
Design, analyse og verifikation
81
1 Design, analyse og verifikation
-
Upload
vittorio-poyntz -
Category
Documents
-
view
29 -
download
0
description
Design, analyse og verifikation. Plan. Algoritmebegrebet Design BevisteknikkerDesign ved hjælp at matematisk induktion • Analyse O-notationLogaritmerBinær søgning Verifikation Programpåstande Et eksempel. - PowerPoint PPT Presentation
Transcript of Design, analyse og verifikation

1
Design, analyse og verifikation

2
• Algoritmebegrebet
• Design BevisteknikkerDesign ved hjælp at matematisk
induktion
• Analyse O-notationLogaritmerBinær søgning
• Verifikation ProgrampåstandeEt eksempel
Plan

3
Hvad er en algoritme?
En algoritme er en fremgangsmåde til løsning af et problem
Bemærk. Det er ikke et krav, at en algoritme skal kunne udføres på en datamat!
Dette kursus omhandler dog mest algoritmer af denne type.
Inddata UddataAlgoritme

4
Tre vigtige områder:
• Design• Analyse• Verifikation
Design: Hvorledes konstrueres en algoritme?
Analyse: Hvor “ressourcekrævende” er en algoritme?
Verifikation: Er en algoritme korrekt?

5
Databegrebet
Data:
En formaliseret repræsentation af kendsgerninger eller forestillinger på en sådan form, at den kan kommunikeres eller omformes ved en eller anden proces.
Datalogi:
Læren om data, deres væsen og brug.
Datastruktur:
Den sammenhæng, der er imellem en række sammenhørende dataelementer.

6
Information:Det betydningsindhold, et menneske tillægger data ud fra en vedtagen konvention.
Informationsteknologi:Enhver form for teknologi, der anvendes til opsamling,
behandling, lagring og formidling af data og information.
Informationsbegrebet

7
Hvad forstås ved en “god” algoritme?
(1) den løser problemet korrekt
(2) den er (tilstrækkelig) hurtig
(3) den kræver et (tilstrækkeligt) lille lagerforbrug
(4) den er simpel
De sidste tre krav kan ofte være i konflikt med hinanden.

8
Teknologi forbedrer hastigheden med en konstant faktor. Med godt algoritmedesign opnås ofte langt større hastighedsforbedringer.
Betydningen af effektive algoritmer
Hvorfor bekymre sig om effektivitet med dagens hurtige computere?
Antag at en algoritmes tidsforbrug er proportional med kvadratet på problemet størrelse (tid = k*n2, hvor k er en konstant, og n er problemstørrelsen). Med anskaffelsen af en ny computer med 10 gange så meget lager, kan der løses problemer, der er 10 gange så store. Men hvis den nye computer “kun” er 10 gange hurtigere, vil det tage 10 gange så lang tid at udføre algoritmen.
Kraftigere computere medfører ønske om at løse større problemer
En dårlig algoritme på en supercomputer kan være langsommere end en god algoritme på en kugleramme.

9
Algoritmebegrebet
Historie: Ordet “algoritme” er oprindelig afledt af “algorisme”: (i middelalderen) at udføre aritmetik med arabertal, i modsætning til “abacisme”: at udføre aritmetik med kugleramme.
Algorisme er igen afledt at navnet på en persisk forfatter af matematiklærebøger:
Abu Ja´far Mohammed ibn Mûsâ al-Khowârizmî (cirka år 825).

10
Euklids algoritme
En af de første ikke-trivielle algoritmer blev designet af Euklid (græsk matematiker cirka 300 år f. Kr.)
Givet Løsning24 og 32 8 og 12 7 og 8
Den største fælles divisor for to positive heltal er det største heltal, der “går op” i begge tal (giver resten 0 ved division).
Problem: Find den største fælles divisor for to givne positive heltal.
84
1

11
Lad gcd(u,v) betegne største fælles divisor for u og v. Problemet kan da formuleres således:
Givet to heltal u ≥ 1 og v ≥ 1. Bestem gcd(u,v).
gcd betegner greatest common divisor
Løsning af problemet er bl.a. relevant ved forkortelse af brøker:
24 = 24/gcd(24,32) = 24/8 = 3 32 32/gcd(24,32) 32/8 4

12
En simpel algoritme er følgende (skrevet i Java):
To simple algoritmer
for (d = 1; d <= u; d++) if (u % d == 0 && v % d == 0) gcd = d;
Algoritmernes ineffektivitet er tydelig for store værdier af u og v, f.eks. 461952 og 116298 (hvor gcd er lig med 18).
d = u < v ? u : v;while (u % d != 0 || v % d != 0) d--;gcd = d;
En anden simpel algoritme er:

13
Euklid benyttede følgende observation til at opnå en mere effektiv algoritme:
Hvis u ≥ v, og d går op i både u og v, så går d også op i differensen imellem u og v.
Euklids algoritme
Hvis u > v, så gælder gcd(u,v) = gcd(u-v,v).
Hvis u = v, så gælder gcd(u,v) = v [ = gcd(0,v) ]
Hvis u < v, så udnyttes, at gcd(u,v) = gcd(v,u) [ u og v ombyttes ]

14
while (u > 0)
if (u < v)
int t = u; u = v; v = t;
u = u - v;
gcd = v;
Euklids algoritme(version 1)
u = 461952, v = 18
u = 461934, v = 18
u = 461916, v = 18
.
.
.
u = 18 , v = 18
u = 0 , v = 18
461952/18 = 25664 iterationerEksempel på kørsel:

15
Kan effektiviteten forbedres?
Ja. Algoritmen trækker v fra u, indtil u bliver mindre end v. Men det er præcis det samme som at dividere u med v, og så sætte u lig med resten. Hvis u > v, så er gcd(u,v) = gcd(u%v,v).
Euklids algoritme(version 2)
while (u > 0) if (u < v) int t = u; u = v; v = t; u = u % v;gcd = v;
Antallet af iterationer ved kørsel af eksemplet fra før reduceres til 1.

16
Udførelse af version 2
u = 461952, v = 116298
u = 113058, v = 116298
u = 3240, v = 113058
u = 2898, v = 3240
u = 342, v = 2898
u = 162, v = 342
u = 18, v = 162
u = 0, v = 18
7 iterationerAlgoritmen er meget effektiv, selv for store værdier af u og v. Hvor effektiv kan bestemmes ved algoritmeanalyse.
antal iterationer ≤ 4.8 log10N - 0.32, gennemsnitligt antal iterationer ≈ 1.94 log10N

17
En alternativ algoritme
Ethvert positivt heltal kan udtrykkes som et produkt af primfaktorer
u = 2u2 . 3u
3 . 5u5 . 7u
7 . 11u11 ... = ∏ pu
p
p primtal
Lad u og v være to heltal. Så kan gcd(u,v) bestemmes som ∏ pmin(up ,vp) .
p primtal
Eksempel: u = 4400 = 24 . 52 . 70 . 111, v =7000 = 23 . 53 . 71 . 110
gcd(u,v) = 23 . 52 . 70 . 110 = 23 . 52 = 8 . 25 = 200
En velkendt metode til forkortelse af brøker:
44007000
=2⋅2⋅2⋅2⋅5⋅5⋅112⋅2⋅2⋅5⋅5⋅5⋅7
=2⋅115⋅7
=2235

18
Der kendes i dag ingen effektiv metode til at opløse et tal i dets
primfaktorer.
Dette faktum udnyttes i dag i mange krypteringsalgoritmer (algoritmer til hemmeligholdelse af meddelelser).
Ulempe ved den alternative algoritme

19
Algoritmebegrebet(præcisering)
Ved en algoritme forstås en fremgangsmåde til løsning af et problem. Udover blot at være en sekvens af operationer skal en algoritme have følgende 4 egenskaber:
(1) Endelighed. Algoritmen skal terminere efter et endeligt antal skridt.
(2) Entydighed. Hvert skridt skal være defineret præcist og utvetydigt.
(3) Effektfuldhed. Hvert skridt skal kunne udføres på endelig tid.
(4) Korrekthed. Udførelse af algoritmen skal resultere i uddata, der opfylder en specificeret relation med de givne inddata.

20
Matematisk definition af begrebet “algoritme”
En beregningsmetode er et tupel (Q, I, Ω, f), hvor Q er en mængde, der omfatter mængderne I og Ω, og f er en funktion fra Q på sig selv. Endvidere skal f(q) være lig med q for alle q i Ω.
Q repræsenterer mængden af beregningstilstande, I mængden af inddatatilstande, Ω mængden af uddatatilstande og f den beregningsmæssige regel.
Ethvert element x i I definerer en beregningssekvens x0 = x, xk+1 = f(xk) for k ≥ 0.
En beregningssekvens siges at terminere i k skridt, hvis k er det mindste heltal, for hvilket xk tilhører Ω.
En algoritme er en beregningsmetode, der for enhver beregningssekvens terminerer i et endeligt antal skridt.

21
Notation for algoritmer
(1) Natursproglig beskrivelse
E1. [Find rest] Divider u med v, og lad r betegne resten. E2. [Er den nul?] Hvis r = 0, så afslut algoritmen med v som svar. E3. [Ombyt] Sæt u lig med v, og v lig med r. Gå til trin E1.
(2) Rutediagram
Start
r = u % v r = 0 ? u = v v = r
Stop
nej
ja

22
(3) Programmeringssproglig beskrivelse, f.eks. i Java (eller en tilpasset delmængde heraf)
while (true) int r = u % v; if (r == 0) gcd = v; break; u = v; v = r;
eller
while ((r = u % v) != 0) u = v; v = r; gcd = v;
eller ved brug af rekursion
int gcd(int u, int v) return v == 0 ? u : gcd(v, u % v);

23
Bevisteknikker(relevant både ved design og verifikation)
Teorem. Der findes uendeligt mange primtal.
Bevis: Antag at der findes et endeligt antal primtal, p1, p2 , ..., pk.
Betragt nu tallet N = p1 . p2
... pk+1. N er større end pk. Men ingen af de kendte primtal går op i N (resten ved division er 1). Så N må være et primtal. Vi har dermed en modstrid, hvilket beviser sætningen.
Bevisførelse ved modstrid (indirekte bevis).
Antag at det givne teorem er falsk. Konkluder at dette vil føre til en modstrid.

24
Matematisk induktionuformel beskrivelse
Hvis (1) jeg kender den forreste person, og
(2) hvis jeg for enhver person, jeg kender i køen, også kender dennes efterfølger,
så kender jeg alle personer i køen. Også selv om køen er uendelig lang.
Nogle personer står i en kø:

25
Lad T være et teorem, der skal bevises, og lad T være udtrykt i termer af heltalsparameteren n.
Teoremet T gælder da for enhver værdi af n ≥ c, hvor c er en konstant, hvis følgende to betingelser er opfyldt:
1. Basistilfældet:
T gælder for n = c, og
2. Induktionsskridtet:
Hvis T gælder for n-1, så gælder T for n.
Matematisk induktion formel beskrivelse
Antagelsen i induktionsskridtet kaldes induktionshypotesen.

26
Eksempler på simpel induktion
Teorem: Summen S(n) af de første n naturlige tal er n(n+1)/2.
Bevis: (1) Basistilfældet.
For n = 1 er S(1) =1, hvilket stemmer med formlen.
(2) Induktionsskridtet. Antag at sætningen gælder for n-1, dvs. S(n-1) = (n-1)n/2.
S(n) = S(n-1) + n = (n-1)n/2 + n = n(n+1)/2.
Dermed gælder sætningen også for n.

27
Bevis: (1) Basistilfældet.
4 kroner kan veksles ved hjælp af to 2-kroner.
(2) Induktionsskridtet. Antag at n-1 kroner kan veksles. Vi kan vise, at denne veksling kan
benyttes som udgangspunkt til at veksle n kroner.
Enten indeholder vekslingen en 5-krone, eller også gør den det ikke. I første tilfælde erstattes 5-kronen med tre 2-kroner. I andet tilfælde erstattes to 2-kroner med en 5-krone.
Teorem: Ethvert beløb ≥ 4 kroner kan veksles i et antal 2-kroner og et antal 5-kroner.

28
Stærk induktion
Teoremet T gælder for enhver værdi af n ≥ c, hvor c er en konstant, hvis følgende to betingelser er opfyldt:
1. Basistilfældet: T gælder for n = c, og
2. Induktionsskridtet: Hvis T gælder for ethvert k, c ≤ k < n, så gælder T for n.

29
Induktionsprincippet kan benyttes konstruktivt. Løsning af små problemer benyttes til at løse større problemer.
Induktion kan benyttes ved design af algoritmer
(1) Start med en vilkårlig instans af problemet.
(2) Prøv at løse dette under antagelse af, at det samme problem - men af mindre størrelse - er blevet løst.

30
Eksempel:Sortering af n tal i stigende rækkefølge
Antag at vi kan sortere n-1 tal.
Vi kan da opnå en sortering af n tal ved
først at sortere n-1 af tallene, og derefter indsætte det n´te tal på den rette plads (sortering ved indsættelse),
eller
bestemme det mindste af de n tal og sætte det forrest, sortere de
resterende n-1 tal, og derefter sætte dem bagefter dette forreste tal (sortering ved udvælgelse).

31
Eksempel:Den maksimale delsekvenssum
Problem. Givet en sekvens (a1,a2, .., an) af reelle tal. Find en delsekvens (ai,ai+1, .., aj) af konsekutive elementer, sådan at summen af dens elementer er størst mulig.
Eksempel. For sekvensen (-2, 11, -4, -1, 13, -5, 2) er den maksimale delsekvens (11, -4, -1, 13) med summen 19.
Hvis alle elementer er positive, er sekvensen selv maksimal.
Hvis alle elementer er negative, er den maksimale delsekvens tom. Idet den tomme delsekvens har summen 0.

32
En simpel algoritme
maxSum = 0;for (i = 1; i <= n; i++) for (j = i; j <= n; j++) sum = 0; for (k = i; k <= j; k++) sum += a[k]; if (sum > maxSum) maxSum = sum;
i j
ai aj

33
Forbedret algoritme
maxSum = 0;for (i = 1; i <= n; i++) sum = 0; for (j = i; j <= n; j++) sum += a[j]; if (sum > maxSum) maxSum = sum;
Fjern den inderste løkke.
Udnyt at akk=i
j∑ = akk=i
j−1∑ +aj

34
Hvis n = 1, så kan den maksimale delsekvens let bestemmes. Hvis tallet er positivt, består den af tallet selv. Ellers er den tom.
Lad S = (a1,a2, .., an) og S’ = (a1,a2, .., an-1).
Lad S’M være den maksimale delsekvens for S’.
a1 a2 anan-1
S
S’
S’M
Hvis S’M er tom, er den maksimale delsekvens for S tom, hvis an er negativ, ellers lig med (an).
Induktionshypotese: Vi ved, hvordan den maksimale delsekvens findes for en sekvens af længde n-1.

35
Hvis j = n-1, udvides S’M med an , hvis og kun hvis an er positiv.
Antag at S’M ikke er tom, dvs. S’M = (ai,ai+1, .., aj), for 1 ≤ i ≤ j ≤n-1.
a1 a2 anan-1
S
S’
S’M

36
Hvis j < n-1 er der to tilfælde:
(1) Enten er S’M også maksimal for S.
(2) Eller der er en anden delsekvens, der ikke er maksimal i S’, men som er maksimal i S, når an tilføjes.
Hvilket tilfælde, der er tale om, kan ikke afgøres på baggrund af den foreliggende information: S’M .
Men da an kun forlænger en delsekvens, der ender i an-1 , dvs. er et suffix for S’, kan afgørelsen træffes, hvis vi kender det maksimale suffix S’E = (ai,ai+1, .., an-1) for S’.
Induktionshypotesen skærpes.
a1 a2 anan-1
S
S’
S’M

37
Skærpet induktionshypotese: Vi ved, hvordan den maksimale delsekvens og det maksimale suffix findes for en sekvens af længde n-1.
Vi når derved frem til følgende algoritme:
maxSum = maxSuffix = 0;for (i = 1; i <= n; i++) maxSuffix += a[i]; if (maxSuffix > maxSum) maxSum = maxSuffix; else if (maxSuffix < 0) maxSuffix = 0;

38
Empirisk undersøgelse af algoritmernes tidsforbrug
static void randomFill(int[] a) java.util.Random r = new java.util.Random(7913); for (int i = 0; i < a.length; i++) a[i] = r.nextInt() % 1000;
public static void main(String [] args) for (int n = 10; n <= 1000000; n *= 10) System.out.println("n = " + n); int a[] = new int[n]; randomFill(a); long startTime = System.currentTimeMillis(); int maxSum = maxSubSum1(a); System.out.println(" Time used: " + (System.currentTimeMillis() - startTime)/1000.0); System.out.println();

39
Observerede køretider(sekunder)
MaxSubSum1 MaxSubSum2 MaxSubSum3100 0.010 0.002 0.000
1000 5.127 0.031 0.00010000 5104.632 2.270 0.001
100000 ikke målt 246.245 0.0081000000 ikke målt ikke målt 0.080
Estimat: cirka 160 år Estimat: cirka 7 timer

40
Kurvefitning med MacCurveFitMaxSubSum1

41

42

43

44

45

46
AlgoritmeanalyseBeskrivelse af algoritmers ressourceforbrug
Vurdering af algoritmers tids- og pladsforbrug. Nyttigt: (1) ved valg imellem
eksisterende algoritmer
(2) ved udvikling af nye algoritmer

47
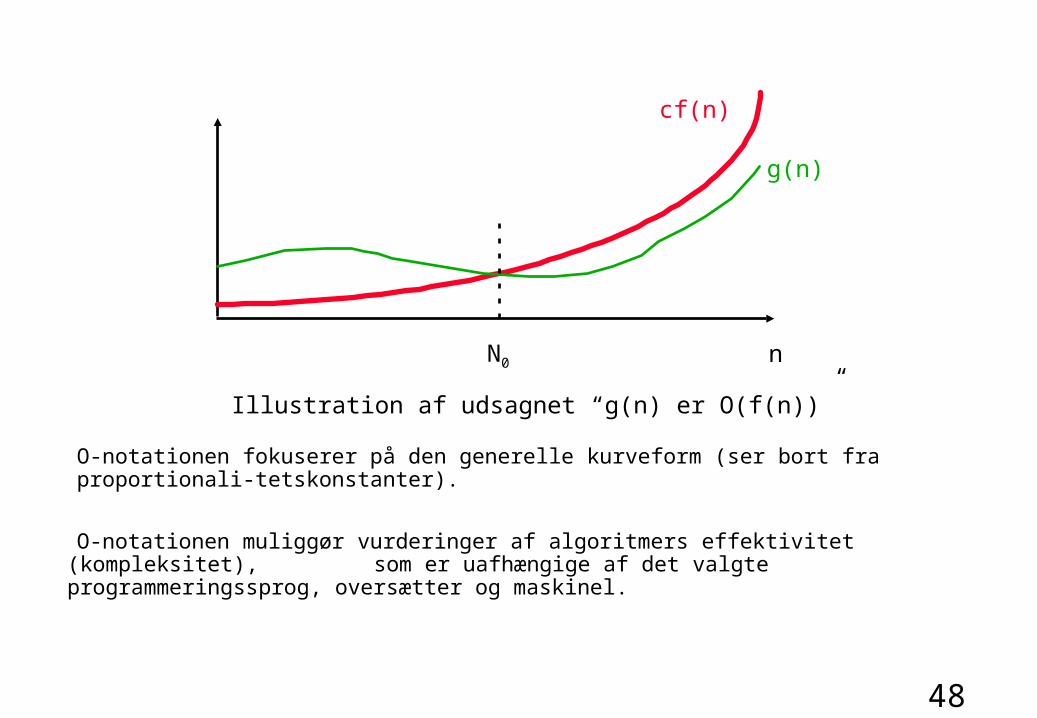
O-notation benyttes til at angive en øvre grænse for en algoritmes ressourceforbrug (tid eller plads), idet der ses bort fra konstante faktorer.
At en algoritmes tidsforbrug er O(f(n)), hvor n er et udtryk for problemets “størrelse”, betyder:
(1) Intuitiv definition:Algoritmens tidsforbrug vokser i værste tilfælde som f(n), når blot n er tilstrækkelig stor.
(2) Formel definition: Der eksisterer to konstanter, c og N0, således at algoritmens tidsforbrug er opadtil begrænset af cf(n) for alle n ≥ N0.
O-notation
48
O-notationen fokuserer på den generelle kurveform (ser bort fra proportionali-tetskonstanter).
O-notationen muliggør vurderinger af algoritmers effektivitet (kompleksitet), som er uafhængige af det valgte programmeringssprog, oversætter og maskinel.
Illustration af udsagnet “g(n) er O(f(n))”
cf(n)
g(n)
N0 n

49
Kurver for n2 , n og log2n
log2n
n2
n

50
logb betegner logaritmefunktionen med base b.
logbN = x bx = N
Værd at vide om logaritmer
Specielt gælderlog10(10N) = 1 + log10Nlog2(2N) = 1 + log2N
To særligt interessante logaritmefunktioner erlog10 og log2.
log10N = x 10x = Nlog2N = x 2x = N
logb(M*N) = logbM + logbN
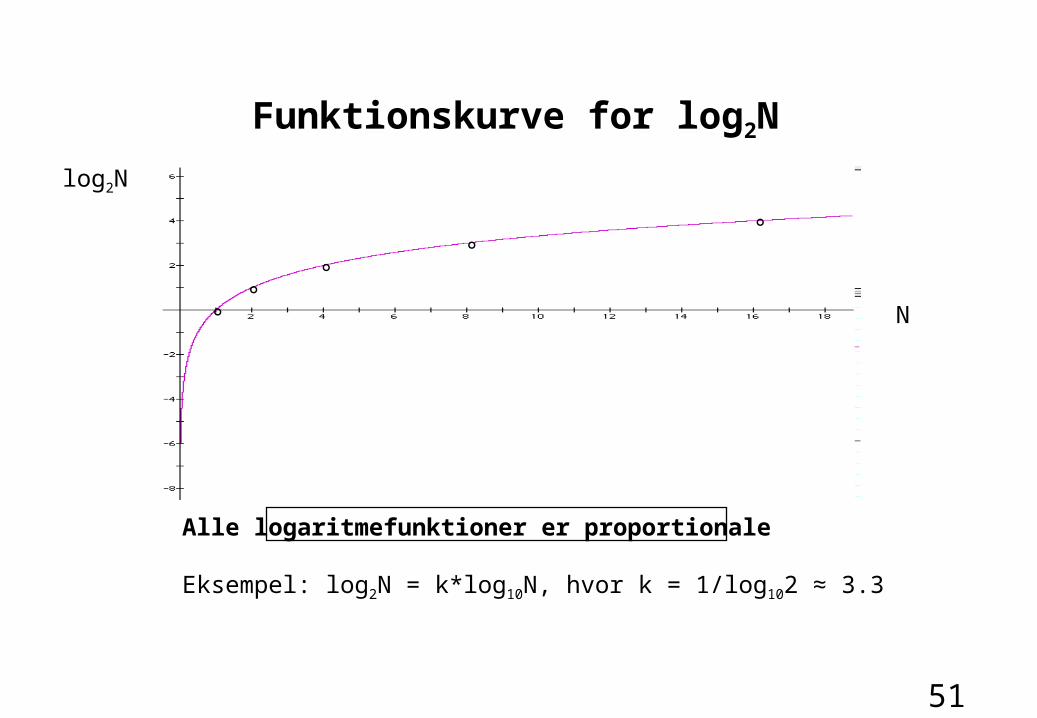
51
Alle logaritmefunktioner er proportionale
Eksempel: log2N = k*log10N, hvor k = 1/log102 ≈ 3.3
Funktionskurve for log2N
N
log2N
°°
°°
°

52
Brug af log2
Gentagen fordobling Hvis vi starter med X = 1, hvor mange gange kan X da fordobles, før X bliver større end eller lig med N?
Svar: log2N det nærmeste heltal, der er større end eller lig med log2N.
Gentagen halvering Hvis vi starter med X = N, hvor mange gange kan X da halveres, før X bliver mindre end eller lig med 1?
Svar: log2N det nærmeste heltal, der er mindre end eller lig med log2N.

53
• Eksempler:
• Hvis f(n) = dominerende led + ikke-dominerende led, så er O(f(n)) = O(dominerende led)
Regneregler for O-notationen
• Præcedensregler:
O(1) < O(log n) < O(n) < O(n log n) < O(n2) < O(n3) < O(2n) < O(10n) < O(n!)
O(1): konstant, O(log n): logaritmisk, O(n): lineær, O(n2): kvadratisk,
O(n3): kubisk, O(nc): polynomiel, O(cn): eksponentiel (hvor c > 1)
O(6n3) = O(n3)
O(logbn) = O(log n)
O(300) = O(1)
O(n3 + n log n) = O(n3)O(n3 - 10000n2 + 10000) = O(n3)

54
x *= i; Tidsforbrug: O(1) (konstant)
Eksempler på analyse
for (i = 1; i <= n; i++) for (j = 1; j <= i; j++) x *= i+j;Tidsforbrug: O(n(n+1)/2) = O(n2/2+n/2) = O(n2)
for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) x *= i+j;Tidsforbrug: O(n2) (kvadratisk)
for (i = 1; i <= n; i++) x *= i;Tidsforbrug: O(n) (lineært)

55
maxSum = 0;
for (i = 1; i <= n; i++)
for (j = i; j <= n; j++)
sum = 0;
for (k = i; k <= j; k++)
sum += a[k];
if (sum > maxSum)
maxSum = sum;
Eksempel på analyse(Den maksimale delsekvenssum)
Tidsforbrug: O(n3) (kubisk)
maxSum1:

56
maxSum = 0;for (i = 1; i <= n; i++) sum = 0; for (j = i; j <= n; j++) sum += a[j]; if (sum > maxSum) maxSum = sum;
Tidsforbrug: O(n2) (kvadratisk)
maxSum2:

57
maxSum = maxSuffix = 0;for (i = 1; i <= n; i++) maxSuffix += a[i]; if (maxSuffix > maxSum) maxSum = maxSuffix; else if (maxSuffix < 0) maxSuffix = 0;
Tidsforbrug: O(n) (lineært)
maxSum3:

58
Søgning er det problem at afgøre, om en mængde af objekter indeholder et objekt, der opfylder visse specificerede krav, og i givet fald finde det.
Søgning
Søgning er genfinding af lagret information. Informationen har form af poster, der hver har en nøgle. Målet med en søgning er at finde den eller de poster, der har en nøgle, der matcher en given søgenøgle.
Søgning er den mest tidsforbrugende aktivitet i mange programmer. At erstatte en dårlig søgemetode med en god giver ofte en væsentlig effektivitetsforbedring.

59
Klassifikation af søgemetoder
• intern/ekstern søgning
• statisk/dynamisk søgning
• søgning baseret på nøglesammenligninger/ digitale egenskaber ved nøglerne
• søgning baseret på de aktuelle nøgler/ transformerede nøgler

60
Interfacet Comparable
public interface Comparable
int compareTo(Object other);
Objekter, der skal sammenlignes, skal implementere dette interface.
lhs.compareTo(rhs), hvor lhs og rhs er to Comparable-objekter, skal returnere en negativ værdi, 0 eller en positiv værdi, alt efter om lhs er “mindre end”, “lig med” eller “større end” rhs.

61
int sequentialSearch(Comparable[] a, Comparable key)
for (int i = 0; i < a.length; i++) if (a[i].compareTo(key) == 0)
return i;
return NOT_FOUND;// -1
Sekventiel (lineær) søgning
Sekventiel søgning i et usorteret array bruger altid N sammenligninger for en mislykket søgning, og gennemsnitligt (N+1)/2 sammenligninger for en succesfuld søgning.
Tidskompleksiteten for sekventiel søgning er O(N).
62
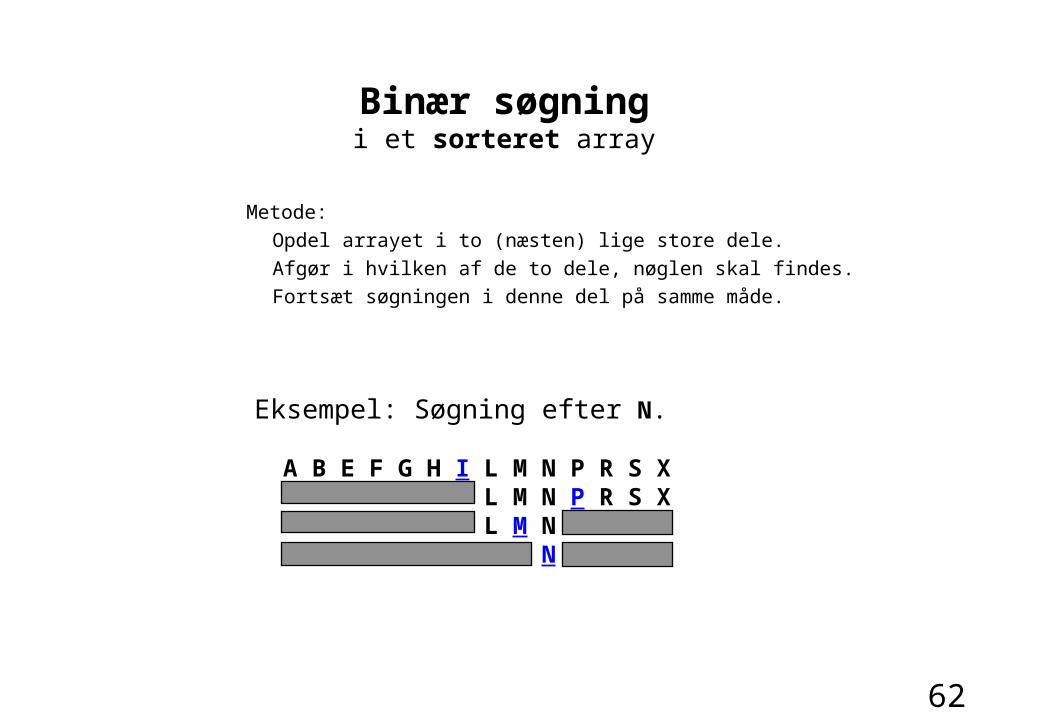
Binær søgningi et sorteret array
Metode:
Opdel arrayet i to (næsten) lige store dele.
Afgør i hvilken af de to dele, nøglen skal findes.
Fortsæt søgningen i denne del på samme måde.
Eksempel: Søgning efter N.
A B E F G H I L M N P R S X L M N P R S X L M N N

63
int binarySearch(Comparable[] a, Comparable key)
int low = 0, high = a.length - 1;
while (low <= high)
int mid = (low + high)/2;
if (a[mid].compareTo(key) < 0)
low = mid + 1;
else if (a[mid].compareTo(key) > 0)
high = mid - 1;
else
return mid;
return NOT_FOUND;
Implementation af binær søgning
Algoritmen bruger altid log2N +1sammenligninger for en mislykket søgning, og
gennemsnitligt log2N sammenligninger for en succesfuld søgning.

64
int binarySearch(Comparable[] a, Comparable key)
int low = 0, high = a.length - 1;
while (low < high)
int mid = (low + high)/2;
if (a[mid].compareTo(key) < 0) low = mid + 1;
else high = mid;
if (a[low].compareTo(key) == 0) return mid;
return NOT_FOUND;
Algoritmen bruger altid log2N +1 sammenligninger for en søgning.
Alternativ implementation afbinær søgning

65
Binær søgning blev første gang beskrevet i 1946.Den første fejlfri udgave blev publiceret i 1962.
I 1986 fandt Bentley, at 90% af de professionelle programmører på hans kurser ikke kunne skrive en fejlfri udgave på to timer.
Hvor svært kan det være?

66
Kompleksiteten af binær søgning
Binær søgning bruger aldrig mere end log2N + 1 sammenligninger - for såvel succesfuld som mislykket søgning.
Binær søgning kan beskrives ved et søgetræ:
I
E
B
A F H L N R X
G M S
P

67
Interpolationssøgning
Indeksintervallet opdeles efter et gæt på nøglens placering. Ved lineær interpolation sammenholdes søgenøglen med nøglerne i de to interval-endepunkter. I binær søgning erstattes mid med next, og
mid = (low + high)/2 med next = low + (key - a[low])*(high -
low)/(a[high] - a[low]).
a[high]
a[low]
key
low next high

68
Kompleksiteten af interpolationssøgning
Interpolationssøgning bruger log2log2N + 1 sammenligninger for både succesfuld og mislykket søgning på “ tilfældige” tabeller.
Færre end 5 forsøg i praksis (225 ≈ 4*1010).
Svagheder: (1) tabellerne er normalt ikke “tilfældige”,
(2) beregningerne af next kan koste mere end de sparede sammenligninger.

69
Kompleksitetsvurdering
3 tilfælde: • det bedste• det værste• det gennemsnitlige
Eksempel - Quicksort:
Bedste: O(n log n) Værste: O(n2) Gennemsnitlige: O(n log n) (hvor n er antallet af elementer, der skal sorteres)
Sædvanligvis vurderes det værste tilfælde, fordi:
(1) vi ønsker en øvre grænse (en garanti), og (2) det er lettest at beregne.

70
O-notationens begrænsning
O-notationen er kun brugbar for “store” værdier af n.
For små værdier af n kan de ikke-dominerende led have en væsentlig betydning.

71
Hvor O(f(n)) kan benyttes til at angive en øvre grænse (≤) for vækst, kan Ω(f(n)) benyttes til at angive en nedre grænse (≥):
g(n) = Ω(f(n)), hvis der findes konstanter, c og N0, således at g(n) ≥ cf(n), når n ≥ N0.
g(n) = (f(n)), hvis væksten for g er mindre end (<) væksten for f. g(n) = (f(n)), hvis og kun hvis g(n) = O(f(n)) og g(n) ≠ (f(n))
g(n) = f(n)), hvis væksten for g er den samme (=) som væksten for f.g(n) = (f(n)), hvis og kun hvis g(n) = O(f(n)) og g(n) = Ω(f(n))
Ω, og

72
At ræsonnere om algoritmer
Evnen til at drage logiske slutninger er nyttig ved
• algoritmedesign
• fejlfinding
• forbedringer
• verifikation (bevis for korrekthed)

73
En algoritme A siges at være partielt korrekt, når der gælder følgende: Hvis A terminerer for et givet legalt input, så vil dens output være korrekt.
Verifikation
Bevisførelse af partiel korrekthed foretages ved brug af påstande (assertions).
En påstand er et logisk udsagn, der er knyttet til et givet punkt i algoritmen, og som er opfyldt, hver gang algoritmen når til dette punkt.
En algoritme A siges at være korrekt (eller totalt korrekt), hvis A er partielt korrekt, og A terminerer for ethvert legalt input.

74
Påstande
• Før-betingelse (precondition) Et udsagn, som gælder før udførelsen af en eller flere sætninger.
• Efter-betingelse (postcondition) Et udsagn, som gælder efter udførelsen af en eller flere sætninger.
• Løkke-invariant (loop invariant) Et udsagn, som gælder umiddelbart før løkke-testen i en løkke.

75
m ≤ n før-betingelsesort(a, m, n);
a[m] ≤ a[m+1] ≤ . . . ≤ a[n] efter-betingelse
Eksempler på påstande
i = m;
while
a[m] ≤ a[m+1] ≤ . . . ≤ a[i-1] ^
a[m .. i-1] ≤ a[i .. n] løkke-invariant (i < n)
min = i;
for (j = i+1; j <= n; j++)
if (a[j] < a[min]) min = j;
x = a[i]; a[i] = a[min]; a[min] = x;
i++;

76
Regler for verifikation
• Tildeling:
P w > 2 v = w; P v > 2
w
• Valg:
Pif (B) P ^ B S1;else P ^ ¬ B S2;
w v

77
Givet algoritmen
q = 0; r = x;
while (r >= y)
r = r - y;
q = q + 1;
hvor x, y, q og r er heltal, x ≥ 0 og y > 0.
Eksempel på verifikation(heltalsdivision)
Bevis at algoritmen bestemmer kvotienten q og resten r ved heltalsdivision af x med y, dvs.
r = x - q*y (0 ≤ r < y)

78
Bevisførelsen
(1) Løkke-invarianten er opfyldt ved indgangen til løkken.
(2) Hvis løkke-invarianten er opfyldt i en given iteration, så er den også opfyldt i den efterfølgende iteration.
(3) Hvis algoritmen terminerer, så er dens efter-betingelse opfyldt.
(4) Algoritmen terminerer.
induktion

79
x ≥ 0, y > 0 algoritmens før-betingelseq = 0;
r = x;
while r = x - qy ^ r ≥ 0 løkke-invariant (r >= y)
r = r - y;
q = q + 1;
r = x - qy ^ 0 ≤ r < y algoritmens efter-betingelse
r = x - qy ^ r ≥ y r - y = x - (q+1)y ^ r - y ≥ 0
r = x - (q+1)y ^ r ≥ 0

80
q = 0; r = x;while (r >= y) r = r - y; q = q + 1;
Algoritmen terminerer.
Terminering
Bevis:
Da y > 0, mindskes r ved hvert gennemløb af løkken. Løkketesten må derfor blive falsk efter et endeligt antal gennemløb.

81
• Læs kapitel 6
• Løs følgende opgaver fra lærebogen
Opgave 9: 5.6 (2 point)
Opgave 10: 5.15, spørgsmål a (1 point)
Opgave 11: 5.24 (2 point, ikke-obligatorisk)
Afleveringsfrist: tirsdag den 16. oktober
Ugeseddel 32. oktober - 9. oktober


















