
Einf uhrung in die Statistik -...
85
Einf¨ uhrung in die Statistik mit Beispielen aus der Biologie Thomas Fabbro “The aim of computing is insight, not numbers.” Was ist Statistik? Die Statistik als Disziplin (“statistics”) besch¨ aftigt sich mit dem Sammeln, Organisieren, Analysieren, Interpretieren und Pr¨ asentieren von Daten (nach Dodge, Cox und Commenges 2006).
-
Upload
truonghanh -
Category
Documents
-
view
226 -
download
0
Transcript of Einf uhrung in die Statistik -...

Einfuhrung in die Statistikmit Beispielen aus der Biologie
Thomas Fabbro
“The aim of computing is insight, not numbers.”
Was ist Statistik?
Die Statistik als Disziplin (“statistics”) beschaftigt sich mit demSammeln, Organisieren, Analysieren, Interpretieren undPrasentieren von Daten (nach Dodge, Cox und Commenges 2006).

Wieso brauchen wir eigentlich Statistik?
Arten von Variablen
Messbare und Zahlbare Variablen
numeric fur kontinuierlich Variablen, alle Zwischenschrittesind moglich
integer fur Ganze Zahlen
Kategorielle Variablen
factor fur Kategorien (z. B. “Fabaceae”, “Rosaceae”,“Apiaceae”).
logical Eine Variable die nur die Werte TRUE oder FALSEannehmen kann (z. B. “mannlich”, “weiblich”).
Diese Einteilung basiert auf der Klasseneinteilung von R.

Beispiele in R
> weight <- c(0.001, 100, 3200000, 1000, 2.56, 0.001,+ 0.01)
> legs <- as.integer(c(0, 0, 4, 0, 0, 8, 6))
> kingdom <- factor(c("animal", "fungi", "animal",+ "animal", "plant", "animal", "animal"))
> animal <- c(TRUE, FALSE, TRUE, TRUE, FALSE, TRUE,+ TRUE)
Es gibt zwei Arten wie man Variablen beschreiben kann:
I Kenngrossen
I graphischen Darstellungen

Charakteristika kontinuierlicher Variablen
Lage
Streuung
Form
Haufung (”cluster”) Werte treten in Klumpen auf.
Kornung (”granularity”) Nur bestimmte Werte treten auf.
Boxplot
Boxplot
gemessene Werte
0 1 2 3 4 5 6
●
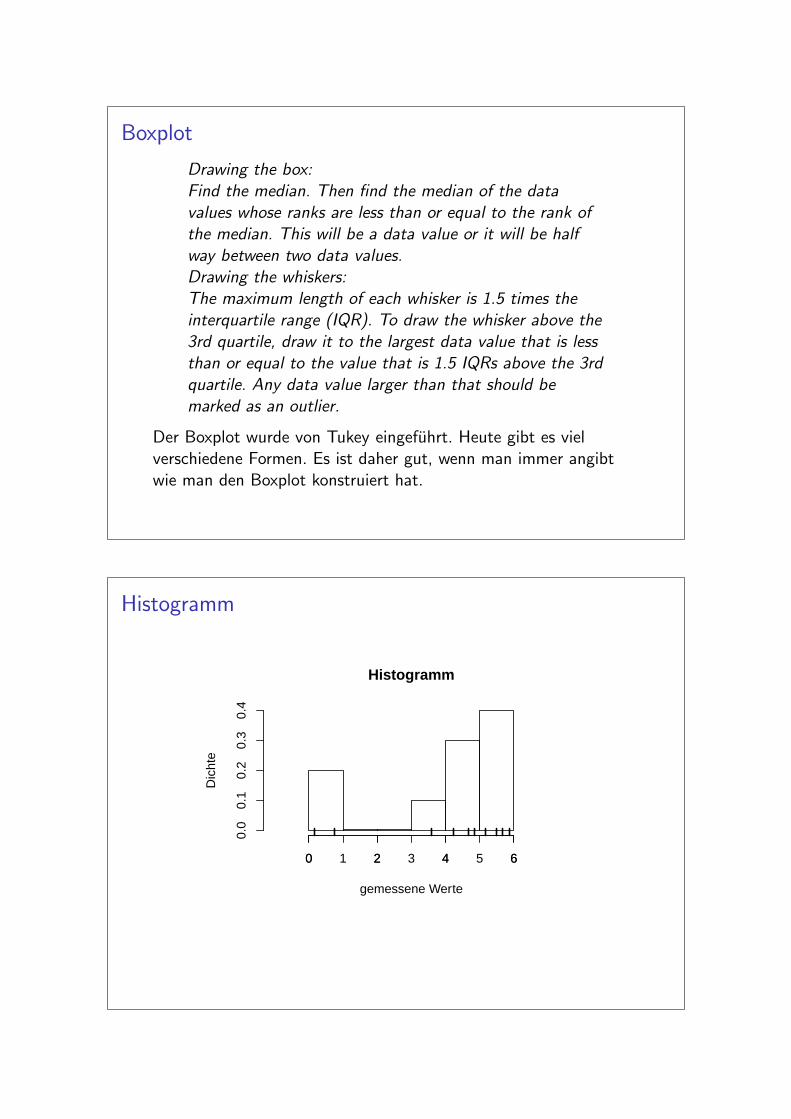
Boxplot
Drawing the box:Find the median. Then find the median of the datavalues whose ranks are less than or equal to the rank ofthe median. This will be a data value or it will be halfway between two data values.Drawing the whiskers:The maximum length of each whisker is 1.5 times theinterquartile range (IQR). To draw the whisker above the3rd quartile, draw it to the largest data value that is lessthan or equal to the value that is 1.5 IQRs above the 3rdquartile. Any data value larger than that should bemarked as an outlier.
Der Boxplot wurde von Tukey eingefuhrt. Heute gibt es vielverschiedene Formen. Es ist daher gut, wenn man immer angibtwie man den Boxplot konstruiert hat.
Histogramm
Histogramm
gemessene Werte
Dic
hte
0 2 4 6
0.0
0.1
0.2
0.3
0.4
0 1 2 3 4 5 6

Histogramm
Um ein Histogramm zeichnen zu konnten muss man folgende zweiPunkte festlegen:
I Kastchenbreite bzw. die Anzahl der Kastchen (Kastchen:“bin”)
I Startpunkt
Auch fur dieselben Werte sieht nicht jedes Histogramm gleich aus!
Histogramm
freq
uenc
y
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
Anzahl Kästchen: 2
freq
uenc
y
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
Anzahl Kästchen: 4
freq
uenc
y
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
0.20
Anzahl Kästchen: 8
freq
uenc
y
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Anzahl Kästchen: 16
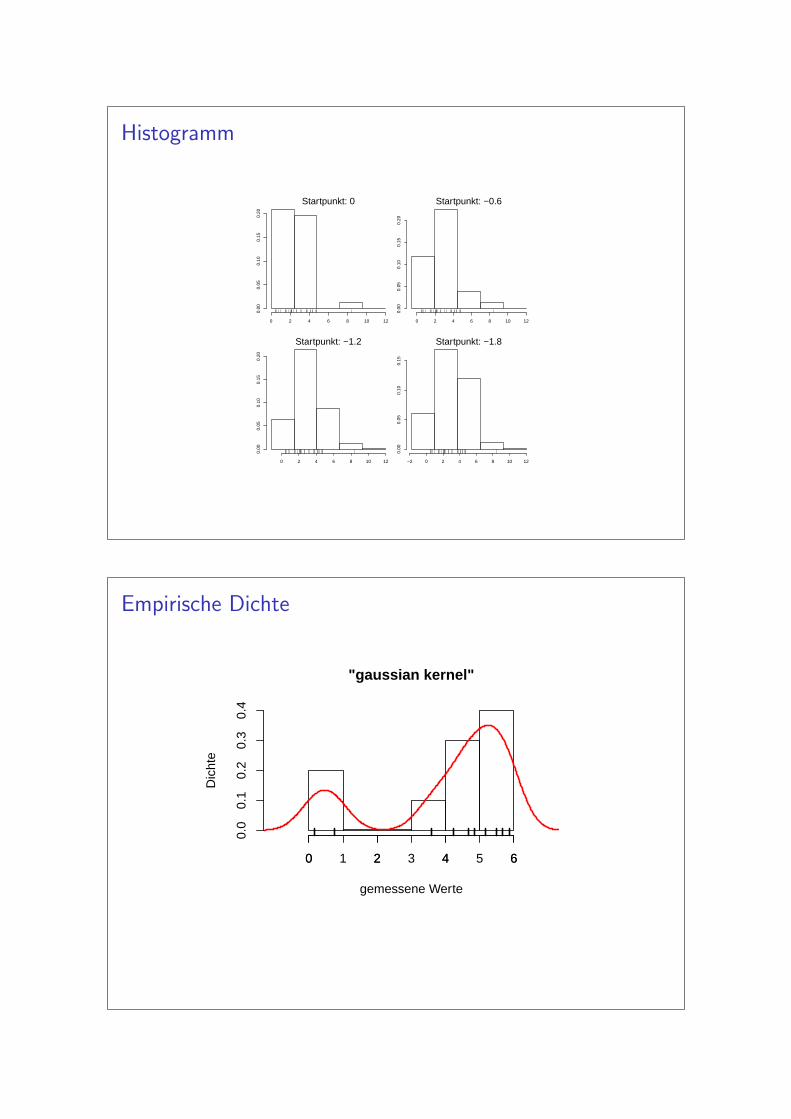
Histogramm
x
Den
sity
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
0.20
Startpunkt: 0
x
Den
sity
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
0.20
Startpunkt: −0.6
Den
sity
0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
0.20
Startpunkt: −1.2
Den
sity
−2 0 2 4 6 8 10 12
0.00
0.05
0.10
0.15
Startpunkt: −1.8
Empirische Dichte
"gaussian kernel"
gemessene Werte
Dic
hte
0 2 4 6
0.0
0.1
0.2
0.3
0.4
0 1 2 3 4 5 6

Wahrscheinlichkeitsverteilung
µx =
1
n
n∑
i=1
xi
Kenngrossen fur kontinuierliche Variablen
Lage Mittelwert, Median, Modus
Streuung Spannweite, Quartilsabstand, Varianz
Form Schiefe: z. B. rechtsschief = linkssteil, linksschief =rechtssteilWolbung: steilgipflig, flachgipfligweitere Begriffe: symmetrisch, unimodal, bimodal,multimodal
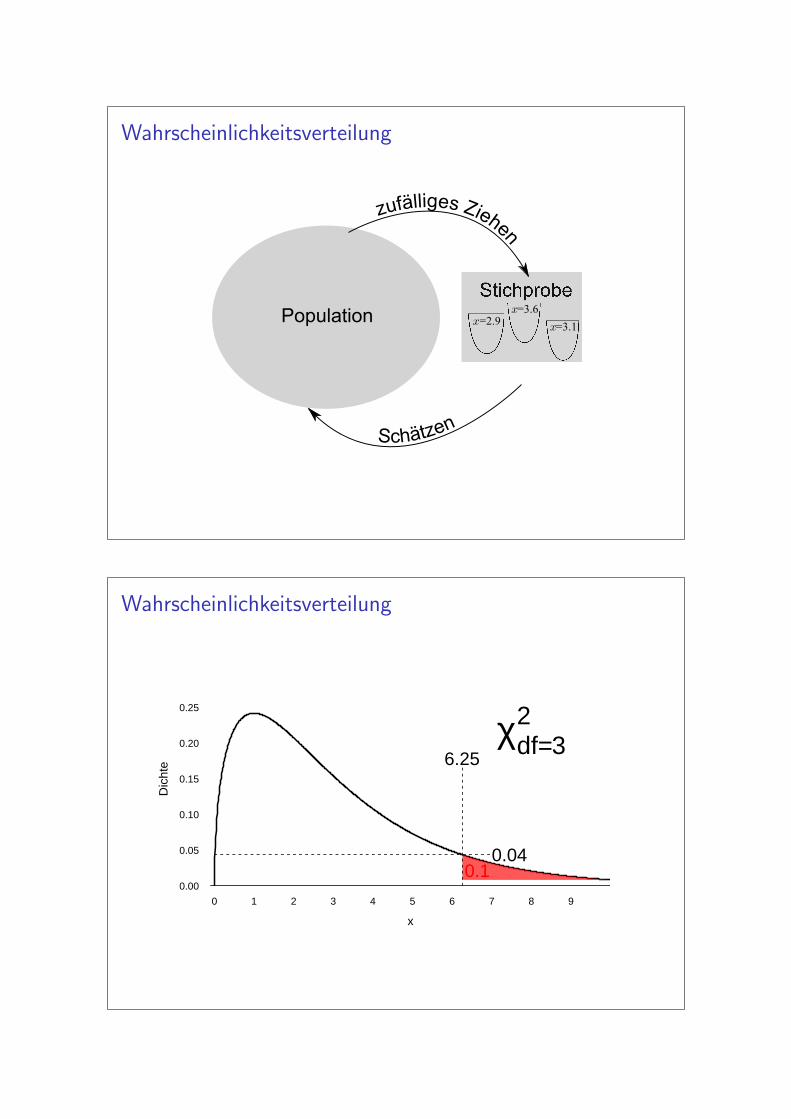
Wahrscheinlichkeitsverteilung
Wahrscheinlichkeitsverteilung
x
Dic
hte
0.00
0.05
0.10
0.15
0.20
0.25
0 1 2 3 4 5 6 7 8 9
0.1
6.25
0.04
χdf=32
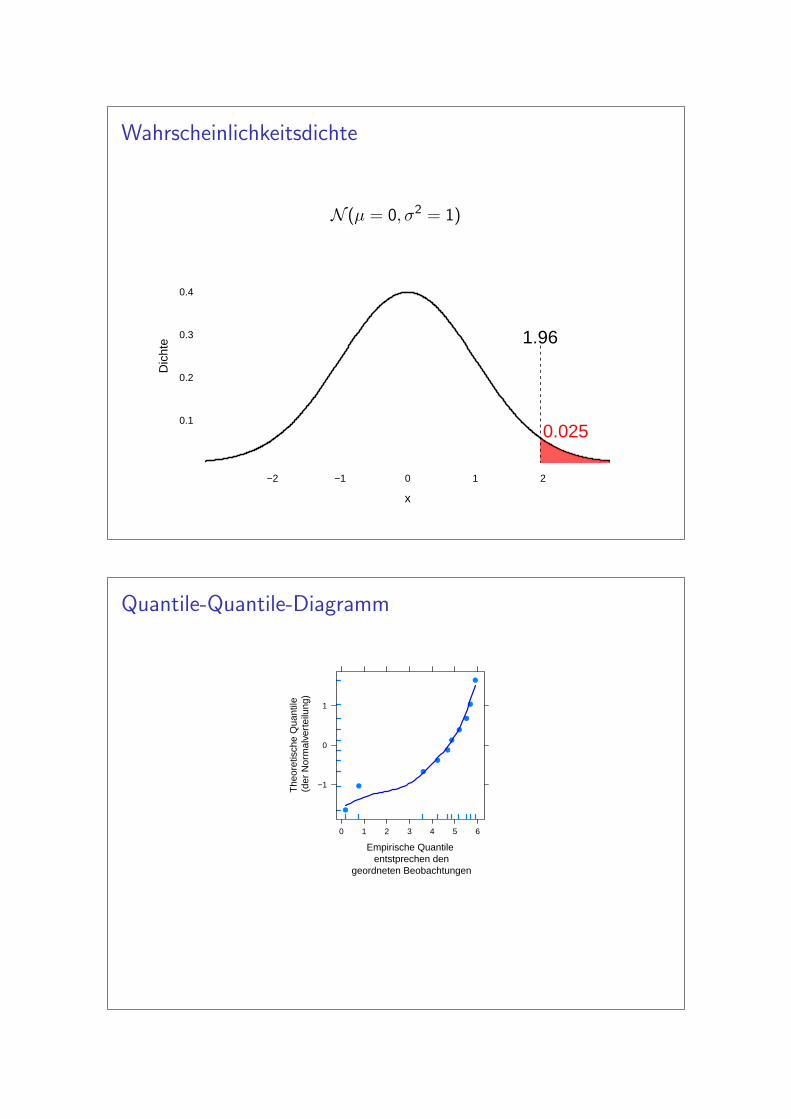
Wahrscheinlichkeitsdichte
N (µ = 0, σ2 = 1)
x
Dic
hte
0.1
0.2
0.3
0.4
−2 −1 0 1 2
0.025
1.96
Quantile-Quantile-Diagramm
Empirische Quantile entstprechen den
geordneten Beobachtungen
The
oret
isch
e Q
uant
ile (
der
Nor
mal
vert
eilu
ng)
−1
0
1
0 1 2 3 4 5 6
●
●
●
●
●
●
●
●
●
●
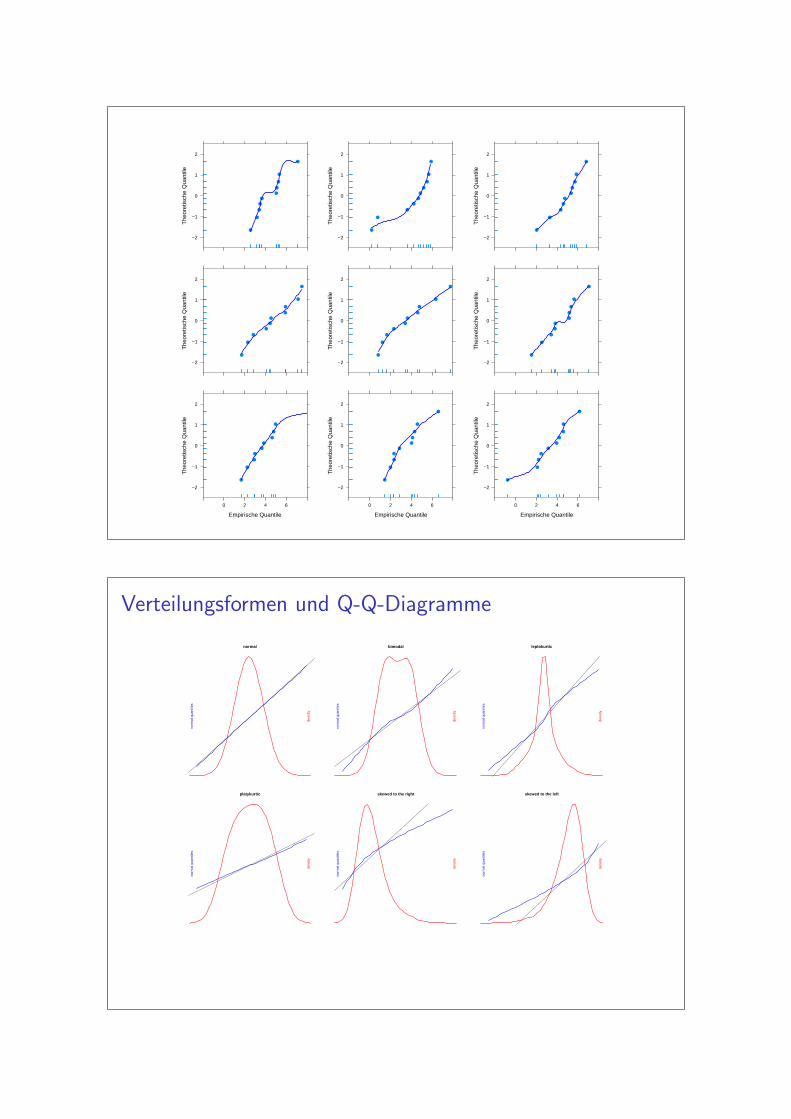
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Empirische Quantile
The
oret
isch
e Q
uant
ile
−2
−1
0
1
2
0 2 4 6
●
●
●
●
●
●
●
●
●
●
Verteilungsformen und Q-Q-Diagramme
normal
norm
al q
uant
iles
dens
ity
bimodal
norm
al q
uant
iles
dens
ity
leptokurtic
norm
al q
uant
iles
dens
ity
platykurtic
norm
al q
uant
iles
dens
ity
skewed to the right
norm
al q
uant
iles
dens
ity
skewed to the left
norm
al q
uant
iles
dens
ity
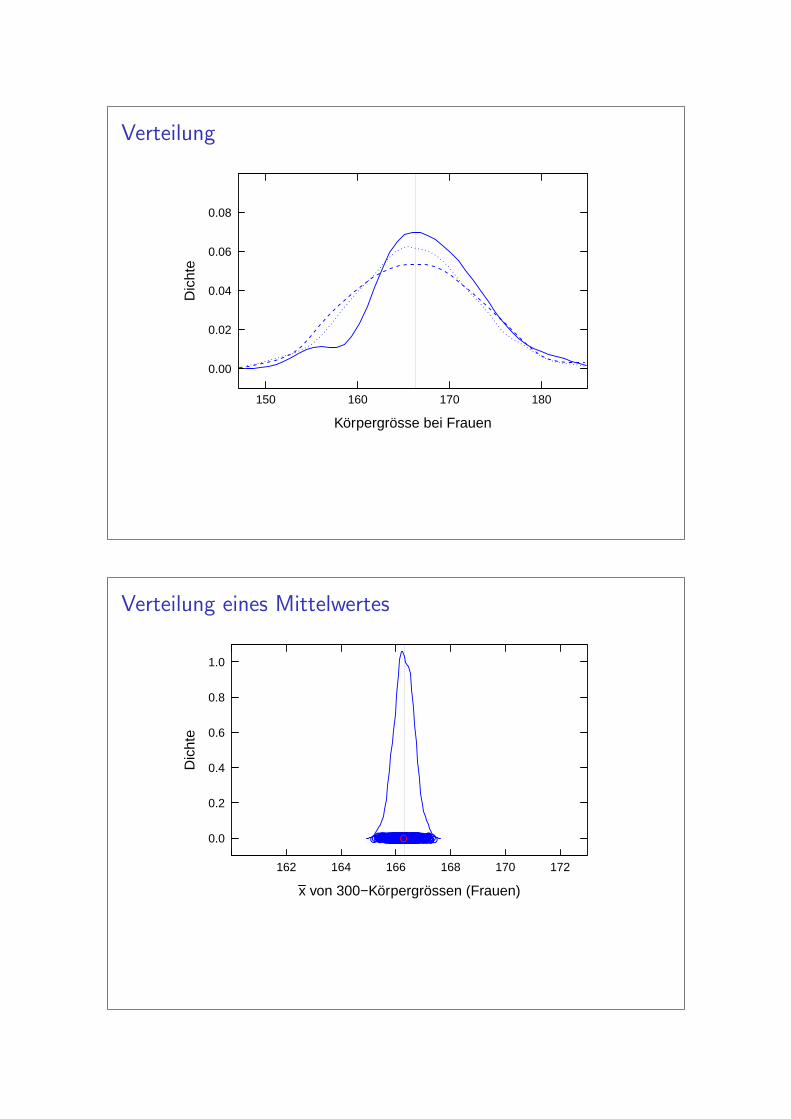
Verteilung
Körpergrösse bei Frauen
Dic
hte
0.00
0.02
0.04
0.06
0.08
150 160 170 180
Verteilung eines Mittelwertes
x von 300−Körpergrössen (Frauen)
Dic
hte
0.0
0.2
0.4
0.6
0.8
1.0
162 164 166 168 170 172
● ●● ●●●●●● ●●●● ●● ●●●● ●● ●●●●●●●●● ●● ●●●●●●●●● ●● ● ●●● ● ●●●● ●● ●● ●●● ●●●●●● ●●●●● ●●● ●●●● ●●●●● ●●● ●● ●● ●●● ●● ●●●●●●●●●●●●●●●● ●●●●●●●● ●●●● ●●●● ●●● ●● ●●● ●●●●●●●●● ●●● ●● ●●●●● ● ●●●●● ●●●● ●●● ●●● ●● ●●●●●● ●●●●● ● ●●●● ●●
● ●●● ● ●●●●●● ●●●● ●●●●●● ●● ●●●●●● ●●●● ●●●●● ●●●●● ● ●●●●●●●●● ● ●● ●● ●●●●●●● ●●●● ●●● ●● ●●● ●●●●●●●● ●●●●●●●● ●●●●●●●● ● ●● ●● ●● ●●●● ●●●● ●●● ● ●●● ●●● ●● ●●●●●
●●●●●● ● ●●●●●●● ●●●● ●● ● ●●●●● ●●● ●● ●●● ●●● ●● ●●●●● ●●●●●● ●●●●● ●●● ●●● ●●● ●●●●●● ●●●●● ● ●●● ●●● ●● ●● ●● ●●● ●●● ●●●● ●●●●●●●●● ●● ●● ●●●● ●●● ●●●● ●● ●●●● ●●● ●●● ●●● ●●●● ●●● ●● ●●● ●●● ●●● ●●●● ●● ●●● ●● ●● ●●●●● ●●● ●●● ●●● ●● ●●● ●●● ●●●●● ●●● ● ●●●● ●●●●●●●●●● ●● ●● ● ●●●● ●●●●●●● ●●●
● ●●● ●●●●●● ●●●●● ●●●●●● ● ●●● ●● ●●● ●●● ●●● ●●●●● ●●●● ●●● ●●● ●●●●● ●●● ●● ●●● ●●● ●● ●●●●● ●●●●● ●●● ●● ●● ●● ●● ●● ●● ●●●● ● ●●●●●●●● ●●● ●● ●●●●●● ●●●●●●● ●●● ●●●● ●●●● ●●●● ●●● ●●● ●● ●●●● ●●●●●●●● ●●●●● ●● ●● ● ●●●●●● ●● ●●●● ●● ●● ●●●●● ● ●● ●●●●●● ●●● ●● ● ●●● ●●● ● ●●●● ●●●● ●●● ●● ●● ●●● ●● ●● ●● ●●● ● ●●● ●●● ●●● ●● ●●●●●● ●●● ● ●●●● ●●● ●●● ● ●● ●● ●●●●●●●●● ●●● ●●●●●● ●●●● ●●●●●● ●● ●●
●●●●● ●● ●●● ●●●● ●●●●● ●●● ●●●●●●●● ● ●● ●●●● ●● ●●● ●● ●●●●● ●●●● ●●● ●●● ●● ●● ●●● ●●●● ●●● ●● ●●● ●●●●●● ●●● ●●●● ●● ●●● ●●●●●● ●● ●●●● ●● ●●●●
●● ●●●●● ●●● ●●● ●● ●● ●●●● ●●
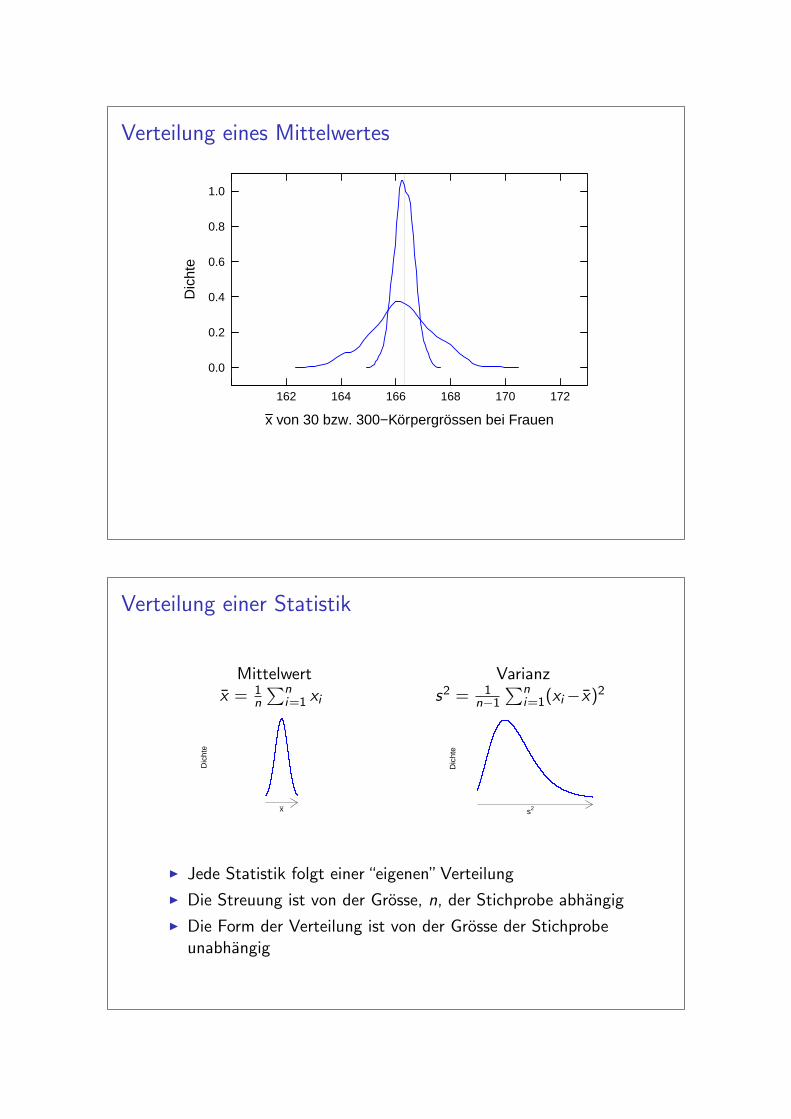
Verteilung eines Mittelwertes
x von 30 bzw. 300−Körpergrössen bei Frauen
Dic
hte
0.0
0.2
0.4
0.6
0.8
1.0
162 164 166 168 170 172
Verteilung einer Statistik
Mittelwertx = 1
n
∑ni=1 xi
x
Dic
hte
Varianzs2 = 1
n−1
∑ni=1(xi− x)2
s2
Dic
hte
I Jede Statistik folgt einer “eigenen” Verteilung
I Die Streuung ist von der Grosse, n, der Stichprobe abhangig
I Die Form der Verteilung ist von der Grosse der Stichprobeunabhangig
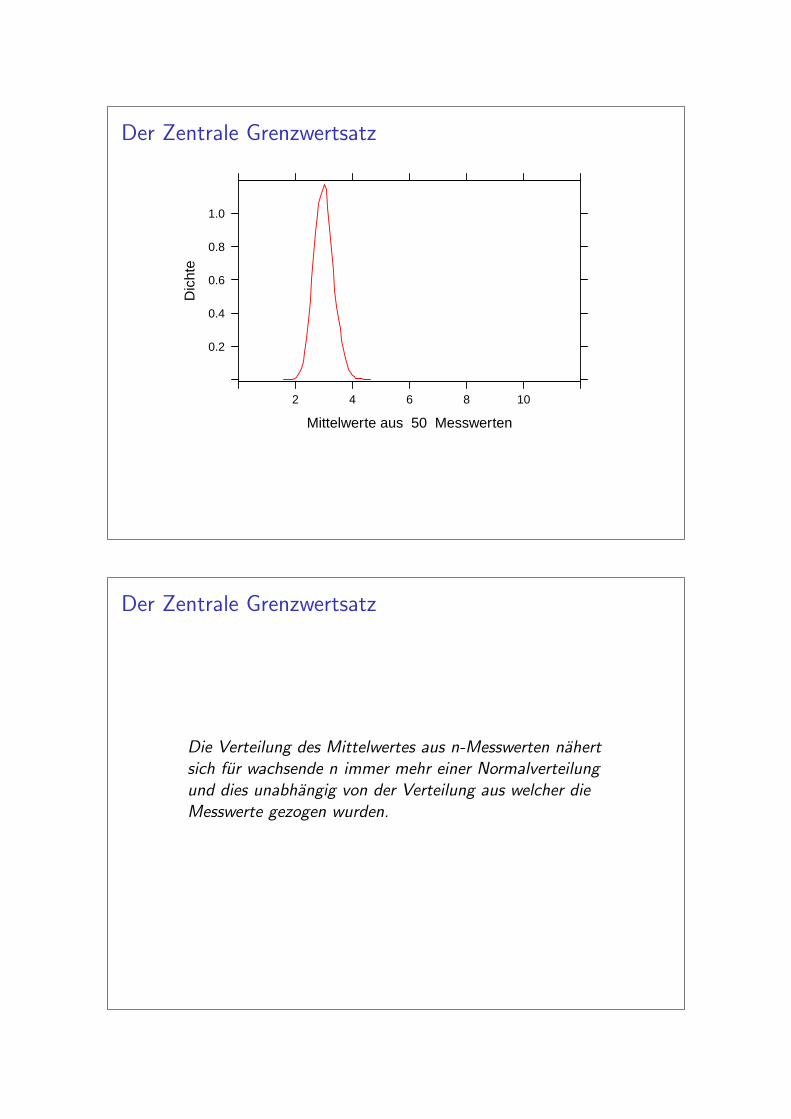
Der Zentrale Grenzwertsatz
Mittelwerte aus 50 Messwerten
Dic
hte
0.2
0.4
0.6
0.8
1.0
2 4 6 8 10
Der Zentrale Grenzwertsatz
Die Verteilung des Mittelwertes aus n-Messwerten nahertsich fur wachsende n immer mehr einer Normalverteilungund dies unabhangig von der Verteilung aus welcher dieMesswerte gezogen wurden.
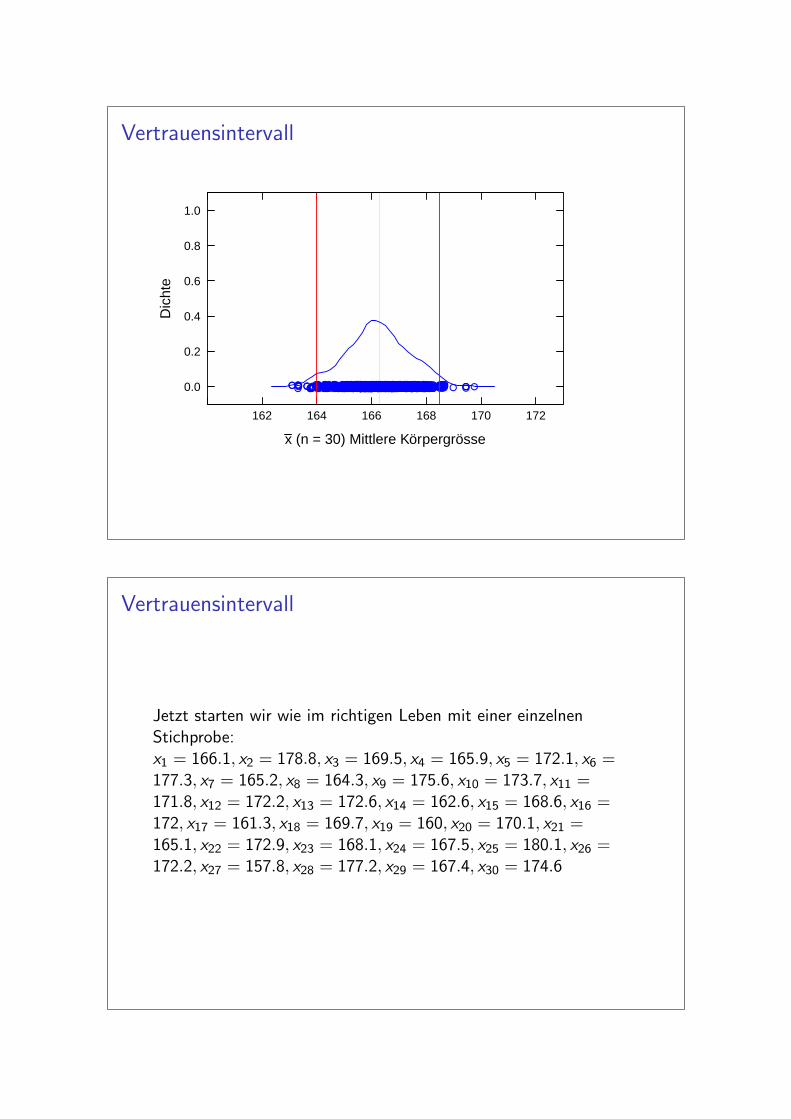
Vertrauensintervall
x (n = 30) Mittlere Körpergrösse
Dic
hte
0.0
0.2
0.4
0.6
0.8
1.0
162 164 166 168 170 172
●●●●●●● ●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●● ● ●●● ●
Vertrauensintervall
Jetzt starten wir wie im richtigen Leben mit einer einzelnenStichprobe:x1 = 166.1, x2 = 178.8, x3 = 169.5, x4 = 165.9, x5 = 172.1, x6 =177.3, x7 = 165.2, x8 = 164.3, x9 = 175.6, x10 = 173.7, x11 =171.8, x12 = 172.2, x13 = 172.6, x14 = 162.6, x15 = 168.6, x16 =172, x17 = 161.3, x18 = 169.7, x19 = 160, x20 = 170.1, x21 =165.1, x22 = 172.9, x23 = 168.1, x24 = 167.5, x25 = 180.1, x26 =172.2, x27 = 157.8, x28 = 177.2, x29 = 167.4, x30 = 174.6

Vertrauensintervall
Zwei Wege:
I Wir konnen eine Annahme Treffen uber dieWahrscheinlichkeitsverteilung aus welcher wir die Stichprobegezogen haben. Dann konnten wir beliebig oft eine Stichprobeder selben Grosse ziehen, den Mittelwert berechnen und so dieVerteilung der Mittelwerte ermitteln.
I Wir konnen den Zentralen Grenzwertsatz anwenden. Dazumussten wir aber die beiden Parameter der Normalverteilungunseres Mittelwertes besser kennen, namentlich denMittelwert und die Varianz.
Vertrauensintervall: Die Lage
Mangels besserer Informationen wahlen wir den Mittelwert unsererStichprobe (x) als Erwartungswert fur die Mittelwerte, ¯x .
Vertrauensintervall: Die Streuung
Der Standardfehler ist die Standardabweichung einer Statistik.Meistens spricht man vom Standardfehler und meint damit dieStandardabweichung des Mittelwertes, welche folgendermassenberechnet wird:
sx =sx√
n
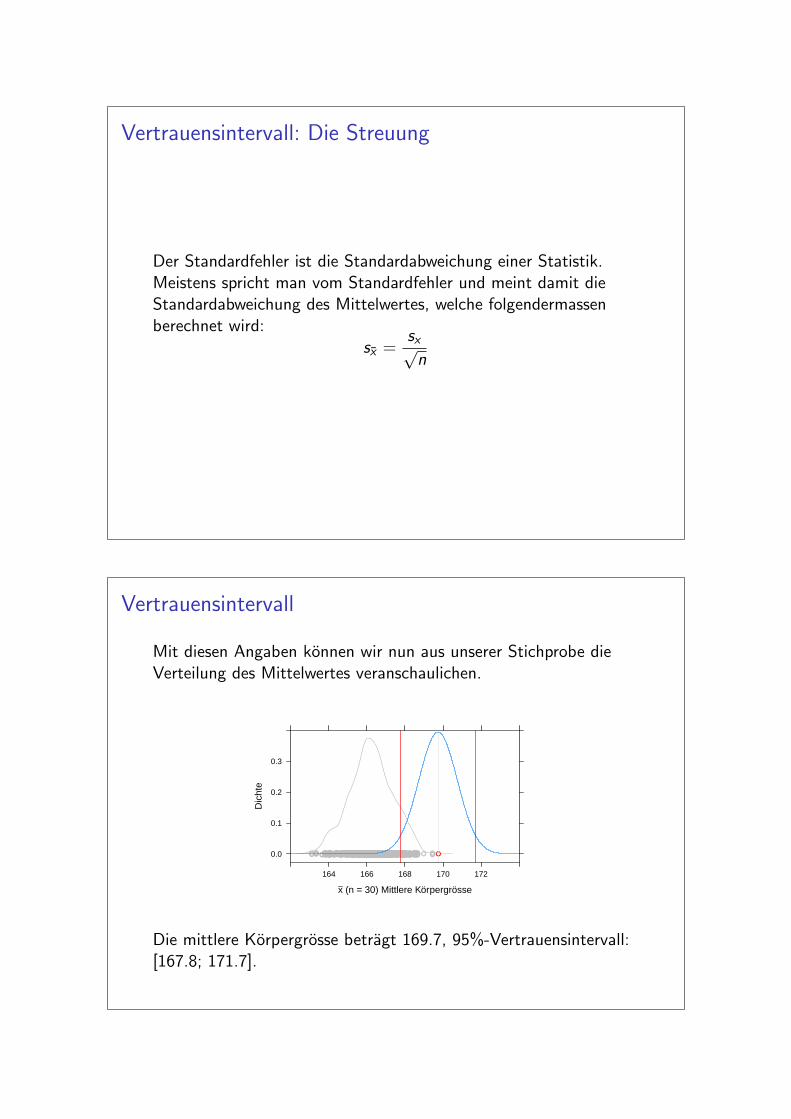
Vertrauensintervall
Mit diesen Angaben konnen wir nun aus unserer Stichprobe dieVerteilung des Mittelwertes veranschaulichen.
x (n = 30) Mittlere Körpergrösse
Dic
hte
0.0
0.1
0.2
0.3
164 166 168 170 172
● ●●●● ●● ●●●● ●● ●●● ● ● ●● ●●●●●● ● ● ●● ●● ● ●● ● ● ●●● ●●● ●●● ● ●●● ●● ●●●● ● ●● ●●●● ●● ● ● ●● ● ●● ●●● ● ● ●● ●●●●●● ● ● ●● ●● ● ●● ● ● ●●● ●●● ●●● ● ●●●● ●●● ●● ●● ●● ●●● ● ●●●●● ●●● ●● ●●●● ●● ● ●●● ●● ●●●●● ●● ●● ●●● ● ●● ●● ●●● ●●●●●● ●● ●● ● ●● ●● ● ●● ● ● ●●●●● ● ●●● ● ●●●●●●●● ● ● ●● ●●●●●● ●● ● ●● ●●● ●● ●●● ●●● ●● ● ●●● ●● ●●● ●●
● ● ● ●●● ● ●● ●● ●●● ●●● ●● ●● ●● ●● ●● ●● ●● ● ●● ●●●● ●●● ●● ●● ●● ● ●●● ●● ●●● ●●● ● ● ●● ●●●●●● ● ●● ●● ●● ●● ●● ●● ●● ●● ●● ●●● ●●● ●●●●●● ● ●●●● ●● ●●●●● ● ●● ●●●● ●● ●● ● ●●●● ●● ●● ●● ●● ●● ● ●● ●●●● ● ●●● ● ●● ●●●●●● ● ●●●● ●●● ●● ●● ●● ●●● ● ●●●●● ●●● ●● ●●●● ●● ● ●●● ●● ●●●●● ●● ●● ●●● ● ●● ●● ●●● ●●●●●● ●● ●● ● ●● ●● ● ●● ● ● ●●●●● ● ●●● ● ●● ●●● ●●● ● ● ●● ●●●●●● ●● ● ●● ●●● ●● ●●● ●●● ●● ● ●●● ●● ●●● ●●● ● ● ●●● ● ●● ●● ●●● ●●● ●● ●● ●● ●● ●● ●● ●● ● ●● ●●●● ●●● ●● ●● ●● ● ●●● ●● ●●● ●●● ● ●● ●●●●●●● ● ●● ●● ●● ●● ●● ●● ●● ●● ●● ●●● ●●● ●●●●●● ● ●●●● ●● ●●●●● ● ●● ●●●● ●● ●● ● ●●●● ●● ●● ●● ●● ●● ● ●●●●●● ● ●●● ● ●● ●●●●●● ●● ●● ●●●● ●● ●● ●● ●●● ● ●●●●● ●●● ●● ●●●● ●● ● ●●● ●● ●●●●● ●● ●● ●●● ● ●● ●● ●●● ●●●●●● ●● ●● ● ●● ●● ● ●● ● ● ●●●●● ● ●●● ● ●● ●●● ●●● ● ●● ●●●●●●● ●● ● ●● ●●● ●● ●●● ●●● ●● ● ●●● ●● ●●● ●●● ● ● ●●● ● ●● ●● ●●● ●●● ●● ●● ●● ●● ●● ●● ●● ● ●● ●●●● ●●● ●● ●● ●● ● ●●● ●● ●●● ●●● ● ●● ●●●●●● ● ● ●● ●● ●● ●● ●● ●● ●● ●● ●● ●●● ●●● ●●●●●● ● ●●●● ●● ●●●●● ● ●● ●●●● ●● ●● ● ●●●● ●● ●● ●● ●● ●● ● ●● ●●●● ● ●●● ● ●● ●●●●●● ●● ●● ●● ●● ● ●
Die mittlere Korpergrosse betragt 169.7, 95%-Vertrauensintervall:[167.8; 171.7].

Vertrauensintervall
Die Formel fur das 1− α-Vertrauensintervall fur den Mittelwertlautet: [
x − z(1−α/2)s√n
; x + z(1−α/2)s√n
].
Mit zα bezeichnen wir das α-Quantil einerStandardnormalverteilung, N (µ = 0, σ2 = 1). Wichtig istbesonders der Wert z(1−α/2) = 1.96.Zum Merken:
Das 95%-Vertrauensintervall umfasst den Mittelwertplus/minus zwei mal den Standardfehler.
Zusammenhange
Gibt es einen Zusammenhang . . .
Lungen-krebs
ein Feuerzeug
mit sichtragen

Aspekte von Zusammenhangen
I Starke
I Folgerichtigkeit
I Spezifitat
I Zeitlichkeit
I Biologischer Gradient
I Plausibilitat
I Stimmigkeit
I Experiment
I Analogie
Austin Bradford Hill, The Environment and Disease: Association or Causation? Proceedings of the RoyalSociety of Medicine, 58 (1965), 295-300.
Zufallige und systematische FehlerZufalliger Fehler Systematischer Fehler, Bias
Diese beiden Fehler treten in Kombination auf, zwei Beispiele:

Systematischer Fehler (Bias): Definition
“Any process at any stage of inference which tends to produceresults or conclusions that differ systematically from the truth.”
Nach Murphy, The Logic of Medicine, Baltimore: John Hopkins University Press, 1976 aus Sackett, Biasin Analytic Research, Journal of Chronic Disease, 1979.
Wann kann ein systematischer Fehler auftreten?
I Literatursuche
I Festlegen und Auswahlen der Studienpopulation
I Durchfuhren der experimentellen Intervention (“Exposure”)
I Messen von “Exposure” und “Outcome”
I Analysieren der Daten
I Interpretieren der Analyse
I Publizieren der Resultate
Basierend auf dieser Einteilung hat Sackett einen Katalog von 35systematischen Fehlern erstellt.
Sackett, Bias in Analytic Research, Journal of Chronic Disease, 1979.
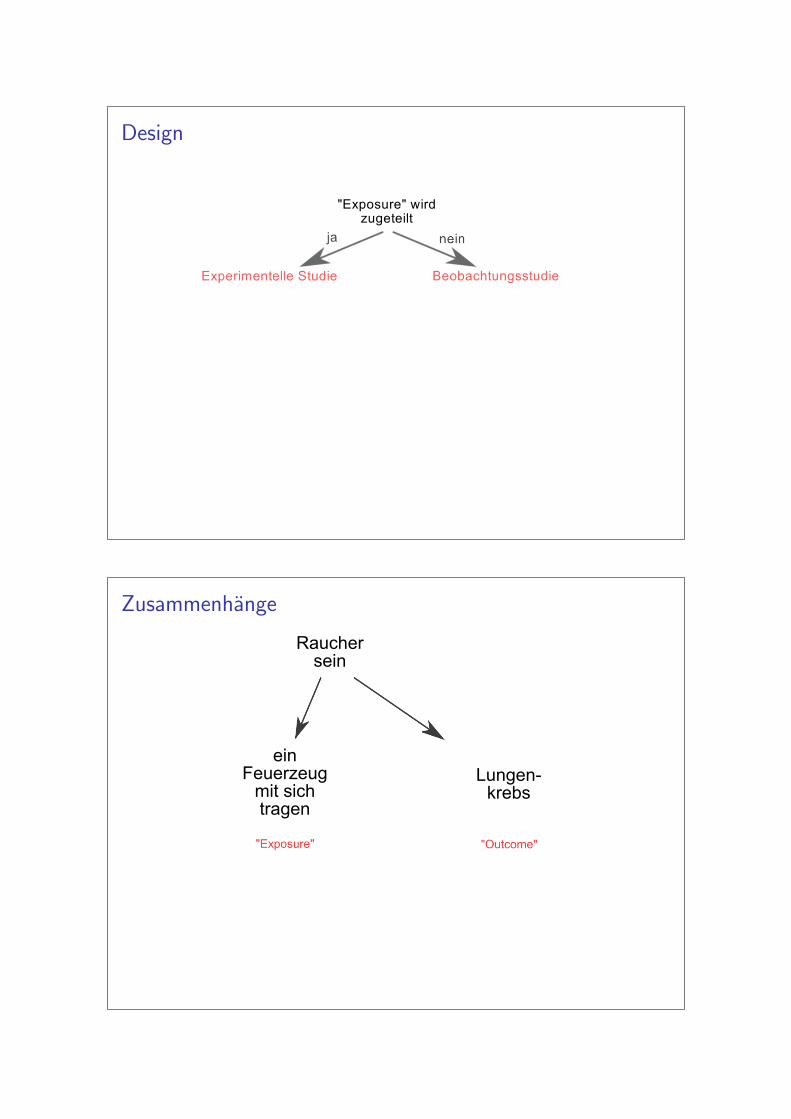
Design
Zusammenhange
Rauchersein
Lungen-krebs
ein Feuerzeug
mit sichtragen

Bias-Einteilung nach Struktur
Confounding Bias Common causes of exposure and outcome.(“Exposure” und “Outcome” haben einegemeinsame Ursache.)
Selection Bias Conditioning on commen effects of exposureand outcome.(Ein gemeinsamer Effekt von “Exposure” und“Outcome” wird berucksichtigt.)
Information Bias Systematisch fehlerhafte Information uber“Exposure”, “Outcome” oder andere Variabelnwelche fur die Studie herangezogen werden.
z.B. Hernan and Robins, A Structural Approach to Selection Bias, Epidemiology, 2004.
Confounding Bias
gemeinsame Ursache
"Exposure""Outcome"
I Anpassen des Studientypen: Zufallige “Exposure”-Zuweisungerlaubt es, “Confounding” durch bekannte und unbekannteVariablen zu verhindern.
I Anpassen der Datenanalyse: Nur mit Fachwissen ist esmoglich, “Confounder” zu identifizieren, zu messen und mitgewissen Annahmen in der Analyse zu berucksichtigen.
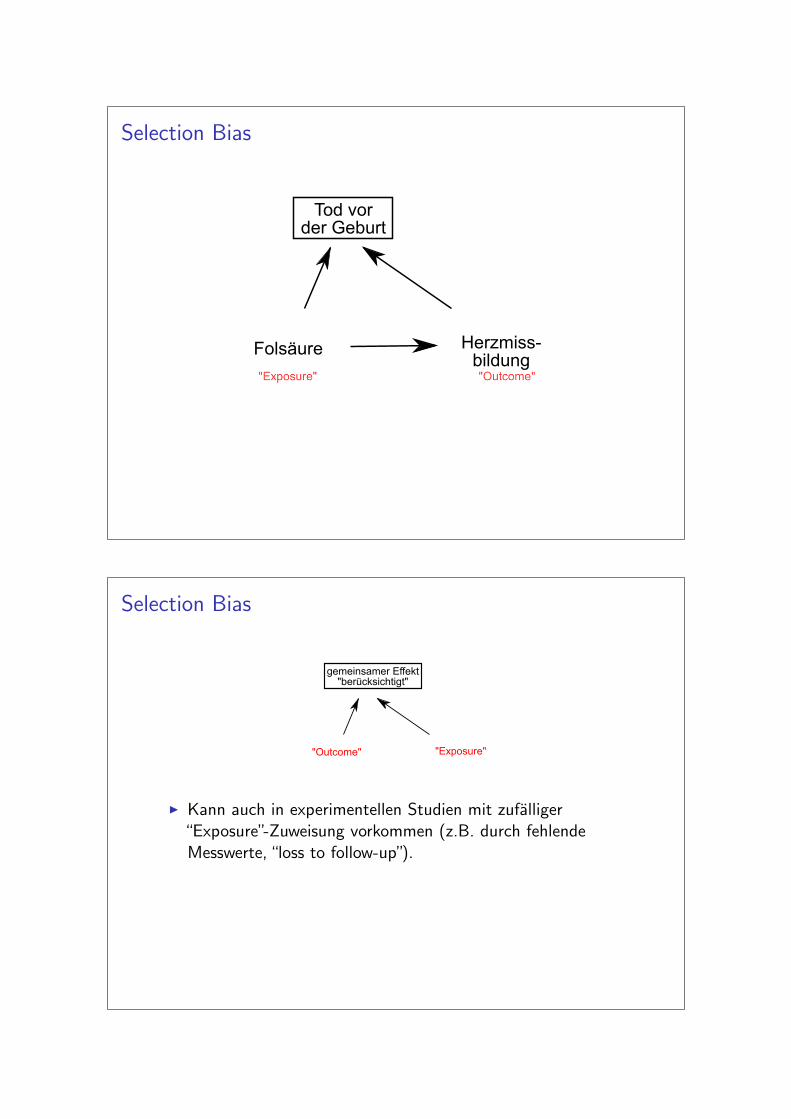
Selection Bias
Herzmiss-bildung
Folsäure
Tod vorder Geburt
Selection Bias
gemeinsamer Effekt"berücksichtigt"
"Exposure""Outcome"
I Kann auch in experimentellen Studien mit zufalliger“Exposure”-Zuweisung vorkommen (z.B. durch fehlendeMesswerte, “loss to follow-up”).

Information Bias
Systematisch fehlerhafte Information uber “Exposure”, “Outcome”oder andere Variabeln welche fur die Studie herangezogen werden.
I Definition ist unabhangig von der kausalen Struktur.
I Wenn es sich um eine kategoriale Messgrosse handelt, sprichtman auch von “Misclassification Bias”.
I Verschiedene Formen konnen unterschiedlich eingeteilt werden(z.B. “differential / non-differential”, “Exposure / Outcome /Covariate Misclassification”).
Hypothesen
Wissenschaftler formulieren gestutzt auf Beobachtungen und vielFachwissen Hypothesen.
Beispiel:Hypothese: Alle Schwane sind weiss.

Falsifikationismus
August Weismann, 1868 meinte, es
lasst sich eine wissenschaftliche Hypothese zwar niemalserweisen, wohl aber, wenn sie falsch ist, widerlegen, undes fragt sich deshalb, ob nicht Thatsachen beigebrachtwerden konnen, welche mit einer der beiden Hypothesenin unaufloslichem Widerspruch stehen und somit dieselbezu Fall bringen.
Hypothesen Test: Analogie zu anderen Testverfahren
Nullhypothese H0: Kein FeuerKein Alarm: H0 akzeptieren
Alternativhypothese HA: FeuerAlarm: H0 verwerfen, HA akzeptieren
H0 wahr HA wahrkein Feuer Feuer
H0 akzeptieren kein Alarm � (1− α) Typ II Fehler, βH0 verwerfen Alarm Typ I Fehler, α � (1− β)
1− α: Vertrauensniveau, misst Vertrauen, dass kein Alarm auchwirklich kein Feuer bedeutet (hohes Vertrauen: falscher Alarmselten)
1− β: Power: misst Wahrscheinlichkeit, dass Feuer auch Alarmauslost

Wurfelbeispiel
Nullhypothese Die Maschine zeigt den Mittelwert von 4 Wurfenmit einem 20-seitigen Wurfel.
Alternativhypothese Die Maschine zeigt nicht den Mittelwert von4 Wurfen mit einem 20-seitigen Wurfel.
H0 wahr HA wahrH0 akzeptieren � (1-α) Typ II Fehler, βH0 verwerfen Typ I Fehler, α � (1-β)
Konventionen des statistischen Testens:
I Wir lehnen die Nullhypothese ab, wenn ein bestimmte“extreme” Statistik beobachtet wird.
I Wir bezeichnen etwas als “extrem”, wenn es mit einerWahrscheinlichkeit von < 5 % auftritt (α < 0.05).
Gibt es einen Zusammenhang
zwichen dem Geschlecht und der Korperlange des DreistachligenStichlings in der Bodenseeregion.
“Exposure” Geschlecht
“Outcome” Korperlange
Nullhypothese Es gibt keinen Unterschied in der Korperlangezwischen mannlichen und weiblichen Fischen.H0 : µ♀ − µ♂ = 0
Alternativhypothese Es gibt einen Unterschied in der Korperlangezwischen mannlichen und weiblichen Fischen.HA : µ♀ − µ♂ = δ
Teststatistik Differenz in der Korperlange zwischen mannlichenund weiblichen Fischen. x♀ − x♂

Hypothesentesten
xweibl. − xmännl.
Dic
hte
H0 : µweibl. − µmännl. = 0
−10 −5 0 5 10 15 20
kritischer Wert
α 2
kritischer Wert
α 2"P−Wert"/ 2"P−Wert"/ 2
H1 : µweibl. − µmännl. = δ
δ
β
Alternative Szenarien
Szenario 1:
Grossere Stichprobe und daher weniger Streuung.
x0 − x1
Dic
hte
Alternative Szenarien
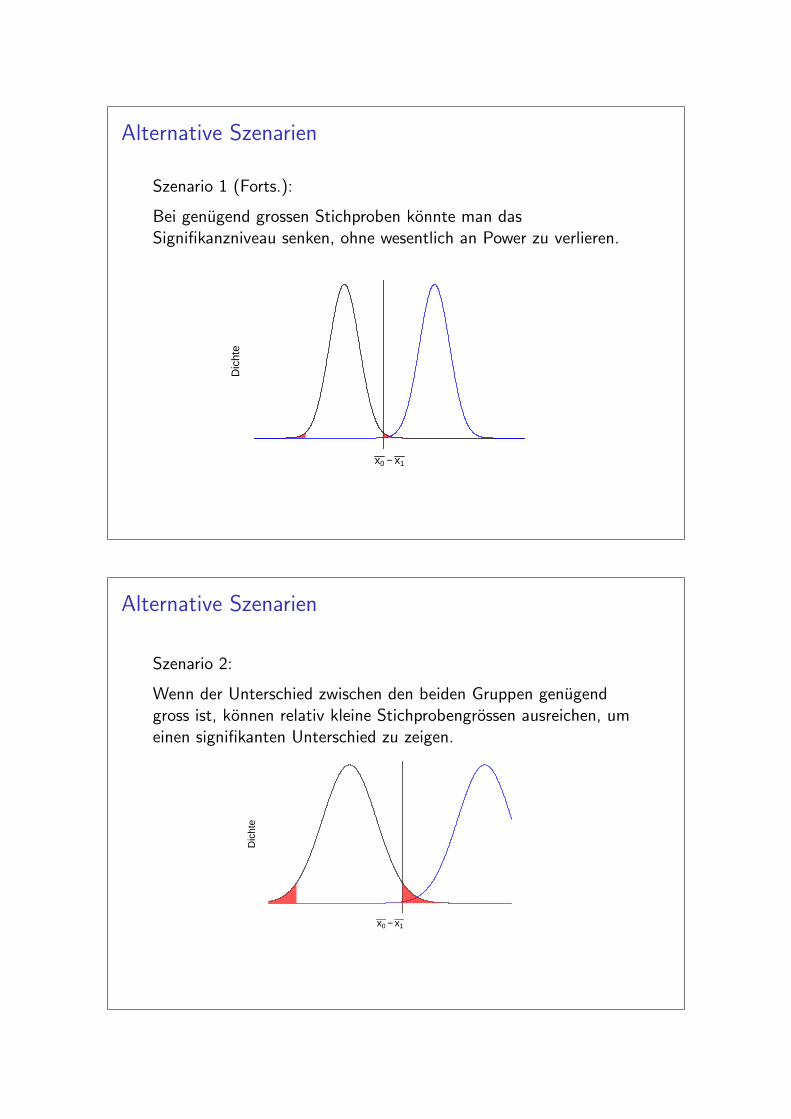
Szenario 1 (Forts.):
Bei genugend grossen Stichproben konnte man dasSignifikanzniveau senken, ohne wesentlich an Power zu verlieren.
x0 − x1
Dic
hte
Alternative Szenarien
Szenario 2:
Wenn der Unterschied zwischen den beiden Gruppen genugendgross ist, konnen relativ kleine Stichprobengrossen ausreichen, umeinen signifikanten Unterschied zu zeigen.
x0 − x1
Dic
hte

Signifikant, oder nicht?
Ein statistischer Test soll helfen zu entscheiden, ob die Daten mitder Nullhypothese im Einklang stehen oder nicht. Wie viele andereTests liefert eine statistischer Test in erster Linie eine “ja/nein”Antwort und dazu braucht es ein Signifikanzniveau, α, welches diekritische Grenze darstellt.
Signifikant, oder nicht?
Der “P-Wert” ist ein verfeinertes Mass ob ein Test signifikant istoder nicht. Leider birgt der “P-Wert” einige Probleme:
Interpretation Der “P-Wert” wird sehr haufig falsch interpretiert.Auch die Bezeichnung “P”, welche meist furWahrscheinlichkeiten verwendet wird, ist trugerisch,da sich die Wahrscheinlichkeit nur auf dashypothetische Wiederholen des Experimentes bzw.der Untersuchung bezieht.
Vereinheitlichung Fur jeden statistischen Test kann man einen“P-Wert” berechnen. Jeder statistische Test bestehtjedoch aus einer Nullhypothese und einer Teststatistikund die Wahl dieses Paares beeinflusst den “P-Wert”.Es besteht also die Gefahr, dass man dieser Zahlmehr Beachtung schenkt, als sie es wert ist und sieallzu sorgenlos ohne weitere Angaben nutzt.

Signifikant, oder nicht?
Ein Mittelweg zwischen “ja/nein” und dem “P-Wert”: DieSternchen-Konvention
Interpretation Notation
P > 0.05 nicht signifikant (n.s.)0.05 ≥ P > 0.01 schwach signifikant *0.01 ≥ P > 0.001 stark signifikant **0.001 ≥ P sehr stark signifikant ***
Relevant, oder nicht?
I Wie gross muss ein Unterschied sein, dass er in einemstatistischen Test signifikant wird?
I Was bedeutet es, wenn bei einem geplanten Experiment der“P-Wert” sehr stark signifikant wird (P ≤ 0.001).
I Was bedeutet es, wenn bei einem geplanten Experiment einstatistischer Test nicht signifikant wird (P > 0.05).
Es ist unerlasslich das Resultat einer Untersuchung uber dieSchatzer zu interpretieren! Die alleinige Aussage, dass einTestresultat signifikant ist erlaubt es nicht dieses zu interpretieren.Genauso kann man nicht sagen, dass ein Unterschied der in einerUntersuchung nicht signifikant wurde nicht relevant sei.
“The abscence of evidence is no evidence for abscence.”Carl Sagan

Ein- oder zweiseitig Testen?
Um den kritischen Wert zu finden fur das Verwerfen derNullhypothese haben wir an beiden Enden der Verteilung jeweilseine Flache von α/2 abgetrennt. Es stellt sich naturlich die Frage,wieso wir nicht einfach α auf einer Seite abtrennen, da wir jasowieso erwarten, dass der Effekt in die bekannte Richtung geht.Sollen wir also ein- oder zweiseitig testen?Ganz einfach - zweiseitig! Weil wir ja nicht sicher sind, dass derEffekt in diese Richtung geht. Einseitig Testen darf man nur, wennder Effekt aus z.B. physikalischen Grunden nur in eine Richtunggehen kann.
Lage-Vergleich zwischen zwei Stichproben
Ein pragmatischer Ansatz:
I Immer den Rangsummentest von Wilcoxon verwenden.
Nullhyothese H0 : Yg ,i F(i .i .d .)Die Verteilung F kann eine beliebige Verteilung sein,aber alle Messwerte Yg ,i mussen aus der selbenVerteilung sein und unabhangig voneinander.
Alternativhypothese HA : Yg=1,i F1,Yg=2,i F2 wobeiF2(x) = F1(x − δ) und δ 6= 0
Teststatistik Die Teststatistik W wird wie folgt berechnet:Rg ,i =Rang(Yg ,i |Yg=1,i=1 . . .Yg=1,i=n1 ,Yg=2,i=1 . . .Yg=2,i=n2)
Ug=1 =∑i=n1
i=1 Rg=1,i
der grossere der beiden WerteWa = n1n2 + n2(n2+1)
2 −Ug=1 und Wb = n1n2−Ug=1
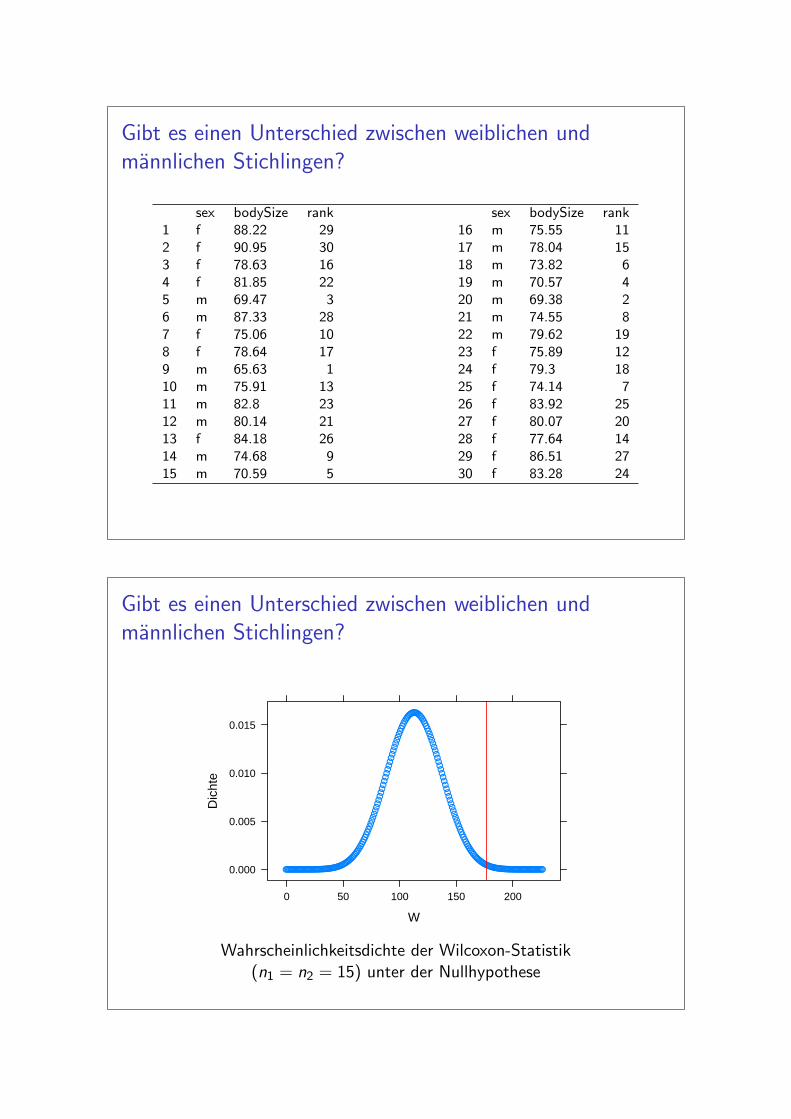
Gibt es einen Unterschied zwischen weiblichen undmannlichen Stichlingen?
sex bodySize rank sex bodySize rank1 f 88.22 29 16 m 75.55 112 f 90.95 30 17 m 78.04 153 f 78.63 16 18 m 73.82 64 f 81.85 22 19 m 70.57 45 m 69.47 3 20 m 69.38 26 m 87.33 28 21 m 74.55 87 f 75.06 10 22 m 79.62 198 f 78.64 17 23 f 75.89 129 m 65.63 1 24 f 79.3 1810 m 75.91 13 25 f 74.14 711 m 82.8 23 26 f 83.92 2512 m 80.14 21 27 f 80.07 2013 f 84.18 26 28 f 77.64 1414 m 74.68 9 29 f 86.51 2715 m 70.59 5 30 f 83.28 24
Gibt es einen Unterschied zwischen weiblichen undmannlichen Stichlingen?
W
Dic
hte
0.000
0.005
0.010
0.015
0 50 100 150 200
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
Wahrscheinlichkeitsdichte der Wilcoxon-Statistik(n1 = n2 = 15) unter der Nullhypothese
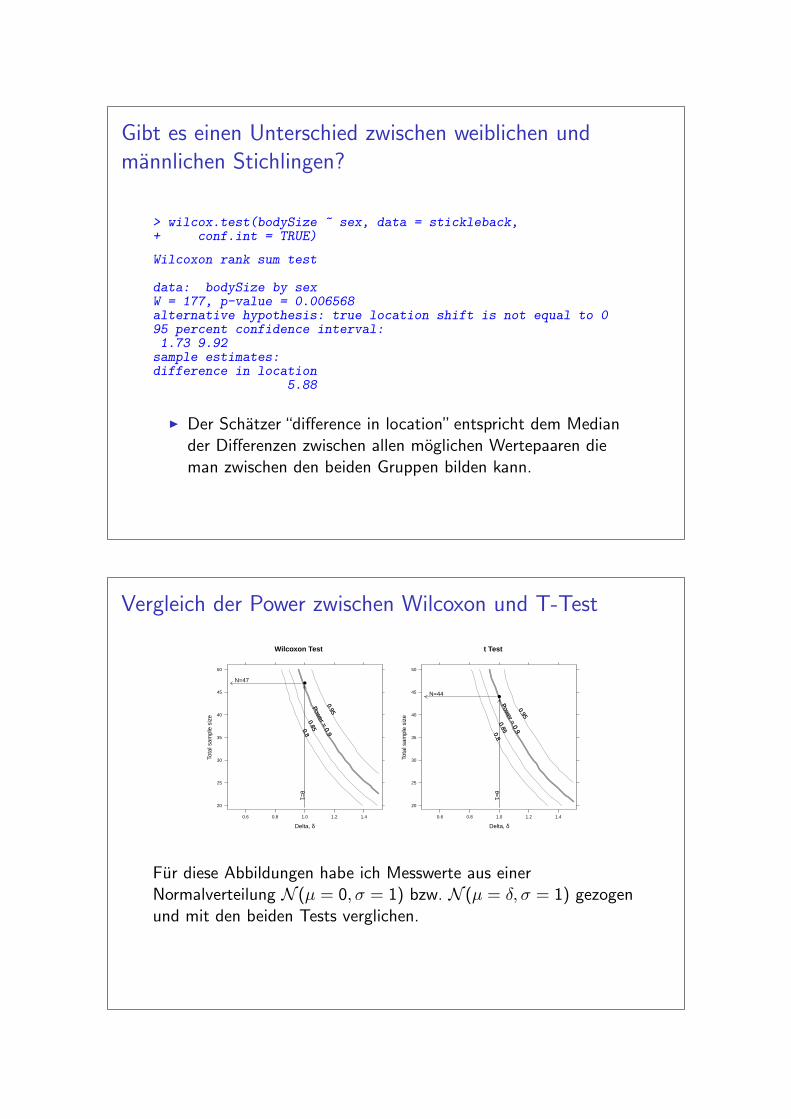
Gibt es einen Unterschied zwischen weiblichen undmannlichen Stichlingen?
> wilcox.test(bodySize ~ sex, data = stickleback,+ conf.int = TRUE)
Wilcoxon rank sum test
data: bodySize by sexW = 177, p-value = 0.006568alternative hypothesis: true location shift is not equal to 095 percent confidence interval:1.73 9.92sample estimates:difference in location
5.88
I Der Schatzer “difference in location” entspricht dem Mediander Differenzen zwischen allen moglichen Wertepaaren dieman zwischen den beiden Gruppen bilden kann.
Vergleich der Power zwischen Wilcoxon und T-Test
Wilcoxon Test
Delta, δ
Tota
l sam
ple
size
20
25
30
35
40
45
50
0.6 0.8 1.0 1.2 1.4
Power = 0.9
Power = 0.9
0.80.85
0.95
0.80.85
0.95
N=47
θ=1
●
t Test
Delta, δ
Tota
l sam
ple
size
20
25
30
35
40
45
50
0.6 0.8 1.0 1.2 1.4
Power = 0.9
Power = 0.90.8
0.85
0.95
0.80.85
0.95
N=44
θ=1
●
Fur diese Abbildungen habe ich Messwerte aus einerNormalverteilung N (µ = 0, σ = 1) bzw. N (µ = δ, σ = 1) gezogenund mit den beiden Tests verglichen.
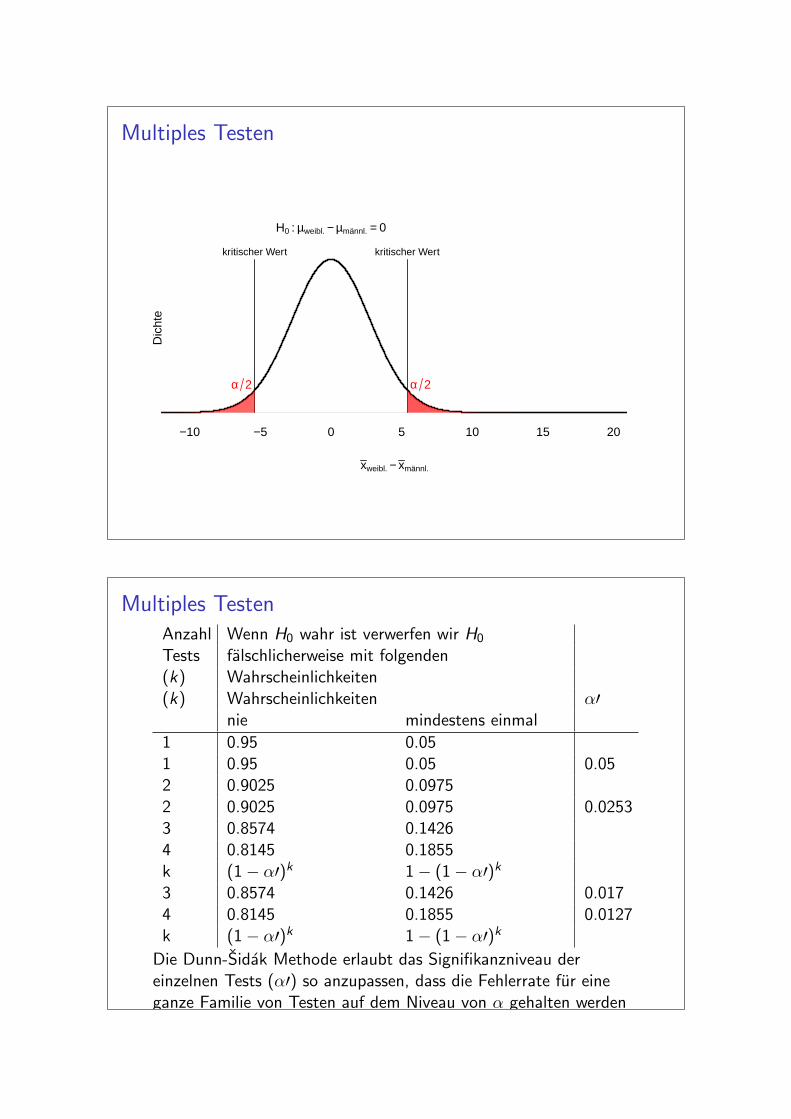
Multiples Testen
xweibl. − xmännl.
Dic
hte
H0 : µweibl. − µmännl. = 0
−10 −5 0 5 10 15 20
kritischer Wert
α 2
kritischer Wert
α 2
Multiples TestenAnzahl Wenn H0 wahr ist verwerfen wir H0
Tests falschlicherweise mit folgenden(k) Wahrscheinlichkeiten(k) Wahrscheinlichkeiten α′
nie mindestens einmal
1 0.95 0.051 0.95 0.05 0.052 0.9025 0.09752 0.9025 0.0975 0.02533 0.8574 0.14264 0.8145 0.1855k (1− α′)k 1− (1− α′)k3 0.8574 0.1426 0.0174 0.8145 0.1855 0.0127k (1− α′)k 1− (1− α′)k
Die Dunn-Sidak Methode erlaubt das Signifikanzniveau dereinzelnen Tests (α′) so anzupassen, dass die Fehlerrate fur eineganze Familie von Testen auf dem Niveau von α gehalten werdenkann.
α = 1− (1− α′)kα′ = 1− (1− α)1/k

Lage-Vergleich zwischen mehrerer Stichproben
Auch um die Lage von mehr als zwei Stichproben zu testen gibt eseinen empfehlenswerten Test basierend auf den Rangen derMesswerte, den Kruskal-Wallis-Test. Er tested ob die Lage allerStichproben gleich ist (Nullhypothese).
> library(asuR)> data(pea)> kruskal.test(length ~ trt, data = pea)
Kruskal-Wallis rank sum test
data: length by trtKruskal-Wallis chi-squared = 38.4368, df = 4, p-value= 9.105e-08
Wir mochten uns jedoch hier auch die parametrische Form etwasgenauer anschauen weil diese die Grundlage ist fur das Verstandnisder meisten Formen des “Modellierens”. Die Methode welche eserlaubt Lageparameter (im speziellen Fall Mittelwerte) ausmehreren Stichproben zu vergleichen nennt man Varianzanalyseoder kurz ANOVA (fur “analysis of variance”).
Formulieren eines linearen Modells
Einweg-ANOVA:
E[yij ] = µiyij ∼ indep. N (µi , σ
2)
mit 1, . . . , i Kategorien, jede mit 1, . . . , j Untersuchungseinheiten.
Das tolle an dieser Formulierung ist, dass sie uns erlaubt denErwartungswert der Kategorien und die Streuung der Messwerteseparat zu beschreiben.
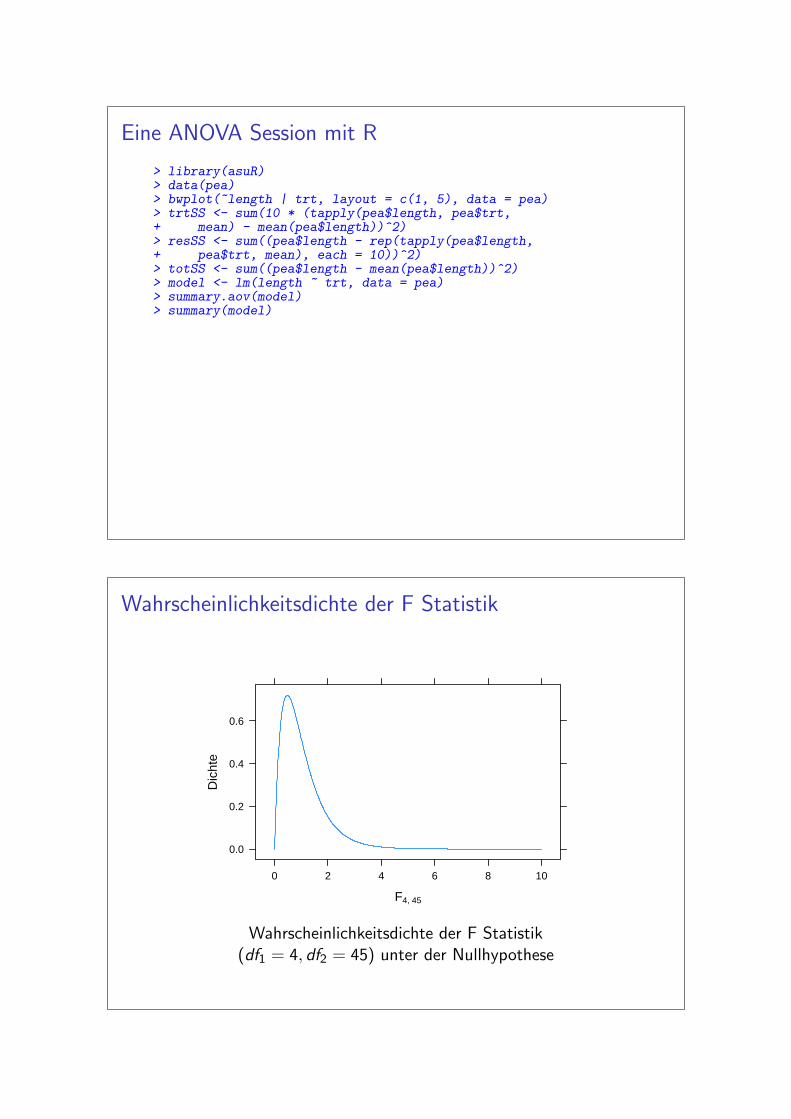
Eine ANOVA Session mit R
> library(asuR)> data(pea)> bwplot(~length | trt, layout = c(1, 5), data = pea)> trtSS <- sum(10 * (tapply(pea$length, pea$trt,+ mean) - mean(pea$length))^2)> resSS <- sum((pea$length - rep(tapply(pea$length,+ pea$trt, mean), each = 10))^2)> totSS <- sum((pea$length - mean(pea$length))^2)> model <- lm(length ~ trt, data = pea)> summary.aov(model)> summary(model)
Wahrscheinlichkeitsdichte der F Statistik
F4, 45
Dic
hte
0.0
0.2
0.4
0.6
0 2 4 6 8 10
Wahrscheinlichkeitsdichte der F Statistik(df1 = 4, df2 = 45) unter der Nullhypothese

Formulieren eines linearen Modells
Einweg-ANOVA: am konkreten Beispiel
E[yij ] = µi
= β0 + β1x1 + β2x2 + β3x3 + β4x4
yij ∼ indep. N (µi , σ2)
mit den Kategorien i = 1, 2, 3, 4, 5, jede mit denUntersuchungseinheiten j = 1, . . . , 10.
Kontraste
Wenn man die Lage von mehr als zwei Stichproben beschreibenmochte, ist man meist nicht nur an der Nullhypothese die besagtdass alle Lageparameter gleich sind (H0 : µ1 = µ2 = . . . = µk)interessiert.Oft mochte man auch einzelne Lageparameter oderLinearkombinationen von Lageparametern vergleichen, man nenntdiese Vergleiche Kontraste, einige Beispiele:
I H0 : µ1 − µ2 = 0 und H0 : µ1 − µ3 = 0 und H0 : µ2 − µ3 = 0Alle paarweisen Vergleiche.
I H0 : µ1 − 12 (µ2 + µ3) = 0, oder besser geschrieben
H0 : 1µ1− 12µ2− 1
2µ3 = 0 zum Testen ob der Mittelwert in derGruppe 1 sich vom Mittel der Gruppen 2 und 3 unterscheidet.

Kontraste
Wenn man die Nullhypothese (die Lage aller Stichproben istidentisch) verwerfen konnte, dann kann man weitere Kontrasteuntersuchen und testen. Allerdings darf man nicht beliebige undauch nicht beliebig viele Kontraste untersuchen. Die Regeln sind:
I Immer nur k − 1 Kontraste konnen getestet werden, wennman k Stichproben untersucht.
I Die Kontraste mussen orthogonal zueinander stehen, d.h. dasProdukt der Koeffizienten muss sich zu Null aufsummieren.Ein Beispiel mit zwei Kontrasten:
1µ1 − 12µ2 − 1
2µ3 = 00µ1 − 1µ2 + 1µ3 = 0
(1× 0) + (−12 ×−1) + (−1
2 ×+1) = 0
Eine ANOVA Session mit R
> contr <- rbind(`control-sugar` = c(1, -1/4, -1/4,+ -1/4, -1/4), `pure-mixed` = c(0, 1/3, 1/3,+ -1, 1/3), `monosaccharides-disaccharides` = c(0,+ 1/2, 1/2, 0, -1), `gluc-fruc` = c(0, 1, -1,+ 0, 0))> ortho(contr)> contrasts(pea$trt) <- mancontr(contr)> model <- lm(length ~ trt, data = pea)> summary(model)

Kontraste: Tukey’s HSD
Student (WS Gosset) hat die Verteilung der t-Statistik entdecktfur zwei Stichproben welche sich nicht im Mittelwertunterscheiden. Wenn es nun k-Stichproben gibt dann gibt esk(k − 1)/2 paarweise Vergleiche mit einem zugehorigen t-Wert.Tukey hat die Verteilung der grossten dieser t-Statistikenbeschrieben. Damit kann man alle paarweisen Vergleiche testenund der Typ I Fehler wird nicht grosser als α. Man nennt dieMethode auch Tukey’s HSD (Honest Significant Difference).
> m0 <- aov(length ~ trt, data = pea)> (t0 <- TukeyHSD(m0))> par.old <- par(mar = c(4, 6, 2, 2))> plot(t0, las = 1)> par(par.old)
Lineare Modelle
Einweg ANOVA:
E[yij ] = µi= β0 + β1x1 + . . .+ βi−1xi−1
yij ∼ indep. N (µ+ αi−1, σ2)
mit i Kategorien, jede mit j Untersuchungseinheiten.
Regression:
E[yij ] = µ(xi ) = α + βxi = β0 + β1xiyij ∼ indep. N (α + βxi , σ
2)mit j gemessenen Untersuchungseinheiten an i Punkten auf der
kontinuierlichen x-Achse.
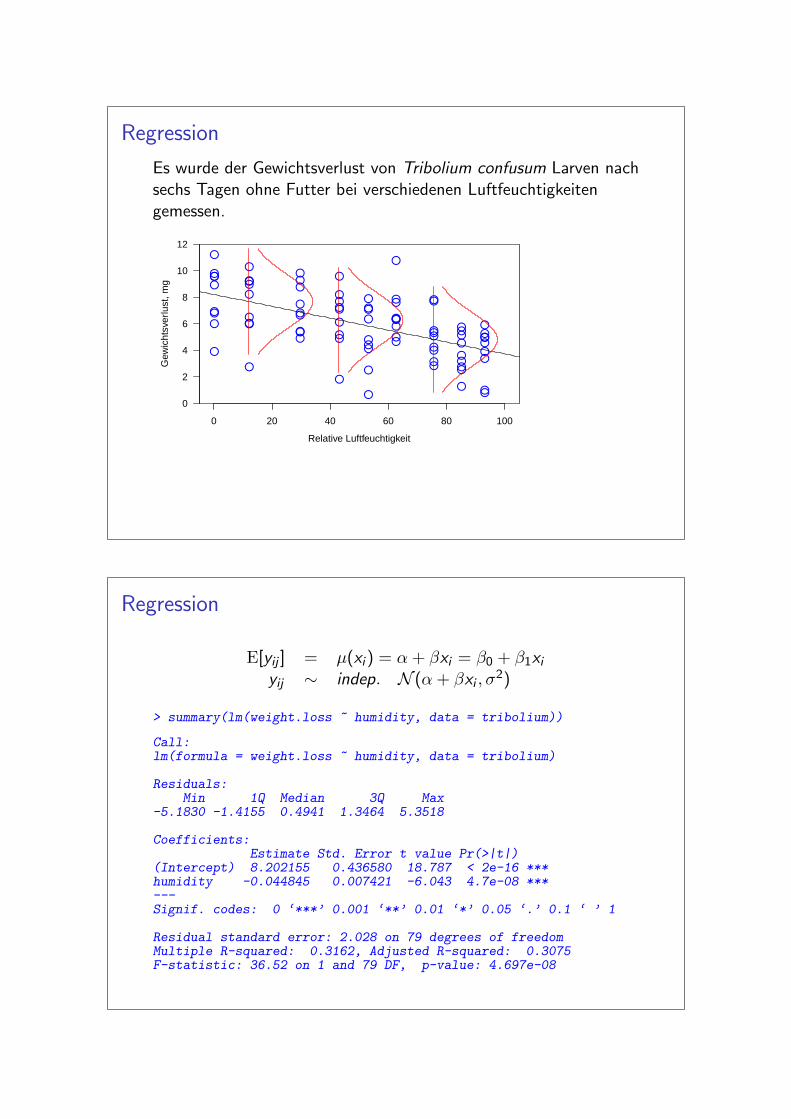
Regression
Es wurde der Gewichtsverlust von Tribolium confusum Larven nachsechs Tagen ohne Futter bei verschiedenen Luftfeuchtigkeitengemessen.
0 20 40 60 80 100
0
2
4
6
8
10
12
Relative Luftfeuchtigkeit
Gew
icht
sver
lust
, mg ●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●● ●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●●
●●
●●●
●
●●●
●
●
●
●●
●
●
●
●●
●●
●
●●●
●
●
●
●
●
Regression
E[yij ] = µ(xi ) = α + βxi = β0 + β1xiyij ∼ indep. N (α + βxi , σ
2)
> summary(lm(weight.loss ~ humidity, data = tribolium))
Call:lm(formula = weight.loss ~ humidity, data = tribolium)
Residuals:Min 1Q Median 3Q Max
-5.1830 -1.4155 0.4941 1.3464 5.3518
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.202155 0.436580 18.787 < 2e-16 ***humidity -0.044845 0.007421 -6.043 4.7e-08 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.028 on 79 degrees of freedomMultiple R-squared: 0.3162, Adjusted R-squared: 0.3075F-statistic: 36.52 on 1 and 79 DF, p-value: 4.697e-08

Regression
Hypothesen Hat die erklarende Variable (X ) einen linearenZusammenhang mit der Zielgrosse (Y ). Dazu testenwir die Nullhypothese H0 : β = 0.
Vorhersage Ein Regressionsmodell erlaubt uns auch fur einegegebene erklarende Variable (X ) eine Vorhersagenfur die Zielgrosse (Y ) zu machen. DieWahrscheinlichkeitsverteilung fur die Vorhersagelautet N (α + βxi , σ
2).
R2 Schatzt wie stark der lineare Zusammenhangzwischen der erklarenden Variable (X ) und derZielgrosse (Y ) ist. Der Wert liegt immer zwischen 0und 1. Leider ist R2 sehr stark von der gewahltenSpannweite der erklarenden Variablen abhangig undkann somit nicht verwendet werden um Modelle vonverschiedenen Datensatzen zu vergleichen.
Voraussetzungen
Das Uberprufen der Voraussetzungen ist ein wesentlicherBestandteil einer Regressionsanalyse. Es geht einerseits darum dieVerletzungen aufzudecken und falsche Ruckschlusse zu vermeidenandererseits aber auch darum ein besseres Modell zu finden.
Residuen I Die Streuung der Residuen ist konstantI Erwartungswert der Residuen ist nullI Residuen sind normalverteilt* Residuen sind unabhangig voneinander
Hebelarm I Alle Messwerte haben denselben Einfluss
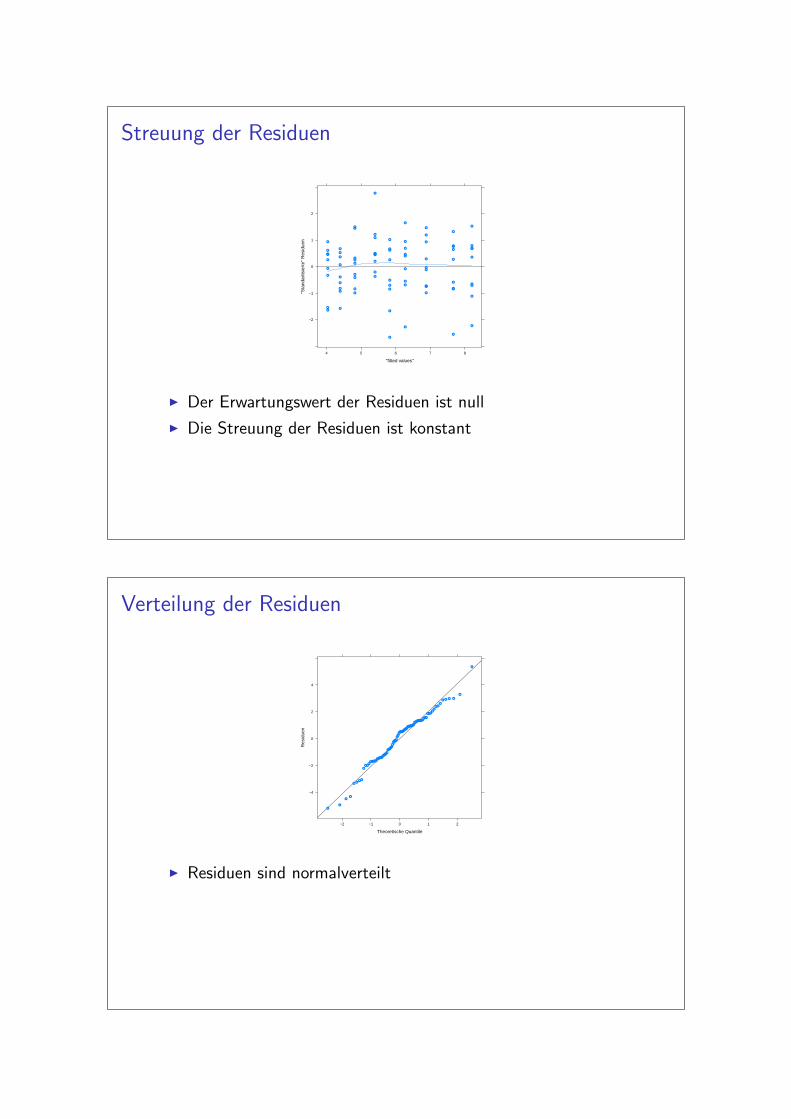
Streuung der Residuen
"fitted values"
"Sta
ndar
tisie
rte"
Res
idue
n
−2
−1
0
1
2
4 5 6 7 8
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
I Der Erwartungswert der Residuen ist null
I Die Streuung der Residuen ist konstant
Verteilung der Residuen
Theoretische Quantile
Res
idue
n
−4
−2
0
2
4
−2 −1 0 1 2
●
●
●●
● ●●●
●●●
●●●●●●
●●●●●●●
●●●●●●
●●●●●
●●●●●●●●●●
●●●●●●●●●
●●●●●
●●●●●●●●
●●●●
●●●
●
● ● ● ●
●
●
I Residuen sind normalverteilt

Ausreisser
Es gibt zwei Arten von Ausreissern
Y – Ausreisser Messwerte welche weit entfernt vomErwartungswert liegen (grosse Residuen) aber einenkleinen Hebelarm haben.
X – Ausreisser Messwerte welche einen sehr grossen Hebelarm(“leverage”) haben. Der Hebelarm gibt an was fur einPotenzial die einzelnen Werte haben das Modell zubeeinflussen. Im Gegensatz zu Werten mit grossenResiduen mussen Werte mit grossem Hebelarm nichtzwingend problematisch sein.
Ausreisser: Potenzial-Residuen
Der Potenzial-Residuen-Plot zeigt welche Rolle einzelne Punkte im“fitting” Prozess spielen.
Potenzial
Res
idue
n
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●
● ●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
I Alle Messwerte haben denselben Einfluss

Ausreisser: Potenzial-Residuen-Diagramm
Interpretation des Potenzial-Residuen-Diagramm (nur als grobeFaustregel):
I Gibt es Punkte mit grossem Potenzial und grossen Residuen(Quadrant oben links) ist alles in Ordnung.
I Gibt es Punkte mit grossem Potenzial und kleinen Residuenlohnt es diese genauer zu untersuchen, sie konnten (!) dasModell stark verzerren.
I Gibt es Punkte mit grossen Residuen aber kleinem Potenzial,dann stimmt das Modell fur diese Punkte nicht. Das kann amModell liegen oder an den Punkten
Graphical Excellence
Graphical excellence is that which gi-ves to the viewer the greatest num-ber of ideas in the shortest time withthe least ink in the smallest space.
Edward R Tufte

Menschliche Wahrnehmung von graphischen Elementen
Rang Aspekt
1 Position entlang einer gemeinsamen Achse2 Position auf identischen aber nicht ausgerichteten Achsen3 Lange4 Winkel5 Steigung6 Flache7 Volumen8 Farbsattigung (schlecht sortierbar, gut diskriminierbar)
Cleveland 1985, Graphical Perception and Graphical Methods for Analyzing Scientific Data, Science, 229,828-833.
Einige Ideen
I Zeigen Sie die Messwerte (e.g. rug()), falls diese zu zahlreichsind kann man auch eine zufallige Auswahl zeigen.
I Lassen Sie den Betrachter uber den Inhalt nachdenken stattuber die Methoden.
I Zeigen Sie was im Zentrum der Untersuchung steht. ZeigenSie z.B. die Differenz zwischen zwei Behandlungen mit einemVertrauensintervall statt die Mittelwerte der einzelnenGruppen.
I Ob der Nullpunkt auf der Achse abgebildet sein soll oder nichtmuss sorgfaltig uberdacht werden.
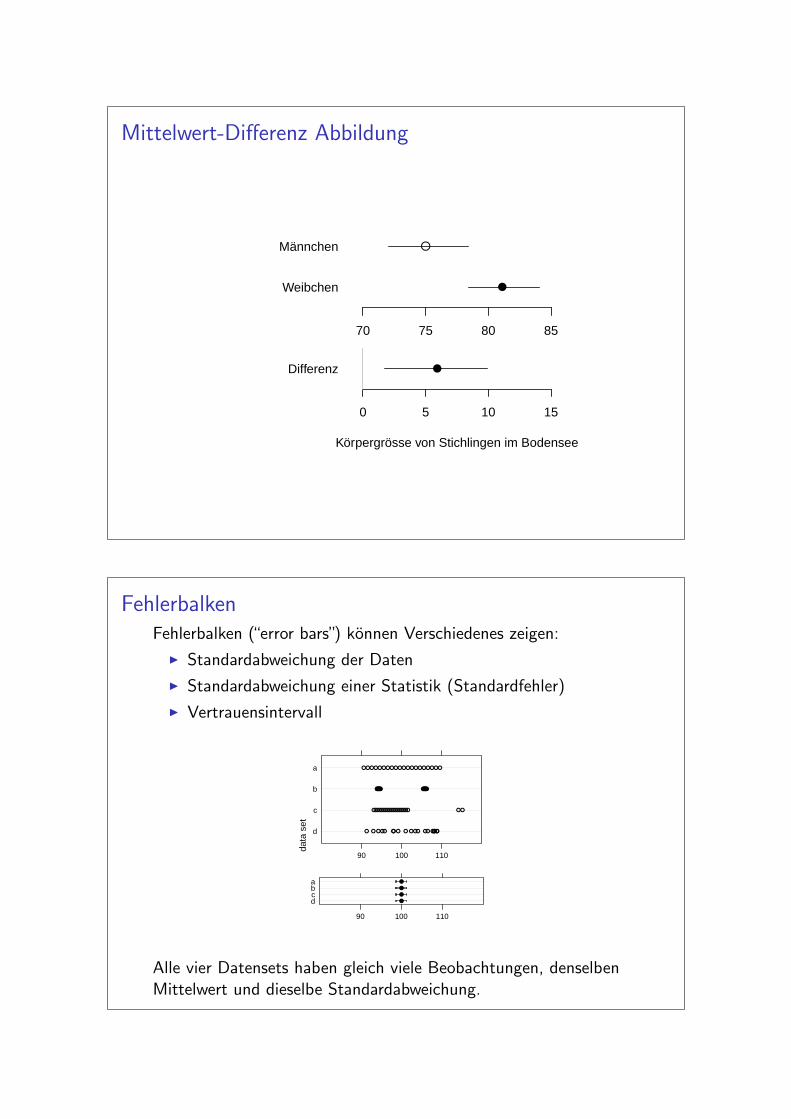
Mittelwert-Differenz Abbildung
70 75 80 85
●
●
Weibchen
Männchen
0 5 10 15
●Differenz
Körpergrösse von Stichlingen im Bodensee
FehlerbalkenFehlerbalken (“error bars”) konnen Verschiedenes zeigen:
I Standardabweichung der Daten
I Standardabweichung einer Statistik (Standardfehler)
I Vertrauensintervall
d
c
b
a
90 100 110
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
dcba
90 100 110
●
●
●
●
data
set
Alle vier Datensets haben gleich viele Beobachtungen, denselbenMittelwert und dieselbe Standardabweichung.

Theoriefragen zu den bisherigen Inhalten
I Was ist der Vorteil der geschatzten empirischen Dichtegegenuber einem Histogramm?
I Erklaren Sie den Begriff Vertrauensintervall.
I Was bedeutet der Begriff “Power” genau?
I Was fur Angaben braucht es um das Resultat einesstatistischen Tests zu interpretieren?Ein Beispiel: Sie haben getestet ob sich die Korpergrosse beiStichlingen hinsichtlich der Herkunft unterscheidet und dazuje 100 Stichlinge aus zwei Zuflussen gemessen. DerUnterschied in der Lage ist sehr stark signifikant. WelcheAngaben fehlen noch?
I Sie mochten zeigen, dass die Stichlinge aus dem Obersee unddem Untersee gleich gross sind. Wie gehen Sie vor?
I Welchen Test verwenden Sie fur das Testen ob sich zweiStichproben hinsichtlich der Lage unterscheiden?
Theoriefragen zu den bisherigen Inhalten
I Wie gross darf der P-Wert hochstens sein, damit ein Resultatrelevant ist?
I Was bedeutet beim statistischen Testen ein Typ I und IIFehler?

Theoriefragen zu den bisherigen Inhalten
I Was sind die drei wichtigsten Charakteristika kontinuierlicherVariablen?
I Wenn man die Wahrscheinlichkeitsdichte einer kontinuierlichenVariablen aufzeichnet, welche Grosse tragt man auf dery-Achse auf und wie interpretiert man diese Grosse?
I Beschreiben Sie was “Standardfehler” bedeutet.
I Welche beiden Voraussetzungen mussen erfullt sein fur einConfounding?
I Was ist der Unterschied zwischen einer Beobachtungsstudieund einer experimentellen Studie?
Multivariate Statistik
Werden an einer Untersuchungseinheit mehrere Variablengemessen, dann erhalt man multivariate Daten.

Korrelation vs. Regression
Sowohl die Korrelation als auch die Regression untersuchen denZusammenhang zwischen zwei Variablen. Trotzdem unterscheidensie sich fundamental:
Korrelation untersucht den Zusammenhang zwischen zwei“gleichberechtigten” Variablen (rY 1,Y 2 = rY 2,Y 1) undist ein rein beschreibendes Mass.
Regression untersucht den Einfluss von einer oder mehreren“erklarenden” Variablen, Xi , auf eine “Zielvariable”, Y .Die Regressionsgerade von X auf Y ist in der Regeleine andere als von Y auf X . Eine Regression erlaubtnicht nur eine Beschreibung des Zusammenhangs,sondern auch eine Vorhersage fur y −Werte wennman die entsprechenden x −Werte kennt.
Pearson Korrelation
Die Pearson Korrelation,
rY 1,Y 2 =1
(n − 1)sy1sy2
n∑
i=1
y1iy2i =sy1y2
sy1sy2, (1)
wobei sy1, sy2 die Standardabweichung von y1 und y2 ist und sy1y2
die Kovarianz zwischen y1 und y2.Die Pearson Korrelation liegt zwischen -1 und 1.Die Pearson Korrelation misst “nur” den linearen Zusammenhang.Achtung, auch ein sehr starker nicht linearer Zusammenhang kanneine Pearson Korrelation rY 1,Y 2 = 0 haben!Die Pearson Korrelation ist ganz und gar nicht robust und manmuss immer ein Auge darauf haben, ob es Werte gibt welche dieKorrelation stark beeinflussen (Scatterplot!).

Pearson Korrelation
> library(MASS)> y1y2 <- mvrnorm(100, mu = c(0, 0), Sigma = matrix(c(1,+ 0.5, 0.5, 1), nrow = 2))> cor(x = y1y2, method = "pearson")
[,1] [,2][1,] 1.000000 0.531472[2,] 0.531472 1.000000
Spearman Rangkorrelation
Die Spearman Rangkorrelation,
rY 1,Y 2 =sRangY 1,RangY 2
sRangY 1sRangY 2
, (2)
misst im Gegensatz zur Pearson Korrelation nicht wie stark ein“linearer”, sondern ein “monotoner” Zusammenhang zwischen denVariablen Y 1 und Y 2 ist. Ein weiterer Vorteil der SpearmanRangkorrelation ist die Robustheit.
> cor(x = y1y2, method = "spearman")
[,1] [,2][1,] 1.0000000 0.5246205[2,] 0.5246205 1.0000000

Interpretation einer Korrelation
Allgemein ist es schwierig Korrelationen zu interpretieren. Wichtigzu beachten ist, dass ein gefundener Zusammenhang noch beiweitem kein kausaler, ursachlicher Zusammenhang sein muss, auchwenn der Zusammenhang sehr stark ist (siehe auch Design undBias).Eine Korrelation ist ein Schatzer fur einen Parameter - dazubraucht es eine Population. Die Uberlegung wie diese Populationdefiniert werden kann ist oft hilfreich bei der Interpretation.Wozu verwendet man Regressionen
I Studium der Zusammenhange (um die Variation derZielvariable erklaren zu konnen)
I Vorhersage (um die Zielvariable moglichst genau vorhersagenzu konnen)
I Statistische Kontrolle (um die Zielvariable moglichst genaueinstellen zu konnen)
Multiple lineare Regression
Untersucht den Zusammenhang zwischen einer Zielgrosse undmehreren erklarenden Variablen.
E[yijk ] = µ(xi ) = β0 + β1x1i + β2x2j
yijk ∼ indep. N (β0 + β1x1i + β2x2j , σ2)

Tribolium Beispiel
ANCOVA
Untersucht den Zusammenhang zwischen einer Zielgrosse undmindestens einer kontinuierlichen und einer kategoriellenerklarenden Variable.
E[yijk ] = β0 + β1j + β2xiyijk ∼ indep. N (β0 + β1j + β2xi , σ
2)

ANCOVA mit Interaktion
Wenn der Einfluss einer erklarenden Variable von einer weiterenVariable abhangt, spricht von von einer Interaktion dieser beidenVariablen.Fur eine ANCOVA wurde das folgendermassen aussehen:
E[yijk ] = β0 + β1j + β2xi + β3xi jyijk ∼ indep. N (β0 + β1j + β2xi + β3xi j , σ
2)
Eine Ubung:
Fitten Sie eine Regression um mit den Variablen “Grosse” und“Geschlecht” das “Gewicht” zu erklaren.
Grosse Geschlecht Gewicht
150 weiblich 50165 mannlich 55180 mannlich 65170 weiblich 70

Zweiweg-ANOVA
E[yijk ] = β0 + β1i + β2j
yijk ∼ indep. N (β0 + β1i + β2j , σ2)
mit 1, . . . , i Kategorien im ersten Faktor und 1, . . . , j Kategorienim zweiten Faktor, jeweils mit 1, . . . , k Untersuchungseinheit.
Zweiweg-ANOVA mit Interaktion
E[yijk ] = β0 + β1i + β2j + β3ij
yijk ∼ indep. N (β0 + β1i + β2j + β3ij , σ2)
Mit diesem Modell kann der Einfluss vom ersten Faktor auf denOutcome abhangig vom zweiten Faktor modelliert werden.
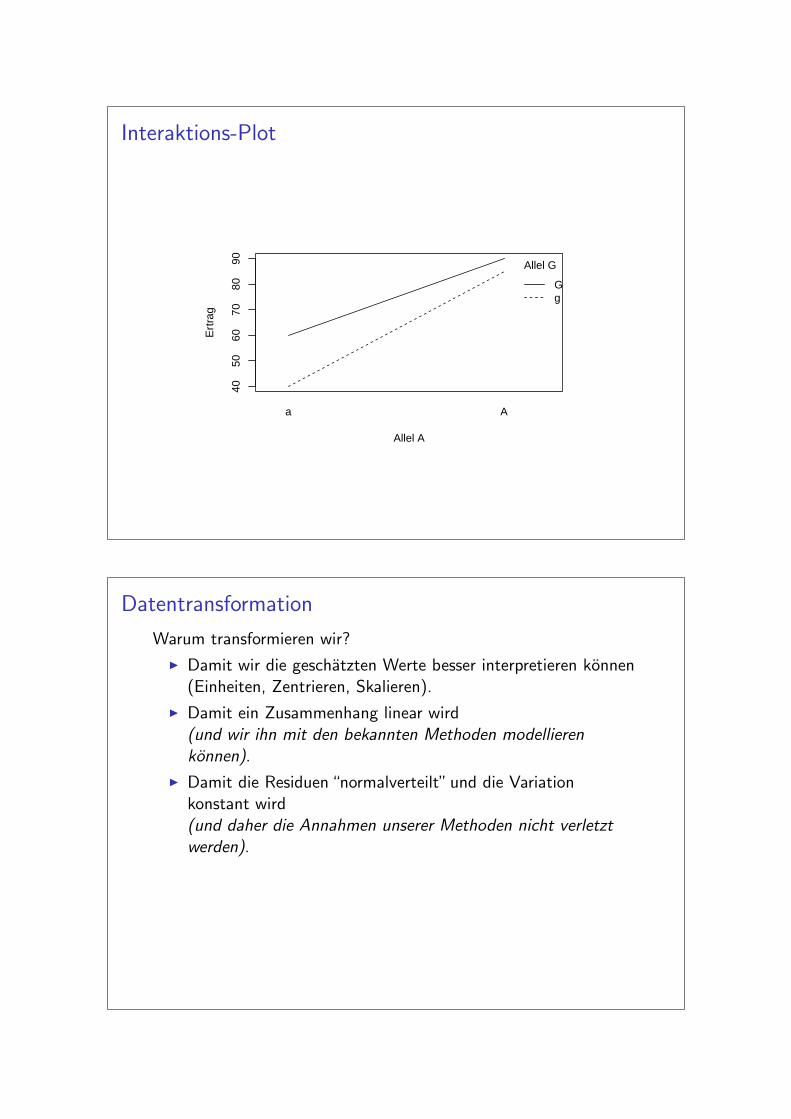
Interaktions-Plot
4050
6070
8090
Allel A
Ert
rag
a A
Allel G
Gg
Datentransformation
Warum transformieren wir?
I Damit wir die geschatzten Werte besser interpretieren konnen(Einheiten, Zentrieren, Skalieren).
I Damit ein Zusammenhang linear wird(und wir ihn mit den bekannten Methoden modellierenkonnen).
I Damit die Residuen “normalverteilt” und die Variationkonstant wird(und daher die Annahmen unserer Methoden nicht verletztwerden).
Exkurs: Allometrie
Beziehung zwischen der Grosse und der Form, Anatomie,Physiologie und auch des Verhaltens eines Organismus.Die klassische Formel
y = axb,
wird in der logarithmischen Form zu
log y = log a + b log x .
In dieser Form konnen wir u.a. durch Anpassen eines linearenModells die Parameter schatzen. Wenn eine Skalierung isometrischist erhalten wir eine Steigung von b = 1. Was fur eine Steigungerwarten wir bei einer isometrischen Skalierung, wenn y eineLangenangabe ist und x ein Volumen (oder Gewicht) darstellt?Durch Umformen ergibt sich log l = ...+ b log l3 = ...+ 3b log lund daher eine Steigung von 3.
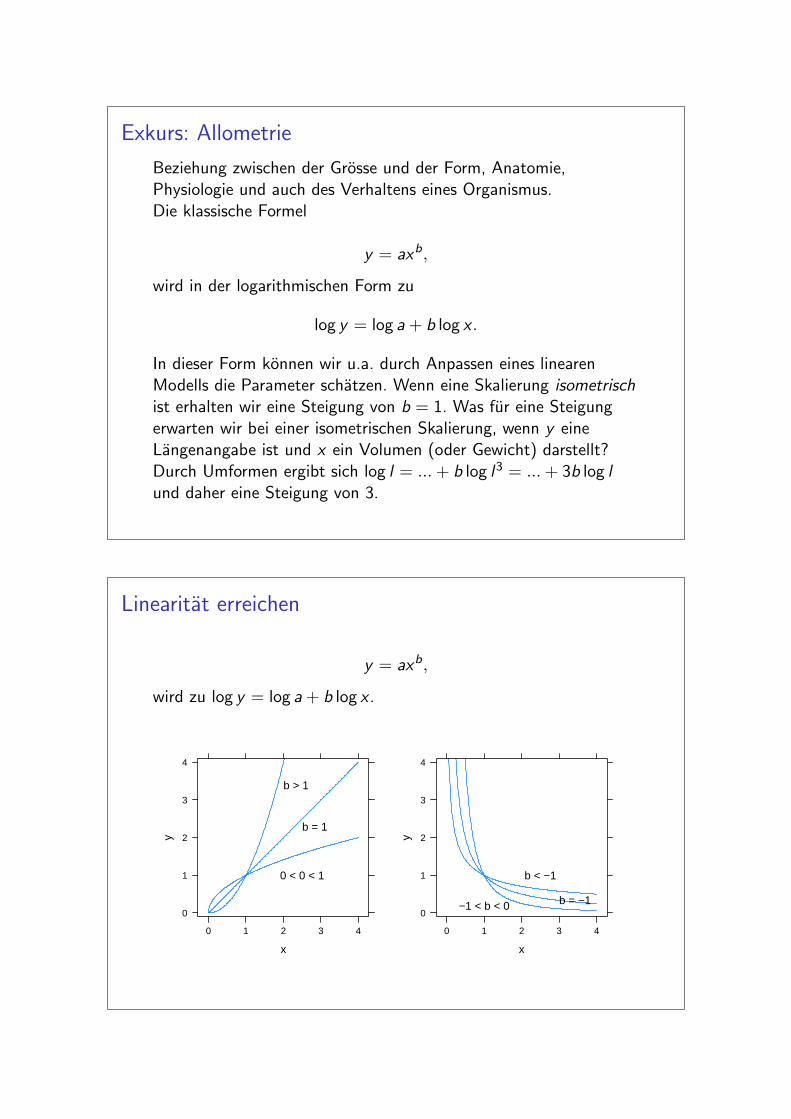
Linearitat erreichen
y = axb,
wird zu log y = log a + b log x .
x
y
0
1
2
3
4
0 1 2 3 4
b > 1
b = 1
0 < 0 < 1
x
y
0
1
2
3
4
0 1 2 3 4
−1 < b < 0 b = −1
b < −1
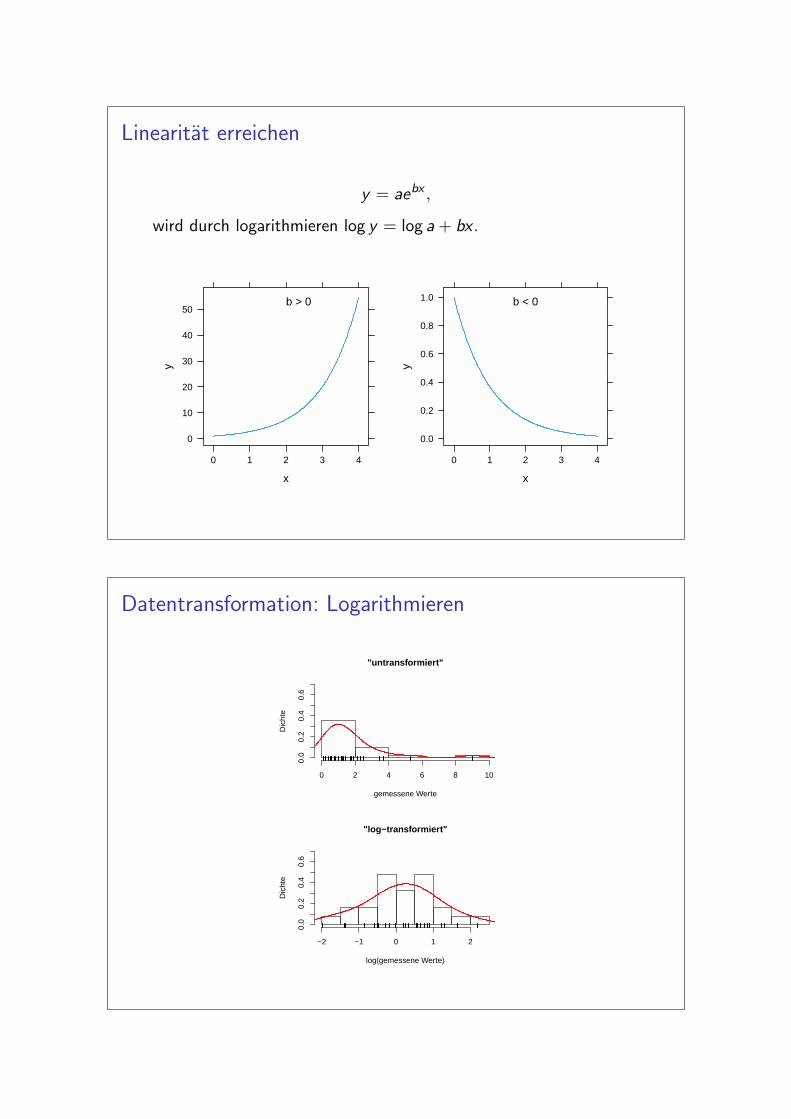
Linearitat erreichen
y = aebx ,
wird durch logarithmieren log y = log a + bx .
x
y
0
10
20
30
40
50
0 1 2 3 4
b > 0
x
y
0.0
0.2
0.4
0.6
0.8
1.0
0 1 2 3 4
b < 0
Datentransformation: Logarithmieren
"untransformiert"
gemessene Werte
Dic
hte
0 2 4 6 8 10
0.0
0.2
0.4
0.6
"log−transformiert"
log(gemessene Werte)
Dic
hte
−2 −1 0 1 2
0.0
0.2
0.4
0.6
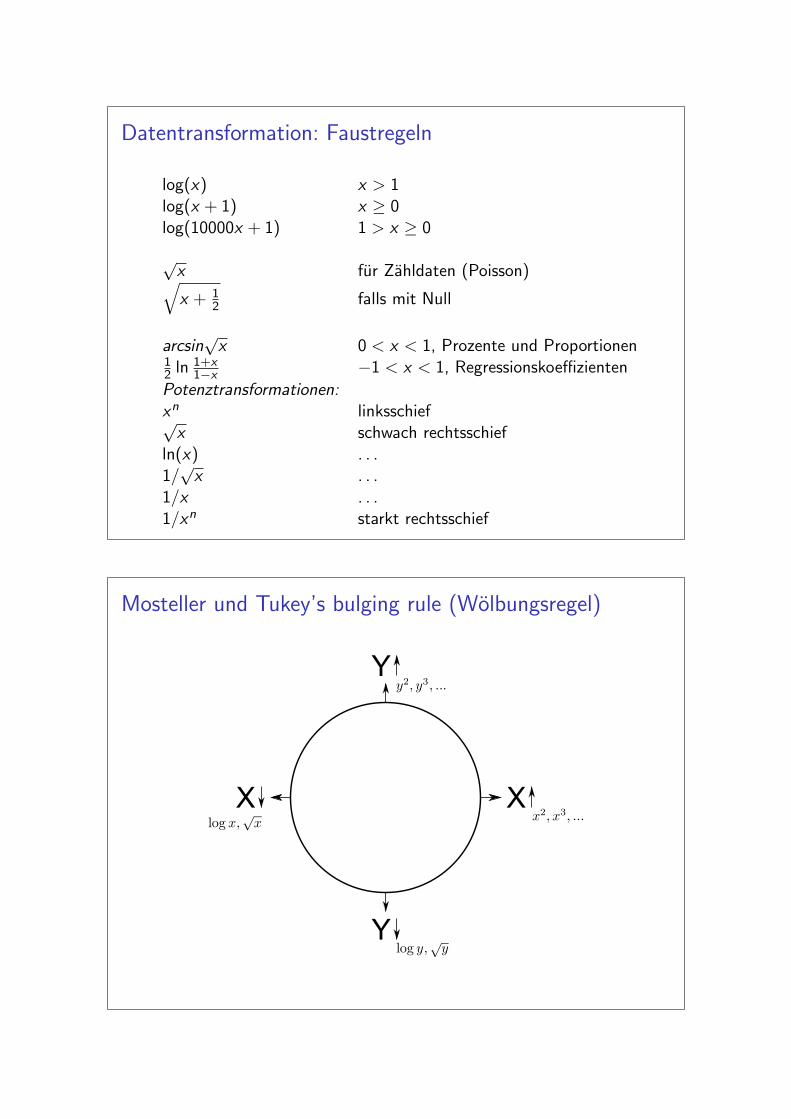
Datentransformation: Faustregeln
log(x) x > 1log(x + 1) x ≥ 0log(10000x + 1) 1 > x ≥ 0
√x fur Zahldaten (Poisson)√x + 1
2 falls mit Null
arcsin√
x 0 < x < 1, Prozente und Proportionen12 ln 1+x
1−x −1 < x < 1, Regressionskoeffizienten
Potenztransformationen:xn linksschief√
x schwach rechtsschiefln(x) . . .1/√
x . . .1/x . . .1/xn starkt rechtsschief
Mosteller und Tukey’s bulging rule (Wolbungsregel)
X
Y
X
Y

Voraussetzungen
E[yij ] = µ(xi ) = α + βxi = β0 + β1xiyij ∼ indep. N (α + βxi , σ
2)
I Die Streuung der Residuen ist konstant
I Erwartungswert der Residuen ist null
I Residuen sind normalverteilt
I Alle Messwerte haben denselben Einfluss/Hebelarm.
I Residuen sind unabhangig voneinander
Nicht unabhangige Residuen
GruppeA
Kör
perg
ewic
ht (
in k
g)
80
90
100
110
120
●
●
●
●
80
90
110
120

Nicht unabhangige Residuen
> summary(lm(y ~ 1))$coefficients
Estimate Std. Error t value Pr(>|t|)(Intercept) 100 9.128709 10.95445 0.001628625
Nicht unabhangige Residuen
GruppeA
Kör
perg
ewic
ht (
in k
g)
80
90
100
110
120
●
●
●
●
●
●
●
●
80
90
110
120
79
92
107
122

Nicht unabhangige Residuen
> summary(lm(y2 ~ 1))$coefficients
Estimate Std. Error t value Pr(>|t|)(Intercept) 100 6.032649 16.57647 7.101236e-07
Nicht unabhangige Residuen
> library(geepack)> summary(geeglm(y2 ~ 1, id = id, data = repData))$coefficients
Estimate Std.err Wald Pr(>|W|)(Intercept) 100 7.962804 157.7132 0

Was fuhrt zu nicht unabhangigen Residuen?
Information in den Daten welche nicht im Modell berucksichtigtwird.
I Zeitliche Abhangigkeiten, z.B. Saisonalitat
I Raumliche Abhangigkeiten
I Genetische Abhangigkeiten
I . . .
Was sind die Folgen von nicht unabhangigen Residuen?
Die Varianz welche geschatzt wird und sich u.a. auf dieStandardfehler der Schatzer und die Signifikanztests ubertragt istfalsch.

Was gibt es fur Losungen
Es muss eine andere Form der Modellierung verwendet werdenwelche es erlaubt die Struktur der Daten richtig zu berucksichtigen.
I Mixed Effects Modelle
I Generalized Estimating Equations (GEE)
I . . .
Ein Beispiel
Sie nehmen auf zwei Feldern (“Field”) jeweils drei Bodenproben(beschriftet mit “MeasurementID”) und bestimmen denStickstoffgehalt. Nun mochten Sie diese Daten analysieren.
> library(geepack)> m.gee <- geeglm(Soilnitrogen ~ Field, id = MeasurementID,+ data = na.omit(nitrogen))

Analyse von kategoriellen Daten
I Was fur Arten von Variabeln kennen Sie?
I Welche Arten von kategoriellen Daten kennen Sie?
Die wichtigsten Verteilungen von kategoriellen Daten
I Binomial Verteilung
I Multinominal Verteilung
I Poisson Verteilung

Binomial Verteilung
Wir gehen davon aus, dass es n unabhangige undidentische Ziehungen y1, y2, ..., yn gibt.
Jede Ziehung ist entweder yi = 0 oder 1 (Misserfolg/ Erfolg, FALSE / TRUE, “kein Event” / “Event”).
Die Wahrscheinlichkeit, dass eine Ziehung ein Erfolgist, bezeichnen wir als π.
Die Summer der Ziehungen folgt einer BinomialVerteilung.
Mittelwert nπ
Varianz nπ(1− π)
Identisch bedeutet, dass die Wahrscheinlichkeit eines Erfolgesbei allen Ziehungen dieselbe ist.
Unabhangig bedeutet, dass die Ziehung nicht von anderenZiehungen abhangt.
Multinominale Verteilung
Wie die binomial Verteilung aber jede unabhangige und identischeZiehung fallt in eine von c Kategorien.
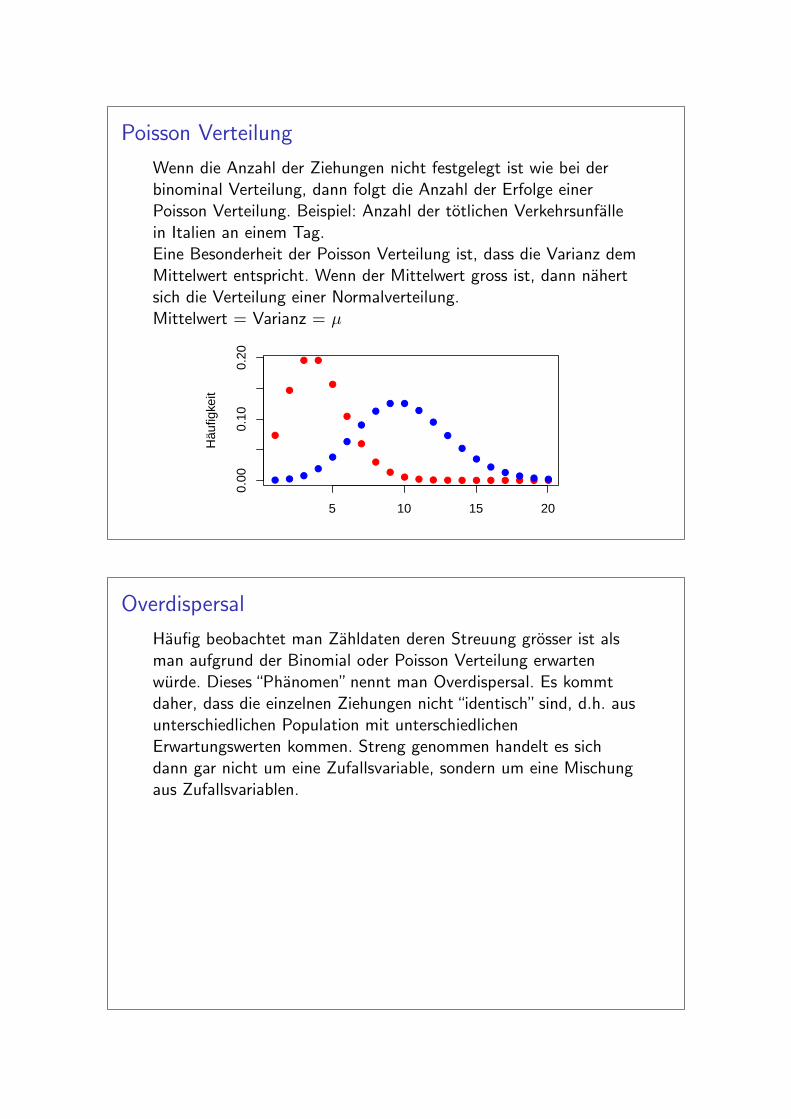
Poisson Verteilung
Wenn die Anzahl der Ziehungen nicht festgelegt ist wie bei derbinominal Verteilung, dann folgt die Anzahl der Erfolge einerPoisson Verteilung. Beispiel: Anzahl der totlichen Verkehrsunfallein Italien an einem Tag.Eine Besonderheit der Poisson Verteilung ist, dass die Varianz demMittelwert entspricht. Wenn der Mittelwert gross ist, dann nahertsich die Verteilung einer Normalverteilung.Mittelwert = Varianz = µ
●
●
● ●
●
●
●
●
●● ● ● ● ● ● ● ● ● ● ●
5 10 15 20
0.00
0.10
0.20
Häu
figke
it
● ● ●●
●
●
●
●● ●
●
●
●
●
●●
● ● ● ●
Overdispersal
Haufig beobachtet man Zahldaten deren Streuung grosser ist alsman aufgrund der Binomial oder Poisson Verteilung erwartenwurde. Dieses “Phanomen” nennt man Overdispersal. Es kommtdaher, dass die einzelnen Ziehungen nicht “identisch” sind, d.h. ausunterschiedlichen Population mit unterschiedlichenErwartungswerten kommen. Streng genommen handelt es sichdann gar nicht um eine Zufallsvariable, sondern um eine Mischungaus Zufallsvariablen.

Kreuztabellen, “contingency tables”
WuchsformFamilie Kraut Busch Baum
Fabaceae 218 56 6 280Rosaceae 76 76 28 180
294 132 34 460
I Beides (Familie und Wuchsform) sind Zielvariablen(“response”, “outcome”) und nicht erklarende Variablen.
I Gibt es einen Zusammenhang zwischen Wuchsform undFamilie?
I Der χ2-Test oder der Fisher-Exakt-Test (nur fur 2 x 2Tabellen) testen dieNullhypothese: Es gibt keinen Zusammenhang.
I Viel wichtiger als der Test ist allerdings die Starke desZusammenhangs.
Testen des Zusammenhangs
Pearson's Chi-squared test
data: table(plants$family, plants$type)X-squared = 67.2916, df = 2, p-value = 2.442e-15
I Was sagt uns dieser Test?
I Was sagt uns dieser Test nicht?

Testen des Zusammenhangs
WuchsformFamilie Kraut Busch Baum
Fabaceae 218 56 6 280Rosaceae 76 76 28 180
294 132 34 460
I Wir erwarten Fabaceae und Rosaceae mit einer Proportionvon 0.61 und 0.39.
I Wir erwarten die Wuchsform Kraut, Busch oder Baum miteiner Proportion von 0.64, 0.29, 0.07.
I Daraus konnen wir die Proportion fur die einzelnen Zellenberechnen (“Erwartungswerte”).
WuchsformFamilie Kraut Busch Baum
Fabaceae 0.39 0.17 0.04
Rosaceae 0.25 0.11 0.03
WuchsformFamilie Kraut Busch Baum
Fabaceae 0.39 0.17 0.04(0.47) (0.12) (0.01)
Rosaceae 0.25 0.11 0.03(0.17) (0.17) (0.06)
WuchsformFamilie Kraut Busch Baum
Fabaceae 0.39 0.17 0.04(0.47) (0.12) (0.01)[2.92] [-2.72] [-3.23]
Rosaceae 0.25 0.11 0.03(0.17) (0.17) (0.06)[-3.64] [3.39] [4.03]
I Um den Ursprung des Testresultates zu untersuchenberechnen wir die “Erwartungswerte” fur die einzelnen Zellenund vergleichen diese mit den Beobachtungen; “Nomenklatur”Erwartungswert (Beobachtete Werte) [Residuen].
I Um die Starke des Zusammenhangs zu beschreiben zerlegenwir die Tabelle in Teile.
Beschreibung von Zusammenhangen kategorieller Variablen
Daten aus einem Pestizidexperimet mit Helothis virescens, einemEulenfalter dessen Larven auf Tabakpflanzen leben.
UberlebenGeschlecht tot lebend
mannlich 4 16 20weiblich 2 18 20
6 34 40
I Differenz zwischen zwei Proportionen, π1 − π2
I Relative Risk, π1/π2
I Odds Ratio

Differenz zwischen zwei Proportionen, π1 − π2
Wird auch als “absolute risk difference” bezeichnet.Wickler Beispiel: pmale − pfemale = 4/20− 2/20 = 1/10
> prop.test(x = c(4, 2), n = c(20, 20))
2-sample test for equality of proportions withcontinuity correction
data: c(4, 2) out of c(20, 20)X-squared = 0.1961, df = 1, p-value = 0.6579alternative hypothesis: two.sided95 percent confidence interval:-0.1691306 0.3691306sample estimates:prop 1 prop 2
0.2 0.1
I Wertebereich: −1, . . . , 1
Relative Risk, π1/π2
Es ist moglich, dass der Unterschied zwischen zwei Differenzenanders zu interpretieren ist, wenn beide π klein oder gross sind, alswenn beide nahe bei 0.5 sind.Wickler Beispiel: pmale/pfemale = (4/20)/(2/20) = 2Das 95% Vertrauensintervall dazu liegt bei [0.43; 7.47].
I Wertebereich: 0, . . . ,∞

Odds Ratio
Fur ein Ereignis mit der Wahrscheinlichkeit π sind die Oddsdefiniert als π/(1− π), wie beim Wetten. Im Beispiel sind also dieOdds fur die Mannchen (4/20)/(16/20) = 0.25. Das bedeutet,dass es fur ein Mannchen vier mal weniger wahrscheinlich ist zusterben, als zu uberleben. Das Verhaltnis
θ =π1/(1− π1)
π2/(1− π2)
nennt man “odds ratio”.Es betragt in unserem Beispiel((4/20)/(16/20))/((2/20)/(18/20)) = 2.25
I Das Odds Ratio andert nicht, wenn wir Zeilen und Spaltenvertauschen, d.h. wir mussen uns nicht auf eine Zielvariablefestlegen.
I Wertebereich: 0, . . . ,∞
Struktur von glm’s (generalized linear model)
E[yij ] = β0 + β1x1 + β2x2 + . . .+ βnxnyij ∼ indep. N (β0 + β1x1 + β2x2 + . . .+ βnxn, σ
2)
I Diese Form kennen wir von Regressionen und in fastidentischer Form kennen wir die Form auch von ANOVAs undANCOVAs.
I Das Anwendungsspektrum lasst sich jedoch stark erweitern,wenn man zusatzliche Flexibilitat einfuhrt.
- andere Verteilungen- eine Funktion welche den Zusammenhang zwischen dem
“linearen predictor” und dem Erwartungswert E[yij ] beschreibt.
E[yi ] = h(ηi )
Die Funktion h bezeichnen wir als “response function”. Haufigwird jedoch die Umkehrfunktion h−1 = g beschrieben, welcheals “link function” oder einfach als “link” bezeichnet wird.

Struktur von glm’s (generalized linear model)
Fur eine “gewohnliche” Regression wurde also die Beschreibunglauten:
ηi = β0 + β1x1 + β2x2 + . . .+ βnxn “linear predictor”E[yi ] = h(ηi ) = ηi “response function”
yi ∼ indep. N (ηi , σ2) “Verteilungsannahme”
Logistische Regression
Ein glm welches sehr haufig verwendet wird ist die logistischeRegression.
ηi = β0 + β1x1 + β2x2 + . . .+ βnxnE[yi ] = πi = h(ηi ) = eη
1+eη
yi ∼ indep. B(πi )
I Fur den “linar predictor”ηi gilt das selbe wie bei einerRegression bzw. ANOVA.
I Als “link function” wahlen wir die sogennante “logit” Funktion,h−1(x) = g(x) = log( x
1−x ) (Der Name “logit” stammt von logwie Logarithmus und Odds).
I Als Verteilung wahlt man eine Bernoulli Verteilung, B(πi ), miteinem Parameter, der Wahrscheinlichkeit π des Ereignisses.

Logistische Regression, Interpretation der Koeffizienten
Wir betrachten einige Umformungen:log πi
1−πi = α + βxiπi
1−πi = eα+βxi
= eαeβxi
Wenn wir nun x um eins erhohen, d.h. x ersetzten durch x + 1,πi
1−πi = eαeβ(xi+1)
= eαeβxi eβ
Daraus sehen wir, dass sich die Odds um den Faktor eβ verandern,wenn wir von x nach x + 1 gehen.
Logistische Regression mit kategoriellen Pradiktoren
UberlebenGeschlecht tot lebend
mannlich 4 16 20weiblich 2 18 20
6 34 40
Odds furs Sterben der Mannchen: om = 4/20(1−4/20) = 0.25.
Odds furs Sterben der Weibchen: of = 2/20(1−2/20) = 0.111.
Odds Ratio: OR = omof
= 2.25
Daraus ergibt sich z.B. of OR = om

> y <- cbind(dead = c(2, 4), alive = c(18, 16))> sex <- factor(c("female", "male"))> glm1 <- glm(y ~ sex, family = "binomial")> summary(glm1)$coefficients
Estimate Std. Error z value Pr(>|z|)(Intercept) -2.1972246 0.745356 -2.9478861 0.003199549sexmale 0.8109302 0.931695 0.8703816 0.384091875
I eα = e−2.2 = 0.11 schatzt uns die Odds fur die Weibchen miteinem Standardfehler.
I e β = e0.81 = 2.25 schatzt uns das Oddsratio, d.h. den Faktormit welchem wir die Odds der Weibchen multiplizieren mussenum die Odds der Mannchen zu erhalten. Auch das Oddsratiowird mit einem Standardfehler geschatzt.
Logistische Regression mit kontinuierlichen Pradiktoren
Im selben Versuch mit Heliothis virescens wurden 6 verschiedeneDosen des selben Wirkstoffes untersucht.
Dosis1 2 4 8 16 32
Geschlecht mannlich 1 4 9 13 18 20weiblich 0 2 6 10 12 16
Wir fokusieren uns zuerst mal nur auf die Mannchen.

Logistische Regression mit kontinuierlichen Pradiktoren
Eine mogliche Forschungsfrage konnte lauten:Nimmt die Sterblichkeit mit zunehmender Dosis signifikant zu?Da wir erwarten, dass sich das Oddsratio jeweils gleich verandert,wenn wir die Dosis verdoppeln, werden wir den Logarithmus derDosis (mit der Basis 2) als Pradiktor verwenden.
> library(asuR)> data(budworm)> glm2 <- glm(cbind(num.dead, num.alive) ~ log2(dose),+ data = budworm[budworm$sex == "male", ], family = "binomial")> summary(glm2)$coefficients
Estimate Std. Error z value Pr(>|z|)(Intercept) -2.818555 0.5479868 -5.143472 2.697066e-07log2(dose) 1.258949 0.2120655 5.936607 2.909816e-09

> summary(glm2)$coefficients
Estimate Std. Error z value Pr(>|z|)(Intercept) -2.818555 0.5479868 -5.143472 2.697066e-07log2(dose) 1.258949 0.2120655 5.936607 2.909816e-09
1 2 4 8 16 32
0
0.2
0.4
0.6
0.8
1
Dosis
Wah
rsch
einl
ichk
eit z
u S
terb
en
1916 11 7 2 0
1 4 9 13 18 20
●
●
●
●
●
●
0.05
0.25
0.82
1.86
9
Inf
●
I eβ = e1.26 = 3.52 gibt an um welchen Faktor die Oddszunehmen wenn wir die Dosis um den Faktor 2 erhohen.
I −α/β gibt uns die Dosis an wo die Halfte der Tiere sterben.
Multivariate logistische Regression
Selbstverstandlich wurde es uns jetzt interessieren mit demDatensatz ein multivariates Modell zu rechnen. Damit konnten wirdie Sterblichkeit mit zwei Pradiktoren Dosis und Geschlechtgleichzeitig erklaren. Dadurch lasst sich u.a. die Frage beantwortenob die Sterblichkeit unterschiedlich ist zwischen den Geschlechtern.
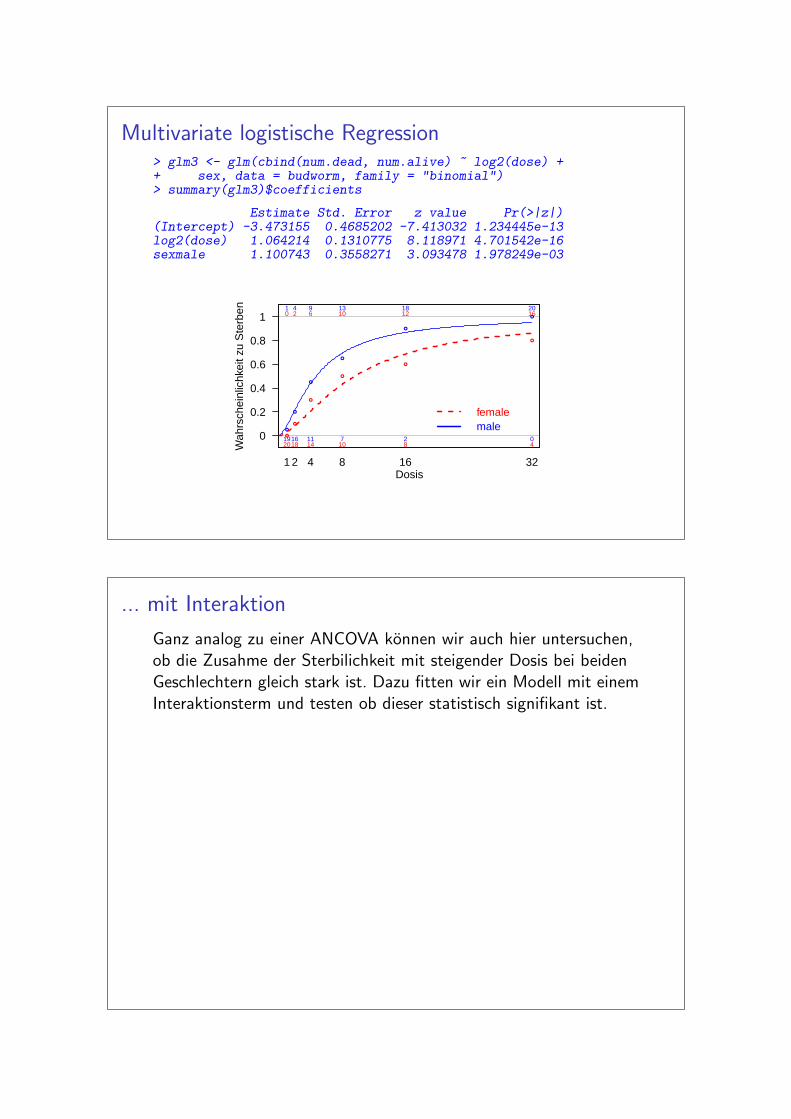
Multivariate logistische Regression> glm3 <- glm(cbind(num.dead, num.alive) ~ log2(dose) ++ sex, data = budworm, family = "binomial")> summary(glm3)$coefficients
Estimate Std. Error z value Pr(>|z|)(Intercept) -3.473155 0.4685202 -7.413032 1.234445e-13log2(dose) 1.064214 0.1310775 8.118971 4.701542e-16sexmale 1.100743 0.3558271 3.093478 1.978249e-03
1 2 4 8 16 32
0
0.2
0.4
0.6
0.8
1
Dosis
Wah
rsch
einl
ichk
eit z
u S
terb
en
1916 11 7 2 0
1 4 9 13 18 20
●
●
●
●
●
●
2018 14 10 8 4
0 2 6 10 12 16
●
●
●
●
●
●
femalemale
... mit Interaktion
Ganz analog zu einer ANCOVA konnen wir auch hier untersuchen,ob die Zusahme der Sterbilichkeit mit steigender Dosis bei beidenGeschlechtern gleich stark ist. Dazu fitten wir ein Modell mit einemInteraktionsterm und testen ob dieser statistisch signifikant ist.

Multivariate logistische Regression
> glm4 <- glm(cbind(num.dead, num.alive) ~ log2(dose) *+ sex, data = budworm, family = "binomial")> round(summary(glm4)$coefficients, 3)
Estimate Std. Error z value Pr(>|z|)(Intercept) -2.994 0.553 -5.416 0.000log2(dose) 0.906 0.167 5.422 0.000sexmale 0.175 0.778 0.225 0.822log2(dose):sexmale 0.353 0.270 1.307 0.191
Multivariate logistische Regression
> glm5 <- glm(cbind(num.dead, num.alive) ~ I(log2(dose) -+ 3) * sex, data = budworm, family = "binomial")> round(summary(glm5)$coefficients, 3)
Estimate Std. Error z value(Intercept) -0.275 0.231 -1.195I(log2(dose) - 3) 0.906 0.167 5.422sexmale 1.234 0.377 3.273I(log2(dose) - 3):sexmale 0.353 0.270 1.307
Pr(>|z|)(Intercept) 0.232I(log2(dose) - 3) 0.000sexmale 0.001I(log2(dose) - 3):sexmale 0.191

Multivariate logistische Regression
> glm6 <- glm(cbind(num.dead, num.alive) ~ I(log2(dose) -+ 3) + sex, data = budworm, family = "binomial")> round(summary(glm6)$coefficients, 3)
Estimate Std. Error z value Pr(>|z|)(Intercept) -0.281 0.243 -1.154 0.249I(log2(dose) - 3) 1.064 0.131 8.119 0.000sexmale 1.101 0.356 3.093 0.002
Overdispersion
Wenn wir eine logistische Regression rechnen ist der sog.“dispersion parameter” immer auf eins gesetzt. Das ist fast einbisschen so wie wenn wir in einer gewohnlichen Regression denStandardfehler, σ, auf eins setzten wurden.Um zu uberprufen, ob die beobachtete Variation grosser ist, als wirunter idealen Bedingungen einer logistischen Regression annahmen,konnen wir den “dispersion parameter” schatzten.Dazu fitten wir ein quasibinomiales GLM.
I Wir sehen wie der “dispersion parameter” geschatzt wird.
I Wir sehen ob das Berucksichtigen des “dispersion parameters”unsere Resultate qualitativ verandert.

Overdispersion> glm6.quasi <- glm(cbind(num.dead, num.alive) ~+ I(log2(dose) - 3) + sex, data = budworm, family = "quasibinomial")> summary(glm6.quasi)
Call:glm(formula = cbind(num.dead, num.alive) ~ I(log2(dose) - 3) +
sex, family = "quasibinomial", data = budworm)
Deviance Residuals:Min 1Q Median 3Q Max
-1.10540 -0.65343 -0.02225 0.48471 1.42944
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.2805 0.1867 -1.503 0.16714I(log2(dose) - 3) 1.0642 0.1006 10.574 2.24e-06 ***sexmale 1.1007 0.2732 4.029 0.00298 **---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasibinomial family taken to be 0.5895578)
Null deviance: 124.8756 on 11 degrees of freedomResidual deviance: 6.7571 on 9 degrees of freedomAIC: NA
Number of Fisher Scoring iterations: 4
GLM FamilienVerteilung mogliche Link-Funktiongaussian identity
log
inverse
binomial logit (logistisch)probit (normal)cauchit
log
cloglog complementary log-logGamma inverse
identity
log
poisson log
identity
sqrt
inverse.gaussian 1/mu^2
inverse
identity
log
Hinweis: Modelle mit dem selben linearen Pradiktoren, η, aber miteiner unterschiedlichen Link-Funktion, g , konnen nur informellverglichen aber nicht “getestet” werden.

Mixed Effects Models
Eine Unterscheidung welche nur auf kategorielle Pradiktorenzutrifft.
“Fixed Effects” Wenn es eine endliche Zahl an Kategorien (“levels”)gibt denen wir einen Effekt zuordnen und wir an denEffekten der einzelnen Kategorien interessiert sind.Das Interesse liegt beim Schatzen der Mittelwerte.
“Random Effects” Wenn es unendlich viele Kategorien gibt abernur ein zufalliger Teil davon in unserer Stichprobegelandet ist und wir nicht an den Effekten dereinzelnen Kategorien interessiert sind. Das Interesseliegt beim Schatzen der Varianz.
Oft ist es direkt aus der Fragestellung moglich zu unterscheiden obein “Random Effect” oder ein “Fixed Effect” vorliegt.
Mixed Effects Models: Ein Beispiel
Sie mochten wissen, ob Knaben (5. Schuljahr) bessere Schulnotenim Fach Mathe haben als Madchen.Dazu haben Sie die Schulnoten eines ganzen Bezirkes erhalten undwissen zu jedem Schuler das Geschlecht, die Bezeichnung derSchule und die Bezeichnung der Klasse.
Schulnote, y Response
Geschlecht, β Fixed Effect
Schule, s Random Effect
Klasse, c Random Effect (genested in Schule)
E[ytijk | si , cij ] = µ+ βt + si + cijytijk | si , cij ∼ indep. N (µ+ βt + si + cij ; σ2
s + σ2c + σ2)
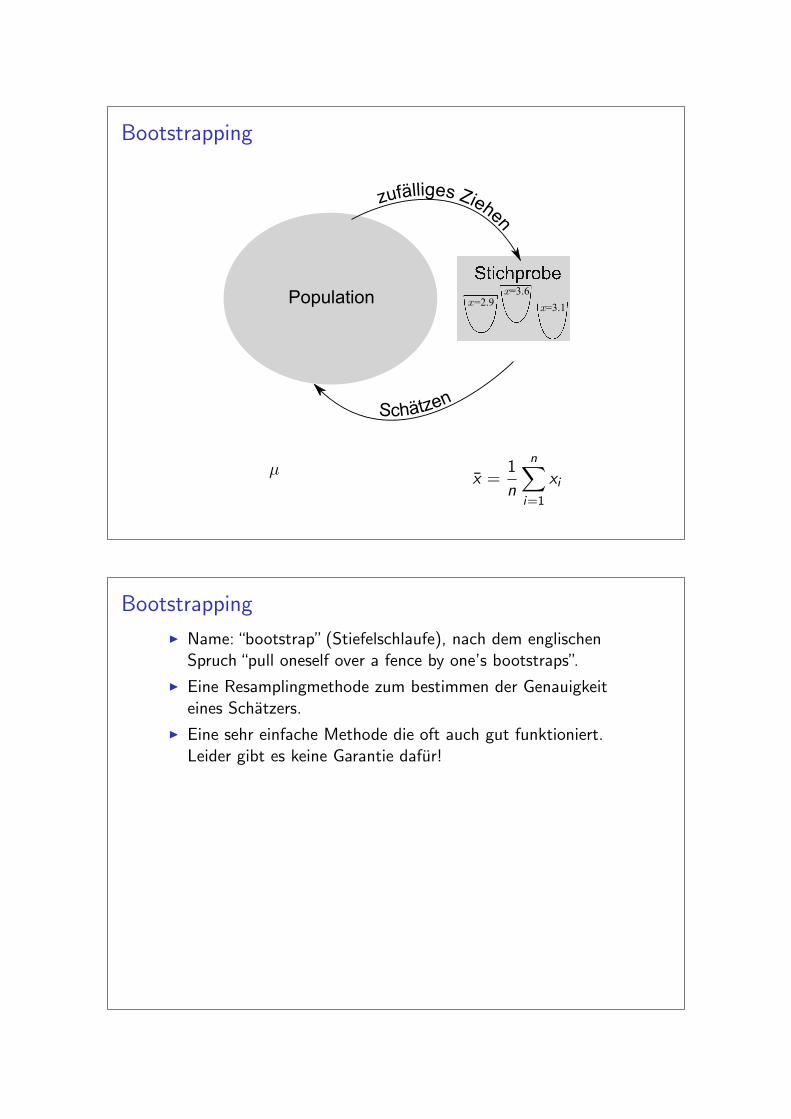
Bootstrapping
µx =
1
n
n∑
i=1
xi
Bootstrapping
I Name: “bootstrap” (Stiefelschlaufe), nach dem englischenSpruch “pull oneself over a fence by one’s bootstraps”.
I Eine Resamplingmethode zum bestimmen der Genauigkeiteines Schatzers.
I Eine sehr einfache Methode die oft auch gut funktioniert.Leider gibt es keine Garantie dafur!

Bootstrapping
I Es gibt viele verschiedene Arten wie wiederholt eine Stichprobegezogen werden kann. Ich mochte kurz auf das parametrischeund das nicht-parametrische Bootstrapping eingehen.
I Das wiederholte Ziehen (“resampling”) fuhrt immer dazu, dassman neben dem Schatzer, t, fur den Parameter, θ, sehr vieleweiter Bootstrap-Schatzer, t∗ generiert. Die Anzahl derZiehungen bezeichnet man meist als R.
I Aus diesen kann dann ein Vertrauensintervall berechnetwerden. Dazu gibt es verschiedene Moglichkeiten. Das sog.“basic” Vertrauensintervall lautet
2t − t∗((R+1)(1−α/2)), 2t − t∗((R+1)(α/2)).
Parametrisches Bootstrapping
I Aus der Stichprobe wird der Mittelwert x und die Varianz σ2
der Population geschatzt.
I Mit diesen Angaben wird die Verteilung beschrieben N (x , σ2)aus der dann wiederholt gezogen wird.
Das Parametrische Bootstrapping liefert oft bessere Resultate alsandere Verfahren.

Nichtparametrisches Bootstrapping
I Das wiederholte Ziehen erfolgt direkt aus der Stichprobe.
Theoriefragen zu den bisherigen Inhalten
I Was misst die Pearson bzw. die Spearman Korrelation?
I Wann verwendet man eine Korrelation, wann eine Regression?
I Durfen die Messungen von verschiedenen Individuen in einerRegression korreliert sein? Begrunden Sie?
I Warum transformieren wir Daten?

Theoriefragen zu den bisherigen Inhalten
I Was bedeutet Overdispersal?
I Wieso tritt bei der gewohnlichen Regression nicht auchOverdispersal auf?
I Was untersucht der χ2-Test oder der Fisher-Exakt-Test?
I Welches sind die drei haufigsten Arten wie man denZusammenhang zwischen Proportionen beschreibt?
I Was ist ein Odds Ratio?
Theoriefragen zu den bisherigen Inhalten
I Nennen Sie die drei Aspekte die man verwenden kann um einGLM zu charakterisieren.
I Wie lautet die Linkfunktion einer logistischen Regression?
I Wie gross ist der “dispersion parameter” in einem GLM?

Affiliation and copyright
Vielen Dank an Dr. Thomas Zumbrunn und Dr. Stefanie von Feltenvon denen ich mehrere Ideen und Beispiele ubernommen habe.© Thomas Fabbro 2012
This work is licensed under the Creative CommonsAttribution-Noncommercial-Share Alike 2.5 Switzerland Licence.
To view a copy of this licence, visithttp://creativecommons.org/licenses/by-nc-sa/2.5/ch/


















