
Einfuhrung in die Numerische Mathematik - math.uni-kiel.de · Einfuhrung in die Numerische...
158
Einf ¨ uhrung in die Numerische Mathematik Malte Braack Mathematisches Seminar Christian-Albrechts-Universit¨ at zu Kiel Vorlesungsskript, 17.02.2017 Alle Rechte bei dem Autor.
Transcript of Einfuhrung in die Numerische Mathematik - math.uni-kiel.de · Einfuhrung in die Numerische...

Einfuhrung in die Numerische
Mathematik
Malte Braack
Mathematisches Seminar
Christian-Albrechts-Universitat zu Kiel
Vorlesungsskript, 17.02.2017
Alle Rechte bei dem Autor.


Inhaltsverzeichnis
1 Interpolation 3
1.1 Polynominterpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Lagrange Interpolation . . . . . . . . . . . . . . . . . . . . . . 4
1.1.2 Newton’sche Darstellung . . . . . . . . . . . . . . . . . . . . . 5
Dividierte Differenzen . . . . . . . . . . . . . . . . . . . 6
1.1.3 Darstellung von Neville-Aitken . . . . . . . . . . . . . . . . . 8
1.1.4 Interpolationsfehler . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2 Hermitesche Interpolation . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Tschebyscheff Polynome . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Tschebyscheff Polynome auf dem Referenz-Intervall . . . . . . 11
1.3.2 Tschebyscheff Polynome in allgemeinen Intervallen . . . . . . 14
1.4 Stabilitat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5 Bestapproximation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.6 Stuckweise Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.7 Splines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.7.1 Lineare Splines . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.7.2 Kubische Splines . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.7.3 Konstruktion kubischer Splines . . . . . . . . . . . . . . . . . 23
1.8 Richardson Extrapolation . . . . . . . . . . . . . . . . . . . . . . . . 26
1.8.1 Anwendung auf die Berechnung von Differenzenquotienten . . 30
1.9 Trigonometrische Interpolation / Diskrete Fourieranalyse . . . . . . . 31
1.9.1 Schnelle Fouriertransformation (FFT) . . . . . . . . . . . . . . 35
2 Approximation 39
2.1 Bestapproximation in euklidischen und unitaren Raumen . . . . . . . 39
2.1.1 Existenz und Eindeutigkeit der Bestapproximation . . . . . . 39
2.1.2 Bestapproximation stetiger Funktionen . . . . . . . . . . . . . 42
Legendre-Polynome . . . . . . . . . . . . . . . . . . . . . . . . 43

ii M. Braack INHALTSVERZEICHNIS
Tschebyscheff-Polynome . . . . . . . . . . . . . . . . . . . . . 45
2.1.3 Gram-Schmidt-Verfahren zur Orthogonalisierung . . . . . . . 46
2.2 Tschebyscheff-Approximation . . . . . . . . . . . . . . . . . . . . . . 47
2.2.1 Alternantensatz fur Haarsche Raume . . . . . . . . . . . . . . 50
2.2.2 Remez-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . 52
2.2.3 Anwendung auf Optimale Wahl von Interpolationsstutzstellen 53
3 Numerische Integration 55
3.1 Interpolatorische Quadraturformeln . . . . . . . . . . . . . . . . . . . 56
3.1.1 Integrationsgewichte bzgl. eines Referenzintervalls . . . . . . . 57
3.2 Newton-Cotes Quadraturformeln . . . . . . . . . . . . . . . . . . . . 58
3.2.1 Mittelpunktsregel . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.2.2 Trapezregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.2.3 Simpsonregel . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.2.4 3/8-Regel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.3 Gauß-Quadratur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.4 Summierte Quadraturformeln . . . . . . . . . . . . . . . . . . . . . . 66
3.4.1 Summierte Mittelpunktsregel . . . . . . . . . . . . . . . . . . 66
3.4.2 Summierte Trapezregel . . . . . . . . . . . . . . . . . . . . . . 67
3.4.3 Summierte Simpsonregel . . . . . . . . . . . . . . . . . . . . . 68
3.5 Konvergenz von Quadraturformeln . . . . . . . . . . . . . . . . . . . 68
3.6 Romberg-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.7 Schrittweiten-Kontrolle . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4 Direkte Loser fur lineare Gleichungssysteme 75
4.1 Direktes Losen bei Dreiecksmatrizen . . . . . . . . . . . . . . . . . . 75
4.1.1 Vorwartselimination . . . . . . . . . . . . . . . . . . . . . . . 75
4.1.2 Ruckwartselimination . . . . . . . . . . . . . . . . . . . . . . . 76
4.2 LU-Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.2.1 LU-Zerlegung per Gauß-Elimination ohne Pivotisierung . . . . 78
4.2.2 LU-Zerlegung mit Zeilen-Pivotisierung . . . . . . . . . . . . . 81
4.3 Cholesky-Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.4 LU-Zerlegung von Bandmatrizen . . . . . . . . . . . . . . . . . . . . 88
4.4.1 Thomas-Algorithmus fur Tridiagonalmatrizen . . . . . . . . . 89
4.5 Rundungsfehleranalysen . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.5.1 Matrizennormen . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.5.2 Beispiele von Matrizennormen . . . . . . . . . . . . . . . . . . 91
4.5.3 Konditionszahl . . . . . . . . . . . . . . . . . . . . . . . . . . 93

INHALTSVERZEICHNIS iii
4.5.4 Lineare Storungstheorie . . . . . . . . . . . . . . . . . . . . . 94
4.6 Defektkorrektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5 Lineare Ausgleichsrechnung 99
5.1 Lineare Regression als Beispiel fur die Ausgleichsrechnung . . . . . . 99
5.2 Normalengleichung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.3 QR-Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5.4 Berechnung der QR-Zerlegung . . . . . . . . . . . . . . . . . . . . . . 107
5.4.1 QR-Zerlegung per Gram-Schmidt-Verfahren . . . . . . . . . . 107
5.4.2 Householder-Matrizen . . . . . . . . . . . . . . . . . . . . . . 107
5.4.3 Householder-Verfahren . . . . . . . . . . . . . . . . . . . . . . 109
5.4.4 Givens-Rotation . . . . . . . . . . . . . . . . . . . . . . . . . . 111
5.5 QR-Zerlegung zur Losung linearer Gleichungssysteme . . . . . . . . . 111
6 Iterative Loser fur lineare Gleichungssysteme 113
6.1 Lineare Iterationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . 113
6.2 Drei einfache lineare Iterations-Verfahren . . . . . . . . . . . . . . . . 117
6.2.1 Jacobi-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.2.2 Gauss-Seidel-Verfahren . . . . . . . . . . . . . . . . . . . . . . 118
6.2.3 Richardson-Iteration . . . . . . . . . . . . . . . . . . . . . . . 119
6.3 Zeilensummenkriterien . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.4 SOR-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.5 Lineare Iterationsverfahren fur positiv definite Matrizen . . . . . . . . 125
7 Losungsverfahren fur nichtlineare Gleichungssysteme 127
7.1 Konvergenzverhalten iterativer Verfahren . . . . . . . . . . . . . . . . 127
7.2 Newton-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
7.3 Varianten des Newton-Verfahrens . . . . . . . . . . . . . . . . . . . . 133
7.3.1 Quasi-Newton-Verfahrens . . . . . . . . . . . . . . . . . . . . 133
7.3.2 Gedampftes Newton-Verfahren . . . . . . . . . . . . . . . . . . 133
7.3.3 Schrittweitenkontrolle . . . . . . . . . . . . . . . . . . . . . . . 134
7.3.4 Broyden-Updates . . . . . . . . . . . . . . . . . . . . . . . . . 134
8 Lineare Optimierung 137
8.1 Beispiele linearer Optimierungsprobleme . . . . . . . . . . . . . . . . 137
8.1.1 Beispiel einer Produktionsoptimierung . . . . . . . . . . . . . 137
8.1.2 Beispiel einer Optimalen Logistik . . . . . . . . . . . . . . . . 138
8.2 Normalform eines Linearen Programms . . . . . . . . . . . . . . . . . 139

INHALTSVERZEICHNIS 1
8.3 Graphische Losung eines Linearen Programms . . . . . . . . . . . . . 140
8.4 Eigenschaften der Losungsmenge . . . . . . . . . . . . . . . . . . . . 141
8.5 Losungstheorie fur Lineare Programme . . . . . . . . . . . . . . . . . 143
8.6 Das Simplexverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
8.6.1 Phase II des Simplexverfahrens . . . . . . . . . . . . . . . . . 146
8.6.2 Phase I des Simplexverfahrens . . . . . . . . . . . . . . . . . . 147
Danksagung: Ich danke Funda Akyuz, Utku Kaya, Britta Ramthun-Kasan und
Leon Schramm fur die inhaltliche und grammatische Durchsicht sowie fur die hilf-
reichen Korrekturvorschlage.

2 M. Braack INHALTSVERZEICHNIS

Kapitel 1
Interpolation
Ziel: Zu gegebenen Stutzstellen x0, . . . , xn ∈ R und Knotenwerten y0, . . . , yn ∈ Rbestimme eine Funktion p eines gewissen Typs (Funktionenklasse), so dass p(xi) = yifur alle i = 0, . . . , n.
Mogliche Funktionenklassen:
1. Polynome
Pn :=
p(x) =
n∑k=0
akxk | ak ∈ R ∀k ∈ 0, . . . , n
2. Rationale Funktionen
r(x) :=p(x)
q(x), p ∈ Pm, q ∈ Pr \ 0
3. Trigonometrische Funktionen
t(x) :=1
2a0 +
m∑k=0
(ak cos(kx) + bk sin(kx))
4. Splines: stuckweise glatte Funktionen (z.B. Polynome) mit gewissen globalen
Stetigkeits- und/oder Differenzierbarkeitseigenschaften
1.1 Polynominterpolation
Satz 1.1 Seien x0, . . . , xn ∈ R paarweise verschieden und y0, . . . , yn ∈ R beliebig.
Dann existiert genau ein Polynom pn ∈ Pn mit
pn(xi) = yi ∀i ∈ 0, . . . , n. (1.1)

4 M. Braack Interpolation
Beweis. Fasse (1.1) als lineares Gleichungssystem Aα = y mit
A :=
1 x0 . . . xn0...
. . ....
1 xn . . . xnn
∈ R(n+1)×(n+1)
und α, y ∈ Rn+1 auf. A ist regular, denn anderenfalls ware der Kern Ker A 6= 0.Dann wurde ein a ∈ Rn+1 existieren mit a 6= 0 und qn(x) :=
∑nk=0 akx
k ein Polynom
in Pn mit n+ 1 Nullstellen x0, . . . , xn ∈ R. Dann ist aber qn ≡ 0 also a = 0.
1.1.1 Lagrange Interpolation
Konstruktion des eindeutigen Interpolationspolynoms via Lagrange Polynome
Li(x) :=∏
j=0,...,n, j 6=i
x− xjxi − xj
fur i ∈ 0, . . . , n. Es gilt Li ∈ Pn und Li(xj) = δij. Dann ist
pn(x) :=n∑i=0
yiLi(x)
das Interpolations-Polynom in Pn zu (1.1). Das Interpolationspolynom ist also schnell
hingeschrieben. Die Nachteile sind allerdings, dass
• viele arithmetische Operationen zur Auswertung p(x) zu x ∈ R notwendig sind
(sofern x 6= xi):
je Lagrange-Polynom Li(x) sind 2n Additionen, n Divisionen und n−1 Multi-
plikationen notwendig. Dies ergibt 4n−1 Operationen fur die Berechnung von
Li(x). Somit sind zur Berechnung von p(x) insgesamt (4n − 1)(n + 1) + n =
4n2 + 4n− 1 Operationen notwendig.
• eine spatere Hinzunahme eines weiteren Punktepaares (xn+1, yn+1) erfordert
eine komplette Neuberechnung aller Lagrange-Polynome.
Im Vergleich zur Darstellung in der Monombasis, pn(x) =∑n
k=0 akxk, per Horner
Schema
pn(x) = a0 + x(a1 + x(a2 + . . .+ xan) · · · )
sind lediglich n Additionen und n Multiplikationen notwendig.

1.1 Polynominterpolation 5
1.1.2 Newton’sche Darstellung
Wir benutzen hier die Newton’sche Polynombasis
N0 ≡ 1
Ni(x) :=i−1∏j=0
(x− xj), i ∈ 0, . . . , n
Es gilt Ni ∈ Pi. Offensichtlich ist Ni : i ∈ 0, 1, . . . , n eine Polynombasis von Pn.
Wir konnen das Interpolationspolynom zu (1.1) also auch in dieser Basis ausdrucken
pn =n∑j=0
αjNj.
Die Koeffizienten α0, . . . , αn erhalt man durch Losen des linearen Gleichungssystems
Aα = y (1.2)
mit der unteren Dreiecks-Matrix
A :=
1... x1 − x0
... x2 − x0 (x2 − x0)(x2 − x1)
... · · · · · · . . .
1 xn − x0 · · · · · ·∏n−1
j=0 (xn − xj)
= (Nj(xi))i,j
Dies sieht man unmittelbar, da Nj(xi) = 0 fur i < j und somit
yi =i∑
j=0
Nj(xi)αj =n∑j=0
Nj(xi)αj = pn(xi).
Das lineare Gleichungssystem (1.2) lasst sich einfach durch Vorwartseinsetzen losen:
αk =1
Nk(xk)
(yk −
k−1∑j=0
Nj(xk)αj
)(1.3)
fur sukzessive k = 0, 1, . . . , n. Der Aufwand zur Berechnung von αk betragt 2k + 1
Operationen. Also sind es insgesamt∑n
k=0(2k + 1) = 2∑n
k=1 k + n + 1 = n(n −1) + n = n2 + 1 Operationen. Hinzu kommt die Berechnung der Werte Nj(xk). Also
erfordert dies insgesamt .... Operationen. Wir werden im Anschluss sehen, dass sich
dies deutlich reduzieren lasst, indem man eine geschicktere Darstellung wahlt.

6 M. Braack Interpolation
Die Hinzunahme eines weiteren Punktes (xn+1, yn+1) ist jetzt unproblematisch:
Man erhalt nach der Berechnung von pn ∈ Pn nun pn+1 ∈ Pn+1 mittels
pn+1 = pn + αn+1Nn+1
mit
αn+1 =1
Nn+1(xn+1)(yn+1 − pn(xn+1))
Dividierte Differenzen Um die Berechnung der Koeffizienten αi zu reduzieren,
bedient man sich der sogenannten dividierten Differenzen. Diese sind rekursiv defi-
niert durch
[xi] := yi, i = 0, . . . , n
xi, ..., xi+k :=[xi+1, . . . , xi+k]− [xi, . . . , xi+k−1]
xi+k − xi
Schema:
[x0]→ [x0, x1]→ [x0, x1, x2]→ · · ·
[x1]→ [x1, x2]→ · · ·
[x2]→ · · ·...
Lemma 1.2 Das Polynom
pi,i+k(x) :=i+k∑j=i
[xi, . . . , xj]
j−1∏l=i
(x− xl)
interpoliert (xi, yi), . . . , (xi+k, yi+k).
Beweis. Per Induktion nach k. Die Induktionsannahme fur k = 0 ergibt sich
unmittelbar:
pi,i ≡ [xi] = yi,

1.1 Polynominterpolation 7
also insbesondere pi,i(xi) = yi. Der Induktionsschritt von k nach k+1 ergibt sich wie
folgt: Das Interpolationspolynom pi,i+k+1 zu den Punkten (xi, yi), . . . , (xi+k+1, yi+k+1)
kann dargestellt werden in der Form
q := pi,i+k+1(x) = pi,i+k(x) + c
i+k∏l=i
(x− xl)
mit geeigneter reeller Zahl c ∈ R. Es genugt daher zu zeigen, dass c = [xi, . . . , xi+k+1].
c ist der Koeffizient zur hochsten Potenz von q, also
q(x) = cxk+1 + r(x)
mit r ∈ Pk. Das Polynom q ∈ Pk+1, gegeben durch
q(x) :=(x− xi)pi+1,i+k+1(x)− (x− xi+k+1)pi,i+k(x)
xi+k+1 − xi
interpoliert die Punkte (xi, yi), . . . , (xi+k+1, yi+k+1) ebenfalls. Also gilt q = q. Der
fuhrende Koeffizient von pi+1,i+k+1 ist nach Induktionsannahme γ1 := [xi+1, . . . , xi+k+1],
der von pi,i+k ist γ2 := [xi, . . . , xi+k]. Der fuhrende Koeffizient c ergibt sich daher zu
c =γ1 − γ2
xi+k+1 − xi=
[xi+1, . . . , xi+k+1]− [xi, . . . , xi+k]
xi+k+1 − xi= [xi, . . . , xi+k+1].
Satz 1.3 Die Koeffizienten αk aus (1.3) sind gegeben durch
αk = [x0, . . . , xk], ∀k ∈ 0, . . . , n.
Beweis. Das Interpolationspolynom pn ist identisch mit p0,n aus dem vorherigen
Lemma, also
p(x) :=n∑j=0
[x0, . . . , xj]Nj(x)
Da die N0, . . . , Nn eine Basis von Pn bilden, ist diese Darstellung sogar eindeutig.
Also gilt αj = [x0, . . . , xj].

8 M. Braack Interpolation
1.1.3 Darstellung von Neville-Aitken
In der Praxis benotigt man selten die explizite Gestalt des Interpolationspolynoms
(also die Koeffizienten ak oder αk) als vielmehr eine schnelle Auswertung p(x) zu
beliebigem x ∈ R. Dies geschieht mit dem Algorithmus von Neville-Aitken ohne den
Umweg uber die Koeffizienten.
Zu x ∈ R setzen wir
[yi,k] := pi,i+k(x).
Fur k = 0 ergibt sich einfach [yi,0] = pi,i(x) = yi. Die ubrigen Großen lassen sich
wieder rekursiv bestimmen uber
[yi,k+1] = [yi,k] + (x− xi)[yi+1,k]− [yi,k]
xi+k+1 − xi
Die Berechnung von [y0,n] = pn(x) erfordert somit n+. . .+1 = 12n(n−1) Berechnun-
gen mit jeweils 6 Operationen, also insgesamt 3n2 − 3n arithmetische Operationen.
Dies ist etwas schneller als uber Lagrange-Polynome (4n2 + 4n− 1).
1.1.4 Interpolationsfehler
Nun interessieren wir uns fur den Interpolationsfehler. Seien x0, . . . , xn ∈ I := [a, b]
paarweise verschieden, x ∈ I beliebig. Ferner sei a := min(x, x0, . . . , xn) und b :=
max(x, x0, . . . , xn).
Satz 1.4 Sei f ∈ Cn+1([a, b]) und pn ∈ Pn das Interpolationspolynom an den Stutz-
stellen paarweise verschiedenen x0, . . . , xn ∈ I := [a, b]. Dann existiert zu jedem
x ∈ I ein ξx ∈ [a, b] so dass
f(x)− pn(x) =f (n+1)(ξx)
(n+ 1)!Nn+1(x),
wobei Nn+1 das Newton’sche Polynom der Ordnung n+ 1 bezeichnet.
Beweis. Wir unterscheiden zwei Falle. Fall 1: Sei x = xk fur ein k. Dann gilt
f(x) = pn(x) und Nn+1(x) = 0. Fall 2: x 6∈ x0, . . . , xn. Setze dann
c :=f(x)− pn(x)
Nn+1(x).
Wir haben die Existenz eines ξx ∈ [a, b] zu zeigen mit der Eigenschaft
f (n+1)(ξx) = (n+ 1)! · c.

1.1 Polynominterpolation 9
Hierzu betrachten wir
F (t) := f(t)− pn(t)− cNn+1(t).
Die Funktion F ist eine Cn+1[a, b]-Funktion und besitzt per Konstruktion in [a, b]
mindestens n+ 1 Nullstellen (namlich x, x0, . . . , xn). Der Satz von Rolle besagt nun,
dass F ′ in [a, b] mindestens n+ 1 Nullstellen besitzt. Dieses Argument wiederholen
wir n+1-mal, so dass letztendlich F (n+1) mindestens eine Nullstelle ξx ∈ [a, b] besitzt,
also
0 = F (n+1)(ξx) = f (n+1)(ξx)− p(n+1)n (ξx)− cN (n+1)
n+1 (ξx)
= f (n+1)(ξx)− c(n+ 1)!,
denn Nn+1 ∈ Pn+1 mit fuhrendem Koeffizienten 1.
Das nachfolgende Korollar besagt, dass die Polynomapproximation fur C∞-Funktionen
mit beschrankten Ableitungen beliebig gut ist.
Korollar 1.5 Sei f ∈ C∞[a, b] mit beschrankten Ableitungen, d.h. ||f (n)||∞ ≤ K fur
alle n ∈ N0. Dann gilt fur die Interpolationspolynome
limn→∞
||f − pn||∞ = 0.
Hierbei bezeichnet ||f ||∞ := maxx∈[a,b] |f(x)|.
Beweis. Nach dem vorherigen Satz gilt mit M := b− a
||f − pn||∞ ≤ K
(n+ 1)!||Nn+1||∞ ≤
K
(n+ 1)!Mn+1 → 0,
fur n→∞, denn fur hinreichend großes n gilt Mn+1/(n+ 1)! ≤ 12Mn/n!.
Die obige Konvergenzaussage gilt i.a. nicht, wenn f nicht beliebig haufig differen-
zierbar ist oder die Ableitungen nicht beschrankt sind. Gegenbeispiele hierzu sind:
• f(x) = |x| im Intervall [−1, 1] und aquidistante Verteilung der Stutzstellen
xi = −1 + i/n. Fur x ∈ (−1, 0) ∪ (0, 1) gilt dann pn(x) 6→ f(x) fur n→∞.
• f(x) = (1 + x2)−1 hat eine Singularitat im Komplexen bei z = ±i. Auch
im Reellen werden die Ableitungen groß, namlich nahe der Null: f (n)(x) =
2nn!O(|x|−2−n). Auch hier erhalt man keine Konvergenz, limn→∞ ||f − pn||∞ 6=0.

10 M. Braack Interpolation
Der Approximationssatz von Weierstrass besagt, dass jede C[a, b] Funktion beliebig
gut durch Polynome in der || · ||∞-Norm approximiert werden kann. Dies geschieht
aber i.a. nicht durch Interpolationspolynome.
Ferner ist zu bemerken, dass der Term Nn+1(x) =∏n
k=0(x − xk) fur x 6∈ I sehr
schnell anwachsen kann. Daher sollte man die Interpolationspolynome nicht außer-
halb des Intervalls verwenden. In diesem Fall eignet sich die sogenannte Extrapolation
besser.
1.2 Hermitesche Interpolation
In diesem Abschnitt formulieren wir eine Verallgemeinerung der vorherigen In-
terpolation. Nun sollen nicht nur Funktionswerte, sondern auch Ableitungswer-
te interpoliert werden. Gegeben seien m + 1 paarweise verschiedene Stutzstellen
x0, . . . , xm ∈ R, sowie Knotenwerte y(k)i ∈ R fur i ∈ 0, . . . ,m und k ∈ 0, . . . , µi
mit µi ∈ N0. Ferner sei
n := m+m∑i=0
µi.
Gesucht ist nun ein pn ∈ Pn mit
p(k)(xi) = y(k)i ∀i ∈ 0, . . . ,m und k ∈ 0, . . . , µi. (1.4)
xi heißt hier µi-fache Stutzstelle.
Satz 1.6 Die hermitesche Interpolationsaufgabe (1.4) besitzt eine eindeutige Losung.
Beweis. Analog zur zuvorigen Interpolationsaufgabe mit µk = 0 fur alle k fallen
Existenz und Eindeutigkeit der Losungen zusammen. Angenommen p, p ∈ Pn seien
zwei Losungen. Dann besitzt q := p − p ∈ Pn eine n + 1-fache Nullstelle (Vielfach-
heiten mitgezahlt). Also gilt q ≡ 0.
Satz 1.7 Sei f ∈ Cn+1[a, b] und pn ∈ Pn das hermitesche Interpolationspolynom an
den paarweise verschiedenen Stutzstellen x0, . . . , xm ∈ I := [a, b]. Dann existiert zu
jedem x ∈ [a, b] ein ξx ∈ [a, b] (a, b definiert wie in Abschnitt 1.1.4) so dass
f(x)− pn(x) =f (n+1)(ξx)
(n+ 1)!
m∏i=0
(x− xi)1+µi .

1.3 Tschebyscheff Polynome 11
Beweis. Der Beweis erfolgt analog zum Beweis von Satz 1.4, indem man jedoch
Ni+1 durch die Funktion
Ψ(x) :=m∏i=0
(x− xi)1+µi
ersetzen muss. Ψ ist ein Polynom vom Grad n + 1 mit fuhrendem Koeffizienten 1,
so dass auch hier gilt Ψ(n+1)(x) = (n+ 1)!. Die Funktion
F (x) := f(x)− pn(x)− cΨ(x)
ist eine Cn+1−Funktion mit mindestens n+1 Nullstellen (Vielfachheiten mitgezahlt).
Die Berechnung des Koeffizienten von pn in der Newton’schen Darstellung erfolgt
durch das Schema der dividierten Differenzen mit folgender Modifikation: Die Stutz-
stellen werden geschrieben in der Form x0, . . . , xn, wobei hier Mehrfachnennungen
vorkommen durfen. Gleiche Stutzstellen sind dann hintereinander geordnet. Fur
xi = xi+1 setzt man [xi, xi+1] = y(1)j(i) und allgemein fur xi = . . . = xi+µj setzt man
[xi, . . . , xi+µj ] = y(µj)
j(i) /(µj!).
1.3 Tschebyscheff Polynome
In diesem Abschnitt untersuchen wir, wie man die Stutzstellen optimal wahlt, so
dass die Ausdrucke ||Nn+1||∞ in der Fehlerabschatzung moglichst klein sind.
1.3.1 Tschebyscheff Polynome auf dem Referenz-Intervall
Dies betrachten wir zunachst auf dem Referenzintervall I = [−1, 1] und definieren
die Tschebyscheff Polynome
T0 :≡ 1,
T1(x) := x,
Tn(x) := 2xTn−1(x)− Tn−2(x) fur n ≥ 2.
Durch ein Induktionsargument sieht man unmittelbar, dass Tn ∈ Pn gilt.
Lemma 1.8 Es gilt fur alle x ∈ I die Darstellung
Tn(x) = cos(n arccosx).
Insbesondere gilt ||Tn||∞,I = 1.
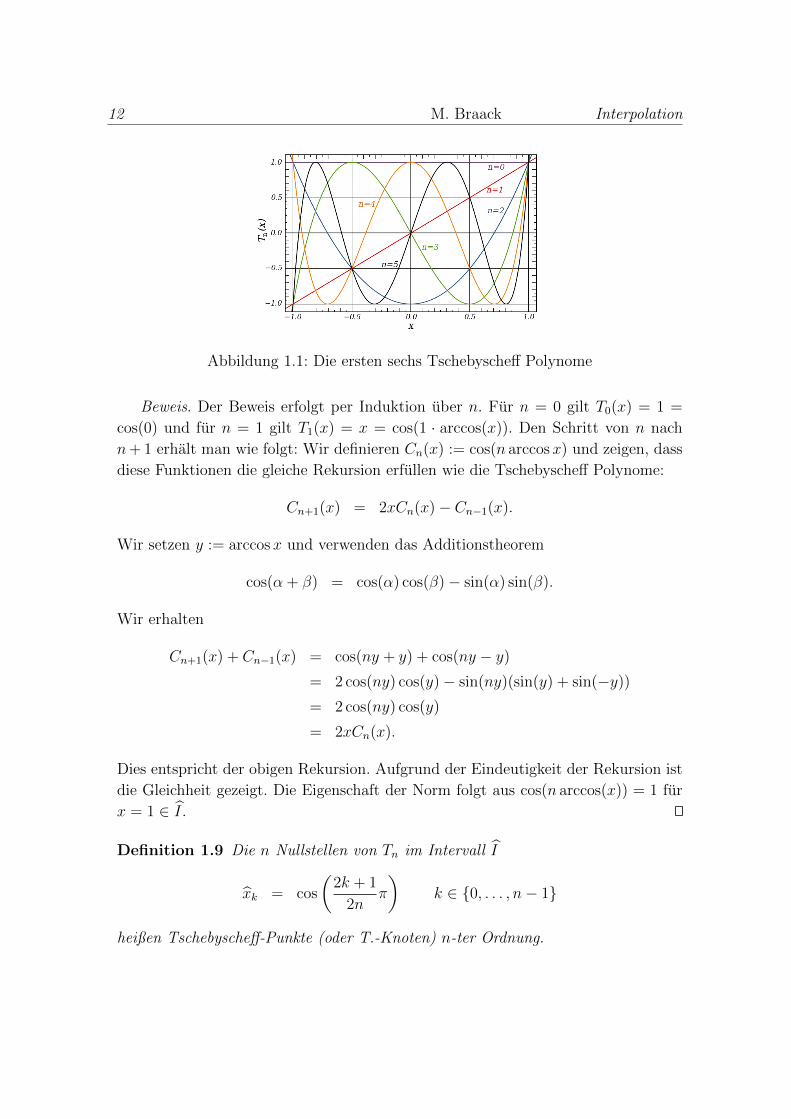
12 M. Braack Interpolation
Abbildung 1.1: Die ersten sechs Tschebyscheff Polynome
Beweis. Der Beweis erfolgt per Induktion uber n. Fur n = 0 gilt T0(x) = 1 =
cos(0) und fur n = 1 gilt T1(x) = x = cos(1 · arccos(x)). Den Schritt von n nach
n+ 1 erhalt man wie folgt: Wir definieren Cn(x) := cos(n arccosx) und zeigen, dass
diese Funktionen die gleiche Rekursion erfullen wie die Tschebyscheff Polynome:
Cn+1(x) = 2xCn(x)− Cn−1(x).
Wir setzen y := arccosx und verwenden das Additionstheorem
cos(α + β) = cos(α) cos(β)− sin(α) sin(β).
Wir erhalten
Cn+1(x) + Cn−1(x) = cos(ny + y) + cos(ny − y)
= 2 cos(ny) cos(y)− sin(ny)(sin(y) + sin(−y))
= 2 cos(ny) cos(y)
= 2xCn(x).
Dies entspricht der obigen Rekursion. Aufgrund der Eindeutigkeit der Rekursion ist
die Gleichheit gezeigt. Die Eigenschaft der Norm folgt aus cos(n arccos(x)) = 1 fur
x = 1 ∈ I.
Definition 1.9 Die n Nullstellen von Tn im Intervall I
xk = cos
(2k + 1
2nπ
)k ∈ 0, . . . , n− 1
heißen Tschebyscheff-Punkte (oder T.-Knoten) n-ter Ordnung.

1.3 Tschebyscheff Polynome 13
Da der cos im Intervall (0, π) streng monoton ist, sind diese Knoten paarweise ver-
schieden.
Lemma 1.10 Sei Nn das Newton-Polynome zu den Tschebyscheff-Punkten x0, . . . , xn−1.
Dann gilt Nn = 21−nTn.
Beweis. Offensichtlich sind Nn, Tn ∈ Pn mit identischen n Nullstellen. Also gilt
Nn = cTn mit einer (von n abhangigen) Konstanten c. Der fuhrende Koeffizient von
Nn ist 1, der von Tn ist laut Definition 2n−1. Es folgt c = 21−n.
Lemma 1.11 Sei f ∈ Cn+1(I), x0, . . . , xn ∈ I die Tschebyscheff-Knoten der Ord-
nung n+ 1 und pn ∈ Pn das zugehorige Interpolationspolynom. Dann gilt
||f − pn||∞,I ≤1
2n(n+ 1)!||f (n+1)||∞,I .
Beweis. Die Behauptung folgt unmittelbar aus Satz 1.4 und dem vorherigen
Lemma:
||Nn+1||∞,I = 2−n||Tn+1||∞,I = 2−n.
Das folgende Resultat liefert die Optimalitat in dem Sinne, dass die Tschebyscheff-
Knoten die obere Schranke fur den Fehler ||f − pn||∞,I minimal wird.
Satz 1.12 Sei Nn+1 das Newton-Polynom zu den Tschebyscheff-Knoten in I und
Nn+1 das Newton-Polynom zu beliebigen n+ 1 paarweise verschiedenen Punkten in
I. Dann gilt
||Nn+1||∞,I ≤ ||Nn+1||∞,I .
Beweis. Der Beweis wird per Widerspruch gefuhrt. Wir nehmen an, die Abschat-
zung gelte nicht. Dann gilt ||Nn+1||∞,I < 2−n. Nun zeigt man, dass der fuhrende
Koeffizient von Nn+1 nicht 1 ist. Damit kann es aber kein Newton-Polynom sei, was
den Widerspruch impliziert.
Die Maximal-/Minimalstellen von Nn+1 (bzw. von Tn+1) sind die n+ 2 Punkte
yk := cos(πk/m), k = 0, . . . ,m,
mit m = n + 1, denn arccos(yk) = πk/m und Tn+1(yk) = cos((n + 1)πk/m) =
cos(πk) = ±1. Es folgt
|Nn+1(yk)| < 2−n = ||Nn+1||∞,I = |Nn+1(yk)|.

14 M. Braack Interpolation
Wir betrachten nun das Polynom q := Nn+1− Nn+1 ∈ Pn+1. Offensichtlich ist q 6≡ 0.
Es gilt außerdem
q(xk) < 0 fur k gerade,
q(xk) > 0 fur k ungerade.
Dann besitzt q aber n+ 1 Nullstellen im Intervall I. Dann ist q ein echtes Polynom
vom Grad n + 1 und nicht etwa vom Grad n. Somit konnen die fuhrenden Koef-
fizienten von Nn+1 und Nn+1 nicht identisch sein. Also insbesondere konnten nicht
beide Newton-Polynome sein. Dies ist der angestrebte Widerspruch.
1.3.2 Tschebyscheff Polynome in allgemeinen Intervallen
Wir verwenden die affin-lineare Transformation Φ : I → I := [a, b],
x = Φ(x) :=a+ b
2+b− a
2x.
Die transformierten Tschebyscheff-Knoten sind nun xk = Φ(xk). Wenn pn ∈ Pn das
Interpolationspolynom zu den Punkten (xk, f(xk)) fur k = 0, . . . , n ist, so ist
pn := pn Φ−1
das Interpolationspolynom zu den Punkten (xk, f(xk)) fur k = 0, . . . , n.
Wir erhalten die folgende Fehlerabschatzung:
Satz 1.13 Sei pn ∈ Pn das Interpolations-Polynom von f ∈ Cn+1(I) zu den trans-
formierten n+ 1 Tschebyscheff-Knoten. Dann gilt:
||f − pn||∞,I ≤2
(n+ 1)!
(b− a
4
)n+1
||f (n+1)||∞,I .
Beweis. pn := pn Φ ist das Interpolationspolynom zu f := f Φ im Referenzin-
tervall. Nun gilt:
||f − pn||∞,I = ||f − pn||∞,I ≤1
2n(n+ 1)!||f (n+1)||∞,I
Nun gilt aber (siehe nachfolgendes Lemma)
f (n+1)(x) =
(|I||I|
)n+1
f (n+1)(x)

1.4 Stabilitat 15
Da |I|/|I| = (b− a)/2 folgt
||f − pn||∞,I ≤1
2n(n+ 1)!
(b− a
2
)n+1
||f (n+1)||∞,I .
Dies ergibt die Behauptung.
Lemma 1.14 Seien I, J ⊂ R zwei abgeschlossene Intervalle, n ∈ N0, f ∈ Cn(I)
und φ : J → I eine affin lineare Bijektion. Dann gilt fur f := f φ und x = Φ(x):
f (n)(x) = λnf (n)(x) ∀x ∈ J,
wobei λ := |I|/|J |.
Beweis. Die Behauptung ist fur n = 0 trivial. Wir zeigen die Behauptung fur
n = 1, alles weitere folgt per Induktion. Zu I = [a, b] und J = [a, b] lautet die
affin-lineare Transformation
φ(x) := a+ (x− a)b− ab− a
= a+ (x− a)λ.
Es gilt φ′ ≡ λ. Die Kettenregel ergibt
f ′(x) = (f φ)′(x) = f ′(φ(x))φ′(x) = f ′(x)λ.
1.4 Stabilitat
Neben der Approximationsgute des Interpolationspolynoms ist die Eigenschaft der
Stabilitat eine wichtige Eigenschaft. Hierbei fragt man sich, ob eine Eigenschaft der
Form
||pn||∞ ≤ c||f ||∞
gilt. Hierbei bezeichnet pn das Interpolationspolynom zu f an gegebenen n Knoten in
einem Intervall I. Die Supremumsnorm || · ||∞ bezieht sich ebenfalls auf das Intervall
I. Die Konstante c wird sicherlich von Einflussgroßen wie n oder den Stutzstellen
abhangen, muss aber unabhangig von f sein.
Zu gegebenen paarweise verschiedenen Knoten x0, . . . , xn ∈ I := [a, b] betrachten
wir den Interpolationsoperator
In : C[a, b]→ Pn, f 7→ Inf := pn.

16 M. Braack Interpolation
Diese Abbildung In ist offensichtlich eine lineare Abbildung des normierten Raums
C[a, b] in den endlich-dimensionalen normierten Raum Pn. Wir definieren die Opera-
tor-Norm
||In||∞ := supf∈C[a,b]\0
||Inf ||∞||f ||∞
∈ [0,∞]
und fragen uns, ob diese Große endlich ist. Die oben erwahnte Konstante c ist dann
gerade ||In||∞.
Definition 1.15 Zu paarweise verschiedenen Knoten x0, . . . , xn ∈ R und den zu-
gehorigen Lagrange-Polynomen L0, . . . , Ln ∈ Pn heißt
Λ :=
∥∥∥∥∥n∑k=0
|Lk|
∥∥∥∥∥∞
die zugehorige Lebesgue-Konstante.
Der folgende Satz liefert uns die Stabilitat der Polynominterpolation.
Satz 1.16 In ist eine Projektion, d.h. I2n = In, und besitzt eine endliche Norm
||In||∞ = Λ.
Beweis. Die Eigenschaft der Projektion ist offensichtlich, da aufgrund der Ein-
deutigkeit des Interpolationspolynoms gilt: I2nf = InInf = Inpn = pn = Inf . Fur
f ∈ C[a, b] gilt
Inf =n∑k=0
f(xk)Lk.
Also erhalt man fur beliebiges x ∈ I:
|Inf(x)| ≤n∑k=0
|f(xk)||Lk(x)| ≤ ||f ||∞n∑k=0
|Lk(x)| ≤ Λ||f ||∞.
Dies liefert die obere Schranke ||In||∞ ≤ Λ. Um ||In||∞ ≥ Λ zu zeigen konstruieren
wir ein spezielles f ∗ ∈ C[a, b], f 6≡ 0, so dass
||Inf ∗||∞ ≥ Λ||f ∗||∞.
Sei hierzu x∗ ∈ I so gewahlt, dass∑n
k=0 |Lk(x∗)| = Λ. Betrachte nun ein stetiges f ∗
mit den Eigenschaften:

1.5 Bestapproximation 17
• ||f ||∞ = 1,
• f(xk) = 1, wenn Lk(x∗) ≥ 0,
• f(xk) = −1, wenn Lk(x∗) < 0.
fur alle n+ 1 Stutzstellen xk. Dann folgt
||Inf ∗||∞ ≥ Inf∗(x∗) =
n∑k=0
f ∗(xk)Lk(x∗) =
n∑k=0
|Lk(x∗)| = Λ = Λ||f ∗||∞.
Dies liefert letztendlich ||In||∞ = Λ.
1.5 Bestapproximation
Satz 1.17 Mit der Lebesgue-Konstante Λ zu paarweise verschiedenen Stutzstellen
x0, . . . , xn ∈ I gilt
||f − Inf ||∞ ≤ (1 + Λ) infq∈Pn||f − q||∞ ∀f ∈ C(I).
Beweis. Fur beliebige Normen gilt aufgrund der Dreiecksungleichung und der
Projektionseigenschaft von In fur beliebiges q ∈ Pn:
||f − Inf || ≤ ||f − q||+ ||q − Inf ||= ||f − q||+ ||Inq − Inf ||= ||f − q||+ ||In(q − f)||
Mit der Stabilitat von In in der Supremumsnorm gilt insbesondere
||f − Inf ||∞ ≤ ||f − q||∞ + Λ||q − f ||∞ = (1 + Λ)||f − q||∞.
Bilden wir nun das Infimum uber alle q ∈ Pn, so erhalten wir die Behauptung.
Der nachfolgende Satz liefert uns nun eine Fehlerabschatzung fur den Fall, dass die
Funktion f nur k-mal differenzierbar ist und n ≥ k ist.
Satz 1.18 Seien k, n ∈ N mit 0 ≤ k ≤ n + 1. Dann gilt fur den Interpolations-
operator In zu n paarweise verschiedenen Stutzstellen im abgeschlossenen Intervall
I:
||f − Inf ||∞ ≤ (1 + Λ)2
k!
(b− a
4
)k||f (k)||∞ ∀f ∈ Ck(I).

18 M. Braack Interpolation
Beweis. Aufgrund der Bestapproximationseigenschaft wissen wir fur stetiges f :
||f − Inf ||∞ ≤ (1 + Λ) infq∈Pn||f − q||∞
≤ (1 + Λ) infq∈Pk−1
||f − q||∞
Wahlen wir nun q ∈ Pk−1 speziell das Interpolationspolynom an den k Tschebyscheff-
Knoten, so erhalten wir fur f ∈ Ck(I):
||f − q||∞ ≤ 2
k!
(b− a
4
)k||f (k)||∞.
Dies ergibt die Behauptung.
1.6 Stuckweise Polynome
Wir haben gesehen, dass die Erh/ohung der Anzahl Stutzstellen und des Polynom-
grades i.a. nicht ausreicht, um die Approximationsgute zu erhohen. Ein anderer Weg
ist es daher, das Intervall zu verkleinern indem man den eigentlichen Definitionsbe-
reich in Teilbereiche unterteilt. Wir zerlegen daher das abgeschlossene Intervall I in
m halboffene Intervalle Ik = (ak−1, ak] fur k ∈ 2, . . . ,m und I1 = [a, a1]:
I = I1 ∪ I2 ∪ . . . ∪ Im.
Ferner betrachten wir die Interpolatonsoperatoren
Im,n : C(I)→q : I → R
∣∣∣ q|Ik ∈ Pn ∀k ∈ 1, . . . ,m
mit
(Im,nf)∣∣Ik
= In(f |Ik).
Fur die so zusammengesetzte Interpolation erhalten wir folgende Fehlerabschatzung:
Satz 1.19 Fur n ∈ N0 und f ∈ Cn+1(I) gilt fur die Supremumsnorm auf I bei
aquidistanter Unterteilung in m Teilintervalle der Lange h = |I|/m:
||f − Im,nf ||∞ ≤ hn+1
(n+ 1)!||fn+1||∞.
Insbesondere folgt
limm→∞
||f − Im,nf ||∞ = 0.

1.7 Splines 19
Beweis. Zunachst gilt
||f − Im,nf ||∞ = maxk∈1,...,m
||f − Im,nf ||∞,Ik .
Nun verwenden wir die lokale Abschatzung der Interpolation auf jedem Teilintervall
||f − Im,nf ||∞,Ik ≤hn+1
(n+ 1)!||f (n+1)||∞,Ik .
Die Behauptung folgt nun mit maxk∈1,...,m || · ||∞,Ik = || · ||∞,I .
1.7 Splines
Die oben besprochene stuckweise Interpolation ist i.a. nicht einmal (global) stetig.
Mochte man, dass die Interpolation stetig oder sogar differenzierbar ist, so gelangt
man zu den sogenannten Splines. Aufgrund der angestrebten Stetigkeit konnen wir
nun abgeschlossene Teilintervalle Ik = [ak−1, ak] benutzen. Die jeweilige Lange der
Teilintervalle sei hk = ak − ak−1 > 0.
Definition 1.20 Zu n ∈ N und obiger Unterteilung in Teilintervalle heißt
Sn :=u ∈ Cn−1(I)
∣∣∣u|Ik ∈ Pn ∀k ∈ 1, . . . ,m
Splineraum der Ordnung n. Die Elemente aus Sn heißen Splines.
Bei diesen Splines ist die globale Differenzierbarkeitsordnung also an die Ordnung
der Polynome gekoppelt.
1.7.1 Lineare Splines
Lineare Splines erhalt man im Fall n = 1. Eine Basis fur den Raum linearer Splines
S1 :=u ∈ C(I)
∣∣∣u|Ik ∈ P1 ∀k ∈ 1, . . . ,m
ist beispielsweise gegeben durch die Dachfunktionen ϕj,
B := ϕ0, . . . , ϕm,
wobei die Werte dieser Dachfunktionen an den Knoten gegeben sind durch
ϕj(xi) := δij.
Wir betrachten nun wieder beliebige Knotenwerte y0, . . . , ym.

20 M. Braack Interpolation
Satz 1.21 B ist eine Basis von S1 und die Interpolationsaufgabe
u ∈ S1 : u(xi) = yi ∀i ∈ 0, . . . ,m (1.5)
ist eindeutig losbar.
Beweis. (a) Offensichtlich ist jeder Sn ein Vektorraum und B ⊆ S1. Ebenso sieht
man aufgrund der Konstruktion, dass die Elemente aus B linear unabhangig sind.
Wir haben daher nur noch zu zeigen, dass S1 ⊆ span 〈B〉 gilt. Zu beliebigem u ∈ S1
betrachten wir die Linearkombination
v :=m∑j=0
u(xj)ϕj ∈ span 〈B〉.
Per Konstruktion gilt v(xi) =∑m
j=0 u(xj)ϕj(xi) =∑m
j=0 u(xj)δij = u(xi) fur alle
Knoten xi. Da sowohl u als auch v zwischen den Knoten linear sind, folgt u = v ∈span 〈B〉.(b) Losbarkeit: Die Losung lautet
u =m∑j=0
yjϕj.
(c) Eindeutigkeit: Es gilt dimS1 = |B| = m + 1. Damit fuhrt (1.5) zu einem qua-
dratischen linearen Gleichungssystem der Dimension m+ 1. Die Eindeutigkeit folgt
aus der Losbarkeit.
Satz 1.22 Fur f ∈ C2(I) gilt fur die lineare Spline-Interpolation u ∈ S1 von f
bezuglich der Maximumsnorm auf I:
||f − u||∞ ≤ 1
2h2||f ′′||∞.
mit h := maxj∈1,...,m hj.
Beweis. Die lineare Spline-Interpolation entspricht der stuckweisen Interpolation
in P1 mit den jeweiligen Stutzstellen xj−1, xj. Daher gilt mit n = 1:
||f − u||∞,Ik ≤1
(n+ 1)!hn+1k ||fn+1||∞,Ik =
1
2h2k||f ′′||∞,Ik .
Hieraus ergibt sich die Behauptung.

1.7 Splines 21
1.7.2 Kubische Splines
Im Fall n = 3 erhalten wir die sogenannten kubischen Splines:
S3 :=u ∈ C2(I)
∣∣∣u|Ik ∈ P3 ∀k ∈ 1, . . . ,m.
Im Fall von s ∈ S3 mit s′′(a) = s′′(b) = 0 spricht man von einem naturlichen
kubischen Spline. Das folgende Lemma macht eine Aussage uber Splines aus dem
Raum
N := w ∈ S3
∣∣w(xj) = 0 ∀j ∈ 0, . . . ,m. (1.6)
Lemma 1.23 Seien u,w ∈ S3, wobei u ein naturlicher Spline sei und w ∈ N . Dann
folgt ∫ b
a
u′′w′′ dx = 0.
Naturliche Splines sind also orthogonal zum Raum N bezuglich des obigen Skalar-
produkts.
Beweis. Es gilt: ∫ b
a
u′′w′′dx =m∑j=1
∫Ij
u′′(x)w′′(x) dx.
Fur jedes Teilintervall gilt per partieller Integration∫Ij
u′′w′′ dx = u′′w′∣∣∣x=xj
x=xj−1
−∫Ij
u′′′w′ dx
= u′′w′∣∣∣x=xj
x=xj−1
− u′′′w∣∣∣x=xj
x=xj−1
+
∫Ij
u(4)w dx
Da nun w(xj) = 0 und u(4)|Ij ≡ 0 folgt∫Ij
u′′w′′ dx = (u′′w′)(xj)− (u′′w′)(xj−1).
In der Summe erhalten wir wegen u′′(a) = u′′(b) = 0:∫I
u′′w′′dx =m∑j=1
((u′′w′)(xj)− (u′′w′)(xj−1)) = (u′′w′)(b)− (u′′w′)(a) = 0.

22 M. Braack Interpolation
Die zugehorige Interpolationsaufgabe ergibt sich wie folgt. Gegeben seien m+ 1
Werte y0, . . . , ym ∈ R, sowie zwei Krummungswerte y(2)a , y
(2)b ∈ R fur die Endpunkte
des Intervalls I. Gesucht ist nun ein s ∈ S3, so dass
s(xj) = yj ∀j ∈ 0, . . . ,m,s′′(a) = y(2)
a ,
s′′(b) = y(2)b .
Satz 1.24 Diese Interpolationsaufgabe besitzt stets eine eindeutige Losung s ∈ S3.
Beweis. Wir formulieren die Interpolationsaufgabe im Raum der stuckweisen Po-
lynome, also s|Ik ∈ P3. Dies liefert 4m Freiheitsgrade. Nun verifizieren wir, dass wir
ebenfalls 4m Bedingungen erfullen mussen, so dass wir insgesamt ein quadratisches
Gleichungssystem der Dimension 4m betrachten mussen:
• Die Interpolationsbedingungen an s(xj) liefern m+ 1 Bedingungen,
• die Bedingungen an die zweiten Ableitungen s′′(a) und s′′(b) liefern 2 Glei-
chungen,
• die globale Stetigkeitsbedingung stellt m− 1 Gleichungen dar,
• die globale Differenzierbarkeitseigenschaft 1. Ordnung stellt m−1 Gleichungen
dar
• die globale Differenzierbarkeitseigenschaft 2. Ordnung stellt m−1 Gleichungen
dar
Wir erhalten damit ein quadratisches LGS. Wir zeigen, dass fur das homogene LGS
nur die triviale Losung s ≡ 0 moglich ist. Wir verwenden wieder den Raum N aus
(1.6). Fur s ∈ N mit s′′(a) = s′′(b) = 0 gilt mit dem vorherigen Lemma∫ b
a
|s′′(x)|2dx = 0.
Dann ist aber s′′ ≡ 0, bzw. s ∈ P1. Wegen s(a) = s(b) = 0 folgt s ≡ 0.
Die folgende Aussage besagt, dass der naturliche interpolierende Spline die Krummung
gewissermaßen minimiert:

1.7 Splines 23
Satz 1.25 Sei f ∈ C2[a, b] und s ∈ S3 ein naturlicher interpolierender kubischer
Spline. Dann gilt ∫ b
a
|s′′|2dx ≤∫ b
a
|f ′′|2dx.
Beweis. Mit der obigen Definition (1.6) von N gilt e := f − s ∈ N . Daher liefert
das obige Lemma ∫ b
a
s′′e′′ = 0.
Wir folgern∫ b
a
|f ′′|2dx =
∫ b
a
|(s+ e)′′|2dx =
∫ b
a
|s′′|2dx+ 2
∫ b
a
s′′e′′dx+
∫ b
a
|e′′|2dx
≥∫ b
a
|s′′|2dx.
Satz 1.26 Sei f ∈ C4[a, b] und s ∈ S3 der interpolierende kubische Spline mit
aquidistanten Stutzstellen mit Abstand h und mit s′′(a) = f ′′(a), s′′(b) = f ′′(b).
Dann gilt fur k ∈ 0, 1, 2 fur die Maximumsnorm auf [a, b]:
||(f − s)(k)||∞ ≤ 1
2h4−k||f (4)||∞.
Beweis. Siehe Werner / Schaback.
1.7.3 Konstruktion kubischer Splines
Wir beschreiben hier die Konstruktion kubischer Splines zu aquidistanter Gitterwei-
te h = |I|/m. Zu diesem Zweck fuhren wir zunachst die hermitesche Basis auf dem
Referenzintervall I = [−1, 1] ein:
p1(x) :=1
4(x− 1)2(x+ 2)
p2(x) :=1
4(x− 1)2(x+ 1)
p3(x) :=1
4(x+ 1)2(2− x)
p4(x) :=1
4(x+ 1)2(x− 1).

24 M. Braack Interpolation
0
-1 -0.5 0 0.5 1
x
Spline Basis
p1 p2 p3 p4
Abbildung 1.2: Kubische Spline-Basis auf dem Referenz-Intervall [−1, 1].
• p1 besitzt 2-fache Nullstellen in 1 und p1(−1) = 1,
• p2 besitzt 2-fache Nullstellen in 1 und eine einfache bei x = −1,
• p3 besitzt 2-fache Nullstellen in −1 und p3(1) = 1,
• p4 besitzt 2-fache Nullstellen in −1 und eine einfache bei x = 1.
Die auf Ik transformierte Basis erhalten wir mit φk(x) = xk + h(x− 1)/2:
pk,j := pj φ−1k .
Der Ansatz lautet nun
s|Ik = yk−1pk,1 + dk−1pk,2 + ykpk,3 + dkpk,4,
mit den freien Parametern dk−1, dk ∈ R. Das so konstruierte Polynom hat folgende
Eigenschaften auf Ik:
s(xk−1) = yk−1,
s(xk) = yk,
s′′(xj) = yk−1p′′k,1(xj) + dk−1p
′′k,2(xj) + ykp
′′k,3(xj) + dkp
′′k,4(xj),
fur j = k − 1 und j = k. Wir berechnen nun einige Ableitungen. So gilt fur l ∈1, . . . , 4 und j = k − 1 oder j = k:
p′k,l(xj) = p′l(±1)(φ−1k )′(xj) =
2
hp′l(±1),
p′′k,l(xj) = p′′l (±1)(φ−1k )′(xk)
2 + p′l(±1)(φ−1k )′′(xk) =
4
h2p′′l (±1),

1.7 Splines 25
da (φ−1k )′ ≡ 2/h und (φ−1
k )′′ ≡ 0. Insbesondere erhalt man
p′k,1(xj) = 0, p′′k,1(xk−1) = − 6
h2, p′′k,1(xk) =
6
h2,
p′k,2(xk−1) =2
h, p′k,2(xk−1) = 0, p′′k,2(xk−1) = − 8
h2, p′′k,2(xk) =
16
h2,
p′k,3(xj) = 0, p′′k,3(xk−1) =6
h2, p′′k,3(xk) = − 6
h2,
p′k,4(xk−1) = 0, p′k,4(xk−1) =2
h, p′′k,4(xk−1) = − 4
h2, p′′k,4(xk) =
8
h2.
Man pruft leicht nach, dass die Stetigkeit der 1. Ableitungen per Konstruktion be-
reits gewahrleistet ist. Die geforderte Stetigkeit der 2. Ableitungen, d.h.
s′′|Ik(xk) = s′′|Ik+1(xk)
erfordert fur jedes k ∈ 1, . . . ,m− 1:
yk−1p′′k,1(xk) + dk−1p
′′k,2(xk) + ykp
′′k,3(xk) + dkp
′′k,4(xk)
= ykp′′k+1,1(xk) + dkp
′′k+1,2(xk) + yk+1p
′′k+1,3(xk) + dk+1p
′′k+1,4(xk)
Unter Verwendung der o.g. Werte fur die zweiten Ableitungen und Multiplikation
mit h2 ergibt dies:
6yk−1 + 4dk−1 − 6yk + 8dk = −6yk − 8dk + 6yk+1 − 4dk+1.
Die Ausdrucke mit yk heben sich gegenseitig weg. Sortiert man nun die verbleibenden
Ausdrucke mit den Koeffizienten dj nach links und die Ausdrucke mit den Werten
yj nach rechts, so erhalt man die Gleichung:
dk−1 + 4dk + dk+1 =3
2(−yk−1 + yk+1) .
Nun erganzt man noch die Werte fur die zweiten Ableitungen an den Endpunkten
a und b.
2d0 + d1 = −h2
4y(2)a +
3
2(y1 − y0),
dm−1 + 2dm =h2
4y
(2)b +
3
2(ym − ym−1).
Insgesamt erhalten wir das LGS:2 1
1 4 1. . . . . . . . .
. . . 4 1
1 2
d0
...
...
...
dm
=
−1
4h2y
(2)a + 3
2(y1 − y0)
32(y2 − y0)
...32(ym − ym−2)
14h2y
(2)b + 3
2(ym − ym−1)

26 M. Braack Interpolation
Diese Matrix ist offensichtlich symmetrisch. Außerdem kann man schnell zeigen,
dass sie positiv definit ist, namlich mit Hilfe der Young’schen Ungleichung (und der
Konvention x−1 = xm+1 = 0):
xTAx =m∑k=0
xk(Ax)k =m∑k=0
xk(xk−1 + 4xk + xk+1)
= 4||x||22 +m∑k=0
xk(xk−1 + xk+1) ≥ 4||x||22 −m∑k=0
|xk|(|xk−1|+ |xk+1|)
≥ 4||x||22 −(
1
2||x||22 + ||x||22
)≥ 2||x||22 > 0,
fur x ∈ Rm \ 0.Nun wollen wir noch einmal zusammentragen, welche Schritte fur die Auswertung
eines kubischen Splines s ∈ S3 in einem Punkt x ∈ I, also fur die Berchnung s(x),
auszufuhren sind:
1. Bestimme k ∈ 1, . . . ,m, so dass x ∈ Ik. Der Aufwand fur eine solche Suche
skaliert wie ln(m).
2. Berechne x = φ−1k (x) = 1 + 2h−1(x− xk). Aufwand O(1).
3. Berechne
s(x) = yk−1p1(x) + dk−1p2(x) + ykp3(x) + dkp4(x).
Auch hier ist der Aufwand O(1).
1.8 Richardson Extrapolation
Gegeben sei eine stetige Funktion a : (0, 1]→ R. Wir fragen uns nach dem Grenzwert
a(0) = limh→0
a(h),
sofern dieser Grenzwert existiert. Hierbei ist es haufig so, dass man a(0) nicht direkt
berechnen kann. Beispiele:
• Differenzenquotienten:
a(h) :=f(x+ h)− f(x)
h

1.8 Richardson Extrapolation 27
• Quotienten mit singularem Zahler und Nenner:
a(x) :=f(x)
g(x),
mit limx→0 f(x) = limx→0 g(x) = 0, falls die Regel von L’Hospital nicht an-
wendbar ist.
Eine Idee ist es, den Ausdruck a(x) durch Polynome pn ∈ Pn zu interpolieren und
den Wert (oder ggf. mehrere Werte fur verschiedene n) pn(0) als Naherung fur a(0)
zu nehmen:
a(0) ≈ pn(0).
Wir wissen aber auch, dass Polynome hohen Grades zu Oszillationen neigen, so
dass ein Grenzubergang n→∞ keine gute Wahl ist. Die Richardson Extrapolation
geht einen anderen Weg: Man halt die Anzahl der Stutzstellen und damit auch
den Polynomgrad n konstant, variiert aber die Stutzstellen, indem man sie gegen
Null konvergieren lasst. Um dies zu konkretisieren, wahlen wir eine streng monoton
fallende Nullfolge (xi)i∈N ⊂ R+, limi→∞ xi = 0 und wahlen jeweils xk, . . . , xk+n als
Stutzstellen zur Berechnung des zugehorigen Interpolationspolynoms pk,k+n ∈ Pn:
pk,k+n(xi) = a(xi) ∀i ∈ k, . . . , k + n.
Wir fragen uns nun, ob bzw. unter welchen Voraussetzungen
a(0) = limk→∞
pk,k+n(0).
gilt. Es wird sich als sinnvoll herausstellen, dass die xi schnell genug gegen Null
konvergieren: wir werden annehmen, dass gilt:
∃ρ ∈ (0, 1) ∀i ∈ N : 0 < xi+1 ≤ ρxi. (1.7)
Die Richardson-Extrapolation berechnet also sukzessive die Werte
αk := pk,k+n(0).
Fur die Auswertung αk = pk,k+n(0) sind sie Werte Li(0) der zugehorigen Lagrange-
Polynome wichtig. Daher benotigen wir zunachst eine Aussage uber diese Werte:
Lemma 1.27 Unter der Voraussetzung (1.7) gilt fur jedes Lagrange-Polynom L ∈Pn, das zu n+ 1 aufeinander folgenden Knoten xk, . . . , xk+n gehort:
|L(0)| ≤ (1− ρ)−n.

28 M. Braack Interpolation
Beweis. Wir betrachten das i-te Lagrange Polynom L = Li (k ≤ i ≤ k + n).
Dann gilt fur die Auswertung im Nullpunkt:
L(0) =i−1∏j=k
xjxj − xi
n+k∏j=i+1
xjxj − xi
Nun gilt fur k ≤ j < i wegen xi/xj ≤ ρi−j ≤ ρ:∣∣∣∣ xjxj − xi
∣∣∣∣ =
∣∣∣∣ 1
1− xi/xj
∣∣∣∣ =
∣∣∣∣1− xixj
∣∣∣∣−1
≤ (1− ρ)−1,
und fur i < j ≤ n+ k wegen xi/xj ≥ ρi−j ≥ ρ−1 > 1:∣∣∣∣ xjxj − xi
∣∣∣∣ =
∣∣∣∣1− xixj
∣∣∣∣−1
=
(xixj− 1
)−1
≤(
1
ρ− 1
)−1
=ρ
1− ρ.
Wir erhalten daher fur das Produkt:
|L(0)| ≤ (1− ρ)−(i−k) ρn+k−i
(1− ρ)n+k−i = (1− ρ)−nρn+k−i.
Die Behauptung folgt nun aus ρ < 1 und n+ k − i ≥ 0.
Satz 1.28 Fur a ∈ C(0, 1] existiere eine asymptotische Entwicklung der Form
a(x) =n+1∑j=0
ajxj + o(xn+1),
mit reellen Koeffizienten a0, . . . , an+1. Dann gilt unter der Voraussetzung (1.7) fur
die Richardson-Extrapolation
|a(0)− αk| = O(xn+1k ).
Beweis. Durch Umsortierung endlicher Summen erhalten wir:
αk = pk,k+n(0) =n∑i=0
a(xk+i)Lk+i(0)
=n∑i=0
(n+1∑j=0
ajxjk+i + o(xn+1
k+i )
)Lk+i(0)
= a0
n∑i=0
Lk+i(0) +n+1∑j=1
aj
n∑i=0
xjk+iLk+i(0) +n∑i=0
o(xn+1k+i )Lk+i(0).

1.8 Richardson Extrapolation 29
Nach Ubungsaufgabe 2.1 gilt
n∑i=0
Lk+i(0) = 1,
n∑i=0
xjk+iLk+i(0) = 0 ∀1 ≤ j ≤ n,
n∑i=0
xn+1k+iLk+i(0) = (−1)n
n∏i=0
xk+i.
Wir erhalten daher zusammen mit a(0) = a0, dem vorherigen Lemma sowie |xk| ≥|xk+i|:
|a(0)− αk| ≤ |an+1|n∏i=0
|xk+i|+ o(xn+1k )
n∑i=0
|Lk+i(0)|
≤ |an+1|xn+1k + o(xn+1
k )(n+ 1)(1− ρ)−n.
Da (n+ 1)(1− ρ)−n unabhangig von k ist, folgt hieraus die Behauptung.
Bei iterativen Methoden stellt sich stets die Frage, wann man die Iteration abbricht.
In diesem Fall fragen wir uns, wann sich die Große αk hinreichend nah an a(0)
befindet. Wir werden sehen, dass sich der Wert a(0) sogar von oben und unten
eingrenzen lasst. Hierfur verwenden wir die zusatzlichen Großen
βk := 2αk − αk−1,
γk :=1
2(αk + βk).
Der nachfolgende Satz zeigt, dass auch γk als Approximation fur a(0) genommen
werden kann.
Satz 1.29 Unter den gleichen Bedingungen wie im vorherigen Satz sowie den zusatz-
lichen Bedingungen, dass fur den Koeffizienten an+1 in der asymptotischen Entwick-
lung gilt an+1 6= 0 sowie ρ < n+1√
1/2. Dann gilt fur hinreichend großes k stets
αk−1 ≤ a(0) ≤ βk oder βk ≤ a(0) ≤ αk−1,
sowie
|a(0)− γk| ≤ |αk − αk−1|.

30 M. Braack Interpolation
Dieser Satz besagt also, dass die Iteration abgebrochen werden kann, wenn |αk−αk−1|kleiner ist als die vorgegebene Toleranz TOL:
Abbruchkriterium: |αk − αk−1| ≤ TOL.
Beweis. (a) Unter Verwendung der Entwicklung innerhalb des letzten Beweises
erhalten wir
βk − a(0) = 2(αk − a(0))− (αk−1 − a(0))
= 2(−1)nan+1
k+n∏i=k
xi − (−1)nan+1
k+n−1∏i=k−1
xi + o(xn+1k−1)
= (−1)n+1an+1
k+n−1∏i=k−1
xi
(1− 2
xk+n
xk−1
)+ o(xn+1
k−1)
Nun gilt 0 <∏k+n−1
i=k−1 xi = O(xn+1k−1) sowie nach Voraussetzung an+1 6= 0 und
1 6= 2xk+nxk−1
. Also dominiert der erste Term fur hinreichend großes k. Dies impli-
ziert, dass das Vorzeichen fur βk − a(0) nicht wechselt. Also konvergiert (βk)k∈Nmonoton gegen a(0) ab einem k ≥ k0.
Analog folgert man, dass (αk)k∈N monoton gegen a(0) konvergiert, aber mit entgegen-
gesetztem Vorzeichen.
(b) Aus (a) folgt
|a(0)− γk| ≤1
2|βk − αk−1| =
1
2|2αk − 2αk−1| = |αk − αk−1|.
1.8.1 Anwendung auf die Berechnung von Differenzenquo-
tienten
Wir wollen die Richardson-Interpolation anwenden, um die Ableitung einer Funktion
f : I → R an einer Stelle ξ ∈ I numerisch zu approximieren. Hierbei verwenden wir
fur die Interpolation als Knotenwerte die zentralen Differenzenquotienten
pk,k+n(xj) = yj = Dxjf(ξ) =1
2xj(f(ξ + xj)− f(ξ − xj)).
Die Konvergenzaussage im vorherigen Abschnitt liefert uns folgendes Resultat:
Korollar 1.30 Die Richardson-Extrapolation in Pn zur Berechnung der numeri-
schen Ableitung einer Funktion f ∈ Cn+3(I) im Punkt ξ ∈ I liefert
|f ′(ξ)− αk| = O(xn+1k ).

1.9 Trigonometrische Interpolation / Diskrete Fourieranalyse 31
Beweis. Da f ∈ Cn+3(I) gilt, liefert die Taylor-Entwicklung
f(ξ + xj) =n+2∑i=0
1
i!xijf
(i)(ξ) +O(xn+3j ),
f(ξ − xj) =n+2∑i=0
1
i!(−xj)if (i)(ξ) +O(xn+3
j ),
yj =n+2∑i=0
1
2(1 + (−1)i+1)
1
i!xi−1j f (i)(ξ) +O(xn+2
j )
= f ′(ξ) + x2jf
(3)(ξ) + . . .+1
(n+ 2)!f (n+2)(ξ)xn+1
j +O(xn+2j ).
Im letzten Schritt wurde n als ungerade angenommen, anderenfalls fallt der vorletzte
Term sogar weg. Das ist aber gerade die geforderte asymptotische Entwicklung aus
Satz 1.28.
1.9 Trigonometrische Interpolation / Diskrete Fou-
rieranalyse
In diesem Abschnitt wollen wir 2π-periodische Funktionen f : [0, 2π] → R durch
Funktionen der Form
tn(x) =1
2a0 +
m∑k=1
(ak cos(kx) + bk sin(kx)) (1.8)
approximieren. Hierbei sei n = 2m und a0, . . . , am, b1, . . . , bm ∈ R geeignete reelle
Koeffizienten. Wir wahlen n+ 1 aquidistante Stutzstellen
xk := 2πk
n+ 1∈ [0, 2π), ∀k ∈ 0, . . . , n.
Fur k ∈ −m, . . . ,−1 definieren wir xk ∈ (−π, 0) nach der gleichen Formel. Die In-
terpolationsaufgabe zu gegebenen Knotenwerten y0, . . . , yn ∈ R lautet daher: Suche
tn obiger Form, so dass
tn(xk) = yk ∀k ∈ 0, . . . , n.
Wir arbeiten jetzt fur eine Weile im Komplexen. Daher bezeichnet i im Folgenden
die imaginare Einheit i =√−1.

32 M. Braack Interpolation
Lemma 1.31 Fur die komplexen Einheitswurzeln wk = eixk gilt:
(i) wjk = wkj ∀k, j ∈ 0, . . . , n,
(ii)n∑j=0
wqj = 0 ∀q ∈ 1, . . . , n,
(iii)n∑j=0
w−jq = 0 ∀q ∈ 1, . . . , n.
Beweis. (i) folgt aus jxk = kxj und der Definition von wk.
(ii) Aufgrund der Telekopsumme und wegen e(n+1)ixq = e2πiq = 1 gilt:
(wq − 1)n∑j=0
wjq =n∑j=0
(wj+1q − wjq) = wn+1
q − 1 = e(n+1)ixq − 1 = 0.
Da wq 6= 1 folgt∑n
j=0 wjq = 0, und (i) impliziert die Behauptung (ii).
(iii) Die dritte Identitat folgt analog aufgrund von
(w−1q − 1)
n∑j=0
w−jq =n∑j=0
(w−j−1q − w−jq ) = w−(n+1)
q − 1 = 0.
Der folgende Satz liefert zunachst die Losbarkeit komplex-wertiger trigonometrischer
Interpolation.
Satz 1.32 Zu n + 1 komplexen Knotenwerten y0, . . . , yn ∈ C existiert genau ein
komplexes trigonometrisches Interpolationspolynom der Form
tn(z) =m∑
k=−m
ckeikz.
Hierbei sind die n+ 1 Koeffizienten ck gegeben durch
ck =1
n+ 1
n∑j=0
yje−ijxk .
Im Fall y0, . . . , yn ∈ R und n ∈ N gerade, ist tn von der Form (1.8).
Beweis. (a) Wir setzen w(z) := eiz und wk := w(xk). Da sich die zuvor behandelte
Polynominterpolation auf die komplexen Zahlen ubertragen lasst, existiert genau ein
komplexes trigonometrisches Polynom qn vom Grad n,
qn(z) =n∑k=0
ck−mzk,

1.9 Trigonometrische Interpolation / Diskrete Fourieranalyse 33
mit Koeffizienten c−m, . . . , cm ∈ C, so dass
qn(wj) = wmj yj ∀j ∈ 0, . . . , n.
Wir betrachten nun das trigonometrisches Polynom pn fur w 6= 0:
pn(w) := w−mqn(w) =n∑k=0
ck−mwk−m =
m∑k=−m
ckwk,
sowie
tn(z) := pn(w(z)) =n∑
k=−n
ckw(z)k =m∑
k=−m
ckeikz.
Per Konstruktion sind die Interpolationsbedingungen erfullt, denn
tn(xj) = pn(wj) = w−mj qn(wj) = yj ∀j ∈ 0, . . . , n.
Die Eindeutigkeit der komplexen Polynom-Interpolation liefert die Eindeutigkeit von
tn. Es verbleibt die explizite Darstellung der Koeffizienten ck. Hierzu verwenden wir
die Ergebnisse der vorherigen Lemmas.
yje−ijxk = pn(wj)w
−jk =
m∑l=−m
clwljw−jk =
m∑l=−m
clwl−kj = ck +
m∑l=−m,l 6=k
clwl−kj .
Nun summieren wir uber j:
n∑j=0
yje−ijxk = (n+ 1)ck +
m∑l=−m,l 6=k
cl
n∑j=0
wl−kj .
Mit dem vorherigen Lemma gilt aber
n∑j=0
wl−kj =n∑j=0
wjl−k = 0, wenn l > k,
n∑j=0
wl−kj =n∑j=0
w−jk−l = 0, wenn l < k.
In der letzten Gleichung haben wir wl−kj = (wk−lj )−1 = (wjk−l)−1 = w−jk−l verwendet.
Wir erhalten also
n∑j=0
yje−ijxk = (n+ 1)ck.

34 M. Braack Interpolation
(b) Im reellwertigen Fall gilt die Aussage von (a) entsprechend. Da n gerade ist,
setzten wir m = n/2 ∈ N. Das komplexe trigonometrische Interpolationspolynom tnlasst sich schreiben in der Form
tn(x) =m∑
k=−m
ckeikx = c0 +
m∑k=1
(cke
ikx + c−ke−ikx) .
Nun verwenden wir die Eulersche Formel der Exponentialfunktion im Komplexen:
eikx = cos(kx) + i sin(kx),
e−ikx = cos(−kx) + i sin(−kx) = cos(kx)− i sin(kx).
Somit erhalten wir
tn(x) = c0 +m∑k=1
((ck + c−k) cos(kx) + i(ck − c−k) sin(kx)) .
Also ist tn formal von der Form (1.8) mit den Koeffizienten mit
ak := ck + c−k und bk = i(ck − c−k).
Es bleibt zu zeigen, dass diese Koeffizienten ak, bk stets reell sind. Wir verwenden
x−k = −xk, cos(z) = 12(eiz + e−iz) sowie sin(z) = 1
2i(eiz − e−iz):
ak :=1
n+ 1
n∑j=0
yj(e−ijxk + eijxk) =
2
n+ 1
n∑j=0
yj cos(jxk) ∈ R,
bk :=i
n+ 1
n∑j=0
yj(e−ijxk − eijxk) =
2i2
n+ 1
n∑j=0
yj sin(−jxk).
Dass auch bk reell ist, folgt aus i2 = −1 und sin(−jxk) = − sin(jxk).
(c) Eindeutigkeit von tn: Die Interpolationsbedingungen lassen sich als ein quadra-
tisches lineares Gleichungssystem der Dimension n + 1 schreiben. Aufgrund der in
(b) gezeigten Losbarkeit fur beliebige Knotenwerte yk folgt auch die Eindeutigkeit.
Bemerkung: Im Fall reeller Knotenwerte yk und ungeradem n muss die Form (1.8)
etwas modifiziert werden, namlich zu m := (n− 1)/2 und
tn(x) =a0
2+
m∑k=1
(ak cos(kx) + bk sin(kx)) +am+1
2cos((m+ 1)x).
Ohne Beweis geben wir folgendes Resultat an:

1.9 Trigonometrische Interpolation / Diskrete Fourieranalyse 35
Satz 1.33 Sei f ∈ C(R) 2π-periodisch. Dann gilt fur die trigonometrische Interpo-
lation mit aquidistanten Stutzstellen:
limn→∞
||f − tn||L2(0,2π) =
(∫ 2π
0
(f(x)− tn(x))2dx
)1/2
= 0.
Gilt außerdem f ∈ C1(R), so gilt sogar
limn→∞
||f − tn||∞ = 0.
Eine erste Aufwandsabschatzung fur diese Art der Interpolation ergibt 2(n + 1)2
Auswertungen der sin und cos Funktion. Insofern vermutet man einen n2 Aufwand.
Wir werden im nachsten Abschnitt sehen, dass man dies auf O(n ln(n)) reduzieren
kann.
1.9.1 Schnelle Fouriertransformation (FFT)
Die FFT setzt voraus, dass n+ 1 eine 2-er Potenz ist. Daher nehmen wir in diesem
Abschnitt n+ 1 = 2p bzw. m+ 1 = 2p−1 an. Ferner verwenden wir die Notationen
yj :=1
n+ 1yj, w := e−ix0 = e−2πi/(n+1).
Wir gehen von einer komplexen Darstellung der Koeffizienten aus. Bei der Methode
von Cooley und Tukey (1965) unterteilt man die Summe in gerade und ungerade
Indizes:
ck =n∑j=0
yjwjk =
m∑j=0
y2jw2jk +
m∑j=0
y2j+1w(2j+1)k.
Nun schauen wir uns zunachst die erste Summe an. Hierbei verwenden wir die Große
k′ ≡ k mod m + 1, also k = k′ + λ(m + 1) mit λ ∈ 0, 1. Wegen w2jλ(m+1) =
wjλ(n+1) = 1 erhalten wir fur die erste Summe:
ck′ :=m∑j=0
y2jw2jk =
m∑j=0
y2j(w2)jk
′
Somit entspricht dieser Koeffizient gerade dem k′-ten Koeffizienten einer Fourier-
Transformation der Dimension m+1 zu den Stutzstellen x0, x2, . . . , xn−1 (geradzah-
lige Indizes) und Knotenwerten y0, y2, . . . , yn−1. Fur die zweite auftretende Summe
gilt entsprechend
ck′ :=m∑j=0
y2j+1w(2j+1)k = wk
m∑j=0
y2j+1w2jk′ .

36 M. Braack Interpolation
Algorithmus FFT(n,y)
1. If n = 0 return y;
2.
m = (n− 1)/2
y′ = (y0, y2, . . . , yn−1)
y′′ = (y1, y3, . . . , yn)
u = FFT(m, y′)
v = FFT(m, y′′)
3. for k = 0 to n
k′ ≡ k mod (m+ 1)
ck = uk′ + vk′e−2πik/(n+1)
4. return c
Tabelle 1.1: Schnelle Fourier-Transformation (FFT) nach Cooley und Tukey (1965)
in Form rekursiver Aufrufe. Aufruf aus dem Hauptprogramm: c=FFT(n,y/(n+1)).
Die hier auftretende Summe entspricht ebenfalls dem k′-ten Koeffizienten einer
Fourier-Transformation der Dimension m + 1 zu den Stutzstellen x0, x2, . . . , xn−1
und Knotenwerten y1, y3, . . . , yn.
Wir iterieren diesen Prozess p mal und erhalten 2p = n+ 1 Fourier-Analyse mit
jeweils nur einem Term. Der gesamte Algorithmus ist in Tabelle 1.1 dargestellt als
Pseudo-Code mit rekursiven Aufrufen.
Satz 1.34 Im Fall n + 1 = 2p, p ∈ N0, benotigt die FFT (Fast Fourier Trans-
formation) zur Berechnung der n + 1 Koeffizienten c0, . . . , cn nicht mehr als 2(n +
1) log2(n+ 1) komplexe Operationen.
Beweis. Der Beweis erfolgt per Induktion uber p. Fur p = 0 gilt c0 = y0 und somit
betragt der Aufwand A(0) = 0, fur p = 1 gerade A(1) = 3 ≤ 4. Wir nehmen an,
dass der Aufwand fur festes p ∈ N durch A(p) ≤ 2p+1 log2(2p) = 2p+1p beschrankt
ist. Der Aufwand fur n + 1 = 2p+1 ergibt sich aus den Berechnungen von ck1 und

1.9 Trigonometrische Interpolation / Diskrete Fourieranalyse 37
ck1 mit dem jeweiligen Aufwand A(p) sowie der Produkte wk (Aufwand n) und den
2(n+ 1) Operationen zur Berechnung der ck. Insgesamt erhalten wir
A(p+ 1) = 2A(p) + n+ 2(n+ 1) ≤ 2p+1p+ 2p+1 + 2p+2
= 2p+1(p+ 1 + 2) ≤ 2p+1(p+ 1)2 = 2p+2(p+ 1).
Dies ist die Behauptung.
Es gibt auch andere Varianten der FFT, die von gleicher Komplexitat sind. So basiert
zum Beispiel das Verfahren von Sande und Tukey (1966) auf einer Unterscheidung
der Koeffizienten ck in gerade und ungerade Indizes k.

38 M. Braack Interpolation

Kapitel 2
Approximation
2.1 Bestapproximation in euklidischen und unitaren
Raumen
Wir erinnern daran, dass ein Vektorraum V uber dem Korper K = R,C mit einem
Skalarprodukt1
〈·, ·〉 : V × V → K
heißt euklidischer Raum im Fall K = R, bzw. unitarer Raum im Fall K = C. Die
zugehorige Norm bezeichnen wir mit || · ||, also ||v|| :=√〈v, v〉.
Die Bestapproximationsaufgabe in einem euklidischen Raum bzw. unitaren Raum
lautet wie folgt: Gegeben v ∈ V und ein Teilraum W ⊆ V . Gesucht ist w∗ ∈ W , so
dass
||v − w∗|| = infw∈W||v − w||.
w∗ heißt dann Bestapproximation von v. In den meisten Fallen ist V ein unendlich-
dimensionaler Raum und W endlich-dimensional.
2.1.1 Existenz und Eindeutigkeit der Bestapproximation
Zunachst formulieren wir ein Kriterium fur die Bestapproximation.
1Skalarprodukt in R ist eine symmetrische positiv-definite Bilinearform, Skalarprodukt in C ist
eine hermitesch positiv definite Sesquilinearform; die Semilinearitat wird fur das erste Argument
vereinbart, d.h. 〈λv,w〉 = λ〈v, w〉.

40 M. Braack Approximation
Satz 2.1 w∗ ∈ W ist genau dann Bestapproximation von v ∈ V , wenn folgende
Orthogonalitatseigenschaft gilt. Im Fall K = R:
〈v − w∗, w〉 = 0 ∀w ∈ W. (2.1)
Im Fall eines unitaren Raums, also K = C, lautet es
Re〈v − w∗, w〉 = 0 ∀w ∈ W. (2.2)
Beweis.⇒: Sei w∗ ∈ W Bestapproximation und w ∈ W beliebig. Wir betrachten
die Funktion
fw : K→ R, fw(λ) =1
2||v − w∗ − λw||2
fw ist eine C1-Funktion und besitzt im Nullpunkt ein lokales Minimum. Also gilt im
Fall K = R
0 = f ′w(0) =1
2
d
dλ〈v − w∗ − λw, v − w∗ − λw〉
∣∣∣λ=0
= 〈−w, v − w∗ − λw〉∣∣∣λ=0
= 〈−w, v − w∗〉.
Dies entspricht der Behauptung (2.1). Im unitaren Fall erhalten wir entsprechend:
0 = f ′w(0) =1
2〈−w, v − w∗〉+
1
2〈v − w∗,−w〉
=1
2〈−w, v − w∗〉+
1
2〈−w, v − w∗〉
= Re〈−w, v − w∗〉.
⇐: K = R: Es gelte (2.1). Dann folgt fur beliebiges w ∈ W wegen w−w∗ ∈ W und
der Cauchy-Schwarz Ungleichung:
||v − w∗||2 = 〈v − w∗, v − w∗〉 = 〈v − w∗, v − w〉+ 〈v − w∗, w − w∗〉︸ ︷︷ ︸=0
= 〈v − w∗, v − w〉 ≤ ||v − w∗||||v − w||.
Im Fall ||v−w∗|| > 0 konnen wir beide Seiten durch diese Große teilen und erhalten:
||v − w∗|| ≤ ||v − w||.

2.1 Bestapproximation in euklidischen und unitaren Raumen 41
Im unitaren Fall K = C folgern wir ganz analog:
||v − w∗||2 = Re〈v − w∗, v − w∗〉 = Re〈v − w∗, v − w〉+Re〈v − w∗, w − w∗〉︸ ︷︷ ︸=0
= Re〈v − w∗, v − w∗〉 ≤ |〈v − w∗, v − w∗〉|≤ ||v − w∗||||v − w||.
Und wieder liefert Division durch ||v − w∗|| die gewunschte Bestapproximationsei-
genschaft.
Definition 2.2 Zu n linear unabhangigen Vektoren ϕ1, . . . , ϕn ∈ V heißt die Matrix
A = (aij)1≤i,j≤n mit Koeffizienten aij = 〈ϕi, ϕj〉 Gram’sche Matrix.
Satz 2.3 Gram’sche Matrizen sind stets symmetrisch (im Fall K = R) bzw. hermi-
tesch (im Fall K = C) und positiv definit, also insbesondere regular.
Beweis. Die Symmetrie (bzw. die Eigenschaft ’hermitesch’) folgt aus der (hermi-
teschen) Symmetrie des Skalarprodukts
aij = 〈ϕi, ϕj〉 = 〈ϕj, ϕi〉 = aji.
Zur positiven Definitheit:
xTAx =n∑i=1
xi
n∑j=1
aijxj =n∑
i,j=1
xi〈ϕi, ϕj〉xj
=
⟨n∑i=1
xiϕi,n∑j=1
xjϕj
⟩= 〈v, v〉 = ||v||2 ≥ 0,
mit v :=∑
i xiϕi. Wenn x 6= 0, so folgt aus der linearen Unabhangigkeit der ϕi,
auch v 6= 0. In diesem Fall gilt also sogar xTAx > 0.
Im Fall eines endlich-dimensionalen Unterraums W kann man mit Hilfe der Gram-
schen Matrix die Bestapproximation konkret berechnen. Sei hierzu ϕ1, . . . , ϕn eine
Basis von W . Zu v ∈ V ist die Bestapproximation w∗ =∑n
j=1 αjϕj ∈ W dann
eindeutig dadurch charakterisiert, dass fur jedes i ∈ 1, . . . , n gilt:
0 = 〈ϕi, v − w∗〉 = 〈ϕi, v〉 −n∑j=1
〈ϕi, ϕj〉αj.
Diese Gleichungen entsprechen dem linearen Gleichungssystem Aα = b mit der
Gram’schen Matrix A und der rechten Seite gegeben durch die Komponenten bi =
〈ϕi, v〉, also
α = A−1b.

42 M. Braack Approximation
Satz 2.4 In euklidischen (bzw. unitaren) Raumen V sind Bestapproximationen stets
eindeutig. Im Fall endlich-dimensionaler Teilraume W ⊆ V ist die Existenz einer
Bestapproximation in W stets gegeben.
Beweis. Eindeutigkeit: Seien w1, w2 ∈ W zwei Bestapproximationen zu v ∈ V so
folgt:
0 = 〈v − w1, w〉 = 〈v − w2, w〉 ∀w ∈ W.
Also insbesondere fur w := w2 − w1:
0 = 〈v − w1 − (v − w2), w2 − w1〉 = 〈w2 − w1, w2 − w1〉 = ||w1 − w2||2.
Also gilt 0 = w1 − w2 bzw. w1 = w2.
Existenz fur dimW < ∞: Wir hatten oben gesehen, dass die Ermittlung der Best-
approximation auf das Losen eines linearen Gleichungssystems mit der Gram’schen
Matrix fuhrt. Deren Regularitat liefert die Existenz der Losung.
2.1.2 Bestapproximation stetiger Funktionen
Wir betrachten den euklidischen Raum V = C[a, b] mit dem L2-Skalarprodukt
(f, g) :=
∫ b
a
f(x)g(x) dx.
Die zugehorige Norm ist
||f ||L2 =
(∫ b
a
f(x)2dx
)1/2
.
Wahlen wir nun einen endlich-dimensionalen Teilraum, z.B. W = Pn, so erhalten
wir:
Korollar 2.5 Fur n ∈ N0 und jedes f ∈ C[a, b] existiert genau ein pn ∈ Pn mit
||f − pn||L2 = infp∈Pn||f − p||L2 .
Wir wollen dies einmal durchfuhren fur den Fall [a, b] = [−1, 1]. Wir betrachten
exemplarisch die Monombasis: Die Eintrage der Gram’schen Matrix lauten dann
aij =
∫ 1
−1
xixjdx =
0 , falls i+ j ungerade
2i+j−1
, , falls i+ j gerade

2.1 Bestapproximation in euklidischen und unitaren Raumen 43
Diese Gram’sche Matrix heißt auch Hilbert-Matrix:
A = 2
1 0 1
30 1
5. . .
0 13
0 15
. . .13
0 15
. . .
0 15
...
Allerdings ist es in vielen Fallen ungunstig, diese Matrix zu verwenden, denn sie ist
schlecht konditioniert. Dies impliziert, dass ihre Invertierung (bzw. das Losen der
zugehorigen linearen Gleichungssysteme) numerisch instabil wird (Rundungsfehler).
Erklarungen hierzu folgen spater im Abschnitt uber lineare Gleichungssysteme.
Legendre-Polynome
Um der Invertierung der Gram’schen Matrix zu umgehen, kann man eine Orthogo-
nalbasis verwenden. Die Legendre-Polynome L0,L1, . . . sind gegeben durch
Ln(x) =1
2nn!
dn
dxn((x2 − 1)n
)n ∈ N0.
Die ersten 5 Legendre-Polynome sind in der Abb. 2.1 visualisiert.
Satz 2.6 Diese Legendre-Polynome bilden ein Orthogonalsystem. Es gilt insbeson-
dere:
1. Normierung: Ln(1) = 1.
2. Paarweise Orthogonalitat:∫ 1
−1
Ln(x)Lm(x) dx =2
2n+ 1δnm ∀n,m ∈ N0
3. Fur n ∈ N ist Ln orthogonal zum ganzen Raum Pn−1.
Beweis. 1. Die Normierung bei x = 1 erhalt man, indem man zeigt (Ubung):
dn
dxn((x2 − 1)n
) ∣∣∣x=1
= 2nn!.
2. Der Nachweis der Orthogonalitat geschieht uber partielle Integration (Ubungs-
aufgabe).
3. Die Eigenschaft Ln ⊥ Pn−1 folgt aus der zuvor gezeigten paarweisen Orthogona-
litat, Ln ⊥ Lj fur 0 ≤ j < n, und der Tatsache, dass L0, . . . ,Ln−1 eine Basis von
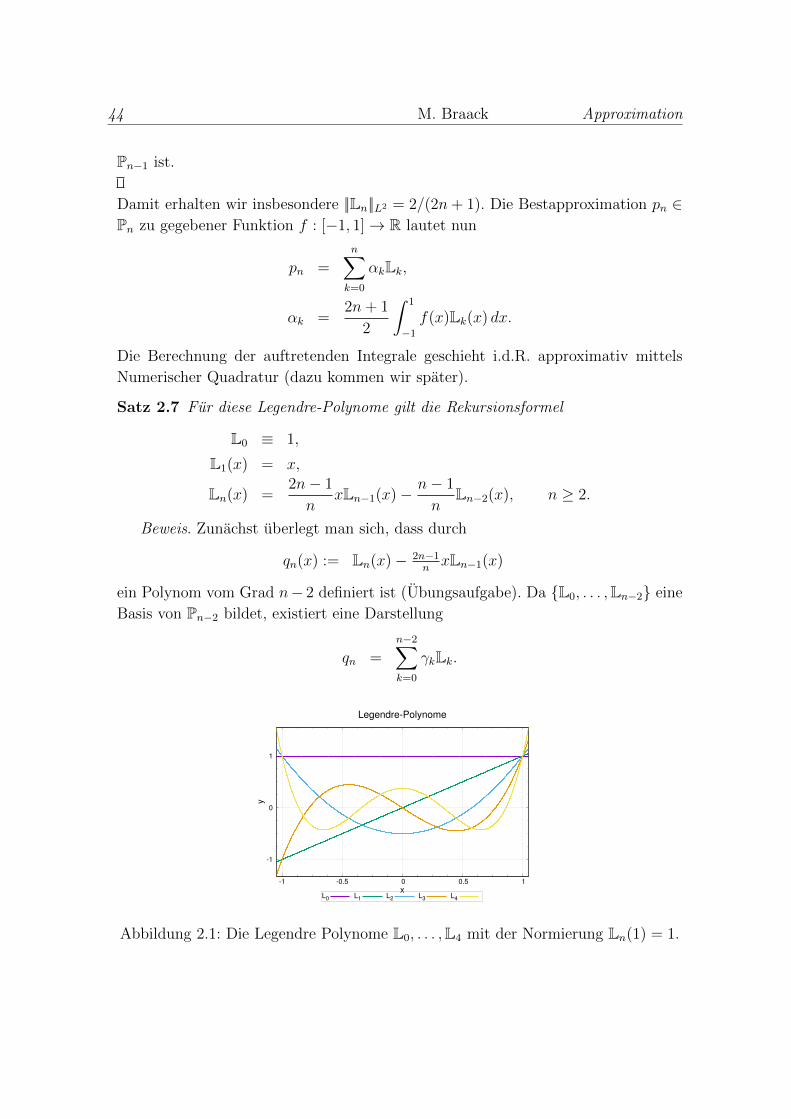
44 M. Braack Approximation
Pn−1 ist.
Damit erhalten wir insbesondere ||Ln||L2 = 2/(2n+ 1). Die Bestapproximation pn ∈Pn zu gegebener Funktion f : [−1, 1]→ R lautet nun
pn =n∑k=0
αkLk,
αk =2n+ 1
2
∫ 1
−1
f(x)Lk(x) dx.
Die Berechnung der auftretenden Integrale geschieht i.d.R. approximativ mittels
Numerischer Quadratur (dazu kommen wir spater).
Satz 2.7 Fur diese Legendre-Polynome gilt die Rekursionsformel
L0 ≡ 1,
L1(x) = x,
Ln(x) =2n− 1
nxLn−1(x)− n− 1
nLn−2(x), n ≥ 2.
Beweis. Zunachst uberlegt man sich, dass durch
qn(x) := Ln(x)− 2n−1nxLn−1(x)
ein Polynom vom Grad n− 2 definiert ist (Ubungsaufgabe). Da L0, . . . ,Ln−2 eine
Basis von Pn−2 bildet, existiert eine Darstellung
qn =n−2∑k=0
γkLk.
-1
0
1
-1 -0.5 0 0.5 1
y
x
Legendre-Polynome
L0 L1 L2 L3 L4
Abbildung 2.1: Die Legendre Polynome L0, . . . ,L4 mit der Normierung Ln(1) = 1.

2.1 Bestapproximation in euklidischen und unitaren Raumen 45
Das Skalarprodukt von qn und einem Lj (0 ≤ j ≤ n − 2) ergibt aufgrund der
Orthogonalitat der Legendre-Polynome
(qn,Lj) =2n− 1
n(xLn−1,Lj) =
2n− 1
n(Ln−1, xLj).
Da Ln−1 orthogonal ist zu jedem Polynom vom Grad ≤ n−2, folgt fur 0 ≤ j ≤ n−3:
0 = (qn,Lj) =n−2∑k=0
γk(Lk,Lj) = γj||Lj||2L2 .
Also gilt 0 = γ0 = . . . = γn−3. Somit erhalten wir die 3-Term-Rekursion
Ln(x) =2n− 1
nxLn−1(x) + γn−2Ln−2(x).
Es bleibt zu zeigen, dass γn−2 = −n−1n
. Hierzu werten wir die Polynome bei x = 1
aus. Wegen der Normierung Ln(1) = Ln−1(1) = Ln−2(1) = 1 folgt aus der obigen
3-Term-Rekursion insbesondere
1 =2n− 1
n+ γn−2.
Somit ergibt sich γn−2 = 1− 2n−1n
= n−2n+1n
= 1−nn.
Tschebyscheff-Polynome
Die bereits eingefuhrten Tschebyscheff-Polynome Tn(x) = cos(n arccosx) bilden
ebenfalls eine Orthogonalbasis von Pn, allerdings zum gewichteten L2-Skalarprodukt
(f, g)L2ω
:=
∫ 1
−1
f(x)g(x)ω(x) dx
mit der Gewichtungsfunktion ω(x) = 1/√
1− x2. Die Bestapproximation pn ∈ Pnzu gegebener Funktion f : [−1, 1]→ R lautet in dieser gewichteten L2-Norm || · ||L2
ω
nun
pn =n∑k=0
βkTk,
βk =1
||Tk||L2ω
∫ 1
−1
f(x)Tk(x)ω(x) dx.

46 M. Braack Approximation
2.1.3 Gram-Schmidt-Verfahren zur Orthogonalisierung
Das Losen des linearen Gleichungssystems kann offensichtlich vermieden werden,
wenn die Gram’sche Matrix gerade die Einheitsmatrix ist. In dem Fall spricht man
von einer Orthonormalbasis, d.h.
〈ϕi, ϕj〉 = δij.
In einem solchen Fall gilt also fur die Koeffizienten in der Darstellung der Bestap-
proximation durch die Basiselemente αi = 〈v, ϕi〉. Die Bestimmung der Bestappro-
ximation lasst sich dann auf die Berechnung von n Skalarprodukten zuruckfuhren:
w∗ =n∑i=1
〈v, ϕi〉ϕi.
Es ist also keine Invertierung eines linearen Gleichungssystems mehr notig. In diesem
Abschnitt stellen wir ein Verfahren zur Orthonormalisierung einer beliebigen Basis
ψ1, . . . , ψn von W dar. Das Gram-Schmidt-Verfahren lautet wie folgt:
1. Setze
ϕ1 :=ψ1
||ψ1||
2. danach iterativ fur k = 2, . . . , n:
ϕk := ψk −k−1∑i=1
〈ψk, ϕi〉ϕi, ϕk :=ϕk||ϕk||
.
Satz 2.8 Dieser Gram-Schmidt-Algorithmus liefert eine Orthonormalbasis ϕ1, . . . ,
ϕn.
Beweis. Per Konstruktion gilt offensichtlich die Normierung 〈ϕk, ϕk〉 = ||ϕk||2 = 1
fur jedes k. Per Induktion uber k zeigen wir nun
〈ϕk, ϕi〉 = 0 ∀i ∈ 1, . . . , k − 1. (2.3)
Fur k = 1 ist nichts zu zeigen. Insofern ist die Induktionsannahme, dass die Glei-
chung (2.3) fur festes k ≤ n gilt, gegeben. Fur k + 1 ≤ n und 1 ≤ i ≤ k gilt
nun
〈ϕk+1, ϕi〉 = 〈ψk+1, ϕi〉 −k∑j=1
〈ψk+1, ϕj〉 〈ϕj, ϕi〉︸ ︷︷ ︸=δji
= 〈ψk+1, ϕi〉 − 〈ψk+1, ϕi〉 = 0.

2.2 Tschebyscheff-Approximation 47
Da sich ϕk+1 und ϕk+1 nur um einen Faktor unterscheiden, folgt 〈ϕk+1, ϕi〉 = 0.
Bemerkungen:
1. Allerdings ist zu bemerken, dass dieses Verfahren in der Praxis nicht hinrei-
chend gut arbeitet. Dies liegt daran, dass aufgrund von Rundungsfehlern die
Orthogonalitat der Vektoren sukzessive verloren gehen kann. Es gibt bessere
Verfahren, die hier stabiler arbeiten. Dazu kommen wir spater (Householder-
Transformation).
2. Man kann zeigen, dass die oben behandelten Orthogonalsysteme von Legendre-
Polynomen und Tschebyscheff-Polynomen (bis auf Normierung) aus dem Gram-
Schmidt-Verfahren resultieren, wenn man das entsprechende Skalarprodukt
(L2 oder L2ω) zugrunde legt und mit der Monombasis 1, x, x2, . . . die Orthogo-
nalsierung aufzieht.
2.2 Tschebyscheff-Approximation
Wenn wir nun anstelle eines Euklidischen Raums nur einen normierten Raum (V, ||·||)(ohne Skalarprodukt) voraussetzen, so ist die Frage nach der Bestapproximation
deutlich schwieriger zu losen. Unter Tschebyscheff-Approximation versteht man die
Suche nach einem best-approximierenden Polynom pn ∈ Pn einer gegebenen Funk-
tion f ∈ C[a, b] in der Maximumsnorm im Intervall [a, b]:
||f − pn||∞ = infq∈Pn||f − p||∞.
Zunachst stellen wir folgendes allgemeines Resultat fest:
Satz 2.9 Sei (V, || · ||) ein normierter Raum und W ⊆ V ein endlich-dimensionaler
Teilraum. Dann existiert zu jedem v ∈ V eine Bestapproximation w∗ ∈ W , also
||v − w∗|| = infw∈W||v − w||.
Beweis. Wir konnen o.E.d.A. v 6= 0 voraussetzen. Wir betrachten zunachst die
kompakte (nichtleere) Teilmenge
W0 := w ∈ W : ||w|| ≤ 3||v||.
Fur beliebigens w1 ∈ W \W0 gilt nun mit der Dreiecksungleichung
infw∈W||v − w|| ≤ ||v − 0|| = ||v|| ≤ ||w1|| − 2||v|| = ||w1|| − ||v|| − ||v||
≤ ||w1 − v|| − ||v||.

48 M. Braack Approximation
Bilden wir das Infimum uber all diese w1, so erhalten wir
infw1∈W\W0
||v − w1|| ≥ infw∈W||v − w||+ ||v|| > inf
w∈W||v − w||.
Daher muss ein eventuelles Infimum w∗ ∈ W auch in W0 liegen. Da W0 eine kompak-
te Menge (beschrankt und abgeschlossen) ist, wird das Infimum in W0 angenommen.
Bemerkung: Die Eindeutigkeit ist i.a. nicht gewahrleistet.
Definition 2.10 Zu f ∈ C[a, b] heißt die Menge
E(f) := x ∈ [a, b] : |f(x)| = ||f ||∞
Extremalpunktmenge von f .
Aufgrund der vorausgesetzen Stetigkeit, ist die Extremalpunktmenge stets kompakt.
Wir geben jetzt ein Kriterium fur die Bestaproximation an:
Satz 2.11 (Kolmogoroff-Kriterium) Sei W ⊆ C[a, b] ein Unterraum, f ∈ C[a, b],
p ∈ W , und e := f − p. Dann ist p genau dann Bestapproximation von f in W ,
wenn
infq∈W
supx∈E(e)
e(x)q(x) ≥ 0. (2.4)
Wir konnen dieses Ergebnis auch wie folgt formulieren:
• p ist genau dann Bestapproximation, wenn kein q ∈ W existiert, das alle
Vorzeichenwechsel des Fehlers e in der Extremalpunktmenge mitmacht.
• Oder auch: p ist keine Bestapproximation, wenn ein q ∈ W existiert, so dass
fur alle Extremalpunkte x ∈ E(e) gilt: e(x)q(x) < 0.
Beweis. ⇐: Wir setzen die Bedingung (2.4) voraus und wahlen ein beliebiges
q ∈ W . Dann ist auch p − q ∈ W . Also existiert ein x ∈ E(e), so dass e(x)(p(x) −q(x)) ≥ 0. Dann folgt
|f(x)− q(x)|2 = |e(x) + p(x)− q(x)|2
= e(x)2 + 2 e(x)(p(x)− q(x))︸ ︷︷ ︸≥0
+ |p(x)− q(x)|2︸ ︷︷ ︸≥0
≥ e(x)2.
Also folgt ||f − q||∞ ≥ ||e||∞.

2.2 Tschebyscheff-Approximation 49
⇒: Sei p Bestapproximation. Wir nehmen an, dass die Bedingung (2.4) nicht
gilt. Also existiert (aufgrund der Kompaktheit von E(e)) ein q ∈ W und ein ε > 0,
so dass
e(x)q(x) ≤ −ε ∀x ∈ E(e).
Da eq ebenfalls eine stetige Funktion ist, existiert eine offene Menge U , die E(e)
umfasst, und fur die gilt:
e(x)q(x) ≤ −ε/2 ∀x ∈ U.
Wir konstruieren jetzt eine bessere Approximation durch Betrachtung der Funktio-
nen
pλ := p− λq,
mit λ > 0. Fur x ∈ U ergibt sich
|f(x)− pλ(x)|2 = (e(x) + λq(x))2
= e(x)2 + 2e(x)λq(x) + λ2q(x)2
≤ e(x)2 − λε+ λ2||q||2∞≤ e(x)2 − λε
2,
sofern λ ≤ ε/(2||q||2∞). Also erhalten wir
||f − pλ||∞,U ≤ ||e||∞ −λε
2.
Auf der Menge [a, b]\U ist |f−p| stets strikt kleiner als ||e||∞. Wegen der Kompaktheit
gilt sogar |(f −p)(x)| < ||e||∞−δ fur alle x ∈ [a, b]\U mit einem hinreichend kleinen
δ > 0. Also gilt fur x ∈ [a, b] \ U
|f(x)− pλ(x)| ≤ ||e||∞ − δ + λ||q||∞ ≤ ||e||∞ −δ
2,
fur 0 < λ < δ/(2||q||∞). Insgesamt erhalten wir fur 0 < λ ≤ min(ε/||q||∞, δ)/(2||q||∞):
||f − pλ||∞ < ||f − p||∞,
was den Widerspruch zur Annahme, dass p eine Bestapproximation war, darstellt.
Anstelle von Polynomraumen kann man verallgemeinerte Raume betrachten, so-
genannte Haar’sche Raume.

50 M. Braack Approximation
2.2.1 Alternantensatz fur Haarsche Raume
Definition 2.12 Ein endlich-dimensionaler Teilraum W ⊂ C[a, b] der Dimension
n ∈ N heißt Haarscher Raum (oder Haar-Raum), wenn gilt: Fur alle paarweise ver-
schiedenen x1, . . . , xn ∈ [a, b] und fur alle y1, . . . , yn ∈ R ist die Interpolationsaufgabe
g ∈ W : g(xi) = yi ∀i ∈ 1, . . . , n
stets losbar.
Lemma 2.13 Sei B = ϕ1, . . . , ϕn eine Basis von W ⊂ C[a, b]. Dann ist W genau
dann Haarscher Raum der Dimension n, wenn fur alle paarweise verschiedenen
x1, . . . , xn ∈ [a, b] die Matrix A = (ϕj(xi))1≤i,j≤n stets regular ist.
Beweis. ⇒: Sei zunachst W ein Haarscher Raum mit Basis B. Dann ist nach
Definition die Interpolationsaufgabe
Suche α ∈ R s. d. ∀i ∈ 1, . . . , nn∑j=1
αjϕj(xi) = yi,
losbar. Dies fuhrt aber gerade auf die Losung eines linearen Gleichungssystems mit
der Matrix A. Also ist diese regular.
⇐: analog.
Als Folgerung erhalten wir:
Lemma 2.14 W ist genau dann Haarscher Raum der Dimension n, wenn nur 0 ∈W n Nullstellen besitzt.
Beweis. Die Eigenschaft Haarscher Raum ist aquivalent zur Regularitat der Ma-
trix A = (ϕj(xi))1≤i,j≤n, unabhangig von der Wahl der Stutzstellen x1, . . . , xn ∈[a, b]. Also ist Ker(A) = 0. Daher ist - unabhangig von der Lage der Nullstellen -
nur die Nullfunktion w ≡ 0 ein moglicher Kandidat fur eine Funktion mit w(xi) = 0
an n Stellen x1, . . . , xn.
Das Standard-Beispiel fur einen Haarschen Raum der Dimansion n ist der Poly-
nomraum Pn−1. Hingegen ist der Polynomraum ohne die Konstanten, also W =
span(x, x2, . . . , xn) kein Haarschen Raum, wenn 0 ∈ [a, b], denn fur x1 = 0 und
y1 = 1 ist die Interpolationsaufgabe w(0) = 1 in W nicht losbar.
Definition 2.15 Gegeben seien g ∈ C[a, b] und m ∈ N. Eine Menge x1, . . . , xm ⊆E(g) heißt (Extremal-)Alternante der Lange m von g, wenn
• a ≤ x1 < . . . < xm ≤ b,

2.2 Tschebyscheff-Approximation 51
• g(xi) = −g(xi−1) fur alle i ∈ 2, . . . ,m.
Satz 2.16 (Alternantensatz) Gegeben seien f ∈ C[a, b], ein Haarscher Raum
W ⊂ C[a, b] der Dimension n ∈ N sowie p ∈ W . Dann ist p genau dann Bestappro-
ximation von f in W , wenn die Extremalpunktmenge E(f − p) eine Alternante der
Lange n+ 1 enthalt.
Beweis.⇐: Wir nehmen an, dass eine Alternante der Lange n+ 1 existiert, aber
dass p keine Bestapproximation sei. Dies wollen wir zum Widerspruch fuhren. Es
existiere also ein p ∈ W , so dass mit e := f − p gilt
||f − p||∞ < ||e||∞.
Dann gilt insbesondere
|f(x)− p(x)| < |e(x)| ∀x ∈ E(e).
Nun betrachten wir die Differenz q := p − p ∈ W . Es gilt fur x ∈ E(e) zum einen
q(x) 6= 0 und zum anderen:
0 ≤ |(e− q)(x)| = |(f − p− p+ p)(x)| = |(f − p)(x)| < |e(x)|.
Also muss q an allen Punkten von E(e) das gleiche Vorzeichen besitzen wie e. Nach
Annahme wechselt e das Vorzeichen in E(e) mindestens n+ 1 mal. Also besitzt q in
[a, b] mindestens n Nullstellen. Nach Lemma 2.14 ist dann aber q ≡ 0 bzw. p = p,
was einen Widerspruch darstellt.
⇒: Wir fuhren den Beweis fur den speziellen Fall, dass W = Pn−1 ist. Der
allgemeine Fall ist aufwandiger. Wir nehmen an, dass es keine Alternante der Lange
n + 1 gibt, es also maximal eine m-elementige Menge E(e) ⊂ E(e) gibt, so dass
e = f − p an diesen Punkten x ∈ E(e) das Vorzeichen wechselt und m ≤ n. Hieraus
folgt zum einen, dass e 6= 0 ist. Zum anderen folgt, dass m offene, paarweise disjunkte
Teilintervalle Ik ⊂ [a, b] existieren, so dass E(e) ⊂ I1 ∪ . . .∪ Im und sgn e(x) fur alle
x ∈ E(e)∩ Ik nur abhangig von k ist, nicht aber von dem jeweiligen Extremalpunkt
x. Da diese Intervalle disjunkt sind, existieren m− 1 ≤ n− 1 Punkte y1, . . . , ym−1 ∈[a, b]\ (I1∪ . . .∪ Im), die jeweils die Teilintervalle separieren. Man kann ein q ∈ Pn−1
finden, so dass q(yk) = 0 fur alle m−1 Punkte yk und sgn q|Ik = −sgn(e(x)) fur ein
x ∈ Ik ∩ E(e). Aufgrund der Konstruktion ist das Vorzeichen unabhangig von dem
speziellen x. Damit folgt
supx∈E(e)
(e(x)q(x)) = supx∈E(e)
−|e(x)| = −||e||∞ < 0.

52 M. Braack Approximation
Nach dem Kriterium von Kolmogoroff (2.4) ist p dann aber keine Bestapproximation
von f .
Als unmittelbare Folgerung ergibt sich:
Korollar 2.17 Ein Polynom p ∈ Pn ist genau dann Bestapproximation von f ∈C[a, b] in Pn, wenn die Extremalpunktmenge E(f − p) eine Alternante der Lange
n+ 2 enthalt.
2.2.2 Remez-Algorithmus
Der Alternantensatz liefert uns eine Idee fur ein Verfahren zur Bestimmung einer
Bestapproximation p∗ ∈ Pn. Sei p0, . . . , pn eine Basis von Pn. Dann existiert eine
Darstellung
p∗ =n∑j=0
αjpj,
mit reellen Koeffizienten α0, . . . , αn. Angenommen wir kennen eine n+ 2 elementige
Alternante a ≤ x0 < . . . < xn+1 ≤ b aus E(e) = E(f − p∗). Dann gilt
f(xk)−n∑j=0
αjpj(xk) = (−1)kβ ∀k ∈ 0, . . . , n+ 1,
mit einer weiteren skalaren Große β ∈ R. Dies entspricht einem linearen Gleichungs-
system der Dimension (n+ 2)× (n+ 2) und der Gestalt1 p0(x0) · · · pn(x0)
−1 p0(x1) p2(x1)...
...
±1 p0(xn+1) · · · pn(xn+1)
β
α0
...
αn
=
f(x0)
...
...
f(xn+1)
Man kann zeigen, dass die hier auftretende Matrix regular ist (Ubungsaufgabe). Die
Idee des Remez-Algorithmus liegt nun darin, dass folgende Korrespondenz gilt:
a ≤ x0 < . . . < xn+1 ≤ b ist Alternante und β = ||f − p∗||∞⇐⇒ p∗ ist Bestapproximation
Insofern startet man mit einer (beliebigen) Punktmenge a ≤ x0 < . . . < xn+1 ≤ b
und loßt das zugehorige lineare Gleichungssystem zur Bestimmung der Koeffizienten

2.2 Tschebyscheff-Approximation 53
α0, . . . , αn+1 und β. Sei p das zugehorige Polynom (mit eben diesen berechneten Ko-
effizienten αj). Im Anschluss ermittelt man ε := ||f − p||∞ − β. Wenn ε eine gewisse
Toleranz nicht uberschreitet, bricht man die Iteration ab und sieht p als (hinrei-
chend gute) Bestapproximation p∗ an. Anderenfalls verandert man die Punktmenge
geschickt. Beispielsweise bestimmt man einen Punkt x′ mit |f(x′)−p(x′)| = ||f−p||∞.
Dann existiert ein k so dass xk < x′ < xk+1 (oder a ≤ x′ < x0 oder xn+1 < x′ ≤ b).
Nun tauscht man xk (oder xk+1) gegen x′ aus in Abhangigkeit der Vorzeichen von
f(x′)−p(x′) und f(xk)−p(xk). Dann beginnt man die Prozedur von vorn (Aufstellen
des LGS etc.).
2.2.3 Anwendung auf Optimale Wahl von Interpolations-
stutzstellen
Die Fehlerabschatzung der Polynominterpolation (Satz 1.4) hat uns inspiriert, die
Stutzstellen so zu wahlen, dass die Norm des Newton-Polynoms, ||Nn+1||∞, minimal
wird. Da dieses Polynom den Grad n+ 1 besitzt und den fuhrenden Koeffizienten 1
besitzt, existiert eine Darstellung
Nn+1(x) = xn+1 − pn(x),
mit pn ∈ Pn. Das Ziel, ||Nn+1||∞ zu minimieren, ist daher aquivalent zu
||g − pn||∞ → min!,
fur g(x) := xn+1. Das Kriterium hierfur ist, dass g − pn eine Alternante der Lange
n+ 2 besitzt.
Im Fall [a, b] = [−1, 1] wahlen wir pn, so dass g− pn gerade das normierte Tsche-
byscheff-Polynom der Ordnung n+ 1 ist:
g − pn = 2−nTn+1,
denn wir wissen, dass die n+ 2 Punkte xk := cos(πk/(n+ 1)), k ∈ 0, . . . , n+ 1 die
Maximalstellen von Tn+1 mit wechselndem Vorzeichen sind. Somit entspricht dies
gerade der gesuchten Alternante von g− pn. Die Normierung mit dem Faktor 2−n ist
notwendig, damit der fuhrende Koeffizient derselbe ist wie der von g − pn, namlich
Eins.
Im Ergebnis erhalten wir, dass Nn+1 = 2−nTn+1 das optimale Newton-Polynom
im obigen Sinne ist. Insofern haben wir das Ergebnis aus Abschnitt 1.3.1 nochmals
(auf einem anderen Weg) rekapituliert.

54 M. Braack Approximation

Kapitel 3
Numerische Integration
Ziel dieses Abschnittes ist es, zu gegebener Funktion f ∈ C[a, b] das Integral
I(f) :=
∫ b
a
f(x) dx
mittels einer Quadraturformel der Gestalt
I(n)(f) :=n∑i=0
wif(xi) (3.1)
zu gewissen Stutzstellen a ≤ x0 < . . . < xn ≤ b zu approximieren. Hierbei sind
w0, . . . , wn ∈ R \ 0 Gewichte, die von der jeweiligen Funktion f unabhangig sind.
Offensichtlich ist
I(n) : C[a, b]→ R
eine lineare Abbildung, also insbesondere I(n)(αf + βg) = αI(n)(f) + βI(n)(g) fur
beliebige f, g ∈ C[a, b] und α, β ∈ R. Da es sicherlich sinnvoll ist, dass zumindest
konstante Funktionen durch die Quadratur exakt integriert werden, sollte stets gel-
ten:n∑i=0
wi = b− a.
Außerdem ist es wunschenswert, dass fur negative Funktionen f ≥ 0, auch das
numerische Integral nicht-negativ ist, I(n)(f) ≥ 0. Daher wahlt man sinnvollerweise
nur positive Integrationsgewichte
wi > 0 ∀i ∈ 0, . . . , n.

56 M. Braack Numerische Integration
Definition 3.1 Eine Quadraturformel (3.1) besitzt den (Exaktheits-) Grad m ∈N, wenn alle Polynome in Pm exakt integriert werden und ein Polynom in Pm+1
existiert, dass nicht exakt integriert wird.
3.1 Interpolatorische Quadraturformeln
Definition 3.2 Bei einer interpolatorischen Quadraturformel wahlt man ein Inter-
polationspolynom aus pn ∈ Pn an den Stutzstellen x0, . . . , xn und setzt
wi :=
∫ b
a
Li(x) dx, (3.2)
wobei Li ∈ Pn das Lagrange-Polynom zur Stutzstelle xi ist.
Satz 3.3 Jede interpolatorische Quadraturformel (3.1) mit den Gewichten (3.2) be-
sitzt mindestens den Grad n.
Beweis. Sei pn ∈ Pn das Interpolationspolynom zu f . Dann ergibt sich
I(n)(f) :=n∑i=0
∫ b
a
Li(x) dxf(xi)
=
∫ b
a
(n∑i=0
Li(x)f(xi)
)dx =
∫ b
a
pn(x) dx = I(pn).
Im Fall f = p ∈ Pn, ist pn = p. Also ist das numerische Integral exakt:
I(n)(p) := I(p).
Satz 3.4 Fur interpolatorische Quadraturformeln I(n) der Form (3.1) mit Grad
m ≥ n gilt folgende Fehlerabschatzung:
|I(f)− I(n)(f)| ≤ 1
(m+ 1)!||f (m+1)||∞
∫ b
a
|Nm+1(x)| dx.
Hierbei bezeichnet || · ||∞ die Maximumsnorm auf [a, b] und Nm+1 das m+ 1-te New-
tonpolynom zu den Stutzstellen x0, . . . , xn und (ggf.) beliebigen weiteren Stutzstellen
xn+1, . . . , xm ∈ [a, b], die von x0, . . . , xn verschieden sind.

3.1 Interpolatorische Quadraturformeln 57
Beweis. Sei pn = pn(f) ∈ Pn das Interpolationspolynom zu f an den Stutzstellen.
Ferner sei pm ∈ Pm ein Interpolationspolynom zu f an den gleichen Stutzstellen und
ggf. weiteren Stellen, falls m > n. Nun gilt
I(f)− I(n)(f) ≤ I(f − pm) + (I(pm)− I(n)(pm)) + I(n)(pm − f).
Wir betrachten die auftretenden Terme separat: Fur den letzten Term nutzen wir
aus, dass pm(xi) = pn(xi) = f(xi) an allen n+ 1 Stutzstellen x0, . . . , xn der Integra-
tionsformel I(n), also ist
I(n)(pm − f) = 0.
Da per Voraussetzung die numerische Integration von pm exakt ist, folgt auch fur
den zweiten Term I(pm)− I(n)(pm) = 0. Die Behauptung folgt nun unmittelbar aus
der punktweisen Identitat
f(x)− pm(x) =1
(m+ 1)!f (m+1)(ξx)Nm+1(x),
mit einer von x abhangigen Stelle ξx ∈ [a, b].
Satz 3.5 Keine interpolatorische Quadraturformel mit n + 1 Stutzstellen besitzt
einen Grad, der großer ist als m = 2n+ 1.
Beweis. Wir betrachten eine Quadraturformel zu den Stutzstellen x0, . . . , xn so-
wie das quadrierte Newton-Polynom p := N2n+1 . Dann ist p ∈ P2(n+1), p ≥ 0 und
insbesondere p 6≡ 0. Somit gilt I(p) > 0. Da aber an allen Stutzstellen p(xi) =
Nn+1(xi)2 = 0 gilt, folgt I(n)(p) = 0. Also gilt fur den Exaktheitsgrad m < 2(n+ 1).
3.1.1 Integrationsgewichte bzgl. eines Referenzintervalls
Nun wollen wir die Integrationsgewichte wi zuruckfuhren auf Integrationsgewichte
wi bzgl. des Einheitsintervalls I := [0, 1]. Dazu benutzen wir wieder die affin-lineare
Transformation
φ : I → I, φ(x) = x = a+ (b− a)x.
Die Knoten xi := φ−1(xi) sind dann die korrespondierenden Stutzstellen auf I. Es
gilt
Li(x) =∏j 6=i
x− xjxi − xj
=∏j 6=i
x− xjxi − xj
=: Li(x).

58 M. Braack Numerische Integration
Also gilt fur die Gewichte per Substitution x = φ−1(x):
wi :=
∫ b
a
Li(x) dx =
∫ b
a
Li(φ−1(x)) dx = (b− a)
∫ 1
0
Li(x) dx = (b− a)wi.
Somit ergibt sich
I(n)(f) := (b− a)n∑i=0
wif(φ(xi)). (3.3)
Eine interpolatorische Quadraturformel ist also durch Angabe von n sowie den Stutz-
stellen x0, . . . , xn ∈ I eindeutig bestimmt. Die Gewichte w0, . . . , wn ∈ R ergeben sich
aus
wi =
∫ 1
0
Li(x) dx =
∫ 1
0
∏j∈Ji
x− xjxi − xj
dx,
mit der Indexmenge Ji = 0, . . . , i − 1, i + 1, . . . , n. Diese Gewichte konnen un-
abhangig von f vorberechnet werden. In der Regel erfahrt man diese Werte aus
Tabellen.
3.2 Newton-Cotes Quadraturformeln
Sind die Stutzstellen aquidistant gewahlt, so spricht man von Newton-Cotes Quadra-
turformeln (NCQF). Man unterscheidet in abgeschlossene Newton-Cotes Formeln:
xi = i/n,
und offene Newton-Cotes Formeln:
xi = (i+ 1)/(n+ 2),
mit jeweils i ∈ 0, . . . , n. Wahrend bei den abgeschlossenen NCQF speziell x0 = 0
und xn = 1 gilt, so gilt fur die offenen NCQF 0 < x0 ≤ xn < 1.
Satz 3.6 Jede NCQF mit einer ungeraden Anzahl von Stutzstellen, also n gerade,
besitzt mindestens den Grad n+ 1.
Beweis. Sei pn+1 ∈ Pn+1 beliebig und pn ∈ Pn dessen Interpolationspolynom zu
den Stutzstellen der Quadraturformel. pn ist also ggf. von einem Grad niedriger als
pn+1. Da I(n)(pn+1) = I(pn) gilt, genugt zu zeigen
I(pn+1) = I(pn). (3.4)

3.2 Newton-Cotes Quadraturformeln 59
Nach Satz 1.4 konnen wir pn+1 in der Form
pn+1(x) = pn(x) +p
(n+1)n+1 (ξx)
(n+ 1)!Nn+1(x),
mit dem n + 1-ten Newton-Polynom Nn+1 und ξx = ξx(x) ∈ [a, b] schreiben. Da
nun aber p(n+1)n+1 konstant ist, gilt pn+1 = pn + cNn+1 mit einer reellen Zahl c. Die
Gleichung (3.4) folgt nun indem man zeigt
I(Nn+1) =
∫ b
a
n∏k=0
(x− xk) dx = 0.
Dies ist wiederum eine Konsequenz daraus, dass Nn+1 ein ungerades Polynom ist,
das bezuglich des Mittelpunktes xM := 12(a+ b) des Intervalls [a, b] antisymmetrisch
ist, d.h.
Nn+1(xM + x) = −Nn+1(xM − x) ∀x ∈ R
sowie
I(Nn+1) =
∫ xM−a
0
(Nn+1(a+ x) +Nn+1(xM + x)) dx
=
∫ xM−a
0
(Nn+1(a+ x)−Nn+1(xM − x)) dx
=
∫ xM−a
0
Nn+1(a+ x) dx−∫ xM−a
0
Nn+1(xM − x) dx
=
∫ xM−a
0
Nn+1(a+ x) dx+
∫ 0
xM−aNn+1(a+ y) dy = 0.
Bemerkung: Die oben erwahnte Positivitat der Gewichte wi > 0 ist bei den NCQF
i.a. nicht gegeben. Beispielsweise treten bei der geschlossenen NCQF mit n = 8 und
auch bei der offenen NCQF mit n = 2 bereits negative Integrationsgewichte auf.
3.2.1 Mittelpunktsregel
Die Mittelpunktsregel ist die offene NCQF zu n = 0. Also gilt x0 = (b− a)/2.
IMP (f) = (b− a)f(x0).
Nach Satz 3.6 ist der (Exaktheits-) Grad 1. Also werden alle linearen Funktionen
exakt integriert.

60 M. Braack Numerische Integration
Lemma 3.7 Fur die Mittelpunktregel gilt im Fall f ∈ C2[a, b] folgende Restglied-
darstellung fur die Integration:
R(f) := I(f)− IMP (f) =(b− a)3
24f ′′(ξ),
mit einem gewissen ξ ∈ [a, b].
Beweis. Der Beweis erfolgt analog zum Beweis der Restglieddarstellung der Simp-
son-Regel (siehe Lemma 3.9). Die genaue Ausformulierung uberlassen wir als Ubungs-
aufgabe.
3.2.2 Trapezregel
Die Trapezregel ist die abgeschlossene NCQF zu n = 1. Also gilt x0 = 0, x1 = 1
bzw. x0 = a, x1 = b.
ITrapez(f) = (b− a)
(1
2f(a) +
1
2f(b)
).
Diese Quadraturformel besitzt den Grad 1, affin-lineare Funktionen werden exakt
integriert. Wir erhalten folgende Fehlerabschatzung:
Lemma 3.8 Fur die Trapezregel gilt im Fall f ∈ C2[a, b] folgende Restglieddarstel-
lung fur die Integration:
R(f) := I(f)− ITrapez(f) = −(b− a)3
12f ′′(ξ),
mit einem gewissen ξ ∈ [a, b].
Beweis. Sei p1 ∈ P1 die lineare Funktion, die f an den Punkten x = a und x = b
interpoliert. Dann gilt
R(f) =
∫ b
a
(f(x)− p1(x)) dx =
∫ b
a
(x− a)(x− b)φ(x) dx
mit
φ(x) :=f(x)− p1(x)
(x− a)(x− b).
Um zu verifizieren, dass φ ∈ C[a, b] gilt, wenden wir die Regel von L’Hospital an. Die
Ableitung des Zahlers ist an den (singularen) Punkten x = a und x = b differenzier-
bar. Der Nenner ist dort ebenfalls differenzierbar mit Ableitungen ±(a − b). Somit

3.2 Newton-Cotes Quadraturformeln 61
ist φ im gesamten Intervall differenzierbar. Ferner gilt (x − a)(x − b) ≤ 0 in [a, b],
d.h. dieser Ausdruck andert sein Vorzeichen nicht. Daher liefert der Mittelwertsatz
der Integralrechnung
R(f) = φ(ξ)
∫ b
a
(x− a)(x− b) dx,
mit einem Zwischenwert ξ ∈ [a, b]. Eine einfache Rechnung ergibt∫ ba(x − a)(x −
b) dx = −(b− a)3/6. Also genugt es zu zeigen, dass ein ξ ∈ [a, b] existiert, so dass
φ(ξ) =1
2f ′′(ξ).
Dies erhalten wir aber gerade durch den Interpolationsfehler:
(ξ − a)(ξ − b)φ(ξ) = f(ξ)− p1(ξ) =1
2f ′′(ξ)N2(ξ),
mit dem Newton-Polynom N2(ξ) = (ξ − a)(ξ − b).
3.2.3 Simpsonregel
Die Simpsonregel ist die abgeschlossene NCQF zu n = 2. Also gilt x0 = 0, x1 = 1/2,
x2 = 1 bzw. x0 = a, x1 = (a+ b)/2 und x2 = b:
ISimpson(f) = (b− a)
(1
6f(a) +
2
3f(a+b
2) +
1
6f(b)
).
Obgleich hier n = 2 ist, wissen wir aufgrund von Satz 3.6, dass diese Quadraturfor-
mel sogar den Grad 3 besitzt.
Lemma 3.9 Fur die Simpsonregel gilt im Fall f ∈ C4[a, b] folgende Restglieddar-
stellung fur die Integration:
R(f) := I(f)− ISimpson(f) = −(b− a)5
2880f (4)(ξ),
mit einem gewissen ξ ∈ [a, b].
Beweis. Fur den Beweis benotigen wir zwei Polynome: zum einen das Interpo-
lationspolynom p2 ∈ P2, das f an den Stellen x0, x1, x2 interpoliert, sowie p3 ∈ P3,
das zusatzlich f ′ an den Stellen x1 interpoliert. Es gilt
p3(x) = p2(x) +4
h2(p′2(x1)− f ′(x1))N3(x),

62 M. Braack Numerische Integration
mit den zu x0, x1, x2 zugehorigen Newton-Polynom N3 ∈ P3 und h = b− a. Fur das
Restglied gilt
R(f) =
∫ b
a
(f(x)− p2(x)) dx
=
∫ b
a
(f(x)− p3(x)) dx+ c
∫ b
a
N3(x) dx,
mit einer reellen Zahl c. Da N3 bzgl. des Mittelpunktes des Intervalls [a, b] symme-
trisch ist, gilt∫ baN3(x) dx = 0. Daher erhalten wir
R(f) =
∫ b
a
(x− a)(x− x1)2(x− b)φ(x) dx
mit
φ(x) :=f(x)− p3(x)
(x− a)(x− x1)2(x− b).
Auch hier verifiziert man schnell mit Hilfe der Regel von L’Hospital, dass φ ∈ C[a, b]
gilt. Daher liefert der Mittelwertsatz der Integralrechnung auch hier
R(f) = φ(ξ)
∫ b
a
(x− a)(x− x1)2(x− b) dx,
mit einem geeigneten ξ ∈ [a, b]. Das hier auftretende Integral besitzt den Wert
−h5/120. Daher ist auch hier noch die Existenz eines ξ ∈ [a, b] zu zeigen, so dass
φ(ξ) =1
4!f (4)(ξ).
Wir verwenden wieder die Fehlerdarstellung aus Satz 1.4, mit der kubischen In-
terpolierenden p3 ∈ P3, die an den Stellen a, x1, b interpoliert und ausserdem die
Ableitung bei x = x1, also f ′(x1) = p′3(x1). Mit dem zugehorigen Newton-Polynom
N3 ∈ P3 gilt dann:
f(ξ)− p3(ξ) =1
4!f (4)(ξ)N3(ξ)(ξ − x1).
Somit
φ(ξ) =f(ξ)− p3(ξ)
N3(ξ)(ξ − x1)=
1
4!f (4)(ξ),
was den Beweis beendet.

3.3 Gauß-Quadratur 63
3.2.4 3/8-Regel
Die 3/8-Regel ist die abgeschlossene NCQF zu n = 3. Also gilt xi = i/3, x1 = 23a+ 1
3b,
x2 = 13a+ 2
3b:
I3/8(f) = (b− a)
(1
8f(a) +
3
8f(x1) +
3
8f(x2) +
1
8f(b)
).
Diese Quadraturformel besitzt ebenfalls den Grad 3.
3.3 Gauß-Quadratur
Wir werden in diesem Abschnitt sehen, dass die sogenannten Gauß’sche-Quadratur-
formeln mit n+ 1 Stutzstellen den maximal moglichen Grad m = 2n+ 1 tatsachlich
erreichen. Es sind sogar die Einzigen, die diese Eigenschaft besitzen. Hierzu betrach-
ten wir die Integration auf dem Referenz-Intervall
I = [−1, 1].
Definition 3.10 Die Gauß’sche-Quadraturformel mit n+1 Stutzstellen ist definiert
indem man als Stutzstellen x0, . . . , xn ∈ [−1, 1] gerade die Nullstellen des Legendre-
Polynoms Ln+1 und als Gewichte die Integrale uber die entsprechenden Lagrange-
Polynome
wi :=
∫ 1
−1
Li(x) dx
wahlt.
Konkret bedeutet dies:
• n = 1: x1 =√
1/3, x0 = −x1, w0 = w1 = 1,
• n = 2, x2 =√
3/5, x1 = 0, x0 = −x2, w0 = w2 = 5/9, w1 = 8/9.
Satz 3.11 Die Gauß’sche-Quadraturformel mit n+ 1 Stutzstellen besitzt den Grad
m = 2n+ 1.

64 M. Braack Numerische Integration
Beweis. Sei pm ∈ Pm beliebig und pn ∈ Pn das Interpolationspolynom zu den
Stutzstellen x0, . . . , xn der Gauß-Quadratur. Seien xn+1, . . . , xm ∈ [−1, 1] weitere
Punkte, die untereinander und auch von den bereits definierten n Stutzstellen paar-
weise verschieden sind. Wir benutzen die Newton’sche Darstellung von pm zu all
diesen m+ 1 Punkten
pm(x) =m∑i=0
[x0, . . . , xi]Ni(x),
mit den, in Kapitel 1 definierten, dividierten Differenzen [x0, . . . , xi] ∈ R und den
Newton-Polynomen Ni ∈ Pi. Fur das interpolierende Polynom vom Grad n gilt
entsprechend
pn(x) =n∑i=0
[x0, . . . , xi]Ni(x),
wobei, aufgrund der Interpolationseigenschaft pn(xi) = pm(xi) fur die Indizes 0 ≤i ≤ n, die gleichen dividierten Differenzen verwendet werden wie oben. Da I(n)(pm) =
I(pn) folgt
I(pm)− I(n)(pm) = I(pm)− I(pn)
= I(pm − pn)
=m∑
i=n+1
[x0, . . . , xi]
∫ 1
−1
Ni(x) dx.
Wir schauen uns die Newton-Polynome Ni mit n+ 1 ≤ i ≤ m genauer an:
Ni(x) =i−1∏j=0
(x− xj) =n∏j=0
(x− xj)i−1∏
j=n+1
(x− xj) = cnLn+1(x)qi(x),
mit einem Polynom qi ∈ Pi−1−n ⊆ Pn und einer (Skalierungs-) Konstanten cn ∈ R.
Da das Legendre-Polynom Ln+1 bzgl. des L2-Skalarproduktes orthogonal auf Pnsteht, folgt fur die Integrale∫ 1
−1
Ni(x) dx = cn
∫ 1
−1
Ln+1(x)qi(x) dx = 0.
Also gilt
I(pm) = I(n)(pm).

3.3 Gauß-Quadratur 65
Lemma 3.12 Die Integrationsgewichte der Gauß-Quadraturformeln sind stets po-
sitiv.
Beweis. Wir betrachten das Intervall [−1, 1] und zu beliebigem i ∈ 0, . . . , n die
Funktion
f(x) := ((x− xi)−1Nn+1(x))2 ≥ 0,
wobei Nn+1 ∈ Pn+1 das n + 1-te Newton-Polynom zu den Gauß-Stutzstellen von
I(n). Da f ∈ P2n, wird f von I(n) exakt integriert, also
I(n)(f) =
∫ 1
−1
f(x) dx > 0.
Andererseits besitzt f an allen Stutzstellen bis auf x = xi eine Nullstelle, so dass
I(n)(f) = wif(xi).
Somit gilt wif(xi) > 0. Da f(xi) > 0, folgt wi > 0.
Satz 3.13 Eine interpolatorische Quadraturformel mit n + 1 Stutzstellen, die vom
Grad m = 2n+ 1 ist, muss eine Gauß-Quadratur sein.
Beweis. Sei I(n) eine interpolatorische Quadraturformel im Intervall [−1, 1] mit
n+ 1 Stutzstellen, also ist sie von der Form
I(n)(f) :=n∑i=0
wif(xi)
mit Gewichten wi und Stutzstellen xi, i ∈ 0, . . . , n. Wir betrachten einen solchen
Index i und wahlen fur f das Polynom pm ∈ Pm, definiert durch
pm(x) :=1
wiLi(x) ·
n∏i=0
(x− xi),
wobei Li das i-te Lagrange-Polynom zu den Nullstellen x0, . . . , xn des Legendre-
Polynoms Ln+1 bezeichnet. Aufgrund des vorherigen Lemmas gilt wi > 0. Dann gilt
nach Voraussetzung
I(n)(pm) = I(pm) =
∫ 1
−1
pm(x) dx.

66 M. Braack Numerische Integration
Andererseits gilt aber per Konstruktion
I(n)(pm) =n∑i=0
wipm(xi) = 0.
Da auch die Gauß-Quadratur I(n) exakt ist, folgern wir
0 = I(n)(pm) =n∑j=0
wjpm(xj) =n∑j=0
wjwiLi(xj) ·
n∏i=0
(xj − xi)
=wiwi·n∏i=0
(xj − xi).
Wegen wi 6= 0 (Lemma 3.12) folgern wir, dass xj = xi fur ein gewisses j gilt. Da
diese Uberlegung fur jedes i gilt, sind die x0, . . . , xn bis auf eine eventuelle Umnum-
merierung identisch mit x0, . . . , xn. Damit gilt I(n) = I(n).
3.4 Summierte Quadraturformeln
Da man (ahnlich wie bei der Interpolation) bei der numerischen Quadratur i.a.
keine Konvergenz erwarten kann, indem man lediglich die Anzahl der Stutzstellen
erhoht, d.h. i.a. gilt limn→∞ I(n(f) 6= I(f), kann man auch die numerische Quadratur
stuckweise vornehmen. Dazu teilen wir das Intervall [a, b] wieder in N Teilintervalle
I1, . . . , IN und wenden auf jedem Teilintervall die oben behandelte Quadratur aus.
Im Fall einer aquidistanten Unterteilung der Teilintervalle, also Ik = [a + (k −1)h, a + kh] mit h = (b − a)/N , bezeichne xk,i ∈ Ik jeweils die i-te Stutzstelle der
interpolatorischen Quadraturformel I(n) auf dem Teilintervall Ik. Die resultierende
summierte (oder auch zusammengesetzte) Quadraturformel lautet dann
I(N,n)(f) =N∑k=1
h
n∑i=0
wif(xk,i).
mit Integrationsgewichten wi ∈ R und Stutzstellen xk,i ∈ Ik fur i ∈ 0, . . . , n und
k ∈ 1, . . . , N.
3.4.1 Summierte Mittelpunktsregel
Die summierte Mittelpunktsregel Mh = I(N,0) zu einer aquidistanten Unterteilung
xi := a+ h(i− 12) und h := (b− a)/N lasst sich schreiben in der Form
Mh(f) := h
N∑i=1
f(xi).

3.4 Summierte Quadraturformeln 67
Satz 3.14 Fur die summierte Mittelpunktsregel mit aquidistanter Schrittweite h =
(b− a)/N und f ∈ C2[a, b] gilt: Es existiert ein ξ ∈ [a, b], so dass
I(f)−Mh(f) =b− a
24h2f ′′(ξ).
Beweis. Die Behauptung folgt aus der stuckweisen Anwendung des Restgliedes
mit gewissen ξk ∈ [xi−1, xi]:
I(f)−Mh(f) =h3
24
N∑i=1
f ′′(ξi) =(b− a)
24h2 1
N
N∑i=1
f ′′(ξi).
Da f ′′ stetig ist, kann man das arithmetische Mittel 1N
∑Ni=1 f
′′(ξi) auch darstellen
als f ′′(ξ) mit einem geeigneten ξ ∈ [a, b].
3.4.2 Summierte Trapezregel
Bei der summierte Trapezregel Th = I(N,1) treten die Integrationspunkte xi ∈ (a, b)
stets zweimal auf, namlich einmal als Start- und einmal als Endpunkt der einzelnen
Teilintervalle. Im Fall einer aquidistanten Unterteilung mit den Knoten xi := a+hi
und der Lange h := (b− a)/N der Teilintervalle sind die Integrationsgewichte stets
wi = h/2. Die Integrationspunkte x0 = a und xN = b treten nur einmal auf. Somit
lasst sich die summierte Trapezregel durch Umsortierung in der Form
Th(f) := h
(1
2f(a) +
N−1∑i=1
f(xi) +1
2f(b)
)
schreiben.
Satz 3.15 Fur die summierte Trapezregel mit aquidistanter Schrittweite h = (b −a)/N und f ∈ C2[a, b] gilt: Es existiert ein ξ ∈ [a, b], so dass
I(f)− Th(f) = −b− a12
h2f ′′(ξ).
Beweis. Die Behauptung folgt aus der stuckweisen Anwendung des Restgliedes
mit gewissen ξk ∈ [xi−1, xi]:
I(f)− Th(f) = −h3
12
N∑i=1
f ′′(ξi) = −(b− a)
12h2 1
N
N∑i=1
f ′′(ξi).

68 M. Braack Numerische Integration
Da f ′′ stetig ist, kann man das arithmetische Mittel 1N
∑Ni=1 f
′′(ξi) auch darstellen
als f ′′(ξ) mit einem geeigneten ξ ∈ [a, b].
Bemerkung: Im Fall einer periodischen Funktion f mit Periode b− a, also f(a) =
f(b), wird die summierte Trapezregel zu
Th(f) = h
N∑i=1
f(xi).
Offensichtlich gleicht sie sich dann sehr der summierten Mittelpunktsregel; lediglich
die Punkte xi sind leicht versetzt.
3.4.3 Summierte Simpsonregel
Die summierte Simpsonregel Sh = I(N,1) zu einer aquidistanten Teilintervallen der
Lange h := (b− a)/N lasst sich durch Umsortieren in der Form
Sh(f) :=h
6
(f(a) + 2
N−1∑i=1
f(xi) + 4N∑i=1
f(xi− 12) + f(b)
)
schreiben. Hier gilt xi = a + hi und xi−1
2= 1
2(xi−1 + xi). Es gibt also den Zusam-
menhang
Sh(f) =1
3Th(f) +
2
3Mh(f).
Insofern ist die summierte Simpsonregel ein gewichtetes Mittel der summierten
Trapez- und Mittelpunktregel.
3.5 Konvergenz von Quadraturformeln
Sowohl interpolatorische Quadraturformeln als auch summierte interpolatorische
Quadraturformeln sind von der Form
I(n)(f) =mn∑i=0
a(n)i f(x
(n)i ), (3.5)
mit mn ∈ N, Gewichten a(n)0 , . . . , a
(n)mn ∈ R und Stutzstellen x
(n)0 , . . . , x
(n)mn ∈ [a, b].
Der nachfolgende Satz liefert uns ein hinreichendes Kriterium fur die Konvergenz.

3.5 Konvergenz von Quadraturformeln 69
Satz 3.16 Gegeben sei eine Folge (I(n))n∈N von Quadraturformeln der Form (3.5).
Ferner gelte fur jedes Polynom p die Konvergenz:
limn→∞
I(n)(p) =
∫ b
a
p(x) dx,
sowie die Existenz eines M ≥ 0, so dass fur die Koeffizienten gilt
n∑i=0
|a(n)i | ≤ M ∀n ∈ N.
Dann gilt fur jedes f ∈ C[a, b]:
limn→∞
I(n)(f) =
∫ b
a
f(x) dx,
Beweis. Sei ε > 0 beliebig gewahlt. Dann existiert nach dem Approximationssatz
von Weierstrass ein k ∈ N und ein pk ∈ Pk, so dass
||f − pk||∞ ≤ ε.
Nun folgt
I(f)− I(n)(f) = I(f − pk) + (I(pk)− I(n)(pk)) + I(n)(pk − f).
Wir betrachten diese Terme separat. Fur den ersten Term erhalten wir
|I(f − pk)| ≤ (b− a)||f − pk||∞ ≤ (b− a)ε.
Fur den zweiten Term I(pk)− I(n)(pk) nutzen wir die Voraussetzung, dass bei Poly-
nomen Konvergenz vorliegt. Fur n ≥ n0(ε) gilt also
|I(pk)− I(n)(pk)| ≤ ε.
Fur den dritten Term gilt im Fall, dass die Summe der Betrage aller Koeffizienten
beschrankt ist:
|I(n)(pk − f)| ≤m(n)∑i=0
|a(n)i ||(pk(x
(n)i )− f(x
(n)i ))| ≤ ||f − pk||∞
m∑i=0
|a(n)i | ≤ Mε.
Also erhalten wir insgesamt fur hinreichend großes n
|I(f)− I(n)(f)| ≤ (b− a+ 1 +M)ε.
Dies beweist die Konvergenz.

70 M. Braack Numerische Integration
Korollar 3.17 Fur eine Folge (I(n))n∈N von Quadraturformeln der Form (3.5), die
fur Polynome konvergiert und deren Koeffizienten alle nicht-negativ sind, a(n)i ≥ 0,
folgt die Konvergenz fur beliebige Funktionen f ∈ C[a, b].
Beweis. Aus der nicht-Negativitat der Koeffizienten und der Konvergenz fur kon-
stante Funktionen folgt
mn∑i=0
|a(n)i | =
mn∑i=0
a(n)i = I(n)(1) →
∫ b
a
dx = b− a.
Also ist die Summe der Betrage der Koeffizienten auch beschrankt. Die Konvergenz
folgt nun aus dem vorherigen Satz.
Korollar 3.18 Fur jedes f ∈ C[a, b] gilt fur die Gauß-Quadraturen I(n):
limn→∞
I(n)(f) = I(f).
Beweis. Wir verifizieren die beiden Bedingungen aus Lemma 3.17. Die Konver-
genz fur Polynome folgt aus dem Exaktheitsgrad der Gauß-Quadratur. Konkret gilt
sogar I(n)(pm) = I(pm) fur alle n ∈ N mit n ≥ (m − 1)/2. Die Positivitat der
Koeffizienten haben wir bereits in Lemma 3.12 gezeigt.
Korollar 3.19 Fur jedes f ∈ C[a, b] konvergieren die summierte Mittelpunktregel,
die summierte Trapezregel und die summierte Simpsonregel bei wachsenden Anzahl
von Teilintervallen N →∞.
Beweis. Die Summe der Koeffizienten ist offensichtlich beschrankt, denn die Ko-
effizienten skalieren stets mit h ∼ N−1. Es genugt daher, die Konvergenz fur Poly-
nome p zu zeigen. Dies folgt aber aus den Restgliedformeln, z.B. fur die summierte
Trapezregel in Satz 3.15:
limh→∞
Th(p)− I(p) ≤ b− a12
limh→∞
h2||p′′||∞,[a,b] = 0.
3.6 Romberg-Verfahren
Die summierten Integrationsformel lassen sich verstandlicherweise nicht fur eine
Schrittweite h = 0 ausfuhren. Man kann aber sehr wohl eine Extrapolation zur

3.6 Romberg-Verfahren 71
Null durchfuhren. Hierzu betrachten wir (wie bereits der Mathematiker Romberg)
die summierte Trapezregel. Da fur h2 → 0 auch h→ 0 gilt, setzen wir
a(h2) := Th(f).
Fur f ∈ C[a, b] konvergiert die Trapezregel fur h→ 0, so dass wir
a0 := limh→0
a(h2) =
∫ b
a
f(x) dx
setzen konnen. Wir werden gleich sehen, weshalb man hier die Quadrate wahlt. Fur
die Extrapolation zum Limes durch ein Polynom vom Grad n ∈ N geht man nun
wie folgt vor:
1. Zu festem h0 > 0 setzt man hi = 2−ih0 und berechnet a(h2i ) per summierter
Trapezregel:
[yi,0] := a(h2i ) = Thi(f) i ∈ 0, . . . , n.
2. Die eigentliche Extrapolation kann mit dem Neville-Schema durchgefuhrt wer-
den. Man berechnet sukzessive fur k ∈ 0, . . . , n− 1:
[yi,k+1] := [yi,k] + h2i
[yi,k]− [yi+1,k]
h2i+k+1 − h2
i
, i ∈ k, . . . , n.
3. Der gesuchte extrapolierte Wert lautet dann
[y0,n] ≈ a0.
Der großte Aufwand besteht hierbei i.d.R. aus Berechnung der n + 1 Trapezregeln
[yi,0] in Schritt 1. Aufgrund der speziellen Wahl der hi gilt hi = hi−1/2, so dass die
Stutzstellen geschachtelt sind. Man kann daher folgenden Zusammenhang zwischen
Thi−1(f) und Thi(f) ausnutzen:
Thi(f) =hi−1
2
(1
2f(a) +
Ni−1−1∑j=1
f(a+ jhi−1) +1
2f(b) +
Ni−1−1∑j=1
f(a+ (2j − 1)hi)
)
=1
2Thi−1
(f) +hi2
Ni−1−1∑j=1
f(a+ (2j − 1)hi).
In dieser Form reduziert sich die Anzahl der Funktionsaufrufe von f um den Faktor
2.
Die obige Nutzung der Quadrate h2 in der Definition von a liegt in der folgenden
asymptotischen Entwicklung begrundet.

72 M. Braack Numerische Integration
Satz 3.20 ( Euler-Maclaurinsche Summenformel) Fur f ∈ C2m[a, b] gilt die
asymptotische Entwicklung:
Th(f) =
∫ b
a
f(x) dx+ (b− a)m∑k=1
B2k
(2k)!f (2k)(ξ2k)h
2k,
mit den Bernoulli-Zahlen B2, . . . , B2m ∈ Q und (von f abhangige Punkte) ξ2, . . . , ξ2m ∈[a, b].
Fur den Beweis verweisen wir beispielsweise auf [5]. Aufgrund dieser asymptoti-
schen Entwicklung in gerade Potenzen der Schrittweite h ist die obige Definition
a(h2) = Th(f) vorteilhaft. Der Satz 1.28 liefert jetzt fur f ∈ C2n+2[a, b] die Konver-
genzordnung ∣∣∣∣∫ b
a
f(x) dx− [y0,n]
∣∣∣∣ = O(h2n+20 ).
3.7 Schrittweiten-Kontrolle
Um bei der numerischen Integration verlassliche Approximationen fur das Integral
zu erhalten, sollte man den Fehler I(f) − I(n)(f) schatzen konnen. Dies lasst sich
beispielsweise durch die Verwendung von Quadraturformeln unterschiedlicher Ge-
nauigkeit erreichen. Dies demonstrieren wir anhand einer summierten Quadratur-
formel Ih mit einer Anzahl N ∼ h−1 von Teilintervallen. Wir nehmen ferner an, dass
die Quadratur eine Fehlerdarstellung der Form
I(f)− Ih(f) = akhk +O(hk+1)
mit k ∈ N besitzt. Bei der Anwendung der Quadraturformel mit halber Schrittweite
h/2 erhalt man entsprechend
I(f)− Ih/2(f) = ak
(h
2
)k+O(hk+1),
bzw.
Ih/2(f)− Ih(f) = akhk(1− 2−k
)+O(hk+1).
Unter Vernachlassigung der Terme mit Ordnung hk+1 erhalt man eine Naherung
I(f)− Ih(f) ≈ akhk ≈
Ih/2(f)− Ih(f)
1− 2−k.

3.7 Schrittweiten-Kontrolle 73
Bei Kenntnis von k kann man die rechte Seite dieser Naherung verwenden, um den
Fehler |I(f)− Ih(f)| zu schatzen. Ein geeignetes Abbruchkriterium zu vorgegebener
Toleranz TOL > 0 konnte dann lauten:
|Ih/2(f)− Ih(f)|1− 2−k
≤ TOL.
Bei der Wahl der Quadraturformel ist zu beachten, dass man bei den summierten
NCQF den Wert von Ih(f) fur die Berechnung von Ih/2(f) wiederverwenden kann
und somit die Anzahl von Funktionsauswertungen reduzieren kann. Wir haben dies
im vorherigen Abschnitt (Romberg-Verfahren) bereits fur die summierte Trapezre-
gel demonstriert. Das ist bei den Gauss-Formeln nicht moglich, da die Stutzstellen
von Ih und Ih/2 komplett verschieden sind. Dies relativiert den Vorteil der hoheren
Ordnung der Gauss-Formeln etwas.

74 M. Braack Numerische Integration

Kapitel 4
Direkte Loser fur lineare
Gleichungssysteme
In diesem Kapitel untersuchen wir zu gegebenem A ∈ Km×n , mit K = R oder
K = C, und b ∈ Km lineare Gleichungssysteme der Form
Ax = b.
Zunachst betrachten wir quadratische LGS, also den Fall m = n, mit Dreiecksma-
trizen.
4.1 Direktes Losen bei Dreiecksmatrizen
4.1.1 Vorwartselimination
Wir gehen zunachst davon aus, dass A eine linke untere Dreiecksmatrix ist, dass
also aij = 0 fur j > i. In diesem Fall bestimmt sich die Losung x einfach sukzessive
durch
xi :=1
aii
(bi −
i−1∑j=1
aijxj
)∀i ∈ 1, . . . , n.
Der numerische Aufwand skaliert offensichtlich wie O(n2). Wichtig ist allerdings,
dass die Diagonalelemente allesamt ungleich Null sind aii 6= 0 fur alle i ∈ 1, . . . , n.Anderenfalls ware A singular.
Lemma 4.1 Eine untere Dreiecksmatrix ist genau dann regular, wenn ihre Haupt-
diagonalelemente alle von Null verschieden sind. Die Inverse einer regularen unteren

76 M. Braack Direkte Loser fur lineare Gleichungssysteme
Dreiecksmatrix ist wieder eine untere Dreiecksmatrix. Das Produkt unterer Dreiecks-
matrizen ist wieder eine untere Dreiecksmatrix. Besitzen diese Matrizen daruber
hinaus nur Einsen auf den Diagonalen, so gilt dies auch fur das Produkt.
Beweis. Ubungsaufgabe.
4.1.2 Ruckwartselimination
Wir gehen nun davon aus, dass A eine rechte obere Dreiecksmatrix ist, dass also
aij = 0 fur j < i. In diesem Fall bestimmt sich die Losung x sukzessive durch
xi :=1
aii
(bi −
n∑j=i+1
aijxj
)
in der Reihenfolge i = n, . . . , 1. Auch hier ist der numerische Aufwand O(n2) und
das Verfahren nur moglich, wenn aii 6= 0 fur alle i.
Analog zum Lemma fur untere Dreiecksmatrizen erhalten wir:
Lemma 4.2 Eine obere Dreiecksmatrix ist genau dann regular, wenn ihre Haupt-
diagonalelemente alle von Null verschieden sind. Die Inverse einer regularen oberen
Dreiecksmatrix ist wieder eine obere Dreiecksmatrix. Das Produkt oberer Dreiecks-
matrizen ist wieder eine obere Dreiecksmatrix.
4.2 LU-Zerlegung
Nun kombinieren wir diese beiden Methoden fur den Fall, dass sich die Matrix A in
eine untere und eine obere Dreiecksmatrix faktorisieren lasst.
Definition 4.3 Eine Zerlegung von A ∈ Kn×n der Form
A = LU (4.1)
mit einer linken unteren Dreiecksmatrix L ∈ Kn×n und einer rechten oberen Drei-
ecksmatrix U ∈ Kn×n heißt LU-Zerlegung oder auch LR-Zerlegung.
Lemma 4.4 Ist A ∈ Kn×n regular, so ist eine LU-Zerlegung A = LU , bei der die
Hauptdiagonale von L nur aus Einsen besteht, eindeutig.

4.2 LU-Zerlegung 77
Beweis. Es gelte A = L1U1 = L2U2 mit unteren Dreiecksmatrizen L1, L2 und
oberen Dreiecksmatrizen U1, U2 sowie (L1)ii = (L2)ii = 1 fur alle i. Dann sind L2
und U1 regular und es gilt
L−12 L1 = U2U
−11 .
Da L−12 wieder eine untere Dreiecksmatrix ist, steht auf der linken Seite ein Produkt
von unteren Dreiecksmatrizen, also wieder eine untere Dreiecksmatrix. Analog steht
rechts eine obere Dreiecksmatrix. Dann folgt aber, dass L−12 L1 bzw. U2U
−11 eine
Diagonalmatrix ist. Da ferner die Diagonalen von L1 und L2 nur aus Einsen bestehen,
gilt es auch fur das Produkt L−12 L1. Also gilt L−1
2 L1 = U2U−11 = I, bzw. L1 = L2
und U1 = U2.
Ist eine LU-Zerlegung (4.1) bekannt, so erhalt man die Losung x von Ax = b
mittels:
Vorwartselimination: Ly = b,
Ruckwartselimination: Ux = y,
denn Ax = LUx = Ly = b.
Lemma 4.5 Sei A = (aij) ∈ Kn×n regular. Dann existiert genau dann eine LU-
Zerlegung von A mit regularen Matrizen L und U , wenn fur jedes m ∈ 1, . . . , ndie sogenannte Hauptuntermatrix
Bm :=
a11 · · · a1m
......
am1 · · · amm
∈ Km×m
regular ist. Ferner kann die Matrix L dann so gewahlt werden, dass ihre Hauptdia-
gonale nur aus Einsen besteht.
Beweis. ⇐: Wir fuhren den Beweis per Induktion nach n. Fur n = 1 gilt nach
Voraussetzung a11 6= 0, so dass wir einfach l11 = 1 und r11 = a11 setzen konnen. Wir
nehmen daher an, dass die Behauptung fur festes n ∈ N gilt und mussen zeigen,
dass die Behauptung dann auch fur Matrizen A ∈ K(n+1)×(n+1) gilt. Wir schreiben
A in der Form
A =
(Bn A∗nAn∗ a
),

78 M. Braack Direkte Loser fur lineare Gleichungssysteme
mit a = an+1,n+1 und A∗n, ATn∗ ∈ Kn. Aufgrund der Induktionsannahme existiert
eine LU -Zerlegung von Bn, also
Bn = LBUB,
mit regularen unteren bzw. oberen Dreiecksmatrizen LB und UB. Außerdem gilt fur
die Hauptdiagonalelemente von LB: lii = 1 fur alle i ∈ 1, . . . , n. Nun setzen wir
L :=
(LB 0
Ln∗ 1
)und U :=
(UB U∗n0 u
),
mit
Ln∗ := An∗U−1B ,
U∗n := L−1B A∗n
und u := a− Ln∗U∗n.
Dann folgt
LU =
(LB 0
Ln∗ 1
)(UB U∗n0 u
)=
(LBUB LBU∗nLn∗UB Ln∗U∗n + u
)=
(Bn A∗nAn∗ a
)= A.
Also erhalten wir die gewunschte Zerlegung fur A. Per Konstruktion besteht die
Hauptdiagonale von L nur aus Einsen. Also ist L regular. Die Regularitat von U
folgt aus der Regularitat von L und A.
⇒: Wir nehmen an, dass die LU-Zerlegung von A existiert. Dann bildet fur m ∈1, . . . , n das Produkt der m-ten Hauptuntermatrizen Lm, Um von L bzw. U eine
LU-Zerlegung von Bm = LmUm. Aufgrund der Regularitat von Lm und Um folgt die
Regularitat von Bm.
4.2.1 LU-Zerlegung per Gauß-Elimination ohne Pivotisie-
rung
Wir verwenden folgende Darstellung in Blockmatrizen:
A =
(a11 A1∗
A∗1 A∗∗
), L =
(1 0
L∗1 L∗∗
), U =
(u11 U1∗
0 U∗∗
),

4.2 LU-Zerlegung 79
mit A1∗, U1∗ ∈ K1×(n−1) , A∗1, L∗1 ∈ K(n−1)×1 und A∗∗, L∗∗, U∗∗ ∈ K(n−1)×(n−1) sowie
u11 ∈ K. Dann ergibt das Produkt LU = A die Gleichung(1 0
L∗1 L∗∗
)(u11 U1∗
0 U∗∗
)=
(u11 U1∗
L∗1u11 L∗1U1∗ + L∗∗U∗∗
)=
(a11 A1∗
A∗1 A∗∗
)Hieraus ergibt sich offensichtlich:
u11 = a11 (4.2)
L∗1 = A∗1/u11 (4.3)
U1∗ = A1∗ (4.4)
A′ = L∗∗U∗∗ = A∗∗ − L∗1U1∗. (4.5)
Hierdurch werden L∗1 und U1∗, also die erste Spalte von L und die erste Zeile von
U , passend erzeugt. Der Block A′ := L∗∗U∗∗ ist noch nicht passend faktorisiert, da
man die individuellen Faktoren L∗∗ und U∗∗ noch nicht kennt, sondern nur deren
Produkt. Da aber A′ ∈ K(n−1)×(n−1) ist, kann man diese Prozedur iterieren.
Der gesamte Algorithmus ist in Tabelle 4.1 dargestellt.
Das nachste Lemma macht eine Aussage, ob der Algorithmus uberhaupt durchfuhr-
bar ist.
Lemma 4.6 A ∈ Kn×n erfulle die gleichen Voraussetzungen wie im Lemma zuvor.
Dann ist obige LU-Zerlegung durchfuhrbar und liefert eine LU-Zerlegung von A.
Beweis. Obige Prozedur ist durchfuhrbar, solange bei der Berechnung der Matrix
L∗1 nicht durch Null geteilt wird und dies auch bei den sukzessiven Faktorisierungen
von L∗∗U∗∗ etc. der Fall ist. Nach Voraussetzung gilt u11 = a11 = detB1 6= 0. Fur
den Koeffizienten c := (L∗∗U∗∗)11 gilt
c = (A∗∗)11 − (L∗1U1∗)11 = a22 −1
a11
(A∗1A1∗)11 = a22 −1
a11
a21a12.
Erweiterung mit a11 liefert
a11c = a11a22 − a21a12 = det(B2) 6= 0.
Es folgt c 6= 0. Somit ist auch der zweite Schritt durchfuhrbar. Die folgenden Schritte
erhalt man analog.
Wenn man diesen Algorithmus zur LU-Faktorisierung auf einem Rechner imple-
mentieren mochte, so wird nicht notwendigerweise zusatzlicher Speicherplatz fur die

80 M. Braack Direkte Loser fur lineare Gleichungssysteme
Algorithmus LU(n,A)
1. for i = 1, . . . , n− 1
2. if aii = 0 STOP; /* Abbruch */
3. for j = i+ 1, . . . , n
4.
5. aji = aji/aii;
6. for k = i+ 1 to n
7. ajk = ajk − ajiaik;
8.
9.
Tabelle 4.1: LU-Zerlegung mit Ubergabe einer Matrix A = (aij) der Dimension n×n,
die durch L und U uberschrieben wird.
Untermatrizen A′ = L∗∗U∗∗ und fur L∗1, U1∗ sowie fur u11 benotigt. Man kann ein-
fach die Speicherplatze von A geeignet uberschreiben. Dies wird durch folgendes
Schema beschrieben: (a11 A1∗
A∗1 A∗∗
)→
(u11 U1∗
L∗1 A′
),
wobei die einzelnen Eintrage gemaß (4.2)-(4.5) berechnet werden. Die Blocke A1∗ und
A∗1 werden fur die weiteren Schritte nicht mehr benotigt. Die finale LU-Zerlegung
speichert man somit in der folgenden Form abu11 · · · · · · · · · u1n
l21 u22 · · · · · · u2n
.... . .
......
. . ....
ln1 ln2 · · · ln,n−1 unn
.
Die Diagonale von L muss nicht abgespeichert werden, da sie per Konstruktion
nur aus Einsen besteht. Diese platzsparende Speicherung der Faktorisierung sollte

4.2 LU-Zerlegung 81
man aber nur machen, wenn die ursprungliche Matrix nicht an anderer Stelle noch
benotigt wird. Anderenfalls kopiert man sich A zunachst und speichert die LU-
Zerlegung in der Kopie wie oben angegeben ab.
Lemma 4.7 Der oben beschriebene Algorithmus zur Bestimmung der LU-Zerlegung
kann mit maximal 23n3 arithmetischen Operationen durchgefuhrt werden.
Beweis. Man muss fur k = n bis k = 2 Berechnungen der Gestalt (4.2)-(4.5)
durchfuhren. Hierbei besteht dann (4.3) aus k− 1 Divisionen und (4.5) aus (k− 1)2
Multiplikationen und nochmal genauso vielen Additionen. In Summe ergeben sich
n∑k=2
((k − 1) + 2(k − 1)2
)=
n−1∑k=1
k + 2n−1∑k=1
k2
=1
2n(n− 1) +
n− 1
3(2n− 1)n =
2
3n3 − n
6(3n+ 1)
Operationen. Hierbei haben wir die Formel∑n
k=1 k2 = 1
6n(2n+1)(n+1) verwendet.
4.2.2 LU-Zerlegung mit Zeilen-Pivotisierung
Wir hatten gesehen, dass die beschriebene LU-Zerlegung die Regularitat aller Haupt-
untermatrizen verlangt. Es gibt aber durchaus regulare Matrizen, deren Hauptun-
termatrizen nicht regular sind. Ein einfaches Beispiel ist die Matrix(0 1
1 0
).
Die Idee ist nun, Vertauschungen von Zeilen zuzulassen. Hierzu fuhren wir Permu-
tationsmatrizen ein. Eine n-stellige Permutation ist eine bijektive Abbildung
π : 1, . . . , n → 1, . . . , n.
Das Vertauschen von Zeilen gemaß einer solchen Permutation kann durch Multipli-
kation von links mit einer regularen Matrix Pπ = (pπ) ∈ Kn×n bewerkstelligt werden,
deren Koeffizienten definiert sind durch
(pπ)ij =
1 falls π(i) = j,
0 sonst.
Entsprechend gilt fur einen Vektor x = (xi):
Pπx =
xπ(1)
...
xπ(n)

82 M. Braack Direkte Loser fur lineare Gleichungssysteme
Da diese Permutationsmatrizen regular sind, ist ein lineares Gleichungssystem Ax =
b aquivalent zu
PπAx = Pπb.
Durch geeignetes Pπ kann evtl. erreicht werden, dass die Hauptuntermatrizen von
PπA regular sind, so dass eine LU-Zerlegung von PπA existiert. Die Losung x von
PπAx = LUx = Pπb.
erhalt man dann entsprechend mittels Vorwarts- und Ruckwartselimination:
Ly = Pπb,
Ux = y.
Lemma 4.8 Fur jede regulare Matrix A ∈ Kn×n existiert eine n-stellige Permu-
tation π, so dass sich PπA durch eine LU-Zerlegung darstellen lasst, bei der die
Diagonale von L nur aus Einsen besteht.
Beweis. Der Beweis erfolgt per Induktion nach n. Fur n = 1 ist die Permutation
π die Identitat, L = I und U = A. Wir nehmen also an, dass die Behauptung fur
ein n ∈ N gilt und fuhren nun den Induktionsschritt nach n + 1 aus. Da die erste
Spalte von A ∈ K(n+1)×(n+1) nicht nur aus Nullen bestehen kann, existiert ein Index
k, so dass ak1 6= 0. Wir betrachten die Permutation π, die die erste und die k-te
Komponente vertauscht und betrachten
B := PπA =
(b11 B1∗
B∗1 B∗∗
)mit b11 = ak1 6= 0. Wir nehmen fur den Moment an, dass die Matrix
B := B∗∗ − b−111 B∗1B1∗ ∈ Kn×n
regular ist. Dann existiert nach Induktionsannahme eine n-stellige Permutation πBund eine LU-Zerlegung von B:
PπBB = LBUB.
Nun setzen wir
L :=
(1 0
L∗1 LB
), U :=
(b11 U1∗
0 UB
),

4.2 LU-Zerlegung 83
mit L∗1 := b−111 PπBB∗1 und U1∗ := B1∗. Dann gilt
LU =
(1 0
L∗1 LB
)(b11 U1∗
0 UB
)=
(b11 U1∗
b11L∗1 L∗1U1∗ + LBUB
)=
(b11 B1∗
PπBB∗1 b−111 PπBB∗1B1∗ + PπBB
)Da
b−111 PπBB∗1B1∗ + PπBB = PπB
(b−1
11 B∗1B1∗ + B)
= PπBB∗∗,
folgt
LU =
(b11 B1∗
PπBB∗1 PπBB∗∗
)=
(1 0
0 PπB
)B =
(1 0
0 PπB
)PπA.
Auf der rechten Seite erscheint die Multiplikation von zwei Permutationsmatrizen,
was der Verkettung von zwei n + 1-stelligen Permutationen π entspricht. Somit
erhalten wir die gewunschte LU-Zerlegung von PπA.
Wir haben nun noch die bislang lediglich angenommene Regularitat von B zu zeigen.
Hierzu genugt es offenbar zu verifizieren, dass die Matrix(b11 B1∗
0 B
)(4.6)
regular ist. Diese Matrix lasst sich als ein Produkt schreiben:(b11 B1∗
0 B
)=
(1 0
−b−111 B∗1 I
)(b11 B1∗
B∗1 B∗∗
).
Die ganz rechte Matrix ist gerade die regulare Matrix B und die vorletzte Matrix
entspricht einer unteren Dreiecksmatrix mit der Diagonalen bestehend aus Einsen.
Also ist die Matrix (4.6) ein Produkt von zwei quadratischen regularen Matrizen
und damit auch selbst regular.
Der Beweis dieses Satzes ist konstruktiv, so dass wir ihn direkt in einen numerischen
Algorithmus ubersetzen konnen, siehe Tab. 4.2. Hierbei wird ein zusatzlicher Vektor
p gefuhlt, in dem die Permutation π abgespeichert wird. Dieser wird benotigt, um
die rechte Seite Pπb entsprechend zu berechnen. Auch hier kann der Speicher fur
die Matrix A wieder genutzt werden und durch die Werte von L (ohne Diagonale)
und U uberschrieben werden. Der insgesamte Aufwand ist vergleichbar zur LU ohne
Pivotisierung.

84 M. Braack Direkte Loser fur lineare Gleichungssysteme
Algorithmus LU-pivot(n,A,p)
1. for i = 1, . . . , n pi = i
2. for i = 1, . . . , n− 1
3. Suche j ∈ i, . . . , n mit maximalem |aji|.
4. if aji = 0 STOP ; /* Abbruch */
5. q = pi; pi = pj; pj = q;
6. for k = 1, . . . , n y = aik ; aik = ajk ; ajk = y
7. for j = i+ 1, . . . , n
8.
9. aji = aji/aii ;
10. for k = i+ 1 to n
11. ajk = ajk − ajiaik ;
12.
13.
Tabelle 4.2: LU-Zerlegung mit Zeilen-Pivotisierung.
Es sei an dieser Stelle noch hervorgehoben, dass die Pivotisierung nicht nur
hilft, Matrizen zu faktorisieren, deren Hauptuntermatrizen nicht alle regular sind.
Durch die Auswahl des betragsmaßig großten Elements aji in Spalte i wird die
Wahrscheinlichkeit, durch kleine Werte aii zu dividieren, verringert. Dadurch erhalt
man kleinere Rundungsfehler und i.a. eine großere numerische Stabilitat.
4.3 Cholesky-Zerlegung
In diesem Abschnitt betrachten wir reellwertige quadratische Matrizen, die symme-
trisch positiv definit sind. Also gilt AT = A und Skalarprodukte der Form xTAx mit

4.3 Cholesky-Zerlegung 85
x 6= 0 sind positiv:
xTAx > 0 ∀x ∈ Rn×n \ 0.
Die Konzepte in diesem Abschnitt ubertragen sich Eins zu Eins auf den komplex-
wertigen Fall A ∈ Cn×n, wenn A hermitesch, also AT = A, und positiv definit ist.
Man spricht in diesem Zusammenhang, also fur K = R oder K = C, auch von selbst-
adjungierten positiv definiten Matrizen. Der Ubersicht halber beschranken wir uns
aber auf den reellwertigen Fall. Es wird sich herausstellen, dass man in diesem Fall
nicht nur eine Halfte der Matrix A abspeichern muss (wegen aij = Aji), sondern man
auch bei der LU-Zerlegung den Faktor 2 in Rechenzeit und Speicherplatz einsparen
kann.
Definition 4.9 Eine LU-Zerlegung A = LU ∈ Rn×n heißt Cholesky-Zerlegung,
wenn R = LT gilt, also A = LLT mit einer unteren Dreiecksmatrix L.
Satz 4.10 Fur jede symmetrisch positiv definite Matrix A ∈ Rn×n existiert genau
eine Cholesky-Zerlegung.
Beweis. Der Beweis wird per vollstandiger Induktion gefuhrt. Fur n = 1 ist die
Behauptung trivialerweise erfullt. Der Induktionsschritt von n nach n+ 1 geschieht
folgendermaßen. Fur eine symmetrisch positiv definite Matrix A ∈ R(n+1)×(n+1) nut-
zen wir die Darstellung
A =
(A∗∗ An∗ATn∗ a
)mit a = an+1,n+1 ∈ R, A∗∗ ∈ Rn×n, An∗ ∈ Rn×1. Da A∗∗ dann ebenfalls symmetrisch
positiv definit ist, existiert eine Cholesky Zerlegung
A∗∗ = LnLTn ,
mit einer unteren Dreiecksmatrix Ln. Wir machen den Ansatz
L :=
(Ln 0
Ln∗ l
).
Dann gilt
LLT =
(Ln 0
Ln∗ l
)(LTn LTn∗0 l
)=
(LnL
Tn LnL
Tn∗
Ln∗LTn Ln∗L
Tn∗ + l2
).

86 M. Braack Direkte Loser fur lineare Gleichungssysteme
Wahlen wir LTn∗ := L−1n An∗ (bzw. Ln∗ := ATn∗L
−Tn ), so folgt LnL
Tn∗ = An∗ und
Ln∗LTn = ATn∗L
−Tn LTn = ATn∗.
Fur l2 = a−Ln∗LTn∗ erhalten wir also die Cholesky-Zerlegung LLT = A. Insofern ist
der Beweis vollstandig, wenn
a− Ln∗LTn∗ ≥ 0
gezeigt ist. Da Ln∗LTn∗ = ATn∗L
−Tn L−1
n An∗ = ATn∗(LnLTn )−1An∗ = ATn∗A
−1∗∗ An∗ gilt fur
den Vektor x := (−A−1∗∗ An∗, 1)T aufgrund der positiven Definitheit von A:
0 < xTAx =(−A−1
∗∗ An∗, 1)( A∗∗ An∗
ATn∗ a
)(−A−1
∗∗ An∗1
)=
(−A−1
∗∗ An∗, 1)( −A∗∗A−1
∗∗ An∗ + An∗−ATn∗A−1
∗∗ An∗ + a
)=
(−A−1
∗∗ An∗, 1)( 0
−Ln∗LTn∗ + a
)= a− Ln∗LTn∗.
Also konnen wir l :=√a− Ln∗LTn∗ wahlen und der Beweis ist vollstandig.
Lemma 4.11 Die Koeffizienten der unteren Dreiecksmatrix L = (lij) der Cholesky-
Zerlegung A = LLT ergeben sich sukzessive fur i = 1, . . . , n:
fur j < i : lij = l−1jj
(aij −
j−1∑k=1
likljk
),
lii =
(aii −
i−1∑k=1
l2ik
)1/2
.
Beweis. Da wir die Existenz der Cholesky-Zerlegung voraussetzen konnen, erhal-
ten wir fur die Koeffizienten der Matrix A:
aij = (LLT )ij =
j∑k=1
likljk =
j−1∑k=1
likljk + lijljj.
Fur j < i erhalten wir die obige Formel fur lij. Fur j = i lautet diese Gleichung
aii =i−1∑k=1
l2ik + l2ii.

4.3 Cholesky-Zerlegung 87
Algorithmus Cholesky(n,A)
1. for i = 1, . . . , n
2. for j = 1, . . . , i− 1
3. for k = 1, . . . , j − 1
4. aij = aij − aikajk
5. aij = aij/ajj
6.
7. for k = 1, . . . , i− 1
8. aii = aii − a2ik
9. aii =√aii
10.
Tabelle 4.3: Cholesky-Zerlegung mit Ubergabe einer symmetrischen positiv definiten
Matrix A = (aij) = LLT der Dimension n × n, deren linker unterer Teil (also fur
j ≤ i) durch L uberschrieben wird.
Also erhalten wir die gewunschte Gleichung fur lii.
Bei der numerischen Umsetzung fur diese Cholesky-Zerlegung kann man auch auf
die Speicherung von LT verzichten, so dass lediglich L abgespeichert werden muss.
Ferner kann auf die Pivotisierung verzichtet werden, da die Hauptdiagonalelemente
bei symmetrisch positiv definiten Matrizen stets positiv sein mussen. In Tab. 4.3
ist der entsprechende Pseudo-Code angegeben. Das nachfolgende Lemma zeigt, dass
der numerische Aufwand im Vergleich zur allgemeinen LU-Zerlegung fur großes n in
etwa um den Faktor 2 reduziert ist.
Lemma 4.12 Der numerische Aufwand der Cholesky-Zerlegung der Dimension n×n kann mit 1
3n3 + 2
3n2 arithmetischen Operationen erreicht werden.
Beweis. Ubungsaufgabe.

88 M. Braack Direkte Loser fur lineare Gleichungssysteme
4.4 LU-Zerlegung von Bandmatrizen
In der Praxis kommen haufiger Matrizen vor, deren Eintrage lediglich ”in der Nahe
der Diagonalen” von Null verschieden sind. Bei diesen Matrizen lassen sich auch
sparsamere LU-Zerlegungen erzeugen.
Definition 4.13 Eine quadratische Matrix A = (aij) ∈ Kn×n heißt (p, q)-Bandmatrix,
wenn gilt
aij 6= 0 =⇒ i− p ≤ j ≤ i+ q.
Die Zahl 1 + p+ q heißt dann Bandbreite.
Offensichtlich ist eine (0, 0)-Bandmatrix gerade eine Diagonalmatrix.
Satz 4.14 Sei A ∈ Kn×n eine regulare (p, q)-Bandmatrix mit LU-Zerlegung A =
LU , bei der die Diagonale von L nur aus Einsen besteht. Dann ist L eine (p, 0)-
Bandmatrix und U eine (0, q)-Bandmatrix.
Beweis. Der Beweis erfolgt per Induktion nach n. Fur n = 1 ist die Aussage
trivial. Der Induktionsschritt von n nach n + 1 erfolgt folgendermaßen. Eine (p, q)-
Bandmatrix A ∈ K(n+1)×(n+1) stellen wir dar in der Form
A =
(a bT
c An
),
mit a ∈ K, b, c ∈ Kn und An ∈ Kn×n. Diese Matrix lasst sich auch als 3er-Produkt
schreiben:
A =
(1 0
a−1c I
)(1 0
0 B
)(a bT
0 I
)mit B := An − a−1cbT . Da A regular ist, mussen die drei Matrizen auf der rechten
Seite ebenfalls regular sein. Dann ist aber auch B regular. Ferner ist B ebenfalls
eine (p, q)-Bandmatrix, da sowohl An als auch cbT jeweils (p, q)-Bandmatrizen sind.
Nach Induktionsannahme gilt dann fur die LU-Zerlegung von B = LBUB, dass LBeine (p, 0)-Bandmatrix und UB eine (0, q)-Bandmatrix ist. Dann ist aber durch
L :=
(1 0
a−1c LB
)und U :=
(a bT
0 UB
)eine LU-Zerlegung von A mit den geforderten Bandstrukturen gegeben.

4.4 LU-Zerlegung von Bandmatrizen 89
Algorithmus LU-band(n,A)
1. for i = 1, . . . , n− 1
2. if aii = 0 STOP; /* Abbruch */
3. for j = i+ 1, . . . ,min(i+ p, n)
4.
5. aji = aji/aii;
6. for k = i+ 1 to min(i+ q, n)
7. ajk = ajk − ajiaik
8.
9.
Tabelle 4.4: LU-Zerlegung fur eine (p, q)-Bandmatrix.
Ein entsprechender Pseudo-Code ist in Tab. 4.4 angegeben. Um moglichst Spei-
cherplatz-effizient zu sein, sollte man keine volle Matrix fur A verwenden (d.h. mit
n2 Eintragen), sondern auch nur Speicherplatz fur das Band bereitstellen (also fur
n(p+ q+ 1) Eintrage). Dies spart nicht nur Speicher, sondern kann auch zu deutlich
kurzeren Zugriffszeiten fuhren. Auch Vorwarts- und Ruckwartselimination vereinfa-
chen sich bei Bandmatrizen entsprechend.
4.4.1 Thomas-Algorithmus fur Tridiagonalmatrizen
Unter Tridiagonalmatrizen versteht man (1, 1)-Bandmatrizen. In diesem Fall ist die
LU-Zerlegung von
A =
a1 c1
b2. . . . . .. . . . . . cn−1
bn an
(4.7)

90 M. Braack Direkte Loser fur lineare Gleichungssysteme
besonders einfach, namlich:
L =
1
l2. . .. . . . . .
ln 1
, U =
u1 c1
. . . . . .. . . cn−1
un
mit u1 = a1, li = biu
−1i−1, ui = ai − lici−1 fur i = 2, . . . , n. Die Koeffizienten
von U konnen offensichtlich auch ohne Speicherung von L bestimmt werden. Die
Vorwartselimination y = L−1d lautet y1 = d1 und yi = di − liyi−1 fur i = 2, . . . , n.
Die Ruckwartselimination x = U−1y lautet entsprechend xn = yn/un und xi =
(yi − cixi+1)/ui fur i = n − 1, . . . , 1. Insgesamt erhalten wir einen Vorwartslauf
(ohne explizite Speicherung von L):
u1 = a1, ui = ai −bici−1
ui−1
,
y1 = d1, yi = di −biyi−1
ui−1
fur i = 2, . . . , n
und einen Ruckwartslauf
xn =ynun, xi =
yi − cixi+1
uifur i = n− 1, . . . , 1.
Dieses Verfahren wird auch Thomas-Algorithmus genannt. Der numerische Aufwand
skaliert offensichtlich wie O(n).
4.5 Rundungsfehleranalysen
Formal gesehen liefern die bislang behandelten direkten Loser die exakte Losung des
linearen Gleichungssystems, wenn die Matrix A regular ist. Durch die Arithmetik
auf den Rechnern mit Maschinenzahlen kommt es aber zu Rundungsfehlern. Diese
konnen sich im Laufe des jeweiligen Algorithmus verstarken. Daher untersuchen wir
in diesem Abschnitt, wie sich Anderungen in der rechten Seite oder in der Matrix
auf die Losung auswirken konnen.
4.5.1 Matrizennormen
In diesem Abschnitt betrachten wir den Kn mit K = R oder K = C und versehen
diesen Raum mit einer Norm || · || : Kn → R. Wir wissen aufgrund der endlichen

4.5 Rundungsfehleranalysen 91
Dimension von K, dass alle Normen auf diesem Raum aquivalent sind; sie lassen
sich also alle gegeneinander unter Zuhilfenahme geeigneter Konstanten abschatzen.
Ferner betrachten wir Normen fur Matrizen || · || : Kn×n → R. Da aus dem Kontext
stets klar ist, ob man eine Norm auf Kn oder auf Kn×n betrachtet, benutzen wir die
gleiche Bezeichnungsweise fur die Normen.
Definition 4.15 Eine Norm || · || : Kn×n → R heißt:
• Matrixnorm, wenn sie submultiplikativ ist, d.h.
||AB|| ≤ ||A|| ||B|| ∀A,B ∈ Kn×n,
• vertraglich mit einer (Vektor-) Norm || · || : Kn → R, wenn
||Ax|| ≤ ||A|| ||x|| ∀A ∈ Kn×n und alle x ∈ Kn,
• von einer (Vektor-) Norm || · || : Kn → R eine naturlich erzeugte Norm, wenn
sie definiert ist mittels
||A|| := supx∈Kn\0
||Ax||||x||
.
Lemma 4.16 Fur die Matrixnorm der Einheitsmatrix I gilt stets ||I|| ≥ 1. Naturlich
erzeugte Normen || · || : Kn → R sind submultiplikativ und es gilt ||I|| = 1.
Beweis. (a) Die Submultiplikativitat impliziert 0 < ||I|| = ||I·I|| ≤ ||I||||I||. Division
durch ||I|| liefert 1 ≤ ||I||.(b) trivial.
4.5.2 Beispiele von Matrizennormen
Wir geben hier einige naturlich erzeugte Matrixnormen fur Matrizen A = (aij)1≤i,j≤n
an.
Zeilensummennorm Die Maximumsnorm || · ||∞ : Kn → R erzeugt die Zeilen-
summennorm || · ||∞ : Kn×n → R:
||A||∞ = max1≤i≤n
n∑j=1
|aij|

92 M. Braack Direkte Loser fur lineare Gleichungssysteme
Spaltensummennorm Die l1-Norm || · ||1 : Kn → R, definiert durch ||x||1 :=∑i |xi|, erzeugt die Spaltensummennorm || · ||1 : Kn×n → R:
||A||1 = max1≤j≤n
n∑i=1
|aij|
Spektralnorm Die von der Euklidischen Norm || · ||2 : Kn → R naturlich erzeugte
Matrixnorm heißt Spektralnorm:
||A||2 := supx∈Kn\0
√∑ni=1 |(Ax)i|2∑ni=1 |xi|2
Der folgende Satz stellt einen Zusammenhang zwischen dieser Spektralnorm und
den Eigenwerten der Matrix her. Hierbei verstehen wir unter dem Spektrum σ(A)
der Matrix A die Menge ihrer Eigenwerte und unter dem Spektralradius
ρ(A) = max|λ| : λ ∈ σ(A)
den Wert des betragsmaßig großten Eigenwerts.
Satz 4.17 Fur A ∈ Kn×n gilt
||A||2 =√ρ(A∗A).
wobei A∗ := AT . Ist A ∈ Kn×n selbstadjungiert (d.h. symmetrisch im Fall K = R,
bzw. hermitesch im Fall K = C) so gilt
||A||2 = ρ(A).
Beweis. Der selbstadjungierte Fall folgt sofort aus dem allgemeinen Fall, da
||A||2 =√ρ(A∗A) =
√ρ(A2) =
√ρ(A)2 = ρ(A).
Die Matrix A∗A ist hermitesch / symmetrisch und positiv semi-definit, denn fur
beliebiges x ∈ Kn gilt
xTA∗Ax = 〈x,A∗Ax〉 = 〈Ax,Ax〉 = ||Ax||2 ≥ 0.
Daher sind die Eigenwerte vonA∗A alle reell und nicht-negativ. Seien daher v1, . . . , vnorthonormale Eigenvektoren zu den Eigenwerten λ2
1, . . . , λ2n von A∗A. Wenn wir

4.5 Rundungsfehleranalysen 93
x ∈ Kn als Linearkombination dieser v1, . . . , vn mit den jeweiligen Koeffizienten
α1, . . . , αn darstellen, so ergibt sich
||x||22 =n∑i=1
|αi|2.
Hieraus folgt
||Ax||22 = 〈x,A∗Ax〉 =n∑i=1
λ2i |αi|2 ≤ ρ(A∗A)||x||22
und daher folgt die obere Schranke
||A||22 ≤ ρ(A∗A).
Die untere Schranke erhalt man, indem man den Eigenvektor vk zum betragsmaßig
großten Eigenwert wahlt:
||A||22 ≥||Avk||22||vk||22
=〈vk, A∗Avk〉||vk||22
= ρ(A∗A).
Dies liefert die Behauptung ||A||2 =√ρ(A∗A).
4.5.3 Konditionszahl
Definition 4.18 Fur regulares A ∈ Kn×n heisst
cond(A) := ||A||||A−1||
die Konditionszahl von A bzgl. der Norm || · ||.
Lemma 4.19 Die Konditionszahl bzgl. Matrizennormen ist stets ≥ 1.
Beweis. Da die Norm der Einheitsmatrix I nach Lemma 4.16 stets nach unten
durch 1 beschrankt ist, erhalten wir aufgrund der Submultiplikativitat:
1 ≤ ||I|| = ||A−1A|| ≤ ||A−1|| ||A|| = cond(A).

94 M. Braack Direkte Loser fur lineare Gleichungssysteme
4.5.4 Lineare Storungstheorie
Bei numerischen Verfahren hat man es u.a. mit Rundungsfehlern zu tun. Daher
mussen wir die Losungen auch mit gestorten Systemen
Ax = b
vergleichen. Hierbei sollen sich A und A, bzw. b und b nur wenig unterscheiden. Wir
fragen uns, welchen Einfluss solche Storungen auf die Losung x besitzt. Wir fragen
uns daher nach ||x− x|| in Abhangigkeit von A− A und b− b. Hierfur benotigen wir
Normen auf Kn und auf Kn×n.
Zunachst betrachten wir Storungen der Einheitsmatrix I.
Satz 4.20 Sei || · || : Kn×n → R eine Matrixnorm, die mit einer (beliebigen) Vektor-
norm auf Kn vertraglich ist, und A ∈ Kn×n mit ||A|| < 1. Dann ist I + A regular.
Handelt es sich zudem um eine naturlich erzeugte Matrixnorm, so gilt fur ihre In-
verse
||(I + A)−1|| ≤ 1
1− ||A||.
Beweis. (a) Wir zeigen zunachst die Injektivitat der Abbildung I + A. Fur be-
liebiges x ∈ Kn und der vertraglichen Vektornorm gilt
||x|| = ||(I + A)x− Ax|| ≤ ||(I + A)x||+ ||Ax||,
bzw.
||(I + A)x|| ≥ ||x|| − ||Ax|| ≥ ||x|| − ||A||||x|| = (1− ||A||)||x||.
Fur x 6= 0 folgt aufgrund der Voraussetzung ||A|| < 1 insbesondere ||(I + A)x|| > 0,
bzw. (I + A)x 6= 0. Also besteht der Kern von I + A nur aus dem Nullvektor. Es
folgt die Regularitat von I + A.
(b) Wir setzen in der soeben gezeigten Ungleichung y := (I + A)x. Dann ist x =
(I + A)−1y und
||y|| ≥ (1− ||A||)||(I + A)−1y||.
Division durch 1− ||A|| > 0 liefert
||(I + A)−1y|| ≤ (1− ||A||)−1||y|| ∀y ∈ Kn.
Da es sich um eine naturlich erzeugte Matrixnorm handeln soll, folgt
||(I + A)−1|| = supy∈Kn\0
||(I + A)−1y||||y||
≤ (1− ||A||)−1.

4.5 Rundungsfehleranalysen 95
Korollar 4.21 Seien A,Aδ ∈ Kn×n mit regularem A und ||Aδ|| < ||A−1|| fur eine
Matrixnorm || · ||. Dann ist auch A+ Aδ regular.
Beweis. Es gilt A + Aδ = A(I + A−1Aδ). Da ||A−1Aδ|| ≤ ||A−1||||Aδ|| < 1, ist mit
Satz 4.20 die Matrix A+ Aδ regular.
Im nachfolgenden Satz betrachten wir nun zu Vektoren b, bδ ∈ Kn und Matrizen
A,Aδ ∈ Kn×n die linearen Probleme:
Ax = b
(A+ Aδ)x = b+ bδ
Satz 4.22 Unter den Voraussetzungen von Korollar 4.21 gelte Ax = b und (A +
Aδ)x = b + bδ. Fur die relativen Fehler ex := ||x − x||/||x||, eb := ||bδ||/||b|| und
eA := ||Aδ||/||A|| (mit der naturlich erzeugten Matrixnorm) gilt
ex ≤cond(A)
1− cond(A)eA(eb + eA).
Beweis. (a) Fur die Fehlerabschatzung betrachten wir zunachst den Fall bδ = 0.
Mit (A+ Aδ)x = b und (A+ Aδ)x = b+ Aδx folgt fur die Differenz der Losungen
x− x = −(A+ Aδ)−1Aδx
= −(I + A−1Aδ)−1A−1Aδx.
Aufgrund der Submultiplikativitat der Matrixnorm folgt mit Satz 4.20:
||x− x|| ≤ ||(I + A−1Aδ)−1||||A−1||||Aδ||||x||
≤ ||A−1||1− ||A−1Aδ||
||Aδ||||x||
=cond(A)
1− ||A−1Aδ||eA||x||.
Nun folgt die Behauptung wegen ||A−1Aδ|| ≤ ||A−1||||Aδ|| = cond(A)eA.
(b) Den Fall bδ 6= 0 lassen wir als Ubungsaufgabe.
Bemerkungen:
1. Im Fall von kleinen Werten eA << cond(A)−1 (z.B. fur Aδ = 0) kann man
den Nenner der rechten Seite durch 1 annahern, so dass die Konditionszahl
cond(A) im Wesentlichen gerade den maximalen Verstarkungsfaktor zwischen
eA + eb und ex darstellt.

96 M. Braack Direkte Loser fur lineare Gleichungssysteme
2. Bei typischer Rundungsfehlergenauigkeit eA, eb ≈ 10−8 und einer Konditions-
zahl cond(A) ≈ 10k mit 0 ≤ k < 8 verliert man also k Dezimalstellen Genau-
igkeit in der Losung x.
3. Diese Abschatzung ist scharf, d.h. man uberschatzt den moglichen Fehler nicht
(wesentlich). Um dies zu sehen, wahlen wir die Euklidische Norm || · ||2 und
eine reelle symmetrische Matrix A. Dann ist die (Spektral-) Konditionszahl
gerade der Quotient aus dem betragsmaßig großten und dem betragsmaßig
kleinsten Eigenwert, cond(A) = |λmax/λmin|. Wenn vmax und vmin nun die
zugehorigen normierten Eigenvektoren sind, so betrachten wir Aδ = 0, b =
λmaxvmax und bδ = λminvmin. Dann lauten die zugehorigen Losungen x = vmaxund x = x + vmin. Fur die relativen Fehler gilt demzufolge ex = 1 und eb =
|λmin/λmax| = cond(A)−1ex.
4.6 Defektkorrektur
In diesem Abschnitt betrachten wir den Fall, dass das lineare Gleichungssystem
Ax = b nur mit einer approximativen Inversen gelost werden kann, beispielsweise
aufgrund einer naherungsweisen LU-Zerlegung Aε = LεUε. Sei xε Losung von
Aεxε = b.
Eine bessere Losung als xε kann in vielen Fallen erhalten werden, indem man mit
der gleichen Matrix Aε eine sogenannte Defektkorrektur ausfuhrt. Hierzu muss man
das Residuum b− Axε genauer berechnen. Sei daher
dδ := b− Aδxε
mit ||A−Aδ|| ≤ ||A−Aε||. Dies bedeutet, dass Aδ eine bessere Approximation an A
sein muss als Aε. Dies ist darin begrundet, dass man fur Aδ keine Inverse benotigt.
Im Idealfall gilt Aδ = A. Der Korrekturschritt lautet nun
Aεxδ = dδ,
xδ,ε := xε + xδ.
Es wird also noch einmal ein Gleichungssystem mit der gleichen Matrix Aε gelost.
Der folgende Satz macht eine Aussage uber die relativen Fehler
eδ,ε =||x− xδ,ε||||x||
, eε =||x− xε||||x||
.

4.6 Defektkorrektur 97
Satz 4.23 Fur diese Defektkorrektur gilt (mit der naturlich erzeugten Matrixnorm):
eδ,ε ≤ ||A−1ε ||(||A− Aε||eε + ||A− Aδ||
||xε||||x||
).
Beweis. Fur die Differenz der exakten und der korrigierten Losung ergibt sich:
xδ,ε − x = xε + xδ − x = A−1ε (dδ + Aε(xε − x))
= A−1ε (b− Aδxε + A(xε − x) + (Aε − A)(xε − x))
= A−1ε ((A− Aδ)xε + (Aε − A)(xε − x))
Somit folgt fur die Norm:
eδ,ε ≤ ||A−1ε ||(||A− Aδ||
||xε||||x||
+ ||A− Aε||eε)
Bemerkungen:
• Man kann schnell zeigen, dass fur Matrizennormen
||A−1ε || ≤
||A−1||1− ||A−1||||A− Aε||
gilt (Ubungsaufgabe). Fur ||A − Aε|| ≤ 2/||A−1|| ergibt sich daher ||A−1ε || ≤
2||A−1||.
• Fur eε ≤ 1 gilt ||xε|| ≤ 2||x||.
• Der Term ||A − Aε||eε in der rechten Seite der Abschatzung ist das Produkt
des Matrixfehlers und des Losungsfehlers und ist daher i.d.R. kleiner als der
zweite Teil in der rechten Seite. Unter all diesen Bedingungen erhalt man dann
eδ,ε ≤ 8 cond(A)||A− Aδ||||A||
.
Insofern kann man den relativen Fehler eδ,ε nach Defektkorrektur beschranken
durch den relativen Fehler in der Matrix ||A− Aδ||/||A|| multipliziert mit dem
Verstarkungsfaktor 8 cond(A).

98 M. Braack Direkte Loser fur lineare Gleichungssysteme

Kapitel 5
Lineare Ausgleichsrechnung
Ist die Matrix A im vorhergehenden Kapitel nicht regular, so ist das zugehorige
lineare Gleichungssystem nicht notwendigerweise losbar oder nicht eindeutig losbar.
Allgemeiner kann man sich fragen, ob zu m,n ∈ N, A ∈ Km×n und b ∈ Km ein
x ∈ Kn existiert, so dass
||Ax− b||2 = infy∈Kn||Ay − b||2 (5.1)
in der euklidischen Norm || · ||2 erfullt ist.
5.1 Lineare Regression als Beispiel fur die Aus-
gleichsrechnung
Bei der linearen Regression versucht man, eine Hypothese durch Messungen zu uber-
prufen. Hierbei nehmen wir an, dass Paare von Messdaten der Form (ai, bi) ∈ R2
fur i ∈ 1, . . . , n mit Eingabegroßen ai und Ausgabegroßen bi gegeben sind. Man
mochte nun die Werte von ai und bi durch einen linearen Zusammenhang approxi-
mieren:
b(a) = c0 + c1a.
Im idealen Fall existieren c0, c1 ∈ R, so dass b(ai) = bi fur alle i. Im Allgemeinen wird
das aber nur naherungsweise gelingen, denn selbst ai = aj und bi 6= bj ist fur gewisse
Indizes i, j prinzipiell nicht ausgeschlossen. Dann mochte man Parameter c0, c1 ∈ Rfinden, so dass die Abweichung in einem gewissen Sinn minimal ist. Hierbei eignet
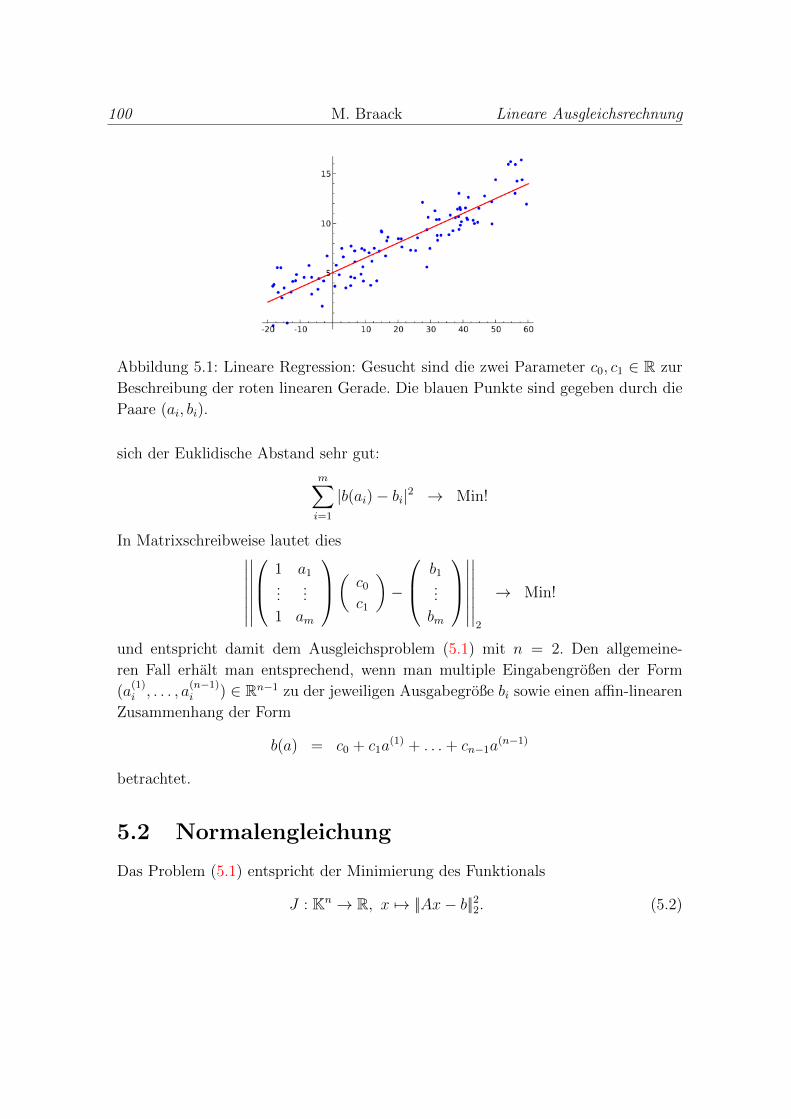
100 M. Braack Lineare Ausgleichsrechnung
Abbildung 5.1: Lineare Regression: Gesucht sind die zwei Parameter c0, c1 ∈ R zur
Beschreibung der roten linearen Gerade. Die blauen Punkte sind gegeben durch die
Paare (ai, bi).
sich der Euklidische Abstand sehr gut:
m∑i=1
|b(ai)− bi|2 → Min!
In Matrixschreibweise lautet dies∣∣∣∣∣∣∣∣∣∣∣∣∣∣ 1 a1
......
1 am
( c0
c1
)−
b1
...
bm
∣∣∣∣∣∣∣∣∣∣∣∣∣∣2
→ Min!
und entspricht damit dem Ausgleichsproblem (5.1) mit n = 2. Den allgemeine-
ren Fall erhalt man entsprechend, wenn man multiple Eingabengroßen der Form
(a(1)i , . . . , a
(n−1)i ) ∈ Rn−1 zu der jeweiligen Ausgabegroße bi sowie einen affin-linearen
Zusammenhang der Form
b(a) = c0 + c1a(1) + . . .+ cn−1a
(n−1)
betrachtet.
5.2 Normalengleichung
Das Problem (5.1) entspricht der Minimierung des Funktionals
J : Kn → R, x 7→ ||Ax− b||22. (5.2)

5.2 Normalengleichung 101
Lemma 5.1 Fur K = R ist das in (5.2) definierte Funktional J stetig differenzier-
bar und besitzt den Gradienten
∇J(x) = 2AT (Ax− b).
Beweis. Zunachst schreiben wir den Gradienten in der Form
∇J(x) = ∇〈Ax− b, Ax− b〉 = ∇〈Ax,Ax〉 − ∇〈b, Ax〉 − ∇〈Ax, b〉+∇||b||22.
Der letzte Term ist von x unabhangig, also ∇||b||2 = 0. Fur die partielle Ableitung
gilt
∂i〈AT b, x〉 =∑j
(AT b)j∂ixj =∑j
(AT b)jδij = (AT b)i.
Dadurch ergibt sich
∇〈b, Ax〉 = ∇〈AT b, x〉 = AT b
und analog
∇〈Ax, b〉 = ∇〈x,AT b〉 = AT b.
Fur den quadratischen Term erhalt man den Gradienten
∇〈Ax,Ax〉 = 2ATAx.
In Summe erhalten wir
∇J(x) = 2AT (Ax− b),
was gerade die Behauptung darstellt.
Satz 5.2 Die Losung x des Minimierungsproblems (5.1) ist aquivalent zur Losung
der sogenannten Normalengleichung:
A∗Ax = A∗b. (5.3)
Beweis. ⇒ fur K = R: Ist x ∈ Rn Losung des Minimierungsproblems (5.1), so
besitzt J in x ein lokales Minimum. Daher gilt die notwendige Bedingung∇J(x) = 0.
Dies fuhrt aufgrund von Lemma 5.1 auf
2AT (Ax− b) = 0.

102 M. Braack Lineare Ausgleichsrechnung
Dies impliziert die Normalengleichung.
⇒ fur K = C: Im Komplexen kann man die Normalengleichung ohne die Verwendung
des Gradienten ∇J zeigen indem man, unter Annahme der Minimalitatsbedingung,
fur beliebiges z ∈ Kn die Gleichung
0 = 〈Ax− b, Az〉 = 〈A∗(Ax− b), z〉
zeigt. Diese Gleichheit zu zeigen, uberlassen wir als Ubungsaufgabe.
⇐: Es gelte fur x ∈ Kn die Normalengleichung (5.3). Dann folgt fur beliebiges
y ∈ Kn:
J(x+ y) = ||Ax+ Ay − b||22 = ||Ax− b||22 + 〈Ax− b, Ay〉+ 〈Ay,Ax− b〉+ ||Ay||22= ||Ax− b||22 + 〈A∗(Ax− b)︸ ︷︷ ︸
=0
, y〉+ 〈y, A∗(Ax− b)︸ ︷︷ ︸=0
〉+ ||Ay||22︸ ︷︷ ︸≥0
≥ ||Ax− b||22 = J(x).
Also ist J(x) minimal.
Satz 5.3 Fur m ≥ n besitzt das Minimierungsproblems (5.1) stets eine Losung.
Besitzt A vollen Rang, also Rang(A) = n, so ist die Losung sogar eindeutig.
Beweis. (a) A∗ kann aufgefasst werden als lineare Abbildung von Km nach Kn.
Der Homomorphiesatz der linearen Algebra besagt nun, dass sich der Urbildraum
Km darstellen lasst als direkte Summe des Bildes von A und des Kerns von A∗:
Km = Im(A)⊕Ker(A∗).
Somit besitzt b eine (eindeutige) Zerlegung b = y + w mit y ∈ Im(A) und w ∈Ker(A∗). Sei nun x ∈ Kn so gewahlt, dass Ax = y. Es folgt
A∗Ax = A∗y = A∗y + A∗w︸︷︷︸=0
= A∗(y + w) = A∗b.
Also erfullt x die Normalengleichung (5.3) und minimiert somit J .
(b) Fur Rang(A) = n ≤ m ist Ker(A) = 0 und daher A∗A positiv definit und da-
her regular. Damit ist die Normalengleichung eindeutig losbar, was die Behauptung
impliziert.
Bemerkungen:
1. Die Normalengleichung ist zwar ein quadratisches lineares Gleichungssystem,
denn A∗A ∈ Rn×n, aber das direkte Losen dieser Gleichung ist numerisch

5.3 QR-Zerlegung 103
haufig heikel. Dies ist darin begrundet, dass die Kondition von A∗A haufig
sehr groß wird. Fur den Fall m = n und einer regularen Matrix A erhalt man
z.B. die obere Schranke
cond(A∗A) = ||A∗A||||(A∗A)−1|| ≤ ||A∗||||A||||A−∗||||A−1||= cond(A∗) cond(A).
2. Durch Rundungsfehler kann zudem die positive Semi-Definitheit von A∗A ver-
loren gehen. Dies zeigt das folgende einfache Beispiel. Fur die Matrix
A =
1.07 1.10
1.07 1.11
1.07 1.15
erhalt man bei exakter und bei 3-stelliger Arithmetik die quadratischen Ma-
trizen
ATA =
(3.4347 3.5952
3.5952 3.7646
)bzw. B =
(3.43 3.60
3.60 3.76
).
Die gerundete Matrix B ≈ ATA ist nicht positiv semi-definit, denn fur x =
(−1, 1)T erhalt man xTBx = −0.01.
5.3 QR-Zerlegung
In diesem Abschnitt benotigen wir zunachst eine Verallgemeinerung der rechten obe-
ren Dreiecksmatrix fur nicht-quadratische Matrizen. R ∈ Km×n heißt rechte obere
Dreiecksmatrix, wenn sie von der Gestalt
R =
(R ∗0 0
)
ist, wobei R ∈ Kk×k eine regulare quadratische rechte obere Dreiecksmatrix darstellt,
die Nullen ’0’ fur beliebige Matrizen bestehend aus lediglich Nullen stehen und ∗ fur
eine beliebige Matrix der Dimension k × (m− k) steht.
Ferner benotigen wir den Begriff der unitaren Matrizen. Eine Matrix Q ∈ Km×m
heißt unitar, wenn sie regular ist und die Inverse gerade die adjungierte Matrix ist,
also Q−1 = Q∗ = QT . Dies ist damit aquivalent, dass die Spalten der Matrix eine
Orthonormalbasis des Km bilden.

104 M. Braack Lineare Ausgleichsrechnung
Lemma 5.4 Sei U ∈ Km×m eine unitare Matrix. Dann gilt
(a) Fur alle Eigenwerte λ ∈ K von U gilt |λ| = 1.
(b) Gilt fur alle Eigenwerte von U stets λ = 1, so ist U = I.
Beweis. (b) Wir wissen, dass eine Basis des Kn existiert, die aus Eigenvektoren
von U besteht. Wenn vk ein solches Basiselement ist, so folgt Uvk = λkvk = vk.
Somit gilt auch Ux = x fur jedes x ∈ Km. Also ist U die Einheitsmatrix.
Definition 5.5 Unter einer QR-Zerlegung einer Matrix A ∈ Km×n versteht man
eine Faktorisierung
A = QR
mit einer unitaren Matrix Q ∈ Km×m und einer rechten oberen Dreiecksmatrix R ∈Km×n.
Wenn man eine QR-Zerlegung von A kennt, so gilt
||Ax− b||2 = ||QRx− b||2 = ||QRx−QQ∗b||2 = ||Q(Rx−Q∗b)||2= ||Rx−Q∗b||2.
Die Minimierung der linken Seite ||Ax− b||2 ist also aquivalent zur Minimierung von
||Rx − Q∗b||2. Wenn wir nun noch annehmen, dass A den Rang n besitzt, so gilt
R ∈ Kn×n und fur x ∈ Kn gilt
Rx =
(Rx
0
).
Daher spalten wir den Vektor Q∗b auf in der Form
Q∗b =
(b
b0
),
mit b ∈ Kn und b0 ∈ Km−n. Dann folgt
||Ax− b||22 = ||Rx−Q∗b||22 = ||Rx− b||22 + ||b0||22.
Insofern reduziert sich die Minimierung der ursprunglichen Große auf die Minimie-
rung von ||Rx − b||2. Da R aber eine regulare quadratische Matrix ist, erhalten wir
folgendes Resultat.

5.3 QR-Zerlegung 105
Satz 5.6 Die Minimierungsaufgabe (5.1) mit einer QR-Zerlegung A = QR, wobei
R =
(R
0
)mit regularer oberer Dreiecksmatrix R ∈ Kn×n und
(b
∗
):= Q∗b ist
aquivalent zur Losung der quadratischen Gleichung
Rx = b.
Beweis. Den Beweis haben wir zuvor schon gefuhrt. Wir wollen dies aber noch
einmal mittels der Normalengleichung zeigen. Die Losung von (5.1) ist gegeben als
Losung der Normalengleichung A∗Ax = A∗b. Setzen wir hier die QR-Zerlegung ein,
so erhalt man
(QR)∗QRx = (QR)∗b.
Per Aquivalenzumformung erhalt man:
R∗Q∗Q︸︷︷︸=I
Rx = R∗Q∗b.
Nun ist aber R∗ =(R∗ 0
)mit einer regularen Matrix R∗ ∈ Kn×n. Die obige
Gleichung schreibt sich daher auch als(R∗ 0
)( R
0
)x =
(R∗ 0
)( b
∗
),
bzw. in der Form R∗Rx = R∗b. Daher ist diese Gleichung aquivalent zu Rx = b, was
gerade die Behauptung ist.
Wenn wir die QR-Zerlegung von A kennen, kann man also die Losung von (5.1)
einfach durch Ruckwartselimination des oberen Teils des Vektors Q∗b berechnen.
Daher mussen wir nun nur noch erfahren, wie man eine solche Zerlegung bestimmt.
Satz 5.7 Zu jeder Matrix A ∈ Km×n mit Rang(A) = n existiert eine QR-Zerlegung
A = QR, mit einer rechten oberen Dreiecksmatrix R ∈ Km×n mit Rang(R) = n
und mit reellen und positiven Hauptdiagonalelementen rkk > 0 fur k ∈ 1, . . . , n.Die Zerlegung mit diesen Eigenschaften ist zudem eindeutig in dem Sinne, dass R
eindeutig ist und die ersten n Spalten von Q eindeutig sind..
Beweis. (a) Existenz: Wir betrachten die Spaltenvektoren a1, . . . , an ∈ Km von A
und orthonormalisieren diese mit dem Gram-Schmidt’schen Orthonormalisierungs-
verfahren bzgl. des Euklidischen Skalarproduktes. Die dabei erhaltenen paarweise

106 M. Braack Lineare Ausgleichsrechnung
orthonormalen Vektoren q1, . . . , qn ∈ Kn fassen wir in der Matrix Q zusammen:
Q :=
q1 · · · qn
.
Somit gilt Q∗Q = I. Ferner gilt folgender Zusammenhang zwischen den Spaltenvek-
toren von A und Q:
ak = qk +k−1∑i=1
〈ak, qi〉qi =k∑i=1
rikqi.
Hierbei ist qk = qk||qk||2, rik := 〈ak, qi〉 fur 1 ≤ i < k und rkk = ||qk||2. Da Rang(A) =
n vorausgesetzt wurde, bricht der Algorithmus fur 1 ≤ k ≤ n nicht ab und es
gilt insbesondere rkk > 0. Wir setzen die verbleibenden Koeffizienten rik = 0 fur
k < i ≤ n und definieren uns hierdurch die Matrix R := (rij). Wir erhalten somit
A = QR und Rang(R) = n.
(b) Eindeutigkeit: Wir nehmen die Existenz zweier QR-Zerlegungen an:
A = Q1R1 = Q2R2,
mit Rang(R1) = Rang(R2) = n und positiven Hauptdiagonalelementen r(1)kk > 0
und r(2)kk > 0 von R1 bzw. von R2. Nun betrachten wir
P := Q∗2Q1 ∈ Km×m.
Wir erhalten
P ∗P = (Q∗2Q1)∗Q∗2Q1 = Q∗1Q2Q∗2Q1 = Q∗1Q1 = I.
Also ist P eine unitare Matrix. Ihre Eigenwerte λ1, . . . , λm haben demzufolge stets
den Betrag Eins. Weiterhin gilt
PR1 = Q∗2Q1R1 = Q∗2A = Q∗2Q2R2 = R2,
sowie analog P ∗R2 = R1. Wir schreiben P,R1 und R2 als Blockmatrizen der Form
P =
(P11 ∗∗ ∗
), R1 =
(R1
0
), R2 =
(R2
0
)
mit P11 ∈ Kn×n und regularen oberen Dreiecksmatrizen R1, R2 ∈ Kn×n. Dann gilt
P11R1 = R2,
P ∗11R2 = R1.

5.4 Berechnung der QR-Zerlegung 107
Dies impliziert, dass P11 = R2R−11 und P ∗11 = R1R
−12 als Produkte rechter oberer
Dreiecksmatrixen ebenfalls rechte obere Dreiecksmatrixen sind. Also muss P11 eine
Diagonalmatrix sein. Ihre Diagonaleintrage sind dann gerade die Eigenwerte λk.
Also folgt fur die Hauptdiagonalelemente von R2: r(2)kk = λkr
(1)kk . Da r
(1)kk > 0 und
r(2)kk > 0 gilt, folgt λk = 1. Also ist nach Lemma 5.4 P11 = I, was wiederum R1 = R2
impliziert. Ferner folgt, dass die ersten n Spalten von Q2 identisch sind mit denen
von Q1.
5.4 Berechnung der QR-Zerlegung
5.4.1 QR-Zerlegung per Gram-Schmidt-Verfahren
Der Beweis von Satz 5.7 liefert uns bereits eine Moglichkeit, die QR-Zerlegung zu be-
rechnen, namlich mit dem Gram-Schmidt-Verfahren. Allerdings ist dieses Verfahren
numerisch instabil, da mit wachsendem m die Orthogonalitat der Vektoren aufgrund
von Rundungsfehlern sukzessive verloren geht.
5.4.2 Householder-Matrizen
Ein anderes Verfahren zur Erstellung einer QR-Zerlegung basiert auf Householder-
Matrizen. Diese benotigen den Begriff des dyadischen Produktes vv∗ ∈ Km eines
Vektors v ∈ Km.
Definition 5.8 Sei v ∈ Kn normiert, also ||v||2 = 1. Dann heißt die Matrix
Hv := I − 2vv∗
Householder-Matrix.
Lemma 5.9 Householder-Matrizen sind unitar und selbstadjungiert.
Beweis. Die Selbstadjungiertheit ist wegen (v∗)∗ = v offensichtlich:
H∗v = (I − 2vv∗)∗ = I∗ − 2(vv∗)∗ = I − 2(v∗)∗v∗ = Hv.
Aufgrund der Normierung ||v||2 = 〈v, v〉 = 1 gilt zunachst:
(vv∗)(vv∗) = v(v∗v)v∗ = v〈v, v〉v∗ = vv∗.
Daher folgt zusammen mit der Selbstadjungiertheit
H∗vHv = HvHv = (I − 2vv∗)(I − 2vv∗) = I − 4vv∗ + 4(vv∗)(vv∗) = I.

108 M. Braack Lineare Ausgleichsrechnung
Abbildung 5.2: Schematische Darstellung der Householder-Transformation Hvx.
Nun untersuchen wir die Wirkung solcher Matrizen. Zunachst gilt
Hvv = (I − 2vv∗)v = v − 2v〈v, v〉 = −v
und fur Vektoren w ∈ Km, die bzgl. des Euklidischen Skalarproduktes senkrecht auf
v stehen, also 〈v, w〉 = 0, gilt
Hvw = (I − 2vv∗)w = w − 2v〈v, w〉 = w.
Da man jeden Vektor x ∈ Km darstellen kann als Linearkombination x = µv + w
mit 〈v, w〉 = 0 gilt
Hvx = −µv + w = x− 2µv.
Daher entspricht im Rm die Multiplikation mit einer Householder-Matrix Hv der
Spiegelung an der Hyperebene die durch den Ursprung und in Richtung senkrecht
zu v verlauft. Dies ist in Abb. 5.2 schematisch abgebildet.
Fur die Konstruktion einer QR-Zerlegung durch Householder-Matrizen benotigen
wir noch folgendes Hilfsresultat:
Lemma 5.10 Sei x ∈ Kn \ 0, λ = sgn(x1)||x||2, e1 = (1, 0 . . . , 0) ∈ Kn der erste
Einheitsvektor, w = x+ λe1 und v = w/||w||2. Dann gilt
Hvx = −λe1.
Beweis. Wegen |λ| = ||x||2 und 〈x, e1〉 = x1 gilt
||w||22 = ||x+ λe1||22 = ||x||22 + 2λx1 + λ2
= 2||x||22 + 2λx1 = 2〈x+ λe1, x〉 = 2〈w, x〉.

5.4 Berechnung der QR-Zerlegung 109
Ferner ist w1 = x1 + sgn(x1)||x||2 stets ungleich Null, also auch w 6= 0. Damit folgt
Hvx = x− 2v〈v, x〉 = x− w2〈w, x〉||w||22
= x− w = −λe1.
5.4.3 Householder-Verfahren
Man kann QR-Zerlegungen erzeugen, indem man durch sukzessive Multiplikation
von links der Matrix A ∈ Km×n mit unitaren Matrizen S1, . . . , Sn ∈ Km×m eine
rechte obere Dreiecksmatrix R erstelllt:
Sn · · ·S1A = R,
denn dann ist auch Q := S∗1 · · ·S∗n unitar und es gilt
QR = S∗1 · · ·S∗nSn︸ ︷︷ ︸=I
· · ·S1A = A.
Durch die Multiplikation mit Sk soll die Dreiecksgestalt sukzessive aufgebaut werden,
also ausgedruckt in Blockstrukturen:(Rk−1,k−1 ∗
0 ∗
)Sk·−→
(Rkk ∗0 ∗
),
mit oberen Dreiecksmatrizen Rkk ∈ Kk×k. Die unitare Matrix Sk soll die ersten k−1
Spalten unverandert lassen und die k-te Spalte auf einen Vektor reduzieren, der an
den letzten Stellen nur Nullen besitzt. Dies leistet die Matrix
Sk =
(Ik−1 0
0 Sk
),
wobei Ik−1 ∈ K(k−1)×(k−1) fur die Einheitsmatrix der Dimension k − 1 steht und die
Matrizen Sk ∈ K(m−k+1)×(m−k+1) werden geeignet gewahlt. Die unitare Matrix Skwird nun als Householder-Matrix zu einem geeigneten Vektor vk ∈ Km−k+1 gewahlt:
Sk := Hvk .
Nun bezeichne a(k−1)k den Vektor, der sich aus den Koeffizienten der k-te Spalte und
der n−k+1 bis n-ten Zeile der bis dahin modifizierten Matrix A(k−1) := Sk−1 · · ·S1A

110 M. Braack Lineare Ausgleichsrechnung
ergibt. In anderen Worten: A(k−1) ist von der Gestalt:
A(k−1) :=
Rk−1,k−1 ∗ ∗
0 ∗0 a
(k−1)k ∗
0 ∗
.
Wir bezeichnen an dieser Stelle die erste Spalte von A(k−1) kurz mit x := a(k−1)k .
Dann wird vk gebildet aus:
λ := sgn(x1)||x||2, wk := x+ λe1 vk :=wk||wk||2
,
wobei e1 den ersten Einheitsvektor im Kn−k+1 bezeichnet. Wir wollen nun sehen, ob
diese Householder-Transformation tatsachlich die gewunschte QR-Zerlegung liefert.
Die Multiplikation von links ergibt:(Ik−1 0
0 Hvk
)(Rk−1,k−1 ∗
0 A(k−1)
)=
(Rk,k ∗
0 HvkA(k−1)
)
mit A(k−1) ∈ K(n−k+1)×(n−k+1). Die mit ∗ gekennzeichneten Matrixblocke sind fur die
Funktionsweise irrelevant. Um zu verifizieren, dass die erste Spalte von HvkA(k−1)
von der gewunschten Struktur ist, namlich abgesehen vom ersten Eintrag nur aus
Nullen besteht, mussen wir die Wirkung von Hvk auf die erste Spalte von A(k−1),
also auf x = a(k−1)k , betrachten: Gemaß Lemma 5.10 gilt:
Hvkx = −λe1.
Dies beweist die Funktionsweise des Householder-Verfahrens.
Vom praktischen Standpunkt aus muss man die Matrix Q nicht notwendiger-
weise speichern, denn nach Satz 5.6 benotigt man lediglich R und das Matrix-
Vektor-Produnkt Q∗b zur Losung des Ausgleichsproblems. In der praktischen Reali-
sierung kann man den Speicher von A zur Speicherung von R verwenden und muss
im Laufe der Erstellung von R noch die jeweiligen Householder-Transformationen
Sn · · ·S1b = Q∗b ausfuhren. In Tab. 5.1 zeigen wir einen Pseudo-Code fur das
Householder-Verfahren (ohne Berechnung von Q∗b).
Lemma 5.11 Der Aufwand der QR-Zerlegung von A ∈ Km×n mit m ≥ n mit dem
Householder-Verfahren betragt O(mn2) arithmetische Operationen.

5.5 QR-Zerlegung zur Losung linearer Gleichungssysteme 111
Beweis. Wir mussen n Householder-Transformationen durchfuhren. Im k-ten
Schritt agiert diese lediglich auf der Matrix A(k−1) ∈ K(m−k+1)×(n−k+1). Dies sind
also weniger als mn Eintrage, die jeweils nur einmal modifiziert werden mussen.
Bemerkung: Eine genauere Analyse liefert maximal
2mn2 − 2
3n3 +O(mn)
arithmetische Operationen.
5.4.4 Givens-Rotation
Anstelle der Householder-Transformation kann man auch die Givens-Rotationen be-
nutzen. Diese sind definiert durch die Matrizen
Gij(θ) :=
Ii−1 0 0
0 Pj−i(θ) 0
0 0 Im−j
∈ Rm×m,
Pk(θ) :=
c 0 · · · 0 s
0 1 0...
. . ....
0 1 0
−s 0 · · · 0 c
∈ Rk+1
mit s = sin(θ) und c = cos(θ) zu gegebenem Winkel θ ∈ [0, 2π]. Die Multiplikation
von links mit der Matrix Gij(θ)T entspricht einer Drehung um den Winkel θ in der
(i, j)-Ebene. Will man den Eintrag an der Matrixposition (i, j) zu Null transformie-
ren, so setzt man c = ajj/ρ und s = aij/ρ mit ρ = sgn(ajj)√a2jj + a2
ij. Auf weitere
Details wollen wir hier nicht eingehen.
5.5 QR-Zerlegung zur Losung linearer Gleichungs-
systeme
Im Fall m = n mit regularer Matrix A ∈ Kn×n entspricht die lineare Ausgleichs-
rechnung dem Losen eines linearen Gleichungssystems. Die QR-Zerlegung benotigt
dann 2nn2 − 23n3 +O(n2) = 4
3n3 +O(n2) arithmetische Operationen. Damit ist sie
ungefahr doppelt so teuer wie eine LU -Zerlegung. Dennoch ist dies eine Alternative
fur Matrizen mit großer Kondition, da die Rundungsfehler bei der QR-Zerlegung i.a.
geringer sind und damit der hohere Aufwand gerechtfertigt sein kann.

112 M. Braack Lineare Ausgleichsrechnung
Algorithmus Householder(m,n,A,v)
1. for k = 1, . . . , n
2. s = 0
3. for j = k, . . . ,m
4. s = s+ |ajk|2
5. if s = 0 STOP; /* Abbruch */
6. λ = sgn(akk)√s;
7. vkk = akk + λ;
8. s =√s− |akk|2 + |vkk|2;
9. vkk = vkk/s;
10. akk = −λ;
11. for j = k + 1, . . . ,m
12.
13. vjk = ajk/s;
14. ajk = 0;
15. t = 0;
16. for i = k + 1 to n
17. t = t+ ajivjk;
18. for i = k + 1 to n
19. aji = aji − 2tvjk;
20.
21.
Tabelle 5.1: Householder-Verfahren zur Bestimmung von R der QR-Zerlegung mit
Ubergabe einer Matrix A = (aij) der Dimension m × n, die durch R (partiell)
uberschrieben wird. In der Marix v werden die Householder-Vektoren v1, . . . , vn ge-
speichert.

Kapitel 6
Iterative Loser fur lineare
Gleichungssysteme
In diesem Kapitel betrachten wir ein weiteres Mal Losungsmethoden fur lineare
Gleichungssysteme
Ax = b. (6.1)
Allerdings untersuchen wir iterative Verfahren, also die sukzessive Bestimmung von
Naherungslosungen x(0), x(1), . . . ∈ Kn. Diese eignen sich besonders fur sehr große
Systeme, also n >> 1, mit dunn besetzten Matrizen A. Dies bedeutet, dass die
uberwiegende Anzahl der n2 Koeffizienten gleich Null sind. Solche Matrizen entste-
hen beispielsweise bei der Diskretisierung partieller Differentialgleichungen. Tridia-
gonalmatrizen und (p, q)-Bandmatrizen mit kleinen Zahlen p, q sind ebenfalls dunn
besetzt.
6.1 Lineare Iterationsverfahren
Definition 6.1 Unter einem linearen Iterationsverfahren φ zur Losung von (6.1)
versteht man ein Verfahren der Form
x(m+1) := φ(x(m), b), (6.2)
wobei φ gegeben ist in der Form
φ(x, b) = Mφx+Nφb
mit (von A abhangigen) Matrizen Mφ, Nφ ∈ Kn×n.

114 M. Braack Iterative Loser fur lineare Gleichungssysteme
Ferner benotigen wir die Begriffe konsistent und konvergent:
Definition 6.2 Ein lineares Iterationsverfahren φ heißt konsistent, wenn jede Losung
x von (6.1) ein Fixpunkt von φ(·, b) ist, also fur jedes b ∈ Kn gilt:
Ax = b =⇒ x = φ(x, b).
φ heißt konvergent, wenn fur jedes b ∈ Kn die Fixpunkt-Iteration (6.2) unabhangig
vom Startwert x(0) ∈ Kn konvergiert.
Satz 6.3 Ist ein lineares Iterationsverfahren φ zu einer regularen Matrix A konsi-
stent und konvergent, so konvergiert die Fixpunkt-Iteration (6.2) stets gegen eine
Losung x ∈ Kn von (6.1).
Beweis. Da φ als konvergent vorausgesetzt wurde, existiert x∗ := limm→∞ x(m) ∈
Kn unabhangig vom Startwert. Wahlen wir nun als Anfangswert x(0) := x die Losung
von Ax = b, so ist x aufgrund der Konsistenz ein Fixpunkt von φ. Dann ist aber
x(m) = x fur alle m und somit x∗ = x bzw. Ax∗ = b.
Satz 6.4 Ein lineares Iterationsverfahren φ ist genau dann konsistent, wenn gilt:
Mφ +NφA = I.
Beweis. ⇐: Es gelte Mφ +NφA = I und Ax = b. Dann folgt
φ(x, b) = Mφx+Nφb = Mφx+NφAx = (Mφ +NφA)x = Ix = x.
Also ist x ein Fixpunkt von φ(·, b), und somit ist φ konsistent.
⇒: φ sei konsistent und x ∈ Kn beliebig. Wir setzen b := Ax. Aufgrund der Konsi-
stenz von φ ist x dann ein Fixpunkt von φ(·, b). Also gilt
x = φ(x, b) = Mφx+Nφb = Mφx+NφAx = (Mφ +NφA)x.
Da x beliebig war, folgt Mφ +NφA = I.
Korollar 6.5 Konsistente lineare Iterationsverfahren sind von der Form
φ(x, b) = x−Nφ(Ax− b).
Beweis. Mit dem vorherigen Satz erhalten wir:
φ(x, b) = Mφx+Nφb = (I −NφA)x+Nφb = x−Nφ(Ax− b).
Bemerkungen:

6.1 Lineare Iterationsverfahren 115
1. Konsistente lineare Iterationsverfahren sind also durch die Wahl von N bereits
eindeutig definiert.
2. Die Wahl Nφ = A−1 (fur regulares A) fuhrt auf ein Iterationsverfahren, das
stets im ersten Schritt die Losung erreicht.
3. Es sollte also gelten Nφ ≈ A−1 und daruberhinaus sollte Nφ moglichst einfach
zu berechnen sein.
Lemma 6.6 Sei A ∈ Cn×n mit Spektralradius ρ(A) und K > ρ(A) beliebig. Dann
existiert eine regulare Matrix V ∈ Cn×n, so dass fur die Zeilensummennorm gilt:
||V −1AV ||∞ ≤ K.
Beweis. Da uber C jede Matrix tridiagonalisierbar ist, existiert eine invertierbare
Matrix S ∈ Cn×n, so dass B := SAS−1 = (bij) eine obere Dreiecksmatrix ist.
Ihre Diagonalelemente sind gerade die Eigenwerte von A. Wir wahlen zudem die
Diagonalmatrix D = diag(1, δ, . . . , δn−1) zu einem hinreichend kleinen 0 < δ < 1. V
wird gewahlt als das Produkt V := S−1D. Nun gilt fur die Koeffizienten von BD:
(BD)ij = δj−1bij
und fur die von D−1BD = D−1SAS−1D = V −1AV :
(V −1AV )ij = δj−ibij.
Da B eine obere Dreiecksmatrix ist, folgt
||V −1AV ||∞ = max1≤i≤n
n∑j=i
δj−i|bij|
≤ max1≤i≤n
|bii|+ max1≤i≤n
n∑j=i+1
δj−i|bij|
≤ ρ(A) + δ max1≤i≤n
n∑j=i+1
|bij|.
Nun sieht man, dass durch eine hinreichend kleine Wahl von δ (in Abhangigkeit von
K − ρ(A), n und den Koeffizienten bij) die Behauptung erreicht werden kann.

116 M. Braack Iterative Loser fur lineare Gleichungssysteme
Satz 6.7 Sei A ∈ Cn×n mit Spektralradius ρ(A) und || · || eine beliebige naturlich
erzeugte Matrizennorm auf Cn×n. Dann gilt stets
ρ(A) ≤ ||A||.
Ferner existiert zu jedem ε > 0 eine Vektornorm auf Cn, so dass fur die zugehorige
Matrizennorm || · ||ε gilt:
ρ(A) ≤ ||A||ε ≤ ρ(A) + ε.
Beweis. (a) Fur den ersten Teil wahlen wir einen Eigenvektor v ∈ Cn mit ||v|| = 1
zum betragsmaßig großten Eigenwert λ, also |λ| = ρ(A). Nun gilt
||A|| = sup||x||=1
||Ax|| ≥ ||Av|| = |λ|||v|| = |λ| = ρ(A).
(b) Wir wahlen gemaß des vorherigen Lemmas die Matrix V ∈ Cn×n, so dass
||V −1AV ||∞ ≤ ρ(A) + ε. Nun definieren wir eine Vektornorm auf Kn mittels
||x||ε := ||V −1x||∞.
Es gilt
||Ax||ε = ||V −1Ax||∞ = ||V −1AV V −1x||∞≤ ||V −1AV ||∞||V −1x||∞ ≤ (ρ(A) + ε)||x||ε.
Fur die zugehorige Matrizennorm ergibt sich daher die obere Schranke
||A||ε = supx∈Kn\0
||Ax||ε||x||ε
≤ ρ(A) + ε.
Die untere Schranke wurde in Teil (a) bereits gezeigt.
Satz 6.8 Fur den Spektralradius von Mφ ∈ Cn×n eines linearen Iterationsverfahrens
φ gelte
ρ(Mφ) < 1. (6.3)
Dann ist φ konvergent. Ist umgekehrt φ konvergent und A ∈ Cn×n regular, so gilt
(6.3).

6.2 Drei einfache lineare Iterations-Verfahren 117
Beweis. ⇐: Es gelte ρ(Mφ) < 1. Dann existiert nach vorherigem Lemma eine
Vektornorm, bezeichnet mit || · ||, und die zugehorige naturlich erzeugte Matrizen-
norm, ebenfalls bezeichnet mit || · ||, so dass
ρ(Mφ) < L := ||Mφ|| < 1.
Die Abbildung φ(·, b) : Cn → Cn ist dann eine Kontraktion, denn fur beliebige
x, y ∈ Cn gilt
||φ(x, b)− φ(y, b)|| = ||Mφx−Mφy|| = ||Mφ(x− y)|| ≤ L||x− y||.
Der Banachsche Fixpunktsatz liefert nun die Konvergenz der Iteration (6.2).
⇒: Sei λ ∈ σ(Mφ) mit |λ| = ρ(Mφ) ≥ 1 und v ∈ Cn\0 der zugehorige Eigenvektor.
Wir betrachten die spezielle rechte Seite b = 0. Dann gilt
φ(v, b) = Mφv +Nφ0 = λv.
Daher gilt mit den Startvektor x(0) := v fur die m-te Iteration: x(m) = λmv. Es folgt
||x(m)|| = |λ|m||v|| ≥ ||v|| > 0. Somit kann die Iteration nicht gegen die (eindeutige)
Losung x = 0 konvergieren.
Bemerkung: Bei diesem Satz ist wichtig, dass man das komplexe Spektrum
σ(Mφ) ⊂ C betrachtet. Wenn man lediglich im Reellen arbeiten mochte, also A ∈Rn×n, so muss man auch die moglichen komplexen Eigenwerte von Mφ betrachten,
um mit dem Spektralradius argumentieren zu konnen. Alternativ folgt zumindest
aus der Eigenschaft
||Mφ|| < 1
fur eine beliebige erzeugte Matrizennorm, das φ konvergent (fur Startwerte in Rn)
ist.
6.2 Drei einfache lineare Iterations-Verfahren
Wir schreiben die Matrix A als Summe von drei Matrizen:
A = L+D +R,
mit einer unteren Dreiecksmatrix L, einer Diagonalmatrix D und einer oberen Drei-
ecksmatrix R:
L =
0 · · · 0
∗ . . ....
∗ ∗ 0
, D =
∗ 0 0
0 ∗ 0
0 0 ∗
R =
0 ∗ ∗...
. . . ∗0 · · · 0
.

118 M. Braack Iterative Loser fur lineare Gleichungssysteme
Man beachte, dass die Diagonalen von L und R aus Nulleintragen bestehen. Die Be-
zeichnung L und R ist an dieser Stelle nicht mit einer LR-Zerlegung zu verwechseln.
6.2.1 Jacobi-Verfahren
Das Jacobi-Verfahren φJacobi erhalt man durch die Wahl
NJacobi := D−1.
Um ein konsistentes Verfahren zu bekommen, wahlt man die Matrix MJacobi als
MJacobi = I −NJacobiA = I −D−1A.
Die entsprechende Iteration lautet nun
x(m+1) = φJacobi(x(m), b) = MJacobix
(m) +NJacobib
= x(m) −D−1Ax(m) +D−1b
= x(m) +D−1(b− Ax(m)).
Der numerische Aufwand besteht in jedem Schritt also lediglich aus der Berechnung
des Residuums b − Ax(m), der Invertierung der Diagonalen D und der Addition
zweier Vektoren. Das Jacobi-Verfahren wird auch Gesamtschritt-Verfahren genannt.
6.2.2 Gauss-Seidel-Verfahren
Das Gauss-Seidel-Verfahren φGS erhalt man durch die Wahl
NGS := (L+D)−1.
Also ist NGS eine untere Dreiecksmatrix. Fur die Konsistenz wahlt man MGS ent-
sprechend
MGS = I −NGSA = I − (L+D)−1A.
Die entsprechende Iteration lautet nun
x(m+1) = φGS(x(m), b) = MGSx(m) +NGSb
= x(m) − (L+D)−1Ax(m) + (L+D)−1b
= x(m) + (L+D)−1(b− Ax(m)).
Der numerische Aufwand besteht in jedem Schritt also ebenfalls aus der Berechnung
des Residuums b−Ax(m) sowie der Vorwartselimination (L+D)−1 und der Addition
zweier Vektoren.

6.3 Zeilensummenkriterien 119
Lemma 6.9 Man kann diese Iteration auch schreiben in der Form:
x(m+1) = D−1(b−Rx(m) − Lx(m+1)
).
Beweis. Den Beweis fuhren wir etwas spater bei der Behandlung des SOR-
Verfahrens, was eine Verallgemeinerung des Gauss-Seidel-Verfahrens darstellt. Man
kann den Beweis aber auch schon hier als Ubungsaufgabe erstellen.
Dieses Verfahren wird auch Einzelschritt-Verfahren genannt.
6.2.3 Richardson-Iteration
Bei der sogenannten Richardson-Iteration wahlt man
NRich = ωI
mit einem positiven Parameter ω > 0. Die Matrix MRich ergibt sich dann entspre-
chend als
MRich = I −NRichA = I − ωA.
Die Iteration lautet
x(m+1) = φRich(x(m), b) = MRichx
(m) +NRichb
= x(m) + ω(b− Ax(m)).
Hier muss also lediglich ein Residuum berechnet und eine Vektoraddition ausgefuhrt
werden.
6.3 Zeilensummenkriterien
Der folgende Satz stellt das starke Zeilensummenkriterium dar:
Satz 6.10 Fur strikt diagonal-dominante Matrizen A ∈ Cn×n, d.h.
|aii| >∑j 6=i
|aij| ∀i ∈ 1, . . . , n,
sind sowohl das Jacobi- als auch das Gauss-Seidel-Verfahren konvergent.

120 M. Braack Iterative Loser fur lineare Gleichungssysteme
Beweis. Wir verwenden stets das Kriterium aus Satz 6.8 und die obere Schranke
||Mφ||∞ fur den Spektralradius gemaß Satz 6.7. Insofern genugt es jeweils zu zeigen:
||Mφ||∞ < 1.
(a) Fur das Jacobi-Verfahren gilt MJacobi = I − D−1A = I − D−1(D + L + R) =
−D−1(L+R) und daher ergibt sich:
||MJacobi||∞ = ||D−1(L+R)||∞ = max1≤i≤n
|a−1ii |∑j 6=i
|aij| < 1.
(b) Fur das Gauss-Seidel-Verfahren gilt MGS = I−(L+D)−1A = I−(L+D)−1(L+
D +R) = −(L+D)−1R.
||MGS||∞ = ||(L+D)−1R||∞
Nun zeigen wir ||MGS||∞ ≤ ||MJacobi||∞, woraus dann die Konvergenz folgt. Sei hierzu
x ∈ Kn mit ||x||∞ = 1 beliebig und y := MGSx mit Komponenten yi. Nun zeigen wir
per Induktion |yi| ≤ ||MJacobi||∞ fur jeden Index i. Fur i = 1 ergibt sich
|y1| =∣∣((L+D)−1Rx)1
∣∣ =
∣∣∣∣∣ 1
a11
n∑j=2
a1jxj
∣∣∣∣∣ ≤ 1
|a11|
n∑j=2
|a1j| ≤ ||MJacobi||∞.
Der Induktionsschritt i→ i+1 lautet nun wegen |yj| ≤ ||MJacobi||∞ < 1 fur 1 ≤ j ≤ i:
|yi+1| =
∣∣∣∣∣ 1
ai+1,i+1
i∑j=1
aijyj +n∑
j=i+2
aijxj
∣∣∣∣∣≤ 1
|ai+1,i+1|
(i∑
j=1
|aij|+n∑
j=i+2
|aij|
)
=1
|ai+1,i+1|
i∑j 6=i
|aij| ≤ ||MJacobi||∞.
Man kann dieses Kriterium etwas abschwachen (schwaches Zeilensummenkriteriun):
Definition 6.11 Eine Matrix A ∈ Kn×n erfullt das schwache Zeilensummenkriteri-
um, wenn

6.3 Zeilensummenkriterien 121
1. A diagonal-dominant ist, d.h.
|aii| ≥∑j 6=i
|aij| ∀i ∈ 1, . . . , n,
2. eine Zeile k ∈ 1, . . . , n von A strikt diagonal-dominant ist, d.h.
|akk| >∑j 6=k
|akj|,
3. und A irreduzibel ist, d.h. es gibt keine nicht-triviale Zerlegung I1 ∪ I2 =
1, . . . , n, s.d.
aij = 0 ∀(i, j) ∈ I1 × I2.
Die Irreduzibilitat ist aquivalent damit, dass keine n-stellige Permutation π existiert,
so dass PπAPTπ folgende Blockstruktur besitzt:
PπAPTπ =
(Ak 0
∗ ∗
),
mit quadratischer Matrix A ∈ Kk×k, k ∈ 1, . . . , n− 1. Lineare Gleichungssysteme
mit reduziblen Matrizen lassen sich in Blockstruktur losen, indem man zunachst Akinvertiert.
Lemma 6.12 Erfullt A ∈ Kn×n das schwache Zeilensummenkriterium, so besitzen
weder MJacobi noch MGS einen Eigenwert λ ∈ C mit |λ| = 1.
Beweis. (a) Angenommen λ ∈ C ware ein Eigenwert von MJacobi mit |λ| = 1,
dann existiert ein zugehoriger Eigenvektor v ∈ Cn mit ||v||∞ = 1. Sei l ∈ 1, . . . , nder Index mit |vl| = 1. Ferner sei k ∈ 1, . . . , n der Index zur strikten Diagonal-
Dominanz, also
|vk| = |λvk| = |(MJacobiv)k| =1
|aki|
∣∣∣∣∣∑j 6=k
akjvj
∣∣∣∣∣ ≤ 1
|aki|∑j 6=k
|akj| |vj|︸︷︷︸≤1
< 1.
Sei nun m ∈ 1, . . . , n ein beliebiger Index fur den lediglich amk 6= 0 gilt. Dann gilt
hierfur
|vm| = |λvm| = |(MJacobiv)m| =1
|ami|
∣∣∣∣∣∑j 6=m
amjvj
∣∣∣∣∣≤ 1
|ami|
(∑j 6=m,k
|amj|+ |amk||vk|
).

122 M. Braack Iterative Loser fur lineare Gleichungssysteme
Aus der Diagonal-Dominanz und der Tatsache, dass 0 < |vk| < 1 ist, folgt dann
|vm| < 1.
Dieses Argument kann man iterieren bis man den Index l erreicht, |vl| < 1, was
einen Widerspruch zur obigen Festlegung |vl| = 1 darstellt. Hierbei ist wichtig, dass
man eine Folge von Indizes i0 = k, . . . , if = l findet, so dass stets aij ,ij+16= 0 gilt.
Das ist aber gerade eine Folgerung der Irreduzibilitat von A.
(b) Im Fall MGS folgert man analog.
Satz 6.13 Erfullt A ∈ Kn×n das schwache Zeilensummenkriterium, so sind sowohl
das Jacobi- als auch das Gauss-Seidel-Verfahren konvergent.
Beweis. Irreduzible Matrizen besitzen insbesondere keine Nullzeilen und damit
gilt in Zusammenhang mit der Diagonal-Dominanz:
|aii| > 0 ∀i ∈ 1, . . . , n.
Somit sind das Jacobi- und das Gauss-Seidel-Verfahren prinzipiell durchfuhrbar. Wie
im Beweis zuvor gilt ||MGS||∞ ≤ ||MJacobi||∞ sowie ||MJacobi||∞ ≤ 1. Mit Satz 6.7 folgt
ρ(MJacobi) ≤ ||MJacobi||∞ ≤ 1.
Das vorherige Lemma besagt nun, dass MJacobi und MGS keinen Eigenwert λ mit
|λ| = 1 besitzt, also gilt sogar
ρ(MJacobi) < 1 und ρ(MGS) < 1.
Mit Satz 6.8 folgt die Konvergenz des Jacobi- und des Gauss-Seidel-Verfahrens.
6.4 SOR-Verfahren
Bei dem succesive overrelaxation (SOR-Verfahren) verwendet man zu einem Parame-
ter ω > 0 eine ahnliche Iterationsmatrix N wie bei Gauss-Seidel, aber die Diagonale
wird mit ω.−1 gewichtet:
Nsor :=
(1
ωD + L
)−1
.
Fur die Konsistenz muss die Matrix Msor wie folgt gebildet werden:
Msor := I −NsorA = I −(
1
ωD + L
)−1
A.

6.4 SOR-Verfahren 123
Die Iterationsfunktion lautet also
φsor(x, b) := Msorx+Nsorb
= x+
(1
ωD + L
)−1
(b− Ax).
Fur ω = 1 erhalten wir das Gauss-Seidel-Verfahren.
Lemma 6.14 Die Iteration des SOR-Verfahrens kann auch geschrieben werden in
der Form
x(m+1) = (1− ω)x(m) + ωD−1(b−Rx(m) − Lx(m+1)
).
In dieser Formulierung tritt x(m+1) auch in der rechten Seite auf. Wenn man diese
Gleichung aber komponentenweise aufschreibt, sieht man, dass zur Berechnung von
x(m+1)i nur die bereits berechneten Werte x
(m+1)1 , . . . , x
(m+1)i−1 benotigt werden.
Beweis. Zunachst gilt
x(m+1) = φsor(x(m), b)
= x(m) +
(1
ωD + L
)−1
(b− Ax(m)).
Jetzt schreiben wir
−A = −(
1
ωD + L
)+
(1
ω− 1
)D −R
und erhalten
x(m+1) =
(1
ωD + L
)−1(b+
(1
ω− 1
)Dx(m) −Rx(m)
).
Wir definieren
y := b+
(1
ω− 1
)Dx(m) −Rx(m),
so dass (1
ωD + L
)x(m+1) = y,
bzw.
x(m+1) = ωD−1y − ωD−1Lx(m+1)
= ω
(1
ω− 1
)x(m) + ωD−1(b−Rx(m) − Lx(m+1)).
Dies liefert die obige Behauptung.

124 M. Braack Iterative Loser fur lineare Gleichungssysteme
Lemma 6.15 Fur jede invertierbare Matrix M ∈ Cn×n gilt fur den Spektralradius
ρ(M) ≥ |det(M)|1/n.
Beweis. Seien λ1, . . . , λn ∈ C alle n Eigenwerte von M (Vielfachheiten mit-
gezahlt). Dann gilt
det(M) =n∏i=1
λn.
Hieraus folgern wir
ρ(M) = max1≤i≤n
|λi| ≥
(∣∣∣∣∣n∏i=1
λn
∣∣∣∣∣)1/n
= |det(M)|1/n.
Satz 6.16 Zu A ∈ Cn×n ist das SOR-Verfahren mit ω ∈ (−∞, 0] ∪ [2,∞) nicht
konvergent.
Beweis. Wir zeigen, dass
ρ(Msor) ≥ |1− ω| (6.4)
gilt. Somit folgt fur ω ∈ (−∞, 0]∪ [2,∞) sofort ρ(Msor) ≥ 1. Mit Satz 6.8 folgt, dass
das Verfahren nicht konvergent sein kann. Wir wollen außerdem das zuvorige Lem-
ma benutzen. Daher benotigen wir Informationen uber die Determinante von Msor.
Hierzu schreiben wir Msor als ein Produkt zweier Matrizen: Die Iterationsvorschrift
gemaß Lemma 6.14 lasst sich auch schreiben in der Form
(I + ωD−1L)x(m+1) = (1− ω)x(m) + ωD−1(b−Rx(m)
)=
((1− ω)I − ωD−1R
)x(m) + ωD−1b
Daher gilt Msor = M−11 M2 mit den Matrizen:
M1 := I + ωD−1L und M2 := (1− ω)I − ωD−1R.
Somit folgt det(Msor) = det(M1)−1 det(M2). Da M1 eine linke untere Dreiecksmatrix
ist, deren Diagonalelemente alle Eins sind, gilt det(M1) = 1. M2 ist eine rechte obere
Dreiecksmatrix mit Diagonalelementen 1−ω ist, gilt det(M2) = (1−ω)n. Somit folgt
det(Msor) = (1− ω)n.
Mit dem Lemma zuvor ergibt sich (6.4).

6.5 Lineare Iterationsverfahren fur positiv definite Matrizen 125
6.5 Lineare Iterationsverfahren fur positiv defini-
te Matrizen
In diesem Abschnitt betrachten wir selbstadjungierte (d.h. symmetrisch bzw. her-
mitesche) Matrizen, die positiv definit sind. Wir benutzen die Schreibweise
0 < A
dann, wenn A positiv definit ist. Ferner schreiben wir
B < A :⇐⇒ 0 < A−B.
Ist A selbstadjungiert und positiv definit, so wird durch
||x||A := < Ax, x >1/2
eine Norm auf Kn definiert. Die hieraus erzeugte Matrizennorm bezeichnen wir eben-
falls mit || · ||A. Ferner existiert dann eine selbstadjungierte, positiv definite Matrix
B ∈ Kn×n, so dass B2 = A. Dann gilt fur beliebige Matrizen M ∈ Kn×n:
||M ||A = ||BMB−1/2||2,
denn
||M ||A = supx∈Kn\0
||Mx||A||x||A
= supx∈Kn\0
〈AMx,Mx〉1/2
〈Ax, x〉1/2
= supx∈Kn\0
〈BMx,B∗Mx〉1/2
〈Bx,B∗x〉1/2= sup
x∈Kn\0
||BMx||2||Bx||2
= supy∈Kn\0
||BMB−1/2y||2||y||2
= ||BMB−1/2||2.
Weiterhin folgt aus A < I fur den Spektralradius ρ(A) < ρ(I) = 1.
Satz 6.17 Sei A ∈ Kn×n selbstadjungiert und positiv definit und φ ein lineares und
konsistentes Iterationsverfahren (zu dieser Matrix A), so dass
A < N−1φ + (N−1
φ )∗.
Dann ist φ konvergent.

126 M. Braack Iterative Loser fur lineare Gleichungssysteme
Beweis. Wir zeigen nun im Folgenden
||Mφ||A < 1. (6.5)
Nun sei B ∈ Kn×n die positiv definite Matrix, so dass B2 = A. Wir betrachten
M := BMφB−1. Es gilt
||Mφ||2A = ||A1/2MφA−1/2||22 = ||BMφB
−1||22 = ||M ||22 = ρ(M∗M). (6.6)
Um das Produkt M∗M zu berechnen, schauen wir uns zunachst M genauer an:
M = B(I −NφA)B−1 = I −BNφAB−1 = I −BNφB.
Also folgt wegen B∗ = B:
M∗M = (I −BNφB)∗(I −BNφB) = (I −BN∗φB)(I −BNφB)
= I −BNφB −BN∗φB +BN∗φBBNφB
= I −B(Nφ +N∗φ)B +BN∗φANφB
< I −B(Nφ +N∗φ)B +BN∗φ(N−1φ +N−∗φ )NφB
= I −B(Nφ +N∗φ)B +BN∗φN−1φ NφB +BN∗φN
−∗φ NφB
= I −B(Nφ +N∗φ)B +BN∗φB +BNφB = I.
Daher gilt
ρ(M∗M) < ρ(I) = 1.
Zusammen mit (6.6) folgt (6.5). Die Konvergenz von φ folgt dann aus der Kombi-
nation von Satz 6.8 und Satz 6.7.
Satz 6.18 Sei A ∈ Kn×n selbstadjungiert und positiv definit. Dann ist das SOR-
Verfahren fur 0 < ω < 2 konvergent. Insbesondere ist dann das Gauss-Seidel-
Verfahren konvergent.
Beweis. (a) Wir benutzen das Resultat aus dem vorherigen Satz. Aufgrund der
Symmetrie von A gilt R = L∗. Ferner impliziert die Symmetrie D∗ = D. Somit folgt
wegen 2/ω > 1:
A = D + L+R = D + L+ L∗ <2
ωD + L+ L∗
= (ω−1D + L) + (ω−1D + L)∗ = N−1sor + (N−1
sor)∗.
(b) Gauss-Seidel entspricht dem SOR-Verfahren fur ω = 1.
Bei genauerer Kenntnis der Matrix A kann man den Parameter ω ∈ (0, 2) evtl.
derart wahlen, dass die Konvergenzrate minimal wird. Dies kann in weiterfuhrenden
Vorlesungen genauer untersucht werden.

Kapitel 7
Losungsverfahren fur nichtlineare
Gleichungssysteme
Nun widmen wir uns der Losung nichtlinearer Gleichungen. Sei hierzu Ω ⊆ Kn ein
Gebiet (also offen und zusammenhangend) und
f : Ω→ Kn
eine total differenzierbare Funktion. Wir suchen eine Nullstelle x ∈ Ω von f :
f(x) = 0.
7.1 Konvergenzverhalten iterativer Verfahren
Auch hier betrachten wir iterative Verfahren φ : Ω→ Ω mit Startwert x(0) ∈ Ω und
xm+1 := φ(xm) ∀m ∈ N, (7.1)
wobei die Verfahrensfunktion φ selbstverstandlich von f abhangt und nicht-linear
sein kann. Wir definieren auch hier die Begriffe ”Konsistenz” und ”Konvergenz”.
Definition 7.1 Das (nicht-lineare) Iterationsverfahren φ heißt konsistent, wenn je-
de Nullstelle von f auch ein Fixpunkt von φ ist.
Definition 7.2 φ heißt konvergent gegen x∗ ∈ Ω von der Ordnung α ≥ 1 (in der
Vektornorm || · ||), wenn ein % > 0 existiert, so dass
||xm − x∗|| ≤ %||xm−1 − x∗||α ∀x0 ∈ Ω und alle m ∈ N.

128 M. Braack Losungsverfahren fur nichtlineare Gleichungssysteme
Im Fall α = 1 spricht man von linearer Konvergenz; die kleinste Konstante % > 0
mit obiger Eigenschaft heißt dann (lineare) Konvergenzrate. φ heisst superlinear
konvergent, wenn eine Nullfolge (cm)m∈N ⊂ R existiert, so dass
||xm − x∗|| ≤ cm||xm−1 − x∗|| ∀x0 ∈ Ω und alle m ∈ N.
Lemma 7.3 Ist φ konvergent gegen x∗ ∈ Ω von der Ordnung α > 1, so ist die Itera-
tion (7.1) fur x0 ∈ Ω hinreichend nah an x∗ konvergent gegen x∗, also limm→∞ xm =
x∗.
Beweis. Es gilt stets
%1/(α−1)||xm − x∗|| ≤ %1/(α−1)+1||xm−1 − x∗||α
≤(%1/(α−1)||xm−1 − x∗||
)α.
Daher folgt per Induktion:
%1/(α−1)||xm − x∗|| ≤(%1/(α−1)||x0 − x∗||
)αm= (βα)m,
mit β := %1/(α−1)||x0 − x∗||. Wenn wir Startwerte mit der Eigenschaft
||x0 − x∗|| < %1/(1−α)
wahlen, so ist βα < β < 1. Hieraus folgt die Konvergenz.
Lemma 7.4 Ist φ linear konvergent gegen x∗ ∈ Ω mit Konvergenzrate % < 1, so ist
die Iteration (7.1) fur alle x0 ∈ Ω konvergent gegen x∗, also limm→∞ xm = x∗.
Beweis. Der Beweis ist offensichtlich.
Im Eindimensionel (n = 1) haben wir folgende Charakterisierung:
Satz 7.5 Sei Ω ⊆ R ein offenes Intervall und φ : Ω → Ω ein (nicht-lineares)
iteratives Verfahren zur Bestimmung eines Fixpunktes x∗ ∈ Ω. Ferner sei φ ∈ Cp(Ω)
mit 2 ≤ p ∈ N. Dann ist φ genau dann von der Ordnung p, wenn fur die Ableitungen
von φ gilt:
φ(k)(x∗) = 0 ∀k ∈ 1, . . . , p− 1.
Beweis. ⇐: Fur x ∈ Ω lasst sich die Taylor-Entwicklung dann schreiben als
xm+1 − x∗ = φ(xm)− φ(x∗)
=
p−1∑k=1
1
k!φ(k)(x∗)(xm − x∗)k +
1
p!φ(ξ)(p)(xm − x∗)p,

7.2 Newton-Verfahren 129
mit ξ ∈ Ω. Wenn nun die ersten p− 1 Ableitungen von φ verschwinden, folgt
|xm+1 − x∗| ≤1
p!|φ(p)(ξ)||xm − x∗|p.
Mit der Wahl % := 1p!
supξ∈Ω |φ(p)(ξ)| folgt die geforderte Darstellung der Konvergen-
zordnung p.
⇒: Wir nehmen an, es gelte φ(q′)(x∗) = 0 und φ(q)(x∗) 6= 0 fur 1 ≤ q′ < q ≤ p − 1.
Dann liefert die Taylor-Entwicklung:
xm+1 − x∗ =1
q!φ(q)(ξm)(xm − x∗)q,
mit |ξm − x∗| ≤ |xm − x∗|. Mit der Stetigkeit von φ(q) folgt nun
φ(q)(x∗) = limm→∞
φ(q)(xm) = q! limm→∞
xm+1 − x∗
(xm − x∗)q
Da φ nach Voraussetzung von der Konververgenzordnung p ist, folgt wegen p−q ≥ 1
|φ(q)(x∗)| = q!% limm→∞
|xm − x∗|p−q = 0.
Dies ist ein Widerspruch zur Annahme φ(q)(x∗) 6= 0.
7.2 Newton-Verfahren
Das Newton-Verfahren ist durch das iterative Verfahren
φ(x) := x−Df(x)−1f(x)
gegeben. Hierzu ist es notwendig, dass f ∈ C1(Ω;Kn) gilt.Df(x) = D(1)f(x) ∈ Kn×n
bezeichnet die Ableitung bzw. Jacobi-Matrix von f an der Stelle x = (x1, . . . , xn)T ∈
Ω. Die Komponenten sind die partiellen Ableitungen
(Df(x))ij =∂fi∂xj
(x).
Offensichtlich ist das Newton-Verfahren konsistent. In einer Dimension, n = 1, lasst
sich das Newton-Verfahren einfach veranschaulichen, siehe hierzu Abb. 7.1. Die Ite-
ration lautet somit:
1. Wahle Startwert x0 ∈ Ω und setze m = 0.
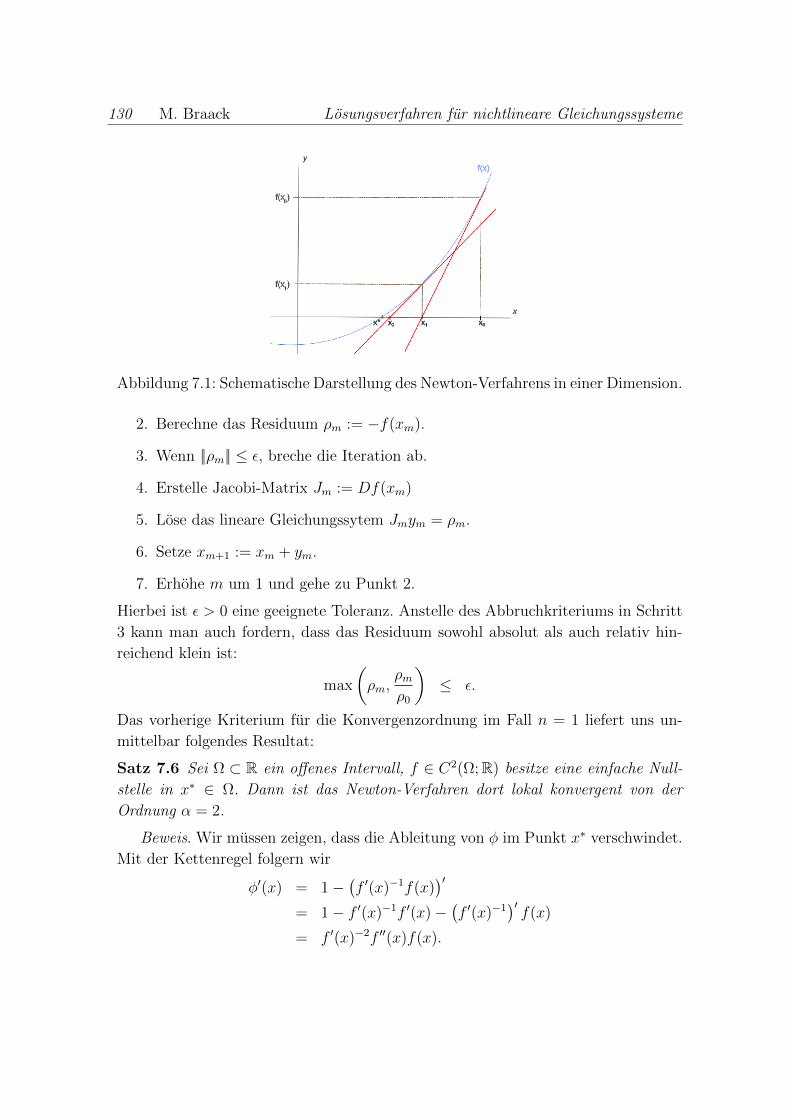
130 M. Braack Losungsverfahren fur nichtlineare Gleichungssysteme
Abbildung 7.1: Schematische Darstellung des Newton-Verfahrens in einer Dimension.
2. Berechne das Residuum ρm := −f(xm).
3. Wenn ||ρm|| ≤ ε, breche die Iteration ab.
4. Erstelle Jacobi-Matrix Jm := Df(xm)
5. Lose das lineare Gleichungssytem Jmym = ρm.
6. Setze xm+1 := xm + ym.
7. Erhohe m um 1 und gehe zu Punkt 2.
Hierbei ist ε > 0 eine geeignete Toleranz. Anstelle des Abbruchkriteriums in Schritt
3 kann man auch fordern, dass das Residuum sowohl absolut als auch relativ hin-
reichend klein ist:
max
(ρm,
ρmρ0
)≤ ε.
Das vorherige Kriterium fur die Konvergenzordnung im Fall n = 1 liefert uns un-
mittelbar folgendes Resultat:
Satz 7.6 Sei Ω ⊂ R ein offenes Intervall, f ∈ C2(Ω;R) besitze eine einfache Null-
stelle in x∗ ∈ Ω. Dann ist das Newton-Verfahren dort lokal konvergent von der
Ordnung α = 2.
Beweis. Wir mussen zeigen, dass die Ableitung von φ im Punkt x∗ verschwindet.
Mit der Kettenregel folgern wir
φ′(x) = 1−(f ′(x)−1f(x)
)′= 1− f ′(x)−1f ′(x)−
(f ′(x)−1
)′f(x)
= f ′(x)−2f ′′(x)f(x).

7.2 Newton-Verfahren 131
Da im Punkt x∗ eine einfache Nullstelle vorausgesetzt wurde, gilt f ′(x∗) 6= 0 und
wegen der Stetigkeit gilt f ′ 6= 0 in einer hinreichend kleinen Umgebung von x∗. Somit
sind die obigen Ausdrucke dort wohldefiniert. Wegen f(x∗) = 0 folgt φ′(x∗) = 0.
Dieses Ergebnis liefert aber noch keine Information uber den eigentlichen Kon-
vergenzbereich. Fur die genauere Analyse des Newton-Verfahren benotigen wir fol-
gendes Hilfsresultat:
Lemma 7.7 Sei Ω ⊂ Rn offen und konvex, f ∈ C1(Ω;Rn), x, y ∈ Ω. Dann gilt
f(x)− f(y) =
∫ 1
0
Df(λx+ (1− λ)y)(x− y) dλ.
Beweis. Wir setzen fur die feste Wahl von x, y ∈ Ω:
F (λ) := f(λx+ (1− λ)y).
Damit ist F ∈ C1([0, 1];Rn). Der Hauptsatz der Differential- und Integralrechnung
liefert nun
f(x)− f(y) = F (1)− F (0) =
∫ 1
0
F ′(λ) dλ.
Fur die Ableitung gilt nach der Kettenregel
F ′(λ) = Df(λx+ (1− λ)y)(x− y).
Setzen wir dies in das obige Integral ein, so erhalten wir die Behauptung.
Satz 7.8 Sei B ⊂ Rn eine offene Kugel um x∗ ∈ Rn und f ∈ C1(B;Rn) mit
folgenden weiteren Eigenschaften:
1. x∗ ist eine Nullstelle von f ,
2. Df(x) ist fur alle x ∈ B eine invertierbare Matrix,
3. es existiert eine Konstante β ≥ 0, so dass
||Df(x)−1|| ≤ β ∀x ∈ B,
4. Df ist in B Lipschitz-stetig mit Lipschitz-Konstante L.
Dann ist das Newton-Verfahren fur alle Startwerte x0 ∈ B1/% konvergent von zweiter
Ordnung und dem Vorfaktor % := 12βL. Hierbei ist B1/% := x ∈ B|||x− x∗|| ≤ 1/%.

132 M. Braack Losungsverfahren fur nichtlineare Gleichungssysteme
Beweis. Wir bezeichnen die Ableitung von f an der Stelle xm mit J := Df(xm)
und an der Zwischenstelle mit Jλ := Df(λxm + (1− λ)x∗). Dann gilt zum einen
||xm+1 − x∗|| = ||xm − J−1f(xm)− x∗||= ||J−1(J · (xm − x∗)− f(xm)||≤ β||J · (xm − x∗)− f(xm)||,
wobei wir die Voraussetzung ||J−1|| ≤ β verwendet haben. Zum anderen gilt aufgrund
des vorherigen Lemmas
J · (xm − x∗) =
∫ 1
0
J · (xm − x∗) dλ,
f(xm) = f(xm)− f(x∗) =
∫ 1
0
Jλ · (xm − x∗) dλ.
Setzen wir dies in die obige Ungleichung ein, so erhalten wir
||xm+1 − x∗|| ≤ β
∫ 1
0
||(J − Jλ)(xm − x∗)|| dλ
≤ β||xm − x∗||∫ 1
0
||J − Jλ|| dλ.
Aufgrund der Lipschitz-Stetigkeit von f ′ gilt∫ 1
0
||J − Jλ||dλ ≤ L
∫ 1
0
||xm − λxm − (1− λ)x∗||dλ
= L||xm − x∗||∫ 1
0
(1− λ) dλ =L
2||xm − x∗||.
Insgesamt erhalten wir die gewunschte Konvergenz 2. Ordnung:
||xm+1 − x∗|| ≤βL
2||xm − x∗||2.
Nun ist noch sicherzustellen, dass man die Kugel B nicht verlasst. Fur xm ∈ B1/%
erhalt man wegen
||xm+1 − x∗|| ≤βL
2%2=
1
%
wieder xm+1 ∈ B1/%. Insofern erhalt man unter der Anfangsvoraussetzung x0 ∈ B1/%
per Induktion, dass jede Iterierte xm in B1/% liegt.

7.3 Varianten des Newton-Verfahrens 133
7.3 Varianten des Newton-Verfahrens
7.3.1 Quasi-Newton-Verfahrens
Von einem Quasi-Newton-Verfahren spricht man, wenn man anstelle der Jacobi-
Matrix Jm = Df(xm) mit einer approximativen Matrix Jm arbeitet. Beispielsweise
kann man Jm := J0 wahlen und mit dieser Matrix auch spatere Schritte m ≥ 1
berechnen. Die Grunde, mit approximativen Jacobi-Matrizen zu arbeiten, konnen
vielfaltig sein:
• Man mochte nicht standig eine neue Jacobi-Matrix aufbauen und invertieren
(bzw. LU-Zerlegungen oder vergleichbare Modifizierungen durchfuhren),
• Jm konnte bessere Losungseigenschaften als Jm besitzen (Symmetrie, Diagonal-
Dominanz etc.),
• die Besetzungsstruktur von Jm konnte sparsamer sein als die von Jm.
Selbstverstandlich hangt die Frage der Konvergenz stark von der Wahl von Jm ab.
Im allgemeinen verliert man die Konvergenzordnung 2.
7.3.2 Gedampftes Newton-Verfahren
Haufig erhalt man die Konvergenz des Newton-Verfahrens nur in der Nahe der
Losung x∗. Wie wir im fruheren Abschnitt gesehen haben, hangt der Konvergenz-
bereich von der Lipschitz-Konstanten der Ableitung von f (Parameter L) und von
der Beschranktheit der Inversen (Parameter β) ab. Ist man weiter von der gesuchten
Nullstelle entfernt, konvergiert das Newton-Verfahren haufig nicht oder nicht gut.
In solchen Fallen kann es sinnvoll sein, das Newton-Verfahren zu dampfen, indem
man nicht die volle Korrektur y auf die derzeitige Losung aufaddiert, sondern nur
einen Anteil 0 < θm ≤ 1. In diesem Fall lautet der Korrekturschritt (Schritt 6. im
vorhergehenden Algorithmus):
xm+1 := xm + θmym.
Im Fall θm = 1 erhalt man das Newton-Verfahren. Fur 0 < θm < 1 findet eine
Dampfung statt. Den Parameter θm kann man an die Reduktion des Residuums
koppeln. Hierfur wird eine weitere Residuumsberechnung benotigt. Man wahlt bei-
spielsweise zunachst θm = 1, berechnet das neue Residuum ρm = −f(xm). Falls nun
ρm ≥ ρm−1 gilt, so reduziert man θm, z.B. θm → θm/2 und berechnet das Residuum

134 M. Braack Losungsverfahren fur nichtlineare Gleichungssysteme
erneut. Dies iteriert man, bis sich das Residuum tatsachlich reduziert. Im nachsten
Newtonschritt sollte man aber zunachst wieder mit θm+1 = 1 starten, um die volle
Konvergenzgeschwindigkeit in der Nahe der Losung zu erreichen.
7.3.3 Schrittweitenkontrolle
Eine Verfeinerung des gedampften Newton-Verfahrens erhalt man, wenn man den
Dampfungsparameter θm in gewisser Hinsicht optimiert. So kann man θm so wahlen,
dass
||f(xm + θmym)|| = inf0<θ≤1
||f(xm + θym)||.
7.3.4 Broyden-Updates
Eine spezielle Form des Quasi-Newton-Verfahrens besteht aus einem Update der
vorherigen Newton-Matrix. Ist Jm−1 ≈ Df(xm−1), so wahlt man hier
Jm := Jm−1 +Bm,
mit einer einfach zu bildenden Matrix Bm ∈ Rn×n. Eine sinnvolle Forderung ist
hierbei
||Jm − Jm|| ≤ ||Jm − Jm−1||,
in gewisser Matrizennorm || · ||, denn sonst ware die Nutzung von Bm aller Voraus-
sicht nach nicht von Vorteil. Unter dem Broyden-Rang-1-Update versteht man die
folgende Strategie fur die Wahl von Bm als ein dyadisches Produkt:
xδ := xm − xm−1,
fδ := f(xm)− f(xm−1),
Bm := ||xδ||−2(fδ − Jm−1xδ)xTδ .
Man spricht hier von einem Rang-1-Update, da Bm eine Matrix mit Rang(B) = 1
ist: Der Kern hat die Dimension n− 1:
x⊥δ = y ∈ Rn | 〈xδ, y〉 = 0 ⊆ Ker(Bm).

7.3 Varianten des Newton-Verfahrens 135
Satz 7.9 Wir betrachten das Newton-Verfahren zu einer affin-linearen Funktion
f : Rn → Rn mit Ableitung J := Df . Ferner sei Jm−1 ∈ Rn×n eine beliebige
Approximation an J und Jm := Jm−1 + ||xδ||−2(fδ − Jm−1xδ)xTδ das entsprechende
Rang-1-Update. Dann gilt
||J − Jm||2 = ||J − Jm−1||2.
Beweis. Zunachst gilt
(J − Jm)xδ = (J − Jm−1)xδ − ||xδ||−2(fδ − Jm−1xδ)xTδ xδ
= (J − Jm−1)xδ − fδ + Jm−1xδ.
Die vorausgesetzte affine Linearitat von f impliziert fδ = Jxδ. Somit folgt
(J − Jm)xδ = 0. (7.2)
Ein beliebiges x ∈ Rn lasst sich darstellen in der Form
x = αxδ + v,
mit α ∈ R, v ∈ Rn und 〈v, xδ〉 = 0. Fur dieses v gilt ||v||2 ≤ ||x||2, denn
||v||22 = 〈v, x− αxδ〉 = 〈v, x〉 ≤ ||v||2||x||2.
Nun erhalten wir mit (7.2):
(J − Jm)x = (J − Jm)v = (J − Jm−1)v.
Insgesamt folgt
||J − Jm||2 = supx∈Rn
||(J − Jm)x||2||x||2
≤ ||J − Jm−1||2 supx∈Rn
||v||2||x||2
≤ ||J − Jm−1||2.

136 M. Braack Losungsverfahren fur nichtlineare Gleichungssysteme

Kapitel 8
Lineare Optimierung
8.1 Beispiele linearer Optimierungsprobleme
Wir motivieren diesen Abschnitt mit zwei Beispielen.
8.1.1 Beispiel einer Produktionsoptimierung
Eine Firma produziere Autos (A) und Busse (B). Die Produktion und der Verkauf
gestalten sich wie folgt:
• Man benotigt je Einheit fur A eine Arbeitsstunde und fur B vier Arbeitsstun-
den. Insgesamt stehen 160 Arbeitsstunden zur Verfugung.
• Fur A entstehen Kosten i.H.v. 10 e und fur B i.H.v. 20 e pro Stuck. Die
Firma hat 1.100 e fur die Gesamtproduktion zur Verfugung.
• Der Gewinn fur A betragt 40 e und fur B 120 e pro Stuck.
• Aus weiteren Kapazitatsgrunden konnen maximal 100 Fahrzeuge (also A und
B zusammen) produziert werden.
Wie teilt man die Produktion auf, so dass der Gewinn maximiert wird?
Wir ubersetzen dieses Problem in ein mathematisches Modell. Gesucht ist x ∈

138 M. Braack Lineare Optimierung
R2, s.d.
Q(x) := 40x1 + 120x2 → max!,
x ≥ 0,
x1 + x2 ≤ 100,
x1 + 4x2 ≤ 160,
10x1 + 20x2 ≤ 1100.
Hierbei wurde der Einfachheit halber nicht berucksichtigt, dass man eigentlich nur
ganzzahlige Mengen produzieren kann.
8.1.2 Beispiel einer Optimalen Logistik
Man stelle sich n ∈ N Fabriken an unterschiedlichen Standorten, die ein und dasselbe
Produkt produzieren, und m ∈ N Konsumenten vor.
• Jede Fabrik produziert eine gegebene Menge des Produktes.
• Jeder Konsument hat einen gegebenen Bedarf an dem Produkt.
• Die Gesamt-Produktion in den n Fabriken soll dem Gesamt-Bedarf der m
Konsumenten entsprechen.
• Fur den Transport von Fabrik Nr. i zum Konsumenten Nummer j entstehen
Kosten i.H.v. cij ≥ 0.
Wie teilt man den Transport von den Fabriken zu den jeweiligen Konsumenten auf,
so dass die Kosten minimal werden?
Auch hier formulieren wir ein entsprechendes mathematisches Modell. Gegeben
sind der jeweilige Bedarf rj des Konsumenten Nr. j sowie die Produktionsmenge pivon Fabrik Nr. i, mit der Bedingung
∑ni=1 pi =
∑mj=1 rj. Gesucht ist X ∈ Rn×m, so
dass gilt
Q(X) :=n∑i=1
m∑j=1
cijXij → min!,
X ≥ 0,m∑j=1
Xij = pi ∀i ∈ 1, . . . , n,
n∑i=1
Xij = rj ∀j ∈ 1, . . . ,m.
Nun bezeichnet Xij die Transportmenge von Fabrik i zum Konsumenten j.

8.2 Normalform eines Linearen Programms 139
8.2 Normalform eines Linearen Programms
Definition 8.1 Unter einem linearen Programm in Normalform (LP) versteht man
die Suche nach einem Minimum x∗ der Form
cTx∗ = mincTx | x ∈M
mit Gleichungsnebenbedingungen und Vorzeichenbedingungen
M = x ∈ Rn | Ax = b, x ≥ 0. (8.1)
Hierbei sind A ∈ Rm×n, b ∈ Rm, c ∈ Rn mit Rang(A) = m ≤ n und b ≥ 0 gegebene
Großen.
Offensichtlich ist M konvex, denn fur x, y ∈ M , λ ∈ [0, 1] und xλ := λx + (1− λ)y
gilt auch Axλ = b und xλ ≥ 0.
Wir wollen nun sehen, dass sich auch andere Formen von Gleichungen und Un-
gleichungen in der Normalform (LP) schreiben lassen:
• Eine Ungleichung der Form∑n
i=1 aixi ≥ β kann durch Multiplikation mit −1
in eine Ungleichung der Form∑n
i=1 aixi ≤ β gebracht werden.
• Eine Ungleichung der Form∑n
i=1 aixi ≤ β kann durch Einfuhrung soge-
nannter ”Schlupfvariablen” y in eine Gleichung und eine Vorzeichenbedingung
uberfuhrt werden:
n∑i=1
aixi + y = β, y ≥ 0
• Bei jeder Gleichung der Form∑n
i=1 aixi = β kann durch evtl. Multiplikation
mit −1 erreicht werden, dass β ≥ 0 gilt.
• Fehlt fur eine Variable xk die Vorzeichenbedingung, so wird xk durch die Dif-
ferenz y1 − y2 zweier neuer Variablen ersetzt und man fordert y1, y2 ≥ 0.
• Durch evtl. Streichen linear abhangiger Zeilen in A, kann Rang(A) = m ≤ n
stets erreicht werden, wobei m fur die Anzahl der Zeilen steht.
• Maximierungsprobleme cTx∗ = maxcTx | x ∈ M konnen durch Multipli-
kation von c mit dem Faktor −1 als ein Minimierungsproblem geschrieben
werden.

140 M. Braack Lineare Optimierung
Satz 8.2 Ist M = ∅, so existiert keine Losung des LP. Ist M 6= ∅ und beschrankt,
so existiert stets eine Losung x∗ von (LP).
Beweis. Der Fall M = ∅ ist trivial. M 6= ∅ ist stets abgeschlossen und gemaß
Voraussetzung auch beschrankt, also kompakt. Das Funktional Q : Rn → R, x 7→cTx, ist stetig und nimmt daher sein Minimum in einem Punkt x∗ ∈M an.
8.3 Graphische Losung eines Linearen Programms
Wir betrachten die Losungsmenge M aus dem Beispiel des Abschnitts 8.1.1 einmal
grafisch. Dies ist in Abb. 8.1 dargestellt. Die Parallelverschiebung der Niveaulinien
von Q nach rechts bis zum Rand der zulassigen Menge M ergibt den maximalen
Wert x∗ ∈ R2. Hier gilt
x∗1 + 4x∗2 = 160,
10x∗1 + 20x∗2 = 1100.
Dies ergibt die Losung x∗ = (60, 25)T . Dieser Punkt ist ein Eckpunkt der polygonalen
MengeM . Wir werden im nachsten Abschnitt sehen, dass dies kein Zufall ist, sondern
man im Falle der Losbarkeit stets eine Eckenlosung finden kann.
Abbildung 8.1: Skizze des zulassigen Bereichs M aus Abschnitt 8.1.1.

8.4 Eigenschaften der Losungsmenge 141
8.4 Eigenschaften der Losungsmenge
In diesem Abschnitt untersuchen wir die Losungsmenge M aus (8.1) etwas genauer.
Definition 8.3 Unter der Menge E(M) aller Extremalpunkte (oder Ecken) der
konvexen Menge M aus (8.1) versteht man alle Punkte x ∈ M , die sich nicht als
echte Konvexkombination in M schreiben lassen, d.h. wenn x = λx + (1 − λ)x mit
x, x ∈M und λ ∈ (0, 1) gilt, so folgt x = x = x.
Lemma 8.4 Ist 0 ∈M so ist 0 ∈ E(M).
Beweis. Ware 0 keine Ecke, so ließe sich 0 als echte Konvexkombination in M
darstellen, also gilt 0 = λx + (1 − λ)x. Dies impliziert aber, dass mindestens eine
Komponente von x (und auch von x) negativ ist. Dies widerspricht aber der Eigen-
schaft x ≥ 0 fur x ∈M . Also lasst sich die Null nicht als echte Konvexkombination
in M schreiben.
Im folgenden verwenden wir fur x ∈M folgende Bezeichnungen:
Ix := i ∈ 1, . . . , n | xi > 0,Jx := j ∈ 1, . . . , n | xj = 0.
Die Spaltenvektoren ai von A mit i ∈ Ix assemblieren wir in der Familie
Bx := (ai | i ∈ Ix) .
Lemma 8.5 Fur x ∈M sind aquivalent:
(a) x ∈ E(M).
(b) Die Vektoren von Bx sind linear unabhangig.
Beweis. (b)⇒ (a) : Angenommen x ∈M ist kein Extremalpunkt. Dann existiert
eine Darstellung
x = λx+ (1− λ)x,
mit x, x ∈ M , λ ∈ (0, 1) und x 6= x. Insbesondere gilt Ax = Ax = b. Dann gilt fur
k ∈ Jx, 0 = xk = xk = xk.
b =n∑k=1
akxk =∑i∈Ix
aixi =∑i∈Ix
aixi.

142 M. Braack Lineare Optimierung
Also ∑i∈Ix
ai(xi − xi) = 0.
Da x 6= x gilt, sind die auftretenden Spaltenvektoren linear abhangig.
(a)⇒ (b) : Bx bestehe aus linear abhangigen Vektoren. Wir nehmen oEdA an, dass
Ix = 1, . . . , k. Dann existiert also ein d ∈ Rk \ 0, so dass
k∑i=1
dkak = 0.
Wir erganzen d durch Nullen, so dass d ∈ Rn und Ad = 0. Da x ∈ M , gilt auch
Ax = b. Somit gilt auch A(x+ λd) = b fur alle λ ∈ R. Fur hinreichend kleine Wahl
von λ0 > 0 gilt ferner x+ λd ≥ 0 fur alle |λ| < λ0. Daher ist auch
x+ λd ∈ M fur − λ0 ≤ λ ≤ λ0.
Dann kann x aber keine Ecke von M sein. Also gilt x 6∈ E(M).
Lemma 8.6 Sei x ∈ E(M) und |Ix| = m. Dann existieren Koeffizienten αij ∈ R,
fur i ∈ Ix und j ∈ Jx, so dass folgendes gilt: Fur einen Vektor y ∈ Rn gilt Ay = b
genau dann, wenn
yi = xi +∑j∈Jx
αijyj ∀i ∈ Ix.
Beweis.⇒: Wieder bezeichnen wir die Spaltenvektoren vonAmit ai, i ∈ 1, . . . , n.Da Ax = Ay = b, gilt ∑
i∈Ix
(yi − xi)ai = −∑j∈Jx
yjaj.
Dies ist eine Gleichung fur Vektoren. Schreiben wir dies komponentenweise auf, so
lautet diese Gleichung∑i∈Ix
aki(yi − xi) = −∑j∈Jx
akjyj ∀k ∈ 1, . . . ,m.
Die Spaltenvektoren zu i ∈ Ix assemblieren wir in der Matrix AI ∈ Rm×m und die
ubrigen zu j ∈ Jx in der Matrix AJ ∈ Rm×(n−m). Entsprechend benutzen wir die

8.5 Losungstheorie fur Lineare Programme 143
Schreibweisen xI , yI ∈ Rk und yJ ∈ Rn−m fur die entsprechenden Komponenten von
x und y. Dann ist die obige Gleichung aquivalent zu
AI(yI − xI) = −AJyJ .
Da x eine Ecke ist, sind die Spaltenvektoren von AI linear unabhangig. Daher exi-
stiert die MInverse A−1I ∈ Rm×m. Es folgt
yI − xI = −A−1I AJyJ .
Wir definieren uns α := −A−1I AJ ∈ Rk×(n−m). Die gesuchten αij entsprechen dann
den entsprechenden Koeffizienten dieser Matrix.
⇐: Diese Richtung folgt analog.
Es kann auch der Fall eintreten, dass |Ix| < m gilt. In diesem Fall spricht man
von einer entarteten Ecke x ∈ E(M). In diesem Fall wird die Ecke von mehr als n
Ungleichungen definiert. Man kann die Indexmenge Ix dann um entsprechend viele
Indizes und Bx um entsprechend viele Basisvektoren erweitern, so dass |Ix| = m
und Bx aus m linear unabhangigen Spaltenvektoren besteht. Allerdings folgt dann
aus i ∈ Ix nicht mehr notwendigerweise xi > 0. Die Implikation [j ∈ Jx ⇒ xj = 0]
bleibt weiterhin gultig.
8.5 Losungstheorie fur Lineare Programme
Satz 8.7 Wenn das lineare Programm (LP) eine Losung x∗ besitzt, so existiert auch
eine Losung x∗∗ ∈ E(M).
Beweis. Sei x∗ ∈ M \ E(M). Dann ist nach Lemma 8.4 insbesondere x∗ 6= 0.
Wir konstruieren nun eine weitere Losung y ∈ M mit Iy ⊂ Ix∗ , Iy 6= Ix∗ . Die wie-
derholte Anwendung fuhrt schließlich auf eine Losung x∗∗ ∈M mit einer so kleinen
Indexmenge Ix∗∗ , so dass die Menge von Spaltenvektoren Bx∗∗ linear unabhangig ist.
Dann gilt aber x∗∗ ∈ E(M). Nun zur Konstruktion von y: Nach Lemma 8.5 sind
die Spaltenvektoren von Bx∗ linear abhangig. Im Beweis des Lemmas 8.5 hatten wir
gesehen, dass ein d ∈ Rn existiert, so dass xλ := x + λd ∈ M und x−λ ∈ M fur
hinreichend kleines λ > 0. Nun gilt
cTxλ = cTx+ λcTd,
cTx−λ = cTx− λcTd.
Da min(cTd,−cTd) ≤ 0 gilt, folgt
min(cTxλ, cTx−λ) ≤ cTx.

144 M. Braack Lineare Optimierung
Aufgrund der Optimalitat von x∗ gilt dann aber cTxλ = cTx−λ = cTx∗ bzw. cTd =
0. Fur hinreichend großes λ verlasst xλ oder x−λ den zulassigen Bereich, da eine
Komponente (z.B. die k.-te Komponente, k ∈ Ix) negativ werden muss. An genau
dieser Grenze gilt fur das entsprechend gewahlte λ: xλ ∈ M und (xλ)k = 0. Nun
gilt Ixλ ⊂ Ix∗ , Ixλ 6= Ix∗ . Daher liefert fur dieses λ die Wahl y := xλ ∈ M das
Gewunschte.
Lemma 8.8 Sei x ∈ E(M) und γj mittels der Koeffizienten αij aus Lemma 8.6
definiert als
γj := cj +∑i∈Ix
ciαij ∀j ∈ Jx.
Dann gilt fur den Zielfunktionswert eines y ∈ Rn mit Ay = b:
Q(y) = Q(x) +∑j∈Jx
γjyj.
Beweis. Da das Zielfunktional linear ist, erhalten wir
Q(y) = Q(x) + cT (y − x)
= Q(x) +∑j∈Jx
cjyj +∑i∈Ix
ci(yi − xi).
Nun stellen wir die Komponenten von yi − xi fur i ∈ Ix mittels Lemma 8.6 dar:∑i∈Ix
ci(yi − xi) =∑i∈Ix
ci∑j∈Jx
αijyj =∑j∈Jx
∑i∈Ix
ciαijyj.
Setzen wir dies in die vorherige Gleichung ein, so erhalten wir die Behauptung.
Korollar 8.9 Sei x ∈ E(M) und γj sei fur j ∈ Jx gemaß des Lemmas 8.8 definiert.
Falls γj ≥ 0 fur alle j ∈ Jx , so ist x eine Losung des Linearen Programms (LP) .
Beweis. Fur jeden zulassigen Punkt y ∈M gilt nach Lemma 8.8:
Q(y) = Q(x) +∑j∈Jx
γj︸︷︷︸≥0
yj︸︷︷︸≥0
≥ Q(x).
Korollar 8.10 Sei x ∈ E(M), αij und γj seien fur i ∈ Ix und j ∈ Jx gemaß der
Lemmata 8.6 und 8.8 definiert. Falls γk < 0 fur ein k ∈ Jx und αik ≥ 0 fur alle
i ∈ Ix. Dann besitzt das Lineare Programm (LP) keine Losung, sondern
inf Q(y)|y ∈M = −∞.

8.5 Losungstheorie fur Lineare Programme 145
Beweis. Wir betrachten den wie folgt konstruierten Vektor y ∈ Rn zu λ > 0:
yi :=
λ wenn i = k,
0 wenn i ∈ Jx \ k,xi + αikλ wenn i ∈ Ix.
Gemaß Konstruktion gilt dann y ≥ 0 und fur die i-te Komponente fur i ∈ Ix:
yi = xi + αikyk = xi +∑j∈Jx
αijyj. (8.2)
Nach Lemma 8.6 folgt dann Ay = b und somit auch y ∈ M fur beliebiges λ > 0.
Fur den Zielfunktionswert gilt nach Lemma 8.8:
Q(y) = Q(x) +∑j∈Jx
γjyj = Q(x) + γkλ→ −∞ (fur λ→∞).
Somit existiert keine Losung des Linearen Programms.
Lemma 8.11 Sei x ∈ E(M), αij und γj seien fur i ∈ Ix und j ∈ Jx gemaß
der Lemmata 8.6 und 8.8 definiert. Wenn γk < 0 fur ein k ∈ Jx und αik < 0
fur ein i ∈ Ix, so existiert ein p ∈ Ix und eine weitere Ecke y ∈ E(M) \ x mit
Iy = (Ix∪k)\p und Q(y) ≤ Q(x). Ist x nicht entartet, so gilt sogar Q(y) < Q(x).
Beweis. Wir fuhren einen konstruktiven Beweis. Dieser wird spater im Simplexal-
gorithmus zur Konstruktion neuer Eckenlosungen genutzt. Gemaß der Voraussetzun-
gen wissen wir, dass die Menge K := i ∈ Ix | αik < 0 nicht leer ist. Wir definieren
uns daher
µ := maxi∈K
xiαik≤ 0.
Ist x eine nicht-entartete Ecke, so gilt sogar µ < 0. p ∈ K sei der zugehorige Index,
also µ = xp/αpk. Nun definieren wir uns neue Indexmengen
Iy := (Ix ∪ k) \ p, Jy := 1, . . . , n \ Iy = (Jx ∪ p) \ k
und den neuen Vektor y ∈ Rn mit den Komponenten
yi :=
−µ wenn i = k,
xi − αikµ wenn i ∈ Iy \ k,0 wenn i ∈ Jy.

146 M. Braack Lineare Optimierung
Wir wollen verifizieren, dass y ∈ E(M) und Q(y) ≤ Q(x). Alle Komponenten sind
nicht-negativ, denn fur i ∈ Iy\K gilt yi = xi−αikµ ≥ xi ≥ 0 und fur i ∈ (Iy\k)∩Kgilt:
yi = αik︸︷︷︸<0
(xiαik− µ
)︸ ︷︷ ︸
≤0
≥ 0.
Es gilt Ay = b, denn fur i ∈ Ix gilt:
yi − xi = αikyk =∑j∈Jx
αijyj
und damit ist das Kriterium aus Lemma 8.6 erfullt. Das Zielfunktional wird nicht
vergroßert:
Q(y) = Q(x) +∑j∈Jx
γjyj = Q(x) + γk︸︷︷︸<0
yk︸︷︷︸≥0
≤ Q(x).
y ist eine Ecke, denn By = (Bx \ ap) ∪ ak. Wegen αpk 6= 0, lasst sich ak nicht
durch die ai mit i ∈ Ix \ p, also ohne ap, linear kombinieren.
8.6 Das Simplexverfahren
Die Idee des Simplexverfahrens besteht darin, dass man ausgehend von einer Ecke
x(k) ∈ E(M) eine neue Ecke x(k+1) ∈ E(M) findet, so dass cTx(k+1) < cTx(k). Dies
iteriert man bis keine weitere Reduktion des Zielfunktionals Q mehr moglich ist.
Man teilt das Simplexverfahren daher in zwei Phasen auf:
Phase I: Bestimmung einer Ecke x(0) ∈ E(M).
Phase II: Sukzessives Wechseln von einer Ecke zu einer angrenzenden bei gleich-
zeitiger Reduktion des Zielfunktionals.
Wir beginnen zunachst mit der Beschreibung der Phase II, da die Phase I teilweise
mit Techniken von Phase II arbeitet:
8.6.1 Phase II des Simplexverfahrens
Gegeben sei eine Ecke x(0) ∈ E(M) und gesucht ist die nachste Ecke x(1) ∈ E(M)
mit cTx(1) < cTx(0) (sofern moglich). Wir betrachten die Indexmengen I0 := Ix(0) ,

8.6 Das Simplexverfahren 147
J0 := Jx(0) sowie die Familie B0 := Bx(0) linear unabhangiger Spaltenvektoren von
A. Aufgrund des Lemmas 8.8 lasst sich das Zielfunktional fur jeden Vektor x ∈ Rn,
der Ax = b erfullt, in der Form
Q(x) = Q(x0) +∑j∈J0
γjxj
schreiben. Insofern lasst sich der Zielfunktionswert Q(x) allein durch Kenntnis von
Q(x0), xj fur j ∈ J0 und der Koeffizienten γj berechnen. Mir machen an dieser Stelle
folgende Beobachtungen:
Fall a: Falls γj ≥ 0 fur alle j ∈ J0, so ist x(0) nach Korollar 8.9 bereits optimal.
Fall b: Falls γk < 0 fur ein k ∈ J0 und αik ≥ 0 fur alle i ∈ I0, so besitzt das Lineare
Programm (LP) nach Korollar 8.10 keine Losung.
Fall c: Falls γk < 0 fur ein k ∈ J0 und αik < 0 fur ein i ∈ I0, so fuhren wir einen
Eckenwechsel wie in Lemma 8.11 beschrieben durch. Wir erhalten eine neue
Ecke x(1) ∈ E(M) mit x(1) 6= x(0) und Q(x(1)) ≤ Q(x(0)).
Dieser Vorgang wird iteriert bis ein Abbruch gemaß Fall a oder b eintritt. Im Fall c
kann, sofern x(0) eine entartete Ecke ist, zunachst keine echte Reduktion des Zielfunk-
tionals garantiert werden, sondern lediglich keine Vergroßerung von Q. Daher muss
man auch hier evtl. haufiger einen Eckenwechsel durchfuhren bis eine echte Reduk-
tion auftritt. Man muss durch geeignete Maßnahmen vermeiden, in einen Zyklus zu
gelangen, bei dem man zwischen entarteteten Ecken iteriert und das Zielfunktional
konstant bleibt.
8.6.2 Phase I des Simplexverfahrens
Wir stellen hier nur eine Moglichkeit vor, eine Startecke x(0) ∈ E(M) zu ermitteln.
Hierzu betrachten wir zunachst ein modifiziertes Lineares Programm (MLP). Dieses
benutzt eine um m Spalten vergroßerte Matrix:
A :=(A | I
)∈ Rm×(n+m),
c := (0, 1)T ∈ Rn+m,
M :=y ∈ Rn+m|Ay = b, y ≥ 0
,
Q(y) := cTy =m∑i=1
yn+i.

148 M. Braack Lineare Optimierung
Das Hilfsproblem (MLP) besteht nun aus der Bestimmung von y∗ ∈ Rm+n, so dass
Q(y∗) = infQ(y) | y ∈ M. (MLP )
Da wir in (LP) b ≥ 0 vorausgesetzt haben, kann man fur (MLP) direkt eine Startecke
angeben, namlich
y(0) := (0, b)T ,
denn die letzten m Spaltenvektoren von A bilden gerade die Einheitsmatrix I und
sind demzufolge linear unabhangig. Somit ist Iy(0) = n+1, . . . , n+m. Wir wenden
auf (MLP) die Phase II des Simplexverfahrens an. Nach der Bestimmung der Losung
y∗ betrachten wir zwei Falle:
Fall 1: Es gilt Q(y∗) = 0.
Dann ist das Minimum y∗ von der Form y∗ = (x, 0)T ∈ Rn+m. Somit gilt
Ax = b und x ≥ 0. Also ist x ∈ M ein zulassiger Punkt von (LP). Da y∗
außerdem eine Ecke von M ist, ist x eine Ecke von M (die Vektoren in By∗
und Bx sind identisch). Somit haben wir eine Startecke x(0) := x von (LP)
gefunden.
Fall 2: Es gilt Q(y∗) > 0.
Man findet dann kein y∗ von der Form y∗ = (x, 0)T . Damit ist M = ∅, d.h.
das Ausgangsproblem (LP) besitzt uberhaupt keinen zulassigen Punkt.
Ein (bislang nicht-verifizierter) Pseudocode fur diesen Simplex-Algorithmus ist in
den Tabellen 8.2-8.4 gegeben.

8.6 Das Simplexverfahren 149
Simplex(m,n,A,b,c)
1. x := (0, . . . , 0) ∈ Rn, y := (0, . . . , 0) ∈ Rm+n
2. SimplexPhase1(y,m,n,A,b)
3. SimplexPhase2(x,y,m,n,A,b,c)
4. Output(x)
Tabelle 8.1: Simplex-Verfahren zur Losung des Linearen Programms (LP).
SimplexPhase1(x,m,n,A,b)
1. A1 := (A | I) ∈ Rm×(m+n)
2. y0 := (0, . . . , 0, b1, . . . , bm) ∈ Rn+m
3. c := (0, . . . , 0, 1, . . . , 1) ∈ Rn+m
4. SimplexPhase2(y, y0,m,m+ n,A1, b)
5. for i = 1, . . . ,m
6. if yn+i > 0 then STOP; /* keine Startecke gefunden */
7. for i = 1, . . . , n do xi = yi
Tabelle 8.2: Phase 1 des Simplex-Verfahrens zum Finden einer Startecke.

150 M. Braack Lineare Optimierung
SimplexPhase2(x,y,m,n,A,b,c)
1. I := (0, . . . , 0) ∈ 0, 1n
2. for i = 1, . . . , n if yi > 0 then Ii = 1
3. DetermineAlpha(α, I, A)
4. for j = 1, . . . , n then
5. if Ij = 0
6. γj := cj,
7. for i = 1, . . . , n if Ii = 1 do γj := γj + αijci
8.
9. k := 0
10. for j = 1, . . . , n
11. if Ij = 0 and γj < 0 do k := j
12. if k = 0 then STOP /* Optimale Losung gefunden */
13. for i = 1, . . . , n
14. if Ii > 0 and αik < 0 do
15. ChangeCorner(y, n, k, I, α),
16. Goto 3.
17. STOP /* es existiert keine Losung */
Tabelle 8.3: Phase 2 des Simplex-Verfahrens zur Losung des Linearen Programms
(LP). In Zeile 3 mussen die Koeffizienten α gemaß des Beweises des Lemmas 8.6
bestimmt werden.

8.6 Das Simplexverfahren 151
ChangeCorner(x,n,k,I,α)
1. p := 0, µ := 0,
2. for i = 1, . . . , n
3. if Ii = 1 and αik < 0
4. if (p = 0 or xi/αik > µ) then p := i, µ := xi/αik
5. Ik := 1, Ip := 0, xk := −µ, xp = 0
6. for i = 1, . . . , n
7. if (Ii = 1 and i 6= k) then do xi := xi − µαik
Tabelle 8.4: Eckenwechsel fur das Simplex-Verfahren.

152 M. Braack Lineare Optimierung

Literaturverzeichnis
[1] S. Borm. Einfuhrung in die Numerische Mathematik. Vorlesungsskript,
https://www.numerik.uni-kiel.de/˜sb/data/Grundlagen.pdf, 2016.
[2] S. Borm. Iterative Loser fur große lineare Gleichungssysteme. Vorlesungsskript,
https://www.numerik.uni-kiel.de/˜sb/data/GLGS.pdf, 2017.
[3] P. Deuflhard. Numerische Mathematik I: Eine algorithmisch orientierte
Einfuhrung. De Gruyter, 381 p., 3 edition, 2002.
[4] R. Ranancher. Einfuhrung in die Numerische Mathematik. Vorlesungsskript,
http://numerik.iwr.uni-heidelberg.de/˜lehre/notes/num0/numerik0.pdf,
2006.
[5] J. Stoer. Numerische Mathematik I. Berlin: Springer. xii, 383 p., 9 edition, 2005.
[6] J. Stoer and R. Bulirsch. Numerische Mathematik II. Berlin: Springer. x, 375 p.,
4 edition, 2000.


















