63 21. A PESQUISA NO ESPAÇO DE SOLUÇÕES E A COMPARAÇÃO AG vs. ES/EP E EPSO.................................64 22. EXEMPLO DE UM ALGORITMO GENÉTICO ......................................................................................................65
4

CAPÍTULO I AS ESTRATÉGIAS DE EVOLUÇÃO E A PROGRAMAÇÃO EVOLUCIONÁRIA
1. INTRODUÇÃO A computação evolucionária inspira-se nos paradigmas da evolução biológica actualmente aceites, embora não se deixe limitar pelas realizações biológicas. Cientificamente, hoje é aceite que a interpretação de Darwin está, na essência, correcta, no que respeita aos mecanismos que comandam a evolução das espécies (com uma ajuda de Mendel e da genética). Porém, outras propostas de explicação da evolução, como as de Lamarck, embora não sendo aceites no mundo biológico, podem todavia ser simuladas nos processos algorítmicos e de engenharia.
Um algoritmo genético visa, primariamente, encontrar a solução óptima de um problema, qualquer que seja a natureza das suas variáveis. Para isso, constitui-se uma população, ou conjunto de soluções possíveis (indivíduos) para o problema. Cada indivíduo é avaliado por uma função a optimizar e os melhores ficam seleccionados para o que se chama reprodução. Segue-se um procedimento que produz novos indivíduos a partir dos seleccionados, constituindo-se uma nova geração. Os indivíduos da nova geração são, por sua vez, avaliados para eliminar os de pior desempenho e segue-se nova fase de reprodução originando uma geração subsequente. Este processo repete-se geração após geração, e a população deverá, em princípio, ir melhorando, ou seja, ir-se enriquecendo de indivíduos com melhor avaliação, até que um certo critério de paragem fica satisfeito. O melhor indivíduo encontrado no processo é tomado, então, como a solução do problema de optimização em causa.
Neste quadro geral, os diversos métodos de computação evolucionária distinguem-se uns dos outros, fundamentalmente, no seguinte:
• na forma de representação (cromossoma) de uma solução ou indivíduo
• na forma de descodificação dos cromossomas
• na forma de efectuar a selecção
• na forma de efectuar a reprodução (ou geração de novos indivíduos).
Este texto dedica a atenção a um ramo das técnicas de computação evolucionária que, por razões históricas, esteve dividido por muitos anos, embora as suas variantes correspondam a uma mesma forma de abordagem algorítmica: falamos das Estratégias de Evolução (ES, de Evolution Strategies) e da Programação Evolucionária (EP, de Evolutionary Programming).
Na verdade, estas variantes correspondem todas ao que poderíamos designar como métodos de fenótipo, ou seja, em que a construção da representação dos soluções de um problema se baseia unicamente nas próprias variáveis do problema, sem passar por qualquer algoritmo intermédio de codificação/descodificação. Na sua essência, os métodos de fenótipo são distintos dos métodos de genótipo, onde cada solução de um problema é codificada numa sequência, designada por cromossoma, cuja interpretação exige a execução de um algoritmo que explicite as variáveis “naturais” do problema. Os métodos de genótipo são mais comummente chamados de Algoritmos Genéticos (GA, de Genetic Algorithms).
A concepção inicial da Programação Evolucionária é atribuída a Lawrence J. Fogel, no início dos anos 60, em paralelo com as propostas de John Holland sobre sistemas adaptativos, e vieram à luz em numerosos artigos, embora a publicação marcante tenha sido a do livro “Artificial Intelligence Through Simulated Evolution” (1966). Enquanto os trabalhos de Holland vieram a desembocar nos Algoritmos Genéticos, Fogel persistiu com êxito numa linha que viria a resultar no que foi apelidado de Programação Evolucionária, com importante relevo para o seu filho, David Fogel, na sua consolidação e divulgação.
As Estratégias de Evolução foram desenvolvidas por I. Rechenberg e H.-P. Schwefel, os quais colaboraram inicialmente na Universidade Técnica de Berlim, em 1963. O seu trabalho estimulou uma actividade intensa de outros pesquisadores que produziu um corpo interessante de resultados teóricos e práticos, sempre com um sentido de generalização de uma família de métodos (daí o plural “estratégias”).
5

Estas duas comunidades evoluíram separadamente, reuniram à sua volta seguidores e organizaram séries independentes de seminários e conferências. É bom lembrar que, nos anos sessenta e setenta, não estava disponível nem o poder de computação de hoje nem a Internet, e a informação não estava acessível ou fluía como presentemente. Para além disso, os grupos publicaram em línguas diferentes (inglês, nos EUA, e alemão, na RFA), em revistas diferentes e dirigindo-se a comunidades diferentes em áreas de aplicação diferentes. Os contactos regulares só se estabeleceram nos anos 80, tendo desde então havido convergência e cooperação entre as duas comunidades.
A exemplo de qualquer processo dito “evolucionário”, ES e EP dependem da definição de uma função de adaptação que estabelece um ambiente e reflecte uma medida da qualidade de cada alternativa (ou solução), também designada como indivíduo. Esta função de adaptação (fitness function) tem o mesmo papel que a função objectivo dos problemas de optimização; como tal, para além da valorização das soluções, ela pode incluir penalidades por violação de restrições.
Na verdade, o conceito de função de adaptação pode ser representado de uma forma bastante flexível. O requisito fundamental é que seja capaz de estabelecer uma relação de ordem no espaço das alternativas, de tal forma que a sua ordenação corresponda às preferências de um Agente de Decisão. Este procedimento pode, portanto, incluir regras, ou avaliações qualitativas, para além de expressões matemáticas – mas a verdade é que a representação mais tradicional de uma função de adaptação é na forma de uma expressão analítica.
Tanto as ES/EP como os GA repousam no princípio da selecção pela adaptação ao ambiente. É interessante notar, porém, que biologicamente este não é o único processo que pode deflagrar e sustentar um processo evolutivo. Por exemplo, a selecção por corrida às armas é outro mecanismo possível; ele requer pelo menos duas populações distintas, em que tipicamente uma é predadora da outra – como leões e gazelas. Mas as ES/EP e os GA baseia-me todos no mesmo paradigma, em que os indivíduos não se confrontam directamente uns com os outros mas são medidos no seu desempenho por uma função externa comum que selecciona os melhores (ou descarta os menos eficientes).
Mas as ES/EP divergem dos GA na forma de representar as alternativas, soluções ou indivíduos numa população. Enquanto os GA confiam no poder de uma representação genética discreta de cada indivíduo para gerar novos indivíduos com melhor possibilidade de sobrevivência, as ES/EP confiam no poder de uma representação directa das soluções. Isto é frequentemente objecto de polémica e confusão e merece algum desenvolvimento.
Um fenótipo é um indivíduo (ou a descrição de um indivíduo); um genótipo é o código (para um programa) para fazer um indivíduo.
A representação fenotípica de um indivíduo pode ser muito complexa; e, como acontece com qualquer representação, ela também exige uma regra de interpretação para um observador. Mas o pressuposto básico é que ela é biunívoca, isto é, que dada uma representação se pode derivar o respectivo indivíduo e vice-versa. Isto significa que não há qualquer limite à forma de representação, e isto inclui formas binárias de representação, igualmente – desde que haja uma correspondência bijectiva ente as representações e as soluções reais respectivas, e que essa correspondência seja natural e directa, sem exigir descodificações, consideraremos que a representação é de tipo fenotípico.
De forma mais clara ainda: mudar uma variável numérica de uma representação decimal para uma representação binária não transforma por si só uma técnica de ES em GA. A escolha da representação fenotípica mais adequada é apenas uma questão de simplicidade e interesse prático e não reflecte qualquer diferença substancial ou teórica.
Há, porém autores que sustentam que uma representação fenotípica corresponde apenas ao uso de variáveis na mesma forma em que a função de adaptação as utiliza directamente para o respectivo cálculo. Isto conduz-nos a distinguir as seguintes formas de representação de uma solução num ambiente de computação evolucionária:
• fenotípica pura – o indivíduo é representado nas mesmas variáveis com a mesma forma que usadas na função de adaptação
• fenotípica transformada – a codificação representando um indivíduo compõe-se das mesmas variáveis que na função de adaptação mas numa forma distinta da utilizada nela
• genética – a descodificação da representação de um indivíduo exige um programa para construir, a partir dela, a sua representação fenotípica.
Qualquer uma destas representações se pode alinhar numa série ou vector de variáveis ou valores, a que habitualmente (e em alguns casos impropriamente) se dá o nome de cromossoma.
Poderemos dizer que uma representação fenotípica pura corresponde a uma série de variáveis cuja interpretação é directa e simples. Uma representação fenotípica transformada é também uma série de variáveis, mas o reconhecimento do seu significado pode exigir uma operação de transformação – mas essa operação é completamente externa à própria
6

representação. A designação de representação genotípica, ou genética, deveria ter sido reservada para aquelas formas em que as instruções de reconstrução do indivíduo estão elas próprias total ou parcialmente codificadas no próprio cromossoma – mas, na literatura, a designação “genético” ganhou uma utilização descontrolada e menos rigorosa.
Além disso, é na representação genética que pode ocorrer uma situação com paralelo na biologia: o facto de a correspondência entre genótipo e fenótipo não ser bi-direccional. Isto é, conhece-se o programa que transforma genótipo em fenótipo (cromossoma em indivíduo) mas não existe forma de realizar a operação inversa ou ela não é unívoca (dito de outra forma, pode haver mais do que um genótipo com a mesma expressão fenotípica). Isto é claro na biologia: de um cromossoma humano pode-se construir um ser humano, mas não se conhece maneira de, a partir de um corpo humano, deduzir o cromossoma que o gerou. Na verdade, não se encontra num cromossoma nenhuma representação directa da altura de um ser, ou da medida do seu pé ou de quase qualquer outra característica física macroscópica – um cromossoma humano é um programa para fazer um humano, e ele próprio codifica programas que são usados para ir constituindo o ser vivo. Isto é em particular bem observável na fase embrionária do desenvolvimento.
Também não se deve confundir a representação de um indivíduo com o comportamento de um indivíduo. Por exemplo, uma representação possível de uma rede neuronal (com uma dada arquitectura) é pelos valores dos pesos das suas ligações. Estes pesos podem receber uma representação como números reais, ou uma representação binária – o que é indiferente para o ponto em discussão, porque ambas serão representações do fenótipo: dados os pesos, tem-se a rede e dada a rede, têm-se os pesos. Isto nada tem a ver com o comportamento do indivíduo, que deriva de uma relação entre o fenótipo e o ambiente a que está submetido – relação mediada pela função de adaptação. No nosso mundo virtual, o indivíduo é a sua representação – e uma mera transformação aplicada a uma variável nada altera nisto.
Se se está perante um problema em que se avalia o desempenho de programas para desempenhar uma dada tarefa, colocados em competição, então cada programa é um indivíduo e a sua representação é feita ao nível de fenótipo. Uma representação ao nível de genótipo exigiria que fosse na forma de um programa para construir um programa/indivíduo. Assumir que programas são indivíduos não é nada estranho à Programação Evolucionária, especialmente nos trabalhos iniciais de L. Fogel, mas a percepção popular é que as ES/EP se baseiam em problemas descritos por variáveis, e neste texto limitar-nos-emos a este entendimento.
Nos GA, é essencial estabelecer uma relação unívoca entre o espaço dos genes e o espaço das variáveis fenotípicas. A variação, ou criação de novos indivíduos, é realizada ao nível dos genótipos, por operações de mutação ou recombinação de genes, enquanto que as consequências dessas transformações são avaliadas a nível do fenótipo, pela função de adaptação. Nos ES/EP, não há nível de genótipo e nenhuma necessidade, portanto, de estabelecimento de associação entre genes e variáveis do problema. Nas versões correntes de ES/EP, cada solução é representada pelas próprias variáveis naturais do problema, com valores inteiros ou reais, dentro dos seus domínios. Portanto, a variação é introduzida directamente ao nível do fenótipo.
A variação ou diversidade é absolutamente essencial para tornar efectiva a selecção. Ela permite a cobertura do espaço de busca ou das soluções. A variação exprime quão diferente são os descendentes das gerações anteriores, enquanto a diversidade se refere a quão diferentes são, entre si, os indivíduos numa mesma geração. Quando a evolução depende fortemente da diversidade, a perda desta conduz usualmente a uma interrupção precoce dos algoritmos evolucionários, em pontos sub-óptimos. Quando a evolução depende fortemente na variação, é necessário garantir que se verifica progresso suficiente de geração para geração: uma variação demasiado pequena pode conservar um processo capturado num óptimo local enquanto que uma variação excessiva pode perturbar irremediavelmente um processo de convergência.
Tanto as Estratégias de Evolução como a Programação Evolucionária usam uma colecção de híbridos de variação e diversidade para acelerar a convergência. Na EP clássica (vista como modelo da evolução de espécies), a variação é introduzida somente por mutação, embora trabalhos precoces com máquinas de estados finitos já usassem formas de recombinação para originar novos indivíduos. Nas ES, que também começaram pelo uso da mutação, processos similares à recombinação foram introduzidos para originar variação e novas expressões dos fenótipos. Ambos os modelos têm vindo a convergir em termos conceptuais e, presentemente, são dificilmente distinguíveis.
2. ESTRATÉGIAS DE EVOLUÇÃO Sob esta designação geral, as ideias concebidas por Rechenberg e Schwefel tiveram um desenvolvimento teórico e experimental notável, em especial na Alemanha.
Em muita literatura ainda se encontra a referência de que o que distingue as ES da EP é que a EP “pura” não adopta recombinação e se baseia apenas na mutação de indivíduos para gerar variação. Esta distinção esbateu-se, porém, e já não faz sentido nos tempos actuais.
7

Nas ES, o problema e as alternativas são representados nas suas variáveis naturais – na verdade, o grosso das aplicações de ES tem sido em problemas com variáveis reais. Trata-se, portanto, de uma representação de fenótipo dos problemas.
A questão inicial tratada no começo dos anos 60 por Rechenberg e Schwefel dizia respeito à determinação de perfis apresentando resistência mínima num túnel de vento – uma aplicação típica de engenharia aeronáutica. Na verdade, o método foi totalmente experimental e não de computação, e as mutações introduzidas em cada desenho foram aplicadas em modelos físicos e testadas no túnel de vento, para se proceder à sua avaliação.
Entre 1963 e 1974, estes pesquisadores desenvolveram os fundamentos teóricos das Estratégias de Evolução. Os resultados, porém, mantiveram-se fechados numa comunidade de engenheiros civis e de estruturas. Há, decerto, uma razão para isto: muitos problemas de optimização estrutural não têm uma representação matemática fechada. Portanto, os engenheiros têm que confiar na sua intuição e julgamento profissional, sem poderem resolver as questões por métodos analíticos.
Hoje em dia há uma variedade de versões de ES. Nas secções seguintes discutiremos alguns aspectos do que pode ser chamado o modelo canónico – o modelo (μ,κ,λ,ρ) ES, de acordo com a notação de [1].
2.1. O modelo canónico (μ,κ,λ,ρ) ES A designação de modelo (μ,κ,λ,ρ) ES foi proposta por Schwefel [Error! Bookmark not defined.] e tem os seguintes parâmetros:
• μ - número total de progenitores numa geração
• κ - número de gerações em que um indivíduo sobrevive ou número de ciclos reprodutivos de um indivíduo
• λ - número total de descendentes criados numa geração
• ρ - número de progenitores de um indivíduo
A esta luz, um modelo de Programação Evolucionária com 1 progenitor por indivíduo com base em mutação e em que os pais não sobrevivem para a geração seguinte pode ser referido como uma Estratégia de Evolução do tipo (μ,0,μ,1)ES. Quer dizer: toda uma família de processos podem ser iniciados, dependendo da escolha de valores para os parâmetros acima. Algumas dessas variantes foram intensamente exploradas e outras ainda permanecem em aberto. Claramente, as formas mais simples foram mais investigadas e permitiram ganhos de compreensão sobre os mecanismos que animam as Estratégias Evolutivas e lhes permitem ter êxito (ou causam divergência e insucesso).
Os primeiros modelos de ES exibiam menos graus de liberdade que os acima descritos. De facto, o primeiro de todos veio a ser conhecido como a estratégia (1+1)ES: tem, em cada geração, um único indivíduo, o qual gera por mutação um novo indivíduo, agindo a selecção sobre o conjunto constituído por progenitor e descendente. Mais tarde, apareceram as estratégias designadas como (μ+λ)ES e (μ,λ)ES, sendo aqui introduzida a notação (,+). Na verdade, enquanto na estratégia (μ+λ)ES os μ sobreviventes para a geração seguinte são escolhidos ou seleccionados de entre o conjunto formado pela união dos μ progenitores anteriores e dos seus λ filhos, na estratégia (μ, λ)ES, com λ ≥ μ ≥ 1, os futuros μ progenitores da geração seguinte e que sobrevivem de uma dada geração são seleccionados dentro do conjunto dos λ descendentes dessa geração apenas, independentemente da qualidade dos seus μ progenitores. Os primeiros modelos da estratégia (,) foram do tipo (1,λ) ES, com um único indivíduo originando λ descendentes de entre os quais o melhor é seleccionado para a geração seguinte.
Foi mostrado que nas estratégias (μ,λ)ES pode ocorrer divergência, se a solução “correntemente melhor” não for guardada externamente ou, pelo menos, preservada para a geração seguinte. Este procedimento determinístico recebe o nome de elitismo.
A estratégia (μ,λ)ES implica que um indivíduo tem descendência apenas uma vez, e que a sua duração de vida cobre apenas uma geração, enquanto que a estratégia (μ+λ)ES não impõe qualquer limite à duração de vida de um indivíduo.
Quando se definem as estratégias e modo mais completo com a notação (μ,κ,λ,ρ)ES, compreendemos que o parâmetro κ origina uma situação intermédia entre os casos extremos (μ,λ)ES e (μ+λ)ES. Por outro lado, o parâmetro ρ, que define quantos progenitores tem um novo indivíduo, introduz explicitamente a operação de recombinação entre ascendentes como mecanismo condicionador da evolução numa dada estratégia.
2.2. Parâmetros objecto e estratégicos Em ES é habitual falar-se de parâmetros objecto (PO) e parâmetros estratégicos (PE). Um indivíduo será, então, composto por uma sequência (PO, PE), tal que
8

PO = (o1, o2, … , ono) e PE = (s1, s2, … , sns)
com “no” parâmetros objecto e “ns” parâmetros estratégicos.
Os parâmetros objecto correspondem basicamente às variáveis do problema (as variáveis compondo o fenótipo). Por vezes acrescenta-se a estes parâmetros um contador da vida (número de gerações) remanescente do indivíduo, nos casos em que se fixa um parâmetro κ > 1.
Os parâmetros estratégicos referem-se habitualmente a desvios padrão σ para as distribuições descrevendo probabilidades de mutação, a qual pode ser global ou distinta em cada uma das “no” dimensões ou variáveis de um indivíduo, e ainda a parâmetros α estabelecendo correlação entre mutações em diferentes variáveis (algumas vezes estes parâmetros são designados como “ângulos”). É interessante observar que estes parâmetros têm um sabor a genéticos, porque podem ser vistos como codificando o modo de construir um indivíduo, em vez de representarem traços do fenótipo de um indivíduo.
2.3. Algoritmo geral O algoritmo geral de uma Estratégia de Evolução pode ser algo como:
Procedure ES (BEGIN) definir parâmetros e operadores fixar μ,κ,λ,ρ e outros parâmetros; fixar operadores(rec, mut, sel); iniciar o contador de gerações g := 0; initializar uma população aleatória P de μ elementos Initpopulation P[g]; Avaliar a adaptação de todos os indivíduos da população Evaluate P[g]; while not done do reprodução – gerar λ descendentes… …por recombinação P’ [g] := recombine(P [g]) …por mutação - introduzir perturbações estocásticas na nova população [g] := Mutate ( P’ [g] ); P~ avaliação – calcular a adaptação dos novos indivíduos Evaluate P [g];
~ selecção - de μ sobreviventes para a geração seguinte, com base no valor da adaptação P [g+1] := select ( P[g] ∪ [g] ); P~ Testar o critério de terminação (baseado na adaptação, número de gerações, etc.) If test is positive then done := TRUE; Incrementar o contador de gerações g := g + 1; End while
End ES
2.4. Mais alguns conceitos básicos Apesar de ainda serem de esperar muitos desenvolvimentos teóricos sobre uma teoria generalizada dos algoritmos evolucionários, há alguns trabalhos aplicados em modelos simplificados que nos iluminam quanto ao modo como funcionam as ES. Nos parágrafos seguintes apresentam-se alguns conceitos básicos que ajudam a essa compreensão – nomeadamente o chamado modelo esférico, que ajuda à compreensão da forma como se realiza a convergência local e que permitiu o desenvolvimento do conceito de taxa de progressão.
A taxa de progressão ϕ define-se como o valor esperado da variação da distância (Euclidiana), de uma geração para a seguinte, entre o óptimo do problema (onde quer que ele esteja) e a localização média da população. O modelo esférico consiste numa função de adaptação isotrópica definida por
9

( )∑=
−+=n
1i
2*iii01 yycc)(F y
com ci = 1 , e o símbolo * sinalizando o óptimo, e sendo yi o valor da variável i (parâmetro objecto) de um indivíduo.
n,...,1i =∀
Este é um modelo com muito interesse por causa da sua simetria radial. Permite que a função e adaptação seja escrita como , onde R é o vector de distância ao óptimo; devido á simetria radial, Q(R) depende apenas do comprimento de R, R = ||R||, ou seja, Q = Q(R) com y* como centro de simetria.
)(Q)(F)(F * RRyy =−=
Dado um indivíduo y, un novo indivíduo gerado por mutação pode definir-se como
Zyy +=~
onde Z é um vector aleatório. Observando a Figura 1, vemos que a taxa de progresso pode ser definida como o valor esperado
{ }rRE −=ϕ
onde r é a distância do indivíduo mutado ao óptimo.
Este foi o modelo adoptado por investigadores como Beyer [2] para analisar, no modelo esférico, a taxa de progresso de uma ES e deduzir leis sobe a Probabilidade de Sucesso, isto é, a probabilidade de o mutado y~ estar localizado dentro do círculo definido por R à volta do óptimo, e sobre como conseguir uma taxa de progressão ideal, ou seja, a mais rápida taxa possível de progressão em direcção ao óptimo.
~y
y
Z r
R
y*
z
Figura 1 – Representação da projecção de um ambiente definido por uma função de adaptação em n = 2 dimensões, com identificação do óptimo y* e de um ponto y descoberto numa dada geração; o círculo com raio R define o domínio de sucesso de mutações Z adicionadas a y, tais que r < R.
2.5. A primeira (1+1)ES e a regra do 1/5 Os primeiros modelos de ES experimentados nos anos 60 usaram apenas um indivíduo e um descendente por geração. Na que agora é chamada a estratégia (1+1)ES, como estratégia mais, ou (+), um indivíduo, numa geração, origina um descendente por aplicação de mutações normalmente distribuídas (com o efeito de que variações mais pequenas são mais prováveis que variações maiores). Se o descendente tem melhor desempenho que o pai, medido pela função de adaptação (ou objectivo), substitui o seu antecessor (é seleccionado); de outro modo, esse descendente é descartado e um novo descendente é gerado a partir do indivíduo original. Não se usa qualquer recombinação, o esquema de mutação é mantido constante ao longo das iterações e há um controlo externo sobre a dimensão média das mutações.
10

Verificamos que este é um esquema simples com selecção elitista. Tão simples, na verdade, que permitiu a derivação de alguns resultados teóricos, nomeadamente sobre a velocidade de convergência e a dimensão das mutações a aplicar. A representação de um indivíduo é simplesmente como ilustrado na Figura 2.
X1 X2 … Xn
Figura 2 – Representação de um indivíduo i com n variáveis reais
O esquema de mutação pode ser descrito da seguinte forma: um salto mutacional é realizado na geração g pela adição ao indivíduo X(g) de uma perturbação Z, produzida de forma aleatória, criando um novo indivíduo X~ :
X~ = X(g) + Z
em que
( ) ( )( )tn1 1,0,...,1,0 ΝΝσ=Z
O indivíduo X é um vector de n variáveis objecto. Nj(0,1) corresponde a uma distribuição Gaussiana com média zero e variância unitária na variável j, e σ é a amplitude de mutação ou passo mutacional, também ainda chamada taxa de mutação. Z fica, assim, como um vector aleatório e, dada a definição anterior, a distribuição da mutação é isotrópica.
A amplitude de mutação σ não pode ser conservada constante, se se deseja uma efectiva convergência. Rechenberg [3] propôs uma regra prática a que chamou a regra do 1/5. Primeiro, definiu o conceito de taxa de sucesso S(h): a razão entre o número e mutações bem sucedidas (seleccionadas para a geração seguinte) e todas as mutações experimentadas nas últimas h gerações. Em seguida, postulou que, a fim de se obter uma velocidade de convergência óptima, a amplitude de mutação σ deve ser aumentada se a taxa de sucesso for maior que 1/5 r diminuída se for menor que 1/5.
De acordo com Rechenberg, existiria um valor óptimo para h que se calcularia multiplicando por 10 o número n de variáveis ou dimensões do espaço de busca. Portanto, se σ for o passo inicial num problema de 10 variáveis, a taxa de sucesso deveria ser avaliada num conjunto de h = 100 gerações e σ deveria ser alterado para a.σ se S(h) > 1/5 e para σ/a se S(h) < 1/5, O valor de a deveria ser escolhido no intervalo [1,2].
Este resultado foi obtido para aproximações lineares (planos) de funções de adaptação marcadamente convexas, do tipo do modelo esférico. O modelo esférico converteu-se numa ferramenta importante de avanços teóricos, porque em muitos casos é uma aproximação local razoável de uma dada função de adaptação. No caso do modelo esférico e similares, provou-se existir uma convergência de ordem linear para a velocidade de convergência. Mas para modelos distintos do modelo esférico, o valor de 1/5 deve ser substituído por outro valor mais adequado, a fim de se uma aproximação a um comportamento óptimo do algoritmo. O “bom” valor a usar depende, pois, em cada caso da topologia do espaço de busca.
Além do mais, esta regra do 1/5 pode até reduzir a eficiência do algoritmo na busca do óptimo. Ela pode acelerar a descoberta do óptimo, mas a probabilidade de realmente permitir a descoberta do óptimo vem diminuída, porque a regra permite que o processo evolucionário fique capturado em óptimos locais. A partir daí, pode ser difícil encontrar melhores soluções na vizinhança e, após um dado número de gerações, a aplicação da regra do 1/5 vai eduzir ainda mais o passo, tornando ainda mais improvável que o algoritmo escape do óptimo local.
2.6. Focando em direcção ao óptimo Mutações que originem importantes alterações nos indivíduos são geralmente benéficas no início de um processo evolucionário, porque permitem aos novos indivíduos saltar para longe dos progenitores e pesquisar novas regiões do domínio viável do problema. Todavia, num estádio mais avançado, grandes perturbações afastam os indivíduos da zona do óptimo. Isto compreende-se com o exame da Figura 3.
11

-1
0
1
2
3
4
5
6
-1 ,5 -1 -0,5 0 0,5 1 1 ,5
Figura 3 – Duas distribuições gaussianas com variâncias diferentes, associadas à mutação de uma variável. O seu valor esperado corresponde ao valor actual da variável. Uma variância menor corresponde a uma maior probabilidade de as perturbações no valor da variável serem pequenas.
O senso comum diz-nos que quando tivermos soluções na vizinhança de um possível óptimo, a dispersão de uma distribuição probabilística regulando as mutações deverá ser menor. Isto permite um ajuste fino e está implícito na regra de Rechenberg, a qual define um procedimento externo para a redução da dispersão das distribuições das mutações, com o incremento do número de gerações. Proposto esta forma, este esquema algo ingénuo é mecânico, determinístico e rígido – e contra a essência própria do processo evolucionário.
2.7. A estratégia auto-adaptativa σSA-(1,λ)ES Numa estratégia (1,λ)ES, um indivíduo X origina λ descendentes por mutação, e a selecção age exclusivamente sobre estes para definir um sobrevivente que, na geração seguinte, origine por sua vez de novo λ descendentes. Pai e filhos nunca competem entre si.
Este modelo permitiu a introdução de um esquema inovador de controlo dinâmico da taxa de mutação σ, ao contrário do esquema determinístico de Rechenberg. Trata-se de um esquema que segue os princípios da evolução e auto-adaptação – significando que uma variável correspondendo à taxa de mutação também fica sujeita ela própria sujeita a mutação e selecção, a fim de adaptar o progresso do algoritmo à taxa de progressão óptima.
Uma família de modelos seguindo esta ideia é a σSA (de σ-Self Adaptive), originalmente desenvolvida por Schwefel [4,5]. A ideia central é que cada indivíduo é governado por parâmetros objecto e por parâmetros estratégicos sujeitos a evolução – e se um indivíduo é seleccionado para a geração seguinte, os seus parâmetros estratégicos sobrevivem com ele. Estes parâmetros estratégicos, se forem óptimos, devem conduzir o processo num regime de taxa de progressão óptima, ou seja, com o máximo valor esperado de progresso por geração.
Na estratégia σSA-(1,λ)ES básica, só temos um parâmetro estratégico evolutível – uma taxa de mutação σ. Um indivíduo numa geração g pode, pois, ser representado como na Figura 4. A esperança num processo auto-adaptativo é que o problema possa “aprender” o valor óptimo do parâmetro estratégico σ* cuja adopção conduza à taxa de progressão maior possível. Infelizmente, este é um valor que não se conhece à partida – a sua determinação depende do conhecimento do local onde se encontra o óptimo do problema e das condições na vizinhança deste, e é esse óptimo que precisamente procuramos. Por isso, se o processo evolutivo conseguir seleccionar bons σ, então é possível que a determinação do óptimo possa ser conseguida com mais rapidez.
X1 X2 … Xn σ
Figura 4 – Representação de um indivíduo com n variáveis reais; existe uma variável extra relacionada com a variância da distribuição gaussiana comandando as mutações que originarão a sua descendência.
Tal como numa estratégia (1+1)ES, na σSA-(1,λ)ES os parâmetros objecto são sujeitos a mutação tal que, partindo de uma geração g, os descendentes são gerados por
k~X = X(g) + Zk , k = 1 a λ
onde
( ) ( )[ ]t)1g(kk 1,0,...,1,0 ΝΝσ= +Z
Mas agora a taxa de mutação σ também é sujeita a mutação da seguinte forma
12

[ ])g()1g(k σΠ=σ +
O operador Π[.] realiza mutações multiplicativas. Isto pode conseguir-se pela multiplicação da taxa de mutação do progenitor por um número aleatório ξ tal que
)g()1g(k ξσ=σ + , k = 1 a λ
O valor esperado de ξ não deve desviar-se da unidade, ou seja,
E{ξ} ≈ 1
Há algumas distribuições da variável aleatória ξ que se podem usar na prática. Uma das mais importantes é a distribuição lognormal, cujo uso foi proposto originalmente por Schwefel, e que tem a propriedade de que um dado valor tem a mesma probabilidade de ser duplicado ou reduzido a metade:
2ln21
e12
1)(p⎟⎠⎞
⎜⎝⎛τξ
−
σ ξπτ=ξ
Em casos práticos, a variável aleatória ξ pode ser gerada a partir de uma Gaussiana N(0,1) – de valor médio 0 e desvio padrão 1 – por uma exponenciação da forma
)1,0(Neτ=ξ
Estas expressões introduzem um novo parâmetro externo τ, o factor de aprendizagem, a ser discutido em breve. O factor de aprendizagem τ condiciona a velocidade e precisão de uma estratégia adaptativa σSA. POR isso, importa ter resposta para a pergunta de como escolher bons valores para τ, o que é ainda tema de investigação.
Outro operador de mutação usado na prática depende de uma distribuição simétrica em que o valor mutado de σk(g+1) na
iteração g+1 é calculado por
( )( )⎪⎩
⎪⎨⎧
>β+σ≤β+σ=σ +
5.0)1,0(U se , 1/5.0)1,0(U se , 1
)g(
)g()1g(
em que U(0,1) é um valor amostrado a partir de uma distribuição Uniforme no intervalo [0,1].Vê-se que também esta distribuição depende de um parâmetro externo β, o qual às vezes também aparece na literatura sob a forma β+=α 1 .
Provou-se que, dados τ e β suficientemente pequenos, o efeito destes dois esquemas de mutação se torna comparável. Foi demonstrado que há uma equivalência entre as duas aproximações através da correspondência β−β=τ 1 , se τ for um valor pequeno.
2.8. Como escolher um bom valor para o factor de aprendizagem? Foi demonstrado, no modelo esférico que, como dissemos, é uma boa aproximação local, que grandes valores para β or τ deveriam ser evitados. O objectivo é encontrar um compromisso que conduza o algoritmo a um desempenho quase-óptimo, medido em termos da taxa de progressão em direcção ao óptimo. A regra de Schwefel estabelece que τ deve ser escolhido proporcional a n/1 , em que n é a dimensão do espaço de busca. Uma regra prática sugerida por Beyer [6] para uma estratégia (1,λ) ES é a seguinte:
Para , 10≥λ λ≈τ ,1cn
1
Para , 104 <λ<)2(
,12,1
,1
d21c2
c
n1
λλ
λ
−+≈τ
O parâmetro recebe o nome de coeficiente de progressão e é designado como coeficiente de progressão de segunda ordem [
λ,1c )2(,1d λ
7]. Eis uma tabela extraída de [6], calculada por integração numérica a pertir de um modelo teórico:
13

Coeficientes a adoptar numa estratégia (1,λ) ES λμ,c
λ λ,1c )2(,1d λ
2 0.5642 1.000 3 0.8463 1.2757 4 1.0294 1.5513 5 1.1630 1.8000 6 1.2672 2.0217 7 1.3522 2.2203 8 1.4236 2.3995 9 1.4850 2.5626 10 1.5388 2.7121 20 1.8675 3.7632 30 2.0428 4.4187 40 2.1608 4.8969 50 2.2491 5.2740 60 2.3193 5.5856 70 2.3774 5.8512 80 2.4268 6.0827 90 2.4697 6.2880 100 2.5076 6.4724 200 2.7460 7.7015 300 2.8778 8.4610
Abaixo de λ = 4, não se pode adoptar a segunda fórmula, porque leva a um resultado imaginário – deve-se usar um valor mais alto para do que o das linhas da tabela. Neste caso, o algoritmo σSA não se pode auto-adaptar de modo a conseguir uma taxa de progressão óptima, mas mesmo assim ainda produzirá uma auto-adaptacão da taxa de mutação.
λ,1c
Como conceito geral, convém dizer que há, de facto, um valor teórico para τ que maximiza a taxa de progressão. Todavia, esse máximo não é simétrico com respeito a τm e há um muito maior risco de degradação do desempenho do algoritmo quando se escolhe um valor de τ demasiado pequeno do que quando se usa τ > /λ,1c n .
Também, como seria de esperar, se observou um período transitório que antecede o estabelecimento de um regime permanente no progresso do algoritmo. A duração do transitório é proporcional a n. Isto não constitui um problema sério se a dimensão do problema não é muito grande, ou se n<200, o que é realista para grande parte dos problemas práticos.
A magnitude do factor de aprendizagem influencia a duração do período transitório, que é inversamente proporcional a τ2. Se τ for escolhido de acordo com a regra que o indica como proporcional a 1/ n , então a duração da fase transitória torna-se proporcional à dimensão do espaço n. Se n for muito grande, por exemplo n>1000, isto pode ser um problema sério e então parece aconselhável manter τ = 0,3 fixo durante um período inicial antes de começar a aplicar as regras acima indicadas.
A escolha do factor de aprendizagem de acordo com a regra de Schwefel conduz a uma progressão quase-óptima do algoritmo, uma vez terminada a fase transitória, exibindo então o algoritmo uma convergência de ordem linear. Há sempre flutuações e não é possível atingir o óptimo teórico da taxa de progressão do algoritmo apenas por manipulação de τ. Por isso, é interessante usar outros mecanismos, como conservar uma memória dos últimos valores das taxas de mutação de modo a seguir uma espécie de média móvel em vez de apenas o valor mais recente.
14

2.9. Extensão de (1,λ)ES para (μ,λ)ES O desenvolvimento natural das Estratégias de Evolução conduziu a modelos (μ,λ)ES, com (μ pais ≤ λ filhos). Nestas estratégias há uma população de μ indivíduos evoluindo no espaço dos parâmetros objecto; eles geram uma descendência de λ indivíduos pela escolha aleatória de um dos μ indivíduos e aplicando-lhe uma mutação, e repetindo esta operação λ vezes. Os μ indivíduos da geração seguinte são seleccionados entre os melhores do conjunto dos λ mutados – trata-se de uma estratégia elitista.
Beyer, em [8], desenvolveu trabalho teórico a fim de explicar a progressão de uma estratégia (μ,λ)ES como um mode4lo generalizado de (1,λ)ES. Conseguiu derivar uma fórmula para a taxa de progressão dependente de um simples parâmetro designado coeficiente de progressão. Abaixo reproduzimos a tabela incluída em [λμ,c 8] que dá indicação quanto ao valor a adoptar:
Coeficientes a adoptar para uma diversidade de estratégias (μ,λ) ES λμ,c
μ\ λ 5 10 20 30 40 50 100 200 300 1 1.16 1.54 1.87 2.04 2016 2025 2.51 2.75 2.88 2 0.92 1.36 1.72 1.91 2.04 2.13 2.40 2.65 2.79 3 0.68 1.20 1.60 1.80 1.93 2.03 2.32 2.57 2.71 4 0.41 1.05 1.49 1.70 1.84 1.95 2.24 2.51 2.65 5 0.00 0.91 1.39 1.62 1.77 1.87 2.18 2.45 2.60 10 0.00 0.99 1.28 1.46 1.59 1.94 2.24 2.40 20 0.00 0.76 1.03 1.20 1.63 1.97 1.15 30 0.00 0.65 0.89 1.41 1.79 1.99 40 0.00 0.57 1.22 1.65 1.86 50 0.00 1.06 1.53 1.75 100 0.00 1.07 1.36
Uma das consequências de se terem μ progenitores é que se podem conservar também μ parâmetros estratégicos distintos σ, cada um associado a um indivíduo e mutado de acordo com os procedimentos anteriormente explicados. Demonstrou-se, todavia, que esta estratégia (μ,λ)ES corre riscos de divergir e, portanto, Schwefel recomenda a adopção de estratégias elitistas, tal como conservar os melhores indivíduos de uma geração para a seguinte. Mas, se se adopta elitismo desta forma, porque não adoptar uma estratégia (μ+λ)ES, e conservar com naturalidade os melhores indivíduos no processo de selecção incluindo pais e filhos?
2.10. Auto-adaptação em σSA(μ,λ)ES A partir das ideias sugeridas pela estratégia σSA(1,λ)ES, algumas variantes foram experimentadas para um número de progenitores μ.
Numa estratégia σSA (μ,λ)ES, consideramos de novo a divisão entre parâmetros objecto (as variáveis do problema) e parâmetros estratégicos, os quais serão uma taxa de mutação σk associada a cada indivíduo k a ser mutado.
Os parâmetros objecto são mutados de acordo com
k~X = Xk
(g) + Zk , k = 1 to λ
em que
( ) ( )[ ]t)1g(kk 1,0,...,1,0 ΝΝσ= +Z
A fim de se conseguir uma taxa de progressão próxima da óptima, os parâmetros σk são mutados de acordo com
k0k0 zzk
zzkk eee~ +σ=σ=σ
15

Como o costume, o símbolo ~ indica uma variável mutada. De acordo com Schwefel [Error! Bookmark not defined.], os factores de mutação z deveriam ser dados por distribuições Gaussianas dependendo de factores de aprendizagem τ tais que
( )200 ,0Nz τ∈ ,
n21K22
0 =τ
( )2kk ,0Nz τ∈ ,
n21K22
k =τ
Para 1<μ<λ, n e λ grandes e μ não demasiado pequeno, pode-se observar uma relação fo termo K destas expressões com a taxa de progressão, tendo-se
μλ
μ≈ ln21K
Com probabilidades de mutação não correlacionadas, associadas a cada variável do problema, consegue-se que a evolução se adapte a uma função de adaptação que defina uma topologia anisotrópica no espaço das soluções. Porém, a pesquisa orienta-se muito como se fosse ao longo dos eixos coordenados do espaço, como ilustra a Figura 5.
X1
X2
Figura 5 – Ilustração do padrão de busca dependente de dois indivíduos em consequência de duas taxas de mutação afectando independentemente as duas variáveis de um problema hipotético
Isto pode ser reconhecido na seguinte função usada por Schwefel para teste [9]:
∑=
=n
1i
2ix.i)(F X
Note-se que cada variável está escalada diferentemente (devido ao produto por i). Neste problema, a auto-adaptação implica a aprendizagem da escala de n diferentes taxas de mutação σi.
Verificou-se que o esquema de auto-adaptação apresentava um êxito importante, com o exame dos resultados de uma série de experiências com uma estratégia σSA (μ.,100), fazendo variar μ entre 1 e 30. Para além disso, descobriu-se que o esquema de maior sucesso foi aquele em que μ = 12 e que valores inferiores ou superiores do número de indivíduos numa geração causavam perda da velocidade de convergência.
A interpretação dada foi a seguinte: para que a auto-adaptação funcione de forma eficiente, ela exige uma certa diversidade representada por um número de indivíduos. Para além disso, descobriu-se que ter λ>μ é importante, bem como estabelecer um limite ao número de gerações κ durante as quais um indivíduo pode sobreviver. Confirmou-se ainda que a aplicação de recombinação aos parâmetros estratégicos também contribuía para o êxito na obtenção de uma velocidade de convergência próxima do óptimo teórico.
16

3. PROGRAMAÇÃO EVOLUCIONÁRIA
3.1. A ponte (μ+λ) para a ES Em vês de uma estratégia (μ,λ)ES, podemos definir uma estratégia (μ+λ)ES. Neste caso, os μ progenitores de uma geração (g+1) são seleccionados de entre os μ indivíduos da geração (g) mais os seus λ descendentes criados por mutação. Em termos práticos, os valores dos parâmetros a adoptat são os mesmos que indicados para as estratégias (μ,λ)ES.
É interessante notar que uma estratégia (μ+λ)ES, com μ=λ, é semelhante e pode ser assimilada a algumas formulações da escola da Programação Evolucionária (EP). Há uma diferença entre ES e EP que é tradicionalmente apontada, mas que tem sido exagerada com a ideia de sustentar que as Estratégias e Evolução e a Programação Evolucionária são dois métodos separados - +e a foprma da selecção. Enquanto que na ES foi comum a adopção de uma selecção elitista (o melhor de cada geração é conservado para a geração seguinte), em EP a tradição consolidou-se à volta do uso de selecção por torneio estocástico.
O torneio estocástico mais simples é o T(1,2) e corresponde: a) à escolha, de forma aleatória, de pares de indivíduos; b) à comparação dos valores de adaptação de cada um dos indivíduos sorteados; c) à selecção, para sobreviver para a geração seguinte, do melhor, com uma dada probabilidade, em geral elevada mas diferente de 1. Isto é repetido tantas vezes quantas as necessárias até que se forme uma nova população de λ indivíduos mutados.
Outras variantes do torneio estocástico podem ser adoptadas, como um modelo T(m,n), ou seja, em que são escolhidos os melhores m indivíduos de um conjunto de n progenitores em cada geração.
O primeiro processo de torneio introduzido em EP em 1988 foi, porém, diferente. Pode ser descrito da seguinte forma: cada solução é levada a competir com uma colecção aleatória de indivíduos, de determinada dimensão. É atribuída uma vitória de forma probabilística, de acordo com uma dada fórmula. As soluções que consigam maior número de vitórias são seleccionadas para a geração seguinte.
Há, porém, modelos de EP em que a natureza probabilística da selecção é substituída por um processo puramente elitista. Por exemplo, pelo simples exame do valor de adaptação de todos os indivíduos e selecção dos melhores μ para formar a geração seguinte.
Em paralelo com a comunidade das Estratégias de Evolução, os seguidores da escola da Programação Evolucionária também desenvolveram um conceito de auto-adaptação. Aplicado à EP, este conceito mereceu o nome de meta-EP [10], em 1992. O processo de mutação governando a evolução do parâmetro de taxa de mutação em cada indivíduo, de uma geração g para uma geração g+1, é dado por
)g()1g( ξσ=σ +
onde ξ é um número aleatório dado por
( )1,01 Ντ+=ξ
e τ é o factor de aprendizagem, fixado externamente. Podemos observar que as mutações na taxa de mutação são ainda de carácter multiplicativo, tal como nas ES, enquanto as mutações nas variáveis do fenótipo são aditivas.
Acontece que o operador de mutação usado na EP, na variante designada como meta-EP, pode ser derivada do operador lognormal discutido para as ES em 2.5, tomando os termos lineares da expansão em série de Taylor, o que dá precisamente
( )1,01 Ντ+=ξ
O valor óptimo do factor de aprendizagem foi objecto de estudos empíricos e teóricos, Em muitos modelos de aplicações práticas verifica-se um processo de tentativa e erro na sua fixação, mas as conclusões derivadas p+ara as ES são perfeitamente aplicáveis na EP. Por isso, a meta-EP proposta por Fogel [11] , com a sua aproximação gaussiana, desde que τ seja suficientemente pequeno, pode englobar-se na classe de modelos (μ+λ) ES e exibe o mesmo tipo de desempenho.
3.2. Um esquema para a Programação Evolucionária Um modelo típico de EP, como em qualquer modelo de computação evolucionária, requer uma definição de uma função de adaptação e uma população de indivíduos. Cada indivíduo é representado pelas suas variáveis, nos respectivos
17

domínios naturais. Se uma solução exige a representação de aspectos estruturais ou topológicos, estes serão representados de forma tão natural quanto possível, nomeadamente por variáveis discretas.
As mutações agem directamente sobre os valores das variáveis de um indivíduo, ou solução de problema. AS variáveis reais são sujeitas a perturbações Gaussianas de valor médio zero, em cada geração. Isto significa que variações menores no valor das variáveis são altamente prováveis, enquanto que variações substanciais se tornam improváveis. O esquema Gaussiano, porém, não as impede.
Este procedimento permite que variáveis reais convirjam continuamente para o óptimo, evitando a natureza discreta de um código binário de representação genética. Por outro lado, a exploração de novas áreas no espaço das decisões fica sustentada em indivíduos que sofram importantes mutações. Para as variáveis discretas, muitas vezes associadas com aspectos estruturais ou topológicos dos problemas, as mutações obedecem a uma distribuição de Poisson para adições ou eliminações.
Eis um pseudo-código para um algoritmo de EP simples:
Procedure EP (BEGIN) Começar o contador de gerações g := 0; initializar uma população P Initpopulation P[g]; avaliar a adaptação de todos os indivíduos de uma população Evaluate P[g]; while not done do reprodução – duplicar a população P’ [g] := P [g] mutação - introduzir perturbações estocásticas na nova população incluindo o parâmetro estratégico σ [g] := Mutate ( P’ [g] ); P~ mutação - calcular a adaptação dos indivíduos Evaluate P [g];
~ selecção – dos sobreviventes com base em valor de adaptação e torneio estocástico P [g+1] := select ( P[g] ∪ [g] ); P~ Teste de implementação de critérios de terminação, etc. If test is positive then done := TRUE; Incrementar o contador de gerações g := g + 1; End while (End EP)
Observando esta peça de pseudo-código, vemos que a selecção age sobre um conjunto composto e pais e filhos – P[g] and P’[g].Isto ajuda a preservar os melhores indivíduos de modo a permitir a exploração de regiões prometedoras por “boas mutações”. No espírito original da Programação Evolucionária, o processo de selecção deveria ser baseado em torneio estocástico e os melhores indivíduos seleccionados para a geração seguinte apenas com dada probabilidade, em geral alta. Todavia, é também habitual encontrar, em aplicações de carácter prático e inovador, critérios de selecção determinística, ditos elitistas, em que o melhor é sempre seleccionado.
3.3. Outras variantes de Programação evolucionária Far-se-á justiça à EP se se mencionar que, para além de problemas com variáveis reais, os seus conceitos foram também aplicados a outros tipos de problemas. Historicamente, na verdade, os primeiros modelos de EP foram aplicados a algoritmos em evolução (máquinas) destinados a fazer a previsão de símbolos emergindo de uma sequência de símbolos. O trabalho de L.Fogel baseou-se em máquinas de 5 estados correndo experiências e Previsão, com uma população de dimensão 3 num processo do tipo (3+3)ES em que a população progenitora e descendente competiam entre si.
18

O facto e que uma linha importante da EP se dedicou a máquinas evolutivas levou a uma certa especialização da EP em variantes, técnicas e operadores realizando mutações, e esta é uma das fontes de percepção de que a EP se dedicou quase exclusivamente à mutação como motor de evolução. Na verdade, em muitos modelos de EP são usados vários operadores de mutação em simultâneo e em combinações complexas, adaptadas à aplicação concreta sob estudo. Neste texto não dedicaremos mais atenção a este tópico que, todavia, veio a produzir linhas de pesquisa extremamente frutuosas, nomeadamente em áreas de aprendizagem designadas como “machine learning”.
4. ASPECTOS COMUNS DA EP E DAS ES
4.1. Potenciando os processos de mutação Depois de terem experimentado uma taxa de mutação global e auto-adaptativa, e de terem definido um factor de aprendizagem global, os investigadores tentaram desacoplar as mutações num indivíduo, por forma a que as diversas variáveis de um problema pudessem seguir distintos esquemas evolutivos. Isto iplicou que, para cada indivíduo, não mais tivéssemos uma única taxa de mutação mas n taxas, uma para cada um dos n parâmetros objecto ou n variáveis do fenótipo.
Este esquema foi tentado com algum êxito. Recordando o modelo esférico, afirmámos que era uma boa aproximação local em muitos casos. Porém, estava implícita a assunção de uma isotropia topológica no espaço de busca. Ao se permitirem distintas taxas de mutação em distintos eixos coordenados (as variáveis do problema), esperava-se uma aproximação mais adaptada em regiões com uma topologia mais do tipo elipsóide. Um esquema com n taxas de mutação permite. Pois, um desacoplamento das taxas de mutação de acordo com os eixos coordenados do espaço das soluções. Em muitos casos, isto foi suficiente para acelerar os processos de meta-EP ou Ep auto-adaptativa.
Todavia, casos há em que se devem reconhecer correlações entre a evolução segundo alguma direcção e outras, sob pena de se ter uma progressão muito lenta do algoritmo ou mesmo divergência.
O esquema original com apenas uma taxa de mutação por indivíduo assumia uma evolução num espaço isotrópico – em que o comprimento R de um vector R, ou ||R||, é dado por ||R|| =RtR. O desacoplamento das várias taxas de mutação é equivalente a admitir uma métrica diagonal no espaço de busca. Isto está ilustrado na Figura 5.
As ES também reconheceram a existência de correlação entre mutações como variáveis estratégicas. Isto equivale a definir uma métrica de Mahalanobis no espaço de pesquisa – o comprimento de um vector R é dado por ||R|| = RtTR, onde T é uma matriz cheia. A Figura 6 procura ilustrar o efeito de se ter covariâncias não nulas entre variáveis exprimindo mutações, permitindo a exploração do espaço segundo direcções não alinhadas com os eixos coordenados.
As ES adoptam um modelo matemático formal para representar as possíveis covariâncias da função de distribuição das mutações em distintas direcções do espaço. O conceito básico é o de “ângulo de inclinação α” – o qual permite a definição de correlações linearmente dependentes em mutações das variáveis objecto.
X1
X2
α
Figura 6 – Ilustração do processo de pesquisa para dois indivíduos exibindo diferente correlação entre variáveis. O ângulo α é tomado como variável estratégica suplementar, sujeita a mutação (e recombinação).
19

Dado um ângulo αj, pode definir-se uma matriz básica de covariâncias entre direcções p e q pela matriz de transformação T, onde apenas as colunas p e q têm elementos distintos de 0 e 1:
( )
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
αα
α−α
=α
1000...
0100cossin
10...
01sincos
...00100001
jj
jj
pqT
O produto de todas as matrizes Tpq de acordo com todas as combinações de p e q dá a matriz C de covariância. Isto permite o cálculo de uma mutação X~ a partir de um indivíduo X dada por
CZXX +=~
onde Z = (z1,…,zn) e . O vector CZ é, pois, um vector aleatório com componentes exibindo distribuição gaussiana e correlação entre componentes dada em função dos αi e dos σi.
),0(Nz 2ii σ∈
As variáveis que podem gerar as correlações ou covariâncias (dando valores não nulos para os elementos fora da diagonal principal de C) são os ângulos de inclinação α; pode facilmente ver-se que, se estes ângulos forem todos fixados em 0 graus, todas as matrizes Tpq ficam reduzidas a matrizes identidade e, portanto, as mutações se desenvolverão independentemente em cada direcção coordenada do espaço. Estes ângulos α correspondem, portanto, a variáveis estratégicas que podem ser também mutadas, originando um processo auto-adaptativo.
Em suma, para estabelecer mutações correlacionadas, procede-se passo a passo:
1. mutando os σi
2. mutando os αk
3. calculando a aplicando a matriz C oara se gerar um novo indivíduo mutado
Os ângulos αk devem ser mutados de acordo com
),0(Nz com z~ 2kkkk β∈+α=α
Os valores de β a utilizar derivam de ensaios experimentais, e Schwefel [Error! Bookmark not defined.] recomendou 5º ou 0,0873 rad como valor que conduz a bons resultados na prática.
Ainda se pode acrescentar que em EP não é raro que sejam usados vários operadores de mutação em simultâneo. A escolha ou os efeitos são regulados por probabilidades que podem manter-se constantes ou variar de geração para geração [12].
4.2. A recombinação como factor principal Até ao momento, apenas discutimos a mutação como factor de progresso num processo evolucionário. Todavia, este é um ponto de vista incorrecto ou, pelo menos, incompleto. Na verdade, a recombinação joga um papel importante e mesmo dominante na aceleração do progresso em direcção ao óptimo e robustece as hipóteses de êxito do processo de busca.
A ideia de recombinação esteve já presente nos primeiros trabalhos de L.Fogel [13], quando uma geração de descendentes de máquinas de estados finitos em evolução era produzida por um mecanismo desse tipo. Na comunidade das ES, a ideia foi adoptada mais tarde, especialmente para problemas de variáveis reais. Na comunidade da EP, nomeadamente neste tipo de problemas, a recombinação foi praticamente esquecida até muito recentemente.
20

Esta distinção entre ES e EP (o uso de recombinação) está registada, por exemplo, no "Glossary - Evolutionary Algorithms - Terms and Definitions", disponível on line na Internet (http://ls11-www.cs.uni-dortmund.de/people/beyer/EA-glossary/) e organizado por H.G.Beyer e outros pesquisadores alemães.
Usando a notação proposta por Schwefel e Rechenberg, que temos adoptado até agora, vamos agora definir estratégias do tipo (μ/ρ,λ)ES. Nesta variante, o parâmetro ρ define o número de progenitores que se combinam para formar um novo indivíduo. As modelos biológicos comuns baseiam-se em ρ=2, mas quando construímos uma Estratégia de Evolução ou organizámos uma Programação Evolucionária não necessitamos de ficar limitados a esta opção e podemos experimentar estratégias com ρ>2.
Recombinação é uma palavra que designa um número de procedimentos cujo efeito é construir uma solução a partir de um conjunto de outras. Eis alguns esquemas de recombinação que têm sido usados em ES:
Cruzamento uniforme – nesta variante, o valor de cada variável no novo indivíduo a formar é obtido por selecção aleatória de um dos pais para “doar” o seu valor respectivo. Quando ρ=2, é tradicional gerar-se uma sequência de bits de comprimento igual ao número de variáveis de uma solução e depois usar-se essa sequência para comandar a recombinação: se o bit tiver valor 1, o valor provém do primeiro pai e se tiver valor 0 será o segundo pai a fornecer o valor da variável.
Recombinação intermediária – nesta variante, o valor de uma variável do descendente recebe uma contribuição de cada progenitor. Isto pode resultar seja de uma média dos valores de todos os pais (recombinação intermediária global) seja de uma média de um subconjunto aleatório dos pais (recombinação intermediária local). Em qualquer destes casos, é possível ainda escolher entre uma média simples e uma média pesada em que os pesos são definidos de forma aleatória. No caso de ρ=2, podemos ter o valor de uma variável dado por
2j,kk1j,kknewk x)u1(xux −+=
onde os índices j1 e j2 se referem a dois progenitores e uk é sorteado de uma distribuição uniforme em [0,1].
Cruzamento pontual – nesta variante, semelhante à adoptada em algoritmos genéticos canónicos, sorteiam-se em primeiro lugar γ (<n – nº de variáveis) pontos de cruzamento, que separam todos os progenitores em partes, e depois o descendente recebe sucessivamente uma parte de cada progenitor.
A experimentação demonstrou o poder da recombinação em acelerar fortemente a progressão dos algoritmos em direcção ao óptimo. Por isso, desenvolveu-se um esforço de tentativa de construção de explicações teóricas para tal.
Na comunidade dos Algoritmos Genéticos ganhou notoriedade a teoria dos Blocos Construtivos (Building Blocks). Ela basicamente sustenta que a recombinação permite que bons blocos dorieundos de cada pai se juntem num descendente que, por isso, fica melhorado. Mas, na comunidade das ES, outras modelizações matemáticas permitiram que visões distintas emergissem. Beyer, por exemplo, argumenta em sentido contrário [14], baseado no seu conceito de taxa de progressão: ele sugere que a recombinação age como um mecanismo de “reparação genética”, compensando os efeitos disruptivos da mutação. Em função disso, com a recombinação torna-se possível usar valores maiores de taxa de mutação e conseguir taxas de progressão melhores.
Para além disto, sob alguns pressupostos, Beyer também demonstrou que o impulso mais forte fornecido pela recombinação ara obtido quando todos os μ indivíduos de uma geração davam uma contribuição para formar um novo indivíduo. Ele justificou esta afirmação com uma demonstração matemática e chamou ao seu modelo uma estratégia (μ/μ,λ)ES. A recombinação, portanto, desempenha um papel fulcral nas modernas Estratégias de Evolução e não é uma técnica secundária.
4.3. Restrições Ao contrário dos Algoritmos Genéticos, as ES ou a EP permitem cuidar de restrições de uma forma muito natural. Como cada solução é codificada nas suas variáveis naturais ou fenotípicas, é em geral bastante fácil forçar o respeito pelas restrições que um problema possa ter.
Um processo de conseguir isso é durante a fase de mutação – de cada vez que um novo indivíduo é formado por mutação, pode ser analisado e se não for viável pode ser descartado, gerando-se novas mutações sucessivamente até que se encontre um indivíduo viável. Muitas vezes, durante a fase de mutação, a própria produção de mutações pode ser condicionada de modo a evitar que qualquer descendente viole restrições e seja, portanto, inviável. Este era, aliás, o esquema original das ES para lidar com restrições – mas pode revelar-se um método muito consumir«dor de tempo de computação.
21

A outra possibilidade (a só usar em caso de o método anterior não ser prático ou possível) é lidar com as restrições durante a fase de selecção, atribuindo um baixo valor de adaptação aos indivíduos que violam restrições. Isto pode ser conseguido através da aplicação de regras simples ou pelo estabelecimento de penalidades, eventualmente de gravidade proporcional à importância da violação.
4.4. Arranque do processo Para dar início a um processo obedecendo a uma Estratégia de Evolução, torna-se necessário gerar uma população inicial de μ indivíduos. Isto pode ser feito tipicamente de duas maneiras:
Sorteando aleatoriamente coordenadas para os μ indivíduos, ou
Gerando mutações a partir de um indivíduo funcionando como semente.
Foi tradicional na comunidade das ES garantir que na primeira geração todos os indivíduos fossem viáveis. Porém, esta condição não é verdadeiramente necessária se um método adequado de lidar com restrições e aplicar penalidades for adoptado.
4.5. Função de adaptação A função de adaptação corresponde em geral à própria função objectivo do problema em resolução. A esta função podem adicionar-se penalidades para representar a violação de restrições. Este é um procedimento adoptado em todas as variantes da Computação Evolucionária.
Uma forma simples e todavia por vezes efectiva de adicionar o efeito da violação de restrições, num problema de maximização, é contar o número de restrições violadas ou somar os valores dos desvios, e atribuir um valor de adaptação de acordo com a seguinte regra:
Se nenhuma violação ocorrer, Adaptação (X) = F(X)
Se ocorrem violações, Adaptação (X) = - Σ violações i, i ∈ conjunto das restrições
4.6. Computação Podem encontrar-se diversas fontes de onde obter software permitindo a implementação de Estratégias e Evolução. Mencionam-se seguidamente alguns exemplos que facilitarão uma pesquisa na Internet.
Uma fonte bem conhecida é evoC, disponível a partir do Bionics and Evolution Department da Technical University de Berlin, Alemanha – é uma aplicação escrita em C que pode ser usada numa variedade de plataformas, de MS-DOS a LINUX. É gratuita mas não é de domínio público, e até recentemente podia ser obtida de ftp://ftp-bionic.fb10.tu-berlin.de sob o directório /pub/software/evoC.
Há um conjunto de ferramentas em MATLAB com interfaces amigáveis desenvolvidas na Universidade de Magdeburgo, Alemanha, que podem ser pedidas a [email protected], Dr. Bihn.
Há também um conjunto de programas com bastante interesse didáctico que foram desenvolvidos e estão disponíveis a paertir do servidor de ftp da Universidade Técnica de Berlim, em ftp://ftp-bionic.fb10.tu-berlin.de. Estas demonstrações estão também disponíveis na Internet e são suportadas por um relatório técnico [15] disponível no mesmo servidor.
GAGS é uma biblioteca de domínio público de aplicações de computação evolucionária orientadas a objectos e apesar de poder ser usada para modelos de GA também pode servir para outros paradigmas como ES/EP. Pode ser consultado em http://kal-el.ugr.es/gags.html.
Uma biblioteca de dimensão razoável de algoritmos evolucionários escritos em Java 1.3 está disponível no site da EvaLife na Dinamarca, http://www.evalife.dk/. Merece ainda referência a EvoWeb - http://evonet.dcs.napier.ac.uk/ - a Rede de Excelência Europeia em computação evolucionária.
5. CONCLUSÕES As Estratégias de Evolução designam uma vasta família de algoritmos evolucionários que têm em comum uma representação fenotípica dos problemas, ou seja, a representação das soluções no espaço das variáveis naturais do problema, em vez de recorrer a codificações, nomeadamente binárias, adoptadas nos Algoritmos Genéticos.
A Programação Evolucionária foi desenvolvida independentemente e as duas escolas, alemã e americana, eventualmente convergiram, em particular no que se refere a problemas com variáveis reais.
22

Há um corpo teórico substancial justificando o êxito das Estratégias de Evolução e da Programação Evolucionária que dá indicações quanto ao modo como sintonizar os algoritmos para se obter a máxima eficiência, medida pela taxa de progressão em direcção ao óptimo. Verifica-se que os modelos que repousam apenas em mutação são, neste aspecto, mais limitados do que os que recorrem também a recombinação, para gerar novos indivíduos.
A teoria e a experiência também sugerem que as melhores estratégias usam um número de pais μ que dão origem a um número de descendentes λ maior (λ>μ), e que processos de recombinação generalizados, usando todos os μ pais para gerar um descendente, oferecem as melhores taxas de progressão.
Finalmente, parace estar demonstrado que os esquemas auto-adaptativos são habitualmente muito eficientes e oferecem as melhores possibilidades de descobrir o óptimo absoluto enquanto que taxas de mutação controladas externamente, ainda que permitindo em casos especiais progressos rápidos em direcção ao óptimo, oferecem também mais elevados riscos de aprisionar o problema em óptimos locais.
23

CAPÍTULO II
ENXAMES DE PARTÍCULAS (PSO) E ENXAMES EVOLUCIONÁRIOS (EPSO)
6. INTRODUÇÃO Os algoritmos evolucionários tiveram a sua inspiração nos processos biológicos da evolução das espécies. Já as redes neuronais também haviam sido uma réplica de fenómenos biológicos com assinalável êxito. Não admira que outros pesquisadores passassem a observar a natureza e a ganhar inspiração para conceberem novos métodos e técnicas.
Em anos recentes, emergiram novas concepções de meta-heurísticas e todas se inspiraram em fenómenos naturais. A mais antiga foi a de simulated annealing, com analogia na formação de cristais. Posteriormente foram propostas as colónias de formigas, com paralelismo na forma como as formigas obreiras descobrem e optimizam as suas trilhas em busca de comida.
Neste texto trataremos dos enxames de partículas, cuja inspiração deriva da observação do comportamento de enxames de insectos, bandos de pássaros, cardumes de peixes ou outros grupos, em que o comportamento de cada indivíduo é em simultâneo influenciado por factores próprios e por factores (ditos sociais) que resultam do comportamento dos restantes.
A optimização por enxame de partículas (PSO – perticle swarm optimization) é relativamente recente. Deve-se à iniciativa de James Kennedy e Russel Eberhardt [16] e veio a mostrar-se competitiva relativamente a outras meta-heurísticas. A PSO trabalha com um conjunto de soluções de um problema a optimizar, que designa como partículas, que evoluem no espaço das alternativas.
Estas partículas movem-se sob acção de três influências (vectores) que se compõem aditivamente, e que recebem os coloridos nomes de hábito ou inércia, memória e cooperação. O primeiro vector impele a partícula numa direcção idêntica à que ela vinha seguindo. O segundo vector atrai a partícula na direcção da melhor posição até ao momento ocupada pela partícula durante a sua vida. O terceiro vector atrai a partícula na direcção do melhor ponto do espaço até ao momento descoberto pelo enxame.
Na PSO, ao contrário dos algoritmos evolucionários, não há competição entre partículas ou auto-adaptação das suas características. Na verdade, se não fosse o termo de cooperação, cada partícula ignoraria olimpicamente as outras. Por outro lado, desde o início os seus promotores se deram conta da necessidade de introduzir controlos no comportamento dos enxames, quer para incrementar a eficiência da busca quer para evitar divergência do enxame. Estes controlos têm sido, nas mais das vezes, aplicados externamente, com base em receitas empíricas, e só muito recentemente começaram a testar-se algumas ideias de auto-adaptação.
A ideia da auto-adaptação já havia sido testada com sucesso nos algoritmos evolucionários, e ela inspirou uma nova proposta de família de algoritmos, os Enxames Evolucionários (EPSO – Evolutionary Particle Swarm Optimization).
Os algoritmos do tipo EPSO podem, efectivamente, ser olhados como sendo ainda enxames de partículas. Todavia, com alguma vantagem poderão perceber-se em vez disso como algoritmos evolucionários do tipo das Estratégias de Evolução auto-adaptativas ou σSA(.)ES, em que há uma nova definição da operação mutação.
Os EPSO foram pela primeira vez propostos em 2002 [17], como método verdadeiramente auto-adaptativo. Antes desta discussão, é de justiça referirem-se outras tentativas de construção de pontes entre os PSO e os algoritmos evolucionários, como em [18], ou a tentativa de dar um carácter adaptativo a algoritmos do tipo enxame, como em [19].
24

7. A OPTIMIZAÇÃO POR ENXAME DE PARTÍCULAS (PSO)
7.1. O modelo simples A PSO tem sido apresentada como ilustrando o movimento de um conjunto de partículas explorando o espaço das decisões ou soluções, de dimensão n de acordo com o número de variáveis do problema. O modelo simples de PSO vem descrito seguidamente.
Cada partícula corresponde a uma alternativa de solução para um dado problema de optimização. Dada uma população de n partículas, cada partícula i tem a seguinte composição:
o Um vector de posição Xi
o Um vector de velocidade Vi
o Um vector de memória bi da melhor posição encontrada durante a sua vida
o Um valor de função objectivo relativo à posição actual Xi
o Um valor de função objectivo relativo à melhor posição bi encontrada pela partícula
Num dado instante de tempo t (correspondendo a uma dada iteração), uma partícula i muda a sua posição de Xi para de acordo com a seguinte regra: novo
iX
novoii
novoi VXX +=
em que é a nova velocidade da partícula i, ou seja, o vector representando a mudança de posição da partícula i, e é dada por
novoiV
)(().Rnd)(().Rnd iGiiiiinovoi XbWcXbWmVV −+−+=
onde
Wmi – matriz diagonal de pesos do termo de memória da partícula i, em que o elemento é o peso para a dimensão k do termo de memória
ikkWm
Wci – matriz diagonal de pesos do termo de cooperação da partícula i, em que o elemento é o peso para a dimensão k do termo de cooperação
ikkWc
bi - melhor solução (posição no espaço) encontrada na história da vida da partícula i
bG – melhor solução (posição no espaço) encontrada pelo enxame até ao momento
Rnd() – números aleatórios sorteados de uma distribuição uniforme em [0,1]
Na Figura 7 apresenta-se uma ilustração da composição dos vários termos resultando no movimento de uma partícula i no espaço das soluções.
Inércia
Memória
Cooperação
Xi
XiNovo
Figura 7 – Ilustração do movimento de uma partícula i, influenciado pelos três termos de inércia, memória e cooperação.
25

Os pesos afectando os vários termos são afectados em cada iteração pelo produto por números aleatórios, o que provoca uma perturbação na trajectória de cada partícula que se demonstrou ser benéfica para a exploração do espaço e a descoberta da solução óptima.
Os pesos, neste modelo simples, são definidos inicial e externamente. Suscita-se, de imediato, um problema de sintonização destes pesos para que a convergência seja conseguida.
As velocidades V iniciais são sorteadas com cada componente num intervalo [-VkMax , Vk
Max], para evitar a atribuição de valores excessivos que poderiam causar divergência. As velocidades durante o processo também
No seu artigo referenciado em [20], Kennedy identificou 4 tipos de PSO com base na manipulação dos pesos:
o Modelo completo – com Wm, Wc >0
o Modelo cognitivo – com Wm > 0 e Wc = 0
o Modelo Social – com Wm = 0 e Wc > 0
o Modelo não egoísta (selfless) – com Wm = 0 , Wc > 0 e G ≠ i
Para uma definição de uma PSO é necessário ter em conta alguns aspectos ainda, a saber:
o Controlo das velocidades – definir o melhor valor para VMax
o O tamanho do enxame – definir o número n de partículas adequado
o O valor dos pesos – definir um conjunto de pesos adequado
o Actualização síncrona ou assíncrona – definir se cada partícula é atraída pelo mais recente óptimo global ou se a actualização do óptimo corrente se faz apenas no final de um movimento de todas as partículas (uma iteração)
7.2. Controlando a convergência As experiências com a PSO simples rapidamente mostraram que, se o método parecia ter propriedades interessantes em convergir para a zona do óptimo, apresentava imensas dificuldades em afinar essa convergência, fundamentalmente porque a velocidade das partículas continuava excessiva quando se pretendia que ela se suavizasse para que aquelas pudessem ir-se aproximando cada vez com maior precisão do ponto óptimo.
Rapidamente se compreendeu que seria útil conceber um mecanismo que fosse gradualmente reduzindo a velocidade das partículas, à medida que estas se aproximassem da solução final. Dois mecanismos essenciais foram experimentados:
a) A aplicação de uma função decrescente no tempo (ou seja, com o avanço das iterações) afectando o termo de inércia
b) A aplicação de coeficientes redutores do movimento, designados coeficientes de constrição.
A aplicação de uma função afectando o termo de inércia conduz ao seguinte modelo da equação das velocidades:
)(().Rnd)(().Rnd).t(Dec iGiiiiiinovoi XbWcXbWmVWiV −+−+=
onde Dec(t) corresponde a uma função decrescente e Wii é um peso afectando o termo de inércia do movimento.
A aplicação de um coeficiente de constrição conduz ao seguinte modelo, para cada coordenada k:
[ ])Xb(Wc().Rnd)Xb(Wm().RndVKV ikGkikikikikikknovoik −+−+=
em que K é o coeficiente de constrição, definido da seguinte forma:
k2kk
kW4WW2
2K−−−
= , kkk WcWmW += , 4Wk ≥
26

8. EPSO – ENXAME DE PARTÍCULAS EVOLUCIONÁRIO
8.1. Uma visão crítica da PSO sob o paradigma das estratégias de evolução Embora os criadores e adeptos da PSO adoptem um vocabulário colorido, com expressões como “voar”, “velocidade”, “trajectória do movimento”, é possível olhar para o método com a perspectiva dos algoritmos evolucionários. Neste sentido, podemos continuar a falar de função de adaptação, de uma população (em vez de enxame), de indivíduos (em vez de partículas), e em vez de movimento de partículas de iteração para iteração podemos falar de criação de novos indivíduos de geração para geração.
Nas ES, uma nova geração de indivíduos é produzida pela aplicação de um operador de reprodução que combina sub-operadores de recombinação e mutação. O objectivo destas operações é criar novas soluções, explorando o espaço das alternativas. Porém, estas operações são neutras, isto é, só por si não resultam em nenhum processo de busca orientado e conduzem apenas a um processo de pesquisa aleatória. O êxito das ES reside na acção do operador de selecção sobre os novos indivíduos criados, tendo como efeito que a adaptação média em cada geração vai melhorando.
Olhando para a PSO como um algoritmo evolucionário, que vemos? Constatamos que, em vez de recombinação+mutação, adopta um operador, que designaremos por equação do movimento, para regular a criação de novos indivíduos em diferentes localizações no espaço; e que o operador selecção é trivial, ou neutro, toda a vez que todos os descendentes de uma geração são aceites em substituição da geração anterior.
O esquema da PSO funciona porque o operador de criação de novos indivíduos introduz um factor de progressão em direcção ao óptimo de tal forma que a média de cada geração também tende a ser melhor que a anterior. Isto é evidência empírica, pois ainda não se pode afirmar que exista um modelo matemático explicativo segundo esta perspectiva.
Olhando para a PSO, observamos que cada indivíduo (partícula) pode ser representado por parâmetros objecto (as variáveis do problema) e parâmetros estratégicos (os pesos, definindo a estratégia reprodutiva de cada partícula).
No processo de produzir descendência de uma população de partículas, num dado momento, a solução clássica da PSO introduz variações nos parâmetros estratégicos,
• por aplicar uma função decrescente no tempo ao peso da inércia, e aplicar mutações, reguladas por números aleatórios de distribuição uniforme, aos pesos dos termos de memória e cooperação
• ou por aplicar um factor de constrição que afecta os pesos em cada iteração.
Isto significa que a PSO depende fortemente de esquemas de controlo que são impostos do exterior, que têm que ser definidos heuristicamente e com base em erro e tentativa. O problema de qualquer esquema externo de controlo de um algoritmo, todavia, é que dificilmente é flexível e igualmente eficiente em todas as situações e em todas as classes de problemas. É intuitivo, por exemplo, que, se o termo de inércia for eliminado precocemente, o algoritmo corre o riso de ficar apanhado num óptimo local. Para evitar este problema, alguns autores propuseram esquemas de “criação” de novas partículas de forma disseminada no espaço de busca.
8.2. Os Enxames Evolucionários como estratégia auto-adaptativa Se os pesos afectando os termos da equação do movimento são os parâmetros estratégicos que condicionam a eficiência do processo de reprodução, um esquema auto-adaptativo deve incluir um mecanismo de selecção desses pesos de modo a conferir a melhor eficiência possível ao algoritmo na progressão para o óptimo.
Essa é a ideia matriz dos métodos EPSO – Enxame Evolucionário de Partículas (Evolutionary Particle Swarm Optimization).
Numa dada iteração, tomemos um conjunto de alternativas, ou indivíduos, que poderemos também continuar designando por partículas. Um indivíduo é constituído por um conjunto de parâmetros objecto e parâmetros estratégicas [X, W]. O esquema geral do EPSOé
REPLICAÇÃO – cada partícula é replicada (clonada) r-1 vezes
MUTAÇÃO – cada clone sofre mutação nos seus parâmetros estratégicos W
REPRODUÇÃO – cada partícula gera 1 descendente de acordo com a equação do movimento
AVALIAÇÃO – cada descendente te a sua adaptação avaliada
SELECÇÃO – por torneio estocástico (ou elitismo) a melhor partícula de cada grupo de r descendentes de cada indivíduo da geração anterior é seleccionada para formar uma nova geração.
27

Temos, portanto, dado um enxame de p partículas, um processo que se poderia definir como p×σSA(1,r)ES: cada partícula gera r descendentes e destes só 1 sobrevive. O processo segue em paralelo para todas as p partículas mas mantém-se um acoplamento entre elas por via do termo de cooperação que condiciona a formação de novas partículas.
A regra do movimento no EPSO é a seguinte: dada uma partícula Xi, uma nova partícula é criada a partir de newiX
novoii
novoi VXX +=
)()( iGiiiiiinovoi XbWcXbWmVWiV −+−+=
Esta formulação parece idêntica à PSO clássica – a regra do movimento conserva os seus termos de inércia, memória e cooperação. Todavia, os pesos, tomados como parâmetros estratégicos, são objecto de mutação. O esquema básico é o seguinte, para qualquer peso W
[ ]τ= )1,0(LogNWW~ ikik
onde
LogN(0,1) é uma variável aleatória com distribuição Lognormal derivada da distribuição Gaussiana N(0,1), de média 0 e variância 1;
τ é um parâmetro de aprendizagem, fixado externamente, controlando a amplitude das mutações – valores mais pequenos conduzem a maior probabilidade de valores próximos de 1
A distribuição Lognormal é classicamente adoptada para parâmetros estratégicos, nas ES, porque, nesta forma multiplicativa de mutação. A probabilidade de se obter um novo valor multiplicado por m é a mesma que a de ter um valor multiplicado por 1/m.
Um esquema aproximado e aceitável é o seguinte:
[ ])1,0(N1WW~ ikik τ+=
desde que τ seja suficientemente pequeno e que o resultado seja controlado de modo a não aparecerem pesos negativos. Este esquema é preferível a mutações aditivas do tipo
)1,0(NWW~ ikik τ+=
porque neste caso o valor da mutação é insensível ao valor de W. Na verdade, as mutações de tipo multiplicativo são as mais comuns, nas Estratégias de Evolução, quando afectando as variáveis estratégicas.
Uma diferença interessante em relação à PSO clássica é o tratamento dado a bG, o óptimo global corrente (o melhor ponto encontrado até ao momento pelo enxame). A ideia é controlar a “dimensão” de uma zona difusa em volta do óptimo corrente encontrado pelo enxame. Na verdade, em muitos processos verifica-se que nas fases finais o peso do termo de inércia tende a reduzir-se, ficando a progressão essencialmente dependente do termo de cooperação. Ora, admitindo-se que o óptimo ainda não foi encontrado, parece óbvio que poderá ser interessante orientar o movimento das partículas para uma vizinhança do óptimo corrente, em vez de as atrair para ele. Deste modo, dado um óptimo corrente encontrado pelo enxame bG, perturba-se esta informação por
)1,0(Nw*4ig
*g += bb
antes de se aplicar a regra do movimento. Esta expressão introduz um novo peso Wi4 que também deverá ser objecto de mutação e selecção, tal como qualquer dos outros parâmetros estratégicos.
Com este procedimento, o processo auto-adaptativo pode focar mais ou menos a orientação de um enxame e permite que este continue a ser “agitado” mesmo quando as partículas já convergiram todas para a mesma região do espaço e se acham muito próximas.
28

Inércia
Memória
Cooperação
Xi (k)
Xi (k+1)
bG
Vi (k
bi
Figura 8 – Ilustração da reprodução de uma partícula no EPSO. Uma partícula i localizada em X, numa iteração (k), origina um descendente na iteração (k+1), sob a influência dos três termos de inércia, memória e cooperação. Relativamente a este último termo, a atracção efectua-se para uma vizinhança definida por uma distribuição Gaussiana do óptimo corrente bG.
8.3. Os méritos do EPSO Estabelecido o algoritmo, cumpre dizer de imediato que o seu comportamento, comparado com os modelos de PSO clássicos, é muito satisfatório. Que razões poderão justificar esse bom desempenho?
O motivo principal parece residir no facto de que, no EPSO, duas operações sucessivas contribuem para uma progressão em direcção ao óptimo: a mutação/recombinação, traduzida na regra do movimento, e a selecção – enquanto que nos métodos evolucionários ou de PSO clássicos apenas um dos operadores contribui para a progressão.
Na verdade, relativamente às ES existe um sólido corpo teórico explicativo de como as ES conseguem convergir e como se atinge uma taxa de progressão quase óptima [21] – e esta explicação repousa nas propriedades do operador selecção, agindo sobre as populações. Por outro lado, as explicações teóricas sobre as razões do sucesso da convergência na PSO repousam em equações diferenciais de movimento (na nossa leitura, de criação sucessiva de novos indivíduos) que pressupõem não existir selecção.
Os EPSO, ao combinar os dois mecanismos com êxito, evita também a introdução de mecanismos reguladores externos, graças às suas características de auto-adaptação. É evidente, como também já decorria das ES, que alguns parâmetros externos têm sempre e inevitavelmente que ser fixados. O que importa notar é que eles são largamente estáveis e que tudo o mais se processa por auto-ajuste, fazendo com que o algoritmo “aprenda” quais os valores numéricos dos pesos que asseguram melhor progressão para o óptimo.
Dadas estas características, poderá já não ser tão surpreendente que o EPSO se tenha revelado como uma meta-heurística robusta, e muito mais robusta que a PSO clássica.
A robustez do algoritmo, nesta classe de meta-heurísticas, tem a ver com a garantia (probabilística) de que, independentemente da inicialização, o algoritmo irá convergir para o óptimo ou sua vizinhança. Ela pode avaliar-se, por exemplo, em casos de teste, determinando experimentalmente a distribuição dos resultados numa amostra de casos de um mesmo problema com inicializações aleatórias. Importará, nesta avaliação, determinar não só quão próximo fica o resultado médio do óptimo real como também qual a variância do resultado, ou melhor, qual o valor médio quadrático do desvio em relação ao melhor resultado. É evidente que métodos que resultem num resultado de qualidade e com desvio médio muito pequeno são preferíveis a outros que apresentem grande desvio ou variância, mesmo que o melhor resultado conseguido até seja superior.
Isto porque, numa aplicação real, não se espera que o algoritmo seja corrido cem ou mil vezes sobre o mesmo problema – espera-se efectuar apenas uma corrida e confiar no resultado. É precisamente esta confiança no resultado que é medida pelo nosso conceito de robustez – espera-se que o algoritmo, se corrido várias vezes, dê sempre um bom resultado com muito pequenos desvios da solução apresentada.
As experiências efectuadas com o EPSO em vários domínios parecem confirmar que o EPSO é um algoritmo robusto, pelo menos mais do que abordagens clássicas de PSO ou de ES.
29

9. EXPERIÊNCIAS COM O EPSO
9.1. O modelo básico O EPSO não é um algoritmo simples mas uma família de algoritmos. As características do seu modelo básico são:
a) Cada partícula só é clonada uma vez, resultando na existência de dois clones- o original e o novo (r=2)
b) Cada clone vê os seus pesos mutados
c) Os clones são deslocados (novas localizações – reprodução)
d) A selecção actua sobre cada conjunto de descendentes de clones por forma a preservar o de melhor desempenho (elitismo)
Neste modelo fica preservada uma certa “história” de cada partícula. Na verdade, é como se cada partícula estivesse submetida a uma processo evolucionário do tipo σSA(1,2)ES; só que, como o processo é repetido para cada uma das p partículas, temos como que um processo paralelo p×σSA(1,2)ES.
O que faz com que estes p processos não sejam independentes é o termo de cooperação. Por isso podemos pensar que a processo reprodutivo do EPSO é uma espécie de recombinação indirecta, mais do que uma mutação. Uma mutação apenas tem em conta as características próprias de um indivíduo, enquanto que uma recombinação envolve mais do que um indivíduo. Ora o termo bG resulta, de facto, na influência de um indivíduo especial (o que encontrou o óptimo corrente) nos restantes, alterando a composição fenotípica da sua descendência. Portanto, a regra do movimento é uma espécie de rocombinação intermediária.
9.2. O EPSO em funções teste Na investigação operacional há muito que se estabeleceram funções teste para pôr à prova os diversos algoritmos. Nos parágrafos seguintes mostraremos como o EPSO se revelou de superior desempenho face a uma PSO clássica.
Os testes foram conduzidos em funções “difíceis” como as de Schaffer, Rosenbrock, Sphere ou Alpine, conduzindo em todos os casos a um melhor desempenho do EPSO. Parte destes resultados estão descritos em diversas publicações [22][23]. Em geral, as conclusões extraídas de ensaios de 100 corridas com inicialização aleatória são as seguintes:
o O EPSO é mais rápido a convergir
o O EPSO é mais exacto (a média dos resultados do EPSO é superior à média do PSO)
o O EPSO é mais robusto (a variância dos resultados do EPSO é muito mais pequena do que para uma PSO clássica
o O EPSO é menos sensível à inicialização dos pesos (o desempenho do PSO degrada-se muito mais rapidamente com a variação dos pesos iniciais, comparada com o EPSO.
As expressões das funções teste são as seguintes:
Função de Schaffer:
min 222
222
1))yx(001.00.1(
5.0)yx(sin5.0)x(f
++
−++=
Função de Rosenbrock:
min ∑=
+ −+−×=n
1i
2i
22i1i2 ))1x()xx(100()x(f
Função Esférica:
min ∑=
−=n
iixxf
1
23 )1()(
Função Alpine: max nn xxxxxf ...)sin()...sin()( 114 ×=
30
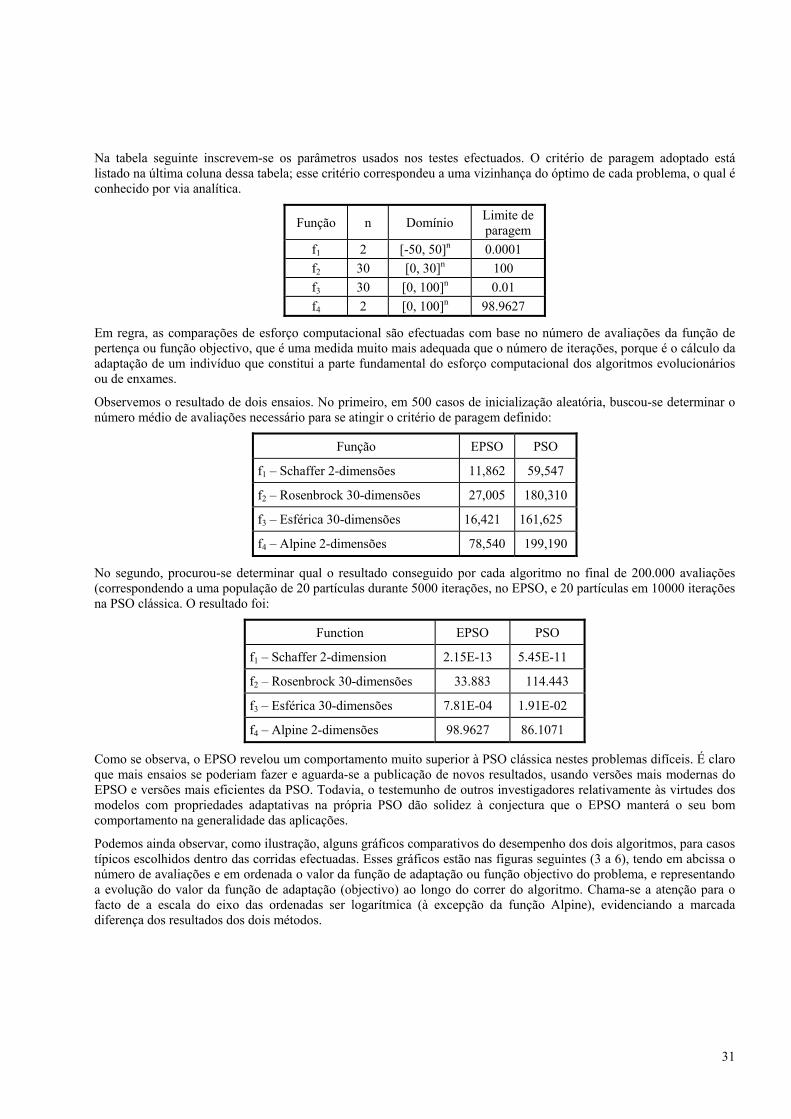
Na tabela seguinte inscrevem-se os parâmetros usados nos testes efectuados. O critério de paragem adoptado está listado na última coluna dessa tabela; esse critério correspondeu a uma vizinhança do óptimo de cada problema, o qual é conhecido por via analítica.
Função n Domínio Limite de paragem
f1 2 [-50, 50]n 0.0001 f2 30 [0, 30]n 100 f3 30 [0, 100]n 0.01 f4 2 [0, 100]n 98.9627
Em regra, as comparações de esforço computacional são efectuadas com base no número de avaliações da função de pertença ou função objectivo, que é uma medida muito mais adequada que o número de iterações, porque é o cálculo da adaptação de um indivíduo que constitui a parte fundamental do esforço computacional dos algoritmos evolucionários ou de enxames.
Observemos o resultado de dois ensaios. No primeiro, em 500 casos de inicialização aleatória, buscou-se determinar o número médio de avaliações necessário para se atingir o critério de paragem definido:
Função EPSO PSO
f1 – Schaffer 2-dimensões 11,862 59,547
f2 – Rosenbrock 30-dimensões 27,005 180,310
f3 – Esférica 30-dimensões 16,421 161,625
f4 – Alpine 2-dimensões 78,540 199,190
No segundo, procurou-se determinar qual o resultado conseguido por cada algoritmo no final de 200.000 avaliações (correspondendo a uma população de 20 partículas durante 5000 iterações, no EPSO, e 20 partículas em 10000 iterações na PSO clássica. O resultado foi:
Function EPSO PSO
f1 – Schaffer 2-dimension 2.15E-13 5.45E-11
f2 – Rosenbrock 30-dimensões 33.883 114.443
f3 – Esférica 30-dimensões 7.81E-04 1.91E-02
f4 – Alpine 2-dimensões 98.9627 86.1071
Como se observa, o EPSO revelou um comportamento muito superior à PSO clássica nestes problemas difíceis. É claro que mais ensaios se poderiam fazer e aguarda-se a publicação de novos resultados, usando versões mais modernas do EPSO e versões mais eficientes da PSO. Todavia, o testemunho de outros investigadores relativamente às virtudes dos modelos com propriedades adaptativas na própria PSO dão solidez à conjectura que o EPSO manterá o seu bom comportamento na generalidade das aplicações.
Podemos ainda observar, como ilustração, alguns gráficos comparativos do desempenho dos dois algoritmos, para casos típicos escolhidos dentro das corridas efectuadas. Esses gráficos estão nas figuras seguintes (3 a 6), tendo em abcissa o número de avaliações e em ordenada o valor da função de adaptação ou função objectivo do problema, e representando a evolução do valor da função de adaptação (objectivo) ao longo do correr do algoritmo. Chama-se a atenção para o facto de a escala do eixo das ordenadas ser logarítmica (à excepção da função Alpine), evidenciando a marcada diferença dos resultados dos dois métodos.
31

Schaffer F6
1.E-12
1.E-10
1.E-08
1.E-06
1.E-04
1.E-02
1.E+000 50000 100000 150000 200000
Número de avaliações
Fitness EPSO PSO
Figura 9 – Exemplo típico de comparação entre o EPSO e uma PSO clássica para a função de Schaffer
R o s e n b r o c k
1 .E + 0 01 .E + 0 11 .E + 0 21 .E + 0 31 .E + 0 41 .E + 0 51 .E + 0 61 .E + 0 71 .E + 0 81 .E + 0 9
0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 2 0 0 0 0 0
E P S OP S O
Fitn
ess
N u m b e r o f e v a lu a t io n sNúmero de avaliações
Figura 10 – Exemplo típico de comparação entre o EPSO e uma PSO clássica para a função de Rosenbrock
S p h e r e
1 .E- 0 4
1 .E- 0 3
1 .E- 0 2
1 .E- 0 1
1 .E+ 0 0
1 .E+ 0 1
1 .E+ 0 2
1 .E+ 0 3
1 .E+ 0 4
1 .E+ 0 5
0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 2 0 0 0 0 0
n s
Fitn
ess
N u m b e r o f e v a lu a t io
EPS O
PS O
Esférica
Número de avaliações
Figura 11 – Exemplo típico de comparação entre o EPSO e uma PSO clássica para a função Esférica
32

0 20 40 60 80
100 120
0 20 40 60 80 100
EPSO PSO
Alpine
Número de avaliações
Figura 12 – Exemplo típico de comparação entre o EPSO e uma PSO clássica para a função Alpine
Como exemplo de robustez do algoritmo apresentamos os resultados de uma comparação do desempenho do EPSO e da PSO clássica em 1000 ensaios com inicialização aleatória, no problema da função Alpine – 2 dimensões, ao fim de 100 iterações.
Alpine 2-dimensões, 1000 ensaios Resultado médio Desvio padrão EPSO 98.69669 1.05910
PSO clássica 90.62233 6.81301
Verifica-se que o EPSO não só produz um resultado em média muito superior como a dispersão de resultados que a PSO apresenta é muito maior. Analisando esses resultados em detalhe, verificou-se que a PSO ficou presa em muitos casos em óptimos locais e que isso influenciou a qualidade dos resultados. Essa dispersão, que nós relacionamos com a designação de robustez, tem como consequência prática a maior ou menor confiança que um algoritmo pode oferecer aos utilizadores, em aplicações industriais.
Pode-se apreciar essa dispersão nos gráficos das figuras seguintes.
Figura 13 – Histograma dos resultados ao fim de 100 iterações da PSO na função Alpine – 2 dimensões. Distribuição de resultados por intervalos de largura 5
33

Figura 14 – Histograma dos resultados ao fim de 100 iterações do EPSO na função Alpine – 2 dimensões. Distribuição de resultados por intervalos de largura 1. Por comparação com a figura anterior, atente-se que a escala do eixo dos xx é diferente.
Mais resultados de ensaios podem encontrar-se em [24].
9.3. Problemas com restrições Até ao momento, discutimos basicamente problemas de variáveis contínuas e sem restrições. Para atender a restrições, a estratégia a seguir é a mesma que qualquer outro problema moldado por um algoritmo evolucionário: ou as restrições ficam implicitamente definidas no movimento que as partículas podem fazer ou se adopta uma estratégia de penalidades sempre que alguma restrição fica violada.
Na PSO, partículas com mau valor de adaptação tendem a ser atraídas para locais melhores e, por isso, tendem a escapar de regiões do espaço onde lhes sejam aplicadas penalidades. No EPSO, em particular, os indivíduos com mau valor de adaptação (por efeito de penalidades, por exemplo) tendem a ser eliminados da população e, portanto, a tendência para a satisfação de restrições vem reforçada.
9.4. Problemas com variáveis discretas ou inteiras Na PSO têm sido feitas propostas de modelos que acomodam variáveis inteiras [25]. O processo poderia ser adoptado para o EPSO. Também se pode adoptar uma estratégia que designaremos de aproximação estocástica e que se caracteriza da seguinte maneira: se uma variável deve ser inteira e assume um valor real não inteiro, ela é arredondada para um inteiro próximo com uma dada probabilidade, a qual decresce com a distância. Este processo probabilístico tem o efeito de impedir que o arredondamento de uma variável funcione como uma armadilha que a prenda a uma solução local – fica garantida uma probabilidade não nula de que a variável escape de um valor a que chega por arredondamento.
9.5. Tamanho dos enxames Está em aberto a definição do tamanho adequado para os enxames no EPSO. NA PSO houve trabalhos dedicados a esse tema , o qual consiste sempre na busca de um compromisso entre capacidade de cálculo , tempo de cálculo e precisão do resultado. Não é líquido que as mesmas regras (empíricas) se apliquem ao EPSO.
9.6. Comunicação entre partículas As partículas comunicam entre si o valor e posição da melhor solução corrente encontrada. O modelo que discutimos até ao momento foi um modelo síncrono em estrela, em que todas são informadas do melhor em cada geração.
A comunicação poderia ser assíncrona, fazendo com que cada partícula usasse a melhor informação disponível no momento do cálculo da sua transformação, em vez de se usar um valor por geração.
Por outro lado, tem também sido experimentado na PSO um modelo de comunicação em anel ou de vizinhança. Num anel, cada partícula apenas comunica com duas vizinhas e, portanto, a propagação do conhecimento de um ponto melhor faz-se com lentidão. O conceito de vizinhança com um número superior de partículas amplia a velocidade de propagação da informação. Na verdade, muitas topologias de comunicação poderiam ser ensaiadas, trabalho que está por fazer no EPSO.
34

10. CONCLUSÕES Os modelos de computação evolucionária fenotípica, representando os problemas pelas suas variáveis naturais, são de simplicidade de desenvolvimento e permitem uma exploração efectiva do espaço das soluções de problemas complexos. Essa exploração foi bem conseguida pelos algoritmos da família PSO, graças à famosa regra do movimento das partículas. Os modelos evolucionários da família EPSO incorporaram com vantagem esse conceito, dando lugar a algoritmos híbridos, robustos e fiáveis e com melhor desempenho que os seus antecessores nos casos testados.
35

CAPÍTULO III EXEMPLOS DIDÁCTICOS
11. INTRODUÇÃO Os Sistemas de Potência, em muitos casos, representam um desafio à aplicação prática de meta-heurísticas do tipo da computação evolucionária como as estratégias de evolução (ES) ou optimização por enxame de partículas (PSO). A razão disso deve-se à complexidade e dimensão dos problemas em conjugação com as exigências de eficiência computacional, que se sentem especialmente naquelas aplicações que exigem respostas em tempo real. Enquanto que em aplicações de planeamento o tempo não é realmente crítico, em aplicações de operação a velocidade de cálculo é crucial.
As ES, a PSO ou os métodos auto-adaptativos tipo EPSO não são, em essência, algoritmos rápidos. O seu poder reside na força da mão invisível da selecção agindo sobre gerações e gerações de populações que se replicam. Portanto, exigem milhares de avaliações da função de adaptação ou função objectivo do problema e se esta avaliação é complexa e pesada então o processo pode exigir um tempo apreciável até convergir. Todavia, não devemos apressarmo-nos em julgar negativamente estes métodos. Na verdade, o conceito de tempo real está ligado à necessidade – o tempo real necessário para uma aplicação de pré-despacho de geração é ordens de magnitude superior ao exigido por uma aplicação de análise preventiva de segurança dinâmica, por exemplo.
Estes requisitos de aplicações de tempo real dependem do ciclo de operações definido no Centro de Controlo em ambiente de EMS – Energy Management System. Se a escala de serviço dos geradores é definida apenas de hora em hora, há cdertemente tempo suficiente para correr um modelo evolucionário e computar uma solução, ainda que tome vários minutos.
Neste capítulo pretende-se, através de alguns exemplos didácticos, ilustrar como funcionam os modelos evolucionários (ES e EPSO) em várias aplicações.
12. ESTRATÉGIAS DE EVOLUÇÃO NO PROBLEMA DE DESPACHO DE GERAÇÃO O problema clássico do despacho económico de geração aparece formulado como um modelo de programação não linear. Todavia, esta formulação clássica negligencia um conjunto de circunstâncias práticas e foi basicamente pensada para sistemas com geração composta por unidades térmicas.
Existe um pressuposto básico nessa formulação – que é o de que, em função de um problema de pré-despacho anteriormente resolvido, já se conhecem quais os grupos que estão disponíveis e que deverão ser despachados. Portanto, todas os grupos assim seleccionados e que entram no problema do despacho económico vão injectar potência na rede, mesmo que seja no seu nível de mínimo técnico.
O problema do despacho aparece nos sistemas eléctricos de estrutura mais ou menos verticalizada, em que as decisões de despacho (minimização do custo global de produção) importam a um agente de decisão que é, em geral, uma empresa concessionária da geração e do transporte de energia.
Nos sistemas desverticalizados e convivendo num mercado regulado, tal objectivo não existe, porque a propriedade da geração está dispersa por vários concorrentes. Existe, sim, um problema parecido com o despacho económico, que é o que preocupa o agente de decisão exercendo as funções de operador independente do sistema, e que consiste na minimização dos seus custos de operação satisfazendo os contratos de fornecimento acertados pelo mercado. Esses custos envolvem, nomeadamente, perdas de energia e custos de aquisição para mais ou para menos de potência necessária para operar de forma óptima o sistema.
No despacho em sistema verticalizado também podem (e devem) entrar preocupações com as perdas de energia. Mas o modelo simples de despacho clássico assume que todos os geradores estão ligados a um barramento único e ignora a existência da rede de transporte, o que tem as seguintes limitações: a) ignora (despreza) as perdas de energia, e b) ignora as limitações ao fluxo de potência impostas pela própria rede de transporte, em função não só dos limites das linhas como da observância das próprias leis de Kirchoff.
Para entrar em conta com as perdas, alguns modelos simplificados foram desenvolvidos, sendo o mais conhecido o dos v«chamados factores B. Este modelo ajuda, de facto a corrigir algo na decisão de despacho, no sentido da economia, mas nada informa sobre a viabilidade da solução. Uma informação sobre isto, embora não completa e envolvendo um
36

certo grau d aproximação, pode ser conseguida integrando no despacho, como restrição, um sistema de equações do tipo do modelo DC de fluxo de potência.
Uma solução completa AC move-nos para terrenos do chamado Fluxo de Potência Óptimo (OPF). Porém, um OPF é um modelo pesado e daí a importância ainda relevante dos modelos de despacho, que fornecem soluções indicativas já muito próximas da decisão final, pelo menos no que respeita ao despacho de potência activa.
Uma formulação AC com representação da rede de transporte é um problema complexo e, por isso, os algoritmos evolucionários podem dar uma contribuição importante, principalmente se houver necessidade de representar regras de operação adicionais, o que se torna interessante tanto no caso de existir geração hidro-eléctrica como de co-existirem produtores independentes ou co-geradores cuja operação obedeça, de alguma forma, a uma lógica distinta da lógica económica do decisor.
Nas secções seguintes vamos mostrar, com intuito didáctico, como construir um possível modelo evolucionário do problema do despacho, seja com ES [26] seja com EPSO[27]. Desde já fazemos o aviso de que o leitor pode ser induzido em erro pelo uso da palavra “geração”, pois ela tanto pode significar produção de energia eléctrica como ter o sentido de população num dado estágio evolucionário. Confiamos que o contexto seja suficiente para dissipar qualquer possível confusão.
12.1. Um exemplo de problema clássico do despacho óptimo de geração Com sentido didáctico, mostraremos como se podem desenvolver algoritmos de ES e EPSO para o problema de despacho óptimo de geração sem inclusão da rede de transporte. Os dados a considerar são:
o O número de geradores – ngen
o Os parâmetros da função custo de cada gerador – assume-se que esta função seja um polinómio até ao grau 3 e, portanto, são necessários 4 parâmetros, designados ai com i = 1 a 4:
33
2210 PaPaPaaC +++=
onde C é o custo associado a um gerador, em €/hora e P é a potência fornecida pelo gerador em MW.
o O mínimo e máximo técnico Pmin e PMax de cada gerador.
o A carga total L
Apreciaremos resultados numéricos, com base num problema com uma carga e 44 MW e de 5 geradores, e com curvas de custo definidas pelos seguintes parâmetros:
Gerador a0 a1 a2 a3 Pmin Pmax g1 1 0,5 0,1 0,03 1 10 g2 2 0,4 0,2 0 2 10 g3 4 0,3 0,3 0 7 10 g4 6 1,5 0,15 0 2 10 g5 0 4 0 0 1 10
37

~~~~~
Figura 15 – Esquema de barramento único para o problema do despacho clássico
12.2. Uma ES não adaptativa Num modelo de ES não adaptativo, definimos um indivíduo como um vector de 5 valores de geração (o espaço de busca fica com n=5).
As mutações serão aplicadas a cada componente desse vector (direcção coordenado do espaço = geração de um gerador) e serão do tipo Gaussiano aditivo, com taxa de mutação fixa σ afectada por um parâmetro de aprendizagem Tau (τ). Uma população é um conjunto de indivíduos, ou seja, de vectores definindo soluções de despacho.
Um algoritmo não adaptativo poderá ser assim:
(INÍCIO) Ler Dados Dados técnicos e de custo dos geradores, e dados necessários para gerar números aleatórios com
distribuição Gaussiana; dimensão da população Pop, número máximo de geradores MaxGen e parâmetro de aprendizagem τ
Gerar a primeira população de progenitores (por inicialização aleatória das potências de cada indivíduo) Desenhar esta rotina de tal forma que os valores das potências possam ser corrigidos e satisfazer a
condição de que a geração tem que ser igual à carga. Há vários modos de conseguir isto – um processo é subtrair o mínimo técnico a cada gerador e ao seu máximo técnico também e o total dos mínimos técnicos à carga; depois, aplica-se uma correcção proporcional aos valores de potência para corrigir o seu valor. Este procedimento evita a aplicação de penalidades para o caso de a potência não atingir ou exceder a carga.
Avaliar a adaptação de cada vector de despacho (cada solução) Para além do cálculo de custos. É necessário definir uma política de penalidades. Este problema
exige a fixação de penalidades para os geradores excedendo PMax, porque a técnica descrita acima evita descidas abaixo de Pmin. Uma expressão para as penalidades que resulta bem neste problema é a que adiciona 1000(P-PMax)2 ao custo de cada gerador que exceda o seu máximo técnico.
Ciclo de 1 a MaxGen Duplicar a população copiando (clonando) a população original Tem-se provisoriamente uma população de dimensão Pop+Pop Mutar a população copiada
38

Aplicar mutações Gaussianas a cada valor de potência dos indivíduos clonados. De seguida, usando um método proporcional, corrigir o despacho por forma a que o total de geração fique igual à carga.
Avaliar a adaptaçãp da populoção clonada mutada Seleccionar os melhores Pop indivíduos Uma selecção elitista numa população progenitores+ descendentes: os melhores Pop num total
de Pop+Pop são guardados, substituindo a população de progenitores Fim do ciclo Apresentar resultados (FIM)
Convida-se o leitor a desenvolver um programa de acordo com estas linhas gerais. Um programa desse tipo pode ser solicitado ao autor, desenvolvido em Visual Basic e correndo por detrás de uma folha de cálculo Excel. A Figura 16 apresenta, para o problema prático acima enunciado, a evolução da adaptação do melhor indivíduo para o caso em que o parâmetro de aprendizagem τ = 0,4 e MaxGen = 100, numa população com 10 indivíduos.
140142144146148150152154156158160
0 10 20 30 40 50 60 70 80 90 100
Figura 16 – Modelo ES não adaptativo. Evolução da adaptação do melhor indivíduo em casa uma das 100 primeiras gerações. Eixo X: n. gerações; eixo Y – adaptação (custo mais penalidades)
A solução final encontrada, relativa à figura, está na coluna central da tabela seguinte (MW). A coluna da direita – MW (cl) – indica a solução óptima encontrada por um algoritmo clássico de PNL com coeficientes de Lagrange.
Gerador MW MW (cl)
g1 5.967 6.085 g2 9.993 10 g3 8.337 7.015 g4 9.768 10 g5 9.935 10 Custo total (€) 141.944 141.674
39

12.3. Uma ES auto-adaptativa Para se construir um modelo auto-adaptativo, é preciso definir agora um indivíduo como um vector contendo as 5 potências geradas mais uma taxa de mutação corrente para o próprio indivíduo. Neste modelo, a taxa de mutação σ corresponde ao desvio padrão de uma distribuição Gaussiana regulando as mutações em todos os valores de potência de cada indivíduo da mesma forma.
A taxa de mutação será ela própria sujeita a mutações durante sucessivas gerações. Esta meta-mutações serão governadas por uma distribuição Lognormal, e o impacto nas taxas de mutação regulado por um coeficiente de aprendizagem τ’, tal que
σnew = σold R[Lognormal] τ’
onde R é um número aleatório produzido por uma distribuição Lognormal. O algoritmo terá a forma seguinte:
INÍCIO) Ler Dados Dados técnicos e de custo dos geradores, e dados necessários para gerar números aleatórios com
distribuição Gaussiana e Lognormal; dimensão da população Pop, número máximo de geradores MaxGen; valor de σ para a primeira geração e coeficiente de aprendizagem τ’
Gerar a primeira população de progenitores (por inicialização aleatória das potências de cada indivíduo) Desenhar esta rotina de tal forma que os valores das potências possam ser corrigidos e satisfazer a
condição de que a geração tem que ser igual à carga. Há vários modos de conseguir isto – um processo é subtrair o mínimo técnico a cada gerador e ao seu máximo técnico também e o total dos mínimos técnicos à carga; depois, aplica-se uma correcção proporcional aos valores de potência para corrigir o seu valor. Este procedimento evita a aplicação de penalidades para o caso de a potência não atingir ou exceder a carga.
Avaliar a adaptação de cada vector de despacho (cada solução) Para além do cálculo de custos. É necessário definir uma política de penalidades. Este problema
exige a fixação de penalidades para os geradores excedendo PMax, porque a técnica descrita acima evita descidas abaixo de Pmin. Uma expressão para as penalidades que resulta bem neste problema é a que adiciona 1000(P-PMax)2 ao custo de cada gerador que exceda o seu máximo técnico.
Ciclo de 1 a MaxGen Duplicar a população copiando (clonando) a população original Tem-se provisoriamente uma população de dimensão Pop+Pop Mutar a população copiada Aplicar uma mutação Lognormal à taxa de mutação de cada indivíduo clonado. Aplicar mutações
Gaussianas a cada valor de potência dos indivíduos clonados, com base nas taxas de mutação individuais. De seguida, usando um método proporcional, corrigir o despacho por forma a que o total de geração fique igual à carga.
Avaliar a adaptaçãp da populoção clonada mutada Seleccionar os melhores Pop indivíduos Uma selecção elitista numa população progenitores+ descendentes: os melhores Pop num total
de Pop+Pop são guardados, substituindo a população de progenitores Fim do ciclo
40
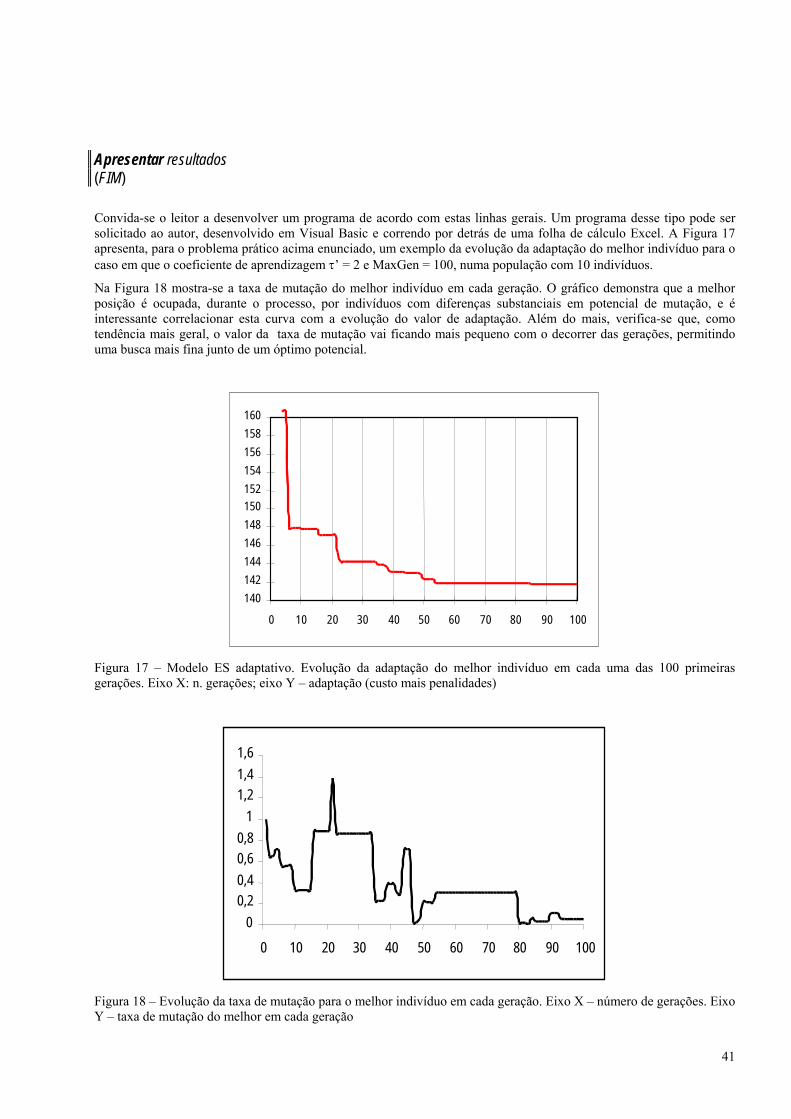
Apresentar resultados (FIM)
Convida-se o leitor a desenvolver um programa de acordo com estas linhas gerais. Um programa desse tipo pode ser solicitado ao autor, desenvolvido em Visual Basic e correndo por detrás de uma folha de cálculo Excel. A Figura 17 apresenta, para o problema prático acima enunciado, um exemplo da evolução da adaptação do melhor indivíduo para o caso em que o coeficiente de aprendizagem τ’ = 2 e MaxGen = 100, numa população com 10 indivíduos.
Na Figura 18 mostra-se a taxa de mutação do melhor indivíduo em cada geração. O gráfico demonstra que a melhor posição é ocupada, durante o processo, por indivíduos com diferenças substanciais em potencial de mutação, e é interessante correlacionar esta curva com a evolução do valor de adaptação. Além do mais, verifica-se que, como tendência mais geral, o valor da taxa de mutação vai ficando mais pequeno com o decorrer das gerações, permitindo uma busca mais fina junto de um óptimo potencial.
140142144146148150152154156158160
0 10 20 30 40 50 60 70 80 90 100
Figura 17 – Modelo ES adaptativo. Evolução da adaptação do melhor indivíduo em cada uma das 100 primeiras gerações. Eixo X: n. gerações; eixo Y – adaptação (custo mais penalidades)
00,20,40,60,8
11,21,41,6
0 10 20 30 40 50 60 70 80 90 100
Figura 18 – Evolução da taxa de mutação para o melhor indivíduo em cada geração. Eixo X – número de gerações. Eixo Y – taxa de mutação do melhor em cada geração
41

A solução final encontrada, relativa a estas figuras, está na coluna central da tabela seguinte (MW). A coluna da direita – MW (cl) – indica a solução óptima encontrada por um algoritmo clássico de PNL com coeficientes de Lagrange.
Gerador MW MW (cl)
g1 6.236 6.085 g2 9,999 10 g3 7.918 7.915 g4 9.847 10 g5 9.999 10
Custo total (€) 141.777 141.674
12.4. Um modelo de EPSO para o despacho económico clássico Para se construir um modelo EPSO básico é preciso definir um indivíduo pelos seus parâmetros objecto (5 potências) e estratégicos (4 pesos). Externamente, tem que fixar-se ainda o parâmetro de aprendizagem τ, que regula as mutações com distribuição Lognormal que afectarão os pesos relativos aos termos de inércia, memória, cooperação e ainda relativo à posição estimada do óptimo global.
O algoritmo terá a forma seguinte:
(INÍCIO) Ler Dados Dados técnicos e de custo dos geradores, e dados necessários para gerar números aleatórios com
distribuição Lognormal; dimensão da população Pop, número máximo de geradores MaxGen; pesos iniciais para a primeira geração e coeficiente de aprendizagem τ
Gerar a primeira população de progenitores (por inicialização aleatória das potências de cada indivíduo) Desenhar esta rotina de tal forma que os valores das potências possam ser corrigidos e satisfazer a
condição de que a geração tem que ser igual à carga. Há vários modos de conseguir isto – o mais simples é aplicar uma correcção proporcional aos valores de potência para corrigir o seu valor. Os valores de potência podem, com este procedimento, violar o mínimo ou o máximo em cada gerador.
Ciclo de 1 a MaxGen Duplicar a população copiando (clonando) a população original Tem-se provisoriamente uma população de dimensão Pop+Pop Mutar os parâmetros estratégicos da população copiada Aplicar uma mutação Lognormal aos pesos de cada indivíduo clonado. Mover a população Pop+Pop Aplicar a regra do movimento das partículas a toda a população (partículas originais e partículas
clonadas), originando novas partículas (enxame de descendentes). Avaliar a adaptaçãp da populoção de descenentes Nesta avaliação aplicar uma política de penalidades.
42

Seleccionar os melhores Pop indivíduos Uma selecção elitista aplicada a cada par de descendentes de uma partícula: os melhores Pop
num total de Pop+Pop são guardados, substituindo a população de progenitores. Com este processo conserva-se a linha histórica de cada partícula e força-se evolução nos parâmetros estratégicos.
Memorizar a história do enxame e de cada partícula A posição melhor na história de cada partícula e a melhor posição encontrada até ao momento
pelo enxame são memorizadas. Fim do ciclo Apresentar resultados (FIM)
Convida-se o leitor a desenvolver um programa de acordo com estas linhas gerais. Um programa desse tipo pode ser solicitado ao autor, desenvolvido em Visual Basic e correndo por detrás de uma folha de cálculo Excel. A Figura 19 apresenta, para o problema prático acima enunciado, um exemplo da evolução da adaptação do melhor indivíduo para o caso em que o coeficiente de aprendizagem τ = 2 e MaxGen = 100, com pesos iniciais de 0,5 para os termos de inércia, memória e cooperação e 0,1 para o óptimo global., num enxame definido inicialmente de 10 partículas. As penalidades aplicadas a soluções fora do domínio foram do tipo 100Δ2, em que Δ corresponde ao desvio da solução em ordem a cada restrição.
140
142
144
146
148
150
0 20 40 60 80 100
Figura 19 – Modelo EPSO. Evolução da adaptação do melhor indivíduo em cada uma das 100 primeiras gerações. Eixo X: n. gerações; eixo Y – adaptação (custo mais penalidades)
Na Figura 20 mostra-se a evolução dos pesos, tomados em cada geração da melhor partícula corrente. Vê-se claramente como o processo evolutivo altera a importância relativa dos pesos na determinação do movimento das partículas. Em particular, é interessante notar a progressiva redução do peso que afecta a perturbação na localização do óptimo global corrente G, no termo de cooperação, denotando um ajuste mais fino do algoritmo à medida que a busca se processa numa zona mais limitada do espaço.
43

0,01
0,1
1
10
0 20 40 60 80 100
inérciamemóriacooperaçãoglobal
Figura 20 – Evolução dos pesos associados à melhor partícula em cada geração. Note-se que a escala é logarítmica.
A solução final encontrada, relativa a estas figuras, está na coluna central da tabela seguinte (MW). A coluna da direita – MW (cl) – indica a solução óptima encontrada por um algoritmo clássico de PNL com coeficientes de Lagrange, com precisão de 0,001 na soma das potências geradas.
Gerador MW MW (cl)
g1 6,180 6,085 g2 9,987 10 g3 7,834 7,915 g4 9,992 10 g5 10,007 10
Custo total (€) 141.692 141,674
Este exemplo ilustra como a aplicação da técnica das penalidades pode permitir ligeiras excursões das soluções para zonas fora do domínio do problema. No caso, temos o Gerador g5 produzindo ligeiramente acima do seu limite de 10 MW.
12.5. Comparação entre modelos ES não adaptativos, auto-adaptativos e EPSO Os resultados acima podem sugerir que uma estratégia auto-adaptativa conduz a melhores resultados do que uma estratégia não adaptativa, e que o EPSO será o algoritmo de melhor comportamento.
Porém, isto poderia resultar de uma escolha fortuita de dados iniciais ou da sorte dos algoritmos, dado que estes também dependem da sequência de números aleatórios usada.
Para verificar o comportamento comparativo dos três modelos, procedeu-se a 200 corridas para cada estratégia, parando o processo ao fim de 200 gerações. Como os algoritmos evolucionários dependem de valores aleatórios, cada corrida apresentará um resultado levemente distinto em termos de solução e seu custo. Calculou-se, portanto, o valor médio do
44

resultado obtido por cada modelo e também uma medida da dispersão dos resultados dada pelo desvio padrão. A tabela seguinte apresenta os resultados deste ensaio:
Média dos melhores valores de cada corrida (€)
Dispersão (desvio padrão em relação à média)
Modelo não adaptativo 141,836 0,0615 Modelo auto-adaptativo 141,696 0,0296 EPSO 141,676 0,0069
Verifica-se que as estratégias adaptativas se mostram mais robustas e, de entre estas, é o EPSO o algoritmo de maior sucesso. Não só promete um resultado mais próximo do óptimo real, em média, como mostra uma menor dispersão dos resultados. Portanto, um utilizador poderá estar mais confiante ma qualidade do resultado de uma única corrida, se estiver correndo um EPSO. É claro que não ficou eliminada a necessidade de impor algum parâmetro externo.
No modelo não adaptativo, experiências mostraram que o valor de τ = 0,4 conduzia aos melhores resultados. No modelo auto-adaptativo, verificou-se que o valor de τ’=2 se mostrou muito satisfatório. Além do mais, os resultados mostraram-se insensíveis a uma larga gama de valores para o valor inicial de σ para a primeira geração, o que não surpreende dada as características auto-correctivas da estratégia σSA adoptada. No EPSO, o coeficiente de aprendizagem utilizado foi de τ = 0,1.
13. CONCLUSÕES A implementação de modelos evolucionários, em especial de computação fenotípica, em que as variáveis do problema são representadas na sua forma natural, revela-se dotada de bastante simplicidade. Na verdade, a complicação dos modelos reside não nas operações evolucionárias mas na concepção das funções de avaliação e na integração das restrições.
Os modelos de tipo EPSO, aliando ao impulso evolucionário operações de recombinação sugeridas pelos modelos de PSO, aparecem como alternativas fiáveis e robustas, com desempenho superior para a mesma precisão exigida ou com melhor precisão para o mesmo esforço computacional.
Os leitores não devem porém ficar iludidos quanto à necessidade de sofisticar os modelos comparativamente com os esboços de algoritmos apresentados nestes capítulos. EM última análise, sempre haverá necessidade de alguma experimentação e sintonização, mesmo que os algoritmos auto-adaptativos reclamem para o seu próprio funcionamento a automatização de uma parte dessa tarefa.
45

CAPÍTULO IV EXEMPLOS DE APLICAÇÃO REAL
14. INTRODUÇÃO Este capítulo tem um carácter informativo e destina-se a revelar a existência de modelos, baseados em Estratégias de Evolução (ES) ou Enxames Evolucionários de Partículas (EPSO), publicados e aplicados a problemas de dimensão real dos sistemas de energia eléctrica.
Nestes modelos poderão encontrar-se pequenas diferenças em relação aos esquemas básicos descritos em capítulos anteriores. Isto não deve causar estranheza, porque os algoritmos evolucionários permitem essa latitude de variação na concepção de modelos, a fim de os adaptar a cada situação em causa.
O enfoque do capítulo é nas questões associadas à gestão de energia reactiva, controlo de tensão e minimização de perdas, cuja complexidade permite evidenciar as virtudes dos modelos evolucionários e, em particular, do EPSO.
15. DESPACHO ECONÓMICO
15.1. Um modelo aplicado na União Europeia para redes isoladas Nesta secção faremos referência à aplicação de Programação Evolucionária (EP) ao problema do despacho económico. O modelo está descrito em detalhe em [28] e aqui apenas referiremos os seus aspectos mais interessantes.
A publicação referenciada descreve o desenvolvimento de um módulo de Despacho Económico no âmbito do projecto CARE – Advanced Control Advice for Power Systems with Large Scale Integration of Renewable Energy Sources, do programa ENN - JOULE da União Europeia. Este projecto conduziu à concepção de um sistema avançado de EMS (Energy Management System) especialmente vocacionado para ilhas ou redes isoladas com elevada penetração de energia eólica, e conduziu ao desenvolvimento de aplicações de software instaladas no Centro de Controlo da ilha de Creta, operado pela PPC – Public Power Corporation, a concessionária nacional da Grécia.
Este modelo corresponde a uma aplicação de conceitos expostos em capítulos anteriores a propósito de um exemplo didáctico sobre o problema do despacho económico. Todavia, também inclui, para além da geração, a representação da rede eléctrica e das limitações que ela impõe.
Em consequência, o cálculo da função de adaptação faz também apelo a uma rotina de Newton-Raphson e a algumas regras sobre o despacho de reactiva a fim de detectar violação de limites de tensão ou violação de limites térmicos de linhas e equipamentos. Esta detecção é importante porque a técnica utilizada para forçar o respeito pelas restrições corresponde à aplicação de penalidades na função objectivo.
A rotina de fluxo de potência serve ainda para determinar um valor para as perdas de energia e, assim, corrigir o despacho por acção num gerador definido como de compensação.
O modelo permite que a geração total exceda a carga (o que é lógico, já que as perdas de energia terão que ser acomodadas pela geração), e confia no poder da evolução para arrastar para um valor correcto quaisquer valores excessivos de potência produzida. Também aplica penalidades por insuficiência de produção.
O modelo inclui uma estratégia auto-adaptativa da taxa de mutação. Os seus autores adoptaram uma aproximação típica da EP, isto é, permitiram que a mutação das taxas de mutação individuais fosse obtida de forma aditiva, somando uma mutação Gaussiana (aleatória) à taxa de mutação a mutar. Este tópico foi já discutido em capítulo anterior e, nessa ocasião, afirmámos que este procedimento, sob certas condições, dá resultados muito parecidos à utilização de mutações multiplicativas do tipo Lognormal.
O processo de selecção é um pouco diferente do descrito anteriormente. Primeiro, um indivíduo é mutado e logo de seguida comparado com o seu progenitor – e, se for melhor, substitui-o na população. No final do processo, depois de submetidos todos os indivíduos a este tipo de selecção elitista, procede-se ainda à eliminação do pior indivíduo e à introdução na população de uma nova cópia (clone) do melhor indivíduo até ao momento detectado – o que reforça ainda mais o carácter elitista deste procedimento de selecção.
46

Os autores reportaram que o modelo de Despacho Económico foi integrado no sistema CARE, implementado para servir a procura de electricidade da ilha de Creta. A rede desta ilha não é extensa mas tem um parque produtor diversificado, com unidades térmicas a vapor, ciclo combinado, turbinas a gás, geradores diesel e uma elevada penetração de energia eólica, formando um modelo em escala reduzida de grandes e complexos sistemas.
Por causa do nível elevado de produção eólica (havendo planos para elevá-la a 30% do total produzido na ilha), a segurança dinâmica é também uma preocupação. O sistema CARE inclui módulos que eecutam uma avaliação da segurança dinâmica em tempo real (usando redes neuronais e árvores de regressão com assinalável êxito) e, portanto, certas penalidades associadas à avaliação de segurança dinâmica podem também ser adicionadas à função de adaptação de um algoritmo evolucionário, conduzindo à busca de soluções baratas e seguras, algo quase impensável com os modelos matemáticos e algorítmicos clássicos.
15.2. Outras propostas Há um diversificado número de trabalhos relatando o desenvolvimento de modelos de computação evolucionária ao problema do despacho económico. Nas referências [29-49] encontram-se alguns dos primeiros trabalhos sobre este tema. A sua característica comum é a de proporem a solução do problema do despacho incluindo muito mais restrições ou condições realistas do que os modelos clássicos alguma vez puderam fazer.
Os modelos de computação evolucionária são exigentes em termos de tempo de computação, temos vindo a repetir. Porém, em alguns artigos os autores explicam que os tempos de execução são compatíveis com o ciclo de despacho no EMS nos centros de controlo. A rotina de despacho só é corrida de tempos a tempos para determinar novos pontos de operação (set points) para a função de AGC (Automátic Generation Control), e o poder de cálculo actualmente disponível, mesmo em computadores moderados, parece mais do que suficiente para afastar quaisquer dúvidas quanto a este aspecto.
16. CONTROLO DE TENSÃO E ENERGIA REACTIVA O problema do controlo da energia reactiva e da tensão numa rede eléctrica é também um tema muito trabalhado, dada a sua importância operacional. A complexidade do problema advém de vários factores:
o Da necessidade de conjugar um objectivo económico (a minimização das perdas de energia na rede) com objectivos operacionais (manter as tensões dos barramentos dentro de bandas especificadas) e objectivos operacionais (manter disponíveis os controlos para futuras acções, ou seja, tanto quanto possível não esgotar a capacidade de controlo de nenhum controlador e manter o seu ponto de operação próximo do ponto central ou nominal).
o Do facto de que vários dos mecanismos de controlo disponíveis se caracterizarem por uma descrição em termos de variável discreta ou inteira, e não contínua. É o caso da utilização de transformadores com tomadas de regulação em carga, ou de bancos de condensadores, em que apenas um conjunto discreto de valores pode ser utilizado. Pelo contrário, alguns outros controlos mantêm a característica de variáveis contínuas, como por exemplo a excitação de geradores e compensadores síncronos ou a regulação de equipamentos do tipo FACTS, quando essa regulação é efectuada com recurso a electrónica de potência.
o Do facto de que um dos objectivos do controlo pode também ser definido como a minimização da utilização dos próprios controlos ao longo da curva de carga, normalmente não só para simplificar a operação como também para minimizar impactos no tempo de vida dos equipamentos mais solicitados e não prejudicar a fiabilidade do sistema ou não encarecer a operação por via do aumento da necessidade de manutenção. Isto implica uma programação de uma sequência temporal de acções de controlo durante um horizonte temporal de planeamento da operação, aumentando inevitavelmente a dimensão do problema.
Isto transforma o problema do controlo de tensão e energia reactiva num problema inteiro-misto e, de um ponto de vista algorítmico, num desafio interessante.
O problema do controlo de energia reactiva pode descrever-se, de forma geral, como um problema multi-critério na forma
Minimizar Perdas activas: )x,u(pϕ
Distância a uma banda de tensão admissível: )x,u(Vϕ Sujeito a 0)p,x,u(G = 0)p,x,u(H ≤ DU∈
47

As perdas activas são calculadas com um modelo AC das equações de fluxo de potência. As variáveis de controlo u representam o seguinte:
o Tensões em barramentos PV onde o controlo de tensão (por excitação dos geradores) é possível.
o Ângulos de regulação de FACTS.
o Posição das tomadas de transformadores com regulação em carga.
o Escalão de capacidade em serviço em bancos de condensadores manobráveis.
As primeiras e segundas variáveis são em geral contínuas enquanto que as restantes têm natureza discreta.
As restrições de igualdade G() correspondem às equações do fluxo de potência e as desigualdades H() descrevem limites operacionais, nomeadamente limites de tensão nos barramentos e limites de fluxo nos ramos da rede, podendo ainda acrescentar-se desigualdades modelizando uma preferência por manutenção das variáveis de controlo bem no interior dos seus limites. No último grupo de restrições sobre as variáveis de controlo U podem ainda existir condições impondo que algumas destas variáveis sejam discretas.
As bandas admissíveis de tensão são em regra definidas como um intervalo [Vmin, VMax] à volta da tensão nominal. A distância para este intervalo é definida por uma função que estabelece uma métrica no espaço através da expressão de
, não necessariamente Euclidiana. )x,u(Vϕ
Todas estas equações, escritas de forma simbólica, devem ser entendidas como se referindo a um modelo AC com as perdas de energia avaliadas, por exemplo, por um algoritmo de Newton-Raphson. Como se trata de um modelo bem conhecido, dispensámo-nos de o apresentar neste texto.
Na função objectivo, além da minimização das perdas também consideraremos um objectivo de minimizar a distância, nas variáveis de controlo, ao ponto central (ou nominal) do intervalo de variação respectivo. Isto é conseguido, na prática, pela aplicação de penalidades à função objectivo, como do tipo representado na Figura 21.
Penalidade
min Max Variável de Controlo
Valor Nominal
Figura 21 – Exemplo de função de penalidade a ser adicionada à expressão das perdas, por cada variável de controlo, escalada por um peso adequado) para favorecer soluções em que os controlos não se encontrem “encostados” aos seus limites.
Tradicionalmente, o controlo de tensão usando excitação de geradores estava reservado aos sistemas de geração-transporte, enquanto nos sistemas de distribuição os controlos básicos se resumiam a actuação em tomadas de transformadores e, por vezes, a escalões de bancos de condensadores. Presentemente, com a expansão do fenómeno da geração dispersa, seja por via da progressiva implantação de geração eólica seja pela proliferação de co-geração, não se pode mais conservar, em termos conceptuais, uma tal distinção. Na verdade, é nas redes de distribuição com geração dispersa que aparecem, presentemente, problemas dos mais complexos de regulação de tensão e a possibilidade de utilizarem as fontes dispersas para apoio da operação revela-se cada vez mais interessante.
Os adeptos dos modelos de Optimização por Enxame de Partículas (PSO) propuseram já alguns modelos para o controlo de energia reactiva – na verdade, trataram-se dos trabalhos pioneiros de aplicação da PSO aos Sistemas de Potência [50][51][52]. Os seus modelos incluíram uma associação de conceitos evolucionários a um modelo básico de PSO, com resultados positivos. Todavia, esse trabalho valioso ficou um passo aquém de uma real auto-adaptação evolucionária.
Essa busca de um modelo adaptativo foi também perseguida por outros autores, como por exemplo em [53], onde um conjunto de estratégias visando flexibilizar a PSO foram introduzidas. Trata-se, porém, ainda de uma verdadeira PSO, pois não existe procedimento de selecção.
48

Referiremos, pois, um outro modelo, com base num algoritmo da família dos EPSO, que permitiu ainda efectuar comparações de desempenho entre várias funções objectivo e ainda competir com um algoritmo de simulated annealing.
16.1. Controlo de tensão, energia reactiva e redução de perdas com EPSO O modelo EPSO cujos resultados descreveremos aparece referenciado em [54][55]. Em primeiro lugar, o problema é modelizado construindo uma função objectivo única na forma
Minimizar K )x,u(pϕ + )x,u(Vϕ
K é um parâmetro que define o tipo de problema a ser resolvido. Pode ser
o Um peso – levando à busca de soluções de compromisso entre redução de perdas e diminuição de violações de limites de tensão; isto permite o cálculo de trade-offs entre os dois objectivos, com uma adequada variação de K.
o Uma variável booleana que desliga ou liga a avaliação de perdas, consoante há ou não violações dos limites de tensão.
Este último caso significa que a consideração dos dois objectivos é hierárquica: a primeira prioridade é para evitar violações dos limites de tensão e só se isto estiver respeitado se procede à minimização de perdas. Como veremos, há casos em que os dois objectivos são conflituantes e em que a minimização das perdas pode agravar os perfis de tensão.
Num algoritmo de EPSO para a resolução deste problema, cada partícula ou indivíduo compõe-se, portanto, de um vector de variáveis de controlo e ainda dos pesos.
Apresentaremos alguns resultados com base no sistema cujos dados foram definidos em [56], correspondendo a um sistema de 24 nós/36 ramos, com 31 linhas de transporte, 5 transformadores, 11 bancos de condensadores e 9 geradores síncronos. A carga do sistema foi aumentada para originar problemas e regulação e perdas excessivas. Basicamente, referiremos duas situações:
o Em que o sistema está muito carregado mas onde ainda se podem encontrar soluções sem violação das margens de tensão, e
o Em que o sistema está extremamente carregado e não se consegue encontrar um ponto de operação que elimine todas as violações de tensão.
OS modelos de EPSO foram corridos com 20 partículas e coeficiente de replicação r=2 e o critério de paragem adoptado foi o de terminar a busca ao fim de 270 iterações sem melhoria sensível da solução (esta melhoria foi definida com base num critério incremental).
16.2. Sistema muito carregado e todos os controlos disponíveis Quando todos os controlos estão disponíveis, torna-se mais fácil encontrar soluções para o despacho de reactiva que respeitem todas as condições do problema. O problema é do tipo inteiro-misto, e para as variáveis inteiras usou-se o esquema de arredondamento probabilístico, em que a probabilidade de uma variável ser arredondada para um valor inteiro próximo diminui com a distância a esse valor.
As figuras seguintes ilustram alguns resultados obtidos com o EPSO. Para conduzir o teste de forma comparativa, definiu-se uma solução inicial hipotética como sendo a melhor de 20 sorteadas no início do processo. Em [55] apresentam-se mais alguns resultados.
49

-4500
-4000
-3500
-3000
-2500
-2000
-1500
-1000
-500
00 100 200 300 400 500
Iterações
Ada
ptaç
ão
Figura 22 – Evolução do valor da função de adaptação da solução melhor corrente com o número de iterações. Note-se que, como é óbvio, este valor nunca decresce.
050
100150200250300350400450500
0 100 200 300 400 50Iterações
Perd
as a
ctiv
as (M
W)
Figura 23 – Evolução do valor das perdas activas associado à solução melhor corrente. Note-se que há um incremento na iteração 73, causado por acções decisivas para a eliminação de violações dos limites de tensão.
0,85
0,9
0,95
1
1,05
1,1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Barramento n.
Tens
ão (p
.u.)
Estado Inicial
Solução final
Figura 24 – Comparação das tensões nodais entre o estado inicial e a solução final. Note-se que todas as tensões foram levadas para o interior da banda admissível de [0,95 ; 1,05] p.u.
50

0,9
0,95
1
1,05
1,1
2 7 13 15 16 18 21 22 23
Barramento n.
Tens
ão (p
.u.)
Estado inicial
Solução final
Figura 25 – Comparação dos valores de tensão controlada pela excitação de geradores, em barramentos PV, entre o estado inicial e a solução final (variáveis contínuas).
0,9
0,92
0,94
0,96
0,98
1
1,02
1,04
1,06
1,08
1,1
24-3 11-9 12-9 11-10 12-10
Transformador (entre barramentos)
Tom
ada
Estado inicial
Solução final
Figura 26 – Comparação da posição das tomadas de transformadores entre o estado inicial e a solução final (variável discreta)
A qualidade dos resultados do EPSO também se pode avaliar pela dispersão de resultados que o método revela quando se corre o mesmo problema repetidas vezes com inicialização aleatória. A tabela seguinte mostra o resultado obtido para enxames de 10 e de 20 partículas, em experiências de mil ensaios cada.
Média das perdas (MW) Desvio padrão (kW) EPSO 10 partículas 61.789 1.966 EPSO 20 partículas 61.788 1.485
A variância em ambos os casos é extremamente pequena, mostrando como o EPSO é um algoritmo robusto no qual se pode confiar de forma elevada, quando executada uma corrida isolada.
51

16.3. Sistema extremamente carregado e apenas com acção nas tomadas de transformadores Neste caso, onde os controlos são representados apenas por variáveis discretas, verificou-se não ser possível conduzir todas as tensões para dentro da banda de tensão admissível.
Definindo
⎩⎨⎧
>−=Δ<−=Δ
maximaxii
miniiminiVVVVV
VV if VVV
podemos observar os reultados do EPSO optimizando quatro funções objectivo diferentes:
o Minimizando a soma dos desvios de tensão fora da banda admissível – critério DV
min ; n - n. de barramentos PQ ∑=
Δn
iiV
1
o Minimizando a soma dos quadrados dos desvios
min∑ =
+Δn
1i
2i )1V(
o Minimizando o máximo desvio da banda admissível – critério Min-Max
{ }n,...,1i),V(Max Min i =Δ
o Minimizando as perdas de energia, independentemente dos valores de tensão – Critério Min loss
Os dois primeiros critérios podem parecer “naturais”, de um ponto de vista matemático. Porém, o terceiro critério pode ser operacionalmente muito interessante: se não se consegue trazer todas as tensões para dentro da banda admissível, pelo menos tenta evitar-se a ocorrência de tensões “muito más”.
O quarto critério permite-nos, com a felicidade que o exemplo oferece, mostrar como a simples minimização das perdas pode levar a valores de tensão inaceitáveis em alguns nós, contrariamente a um certo senso comum que argumentaria que a diminuição de perdas resulta da subida dos níveis de tensão. Por isso, a combinação dos critérios de minimização de perdas e minimização dos desvios de tensão é necessária.
A Figura 27 mostra claramente que o critério Min loss coloca tensões (barramentos 4, 5, 8, 9, 10) abaixo das tensões sugeridas pelo critério Min-Max. Em particular, a tensão no barramento 5 é particularmente prejudicada.
0,75
0,8
0,85
0,9
0,95
1
1,05
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Barramento n.
Tens
ão (p
.u.)
DV DV2Min Max Min loss
Figura 27 – Comparação das tensões nodais em quatro critérios de optimização, quando os controlos estão restringidos à utilização das tomadas de transformadores.
52

Na tabela seguinte vê-se qual o pior valor de tensão que ocorre na solução sugerida por cada critério.
Critério Pior tensão nodal (p.u.) DV 0,8342 DV2 0,8471 Min Max 0,8536 Min loss 0,8338
Como seria de esperar, o critério Min-Max é o que produz o resultado “menos mau”. Já o que é surpreendente é que o critério Min loss é o que produz a pior solução de todas! Isto indica claramente que há casos em que poderá ter que se ter em conta um trade-off entre minimização de perdas de energia e degradação da qualidade da tensão – não se pode assumir, simplesmente, que maiores tensões conduzirão a menores perdas.
Como se pode apreciar, um modelo de controlo de energia reactiva e de tensão baseado num algoritmo do tipo EPSO é não só prometedor como robusto. Acresce ainda que o EPSO mostrou bom desempenho com diferentes tipos de objectivo, incluindo o sempre difícil critério max-min, que traduz uma métrica de Chebychev. Isto pode ser utilmente aproveitado para todo o tipo de problemas que envolva segurança e em que os casos extremos sejam mais importantes que o comportamento médio.
Como aplicação real de um EPSO, referiremos a descrita em [57], pelo seu interesse particular. Com efeito, trata-se de uma aplicação em distribuição de energia eléctrica em que se procura aproveitar a existência de geração dispersa numa rede do norte de Portugal para diminuir as perdas de energia. Este aproveitamento tem consequências importantes numa situação de mercado regulado, pois pode implicar novas formas de negócio entre um operador de sistema e produtores em regime especial ou independentes, se estes cederem o controlo da tensão à saída dos seus geradores ao concessionário da rede, caso que presentemente não se verifica. È mais um argumento em favor da geração dispersa, compensando o acréscimo de complexidade derivado da existência de potências não despacháveis na rede.
16.4. EPSO na minimização de perdas de uma rede de distribuição de empresa europeia Nesta secção faremos referência a um estudo realizado para uma empresa da União Europeia visando avaliar o interesse da utilização da geração dispersa (os designados “produtores em regime especial” – PRE) como factor positivo na gestão das redes de distribuição, contrariando uma ideia que por vezes aparece de que a geração dispersa é factor de perturbação e perda de eficiência para uma concessionária da distribuição.
Por motivos de confidencialidade, não é possível dar detalhes nem identificar as partes envolvidas. Todavia, esta referência tem interesse não só por ser inovadora no tratamento deste problema como também porque envolveu um algoritmo do tipo EPSO.
Tomaremos como exemplo uma dada região da União Europeia em que o sistema de distribuição se compõe de uma rede malhada a 60 kV e redes exploradas de forma radial a 30kV ou a 15 kV, para a qual foram definidos dois cenários de estudo – ponta e vazio.
Na rede a 60KV encontramos
Barramentos Linhas Geradores Transformadores Baterias Cargas
50 37 36 26 10 16
Em 32 destes barramentos dispõe-se de disponibilidade de controlo, por acção na excitação de geradores síncronos ou em sistemas com interface electrónico controlável (16 casos), em baterias e condensadores comutáveis (12 casos) ou em transformadores com regulação em carga. Em 6 barramentos encontramos ainda geração assíncrona. É claro que há barramentos em que dois ou mesmo três destes meios de controlo estão disponíveis.
A composição da geração distribuída é a seguinte
Geradores Tipo n.º Potência Total Instalada (MVA)
Síncrono 17 105,6 hídricos
Assíncrono 2 1.0
Síncrono 5 34.6 eólicos
Assíncrono 8 46.6
Total 32 187,8
53

A potência instalada representa, neste caso, cerca de 85% do consumo máximo da rede (aproximadamente 220 MVA). Este é um valor tão importante que há o risco de situações em que possa fluir potência, em particular reactiva, do sistema de 60kV para o nível de tensão superior (220 kV), caso que, por motivos contratuais e legais, foi necessário impedir com a aplicação das restrições adequadas. Foi, por isso, necessário definir um equivalente para a rede de 220 kV, comunicando com um super-nó conectado aos pontos injectores na rede de 60 kV. Esse modelo foi validado com corridas sobre o modelo completo da rede nacional de transporte.
Foram definidos limites para a produção de energia reactiva nos geradores síncronos, enquanto que nas instalações com geradores assíncronos sem acoplamento electrónico à rede se representaram directamente as baterias de condensadores que a lei impõe.
Quanto à geração de potência activa pelos PRE, e em face do histórico existente, foi admitido um cenário exigente em que, na hora de ponta, a produção daqueles se situa em 60% da potência instalada. Na hora de vazio a produção dos hídricos foi fixada em 30% da potência instalada, mantendo-se os eólicos nos 60%. Os valores de tan φ adoptados corresponderam ao respeito pelos regimes legais em vigor. Na definição das cargas foram utilizados valores históricos com as necessárias correcções, sendo o regime de carga de vazio 40% do de ponta.
Um diagrama simplificado representativo da rede está na Figura 28. A rede inclui linhas aéreas e cabos subterrâneos.
~
~
~
~
~
~
~
~
220 kV
220 kV
220 kV
~
Ligação à rede 220 kV
Geração dispersa
Tranformadores com regulação
60 kV
Figura 28 – Diagrama simplificado da rede de 60 kV com geração dispersa e três pontos de ligação à rede de transporte a 60 kV, e geração dispersa constituída por grupos hídricos e parques eólicos de propriedade de privados.
O objectivo foi definido como a minimização das perdas de energia nos dois cenários de carga, sendo alvo de investigação se a concessionária poderia usar com vantagem a operação da geração distribuída para melhorar as
54

condições de exploração. A tensão foi avaliada nomeadamente na entrega de potência às redes de 30 e 15 kV (no secundário dos transformadores 60/30 e 60/15 kV), as quais não fecham anel e são exploradas em configuração radial.
Complementarmente, foi estudada uma rede de 15 kV com a seguinte dimensão:
Barramentos Linhas Geradores Transformadores Baterias Cond. Cargas
361 364 11 2 1 178
Nesta rede estão ligados 11 produtores em regime especial. Todos são cogeradores eléctricos e térmicos, alimentando unidades industriais, equipados com geradores síncronos, estando a sua designação e potência expressos na tabela seguinte, com as designações reais protegida por motivos de confidencialidade.
Potência Gerador Nome Produtor (fictício)
Inst.(MVA) Nº Tipo XXX Têxteis. SA 5,425 1 Sinc
YYYtêxtil. ACE 8,200 1 Sinc ZZZ Energia. Lda. 7,500 2 Sinc
Energia WWW Lda. 6,910 2 Sinc AVE-EléctricaSA 4,650 1 Sinc
FFFF Energéticos. SA 4,645 1 Sinc JJJ Energia. SA 5,225 1 Sinc JJJJ Energia. SA 4,650 1 Sinc
SPSP Energia. SA 4,645 1 Sinc Têxtil KKK SA 5,425 1 Sinc
VVV Energética. SA 7,225 1 Sinc
Para a avaliação da capacidade dos geradores dos PRE participarem na regulação de tensão consideraram-se ainda limites para a produção de potência reactiva, definidos seguindo o raciocínio descrito anteriormente.
As optimizações foram conseguidas com recurso a um modelo EPSO com variáveis contínuas e discretas, corrido numa plataforma desenvolvida no INESC Porto. Esse modelo produziu resultados de acordo com o descrito anteriormente, isto é, em várias corridas encontrou consistentemente o mesmo óptimo, exibindo as características de robustez do algoritmo.
Eis alguns resultados interessantes conseguidos:
o Na rede de 60 kV conseguiu-se, no cenário de ponta, uma redução de 316 kW em perdas, representando 16% de economia em relação à situação anterior. É especialmente relevante verificar que este resultado foi conseguido conservando todas as variáveis dentro dos seus limites operacionais e com melhoria dos perfis de tensão.
1944
1628
316
0
500
1000
1500
2000
2500
kW
Perdas IniciaisPerdas Finais
Diferença
Figura 29 – Potência de perdas sem e com recurso à geração distribuída, sentida na rede de 60 kV
55

o Subida geral das tensões na rede de 60 kV e correcção de algumas tensões excessivas.
0.98
1.00
1.02
1.04
1.06
1.08
1.10
1.12
1.14
Tensão (p.u.)
Barramentos 60 kV
Cenário Corrigido Cenário Inicial
Figura 30 – Perfil de tensão nos 60 kV, notando-se uma melhoria e melhor equilíbrio
o Forte correcção na tan φ dos PRE (geração dispersa), com o abandono das condições rígidas anteriores e passagem do seu controlo para a concessionária. É interessante verificar como a tan φ cai a zero em grande parte dos PRE, dispensando estes de qualquer produção de potência reactiva, ao contrário da exigência dos mecanismos legais mais comuns.
-0.30
-0.20
-0.10
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70 Cenário Inicial Cenário Corrigido
Figura 31 – Tan φ nos PRE – produtores em regime especial (geração dispersa)
o Descongestionamento dos ramos mais carregados, havendo mesmo um caso de redução de 48% para 18 % da capacidade máxima de transporte da linha.
Outros estudos foram feitos, nomeadamente considerando cenários de adição de novas baterias e condensadores.
56

A conclusão fundamental, do ponto de vista prático, é que a presença de geração dispersa, ao contrário de ser um incómodo e uma fonte de problemas para o operador da rede, pode ser transformada num instrumento útil de operação com interessantes ganhos em redução de perdas. Isto implica que os quadros regulatórios prevejam mecanismos de negociação entre PRE e operadores de rede a fim de que o controlo da reactiva possa ser efectuado de forma integrada. Também implica que mecanismos legais simplistas, fixando uma tan φ ou cos φ no ponto de entrega de energia por parte da geração dispersa, ainda que bem intencionados, podem redundar, de facto, num prejuízo global para o sistema e, no limite, para os consumidores que acabarão pagando os desperdícios.
16.5. Planeamento de energia reactiva – exemplo com ES O planeamento de energia reactiva é um problema geralmente definido numa base económica, em que se procura definir uma carteira de investimentos em compensação reactiva e/ou FACTS com obtenção de ganhos operacionais, sendo o mais típico deles o da redução de perdas – mas também se poderia procurar um aumento da capacidade de transporte de potência de uma rede, em especial com a introdução de transformadores esfasadores ou FACTS do tipo UPFC (Unified Power Flow Controller) por exemplo.
O problema é mais complexo que o anterior porque exige a consideração de cenários e a compatibilização entre investimentos e custos de operação.
Havendo vários modelos propostos, referiremos um [58], de planeamento da instalação de condensadores em nós da rede, pelas suas particularidades interessantes. Trata-se de um modelo de ES embora os autores lhe tenham originalmente chamado algoritmo genético. Na verdade, essa publicação compara de facto o desempenho de um algoritmo genético simples com dois modelos de computação fenotípica, sendo que um deles (o mais eficiente) beneficia de hibridação com um modelo matemático dos fluxos de energia reactiva na rede e dos coeficientes de sensibilidade (derivadas) que lhe estão associados.
O modelo de melhor desempenho tem por base a seguinte formulação geral:
Minimizar OBJ = [ CC + EC + VL ] (1)
Sujeito a: f(X,u) = 0 (2) (3) maximin SNSCS ≤≤ (4) maximin FNFCF ≤≤onde CC = função de investimento em condensadores EC = custo das perdas de energia VL = penalidades por desvios de tensão f(X,u) = equações do fluxo de potência NFCi = quantidade de condensadores fixos num barramento i NSCi = quantidade de condensadores comutáveis num barramento i
Na fixação de condensadores admite-se que possa haver uma capacidade fixa, não comutável, e uma capacidade comutável por escalões, que permite uma adaptação ao diagrama de carga. Os custos de uma e outra parte serão naturalmente diferentes. A função CC fica assim definida:
CC = sfC ⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛××⎟
⎟⎠
⎞⎜⎜⎝
⎛× ∑∑
==
n
1ii
n
1ii CSNSCCFNFC
onde sfc = factor de escala da função de investimento NFCi = quantidade de condensadores fixos instalados no barramento i NSCi = quantidade de condensadores comutáveis no barramento i CF = custo unitário de condensadores fixos CS = custo unitário de condensadores comutáveis em carga
Quanto à valorização das perdas de energia, ela foi assim modelizada:
EC = sfE ⎥⎥⎦
⎤
⎢⎢⎣
⎡××∑
=ii
m
1ii MCTPL
onde sfE = factor de escala da função das perdas de energia PLi = perdas no nível de carga i
57

Ti = tempo de duração do nível de carga i m = número de níveis do diagrama de carga considerados MCi = custo marginal da energia no período i
Foram ainda aplicadas penalidades aos desvios de tensão em ordem a bandas admissíveis.
O algoritmo evolucionário do tipo ES definiu um indivíduo como um vector de inteiros, cada elemento representando o número de escalões de condensadores a colocar em cada barramento definido como candidato, em cada período em que foi dividido o diagrama de cargas. Nas operações de reprodução usou-se recombinação e mutação.
A recombinação foi definida como cruzamento uniforme de dois indivíduos. A mutação obedeceu a uma distribuição Gaussiana, sendo o resultado arredondado para o inteiro mais próximo.
Usou-se ainda um esquema de “melhoramento” de indivíduos, substituindo os piores por novos indivíduos, gerados em locais indicados por um modelo matemático dos fluxos de potência reactiva. Esse modelo é um modelo de gradiente e baseia-se na seguinte igualdade:
GLOSS PP Δ=Δ
em que - desvio incremental das perdas de energia do sistema LOSSPΔ
- desvio incremental da potência injectada no barramento de referência, quando se calcula o fluxo de potência com um modelo de Newton-Raphson
GPΔ
Assim, usando os coeficientes de sensibilidade do nó de referência, derivados das equações de potência injectada e do inverso do Jacobiano do Newton-Raphson, pode obter-se um vector gradiente das perdas relativamente às variações de injecção de potência reactiva em cada nó i:
iQiVn
1i iVGP
iQin
1i iδGP
iΔQlossΔP
∂∂
∑= ∂
∂+
∂δ∂
∑= ∂
∂=
Este vector é usado para encontrar uma solução possivelmente melhor para as injecções de reactiva, de acordo com a seguinte expressão:
i
lossoldi
newi Q
PQQ
ΔΔ
α−=
onde - potência reactiva injectada no nó i oldiQ
- nova potência a injectar newiQ
α - passo de iteração (positivo)
Esta correcção de potência reactiva a injectar é, depois, transformada em capacidade colocada nos nós respectivos, com o arredondamento necessário.
Isto, de facto, corresponde à destruição de um indivíduo de mau desempenho e sua substituição por um indivíduo mais promissor. Este procedimento é activado sempre que a adaptação de um indivíduo se mantém inferior a um determinado limiar, fixado como sendo a adaptação do melhor indivíduo numa dada geração anterior – é, pois, um limite dinâmico. Portanto, o mérito deste modelo consiste na utilização do conhecimento sobre o modelo matemático do sistema como um operador de criação de novos indivíduos, mais prometedores que os anteriormente gerados. Resulta, portanto, num algoritmo híbrido matemático e evolucionário – cuja eficiência parece demonstrada.
A criação de um novo indivíduo por via das sensibilidades do modelo matemático dos fluxos de potência, se repetida excessivamente, pode capturar o problema num óptimo local. Por isso é que foi adoptada para “reparar” indivíduos de pior desempenho e não para melhorar os melhores indivíduos de uma geração. Para além disso, não é um método exacto, pois não só os seus resultados têm que ser arredondados para um valor discreto como a relação entre potência reactiva e a capacidade dos condensadores depende da tensão.
Os resultados deste algoritmo foram muito satisfatórios e aparecem ilustrados na publicação [58]. O diagrama da Figura 32 corresponde ao esquema simplificado do sistema eléctrico de uma das ilhas dos Açores, sob a responsabilidade da EDA – Electricidade dos Açores, SA. Na ilha existe geração diesel, hidroeléctrica e eólica, bem como redes a 30 e 15
58

kV. O problema tratado consistiu no estudo da introdução de compensação reactiva nos barramentos PQ, já que nos barramentos PV o controlo da excitação dos geradores (diesel e hidroeléctricos) já assegura algum controlo de tensão.
18
11
22 21 20 19
65
10
9
21 3 4
8
17
7
16
15
14
12
400V
400V
30kV
30kV
30kV
400V
15kV
15kV
15kV
6.6kV
6.6kV
6kV
13
25 24 23
0.8MVA
0.8MVA
8MVA
10MVA
10MVA
4MVA
4MVA
1MVA
5MVA
0.52MW0.32Mvar
2.9MW1.8Mvar
2.2MW1.4Mvar
2.2MW1.4Mvar
2.2MW1.4Mvar
2.7MW1.7Mvar
0.8MW0.5Mvar
16MVA
15.65MVA
G1
G2
0.9MVA
Dieselstation
Hydrostation
0.6MW
windturbine
Figura 32 – Diagrama unifilar simplificado da rede de uma das ilhas dos Açores
Em cada nó foi prevista a adição de capacidade fixa e capacidade comutável. Por questão de protecção de dados, exemplo numérico apresentado usaram-se custos fictícios, da ordem de €90 e €150 por 100 kVAr, respectivamente. O custo marginal da energia foi avaliado em €0,06/kWh, para fim de cálculo do custo das perdas. Foram ainda definidos três níveis de carga (ponta, média e vazio) reflectindo a forma do diagrama de carga típico da rede. A estes níveis fizeram-se corresponder as durações adequadas.
O algoritmo evolucionário definiu um fenótipo com um comprimento igual ao número de barramentos PQ do sistema e candidatos a receber baterias de condensadores, num total de 23. O algoritmo evolucionário foi montado com 30 indivíduos, fixando-se uma probabilidade de recombinação de 0,9 e uma probabilidade de mutação de 0,05. Isto aproximou de alguma forma o modelo dos procedimentos assumidos em algoritmos genéticos.
Permitiu-se ao algoritmo correr durante 300 gerações. Para definir o limiar desencadeando o processo de “reparação” invocando o modelo matemático de gradiente, tomou-se como referência o valor do melhor indivíduo 10 gerações atrás. Isto é, numa dada geração g, todos os indivíduos com valor de adaptação inferior ao valor de adaptação do melhor indivíduo da geração (g-10) são objecto de uma tentativa de substituição por indivíduos melhorados seguindo as equações de gradiente descritas.
59

Como resultados, na comparação entre a situação anterior e a solução encontrada pelo algoritmo, uma diferença mensal de 48%, de €6283,3 para €3254,8 em perdas de energia, para um custo de instalação estimado de €6531 (valores com base nos custos admitidos como dados do problema) para a instalação de 7,3 kVAr de condensadores.
Eis um exemplo de solução, obtida para uma definição do diagrama de cargas sem distinção entre períodos de vazio, médio e ponta:
Barramento 1 2 3 4 6 7 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 25 25N. módulos de 100 kVAr 2 1 1 0 0 4 6 0 0 9 4 9 0 13 15 9 0 0 0 0 0 0 0
Vê-se claramente que o algoritmo seleccionou os barramentos onde colocar injecção de reactiva, para obter uma solução óptima no compromisso entre redução de custos e investimentos. Neste caso, trata-se exclusivamente de capacidades fixas ou não comutáveis, porque o problema tinha um perfil de carga horizontal. Definir um perfil assim, com três períodos mas de carga igual, é um teste fundamental à qualidade do algoritmo, porque exige que a solução dê o mesmo número de condensadores para todos os períodos. Como se descreve em [58], outros algoritmos, não incluindo o procedimento de reparação de indivíduos pelo processo do gradiente, não conseguem convergir para este tipo de solução coerente.
0,88
0,9
0,92
0,94
0,96
0,98
1
No.7 No.14 No.15 No.16 No.17
N. Barramento
Ten
são
(p.u
) InicialFinal
Figura 33 – Melhoramento da tensões por efeito da adição de condensadores na rede, em alguns dos barramentos. A situação designada “inicial” corresponde à rede sem adições.
17. CONCLUSÕES Os modelos evolucionários conhecem uma explosão de propostas para dar solução aos problemas de gestão da energia reactiva, controlo de tensão e minimização de perdas nas redes eléctricas. Em particular, o EPSO está a mostrar-se como um método muito robusto e fiável na produção de resultados de qualidade.
60

CAPÍTULO V OS ALGORITMOS GENÉTICOS
18. INTRODUÇÃO Se os capítulos anteriores foram dedicados àquilo que designámos por computação fenotípica, este terá por objecto fazer referência à técnica irmã que está generalizadamente conhecida como Algoritmos Genéticos (AG). É um método da família evolucionária e, portanto, quanto ao princípio geral não tem segredos e não difere essencialmente das Estratégias de Evolução e da Programação Evolucionária (ES/EP).
O elemento diferenciador original foi, na verdade, o conceito de cromossoma como representação binária das soluções e esse elemento constitui-se num factor notável de marketing da própria técnica, pela assimilação inevitável aos conceitos biológicos da genética e da codificação do ADN. Para além disso, a geração de soluções novas pelo mecanismo do cruzamento (crossover) encontrou imediata analogia nos fenómenos ocorrentes na meiose celular, pelo que a sensação de imitação da natureza deve, com certeza, ter aumentado o poder de atracção da técnica sobre os investigadores e, em particular sobre os jovens. Como instrumento de marketing, é quase perfeito: se a Natureza é tão bem sucedida a optimizar (então não produziu o homem?), a sua imitação decerto é um instrumento de sucesso.
A escola dos algoritmos genéticos deve o seu êxito aos trabalhos de Holland [59], Goldberg [60], Grefenstette [61], para mencionar os mais conhecidos, e ao entusiasmo de inúmeros seguidores. A aplicação de Algoritmos Genéticos aos Sistemas de Potência começou a registar inúmeras propostas a partir dos primeiros anos da década de 1990, conforme regista uma recolha publicada na época [62]. Já nessa época se registavam aplicações numa variedade de áreas, descritas na tabela seguinte, sendo a vasta maioria com variantes de AG:
ÁREA CAMPO
A1. Geração-transmissão A2. Transmissão-distribuição
A. Planeamento estrutural ou da expansão
A3. Planeamento de reactiva, localização de condensadores B1. Pré-despacho de geração, escala de serviço de geradores B2. Despacho B3. Despacho de reactiva, controlo de tensão B4. Planeamento da manutenção
B. Planeamento da transmissão
B5. Avaliação de segurança C1. Minimização de perdas, manobras em redes C2. Processamento de alarmes, diagnóstico de avarias C3. Recuperação de serviço C4. Gestão de carga C5. Previsão de carga C6. Estimação de estado
C. Operação de geração/transmissão e de distribuição
C7. FACTS D1. Fluxo de potência D. Análise D2. Harmónicos
E. Controlo E1. Estimação de parâmetros, sintonização de controladores
19. CARACTERÍSTICAS PRÓPRIAS DOS ALGORITMOS GENÉTICOS A característica mais distintiva dos AG, no início da expansão da sua utilização, foi a representação de soluções na forma de um cromossoma composto por uma sequência (string) de bits. Alegava-se que as variáveis binárias ficavam representadas com naturalidade, as inteiras podiam ser representadas em numeração binária e as reais em representação
61

binária em vírgula flutuante − por isso, toda a representação de um problema se poderia codificar num cromossoma de bits.
Sobre cromossomas assim constituídos, incidem as operações de recombinação e de mutação. A recombinação começou por ser apenas cruzamento simples entre dois cromossomas, com troca de partes de cada cromossoma (executado com probabilidade alta, tipicamente de 0,8) e mais tarde evoluiu para outras formas. A mutação começou por ser uma simples inversão do valor de um bit, condicionada por dada probabilidade em geral baixa (por exemplo, 1 em cada 500 bits).
Embora bastante investigação se tenha efectuado sobre modelos com cromossomas de comprimentos variáveis, a verdade é que, na prática, a grande maioria das aplicações usa cromossomas de comprimento fixo.
Anos atrás, afirmava-se que o que diferenciava os Algoritmos Genéticos clássicos dos métodos de optimização tradicionais seria o seguinte:
• Os AG codificam as variáveis de um problema numa sequência de bits e não como valores naturais das variáveis. O significado dos bits é indiferente para a operação do algoritmo
• Os AG efectuam uma pesquisa no espaço a partir de múltiplos pontos no espaço em vez de apenas um ponto
• Os AG apenas precisam da definição de uma função objectivo (habitualmente designada como função de adaptação ou de aptidão) e dispensam conhecimento de derivadas ou outras informações sobre a estrutura dos problemas.
• Os AG usam regras de transição probabilística (cruzamento, mutação) em vez de regras determinísticas para fazer progredir o processo.
Hoje em dia, a apreciação do desempenho dos AG levou a alguma evolução nestes conceitos. Por exemplo, presentemente é assumido que a incorporação de informação suplementar sobre as características dos problemas pode conduzir a maior eficiência na sua resolução.
Num AG canónico usam-se, pois, três operadores genéticos (Selecção, Cruzamento e Mutação) e cromossomas de comprimento fixo, lineares e binários. Cada nova geração é criada pelo operador Selecção e alterada por cruzamento e mutação. A primeira população é criada de forma aleatória.
Cada cromossoma representa uma possível solução do problema e deve ser representado por uma sequência binária. Por exemplo, no intervalo de inteiros [1, 31], pode-se codificar uma variável usando 5 bits (como, por exemplo, 10110 ou 00011). Se as variáveis forem binárias, então basta um bit por variável. Num problema com múltiplas variáveis, todas têm que ter representação binária no cromossoma.
Cada solução deve ser avaliada pela função de adaptação para produzir um valor. Se quisermos, num problema, maximizar a função f(x) = x2, teremos que o cromossoma 10110 recebe o valor de adaptação 222 enquanto que o cromossoma 00011 recebe o valor 32, sendo, portanto, um indivíduo pior, com relação ao objectivo – ou seja, sendo menos adaptado ao ambiente criado pela função de adaptação, sendo um indivíduo menos apto.
Em muitos casos, bastaria assimilar o conceito de função de adaptação ao de função objectivo da optimização clássica. Todavia, um excessivo desejo de imitar conceitos ecológicos tem feito com que alguns investigadores transformem as funções objectivo dos seus problemas de modo a trabalharem com funções de adaptação crescentes (com a ideia de que um maior valor de adaptação é preferível). Este exercício é completamente inútil, porém, a não ser que o processo de selecção tenha em conta o valor da adaptação para dar maior probabilidade de sobrevivência em função dele. É o caso da selecção por roleta, em que a probabilidade de selecção para a geração seguinte é proporcional ao valor da adaptação. Já não é o caso do torneio estocástico, que é o processo presentemente mais usado, em que a probabilidade de selecção depende apenas da relação de ordem entre os indivíduos comparados – no torneio estocástico mais simples, um par de cromossomas é sorteado e comparado e sobrevive o indivíduo de melhor adaptação, com uma alta probabilidade (tipicamente 0,8).
A função de adaptação, como em qualquer Algoritmo Evolucionário, não precisa de ser numérica, podendo ter aspectos qualitativos, desde que a selecção adopte processos de torneio estocástico.
A recombinação canónica, como dissemos, é o procedimento de cruzamento simples. Dado um par de cromossomas, um ponto de cruzamento é escolhido de forma aleatória e duas metades dos cromossomas são trocadas − veja-se a ilustração na Figura 34, onde dois indivíduos A e B escolhidos aleatoriamente de entre os seleccionados para a geração seguinte são origem a dois novos indivíduos A’ e B’.
62

1 0 0 0 1 1 1
1 1 0 1 1 1 1
1 0 0 0 0 1 0
1 1 0 1 0 1 0
Ponto de cruzamento
A
B
A'
B'
Figura 34 – Ilustração da acção do operador Cruzamento. Uma vez sorteado um ponto de cruzamento, duas partes correspondentes de dois cromossomas são trocadas.
20. DISTINÇÃO ENTRE AG E ES/EP Os Algoritmos Genéticos e as Estratégias de Evolução/Programação Evolucionária são dois ramos da família dos Algoritmos Evolucionários e, portanto, têm em comum todo o fundamento do progresso por selecção sobre uma população evolutiva. Inicialmente, começaram por ter características claramente marcadas, resumidas na tabela seguinte:
AG ES/EP
Codificação das soluções Numa sequência de bits Num vector de variáveis reais
Mecanismo preferencial para gerar novas soluções
Recombinação (cruzamento), com pequena contribuição de mutação por inversão de bit
Mutação gaussiana
Interpretação das soluções Algoritmo de descodificação dos cromossomas
Leitura natural dos valores das variáveis
Nos últimos anos, tem-se assistido a uma evolução convergente destas técnicas. Assim,
• As ES/EP começaram a adoptar esquemas de recombinação, seguindo o exemplo dos AG, experimentando outros esquemas para além do cruzamento simples
• Os AG começaram a adoptar o que chamaram de cromossomas com variáveis reais, em vez de sequências de bits, o que significa passarem a adoptar representações semelhantes às ES/EP
• Os AG começaram a experimentar processos de recombinação diferentes do cruzamento simples, semelhantemente às ES/EP
• Os AG começaram a experimentar taxas de mutação auto-adaptativas, o que também os aproxima dos conceitos explorados nas ES/EP.
Portanto, que distingue verdadeiramente hoje os AG das ES/EP? Honestamente, sobra muito pouco, excepto rivalidades entre escolas de pensamento e, porventura, entre protagonismos de personalidades no mundo científico, que os possa distinguir. Por isso, aparecem hoje publicados modelos a que os autores chamam Algoritmos Genéticos, e que outros autores poderiam perfeitamente chamar Programação Evolucionária: questão de gosto, ou fidelidade...
A verdadeira discussão, portanto, que poderá levar a opções importantes sobre o tipo de modelo e algoritmo a adoptar face a um problema de optimização concreto, não parece estar centrada tanto sobre se será Algoritmo Genético ou Programação Evolucionária, porque começa a ser preciso ter uma fortíssima lupa para os distinguir, pelo menos nas formas que mais os aproximam.
Uma verdadeira distinção, isso sim, aparecerá entre o que chamamos de Computação Evolucionária Fenotípica e Computação Evolucionária Genotípica. Ou seja, entre modelos que estabelecem correspondência bi-unívoca entre solução e codificação da solução e os métodos em que a correspondência é apenas unívoca ou, pelo menos, não se conhece mecanismo útil para, dada uma solução, descobrir qual o cromossoma que a codifica.
Este último caso é o caso da evolução biológica. A codificação de um ser vivo reside no ADN, mas o que lá está gravado não são os parâmetros físicos e químicos do indivíduo, mas programas para construir um indivíduo. Nesse
63

sentido, dado um cromossoma, pode-se construir o indivíduo mas dado o indivíduo é virtualmente impossível recompor o cromossoma.
A atracção pelas soluções da biologia é inegável, o fascínio é imenso. Mas, em engenharia, não haverá processos alternativos mais eficientes?
21. A PESQUISA NO ESPAÇO DE SOLUÇÕES E A COMPARAÇÃO AG vs. ES/EP E EPSO Para se construir um algoritmo evolucionário robusto, este deve garantir duas propriedades de certa forma contraditórias: exploração (do espaço) e aprofundamento (de regiões prometedoras). O papel das operações de recombinação e de mutação, e também de movimento de partículas, nos modelos EPSO, é garantir essas duas propriedades, no momento da criação de novos indivíduos. Podemos afirmar que cada uma daquelas operações introduz, no problema, um conceito de “vizinhança”: cada solução tem como vizinhos, não outras soluções definidas no espaço cartesiano e euclidiano das variáveis de decisão, mas as soluções para onde o problema pode “saltar”, por aplicação dos operadores. Cada operador, aplicado a uma representação ou forma de cromossoma codificando uma solução, induz, assim, uma relação topológica de vizinhança.
Compreender isto é muito relevante para a eficiência dos algoritmos.
Olhando para uma representação cromossómica na forma de sequência de bits de um AG, podemos compreender que a mutação de um bit origina uma nova solução. Agora, depende do algoritmo que interpreta o cromossoma se essa nova solução fica muito distante (é muito diferente, na sua expressão do fenótipo), ou não, da progenitora. Se for, favorece a exploração; se não for, favorece o aprofundamento.
O mesmo diremos sobre a recombinação.
Ora a compreensão deste mecanismo depende do próprio processo (mais ou menos engenhoso) de codificar as soluções. E torna-se agora fácil de entender que os modelos de ES/EP, ao codificarem as soluções nas suas variáveis naturais, são mais susceptíveis de serem entendidos pelas pessoas que os têm que interpretar – é mais fácil compreender que tipo de vizinhanças estão a ser geradas pelos operadores e mais fácil de experimentar variantes nos operadores para obter efeitos específicos desejados.
Pelo contrário, uma codificação não natural, ou do tipo genotípico, em que o cromossoma é um programa para construir um indivíduo, torna-se opaca à interpretação. Aí, efeitos surpreendentes podem emergir de mutações simples. Infelizmente, esses efeitos, se algumas vezes produzem melhores soluções, concorrem muitas outras vezes para afastar a busca para muito longe de regiões prometedoras, ao induzirem saltos importantes.
Por outro lado, é muito importante, para a eficiência de um algoritmo evolucionário, que poucas ou nenhumas soluções inviáveis sejam geradas pelo processo de reprodução. Os modelos que geram elevada percentagem de indivíduos inviáveis convergem muito lentamente ou mesmo não convergem.
Existem três técnicas básicas de controlar o problema dos inviáveis:
• pela aplicação de penalidades;
• pela definição de uma codificação que implicitamente inclua as restrições, de tal forma que mutações ou recombinações só gerem descendentes viáveis;
• e pelo controlo dos processos de mutação e recombinação, para o mesmo efeito.
O processo menos eficiente é o primeiro. Se for adoptado em vez dos dois últimos, o algoritmo evolucionário terá muito menos possibilidades de ter uma boa convergência.
Compreende-se que nos Algoritmos Genéticos a aplicação das duas últimas técnicas possa ser mais difícil, porque é também mais difícil compreender os efeitos de mutações ou recombinações, quando incidindo sobre os bits. E isto favorece mais uma vez a adopção prática de modelos próximos do paradigma ES/EP.
Do ponto de vista da engenharia, compreender como funciona um algoritmo, num determinado problema particular, é muito importante. Por isso, os modelos das Estratégias de Evolução/Programação Evolucionária, e EPSO, são mais fáceis de implementar do que modelos mais próximos do paradigma genético – e também são mais fáceis de sintonizar nos parâmetros que os controlam.
Não quer isto dizer que um Algoritmo Genéticos não possa apresentar um bom desempenho. Apenas quer dizer que, do ponto de vista do custo de desenvolvimento de uma boa solução algorítmica, os modelos de ES/EP tenderão a ser mais económicos e, possivelmente, mais robustos.
64

22. EXEMPLO DE UM ALGORITMO GENÉTICO Os projectos CARE e MORE-CARE, desenvolvidos dentro do programa JOULE-THERMIE dos Programas-Quadro de investigação da União Europeia, tiveram por objectivo o desenvolvimento de novos conceitos para centros de controlo de redes isoladas ou fracas e que dispusessem de geração térmica clássica e de geração eólica. Várias instituições e empresas formaram os consórcios dos projectos, oriundas de vários países, entre as quais a França (ARMINES), Grécia (NTUA, Univ. Thessaloniki), Portugal (INESC Porto), UK (UMIST), um fabricante e fornecedor de soluçóes (EFACEC, Portugal) e duas concessionárias (a PPC, a empresa nacional da Grécia e a EDA, a concessionária das ilhas dos Açores, Portugal. Presentemente, vários sistemas em ilhas, na UE, são operados com aplicações geradas naqueles projectos, como seja o caso da ilha de Creta, na Grécia, operada pela PPC.
Um dos módulos que foi desenvolvido para incorporar o EMS (Energy Management System) foi o de pré-despacho de geração (unit commitment), concebido especialmente para acomodar a previsão de geração eólica na produção de uma escala de serviço da geração clássica, composta de unidades a vapor, a gás, ciclo combinado, diesel e hidroeléctricas. O vento não pode ser considerado como um recurso despachável embora se possa controlar a produção pelo desligamento de geradores. Isto pode ser especialmente relevante, em sistemas isolados, nas horas de vazio, em que a geração eólica pode ultrapassar limiares percentuais de segurança relativamente à produção por outras fontes.
O modelo desenvolvido no INESC Porto tem as seguintes características:
• Adopção de um modelo evolucionário do tipo genético com características especiais de compressão de código, reparação de cromossomas e Lamarckismo (melhoria de soluções).
• Aceitação da previsão da carga e, em especial, do vento, na forma de intervalos de incerteza em vez de números reais determinísticos
• Adopção de restrições difusas (com base em conceitos dos conjuntos difusos − fuzzy sets), em especial relativamente ao vento e ao seu grau de penetração, em função da incerteza na sua previsão
• Inclusão de todos os tipos de custos, como seja associados a combustível, tomada de carga (ramping), arranque e paragem
• Inclusão de todo o tipo de limites técnicos como seja tempos mínimos de paragem e ainda dos procedimentos de tomada de carga pelas unidades térmicas, a frio ou a quente, de acordo com procedimentos técnicos definidos na forma de regras, e ainda equilíbrio de potência, penetração máxima de geração eólica
• Inclusão de condições para garantir reserva girante, podendo ser escolhido um critério percentual relativamente à carga prevista ou um critério probabilístico relativamente à probabilidade de, no próximo período de tempo, ocorrerem eventos que conduzam à incapacidade de alimentação da carga.
O conceito desenvolvido no projecto CARE tem por base a seguinte sequência de operações:
• Um pré-despacho para as 48 horas seguintes (48-UC), estabelecido numa base horária
• Um pré-despacho para as 8 horas seguintes (8-UC), numa base de períodos de 10 minutos, usando os resultados anteriores como condicionante para os últimos intervalos de 10 minutos
Os algoritmos que procedem ao cálculo destas operações são ambos do tipo AG e semelhantes. Todavia, entram em níveis de detalhe diferente. Por exemplo, no 48-UC de médio prazo, a tomada de carga dos geradores (ramping) é representada apenas por um valor aproximado, enquanto que no 8-UC todo o procedimento de arranque, aquecimento e tomada de carga por sucessivos patamares aparece representado de acordo com as instruções a que obedecem os operadores.
Esta abordagem foi efectivamente implementada e está instalada em alguns países, tendo sido a primeira instalação em Creta, ilha onde a concessionária é a PPC (Public Power Corporation), empresa pública da Grécia. Segue-se uma breve descrição.
Comentários gerais – O procedimento CARE, com base em Algoritmos Genéticos, busca o óptimo global dos custos de pré-despacho e despacho considerando uma grande dicersidade de custos e restrições, referidos anteriormente. O Algoritmo Genético implementado usa uma função de adaptação que inclui penalidades em caso de violação de certas restrições.
Cromossomas − Uma representação clássica simples seria na forma de 1 bit por gerador e por hora, indicando se esse gerador se encontra em serviço (1) ou fora de serviço (0) nessa hora. Porém, para sistemas com grande número de
65

geradores, isso conduz a um cromossoma muito extenso, o que dificulta muito a convergência. Veja-se que um sistema com 50 geradores, em 24 horas, teria um cromossoma de comprimento igual a 1200 bits. Constatando-se, porém que existem tipicamente horas seguidas onde o parque de geração em serviço se mantém constante, pode-se conceber um cromossoma comprimido, organizado por blocos de horas, como ilustrado na Figura 35.
1 0 0 1 1 1 0 1 1 1 1 1 0 1 1 1 0 0 1 0
G1 G2 G3 G4 G5 G1 G2 G3 G4 G5 G1 G2 G3 G4 G5 G1 G2 G3 G4 G5
1º Bloco 2º Bloco 3º Bloco 4º Bloco 5 horas 8 horas 3 horas 8 horas
Figura 35 – Cromossoma clássico para o problema do pré-despacho, organizado por blocos horários – exemplo para 5 geradores e 4 blocos em 24 horas. Em cada bloco, um bit por gerador indica se o gerador se encontra em serviço ou desligado durante as horas correspondentes.
Esta estratégia é claramente sub-óptima, dada a rigidez dos blocos. A inovação consistiu em adicionar a cada bloco mais 3 bits, a saber:
• 1 bit S que liga ou desliga o bloco inteiro, isto é, que prolonga pelas horas do bloco a definição do bloco anterior
• 2 bits T1 e T2 que permitem antecipar ou atrasar a hora de início do bloco
Na Figura 36 encontra-se uma ilustração deste tipo de cromossoma. Note-se que, neste exemplo, o Bloco 3 está desligado e, portando, a escala de serviço do Bloco 2 prolonga-se até ao Bloco 4. Os bits T1 e T2 do Bloco 4, porém, estão ligados, podendo significar que este bloco antecipa o seu início em 3 horas.
1 0 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1 1 0 1 1 1 1 1 1 0 0 1 0
S T1 T2 G1 G2 G3 G4 G5 S T1 T2 G1 G2 G3 G4 G5 S T1 T2 G1 G2 G3 G4 G5 S T1 T2 G1 G2 G3 G4 G5
1º Bloco 2º Bloco 3º Bloco 4º Bloco 5 horas 8 horas 3 horas 8 horas
Figura 36 − Cromossoma por blocos horários, com bit S ligando ou desligando o bloco e 2 bits T1 e T2 ajustando a hora de início do bloco
Na verdade, a mesma solução poderia ter sido obtida mantendo o 3º Bloco ligado, assegurando que os seus bits teriam idêntico valor ao Bloco 2, e desligando os bits T do bloco 4. Mas, além de ser muito mais laborioso conseguir esse resultado, verifica-se que não há, na verdade, uma correspondência bi-unívoca entre genótipo e fenótipo, tornando este modelo muito mais próximo das soluções biológicas.
Este tipo de cromossoma é interessante, porque já não é apenas fenotípico e daí servir-nos de exemplo. Ele encerra em si as instruções para construir um pré-despacho, mas não constitui o pré despacho em si mesmo. Note-se que o efeito de uma mutação pode ser ligeiro (alteração do estado de um gerador) ou importante (alteração drástica da organização do pré-despacho). E, ainda assim, é um cromossoma muito mais compacto do que a representação clássica simples. Para 50 geradores, seriam precisos apenas 212 bits neste exemplo de 24 horas.
Avaliação – O valor da função de adaptação é calculado somando os custos de arranque e paragem, e outros dependentes da escala de serviço, com os custos de operação calculados pela corrida de uma rotina de despacho de geração aplicada a cada ora em função da previsão de carga e vento. Esta rotina tem por base o modelo de despacho de potência activa em sistema de barramento único e inclui restrições difusas para a previsão da potência eólica disponível.
Reserva girante – A exigência de reserva girante é assegurada pela inclusão na função de adaptação, na forma de penalidade, de um desvio em relação a limites fixados, de percentagem da carga ou de probabilidade de corte de carga.
66

Selecção − Adoptou-se o método designado como deterministic crowding [63]. Neste método, dois indivíduos sorteados numa geração são recombinados e mutados, dando origem a dois descendentes; os descendentes são emparelhados com os progenitores por forma a maximizar a semelhança nos pares formados, e os dois mais aptos sobrevivem para a geração seguinte. Este método tem por objectivo tentar preservar a diversidade na população.
Recombinação − Adoptou-se o cruzamento clássico com um ponto sorteado.
Mutação − A taxa de mutação é incrementada sempre que o algoritmo parece não progredir, e reduzida logo que progressos são obtidos
Reparação e melhoria de soluções − Foram implementados esquemas Lamarckistas de correcção de soluções, recuperando cromossomas inviáveis e, para certos cromossomas já correspondendo a boas soluções, buscas na sua vizinhança na tentativa de encontrar melhores alternativas.
Resultados − Apresentam-se, seguidamente, ilustrações de resultados para a ilha de Creta, com um sistema composto por 17 geradores compreendendo 6 turbinas a vapor, 4 diesel, 7 a gás e ainda 3 parques eólicos. Na Figura 37 e na Figura 38 vêem-se exemplos para a fase 1 (48-UC) e para a fase 2 (8-UC). A Figura 39 apresenta a interface para o operador do sistema que incorpora o Algoritmo Genético de pré-despacho, em exploração em Creata (Grécia).
GT7GT6GT5GT4 GT1 Diesel 4 Dies
el 3Diesel 2
Diesel 1
Gas2Gas1Steam 6
Steam 5
Steam 4
Steam 3
Steam 2 Stea
m 1 Total Wind Generation
Reserve req.
Spin. Reserve
0
20
40
60
80
100
120
140
160
180
200
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47
Hours
MW
Figura 37 − Exemplo de resultado de pré-despacho para Creta, do tipo 48-UC. Note-se como a reserva girante disponível excede sempre o limiar fixado (linha tracejada). Neste caso, a geração eólica ocupa a faixa inferior do diagrama.
67

0
20
40
60
80
100
120
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47
Intervals
MW
GT7GT6GT5GT4GT1Diesel4Diesel3Diesel2Diesel1Gas2Gas1Steam6Steam5Steam4Steam3Steam2Steam1WP3WP2WP1With S. ReserveLoad
Figura 38 – Ilustração de resultados do procedimento 8-UC. Pré-despacho para 8 horas com resolução de 20 minutos.
Figura 39 − Interface do sistema CARE mostrando a curva de carga efectiva e a previsão para as horas seguintes, bem como os módulos accionados (à direita).
68

69

REFERENCES
[1] H.-P. Schwefel, G. Rudolph “Contemporary evolution strategies” in F. Morán, A. Moreno, J. J. Merelo and P. Chacón, ed., “Advances in Artificial Life”, 3rd International Conference on Artificial Life, vol 929 of Lecture Notes in Artificial Intelligence, pag. 893-907. Springer, Berlin, 1995.
[2] Beyer, H.-G., “Towards a Theory of Evolution Strategies: Some Asymptotical Results from the (1,+λ)-Theory, in Evolutionary Computation, vol. 1, no. 2, pag. 165-188, 1993
[3] Rechenberg, I., “Evolutionsstrategie-Optimierung technischer Systeme nach Prinzipen der biologischen Evolution”, Frommann-Holzboog, Stuttgart, 1973
[4] Schwefel, H.-P., “Adaptive Mechanismen in der biologischen Evolution und ihr Einfluß auf die Evolutionsgeschwindigkeit”, Technical report, Technical University Berlin, 1974
[5] Schwefel, H.-P., Evolution and Optimum Seeking, Ed. Wiley, New York NY, 1995
[6] Beyer, H.-G., “Toward a Theory of Evolution Strategies: Self-Adaptation”, in Evolutionary Computation, vol. 3, no. 3, pag. 311-347, 1996
[7] Beyer, H.-G., “Towards a theory of Evolution Strategies: Progress Rates and Quality Gain for (1,+λ) Strategies on (Nearly) Arbitrary Fitness Functions”, in Y.Davidor, R.Männer and H.-P. Schwefel (eds.), “Parallel Problem Solving from Nature”, 3, Heidelberg, pp. 58-67, Springer Verlag, 1994
[8] 8. Beyer, H.-G., “Toward a Theory of Evolution Strategies: the (μ,λ) Theory”, in Evolutionary Computation, vol. 2, no. 4, pag. 381-407, 1995
[9] H.-P. Schwefel, “Natural Evolution and Collective Optimum-Seeking”, in A. Sydow ed., “Computational System Analysis: Topics and Trends”, pag. 5-14, Elsevier, Amsterdam, 1992
[10] D.B.Fogel, “Evolving Artificial Intelligence”, Ph.D. Thesis, University of California, San Diego, 1992
[11] D.B.Fogel, L.J.Fogel, J.W.Atmar, “Meta-evolutionary programming”, in R.R.Chen ed., “Proceedings of the 25th Asilomar Conference on Signals, Systems and Computers, San Jose CA, USA, Maple Press, pag. 540-545, 1991
[12] D.B. Fogel, "Evolutionary Computation: Toward a New Philosophy of Machine Intelligence" (second edition), IEEE Press, 2000
[13] L Fogel et al., "Artificial Intelligence Through Simulated Evolution", 1966, John Wiley & Sons
[14] Beyer, H.-G., “Toward a Theory of Evolution Strategies: on the benefits of Sex - the (μ/μ,λ) Theory”, in Evolutionary Computation, vol. 3, no. 1, pag. 81-111, 1995
[15] M. Herdy, G. Patone, “Evolution Strategy in Action – 10 ES-Demonstrations”, proceedings of the International Conference on Evolutionary Computation, Jerusalem, Israel, October 1994
[16] Kennedy, J., Eberhart, R.C. (1995), “Particle Swarm Optimization”, Proceedings of the 1995 IEEE International Conference on Neural Networks (Perth, Australia), pp. 1942-1948
[17] Vladimiro Miranda, Nuno Fonseca, "EPSO – Best-Of-Two-Worlds Meta-Heuristic Applied To Power System Problems ", Proceedings of WCCI'2002 - CEC - World Congress on Computational Intelligence - Conference on Evolutionary Computing, Proceedings of, May, 2002.
[18] Lovberg, M. et al. (2001), “Hybrid Particle Swarm Optimiser with Breeding and Sub-populations”, Proceedings of GECCO2001 - Genetic and Evolutionary Computation Conference 2001(pp. 409), July 7-11 2001, San Francisco CA, USA
[19] Clerc, M. (1999), “The Swarm and the Queen: Towards a Deterministic and Adaptive Particle Swarm Optimization”, Proceedings of the 1999 Congress of Evolutionary Computation, vol. 3, 1951-1957, IEEE Press
[20] Kennedy, J. (1997), “The Particle Swarm: Social Adaptation of Knowledge”, Proceedings of the 1997 International Conference on Evolutionary Computation, pp. 303-308, IEEE Press
[21] Beyer, H.-G. (1996), “Toward a Theory of Evolution Strategies: Self-Adaptation”, in Evolutionary Computation, vol. 3, no. 3, pag. 311-347
70

[22] Miranda, V., Fonseca, N., “EPSO – Best-of-Two-Worlds Meta-Heuristic Applied to Power System Problems”, Proceedings of WCCI/CEC – World Conference on Computational Intelligence, Conference on Evolutionay Computation, Honolulu (Hawaii), USA, June 2002
[23] Miranda, V., Fonseca, N., "EPSO - Evolutionary Particle Swarm Optimization, a New Algorithm with Applications in Power Systems ", Proceedings of IEEE/PES Transmission and Distribution Conference and Exhibition 2002: Asia Pacific, vol.2, pp.745-750, October, 2002
[24] Miranda, V., Fonseca, N., “EPSO - Evolutionary self-adapting Particle Swarm Optimization”, Internal report v. 2.0, 24/4/2002 , INESC Porto, Portugal
[25] Kennedy, J., Eberhart, R.C. (1997), “A discrete binary version of the particle swarm algorithm”, Proceedings of IEEE Conf. on Systems, Man, and Cybernetics, pag. 4104–4109
[26] V. Miranda, “Tutorial on Modern Heuristic Optimization Techniques with Applications to Power Systems” (Ch.12), IEEE Power Engineering Society, K.Y.Lee and M.El-Sharkawi ed., IEEE pub. No. 02TP160, Jan 2002
[27] Vladimiro Miranda, Nuno Fonseca, “EPSO- Evolutionary self-adapting Particle Swarm optimization”, internal report INESC Porto, July 2001 (obtainable from the authors by request).
[28] L.M.Proença, J. Luis Pinto, Manuel M. Matos, “Economic dispatch in isolated networks with renewables using evolutionary programming”, Proceedings of IEEE Budapest Power Tech’99, paper BPT99-361-25, Budapest, Hungary, Aug 29-Sep 2, 1999
[29] D. C. Walters, G. B. Sheble, "Genetic algorithm solution of economic dispatch with valve point loading", IEEE Transactions on Power Systems, Vol. 8, 1993, pp. 1325-1332.
[30] D. Srinivasan, A. Tettamanzi, "An evolutionary algorithm for evaluation of emission compliance options in view of the Clean Air Act Amendments", paper no. 96 WM 294-9-PWRS, presented at IEEE PES Winter Power Meeting, Baltimore, USA, January 21-25, 1996.
[31] D. Srinivasan, A. Tettamanzi, "An integrated framework for devising optimum generation schedules", Proceedings of the IEEE International Conference on Evolutionary Computation (ICEC’95), Perth, Australia, December 1995, Vol. 1, pp. 1-4.
[32] F. Li, R. Morgan, D. Williams, Y. H. Song, "Constrained economic dispatch scheduling in a real public electricity supply system using a genetic approach", Proceedings of the 30th Universities Power Engineering Conference, Vol. 2, 1995, London, UK, pp. 439-442.
[33] F. Li, R. Morgan, D. Williams, Y. H. Song, "Handling constrained power dispatch with genetic algorithms", Proceedings of the First IEE/IEEE International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications (GALESIA’95), Sheffield, UK, 12-14 September 1995, pp. 181-187.
[34] F. Li, Y. H. Song, R. Morgan, "Genetic algorithm based optimization approach to power system economic dispatch", Proceedings of the 29th Universities Power Engineering Conference, Part 2, Galway, Ireland, 1994, pp. 680-683.
[35] G. B. Sheble, K. Brittig, "Refined genetic algorithm - Economic dispatch example", IEEE Transactions on Power Systems, Vol. 10, 1995, pp. 117-124.
[36] H. C. Chang, P. H. Chen, "A novel economic dispatch approach - Implementation of genetic algorithm", Proceedings of IEEE/KTH Stockholm Power Tech Conference, Stockholm, Sweden, June 18-22, 1995, pp. 48-54.
[37] H. Ma, A. A. El-Keib, R. E. Smith, "Genetic algorithm-based approach to economic dispatch of power systems", Proceedings of the IEEE SOUTHEASTCON’94, Miami, FL, USA, 1994, pp. 212-216.
[38] H. Mori, T. Horiguchi, "A genetic algorithm based approach to economic load dispatching", Proceedings of the Second International Forum on Applications on Neural Networks to Power Systems (ANNPS’93), Japan, 1993, pp. 145-150.
[39] H. T. Yang, P. C. Yang, C. L. Huang, "Evolutionary programming based economic dispatch for units with non-smooth fuel cost functions", IEEE Transactions on Power Systems, Vol. 10, 1995.
71

[40] K. P. Wong, Y. W. Wong, "Genetic and genetic/simulated annealing approaches to economic dispatch", IEE Proceedings Part C - Generation, Transmission and Distribution, Vol. 141, 1994, pp. 507-513.
[41] K. P. Wong, Y. W. Wong, "Thermal generator scheduling using hybrid genetic/simulated annealing approach", IEE Proceedings Part C - Generation, Transmission and Distribution, Vol. 142, No. 4, July 1995, pp. 372-380.
[42] K. S. Swarup, M. Yoshimi, Y. Izui, N. Nagai, "Genetic algorithm approach to environmental constrained economic dispatch", Proceedings of International Conference on Intelligent Systems Applications to Power Systems (ISAP’94), France, September 1994, pp. 707-714.
[43] M. Salami, G. Cain, "Multiple genetic algorithm processor for the economic power dispatch problems", Proceedings of the First IEE/IEEE International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications (GALESIA’95), Sheffield, UK, 12-14 September 1995, pp. 188-193.
[44] M. Yoshimi, K. S. Swarup, Y. Izui, "Optimal economic power dispatch using genetic algorithms", Proceedings of the Second International Forum on Applications on Neural Networks to Power Systems (ANNPS’93), Japan, 1993, pp. 157-162.
[45] P. H. Chen, H. C. Chang, "Genetic aided scheduling of hydraulically coupled plants in hydro-thermal co-ordination", paper no.: 95 SM 570-2-PWRS, presented at IEEE-PES Summer Meeting at Portland, USA, July 23-27, 1995.
[46] P. H. Chen, H. C. Chang, "Large-scale economic dispatch by genetic algorithm", ", IEEE Transactions on Power Systems, Vol. 10, 1995.
[47] S. O. Orero, M. R. Irving, "Genetic algorithm for generator scheduling in power systems", International Journal of Electrical Power and Energy System, Vol. 18, No. 1, Jan 1996, pp. 19-26.
[48] S. O. Orero, M. R. Irving, "Scheduling of generators with a hybrid genetic algorithm", Proceedings of the First IEE/IEEE International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications (GALESIA’95), Sheffield, UK, 12-14 September 1995, pp. 200-206.
[49] Y. H. Song, F. Li, R. Morgan, D. T. Y. Cheng, "Effective implementation of genetic algorithms on power economic dispatch", Proceedings of the International Power Engineering Conference (IPEC’95), Singapore, March 1995, pp. 268-274.
[50] Yoshida, H., Fukuyama, Y., Takayama, S. and Nakanishi, Y., “A particle swarm optimization for reactive power and voltage control in electric power systems considering voltage security assessment”, IEEE Proc. of SMC '99 , Vol. 6, pp.497 -502, 1999
[51] H. Yoshida, K. Kawata, Y. Fukuyama, S. Takayama, and Y. Nakanishi, “A Particle Swarm Optimization for Reactive Power and Voltage Control Considering Voltage Security Assessment”, IEEE Trans. on Power Systems, vol. 15, no. 4, pp.1232-1239, Nov. 2000
[52] Fukuyama, Y., Yoshida, H., “A particle swarm optimization for reactive power and voltage control in electric power systems”, IEEE Proc. of Evolutionary Computation 2001 , Vol.1 , pp. 87 -93, 2001
[53] Wen Zhang, Yutian Liu, Maurice Clerc, “An adaptive PSO algorithm for reactive power optimization”, APSCOM – Advances in Power System Control Operation and Management, S6: Application of Artificial Intelligence Techniques (part I), 11-14 November 2003, Hong Kong
[54] Miranda, V., Fonseca, N., “New Evolutionary Particle Swarm Algorithm (EPSO) Applied to Voltage/Var Control”, Proceedings of PSCC’02 – Power System Computation Conference, Sevilla, Spain, June 24-28, 2002.
[55] Miranda, V., Fonseca, N., “Reactive Power Dispatch with EPSO – Evolutionary Particle Swarm Optimization”, Proceedings of PMAPS 2002 – International Conference on Probabilistic Methods Applied to Power Systems, Naples, Italy, Sep 2002.
[56] Reliability Test System Task Force of the Application of Probability Methods Subcommittee, “IEEE Reliability Test System ”, IEEE Trans. On Power Apparatus and Systems, vol. PAS-98, no. 6, Nov./Dec. 1979
[57] J. A. Peças Lopes et al., “Avaliação do Impacto da Produção em Regime Especial nas Redes de Distribuição de AT e MT”, relatório interno INESC Porto, Março 2003
72

[58] V.Miranda, Naing Win Oo, J.N. Fidalgo, “Experimenting in the Optimal Capacitor Placement and Control Problem with Hybrid Mathematical-Genetic Algorithms”, Proceedings of ISAP 2001, Budapest, Hungary, Jun 2001
[59] J. H. Holland, "Adaption in Natural and Artificial Systems", The University of Michigan Press, 1975 Ann Arbor
[60] D. E. Goldberg, "Genetic Algorithms In Search, Optimization And Machine Learning", 1989 Addison-Wesley
[61] J. Grefenstette, "Conditions for Implicit Parallelism", Navy Center for Applied Research in Artificial Intelligence, Internal Report, 1991 Washington
[62] V. Miranda, D. Srinivasan, L.M. Proença, “Evolutionary Computation in Power Systems”, International Journal in Electrical Power and Energy Systems, Jan 1998
[63] Mahfoud, “Niching methods for Genetic Algorithms”, IlliGAL Report n. 95001, Illinois Genetic Algorithm Laboratory, May 1995 (as collected from the web page)
73


















