Docker Orchestration: Beyond the Basics · Docker Orchestration: Beyond the Basics Aaron Lehmann...
62
Docker Orchestration: Beyond the Basics Aaron Lehmann Software Engineer, Docker
Transcript of Docker Orchestration: Beyond the Basics · Docker Orchestration: Beyond the Basics Aaron Lehmann...

Docker Orchestration: Beyond the BasicsAaron Lehmann Software Engineer, Docker

2
About me• Software engineer at Docker • Maintainer on SwarmKit and Docker Engine open source
projects • Focusing on distributed state, task scheduling, and rolling
updates

Swarm mode

4
Swarm mode is Docker’s built in orchestration• Docker can orchestrate containers over multiple machines
without extra software • Example: running a instances of a web service on several
machines

5
Getting started with swarm mode• Initialize a new swarm: mgr-1$ docker swarm init
• Join an existing swarm: worker-1$ docker swarm join --token <token> 192.168.65.2:2377

6
Swarm mode: Services• Swarm mode deals with services, not individual containers • Each service creates one or more replica tasks, which are run as
containers • On manager, create a new service for a search microservice
application:
mgr-1$ docker service create -p 8080:8080 --name search \
--replicas 4 searchsvc:v1.0
mgr-1$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
2xtw9qipmbe9 search 4/4 searchsvc:v1.0

7
Swarm mode: Nodes• Worker nodes just run service tasks • Manager nodes manage the swarm
mgr-1$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
drwxwi4h2fb0tcrwgmpmma2x0 * mgr-1 Ready Active Leader
1mhtdwhvsgr3c26xxbnzdc3yp mgr-2 Ready Active Reachable
516pacagkqp2xc3fk9t1dhjor mgr-3 Ready Active Reachable
9j68exjopxe7wfl6yuxml7a7j worker-1 Ready Active
03g1y59jwfg7cf99w4lt0f662 worker-2 Ready Active
dxn1zf6l61qsb1josjja83ngz worker-3 Ready Active

8
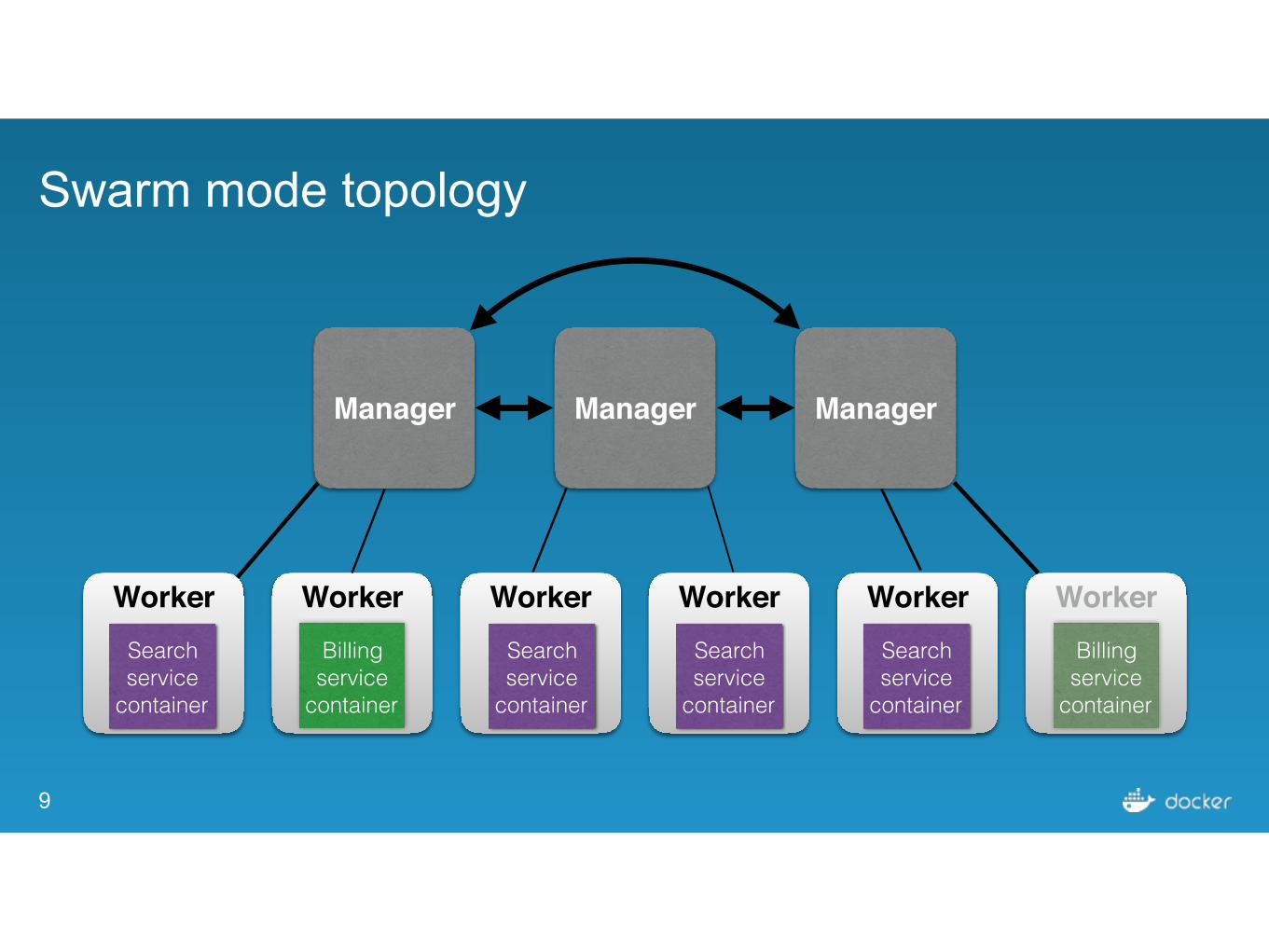
Swarm mode topology
Manager Manager Manager
Worker Worker Worker Worker Worker WorkerSearch service
container
Billing service
container
Search service
container
Search service
container
Billing service
container
Search service
container
9
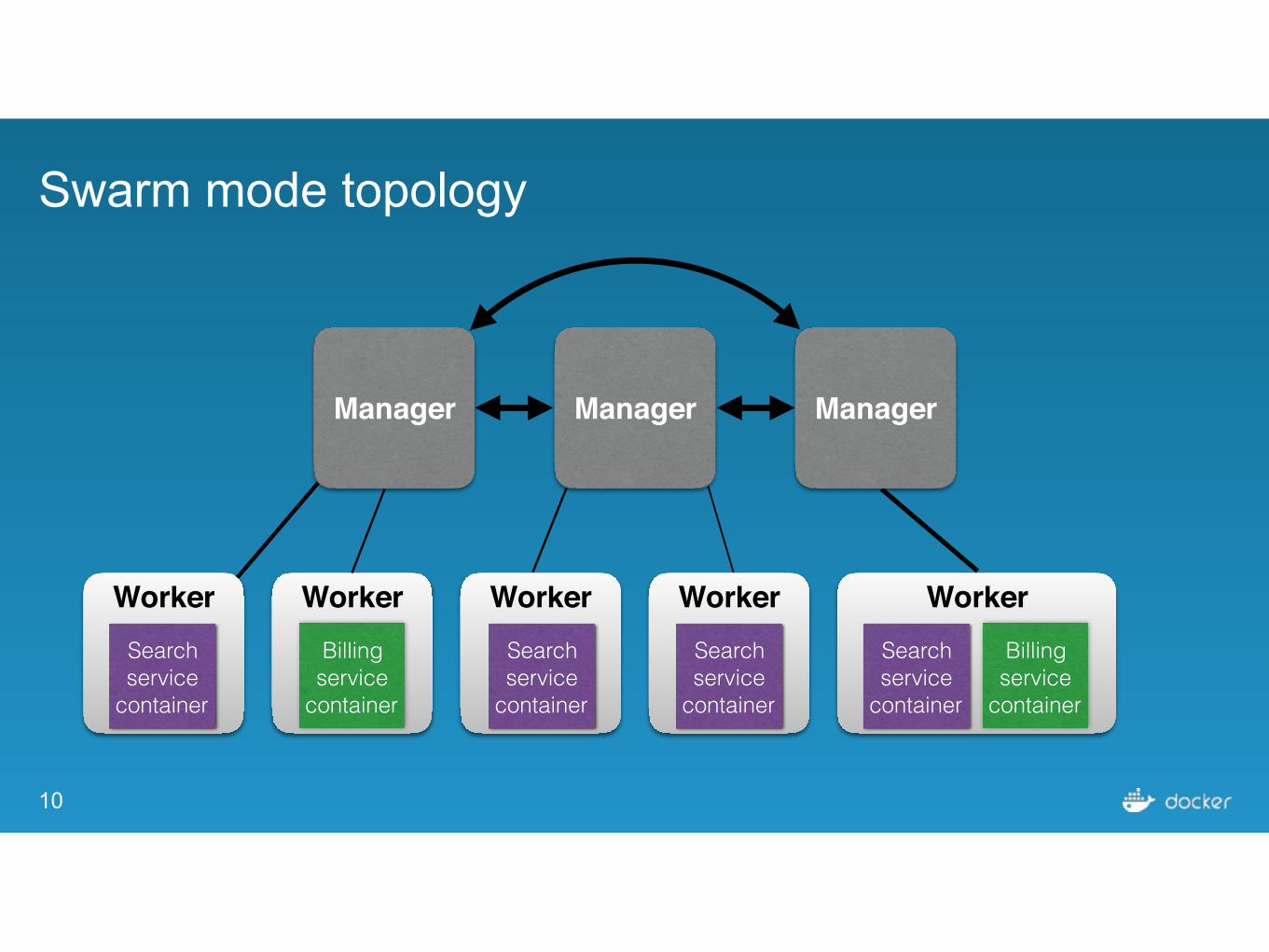
Swarm mode topology
Worker Worker Worker Worker Worker WorkerSearch service
container
Billing service
container
Search service
container
Search service
container
Billing service
container
Search service
container
Manager Manager Manager
10
Swarm mode topology
Worker Worker Worker Worker WorkerSearch service
container
Billing service
container
Search service
container
Search service
container
Search service
container
Billing service
container
Manager Manager Manager

High availability

12
High availability• Survive failures of some portion of workers and managers • If a worker fails, its assigned tasks are rescheduled
elsewhere

13
High availability• What about manager failures? • Managers are part of a Raft cluster that replicates the
state of the swarm

14
Raft• Raft is a protocol for maintaining a strongly consistent
distributed log • Way to avoid a single point of failure

15
Raft concepts• Quorum: A majority of managers • Leader: Randomly chosen manager that can add
information to the distributed log • Election: The process of choosing a new leader

16
High availability• The leader is the manager that:
• Makes the scheduling decisions • Keeps track of node health • Handles API calls

17
High availability• If the leader fails, another manager is elected in its place • For Raft to function, more than half the managers (a
quorum) must be reachable

18
How many managers for a swarm?• A single manager is fine in some scenarios • Any swarm meant to survive a manager failure should
have 3 or 5 managers • No scaling benefit to adding additional managers
• Each one replicates a full copy of the swarm's state

19
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 0

20
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 0

21
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 03 2 14 3 1

22
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 03 2 14 3 1

23
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 03 2 14 3 15 3 26 4 2

24
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 03 2 14 3 15 3 26 4 2

25
Manager fault toleranceNumber of managers Majority Tolerated Failures
1 1 02 2 03 2 14 3 15 3 26 4 27 4 38 5 39 5 4

26
Where to deploy the managers• Managers must have static IP addresses • Managers should have very reliable connectivity to each
other • Swarms that span a big geographic area aren't
recommended • Looking at federation as an eventual solution for multi-
region • Spreading managers across a cloud provider's "availability
zones" in one region may make sense

27
Advertised IP addresses• All managers must be reachable by all other managers • Managers need to know their own IP addresses so they
can tell other managers how to reach them • The address is autodetected if there is only one network
device, or in the process of joining an existing swarm

28
Advertised IP addresses• If the address can't be autodetected, provide--advertise-addr when runningdocker swarm init
• Many swarm instability issues are actually caused by managers not being able to communicate

29
What to do if quorum is lost• Suppose two out of three managers fail • The swarm won't be able to schedule tasks or perform
administrative functions • You will see timeouts from commands likedocker node ls if this happens

30
What to do if quorum is lost• What if these managers are gone forever? • docker swarm init --force-new-cluster on the
surviving manager recovers from this state • This modifies the swarm so that it only has a single
manager • From that point, new managers can be added

31
Protecting managers from accidental overloading• By default, managers will be assigned tasks just like
workers • This makes sense on a laptop-scale deployment • Best practice for serious deployments: avoid running
container workloads on managers

32
Protecting managers from accidental overloading• Drain the managers to prevent them from running service
tasks:
mgr-1$ docker node update --availability=drain <manager id>
• Alternatively, set the node.role == worker constraint on all services

33
Rolling updates• Important to avoid downtime during updates • docker service update is a rolling update by default • Parameters:
• Update delay (--update-delay) • Update failure action: pause or continue
(--update-failure-action) • Parallelism (--update-parallelism)

34
Rolling updatesPrepare
new
Stop old
Start new Health checks
Update delay
Prepare new
Stop old
Start new
Health checks
Update delay
Prepare new
Stop old
Prepare new
Stop old
Time
Upd
ate
para
llelis
m{

Security

36
Security model• All swarm connections are encrypted and authenticated
with mutual TLS • Each node is identified by its certificate (CN = node ID) • The certificate authorizes the node to act as either a
worker or manager (OU = swarm-manager or OU = swarm-worker)
• By default, each manager operates as a certificate authority with the same CA key

37
Security around adding nodes• How does a new node authenticate itself before having a
certificate? • It presents a join token which is provided todocker swarm join

38
Security around adding nodes• The join token contains a secret that authorizes the new
node to receive either a worker or manager certificate • It also contains a digest of the root CA certificate, for
protection against man-in-the-middle attacks • The node does not use or store the join token after joining

39
Node joining example: adding a new worker• On a manager, retrieve the join token:
mgr-1$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join \ --token SWMTKN-1-5f7umqonkff6je2l1kqpxdsok3bwipn73hlr5dxtvx4lusy809-5yn6jy5zqqq3tnummvq365y7m \ 172.17.0.2:2377

40
Node joining example: adding a new worker• Run the command on the new worker:
worker-1$ docker swarm join --token \ SWMTKN-1-5f7umqonkff6je2l1kqpxdsok3bwipn73hlr5dxtvx4lusy809-5yn6jy5zqqq3tnummvq365y7m \ 172.17.0.2:2377
This node joined a swarm as a worker.

41
Node joining flow
Joining node Manager
Join token, certificate request
Signed certificate
Node registration
Task assignments
= TLS with no client certificate= Mutually authenticated TLS

42
Rotating join tokens• The join tokens remain valid until they are rotated • It is good practice to periodically rotate them
• docker swarm join-token --rotate worker generates a new worker token to replace the old one
• docker swarm join-token --rotate manager generates a new manager token to replace the old one

43
Rotating join tokensmgr-1$ docker swarm join-token --rotate workerSuccesfully rotated worker join token.
To add a worker to this swarm, run the following command:
docker swarm join \ --token SWMTKN-1-5f7umqonkff6je2l1kqpxdsok3bwipn73hlr5dxtvx4lusy809-6cq1skbwkkrp2xgv4ak0cgn01 \ 172.17.0.2:2377

44
Certificate renewal• By default, certificates issued to nodes by the Swarm
manager are valid for 90 days • Before they expire, nodes automatically renew their
certificates • Jitter is added to the renewal time

45
Certificate renewal• Renewal does not involve join tokens • A manager will issue a renewed certificate to any node that
can prove its identity with mutual TLS • The certificate validity period can be changed with
mgr-1$ docker swarm update --cert-expiry=1000h
• A shorter expiration time limits the time window where a leaked certificate is useful to an attacker

46
External certificate authorities• Some may prefer to use a hardened external CA • Swarm mode can be set up to call out to an external CA
$ docker swarm init --external-ca \ protocol=cfssl,url=https://myca.domain.com

47
Node joining flow (external CA)
Joining node Manager
Join token, cert request
Signed certificate
Node registration
Task assignments
= TLS with no client certificate= Mutually authenticated TLS
External CA
Cert request
Signed cert

48
External certificate authorities• Initially supported protocol is cfssl's JSON API • Swarm manager authenticates with the external CA using
mutual TLS with its manager certificate • External CA becomes a single point of failure for granting
and renewing certificates

49
Registry credentials• Some images are private, meaning a password or token is
needed to pull them • If I just run: mgr-1$ docker service create myprivateimage
...workers won't be able to pull the image

50
Registry credentials• docker login credentials are forwarded to nodes
executing containers from the service if--with-registry-auth is specified:
mgr-1$ docker service create \ --with-registry-auth myprivateimage
• Note that the password or token is exposed to workers where the tasks are scheduled

51
Registry credentials• Alternative to --with-registry-auth: pre-pull private
images on all nodes • Consider using constraints to limit private images to
hardened nodes

Upcoming improvements

53
Upcoming improvements: Secrets management• Include secrets such as crypto keys with services • The associated secrets are sent to the nodes where the
service's tasks are assigned • They are made available inside a RAM filesystem
mounted inside the container • Secrets are not written to disk as part of task execution

54
Upcoming improvements: Visibility into container logs• Currently no swarm-level support for container logs • It will be possible to access logs from any task through a
manager, regardless of where the task is running

55
Upcoming improvements: High availability scheduling• Improves scheduling algorithm to spread out replicas over
as many nodes as possible • This avoids concentrating the service's tasks on one node
or a few nodes • Then it's harder for hardware/network failures to take out
all replicas

56
Upcoming improvements: High availability schedulingScale up search service to 3 replicas, old scheduling algorithm:
Node 2
Billing service
Billing service
Billing service
Node 1
Searchservice
Searchservice
Searchservice
Node 1 has fewest tasks, so it receives the new task
Searchservice

57
Upcoming improvements: High availability schedulingScale up search service to 3 replicas, new scheduling algorithm:
Node 2
Billing service
Billing service
Billing service
Node 1
Searchservice
Searchservice
Searchservice
Node 2 has fewest replicas of the search service, so it receives the new task
Searchservice

58
Upcoming improvements: Roll back service updates• If you accidentally roll out a bad update to a service, it will
be possible to roll it back with a simple command:
mgr-1$ docker service update --rollback <servicename>
• This reverts to the previous version of the service

59
Upcoming improvements: Roll back service updates• Related enhancement: rolling updates can pause after a
configurable fraction of the new tasks fail • Configurable time period to monitor each new task for
failure

60
Upcoming improvements: Roll back service updates
Prepare task 1
Stop old
Start task 1
Health checks
Update delay
Prepare task 2
Stop old
Time
Monitoring period for task 1
Task 1 fails

61
Other resources• Swarm mode documentation:
https://docs.docker.com/engine/swarm/ • Overview of Raft:
http://thesecretlivesofdata.com/raft/ • SwarmKit project GitHub repository:
https://github.com/docker/swarmkit

Thanks!










![Docker Networking with Container Orchestration Engines [Docker Meetup Santa Clara | April 2016]](https://static.fdocuments.net/doc/165x107/589d91871a28abfb088b738d/docker-networking-with-container-orchestration-engines-docker-meetup-santa.jpg)






![[221] docker orchestration](https://static.fdocuments.net/doc/165x107/58700b341a28ab427f8b7193/221-docker-orchestration.jpg)
