
Design databáze - PROFINIT · UML – notace dle standardu UML, použita ve všechny nástroje...
59
1 Design databáze RNDr. Ondřej Zýka
Transcript of Design databáze - PROFINIT · UML – notace dle standardu UML, použita ve všechny nástroje...

1
Design databáze
RNDr. Ondřej Zýka

2 2
Návrh databáze
Čtyři kroky
Shromáždění business požadavků
Konceptuální model
Logický model
Fyzický model
Modelování od začátku nebo rozvoj stávajících systémů
Nutnost začlenění okolních systémů (prostředí)
Vazba na logický model organizace
Vazba na existující datové modely

3 3
Shromáždění business požadavků
Cíle
Pochopit business doménu
Porozumět potřebám a požadavkům zadavatelů a uživatelů
Ověřit pochopení zadání
Prostředky
Interview
Studium a dokumentace systémů
Spolupráce s experty v business oblasti
Informace o organizační struktuře a další dokumenty
Data assesment
Review stávajících systémů a procesů
Výstup
Prioritizovaný seznam požadavků
Dokument popisující doménu (byznys slovník)
Data-flow diagram

4 4
Data-flow diagram
Data-flow diagram popisuje
S jakými daty se pracuje
Kdo data vytváří
Kdo a jak data zpracovává (modifikuje)
Kde jsou data uložena
Kdo data používá
Interface na úrovni dat
Použití
Datové toky na různých úrovních granularity
Podnikové toky dat (obchodní procesy)
Toky dat na technické úrovni
Popisy ETL procesů
Popisy integračních procesů
Ověření
Všechna data jsou definována
Persistentní data jsou uložena
Každá data mají zdroj
Pro každá data existuje odběratel
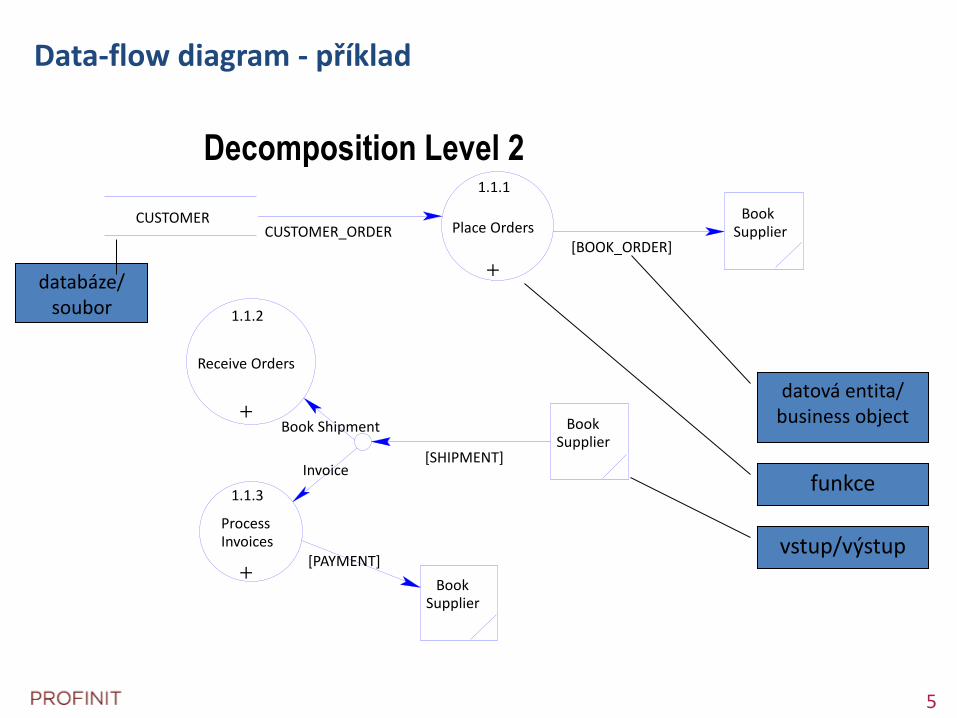
5 5
Data-flow diagram - příklad
CUSTOMER_ORDER
Invoice
Book Shipment
[PAYMENT]
[SHIPMENT]
[BOOK_ORDER]
Book Supplier
Book Supplier
Book Supplier
1.1.1
Place Orders
+
1.1.2
Receive Orders
+
1.1.3
Process Invoices
+
Decomposition Level 2
CUSTOMER
databáze/ soubor
funkce
datová entita/ business object
vstup/výstup
6 6
Seznam požadavků

7 7
Seznam požadavků
ID požadavku
Krátký popis
Podrobné vysvětlení
Oblast / systém
Vazba na další požadavky
Zadavatel
Priorita
Funkční / nefunkční požadavky

8 8
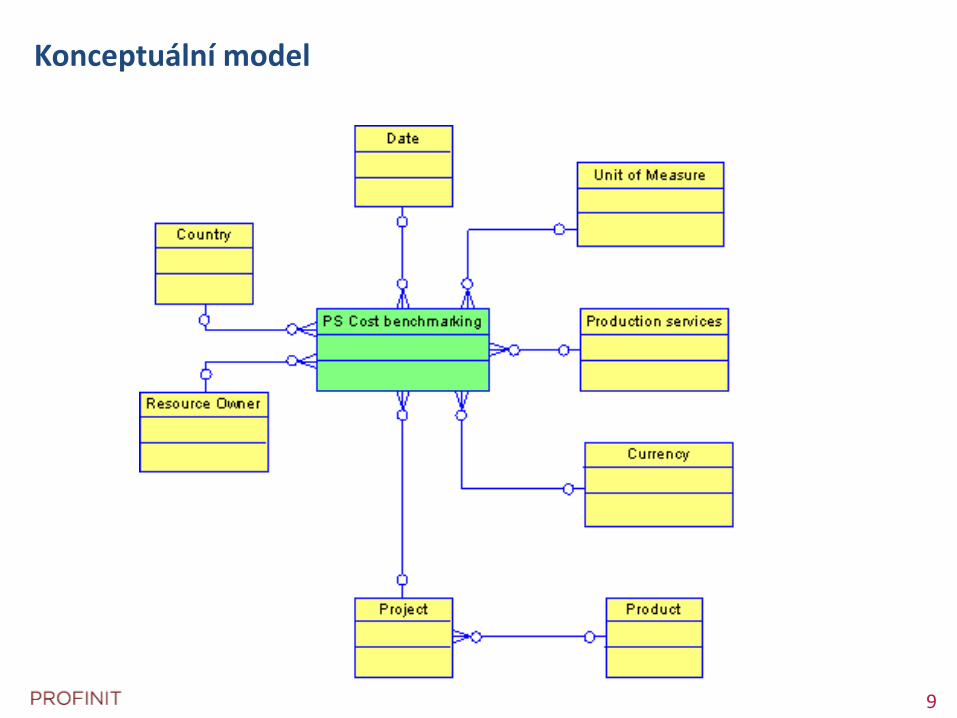
Konceptuální model
Cíle
Určit entity a jejich atributy
U atributů určit jejich hodnoty a vlastnosti
U entit určit jejich potenciální klíče (identifikátory)
Identifikovat vazby mezi entitami
Kardinalita relace
Jméno relace
Popis (role)
Výstupy
ER diagram
Formální ověření E/R diagramu
Mezi každými dvěma entitami je maximálně jedna relace.
Neexistuje cyklická závislost.
Entity s relací typu 1:1 zřejmě budou tvořit pouze jednu entitu.
Žádná entita nemá atribut, který je kandidátním klíčem jiné entity.
Nepřímé relace jsou asi zbytečné.
9 9
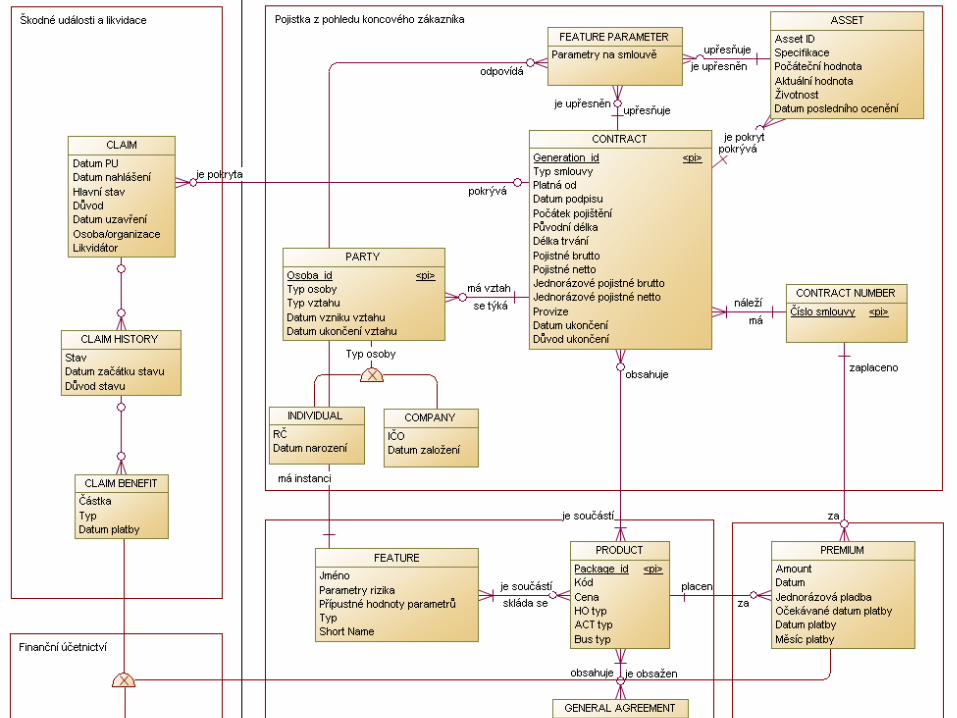
Konceptuální model
10 10

11 11
Notace
Mnoho standardů a dodavatelských specifik.
UML – notace dle standardu UML, použita ve všechny nástroje podporující UML.
Information Engineering – standard používaný v mnoha nástrojích. Existuje několik verzí. Obecně, entity jsou obdélníka a relace jsou linky s různými zakončeními.
IDEF1X – standardní notace pro modelování relací a entit. Symboly označují kombinaci volitelnosti a kardinality entity.
Barker – Vytvořena Richardem Barkerem. Používaná zejména case nastroji Oracle. Speciální notace pro dědičnost, vlastní notace pro násobnost a speciální značky pro atributy.
Filtered IE – pouze v Embarcadero. Nezobrazuje cizí klíče.
Entity/Relationship – Sybase specific, Entity/Relationship je speciální verze IE notace.
Merise – používá asociace místo relací.
Crow's Feed – Jedna z verzí IE notace, tuto notaci používá FSLDM.
12 12
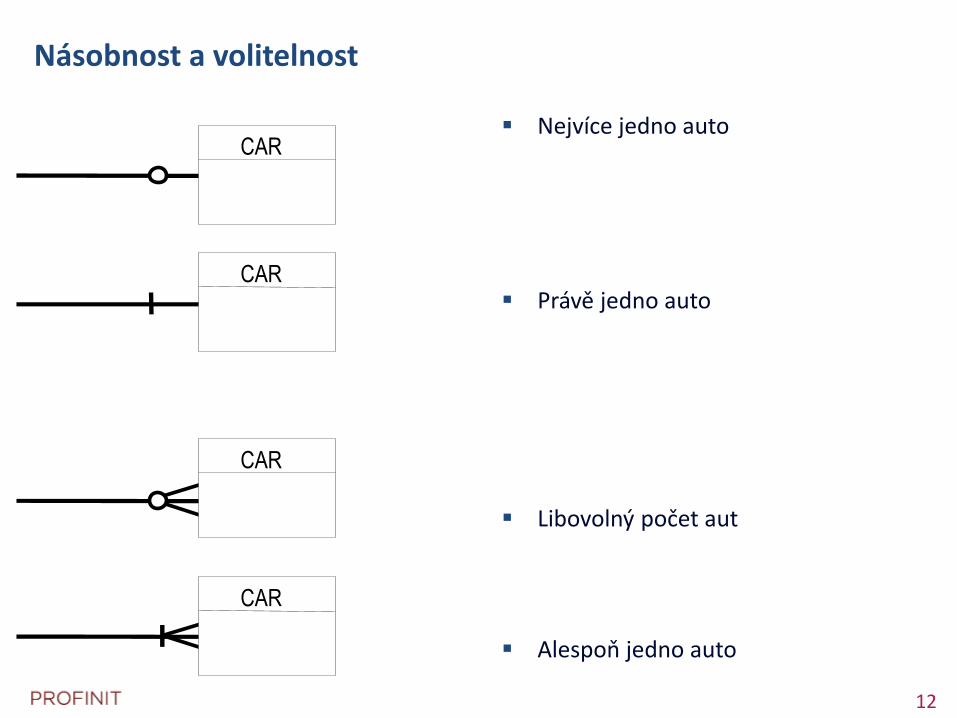
Násobnost a volitelnost
Nejvíce jedno auto
Právě jedno auto
Libovolný počet aut
Alespoň jedno auto
CAR
CAR
CAR
CAR
13 13
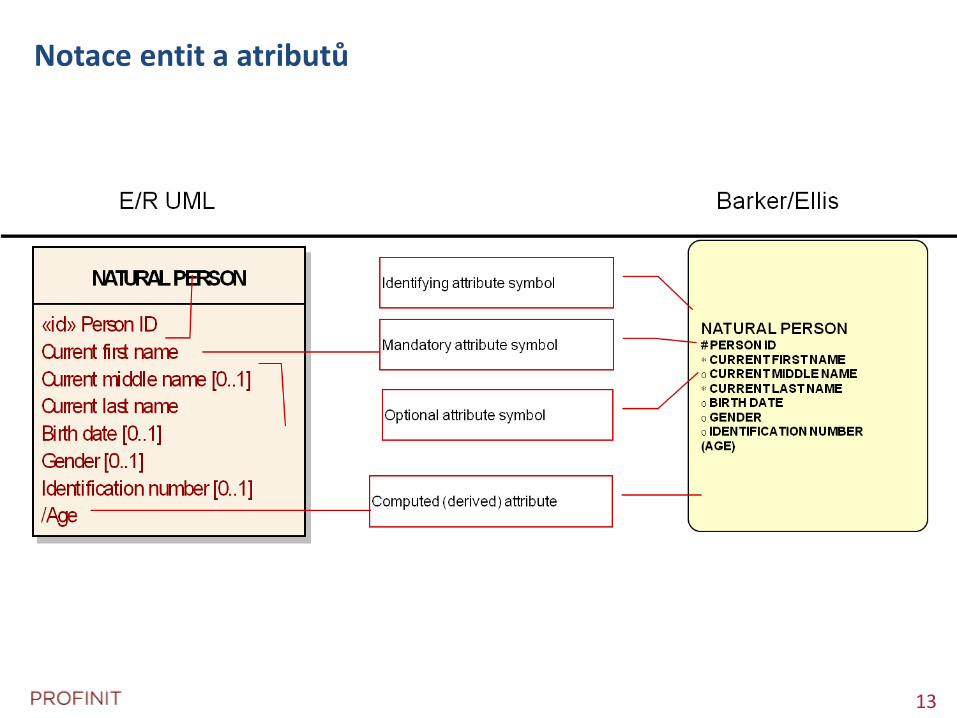
Notace entit a atributů
14 14
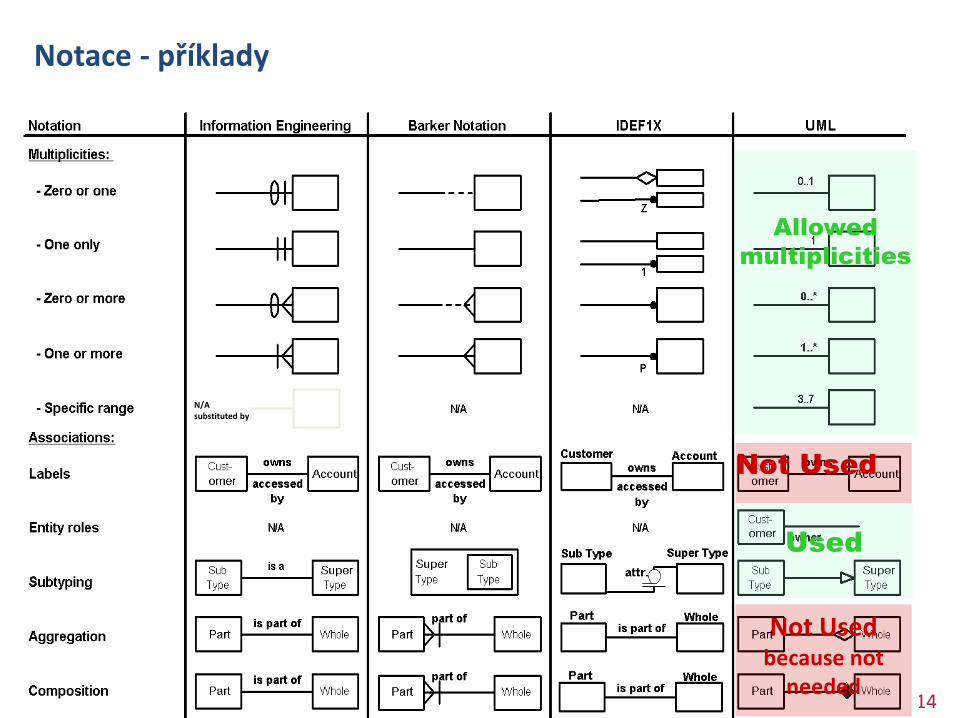
Notace - příklady
Not Used because not
needed
Allowed
multiplicities
Not Used
Used
N/A substituted by

15 15
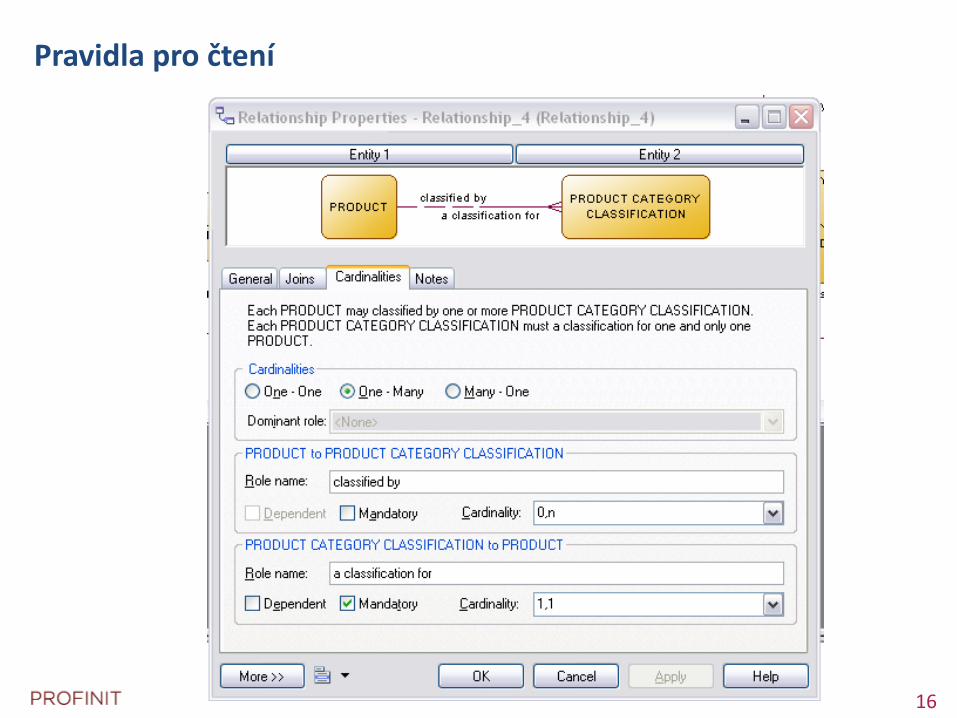
Pravidla pro čtení relací
Assertion 2: "Each LINE ITEM must be part of exactly one ORDER "
Assertion 2: "Each ORDER may be composed of one or more LINE ITEMS "
Reading direction
ORDER
Order number
Order date
LINE ITEM
Line number
Quantity
Price
Delivery date
composed of
1part of
0..*
16 16
Pravidla pro čtení

17 17
Vytvoření logického modelu
Cíle Vytvořit platformově nezávislý logický datový model
Postup Převést entity na tabulky Rozhodnout, jak se bude pracovat se složitými atributy Použít vhodné patterny Rozhodnout, jak se bude pracovat s atributy nabývajícími více hodnot Výběr primárních klíčů Převést binární relace (závislosti) typu 1:n na cizí klíče Vyřešit n-ární relace a relace typu n:n Rozhodnout o způsobu reprezentace subtypů Normalizace modelu
Výstup Logický datový model

18 18
Kritéria pro výběr primárního klíče
Primární klíč:
musí mít vždy definovanou hodnotu (not null),
musí mít stálou hodnotu (během celého životního cyklu řádku),
musí být co možná nejmenší,
nesmí obsahovat žádné zakódované informace,
musí být přístupný pro všechny uživatele.
Umělý klíč
Nevýhody: přidává sloupec do tabulky (s indexem), hodnoty nemají význam pro uživatele
Výhody: snadná implementace rozhraní, uniformní řešení

19 19
Vazba na objektové modelování
Object-relational impedance mismatch
Declarative vs. imperative interfaces
RM – data jako interface
Schema bound
RM – Sloupec k jedné tabulce, tabulka do schématu, OOM – dědičnost objektů
Access rules
RM – relační algebra, OOM – volnější a složitější konstrukty
Relationship between nouns and actions
OOM - úzká vazba mezi objekty a operacemi
Uniqueness observation
RM – identifikace na základě klíče s jasným obsahem
Normalization
OOM – nepoužívá se normalizace
Schema inheritance
RM – nepoužívá se
Structure vs. Behaviour
OOM – údržba, srozumitelnost, upravovatelnost, rozšiřitelnost, reuse, RM – logická integrita, efektivita, fault-tolerance
Set vs. graph relationships
20 20
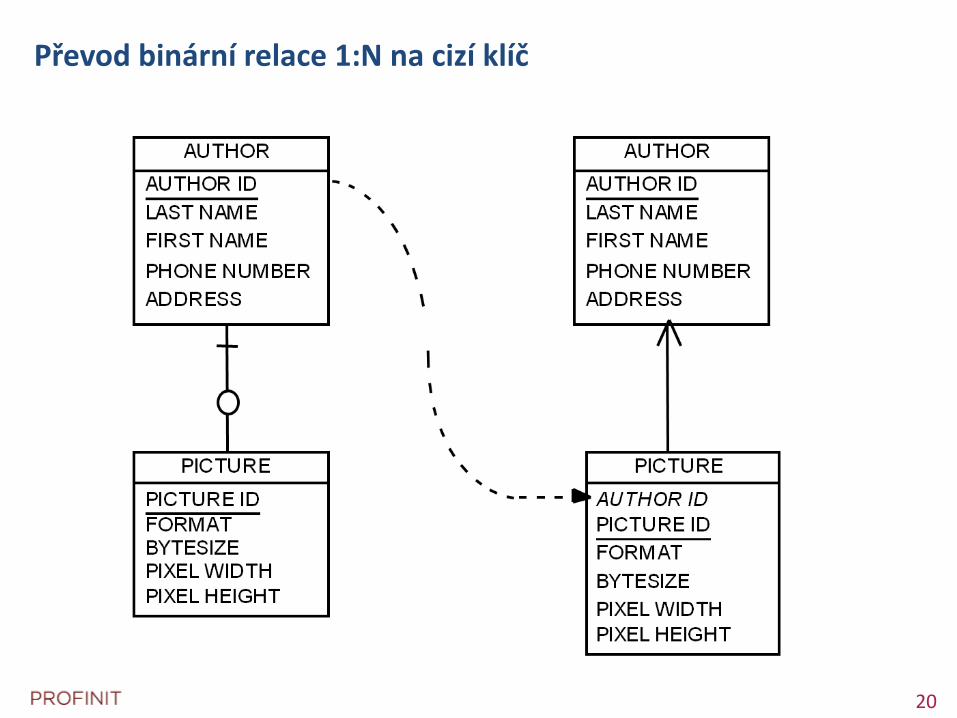
Převod binární relace 1:N na cizí klíč
21 21
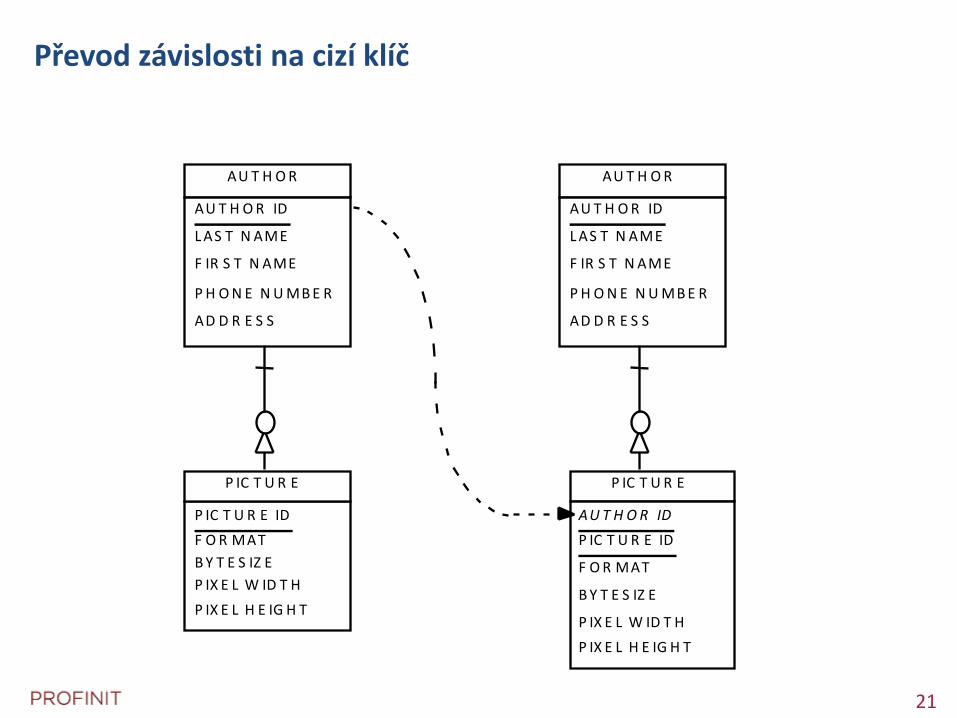
Převod závislosti na cizí klíč
A U T H O R
A U T H O R I D
L A S T N A M E
F I R S T N A M E
P H O N E N U M B E R
A D D R E S S
A U T H O R
A U T H O R I D
L A S T N A M E
F I R S T N A M E
P H O N E N U M B E R
A D D R E S S
P I C T U R E P I C T U R E
P I C T U R E I D
F O R M A T
B Y T E S I Z E
P I X E L W I D T H
P I X E L H E I G H T
P I C T U R E I D
F O R M A T
B Y T E S I Z E
P I X E L W I D T H
P I X E L H E I G H T
A U T H O R I D
22 22
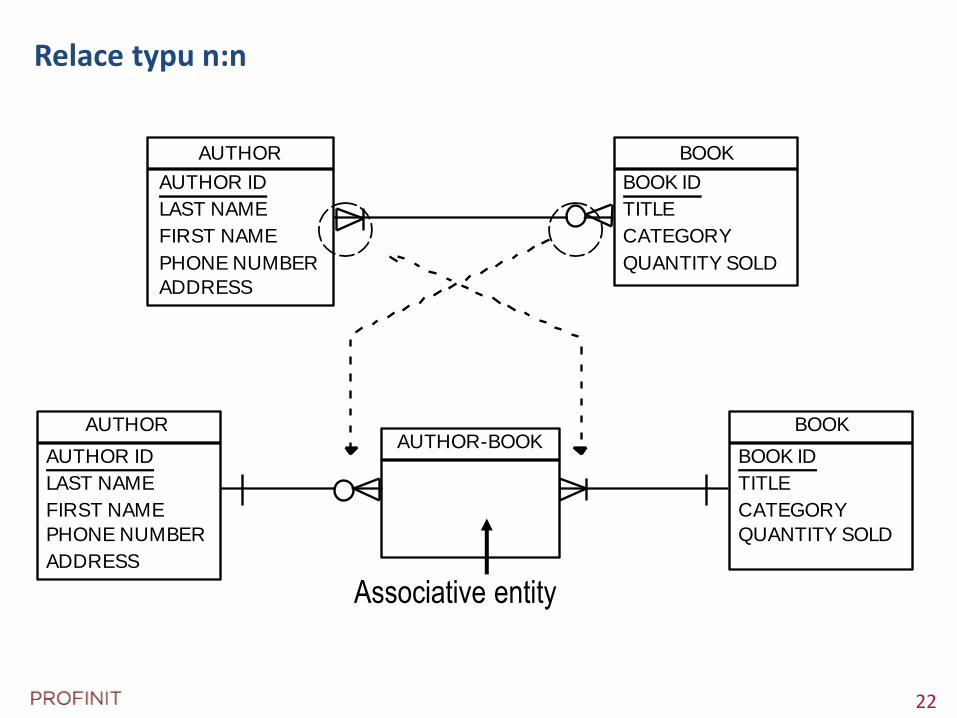
Relace typu n:n
BOOK
BOOK ID
TITLE
CATEGORY
QUANTITY SOLD
AUTHOR
AUTHOR ID
LAST NAME
FIRST NAME
PHONE NUMBER
ADDRESS
AUTHOR-BOOKBOOK
BOOK ID
TITLE
CATEGORY
QUANTITY SOLD
AUTHOR
AUTHOR ID
LAST NAME
FIRST NAME
PHONE NUMBER
ADDRESS
Associative entity
23 23
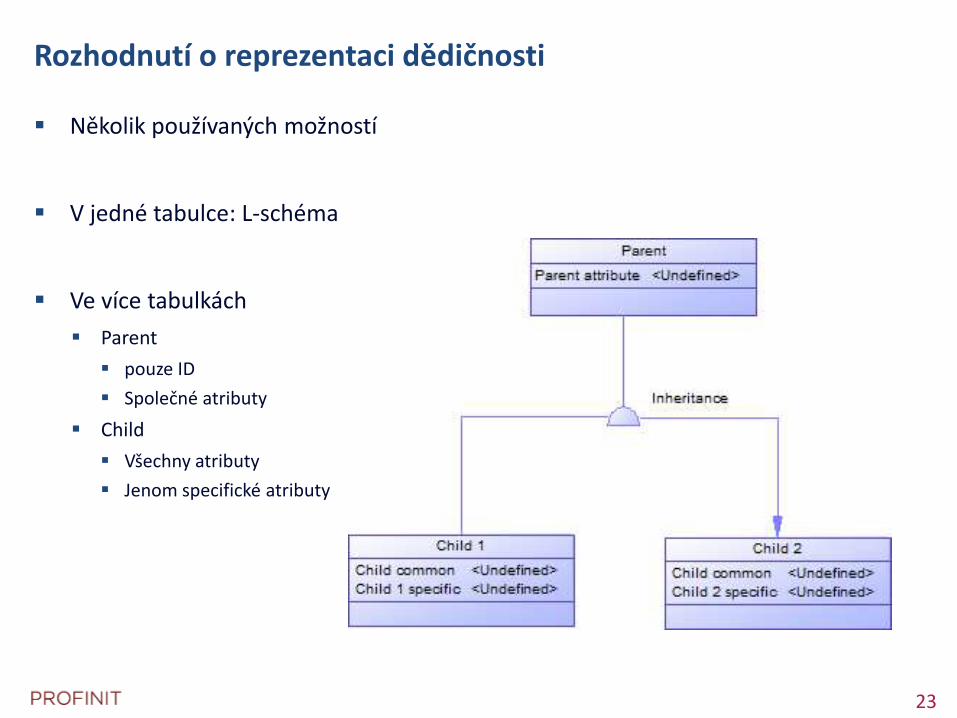
Rozhodnutí o reprezentaci dědičnosti
Několik používaných možností
V jedné tabulce: L-schéma
Ve více tabulkách
Parent
pouze ID
Společné atributy
Child
Všechny atributy
Jenom specifické atributy

24 24
První normální forma
Tabulka je v první normální formě, když každý sloupec obsahuje právě jeden atomický datový typ, který již nemá vnitřní strukturu z pohledu businessu.
Business pohled je podstatný pro rozhodnutí o první normální formě.

25 25
Vytvoření fyzického modelu
Cíle Vytvořit fyzický model s ohledem na specifika aplikace a použitý typ databáze, použitý
hardware
Postup Tabulky (jmenné konvence)
Datové typy
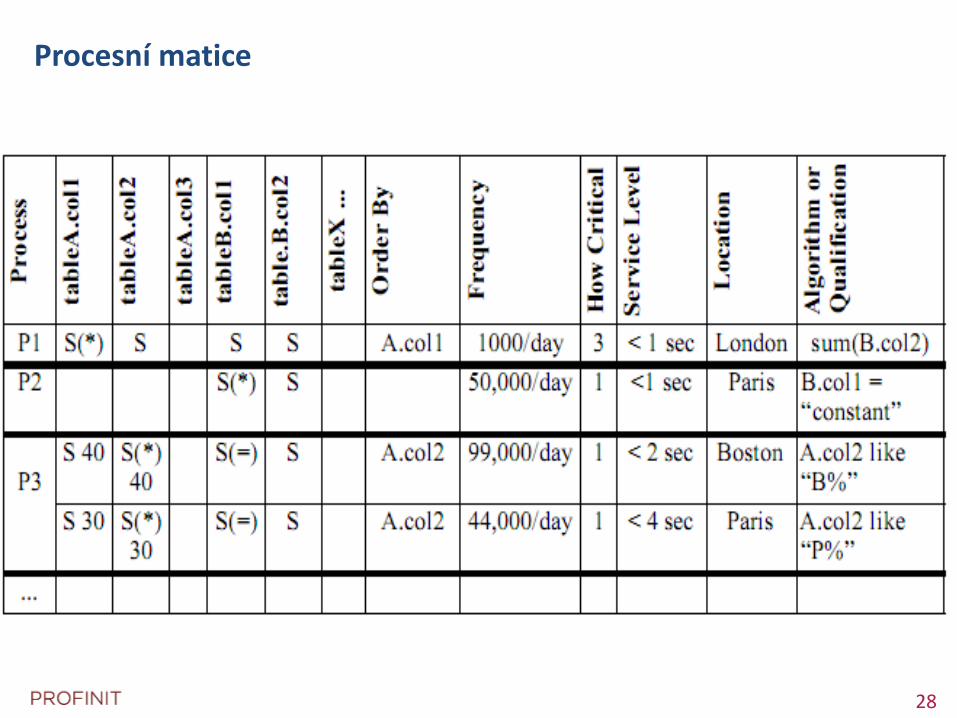
Vytvoření procesní matice
Rozhodnutí o struktuře tabulek
Rozhodnutí o primárním klíči (indexu)
Implementace business pravidel - constraints
Indexy, partitioning,
Denormalizace, uložení redundantních dat, spojení tabulek
Fyzické uložení tabulek
Výstup Fyzický datový model
Implementační skripty

26 26
Tabulky (jmenné konvence)
Case sensitive/case insensitive servery
Omezení délky jména tabulek (Oracle 30 znaků)
Omezení délky jmen sloupců
Omezení na jmenné prostory (tabulky, view, indexy, procedury, …)
Porozumění modelu
Datové tabulky
Číselníky
Logy
Uživatelské tabulky
Natural join

27 27
Datové typy
Domain – uživatelské datové typy + lepší porozumění
+ zajištění konzistence
- nároky na údržbu
Char, varchar, nvarchar, …
Numerické datové typy int, tinyint, bigint, numeric(p,s), …
Datum – rozsah, přesnost, způsob práce Timestamp – je to čas nebo není
Binary, image, text, memo, …
Boolean - raději "column_name" CHAR(1) default 'A' not null constraint
CKC_check_name check ("column_name" in ('A','Y'))
Identity, Autoincrement
NULL, Not null, Default value
Speciální datové typy
28 28
Procesní matice

29 29
Rozhodnutí o struktuře tabulek
Cíle:
Minimalizovat velikost
Použít optimální přístupové metody
Standardní tabulka
Insert, Delete, Update, Scan, Index
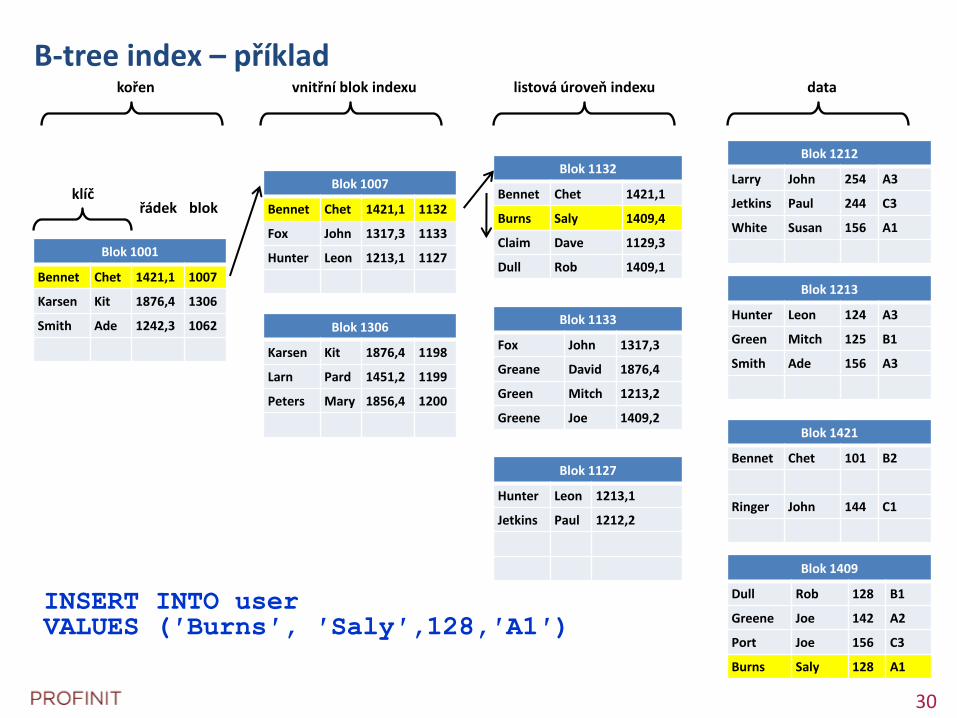
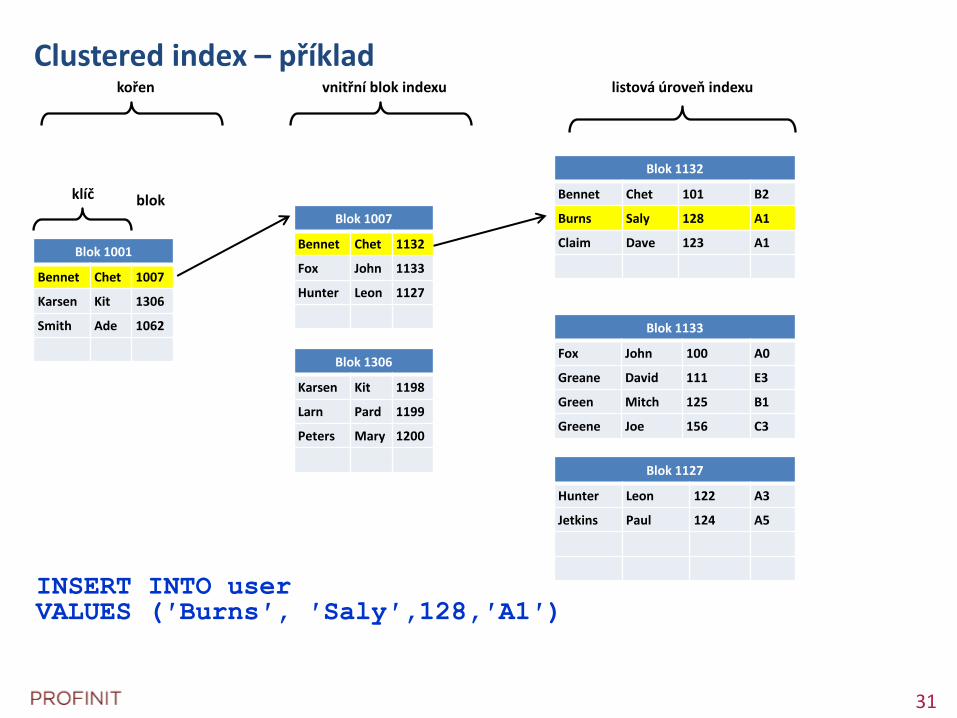
Index-organized tables (Clustered index)
+ menší
+ rychlejší přístup po indexu
- náročnější insert, delete (update)
Oracle – novější implementace, podpora 7x24
30 30
Blok 1001
Bennet Chet 1421,1 1007
Karsen Kit 1876,4 1306
Smith Ade 1242,3 1062
Blok 1007
Bennet Chet 1421,1 1132
Fox John 1317,3 1133
Hunter Leon 1213,1 1127
Blok 1306
Karsen Kit 1876,4 1198
Larn Pard 1451,2 1199
Peters Mary 1856,4 1200
Blok 1132
Bennet Chet 1421,1
Burns Saly 1409,4
Claim Dave 1129,3
Dull Rob 1409,1
Blok 1212
Larry John 254 A3
Jetkins Paul 244 C3
White Susan 156 A1
Blok 1213
Hunter Leon 124 A3
Green Mitch 125 B1
Smith Ade 156 A3
Blok 1421
Bennet Chet 101 B2
Ringer John 144 C1
Blok 1409
Dull Rob 128 B1
Greene Joe 142 A2
Port Joe 156 C3
Burns Saly 128 A1
Blok 1133
Fox John 1317,3
Greane David 1876,4
Green Mitch 1213,2
Greene Joe 1409,2
Blok 1127
Hunter Leon 1213,1
Jetkins Paul 1212,2
klíč řádek blok
kořen vnitřní blok indexu listová úroveň indexu data
INSERT INTO user VALUES (′Burns′, ′Saly′,128,′A1′)
B-tree index – příklad
31 31
Blok 1001
Bennet Chet 1007
Karsen Kit 1306
Smith Ade 1062
Blok 1007
Bennet Chet 1132
Fox John 1133
Hunter Leon 1127
Blok 1306
Karsen Kit 1198
Larn Pard 1199
Peters Mary 1200
Blok 1132
Bennet Chet 101 B2
Burns Saly 128 A1
Claim Dave 123 A1
Blok 1133
Fox John 100 A0
Greane David 111 E3
Green Mitch 125 B1
Greene Joe 156 C3
Blok 1127
Hunter Leon 122 A3
Jetkins Paul 124 A5
klíč blok
kořen vnitřní blok indexu listová úroveň indexu
INSERT INTO user VALUES (′Burns′, ′Saly′,128,′A1′)
Clustered index – příklad

32 32
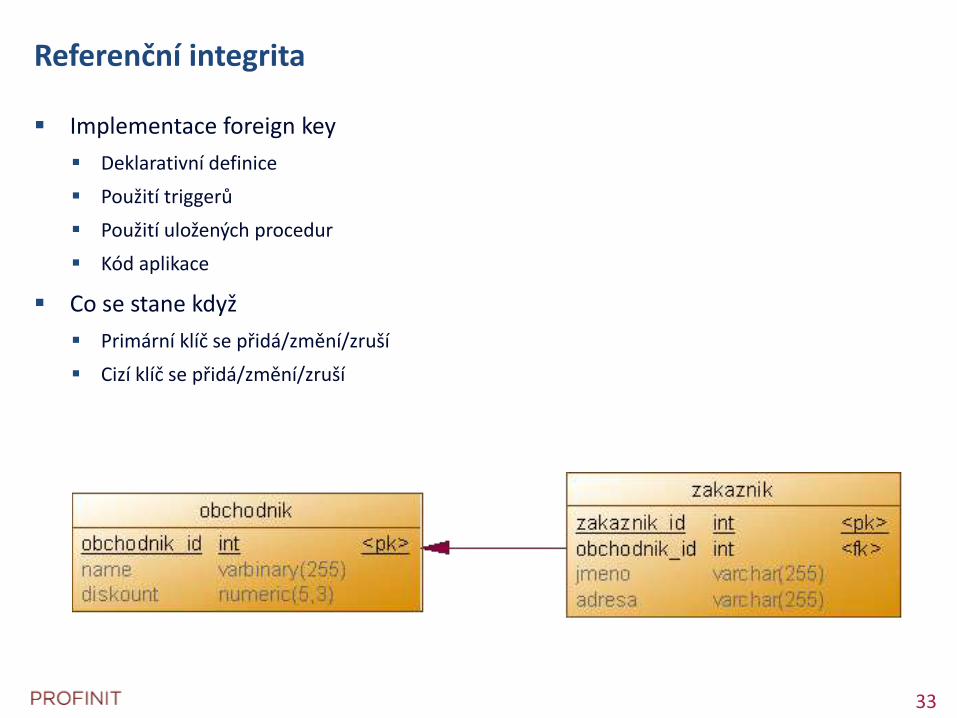
Implementace business pravidel
Domain integrity - Check
Na úrovni sloupce Null/Not null
Default
Check (format)
Na úrovni řádku
Entity integrity - primary key
implementováno unikátním indexem na not null sloupcích
záznam v katalogu
Unikátnost hodnot
implementováno unikátním indexem
33 33
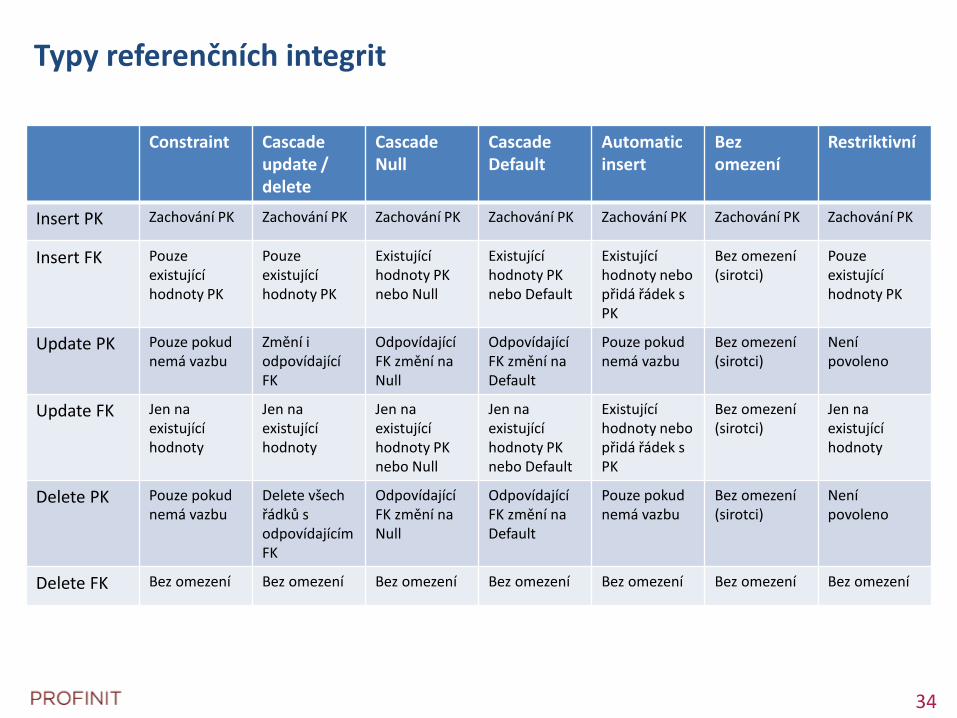
Referenční integrita
Implementace foreign key
Deklarativní definice
Použití triggerů
Použití uložených procedur
Kód aplikace
Co se stane když
Primární klíč se přidá/změní/zruší
Cizí klíč se přidá/změní/zruší
34 34
Typy referenčních integrit
Constraint Cascade update / delete
Cascade Null
Cascade Default
Automatic insert
Bez omezení
Restriktivní
Insert PK Zachování PK Zachování PK Zachování PK Zachování PK Zachování PK Zachování PK Zachování PK
Insert FK Pouze existující hodnoty PK
Pouze existující hodnoty PK
Existující hodnoty PK nebo Null
Existující hodnoty PK nebo Default
Existující hodnoty nebo přidá řádek s PK
Bez omezení (sirotci)
Pouze existující hodnoty PK
Update PK Pouze pokud nemá vazbu
Změní i odpovídající FK
Odpovídající FK změní na Null
Odpovídající FK změní na Default
Pouze pokud nemá vazbu
Bez omezení (sirotci)
Není povoleno
Update FK Jen na existující hodnoty
Jen na existující hodnoty
Jen na existující hodnoty PK nebo Null
Jen na existující hodnoty PK nebo Default
Existující hodnoty nebo přidá řádek s PK
Bez omezení (sirotci)
Jen na existující hodnoty
Delete PK Pouze pokud nemá vazbu
Delete všech řádků s odpovídajícím FK
Odpovídající FK změní na Null
Odpovídající FK změní na Default
Pouze pokud nemá vazbu
Bez omezení (sirotci)
Není povoleno
Delete FK Bez omezení Bez omezení Bez omezení Bez omezení Bez omezení Bez omezení Bez omezení

35 35
Důsledky použití integritních omezení
+ zaručují konzistentní model
- zvyšují výpočetní složitost
i v případě, kdy nedochází ke změnám (Oracle not null)
- komplikují údržbu
povolení/zakázání ověřování integritních omezení

36 36
Denormalizace
Partitioning
Horizontální
Vertikální
Uložení vypočtených hodnot
Eliminace nákladných joinů

37 37
Horizontální rozdělení tabulek
Přístupy pouze na část tabulky
Příklady:
Aktivní a neaktivní položky
Historické záznamy
Možnosti
Rozdělení tabulek
Přidání tabulky (duplicitní záznamy)
Partitioning
Synchronizace
Table partitioning
Triggery
Aplikační logika
38 38
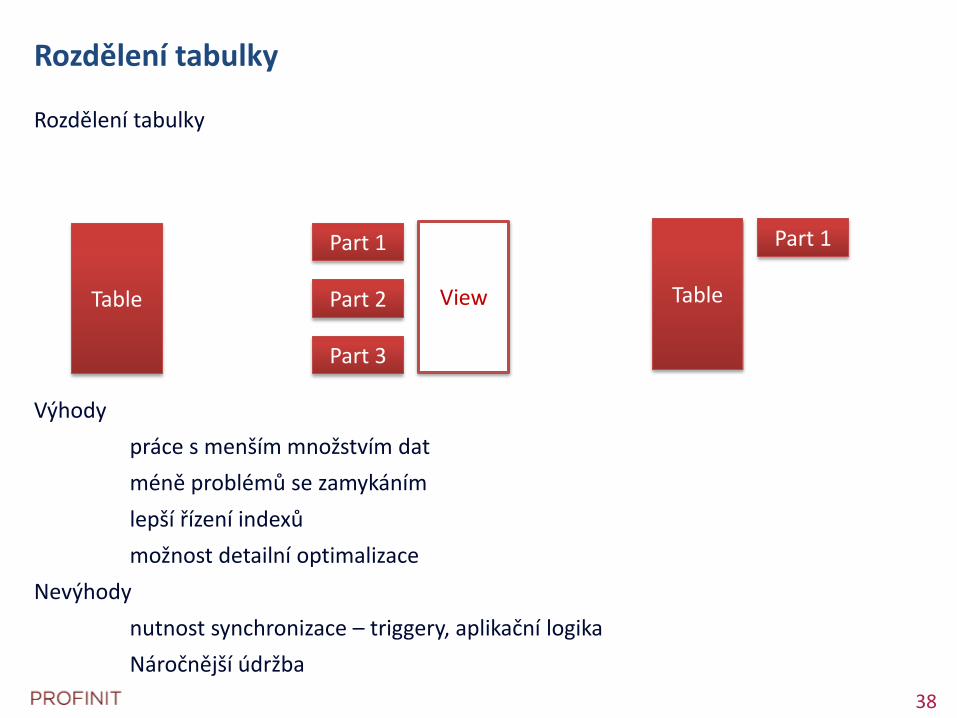
Rozdělení tabulky
Rozdělení tabulky
Výhody
práce s menším množstvím dat
méně problémů se zamykáním
lepší řízení indexů
možnost detailní optimalizace
Nevýhody
nutnost synchronizace – triggery, aplikační logika
Náročnější údržba
Table
Part 1
Part 2
Part 3
View Table
Part 1

39 39
Partitioning
Transparentní z pohledu aplikace
Rozdělení dle daného rozsahu nebo hodnot
Dynamicky podle hodnot
Dynamicky vytvářeno pro každý měsíc
Nejčastější použití
Podle hash klíče (určuje se pouze počet partitions)
Více úrovňový partitioning
Podle času, podle pobočky
Možnost individuálního řízení partition
Omezený počet partition podle implementace
Part 1
Part 2
Part 3
Part 4

40 40
Vertikální rozdělení tabulek
Přístupy pouze na některé sloupce tabulky
Příklady:
Bloby, obrázky, popisy
Možnosti
Rozdělení tabulek
Přidání tabulky (duplicitní záznamy)
Vytvoření indexu
Synchronizace
Triggery
Aplikační logika
41 41
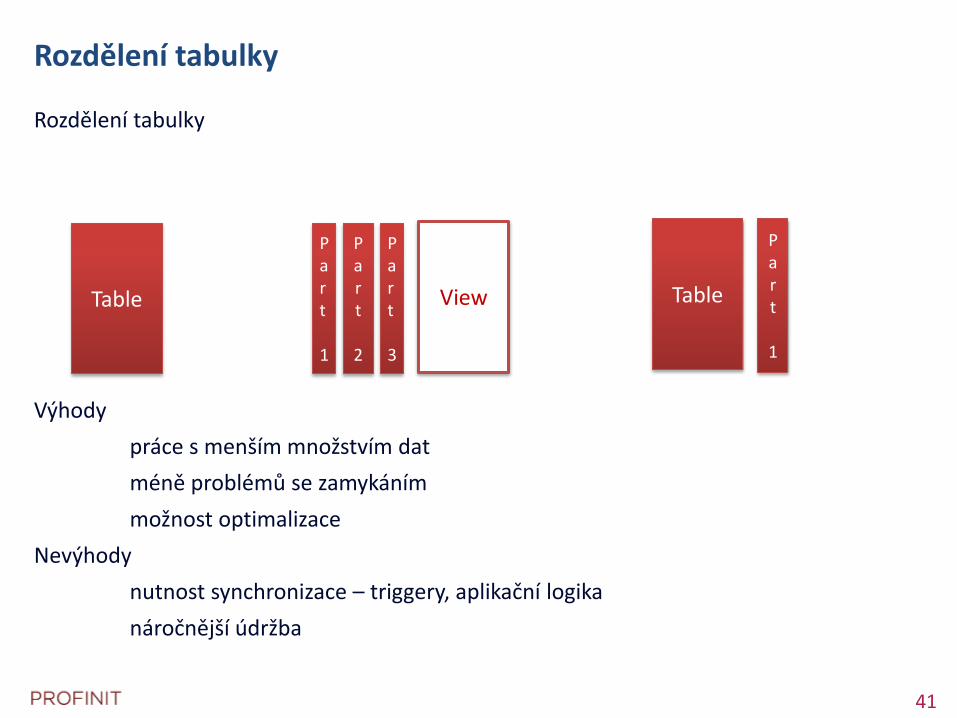
Rozdělení tabulky
Rozdělení tabulky
Výhody
práce s menším množstvím dat
méně problémů se zamykáním
možnost optimalizace
Nevýhody
nutnost synchronizace – triggery, aplikační logika
náročnější údržba
Table
Part
1
Part
2
Part 3
View Table
Part 1

42 42
Přidání indexů
Transparentní z pohledu aplikace
Jeden clustrovaný index
Libovolný počet dalších indexů
Automatická údržba
Pokrývající dotazy
Nároky na diskový prostor
Snížení výkonu pro OLTP aplikace
Index 1
Index 2

43 43
Uložení vypočtených dat
Přidání sloupce
Přidání tabulky
Synchronizace
Trigerry
Uložené procedury
Aplikační logika
Nutno zavést procedury pro údržbu a resynchronizaci

44 44
Materializovaná view
Transparentní z pohledu aplikace
Automatické řízení výpočtu view
Nákladné výpočty, nutnost možnosti řízení výpočtů asynchronně
Duplicitní uložení dat
nároky na diskový prostor

45 45
Eliminace nákladných joinů
Neustálé dotahování hodnot z číselníků
Omezení datových serverů (Sybase třicet tabulek v jednom joinu)
Suptype/supertype vazba
Možnosti
Redundantní data
Spojení tabulek

46 46
Fyzické uložení tabulek
Cíl
Distribuce zátěže na co nejvíce fyzických disků
Rozložení tabulek/indexů na disky
Možnosti datových serverů (tablespace, segment)
Možnosti hardware (SAN, NAS, diskové pole)
Pouze RAID 1+0
Vazba na počet procesorů
Možnosti paralelního zpracování datového serveru

47 47
Indexy – přístupové metody
Typy indexů
B-tree
Clustered/nonclustered
Bitmapové indexy
Standardní index
Hledání podle indexu
Scan nejnižší úrovně
Dotaz pokrytý indexem
Ignorování indexu – scan dat
Clustered index
Hledání podle indexu
Scan dat od nalezeného řádku
Scan nejnižší úrovně (scan dat)

48 48
Použití indexů
Select
Pokrývající query
Group by
Order by
Join
Nepoužívat indexy pro malé tabulky
Selektivita indexů

49 49
Data uložená po sloupcích
Vertica
SAP Sybase IQ
Oracle – bitmapové indexy
50 50
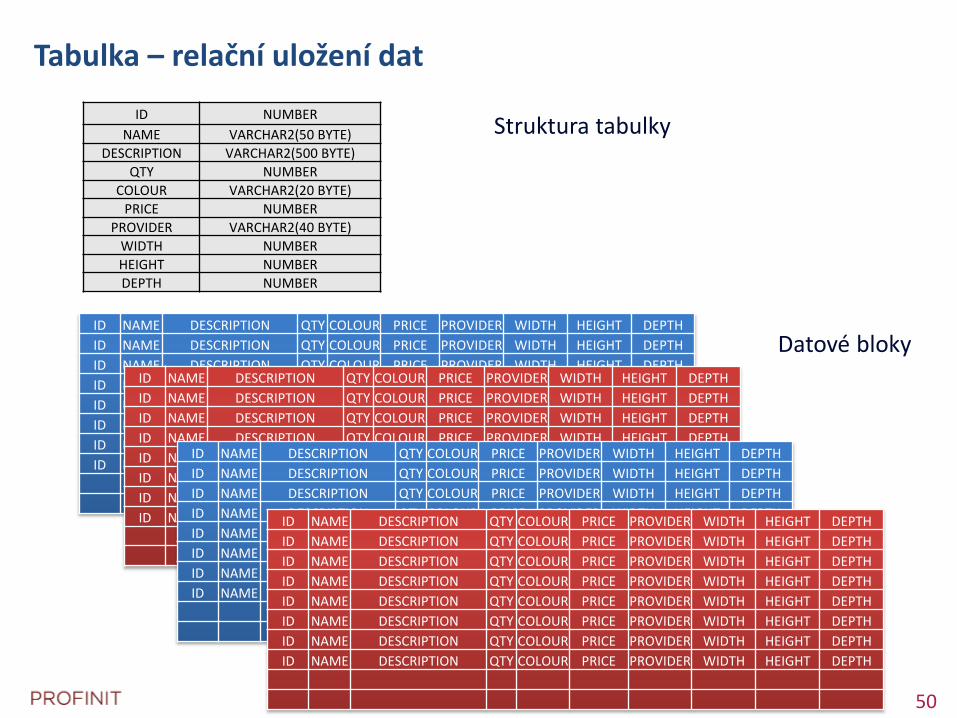
Tabulka – relační uložení dat
Struktura tabulky
Datové bloky
ID NUMBER
NAME VARCHAR2(50 BYTE)
DESCRIPTION VARCHAR2(500 BYTE)
QTY NUMBER
COLOUR VARCHAR2(20 BYTE)
PRICE NUMBER
PROVIDER VARCHAR2(40 BYTE)
WIDTH NUMBER
HEIGHT NUMBER
DEPTH NUMBER
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
ID NAME DESCRIPTION QTY COLOUR PRICE PROVIDER WIDTH HEIGHT DEPTH
51 51
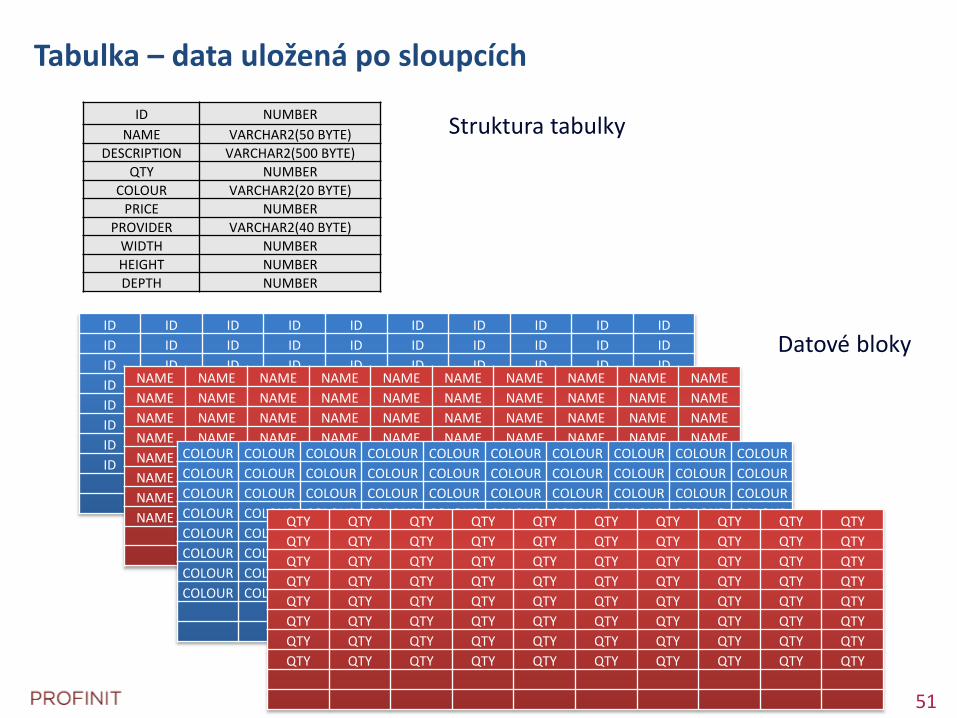
Tabulka – data uložená po sloupcích
Struktura tabulky
Datové bloky
ID NUMBER
NAME VARCHAR2(50 BYTE)
DESCRIPTION VARCHAR2(500 BYTE)
QTY NUMBER
COLOUR VARCHAR2(20 BYTE)
PRICE NUMBER
PROVIDER VARCHAR2(40 BYTE)
WIDTH NUMBER
HEIGHT NUMBER
DEPTH NUMBER
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
ID ID ID ID ID ID ID ID ID ID
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
NAME NAME NAME NAME NAME NAME NAME NAME NAME NAME
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR COLOUR
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
QTY QTY QTY QTY QTY QTY QTY QTY QTY QTY
52 52
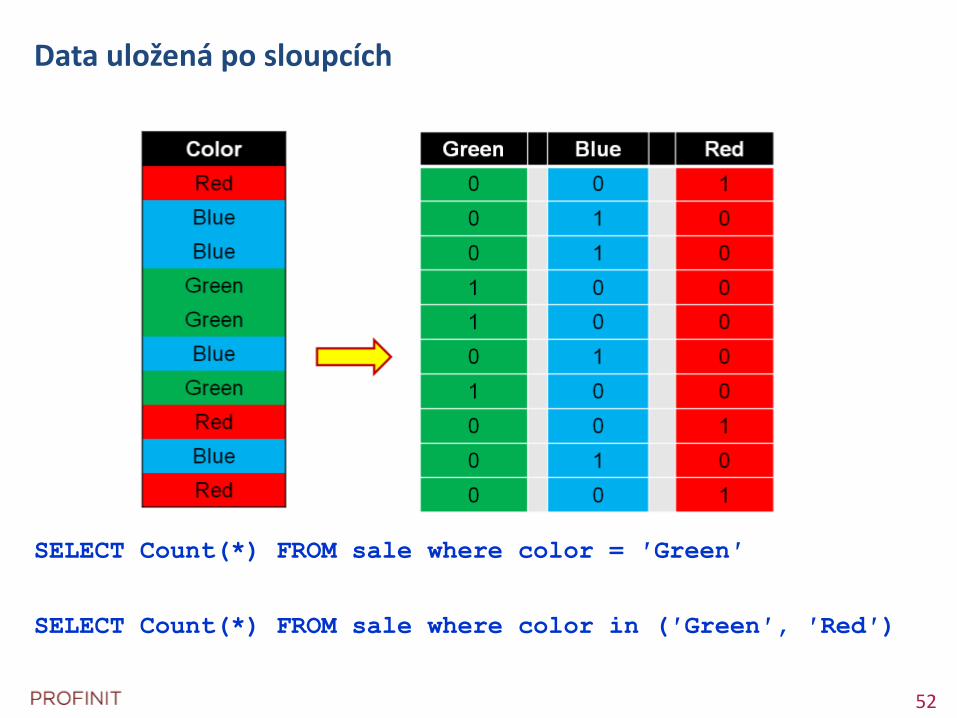
Data uložená po sloupcích
SELECT Count(*) FROM sale where color = ′Green′
SELECT Count(*) FROM sale where color in (′Green′, ′Red′)

53 53
Data uložená po sloupcích
SELECT SUM(qty) FROM sale
(2 * 64) + (3 * 32) + (2 * 16) + (1 * 8) + (3 * 4) + (2 * 2) + (3 * 1) = 283

54 54
Bitmapové indexy
Rychlé pro sloupce s malou kardinalitou
Rychlé pro operace na málo sloupcích
Složitý update
Zamykání a rebuild velkých bloků
Pomalé pro dotaz na jeden konkrétní řádek

55 55
Metody ukládání bitmapových indexů
Samé nuly nebo jedničky
Bloky se neukládají – pouze indikátor jejich existence
Do 20% nul nebo jedniček
Data se kódují jako souvislé množiny hodnot
Mezi 20% a 80% jedniček
Ukládá se skutečná mapa hodnot

56 56
Typy sloupcových indexů
Mnoho různých typů
Více indexů na jednom sloupci
Bitový index pro sloupce s malou kardinalitou
Bitový index pro sloupce s velkou kardinalitou a malou selektivností
Indexy pro sloupce s velkou kardinalitou G-Array (příbuzný B-tree)
Prosté komprimované uložení dat (pro textové řetězce)
Speciální indexy pro čas a datum
Indexy pro joiny, porovnání a další operace
57 57
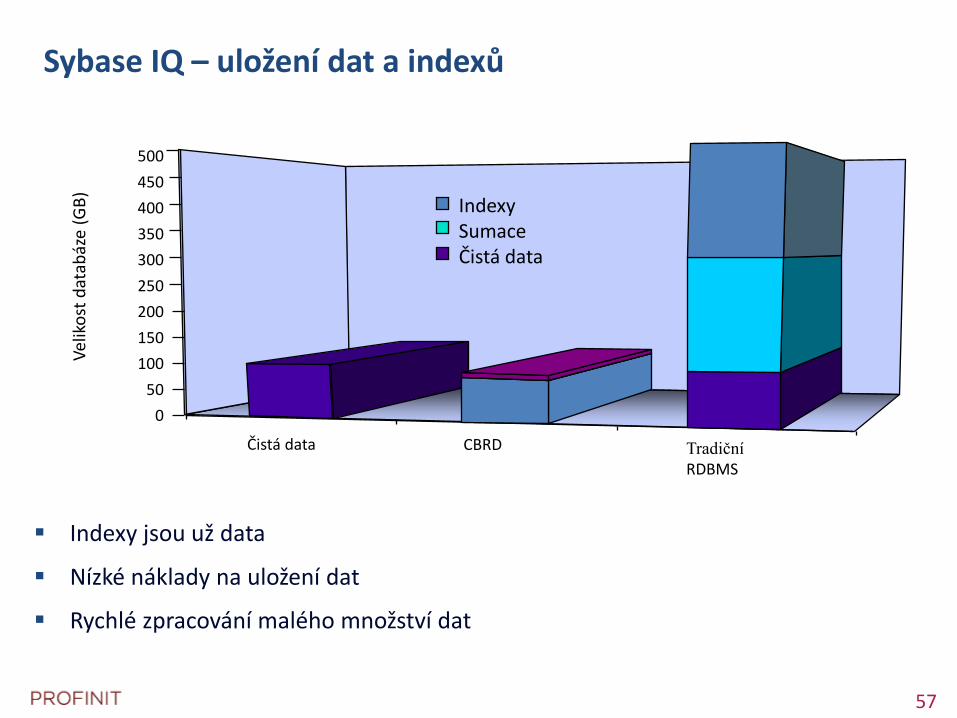
Sybase IQ – uložení dat a indexů
Indexy jsou už data
Nízké náklady na uložení dat
Rychlé zpracování malého množství dat
Vel
iko
st d
atab
áze
(GB
)
Čistá data Tradiční RDBMS
CBRD
500
450
400
350
300
250
200
150
100
50
0
Indexy Sumace Čistá data

58 58
Co si zapamatovat
Jaké jsou hlavní kroky při návrhu datového modelu
Co to je konceptuální model a co obsahuje
Co je cílem sběru byznys požadavků při vytváření konceptuálního modelu
Co je logický model a co obsahuje
Jaké aktivity je nutné provést při převodu konceptuálního datového modelu na logický datový model
Jaké požadavky je potřeba brát v úvahu při výběru primárních klíčů
Jaké jsou hlavní rozdíly mezi relačním a objektově orientovaném modelování
Kdy a proč se vytváří fyzický datový model
Které aktivity je nutné provést při převodu logického datového modelu na fyzický datový model
Co to je denormalizace
Jaké typy denormalizace znáte
Jaký je rozdíl mezi strukturou tabulky s klastrovaným a neklastrovaným indexem
K čemu slouží indexy a pro jaké přístupové metody k datům se používají
Jak vypadají bitmapové indexy
Co to je sloupcové uložení dat (sloupcové indexy)

59
Diskuse • Otázky • Poznámky • Komentáře • Připomínky


















