
A. Moshovos ©ECE1773 - Fall ‘07 ECE Toronto Out-of-Order Execution Structures.
Upload
elinor-pearsonCategory
view
218download
0
ECE1773 Spring ‘02© A. Moshovos (Toronto)
Roadmap• Fetching Multiple Instructions• Scheduling Memory Operations• Checkpoint/Restore

ECE1773 Spring ‘02© A. Moshovos (Toronto)
The Need for Multiple-Instruction Fetch
• Can’t execute more than we fetch• Today: 6-way issue
– Fetch at least 6 instructions per cycle
• Three main issues. Per cycle:1. Align instructions to feed scheduler
2. Fetch Multiple Cache Lines?
3. Predict Multiple Branches?
ECE1773 Spring ‘02© A. Moshovos (Toronto)
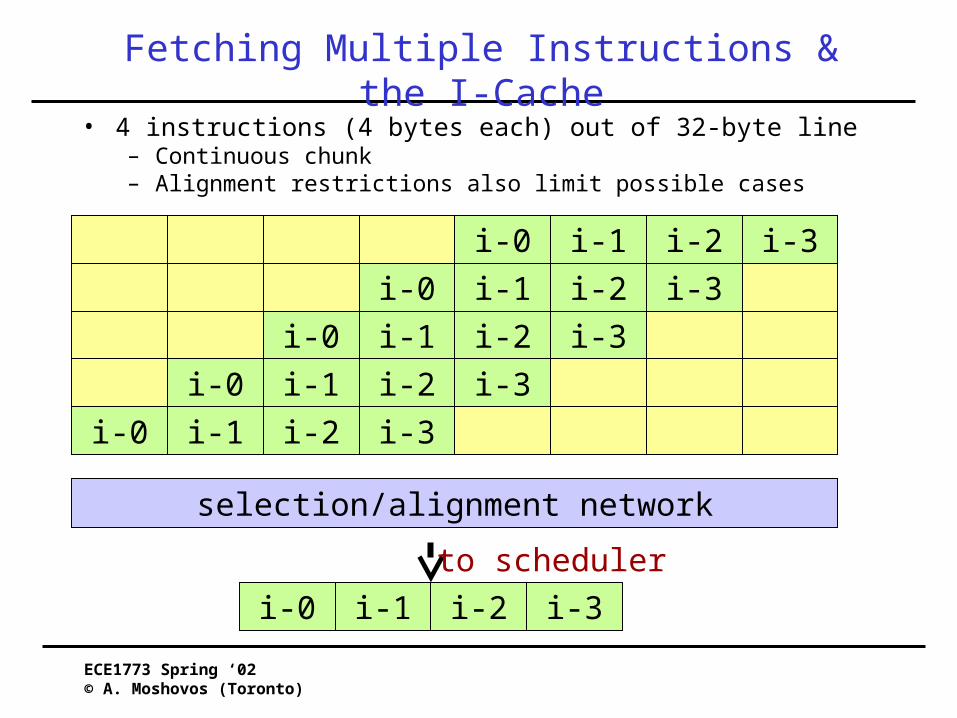
Fetching Multiple Instructions & the I-Cache• 4 instructions (4 bytes each) out of 32-byte line
– Continuous chunk– Alignment restrictions also limit possible cases
i-0 i-1 i-2 i-3
i-0 i-1 i-2 i-3
i-0 i-1 i-2 i-3
i-0 i-1 i-2 i-3
i-0 i-1 i-2 i-3
selection/alignment network
to scheduler
i-0 i-1 i-2 i-3

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Sequential Fetch Concept and Hardware
ECE1773 Spring ‘02© A. Moshovos (Toronto)
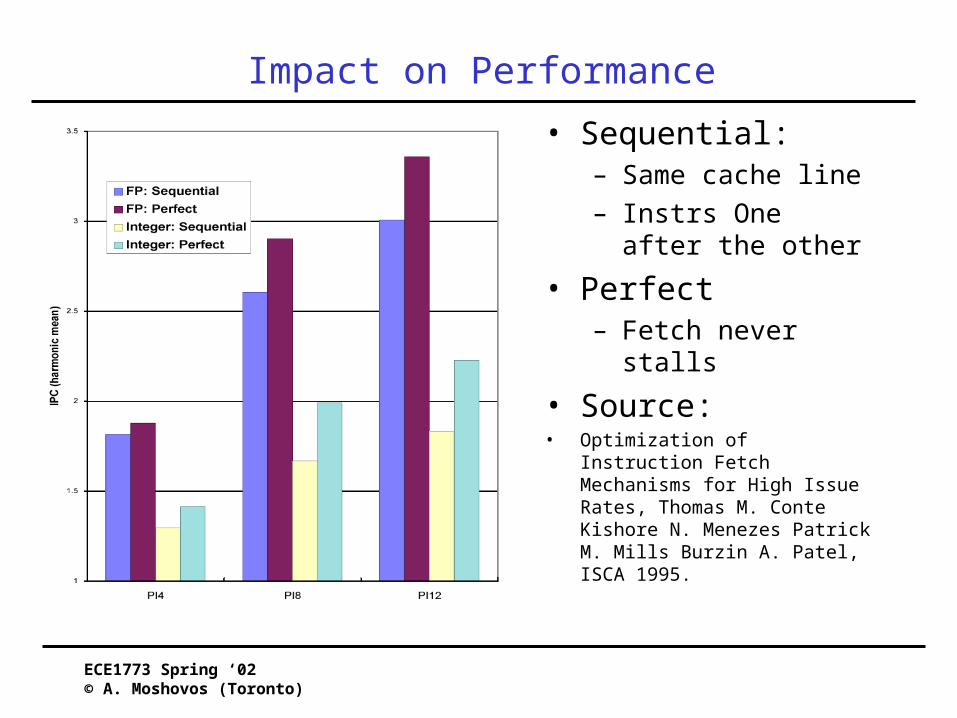
Impact on Performance• Sequential:
– Same cache line– Instrs One after the other
• Perfect– Fetch never stalls
• Source:• Optimization of Instruction Fetch
Mechanisms for High Issue Rates, Thomas M. Conte Kishore N. Menezes Patrick M. Mills Burzin A. Patel, ISCA 1995.
ECE1773 Spring ‘02© A. Moshovos (Toronto)
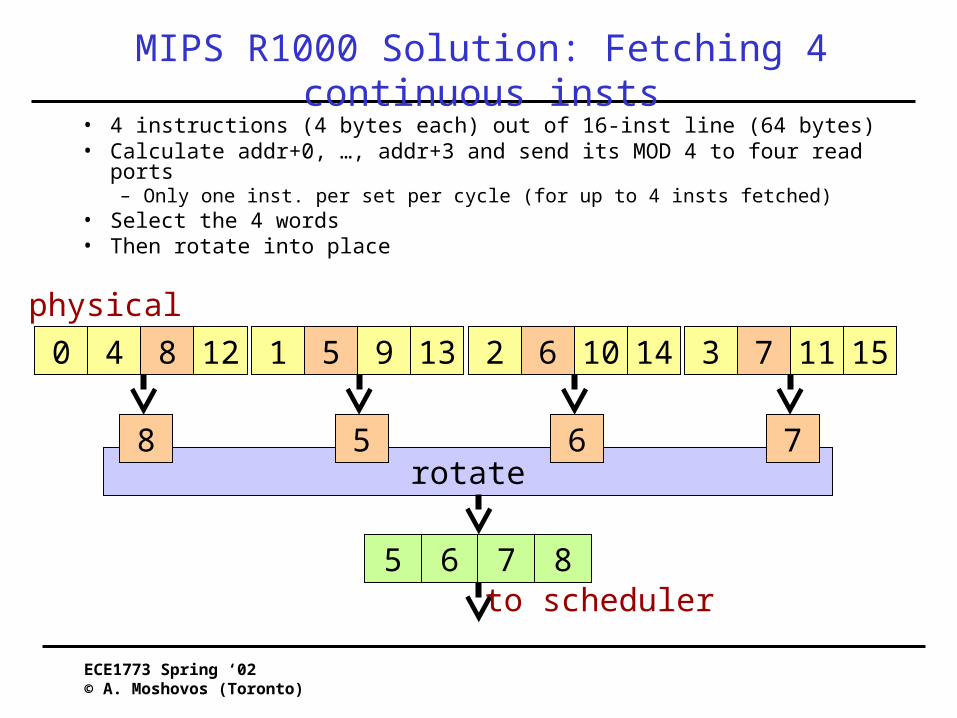
MIPS R1000 Solution: Fetching 4 continuous insts
5 6 7 8to scheduler
rotate
0 4 8 12 3 7 11 151 5 9 13 2 6 10 14
physical
• 4 instructions (4 bytes each) out of 16-inst line (64 bytes)• Calculate addr+0, …, addr+3 and send its MOD 4 to four read ports
– Only one inst. per set per cycle (for up to 4 insts fetched)• Select the 4 words• Then rotate into place
8 75 6

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Crossing Cache lines
• Say we need 8 insts:
i-0 i-1 i-2 i-3
i-4 i-5 i-6 i-7n
n+1
continuous sequence
i-0 i-1 i-2 i-3 i-4
i-5 i-6 i-7m
m+1
i-0 i-1 i-2 i-3 i-4 i-5 i-6 i-7
i-0 i-1 i-2 i-3 i-4 i-5 i-6 i-7
want
want

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Low-End Solution: Do not support
• Recall, try easy thing first– Try this in simplescalar to see how much you lose
• Hardware detects that fetch set spills over• Fetches only as many instructions as possible

ECE1773 Spring ‘02© A. Moshovos (Toronto)
High-End Solution: Full Support• Allow multiple cache line accesses per cycle
– Can be expensive– Multiple access paths– Multi-ported cache– Banked
• Routing network complexity?
• Bottom line: – Can be made to work– Complex: slow and expensive
• Would prefer to do without

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Full Support: How Many Cache Lines Per Cycle?
• If no control flow: 2 is enough• But with control flow?
– Worst case: 8 cache lines • Every inst a branch • Or every other instruction a branch that points to the last
inst in a cache line – Since 1 in 5 insts is a branch it is to be expected that there
are going to be about 2 branches in every 8 insts.

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Multiple Branches per Cycle?
• We also need to predict multiple branches per cycle:• Multi-port predictor• History-based (pattern)
– Precise• Wait for first prediction then do second• Do second with both possible outcomes for first and then
select expensive– Imprecise
• Just use present history for both

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Interleaved Sequential
• Fetch two consecutive cache lines• Extract a sequential portion
– No branches in-between• Goal:
– Larger Sequential Blocks of Code• Need two cache banks
– Bank (a mod 2) = 0– Bank (a mod 2) = 1
• Two hardware structures needed:
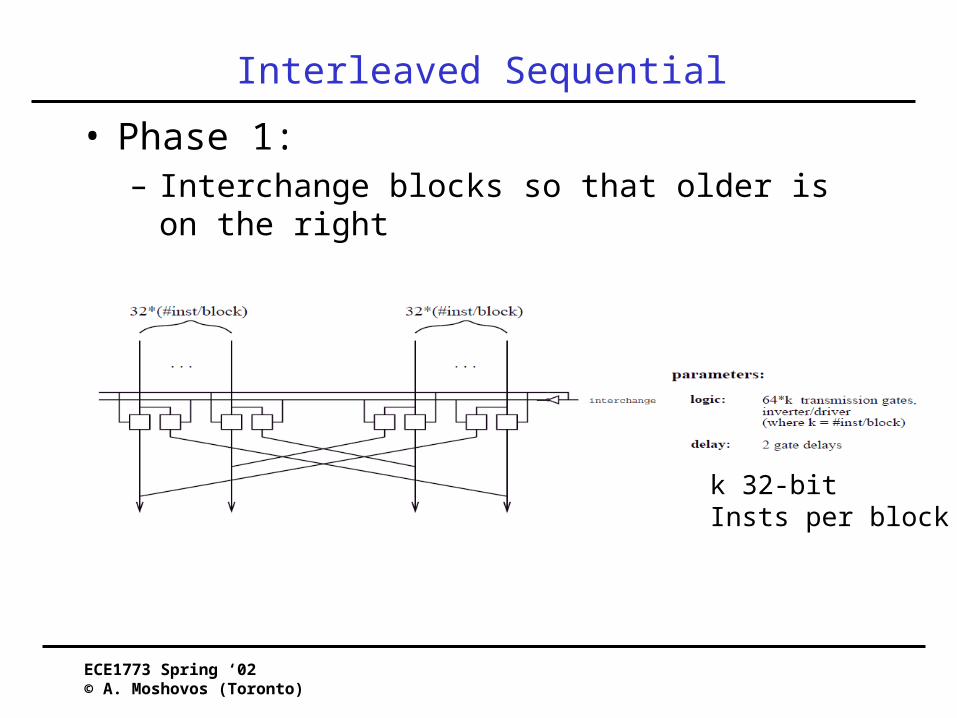
ECE1773 Spring ‘02© A. Moshovos (Toronto)
Interleaved Sequential
• Phase 1:– Interchange blocks so that older is on the right
k 32-bitInsts per block
ECE1773 Spring ‘02© A. Moshovos (Toronto)
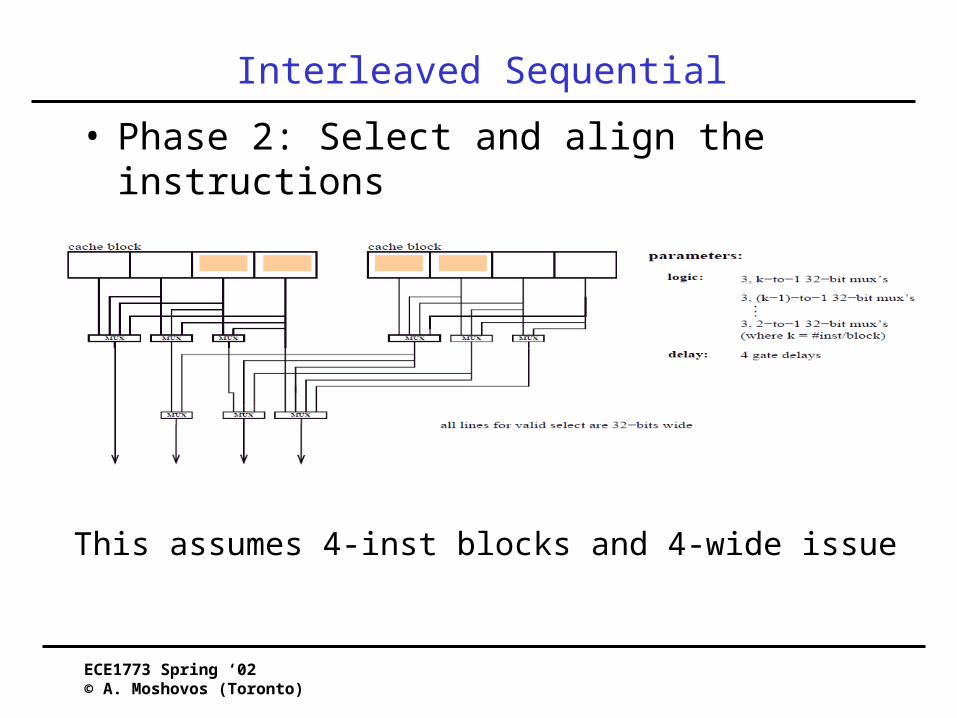
Interleaved Sequential
• Phase 2: Select and align the instructions
This assumes 4-inst blocks and 4-wide issue

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Banked Sequential
• Allows for inter-block branches
• Identical to interleaved sequential
ECE1773 Spring ‘02© A. Moshovos (Toronto)
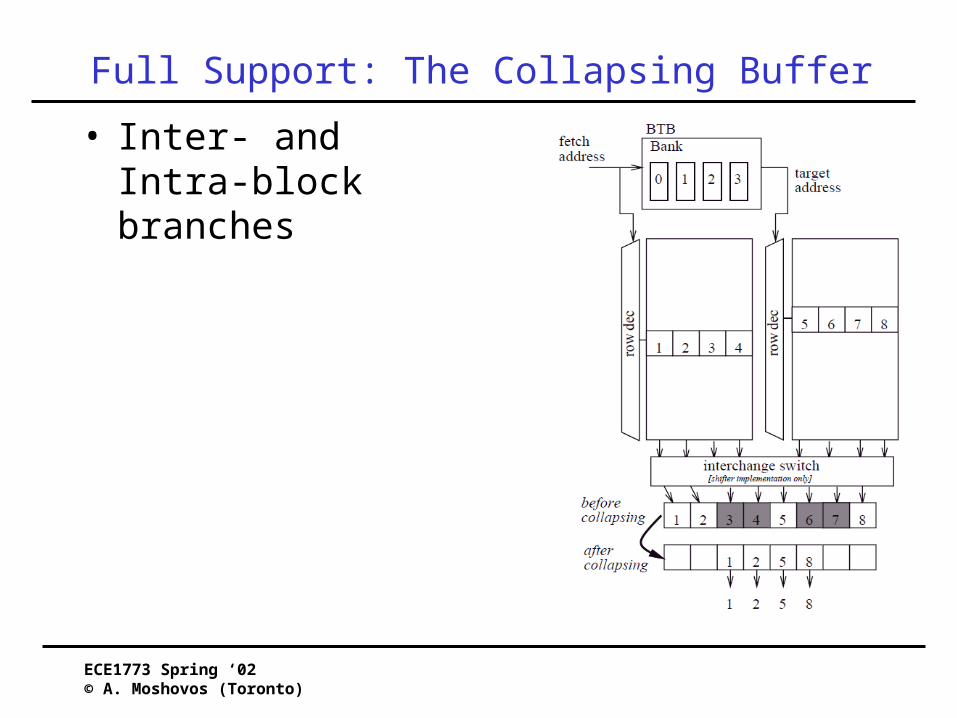
Full Support: The Collapsing Buffer
• Inter- and Intra-block branches

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Collapsing Buffer

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Performance

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Challenges
• Must generate addresses of all noncontiguous blocks before fetching can begin
• I-Cache must support multiple simultaneous accesses to noncontiguous cache lines
• Instructions must be assembled into the dynamic, contiguous sequence
ECE1773 Spring ‘02© A. Moshovos (Toronto)
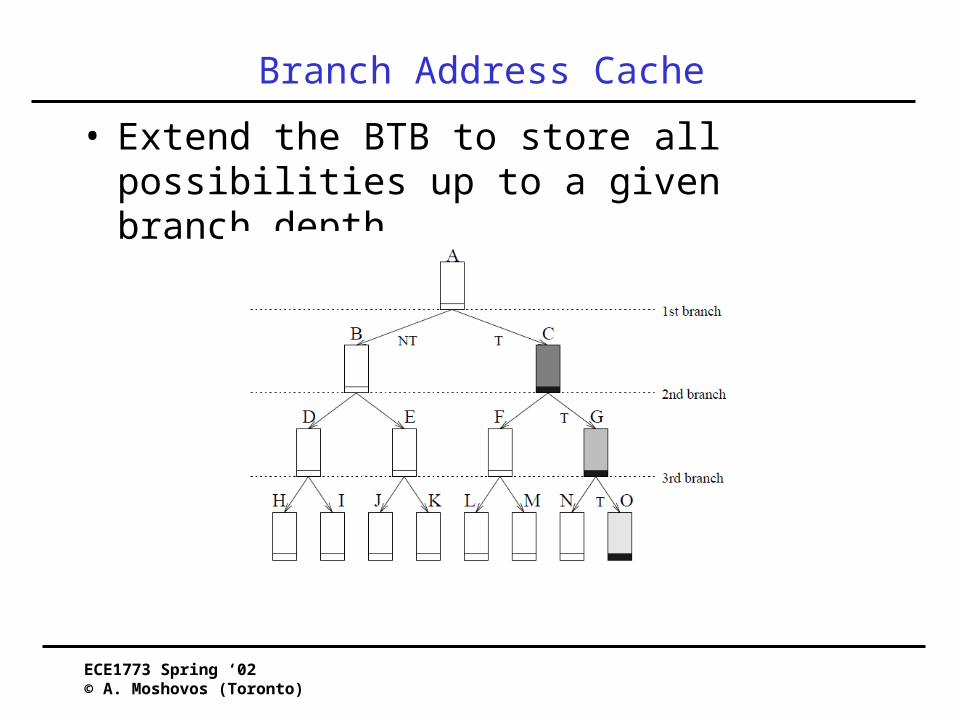
Branch Address Cache
• Extend the BTB to store all possibilities up to a given branch depth
ECE1773 Spring ‘02© A. Moshovos (Toronto)
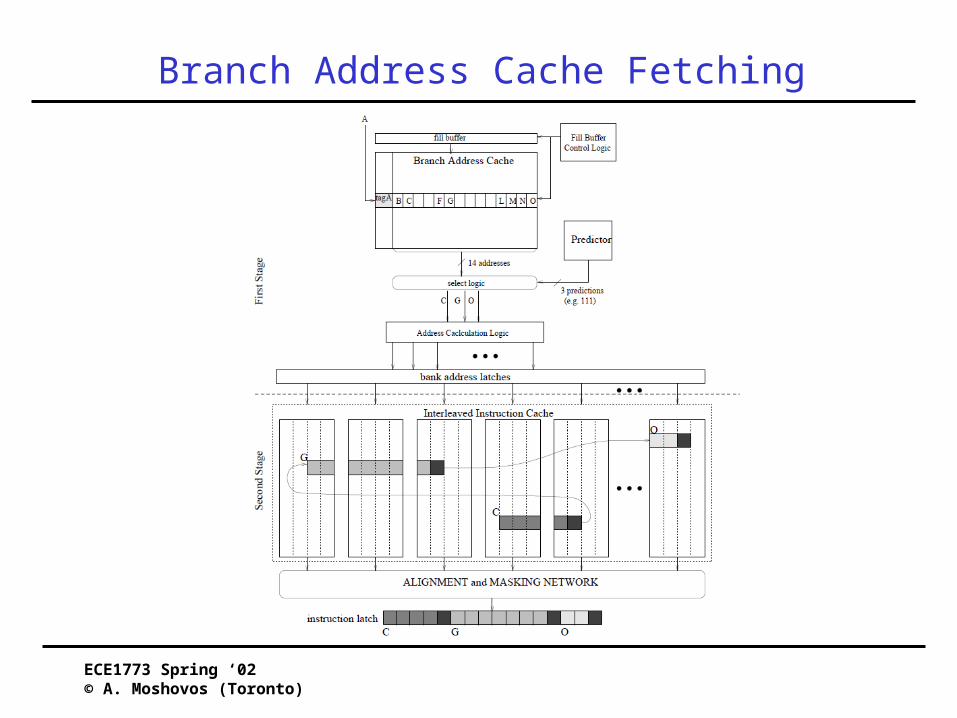
Branch Address Cache Fetching

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Cache
• Conventional cache:– Stores instructions in static order
• Trace cache:– Stores instructions in the order they were executed
If we execute the same sequence again then the trace cache can provide all the instructions, nicely aligned in
one access
• Trace:– Sequence of instructions as they were executed

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Cache – Main Idea
• Optimize based on program behavior– Programs tend to execute the same trace many times and
close in time• Idea: • Pay the penalty once
– Use conventional cache and branch predictor the first time– As instructions commit form trace
• Next time use constructed trace• Implicitly predict multiple branches and fetch all
instructions
ECE1773 Spring ‘02© A. Moshovos (Toronto)
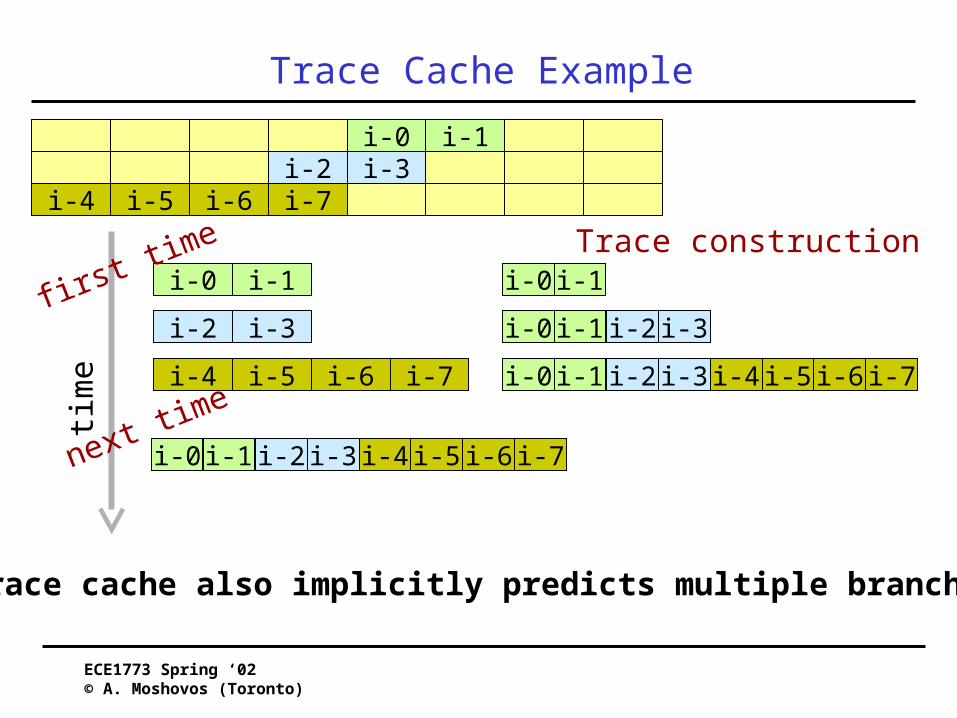
Trace Cache Example
i-0 i-1i-2 i-3
i-4 i-5 i-6 i-7
i-0 i-1
i-2 i-3
i-4 i-5 i-6 i-7
time
Trace constructioni-0 i-1
i-2 i-3i-0 i-1
i-4 i-5 i-6 i-7i-2 i-3i-0 i-1
i-4 i-5 i-6 i-7i-2 i-3i-0 i-1
first time
next time
Trace cache also implicitly predicts multiple branches

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Cache Structures
• Trace Cache: Keeps the trace– lead PC– Bit vector for branch directions: m-bits– Branch count: < m (lg m bits)– Last inst a branch
• Trace still correct if the last branch is miss-predicted– Fall through address– Target address– n instructions

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Cache Issues
• Same instructions may appear multiple times
• Careful trace selection can increase trace cache efficiency
A
B
C
D
E
A B C
D E A
B C D
E A B
C D E

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Selection
• When to Start and End a trace?• Arbitrary points can lead to low storage efficiency and
utilization• Start at Branch targets• Start at Function calls and returns

ECE1773 Spring ‘02© A. Moshovos (Toronto)
How to use the Trace Cache
• Use PC + multiple branch prediction bits as index– Predictions may come from separate predictor
• Alternatively, treat f(PC, multiple predictions) as the unit for the predictor
• Increase effectiveness by predicting two traces– Trace1: Very likely, first choice– Trace2: Somewhat likely, fallback

ECE1773 Spring ‘02© A. Moshovos (Toronto)
The P4 Trace Cache
• 12k uops• X86 instructions are translated to sequences of uops
– This process is expensive and complicated due to variable length encoding
• Cache past translations into the trace cache
ECE1773 Spring ‘02© A. Moshovos (Toronto)
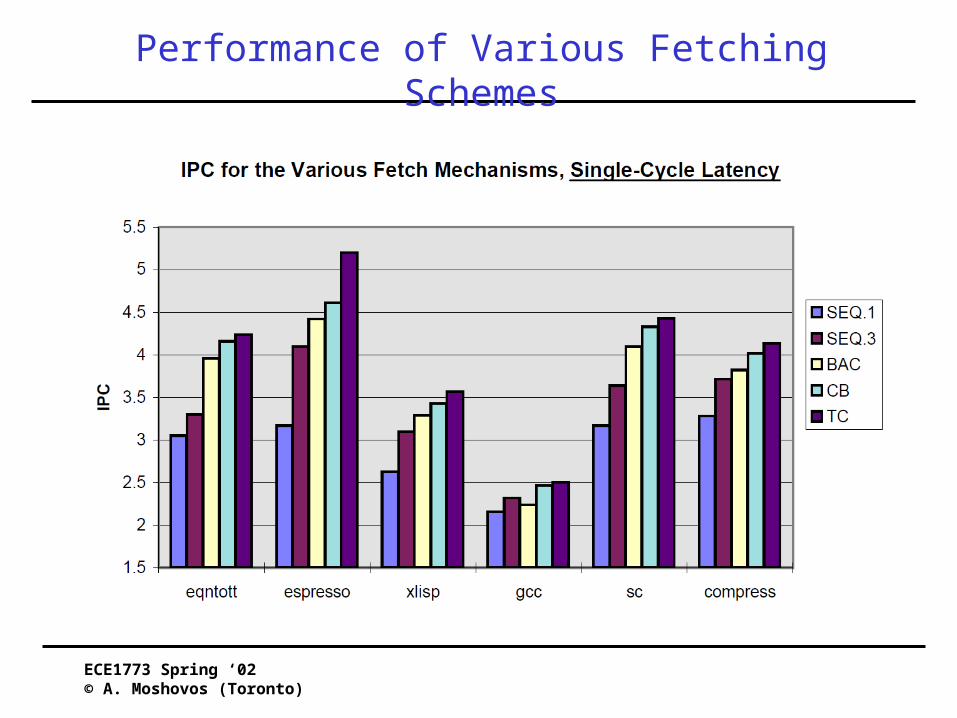
Performance of Various Fetching Schemes

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Trace Cache Bibliography[1] A. Peleg, U. Weiser, “Dynamic Flow Instruction Cache Memory
Organized around Trace Segments Independent of Virtual Address Line", US Patent number 5,381,533, Intel Corporation, 1994.
[2] D. Friendly, S. Patel, and Y. Patt, "Alternative Fetch and Issue Policies for the Trace Cache Fetch Mechanism", in Proceedings of the 30th International Symposium on Microarchitecture, November 1997.
[3] Q. Jacobson, E. Rotenberg, and J. Smith, "Path-Based Next Trace Prediction," in Proceedings of the 30th International Symposium on Microarchitecture, November 1997.
[4] E. Rotenberg, S. Bennett, and J. Smith, “Trace Cache: a Low Latency Approach to High Bandwidth Instruction Fetching", in Proceedings of the 29th Annual ACM/IEEE International Sym posium on Microarchitecture, 1996
Many other studies on improvements/alternatives

ECE1773 Spring ‘02© A. Moshovos (Toronto)
OOO and Load/Store Instructions
• Support for Speculative Stores• Stores write into temporary store buffer
– Entries tagged with address and contain data– Entries allocated at dispatch in program order
• Loads access first the store buffer– Scan backward with address to find matching store– Get data if available– Otherwise access memory
• Implements memory renaming

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Store Buffer Renaming Example• Associative searches• Ordering enforcing
0x100 30
addr data
store
type
0x200 40store
0x100 NAload
0x100 50store
0x100 NAload

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Store buffer complications
• Data types: complications– Store byte 0x100, 10– Load word 0x100 r1
• Access cache and combine
ECE1773 Spring ‘02© A. Moshovos (Toronto)
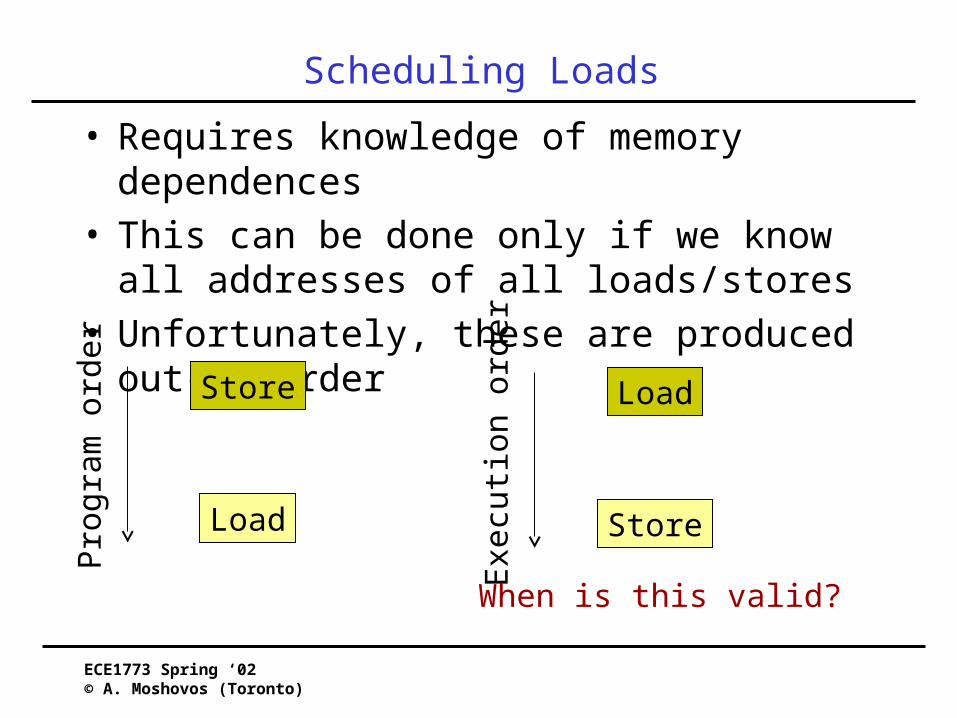
Scheduling Loads
• Requires knowledge of memory dependences• This can be done only if we know all addresses of all
loads/stores• Unfortunately, these are produced out-of-order
Store
LoadProg
ram
ord
er
Load
StoreExec
utio
n or
der
When is this valid?

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Memory Dependence
• A load is truly dependent on an earlier store if:– they both access the same memory address– There is no intervening store that does the same
• A load can execute before an earlier store if it is independent of the store
• But we need to know the addresses• Problem is that the address are calculated at runtime• Can’t use register scheduler as-is

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Scheduling Loads – No Speculation
• Solution #1: – Loads wait for all preceding stores
• To calculate their addresses• To have their data ready
• OK for small windows, BAD for large windows

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Common Scenario
store
load
inst
inst
inst
inst
inst
inst
inst
inst
Tim
e
Store address known
Load executes
Lost parallelism
Load address known

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Scheduling Loads
• Wait until you can determine all memory dependences• Wait until all preceding stores calculate their address
– Wait only for those that you have a conflict with
• Mechanism is fairly elaborate

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Scheduling Loads
• Use the store buffer as a load scheduler• Loads and stores post their addresses and data• Load can execute when:
– All preceding store address are known– Either there is no conflict with preceding store– There is a conflict with a store that has its data ready

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Load/Store Scheduler Actions
• At dispatch:– Allocate next sequential entry– Mark addr and data as unavailable

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Load/Store Scheduler
• Store address becomes available– Scan forward– Stop if store with unknown address– Stop if store with same address– Wakeup non-matching loads if no preceding store with
unknown address– Wakeup matching loads if have data
• Store data after address– Repeat above

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Load/Store Scheduler
• Load address calculated– Scan backward– Stop if matching store with data can execute– Stop if store with unknown address can’t execute– Stop if matching store without data can’t execute– If reached the front of the queue can execute
• Performs better than no scheduling at all• Not good for larger instruction windows
ECE1773 Spring ‘02© A. Moshovos (Toronto)
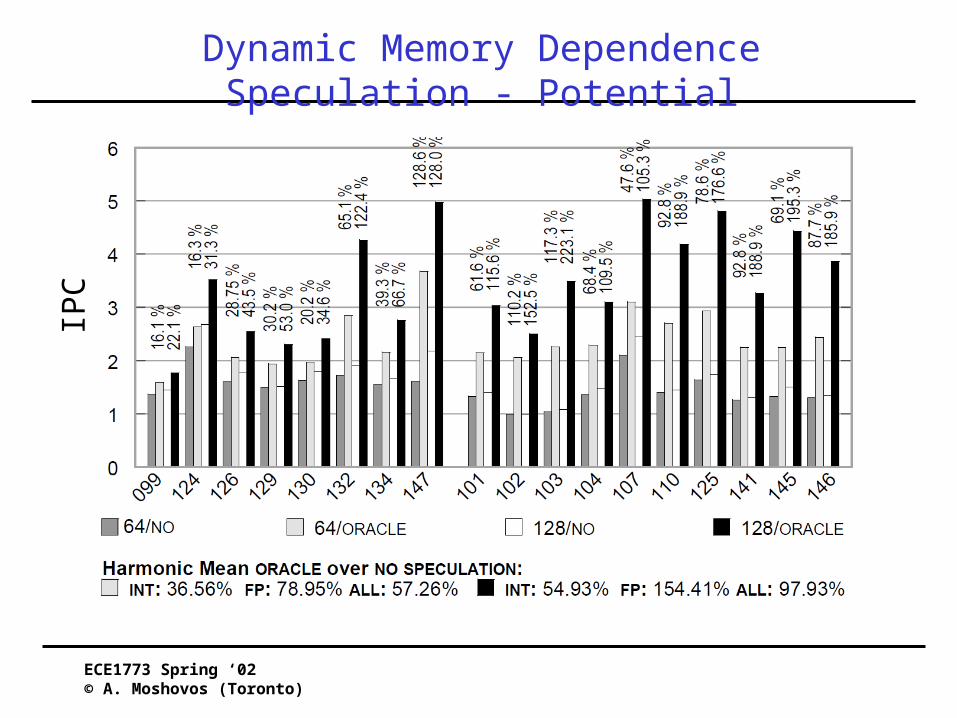
Dynamic Memory Dependence Speculation - PotentialIPC

ECE1773 Spring ‘02© A. Moshovos (Toronto)
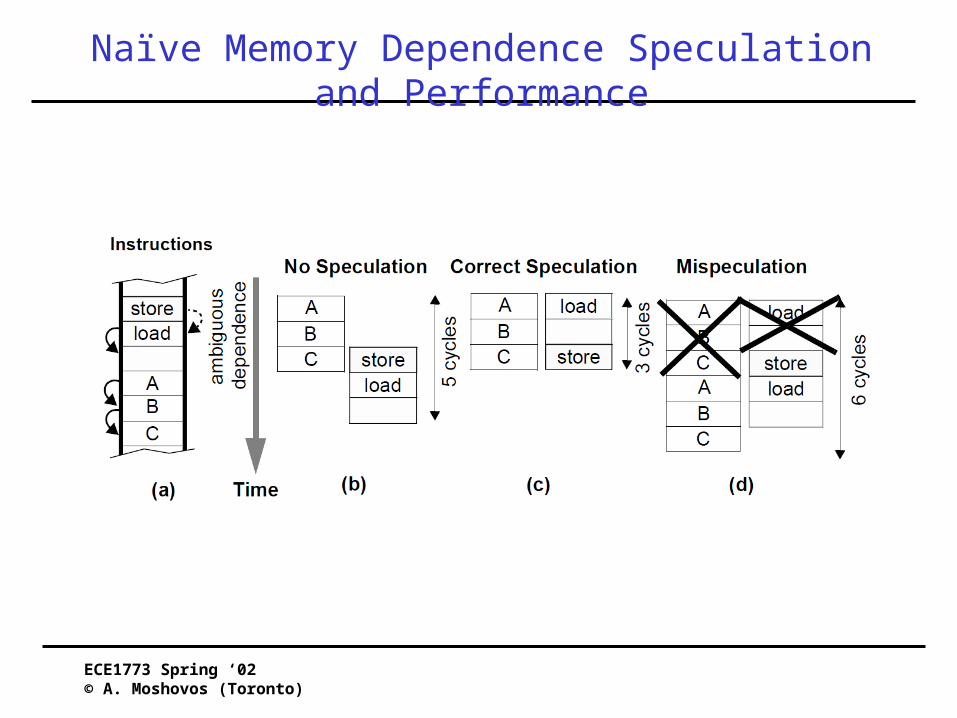
Memory Dependence Speculation• Allow a load to execute before a store with which a
memory dependence may exist• Naïve Speculation:
– Load with address known executes immediately– If a preceding store later detects a dependence
• Load and everything after it are squashed– Very much like branch miss-prediction
– If not performance improves since load got to execute early
• This works fairly well: few loads have dependences• But, dependence frequency rises for larger windows
ECE1773 Spring ‘02© A. Moshovos (Toronto)
Naïve Memory Dependence Speculation and Performance

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Memory Dependence Speculation Revisited
• For large instruction windows– More loads have dependences– Naïve speculation miss-predicts often enough so that there is
room for improvement• Need more intelligent speculation methods• Key observation
– Dependence violations tend to be stable– History-based prediction works well
ECE1773 Spring ‘02© A. Moshovos (Toronto)
Dynamic Memory Dependence Policies

ECE1773 Spring ‘02© A. Moshovos (Toronto)
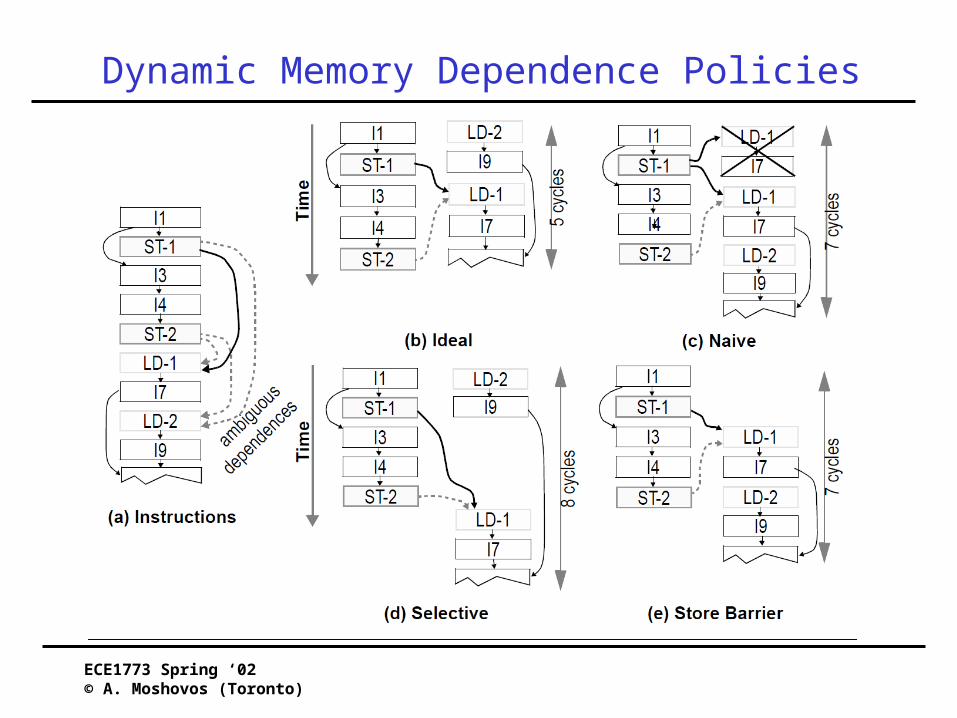
Store Barrier
• Start with naïve speculation• On miss-speculation record PC of offending branch
– In a prediction table• Next time make the same store is fetched
– Make all loads after it wait until it calculates its address
• Delays many loads unnecessarily• Good for small windows• Was planned for PPC 620

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Selective Speculation
• Start with naïve• On miss-prediction record PC of load• Next time the load is fetched make it wait for all
preceding stores
• Tricky tradeoff• Sometimes its faster to speculate, squash and re-
execute than wait– When store and load are far apart– This is the common case in large windows

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Speculation/Synchronization
• Start with naïve• On miss-prediction, record the PCs of the offering store
and load• Next time synchronize• Attempts to approximate the ideal
– A load waits only for the store it depends on if any

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Speculation/Synchronization
• Can use regular register renaming hardware to do the synchronization
• A dependent load and store are associated with the same name (synonym) on miss-prediction
• Upon decoding the store, the synonym is predicted and renamed into a dummy register
• Upon decoding the load, the synonym is predicted, it is used to locate the dummy register and the load is forced to wait for the store

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Speculation/Synchronization Hardware• Memory Dependent Prediction Table
– Load or Store PC synonym – Synonym = a name to use for synchronization
• Initially MDPT is empty• Use Naïve Speculation• Upon detecting a violation store load and store PC with
a new synonym• Next time around• Store allocate synonym• Load wait on synonym• Store signal waiting loads on synonym

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Naïve Memory Dependence Speculation Performance

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Speculation/Synchronization

ECE1773 Spring ‘02© A. Moshovos (Toronto)
Memory Dependence Speculation Bibliography1. G. J. Hinton, R. W. Martell, M. A. Fetterman, D. B. Papworth, and J. L.
Schwartz. Circuit and method for scheduling instructions by predicting future availability of resources required for execution, US Patent 5,555,432, filed on Aug. 19, 1994, September 1996.
2. A. Moshovos, S.E. Breach, T.N. Vijaykumar, and G.S. Sohi. Dynamic speculation and synchronization of data dependences. In Proc. ISCA-24, June 1997.
3. G. Z. Chrysos and J. S. Emer. Memory dependence prediction using store sets. In Proc. ISCA-25, June 1998.
4. A. Moshovos and G. S. Sohi, Memory Dependence Speculation Tradeoffs in Dynamically-Scheduled, Superscalar Processors, Proc. HPCA-6, Feb. 2000.
• Also the Memory Conflict Buffer is a software/hardware solution primarily for VLIW processors, but in principle applicable to any processor
• Transmeta’s Crusoe implements the MCB and so does Intel’s EPIC


















