
Document Clustering and Social Networks Edward J. Wegman George Mason University, College of Science...
44
Document Clustering Document Clustering and Social Networks and Social Networks Edward J. Wegman Edward J. Wegman George Mason University, College of George Mason University, College of Science Science Classification Society Annual Meeting Classification Society Annual Meeting Washington University School of Medicine Washington University School of Medicine June 12, 2009 June 12, 2009
-
Upload
angelina-henderson -
Category
Documents
-
view
214 -
download
0
Transcript of Document Clustering and Social Networks Edward J. Wegman George Mason University, College of Science...

Document Clustering Document Clustering and Social Networksand Social Networks
Edward J. WegmanEdward J. WegmanGeorge Mason University, College of George Mason University, College of
ScienceScience
Classification Society Annual MeetingClassification Society Annual MeetingWashington University School of MedicineWashington University School of Medicine
June 12, 2009June 12, 2009

OutlineOutline
Overview of Text MiningOverview of Text Mining Vector Space Text ModelsVector Space Text Models
– Latent Semantic IndexingLatent Semantic Indexing Social NetworksSocial Networks
– Graph and Matrix DualityGraph and Matrix Duality– Two Mode NetworksTwo Mode Networks– Block Models and ClusteringBlock Models and Clustering
Document Clustering with Mixture Document Clustering with Mixture ModelsModels
Conclusions and AcknowledgementsConclusions and Acknowledgements

Text MiningText Mining
Synthesis of …Synthesis of …– Information RetrievalInformation Retrieval
Focuses on retrieving documents from a fixed databaseFocuses on retrieving documents from a fixed database Bag-of-words methodsBag-of-words methods May be multimedia including text, images, video, audioMay be multimedia including text, images, video, audio
– Natural Language ProcessingNatural Language Processing Usually more challenging questionsUsually more challenging questions Vector space modelsVector space models Linguistics: morphology, syntax, semantics, lexicon Linguistics: morphology, syntax, semantics, lexicon
– Statistical Data MiningStatistical Data Mining Pattern recognition, classification, clusteringPattern recognition, classification, clustering

Text Mining TasksText Mining Tasks
Text ClassificationText Classification– Assigning a document to one of several pre-specified Assigning a document to one of several pre-specified
classesclasses Text ClusteringText Clustering
– Unsupervised learning – discovering cluster structureUnsupervised learning – discovering cluster structure Text SummarizationText Summarization
– Extracting a summary for a documentExtracting a summary for a document– Based on syntax and semanticsBased on syntax and semantics
Author Identification/DeterminationAuthor Identification/Determination– Based on stylistics, syntax, and semanticsBased on stylistics, syntax, and semantics
Automatic TranslationAutomatic Translation– Based on morphology, syntax, semantics, and lexiconBased on morphology, syntax, semantics, and lexicon
Cross Corpus DiscoveryCross Corpus Discovery– Also known as Literature Based DiscoveryAlso known as Literature Based Discovery

Text PreprocessingText Preprocessing
DenoisingDenoising– Means removing stopper words … words Means removing stopper words … words
with little semantic meaning such as with little semantic meaning such as the, the, an, and, of, by, thatan, and, of, by, that and so on. and so on.
– Stopper words may be context dependent, Stopper words may be context dependent, e.g. e.g. Theorem Theorem and and ProofProof in a mathematics in a mathematics documentdocument
StemmingStemming– Means removal suffixes, prefixes and Means removal suffixes, prefixes and
infixes to rootinfixes to root– An example: An example: wake, waking, awake, woke wake, waking, awake, woke
wake wake

Vector Space ModelVector Space Model
Documents and queries are Documents and queries are represented in a high-represented in a high-dimensional vector space in dimensional vector space in which each dimension in the which each dimension in the space corresponds to a word space corresponds to a word (term) in the corpus (term) in the corpus (document collection).(document collection).
The entities represented in The entities represented in the figure are the figure are qq for query for query and and dd11, d, d22, , and and dd33 for the for the three documents. three documents.
The term weights are The term weights are derived from occurrence derived from occurrence counts.counts.

Vector Space MethodsVector Space Methods
The classic structure in vector The classic structure in vector space text mining methods is a space text mining methods is a term-document matrix whereterm-document matrix where– Rows correspond to terms, columns Rows correspond to terms, columns
correspond to documents, andcorrespond to documents, and– Entries may be binary or frequency Entries may be binary or frequency
counts.counts. A simple and obvious A simple and obvious
generalization is a bigram generalization is a bigram (multigram)-document matrix (multigram)-document matrix wherewhere– Rows correspond to bigrams, columns Rows correspond to bigrams, columns
to documents, and again entries are to documents, and again entries are either binary or frequency counts.either binary or frequency counts.

Vector Space Methods
• Latent Semantic Indexing (LSI) is a technique thatprojects queries and documents into a space withlatent semantic dimensions.
• Co-occuring terms are projected into the samesemantic dimensions and non-co-occuring termsonto different dimensions.
• In latent semantic space, a query and adocument can have high cosine similarity even ifthey do not share any terms as long as their termsare semantically similar according to the co-occurence analysis.

Latent Semantic Indexing
• LSI is the application of Singular ValueDecomposition (SVD) to the term-document matrix.
• SVD takes a matrix and represents it as in a lower dimensional space such that the two-norm isminimized, i.e. .
• The SVD projects an -dimensional space onto a -dimensional space where

Latent Semantic Indexing
• In our application to word-document matrices, is the number of word types (terms) in the corpus(document collection).
• Typically is chosen between 100 to 150.
• The SVD projection is computed by decomposingthe term-document matrix into the product of three matrices
†
where .

Latent Semantic Indexing
• These matrices have columns. Thisorthonormalmeans the column vectors are of unit length andare orthogonal to each other. In particular
† †(the identity matrix)
• The diagonal matrix contains the singular valuesof in descending order. The singular values
indicates the amount of variation along the axis.
• By restricting the matrices and to the first columns, we obtain and
†
with
†

LSI - Some Basic Relations
• † † † † † † †
† † † † † †
• † † † † † † †
† †
• † † † † † †

Social NetworksSocial Networks
Social networks can be represented as graphsSocial networks can be represented as graphs– A graph G(V, E), is a set of vertices, V, and edges, EA graph G(V, E), is a set of vertices, V, and edges, E– The social network depicts actors (in classic social The social network depicts actors (in classic social
networks, these are humans) and their connections networks, these are humans) and their connections or tiesor ties
– Actors are represented by vertices, ties between Actors are represented by vertices, ties between actors by edgesactors by edges
There is one-to-one correspondence between There is one-to-one correspondence between graphs and so-called adjacency matrices graphs and so-called adjacency matrices
Example: Author-Coauthor NetworksExample: Author-Coauthor Networks

Graphs versus Graphs versus MatricesMatrices

Two-Mode NetworksTwo-Mode Networks
When there are two types of actorsWhen there are two types of actors– Individuals and Institutions Individuals and Institutions – Alcohol Outlets and Zip CodesAlcohol Outlets and Zip Codes– Paleoclimate Proxies and PapersPaleoclimate Proxies and Papers– Authors and DocumentsAuthors and Documents– Words and DocumentsWords and Documents– Bigrams and DocumentsBigrams and Documents
SNA refers to these as two-mode networks, SNA refers to these as two-mode networks, graph theory as bi-partite graphsgraph theory as bi-partite graphs– Can convert from two-mode to one-modeCan convert from two-mode to one-mode

Two-Mode Two-Mode ComputationComputation
Consider a bipartite individual by institution social network. Let Am×n be the individual by institution adjacency matrix with m = the number of individuals and n = the number of institutions. Then
Cm×m = Am×nATn×m=
Individual-Individual social network adjacency matrix with cii = ∑jaij = the strength of ties to all individuals in i’s social network and cij = the tie strength between individual i and individual j.

Two-Mode Two-Mode ComputationComputation
Similarly,
Pn×n = ATn×m Am×n=
Institution by Institution social network adjacency matrix with pjj=∑iaij= strength of ties to all institutions in i’s social network with pij the tie strength between institution i and institution j.

Two-Mode Two-Mode ComputationComputation
Of course, this exactly resembles the Of course, this exactly resembles the computation for LSI.computation for LSI.
Viewed as a two-mode social network, this Viewed as a two-mode social network, this computation allows us: computation allows us: – to calculate strength of ties between terms relative to calculate strength of ties between terms relative
to this document database (corpus)to this document database (corpus)– And also to calculate strength of ties between And also to calculate strength of ties between
documents relative to this lexicondocuments relative to this lexicon If we can cluster these terms and these If we can cluster these terms and these
documents, we can discover:documents, we can discover:– similar sets of documents with respect to this lexiconsimilar sets of documents with respect to this lexicon– sets of words that are used the same way in this sets of words that are used the same way in this
corpuscorpus

Example of a Two-Mode Example of a Two-Mode NetworkNetwork
Our A matrix

Example of a Two-Mode Example of a Two-Mode NetworkNetwork
Our P matrix

Block ModelsBlock Models
A A partition of a networkpartition of a network is a clustering of is a clustering of the vertices in the network so that each the vertices in the network so that each vertex is assigned to exactly one class or vertex is assigned to exactly one class or cluster. cluster.
Partitions may specify some property that Partitions may specify some property that depends on attributes of the vertices. depends on attributes of the vertices.
Partitions divide the vertices of a network Partitions divide the vertices of a network into a number of mutually exclusive subsets. into a number of mutually exclusive subsets. – That is, a partition splits a network into parts. That is, a partition splits a network into parts.
Partitions are also sometimes called Partitions are also sometimes called blocks blocks or block modelsor block models. . – These are essentially a way to cluster actors These are essentially a way to cluster actors
together in groups that behave in a similar way. together in groups that behave in a similar way.
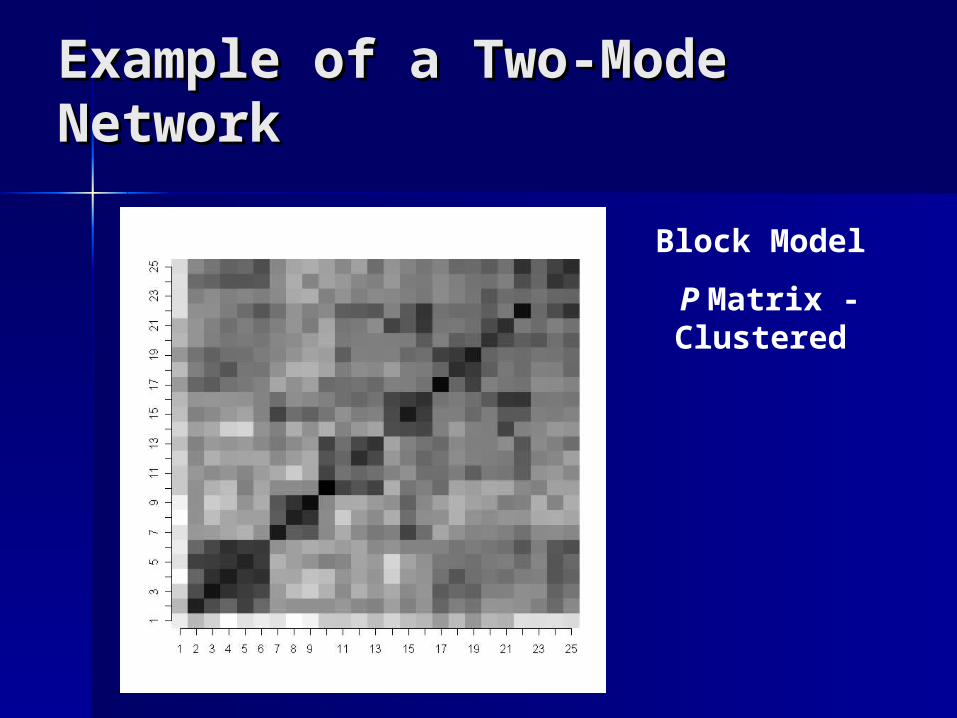
Example of a Two-Mode Example of a Two-Mode NetworkNetwork
Block Model
P Matrix - Clustered

Example of a Two-Mode Example of a Two-Mode NetworkNetwork
Block Model Matrix – Our C
Matrix Clustered

Example DataExample Data
The text data were collected by the Linguistic The text data were collected by the Linguistic Data Consortium in 1997 and were originally Data Consortium in 1997 and were originally used in Martinez (2002)used in Martinez (2002)
– The data consisted of 15,863 news reports The data consisted of 15,863 news reports collected from Reuters and CNN from July 1, collected from Reuters and CNN from July 1, 1994 to June 30, 19951994 to June 30, 1995
– The full lexicon for the text database included The full lexicon for the text database included 68,354 distinct words68,354 distinct words
In all 313 stopper words are removedIn all 313 stopper words are removed after denoising and stemming, there remain after denoising and stemming, there remain
45,021 words in the lexicon45,021 words in the lexicon
– In the examples that I report here, there are In the examples that I report here, there are 503 documents only503 documents only

Example DataExample Data
A simple 503 document corpus we have A simple 503 document corpus we have worked with has 7,143 denoised and worked with has 7,143 denoised and stemmed entries in its lexicon and 91,709 stemmed entries in its lexicon and 91,709 bigrams.bigrams.– Thus the TDM is 7,143 by 503 and the BDM Thus the TDM is 7,143 by 503 and the BDM
is 91,709 by 503.is 91,709 by 503.– The term vector is 7,143 dimensional and The term vector is 7,143 dimensional and
the bigram vector is 91,709 dimensional.the bigram vector is 91,709 dimensional.– The BPM for each document is 91,709 by The BPM for each document is 91,709 by
91,709 and, of course, very sparse.91,709 and, of course, very sparse. A corpus can easily reach 20,000 documents A corpus can easily reach 20,000 documents
or more.or more.

Term-Document Matrix Term-Document Matrix AnalysisAnalysis
Zipf’s Law

Term-Document Matrix Term-Document Matrix AnalysisAnalysis
sai
peopl
on
north
go
said
here
two
outjust
cnntime
well
know
korea
report
getright
state
think
newoffici
korean
see
area
hous
dai
like
todai
presid
hourlook
white
citi
year
first
hall
build
still
talk
take
happen
unit
be
comet
fire
want
morn
last
bomb
back
work
thank
polic
jupit
thing
kim
releas
defens
through
south
clinic
try
offic
live
told
american
good
call
make wai
pilot
join
continu
govern
case
investig
even
tell
point
mile
ago
week
feder
question
plane
john
militari
air
lot
believ
helphelicopt
simpson
hit
crash
astronom
clinton
scene
test
someth
secur
rescu
far
nation
oklahoma
hear
kind
possibl
kobe
il
expect
abl
hope
man
death
explos
inform
us
world
realli
forc
kill
number
japan
home
evid
issu
serb
fact
ask
train
situat
cours
partanyth
seen
court
come
earthquak
shot
made
incid
latest
famili
deal
countri
search
few
remainlittl
place
center
chief
yesterdai
sever
close
show
author
oper
salvi
impact
find
bloodjudg
abort
pictur
involv
attornei
earth
whether
meet
came
nuclear
charg
side
person
start
iraq
long
mean
space
problem
second
need
return
depart
york
went
night
earlier
mr
water
bosnian fragment
suspect
later
stori
ground
bobbi
appar
concern
give
bodi
left
seem
heard
shoot
leader
awai
washington
hand
sure
servic
big
found
sawdamag
injur
planet
mission
safe
car
minut
indic
flood
turn
dna
iraqi
gener
prosecut
bosnia
wordmove
against
least
respons
appear
effort
month
perhap
feelsort
five
flight
confirm
open
nato
massachusett
quak
telescop
causprobabl
fbi
done
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 28
29
3031
3233
3435
36
37
38
3940
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
7273
74
75
7677
78
79 80 81
8283
84
85
8687
88
89
9091
92
9394
9596
97
98
99
100
101102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123124
125
126127
128
129
130
131
132
133
134
135
136
137
138
139
140141
142
143
144
145 146
147
148149
150
151
152
153
154
155
156
157
158159
160
161
162
163
164
165 166
167
168
169
170
171
172
173174
175
176
177
178179180
181 182
183
184
185186
187
188
189
190
191
192
193
194
195196197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214215
216
217
218
219
220
221222
223
224
225226
227
228
229
230
231232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277278
279
280
281
282
283
284
285
286
287
288
289
290
291
292 293
294
295
296
297
298
299
300301
302
303304
305
306
307
308
309
310
311312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368369
370
371
372373
374
375
376
377
378 379
380
381
382
383
384
385
386
387
388
389
390
391
392393
394
395
396
397
398
399
400
401
402
403
404
405
406407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424 425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490491
492
493
494495
496
497498499
500
501
502
503

Mixture Models for Mixture Models for ClusteringClustering
Mixture models fit a mixture of Mixture models fit a mixture of (normal) distributions(normal) distributions
We can use the means as We can use the means as centroids of clusterscentroids of clusters
Assign observations to the Assign observations to the “closest” centroid“closest” centroid
Possible improvement in Possible improvement in computational complexitycomputational complexity

Our Proposed Our Proposed AlgorithmAlgorithm
Choose the number of desired clusters.Choose the number of desired clusters. Using a normal mixtures model, calculate Using a normal mixtures model, calculate
the mean vector for each of the document the mean vector for each of the document proto-clusters. proto-clusters.
Assign each document (vector) to a proto-Assign each document (vector) to a proto-cluster anchored by the closest mean cluster anchored by the closest mean vector.vector.– This is a Voronoi tessellation of the 7143-This is a Voronoi tessellation of the 7143-
dimensional term vector space. The Voronoi dimensional term vector space. The Voronoi tiles correspond to topics for the documents.tiles correspond to topics for the documents.
Or assign documents based on maximum Or assign documents based on maximum posterior probability.posterior probability.

Normal Mixtures
where is taken as the
multivariate normal density, are the mixing coefficients, is the number of mixing terms, and is the mean vector and covariancematrix. The sample size we denote by , in our case The dimension, , of the vector is

EM Algorithm for NormalMixtures
;
; †
is the estimated posterior probability that belongs to component is the estimated mixing , coefficient, and are the estimated mean and covariance matrix respectively.

Notation
• ; the number of documents.
• the desired number of clusters
• the dimension of the term vector the size of the lexicon for this corpus

Considerations about theNormal Density
Because the dimensionality of the term vectors is solarge, there are some considerations about the EMalgorithm to be made. Recall
†
tends to be singular, certainly ill-conditioned. Inour experience just used as a raw estimate roundofferror causes to have a zero determinant. Morover, also rounds to zero.

Revised EM Algorithm
In order to regularize the computation, we take , the identity matrix. Then the EM algorithmbecomes
†
†
And of course we no longer estimate . We arereally only interested in estimating the means.

Comuptational Complexity
The computation of has complexity , the computation of has complexity and the computation of has complexity The EM algorithm is a recursivealgorithm. The number of recursions can bedetermined by a stopping algorithm or fixed bythe user. In either case, if the number ofrecursions is , then the overall complexity ofthe EM phase is . It is linear in all the key size variables.
The Voronoi computation is

Results
In the present data set, , , and Time inseconds from loading file tomembership computation is seconds. This computation was doneon an Intel Centrino Dual Coreprocessor running at 1.6 gigahertz.

WeightsWeights

Cluster Size Cluster Size Distribution Distribution
(Based on Voronoi Tessellation)(Based on Voronoi Tessellation)

Cluster Size Cluster Size DistributionDistribution
(Based on Maximum Estimated (Based on Maximum Estimated Posterior Probability, Posterior Probability, ijij))
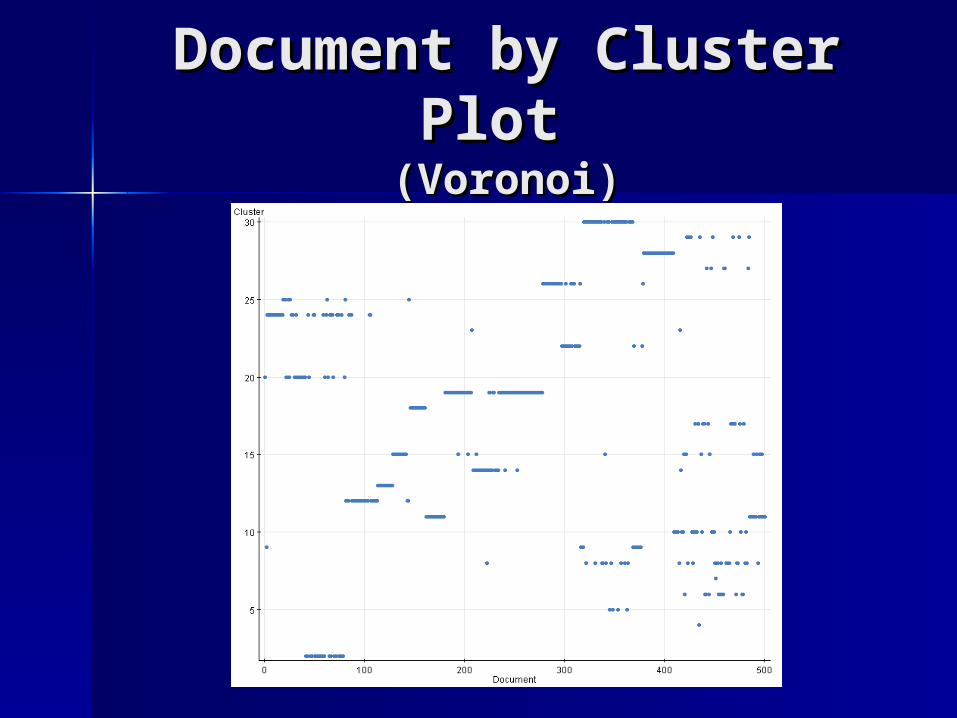
Document by Cluster Document by Cluster Plot Plot
(Voronoi)(Voronoi)

Document by Cluster Document by Cluster Plot Plot
(Maximum Posterior (Maximum Posterior Probability)Probability)

Cluster IdentitiesCluster Identities
Cluster 02: Comet Shoemaker Levy Crashing into Cluster 02: Comet Shoemaker Levy Crashing into Jupiter.Jupiter.
Cluster 08: Oklahoma City Bombing.Cluster 08: Oklahoma City Bombing. Cluster 11: Bosnian-Serb Conflict.Cluster 11: Bosnian-Serb Conflict. Cluster 12: Court-Law, O.J. Simpson Case.Cluster 12: Court-Law, O.J. Simpson Case. Cluster 15: Cessna Plane Crashed onto South Lawn Cluster 15: Cessna Plane Crashed onto South Lawn
White House.White House. Cluster 19: American Army Helicopter Emergency Cluster 19: American Army Helicopter Emergency
Landing in North Korea.Landing in North Korea. Cluster 24: Death of North Korean Leader (Kim il Cluster 24: Death of North Korean Leader (Kim il
Sung) and North Korea’s Nuclear Ambitions.Sung) and North Korea’s Nuclear Ambitions. Cluster 26: Shootings at Abortion Clinics in Boston.Cluster 26: Shootings at Abortion Clinics in Boston. Cluster 28: Two Americans Detained in Iraq. Cluster 28: Two Americans Detained in Iraq. Cluster 30: Earthquake that Hit Japan.Cluster 30: Earthquake that Hit Japan.

AcknowledgmentsAcknowledgments
This is joint work with Dr. Yasmin Said This is joint work with Dr. Yasmin Said and and
Dr. Walid Sharabati.Dr. Walid Sharabati. Dr. Angel MartinezDr. Angel Martinez Army Research Office (Contract W911NF-Army Research Office (Contract W911NF-
04-1-0447)04-1-0447) Army Research Laboratory (Contract Army Research Laboratory (Contract
W911NF-07-1-0059) W911NF-07-1-0059) National Institute On Alcohol Abuse And National Institute On Alcohol Abuse And
Alcoholism (Grant Number F32AA015876) Alcoholism (Grant Number F32AA015876) Isaac Newton InstituteIsaac Newton Institute Patent PendingPatent Pending

Contact Information
Edward J. Wegman
Department of Computational and Data Sciences
MS 6A2, George Mason University
4400 University Drive
Fairfax, VA 22030-4444 USA
Email: [email protected]
Phone: (703) 993-1691


















