
Document Analysis Research at the NLPR Analysis 20140829.pdf · 2015-02-04 · • “Visual...
77
Document Analysis Research at the NLPR Cheng-Lin Liu National Lab of Pattern Recognition (NLPR) Institute of Automation of CAS August 29, 2014
Transcript of Document Analysis Research at the NLPR Analysis 20140829.pdf · 2015-02-04 · • “Visual...

Document Analysis Research at the NLPR
Cheng-Lin Liu
National Lab of Pattern Recognition (NLPR)
Institute of Automation of CAS
August 29, 2014

Institute of Automation of CAS
• Chinese Academy of Sciences (CAS)
– ~100 institutes, ~30 in Beijing
– Various areas of science, a few in engineering
• Institute of Automation of CAS
– Founded in 1956
– Main areas: automatic control and robotics, information processing
– People: ~400 permanent, ~300 contract, ~600 graduate students
– Departments: two state key laboratories (SKLs), five engineering centers

National Lab of Pattern Recognition (NLPR)
• Opened 1987, one of first SKLs in China – Currently >300 in total, 31 in information
• Fields – Fundamentals of PR – Image understanding and computer vision – Speech and language processing
• People – 95 research staffs, 6 support staffs – 149 PhD, 79 Master students, 13 postdoctors – 40 contract members, 80 visiting students
• Yearly budget: ~600M RMB (10M U$) – About 90% from government, 10% from industry
• Yearly publications – ~100 int’l journal, 180~200 int’l conferences

• Pattern Analysis and Learning (PAL) Group
– Founded in 2005, led by Cheng-Lin Liu
– Fields
• PR Fundamentals: classification, feature extraction, graph-based learning
• Document analysis: handwritten documents, scene text, video text, Web document images
• Computer vision: image classification and applications
– People
• 5 research staffs, 2 engineers, one support staff
• 9 PhD students, 7 Master students
• One postdoctor
• 2 visiting students

• Pattern Analysis and Learning (PAL) Group Projects
– Ongoing projects
• “Computing and understanding of sensory data in physical space”, National Basic Research Program of China (973 Program) sub-project (2012-2016)
• “Visual Perception and Semantic Computing”, Strategic Priority Research Program of the CAS (2012-2016)
• “Theory and Key Techniques for Perturbation based Character Recognition”, NSFC project (2012-2015)
• “Analysis and Understanding of Document Images in Network Media (AUDINM)”, NSFC-ANR joint point, co-PI with Jean-Marc Ogier, 2015-2018
– Completed projects
• “Recognition and Retrieval of Naturally Written Offline Chinese Handwritten Documents”, key project of NSFC (2010-2013)
• “Pattern Recognition Theory, Methods and Applications”, Outstanding Youth Fund of NSFC (2009-2012)

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Background
• Format of Characters – Text: ASCII codes, GB codes, Unicode
– Image: Offline character recognition • Optical character recognition (OCR)
– Stroke trajectory: Online character recognition
7

• Online Recognition: Applications – Pen-based text entry
– Particularly suitable for mobile devices without keyboard
– Advantage over speech: no noise
Tablet PC Anoto Pen 8

• Offline Recognition: Applications – Paper documents conversion
• Huge volume of documents generated in the history, increased everyday
• Printed, handwritten
– Reading aid for disabled people – Scene text reading and translation
9

• Scene text: sign boards, license plates
10

Brief History
Time Methods Target/Application Events
1920s Optical template matching Printed digits/letters 1st patent on OCR
1950s-1960s
Correlated matching, simple structural analysis
Printed digits/letters Printed Chinese (1966)
1st PR Workshop in 1966
1970s- 1980s
Feature matching (normalization, feature extraction), Structural matching, Statistical PR
Handprinted digits/letters Printed/handprinted words Handprinted Japanese/Chinese
1st ICPR in 1972 IAPR founded in 1978
1990s Research of various issues, including layout analysis and segmentation
Practical applications in various areas (document entry, mail sorting, forms, business cards, text input)
PC got popular Internet 1st IWFHR/ICDAR/ DAS in 1990/91/94
2000s Attack hard problems: unconstrained handwriting, degraded image
Improve existing apps Explore new apps (e.g., camera-based, ink documents, retrieval, translation)
Google, Baidu Facebook, twitter, Weibo Mobile Internet Big data

Challenges
• Printed Documents – Complex layout
– Degraded image
• Handwritten Documents • Character segmentation
• Deformation, style variation
• Camera-based Documents – Illumination, viewpoint
– Scene text: cluttered background, font/color, line orientation
– Low resolution

• Challenges in Chinese Handwriting Recognition – Large character set
– Writing shape variation in unconstrained writing

• Challenges in Chinese Handwriting Recognition
– Segmentation: text line segmentation, character segmentation

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Chinese Handwriting Database
• CASIA Online/Offline Databases
– Collected in 2007-2010
– Concurrent online-offline data using Anoto Pen
– Over 1,300 writers
– Isolated characters and continuous texts
– Segmented and annotated


Character Extraction (Thresholding)
Gray level preserved

驿寄梅花,鱼传尺素,砌成此恨无重数。
郴江幸自绕郴山,为谁流下潇湘去?
Handwritten Text Annotation: Transcript Mapping
DTW
F. Yin, Q.-F. Wang, C.-L. Liu, Transcript mapping for handwritten Chinese documents by
integrating character recognition model and geometric context, Pattern Recognition, 2013.

Released Databases
• 1,020 writers
• Isolated Characters Data
– 7,356 categories (including 7,185 Chinese)
– 3.9 million samples
– Offline: HWDB1.0, HWDB1.1, HWDB1.2
– Online: OLHWDB1.0, OLHWDB1.1, OLHWDB1.2
• Handwritten Texts Data
– ~5,090 pages, 1.35 million characters
http://www.nlpr.ia.ac.cn/databases/handwriting/Home.html

Released Isolated Character Datasets
Dataset #writers total symbol Chinese/#class
OLHWDB1.0 420 1,694,741 71,806 1,622,935/3,866
OLHWDB1.1 300 1,174,364 51,232 1,123,132/3,755
OLHWDB1.2 300 1,042,912 51,181 991,731/3,319
Total 1,020 3,912,017 174,219 3,737,798/7,185
HWDB1.0 420 1,680,258 71,122 1,609,136/3,866
HWDB1.1 300 1,172,907 51,158 1,121,749/3,755
HWDB1.2 300 1,041,970 50,981 990,989/3,319
Total 1,020 3,895,135 173,261 3,721,874/7,185
On
line O
ffline

Released Handwritten Text Datasets
Dataset #writers #pages #lines #char/#class
OLHWDB2.0 420 2,098 20,573 540,009/1,214
OLHWDB2.1 300 1,500 17,282 429,083/2,256
OLHWDB2.2 299 1,494 14,365 379,812/1,303
Total 1,019 5,092 52,221 1,348,904/2,655
HWDB1.0 419 2,092 20,495 538,868/1,222
HWDB1.1 300 1,500 17,292 429,553/2,310
HWDB1.2 300 1,499 14,443 380,993/1,331
Total 1,019 5,091 52,230 1,349,414/2,703
Onlin
e O
ffline

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Handwritten Character Recognition
• Isolated Character Datasets
#writer Total GB2312-80 (GB1)
total train test #class #sample #class #sample #train #test
OLHWDB1.0 420 336 84 4,037 1,694,741 3,740 1,570,051 1,256,009 314,042
HWDB1.0 420 336 84 4,037 1,680,258 3,740 1,556,675 1,246,991 309,684
OLHWDB1.1 300 240 60 3,926 1,174,364 3,755 1,123,132 898,573 224,559
HWDB1.1 300 240 60 3,926 1,172,907 3,755 1,121,749 897,758 223,991
Recommendation •Fundamental research using DB1.1 (GB1, 3,755 classes)
•Extending training set with DB1.0 (3,740 classes in GB1)
C.-L. Liu, F. Yin, D.-H. Wang, Q.-F. Wang, Online and offline handwritten Chinese character
recognition: Benchmarking on new databases, Pattern Recognition, 2013.

Character Recognition Approach
25
啊, 阿, 呵 0.7, 0.1, 0.1
Classification Character
Normalization Feature
Extraction
( | )P cx x
Deep Learning?

Offline Recognition
• Input Image
– Binary
– Gray-scale: gray level inversion, foreground gray level normalization

• Normalization
– Linear, nonlinear (NLN), moment, bi-moment
– Pseudo 2D NLN (P2DNLN), P2D moment (P2DMN), P2D bi-moment (P2DBMN), line density projection interpolation (LDPI)
C.-L. Liu, K. Marukawa, Pseudo two-dimensional shape normalization methods for
handwritten Chinese character recognition, Pattern Recognition, 2005.
' ( , )
' ( , )
x u x y
y v x y
' ( )
' ( )
x u x
y v y

• Feature Extraction – 8-direction decomposition, 8x8 sampling by Gaussian blurring,
512D
– Normalization-cooperated contour feature (NCCF): continuous NCFE, for binary only
– Normalization-based gradient feature (NBGF)
– Normalization-cooperated gradient feature (NCGF)
NCCF
NBCF
NBGF
C.-L. Liu, Normalization-cooperated gradient feature extraction for handwritten character
recognition, IEEE Trans. PAMI, 2007.

Online Recognition
• Input Data – Sequence of coordinates
• Normalization – Linear, moment, bi-moment – P2D moment (P2DMN), P2D bi-moment (P2DBMN)
C.-L. Liu, X.-D. Zhou, Online Japanese character recognition using trajectory-based
normalization and direction feature extraction, Proc. 10th IWFHR, 2006

• Feature Extraction – Normalization and feature extraction directly on stroke
trajectory
– 8-direction decomposition, 8x8 sampling by Gaussian blurring, 512D
– Original direction, normalized direction
– Option: imaginary strokes (weight 0.5) • Ding, Deng, Jin, ICDAR 2009.

Classification • Directionality Reduction
– FLDA, 512160
• MQDF (Modified Quadratic Discriminant Function) – 50 principal eigenvectors per class – Unified minor eigenvalue selected by holdout CV – 200 candidates by Euclidean distance to class means
• Prototype Classifier – Training criterion: LOGM (logarithm of margin) – Option: DFE (discriminative feature extraction)
• Subspace parameters and prototypes optimized jointly
• DLQDF (Discriminative Learning QDF) – Initialized as MQDF – Dimensionality reduction by LDA or DFE
C.-L. Liu, High accuracy handwritten Chinese character recognition using quadratic
classifiers with discriminative feature extraction, Proc. 18th ICPR, 2006

Recognition Results: Offline Binary image
Gray-scaled
DB1.1 train
DB1.1 test

Recognition Results: Online
Original enhanced: histogram of original stroke direction enhanced
with imaginary stroke (pen lifts)

Training with DB1.0+DB1.1, offline
ICDAR2011 Competition
92.18% ICDAR2013
94.77%
Enlarge training set, compare classifiers

Training with DB1.0+DB1.1, online
ICDAR2011 Competition
95.77% ICDAR2013
97.39%

Miswrite/
mislabel
Very
similar

HCCR with Discriminative Quadratic Feature Extraction
• Increasing the Feature Dimensionality
– Regional covariance of gradient histograms • 50 covariance/correlation matrices
– 1+4+9+16 regional in 4 levels
– 4+6+8 strips in 3 levels
– 1 center+1 border
• 12-direction, 768D
• Quadratic 50*12*13/2=3900
– Dimensionality reduction by DFE
– Classifier: MQDF, DLQDF
M. Zhou, X.-Y. Zhang, F. Yin, C.-L. Liu, Improving handwritten Chinese character recognition with discriminative quadratic feature extraction, ICPR 2014.

•Generate distorted samples by geometric transform,
local resizing and elastic distortion

Test accuracies with gradient direction histogram (GDH)
and correlation/covariance features
Effects of training set expansion with variable subspace
dimensionality
• Ongoing
– Further increase the dimensionality by local polynomial expansion
– Latest result: test accuracy 94.60%, competitive to CNN

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Handwritten Text Line Segmentation by MST Clustering
Connected
components
Determine the number
of clusters (text lines)
Minimum
spanning tree
Sub-trees
41 F. Yin, C.-L. Liu, Handwritten Chinese text line segmentation by clustering with distance
metric learning, Pattern Recognition, 2009.

• Effect of Distance Metric Learning – Components in same line mostly connected
– Less between-line edges

Result: Proposed Method
43

Result: X-Y Cut, Docstrum
44

Result: Proposed Method
45

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Text Line Recognition: Taxonomy of Methods
Character segmentation:
Chicken-and-egg problem

Handwritten Text Line Recognition • Candidate Segmentation-Recognition Path Evaluation
and Search
Q.-F. Wang, F. Yin, C.-L. Liu, Handwritten Chinese text recognition by integrating multiple contexts,
IEEE Trans. PAMI, 2012

• Path Evaluation based on Bayesian Decision
( | ) ( , | ) ( | ) ( | , ) ( | ) ( | )s
s s s
P C X P C s X P s X P C s X P s X P C X
*
,argmax ( | ) ( | )s
s CC P s X P C X
p ui g bi
1
( | ) ( 1| ) ( 1| )m
i i i i
i
P s X p z g p z g
1
1
uc bc1 1
( | ) ( | )1( | )
( | ) ( | )
imi i is
mi i i i i i
p c c p c xP C X
P p c g p c c g
1
1 1
1 1
uc bc
2 3 1
1 1
p ui g bi
4 5 6
1 1
( , ) log ( | ) log ( | )
log ( | ) log ( | )
log ( 1| ) log ( 1| )
m ms i
i i i
i im m
i i i i i
i im m
i i i i
i i
f X C p c x p c c
p c g p c c g
p z g p z g m
Class-independent
geometry Class-dependent
geometry
Language Classifier
Extended to weighted fusion

50
Normalization by Path Length (NPL)
Weighting by Segments Number (WSN)
Weighting by Character Width (WCN)
1 uc
1 1 2
1 1 1
bc p ui g bi
3 1 4 5
1 1 1
log ( | ) log ( | ) log ( | )1
( , )
log ( | ) log ( 1| ) log ( 1| )
m m mi
i i i i is i i i
m m m
i i i i i i i
i i i
p c x p c c p c g
f X Cm p c c g p z g p z g
1 uc
1 1 211 1
bc p ui g bi
3 1 4 5
1 1 1
( , ) log ( | ) log ( | ) log ( | )
log ( | ) log ( 1| ) log ( 1| )
m mms i
i i i i i iii i
m m m
i i i i i i i
i i i
f X C k P c x p c c p c g
p c c g p z g p z g
1 uc
1 1 211 1
bc p ui g bi
3 1 4 5
1 1 1
( , ) log ( | ) log ( | ) log ( | )
log ( | ) log ( 1| ) log ( 1| )
m mms i
i i i i i iii i
m m m
i i i i i i i
i i i
f X C w P c x p c c p c g
p c c g p z g p z g
Heuristic Modifications

• More Technical Points
– Maximum Character Accuracy (MCA) Training
– Refined Beam Search for high-order context
– Candidate character accumulation
– Various language models (char-based, word-based)
• Experimental Results
– Training data: isolated characters and texts of 816 writers
– Test data: 204 writers, 1,015 pages, 10,449 lines
– Performance metric: character correct rate (CR) accurate rate (AR)

AR (%) CR (%)
No language model 77.34 79.43
Cbi (char bi-gram) 89.56 90.27
Cti (char tri-gram) 90.20 90.80
Iwc (word-level) 90.53 91.17
Iwc+cca 90.75 91.39
AR (%) CR (%)
Cls+g+cti 89.95 91.52
Cls+g+iwc 91.68 92.57
Cls+g+iwc+cca 91.86 92.72
Su et al. (PR 2009) 35.64 39.37
Results on CASIA-HWDB
Results on HIT-MW (383 lines)

An Example of Document Recognition

54

Online Handwritten Text Recognition Using Semi-Markov CRF
• Linear chain CRF P(Y|X), semi-CRF P(S,Y|X) – X: Input component sequence
– Y: Output label sequence
– S: Segmented sequence
• Probabilistic model
• Parameters to be learned
55
t1 t2 t3 t4 t5 t6
X.-D. Zhou, et al., Handwritten Chinese/Japanese text recognition using semi-Markov
conditional random fields, IEEE Trans. PAMI, 2013

• Parameter Learning
– Training samples: {(Xi,Si,Yi)|i=1,…,N}
Conditional log-likelihood (CLL) loss
• MAP criterion, 0/1 cost
• Convex and differentiable, gradient descent
– Max-Margin
• To find Λ such that the energy difference of an incorrect path (S,Y) from correct path (Si,Yi) is at least l((S,Y),(Si,Yi))
56

• Applied to character string recognition
– Feature functions • Character classifier
• Language model: character n-gram
• Geometric modes: unary, binary
– Results on CASIA-OLHWDB (CR: character correct rate)
57
Effects of feature functions. Classifier: class-unspecific (cu), class-specific (cs)
Effects of character classifier. DFE: discriminative subspace learning

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Video and Scene Text Recognition
• Motivation – Wide applications: video retrieval, surveillance, visual aid,
Web data search and security
• Challenges – Complex background, low resolution – Variable illumination/perspective

Fast video text detection based on stroke edge pair statistics
Edge density
Edge orientation
variance
Opposite edge pair
B. Bai, F. Yin, C.-L. Liu, A fast stroke-based method for text detection in video,
Proc. DAS, 2012
Text confidence map

a
h g f
e d c
b
Edge density Edge orientation variance Opposite edge pair
Text
confidence
TC
binarized

a
h g f
e d c
b
Text
confidence
TC
binarized
After component filtering

Foreground/background classification
我理解(胡总书记的讲话)
• Text Extraction and Recognition
Over-segmentation
Text line recognition

Scene Text Localization Using CRF
Combine region
classification and
component classification,
incorporating spatial
context by CRF
Input
Image
Text Region
Detector
Confidence and Scale Map
Binarized Image
CC Analysis by
CRF
Text Localization
by CRF Final Results
Y.-F. Pan, X. Hou, C.-L. Liu, A robust approach to detect and localize texts in natural
scene images, IEEE Trans. Image Processing, 2011

• Results on ICDAR2005 Text Locating Competition Dataset

Scene Text Localization using Gradient Local Correlation
• Motivation – Text properties: pairwise edges with opposite gradient
directions, uniform stroke width – Stroke width transform (SWT): line search from edges
• Method – Gradient local correlation (GLC) of two opposite directions – Variable displacement (corresponding to hypothesized stroke
width
– Stroke width consistency
– Generate text confidence map (TCM) – Region segmentation, letter classification and grouping
66 Bai, Yin, Liu, ICDAR 2013

Multi-scale confidence map Text components extraction and filtering
67

Results on ICDAR2003 competition dataset (word localization)
68
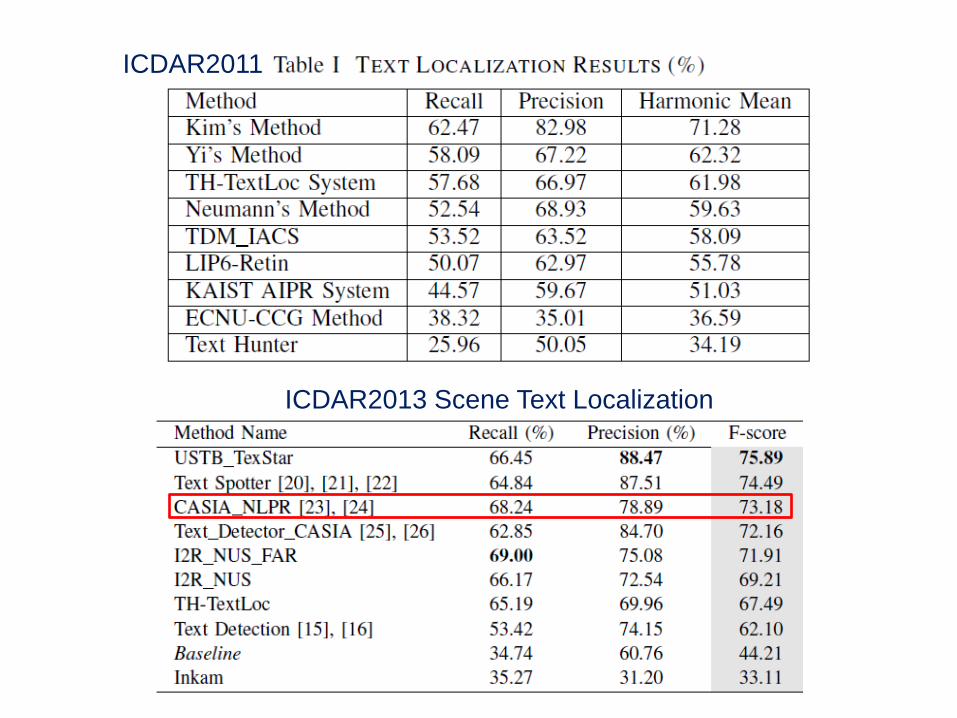
ICDAR2011
ICDAR2013 Scene Text Localization

Outline
• Background
• Chinese Handwriting Recognition – Database building
– Isolated character recognition
– Handwritten document segmentation
– Handwritten text line recognition
• Video and Scene Text Recognition
• Remaining Problems

Remaining Problems
• Video/Scene Text Recognition
– Main challenge: localization and extraction
– Increasing attention in CV community (CVPR, ICCV, ECCV, ACCV)
– Research issues: text saliency, fast detection, spatial context exploration, integration with recognition and language model
• Camera-Captured Documents
– Challenge: layout distortion, lighting variation
– Research issues: lighting/distortion correction, fast algorithms for applications to hand-held devices

• Handwritten Chinese Character Recognition – State of the art: 94~95% (CASIA-HWDB1.1)
– Research issues: feature extraction/learning, training with huge data, style adaptation
– To simulate and compete with deep learning
• Handwritten Text Recognition – Segmented character recognition 83.78%,
Chinese characters 87.28% (CASIA-HWDB2)
– Character correct rate in text line 92.19%
– Research issues • Touching character splitting
• Higher classification accuracy
• Higher-order language model: representation and search
• String-level model learning
• Mixed/multi language: low accuracy of symbols in Chinese documents
Effect of context

Application Prospects
• Online Handwritten Documents
– Devices: Electronic whiteboards, digital pen, smart phones
– Tendency: from isolated to continuous writing, documents mixed with text and graphics
• Offline Documents
– Handwritten: personal notes, forms, archives, etc
– Camera-captured: scene images, printed documents
– Web video/pictures: retrieval, translation, security
– Historical documents • Huge volumes, low access
• Challenges: image degradation, complex layout, font inflection, small labeled sample

Some Thoughts for DA Community
• How long will the field exist?
– Needs continue to exist, but technology should evolve fast to catch the opportunity • Forms and address: cannot wait for a long time
• Historical documents: un-avoidable
• Any big application?
– Historical documents: who to pay?
– Camera-based and web documents: how academia collaborate/compete with industry
– Make it big: DA with knowledge extraction and translation
• What are scientific problems
– Technical challenges imply lots of scientific problems
– Methodological progress of DA much slower than CV & ML

• DA conferences
– Acceptance rate should decrease or not
– Why ICDAR ranks higher than ICPR (core.edu.au)
• Impact of deep learning
– Will DNN replaces/excels all traditional methods as in vision? Need to be alert
– Text line (string) recognition needs more complicated model
• How to attract young people to DA?
– Employment opportunities: not bad
– PhD student: easy to produce papers of high IF?
– Difficult to enter the field • New groups very rare, except scene text (more like vision problem)
• Multitude of knowledge and skills to become a good researcher
• Lacking of open sources (cf. CV & ML)

Acknowledgements
• Collaborators – Offline handwriting: Fei Yin, Qiu-Feng Wang, Yi-Chao Wu
– Online handwriting: Xiang-Dong Zhou, Da-Han Wang, Adrien Delaye
– Scene text: Xinwen Hou, Yi-Feng Pan, Bo Bai
– Video text: Bo Bai
– Others: Ming-Ke Zhou, Kai Chen, Quan Qiu, etc.
• Sponsors – Chinese Academy of Sciences (100 Talents Program)
– National Natural Science Foundation of China (NSFC)
– Ministry of Science & Technology (SKL Special Fund, 973)
– Industrial sponsors: Hitachi, Fujitsu, etc.

Thank You















