
807 - TEXT ANALYTICS Massimo Poesio Lecture 9: Social media.
Upload
bruno-fosterCategory
view
219download
2
EMPIRICAL INVESTIGATIONS OF ANAPHORA AND SALIENCE
Massimo PoesioUniversità di Trento and University of Essex
Vilem Mathesius Lectures Praha, 2007

Plan of the series
Wednesday: Annotating context dependence, and particularly anaphora
Yesterday: Using anaphorically annotated corpora to investigate local & global salience
Today: Using anaphorically annotated corpora to investigate anaphora resolution

Today’s lecture
The Vieira / Poesio work on robust definite description resolution
Bridging references Discourse-new (If time allows):Task-oriented evaluation

Preliminary corpus study (Poesio and Vieira, 1998)
Annotators asked to classify about 1,000 definite descriptions from the ACL/DCI corpus (Wall Street Journal texts) into three classes:
DIRECT ANAPHORA: a house … the house
DISCOURSE-NEW: the belief that ginseng tastes like spinach is more widespread than one would expect
BRIDGING DESCRIPTIONS:the flat … the living room; the car … the vehicle
Massimo Poesio:
Add better examples (e.g., from The book of evidence)
Massimo Poesio:
Add better examples (e.g., from The book of evidence)

Poesio and Vieira, 1998
Results:
More than half of the def descriptions are first-mention
Subjects didn’t always agree on the classification of an antecedent (bridging descriptions: ~8%)

The Vieira / Poesio system for robust definite description resolution
Follows a SHALLOW PROCESSING approach (Carter, 1987; Mitkov, 1998): it only uses
Structural information (extracted from Penn Treebank)
Existing lexical sources (WordNet)
(Very little) hand-coded information
(Vieira & Poesio, 1996 / Vieira, 1998 / Vieira & Poesio, 2001)

Methods for resolving direct anaphors
DIRECT ANAPHORA:
the red car, the car, the blue car: premodification heuristics
segmentation: approximated with ‘loose’ windows

Methods for resolving discourse-new definite descriptions
DISCOURSE-NEW DEFINITES
the first man on the Moon, the fact that Ginseng tastes of spinach: a list of the most common functional predicates (fact, result, belief) and modifiers (first, last, only… )
heuristics based on structural information (e.g., establishing relative clauses)

A `knowledge-based’ classification of bridging descriptions (Vieira, 1998)
Based on LEXICAL RELATIONS such as synonymy, hyponymy, and meronimy, available from a lexical resource such as WordNetthe flat … the living room
The antecedent is introduced by a PROPER NAMEBach … the composer
The anchor is a NOMINAL MODIFIER introduced as part of the description of a discourse entity:selling discount packages … the discounts

… continued (cases NOT attempted by our system)
The anchor is not explicitly mentioned in the text, but is a `discourse topic’the industry (in a text about oil companies)
The resolution depends on more general commonsense knowledgelast week’s earthquake … the suffering people
The anchor is introduced by a VP:Kadane oil is currently drilling two oil wells. The activity…

Distribution of bridging descriptions
Class Total Percentage
Syn/Hyp/Mer 12/14/12 19%
Names 49 24%
Compound Nouns
25 12%
Events 40 20%
Discourse Topic 15 7%
Inference 37 18%
Total 204 100%

The (hand-coded) decision tree
1. Apply ‘safe’ discourse-new recognition heuristics
2. Attempt to resolve as same-head anaphora
3. Attempt to classify as discourse new
4. Attempt to resolve as bridging description. Search backward 1 sentence at a time and apply heuristics in the following order:1. Named entity recognition heuristics – R=.66, P=.95
2. Heuristics for identifying compound nouns acting as anchors – R=.36
3. Access WordNet – R, P about .28

Overall Results
Evaluated on a ‘test corpus’ of 464 definite descriptions
Overall results:
R P F
Version 1 53% 76% 62%
Version 2 57% 70% 62%
D-N def 77% 77% 77%

Overall Results
Results for each type of definite description:
R P F
Direct anaphora
62% 83% 71%
Disc new 69% 72% 70%
Bridging 29% 38% 32.9%

Questions raised by the Vieira / Poesio work
Do these results hold for larger datasets? Do discourse-new detectors help? Bridging:
– How to define the phenomenon?– Where to get the information?– How to combine salience with lexical & commonsense
knowledge?
Can such a system be helpful for applications?

Mereological bridging references
Cartonnier (Filing Cabinet) with Clock
This piece of mid-eighteenth-century furniture was meant to be used like a modern filing cabinet; papers were placed in leather-fronted cardboard boxes (now missing) that were fitted into the openshelves. A large table decorated in the same manner would have been placed in front for working with those papers. Access to the cartonnier's lower half can only be gained by the doors at the sides, because the table would have blocked the front.

PREVIOUS RESULTS
A series of experiments using the Poesio / Vieira dataset, containing 204 bridging references, including 39 `WordNet’ bridges
(Vieira and Poesio, 2000, but also Carter 1985, Hobbs - a number of papers-, etc) need lexical knowledge
But: even large lexical resources such as WordNet not enough, particularly for mereological references (Poesio et al, 1997; Vieira and Poesio, 2000; Poesio, 2003; Garcia-Almanza, 2003)
Partial solution: use lexical acquisition (HAL, Hearst-style construction method). Best results (for mereology): construction-style

FINDING MERONYMICAL RELATIONS USING SYNTACTIC INFORMATION
Some syntactic constructions suggest semantic relations
– (Cfr. Hearst 1992, 1998 for hyponyms) Ishikawa 1998, Poesio et al 2002: use syntactic
constructions to extract mereological information from corpora
– The WINDOW of the CAR– The CAR’s WINDOW– The CAR WINDOW
See also Berland & Charniak 1999, Girju et al 2002

LEXICAL RESOURCES FOR BRIDGING: A SUMMARY
Class Syn Hyp Mer Total WN
Total 12 14 12 38
WordNet 4 (33.3%) 8 (57.1%) 3 (33.3%) 15 (39%)
HAL 4 (33.3%) 2 (14.3%) 2 (16.7%) 8 (22.2%)
Constructions 1 (8.3%) 0 8 (66.7%) 9 (23.7%)
(All using the Vieira / Poesio dataset.)

FOCUSING AND MEREOLOGICAL BRIDGES
Cartonnier (Filing Cabinet) with Clock
This piece of mid-eighteenth-century furniture was meant to be used like a modern filing cabinet; papers were placed in leather-fronted cardboard boxes (now missing) that were fitted into the openshelves. A large table decorated in the same manner would have been placed in front for working with those papers. Access to the cartonnier's lower half can only be gained by the doors at the sides, because the table would have blocked the front.
(See Sidner, 1979; Markert et al, 1995.)

FOCUS (CB) TRACKING + GOOGLE SEARCH (POESIO, 2003)
Analyzed 169 associative BDs in GNOME corpus (58 mereology)
Correlation between distance and focusing (Poesio et al, 2004) and choice of anchor
– 77.5% anchor same or previous sentence; 95.8% in last five sentences
– CB(U-1) anchor for only 33.6% of BDs,– but 89% of anchors had been CB or CP
Using `Google distance’ to choose among salient anchor candidates

FINDING MEREOLOGICAL RELATIONS USING GOOGLE
Lexical vicinity measure (for MERONYMS) between NBD and NPA
– Search in Google for “the NBD of the NPA” (cfr. Ishikawa, 1998; Poesio et al, 2002)
E.g., “the drawer of the cabinet”– Choose as anchor the PA whose NPA results in the greater
number of hits Preliminary results for associative BDs: around 70%
P/R (by hand) See also: Markert et al, 2003, 2005; Modjeska et al,
2003

NEW EXPERIMENTS (Poesio et al, 2004)
Using the GNOME corpus – 58 mereological bridging refs realized by the-nps– 153 mereological bridging references in total– Reliably annotated
Completely automatic feature extraction– Google & WordNet for lexical distance– Using (an approximation of) salience
Using machine learning to combine the features

More (and reliably annotated) data: the GNOME corpus
Texts from 3 genres (museum descriptions, pharmaceutical leaflets, tutorial dialogues)
Reliably annotated syntactic, semantic and discourse information
– grammatical function, agreement features– anaphoric relations– uniqueness, ontological information, animacy, genericity, …
Reliable annotation of bridging references http://cswww.essex.ac.uk/Research/NLE/corpora/GNOME

METHODS
Salience features:– Utterance distance– First mention– ‘Global first mention’ (approximate CB)
Lexical distance:– WordNet (using a pure hypernym-based search strategy)– Google– Tried both separately and together
Statistical classifiers: MLP, Naïve Bayes – (MatLab / Weka ML Library)

Computing WordNet Distance: Get the head noun of the anaphor and find all the (noun)
senses for the head noun. Get all the noun senses for the head noun of the potential
antecedent under consideration. Retrieve the hypernym trees from WordNet for each sense of
anaphor and the antecedent. Traverse each unique path in these trees and find a common
parent for the anaphor and the antecedent; count the no. of nodes they are apart.
Select the least distance path across all combinations. If no common parent is found, assign an hypothetical
distance (30).
Lexical Distance 1 (WordNet)

Lexical Distance, 1: WordNet

Lexical Distance 2 (Google)
As in (Poesio, 2003) But use Google API to access the Google search engine Computing Google hits:
– Get the head noun for BR and potential candidate.– Check whether the potential candidate is a mass or count noun.– If count, build the query as “the body of the person” and search
for the pattern.– Retrieve the no. of Google hits

WN vs GOOGLE
Description Results
No path in WordNet 503/1720
No path in WordNet between BD and correct anchor 10/58
Anchor with Min WN Distance correct 8/58
Zero Google Hits 1089/1720
Zero Google Hits for correct anchor 24/58
Max Google Hits identify correct candidate 8/58

BASELINES
BASELINE ACCURACY
Random choice (previous 5) 4%
Random choice (previous) 19%
Random choice among FM 21.3%
Min Google Distance 13.8%
Min WN Distance 13.8%
FM entity in previous sentence 31%
Min Google in previous sentence 17.2%
Min WN in previous sentence 25.9%
Min Google among FM 12%
Min WN among FM 24.1%

RESULTS (58 THE-NPs, 50:50)
WN DISTANCE GOOGLE DISTANCE
MatLab NN, self-tuned 92 (79.3%) 89 (76.7%)
Weka NN Algorithm 91 (78.4%) 86 (74.1%)
Weka Naïve Bayes 88 (75.9%) 85 (73.3%)
Prec Recall F
WN distance 75.4% 84.5% 79.6%
Google distance 70.6% 86.2% 77.6%

MORE RESULTS
Accuracy F
WN distance 224 (74.2%) 76.3%
Google distance 230 (75.2%) 75.8%
1:3 dataset:
all 153 mereological BRs:
Accuracy F
WN distance 80.6% 55.7%
Google distance 82% 56.7%

MEREOLOGICAL BDS REALIZED WITH BARE-NPS
The combination of rare and expensive materials used on this cabinet indicates that it was a particularly expensive commission. The four Japanese lacquer panels date from the mid- to late 1600s and were created with a technique known as kijimaki-e. For this type of lacquer, artisans sanded plain wood to heighten its strong grain and used it as the background of each panel. They then added the scenic elements of landscape, plants, and animals in raised lacquer. Although this technique was common in Japan, such large panels were rarely incorporated into French eighteenth-century furniture.
Heavy Ionic pilasters, whose copper-filled flutes give an added rich color and contrast to the gilt-bronze mounts, flank the panels. Yellow jasper, a semiprecious stone, rather than the usual marble, forms the top.
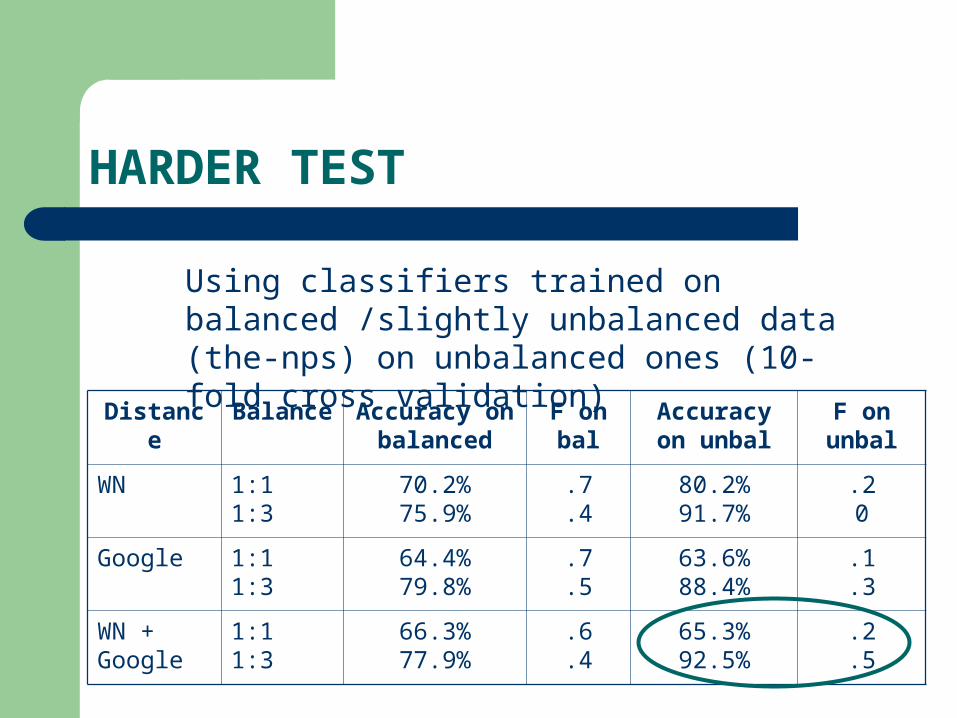
HARDER TEST
Distance Balance Accuracy on balanced
F on bal
Accuracy on unbal
F on unbal
WN 1:11:3
70.2%75.9%
.7
.480.2%91.7%
.20
Google 1:11:3
64.4%79.8%
.7
.563.6%88.4%
.1
.3
WN + Google
1:11:3
66.3%77.9%
.6
.465.3%92.5%
.2
.5
Using classifiers trained on balanced /slightly unbalanced data (the-nps) on unbalanced ones (10-fold cross validation)

DISCUSSION
Previous results:– Construction-based techniques provide adequate lexical
resources, particularly when using Web as corpus– But need to combine lexical knowledge and salience
modeling This work:
– Combining (simple) salience with lexical resources results in significant improvements
Future work:– Larger dataset – Better approximation of focusing

Back to discourse-new detection
The GUITAR system Recent results

GUITAR (Kabadjov, to appear)
A robust, usable anaphora resolution system designed to work as part of an XML pipeline
Incorporates:– Pronouns: the Mitkov algorithm – Definite descriptions: the Vieira / Poesio algorithm– Proper nouns: the Bontcheva alg.
Several versions– Version 1: (Poesio & Kabadjov, 2004): direct anaphora– Version 2: DN detection– Version 3: proper name resolution
Freely available from http://privatewww.essex.ac.uk/~malexa/GuiTAR/

DISCOURSE-NEW DEFINITE DESCRIPTIONS
Poesio and Vieira (1998): about 66% of definite descriptions in their texts (WSJ) are discourse-new
(1) Toni Johnson pulls a tape measure across the front of what was once a stately Victorian home.
(2) The Federal Communications Commission allowed American Telephone & Telegraph Co. to continue offering discount phone services for large-business customers and said it would soon re-examine its regulation of the long-distance market.

WOULD DNEW RECOGNITION HELP?
First version of GUITAR without DN detection on subset of DDs in GNOME corpus - 574 DDs, of which - 184 anaphoric (32%)- 390 discourse-new (67.9%)
Total Sys Ana
Corr NM WM SM R P F
574(184)
198 457(119)
38 27 5226.3%
79.6(60.1)
79.6(64.7)
79.6(62.3)

SPURIOUS MATCHES
If your doctor has told you in detail HOW MUCH to use and HOW OFTEN then keep to this advice.
….. If you are not sure then follow the advice on
the back of this leaflet.

GOALS OF THE WORK
Vieira and Poesio’s (2000) system incorporated DISCOURSE-NEW DD DETECTORS (P=69, R=72, F=70.5)
Two subsequent strands of work:– Bean and Riloff (1999), Uryupina (2003) developed
improved detectors (e.g., Uryupina: F=86.9)– Ng and Cardie (2002) questioned whether such detectors
improve results Our project: systematic investigation of whether DN
detectors actually help– ACL 04 ref res: features, preliminary results– THIS WORK: results of further experiments

DN CLASSIFIER:THE UPPER BOUND
Current number of SMs: 52/198 (26.3%) If SM = 0,
P=R=F overall = 509/574 = 88.7– (P=R=F on anaphora only: 119/146= 81.5)

VIEIRA AND POESIO’S DN DETECTORS
Recognize SEMANTICALLY FUNCTIONAL descriptions: SPECIAL PREDICATES / PREDICATE MODIFIERS (HAND-CODED) the front of what was once a stately Victorian home
the best chance of saving the youngest children PROPER NAMES. the Federal Communications Commission …
LARGER SITUATION descriptions (HAND-CODED): the City, the sun, ….

VIEIRA AND POESIO’S DN DETECTORS, II
Descriptions ESTABLISHED by modification: The warlords and private militias who were once regarded as the West’s staunchest allies are now a greater threat to the country’s security than the Taliban …. (Guardian, July 13th 2004, p.10)
PREDICATIVE descriptions: COPULAR CLAUSES: he is the hardworking son of a Church of Scotland minister …. APPOSITIONS. Peter Kenyon, the Chelsea chief executive …

VIEIRA AND POESIO’S DECISION TREES
Tried both hand-coded and ML
1. Try the DN detectors with highest accuracy (attempt to classify as functional using special predicates, and as predicative by looking for apposition)
Hand-coded decision tree:
2. Attempt to resolve the DD as direct anaphora
3. Try other DN detectors in order: proper name, establishing clauses, proper name modification ….
ML DT: swap 1. and 2.

VIEIRA AND POESIO’S RESULTS
P R F
Baseline 50.8 100 67.4
DN detection 69 72 70
Hand-coded DT(partial)
62 85 71.7
Hand-coded DT(total)
77 77 77
ID3 75 75 75

BEAN AND RILOFF (1999)
Developed a system for identifying DN definites
SENTENCE-ONE (S1) EXTRACTION identify as discourse-new every description found in first sentence of a text.
Adopted syntactic heuristics from Vieira and Poesio, and developed several new techniques:
DEFINITE PROBABILITY create a list of nominal groups encountered at least 5 times with definite article, but never with indefinite
VACCINES: block heuristics when prob. too low.

BEAN AND RILOFF’S ALGORITHM
1. If the head noun appeared earlier, classify as anaphoric
2. If DD occurs in S1 list, classify as DN unless vaccine
3. Classify DD as DN if one of the following applies: (a) high definite probability; (b) matches a EHP pattern; (c) matches one of the syntactic heuristics
4. Classify as anaphoric

BEAN AND RILOFF’S RESULTSP R
Baseline 100 72.2
Syn heuristics 43 93.1
Syn Heuristics +S1EHPDO
66.360.769.2
84.387.383.9
Syn Heuristics + S1 + EHP + DO
81.7 82.2
Syn Heuristics + S1+ EHP + DO + V
79.1 84.5

NG AND CARDIE (2002)
Directly investigate question of whether discourse-new detectors improves performance of anaphora resolution system
Dealing with ALL types of anaphoric expressions

NG AND CARDIE’S METHODS DN detectors:
– statistical classifiers trained using C4.5 and RIPPER– Features: predicate & superlative detection / head match /
position in text of NP – Tested over MUC-6 (F=86) and MUC-7 (F=84)
2 architectures for integration of detectors and AR:1. Run DN detector first,
apply AR on NPs classified as anaphoric2. Run AR if str_match or alias=Y;
otherwise, as in 1.

NG AND CARDIE’S RESULTS
MUC-6 MUC-7
P R F P R F
Baseline (no DN detection)
70.3 58.3 63.8 65.5 58.2 61.6
DN detection runs first
57.4 71.6 63.7 47.0 77.1 58.4
Same head runs first
63.4 68.3 65.8 59.7 69.3 64.2

NG AND CARDIE’S RESULTS
MUC-6 MUC-7
P R F P R F
Baseline (no DN detection)
70.3 58.3 63.8 65.5 58.2 61.6
DN detection runs first
57.4 71.6 63.7 47.0 77.1 58.4
Same head runs first
63.4 68.3 65.8 59.7 69.3 64.2

URYUPINA’S METHODS
A DN statistical classifier trained using RIPPER
Trained / tested over Ng and Cardie’s MUC-7 data

URYUPINA’S FEATURES:WEB-BASED DEFINITE PROBABILITY
Y" a"
Y" the"
Y""
Y" the"
H" a"
H" the"
H""
H" the"

URYUPINA’S RESULTS(DNEW CLASSIFIER)
P R F
All NPs No Def Prob 87.9 86.0 86.9
Def Prob 88.5 84.3 86.3
Def NPs No Def Prob 82.5 79.3 80.8
Def Prob 84.8 82.3 83.5
(On MUC-7)

URYUPINA’S RESULTS(DNEW CLASSIFIER)
P R F
All NPs No Def Prob 87.9 86.0 86.9
Def Prob 88.5 84.3 86.3
Def NPs No Def Prob 82.5 79.3 80.8
Def Prob 84.8 82.3 83.5
(On MUC-7)

PRELIMINARY CONCLUSIONS
Quite a lot of agreement on features for DN recognition:
– Recognizing predicative NPs– Recognizing establishing relatives– Recognizing DNEW proper names– Identifying functional DDs
Automatic detection of these better Using the Web best
All these systems integrate DN detection with some form of AR resolution
– See Ng’s results concerning how `globally optimized’ classifiers are better than `locally optimized’ ones (ACL 2004)

PRELIMINARY CONCLUSIONS, II
Ng and Cardie’s results not the last word:– Performance of their DN detector not as high as
Uryupina’s (F=84 vs. F=87 on same dataset, MUC-7)– Overall performance of their resolution system not that
high best performance: F=65.8 on ALL NPs But on full NPs (i.e., excluding PNs and pronouns): F=31.7
(GUITAR on DDs, unparsed text: F=56.4)
Room for improvement

A NEW SET OF EXPERIMENTS
Incorporate the improvements in DN detection technology to
– the Vieira / Poesio algorithm, as reimplemented in a state-of-the-art `specialized’ AR system, GUITAR
– a statistical `general purpose’ AR resolver (Uryupina, in progress)
Test over a large variety of data– New: GNOME corpus (623 DDs)– Original Vieira and Poesio dataset (1400 DDs)– MUC-7 (for comparison with Ng and Cardie, Uryupina)
(3000 DDs)

ARCHITECTURE
A two-level system:– Run GUITAR’s direct anaphora resolution– Results used as one of the features of a statistical
discourse-new classifier – A `globally optimized’ system (Ng, ACL 2004)
Trained / tested over – GNOME corpus– Vieira / Poesio dataset, converted to MMAX, converted to
MAS-XML (still correcting the annotation)

A NEW SET OF FEATURESDIRECT ANAPHORA Run the Vieira / Poesio algorithm; -1 if no result else distance
PREDICATIVE NP DETECTOR DD occurs in apposition DD occurs in copular construction
PROPER NAMES c-head c-premod Bean and Riloff’s S1

A REVISED SET OF FEATURES (II)
FUNCTIONALITY Uryupina’s four definite probabilities (computed off the Web) superlative
ESTABLISHING RELATIVE (a single feature)
POSITION IN TEXT OF NP (Ng and Cardie) header / first sentence / first para

LEARNING A DN CLASSIFIER
Use of the data:– 8% for parameter tuning– 10-fold cross-validation over the rest
Classifiers: from the Weka package– Decision Tree (C4.5), NN (MLP), SVM
3 evaluations (overall, DN, DA) Performance comparison: t-test (cfr. Dietterich
98

3 EVALUATIONS
OVERALL DADN
DADNR
DADN
DADNP syssys
syssys
corrcorr
,
DA DA
DAR
DA
DAP sys
sys
corr ,
DN DN
DNR
DN
DNP sys
sys
corr ,

RESULTS:OVERALL
T Res C P=R=F
GuiTAR 574 574 457 79.6
GuiTAR +MLP 574 574 473 82.4
GuiTAR +C4.5 574 574 466 81.18
p .1
notsig

RESULTS:DNEW CLASSIFICATION
P R F A
DNC4.5 86.9 92.3 89.3 85.04
DNMLP 86.4 94.6 90.2 85.89
DNSVM 90.0 86.4 88.1 84.15
BASELINE(all DDs are DN)
67.5 100 80.6 67.5

RESULTS:DIRECT ANAPHORA RESOLUTION
T Res C NM WM SM P R F
GuiTAR 184 198 119 38 27 52 60.1 64.7 62.3
GuiTAR +MLP 184 142 104 60 20 18 74.1 56.5 63.4
GuiTAR +C4.5 184 158 106 56 22 30 68.9 57.7 62.1
GuiTAR +SVM 184 198 119 38 27 52 60.1 64.7 62.3

ERROR ANALYSIS
A 65% reduction in spurious matches:– “the answer to any of these questions“– “the title of cabinet maker and sculptor to Louis
XIV, King of France”– “the other half of the plastic“
But: a 58% increase in no matches– “the palm of the hand”

THE DECISION TREE
DirectAna <= -1?
DNEW (339/36) DirectAna <= 20?
Y N
DNEW (11/1)
N
TheY/A Y <= 201.2?
Y
NY
1stPar = 0?Relative = 0?
NY
DNEW (12/1)ANAPH
NY
DNEWDirectAna <= 12?

RESULTS:THE VIEIRA/POESIO CORPUS
Tested on 400 DDs (the ‘test’ corpus) Initial results at DN detection very poor Problem: the two conversions resulted in the
loss of much information about modification, particularly relatives
Currently correcting the annotation by hand

RESULTS:AUTOMATIC PARSING
GUITAR without DN detection over the same texts, but using a chunker: 10% less accuracy
Main problem: many DDs not detected (particularly possessives)
Currently experimenting with full parsers (tried several, settled on Charniak’s)

CONCLUSIONS AND DISCUSSION
All results so far support the idea that DN detectors improve the performance of AR with DD (if perhaps by only a few percent)
Some agreement on what features are useful– One clear lesson: interleave AR and DN detection!
But: will need to test on larger corpora (also to improve performance of classifier)
Current work:– Test on unparsed text– Test on MUC-7 data

Task-based evaluation
RANLP / EMNLP slides

Conclusions

URLs
Massimo Poesio: http://cswww.essex.ac.uk/staff/poesio
GUITAR: http://privatewww.essex.ac.uk/~malexa/GuiTAR/
WEKA:http://www.cs.waikato.ac.nz/~ml












![a word about design - vilem flusser [final]](https://static.fdocuments.net/doc/165x107/568c0f1c1a28ab955a92ec3d/a-word-about-design-vilem-flusser-final.jpg)
![Vilem Vychodil arXiv:1405.7076v2 [cs.AI] 20 Aug 2014](https://static.fdocuments.net/doc/165x107/620a01a973e90b36600dc4ef/vilem-vychodil-arxiv14057076v2-csai-20-aug-2014.jpg)




