![SOFTWARE OpenAccess QUADrATiC:scalablegeneexpression ... · an open-source library called Akka [16, 17]. Akka is a lightweight and efficient implementation of the actor paradigm,](https://static.fdocuments.net/doc/165x107/5ee13ad0ad6a402d666c2ee2/software-openaccess-quadraticscalablegeneexpression-an-open-source-library.jpg)
Developing an Akka Edge4-5
66
Developing an Akka Edge Chapter 4-5
Transcript of Developing an Akka Edge4-5

Developing an Akka Edge
Chapter 4-5

この本について
Developing an Akka Edge(著)Thomas Lockney, Raymond Tay
Akka初心者向けの洋書全191ページ・10章
せっかく読んでるので要約しました※自分で調べた事や、考えた例も載せたのでスライドに正しくないことが書いてある可能性があります※

各章の概要
Chapter 4…SupervisorStrategyを使ったエラーハンドリング
Chapter 5…Routerについていろんな種類のRouterの紹介
Chapter1~3も別スライドにまとめてあります

前回のおさらい
(Chapter 4-5の前に…)

結局
・メッセージが来たらアクターのMailboxに貯まる
・メッセージを到着した順に1つずつ処理する
・あらかじめ定義されたふるまいを実行する
Putting actors to work
アクターを使うのにまず必要な事
・akka.actor.Actorトレイトを継承したクラスと、そこにreceiveメソッドを定義・ActorSystemを作る
・ActorSystemからアクターを生成

ヒエラルキー
Akkaの構造がヒエラルキーになっている理由⇒耐障害性
親アクターは子アクターにExceptionが発生した時にどうするか決められる・子アクターを再起動させる・子アクターを再開させる・子アクターを終了させる・例外を次の親に投げる

ヒエラルキーはファイルシステム的な感じで、分かりやすい
例:accountingというActorsystemから作られたaccountMonitorというアクターから作られたaccountCrediterというアクター
akka://accounting/user/accountMonitor/accountCreditor

Developing an Akka Edge
Chapter 4-5

Chapter 4.Handling Faults
and Actor Hierarchy
*この章のポイント*
・ヒエラルキーの中で、どうやってエラーハンドリングをするか
⇒SupervisorStrategy
・アクターのライフサイクル
・アクターのヒエラルキーについて(最上部がどうなってるかとか)

・「Failure happen.」ネットワークの切断、ロジックの間違い、環境の問題…etc
・try/catch
大抵の言語で実装されているが…
エラーが起きた時、システムがどんな状態にあるかを理解しないといけない
通常の状態に戻れたか確認しなければいけない
Chapter 4.Handling Faults
and Actor Hierarchy

Typical failure handling
Scalaのエラーハンドリング①try/catch/finally
例外の種類をcase文で
②Try[T]
例外が投げられたらFailure[T]インスタンスが返ってくる(成功はSuccess[T])
他の処理をチェーンして、成功した時のみ実行できる⇒シンプルに書ける
③Either[A,B]
一般的にAが成功時、Bが失敗時に使われる例外の型をしっていなければいけない

Let it crash
「失敗を受け入れて適切に扱おう」というアイディア「適切に扱う」とは…適切にアクターを設計する

Let it crash
例:アクターが値を保持していて、外部のシステムから値をとってきて定期的に更新しなければならない
Actor
count = 1
System
count = 3Request
{“count”:3}
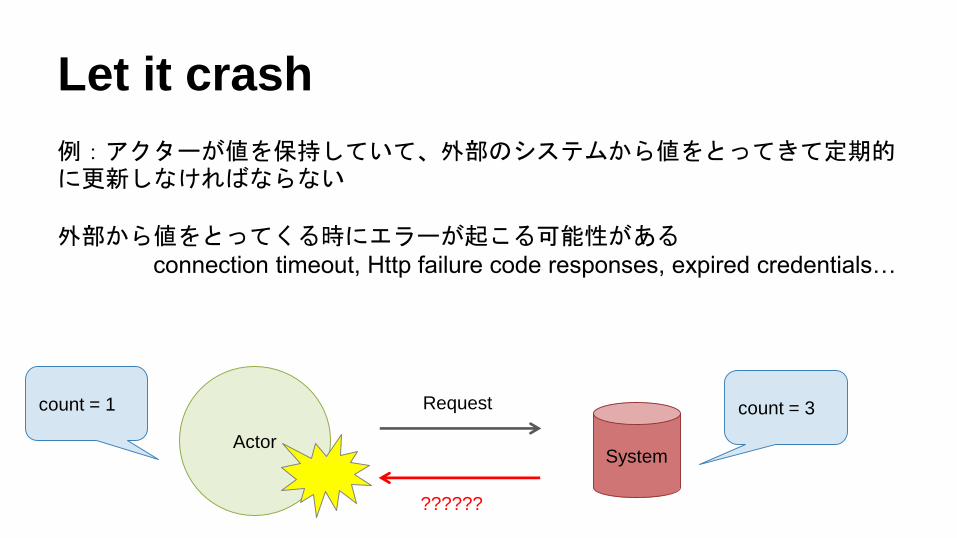
Let it crash
例:アクターが値を保持していて、外部のシステムから値をとってきて定期的に更新しなければならない
外部から値をとってくる時にエラーが起こる可能性があるconnection timeout, Http failure code responses, expired credentials…
Actor
count = 1
System
count = 3Request
??????

Let it crash
例:アクターが値を保持していて、外部のシステムから値をとってきて定期的に更新しなければならない
外部から値をとってくる時にエラーが起こる可能性があるconnection timeout, Http failure code responses, expired credentials…
子アクターを生成して、外部へのリクエストを分離する
Actor
count = 1
System
count = 3Request
{“count”:3}
Child
Actor
Request
{“count”:3}

Fail fast
・原則、アクターは「なるべく小さく・1つの目的」で使う例外処理のロジックを含まず、エラーが起きたら再起動or作り直す
・Supervisorが鍵となるsupervisor…子アクターにとっての親アクターどんなアクターにも親アクターがいる(最上位については後述)
子アクターが処理できない例外が発生 ⇒ 親がどうするか決める
ActorChild
Actor
Restart! Exception

Fail fast
子アクターが処理できない例外は、親アクターがSupervisorStrategyに沿って処理
2種類のSupervisorStrategy
OneForOneStrategy
AllForOneStrategy
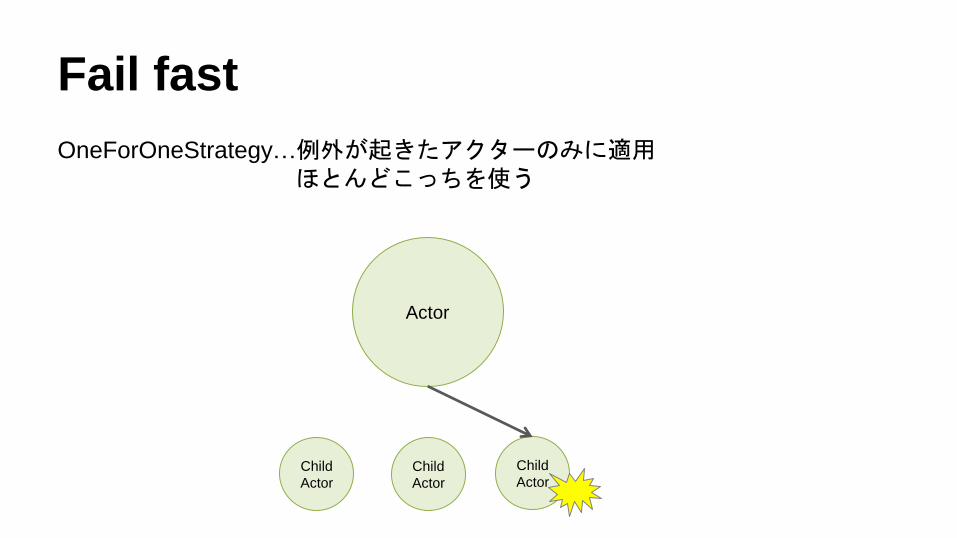
Fail fast
OneForOneStrategy…例外が起きたアクターのみに適用ほとんどこっちを使う
Actor
Child
ActorChild
Actor
Child
Actor

Fail fast
AllForOneStrategy...supervisorの全ての子アクターに適用兄弟アクターが相互依存関係にある時はこっち
Actor
Child
ActorChild
Actor
Child
Actor

Fail fast
子アクターに例外が発生した時Resume… 再開するだけ(内部の状態は保持)
Restart… 全ての状態を再設定して、再起動
Stop… 止まるだけ
Escalate… supervisorの親に拡散Actor
Child
ActorChild
Actor
Child
Actor
Grandpa
Actor
Actor

Fail fast
・Resume,Restartを使う時は、次々同じエラーが出ないかどうか確かめる!
・Resume,Restartについては、何度まで再開・再起動できるか設定できる
60秒間に5回まで(超えるとEscalateされる)

Fail fast
・デフォルトの挙動(strategyが定義されていない時)- Stop
ActorInitializationException(初期化失敗)ActorKilledException(akka.actor.Killメッセージを受信した時)
- Restart
他のException
- Escalate
他のThrowable
*OneForOneStrategyで、Restartの回数に制限なし*

Fail fast
*ポイント*
・どう扱うか判断できない時はEscalateする
・strategyが定義されていない時、一般的な例外だとアクターは再起動する

The actor-lifecycle
actorOf(Props[Actorの名前])を呼んだら生成される
起動前・終了前・再起動前後で実行されるメソッド- preStart
- postStop
- preRestart
- postRestart
preStartは初期化系preRestartは相互依存してるリソースを掃除するのに使う

The actor-lifecycle
pre/postRestartは、再起動の原因になったThrowableインスタンスを引数に取る
postRestartはpreStartメソッドを呼んでいるので、overrideする時は呼ぶこと!
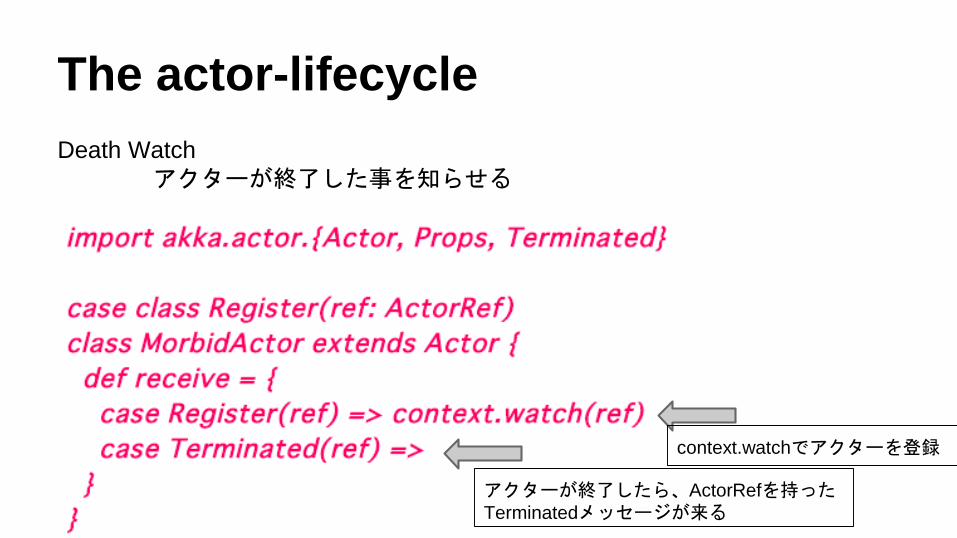
The actor-lifecycle
Death Watch
アクターが終了した事を知らせる
アクターが終了したら、ActorRefを持ったTerminatedメッセージが来る
context.watchでアクターを登録

The actor-lifecycle
・Death Watchはあるアクターの終了をトリガーにして何かしたい時に便利
・それぞれのアクターのライフサイクルを考慮した上で依存関係を構築しよう

A bit more about the hierarchy
ヒエラルキーの最上位はどうなっているか…
「guardianと呼ばれる」3つの特別なアクター- root guardian
- user guardian
- system guardian

A bit more about the hierarchy
・user guardian
system.actorOf()を使って生成されるアクター達のトップ⇒作ったアクターがハンドリングできなかったエラーは最終的にここに来る
SupervisorStrategyは、akka.actor.guardian-supervisor-startegyで上書きできる

ヒエラルキーはファイルシステム的な感じで、分かりやすい
例:accountingというActorsystemから作られたaccountMonitorというアクターから作られたaccountCrediterというアクター
akka://accounting/user/accountMonitor/accountCreditor
実はChapter.1にも出てた

A bit more about the hierarchy
・system guardian
user-levelのアクターが必要とするサービスを提供(順番にshut-downさせるとか)user guardiaをwatchしてる
・root guardian
ヒエラルキーのトップに存在して、guardianからEscalateされたエラーを処理する

A bit more about the hierarchy
root guardianもアクターなので、supervisorが必要⇒ActorSystemの外側に、疑似アクターのsupervisorが居る
どんなエラーが起きても、子アクター(root guardian)をStopさせる。

Guidelines for handling failures
・危険な処理を隔離して、エラーが起きても良い設計にしよう!
・error kernel pattern…エラーハンドリングを、発生する場所の近くに分散させる
例:DBとのやりとりは、別のアクターにする

Guidlines for handling failures
・更なるアプローチとして特定の役割を持ったアクターと、supervisorをセットで作る
危険な仕事をするアクター + そのアクターを監視するアクター
ロジックを抽象化できる
System
count = 3Request
{“count”:3}
Child
Actor
Supervise
SupervisorStorategy

まとめ
SupervisorStrategyを使って子アクターのエラーをハンドリングできる
↓
エラーが起きそうな部分を隔離してハンドリングしよう

Chapter 5.Routers
*この章のポイント*・Routerについて
・いろんな種類のRouterがある
・Routerにはいろんなパラメータがある
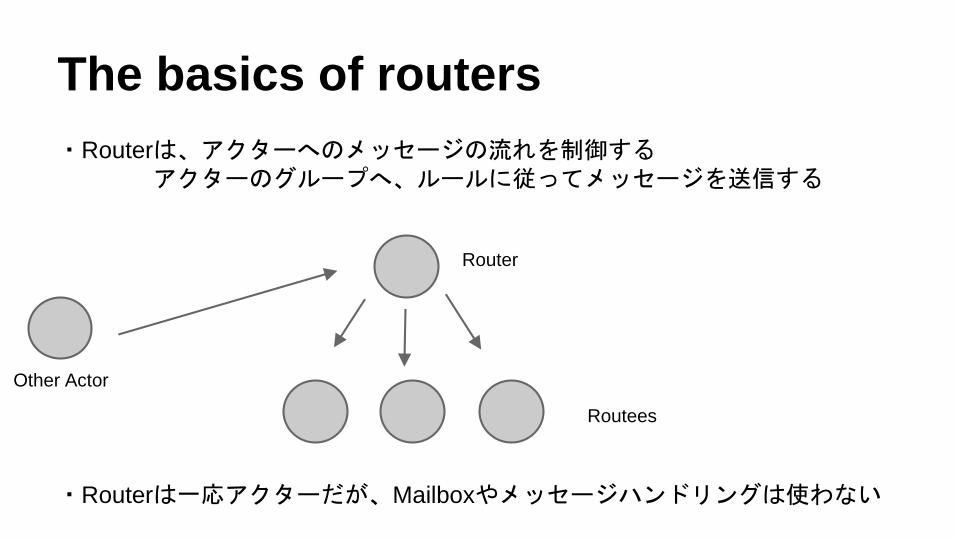
The basics of routers
・Routerは、アクターへのメッセージの流れを制御するアクターのグループへ、ルールに従ってメッセージを送信する
・Routerは一応アクターだが、Mailboxやメッセージハンドリングは使わない
Router
Routees
Other Actor

The basics of routers
Routerの用途負荷分散したい少ないリソースを効率的に使いたい少しでも速く処理したい(後述)etc
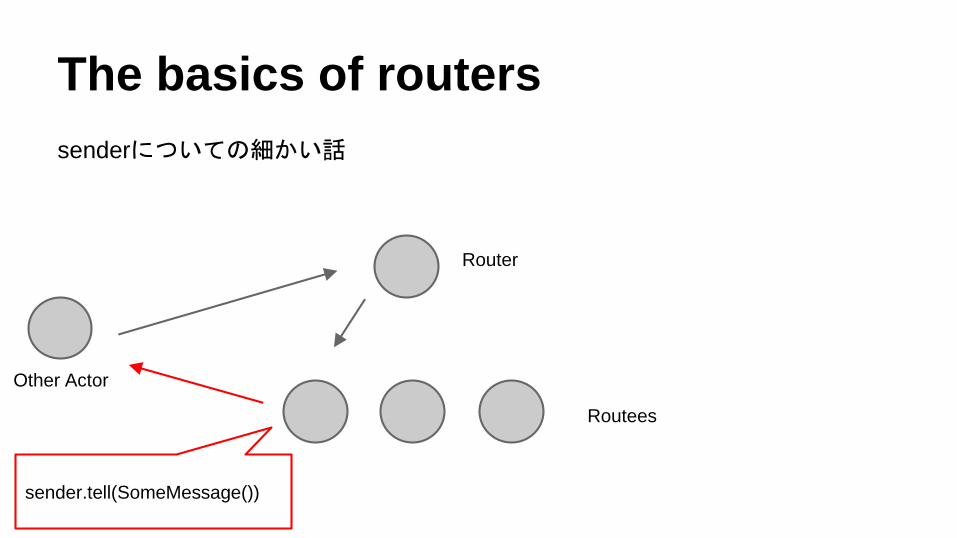
The basics of routers
senderについての細かい話
Router
Routees
Other Actor
sender.tell(SomeMessage())
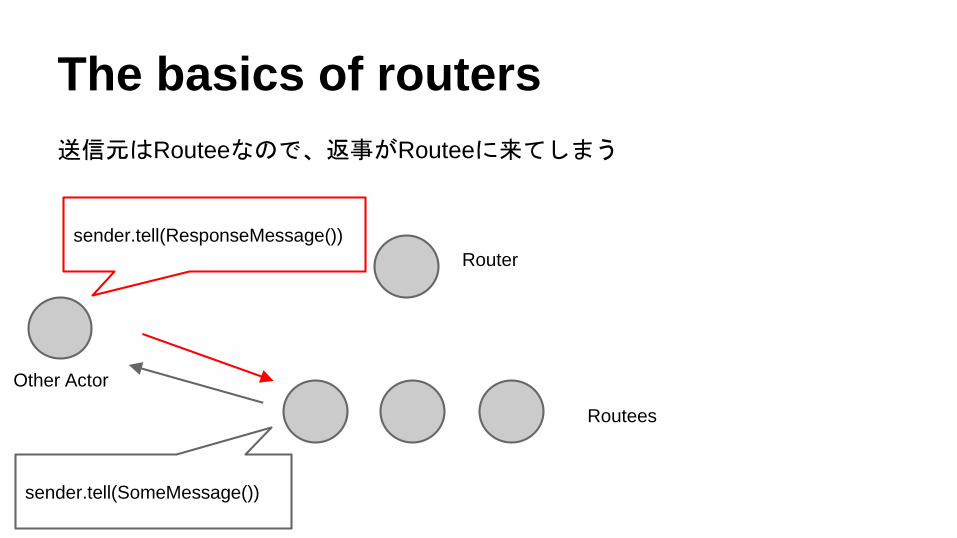
The basics of routers
送信元はRouteeなので、返事がRouteeに来てしまう
Router
Routees
Other Actor
sender.tell(SomeMessage())
sender.tell(ResponseMessage())

The basics of routers
送信元を親(Router)にすると…
Router
Routees
Other Actor
sender.tell(SomeMessage(),context.parent)第二引数で送信元を指定

The basics of routers
Routerに送信され、いずれかのRouteeに送信される
Router
Routees
Other Actor
sender.tell(ResponseMessage())
sender.tell(SomeMessage(),context.parent)

Built-in router types
Akkaが提供しているいろんなRouterがある
- RoundRobinRouter
- SmallMailboxRouter
- BroadcastRouter
- RandomRouter
- ScatterGatherFirstCompleteRouter
- ConsistentHashingRouter
- Other(カスタムRouterを自分でつくれる)
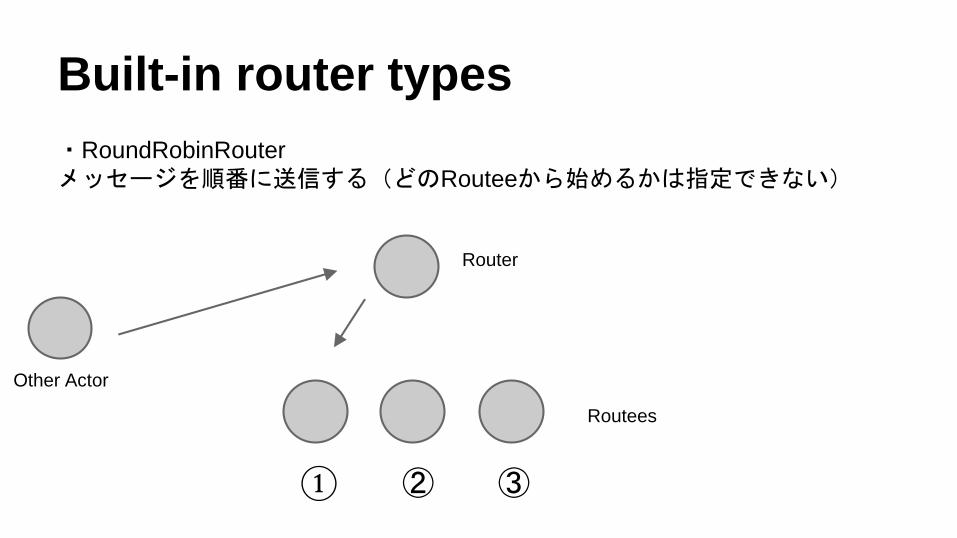
Built-in router types
・RoundRobinRouter
メッセージを順番に送信する(どのRouteeから始めるかは指定できない)
Router
Routees
Other Actor
① ② ③

Built-in router types
・RoundRobinRouter
タスクにかかる時間にばらつきがある時は注意!!
A B
Router
① ②
③ ④①
②
③
④

Built-in router types
・RoundRobinRouter
タスクにかかる時間にばらつきがある時は注意!!
A B
Router
① ②
③ ④①
②
③
④
受信したメッセージが処理に時間のかかるものに偏るとAにメッセージが貯まっていってしまう…

Built-in router types
・SmallestMailboxRouter
Mailboxにたまっているメッセージが少ないアクターに送信
Router
Routees
Other Actor

Built-in router types
・SmallestMailboxRouter
Mailboxに今この瞬間どれくらいたまっているか、正確には分からない
情報が古いかもしれない(どのタイミングで取得してるのか謎)
リモートアクターのMailboxサイズは分からない⇒送信の優先順位が低くなる

Built-in router types
・BroadcastRouter
全てのRouteeに送信
主に監視に使われる
Router
Routees
Other Actor

Built-in router types
・RandomRouter
ランダムに送信
Router
Routees
Other Actor

Built-in router types
・ScatterGatherFirstCompletedRouter
Routeeにブロードキャストして、一番速く返ってきたレスポンスを受け取る
scatter…まき散らす
Router
Routees
Other Actor
fastest

Built-in router types
・ScatterGatherFirstCompleteRouter
askメソッドでRouterからFutureを得るこのRouterはFutureをラップしている
時間に関してsensitiveな場面で使う

Built-in router types
・ConsistentHashingRouter
受け取ったリクエストを、どのサーバに送るか決められる(?)
この話だけでかなりボリュームがあるので、省略
Router
Routees
Other Actor

Using routers
Routerの定義の仕方は2つ①configurationに記述
②コードの中に記述
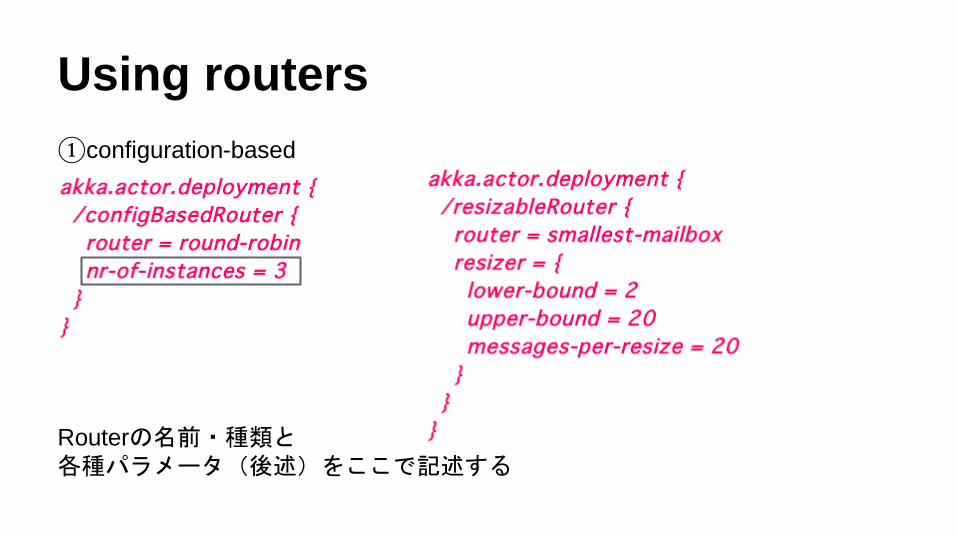
Using routers
①configuration-based
Routerの名前・種類と各種パラメータ(後述)をここで記述する

Using routers
①configuration-based
定義したRouterのインスタンスを生成
Props.withRouterメソッドを使う

Using routers
各種パラメータ+ lower-bound
+ upper-bound
+ messages-per-resize
+ pressure-threshold
+ rampup-rate
+ backoff-threshold
+ backoff-rate
+ (stop-delay)
他にもありそう…

Using routers
lower-bound…Routeeの最小数初期のRoutee数になる(?)
upper-bound…Routeeの最大数
messages-per-resize…リサイズの頻度
リサイズに関するパラメータがたくさん…

Using routers
+ pressure-threshold(0)
0 ⇒メッセージを処理中のRouteeはbuzy
1 ⇒メッセージを処理中で、Mailboxにメッセージがあればbuzy
+ rampup-rate(0.2)
全てのアクターがbuzyの時、Routeeをどのくらい増やすか
+ backoff-threshold(0.3)
buzyなRouteeが何割以下になったら、Routeeを減らすか
+ backoff-rate(0.1)
Routeeを減らす時、どのくらい減らすか

Programatic router creation
②コードの中でRouterインスタンスを作る

Programatic router creation
既に存在するアクターをRouteeにできる(config-basedでもできる???)

Programatic router creation
コード内でRouterを定義するメリット ⇒ SupervisorStrategyを定義できる
デフォルトではRouterはEscalateしかしない

まとめ
・負荷分散とかにいろんな種類のRouterが使える
・Routeeの数に関するパラメータがたくさんあるconfigurationかコードの中に記述する
・Props.withRouterメソッドを使って生成する

やっと半分終わりました!
残り5章…

残り
- Chapter 6.Dispatchers
- Chapter 7.Remoting
- Chapter 8.Dividing Deeper into Futures
- Chapter 9.Testing
- Chapter 10.Clusters







![Developing Scalable Applications with Actors · 2014-11-05 · Akka [8] is an alternative toolkit and runtime system for developing event-based actors in Scala, but also providing](https://static.fdocuments.net/doc/165x107/5ec98ca8677e3c7a135932ab/developing-scalable-applications-with-2014-11-05-akka-8-is-an-alternative-toolkit.jpg)










