
Designing efficient high performance server-centric data...
14
Designing efficient high performance server-centric data center network architecture Ting Wang ⇑ , Zhiyang Su, Yu Xia, Jogesh Muppala, Mounir Hamdi Department of Computer Science and Engineering, Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong article info Article history: Received 28 August 2014 Received in revised form 26 December 2014 Accepted 13 January 2015 Available online 29 January 2015 Keywords: Data center network Network topology Interconnection architecture Server-centric Flat network abstract Data center network (DCN) architecture is regarded as one of the most important determi- nants of network performance. As the most typical representatives of DCN architecture designs, the server-centric scheme stands out due to its good performance in various aspects. In this paper, we firstly present the design, implementation and evaluation of SprintNet, a novel server-centric network architecture for data centers. SprintNet achieves high performance in network capacity, fault tolerance, and network latency. SprintNet is also a scalable, yet low-diameter network architecture where the maximum shortest dis- tance between any pair of servers can be limited by no more than four and is independent of the number of layers. The specially designed routing schemes for SprintNet strengthen its merits. However, all of these kind of server-centric architectures still suffer from some crit- ical shortcomings owing to the server’s responsibility of forwarding packets. With regard to these issues, in this paper, we then propose a hardware based approach, named ‘‘For- warding Unit’’ to provide an effective solution to these drawbacks and improve the effi- ciency of server-centric architectures. Both theoretical analysis and simulations are conducted to evaluate the overall performance of SprintNet and the Forwarding Unit approach with respect to cost-effectiveness, fault-tolerance, system latency, packet loss ratio, aggregate bottleneck throughput, and average path length. The evaluation results convince the feasibility and good performance of both SprintNet and Forwarding Unit. Ó 2015 Elsevier B.V. All rights reserved. 1. Introduction Data centers, implemented as an agglomeration of mas- sive number of servers, are increasingly playing an impor- tant role in supporting enterprise computing needs, cloud computing services (such as web search, email, online gaming, and social networking) and infrastructure-based services (like GFS [9], BigTable [6], MapReduce [7], Dryad [14], etc.). With data availability and security at stake, the role of the data center is more critical than ever. To support the growing cloud computing needs, the number of servers in today’s data centers are increasing exponen- tially, thus resulting in enormous challenges to network design for interconnecting these servers. As a result, sev- eral novel proposals, such as Fat Tree [3], DCell [12], BCube [11], VL2 [10], FiConn [15], Portland [20], FlatNet [17], HyperBcube [16], NovaCube [24], CamCube [2] and Small-World [22] have been proposed aiming to efficiently interconnect the servers inside a data center to deliver peak performance to users. The data center architecture is regarded as the most important factor, since it not only determines the reliability of a data center, but also plays a dominate role in network capacity, fault tolerance, latency, and routing efficiency. Generally, the design goals http://dx.doi.org/10.1016/j.comnet.2015.01.006 1389-1286/Ó 2015 Elsevier B.V. All rights reserved. ⇑ Corresponding author. E-mail addresses: [email protected] (T. Wang), [email protected] (Z. Su), [email protected] (Y. Xia), [email protected] (J. Muppala), [email protected] (M. Hamdi). Computer Networks 79 (2015) 283–296 Contents lists available at ScienceDirect Computer Networks journal homepage: www.elsevier.com/locate/comnet
Transcript of Designing efficient high performance server-centric data...

Computer Networks 79 (2015) 283–296
Contents lists available at ScienceDirect
Computer Networks
journal homepage: www.elsevier .com/ locate/comnet
Designing efficient high performance server-centric data centernetwork architecture
http://dx.doi.org/10.1016/j.comnet.2015.01.0061389-1286/� 2015 Elsevier B.V. All rights reserved.
⇑ Corresponding author.E-mail addresses: [email protected] (T. Wang), [email protected]
(Z. Su), [email protected] (Y. Xia), [email protected] (J. Muppala),[email protected] (M. Hamdi).
Ting Wang ⇑, Zhiyang Su, Yu Xia, Jogesh Muppala, Mounir HamdiDepartment of Computer Science and Engineering, Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong
a r t i c l e i n f o
Article history:Received 28 August 2014Received in revised form 26 December 2014Accepted 13 January 2015Available online 29 January 2015
Keywords:Data center networkNetwork topologyInterconnection architectureServer-centricFlat network
a b s t r a c t
Data center network (DCN) architecture is regarded as one of the most important determi-nants of network performance. As the most typical representatives of DCN architecturedesigns, the server-centric scheme stands out due to its good performance in variousaspects. In this paper, we firstly present the design, implementation and evaluation ofSprintNet, a novel server-centric network architecture for data centers. SprintNet achieveshigh performance in network capacity, fault tolerance, and network latency. SprintNet isalso a scalable, yet low-diameter network architecture where the maximum shortest dis-tance between any pair of servers can be limited by no more than four and is independentof the number of layers. The specially designed routing schemes for SprintNet strengthen itsmerits. However, all of these kind of server-centric architectures still suffer from some crit-ical shortcomings owing to the server’s responsibility of forwarding packets. With regardto these issues, in this paper, we then propose a hardware based approach, named ‘‘For-warding Unit’’ to provide an effective solution to these drawbacks and improve the effi-ciency of server-centric architectures. Both theoretical analysis and simulations areconducted to evaluate the overall performance of SprintNet and the Forwarding Unitapproach with respect to cost-effectiveness, fault-tolerance, system latency, packet lossratio, aggregate bottleneck throughput, and average path length. The evaluation resultsconvince the feasibility and good performance of both SprintNet and Forwarding Unit.
� 2015 Elsevier B.V. All rights reserved.
1. Introduction
Data centers, implemented as an agglomeration of mas-sive number of servers, are increasingly playing an impor-tant role in supporting enterprise computing needs, cloudcomputing services (such as web search, email, onlinegaming, and social networking) and infrastructure-basedservices (like GFS [9], BigTable [6], MapReduce [7], Dryad[14], etc.). With data availability and security at stake,
the role of the data center is more critical than ever. Tosupport the growing cloud computing needs, the numberof servers in today’s data centers are increasing exponen-tially, thus resulting in enormous challenges to networkdesign for interconnecting these servers. As a result, sev-eral novel proposals, such as Fat Tree [3], DCell [12], BCube[11], VL2 [10], FiConn [15], Portland [20], FlatNet [17],HyperBcube [16], NovaCube [24], CamCube [2] andSmall-World [22] have been proposed aiming to efficientlyinterconnect the servers inside a data center to deliverpeak performance to users. The data center architectureis regarded as the most important factor, since it not onlydetermines the reliability of a data center, but also playsa dominate role in network capacity, fault tolerance,latency, and routing efficiency. Generally, the design goals

284 T. Wang et al. / Computer Networks 79 (2015) 283–296
of data center networks are high scalability, good fault tol-erance, low latency and high network capacity [23,12,19].
Scalability: In order to meet the increasing demands forservices and better performance, the physical structuremust have good scalability enabling incremental expan-sion without affecting the existing servers. Correspond-ingly, the routing algorithm should also be scalable andeasily adapt to the new expanded interconnection.
Fault tolerance: A fault-tolerant architecture allowsthe system to continue with its current task even in thepresence of failures. From the perspective of the networkdesign, good fault tolerance can be achieved throughredundant physical connections and fault-tolerant routingschemes. However, the richly connected network may beconfronted with a high wiring complexity, where a satis-factory compromise should be made.
Latency: Primarily the network latency consists of thequeuing delay at each hop, transmission delay and propa-gation delay, of which the buffer queuing at each hop is themajor contributor to latency. Therefore, a smaller networkdiameter, which leads to lowering the latency should beoffered as a basic feature of the network design enablingthe data center to provide faster services. Besides, thedesign of traffic-aware routing algorithm or deadline-aware transport protocol also help reducing the overalllatency.
Network capacity: Large-scale data centers providingcloud services are usually bandwidth hungry. Hence, thedata center should provide high network capacity to sup-port the high volumes of traffic generated by many onlineinfrastructure services, such as GFS [9] and MapReduce [7].
Aiming to meet these challenging design goals, in thispaper, we propose a novel server-centric data center net-work architecture named SprintNet, which is recursivelydefined with rich connectivity, exhibits good fault toler-ance and scalability. Furthermore, the diameter of Sprint-Net can be limited within four, which implies potentiallylow network latency. Moreover, SprintNet also demon-strates high performance in terms of bisection bandwidthand aggregate bottleneck throughput.
Compared with other architectures (e.g. switch-centricarchitecture), the server-centric network scheme standsout owing to its own many superiorities. Firstly, thelevel-based and recursively defined architectures are morelikely to achieve a good scalability and easier to design alarge-scale DCN (e.g. DCell scales double exponentiallyand FlatNet scales at O(n3) with only 2 layers of networkusing n-port switches). Secondly, it achieves better perfor-mance in aggregate throughput and average packet delayfor small sized network [5]. Thirdly, the server-centricarchitectures are more cost-effective than other candidates(e.g. Fat Tree) [21]. Fourthly, it holds good fault-tolerancebecause of numerous node-disjointed paths [12,11,19].Lastly but not least, it only uses cheaper low-end commod-ity switches without any modifications to them.
Although the server-centric scheme receives numeroushighlights, there still exist many practical issues which areenumerated in Section 5. In responding to these issues, thispaper then provides an effective approach which can solvethese shortcomings and improve the efficiency of server-centric architectures including SprintNet.
The primary contributions of this paper can be summa-rized as follows:
(1) A new high performance server-centric architectureSprintNet enjoying four major desirable features fordata center networks is proposed.
(2) Theoretical analysis of typical features of SprintNetand a comprehensive comparison with otherproposals from various aspects.
(3) Design of two routing schemes for SprintNet takingsome practical issues into consideration.
(4) Address the critical shortcomings which exist andneed to be solved in server-centric data center net-work architectures.
(5) Propose a hardware based approach to achieve a log-ically flat DCN and solve the issues of server-centricarchitectures.
(6) Conduct extensive simulations to evaluate theperformance of SprintNet and the feasibility of thehardware based approach.
The rest of the paper is organized as follows. First webriefly review the related research literature in Section 2.Then Section 3 introduces the SprintNet structure in detail.Subsequently, the routing schemes designed for SprintNetare described in Section 4. Afterwards, Section 5 addressesthe existing drawbacks of server-centric architectures fol-lowed by Section 6 which illustrates the hardware basedsolution to these drawbacks. Section 7 demonstrates theevaluations of SprintNet and forwarding unit. Finally, Sec-tion 8 concludes the paper.
2. Related work
Considerable research has been conducted in finding asuitable interconnection architecture for data center net-works. The proposed data center architectures so far canbe generally classified into two categories: server-centricand switch-centric. Unlike switch-centric scheme whichplaces the interconnection and routing intelligence onswitches, the server-centric scheme expects the serversalso to forward packets. The server-centric architectureswell implement the network locality forming the serversin close proximity of each other, which can help increasethe communication efficiency. DCell [12], BCube [11],FiConn [15], FlatNet [17], CamCube [2], Small-World [22]and NovaCube [24] are examples of server-centric architec-tures. The switch-centric architectures are typically con-structed around top of rack (ToR) switches, which arethen interconnected through one or more higher levels ofswitches (such as aggregation level and core level). FatTree [3], Portland [20], and VL2 [10] are some typical rep-resentatives of switch-centric architectures.
2.1. Switch-centric architecture
Fat Tree [3] is a three-layer Clos network built in theform of multi-rooted tree. It is a rearrangeably non-block-ing structure, which provides an oversubscription ratio of1:1 to all servers. A Fat Tree built with n-port switches

T. Wang et al. / Computer Networks 79 (2015) 283–296 285
has n pods, each of which contain two layers of n/2switches. It consists of (n/2)2 core switches, n2/2 aggrega-tion and n2/2 edge switches respectively, and supportsn3/4 servers in total. However, the wiring complexity isO(n3) which is a serious challenge.
Portland [20] is a scalable, easily manageable, fault-tolerant, and efficient layer 2 Ethernet-compatible routing,forwarding and address resolution protocol for data centerenvironments. It uses a pre-determined Fat-Tree topology,hierarchical pseudo-MAC (PMAC) address, and logicallycentralized directory (Fabric Manager) to resolve PMACto actual MAC (AMAC) addresses to enable Ethernet-com-patible plug-n-play networking. Besides, based on multi-rooted Fat-Tree architecture, it exploits the knowledge ofthe underlying topology of a data center, and completelyavoids broadcast-based mechanisms, and stresses on fastand easy virtual machine mobility within the data center.
VL2 [10] is an agile and cost effective network architec-ture, which is built from numerous switches arranged intoa Clos topology. VL2 employs Valiant Load Balancing (VLB)to spread traffic across network paths, and uses addressresolution to support large server pools. Besides, VL2applies flat addressing to eliminate fragmentation ofresources and allow any service to be assigned to any ser-ver anywhere in the data center. However, the centralizeddirectory system may become a bottleneck in the case ofheavy network load.
2.2. Server-centric architecture
DCell [12] uses servers with multiple ports and low-endmini-switches to build its recursively defined architecture.In DCell, the most basic element named DCell0 consists of nservers and one n-port switch. Each server in a DCell0 isconnected to the switch in the same DCell0. Generally,DCellk (i.e. level-k DCell) is created by tk-1+1 DCellk-1s,where tk-1 is the number of servers in each DCellk-1. Thenode degree of each server in a DCellk is k + 1, and thelevel-i link connects to a different DCelli�1 within the sameDCelli. DCell scales out at a double exponential speed, andits fault-tolerant DFR routing protocol which introduceslocal-reroute achieves good results. However, the lowerlevel links carry more traffic causing higher link utilization,thus may become a bottleneck and result in low aggregatebottleneck throughput.
BCube [11] is also a recursively defined structure, whichis specially designed for shipping container based modulardata centers. Its most basic element BCube0 is the same asDCell0 : n servers connect to one n-port switch. While con-structing a BCube1;n extra switches are used, connectingto exactly one server in each BCube0. More generally,BCubek is derived from n BCubek-1s and nk n-port COTSswitches. Different from DCell, the servers in BCube onlyconnect to switches without connecting other servers.BCube accelerates 1-to-n traffic patterns and also demon-strates a good network capacity for all-to-all network traf-fic. However, BCube is deficient in scalability withrelatively high wiring complexity.
FiConn [15] shares similar design principle as DCell. Thedifference is that the degree of each server in FiConn isalways two while in DCell it is k + 1. Likewise, a high-level
FiConn is derived from number of low-level FiConns. Andthe routing algorithm in FiConn is traffic-aware whichcan help it in utilizing the link capacities referring to trafficstates, resulting in a good aggregate throughput. However,the fault tolerance and network capacity in FiConn are notso good. Besides, the average path length is relatively long.
FlatNet [17] is a 2-layer server-centric architecture,which scales at a speed of n3. Briefly, the first-layer of Flat-Net consists of n servers which connect to one n-portswitch. And the second-layer of FlatNet is constructed byn2 1-layer FlatNets. Different subsystems (1-layer Cells)are interconnected to each other using extra n2 n-portswitches.
Another special server-centric architecture proposed byresearchers with great novelty is to directly connect serv-ers to other servers. This is a switchless network intercon-nection without any switches, routers, or other networkdevices. CamCube [2], Small-World [22] and NovaCube[24], which are built based on a regular pattern, for exam-ple cube and torus, can be classified into this category. TheCamCube is designed targeting at shipping container-sizeddata centers. With the benefit of Torus architecture and theflexibility offered by CamCube API, it allows applications toimplement their own routing protocols so as to achievebetter application-level performance. However, this kindof design consistently suffers from poor routing efficiencycompared to other designs and this was mainly due tothe relatively long routing paths, for example, the networkdiameter in 3D torus is OðN1=3Þ hops within a N-serversized network.
3. SprintNet network structure
In this section, we firstly describe the SprintNet archi-tecture that interconnects commodity switches and serv-ers in line with server-centric scheme, and then presentits key properties.
3.1. SprintNet physical structure
SprintNet is recursively constructed, where a high-levelSprintNet is built from a certain number of lower-levelSprintNets. The basic building unit is named Cell (or 0-layer), which is the building block to construct a largerSprintNet. Each Cell is constructed with c n-port switches,where c
cþ1 n ports of each switch connect to ccþ1 n servers
and 1cþ1 n ports for inter-Cell connections. Accordingly, each
Cell contains c n-port switches and ccþ1 n servers. All the
switches and servers are fully-connected.The 1-layer SprintNet consists of c
cþ1 nþ 1 Cells, and sup-
ports ð ccþ1Þ
2n2 þ ccþ1 n servers in total. Each server has c þ 1
ports, c ports of which connect to c switches inner Celland one port is used for inter-Cell connection which con-nects to a switch in another Cell.
The higher k-layer SprintNet is constructed by addingc
cþ1 n Cells each time and fully connected to each other inthe same way. There will be k� cn
cþkþ 1 different Cells. cncþk
ports of each n-port switch connect to cncþk servers within

286 T. Wang et al. / Computer Networks 79 (2015) 283–296
a Cell, and kncþk ports interconnects different Cells. As a result,
a k-layer SprintNet can support k� ð ccþkÞ
2n2 þ ccþk n servers.
Fig. 1 shows an example of a 20-server SprintNet con-structed by using 6-port switches when c ¼ 2;n ¼ 6 andk ¼ 1. Each Cell is composed of 2 switches and 4 servers.
3.2. Properties of SprintNet
In this subsection, some typical features of SprintNet areexplored and analyzed. The analysis of the structural prop-erties of SprintNet are summarized in Table 1, which alsopresent comparisons with other network architecturesfrom different aspects.
3.2.1. Network diameterThe diameter indicates the maximum shortest path
length (denoted by the number of links) among all the ser-ver pairs. Compared with other architecture proposals asshown in Table 1, SprintNet achieves a lower networkdiameter. The physical interconnection of SprintNet deter-mines the path length between any two servers within aCell is 2, and the distance between any pair of servers indifferent Cells is 2 or 4. Therefore, the network diameterof SprintNet can be restricted by 4, which is a constantnumber. Comparatively, the network diameters of otherarchitectures are much higher, some of which (e.g. DCell,BCube) increase accordingly as the number of layersincreases (limited by the port numbers on switches, a lar-ger sized network usually needs more layers to scale up),as shown in Fig. 2.
Furthermore, SprintNet has another competitive edgederived from its low network diameter – the potentiallow network latency, where smaller diameter leads tomore effective routing with smaller number of hops and
Cell 0
[3,0][3,1]
[3,2][3,3]
[2,1][2,2]
[2,3]
[1,0][1,1]
[0,0] [0,1] [0,2] [0,3]
Fig. 1. A 20-server SprintNet using tw
lower queuing delay (buffering at each hop), and alsolower transmission latency in practice [19].
3.2.2. Scalability and physical costFor a 2-layer architecture, as shown in Table 1, SprintNet
achieves scalability of Oðn2Þwhich is the same as DCell andBCube. The wiring complexity of SprintNet is slightly higherthan DCell and BCube though they are all at the same levelof Oðn2Þ. However, this is still better than Fat Tree, VL2 andFlatNet, whose wiring complexity is Oðn3Þ. Additionally,the number of switches used in SprintNet depends on thevalue of c and increases at the speed of OðnÞ which alsooutperforms Fat Tree, VL2 and FlatNet.
Thus, to sum up the above analysis, though the scalabil-ity and link complexity of SprintNet are not superior to thebest competitors, yet still can be acceptable.
3.2.3. Bisection bandwidthThe bisection bandwidth is depicted as the sum of link
capacities between two equally-sized parts which the net-work is partitioned into. It can be used to measure theworst-case network capacity [8].
The bisection bandwidth of SprintNet is c2n2
2ðcþ1Þ2þ cn,
which is around two times that of DCell’s. Moreover, itcan be seen from Table 1 that the bisection bandwidthper server also outperforms the other candidates.
3.2.4. Network capacityThe aggregate bottleneck throughput (ABT) can be used
to measure the overall network capacity of an architectureunder the all-to-all traffic pattern, where every servercommunicates with all other servers. For each server,among all of its flows on different routes, the flows with
Structure Unit: Cell
server switch
[2,0]
[1,2][1,3]
o 6-port switches in each cell.
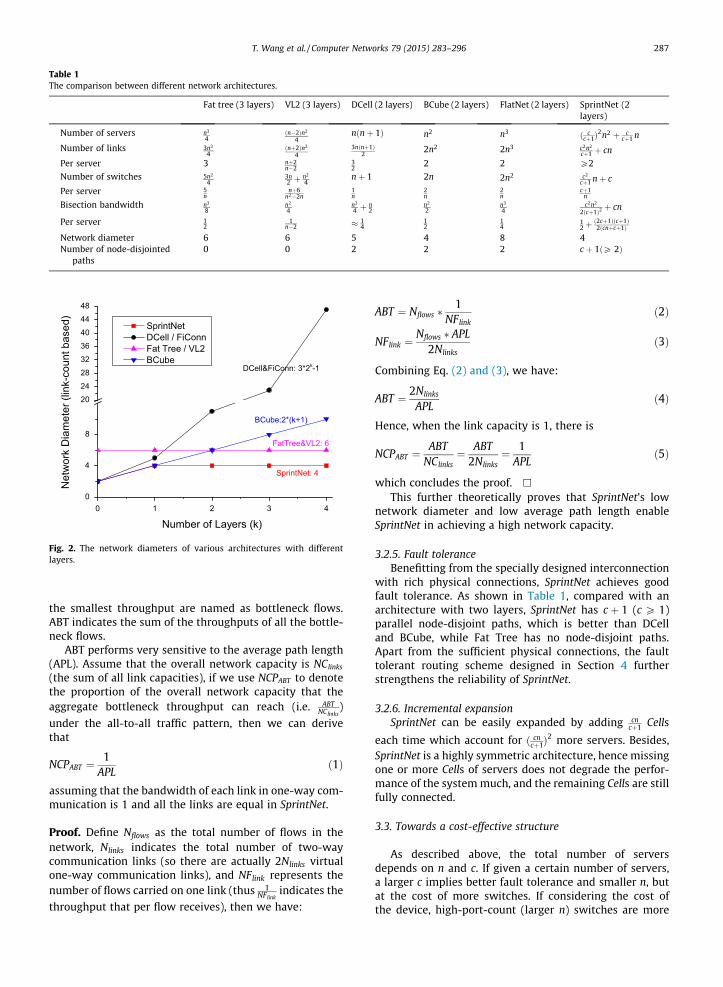
Table 1The comparison between different network architectures.
Fat tree (3 layers) VL2 (3 layers) DCell (2 layers) BCube (2 layers) FlatNet (2 layers) SprintNet (2layers)
Number of servers n3
4ðn�2Þn2
4nðnþ 1Þ n2 n3 ð c
cþ1Þ2n2 þ c
cþ1 n
Number of links 3n3
4ðnþ2Þn2
43nðnþ1Þ
22n2 2n3 c2n2
cþ1 þ cn
Per server 3 nþ2n�2
32
2 2 P2
Number of switches 5n2
43n2 þ n2
4nþ 1 2n 2n2 c2
cþ1 nþ cPer server 5
nnþ6
n2�2n1n
2n
2n
cþ1n
Bisection bandwidth n3
8n2
4n2
4 þ n2
n2
2n3
4c2n2
2ðcþ1Þ2þ cn
Per server 12
1n�2 � 1
412
14
12þ
ð2cþ1Þðcþ1Þ2ðcnþcþ1Þ
Network diameter 6 6 5 4 8 4Number of node-disjointed
paths0 0 2 2 2 c þ 1ðP 2Þ
0 1 2 3 40
4
8
20
24
28
32
36
40
44
48
NetworkDiameter(link-countbased)
Number of Layers (k)
SprintNetDCell / FiConnFat Tree / VL2BCube
DCell&FiConn: 3*2k-1
BCube:2*(k+1)
FatTree&VL2: 6
SprintNet: 4
Fig. 2. The network diameters of various architectures with differentlayers.
T. Wang et al. / Computer Networks 79 (2015) 283–296 287
the smallest throughput are named as bottleneck flows.ABT indicates the sum of the throughputs of all the bottle-neck flows.
ABT performs very sensitive to the average path length(APL). Assume that the overall network capacity is NClinks
(the sum of all link capacities), if we use NCPABT to denotethe proportion of the overall network capacity that theaggregate bottleneck throughput can reach (i.e. ABT
NClinks)
under the all-to-all traffic pattern, then we can derivethat
NCPABT ¼1
APLð1Þ
assuming that the bandwidth of each link in one-way com-munication is 1 and all the links are equal in SprintNet.
Proof. Define Nflows as the total number of flows in thenetwork, Nlinks indicates the total number of two-waycommunication links (so there are actually 2Nlinks virtualone-way communication links), and NFlink represents thenumber of flows carried on one link (thus 1
NFlinkindicates the
throughput that per flow receives), then we have:
ABT ¼ Nflows �1
NFlinkð2Þ
NFlink ¼Nflows � APL
2Nlinksð3Þ
Combining Eq. (2) and (3), we have:
ABT ¼ 2Nlinks
APLð4Þ
Hence, when the link capacity is 1, there is
NCPABT ¼ABT
NClinks¼ ABT
2Nlinks¼ 1
APLð5Þ
which concludes the proof. h
This further theoretically proves that SprintNet’s lownetwork diameter and low average path length enableSprintNet in achieving a high network capacity.
3.2.5. Fault toleranceBenefitting from the specially designed interconnection
with rich physical connections, SprintNet achieves goodfault tolerance. As shown in Table 1, compared with anarchitecture with two layers, SprintNet has c þ 1 (c P 1)parallel node-disjoint paths, which is better than DCelland BCube, while Fat Tree has no node-disjoint paths.Apart from the sufficient physical connections, the faulttolerant routing scheme designed in Section 4 furtherstrengthens the reliability of SprintNet.
3.2.6. Incremental expansionSprintNet can be easily expanded by adding cn
cþ1 Cells
each time which account for ð cncþ1Þ
2 more servers. Besides,SprintNet is a highly symmetric architecture, hence missingone or more Cells of servers does not degrade the perfor-mance of the system much, and the remaining Cells are stillfully connected.
3.3. Towards a cost-effective structure
As described above, the total number of serversdepends on n and c. If given a certain number of servers,a larger c implies better fault tolerance and smaller n, butat the cost of more switches. If considering the cost ofthe device, high-port-count (larger n) switches are more

288 T. Wang et al. / Computer Networks 79 (2015) 283–296
expensive than low-port-count ones , but a larger n leadsto less switches (e.g. supporting 24 servers in each Cellshould use two 36-port switches or only one 48-portswitch). In order to find the most beneficial c and n so asto make a reasonable trade-off between the cost ofswitches and fault tolerance, we formulate this probleminto an optimization model as below (for simplicity, with-out loss of generality, we consider the case of SprintNetwith two layers).
Objective : Minimize f ðc;nÞ ¼ CostðswitchesÞFT
ð6Þ
Subject to:
CostðswitchesÞ ¼ Nswitch � Pricen�port�switch ð7Þ
¼ c2
c þ 1� nþ c
� �� Pricen�port�switch ð8Þ
FT ¼ c þ 1 ð9Þc
c þ 1
� �2
� n2 þ cc þ 1
� n ¼ Nserver ð10Þ
where CostðswitchesÞ denotes the total cost of switches, FTmeans fault tolerance indicating the number of parallelnode-disjointed paths, Nswitch is defined as the total numberof switches, Pricen�port�switch gives the price of a n-portswitch, and Nserver represents the total number of serversthe network can support.
The goal is to achieve as high fault tolerance as possiblewith the minimum cost of switches, which leads to a min-imal ratio f ðc;nÞ. The solution to Eq. (6) is provided asfollows:
CostðswitchesÞFT
¼ð c2
cþ1 � nþ cÞ � Pricen�port�switch
c þ 1
¼ c2
ðc þ 1Þ2� nþ c
c þ 1
!� Pricen�port�switch
¼ c2
ðc þ 1Þ2� n2 þ c
c þ 1� n
!� Pricen�port�switch
n
¼ Nserver �Pricen�port�switch
n
Given a certain Nserver sized network, the Pricen�port�switch isexponential or in direct proportion to n, so we can computethe most cost-effective n based on the actual prices of thedevices, and further obtain the corresponding c, where
c ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi4Nserver þ 1p
� 12n�
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi4Nserver þ 1p
þ 1:
This provides a satisfactory trade-off between cost andreliability to construct a cost-effective Nserver sizedSprintNet.
Table 2Routing path length distribution.
Route Route0 Route1 Rout
Path length 2 2 2
4. Routing in SprintNet
This section presents specially designed routing algo-rithms for SprintNet, which aim to help SprintNet achieveits maximum theoretical performance.
4.1. Naïve routing scheme
The naïve routing scheme (NRS) is a shortest path rout-ing algorithm. It is required to compute the shortest pathsfor all the servers to every destination and store the rout-ing table on each node. A node may use broadcasting orflooding based technique to compute the routing table, orit may resort to the already existing protocols, such asthe OSPF (Open Shortest Path First) protocol.
The principle of the broadcasting-based method is sim-ple. Primarily, each server only keeps the connectivity sta-tus of its neighbor servers. In order to compute the shortestrouting path from server a to server b, starting from servera the broadcasting is recursively carried out in each step inthe network. When the broadcasting packet arrives at ser-ver b, then it retraces back to server a along the reversepath reaching b. In this way, multiple paths between servera and b may be obtained, then the route with the shortestlength will be chosen as the final routing path and stored inthe routing table at server b. When there is more than oneshortest path, the route will be chosen at random from thecandidate routes, which can positively contribute to theload balancing of the system to some extent. The routingtables can be pre-computed and then in the future useddirectly at the complexity of Oð1Þ.
In order to avoid ceaseless broadcasting packets in anendless loop and thus reduce the network workload, inthe implementation of NRS each broadcasting packet isattached with a counter TTL to denote its maximum life-span (the number of hops). Once the counter exceeds thepredetermined threshold, the broadcasting packet is dis-carded. Since the network diameter of SprintNet is 4, whichmeans the maximum shortest path length will not be lar-ger than 4, hence we conservatively set the lifespan coun-ter to 5 as default.
Although this routing scheme is simple in implementa-tion and can achieve the optimal shortest path, there aresome implicit shortcomings. On the one hand, the broad-casting increases the network workload resulting in addi-tional bandwidth cost. On the other hand, the size of therouting table stored on each node is linear to the size ofthe data center, which may become a heavy burden forthe limited memory resource and TCAM. Finally, naïverouting is not traffic-aware and the routing decisions aremade without regard to the network state. This may leadto poor link utilization and even congestion. With responseto these issues, we propose the Traffic-aware AdaptiveRouting scheme.
e2 Route3 Route4 Route5
4 4 4

T. Wang et al. / Computer Networks 79 (2015) 283–296 289
Algorithm 1. Traffic-aware Adaptive Routing: TAR(src,dst)
if src:failðÞkdst:failðÞ thenreturn null;
elseif s1 == d1 then
return Route0: src! switch x! dst;else
if src == n && dst!= m && j:onðÞ thenreturn Route1: src ! switch j! dst;
else if src!= n && dst == m && i:onðÞ thenreturn Route2: src ! switch i! dst;
else if src == n && dst == m thenif linkðsrc; iÞ.abw > linkðsrc; jÞ.abw then
return Route1;else
return Route2;end if
elseif i:onð Þ && j:onð Þ && m:onð Þ &&n:onð Þ then
Route3: src! switchi! m! switch y! dst;Route4: src! switchx! n! switch j! dst;return Route3 or Route4 at random;
else if ði:failð Þkm:failð ÞÞ && n:onð Þ && j:onð Þthen
return Route4;else if ðn:failð Þkj:failð ÞÞ && i:onð Þ && m:onð Þthen
return Route3;else if ði:failð Þkm:failð ÞÞ && ðn:failð Þkj:failð ÞÞthen
return Route5: src! intermediate Cellt ! dst;end if
end ifend if
end if
4.2. Traffic-aware adaptive routing scheme
The traffic-aware adaptive routing (TAR) is a custom-ized fault tolerant routing scheme for SprintNet, also basedon shortest path routing. TAR takes the network state intoconsideration when making routing decisions so as toavoid network congestion and achieve good load balanc-ing. Moreover, TAR scheme follows the way of flow-basedsingle path routing which does not divide flows amongmultiple paths for the sake of avoiding packet reordering.
In the TAR scheme, each server is identified using twocoordinates (cid; sid), which indicates the sid-th server inthe cid-th Cell. Given a pair of servers src½s1; s2� anddst½d1; d2�, a route between them with the path length oftwo or four can be computed according to Algorithm 1.
The whole routing procedure can be generally dividedinto two cases as shown in the pseudocode of Algorithm1. Firstly, if the source src½s1; s2� and destination dst½d1; d2�are located in the same Cell (s1=d1), then they can directlyreach each other via any switch within the Cell. In addition,
switch x whose link connecting to server src has the mostavailable bandwidth is preferentially selected. Fromanother perspective, when a switch or port fails, its linkbandwidth can be regarded as zero, so the traffic can berouted by other switches to handle network faults. Sec-ondly, src and dst are placed in two different Cells: Cells1
and Celld1 . There are four situations for this case. Weassume that switch i of Cells1 connects to serverm½m1;m2� of Celld1 , and server n½n1;n2� of Cells1 connectsto switch j of Celld1 . The first situation is that src is rightthe server n, then the traffic will traverse the path Route1:src! switchj! dst. When switch j fails, it takes Route3:src! switchi! m! switchy! dst instead to circumnavi-gate the fault, where y is satisfied that link ðm; yÞ has themost available bandwidth. If even switch i also fails, thenit will firstly route to the switch, which connects to src,of an intermediate Cellt then finally transfer to dst. The sec-ond situation is that the destination server dst is just theserver m, and as described in Algorithm 1 its routing strat-egy is similar to the first situation. The third situation hap-pens when src ¼ n and at the same time dst ¼ m, then wewill choose the route with the most available bandwidthfrom Route1 and Route2 aiming to avoid network conges-tion and achieve lowest latency. The last situation mainlydeals with the faulty cases when src – n and dst – m. Ifall the interconnection points (i.e. switch i; j and serverm;n) connecting the Cells1 and Celld1 are available, thenthe algorithm chooses Route3 or Route4 at random tryingto contribute to load balancing. If in case one endpoint ofthe interconnection link ði;mÞ fails, then Route4 will bepicked as the alternative route. Similarly, Route3 will beselected for the case of link ðn; jÞ failure. The worst caseis that all the interconnection points i; j;m; n becomeunavailable, in this case the traffic will be rerouted to thedestination via an intermediate Cellt .
Following the above procedures strictly, the traffic willbe forwarded along the shortest path with the most avail-able bandwidth and be fault tolerant. The statistics of pathlength distribution for all the TAR routing cases are sum-marized as in Table 2, which reveals that theoretically inany case the distance between any pair of servers in aSprintNet can be restricted within four. By comparison,the maximum path lengths of Ficonnk and BCubek are
2 � 3k � 1 and 2kþ 2 respectively, which are much longerthan SprintNet. Therefore, SprintNet is a comparativelylow-diameter network.
5. Issues of the server-centric scheme
The computational servers in server-centric architec-tures are not only running regular applications but alsoacting as switches to relay the traffic in the system. Thoughthis brings numerous advantages and convenience, it isalso accompanied by several critical drawbacks:
(1) The network becomes not transparent to servers.Besides, servers cannot be independent of the network,and in some cases of routings, server’s intervention isneeded.
(2) The Operating System kernel or the networkprotocol of a server has to be modified to implement the

290 T. Wang et al. / Computer Networks 79 (2015) 283–296
automatic fault-tolerant routing and flow-level load-bal-ancing. Specifically, the OS must be able to detect currentnetwork status (e.g. connectivity, variation of delay, etc.)and discover feasible alternative routing paths in real-time.Moreover, certain routing protocol (e.g. source routingscheme) must be implemented in order to allow a singleflow transfer through multiple paths simultaneously. How-ever, modifying the OS kernel could be very complicatedand time-consuming in practice (e.g. DCell involves morethan 13,000 lines of C code [12]).
(3) The server may become the bottleneck of overallnetwork performance and leads to additional packetdelays, increased packet loss ratio and deceased aggregatebottleneck throughput, especially when suffering frominsufficient software resources, e.g. CPU time and memorybandwidth [12], and servers cannot completely focus oncomputing and providing regular services.
(4) A certain number of NICs are needed to be installedon each server to meet the future scaling out, which maybe not very practical since most of current data centerservers only have two built-in ports.
(5) It is difficult to implement a Green Data Center sinceservers cannot be powered off even though they are idlefor computing because they still undertake forwardingtasks.
All of the above issues are caused mainly due to puttingthe servers onto the network side and enabling them toforward packets. Based on this careful observation, in Sec-tion 6 we put forward a hard-ware based approach againstthese issues.
6. Approach to improve the performance ofserver-centric scheme
The forwarding tasks of servers in DCell and BCube aresoftware implemented, where they use software for packetforwarding which relies too much on CPU, and the CPUbecomes the major bottleneck hindering the system toachieve all potential capacity gains according to theirexperimental results. As noted in [11,12], the researchersalso expect (not implemented) to use a specially-designednetwork card in the server in future so that server can exe-
A Server: A Server:
Fig. 3. Shifting forwarding task fro
cute the forwarding without the involvement of CPU. Tosome extent this design can reduce the forwarding delay,however, it cannot make the data center network com-pletely transparent to servers. And in the cases of fault-tol-erant routings, it still needs server’s intervention.
In order to totally overcome the drawbacks addressedabove, intuitively the most beneficial way is to shift theforwarding/routing tasks from a server to the networkcompletely which makes servers independent from thenetwork. In view of the above, we propose an efficienthardware-based approach by introducing a dedicatedhardware named ‘‘Forwarding Unit’’. The basic idea underthis approach is as illustrated in Fig. 3. The forwarding unitisolates the server from the network completely and oper-ates as a middleware. In other words, this forwarding unitis totally responsible for the forwarding tasks and the ser-ver does not relay the traffic any more and thus no longercares about the network status. Relieving the CPU from theforwarding work, the server only focuses on computingand its CPU resources can be saved to achieve a better per-formance of services. Furthermore, from the perspective ofusers, the entire data center network can be simplyregarded as a giant switch as shown in Fig. 3 (right), andthe architecture is then reduced down to a logical single-layer data center network in a high level view.
In order to better illustrate the design of forwardingunit, without loss of generality we take a two-layeredSprintNet as the representative of server-centric architec-tures. Fig. 4 shows the internal structure of a forwardingunit which is specially designed for SprintNet. For a certaingiven node in SprintNet, there are at most c
cþ1 nþ 1 possibil-ities of routing path (because each layer contains only
ccþ1 nþ 1 subsystems), and each node has only up to3 � c
cþ1 n� 1 choices for one hop (because each node canreach 3 � c
cþ1 n� 1 nodes in one hop via one switch), hencea route table with the size of only ð c
cþ1 nþ 1Þlog2
ð3 � ccþ1 n� 1Þ bits can describe its routing behaviors. There-
fore, for a SprintNet with 9312 servers wheren ¼ 128; c ¼ 3, the route table stored in the forwardingunit is just 99 bytes which implies a very small hardwarecost. This provides the possibility that all the route tablescan be pre-calculated and be stored in the forwarding units
Data Center Network
(as a giant switch)
server
m a server to the network.

st ndst nd
* The content of the is pre-calculated and customized for each individual server according to its loca�on in a SprintNet.
Fig. 4. The internal structure of a forwarding unit.
T. Wang et al. / Computer Networks 79 (2015) 283–296 291
in advance, and then in the future be used directly at thecomplexity of Oð1Þ, which can save much time cost in com-puting routing paths. In this way, the system behaves moreeffectively without wasting time in calculating the routetables before determining a path and avoids the high net-work overhead brought by broadcasting path-probingpackets. Under the circumstances of fault-tolerance or net-work virtualization, we can offline calculate the routingstrategies, and then make appropriate corresponding con-figurations to the forwarding units.
Moreover, this forwarding unit based approach whichshifts the control of routing/forwarding from servers tothe network is also in line with the principle of currenttrend of Software Defined Network. The system can adoptOpenFlow-like technology to achieve a global configura-tion and management for the routing behaviors. The con-troller can be an independent server or hosted on acompute server. In order to deal with the single point fail-ure of the controller, multiple controllers can be used,where these controller have different roles: OFPCR_RO-LE_EQUAL, OFPCR_ROLE_MASTER, and OFPCR_ROLE_-SLAVE (as specified in [1]) to guarantee the robustness ofthe system. The forwarding unit should be Openflowenabled by installing flow tables and group tables so asto implement the pipeline processing. The controller-to-switch messages (such as feature messages, switchconfiguration messages, flow table configuration messages,modify-state messages, read-state messages, packet-out,barrier message, and role request messages), asynchronousmessages (OFPT_PACKET_IN, OFPT_FLOW_REMOVED,OFPT_PORT_STATUS, and OFPT_ERROR_MSG) and sym-metric messages (Hello messages, Echo messages andExperimenter messages) can be transmitted throughOpenflow secure channel either in band or out of band.With the help of Openflow technology, the system can gaina better flow scheduling in data center networks, and canbetter realize the network virtualization as well. Besides,against the shortcomings that the routing paths inserver-centric architectures are comparatively long andmultiple additional forwarding actions are needed, the
OpenFlow-like technology is much easier to manage themglobally which can further improve the system’s flexibility.
Additionally, following this scheme the entire data cen-ter network can be designed as a whole, and its internalrouting is simplified, for example, there is no need to con-sider the case of server failures. The complex cablingwithin the data center network can be directly imple-mented on the PCB or with the help of a dedicated physicalport which makes the deployment simplified. And the sys-tem becomes more reliable.
The common problem of adopting openflow technologyis that the extra latency (such as round-trip time and routecomputing time) incurred by interaction between the for-warding unit and the controller even though such latencyis acceptable for elephant flows.
Concluding from the above analysis and discussions, onthe one hand the forwarding unit is a hardware-basedimplementation approach which logically flattens the datacenter network and makes the internal network work as alogical giant switch. On the other hand, it provides an effi-cient way to improve the performance of server-centricarchitectures. Additionally, it follows the core idea of soft-ware defined network, but without changing the switch,and it also gives full consideration on the hardware’s costproblem of forwarding unit (more in subSection 7.3).
7. Evaluation
In this section, extensive simulations are conducted toevaluate the performance of SprintNet and forwarding unitapproach under various network conditions using the TARrouting scheme.
7.1. Simulation overview
All simulations are conducted using our DCNSim [18]simulator, which can simulate several data center networktopologies (such as DCell, FatTree, BCube, FlatNet, andHyperBCube) and compute various metrics, such asthroughput, network latency, average path length, fault-tolerance, and so on. We implement SprintNet architectureand its traffic-aware routing algorithm in DCNSim to enableconducting comprehensive evaluation. The all-to-all trafficpattern, which simulates the most intensive network activ-ities, is used to evaluate the guaranteed performance underthe most rigorous cases. Furthermore, according to thefindings in [4] about the characteristics of the packet-levelcommunications, the packet inter-arrival time reveals anON/OFF pattern and its distribution follows the Lognormalmode for OFF phase, while the distribution varies betweenLognormal mode, Weibull mode and Exponential mode indifferent data centers during the application-sensitive ONphase. In our simulations, the Lognormal distribution mode(directly using the Simjava package of eduni.simjava.distri-butions [13]) is applied to determine the inter-arrival timeof packets. All the links are capable of bidirectional commu-nications with 1 GBps unidirectional link bandwidth. Thepacket size is set to be 1500 bytes which equals to thedefault MTU of a link. Additionally, the default TTL of apacket in TAR routing is set as 128.

Table 4The statistics for the case of 1056-server SprintNet.
All-to-all traffic pattern & Uniform distribution flow mode
Flow statistics (4,257,792 flowsin total)
3,176,448 flows using 2112level-0 links1,081,344 flows using 1056level-1 links
Route statistics (1,114,080routes in total)
99,264 paths of length 21,014,816 paths of length 4
Average path length 3.82
Table 5The ABT of 2352-server SprintNet and DCell.
ABT NClinks NCPABT (%) 1APL (%)
All-to-all traffic pattern (2352-server network)SprintNet 4762 18,816 25.31 1
3:88 ¼ 25:77DCell 1213 7056 17.19 1
4:86 ¼ 20:58
292 T. Wang et al. / Computer Networks 79 (2015) 283–296
7.2. Evaluation of SprintNet
This subsection presents the simulation results of theSprintNet evaluation. In order to better illustrate the overallperformance of this architecture, the simulations are con-ducted from the following four aspects.
7.2.1. Average path lengthIn order to evaluate the overall performance of the
whole network, the link-count based average path length(APL) is used, where APL has a great impact on packetdelay. Table 3 demonstrates the simulation results aboutAPL for eight different sized 2-layer SprintNets and DCells.And Table 4 illustrates the detailed statistics of flows androutes for the case of 1056-server SprintNet. It can be seenfrom Table 3 that SprintNet owns shorter APL comparingwith DCell regardless of the network size. Besides, theexperiment also reveals that the APL varies slightly for dif-ferent sizes of SprintNet, and in general a larger sizedSprintNet holds longer APLs.
7.2.2. Aggregate bottleneck throughputAs illustrated in Eq. (1) in Section 3.2, the aggregate bot-
tleneck throughput ABT is inversely proportion to the aver-age path length APL (i.e. NCPABT ¼ 1
APL). Table 5 presents theexperimental results of ABT for 2353-server SprintNet andDCell under all-to-all traffic pattern. The result shows thatSprintNet achieves both higher ABT and NCPABT than DCell.Take SprintNet for example, as shown in Table 5, the Nlinks ofa 2353-server SprintNet is 9408, hence its NClinks is9408⁄2 = 18,816 (two-way communication). Given theAPL of a 2352-server SprintNet is 3.88, its ABT reaches4762, therefore its NCPABT ¼ 4762
18;816 ¼ 25:31%, which isalready very close to its theoretical limit( 1
APL ¼ 13:88 ¼ 25:77%). This reveals the good performance
of the SprintNet in the aggregate bottleneck throughput.
7.2.3. Speedup of the first layerLike other server-centric proposals, in SprintNet, the
network traffic burden carried on different layers differs.According to the simulation results as shown in Table 4,the level-0 links undertake higher network loads whichresults in a higher link utilization rate. This careful obser-vation reveals that the first layer is more likely to occur
Table 3The average path length statistics.
Network size-number of servers Average path length
SprintNet
20 (ns ¼ 6, c = 2, nd ¼ 4) 2.9572 (ns ¼ 12, c = 2, nd ¼ 8) 3.38156 (ns ¼ 18, c = 2, nd ¼ 12) 3.56272 (ns ¼ 24, c = 2, nd ¼ 16) 3.66600 (ns ¼ 30, c = 2, nd ¼ 24) 3.771056 (ns ¼ 48, c = 2, nd ¼ 32) 3.821332 (ns ¼ 48, c = 3, nd ¼ 36) 3.842352 (ns ¼ 64, c = 3, nd ¼ 48) 3.88
⁄ns and c denote the number of ns-port switches per Cell in SprintNet is c.nd indicates nd-port switch used in DCell.
network congestion and become the system’s bottleneck.Fig. 5 presents the simulation results for three differentsized SprintNet with different speedup factors using TARand NRS routing schemes, which exhibits that the aggre-gate bottleneck throughput can be further improved withcertain speedup of first layer. Another intuitive finding,which can be derived from Fig. 5, is that NRS schemeobtains slightly higher ABT than TAR scheme mainly dueto the induced higher extra network load by NRS. Accord-ing to the evaluation results, the most beneficial speedupfactor to the first layer network is suggested as 1.3�1.5,which leads to a more cost-effective data center network.
7.2.4. Network reliabilityFigs. 6 and 7 demonstrate the performance of a 1056-
sever SprintNet in ABT and APL under various faulty condi-tions applying the Traffic-aware Adaptive Routing scheme.Although the ABT degrades as the failure rate increases, asshown in Fig. 6, the network still achieves 86.5%, 87.9%,and 89.3% of the fault-free ABT (failure rate = 0%) whenthe switch/server/link failure rate reaches 10% respec-tively. The ABT decreases most for the switch failure case,where its ABT reduces to 1260.98 for 10% failure rate.
Diameter
DCell SprintNet DCell
3.68 4 54.25 4 54.48 4 54.60 4 54.72 4 54.79 4 54.81 4 54.86 4 5
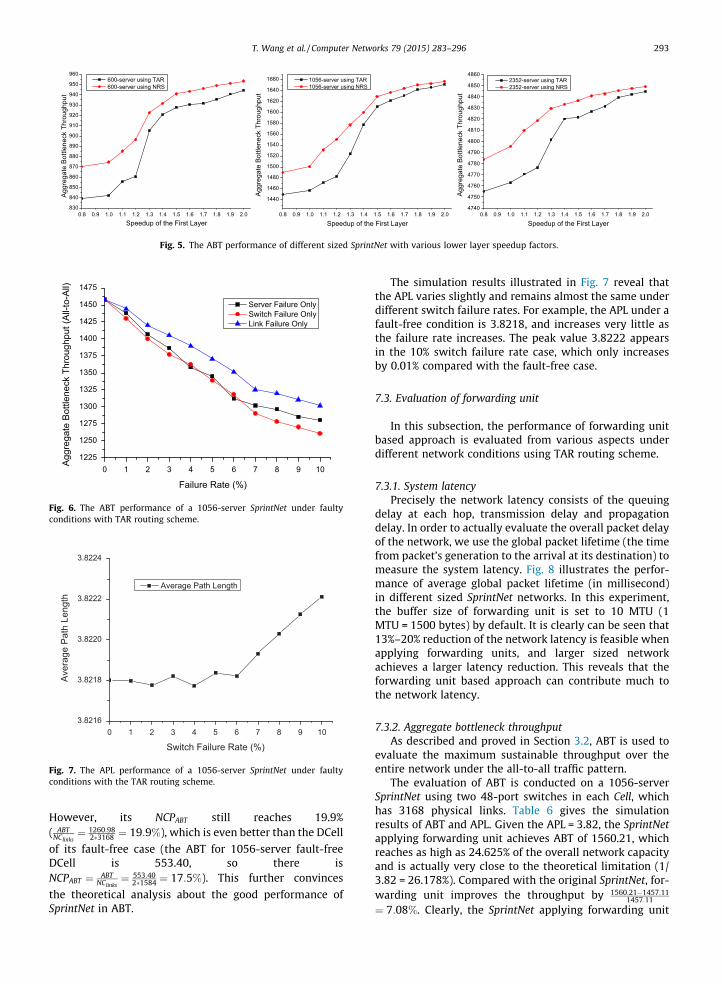
0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0830
840
850
860
870
880
890
900
910
920
930
940
950
960
0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
1440
1460
1480
1500
1520
1540
1560
1580
1600
1620
1640
1660
0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.04740
4750
4760
4770
4780
4790
4800
4810
4820
4830
4840
4850
4860
AggregateBottleneckThroughput
Speedup of the First Layer
600-server using TAR600-server using NRS
AggregateBottleneckThroughput
Speedup of the First Layer
1056-server using TAR1056-server using NRS
AggregateBottleneckThroughput
Speedup of the First Layer
2352-server using TAR2352-server using NRS
Fig. 5. The ABT performance of different sized SprintNet with various lower layer speedup factors.
0 1 2 3 4 5 6 7 8 9 101225
1250
1275
1300
1325
1350
1375
1400
1425
1450
1475
AggregateBottleneckThroughput(All-to-All)
Failure Rate (%)
Server Failure OnlySwitch Failure OnlyLink Failure Only
Fig. 6. The ABT performance of a 1056-server SprintNet under faultyconditions with TAR routing scheme.
0 1 2 3 4 5 6 7 8 9 103.8216
3.8218
3.8220
3.8222
3.8224
AveragePathLength
Switch Failure Rate (%)
Average Path Length
Fig. 7. The APL performance of a 1056-server SprintNet under faultyconditions with the TAR routing scheme.
T. Wang et al. / Computer Networks 79 (2015) 283–296 293
However, its NCPABT still reaches 19.9%( ABT
NClinks¼ 1260:98
2�3168 ¼ 19:9%), which is even better than the DCell
of its fault-free case (the ABT for 1056-server fault-freeDCell is 553.40, so there isNCPABT ¼ ABT
NClinks¼ 553:40
2�1584 ¼ 17:5%). This further convinces
the theoretical analysis about the good performance ofSprintNet in ABT.
The simulation results illustrated in Fig. 7 reveal thatthe APL varies slightly and remains almost the same underdifferent switch failure rates. For example, the APL under afault-free condition is 3.8218, and increases very little asthe failure rate increases. The peak value 3.8222 appearsin the 10% switch failure rate case, which only increasesby 0.01% compared with the fault-free case.
7.3. Evaluation of forwarding unit
In this subsection, the performance of forwarding unitbased approach is evaluated from various aspects underdifferent network conditions using TAR routing scheme.
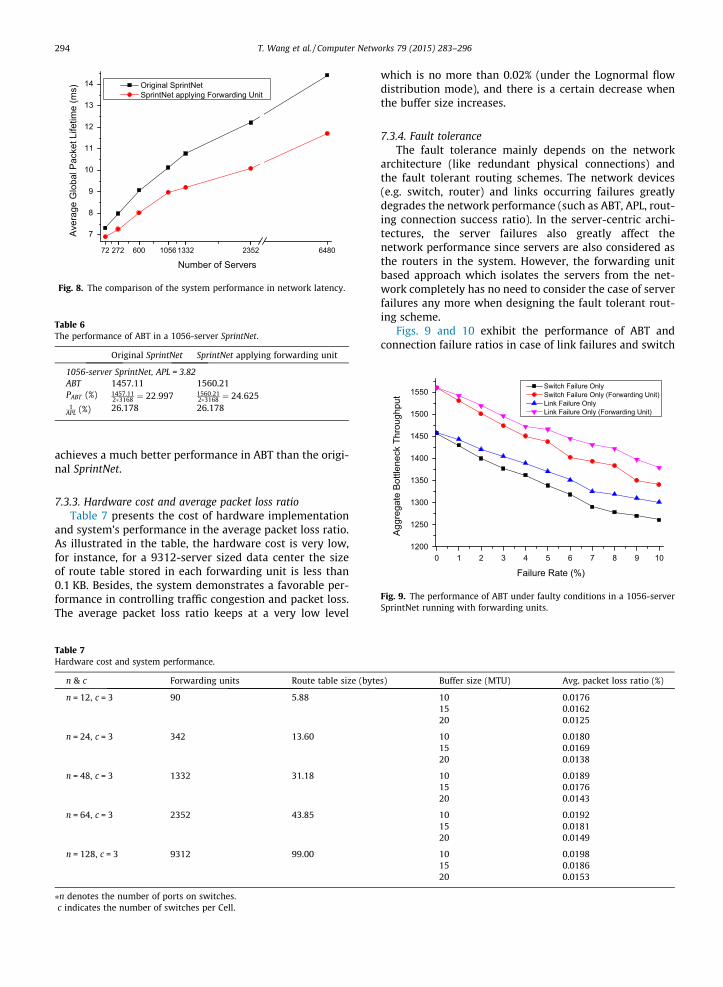
7.3.1. System latencyPrecisely the network latency consists of the queuing
delay at each hop, transmission delay and propagationdelay. In order to actually evaluate the overall packet delayof the network, we use the global packet lifetime (the timefrom packet’s generation to the arrival at its destination) tomeasure the system latency. Fig. 8 illustrates the perfor-mance of average global packet lifetime (in millisecond)in different sized SprintNet networks. In this experiment,the buffer size of forwarding unit is set to 10 MTU (1MTU = 1500 bytes) by default. It is clearly can be seen that13%–20% reduction of the network latency is feasible whenapplying forwarding units, and larger sized networkachieves a larger latency reduction. This reveals that theforwarding unit based approach can contribute much tothe network latency.
7.3.2. Aggregate bottleneck throughputAs described and proved in Section 3.2, ABT is used to
evaluate the maximum sustainable throughput over theentire network under the all-to-all traffic pattern.
The evaluation of ABT is conducted on a 1056-serverSprintNet using two 48-port switches in each Cell, whichhas 3168 physical links. Table 6 gives the simulationresults of ABT and APL. Given the APL = 3.82, the SprintNetapplying forwarding unit achieves ABT of 1560.21, whichreaches as high as 24.625% of the overall network capacityand is actually very close to the theoretical limitation (1/3.82 = 26.178%). Compared with the original SprintNet, for-warding unit improves the throughput by 1560:21�1457:11
1457:11
¼ 7:08%. Clearly, the SprintNet applying forwarding unit
72 272 600 10561332 2352 6480
7
8
9
10
11
12
13
14AverageGlobalPacketLifetime(ms)
Number of Servers
Original SprintNetSprintNet applying Forwarding Unit
Fig. 8. The comparison of the system performance in network latency.
Table 6The performance of ABT in a 1056-server SprintNet.
Original SprintNet SprintNet applying forwarding unit
1056-server SprintNet, APL = 3.82ABT 1457.11 1560.21PABT (%) 1457:11
2�3168 ¼ 22:997 1560:212�3168 ¼ 24:625
1APL (%) 26.178 26.178
1400
1450
1500
1550ttleneckThroughput
Switch Failure OnlySwitch Failure Only (Forwarding Unit)Link Failure OnlyLink Failure Only (Forwarding Unit)
294 T. Wang et al. / Computer Networks 79 (2015) 283–296
achieves a much better performance in ABT than the origi-nal SprintNet.
0 1 2 3 4 5 6 7 8 9 101200
1250
1300
1350
AggregateBo
Failure Rate (%)
Fig. 9. The performance of ABT under faulty conditions in a 1056-serverSprintNet running with forwarding units.
7.3.3. Hardware cost and average packet loss ratioTable 7 presents the cost of hardware implementation
and system’s performance in the average packet loss ratio.As illustrated in the table, the hardware cost is very low,for instance, for a 9312-server sized data center the sizeof route table stored in each forwarding unit is less than0.1 KB. Besides, the system demonstrates a favorable per-formance in controlling traffic congestion and packet loss.The average packet loss ratio keeps at a very low level
Table 7Hardware cost and system performance.
n & c Forwarding units Route table size (byte
n = 12, c = 3 90 5.88
n = 24, c = 3 342 13.60
n = 48, c = 3 1332 31.18
n = 64, c = 3 2352 43.85
n = 128, c = 3 9312 99.00
⁄n denotes the number of ports on switches.c indicates the number of switches per Cell.
which is no more than 0.02% (under the Lognormal flowdistribution mode), and there is a certain decrease whenthe buffer size increases.
7.3.4. Fault toleranceThe fault tolerance mainly depends on the network
architecture (like redundant physical connections) andthe fault tolerant routing schemes. The network devices(e.g. switch, router) and links occurring failures greatlydegrades the network performance (such as ABT, APL, rout-ing connection success ratio). In the server-centric archi-tectures, the server failures also greatly affect thenetwork performance since servers are also considered asthe routers in the system. However, the forwarding unitbased approach which isolates the servers from the net-work completely has no need to consider the case of serverfailures any more when designing the fault tolerant rout-ing scheme.
Figs. 9 and 10 exhibit the performance of ABT andconnection failure ratios in case of link failures and switch
s) Buffer size (MTU) Avg. packet loss ratio (%)
10 0.017615 0.016220 0.0125
10 0.018015 0.016920 0.0138
10 0.018915 0.017620 0.0143
10 0.019215 0.018120 0.0149
10 0.019815 0.018620 0.0153
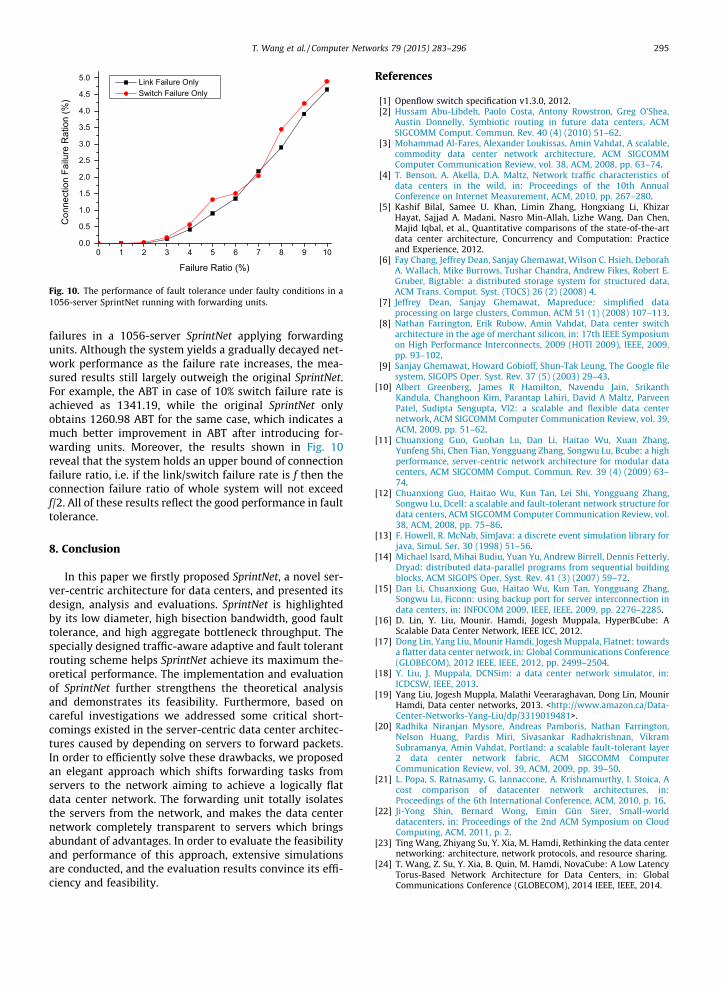
0 1 2 3 4 5 6 7 8 9 100.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
ConnectionFailureRation(%)
Failure Ratio (%)
Link Failure OnlySwitch Failure Only
Fig. 10. The performance of fault tolerance under faulty conditions in a1056-server SprintNet running with forwarding units.
T. Wang et al. / Computer Networks 79 (2015) 283–296 295
failures in a 1056-server SprintNet applying forwardingunits. Although the system yields a gradually decayed net-work performance as the failure rate increases, the mea-sured results still largely outweigh the original SprintNet.For example, the ABT in case of 10% switch failure rate isachieved as 1341.19, while the original SprintNet onlyobtains 1260.98 ABT for the same case, which indicates amuch better improvement in ABT after introducing for-warding units. Moreover, the results shown in Fig. 10reveal that the system holds an upper bound of connectionfailure ratio, i.e. if the link/switch failure rate is f then theconnection failure ratio of whole system will not exceedf/2. All of these results reflect the good performance in faulttolerance.
8. Conclusion
In this paper we firstly proposed SprintNet, a novel ser-ver-centric architecture for data centers, and presented itsdesign, analysis and evaluations. SprintNet is highlightedby its low diameter, high bisection bandwidth, good faulttolerance, and high aggregate bottleneck throughput. Thespecially designed traffic-aware adaptive and fault tolerantrouting scheme helps SprintNet achieve its maximum the-oretical performance. The implementation and evaluationof SprintNet further strengthens the theoretical analysisand demonstrates its feasibility. Furthermore, based oncareful investigations we addressed some critical short-comings existed in the server-centric data center architec-tures caused by depending on servers to forward packets.In order to efficiently solve these drawbacks, we proposedan elegant approach which shifts forwarding tasks fromservers to the network aiming to achieve a logically flatdata center network. The forwarding unit totally isolatesthe servers from the network, and makes the data centernetwork completely transparent to servers which bringsabundant of advantages. In order to evaluate the feasibilityand performance of this approach, extensive simulationsare conducted, and the evaluation results convince its effi-ciency and feasibility.
References
[1] Openflow switch specification v1.3.0, 2012.[2] Hussam Abu-Libdeh, Paolo Costa, Antony Rowstron, Greg O’Shea,
Austin Donnelly, Symbiotic routing in future data centers, ACMSIGCOMM Comput. Commun. Rev. 40 (4) (2010) 51–62.
[3] Mohammad Al-Fares, Alexander Loukissas, Amin Vahdat, A scalable,commodity data center network architecture, ACM SIGCOMMComputer Communication Review, vol. 38, ACM, 2008, pp. 63–74.
[4] T. Benson, A. Akella, D.A. Maltz, Network traffic characteristics ofdata centers in the wild, in: Proceedings of the 10th AnnualConference on Internet Measurement, ACM, 2010, pp. 267–280.
[5] Kashif Bilal, Samee U. Khan, Limin Zhang, Hongxiang Li, KhizarHayat, Sajjad A. Madani, Nasro Min-Allah, Lizhe Wang, Dan Chen,Majid Iqbal, et al., Quantitative comparisons of the state-of-the-artdata center architecture, Concurrency and Computation: Practiceand Experience, 2012.
[6] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, DeborahA. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E.Gruber, Bigtable: a distributed storage system for structured data,ACM Trans. Comput. Syst. (TOCS) 26 (2) (2008) 4.
[7] Jeffrey Dean, Sanjay Ghemawat, Mapreduce: simplified dataprocessing on large clusters, Commun. ACM 51 (1) (2008) 107–113.
[8] Nathan Farrington, Erik Rubow, Amin Vahdat, Data center switcharchitecture in the age of merchant silicon, in: 17th IEEE Symposiumon High Performance Interconnects, 2009 (HOTI 2009), IEEE, 2009,pp. 93–102.
[9] Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung, The Google filesystem, SIGOPS Oper. Syst. Rev. 37 (5) (2003) 29–43.
[10] Albert Greenberg, James R Hamilton, Navendu Jain, SrikanthKandula, Changhoon Kim, Parantap Lahiri, David A Maltz, ParveenPatel, Sudipta Sengupta, Vl2: a scalable and flexible data centernetwork, ACM SIGCOMM Computer Communication Review, vol. 39,ACM, 2009, pp. 51–62.
[11] Chuanxiong Guo, Guohan Lu, Dan Li, Haitao Wu, Xuan Zhang,Yunfeng Shi, Chen Tian, Yongguang Zhang, Songwu Lu, Bcube: a highperformance, server-centric network architecture for modular datacenters, ACM SIGCOMM Comput. Commun. Rev. 39 (4) (2009) 63–74.
[12] Chuanxiong Guo, Haitao Wu, Kun Tan, Lei Shi, Yongguang Zhang,Songwu Lu, Dcell: a scalable and fault-tolerant network structure fordata centers, ACM SIGCOMM Computer Communication Review, vol.38, ACM, 2008, pp. 75–86.
[13] F. Howell, R. McNab, SimJava: a discrete event simulation library forjava, Simul. Ser. 30 (1998) 51–56.
[14] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, Dennis Fetterly,Dryad: distributed data-parallel programs from sequential buildingblocks, ACM SIGOPS Oper. Syst. Rev. 41 (3) (2007) 59–72.
[15] Dan Li, Chuanxiong Guo, Haitao Wu, Kun Tan, Yongguang Zhang,Songwu Lu, Ficonn: using backup port for server interconnection indata centers, in: INFOCOM 2009, IEEE, IEEE, 2009, pp. 2276–2285.
[16] D. Lin, Y. Liu, Mounir. Hamdi, Jogesh Muppala, HyperBCube: AScalable Data Center Network, IEEE ICC, 2012.
[17] Dong Lin, Yang Liu, Mounir Hamdi, Jogesh Muppala, Flatnet: towardsa flatter data center network, in: Global Communications Conference(GLOBECOM), 2012 IEEE, IEEE, 2012, pp. 2499–2504.
[18] Y. Liu, J. Muppala, DCNSim: a data center network simulator, in:ICDCSW, IEEE, 2013.
[19] Yang Liu, Jogesh Muppla, Malathi Veeraraghavan, Dong Lin, MounirHamdi, Data center networks, 2013. <http://www.amazon.ca/Data-Center-Networks-Yang-Liu/dp/3319019481>.
[20] Radhika Niranjan Mysore, Andreas Pamboris, Nathan Farrington,Nelson Huang, Pardis Miri, Sivasankar Radhakrishnan, VikramSubramanya, Amin Vahdat, Portland: a scalable fault-tolerant layer2 data center network fabric, ACM SIGCOMM ComputerCommunication Review, vol. 39, ACM, 2009, pp. 39–50.
[21] L. Popa, S. Ratnasamy, G. Iannaccone, A. Krishnamurthy, I. Stoica, Acost comparison of datacenter network architectures, in:Proceedings of the 6th International Conference, ACM, 2010, p. 16.
[22] Ji-Yong Shin, Bernard Wong, Emin Gün Sirer, Small-worlddatacenters, in: Proceedings of the 2nd ACM Symposium on CloudComputing, ACM, 2011, p. 2.
[23] Ting Wang, Zhiyang Su, Y. Xia, M. Hamdi, Rethinking the data centernetworking: architecture, network protocols, and resource sharing.
[24] T. Wang, Z. Su, Y. Xia, B. Quin, M. Hamdi, NovaCube: A Low LatencyTorus-Based Network Architecture for Data Centers, in: GlobalCommunications Conference (GLOBECOM), 2014 IEEE, IEEE, 2014.

296 T. Wang et al. / Computer Networks 79 (2015) 283–296
Ting Wang received his Bachelor Sci. degreefrom University of Science and TechnologyBeijing, China, in 2008, and received hisMaster Eng. degree from Warsaw Universityof Technology, Poland, in 2011. From 02.2012to 08.2012 he interned as a research assistantin the Institute of Computing Technology,Chinese Academy of Sciences. He is currentlyworking towards the Ph.D. degree in HongKong University of Science and Technology.His research interests include data centernetworks, cloud computing, green computing,
and software defined network.
Zhiyang Su received his B.E. degree in com-puter science and technology from ChinaUniversity of Geosciences (Beijing) in 2009,and M.S. degree in computer network andapplication from Peking University in 2012.Currently, he is pursuing Ph.D. degrees inHong Kong University of Science and Tech-nology. His research interests focus on soft-ware defined networking (SDN) and datacenter networking, especially on improvingthe performance of SDN.
Yu Xia is currently a postdoctoral fellow inDepartment of Computer Science and Engi-neering, the Hong Kong University of Scienceand Technology. He received the Ph.D. incomputer science from Southwest JiaotongUniversity, China. He was a joint Ph.D studentand a visiting scholar at Polytechnic Instituteof New York University. His research interestsinclude high-performance packet switches,data center networks and network architec-tures.
Jogesh Muppala received the Ph.D. degree inElectrical Engineering from Duke University,Durham, NC in 1991, the M.S. degree inComputer Engineering from The Center forAdvanced Computer Studies, University ofSouthwestern Louisiana (now University ofLouisiana at Lafayette), Lafayette, LA in 1987and the B.E. degree in Electronics and Com-munication Engineering from Osmania Uni-versity, Hyderabad, India in 1985. He iscurrently an associate professor in theDepartment of Computer Science and Engi-
neering, The Hong Kong University of Science and Technology, ClearWater Bay, Kowloon, Hong Kong. He is also currently serving as the
program director for the Master of Science in Information Technology(MSc(IT)) program. He also served as the Undergraduate Studies Directorin the Computer Science Department from August 1999 to August 2001,and the Chair of Facilities Committee in the department from September2005 to August 2007. He was previously a Member of the Technical Staffat Software Productivity Consortium (Herndon, Virginia, USA) from 1991to 1992, where he was involved in the development of modeling tech-niques for systems and software. While at Duke University, he partici-pated in the development of two modeling tools, the Stochastic Petri NetPackage (SPNP) and the symbolic Hierarchical Automated Reliability andPerformance Evaluator (SHARPE), both of which are being used in severaluniversities and industry in the USA. He co-founded the InternationalWorkshop on Dependability of Clouds, Data Centers and Virtual MachineTechnology (DCDV). He was also the program co-chair for the 1999 PacificRim International Symposium on Dependable Computing held in HongKong in December 1999. He also co-founded and organized The 1st Asia–Pacific Workshop on Embedded System Education and Research (APE-SER). He has also served on program committees of many internationalconferences.
Mounir Hamdi received the B.S. degree inElectrical Engineering – Computer Engineer-ing minor (with distinction) from the Uni-versity of Louisiana in 1985, and the MS andthe PhD degrees in Electrical Engineeringfrom the University of Pitts-burgh in 1987 and1991, respectively. He is a Chair Professor atthe Hong Kong University of Science andTechnology, and was the head of departmentof computer science and engineering. Now heis the Dean of the College of Science, Engi-neering and Technology at the Hamad Bin
Khalifa University, Qatar. He is an IEEE Fellow for contributions to designand analysis of high-speed packet switching. He is/was on the EditorialBoard of various prestigious journals and magazines including IEEE
Transactions on Communications, IEEE Communication Magazine, Com-puter Networks, Wireless Communications and Mobile Computing, andParallel Computing as well as a guest editor of IEEE CommunicationsMagazine, guest editor-in-chief of two special issues of IEEE Journal onSelected Areas of Communications, and a guest editor of Optical NetworksMagazine. He has chaired more than 20 international conferences andworkshops including The IEEE International High Performance Switchingand Routing Conference, the IEEE GLOBECOM/ICC Optical networkingworkshop, the IEEE ICC High-speed Access Workshop, and the IEEE IPPSHiNets Workshop, and has been on the program committees of more than200 international conferences and workshops. He was the Chair of IEEECommunications Society Technical Committee on Transmissions, Accessand Optical Systems, and Vice-Chair of the Optical Networking TechnicalCommittee, as well as member of the ComSoc technical activities council.He received the best paper award at the IEEE International Conference onCommunications in 2009 and the IEEE International Conference onInformation and Networking in 1998. He also supervised the best PhDpaper award among all universities in Hong Kong.

















