
Deskriptiv statistik -...
19
Deskriptiv (beskrivende) statistik er den disciplin, der trækker de væsentligste oplysninger ud af et ofte uoverskueligt materiale. Det sker f.eks. ved at konstruere forskellige deskriptorer, d.v.s. regnestørrelser, der udtrykker materialets karakteristiske egenskaber. Specielt kan nævnes sumkurver og boksplot. Deskriptiv statistik Version 5.1 Henrik S. Hansen, Sct. Knuds Gymnasium Der er opgaver til noterne. PDF Facit til opgaverne. PDF
Transcript of Deskriptiv statistik -...

Deskriptiv (beskrivende) statistik er den
disciplin, der trækker de væsentligste
oplysninger ud af et ofte uoverskueligt
materiale. Det sker f.eks. ved at
konstruere forskellige deskriptorer, d.v.s.
regnestørrelser, der udtrykker materialets
karakteristiske egenskaber. Specielt kan
nævnes sumkurver og boksplot.
Deskriptiv
statistik
Version 5.1
Henrik S. Hansen, Sct. Knuds Gymnasium
Der er opgaver til noterne. PDF
Facit til opgaverne. PDF

Henrik S. Hansen, Sct. Knuds Gymnasium
Indhold Deskriptiv statistik ............................................................................................................................... 1
Ikke grupperet observationer ............................................................................................................... 2
Statistiske deskriptorer ..................................................................................................................... 2
Pindediagram ................................................................................................................................... 3
Trappediagram ................................................................................................................................. 4
Grupperet observationer ....................................................................................................................... 6
Statistiske deskriptorer ..................................................................................................................... 7
Histogram ......................................................................................................................................... 7
Sumkurve ......................................................................................................................................... 8
Fraktiler ................................................................................................................................................ 9
Kvartilsæt for ikke grupperede observationer ................................................................................ 10
Kvartilsættet for et grupperet observationssæt............................................................................... 11
Boksplot ............................................................................................................................................. 11
Normalfordeling ................................................................................................................................. 13
Definition: Normalfordeling .......................................................................................................... 14
Påvise en normalfordeling: ........................................................................................................ 14
Spredning/standardafvigelse .......................................................................................................... 16
Sætning: spredning ......................................................................................................................... 16

Henrik S. Hansen, Sct. Knud Gymnasium 1
Deskriptiv statistik Deskriptiv statistik betyder ”beskrivende” statistik (video). Vi kan ud fra nogle observationer
udlede nogle interessante informationer, som vi så kan anskueliggøre bl.a. billedligt ved grafer.
Dette felt inden for matematik er i særdeleshed et godt redskab til især samfundsfag og det daglige
liv.
Deskriptiv statistik kan deles op i to afdelinger:
1. En afdeling som kigger på de enkelte observationer i et observationssæt som (oftest) kun
indeholder hele tal på et begrænset interval. Det kunne være karakterer, antal elever i
klasserne mm. Dette kaldes de IKKE grupperet observationssæt.
2. En afdeling som kigger på observationer, som kan puttes i ”kasser” også kaldet intervaller.
Her er der mulighed for at medtage decimaltal. Det kunne være højden på 1g elever,
kondital for 1g elever mm. Dette kaldes et grupperet observationssæt.
Helt grundlæggende så har vi i begge situationer et observationssæt, som ser sådan her ud.
Observation 𝑜𝑏𝑠1𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡1 𝑜𝑏𝑠2 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡2 𝑜𝑏𝑠3 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡3 … 𝑜𝑏𝑠𝑘 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡𝑘
Hyppighed ℎ𝑦𝑝1 ℎ𝑦𝑝2 ℎ𝑦𝑝3 … ℎ𝑦𝑝𝑘
Her kan vi så udtrække de tre statistiske deskriptorer.
1. Observationssættets størrelse, også kaldet n
2. Typetallet/type intervallet, som er det tal/interval, som har den største hyppighed. Der kan
godt være flere typetal/intervaller.
3. Middelværdien, som er den gennemsnitlige værdi af observationerne, og den bestemmes ved
at lægge alle observationer sammen og dividere med det samlede antal observationer.
Her efter kan vi udfærdige dette skema:
Observation 𝑜𝑏𝑠1 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡1 𝑜𝑏𝑠2 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡2 𝑜𝑏𝑠3 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡3 … 𝑜𝑏𝑠𝑘 𝑒𝑙𝑙𝑒𝑟 𝑖𝑛𝑡𝑘
Hyppighed ℎ𝑦𝑝1 ℎ𝑦𝑝2 ℎ𝑦𝑝3 … ℎ𝑦𝑝𝑘
Frekvens 𝑓𝑟𝑒𝑘1 𝑓𝑟𝑒𝑘2 𝑓𝑟𝑒𝑘3 … 𝑓𝑟𝑒𝑘𝐾
Kumuleret frekvens 𝑘𝑢𝑚1 𝑘𝑢𝑚2 𝑘𝑢𝑚3 … 𝑘𝑢𝑚𝐾
Frekvensen beregnes som ℎ𝑦𝑝
𝑛 eller i procent som
ℎ𝑦𝑝
𝑛∙ 100%.
Den kumulerede frekvens er en betegnelse for den opsummerede frekvens fra start og til den
pågældende observation.
Det vil sige at eks. 𝑘𝑢𝑚3 = 𝑓𝑟𝑒𝑘1 + 𝑓𝑟𝑒𝑘2 + 𝑓𝑟𝑒𝑘3 eller 𝑘𝑢𝑚3 = 𝑘𝑢𝑚2 + 𝑓𝑟𝑒𝑘3
Ud fra ovenstående tabel kan vi så tegne diverse grafer som illustration af observationssættet,
hvilket vi vil komme ind på i det næste.
Lav opgaver i hæftet

Henrik S. Hansen, Sct. Knud Gymnasium 2
Ikke grupperet observationer
Til at belyse det tekniske indenfor ikke grupperede observationer, tager vi udgangspunkt i et
eksempel, som så vil blive belyst hele vejen igennem dette afsnit. Der vil løbende være forklaring til
hvordan TI Nspire kan inddrages. (video)
Til en matematikeksamen på matematik B har der for 10 klasser været følgende fordeling af
karakterer (opdigtet).
Karakter -3 0 2 4 7 10 12
Antal 5 24 34 58 80 52 25
Som en start kan jeg i TI Nspire definere to lister med de nævnte værdier:
Se her for grundlæggende beregninger i TI Nspire (video)
Statistiske deskriptorer
De tre statistiske deskriptorer bliver her:
1. Observationssættets størrelse n bliver 5 + 24 + 34 + 58 + 80 + 52 + 25 = 278
I TI Nspire kan vi gøre det ved 𝑛: = 𝑠𝑢𝑚(ℎ𝑦𝑝_𝑙𝑖𝑠𝑡)
2. Typetallet er 7, da dette er blevet set 80 gange.
3. Middelværdien bestemmes ved formlen 𝑜𝑏𝑠1∙ℎ𝑦𝑝1+𝑜𝑏𝑠2∙ℎ𝑦𝑝2+⋯+𝑜𝑏𝑠𝑘∙ℎ𝑦𝑝𝑘
𝑛
−3 ∙ 5 + 0 ∙ 24 + 2 ∙ 34 + 4 ∙ 58 + 7 ∙ 80 + 10 ∙ 52 + 12 ∙ 25
278
I TI Nspire kan vi gøre det ved
Lav opgaver i hæftet
obs_list := -3, 0, 2, 4, 7, 10, 12hyp_list := 5, 24, 34, 58, 80, 52, 25
meanobs_list , hyp_list 5.98921
Henrik S. Hansen, Sct. Knud Gymnasium 3
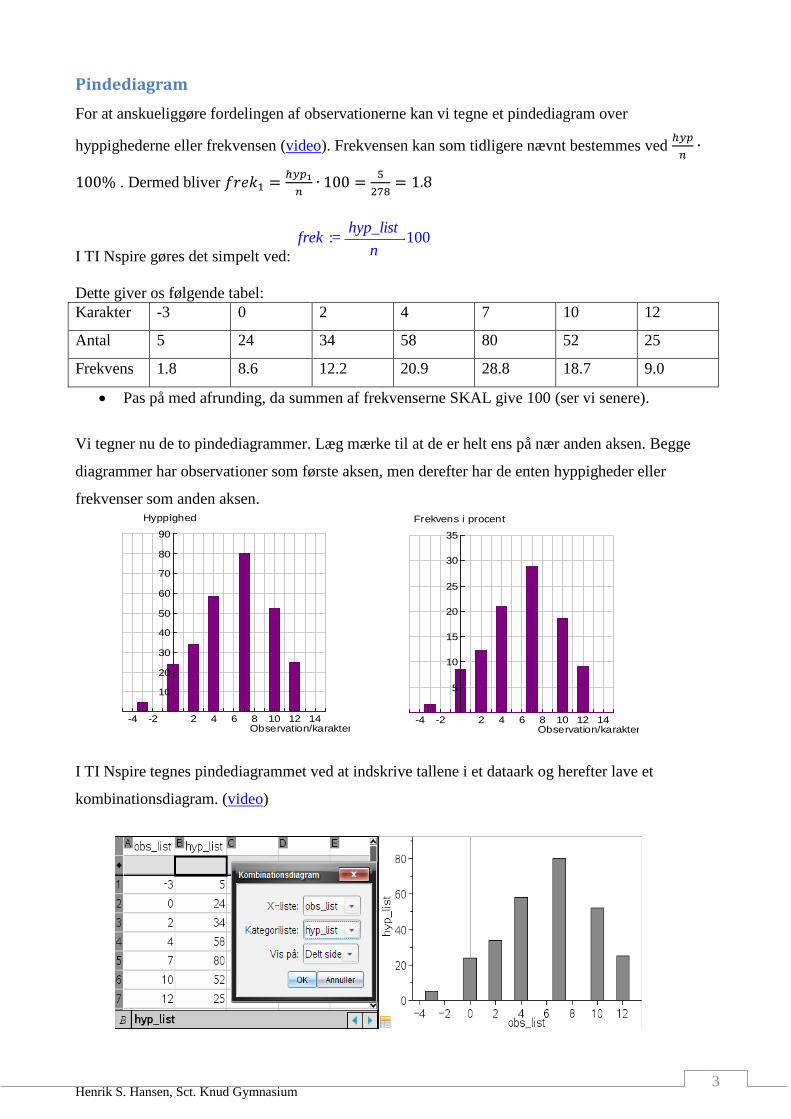
Pindediagram
For at anskueliggøre fordelingen af observationerne kan vi tegne et pindediagram over
hyppighederne eller frekvensen (video). Frekvensen kan som tidligere nævnt bestemmes ved ℎ𝑦𝑝
𝑛∙
100% . Dermed bliver 𝑓𝑟𝑒𝑘1 =ℎ𝑦𝑝1
𝑛∙ 100 =
5
278= 1.8
I TI Nspire gøres det simpelt ved:
Dette giver os følgende tabel:
Karakter -3 0 2 4 7 10 12
Antal 5 24 34 58 80 52 25
Frekvens 1.8 8.6 12.2 20.9 28.8 18.7 9.0
Pas på med afrunding, da summen af frekvenserne SKAL give 100 (ser vi senere).
Vi tegner nu de to pindediagrammer. Læg mærke til at de er helt ens på nær anden aksen. Begge
diagrammer har observationer som første aksen, men derefter har de enten hyppigheder eller
frekvenser som anden aksen.
I TI Nspire tegnes pindediagrammet ved at indskrive tallene i et dataark og herefter lave et
kombinationsdiagram. (video)
frek := hyp_list
n100 1.79856, 8.63309, 12.2302, 20.8633, 28.777, 18.705, 8.99281
-4 -2 2 4 6 8 10 12 14
10
20
30
40
50
60
70
80
90
Hyppighed
Observation/karakter-4 -2 2 4 6 8 10 12 14
5
10
15
20
25
30
35
Observation/karakter
Frekvens i procent
Henrik S. Hansen, Sct. Knud Gymnasium 4
-4 -2 2 4 6 8 10 12 14
10
20
30
40
50
60
70
80
90
100
Kumuleret frekvens i procent
Observation/karakter
Frekvensen kan eksempelvis bruges til at bestemme hvor mange procent af eleverne der fik enten 2,
4 eller 7.
Svaret må være 12.2% + 20.9% + 28.8% = 51.9%
(Men vi kan gøre det nemmere for os selv ved at indføre den opsummerende frekvens.)
Lav opgaver i hæftet
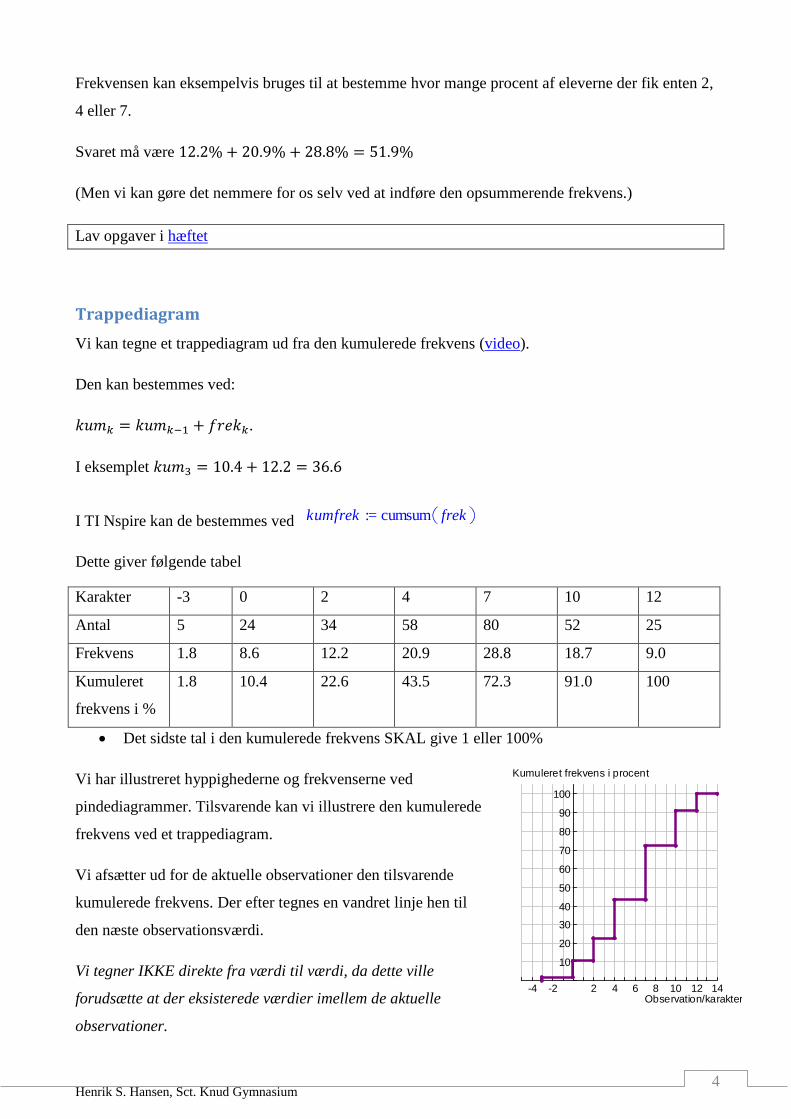
Trappediagram
Vi kan tegne et trappediagram ud fra den kumulerede frekvens (video).
Den kan bestemmes ved:
𝑘𝑢𝑚𝑘 = 𝑘𝑢𝑚𝑘−1 + 𝑓𝑟𝑒𝑘𝑘.
I eksemplet 𝑘𝑢𝑚3 = 10.4 + 12.2 = 36.6
I TI Nspire kan de bestemmes ved
Dette giver følgende tabel
Karakter -3 0 2 4 7 10 12
Antal 5 24 34 58 80 52 25
Frekvens 1.8 8.6 12.2 20.9 28.8 18.7 9.0
Kumuleret
frekvens i %
1.8 10.4 22.6 43.5 72.3 91.0 100
Det sidste tal i den kumulerede frekvens SKAL give 1 eller 100%
Vi har illustreret hyppighederne og frekvenserne ved
pindediagrammer. Tilsvarende kan vi illustrere den kumulerede
frekvens ved et trappediagram.
Vi afsætter ud for de aktuelle observationer den tilsvarende
kumulerede frekvens. Der efter tegnes en vandret linje hen til
den næste observationsværdi.
Vi tegner IKKE direkte fra værdi til værdi, da dette ville
forudsætte at der eksisterede værdier imellem de aktuelle
observationer.
kumfrek := cumsum frek 1.79856, 10.4317, 22.6619, 43.5252, 72.3022, 91.0072, 100.

Henrik S. Hansen, Sct. Knud Gymnasium 5
Det kan være svært at tegne et trappediagram i TI Nspire, men hvis afstanden mellem de
observerede værdier er lige store, så kan vi godt (udvider blot bredden på pindene i
pindediagrammet)
I Nspire kunne det se således ud:
Læg mærke til at vi gør intervallerne lige store og ”flytter” søjlerne. (video)
Lav opgaver i hæftet

Henrik S. Hansen, Sct. Knud Gymnasium 6
Grupperet observationer
Hvis vi har et observationssæt, som har MANGE forskellige observationer eks. højden af
gymnasieelever, vægt på køer mm. så opstiller vi et grupperet observationssæt (video). Vi putter
simpelthen vores observationer i ”kasser” også kaldet intervaller.
Vores intervaller skal sikre at ALLE tænkelige observationer kan medtages.
Til at belyse det tekniske indenfor grupperede observationer, tager vi udgangspunkt i et eksempel,
som så vil blive belyst hele vejen igennem dette afsnit. Der vil løbende være forklaring til hvordan
TI NSPIRE kan inddrages.
Eleverne som tog eksamen i matematik (i afsnittet om ikke grupperede observationer) fik også målt
deres højde. Højden blev målt i cm. Der var ingen under 160 cm og ingen over 200 cm
Højde [155;160] ]160;165] ]165;170] ]170;175] ]175;180] ]180;185] ]185;190] ]190;200]
Antal 0 19 39 64 70 50 26 10
Den første række kaldes nulrækken, og er en, som man med fordel kan vælge at sætte ind,
da dette gør det nemmere når diverse grafer skal tegnes.
Jeg får senere brug for følgende tre lister:
Værdierne midt i intervallerne
Intervalendepunkterne
Hyppighederne
En vigtig pointe i ovenstående lister er, at vi går ud fra at:
observationerne er ligeligt fordelt i intervallerne.
midt_list := 157.5, 162.5, 167.5, 172.5, 177.5, 182.5, 187.5, 195
endepunkt := 160, 165, 170, 175, 180, 185, 190, 200
hyp_list := 0, 19, 39, 64, 70, 50, 26, 10

Henrik S. Hansen, Sct. Knud Gymnasium 7
Statistiske deskriptorer
De tre statistiske deskriptorer bliver her:
1. Observationssættets størrelse n bliver 19 + 39 + 64 + 70 + 50 + 26 + 10 = 278
I TI NSPIRE kan vi gøre det ved 𝑛: = 𝑠𝑢𝑚(ℎ𝑦𝑝_𝑙𝑖𝑠𝑡)
2. Typeintervallet er ]175-180], da dette er blevet set 70 gange.
3. Middelværdien bestemmes ved formlen 𝑚𝑖𝑑𝑡1∙ℎ𝑦𝑝1+𝑚𝑖𝑑𝑡2∙ℎ𝑦𝑝2+⋯+𝑚𝑖𝑑𝑡𝑘∙ℎ𝑦𝑝𝑘
𝑛
𝜎 =162,5 ∙ 19 + 167,5 ∙ 39 + 172,5 ∙ 64 + ⋯ + 187,5 ∙ 26 + 195 ∙ 10
278= 176.4
I TI NSPIRE kan vi gøre det ved
Dette kaldes for den teoretiske middelværdi, da vi jo antog at observationerne er ligeligt
fordelt i intervallerne.
Lav opgaver i hæftet
Histogram
For at anskueliggøre fordelingen af observationerne kan vi tegne et histogram over hyppighederne
eller frekvensen (video).
Vi udfærdiger derfor tabellen, da proceduren for frekvens og kumuleret frekvens er den samme som
tidligere nævnt:
Frekvensen i procent
Nu har vi tabellen:
Højde [155;160] ]160;165] ]165;170] ]170;175] ]175;180] ]180;185] ]185;190] ]190;200]
Antal 0 19 39 64 70 50 26 10
Frek 0 6.8 14.0 23.0 25.2 18.0 9.4 3.4
Vi kan se at der er 23% + 25.2% = 48.2% af eleverne der var mellem 170 og 180 cm høje
Vi kan nu tegne histogrammet.
meanmidt_list , hyp_list 176.385
frek := hyp_list
n100 0., 6.83453, 14.0288, 23.0216, 25.1799, 17.9856, 9.35252, 3.59712

Henrik S. Hansen, Sct. Knud Gymnasium 8
Begge diagrammer har observationer som første aksen, hvor vi indsætter ”kasser” på de aktuelle
intervaller. Kasserne har et areal, som svarer til deres indhold (læg især mærke til det sidste
interval).
Første graf er over hyppighederne. Anden graf er over frekvenserne. Det som er helt specielt ved
histogrammer er, at de ikke har nogen anden-akse. Det vi afbilder, det er arealer. Her kan du se
hvordan vi kan gøre det i TI Nspire (video)
Lav opgaver i hæftet
Sumkurve
Vi har illustreret hyppighederne og frekvenserne ved histogrammer. Tilsvarende kan vi illustrere
den kumulerede frekvens ved en sumkurve (video). Men først skal vi bruge den kumulerede
frekvens.
Den kumulerede frekvens kan i Nspire beregnes således
Højde [155;160] ]160;165] ]165;170] ]170;175] ]175;180] ]180;185] ]185;190] ]190;200]
Antal 0 19 39 64 70 50 26 10
Frek 0 6.8 14.0 23.0 25.2 18.0 9.4 3.4
Kum 0 6.8 20.8 43.8 69.0 87.0 96.4 100
Vi kan ud fra den kumulerede frekvens aflæse at 87% var under 185cm.
kum_frek := cumsum frek
0., 6.83453, 20.8633, 43.8849, 69.0647, 87.0504, 96.4029, 100.
155 160 165 170 175 180 185 190 195 200
2.5%
155 160 165 170 175 180 185 190 195 200
10 personer

Henrik S. Hansen, Sct. Knud Gymnasium 9
For at tegne sumkurven skal vi bruge
vores intervalendepunkter, som bliver
afsat på første aksen. VIGTIGT at det er
intervalendepunkter da vi skal
anskueliggøre hele intervallet.
Vi afsætter ud for de aktuelle
intervalendepunkter den tilsvarende
kumulerede frekvens. Derefter forbindes
punkterne. Vi forbinder punkterne, fordi
at vi antager, at alle observationerne i intervallerne er ligeligt fordelt.
Se her hvordan du kan gøre det i TI Nspire (video)
Lav opgaver i hæftet
Fraktiler
Kigger vi i den store danske ordbog, så står der:
fraktil, (af lat.fractus 'brudt', af frangere 'bryde, brække itu'), i beskrivende statistik
afgrænsning af en vis andel af en mængde observationer.
Når vi tager alle vores observationer og lister dem op i rækkefølge, så kan vi aflæse det der kaldes
fraktiler, som er værdien på en bestemt plads i rækken af observationer (video).
Vi kunne eksempelvis liste vores observationer fra det ikke grupperede observationssæt op. Det er
det samme princip for det grupperede (hvis vi da kender alle observationernes nøjagtige værdi.)
𝑜𝑏𝑠 = {−3, −3, −3, −3, −3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2, … ,12,12,12}
Et eksempel:
10% fraktilen aflæses ved at tage 10% af observationssættets størrelse, og så tælle ind i rækken, og
aflæse værdien:

Henrik S. Hansen, Sct. Knud Gymnasium 10
Hvis vi lander lige oven på en observation, så er fraktilen denne værdi.
Hvis positionen er imellem to observationer, så er der to metoder:
1. Danskstandard: Vi tager den ”største” værdi, nemlig værdien til højre.
2. Internationalstandard: Vi tager et snit af de to. TI NSPIRE kører på denne standard.
De mest benyttede fraktiler er 25%-, 50%- og 75%-fraktilen. De kaldes nedre kvartil, median og
øvre kvartil – tilsammen udgør de det, som hedder kvartilsættet.
I vores eksempel ville 10% fraktilen lande på plads 27,8 altså mellem plads 27 og 28.
Danskstandard giver værdien af 28 og internationalstandard er gennemsnittet af de to. Vi kan se at
de to værdier er 0 og 0, så uanset standard, så er 10% fraktilen 0.
Men oftest så kan vi aflæse direkte fra vores grafer.
Kvartilsæt for ikke grupperede observationer
Lad os vende tilbage til vores trappediagram og vores sumkurve, hvor vi kan aflæse vores fraktiler.
Vi tegner en vandret linje ud for den givne fraktal
(procent) og der hvor den rammer trappen/kurven går vi
lodret ned og aflæser værdien af fraktalen.
Kvartilsæt ikke grupperet:
Nedre kvartil er 4
Medianen er 7
Den øvre kvartil er 10
Kvartilsættet samt mindste værdi og maksimale værdi kan bruges til at tegne et boksplot.
𝑜𝑏𝑠 = {−3, −3, −3, −3, −3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2, … ,12,12,12}
-4 -2 2 4 6 8 10 12 14
10
20
30
40
50
60
70
80
90
100
Kumuleret frekvens i procent
Observation/karakter
DETTE ER DANSK STANDARD

Henrik S. Hansen, Sct. Knud Gymnasium 11
I TI Nspire kan vi bestemme kvartilsættet samt
andre statistiske størrelser for et ikke grupperet
observationssæt ved at lave ”statistik med en
variabel” på vores observationsliste og vores
hyppighedsliste.
DETTE ER INTERNATIONALSTANDARD
Lav opgaver i hæftet
Kvartilsættet for et grupperet observationssæt
For at bestemme kvartilsættet for et grupperet observationssæt, så kræver det at vi har en sumkurve.
Vi kan ikke som under ikke grupperede observationer lave en statistisk analyse, da vi jo ikke har
samtlige observationer, men kun et estimat af hvordan de fordeler sig. (Video)
Vi indtegner tre vandrette linjer
(𝑓1(𝑥) = 25 𝑜𝑔 𝑓2(𝑥) = 50 𝑜𝑔 𝑓3(𝑥) =
75). Der hvor de skærer vores sumkurve kan
vi aflæse vores kvartiler som
førstekoordinaten.
I eksemplet har er følgende fundet: Nedre
kvartil 171, median 176 og øvre kvartil
182. Her ud over er minimum 160 og
maksimum 200.
Lav opgaver i hæftet

Henrik S. Hansen, Sct. Knud Gymnasium 12
Boksplot
Når man kender kvartilerne i et observationssæt, kan man skaffe sig et overblik over disse ved at
tegne et boksplot (video).
Boksplottet illustrerer hvor stort et interval af kvartilerne (altså 25 % af observationssættet) fordeler
sig over.
Når vi skal tegne et boksplot kan vi gøre det i hånden ved at sætte en lille lodret streg ud for den
mindste værdi der er observeret. Der næst afsættes en lidt større lodretstreg ud for nedre kvartil.
Disse to forbindes med en streg. Så afsættes som
ved den nedre kvartil medianen og den øvre
kvartil. Disse lodrettes streger tegnes nu som en
kasse. Til sidst afsættes som ved mindste værdi
den største observerede værdi. Denne forbindes
til kassen.
Eller vi kan få TI Nspire til det. Vi skal blot definere en liste med kvartilsættet samt minimum og
maksimum. Husk at lade medianen gå igen to gange, eller lade BÅDE den nedre kvartil og den øvre
kvartil gå igen to gange (video)
Ud fra et boksplot kan vi så udtale os om spredningen hen over kvartilerne. Eksempelvis kan vi se
at højden fordeler sig således at 25% er mellem 160 og 171. Der er større spredning på de 25%
største, og noget mindre spredning på 25%-50%. De midterste 50% fordeler sig mellem 171 og 182
cm.
Lav opgaver i hæftet

Henrik S. Hansen, Sct. Knud Gymnasium 13
Normalfordeling
Normalfordelingen er en af de vigtigste sandsynlighedsfordelinger og benævnes også
Gaussfordelingen. Den er kontinuert og kan principielt omfatte alle reelle tal. Den er symmetrisk og
kan entydigt bestemmes ved observationssættets middelværdi og varians. (se video)
Normalfordelingen bruges som en "model" af hvordan et stort antal statistiske elementer fordeler
sig omkring deres gennemsnit/middelværdi. Hvis man for eksempel måler højden eller vægten af
hver enkelt i en stor, ensartet gruppe af personer, vil de fleste ligge omkring et vist gennemsnit,
mens meget store eller små personer er mere sjældne.
Vi kobler normalfordelingen til grupperet observationer, da alle værdier i intervallet skal kunne
forekomme. Vi kan derfor kun bruge normalfordelingen i forbindelse med grupperet observationer.
Både erfaring og teoretiske argumenter viser, at når der er stokastiske elementer, dvs. tilfældighed,
med i spillet, fremkommer der en symmetrisk „klokkekurve“. Kurven kan være smal eller bred,
men den har næsten altid samme grundform. Mange størrelser som soldaters højde, tandpastatubers
vægt og menneskers intelligens fordeler sig på denne måde.
Du to grafer, som vi kigger på i denne sammenhæng er tæthedsfunktionen som er et udtryk for
klokkens form (histogram), og så fordelingsfunktionen som viser det udstrakte S (sumkurven).
Begge grafer viser altså fordelingen af sandsynlighederne.
2:Hvis et observationssæt er normalfordelt, vil
man kunne tegne en klokke form over
histogrammet. (tæthedsfunktionen)
1: Hvis et observationssæt er normalfordelt, så kan man
tegne en sumkurve som er symmetrisk omkring medianen.
(fordelingsfunktionen)

Henrik S. Hansen, Sct. Knud Gymnasium 14
Definition: Normalfordeling
Udfaldene x fra et eksperiment med uendeligt mange tætliggende udfald siges at være
normalfordelte, hvis tæthedsfunktionen har forskriften.
𝑦 =1
𝜎 ∙ √2𝜋∙ 𝑒
−(𝑥−𝜇)2
2∙𝜎2
Tallet 𝜇 kaldes den teoretiske middelværdi og tallet 𝜎 kaldes den teoretiske spredning.
I praksis til at bestemme om et datasæt er normalfordelt kan man men fordel benytte et
normalfordelingspapir.
Påvise en normalfordeling:
Hvis man bliver bedt om at redegøre for, at nogle observationer er normalfordelte er det ikke
tilstrækkeligt at tegne et histogram over fordelingen, og dermed vise, der er tale om noget, der
næsten ligner en klokke.
På et normalfordelingspapir afsættes som på samme måde som ved sumkurven punkterne (højre
intervalendepunkt, kumuleret frekvens). Hvis der forekommer en tilnærmelsesvis ret linje så er
observationssættet normalfordelt.
VIGTIGT: vi afsætter ikke 0% og 100%

Henrik S. Hansen, Sct. Knud Gymnasium 15
Vi kan se at vores observationssæt med gymnasieelevernes højder er normalfordelte, da
der forekommer en tilnærmelsesvis ret linje på normalfordelingspapiret.
Lav opgaver i hæftet
Henrik S. Hansen, Sct. Knud Gymnasium 16
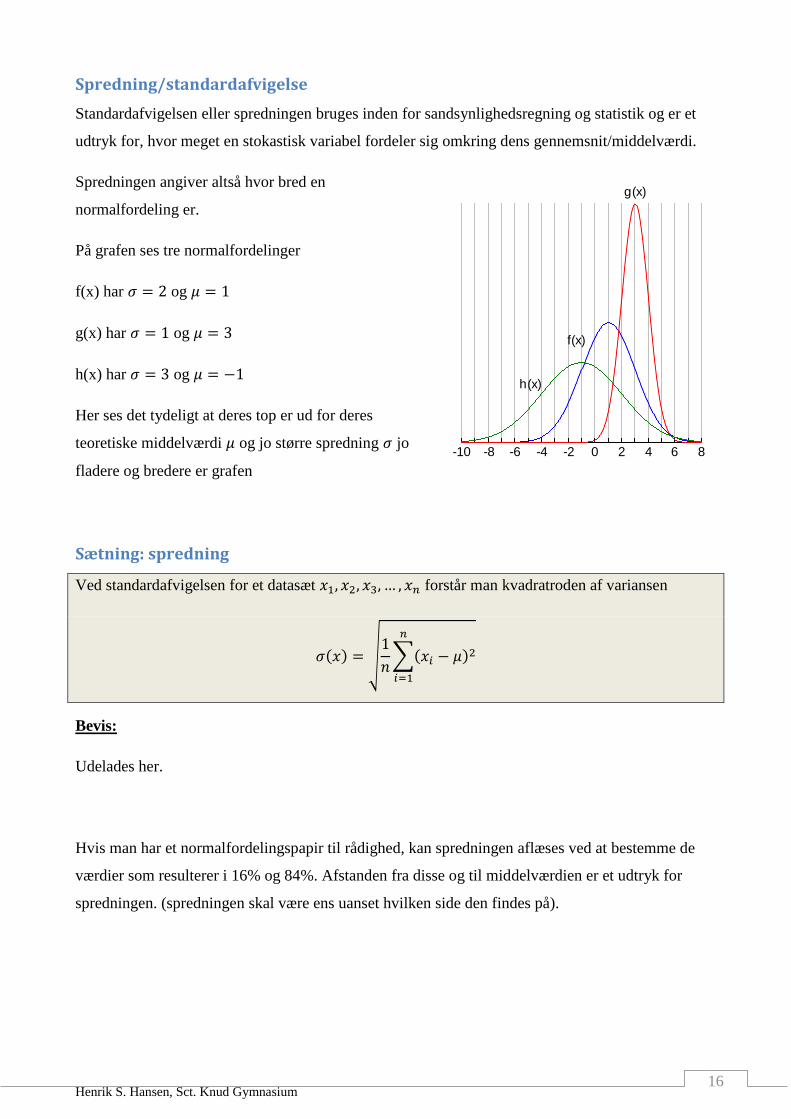
Spredning/standardafvigelse
Standardafvigelsen eller spredningen bruges inden for sandsynlighedsregning og statistik og er et
udtryk for, hvor meget en stokastisk variabel fordeler sig omkring dens gennemsnit/middelværdi.
Spredningen angiver altså hvor bred en
normalfordeling er.
På grafen ses tre normalfordelinger
f(x) har 𝜎 = 2 og 𝜇 = 1
g(x) har 𝜎 = 1 og 𝜇 = 3
h(x) har 𝜎 = 3 og 𝜇 = −1
Her ses det tydeligt at deres top er ud for deres
teoretiske middelværdi 𝜇 og jo større spredning 𝜎 jo
fladere og bredere er grafen
Sætning: spredning
Ved standardafvigelsen for et datasæt 𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑛 forstår man kvadratroden af variansen
𝜎(𝑥) = √1
𝑛∑(𝑥𝑖 − 𝜇)2
𝑛
𝑖=1
Bevis:
Udelades her.
Hvis man har et normalfordelingspapir til rådighed, kan spredningen aflæses ved at bestemme de
værdier som resulterer i 16% og 84%. Afstanden fra disse og til middelværdien er et udtryk for
spredningen. (spredningen skal være ens uanset hvilken side den findes på).
-10 -8 -6 -4 -2 0 2 4 6 8
f(x)
g(x)
h(x)

Henrik S. Hansen, Sct. Knud Gymnasium 17
’
Den kan aflæses til ca 7.5. Men aflæsningen er klart mest upræcist.
Vi prøver nu at bestemme spredningen via formlerne:
Den kan altså beregnes til ca. 7.67. Så 68% af observationerne ligger inden for 176.23 ± 7.67.
Lav opgaver i hæftet
hyp := 19, 39, 64, 70, 50, 26, 10midt := 162.5, 167.5, 172.5, 177.5, 182.5, 187.5, 195n := 278
spredning = sumlisthyp
2midt - 176.23
nspredning = 7.66861


















