
Effect of the Sampling of a Dataset in the Hyperparameter...
17
Research Article Effect of the Sampling of a Dataset in the Hyperparameter Optimization Phase over the Efficiency of a Machine Learning Algorithm Noem- DeCastro-Garc-a , 1 Ángel Luis Muñoz Castañeda, 2 David Escudero Garc-a, 2 and Miguel V. Carriegos 1 1 Departamento de Matem´ aticas, Universidad de Le´ on, Campus de Vegazana s/n, 24071 Le´ on, Spain 2 Research Institute on Applied Sciences in Cybersecurity, Universidad de Le´ on, Campus de Vegazana s/n, 24071 Le´ on, Spain Correspondence should be addressed to Noem´ ı DeCastro-Garc´ ıa; [email protected] Received 7 December 2018; Accepted 17 January 2019; Published 4 February 2019 Guest Editor: Fernando S´ anchez Lasheras Copyright © 2019 Noem´ ı DeCastro-Garc´ ıa et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Selecting the best configuration of hyperparameter values for a Machine Learning model yields directly in the performance of the model on the dataset. It is a laborious task that usually requires deep knowledge of the hyperparameter optimizations methods and the Machine Learning algorithms. Although there exist several automatic optimization techniques, these usually take significant resources, increasing the dynamic complexity in order to obtain a great accuracy. Since one of the most critical aspects in this computational consume is the available dataset, among others, in this paper we perform a study of the effect of using different partitions of a dataset in the hyperparameter optimization phase over the efficiency of a Machine Learning algorithm. Nonparametric inference has been used to measure the rate of different behaviors of the accuracy, time, and spatial complexity that are obtained among the partitions and the whole dataset. Also, a level of gain is assigned to each partition allowing us to study patterns and allocate whose samples are more profitable. Since Cybersecurity is a discipline in which the efficiency of Artificial Intelligence techniques is a key aspect in order to extract actionable knowledge, the statistical analyses have been carried out over five Cybersecurity datasets. 1. Introduction A Machine Learning (ML) solution for a classification prob- lem is effective if it works efficiently in terms of accuracy and the required computational cost. e improvement of the first factor is faced on by several points of view that could affect to the second one in different forms. e simplest way to get a ML model with a good accuracy is by testing and comparing different ML algorithms for the same problem and choosing, finally, the one that performs better. However, it is clear that, for instance, a decision tree model does not require, in general, as much computational time and memory to be trained as a Multilayer Perceptron. So, we will need to adjust the achieved accuracy with the available resources. Another usual effective approach to reach a high accuracy is working with large training datasets. Nevertheless, this solution is limited because of the associated computational cost (obtaining and storing the data, cleaning and transfor- mation processes, and learning from the data). A possible alternative to the mentioned problem is to reduce the training without losing too much information [1, 2]. However, these kinds of solutions used to need an expensive data preprocess- ing phase. e research related to this aspect, in addition to usual filtering the data, is focused on how to optimize the training set, and not only reduce it. e progressive sampling method shows that the performance with random samples with determined sizes is equal or more effective than working with the entire dataset [3]. Also, this solution used to be perfected with specifications about the classes’ distribution, the selection of the samples, or the treatment of unbalanced datasets [4–6]. Hindawi Complexity Volume 2019, Article ID 6278908, 16 pages https://doi.org/10.1155/2019/6278908
Transcript of Effect of the Sampling of a Dataset in the Hyperparameter...

Research ArticleEffect of the Sampling of a Dataset inthe Hyperparameter Optimization Phase over the Efficiency ofa Machine Learning Algorithm
Noem- DeCastro-Garc-a 1 Aacutengel Luis Muntildeoz Castantildeeda2
David Escudero Garc-a2 and Miguel V Carriegos1
1Departamento de Matematicas Universidad de Leon Campus de Vegazana sn 24071 Leon Spain2Research Institute on Applied Sciences in Cybersecurity Universidad de Leon Campus de Vegazana sn 24071 Leon Spain
Correspondence should be addressed to Noemı DeCastro-Garcıa ncasgunileones
Received 7 December 2018 Accepted 17 January 2019 Published 4 February 2019
Guest Editor Fernando Sanchez Lasheras
Copyright copy 2019 Noemı DeCastro-Garcıa et alThis is an open access article distributed under the Creative Commons AttributionLicensewhichpermits unrestricteduse distribution and reproduction in anymedium provided the original work is properly cited
Selecting the best configuration of hyperparameter values for a Machine Learning model yields directly in the performanceof the model on the dataset It is a laborious task that usually requires deep knowledge of the hyperparameter optimizationsmethods and the Machine Learning algorithms Although there exist several automatic optimization techniques these usuallytake significant resources increasing the dynamic complexity in order to obtain a great accuracy Since one of the most criticalaspects in this computational consume is the available dataset among others in this paper we perform a study of the effect of usingdifferent partitions of a dataset in the hyperparameter optimization phase over the efficiency of a Machine Learning algorithmNonparametric inference has been used tomeasure the rate of different behaviors of the accuracy time and spatial complexity thatare obtained among the partitions and the whole dataset Also a level of gain is assigned to each partition allowing us to studypatterns and allocate whose samples are more profitable Since Cybersecurity is a discipline in which the efficiency of ArtificialIntelligence techniques is a key aspect in order to extract actionable knowledge the statistical analyses have been carried out overfive Cybersecurity datasets
1 Introduction
AMachine Learning (ML) solution for a classification prob-lem is effective if it works efficiently in terms of accuracy andthe required computational costThe improvement of the firstfactor is faced on by several points of view that could affect tothe second one in different forms
The simplest way to get aMLmodel with a good accuracyis by testing and comparing different ML algorithms for thesame problem and choosing finally the one that performsbetter However it is clear that for instance a decision treemodel does not require in general as much computationaltime andmemory to be trained as aMultilayer Perceptron Sowewill need to adjust the achieved accuracywith the availableresources
Another usual effective approach to reach a high accuracyis working with large training datasets Nevertheless this
solution is limited because of the associated computationalcost (obtaining and storing the data cleaning and transfor-mation processes and learning from the data) A possiblealternative to thementioned problem is to reduce the trainingwithout losing too much information [1 2] However thesekinds of solutions used to need an expensive data preprocess-ing phase
The research related to this aspect in addition to usualfiltering the data is focused on how to optimize the trainingset and not only reduce it The progressive sampling methodshows that the performance with random samples withdetermined sizes is equal or more effective than workingwith the entire dataset [3] Also this solution used to beperfected with specifications about the classesrsquo distributionthe selection of the samples or the treatment of unbalanceddatasets [4ndash6]
HindawiComplexityVolume 2019 Article ID 6278908 16 pageshttpsdoiorg10115520196278908
2 Complexity
On the other hand tuning hyperparameters of a MLalgorithm is a critical aspect of the model training processthat is considered the best practice for obtaining a successfulMachine Learning application [7] The HyperparametersOptimization (HPO) problem requires a deep understandingof the ML model at hand due to the hyperparameters valuessettings and their effectivity depending strongly on theML algorithm and the type of hyperparameter discrete orcontinuous values Also it is a very costly process due tothe large number of possible combinations to test and theneeded resources to carry out the computations Excludingthe human expert of the process and minimizing the hyper-parameter configurations to test are the underlying ideas inthe automatic HPO
Given a supervised ML algorithm the continuous HPOis usually solved by gradient descent-based methods [8ndash10] In the discrete case not all optimization methods aresuitable Themost common approaches to the HPO problemin the discrete case can be divided into two Bayesian [11]and decision-theoretic methods However there are otheroptimization algorithms that are applied to the problem ofhyperparameter values selectionThis is the case for instanceof the derivative-free optimization the genetic algorithmssuch as Covariance Matrix Adaptation Evolutionary Strate-gies (CMA-ES) or the simplex Nelder-Mead (NM) method[12ndash14] In addition continuous optimization methods suchas the Particle Swarm (PS) used for the ML algorithmsof least-squares support vector machines [15ndash17] could beapplied over discrete HPO problems [18]
Bayesian HPO algorithms balance the exploration pro-cess for finding promising hyperparameter configurationsand the exploitation of the setting configuration in order toobtain always better results or gain more information witheach test [19] Consequently Bayesian HPO are serializedmethods that are difficult to parallelize but they usuallycan find better combinations of hyperparameters in a fewiterationsOne of themost important BayesianHPOmethodsis the Model-Based Optimization (SMBO) In the SMBOtechniques the way to construct the surrogate function tomodel the error distribution provides different methodsThere are those that use Gaussian Process (GP) [20] or tree-based algorithms such as the Sequential Model AutomaticConfiguration (SMAC) or the Tree Parzen Estimators (TPE)method [21 22] On the other hand the decision-theoreticapproaches are based on the idea to search combinationsof hyperparameter in the hyperparameter space computingtheir accuracy and finally pick the one that performed thebest If we test over a fixed domain of hyperparameters valueswe have the grid search More effective than grid search eventhan some Bayesian optimization techniques is the randomsampling of different choices Random Search (RS) [23] It iseasy to implement independent of previous knowledge andeasily parallelizableOther optimization approaches also havereached very good results when applied to the selection ofhyperparameter values This is the case of research of [24]where evolutionary computation is used over deep neuralnetworks
Although applying HPO algorithms on a ML modelreflects a great improvement in the resultsrsquo quality of the
modelsrsquo accuracy we cannot overlook the computationalcomplexity to implement these techniques It is a critical issuebecause obtaining a good performance by applying HPOcould require generationsrsquo samples several function evalua-tions and expensive computational resources For examplethe GP methods usually require a high number of itera-tions Likewise some derivative-free optimizations behavepoorly in hyperparameter optimization problems because theoptimization target is smooth [25] In addition some MLalgorithms such as the neural networks are especially delicatebecause the number of possible values for the hyperparame-ters grows exponentially with the number of hidden layersOther HPO algorithms are designed taking into accountthese limitations
Recently a Radial Basis Function (RBF) has been pro-posed as a deterministic surrogate model to approximatethe error function of the hyperparameters through dynamiccoordinate search that requires fewer evaluations in Mul-tilayer Perceptron (MLP) and convolutional neural net-works [26] In [27] the Nelder-Mead and coordinate-search(derivative-free) methods are tested over deep neural net-works presenting more efficient numerical results than otherwell-known algorithms Another option is to try to acceleratethe algorithm In [28] one way to implement the schemeSuccessive Halving (SH) is developed The main ingredientbehind SH is based on the observation that most of theHPOalgorithms are iterativewhich suggests that stopping thealgorithm when testing with a set of hyperparameters is notgiving good results can be a good option
Examples of this application are the accelerated RSversion (2x) [29 30] orHyperband [31] which is based on thebandit-based approach In this problem a fixed finite set ofresources must be distributed between different choices in away that maximizes their expected gain One recent exampleis developed in [19] where an algorithm for optimizationof discrete hyperparameters based on compressed sensing isintroduced Harmonica
We can also find studies about the effect of these HPOmethods in the efficiency of the ML algorithms comparingdifferent methods [32] or the possible options that can betuned when a HPO algorithm runs over a dataset such asthe number of iterations number of hyperparameters typeof optimization etc [24 33] As far as we know in theabove context analyzing the efficiency of the automatic HPOmethods for specific supervised ML problems in terms of thesize of the used dataset is needed
The goal in this article is to carry out an empiricalstatistical analysis about the effect of the factor size of datasetsused in the stage of the HPO in the performance of severalML algorithms The studied response variables are the mainissues in the efficiency of the algorithm quality and dynamiccomplexity [34] Regarding the quality we take into accountthe most used metric for the goodness of a ML model thatis the Accuracy The others variables are the time complexityand the spatial complexity (amount of memory it requiresfor execution with a given input) due to these issues usuallyare influent limited resources The underlying idea is toallocate the proportion of the whole dataset that maintainsor improves the quality of the accuracy of the obtained
Complexity 3
ML models and optimizing the dynamic complexity of thealgorithms
The research questions that will be studied are the follow-ing
RQ1 Given a dataset are there statistically meaningfuldifferences in the performance (accuracy time and specialcomplexity) of a ML algorithm when the HPO method it isapplied to samples of different size of the dataset
In the case that we obtain a positive answer we follow tothe next questions
RQ2 Which are the effect and the behavior of each HPOalgorithm depending on the datasetrsquos size In which cases wecan gain efficiency if the HPO algorithm operates over smallsamples
RQ3 Are the above results reliable That is are theresults consistent for different HPO algorithms and differentdatasets
In order to answer the research questions formulatedabove an experiment has been carried out with different pub-licly available datasets about learning some tasks regardingcybersecurity events Cybersecurity is a challenging researcharea due to the sophistication and the amount of kindof Cybersecurity attacks which in fact increase very fastas time goes by In this framework the traditional toolsand infrastructures are not useful because we deal withbig data created with a high velocity and the solutionsand predictions must be faster than the threats ArtificialIntelligence and ML analytics have turned out in one ofthe most powerful tools against the cyberattackers (see [35ndash41]) but obtaining actionable knowledge from a databaseof Cybersecurity events by applying ML algorithms usuallyis a computationally expensive task for several reasons Adatabase of Cybersecurity contains in general a huge amountof dynamical and unstructured but highly correlated andconnected data sowe need to deal with some costly aspects ofthe quality of the data such as noise trustworthiness securityprivacy heterogeneity scaling or timeliness [42ndash44] Alsothe information is highly volatile so the key issue is to get theprofit as faster as possible with the best possible performanceand the smallest cost of resources and time Then the studyof the complexity of applying Data Science over databasesof Cybersecurity is an emergent and necessary field in orderto increase confidence and social profit from automatizingprocesses and develop prescriptive policies to prevent andreact to incidents faster and more secure
Experimental analyses have been carried out in order toinvestigate the possible statistical differences over the effi-ciency of the Machine Learning algorithms Random Forest(RF) Gradient Boosting (GB) and MLP among using dif-ferent sizes of samples in several HPO selection algorithmsWe have used nonparametric statistical inference becausein an experimental design in the field of computationalintelligence these types of techniques are very useful toanalyze the behavior of a method with respect to a set ofalgorithms [45] In addition and based on the results of theabove tests we have assigned a profit level for each size of thewhole dataset in terms of the response variables accuracytime and spatial complexity Finally we have discussed theobserved patterns and obtained results
The paper is structured as follows In Section 2 wedescribe the problem definition In Section 3 we develop theMaterials and Methods This section includes the analyzedselected methods both HPO and ML algorithms with thelibraries or tools that we have used Also the tested datasetsand the sampling of partitions have been explained as wellas the statistical analyses that have been carried out InSection 4 the results and the discussion are included Finallyour conclusions and references are given
2 Problem Definition
LetP be a distribution function A Machine Learning algo-rithm 119860 is a functional that maps each data set containingiid samples from P 119863119905119903119886119894119899 to a function 119891119860119863119905119903119886119894119899 fl119860(119863119905119903119886119894119899) that belongs to certain space of functions and thatminimizes a fixed expected loss L(119863119905119903119886119894119899 119891119860119863119905119903119886119894119899) Usuallyone has two more ingredients in this general frameworkOn one hand the target space of functions of the algorithmdepends on certain parameters 120582 = (1205821 120582119899) that mighttake discrete or continuous values and that has to be fixedbefore applying the algorithm In order to make explicit thedependency on 120582 we will use the notation 119860120582 to refer to thealgorithm and 119891120582 to refer to the target functions of 119860120582 Onthe other hand another data set obtained from P 119863119905119890119904119905 isgiven and serves to evaluate the lossL(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899) of thefunction provided by the algorithm over data independentfrom119863119905119903119886119894119899
Let Λ be the hyperparameter space that is the spacein which 120582 takes values and fix both the train and the testdata sets Denote by 119863 fl 119863119905119903119886119894119899 cup 119863119905119890119904119905 the union of bothdata sets In this situation the only data that remains free inL(119863119905119890119904119905 119891119860120582119863119905119903119886119894119899) are the hyperparameters 120582 = (1205821 120582119899)Assume further that we are dealing with a classificationMachine Learning problem so that we can take L to be theerror rate that is oneminus the cross-validation value In thissituation one can define the following function
Φ119860119863 Λ 997888rarr [0 1]
120582 997891997888rarr mean119863119905119890119904119905L (119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899)(1)
The HPO problem consists on minimizing Φ119860119863 and there-fore a HPO algorithm is a procedure that tries to reach 120582lowast flmin120582(mean119863119905119890119904119905L(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899))
Usually in practice one has a dataset 119863 that is split intotwo parts 1198631 1198632 one for the optimization of the hyperpa-rameters of theMachine Learning model and another one fortraining (and testing) the Machine Learning model with thegiven hyperparameters The goal of the article is focused onhow the size of the dataset in the HPO phase influences theperformance of classifier given at the output of the trainingphase
Suppose we have a ML model 119860 a HPO algorithm 119867and a dataset 119863The dataset 119863 is split into different partitionsrandomly We denote by 119875119895(119863) the partition 119895 of the dataset119863 andwe assume that the size of119875119895(119863) is smaller than the sizeof119875119897(119863) for 119895 lt 119897Then applying119867 to the problem defined byΦ119860119875119895(119863) we find optimal hyperparameters120582119895 that can be used
4 Complexity
Table 1 HPO algorithms The star symbol lowast means that the chosen algorithms have needed some minor modifications
Name Reference Ready Python minimal version Smart LibraryPS [15 16] radic 27 y 3 X [18]TPE [21] radiclowast 27 y 3 X [51]CMA-ES [13] radic 27 y 3 X [52]NM [14] radic 27 y 3 radic [52]RS [23] radic 27 y 3 X [52]SMAC [22] radic 3 X [53]
over119863119905119903119886119894119899 to create a classifier that will be tested on119863119905119890119904119905 Wedenote the cross-validation value obtained in this last processby119860119888119888119895 Also the train time and the total time of the processand the spatial complexity spent will be collected (denoted by119879119862119895 and 119878119862119895 respectively) for the analysis
The study that will be done is statistical so we will con-sider several datasets as well as manyMachine Learning algo-rithms Different state-of-the-art HPO algorithms will beconsidered and applied to every possible combination ofMachine Learning models and datasets in order to comparethem
3 Materials and Methods
Experiments were conducted testing eight HPO methodsover five cybersecurity datasets for three ML algorithms
31 HPO Methods and ML Algorithms As we mentionedabove we have evaluated the efficiency of the three well-known classifiers and predictorMachine Learning techniquesalgorithms RF GB and MLP commonly used in classifica-tion and prediction problems The library used is [46]
Ensembles methods are commonly used because arebased on the underlying idea that many different joint pre-dictors will perform in a better way than any single predictoralone Ensembling techniques could be divided into baggingand boosting methods
First ones build many independent learners that arecombined with average methods in order to give a finalprediction These handle overfitting and reduce the varianceThemost known example of bagging ensemblemethods is theRF An RF is a classifier consisting of a chain of decision treealgorithms Each tree is constructed by applying an algorithmto the training set and an additional random vector that issampled via bootstrap resampling so the trees will run andgive independent results (see [47]) The scikit-learn imple-mentation RandomForestClassifier combines classifiers bycalculating an average of their probabilistic prediction incontrast to the original publication In the case of RF wehave twomainhyperparameters the number of decision treesthat we should use and the maximum depth for each ofthem
Second ones Boosting are ensemble techniques in whichthe predictors are made sequentially learning from themistakes of the previous predictor in order to optimize thesubsequent learner It usually takes less timeiterations toreach close to actual predictions but we have to choose the
stopping criteria carefully These reduce bias and varianceand can with the overfitting One example of the mostcommon boosting methods is GB The library that is usedis the GradientBoostingClassifier and we tune the discretehyperparameters that are the number of predictors and themaximum depth of them
On the other hand an artificial neural network is a modelthat is organized in layers (input layer output layer andhidden layers) An MLP is a modification of the standardlinear perceptron where multiple layers of connected nodesare allowedThe standard algorithm for training aMLP is thebackpropagation algorithm (see [48 49]) Class MLPClas-sifier in Scikit-learn implements MLP training algorithmsfor this ML model By default MLPClassifier has only onehidden layer with 100 neurons the activation function for thehidden layer is f (x) = max(0 x) and the solver for weightoptimization is ldquoAdamrdquo [50] In this study we will allow twohidden layers and we will run the number of neurons in eachof these hidden layers
In Table 1 the selected HPO algorithms to study aredeveloped Also the references related to each one are givenas well as the minimal version of Python for which thesealgorithms work In addition we highlight if they are smartthat it is if they stop by themselves in contrast to a number ofiterations (trials) must be proposed
32 Datasets The choice of datasets selected for the experi-ments was motivated by different reasons available in publicservers diversity in the number of instances classes andfeatures and relating to cybersecurity The set of datasetsD = 1198631 1198632 1198633 1198634 1198635 is described in Table 2
Regarding the transformation of features data of treatabledatasets this has been performed manually by Python
Dataset 1198631 is a collection of spam (advertisements forproductsweb sites make money fast schemes chain letterspornography etc) and nonspam e-mails whose purpose is toconstruct spam filters Dataset 1198632 is a database obtained by areal-time localization system for an autonomous robot withexamples that are constructed with simulated attacks (Denialof Service and Spoofing) and nonattacks Dataset 1198633 is aboutde detection of Phishing websites 1198634 is a data set suggestedto solve some of the inherent problems of the well-knownKDD101584099 data setThis has been treated by the approach givenin [59 60] Finally 1198635 contains transactions made by creditcards This unbalanced collection of data includes exampleslabeled as fraudulent or genuine Also the features are theresult of a PCA transformation
Complexity 5
Table 2 Description of the set of datasetsD
Dataset Name Instances Features Classes Reference1198631 Spambase 4601 57 2 [54]1198632 Robots in RTLS 6422 12 3 [55]1198633 Phishing websites 11055 30 2 [56ndash58]1198634 Intrusion Detection (NSL-KDD) 148517 39 5 [59 60]1198635 Credit Card Fraud Detection 284807 30 2 [61]
Table 3 Description of the partitions of the set of datasetsD
Dataset 1198751 1198752 1198753 11987541198631 383 766 2300 46011198632 535 1070 3211 64221198633 921 1842 5527 110551198634 12376 24752 74258 1485171198635 23733 47467 142403 284807
Also the datasets have different number of instances aswell as features and number of classes of the target variable
33 Sampling and Collection of Data For each dataset 119863119894four partitions 119875119895(119863119894)119895=14 have been created in a randomway These correspond to the proportions that are obtainedwhen multiplied by 12 16 112 the whole set (P = 1198751 =8 3 1198752 = 16 3 1198753 = 50 1198754 = 119863119894) We denote by119875119895(119863119894) the partition on the dataset 119863119894 where 119894 = 1 5and 119895 = 1 2 3 4 These proportions have been chosen dueto the fact that in this way we can deal with an amountof instances of different order of magnitude (102 103 104and 105 having similar orders in the same partition of eachdataset see Table 3
On the other hand we fix once and for all a partition119863119905119903119886119894119899119894 cup 119863V119886119897119894119889
119894 = 119863119894 for each 119863119894 into train data (80) andvalidation data (20) as well as a partition with the sameproportion for each partition 119875119895(119863119894)
Finally in order to build response variables to measurethe goal of the study we apply each 119867119896 isin H over theall partitions 119875119895(119863119894) obtaining the hyperparameter config-uration 120582119896119894119895 Then the learning algorithm with the obtainedhyperparameter configuration is run over 119863119905119903119886119894119899119894 to constructa classifier that is validated over119863V119886119897119894119889
119894 At this step we collectthe accuracy obtained This scenario is repeated 50 iterationsAlso the total time and spatial complexity of all process arestored Then we create three response variables We denoteby 119860119888119888119896119894119895 the 50 times 1 array where the 119898-th component isthe accuracy of the predictive model tested on 119863V119886119897119894119889
119894 thatwas trained over 119863119905119903119886119894119899119894 with the hyperparameters (120582119896119894119895)119898 atthe 119898-th iteration We can measure the time and the spatialcomplexity used along this process and collect these data intwo 50 times 1 arrays 119879119862119896119894119895 and 119878119862119896119894119895 respectively
The time complexity measured in seconds is the sumof the time needed by the HPO algorithm for finding theoptimum hyperparameters and the time needed by the MLalgorithm for the training phase The spatial complexity
measured in Kb is defined as the maximum of use ofmemory along theHPOalgorithm run including the internalstructures of the algorithm as well as train and test datasetsload
34 Technical Specifications The analyses have been carriedby the authors at high-performance computing facilitated bySCAYLE (wwwscaylees) over HP ProLiant SL270s Gen8 SEwith 2 processors Intel Xeon CPU E5-2670 v2 250GHzwith 10 cores each one and 128 GB of RAM memory Theyare equipped with 1 hard disk of 1TB and cards InfinibandFDR 56Gbps
The analyses script has been implemented in Pythonlanguage Python uses an automated manager system ofmemory called garbage collector that releases the unusedmemory spaceThis phenomenonmight be nondeterministicand certain fluctuations shown in the results may be due tonot releasing the memory in that case
It is worth noting that different technical tools (eithersoftware or hardware) could affect to the data about time andspatial complexity that have been collected This is a fact thatshould be taken into account if we want to measure the effectof data sizes over the response variables in absolute termsthat is over a single HPO algorithm However the influenceof the technical specifications in the response variables isnot a relevant factor in this study This is a comparativestudy in which all the measures are collected under the sameconditions and the possible effect of the technical elementson the data is the same in each experiment It is expected thatthe same behavior of the comparative encountered patternswill appear with other technical characteristics
35 Analysis The aim of the study is to decide if the sizeof data is a factor that influences in the efficiency of a MLalgorithm using a HPOmethod among partitions of the data
We perform the following statistical analysis
(1) First for each level of the size that is the partitions 119875119895where 119895 = 1 2 3 4 we study the normality of 119860119888119888119896119894119895
6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

2 Complexity
On the other hand tuning hyperparameters of a MLalgorithm is a critical aspect of the model training processthat is considered the best practice for obtaining a successfulMachine Learning application [7] The HyperparametersOptimization (HPO) problem requires a deep understandingof the ML model at hand due to the hyperparameters valuessettings and their effectivity depending strongly on theML algorithm and the type of hyperparameter discrete orcontinuous values Also it is a very costly process due tothe large number of possible combinations to test and theneeded resources to carry out the computations Excludingthe human expert of the process and minimizing the hyper-parameter configurations to test are the underlying ideas inthe automatic HPO
Given a supervised ML algorithm the continuous HPOis usually solved by gradient descent-based methods [8ndash10] In the discrete case not all optimization methods aresuitable Themost common approaches to the HPO problemin the discrete case can be divided into two Bayesian [11]and decision-theoretic methods However there are otheroptimization algorithms that are applied to the problem ofhyperparameter values selectionThis is the case for instanceof the derivative-free optimization the genetic algorithmssuch as Covariance Matrix Adaptation Evolutionary Strate-gies (CMA-ES) or the simplex Nelder-Mead (NM) method[12ndash14] In addition continuous optimization methods suchas the Particle Swarm (PS) used for the ML algorithmsof least-squares support vector machines [15ndash17] could beapplied over discrete HPO problems [18]
Bayesian HPO algorithms balance the exploration pro-cess for finding promising hyperparameter configurationsand the exploitation of the setting configuration in order toobtain always better results or gain more information witheach test [19] Consequently Bayesian HPO are serializedmethods that are difficult to parallelize but they usuallycan find better combinations of hyperparameters in a fewiterationsOne of themost important BayesianHPOmethodsis the Model-Based Optimization (SMBO) In the SMBOtechniques the way to construct the surrogate function tomodel the error distribution provides different methodsThere are those that use Gaussian Process (GP) [20] or tree-based algorithms such as the Sequential Model AutomaticConfiguration (SMAC) or the Tree Parzen Estimators (TPE)method [21 22] On the other hand the decision-theoreticapproaches are based on the idea to search combinationsof hyperparameter in the hyperparameter space computingtheir accuracy and finally pick the one that performed thebest If we test over a fixed domain of hyperparameters valueswe have the grid search More effective than grid search eventhan some Bayesian optimization techniques is the randomsampling of different choices Random Search (RS) [23] It iseasy to implement independent of previous knowledge andeasily parallelizableOther optimization approaches also havereached very good results when applied to the selection ofhyperparameter values This is the case of research of [24]where evolutionary computation is used over deep neuralnetworks
Although applying HPO algorithms on a ML modelreflects a great improvement in the resultsrsquo quality of the
modelsrsquo accuracy we cannot overlook the computationalcomplexity to implement these techniques It is a critical issuebecause obtaining a good performance by applying HPOcould require generationsrsquo samples several function evalua-tions and expensive computational resources For examplethe GP methods usually require a high number of itera-tions Likewise some derivative-free optimizations behavepoorly in hyperparameter optimization problems because theoptimization target is smooth [25] In addition some MLalgorithms such as the neural networks are especially delicatebecause the number of possible values for the hyperparame-ters grows exponentially with the number of hidden layersOther HPO algorithms are designed taking into accountthese limitations
Recently a Radial Basis Function (RBF) has been pro-posed as a deterministic surrogate model to approximatethe error function of the hyperparameters through dynamiccoordinate search that requires fewer evaluations in Mul-tilayer Perceptron (MLP) and convolutional neural net-works [26] In [27] the Nelder-Mead and coordinate-search(derivative-free) methods are tested over deep neural net-works presenting more efficient numerical results than otherwell-known algorithms Another option is to try to acceleratethe algorithm In [28] one way to implement the schemeSuccessive Halving (SH) is developed The main ingredientbehind SH is based on the observation that most of theHPOalgorithms are iterativewhich suggests that stopping thealgorithm when testing with a set of hyperparameters is notgiving good results can be a good option
Examples of this application are the accelerated RSversion (2x) [29 30] orHyperband [31] which is based on thebandit-based approach In this problem a fixed finite set ofresources must be distributed between different choices in away that maximizes their expected gain One recent exampleis developed in [19] where an algorithm for optimizationof discrete hyperparameters based on compressed sensing isintroduced Harmonica
We can also find studies about the effect of these HPOmethods in the efficiency of the ML algorithms comparingdifferent methods [32] or the possible options that can betuned when a HPO algorithm runs over a dataset such asthe number of iterations number of hyperparameters typeof optimization etc [24 33] As far as we know in theabove context analyzing the efficiency of the automatic HPOmethods for specific supervised ML problems in terms of thesize of the used dataset is needed
The goal in this article is to carry out an empiricalstatistical analysis about the effect of the factor size of datasetsused in the stage of the HPO in the performance of severalML algorithms The studied response variables are the mainissues in the efficiency of the algorithm quality and dynamiccomplexity [34] Regarding the quality we take into accountthe most used metric for the goodness of a ML model thatis the Accuracy The others variables are the time complexityand the spatial complexity (amount of memory it requiresfor execution with a given input) due to these issues usuallyare influent limited resources The underlying idea is toallocate the proportion of the whole dataset that maintainsor improves the quality of the accuracy of the obtained
Complexity 3
ML models and optimizing the dynamic complexity of thealgorithms
The research questions that will be studied are the follow-ing
RQ1 Given a dataset are there statistically meaningfuldifferences in the performance (accuracy time and specialcomplexity) of a ML algorithm when the HPO method it isapplied to samples of different size of the dataset
In the case that we obtain a positive answer we follow tothe next questions
RQ2 Which are the effect and the behavior of each HPOalgorithm depending on the datasetrsquos size In which cases wecan gain efficiency if the HPO algorithm operates over smallsamples
RQ3 Are the above results reliable That is are theresults consistent for different HPO algorithms and differentdatasets
In order to answer the research questions formulatedabove an experiment has been carried out with different pub-licly available datasets about learning some tasks regardingcybersecurity events Cybersecurity is a challenging researcharea due to the sophistication and the amount of kindof Cybersecurity attacks which in fact increase very fastas time goes by In this framework the traditional toolsand infrastructures are not useful because we deal withbig data created with a high velocity and the solutionsand predictions must be faster than the threats ArtificialIntelligence and ML analytics have turned out in one ofthe most powerful tools against the cyberattackers (see [35ndash41]) but obtaining actionable knowledge from a databaseof Cybersecurity events by applying ML algorithms usuallyis a computationally expensive task for several reasons Adatabase of Cybersecurity contains in general a huge amountof dynamical and unstructured but highly correlated andconnected data sowe need to deal with some costly aspects ofthe quality of the data such as noise trustworthiness securityprivacy heterogeneity scaling or timeliness [42ndash44] Alsothe information is highly volatile so the key issue is to get theprofit as faster as possible with the best possible performanceand the smallest cost of resources and time Then the studyof the complexity of applying Data Science over databasesof Cybersecurity is an emergent and necessary field in orderto increase confidence and social profit from automatizingprocesses and develop prescriptive policies to prevent andreact to incidents faster and more secure
Experimental analyses have been carried out in order toinvestigate the possible statistical differences over the effi-ciency of the Machine Learning algorithms Random Forest(RF) Gradient Boosting (GB) and MLP among using dif-ferent sizes of samples in several HPO selection algorithmsWe have used nonparametric statistical inference becausein an experimental design in the field of computationalintelligence these types of techniques are very useful toanalyze the behavior of a method with respect to a set ofalgorithms [45] In addition and based on the results of theabove tests we have assigned a profit level for each size of thewhole dataset in terms of the response variables accuracytime and spatial complexity Finally we have discussed theobserved patterns and obtained results
The paper is structured as follows In Section 2 wedescribe the problem definition In Section 3 we develop theMaterials and Methods This section includes the analyzedselected methods both HPO and ML algorithms with thelibraries or tools that we have used Also the tested datasetsand the sampling of partitions have been explained as wellas the statistical analyses that have been carried out InSection 4 the results and the discussion are included Finallyour conclusions and references are given
2 Problem Definition
LetP be a distribution function A Machine Learning algo-rithm 119860 is a functional that maps each data set containingiid samples from P 119863119905119903119886119894119899 to a function 119891119860119863119905119903119886119894119899 fl119860(119863119905119903119886119894119899) that belongs to certain space of functions and thatminimizes a fixed expected loss L(119863119905119903119886119894119899 119891119860119863119905119903119886119894119899) Usuallyone has two more ingredients in this general frameworkOn one hand the target space of functions of the algorithmdepends on certain parameters 120582 = (1205821 120582119899) that mighttake discrete or continuous values and that has to be fixedbefore applying the algorithm In order to make explicit thedependency on 120582 we will use the notation 119860120582 to refer to thealgorithm and 119891120582 to refer to the target functions of 119860120582 Onthe other hand another data set obtained from P 119863119905119890119904119905 isgiven and serves to evaluate the lossL(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899) of thefunction provided by the algorithm over data independentfrom119863119905119903119886119894119899
Let Λ be the hyperparameter space that is the spacein which 120582 takes values and fix both the train and the testdata sets Denote by 119863 fl 119863119905119903119886119894119899 cup 119863119905119890119904119905 the union of bothdata sets In this situation the only data that remains free inL(119863119905119890119904119905 119891119860120582119863119905119903119886119894119899) are the hyperparameters 120582 = (1205821 120582119899)Assume further that we are dealing with a classificationMachine Learning problem so that we can take L to be theerror rate that is oneminus the cross-validation value In thissituation one can define the following function
Φ119860119863 Λ 997888rarr [0 1]
120582 997891997888rarr mean119863119905119890119904119905L (119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899)(1)
The HPO problem consists on minimizing Φ119860119863 and there-fore a HPO algorithm is a procedure that tries to reach 120582lowast flmin120582(mean119863119905119890119904119905L(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899))
Usually in practice one has a dataset 119863 that is split intotwo parts 1198631 1198632 one for the optimization of the hyperpa-rameters of theMachine Learning model and another one fortraining (and testing) the Machine Learning model with thegiven hyperparameters The goal of the article is focused onhow the size of the dataset in the HPO phase influences theperformance of classifier given at the output of the trainingphase
Suppose we have a ML model 119860 a HPO algorithm 119867and a dataset 119863The dataset 119863 is split into different partitionsrandomly We denote by 119875119895(119863) the partition 119895 of the dataset119863 andwe assume that the size of119875119895(119863) is smaller than the sizeof119875119897(119863) for 119895 lt 119897Then applying119867 to the problem defined byΦ119860119875119895(119863) we find optimal hyperparameters120582119895 that can be used
4 Complexity
Table 1 HPO algorithms The star symbol lowast means that the chosen algorithms have needed some minor modifications
Name Reference Ready Python minimal version Smart LibraryPS [15 16] radic 27 y 3 X [18]TPE [21] radiclowast 27 y 3 X [51]CMA-ES [13] radic 27 y 3 X [52]NM [14] radic 27 y 3 radic [52]RS [23] radic 27 y 3 X [52]SMAC [22] radic 3 X [53]
over119863119905119903119886119894119899 to create a classifier that will be tested on119863119905119890119904119905 Wedenote the cross-validation value obtained in this last processby119860119888119888119895 Also the train time and the total time of the processand the spatial complexity spent will be collected (denoted by119879119862119895 and 119878119862119895 respectively) for the analysis
The study that will be done is statistical so we will con-sider several datasets as well as manyMachine Learning algo-rithms Different state-of-the-art HPO algorithms will beconsidered and applied to every possible combination ofMachine Learning models and datasets in order to comparethem
3 Materials and Methods
Experiments were conducted testing eight HPO methodsover five cybersecurity datasets for three ML algorithms
31 HPO Methods and ML Algorithms As we mentionedabove we have evaluated the efficiency of the three well-known classifiers and predictorMachine Learning techniquesalgorithms RF GB and MLP commonly used in classifica-tion and prediction problems The library used is [46]
Ensembles methods are commonly used because arebased on the underlying idea that many different joint pre-dictors will perform in a better way than any single predictoralone Ensembling techniques could be divided into baggingand boosting methods
First ones build many independent learners that arecombined with average methods in order to give a finalprediction These handle overfitting and reduce the varianceThemost known example of bagging ensemblemethods is theRF An RF is a classifier consisting of a chain of decision treealgorithms Each tree is constructed by applying an algorithmto the training set and an additional random vector that issampled via bootstrap resampling so the trees will run andgive independent results (see [47]) The scikit-learn imple-mentation RandomForestClassifier combines classifiers bycalculating an average of their probabilistic prediction incontrast to the original publication In the case of RF wehave twomainhyperparameters the number of decision treesthat we should use and the maximum depth for each ofthem
Second ones Boosting are ensemble techniques in whichthe predictors are made sequentially learning from themistakes of the previous predictor in order to optimize thesubsequent learner It usually takes less timeiterations toreach close to actual predictions but we have to choose the
stopping criteria carefully These reduce bias and varianceand can with the overfitting One example of the mostcommon boosting methods is GB The library that is usedis the GradientBoostingClassifier and we tune the discretehyperparameters that are the number of predictors and themaximum depth of them
On the other hand an artificial neural network is a modelthat is organized in layers (input layer output layer andhidden layers) An MLP is a modification of the standardlinear perceptron where multiple layers of connected nodesare allowedThe standard algorithm for training aMLP is thebackpropagation algorithm (see [48 49]) Class MLPClas-sifier in Scikit-learn implements MLP training algorithmsfor this ML model By default MLPClassifier has only onehidden layer with 100 neurons the activation function for thehidden layer is f (x) = max(0 x) and the solver for weightoptimization is ldquoAdamrdquo [50] In this study we will allow twohidden layers and we will run the number of neurons in eachof these hidden layers
In Table 1 the selected HPO algorithms to study aredeveloped Also the references related to each one are givenas well as the minimal version of Python for which thesealgorithms work In addition we highlight if they are smartthat it is if they stop by themselves in contrast to a number ofiterations (trials) must be proposed
32 Datasets The choice of datasets selected for the experi-ments was motivated by different reasons available in publicservers diversity in the number of instances classes andfeatures and relating to cybersecurity The set of datasetsD = 1198631 1198632 1198633 1198634 1198635 is described in Table 2
Regarding the transformation of features data of treatabledatasets this has been performed manually by Python
Dataset 1198631 is a collection of spam (advertisements forproductsweb sites make money fast schemes chain letterspornography etc) and nonspam e-mails whose purpose is toconstruct spam filters Dataset 1198632 is a database obtained by areal-time localization system for an autonomous robot withexamples that are constructed with simulated attacks (Denialof Service and Spoofing) and nonattacks Dataset 1198633 is aboutde detection of Phishing websites 1198634 is a data set suggestedto solve some of the inherent problems of the well-knownKDD101584099 data setThis has been treated by the approach givenin [59 60] Finally 1198635 contains transactions made by creditcards This unbalanced collection of data includes exampleslabeled as fraudulent or genuine Also the features are theresult of a PCA transformation
Complexity 5
Table 2 Description of the set of datasetsD
Dataset Name Instances Features Classes Reference1198631 Spambase 4601 57 2 [54]1198632 Robots in RTLS 6422 12 3 [55]1198633 Phishing websites 11055 30 2 [56ndash58]1198634 Intrusion Detection (NSL-KDD) 148517 39 5 [59 60]1198635 Credit Card Fraud Detection 284807 30 2 [61]
Table 3 Description of the partitions of the set of datasetsD
Dataset 1198751 1198752 1198753 11987541198631 383 766 2300 46011198632 535 1070 3211 64221198633 921 1842 5527 110551198634 12376 24752 74258 1485171198635 23733 47467 142403 284807
Also the datasets have different number of instances aswell as features and number of classes of the target variable
33 Sampling and Collection of Data For each dataset 119863119894four partitions 119875119895(119863119894)119895=14 have been created in a randomway These correspond to the proportions that are obtainedwhen multiplied by 12 16 112 the whole set (P = 1198751 =8 3 1198752 = 16 3 1198753 = 50 1198754 = 119863119894) We denote by119875119895(119863119894) the partition on the dataset 119863119894 where 119894 = 1 5and 119895 = 1 2 3 4 These proportions have been chosen dueto the fact that in this way we can deal with an amountof instances of different order of magnitude (102 103 104and 105 having similar orders in the same partition of eachdataset see Table 3
On the other hand we fix once and for all a partition119863119905119903119886119894119899119894 cup 119863V119886119897119894119889
119894 = 119863119894 for each 119863119894 into train data (80) andvalidation data (20) as well as a partition with the sameproportion for each partition 119875119895(119863119894)
Finally in order to build response variables to measurethe goal of the study we apply each 119867119896 isin H over theall partitions 119875119895(119863119894) obtaining the hyperparameter config-uration 120582119896119894119895 Then the learning algorithm with the obtainedhyperparameter configuration is run over 119863119905119903119886119894119899119894 to constructa classifier that is validated over119863V119886119897119894119889
119894 At this step we collectthe accuracy obtained This scenario is repeated 50 iterationsAlso the total time and spatial complexity of all process arestored Then we create three response variables We denoteby 119860119888119888119896119894119895 the 50 times 1 array where the 119898-th component isthe accuracy of the predictive model tested on 119863V119886119897119894119889
119894 thatwas trained over 119863119905119903119886119894119899119894 with the hyperparameters (120582119896119894119895)119898 atthe 119898-th iteration We can measure the time and the spatialcomplexity used along this process and collect these data intwo 50 times 1 arrays 119879119862119896119894119895 and 119878119862119896119894119895 respectively
The time complexity measured in seconds is the sumof the time needed by the HPO algorithm for finding theoptimum hyperparameters and the time needed by the MLalgorithm for the training phase The spatial complexity
measured in Kb is defined as the maximum of use ofmemory along theHPOalgorithm run including the internalstructures of the algorithm as well as train and test datasetsload
34 Technical Specifications The analyses have been carriedby the authors at high-performance computing facilitated bySCAYLE (wwwscaylees) over HP ProLiant SL270s Gen8 SEwith 2 processors Intel Xeon CPU E5-2670 v2 250GHzwith 10 cores each one and 128 GB of RAM memory Theyare equipped with 1 hard disk of 1TB and cards InfinibandFDR 56Gbps
The analyses script has been implemented in Pythonlanguage Python uses an automated manager system ofmemory called garbage collector that releases the unusedmemory spaceThis phenomenonmight be nondeterministicand certain fluctuations shown in the results may be due tonot releasing the memory in that case
It is worth noting that different technical tools (eithersoftware or hardware) could affect to the data about time andspatial complexity that have been collected This is a fact thatshould be taken into account if we want to measure the effectof data sizes over the response variables in absolute termsthat is over a single HPO algorithm However the influenceof the technical specifications in the response variables isnot a relevant factor in this study This is a comparativestudy in which all the measures are collected under the sameconditions and the possible effect of the technical elementson the data is the same in each experiment It is expected thatthe same behavior of the comparative encountered patternswill appear with other technical characteristics
35 Analysis The aim of the study is to decide if the sizeof data is a factor that influences in the efficiency of a MLalgorithm using a HPOmethod among partitions of the data
We perform the following statistical analysis
(1) First for each level of the size that is the partitions 119875119895where 119895 = 1 2 3 4 we study the normality of 119860119888119888119896119894119895
6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 3
ML models and optimizing the dynamic complexity of thealgorithms
The research questions that will be studied are the follow-ing
RQ1 Given a dataset are there statistically meaningfuldifferences in the performance (accuracy time and specialcomplexity) of a ML algorithm when the HPO method it isapplied to samples of different size of the dataset
In the case that we obtain a positive answer we follow tothe next questions
RQ2 Which are the effect and the behavior of each HPOalgorithm depending on the datasetrsquos size In which cases wecan gain efficiency if the HPO algorithm operates over smallsamples
RQ3 Are the above results reliable That is are theresults consistent for different HPO algorithms and differentdatasets
In order to answer the research questions formulatedabove an experiment has been carried out with different pub-licly available datasets about learning some tasks regardingcybersecurity events Cybersecurity is a challenging researcharea due to the sophistication and the amount of kindof Cybersecurity attacks which in fact increase very fastas time goes by In this framework the traditional toolsand infrastructures are not useful because we deal withbig data created with a high velocity and the solutionsand predictions must be faster than the threats ArtificialIntelligence and ML analytics have turned out in one ofthe most powerful tools against the cyberattackers (see [35ndash41]) but obtaining actionable knowledge from a databaseof Cybersecurity events by applying ML algorithms usuallyis a computationally expensive task for several reasons Adatabase of Cybersecurity contains in general a huge amountof dynamical and unstructured but highly correlated andconnected data sowe need to deal with some costly aspects ofthe quality of the data such as noise trustworthiness securityprivacy heterogeneity scaling or timeliness [42ndash44] Alsothe information is highly volatile so the key issue is to get theprofit as faster as possible with the best possible performanceand the smallest cost of resources and time Then the studyof the complexity of applying Data Science over databasesof Cybersecurity is an emergent and necessary field in orderto increase confidence and social profit from automatizingprocesses and develop prescriptive policies to prevent andreact to incidents faster and more secure
Experimental analyses have been carried out in order toinvestigate the possible statistical differences over the effi-ciency of the Machine Learning algorithms Random Forest(RF) Gradient Boosting (GB) and MLP among using dif-ferent sizes of samples in several HPO selection algorithmsWe have used nonparametric statistical inference becausein an experimental design in the field of computationalintelligence these types of techniques are very useful toanalyze the behavior of a method with respect to a set ofalgorithms [45] In addition and based on the results of theabove tests we have assigned a profit level for each size of thewhole dataset in terms of the response variables accuracytime and spatial complexity Finally we have discussed theobserved patterns and obtained results
The paper is structured as follows In Section 2 wedescribe the problem definition In Section 3 we develop theMaterials and Methods This section includes the analyzedselected methods both HPO and ML algorithms with thelibraries or tools that we have used Also the tested datasetsand the sampling of partitions have been explained as wellas the statistical analyses that have been carried out InSection 4 the results and the discussion are included Finallyour conclusions and references are given
2 Problem Definition
LetP be a distribution function A Machine Learning algo-rithm 119860 is a functional that maps each data set containingiid samples from P 119863119905119903119886119894119899 to a function 119891119860119863119905119903119886119894119899 fl119860(119863119905119903119886119894119899) that belongs to certain space of functions and thatminimizes a fixed expected loss L(119863119905119903119886119894119899 119891119860119863119905119903119886119894119899) Usuallyone has two more ingredients in this general frameworkOn one hand the target space of functions of the algorithmdepends on certain parameters 120582 = (1205821 120582119899) that mighttake discrete or continuous values and that has to be fixedbefore applying the algorithm In order to make explicit thedependency on 120582 we will use the notation 119860120582 to refer to thealgorithm and 119891120582 to refer to the target functions of 119860120582 Onthe other hand another data set obtained from P 119863119905119890119904119905 isgiven and serves to evaluate the lossL(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899) of thefunction provided by the algorithm over data independentfrom119863119905119903119886119894119899
Let Λ be the hyperparameter space that is the spacein which 120582 takes values and fix both the train and the testdata sets Denote by 119863 fl 119863119905119903119886119894119899 cup 119863119905119890119904119905 the union of bothdata sets In this situation the only data that remains free inL(119863119905119890119904119905 119891119860120582119863119905119903119886119894119899) are the hyperparameters 120582 = (1205821 120582119899)Assume further that we are dealing with a classificationMachine Learning problem so that we can take L to be theerror rate that is oneminus the cross-validation value In thissituation one can define the following function
Φ119860119863 Λ 997888rarr [0 1]
120582 997891997888rarr mean119863119905119890119904119905L (119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899)(1)
The HPO problem consists on minimizing Φ119860119863 and there-fore a HPO algorithm is a procedure that tries to reach 120582lowast flmin120582(mean119863119905119890119904119905L(119863119905119890119904119905 119891119860120582 119863119905119903119886119894119899))
Usually in practice one has a dataset 119863 that is split intotwo parts 1198631 1198632 one for the optimization of the hyperpa-rameters of theMachine Learning model and another one fortraining (and testing) the Machine Learning model with thegiven hyperparameters The goal of the article is focused onhow the size of the dataset in the HPO phase influences theperformance of classifier given at the output of the trainingphase
Suppose we have a ML model 119860 a HPO algorithm 119867and a dataset 119863The dataset 119863 is split into different partitionsrandomly We denote by 119875119895(119863) the partition 119895 of the dataset119863 andwe assume that the size of119875119895(119863) is smaller than the sizeof119875119897(119863) for 119895 lt 119897Then applying119867 to the problem defined byΦ119860119875119895(119863) we find optimal hyperparameters120582119895 that can be used
4 Complexity
Table 1 HPO algorithms The star symbol lowast means that the chosen algorithms have needed some minor modifications
Name Reference Ready Python minimal version Smart LibraryPS [15 16] radic 27 y 3 X [18]TPE [21] radiclowast 27 y 3 X [51]CMA-ES [13] radic 27 y 3 X [52]NM [14] radic 27 y 3 radic [52]RS [23] radic 27 y 3 X [52]SMAC [22] radic 3 X [53]
over119863119905119903119886119894119899 to create a classifier that will be tested on119863119905119890119904119905 Wedenote the cross-validation value obtained in this last processby119860119888119888119895 Also the train time and the total time of the processand the spatial complexity spent will be collected (denoted by119879119862119895 and 119878119862119895 respectively) for the analysis
The study that will be done is statistical so we will con-sider several datasets as well as manyMachine Learning algo-rithms Different state-of-the-art HPO algorithms will beconsidered and applied to every possible combination ofMachine Learning models and datasets in order to comparethem
3 Materials and Methods
Experiments were conducted testing eight HPO methodsover five cybersecurity datasets for three ML algorithms
31 HPO Methods and ML Algorithms As we mentionedabove we have evaluated the efficiency of the three well-known classifiers and predictorMachine Learning techniquesalgorithms RF GB and MLP commonly used in classifica-tion and prediction problems The library used is [46]
Ensembles methods are commonly used because arebased on the underlying idea that many different joint pre-dictors will perform in a better way than any single predictoralone Ensembling techniques could be divided into baggingand boosting methods
First ones build many independent learners that arecombined with average methods in order to give a finalprediction These handle overfitting and reduce the varianceThemost known example of bagging ensemblemethods is theRF An RF is a classifier consisting of a chain of decision treealgorithms Each tree is constructed by applying an algorithmto the training set and an additional random vector that issampled via bootstrap resampling so the trees will run andgive independent results (see [47]) The scikit-learn imple-mentation RandomForestClassifier combines classifiers bycalculating an average of their probabilistic prediction incontrast to the original publication In the case of RF wehave twomainhyperparameters the number of decision treesthat we should use and the maximum depth for each ofthem
Second ones Boosting are ensemble techniques in whichthe predictors are made sequentially learning from themistakes of the previous predictor in order to optimize thesubsequent learner It usually takes less timeiterations toreach close to actual predictions but we have to choose the
stopping criteria carefully These reduce bias and varianceand can with the overfitting One example of the mostcommon boosting methods is GB The library that is usedis the GradientBoostingClassifier and we tune the discretehyperparameters that are the number of predictors and themaximum depth of them
On the other hand an artificial neural network is a modelthat is organized in layers (input layer output layer andhidden layers) An MLP is a modification of the standardlinear perceptron where multiple layers of connected nodesare allowedThe standard algorithm for training aMLP is thebackpropagation algorithm (see [48 49]) Class MLPClas-sifier in Scikit-learn implements MLP training algorithmsfor this ML model By default MLPClassifier has only onehidden layer with 100 neurons the activation function for thehidden layer is f (x) = max(0 x) and the solver for weightoptimization is ldquoAdamrdquo [50] In this study we will allow twohidden layers and we will run the number of neurons in eachof these hidden layers
In Table 1 the selected HPO algorithms to study aredeveloped Also the references related to each one are givenas well as the minimal version of Python for which thesealgorithms work In addition we highlight if they are smartthat it is if they stop by themselves in contrast to a number ofiterations (trials) must be proposed
32 Datasets The choice of datasets selected for the experi-ments was motivated by different reasons available in publicservers diversity in the number of instances classes andfeatures and relating to cybersecurity The set of datasetsD = 1198631 1198632 1198633 1198634 1198635 is described in Table 2
Regarding the transformation of features data of treatabledatasets this has been performed manually by Python
Dataset 1198631 is a collection of spam (advertisements forproductsweb sites make money fast schemes chain letterspornography etc) and nonspam e-mails whose purpose is toconstruct spam filters Dataset 1198632 is a database obtained by areal-time localization system for an autonomous robot withexamples that are constructed with simulated attacks (Denialof Service and Spoofing) and nonattacks Dataset 1198633 is aboutde detection of Phishing websites 1198634 is a data set suggestedto solve some of the inherent problems of the well-knownKDD101584099 data setThis has been treated by the approach givenin [59 60] Finally 1198635 contains transactions made by creditcards This unbalanced collection of data includes exampleslabeled as fraudulent or genuine Also the features are theresult of a PCA transformation
Complexity 5
Table 2 Description of the set of datasetsD
Dataset Name Instances Features Classes Reference1198631 Spambase 4601 57 2 [54]1198632 Robots in RTLS 6422 12 3 [55]1198633 Phishing websites 11055 30 2 [56ndash58]1198634 Intrusion Detection (NSL-KDD) 148517 39 5 [59 60]1198635 Credit Card Fraud Detection 284807 30 2 [61]
Table 3 Description of the partitions of the set of datasetsD
Dataset 1198751 1198752 1198753 11987541198631 383 766 2300 46011198632 535 1070 3211 64221198633 921 1842 5527 110551198634 12376 24752 74258 1485171198635 23733 47467 142403 284807
Also the datasets have different number of instances aswell as features and number of classes of the target variable
33 Sampling and Collection of Data For each dataset 119863119894four partitions 119875119895(119863119894)119895=14 have been created in a randomway These correspond to the proportions that are obtainedwhen multiplied by 12 16 112 the whole set (P = 1198751 =8 3 1198752 = 16 3 1198753 = 50 1198754 = 119863119894) We denote by119875119895(119863119894) the partition on the dataset 119863119894 where 119894 = 1 5and 119895 = 1 2 3 4 These proportions have been chosen dueto the fact that in this way we can deal with an amountof instances of different order of magnitude (102 103 104and 105 having similar orders in the same partition of eachdataset see Table 3
On the other hand we fix once and for all a partition119863119905119903119886119894119899119894 cup 119863V119886119897119894119889
119894 = 119863119894 for each 119863119894 into train data (80) andvalidation data (20) as well as a partition with the sameproportion for each partition 119875119895(119863119894)
Finally in order to build response variables to measurethe goal of the study we apply each 119867119896 isin H over theall partitions 119875119895(119863119894) obtaining the hyperparameter config-uration 120582119896119894119895 Then the learning algorithm with the obtainedhyperparameter configuration is run over 119863119905119903119886119894119899119894 to constructa classifier that is validated over119863V119886119897119894119889
119894 At this step we collectthe accuracy obtained This scenario is repeated 50 iterationsAlso the total time and spatial complexity of all process arestored Then we create three response variables We denoteby 119860119888119888119896119894119895 the 50 times 1 array where the 119898-th component isthe accuracy of the predictive model tested on 119863V119886119897119894119889
119894 thatwas trained over 119863119905119903119886119894119899119894 with the hyperparameters (120582119896119894119895)119898 atthe 119898-th iteration We can measure the time and the spatialcomplexity used along this process and collect these data intwo 50 times 1 arrays 119879119862119896119894119895 and 119878119862119896119894119895 respectively
The time complexity measured in seconds is the sumof the time needed by the HPO algorithm for finding theoptimum hyperparameters and the time needed by the MLalgorithm for the training phase The spatial complexity
measured in Kb is defined as the maximum of use ofmemory along theHPOalgorithm run including the internalstructures of the algorithm as well as train and test datasetsload
34 Technical Specifications The analyses have been carriedby the authors at high-performance computing facilitated bySCAYLE (wwwscaylees) over HP ProLiant SL270s Gen8 SEwith 2 processors Intel Xeon CPU E5-2670 v2 250GHzwith 10 cores each one and 128 GB of RAM memory Theyare equipped with 1 hard disk of 1TB and cards InfinibandFDR 56Gbps
The analyses script has been implemented in Pythonlanguage Python uses an automated manager system ofmemory called garbage collector that releases the unusedmemory spaceThis phenomenonmight be nondeterministicand certain fluctuations shown in the results may be due tonot releasing the memory in that case
It is worth noting that different technical tools (eithersoftware or hardware) could affect to the data about time andspatial complexity that have been collected This is a fact thatshould be taken into account if we want to measure the effectof data sizes over the response variables in absolute termsthat is over a single HPO algorithm However the influenceof the technical specifications in the response variables isnot a relevant factor in this study This is a comparativestudy in which all the measures are collected under the sameconditions and the possible effect of the technical elementson the data is the same in each experiment It is expected thatthe same behavior of the comparative encountered patternswill appear with other technical characteristics
35 Analysis The aim of the study is to decide if the sizeof data is a factor that influences in the efficiency of a MLalgorithm using a HPOmethod among partitions of the data
We perform the following statistical analysis
(1) First for each level of the size that is the partitions 119875119895where 119895 = 1 2 3 4 we study the normality of 119860119888119888119896119894119895
6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
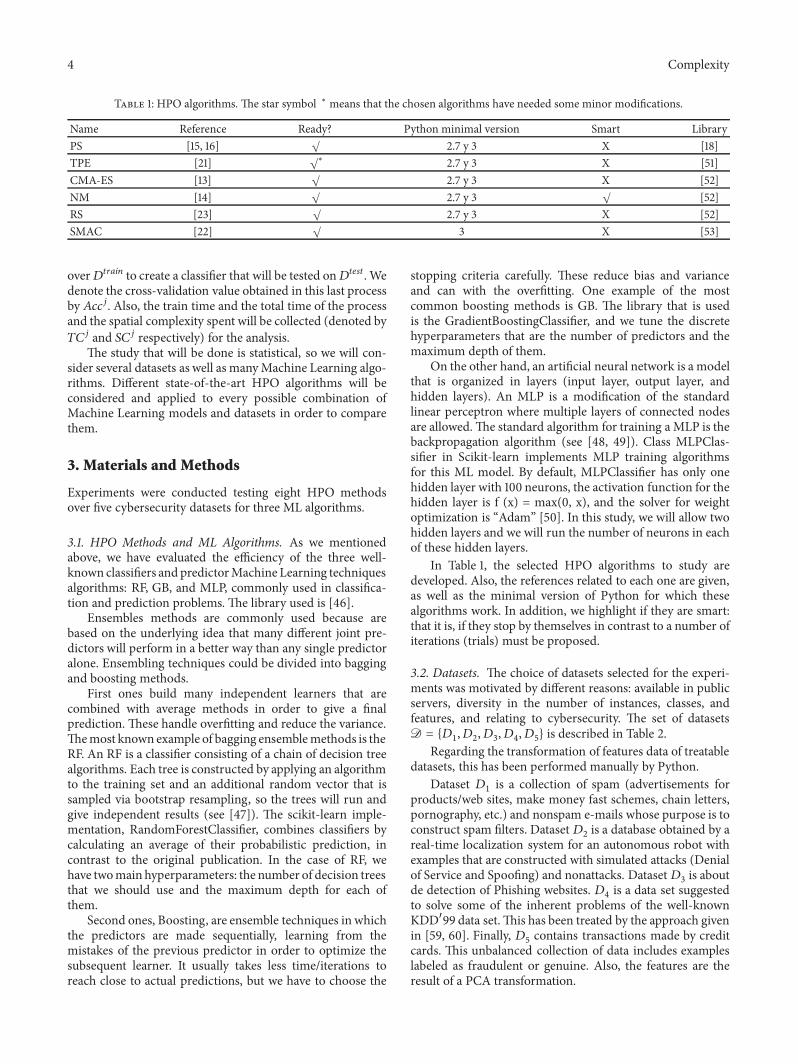
4 Complexity
Table 1 HPO algorithms The star symbol lowast means that the chosen algorithms have needed some minor modifications
Name Reference Ready Python minimal version Smart LibraryPS [15 16] radic 27 y 3 X [18]TPE [21] radiclowast 27 y 3 X [51]CMA-ES [13] radic 27 y 3 X [52]NM [14] radic 27 y 3 radic [52]RS [23] radic 27 y 3 X [52]SMAC [22] radic 3 X [53]
over119863119905119903119886119894119899 to create a classifier that will be tested on119863119905119890119904119905 Wedenote the cross-validation value obtained in this last processby119860119888119888119895 Also the train time and the total time of the processand the spatial complexity spent will be collected (denoted by119879119862119895 and 119878119862119895 respectively) for the analysis
The study that will be done is statistical so we will con-sider several datasets as well as manyMachine Learning algo-rithms Different state-of-the-art HPO algorithms will beconsidered and applied to every possible combination ofMachine Learning models and datasets in order to comparethem
3 Materials and Methods
Experiments were conducted testing eight HPO methodsover five cybersecurity datasets for three ML algorithms
31 HPO Methods and ML Algorithms As we mentionedabove we have evaluated the efficiency of the three well-known classifiers and predictorMachine Learning techniquesalgorithms RF GB and MLP commonly used in classifica-tion and prediction problems The library used is [46]
Ensembles methods are commonly used because arebased on the underlying idea that many different joint pre-dictors will perform in a better way than any single predictoralone Ensembling techniques could be divided into baggingand boosting methods
First ones build many independent learners that arecombined with average methods in order to give a finalprediction These handle overfitting and reduce the varianceThemost known example of bagging ensemblemethods is theRF An RF is a classifier consisting of a chain of decision treealgorithms Each tree is constructed by applying an algorithmto the training set and an additional random vector that issampled via bootstrap resampling so the trees will run andgive independent results (see [47]) The scikit-learn imple-mentation RandomForestClassifier combines classifiers bycalculating an average of their probabilistic prediction incontrast to the original publication In the case of RF wehave twomainhyperparameters the number of decision treesthat we should use and the maximum depth for each ofthem
Second ones Boosting are ensemble techniques in whichthe predictors are made sequentially learning from themistakes of the previous predictor in order to optimize thesubsequent learner It usually takes less timeiterations toreach close to actual predictions but we have to choose the
stopping criteria carefully These reduce bias and varianceand can with the overfitting One example of the mostcommon boosting methods is GB The library that is usedis the GradientBoostingClassifier and we tune the discretehyperparameters that are the number of predictors and themaximum depth of them
On the other hand an artificial neural network is a modelthat is organized in layers (input layer output layer andhidden layers) An MLP is a modification of the standardlinear perceptron where multiple layers of connected nodesare allowedThe standard algorithm for training aMLP is thebackpropagation algorithm (see [48 49]) Class MLPClas-sifier in Scikit-learn implements MLP training algorithmsfor this ML model By default MLPClassifier has only onehidden layer with 100 neurons the activation function for thehidden layer is f (x) = max(0 x) and the solver for weightoptimization is ldquoAdamrdquo [50] In this study we will allow twohidden layers and we will run the number of neurons in eachof these hidden layers
In Table 1 the selected HPO algorithms to study aredeveloped Also the references related to each one are givenas well as the minimal version of Python for which thesealgorithms work In addition we highlight if they are smartthat it is if they stop by themselves in contrast to a number ofiterations (trials) must be proposed
32 Datasets The choice of datasets selected for the experi-ments was motivated by different reasons available in publicservers diversity in the number of instances classes andfeatures and relating to cybersecurity The set of datasetsD = 1198631 1198632 1198633 1198634 1198635 is described in Table 2
Regarding the transformation of features data of treatabledatasets this has been performed manually by Python
Dataset 1198631 is a collection of spam (advertisements forproductsweb sites make money fast schemes chain letterspornography etc) and nonspam e-mails whose purpose is toconstruct spam filters Dataset 1198632 is a database obtained by areal-time localization system for an autonomous robot withexamples that are constructed with simulated attacks (Denialof Service and Spoofing) and nonattacks Dataset 1198633 is aboutde detection of Phishing websites 1198634 is a data set suggestedto solve some of the inherent problems of the well-knownKDD101584099 data setThis has been treated by the approach givenin [59 60] Finally 1198635 contains transactions made by creditcards This unbalanced collection of data includes exampleslabeled as fraudulent or genuine Also the features are theresult of a PCA transformation
Complexity 5
Table 2 Description of the set of datasetsD
Dataset Name Instances Features Classes Reference1198631 Spambase 4601 57 2 [54]1198632 Robots in RTLS 6422 12 3 [55]1198633 Phishing websites 11055 30 2 [56ndash58]1198634 Intrusion Detection (NSL-KDD) 148517 39 5 [59 60]1198635 Credit Card Fraud Detection 284807 30 2 [61]
Table 3 Description of the partitions of the set of datasetsD
Dataset 1198751 1198752 1198753 11987541198631 383 766 2300 46011198632 535 1070 3211 64221198633 921 1842 5527 110551198634 12376 24752 74258 1485171198635 23733 47467 142403 284807
Also the datasets have different number of instances aswell as features and number of classes of the target variable
33 Sampling and Collection of Data For each dataset 119863119894four partitions 119875119895(119863119894)119895=14 have been created in a randomway These correspond to the proportions that are obtainedwhen multiplied by 12 16 112 the whole set (P = 1198751 =8 3 1198752 = 16 3 1198753 = 50 1198754 = 119863119894) We denote by119875119895(119863119894) the partition on the dataset 119863119894 where 119894 = 1 5and 119895 = 1 2 3 4 These proportions have been chosen dueto the fact that in this way we can deal with an amountof instances of different order of magnitude (102 103 104and 105 having similar orders in the same partition of eachdataset see Table 3
On the other hand we fix once and for all a partition119863119905119903119886119894119899119894 cup 119863V119886119897119894119889
119894 = 119863119894 for each 119863119894 into train data (80) andvalidation data (20) as well as a partition with the sameproportion for each partition 119875119895(119863119894)
Finally in order to build response variables to measurethe goal of the study we apply each 119867119896 isin H over theall partitions 119875119895(119863119894) obtaining the hyperparameter config-uration 120582119896119894119895 Then the learning algorithm with the obtainedhyperparameter configuration is run over 119863119905119903119886119894119899119894 to constructa classifier that is validated over119863V119886119897119894119889
119894 At this step we collectthe accuracy obtained This scenario is repeated 50 iterationsAlso the total time and spatial complexity of all process arestored Then we create three response variables We denoteby 119860119888119888119896119894119895 the 50 times 1 array where the 119898-th component isthe accuracy of the predictive model tested on 119863V119886119897119894119889
119894 thatwas trained over 119863119905119903119886119894119899119894 with the hyperparameters (120582119896119894119895)119898 atthe 119898-th iteration We can measure the time and the spatialcomplexity used along this process and collect these data intwo 50 times 1 arrays 119879119862119896119894119895 and 119878119862119896119894119895 respectively
The time complexity measured in seconds is the sumof the time needed by the HPO algorithm for finding theoptimum hyperparameters and the time needed by the MLalgorithm for the training phase The spatial complexity
measured in Kb is defined as the maximum of use ofmemory along theHPOalgorithm run including the internalstructures of the algorithm as well as train and test datasetsload
34 Technical Specifications The analyses have been carriedby the authors at high-performance computing facilitated bySCAYLE (wwwscaylees) over HP ProLiant SL270s Gen8 SEwith 2 processors Intel Xeon CPU E5-2670 v2 250GHzwith 10 cores each one and 128 GB of RAM memory Theyare equipped with 1 hard disk of 1TB and cards InfinibandFDR 56Gbps
The analyses script has been implemented in Pythonlanguage Python uses an automated manager system ofmemory called garbage collector that releases the unusedmemory spaceThis phenomenonmight be nondeterministicand certain fluctuations shown in the results may be due tonot releasing the memory in that case
It is worth noting that different technical tools (eithersoftware or hardware) could affect to the data about time andspatial complexity that have been collected This is a fact thatshould be taken into account if we want to measure the effectof data sizes over the response variables in absolute termsthat is over a single HPO algorithm However the influenceof the technical specifications in the response variables isnot a relevant factor in this study This is a comparativestudy in which all the measures are collected under the sameconditions and the possible effect of the technical elementson the data is the same in each experiment It is expected thatthe same behavior of the comparative encountered patternswill appear with other technical characteristics
35 Analysis The aim of the study is to decide if the sizeof data is a factor that influences in the efficiency of a MLalgorithm using a HPOmethod among partitions of the data
We perform the following statistical analysis
(1) First for each level of the size that is the partitions 119875119895where 119895 = 1 2 3 4 we study the normality of 119860119888119888119896119894119895
6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 5
Table 2 Description of the set of datasetsD
Dataset Name Instances Features Classes Reference1198631 Spambase 4601 57 2 [54]1198632 Robots in RTLS 6422 12 3 [55]1198633 Phishing websites 11055 30 2 [56ndash58]1198634 Intrusion Detection (NSL-KDD) 148517 39 5 [59 60]1198635 Credit Card Fraud Detection 284807 30 2 [61]
Table 3 Description of the partitions of the set of datasetsD
Dataset 1198751 1198752 1198753 11987541198631 383 766 2300 46011198632 535 1070 3211 64221198633 921 1842 5527 110551198634 12376 24752 74258 1485171198635 23733 47467 142403 284807
Also the datasets have different number of instances aswell as features and number of classes of the target variable
33 Sampling and Collection of Data For each dataset 119863119894four partitions 119875119895(119863119894)119895=14 have been created in a randomway These correspond to the proportions that are obtainedwhen multiplied by 12 16 112 the whole set (P = 1198751 =8 3 1198752 = 16 3 1198753 = 50 1198754 = 119863119894) We denote by119875119895(119863119894) the partition on the dataset 119863119894 where 119894 = 1 5and 119895 = 1 2 3 4 These proportions have been chosen dueto the fact that in this way we can deal with an amountof instances of different order of magnitude (102 103 104and 105 having similar orders in the same partition of eachdataset see Table 3
On the other hand we fix once and for all a partition119863119905119903119886119894119899119894 cup 119863V119886119897119894119889
119894 = 119863119894 for each 119863119894 into train data (80) andvalidation data (20) as well as a partition with the sameproportion for each partition 119875119895(119863119894)
Finally in order to build response variables to measurethe goal of the study we apply each 119867119896 isin H over theall partitions 119875119895(119863119894) obtaining the hyperparameter config-uration 120582119896119894119895 Then the learning algorithm with the obtainedhyperparameter configuration is run over 119863119905119903119886119894119899119894 to constructa classifier that is validated over119863V119886119897119894119889
119894 At this step we collectthe accuracy obtained This scenario is repeated 50 iterationsAlso the total time and spatial complexity of all process arestored Then we create three response variables We denoteby 119860119888119888119896119894119895 the 50 times 1 array where the 119898-th component isthe accuracy of the predictive model tested on 119863V119886119897119894119889
119894 thatwas trained over 119863119905119903119886119894119899119894 with the hyperparameters (120582119896119894119895)119898 atthe 119898-th iteration We can measure the time and the spatialcomplexity used along this process and collect these data intwo 50 times 1 arrays 119879119862119896119894119895 and 119878119862119896119894119895 respectively
The time complexity measured in seconds is the sumof the time needed by the HPO algorithm for finding theoptimum hyperparameters and the time needed by the MLalgorithm for the training phase The spatial complexity
measured in Kb is defined as the maximum of use ofmemory along theHPOalgorithm run including the internalstructures of the algorithm as well as train and test datasetsload
34 Technical Specifications The analyses have been carriedby the authors at high-performance computing facilitated bySCAYLE (wwwscaylees) over HP ProLiant SL270s Gen8 SEwith 2 processors Intel Xeon CPU E5-2670 v2 250GHzwith 10 cores each one and 128 GB of RAM memory Theyare equipped with 1 hard disk of 1TB and cards InfinibandFDR 56Gbps
The analyses script has been implemented in Pythonlanguage Python uses an automated manager system ofmemory called garbage collector that releases the unusedmemory spaceThis phenomenonmight be nondeterministicand certain fluctuations shown in the results may be due tonot releasing the memory in that case
It is worth noting that different technical tools (eithersoftware or hardware) could affect to the data about time andspatial complexity that have been collected This is a fact thatshould be taken into account if we want to measure the effectof data sizes over the response variables in absolute termsthat is over a single HPO algorithm However the influenceof the technical specifications in the response variables isnot a relevant factor in this study This is a comparativestudy in which all the measures are collected under the sameconditions and the possible effect of the technical elementson the data is the same in each experiment It is expected thatthe same behavior of the comparative encountered patternswill appear with other technical characteristics
35 Analysis The aim of the study is to decide if the sizeof data is a factor that influences in the efficiency of a MLalgorithm using a HPOmethod among partitions of the data
We perform the following statistical analysis
(1) First for each level of the size that is the partitions 119875119895where 119895 = 1 2 3 4 we study the normality of 119860119888119888119896119894119895
6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

6 Complexity
Table 4 Level of gains where lsquo =ltgtrsquo denotes statistically meaningful equality and differences 119872119890 represents the median and 119895 lt 119897
Level Condition9 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)8 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)7 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897)6 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897)5 If 119872119890(119860119888119888119896119894119895) gt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119878119862
119896119894 ) lt Δ 119895119905(119879119862119896119894 )
4 If 119872119890(119860119888119888119896119894119895) = 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) lt Δ 119895119905(119879119862119896119894 )
3 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) lt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119878119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )
2 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897)amp 119872119890(119878119862119896119894119895) = 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 )1 If 119872119890(119860119888119888119896119894119895) lt 119872119890(119860119888119888119896119894119897) amp 119872119890(119878119862119896119894119895) gt 119872119890(119878119862119896119894119897) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119860119888119888119896119894 ) amp Δ 119895119905(119879119862119896119894 ) gt Δ 119895119905(119878119862
119896119894 )
0 In another case
(resp 119879119862119896119894119895 and 119878119862119896119894119895) Once it has been determinedthat these data do not follow a normal statisticaldistribution we have performed nonparametric testsWilcoxonrsquo test for two paired samples was conductedin order to decide whether there are statisticallymeaningful differences or not among 1198601198881198881198961198941 11986011988811988811989611989421198601198881198881198961198943 and1198601198881198881198961198944 (resp for119879119862119896119894119895 and 119878119862119896119894119895 ) for all119863119894 isinD 119867119896 isin H and for the three selected ML algorithms(RF GB and MLP) The choice of this test is due tothe fact that the response variables that we compareare obtained by the application of the ML algorithmsover the dataset 119863119894 with the splits 119863119905119903119886119894119899119894 and 119863V119886119897119894119889
119894 but with the different setting (120582119896119894sdot)
lowast and (1205821198961198944)lowast The
study has been carried out with a significance level120572 = 005
(2) At this point we have applied the inference describedover the accuracy the time and the spatial com-plexity Then we have obtained the 119901-values of eachpartitionrsquos comparison for each response variablefor each HPO method and for each 119863119894 That is sixcomparisons for 11987511198811199041198754 along five datasets providinga total of 30 decisions about statistical equality or notfor each ML algorithm (the same process for 1198752119881119904119875411987531198811199041198754 respectively) Then we have computed therate of 119901-values that provides statistical differences bycomparison of partitions by response variables andin a total way
(3) From the results obtained in Wilcoxonrsquos tests weassign to each 119875119895(119863119894) a level of gain with regard to1198754(119863119894) for 119895 = 1 2 3 The mapping is carried outaccording to Table 4 where 119895119905(119860119888119888119896119894 ) denotes therate of absolute difference of the median accuracybetween operating with the model obtained throughHPO on 119875119895(119863119894) and 1198754(119863119894) (resp spatial and timecomplexity) Namely
119895119905
(119860119888119888119896119894 ) =10038161003816100381610038161003816119872119890 (119860119888119888119896119894119895) minus 119872119890 (119860119888119888119896119894119905)
10038161003816100381610038161003816min [119872119890 (119860119888119888119896119894119895) 119872119890 (119860119888119888119896119894119905)]
(2)
119895119905
(119878119862119896119894 ) =10038161003816100381610038161003816119872119890 (119878119862119896119894119895) minus 119872119890 (119878119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119878119862119896119894119895) 119872119890 (119878119862119896119894119905)]
(3)
119895119905
(119879119862119896119894 ) =10038161003816100381610038161003816119872119890 (119879119862119896119894119895) minus 119872119890 (119879119862119896119894119905)
10038161003816100381610038161003816min [119872119890 (119879119862119896119894119895) 119872119890 (119879119862119896119894119905)]
(4)
This correspondence is shown for each algorithm 119867119896and dataset 119863119894The design of Table 4 was done based on how manyresponse variables show a positive efficiency ratewhen optimizing the hyperparameter values with asmaller partitions instead of the whole dataset Firstwe have created nine levels of gain (9 is the highestlevel) each of them determined by the number ofresponse variables in which we reach more efficientresults prioritizing the accuracy against TC and SCAlso we have sorted the levels of gain from the bestcombination to the worst dropping those combi-nations in which the loss is larger than the profitDue to the Python garbage collector the responsevariable with a more clear increasing trend shouldbe the time complexity instead of spatial complexityThen we suppose that the inequality TC(119875119895(119863119894)) ltTC(1198754(119863119894)) holds always true
(4) Finally we compute the average of gain of the smallerpartitions in a general way per datasets and MLalgorithms These results let us measure the reliabilityof the conclusions
4 Results and Discussion
The first research question deals with whether the size of apartition used in the HPO phase influences in certain senseon the efficiency of the algorithmOnce the comparisonrsquos testsdescribed in the above section have been done we accountfor each ML model how many combinations show statis-tically significant differences across all the HPO methodsand all the datasets Although we find an influence on theresponse variables we do not know whether this influence ispositive or not So the second research question is focused on
Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 7
Table 5 Statistically significant differences in each dimension for all HPO across all119863119894 of RF for each comparison between 119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1330 = 4333 3030 = 100 3030 = 100 7390 = 81111198752 Vs 1198754 1230 = 40 2930 = 9666 3030 = 100 7190 = 78881198753 Vs 1198754 330 = 10 2930 = 9666 3030 = 100 6290 = 6888(1198751 + 1198752 + 1198753) Vs 1198754 2890 = 3111 8890 = 9777 9090 = 100
Table 6 Statistically significant differences in each dimension for all HPO across all119863119894 of GB for each comparison between119875119895(119863119894) and1198754(119863119894)and the total ()
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 1930 = 6333 2930 = 9666 3030 = 100 7890 = 86661198752 Vs 1198754 2030 = 6666 2930 = 9666 2930 = 9666 7890 = 86661198753 Vs 1198754 1430 = 4666 2830 = 9333 3030 = 100 7290 = 80(1198751 + 1198752 + 1198753) Vs 1198754 5390 = 5888 8690 = 9555 8990 = 9888
Table 7 Statistically significant differences in each dimension for all HPO across all 119863119894 of MLP for each comparison between 119875119895(119863119894) and1198754(119863119894) and the total ())
Combination Accuracy Time Complexity Spatial Complexity (Acc+TC+SC)1198751 Vs 1198754 430 = 1333 2930 = 9666 3030 = 100 6390 = 701198752 Vs 1198754 530 = 1666 2830 = 9333 3030 = 100 6390 = 701198753 Vs 1198754 130 = 333 2630 = 8666 3030 = 100 5790 = 6333(1198751 + 1198752 + 1198753) Vs 1198754 1090 = 1111 8390 = 9222 9090 = 100
the study of this differences and equalities Next we analyzethe reliability of the results Finally we include an overviewof the global results that are obtained
41 ResearchQuestion 1 In the case of RF the results includedin Table 5 show that the obtained accuracy in the 3111 ofpossible combinations between the smaller partitions andthe whole dataset can be considered statistically differentHowever the time and spatial complexity have a very highamount of statistically significant differences (9777 and100 respectively) Hence spatial and time complexity areaffected by the size of the dataset (as expected) But on theother hand the size of the dataset does not impact on theaccuracy in a critical way
Also we can see that the partition 1198751(119863119894) reaches thehighest number of differences in the accuracies as well asin time and spatial complexity while the behavior of thepartition 1198753(119863119894) is the more statistically similar to the wholedataset Note that in the 90 of the cases the accuracyobtained with this partition can be considered equal toaccuracy obtained with 1198754 = 119863119894 Note that the behavior ofthe accuracies shows an increasing trend of similarity relatedto the increasing size of the partition
In the case of GB the results included in Table 6 show thatthe obtained accuracy in the 4112 of possible combinationsamong the smaller partitions and the whole dataset can beconsidered statistically equivalent However the time andspatial complexity have a very high amount of statisticallysignificant differences (9555 and 9888 respectively) So
we can confirm that the datasetrsquos size has an effect on theselast dimensions in a strong way and over the accuracy in amedium level
Regarding the concrete partitions we have a greaterhomogeneity of the results in the GB than in RF although1198753(119863119894) remains as the partition with the most similar accu-racy with respect to the whole dataset (5334 ) If wetake into account the three response variables the rate ofdifferences is quite high 1198753(119863119894) being the most similarwith an 80 of differences Note that in this case there is noincreasing trend of similarity in the accuracies as the sizegrows up
Finally in the case of MLP the results included inTable 7 show that the obtained accuracies in the 8889 of possible combinations among the smaller partitions andthe whole dataset can be considered statistically equal Thenthe accuracy is not being quite affected by the size of thedataset used in the HPO phase However the time andspatial complexities have a very high amount of statisti-cally significant differences (9222 and 100 respective-ly)
It is worth noting that 1198753(119863119894) has obtained 9667 ofequivalent accuracies but the behavior of the similarity in theaccuracies sorted by the size of the partition is not foundeither in this case
In general we have found a high effect of the datasetrsquossize used in the HPO over the time and spatial complexityfor the three ML algorithms In the case of the accuracythe ensemble methods (RF and GB) show a medium effect
8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

8 Complexity
Table 8 Patterns of profit
ML method Pattern 1 Pattern 2 Pattern 3 Pattern 4RF NM SMAC RS PS TPE CMA-ESGB RS NM TPE CMA-ES SMAC PSMLP RS SMAC CMA-ES PS TPE NM
Table 9 Average rate of statistically significant differences in each dimension for all HPO across all 119863119894 for all ML algorithms and for eachcomparison between 119875119895(119863119894) and 1198754(119863119894) ()
Combination Accuracy Time Complexity Spatial Complexity1198751 Vs 1198754 3999 9777 1001198752 Vs 1198754 4110 9555 98881198753 Vs 1198754 1999 9221 100(1198751 + 1198752 + 1198753) Vs 1198754 337 9518 9962
(around a rate of 40) while in the MLP the level of effect isvery low
42 Research Question 2 In order to study in depth whetherthe considered effect is positive or negative when we workwith smaller partitions the evolution of the response vari-ables as the size of the partition grows up is developed Weare going to study how are the encountered differences in eachdimension of the efficiency
In Figures 1 2 and 3 the charts of the evolution of thebehavior of the studied dimensions are shown for each dataset119863119894 and for RF GB and MLP respectively
Both the time and spatial complexity appear with anincreasing trend the first one being more highlighted Alsothe case of spatial complexity is more variable in the caseof MLP than in the ensemble methods So in order to gainefficiency when tuning the hyperparameters with a smallerproportion of data different levels are assigned according toTable 4 As we have mentioned above the levels of profit areproposed in terms of the gain in the accuracy and spatialcomplexity due to the fact that the time complexity shows aclear increasing trend
Note that in general is not true that the accuracyincreases as the size of the partition used for the HPO phasedoes This can be seen more clearly when the ML model isGB or MLP and certainly depends on the dataset See forinstance the three charts for1198632 and1198633 in Figures 1 2 and 3
The gainrsquos averages obtained in RF GB and MLP areincluded in Figures 4 5 and 6
In all the studied ML algorithms we can obtain a gainwhen smaller partitions are used toHPOAlso we can clearlyfind four different patterns (see Table 8)The first and secondone show that the partition 1198752 obtains the highest and thelowest profit The third one is an increasing trend from 1198751 to1198753 In the case of MLP we also detect another pattern thatstabilizes the gain from 1198752
In the case of RF the lowest level of gain is 45 and themaximum value is 7 The other ensemble method GB hasobtained levels of profit between 25 and 8 Finally the MLPalgorithm shows values between 5 and 75 Then the neural
network is the algorithm in which the HPO phase performsbetter with smaller partitions followed by RF and GB
In addition for all ML algorithms there is at least oneHPO algorithm that obtains a profit of level greater than 6 inthe smaller partitions 1198751 and 1198752 namely the NM algorithmIn case of 1198753 it is should be noted that the minimum level ofgain is 55 for all HPO and ML techniques
43 Research Question 3 If we compute the average of gainin each dataset we obtain the results shown in Figure 7
The averages of the profit level for RF are between 32and 85 being the largest dataset 1198635 the one in which wereach more efficiency working with smallest partition andshowing a decreasing trend On the other hand the dataset1198633 is the one in which we get less gain of efficiency Thesame behavior is presented in MLP up to a little loss of levelbetween 25 and 75 In the case of GB the averages of theprofit level are between 32 and 72 being the largest dataset1198634 the one in which we reach more efficiency working withsmallest partition
Finally we can conclude that in a general way in alldatasets we obtain efficiency optimizing the hyperparametervalues with smaller partition although the data were differentin terms of features number of instances or classes of thetarget variable So the results are consistent and reliable
44 Global Results In Table 9 we include the global averagerate of statistically significant differences in each dimension(see Tables 5 6 and 7) As we have mentioned above timeand spatial complexity show an increasing trend directlyrelated to the size of the partition Therefore the high rate ofdifferences appearing in these variables in Table 9 is intuitiveand expected However the behavior of the accuracy isdifferent We can observe that the accuracy that we get withsmaller partitions is statistically equivalent to the obtainedaccuracy with the whole dataset in more than the 60 of thecases This rate is greater than 80 for P3 (the 50 of the alldataset) This fact should be taken into account especially incase of big data contexts in order to optimize the available
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
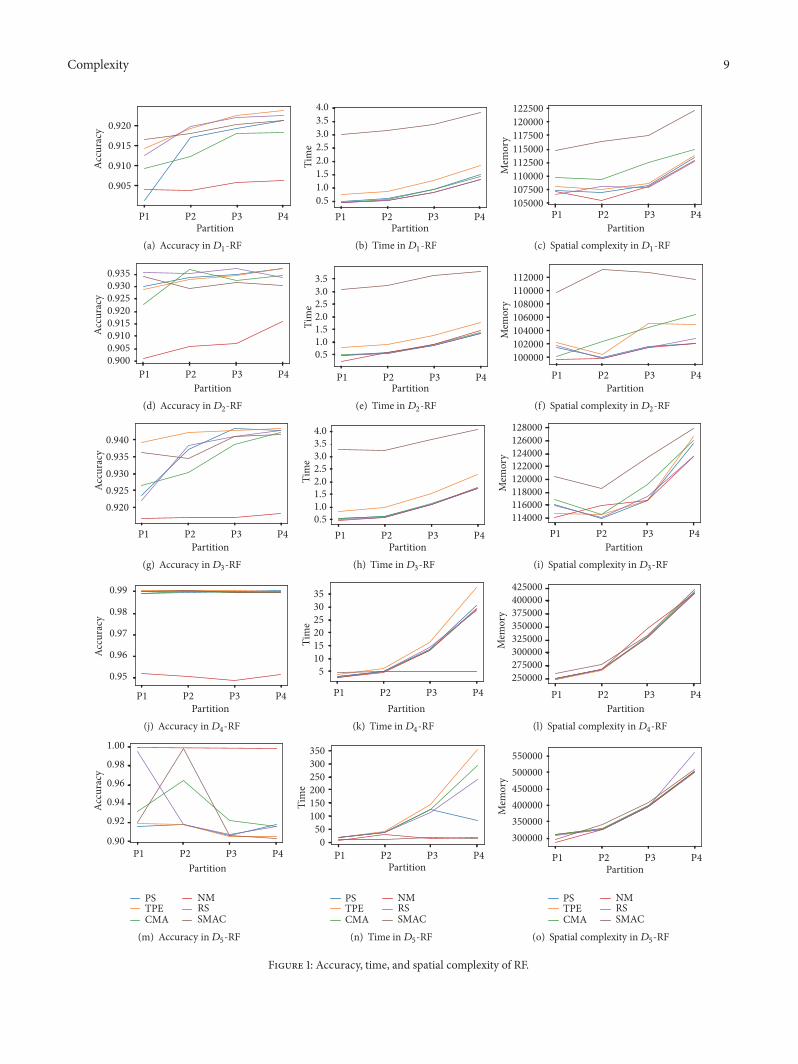
Complexity 9
P1 P2 P3 P4Partition
0905
0910
0915
0920
Accu
racy
(a) Accuracy in1198631-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(b) Time in1198631-RF
P1 P2 P3 P4Partition
105000107500110000112500115000117500120000122500
Mem
ory
(c) Spatial complexity in1198631-RF
P1 P2 P3 P4Partition
09000905091009150920092509300935
Accu
racy
(d) Accuracy in1198632-RF
P1 P2 P3 P4Partition
05101520253035
Tim
e
(e) Time in1198632-RF
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000
Mem
ory
(f) Spatial complexity in1198632-RF
P1 P2 P3 P4Partition
09200925093009350940
Accu
racy
(g) Accuracy in1198633-RF
P1 P2 P3 P4Partition
0510152025303540
Tim
e
(h) Time in1198633-RF
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-RF
P1 P2 P3 P4Partition
095
096
097
098
099
Accu
racy
(j) Accuracy in1198634-RF
P1 P2 P3 P4Partition
5101520253035
Tim
e
(k) Time in1198634-RF
P1 P2 P3 P4Partition
250000275000300000325000350000375000400000425000
Mem
ory
(l) Spatial complexity in1198634-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
(m) Accuracy in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(n) Time in1198635-RF
PSTPECMA
NMRSSMAC
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(o) Spatial complexity in1198635-RF
Figure 1 Accuracy time and spatial complexity of RF
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
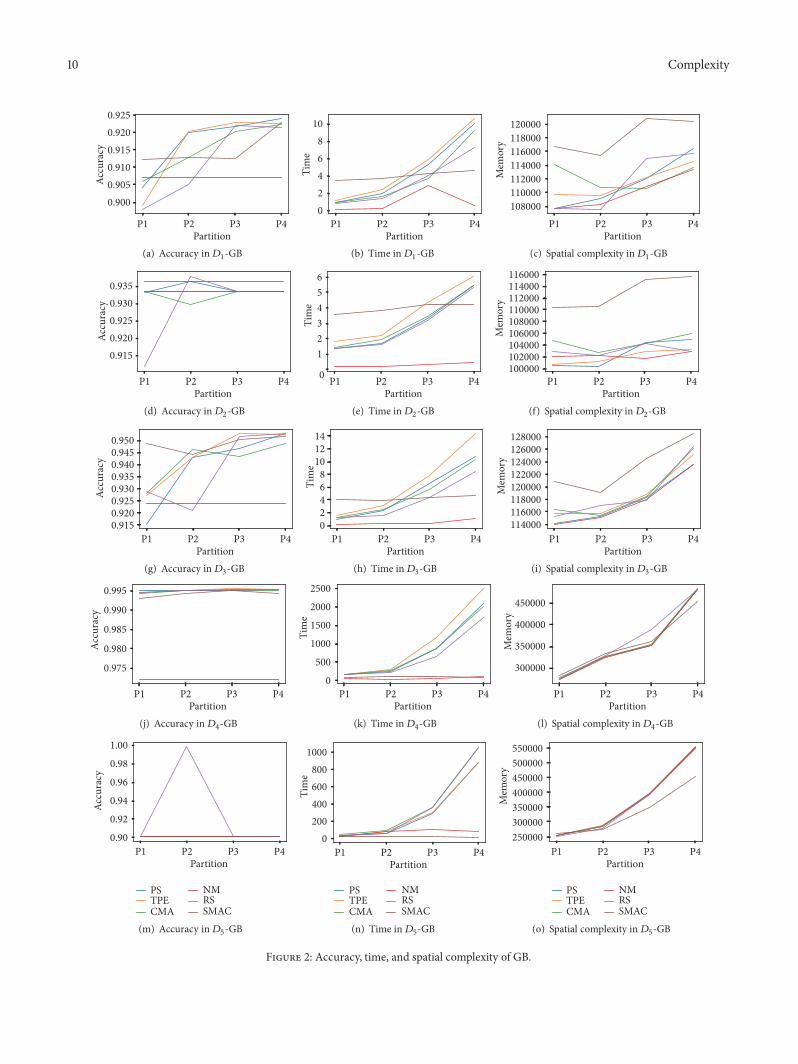
10 Complexity
P1 P2 P3 P4Partition
090009050910091509200925
Accu
racy
(a) Accuracy in1198631-GB
P1 P2 P3 P4Partition
02468
10
Tim
e
(b) Time in1198631-GB
P1 P2 P3 P4Partition
108000110000112000114000116000118000120000
Mem
ory
(c) Spatial complexity in1198631-GB
P1 P2 P3 P4Partition
09150920092509300935
Accu
racy
(d) Accuracy in1198632-GB
P1 P2 P3 P4Partition
0
123456
Tim
e
(e) Time in1198632-GB
P1 P2 P3 P4Partition
100000102000104000106000108000110000112000114000116000
Mem
ory
(f) Spatial complexity in1198632-GB
P1 P2 P3 P4Partition
09150920092509300935094009450950
Accu
racy
(g) Accuracy in1198633-GB
P1 P2 P3 P4Partition
02468
101214
Tim
e
(h) Time in1198633-GB
P1 P2 P3 P4Partition
114000116000118000120000122000124000126000128000
Mem
ory
(i) Spatial complexity in1198633-GB
P1 P2 P3 P4Partition
0975
0980
0985
0990
0995
Accu
racy
(j) Accuracy in1198634-GB
P1 P2 P3 P4Partition
0
500
1000
1500
2000
2500
Tim
e
(k) Time in1198634-GB
P1 P2 P3 P4Partition
300000
350000
400000
450000
Mem
ory
(l) Spatial complexity in1198634-GB
P1 P2 P3 P4Partition
090
092
094
096
098
100
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-GB
P1 P2 P3 P4Partition
0200400600800
1000
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-GB
P1 P2 P3 P4Partition
250000300000350000400000450000500000550000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-GB
Figure 2 Accuracy time and spatial complexity of GB
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
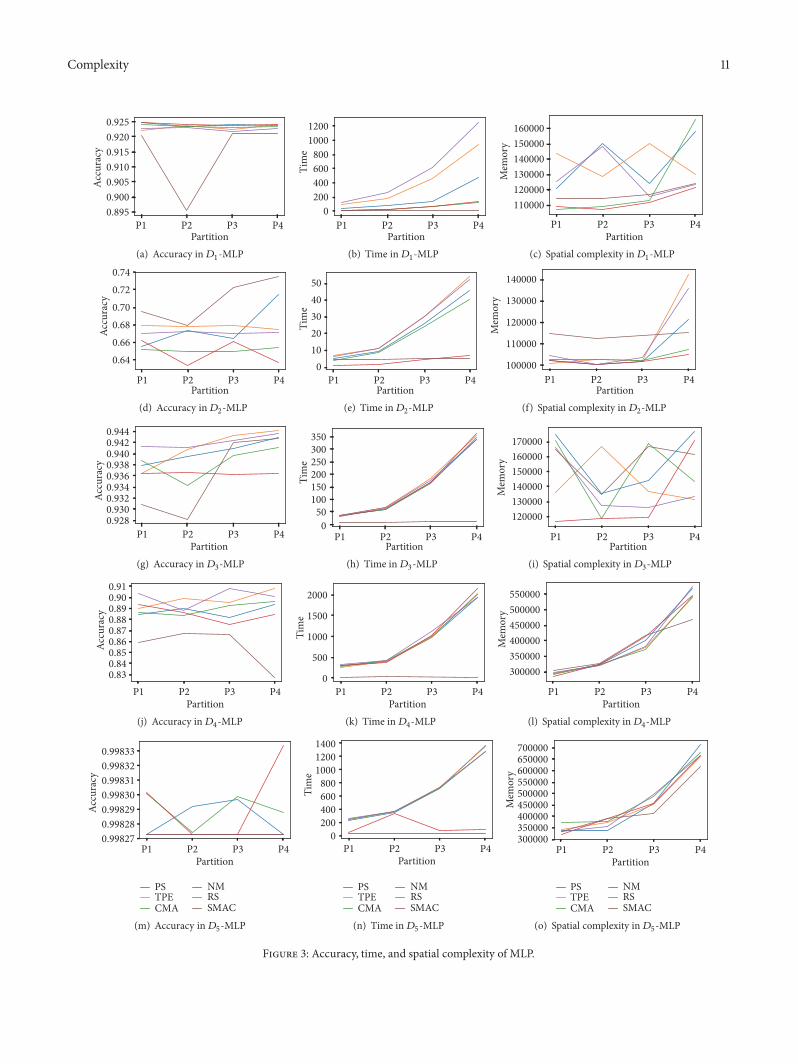
Complexity 11
P1 P2 P3 P4Partition
0895090009050910091509200925
Accu
racy
(a) Accuracy in1198631-MLP
P1 P2 P3 P4Partition
0200400600800
10001200
Tim
e
(b) Time in1198631-MLP
P1 P2 P3 P4Partition
110000120000130000140000150000160000
Mem
ory
(c) Spatial complexity in1198631-MLP
P1 P2 P3 P4Partition
064066068070072074
Accu
racy
(d) Accuracy in1198632-MLP
P1 P2 P3 P4Partition
01020304050
Tim
e
(e) Time in1198632-MLP
P1 P2 P3 P4Partition
100000
110000
120000
130000
140000
Mem
ory
(f) Spatial complexity in1198632-MLP
P1 P2 P3 P4Partition
092809300932093409360938094009420944
Accu
racy
(g) Accuracy in1198633-MLP
P1 P2 P3 P4Partition
050
100150200250300350
Tim
e
(h) Time in1198633-MLP
P1 P2 P3 P4Partition
120000130000140000150000160000170000
Mem
ory
(i) Spatial complexity in1198633-MLP
P1 P2 P3 P4Partition
083084085086087088089090091
Accu
racy
(j) Accuracy in1198634-MLP
P1 P2 P3 P4Partition
0
500
1000
1500
2000
Tim
e
(k) Time in1198634-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000
Mem
ory
(l) Spatial complexity in1198634-MLP
P1 P2 P3 P4Partition
099827099828099829099830099831099832099833
Accu
racy
PSTPECMA
NMRSSMAC
(m) Accuracy in1198635-MLP
P1 P2 P3 P4Partition
0200400600800
100012001400
Tim
e
PSTPECMA
NMRSSMAC
(n) Time in1198635-MLP
P1 P2 P3 P4Partition
300000350000400000450000500000550000600000650000700000
Mem
ory
PSTPECMA
NMRSSMAC
(o) Spatial complexity in1198635-MLP
Figure 3 Accuracy time and spatial complexity of MLP
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
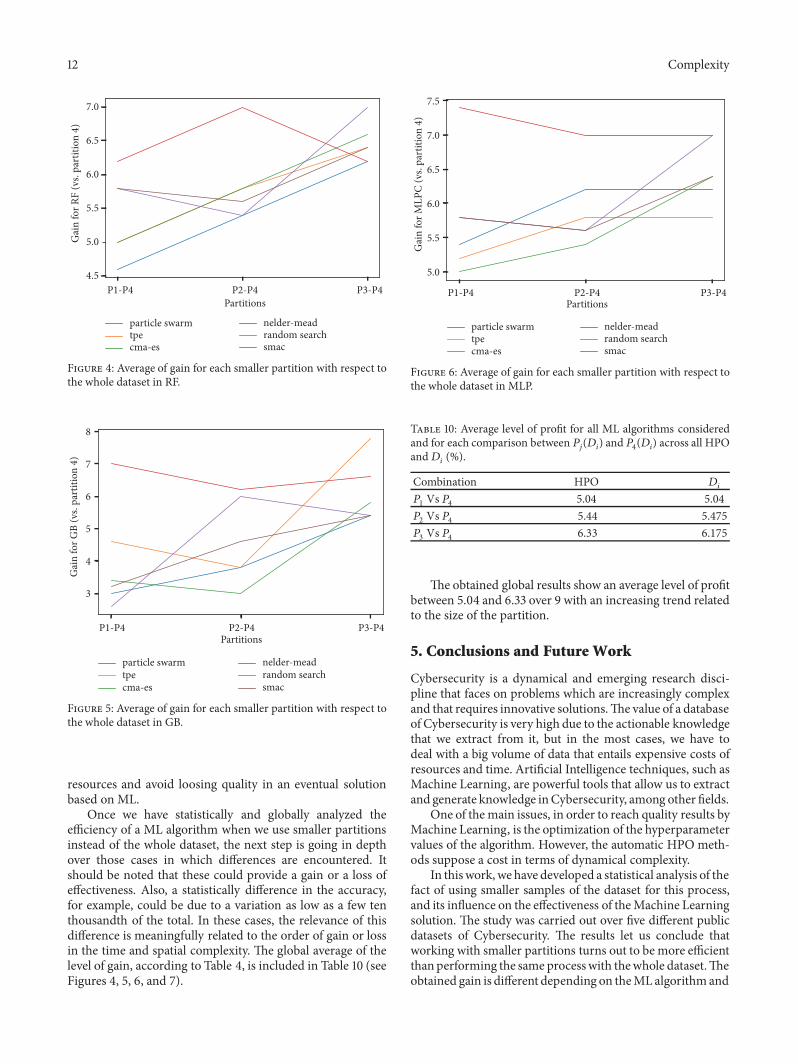
12 Complexity
P1-P4 P2-P4 P3-P4Partitions
45
50
55
60
65
70
Gai
n fo
r RF
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 4 Average of gain for each smaller partition with respect tothe whole dataset in RF
P1-P4 P2-P4 P3-P4Partitions
3
4
5
6
7
8
Gai
n fo
r GB
(vs
part
ition
4)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 5 Average of gain for each smaller partition with respect tothe whole dataset in GB
resources and avoid loosing quality in an eventual solutionbased on ML
Once we have statistically and globally analyzed theefficiency of a ML algorithm when we use smaller partitionsinstead of the whole dataset the next step is going in depthover those cases in which differences are encountered Itshould be noted that these could provide a gain or a loss ofeffectiveness Also a statistically difference in the accuracyfor example could be due to a variation as low as a few tenthousandth of the total In these cases the relevance of thisdifference is meaningfully related to the order of gain or lossin the time and spatial complexity The global average of thelevel of gain according to Table 4 is included in Table 10 (seeFigures 4 5 6 and 7)
P1-P4 P2-P4 P3-P4Partitions
50
55
60
65
70
75
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
particle swarmtpecma-es
nelder-meadrandom searchsmac
Figure 6 Average of gain for each smaller partition with respect tothe whole dataset in MLP
Table 10 Average level of profit for all ML algorithms consideredand for each comparison between 119875119895(119863119894) and 1198754(119863119894) across all HPOand 119863119894 ()
Combination HPO 1198631198941198751 Vs 1198754 504 5041198752 Vs 1198754 544 54751198753 Vs 1198754 633 6175
The obtained global results show an average level of profitbetween 504 and 633 over 9 with an increasing trend relatedto the size of the partition
5 Conclusions and Future Work
Cybersecurity is a dynamical and emerging research disci-pline that faces on problems which are increasingly complexand that requires innovative solutionsThe value of a databaseof Cybersecurity is very high due to the actionable knowledgethat we extract from it but in the most cases we have todeal with a big volume of data that entails expensive costs ofresources and time Artificial Intelligence techniques such asMachine Learning are powerful tools that allow us to extractand generate knowledge inCybersecurity among other fields
One of the main issues in order to reach quality results byMachine Learning is the optimization of the hyperparametervalues of the algorithm However the automatic HPO meth-ods suppose a cost in terms of dynamical complexity
In thiswork we have developed a statistical analysis of thefact of using smaller samples of the dataset for this processand its influence on the effectiveness of theMachine Learningsolution The study was carried out over five different publicdatasets of Cybersecurity The results let us conclude thatworking with smaller partitions turns out to bemore efficientthanperforming the same processwith thewhole datasetTheobtained gain is different depending on theML algorithmand
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom
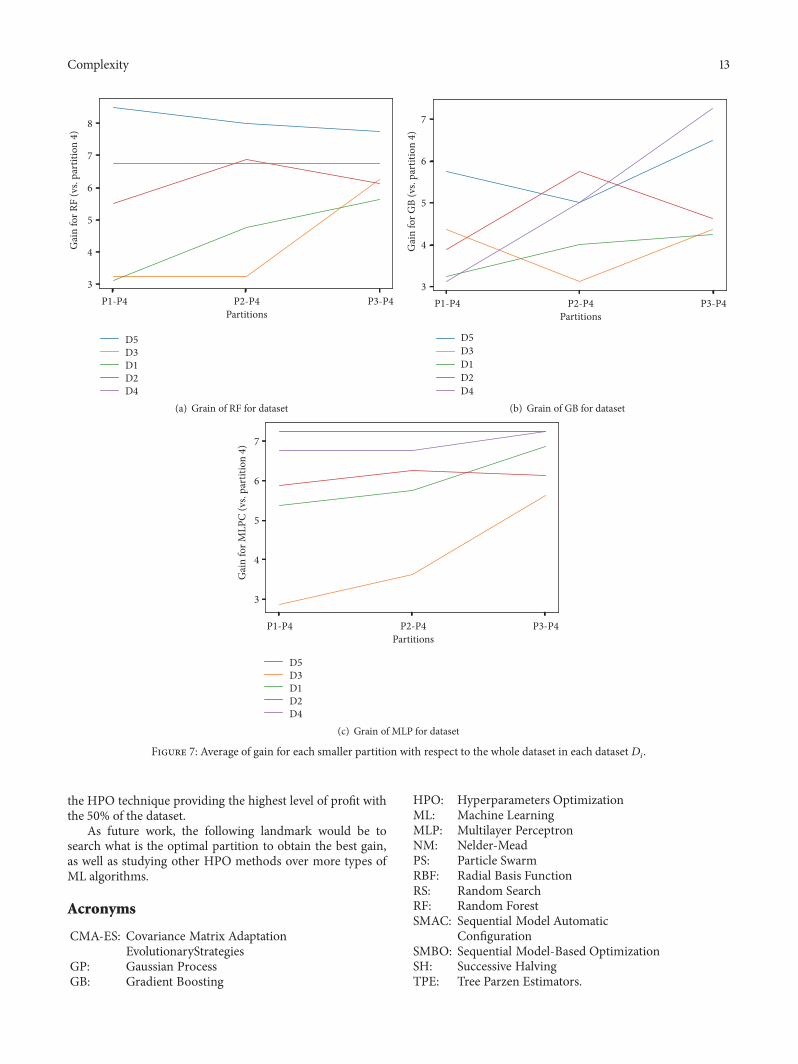
Complexity 13
P1-P4 P3-P43
4
5
6
7
8
Gai
n fo
r RF
(vs
part
ition
4)
D5D3D1D2D4
P2-P4Partitions
(a) Grain of RF for dataset
D5
P1-P4 P3-P43
4
5
6
7
Gai
n fo
r GB
(vs
part
ition
4)
D3D1D2D4
P2-P4Partitions
(b) Grain of GB for dataset
P1-P4 P3-P4
3
4
5
6
7
Gai
n fo
r MLP
C (v
s pa
rtiti
on 4
)
D5D3D1D2D4
P2-P4Partitions
(c) Grain of MLP for dataset
Figure 7 Average of gain for each smaller partition with respect to the whole dataset in each dataset 119863119894
the HPO technique providing the highest level of profit withthe 50 of the dataset
As future work the following landmark would be tosearch what is the optimal partition to obtain the best gainas well as studying other HPO methods over more types ofML algorithms
Acronyms
CMA-ES Covariance Matrix AdaptationEvolutionaryStrategies
GP Gaussian ProcessGB Gradient Boosting
HPO Hyperparameters OptimizationML Machine LearningMLP Multilayer PerceptronNM Nelder-MeadPS Particle SwarmRBF Radial Basis FunctionRS Random SearchRF Random ForestSMAC Sequential Model Automatic
ConfigurationSMBO Sequential Model-Based OptimizationSH Successive HalvingTPE Tree Parzen Estimators
14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

14 Complexity
Data Availability
The datasets supporting this meta-analysis are from previ-ously reported studies and datasets which have been citedThe processed data are available from the correspondingauthor upon request
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
The authors would like to thank the Spanish NationalCybersecurity Institute (INCIBE) who partially supportedthis work Also in this research the resources of the Centrode Supercomputacion de Castilla y Leon (SCAYLE wwwscaylees) funded by the ldquoEuropean Regional DevelopmentFund (ERDF)rdquo have been used
References
[1] Z Cheng and Z Lu ldquoA Novel Efficient Feature DimensionalityReduction Method and Its Application in Engineeringrdquo Com-plexity vol 2018 Article ID 2879640 14 pages 2018
[2] I Czarnowski and P Jędrzejowicz ldquoAn Approach to DataReduction for Learning fromBigDatasets Integrating StackingRotation and Agent Population Learning Techniquesrdquo Com-plexity vol 2018 Article ID 7404627 13 pages 2018
[3] F Provost D Jensen and T Oates ldquoEfficient progressive sam-plingrdquo in Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining pp 23ndash32San Diego Calif USA 1999
[4] W Ng and M Dash ldquoAn Evaluation of Progressive Samplingfor Imbalanced Data Setsrdquo in Proceedings of the Sixth IEEEInternational Conference on Data Mining Workshops HongKong China 2006
[5] F Portet F Gao J Hunter and R Quiniou ldquoReduction of LargeTraining Set by Guided Progressive Sampling Application toNeonatal Intensive Care Datardquo in Proceedings of the IntelligentData International Workshop on Analysis in Medicine and Phar-macology (IDAMAP2007) pp 1-2 Amsterdam NetherlandsJuly 2007
[6] G M Weiss and F Provost ldquoLearning when training data arecostlyThe effect of class distribution on tree inductionrdquo Journalof Artificial Intelligence Research vol 19 pp 315ndash354 2003
[7] C Thornton F Hutter H H Hoos and K Leyton-BrownldquoAuto-WEKA Combined selection and hyperparameter opti-mization of classification algorithmsrdquo in Proceedings of the19th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining (KDD 2013) pp 847ndash855 2013
[8] Y Bengio ldquoGradient-based optimization of hyperparametersrdquoNeural Computation vol 12 no 8 pp 1889ndash1900 2000
[9] J Luketina M Berglund K Greff and T Raiko ldquoScalablegradient-based tuning of continuous regularization hyperpa-rametersrdquo CoRR 2015 httpsarxivorgabs151106727
[10] D Maclaurin D Duvenaud and R P Adams ldquoGradient-based hyperparameter optimization through reversible learn-ingrdquo in Proceedings of the 32Nd International Conference onInternational Conference onMachine Learning (ICMLrsquo15) vol 37
pp 2113ndash2122 2015 httpdlacmorgcitationcfmid=30451183045343
[11] L Mockus V Tiesis and A Zilinskas ldquoThe application ofbayesian methods for seeking the extremumrdquo Towards GlobalOptimization 1978
[12] A R Conn K Scheinberg and L N Vicente Introduction toderivatibe-free otpimization MPSSIAM Series on Optimization2009 httpepubssiamorgdoibook10113719780898718768
[13] N Hansen and A Ostermeier ldquoCompletely derandomized self-adaptation in evolution strategiesrdquo Evolutionary Computationvol 9 no 2 pp 159ndash195 2001
[14] J A Nelder and R Mead ldquoA simplex method for functionminimizationrdquoThe Computer Journal vol 7 no 4 pp 308ndash3131965
[15] M Clerc and J Kennedy ldquoThe particle swarm-explosion sta-bility and convergence in a multidimensional complex spacerdquoIEEE Transactions on Evolutionary Computation vol 6 no 1pp 58ndash73 2002
[16] X C Guo J H Yang C G Wu C Y Wang and Y C LiangldquoA novel LS-SVMs hyper-parameter selection based on particleswarm optimizationrdquo Neurocomputing vol 71 no 16-18 pp3211ndash3215 2008
[17] J Kennedy and R C Eberhart Swarm Intelligence MorganKaufmann 2001
[18] F Fortin F De Rainville M Gardner M Parizeau and CGagne ldquoDEAP Evolutionary algorithms made easyrdquo Journalof Machine Learning Research vol 13 pp 2171ndash2175 2012httpsgithubcomDEAPdeap
[19] E Hazan A Klivans and Y Yuan ldquoHyperparameter Opti-mization A Spectral Approachrdquo in In Proceedings of the SixthInternational Conference on Learning Representations 2018
[20] J Snoek H Larochelle and R P Adams ldquoPractical Bayesianoptimization of machine learning algorithmsrdquo in Proceedings ofthe Advances in Neural Information Processing Systems 25 26thAnnual Conference on Neural Information Processing Systems2012 (NIPS 2012) pp 2960ndash2968 2012
[21] J Bergstra R Bardenet Y Bengio and B Kegl ldquoAlgorithmsfor hyper-parameter optimizationrdquo in Proceedings of the NeuralInformation Processing Systems 2011 (NIPS 2011) pp 2546ndash25542011
[22] F Hutter H H Hoos and K Leyton-Brown ldquoSequentialModel-Based Optimization for General Algorithm Configura-tionrdquo in Learning and Intelligent Optimization (LION) C A CCoello Ed vol 6683 of Lecture Notes in Computer Science pp507ndash523 Springer Berlin Germany 2011
[23] J Bergstra and Y Bengio ldquoRandom search for hyper-parameteroptimizationrdquo Journal of Machine Learning Research vol 13 pp281ndash305 2012
[24] W Konen P Koch O Flasch et al ldquoTuned Data Mining ABenchmark Study on Different Tunersrdquo in Proceedings of the13th Annual Conference on Genetic and Evolutionary Computa-tion (GECCO-2011) SIGEVOACM New York NY USA 2011
[25] E R Sparks A Talwalkar D Haas et al ldquoAutomating modelsearch for large scale machine learningrdquo in Proceedings of theSixth ACM Symposium on Cloud Computing (SoCC 2015) pp368ndash380 2015
[26] I Ilievski T Akhtar J Feng and C A Shoemaker ldquoEfficienthyperparameter optimization for deep learning algorithmsusing deterministic RBF surrogatesrdquo in Proceedings of theThirty-First AAAI Conference on Artificial Intelligence pp 822ndash829 San Francisco Calif USA 2017
Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 15
[27] Y Ozaki M Yano and M Onishi ldquoEffective hyperparameteroptimization using Nelder-Mead method in deep learningrdquo inProceedings of the IPS Transactions on Computer Vision andApplications pp 9ndash20 2017
[28] K G Jamieson and A Talwalkar ldquoNon-stochastic best armidentification and hyperparameter optimizationrdquo in In Proceed-ings of the 19th International Conference on Artificial Intelligenceand Statistics (AISTATS 2016) pp 240ndash248 2016
[29] B Recht Embracing the random 2016 httpwwwargminnet20160623hyperband
[30] B RechtThenews of auto-tuning 2016 httpwwwargminnet20160620hypertuning
[31] L Li K Jamieson G DeSalvo A Rostamizadeh and A Tal-walkar ldquoHyperband a novel bandit-based approach to hyper-parameter optimizationrdquo Journal of Machine Learning Research(JMLR) vol 18 pp 1ndash52 2017
[32] P Koch B Wujek O Golovidov and S Gardner ldquoAutomatedHyperparameter Tuning for Effective Machine Learningrdquo inProceedings of the SAS Global Forum 2017 Conference SASInstitute Inc Cary NC USA 2017 httpsupportsascomresourcespapersproceedings17SAS514-2017pdf
[33] K Eggensperger F Hutter H H Hoos and K Leyton-BrownldquoEfficient benchmarking of hyperparameter optimizers viasurrogatesrdquo in Proceedings of the Twenty-Ninth Association forthe Advancement of Artificial Intelligence pp 1114ndash1120 2015
[34] P Turney ldquoTypes of cost in inductive concept learningrdquo inProceedings of the ICML rsquo2000 Workshop on Cost-SensitiveLearning pp 15ndash21 2000
[35] D Bogdanova P Rosso and T Solorio ldquoExploring high-levelfeatures for detecting cyberpedophiliardquo Computer Speech andLanguage vol 28 no 1 pp 108ndash120 2014
[36] P Galan-Garcıa J Gaviria de la Puerta C Laorden GomezI Santos and P G Bringas ldquoSupervised Machine Learningfor the Detection of Troll Profiles in Twitter Social NetworkApplication to a Real Case of Cyberbullyingrdquo in Proceed-ings of the International Joint Conference SOCOrsquo13-CISISrsquo13-ICEUTErsquo13 Advances in Intelligent Systems and Computing AHerrero et al Ed vol 239 Springer 2014
[37] S Miller and C Busby-Earle ldquoThe role of machine learningin botnet detectionrdquo in Proceedings of the 11th InternationalConference for Internet Technology and Secured Transactions(ICITST) pp 359ndash364 Barcelona Spain 2016
[38] J R Moya N DeCastro-Garcıa R Fernandez-Dıaz and J LTamargo ldquoExpert knowledge and data analysis for detectingadvanced persistent threatsrdquo Open Mathematics vol 15 no 1pp 1108ndash1122 2017
[39] A Shenfield D Day and A Ayesh ldquoIntelligent intrusiondetection systems using artificial neural networksrdquo ICT Expressvol 4 no 2 pp 95ndash99 2018
[40] F Vanhoenshoven G Napoles R Falcon K Vanhoof and MKoppen ldquoDetecting malicious URLs using machine learningtechniquesrdquo in Proceedings of the 2016 IEEE Symposium Serieson Computational Intelligence (SSCI) pp 1ndash8 Athens GreeceDecember 2016
[41] M Zanin M Romance S Moral and R Criado ldquoCreditCard Fraud Detection through Parenclitic Network AnalysisrdquoComplexity vol 2018 Article ID 5764370 9 pages 2018
[42] N DeCastro-Garcıa A L Munoz Castaneda M FernandezRodrıguez and M V Carriegos ldquoOn Detecting and RemovingSuperficial Redundancy in Vector Databasesrdquo MathematicalProblems in Engineering vol 2018 Article ID 3702808 14 pages2018
[43] V N Gudivada R Baeza-Yates and V V Raghavan ldquoBig dataPromises and problemsrdquo The Computer Journal vol 48 no 3pp 20ndash23 2015
[44] R Baeza-Yates ldquoBig Data or Right Datardquo in Proceedings of the7th Alberto Mendelzon International Workshop on Foundationsof Data Managements CEURWorkshop Proceedings 1087 p 142013
[45] S Garcia A Fernandez J Luengo and F Herrera ldquoAdvancednonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data miningexperimental analysis of powerrdquo Information Sciences vol 180no 10 pp 2044ndash2064 2010
[46] F Pedregosa G Varoquaux A Gramfort et al ldquoScikit-learnmachine learning in Pythonrdquo Journal of Machine LearningResearch vol 12 pp 2825ndash2830 2011
[47] L Breiman ldquoRandom forestsrdquoMachine Learning vol 45 no 1pp 5ndash32 2001
[48] F Rosenblatt Principles of Neurodynamics Perceptrons and theTheory of Brain Mechanisms Spartan Books Washington DCUSA 1961
[49] D E Rumelhart G E Hinton and R J Williams ldquoLearningInternal Representations by Error Propagationrdquo in ParallelDistributed Processing Explorations in the Microstructure ofCognition D E Rumelhart J L McClelland and The PDPresearch group Eds vol 1 MIT Press 1986
[50] D Kingma and J Ba ldquoAdam Amethod for stochastic optimiza-tionrdquo 2014 httpsarxivorgabs14126980
[51] J Bergstra J D Yamins and D Cox ldquoHyperopt a Pythonlibrary for optimizing the hyperparameters ofmachine learningalgorithmsrdquo in In Proceedings of the 12th Python in ScienceConference (SciPy 2013) pp 13ndash20 2013
[52] M Claesen J Simm D Popovic Y Moreau and B De MoorEasy Hyperparameter Search Using Optunity 2014 httpsgithubcomclaesenmoptunity
[53] M Lindauer K Eggensperger M Feurer et al SMAC v3Algorithm Configuration in Python 2017 httpsgithubcomautomlSMAC3
[54] M Hopkins E Reeber G Forman and J Suermondt ldquoDatasetSpambaserdquo UCI Machine Learning Repository [httparchiveicsuciedumldatasetsspambase] Irvine CA University ofCalifornia School of Information and Computer Science 2017
[55] AMGuerrero-HiguerasNDeCastro-Garcıa andVMatellanldquoDetection of Cyber-attacks to indoor real time localizationsystems for autonomous robotsrdquo Robotics and AutonomousSystems vol 99 pp 75ndash83 2018
[56] M Rami T L McCluskey and F A Thabtah ldquoAn Assessmentof Features Related to Phishing Websites using an AutomatedTechniquerdquo in Proceedings of the International Conferece ForInternet Technology And Secured Transactions (ICITST 2012)pp 492ndash497 IEEE London UK 2012
[57] R M Mohammad F Thabtah and L McCluskey ldquoIntelligentrule-based phishing websites classificationrdquo IET InformationSecurity vol 8 no 3 pp 153ndash160 2014
[58] R M Mohammad F Thabtah and L Mc-Cluskey ldquoPredictingphishing websites based on self-structuring neural networkrdquoNeural Computing and Applications vol 25 no 2 pp 443ndash4582014
[59] L Dhanabal and S P Shantharajah ldquoA Study on NSL-KDDDataset for Intrusion Detection System Based on ClassificationAlgorithmsrdquo International Journal of Advanced Research inComputer and Communication Engineering vol 4 no 6 2015
16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

16 Complexity
[60] ldquoNSL-KDD Datasetrdquo httpsgithubcomdefcom17NSL KDD2015
[61] A D Pozzolo O Caelen R A Johnson and G BontempildquoCalibrating Probability with Undersampling for UnbalancedClassificationrdquo in Symposium on Computational Intelligence andData Mining (CIDM) IEEE 2015 httpswwwopenmlorgd1597
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom


















