
Reinforcement Learning - 4. Model-free reinforcement Learning

Distributed Deep Reinforcement Learning for Fighting Forest Fireswith a Network of Aerial Robots*
Ravi N. Haksar1 and Mac Schwager2
Abstract— This paper proposes a distributed deep reinforce-ment learning (RL) based strategy for a team of UnmannedAerial Vehicles (UAVs) to autonomously fight forest fires. Wefirst model the forest fire as a Markov decision process (MDP)with a factored structure. We consider optimally controllingthe forest fire without agents using dynamic programming, andshow any exact solution and many approximate solutions arecomputationally intractable. Given the problem complexity, weconsider a deep RL approach in which each agent learns apolicy requiring only local information. We show with MonteCarlo simulations that the deep RL policy outperforms a hand-tuned heuristic, and scales well for various forest sizes anddifferent numbers of UAVs as well as variations in modelparameters. Experimental demonstrations with mobile robotsfighting a simulated forest fire in the Robotarium at the GeorgiaInstitute of Technology are also presented.
I. INTRODUCTION
Forest fires are responsible for a significant amount ofeconomic, property, and environmental damage all overthe world. Studies have shown that the economic impactalone can reach over a billion US dollars per incident forsuppression efforts, environment rehabilitation, and publicassistance [1].
Monitoring and controlling forest fires is therefore anappealing application for aerial robotics as terrain, weather,and other factors can pose serious challenges for firefighters –including the potential for loss of life. An attractive solutionis to use autonomous multi-agent systems, such as a team ofUnmanned Aerial Vehicles (UAVs), in this domain. UAVsare agile, potentially disposable, can be deployed in largenumbers, and can form a distributed system, eliminating theneed for a central decision maker. Information from a multi-agent system can be provided to firefighters to assist theirplanning, monitoring, and control efforts.
In this paper we first introduce a simplified lattice-basedstochastic model that captures the bulk behavior of a forestfire and an agent model that includes motion, communi-cation, and action constraints. We establish the infeasibil-ity of exact and approximate control methods that requireenumerating the state space. We discuss task decompositionto address problem complexity and describe a hand-tunedheuristic to generate control inputs for the UAV agents. Wethen develop a novel extension of Q-learning for multi-agent
*This research was supported in part by NSF grant IIS-1646921. We aregrateful for this support.
1R. N. Haksar is with the Department of Mechanical Engineering,Stanford University, Stanford, CA 94305 [email protected]
2M. Schwager is with the Department of Aeronautics& Astronautics, Stanford University, Stanford, CA [email protected]
Fig. 1: Example forest fire simulation. Cell color denotestree state: green is healthy, red is on fire, and black is burnt.Gold lines show sample UAV trajectories.
systems to create a decentralized and scalable solution bywhich a network of aerial agents can effectively containthe spread of a forest fire. Specifically, the solution scalesindependent of the forest size and the number of agents.Simulation and hardware experiments validate its efficacy.
Prior work on the application of robotics to assisting withforest fires has focused on the modeling and monitoring as-pects. A number of models have been introduced to describethe spread of a wildfire, including elliptical PDE models [2],vector propagation models using spatial data [3] (used by theUS Department of Agriculture Forest Service), and stochasticlattice-based models [4], [5].
Several methods have been published on using au-tonomous agents to surveil and monitor a forest fire. Methodsinclude using computer vision techniques to detect a fire[6], [7] or to monitor a fire and relevant data of the fire(e.g. temperature and flame height) [8], [9], [10], [11].Decentralized monitoring systems with UAVs have also beeninvestigated [12]. In general, persistent surveillance is abroad research topic with methods that could be appliedto forest fire models. Surprisingly, there are relatively fewpublished methods for autonomous agents to control a forestfire. One method [13] constructs a fully decentralized methodusing potential fields and the agents are able to surround andsuppress a wildfire. Another method [14] uses a centralizedformulation with one agent collecting observations that aresent to a base station which then determines actions for theother agents. In [4], the authors also develop two centralizedpolicies that are idealized and provide conditions necessaryfor agents to stabilize a fire under their model. Other workhas posed forest fire fighting as a centralized resource allo-cation problem without autonomous agents [15], [16].

Reinforcement learning (RL) approaches also mainly fo-cus on persistent monitoring of forest fires. Ure et al. [17]developed an online decentralized cooperative method foragents to build an estimated model of a forest fire process.Julian et al. [18] proposed two deep reinforcement learningmethods for fixed-wing aircraft with imperfect sensors tomaximize sensor coverage of a forest fire. The applicationof RL in prior work for modeling and sensor coverage [17],[18] provided inspiration for using RL methods to producea decentralized policy for agents to suppress a forest fire.Bertsimas et al. [19] applied Monte Carlo tree search androlling horizon optimization to forest fire management for acentralized decision maker and assume suppression resourcescan instantaneously be assigned to any location.
Model-based RL is the appropriate framework for solvingthe described problem, but exact methods and many approx-imate methods either cannot address the domain complexityor require recomputing solutions when changing problemparameters. To address domain complexity, we leveragetask abstraction which has been shown to be effective forimproving long-term planning [20], [21]. For scalability, wepropose a novel extension of deep Q-learning.
The rest of this work is organized as follows. Section IIestablishes the forest fire and agent models and establishesthe problem complexity. In Section III we describe a hand-tuned heuristic to generate agent control actions that isdecentralized and scales independently of forest size andnumber of agents. In Section IV we propose a novel Q-learning algorithm based on deep reinforcement learning(RL) to improve upon the heuristic. Finally, Section Vpresents performance metrics of the multi-agent solution.
II. PROBLEM FORMULATION
A. Forest Fire Model
A stochastic discrete-time model, inspired by [4], is usedto describe the forest fire dynamics. The forest is modeledas a set of m total trees represented by nodes on a twodimensional plain square lattice Z2 (the set Z2 is the integergrid). The position of a tree i is given by qi ∈ Z2 and theinter-tree distance on the lattice is assumed to be one unit. Ateach time t, the tree state xti is one of three possible values,Xi = {H,F,B} = {healthy, on fire, burnt}. Actions cor-respond to dumping fire retardant on a tree and are binaryvariables, ati ∈ Ai = {0, 1}. The potential to dump fireretardant on a tree is only available if a UAV is located overthe tree. The UAV model is described below in Section II-B.
The notation xtO(i) is used to represent the states of treesin the set O(i) ⊆ {1, . . . ,m}, xtO(i) = {xtj | j ∈ O(i)}.Similar notation is used for the action variables, atO(i) =
{atj | j ∈ O(i)}. An aggregate state and action space canbe defined by the Cartesian products, X =
∏mi=1 Xi and
A =∏mi=1Ai. The subscript of variables is omitted when
referring to aggregate values, such as xt ∈ X and at ∈ A.The state transitions of a single tree are influenced by the
tree’s current state as well as “neighbor” trees, which aretrees one unit away in Manhattan distance. The neighbor set
TABLE I: Single tree transitions pi for forest fire model
xti
xt+1i Healthy On Fire Burnt
Healthy pHF (xtN(i)
) 1− pHF (xtN(i)
) 0
On Fire 0 pFF (ati) 1− pFF (ati)
Burnt 0 0 1
function N(i) represents the neighbor trees for tree i, N(i) ={j | ‖qi − qj‖1 = 1 ∀j ∈ {1, . . . ,m}}. The parent functionΓ(i) represents all trees that influence the state evolution oftree i, Γ(i) = i ∪ N(i). Figure 2a provides an example ofthe neighbor set and parent function for the model.
Table I summarizes the probabilistic transition function pifor a single tree which is parameterized by pHF and pFF .A tree that is healthy will probabilistically transition to onfire only if at least one tree in its neighbor set is on fire,
pHF (xtN(i)) = 1− αfti ,
where f ti is the number of neighbor trees on fire, f ti =∑j∈N(i) 1F (xtj). The parameter α ∈ [0, 1] is a known
constant that describes the likelihood of a tree on firespreading fire to a healthy tree, independent of other treestates. The notation 1A(x) represents the indicator functionand equals one when x ∈ A and zero otherwise.
A tree on fire will either remain on fire or transition toburnt after one time step. The probability of remaining onfire is a function of the action,
pFF (ati) = β − ati∆β,
where β ∈ [0, 1] and ∆β ≤ β are known quantities thatdescribe the average number of time steps a fire will persistand how effective actions are, respectively. Only trees onfire are affected by the choice of action ati; this is the onlyinfluence of control actions in the model.
Finally, a tree that is burnt will remain burnt for alltime. The parameters α, β, and ∆β can also be extendedto include other effects, such as wind and varying terrain(α(xi, t), β(xi, t), and ∆β(xi, t), respectively). For thiswork, these parameters are held constant, although we intendto investigate varying these parameters in future work.
The transition function of the aggregate state (all trees inthe forest) is described by the joint probability distribution,p(xt+1 | xt, at) =
∏mi=1 pi(x
t+1i | xtΓ(i), a
ti).
B. Agent Model
The UAV agent model includes motion constraints, com-munication limits, and simple sensors. We use the index kto refer to the kth agent, as before we use i to refer to theith tree. There is a total of C agents operating in the domainand the UAVs are considered agile in the sense that ulimitactions can be executed before the forest fire model updates.
Due to the disparity of time steps for model updates andtime steps for agent actions, the time index τ is used whenreferring to time-dependent agent quantities.Motion. Each agent moves on the same plain square two-dimensional lattice Z2 as the forest. The agent is also

(a) Neighbor set (b) Agent movement
Fig. 2: (both) The lattice is visualized as a grid of cells. (a)For the gold cell, the neighbor set includes the blue cells andthe parent function returns the gold and blue cells. Whitecells are part of the forest but are not in the neighbor setnor a parent cell. (b) Feasible movements for an agent (goldcircle). Agents can also choose not to move.
not constrained to stay within any boundaries — it canmove infinitely away from the lattice in any direction. Theposition of an agent k is represented by pτk ∈ Z2. The agentaction space contains nine possible actions which modifythe position, pτ+1
k = pτk + uτk with uτk ∈ U and,
U =
{[ij
] ∣∣∣ (i, j) ∈ {−1, 0, 1} × {−1, 0, 1}}.
Note that action set A refers to actions that influence thetransitions of the forest and action set U refers to actionsthat modify the position of agents. Figure 2b shows a visualrepresentation of the action set U .Sensors. Each agent is equipped with two sensors.
i. Camera. A downward facing Infrared (IR) cameracaptures the states of an h × w sized grid of trees.The agent is located at the center of the image and ifimages are taken at an edge of the forest, the image ispadded with healthy trees.
ii. Radio. The agents are notified of the initial averageposition qfire of the trees on fire over the entire forest,qfire =
(∑mi=1 1F (x0
i )qi)/∑mi=1 1F (x0
i ).Example sensor data for an agent is shown in Figure 3a.Communication. Agents communicate with the nearestagent, jcomm = arg min
j=1,...,C∧j 6=i‖pτi − pτj ‖2. Agent jcomm
transmits the position pτjcommand the label jcomm to agent k;
no other information is shared. Agent k does not transmitinformation to agent jcomm unless agent k is also the nearestagent. The nearest agent may change at each time step τas the agents move on the lattice. Figure 3b provides anexample of the communication model for three agents.Control action. Fire retardant is applied to a tree when anyagent’s position coincides with a tree on fire,
ati =
{1 if 1F (xti) ∧ pτk = qi ∧ τ ∈ [t, t+ ulimit],
0 otherwise.
The effect of retardant does not compound if multipleagents move to the same tree within the interval [t, t+ ulimit]and therefore agents will need to cooperate to avoid wastingcontrol effort. A retardant capacity can be specified, dk ∈Z+, to limit the number of trees on fire an agent can dumpretardant on. If an agent runs out of retardant, the agent
(a) Agent sensor data (b) Agent communication
Fig. 3: (a) Example sensor data for an agent (blue circle):an image (here, h = w = 3) of tree states and the initialfire location qfire (red circle). In the image, color indicatestree state: green is healthy, red is on fire, black is burnt. (b)Example communication based on distance for three agents(red, green, and blue circles). Arrow directions show the flowof information and color indicates the broadcasting agent.
returns to a base station near the edge of the forest, itsretardant capacity is refilled, and it is re-deployed into theforest at the station.We assume that agents without retardant have a greatermaximum speed and that refilling takes a negligible amountof time. Therefore, a depleted agent is refilled and re-deployed at the station at the next time step τ .Memory. Agents track if their position has coincided witha tree that is on fire or burnt, ck ∈ {True,False}, which isdetermined by the image data. Initially, ck is False and thevalue is changed only once,
ck = True if 1{F,B}(xti) ∧ pτk = qi ∧ τ ∈ [t, t+ ulimit] ,
for any time t during the forest fire model simulation.The agent modeling assumptions can reasonably be imple-mented on a sub-class of UAVs. Mellinger et al. [22] describea 3D trajectory and altitude controller for quadrotor vehicles.The quadrotors can be commanded to maintain a constantaltitude and move laterally to achieve the discrete motiondescribed in the agent motion model.
Cameras and High Frequency (HF) radios are compact andrelatively inexpensive sensors and many quadrotor platformsincorporate both for various applications. We assume theagents are distributed throughout a forest (e.g. uniformly orrandomly) for a task, such as persistent monitoring, prior tothe fire ignition. The fire ignition location is assumed to beknown and is sent to the agents through HF broadcasting.
Dense communication networks (e.g. all-to-all communi-cation) with high bandwidth are possible but are difficult andcostly to implement. Instead, a passive method is describedwhere agents can continually broadcast their position andindex label and receive the same information via HF radios.The communication model is relatively low bandwidth anddoes not require reciprocal data transfer or acknowledgementof transmission or reception, resulting in less susceptibilityto errors. Lastly, we assume a practical amount of fireretardant can be stored on-board the agents; enough to dumpretardant on 10 trees before returning to the base stationfor a refill. Although the forest fire and agent models arehighly abstracted, we believe they retain the key attributes

for designing a fire fighting policy for a team of UAVs.
C. Problem ComplexityEach tree in the forest, given the state of its parents
Γ(i) and a reward function ri, is described as an infinitehorizon, discounted Markov decision process (MDP). Aninfinite horizon, discounted MDP is defined by the tuple〈X ,A, p, R〉, where X is the state space, A is a set offeasible actions, p is a probabilistic transition function, andR is the immediate reward function. For a single time step,it is relatively simple to statistically predict the distributionof next states for a single tree.
The whole forest is a network of locally-interacting MDPs,where the region of interaction for each tree is the neighborset N(i). As a result, the number of possible forest configu-rations is astronomical—a forest of m trees has 3m possibleconfigurations. A 100 tree forest has more states than thereare grains of sand on Earth, and a 250 tree forest has morestates than atoms in the universe [23]. For comparison, thereare approximately 26,000 trees in New York’s Central Park,which is a relatively small sized forest. The number of statesfor any practical forest size suggest that controlling thisnetworked MDP will be difficult.
A simple way to reduce this complexity is to only considerforest configurations that have a non-zero probability ofoccurring. Considering only non-zero probability transitions,there are 2k configurations after one time step, where k =∑mi=1 1F (xti) + 1H(xti)1R+(1 − pHF (xtN(i))). The quantity
k describes the number of trees on fire and the number ofhealthy trees that may transition to on fire. As an example,consider a 4 × 4 grid of trees on fire in the center ofa large forest. There are 16 trees on fire and 16 healthytrees that are neighbors of the trees on fire. Therefore, thenumber of possible forest configurations after one time stepis 232 ≈ 4.29 × 109, a very large number even when onlyconsidering reachable states for a small fire.
The previous discussion elucidates the issue of enumer-ating the aggregate state space. In addition, with a limitednumber of agents acting in the forest with restricted fieldof view sensors (e.g. a camera) to observe the forest, theproblem description also includes both motion and partialobservability constraints. Therefore, the partially observableMDP (POMDP) framework is more appropriate for model-ing the full problem with additional agent and observationconstraints. However, exact POMDP solutions are PSPACE–complete for finite horizon problems, and undecidable forinfinite horizon problems [24], [25].
Extreme model complexity does not itself preclude theexistence of a simple policy that optimizes a performancemetric. In the next section, we discuss how to pose the forestfire model in the relevant framework from literature and showthat an exact policy, excluding agent and action constraints,is in fact intractable.
D. Factored MDPs (FMDPs)In comparison to traditional MDP descriptions, Fac-
tored MDPs (FMDPs) [26] leverage problem struc-ture to create a compact representation. An infinite
horizon, discounted FMDP is defined by the tuple〈{Xi ∀i}, {Ai ∀i}, {pi ∀i}, {ri ∀i}〉 where the individualstate space, action space, transition function, and rewardfunction are stored for each constituent MDP, as opposed toforming aggregate spaces which are exponential quantities.In addition, the joint probability transition function is repre-sented compactly by a two-slice temporal Bayesian network.The reward function is additively composed, R(xt, at) =∑mi=1 ri(x
tO(i), a
tO(i)) where the functions ri typically have
a restricted domain, O(i) ⊆ X with |O(i)| � m.A FMDP can be used to describe the forest fire model,
where there are m copies of the state space, action space,transition function, and reward function for a single tree.A solution to the forest fire FMDP is a value functionv(xt) describing the value of a forest state assuming that themaximizing action at is always taken. Despite the compactrepresentation of FMDPs, the structure does not translateinto structure in the value function and exact solutions stillrequire enumerating the aggregate state space [27]. As aresult, approximate methods for both FMDPs and factoredrepresentations of POMDPs have been proposed in literature.
In contrast to approximate methods in literature, we seeka solution method that does not need to be recomputedif the number of total trees m is varied. In addition,many approximate methods will struggle with the addedcomplexity of partial observability constraints. Ultimately,deep RL approximate methods will be able to address theoverwhelming complexity and generate a scalable solution.
III. HEURISTIC APPROACH
We now describe a hand-tuned method to generate actionsfor agents that does not depend on the forest size or thenumber of agents.
A. Task Decomposition
Section II-C demonstrates the difficulty in finding so-lutions to the full problem, which includes agent motion,sensing, and communication constraints. Therefore, we de-compose the problem at the agent level. Each agent is taskedwith completing two objectives, described as
1) approach the initial forest fire location,2) move to suppress the forest fire.
The first task is equivalent to finding the shortest pathbetween an agent’s position pτk and the location qfire. Agentcommunication and cooperation are ignored to further sim-plify the task. The solution is described in closed-form as,
uτk = arg minu∈U‖pτk + u− qfire‖2. (1)
Once an agent moves “close enough” to the initial firelocation, the agent switches to the second task. The memoryck determines when to switch tasks as ck describes when anagent first encounters a tree that is not healthy, an indicationthat the agent is near a fire.

B. Algorithm Description
Algorithm 1 describes the heuristic that generates actionsfor both tasks. The method uses information derived from anagent’s sensors which is encapsulated in a feature set denotedsτk for notational convenience.
Agent Feature Set sτk.i. Memory cτk.
ii. Image Iτk . The camera image is vectorized to Iτk .iii. Avoidance eτk ∈ {True, False}. Agents use right-of-
way priority by comparing their index with the nearestagent’s index. The value is eτk = True if k > jcommand False otherwise. Agents with higher indices areresponsible for yielding to agents with lower indices.
iv. Rotation vector vτk . The vector vτk,cen = pτk − qfireinforms the agent of its relative position with respectto the initial fire location. The rotation vector isvτk = R⊥v
τk,cen where R⊥ is the 2D rotation matrix
that rotates a vector through −90◦. The vector vτk is
constructed so that always taking the action uτk =arg min
u∈U‖u/‖u‖2 − vτk‖2 will continuously move the
agent clockwise about the location qfire.v. Nearest agent vector wτk . The vector wτk = pτk − pτjcomm
informs the agent of its relative position with respect tothe closest agent. If agent k is responsible for avoidingagent jcomm (determined by eτk) then it should not movewithin a safety radius of one of agent jcomm.
The feature set sτk is formed by the concatenation of thisinformation into a vector, sτk =
[ck Iτk vτk eτk wτk
]T.
Figure 4a provides an example of the direction vectors.Both the heuristic and the deep RL method proposed inSection IV use this feature set as the only input for eachagent to determine its control action.
Once ck = True, the heuristic first proposes to simply rotateclockwise about the fire center (line 4). The purpose of thisaction is to make each agent “patrol” and apply retardantalong the set of “boundary” trees of the forest fire.
Definition 1 (Boundary tree). A tree i is considered a“boundary tree” if xti ∈ {F,B} and
∑j∈N(i) 1H(xtj) > 0.
The rotational action may sometimes skip applying re-tardant to trees on fire since the fire grows stochastically.Therefore, the heuristic also considers two “left” actionsdefined relative to the proposed action so agents can moveappropriately as the fire grows (lines 5 and 7). These actionsare defined relative to an action uτk =
[i j
]Tas uleft,1 =[
−j i]T
and uleft,2 = 1max{|i+j|,|i−j|,1}
[i− j i+ j
]T.
On the other hand, the agent may move far away fromboundary trees if the fire does not grow as quickly asanticipated. A “right” action is taken when the agent believesthe proposed action would move it to a healthy tree that isfar from a boundary tree. Specifically, if the new positionpτ+1k = pτk + uτk coincides with a healthy tree xti that has
many nearby healthy trees,∑j∈H 1H(xtj) ≥ 6 where
H = {j | 0 < ‖qj − qi‖2 ≤ 2 ∀j ∈ {1, . . . ,m}},
(a) Direction vectors (b) Left and right actions
Fig. 4: (a) Example direction vectors vτk,cen, vτk , and wτk fora given agent (gold circle). The red circle denotes the fireignition location qfire and the blue circle denotes the nearestagent. (b) In the heuristic, the agent considers left and rightactions (red and blue vectors) relative to an action uτk.
Algorithm 1 Heuristic
1: Input: agent feature set sτk2: Output: agent action uτk3: if ck = True then4: uτk = arg min
u∈U‖u/‖u‖2 − vτk‖2
5: if tree on fire to “left” of agent then6: uτk = move to tree on fire7: else if burnt tree to “left” of agent then8: uτk = move to burnt tree9: else if agent moves and sees many healthy trees then
10: uτk = move “right”11: if eτk = True ∧ ‖wτk + uτk‖2 ≤ 1 then12: uτk = “stop”13: else uτk = use Equation 1
then the proposed action is switched to a “right” action (line9), defined relative to uτk as uright =
[j −i
]T. Figure 4b
shows an example of left and right actions for a proposedaction. Lastly, the agent chooses to “stop” if eτk = True andit will move within the safety radius of the nearest agent(line 11), where the stop action is u =
[0 0
]T.
We stress that this complex hand-tuned heuristic encapsu-lates significant expertise from the authors. It is then note-worthy that the deep RL approach we describe next producesa policy that significantly outperforms this heuristic.
A reward function for the second task is described inAlgorithm 2 and is used for the deep RL approach. Ad-ditional performance metrics are presented in Section V toevaluate both methods. Agents are rewarded for applyingcontrol to boundary trees on fire (line 4) as well as movingnear the boundary (line 6). Agents are heavily penalizedif they fail to avoid collisions (line 9) and rewarded ifthey move further away from other agents (line 11). Agentsare rewarded for moving clockwise about qfire (line 13), if−[0 0 1
]·(vτk,cen × uτk/‖uτk‖2
)≥ 0.
IV. DEEP Q-LEARNING APPROACH
Our deep RL approach generates a decentralized solutionthat outperforms the heuristic and scales independently ofthe forest size and the number of agents. A neural network

Algorithm 2 Agent Reward
1: Input: agent feature set sτk and action uτk2: Output: agent reward rτk3: Initialize rτk = 04: if agent moved to a boundary tree on fire then5: rτk = rτk + 1 else rτk = rτk − 26: else if agent moved to a healthy tree then7: if tree has at least one on fire or burnt neighbor then8: rτk = rτk + 0.5 else rτk = rτk − 1
9: if eτk = True ∧‖wτk + uτk‖2 ≤ 1 then10: rτk = rτk − 10
11: if eτk = True ∧‖wτk‖2 ≤ 1 ∧ ‖wτk + uτk‖2 > 112: then rτk = rτk + 113: if agent moved “clockwise” then rτk = rτk + 1
Fig. 5: Network architecture. The input is an agent’s featureset sτk (black rectangle). Hidden layers are fully-connectedwith ReLU activations (blue rectangles). The output is avector containing a value for each action uτk (red rectangle).
is used to represent the state-action utility function Q(s, a)following [28]. The network outputs values for all agentactions u ∈ U given an agent feature vector sτk and thearchitecture consists of three fully-connected layers withReLU activations, represented schematically in Figure 5.
The training algorithm for the Multi-Agent Deep Q Net-work (MADQN) is given in Algorithm 3. Every episodeconsists of specifying an initial set of trees on fire and agentlocations with an example shown in Figure 6a. Each agentcontributes experiences
(sτk, u
τk, r
τk , s
τ+1k
)to shared memory
once ck = True (centralized training). Experience replay isused to break up correlations between experiences (line 19).After training, agents use the same copy of the final trainednetwork to generate actions online (decentralized execution).
Target networks are used for stable training of the neu-ral network (line 20). In addition, simulation episodes arecapped at a fixed number of model updates, set by tlimit (line5), to bound the maximum cumulative reward.
The training algorithm linearly anneals the explorationrate ε from εinit to εfinal over zlearn updates of the network.The heuristic (Algorithm 1) is used to populate the replaymemory with experiences before network training starts. Theheuristic also provides guided exploration of the state spaceby occasionally providing agent actions (line 10)
Algorithm 3 Multi-Agent Deep Q Network (MADQN)
1: Initialize network Q with random θ2: Initialize target Q with θ− = θ, initialize replay D3: for episode 1, . . . , N do4: Initialize simulator, agent positions and memory5: while less than tlimit simulator updates do6: for each agent k do7: Generate sτk and update ck with image data8: if ck = False then uτk = Equation 19: else sample b uniformly from [0, 1]
10: if b ≤ ε then uτk = query heuristic11: else uτk = query network12: Generate reward rτk (Algorithm 2)13: if ulimit actions taken then update simulator14: if episode ends then continue to next episode15: Update agent positions using current actions16: for each agent k do17: if ck = False then skip agent18: Generate sτ+1
k , add(sτk, u
τk, r
τk , s
τ+1k
)to D
19: Sample minibatch from D and update network20: if zlimit updates then update θ− = θ21: Drop experiences if |D| > Dmax, anneal rate ε
(a) Sample initial condition (b) MADQN vs Heuristic
Fig. 6: (both) Red cells are trees on fire and black cells areburnt trees. (a) Sample initial condition with random initialagent positions (blue circles) and a 4×4 grid of trees on fire.Base station is shown as a gold square. (b) Comparison ofheuristic (blue) and MADQN (green) paths. Agent numberindicates initial position and X’s are final positions.
V. EXPERIMENTS AND RESULTS
A. Simulation and Model Parameters
Following [4], the spatial spreading parameter is α =0.7237 and the fire persistence parameter is β = 0.9048. Theeffect of retardant is ∆β = 0.54. The MADQN architectureuses three hidden layers of sizes (2048, 2048, 2048). Thereplay memory was initialized by the heuristic with 5,000experiences, the memory limit was Dlimit = 1,000,000, andthe discount factor was γ = 0.95. The exploration rate εstarted at one and was linearly annealed to 0.15 over 20,000updates. For training, 110 episodes were run on a 50 × 50sized forest with 10 agents and 16 initial trees on fire.Episodes were terminated after tlimit = 100 model updates.
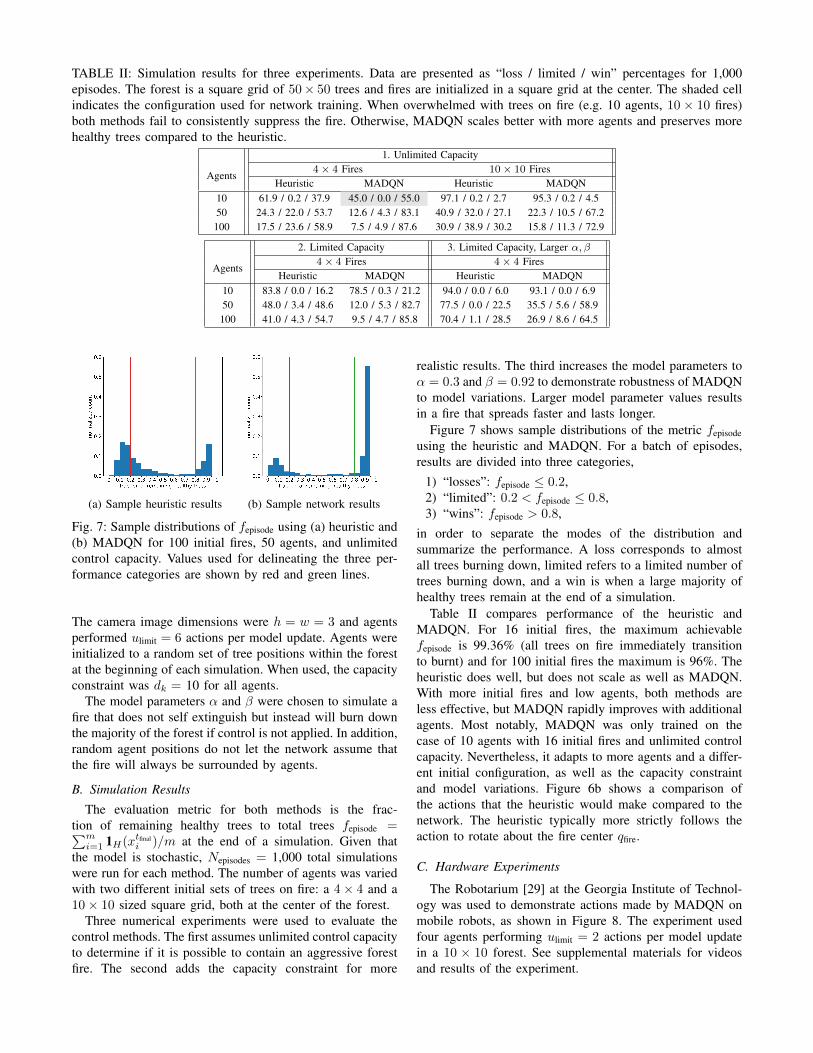
TABLE II: Simulation results for three experiments. Data are presented as “loss / limited / win” percentages for 1,000episodes. The forest is a square grid of 50× 50 trees and fires are initialized in a square grid at the center. The shaded cellindicates the configuration used for network training. When overwhelmed with trees on fire (e.g. 10 agents, 10× 10 fires)both methods fail to consistently suppress the fire. Otherwise, MADQN scales better with more agents and preserves morehealthy trees compared to the heuristic.
1. Unlimited Capacity
Agents4× 4 Fires 10× 10 Fires
Heuristic MADQN Heuristic MADQN10 61.9 / 0.2 / 37.9 45.0 / 0.0 / 55.0 97.1 / 0.2 / 2.7 95.3 / 0.2 / 4.550 24.3 / 22.0 / 53.7 12.6 / 4.3 / 83.1 40.9 / 32.0 / 27.1 22.3 / 10.5 / 67.2
100 17.5 / 23.6 / 58.9 7.5 / 4.9 / 87.6 30.9 / 38.9 / 30.2 15.8 / 11.3 / 72.9
2. Limited Capacity 3. Limited Capacity, Larger α, β
Agents4× 4 Fires 4× 4 Fires
Heuristic MADQN Heuristic MADQN10 83.8 / 0.0 / 16.2 78.5 / 0.3 / 21.2 94.0 / 0.0 / 6.0 93.1 / 0.0 / 6.950 48.0 / 3.4 / 48.6 12.0 / 5.3 / 82.7 77.5 / 0.0 / 22.5 35.5 / 5.6 / 58.9100 41.0 / 4.3 / 54.7 9.5 / 4.7 / 85.8 70.4 / 1.1 / 28.5 26.9 / 8.6 / 64.5
(a) Sample heuristic results (b) Sample network results
Fig. 7: Sample distributions of fepisode using (a) heuristic and(b) MADQN for 100 initial fires, 50 agents, and unlimitedcontrol capacity. Values used for delineating the three per-formance categories are shown by red and green lines.
The camera image dimensions were h = w = 3 and agentsperformed ulimit = 6 actions per model update. Agents wereinitialized to a random set of tree positions within the forestat the beginning of each simulation. When used, the capacityconstraint was dk = 10 for all agents.
The model parameters α and β were chosen to simulate afire that does not self extinguish but instead will burn downthe majority of the forest if control is not applied. In addition,random agent positions do not let the network assume thatthe fire will always be surrounded by agents.
B. Simulation Results
The evaluation metric for both methods is the frac-tion of remaining healthy trees to total trees fepisode =∑mi=1 1H(xtfinal
i )/m at the end of a simulation. Given thatthe model is stochastic, Nepisodes = 1,000 total simulationswere run for each method. The number of agents was variedwith two different initial sets of trees on fire: a 4× 4 and a10× 10 sized square grid, both at the center of the forest.
Three numerical experiments were used to evaluate thecontrol methods. The first assumes unlimited control capacityto determine if it is possible to contain an aggressive forestfire. The second adds the capacity constraint for more
realistic results. The third increases the model parameters toα = 0.3 and β = 0.92 to demonstrate robustness of MADQNto model variations. Larger model parameter values resultsin a fire that spreads faster and lasts longer.
Figure 7 shows sample distributions of the metric fepisodeusing the heuristic and MADQN. For a batch of episodes,results are divided into three categories,
1) “losses”: fepisode ≤ 0.2,2) “limited”: 0.2 < fepisode ≤ 0.8,3) “wins”: fepisode > 0.8,
in order to separate the modes of the distribution andsummarize the performance. A loss corresponds to almostall trees burning down, limited refers to a limited number oftrees burning down, and a win is when a large majority ofhealthy trees remain at the end of a simulation.
Table II compares performance of the heuristic andMADQN. For 16 initial fires, the maximum achievablefepisode is 99.36% (all trees on fire immediately transitionto burnt) and for 100 initial fires the maximum is 96%. Theheuristic does well, but does not scale as well as MADQN.With more initial fires and low agents, both methods areless effective, but MADQN rapidly improves with additionalagents. Most notably, MADQN was only trained on thecase of 10 agents with 16 initial fires and unlimited controlcapacity. Nevertheless, it adapts to more agents and a differ-ent initial configuration, as well as the capacity constraintand model variations. Figure 6b shows a comparison ofthe actions that the heuristic would make compared to thenetwork. The heuristic typically more strictly follows theaction to rotate about the fire center qfire.
C. Hardware Experiments
The Robotarium [29] at the Georgia Institute of Technol-ogy was used to demonstrate actions made by MADQN onmobile robots, as shown in Figure 8. The experiment usedfour agents performing ulimit = 2 actions per model updatein a 10 × 10 forest. See supplemental materials for videosand results of the experiment.

Fig. 8: Still frame taken from hardware experiments con-ducted using the robotarium. An overhead projector displaysimages to represent healthy, on fire, and burnt trees. Mobilerobots represent firefighting UAVs.
VI. CONCLUSIONS
This work proposes a deep RL approach to generate a de-centralized control strategy for fighting forest fires with agentmotion, sensing, and communication constraints. Despite theoverwhelming complexity, a tractable and scalable methodwas developed and the performance was validated by MonteCarlo simulations. Future work will address several aspectsof this work to further improve upon the performance.The choice of task decomposition influences the solutionquality and methods have been proposed in literature toguide the decomposition of complex problems. Realisticforest fires will include additional aspects, such as wind andterrain effects and multiple initial fire locations. The currentapproach will need to be modified to address these aspectsto be effective in real-world environments. More extensiveexperiments, using quadrotors with appropriate sensors anda simulated forest fire, are planned to further validate thepracticality of our deep RL solution.
REFERENCES
[1] J. M. Diaz, “Economic impacts of wildfire,” Southern Fire Exchange,2012.
[2] G. D. Richards, “An elliptical growth model of forest fire fronts andits numerical solution,” International Journal for Numerical Methodsin Engineering, vol. 30, no. 6, pp. 1163–1179, 1990.
[3] M. A. Finney, “Farsite: Fire area simulator–model development andevaluation, united states department of agriculture forest servicerocky mountain research station research paper,” RMRS-RP-4 RevisedMarch 1998, revised February, Tech. Rep., 2004.
[4] A. Somanath, S. Karaman, and K. Youcef-Toumi, “Controllingstochastic growth processes on lattices: Wildfire management withrobotic fire extinguishers,” in 53rd IEEE Conference on Decision andControl, Dec 2014, pp. 1432–1437.
[5] D. Boychuk, W. J. Braun, R. J. Kulperger, Z. L. Krougly, and D. A.Stanford, “A stochastic forest fire growth model,” Environmental andEcological Statistics, vol. 16, no. 2, pp. 133–151, 2009.
[6] J. R. Martinez-de Dios, B. C. Arrue, A. Ollero, L. Merino, andF. Gomez-Rodrıguez, “Computer vision techniques for forest fireperception,” Image and vision computing, vol. 26, no. 4, pp. 550–562,2008.
[7] D. Stipanicev, M. Stula, D. Krstinic, L. Seric, T. Jakovcevic, andM. Bugaric, “Advanced automatic wildfire surveillance and monitoringnetwork,” in 6th International Conference on Forest Fire Research,Coimbra, Portugal.(Ed. D. Viegas), 2010.
[8] P. B. Sujit, D. Kingston, and R. Beard, “Cooperative forest firemonitoring using multiple uavs,” in 2007 46th IEEE Conference onDecision and Control, Dec 2007, pp. 4875–4880.
[9] L. Merino, F. Caballero, J. R. Martınez-de Dios, J. Ferruz, andA. Ollero, “A cooperative perception system for multiple uavs: Appli-cation to automatic detection of forest fires,” Journal of Field Robotics,vol. 23, no. 3-4, pp. 165–184, 2006.
[10] L. Merino, F. Caballero, J. R. Martınez-de Dios, I. Maza, andA. Ollero, “An unmanned aircraft system for automatic forest fire mon-itoring and measurement,” Journal of Intelligent & Robotic Systems,vol. 65, no. 1, pp. 533–548, 2012.
[11] D. W. Casbeer, R. W. Beard, T. W. McLain, S.-M. Li, and R. K. Mehra,“Forest fire monitoring with multiple small uavs,” in Proceedings ofthe 2005, American Control Conference, 2005., June 2005, pp. 3530–3535 vol. 5.
[12] D. W. Casbeer, D. B. Kingston, R. W. Beard, and T. W. McLain,“Cooperative forest fire surveillance using a team of small unmannedair vehicles,” International Journal of Systems Science, vol. 37, no. 6,pp. 351–360, 2006.
[13] M. Kumar, K. Cohen, and B. HomChaudhuri, “Cooperative controlof multiple uninhabited aerial vehicles for monitoring and fightingwildfires,” Journal of Aerospace Computing, Information, and Com-munication, vol. 8, no. 1, pp. 1–16, 2011.
[14] C. Phan and H. H. T. Liu, “A cooperative uav/ugv platform forwildfire detection and fighting,” in 2008 Asia Simulation Conference- 7th International Conference on System Simulation and ScientificComputing, Oct 2008, pp. 494–498.
[15] L. Ntaimo, J. A. Gallego-Arrubla, J. Gan, C. Stripling, J. Young,and T. Spencer, “A simulation and stochastic integer programmingapproach to wildfire initial attack planning,” Forest Science, vol. 59,no. 1, pp. 105–117, 2013.
[16] X. Hu and L. Ntaimo, “Integrated simulation and optimization forwildfire containment,” ACM Transactions on Modeling and ComputerSimulation (TOMACS), vol. 19, no. 4, p. 19, 2009.
[17] N. K. Ure, S. Omidshafiei, B. T. Lopez, A. a. Agha-Mohammadi, J. P.How, and J. Vian, “Online heterogeneous multiagent learning underlimited communication with applications to forest fire management,”in 2015 IEEE/RSJ International Conference on Intelligent Robots andSystems (IROS), Sept 2015, pp. 5181–5188.
[18] K. D. Julian and M. J. Kochenderfer, “Autonomous distributed wild-fire surveillance using deep reinforcement learning,” in 2018 AIAAGuidance, Navigation, and Control Conference, 2018, p. 1589.
[19] D. Bertsimas, J. D. Griffith, V. Gupta, M. J. Kochenderfer, and V. V.Misic, “A comparison of monte carlo tree search and rolling horizonoptimization for large-scale dynamic resource allocation problems,”European Journal of Operational Research, vol. 263, no. 2, pp. 664–678, 2017.
[20] T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum, “Hier-archical deep reinforcement learning: Integrating temporal abstractionand intrinsic motivation,” in Advances in Neural Information Process-ing Systems 29, 2016, pp. 3675–3683.
[21] A. S. Vezhnevets, S. Osindero, T. Schaul, N. Heess, M. Jaderberg,D. Silver, and K. Kavukcuoglu, “Feudal networks for hierarchicalreinforcement learning,” in International Conference on MachineLearning, 2017, pp. 3540–3549.
[22] D. Mellinger, N. Michael, and V. Kumar, “Trajectory generationand control for precise aggressive maneuvers with quadrotors,” TheInternational Journal of Robotics Research, vol. 31, no. 5, pp. 664–674, 2012.
[23] D. Blatner, Spectrums: Our Mind-boggling Universe from Infinitesimalto Infinity. A&C Black, 2013.
[24] C. H. Papadimitriou and J. N. Tsitsiklis, “The complexity of markovdecision processes,” Mathematics of operations research, vol. 12,no. 3, pp. 441–450, 1987.
[25] O. Madani, S. Hanks, and A. Condon, “On the undecidability ofprobabilistic planning and related stochastic optimization problems,”Artificial Intelligence, vol. 147, no. 1-2, pp. 5–34, 2003.
[26] C. Boutilier, R. Dearden, and M. Goldszmidt, “Exploiting structurein policy construction,” in Proceedings of the 14th International JointConference on Artificial Intelligence, 1995, pp. 1104–1111.
[27] D. Koller and R. Parr, “Computing factored value functions for policiesin structured mdps,” in IJCAI, vol. 99, 1999, pp. 1332–1339.
[28] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou,D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcementlearning,” in NIPS Deep Learning Workshop, 2013.
[29] D. Pickem, P. Glotfelter, L. Wang, M. Mote, A. Ames, E. Feron, andM. Egerstedt, “The robotarium: A remotely accessible swarm roboticsresearch testbed,” in 2017 IEEE International Conference on Roboticsand Automation (ICRA), May 2017, pp. 1699–1706.


















