
Document Indexing: SPIMI Contents: 1. Single-pass in-memory indexing (SPIMI) 2. Distributed Indexing...
13
Document Indexing: SPIMI Contents: 1. Single-pass in-memory indexing (SPIMI) 2. Distributed Indexing 3. Some simple examples
-
Upload
margaretmargaret-marsh -
Category
Documents
-
view
316 -
download
0
Transcript of Document Indexing: SPIMI Contents: 1. Single-pass in-memory indexing (SPIMI) 2. Distributed Indexing...

Document Indexing: SPIMI
Contents:1. Single-pass in-memory indexing (SPIMI)2. Distributed Indexing3. Some simple examples

Problems With Earlier Approaches
Some Important Points:
1. Blocked sort-based indexing has excellent scaling properties, but it needs a data structure for mapping terms to term. For very large collections, this data structure does not fit into memory.
2. A SPIMI uses term instead of termID’s, writes each blocks dictionary to disk and then starts a new dictionary for next block.
3. A difference between BSBI and SPIMI is that, SPIMI adds a posting directly to its posting list. Instead of first collecting all termID - docID pairs and then sorting them.

SPIMI: Single-pass in-memory indexing
Sec. 4.3
Important Points:
• Different from BSBI, it generates separate dictionaries for each block. Thus it does not maintain term-termID mapping across blocks (which requires huge in-memory operations).
• It does not apply “term-id”, “doc-id” based sorting. Accumulate postings in postings lists as they occur.
• It uses dictionary to generate a complete inverted index for each block.
• These separate indexes can then be merged into one big index.

SPIMI-Invert
• Merging of blocks is analogous to BSBI.
Sec. 4.3

SPIMI: Compression
• Compression makes SPIMI even more efficient.– Compression of terms– Compression of postings
Sec. 4.3

Distributed indexing
• For web-scale indexing :must use a distributed computing cluster
• Individual machines are fault-prone– Can unpredictably slow down or fail
• How do we exploit such a pool of machines?
Sec. 4.4

Distributed indexing
• Uses a Large number of inexpensive servers instead of a single expensive machine.
• Maintain a master machine directing the indexing jobprepare clusters of machine and Considers each node of cluster as safe.
• Breaks the indexing into sets of (parallel) tasks and passes it to different machines (nodes).
• Master machine assigns each task to an idle machine from a pool.
• MapReduce is a distributed programming tool designed for indexing and analysis tasks
Sec. 4.4

Example “Collection”
Ref: Information Retrieval in Practice, Addison Wesley, 2008

Simple Inverted Index
Ref: Information Retrieval in Practice, Addison Wesley, 2008

Inverted Indexwith counts
• supports better ranking algorithms
Ref: Information Retrieval in Practice, Addison Wesley, 2008

Inverted Indexwith positions
• supports proximity matches
Ref: Information Retrieval in Practice, Addison Wesley, 2008
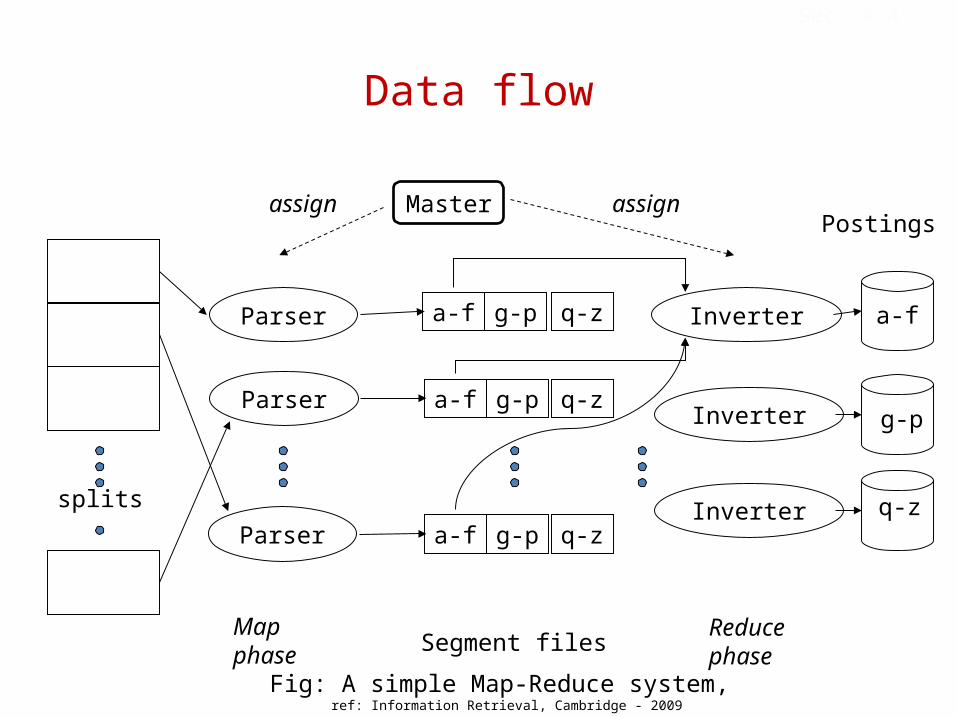
Data flow
splits
Parser
Parser
Parser
Master
a-f g-p q-z
a-f g-p q-z
a-f g-p q-z
Inverter
Inverter
Inverter
Postings
a-f
g-p
q-z
assign assign
Mapphase Segment files
Reducephase
Sec. 4.4
Fig: A simple Map-Reduce system, ref: Information Retrieval, Cambridge - 2009

Reference
• Information Retrieval, Cambridge-2009.• Information Retrieval in Practice, Addison Wesley, 2008.• Original publication on SPIMI: Heinz and Zobel (2003)• Original publication on MapReduce: Dean and Ghemawat (2004)


















