
LYU0002 Wireless Cyber Campus Supervisor: Prof. Michael R. Lyu Student:Jang Kim Fung Tang Ho Man.
Upload
cameron-morrisonCategory
view
215download
0
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 11
Learning From Data Learning From Data Locally and GloballyLocally and Globally
Kaizhu HuangKaizhu Huang
Supervisors: Supervisors: Prof. Irwin King, Prof. Irwin King,
Prof. Michael R. LyuProf. Michael R. Lyu

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 22
OutlineOutline
BackgroundBackground• Linear Binary classifierLinear Binary classifier• Global LearningGlobal Learning
Bayes optimal ClassifierBayes optimal Classifier• Local LearningLocal Learning
Support Vector MachineSupport Vector Machine ContributionsContributions Minimum Error Minimax Probability Machine (MEMPM)Minimum Error Minimax Probability Machine (MEMPM)
• Biased Minimax Probability Machine (BMPM)Biased Minimax Probability Machine (BMPM) Maxi-Min Margin Machine (MMaxi-Min Margin Machine (M44))
• Local Support Vector Regression (LSVR)Local Support Vector Regression (LSVR) Future workFuture work ConclusionConclusion
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 33
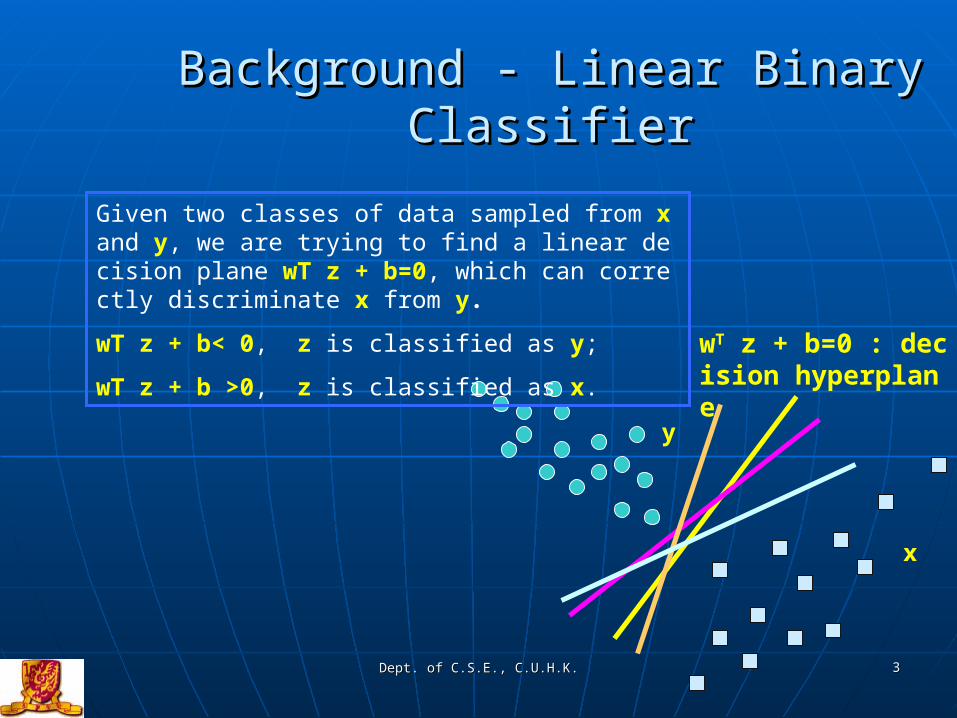
Given two classes of data sampled from x and y, we are trying to find a linear decision plane wT z + b=0, which can correctly discriminate x from y.
wT z + b< 0, z is classified as y;
wT z + b >0, z is classified as x. wT z + b=0 : decision hyperplane
y
x
Background - Linear Binary ClassifierBackground - Linear Binary Classifier
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 44
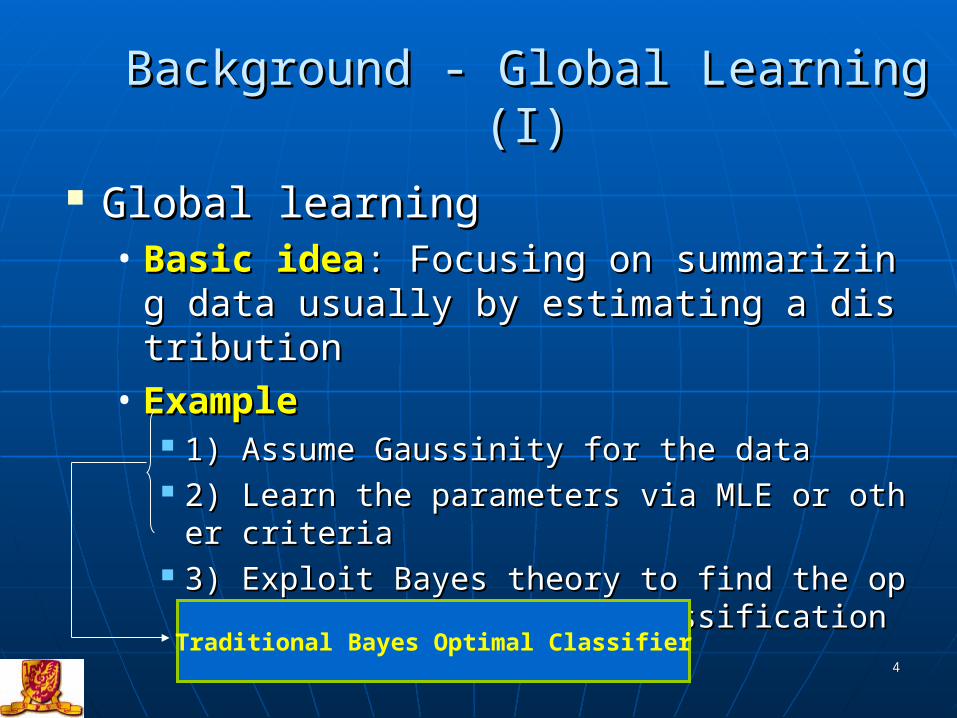
Background - Global Learning (I)Background - Global Learning (I)
Global learningGlobal learning• Basic ideaBasic idea: Focusing on summarizing data u: Focusing on summarizing data u
sually by estimating a distributionsually by estimating a distribution• ExampleExample
1) Assume Gaussinity for the data 1) Assume Gaussinity for the data 2) Learn the parameters via MLE or other criteria2) Learn the parameters via MLE or other criteria 3) Exploit Bayes theory to find the optimal thres3) Exploit Bayes theory to find the optimal thres
holding for classificationholding for classification
Traditional Bayes Optimal Classifier

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 55
ProblemsProblems Usually have to assume specific models on data, which Usually have to assume specific models on data, which
may NOT always coincide with datamay NOT always coincide with data ““all models are wrong but some are useful…”—by George Boxall models are wrong but some are useful…”—by George Box
Estimating distributions may be wasteful and impreciseEstimating distributions may be wasteful and imprecise
Finding the ideal generator of the data, i.e., the distribution, is Finding the ideal generator of the data, i.e., the distribution, is only an intermediate goal in many settings, e.g., in only an intermediate goal in many settings, e.g., in classification or regression. classification or regression. Optimizing an intermediate Optimizing an intermediate objective may be inefficient or wastefulobjective may be inefficient or wasteful..
Background - Global Learning (II)Background - Global Learning (II)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 66
Background- Local Learning (I)Background- Local Learning (I)
Local learningLocal learning• Basic ideaBasic idea: Focus on exploiting part of : Focus on exploiting part of
information, which is directly related to the information, which is directly related to the objective, e.g., the classification accuracy objective, e.g., the classification accuracy instead of describing data in a holistic wayinstead of describing data in a holistic way
• ExampleExample
In classification, we need to accurately In classification, we need to accurately model the data around the (possible) model the data around the (possible) separating plane, while inaccurate modeling separating plane, while inaccurate modeling of other parts is certainly acceptable (as is of other parts is certainly acceptable (as is done in SVM).done in SVM).

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 77
Support Vector Machine (SVM)Support Vector Machine (SVM)
------The current state-of-the-art classifierThe current state-of-the-art classifierDecision Plane
Support Vectors
Margin
Background - Local Learning (II)Background - Local Learning (II)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 88
ProblemsProblems The fact that the objective is exclusively The fact that the objective is exclusively
determined by local information may determined by local information may lose the overall view of datalose the overall view of data
Background - Local Learning (III)Background - Local Learning (III)
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 99
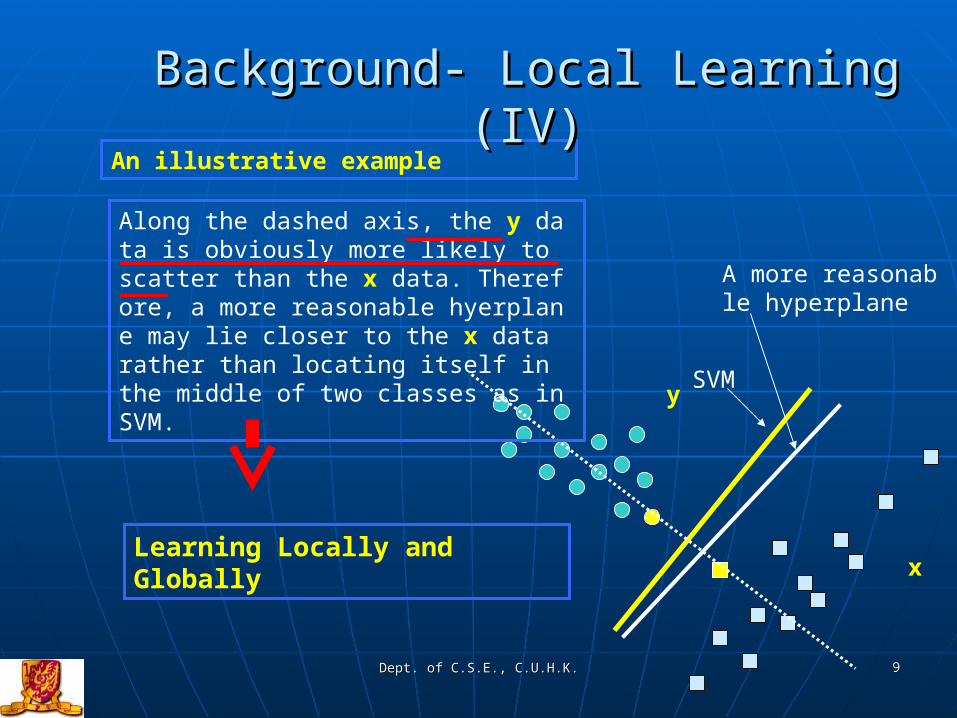
y
x
Along the dashed axis, the y data is obviously more likely to scatter than the x data. Therefore, a more reasonable hyerplane may lie closer to the x data rather than locating itself in the middle of two classes as in SVM.
SVM
Learning Locally and Globally
An illustrative example
A more reasonable hyperplane
Background- Local Learning (IV)Background- Local Learning (IV)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1010
Learning Locally and GloballyLearning Locally and Globally
Basic ideaBasic idea: Focus on using : Focus on using both local both local informationinformation andand certain robust global certain robust global informationinformation• Do not try to estimate the distribution as in Do not try to estimate the distribution as in
global learning, which may be inaccurate and global learning, which may be inaccurate and indirectindirect
• Consider robust global information for Consider robust global information for providing a roadmap for local learningproviding a roadmap for local learning

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1111
Summary of BackgroundSummary of Background
Assume specific modelsAssume specific models
Optimizing an intermediate objectiveOptimizing an intermediate objective
ProbleProblemm
ProblemProblem
ProblemProblem Focusing on local info may lose the roadmap of dataFocusing on local info may lose the roadmap of data
Can we directly optimize the objective??
Without specific model assumption?
Can we learn both globally and locally??
Distribution-free Bayes optimal classifier Distribution-free Bayes optimal classifier ------Minimum Error Minimax Probability Machine (MEMPM)Minimum Error Minimax Probability Machine (MEMPM)
Maxi-Min Margin Machine (M4)
Local LearningLocal Learning,, e.g., SVMe.g., SVM
Glo
bal
Learn
ing
Local L
earn
ing

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1212
ContributionsContributions
Mininum Error Minimax Probability MachineMininum Error Minimax Probability Machine(Accepted by JMLR 04)(Accepted by JMLR 04)• A A worst-case distribution-free Bayes Optimal Classifierworst-case distribution-free Bayes Optimal Classifier• Containing Minimax Probability Machine (MPM) and Containing Minimax Probability Machine (MPM) and Biased MiBiased Mi
nimax Probability Machinenimax Probability Machine (BMPM (BMPM)()(AMAI04AMAI04,,CVPR04CVPR04)) as special ca as special casesses
Maxi-Min Margin Machine (MMaxi-Min Margin Machine (M44) ) ((ICML 04+SubmittedICML 04+Submitted))• A A unified frameworkunified framework that learns locally and globally that learns locally and globally
Support Vector Machine (SVM)Support Vector Machine (SVM) Minimax Probability Machine (MPM)Minimax Probability Machine (MPM) Fisher Discriminant Analysis (FDA)Fisher Discriminant Analysis (FDA) Can be linked with MEMPMCan be linked with MEMPM
• Can be extended into regression: Can be extended into regression: Local Support Vector RegresLocal Support Vector Regression (LSVR) sion (LSVR) (submitted)(submitted)
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1313
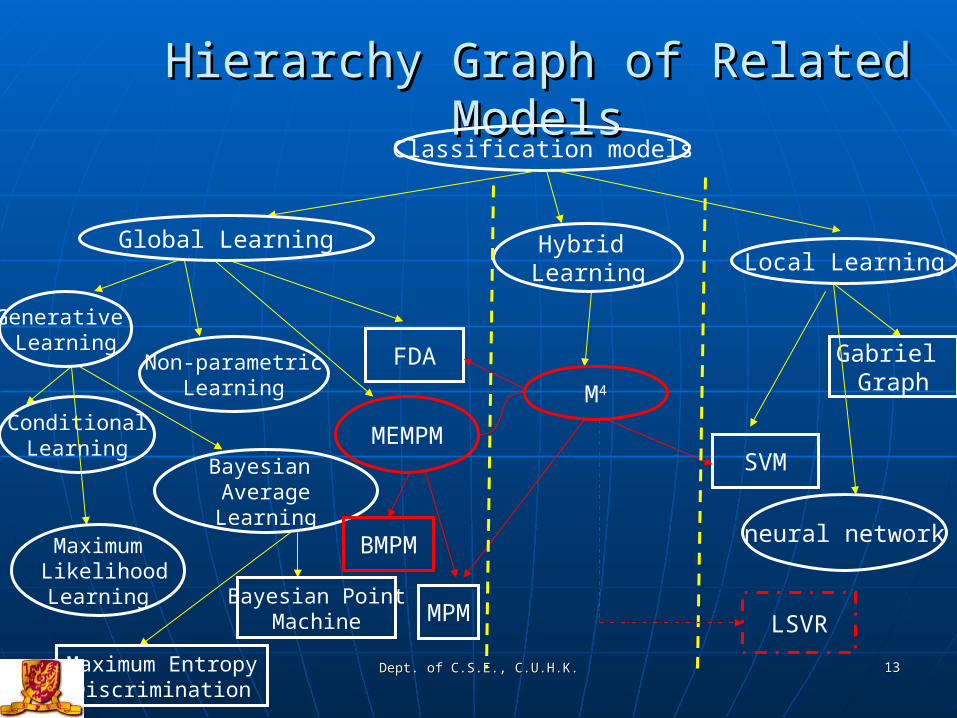
Hierarchy Graph of Related ModelsHierarchy Graph of Related ModelsClassification models
Global LearningLocal Learning
Hybrid Learning
ConditionalLearning
Maximum LikelihoodLearning
Bayesian AverageLearning
Bayesian PointMachine
Maximum EntropyDiscrimination
Non-parametricLearning
MEMPM
BMPM
FDA
M4
MPM
SVM
Gabriel Graph
neural network
LSVR
Generative Learning

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1414
Minimum Error Minimax Probability MaMinimum Error Minimax Probability Machine (MEMPM)chine (MEMPM)
.}Pr{inf
,}Pr{inf
s.t.,)1(max
),(~
),(~
,,,
b
b
T
T
b
y
x
y
x
yy
xx
0
w
w
w
• θ: prior probability of class x; α(β): represents the worst-case accuracy for class x (y)
Model Definition:
:),(~ xxx The class of distributions that have prescribed
mean and covariance
likewise
x x
:),(~ yyy
x
y {w,b}
wTx≥b
wTy≤b

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1515
MEMPM: Model ComparisonMEMPM: Model Comparison
.}Pr{inf
,}Pr{inf
s.t.,)1(max
),(~
),(~
,,,
b
b
T
T
b
y
x
y
x
yy
xx
0
w
w
w
MEMPM (JMLR04) MPM (Lanckriet et al. JMLR 2002)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1616
MEMPM: AdvantagesMEMPM: Advantages
A A distribution-freedistribution-free Bayes optimal Classifier in the Bayes optimal Classifier in the worst-case scenarioworst-case scenario
Containing an Containing an explicit accuracy boundexplicit accuracy bound, namely, , namely,
Subsuming a special case Subsuming a special case Biased Minimax ProbabiBiased Minimax Probability Machinelity Machine for biased classificationfor biased classification
)1(

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1717
MEMPM: Biased MPMMEMPM: Biased MPMBiased Classification:Diagnosis of epidemical disease: Classifying a patient who is infected with a disease into an opposite class results in more serious consequence than the other way around.The classification accuracy should be biased towards the class with disease.
An ideal model for biased classification.
A typical setting: We should maximize the accuracy for the important class as long as the accuracy for the less important class is acceptable (greater than an acceptable level ).
BMPM
,}Pr{inf
,}Pr{inf
s.t.,max
),(~
),(~
,,,
b
b
T
T
b
y
x
y
x
yy
xx
0
w
w
w

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1818
Objective Objective
Equivalently Equivalently
MEMPM: Biased MPM (I)MEMPM: Biased MPM (I)
)()(
1)(
)()(1s.t.)(max,,,
yx
yx0
T
TT
b
w
wwwww
11 )(,)(
}Pr{ inf
}Pr{infs.t.max
),(~
),(~,,,
b
b
T
T
b
y
x
y
x
yy
xx0a
w
w

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 1919
Objective Objective
Equivalently, Equivalently,
Equivalently,Equivalently,
MEMPM: Biased MPM (II)MEMPM: Biased MPM (II)
)()(
1)(
)()(1s.t.)(max,,,
yx
yx0
T
TT
b
w
wwwww
)()(,1)(s.t.)(1
max),(
yxx
y
0
T
T
T
www
www
1)(s.t.)(1
max
yxx
y
0
T
T
T
www
www
Conave-Convex Fractional Programming problem
1. Each local optimum is the
global optimum 2. Can be solved in
O(n3+Nn2)
N: number of data points n: Dimension

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2020
ObjectiveObjective
Equivalently Equivalently
MEMPM: Optimization (I)MEMPM: Optimization (I)
1)(
)()(1
s.t.,)1(max,,
yx
yx
0
T
TT
w
wwww
w
1)(
)()(1
s.t.,1)(
1
1)(min
22),(),(
yx
yx
0
T
TT
w
wwww
w

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2121
ObjectiveObjective
Line search + BMPM method Line search + BMPM method
MEMPM: Optimization (II)MEMPM: Optimization (II)
ww
ww
w
w
x
y
0
yx
T
T
T
where)(1
)(
,1)(
s.t.,)1(1)(
)(max
2
2
,,

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2222
MEMPM: ProblemsMEMPM: Problems
As a global learning approach, the decision As a global learning approach, the decision plane is plane is exclusivelyexclusively dependent on dependent on global global informationinformation, i.e., up to second-order , i.e., up to second-order moments. moments.
These moments may These moments may NOT be accuratelyNOT be accurately estimated! –We may need local estimated! –We may need local information to neutralize the negative information to neutralize the negative effect caused.effect caused.
Learning Locally and Globally

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2323
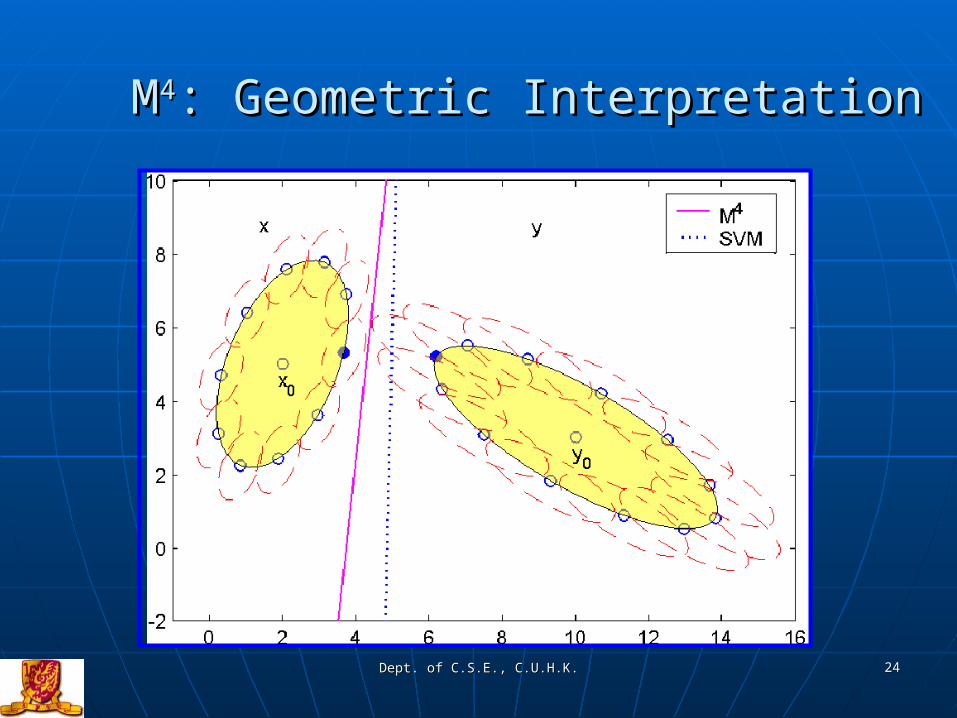
Learning Locally and Globally:Learning Locally and Globally:Maxi-Min Margin Machine (MMaxi-Min Margin Machine (M44))
y
x
SVM
A more reasonable hyperplane
Model Definition
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2424
MM44: Geometric Interpretation: Geometric Interpretation

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2525
MM44: Solving Method (I): Solving Method (I)
Divide and Conquer:
If we fix ρ to a specific ρn , the problem changes to check whether this ρn satisfies the following constraints:
If yes, we increase ρn; otherwise, we decrease it.
Second Order Cone Programming Problem!!!
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2626
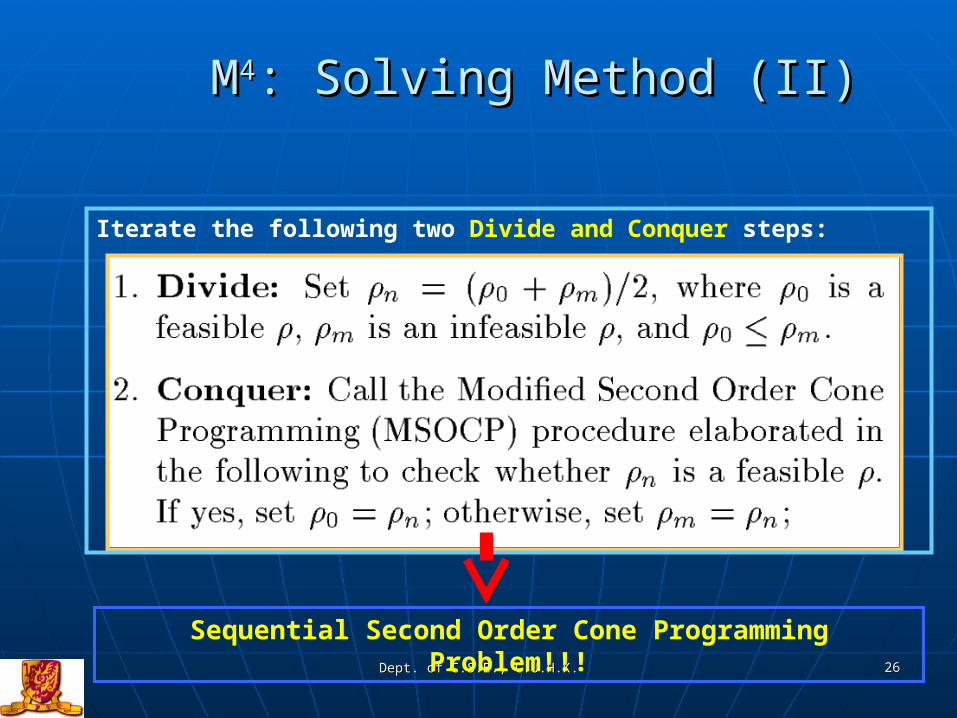
MM44: Solving Method (II): Solving Method (II)
Iterate the following two Divide and Conquer steps:
Sequential Second Order Cone Programming Problem!!!

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2727
can it satisfy the constraints?
YesNo
MM44: Solving Method (III): Solving Method (III)
The worst-case iteration number is log(L/)
L: ρmax -ρmin (search range) : The required precision
Each iteration is a Second Order Cone Programming problem yielding O(n3) Cost of forming the constraint matrix O(N n3)
Total time complexity= O(log(L/) n3+ N n3) O(N n3)N: number of data points n: Dimension

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2828
MM44: Links with MPM (I): Links with MPM (I)
+
Span all the data points and add them
together
Exactly MPM Optimization Problem!!!
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 2929
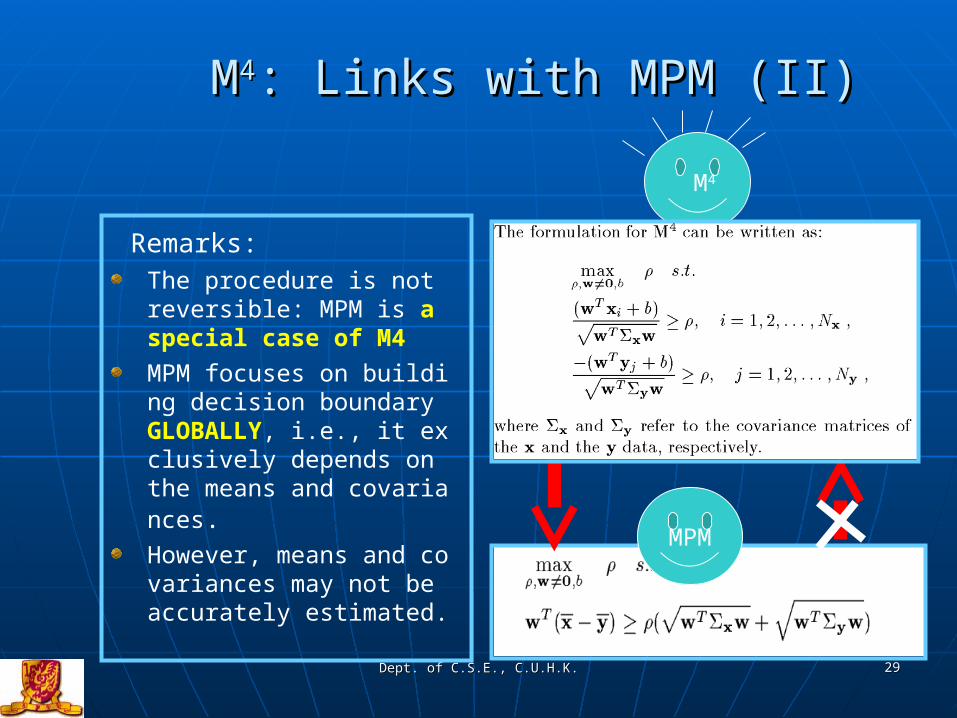
MM44: Links with MPM (II): Links with MPM (II)
MPM
M4
Remarks: The procedure is not reversible: MPM is a special case of M4MPM focuses on building decision boundary GLOBALLY, i.e., it exclusively depends on the means and covariances. However, means and covariances may not be accurately estimated.

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3030
If one assumes ∑=I
MM44: Links with SVM (I): Links with SVM (I)
1
2
3
4
Support Vector Machines
SVM is the special case of MM44
The magnitude of w can scale up without influencing the optimizati
on. Assume ρ(wT ∑w)0.5=1

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3131
MM44: Links with SVM (II): Links with SVM (II)
These two assumptions of SVM are inappropriate
If one assumes ∑=I
Assumption 1Assumption 2
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3232
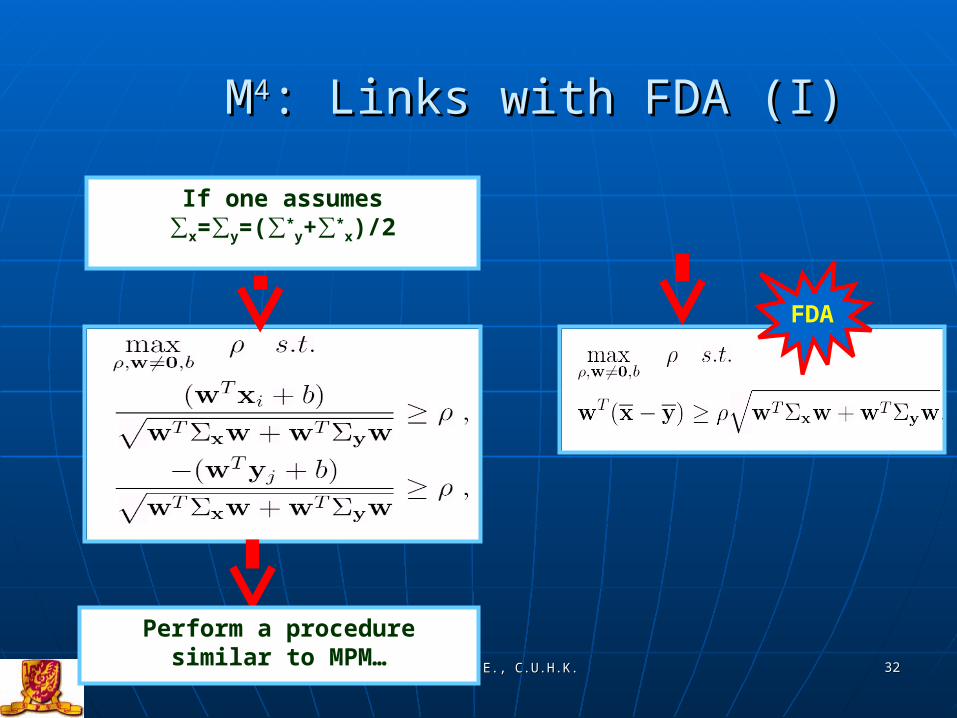
MM44: Links with FDA (I): Links with FDA (I)
If one assumes ∑x=∑y=(∑*
y+∑*x)/2
Perform a procedure similar to MPM…
FDA

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3333
MM44: Links with FDA (II): Links with FDA (II)
Assumption
Still inappropriate?If one assumes
∑x=∑y=(∑*y+∑*x)/2

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3434
MM44: Links with MEMPM: Links with MEMPM
M4 (a globalized version) MEMPM
T and s Κ(α) and Κ(β) :
The margin from the mean to the decision plane
The globalized M4 maximizes the weighted margin, while MEMPMMaximizes the weighted worst-case accuracy.

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3535
MM44 :Nonseparable Case :Nonseparable CaseIntroducing slack variables
How to solve?? Line Search+Second Order Cone Programming
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3636
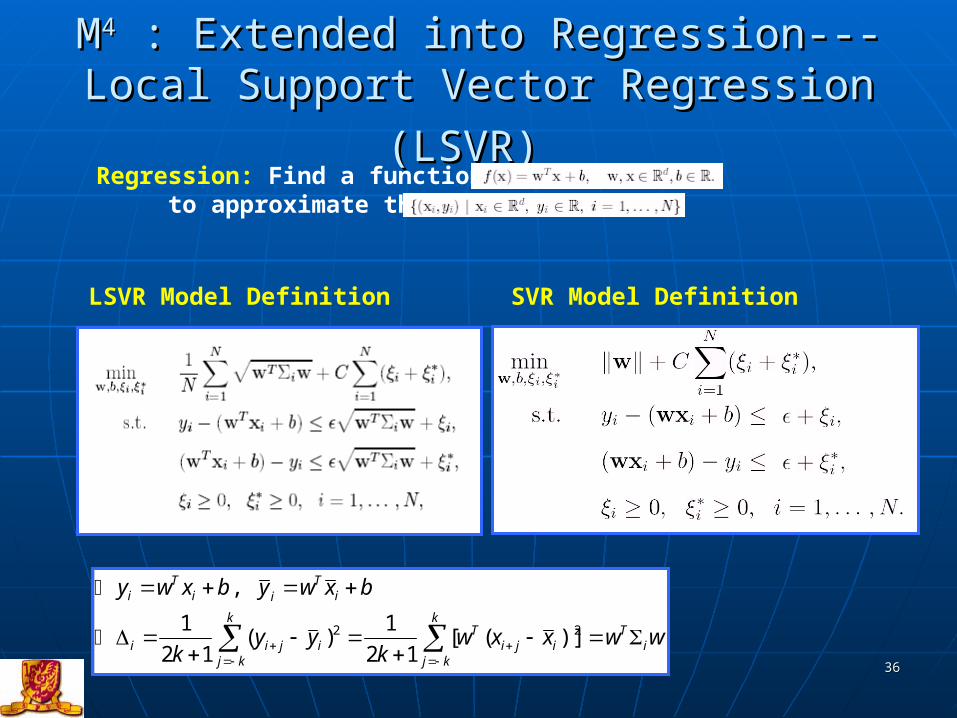
MM44 : Extended into Regression--- : Extended into Regression---
Local Support Vector Regression (LSVR)Local Support Vector Regression (LSVR)
LSVR Model Definition SVR Model Definition
Regression: Find a function to approximate the data
k
kji
Tiji
Tk
kjijii
iT
iiT
i
wwxxwk
yyk
bxwybxwy
22 )]([12
1)(
12
1
,

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3737
Local Support Vector Regression (LSVR)Local Support Vector Regression (LSVR)
When supposing ∑When supposing ∑ii=I for each =I for each observation, LSVR is equivalent with observation, LSVR is equivalent with ll11--SVR under a mild assumptionSVR under a mild assumption..
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3838
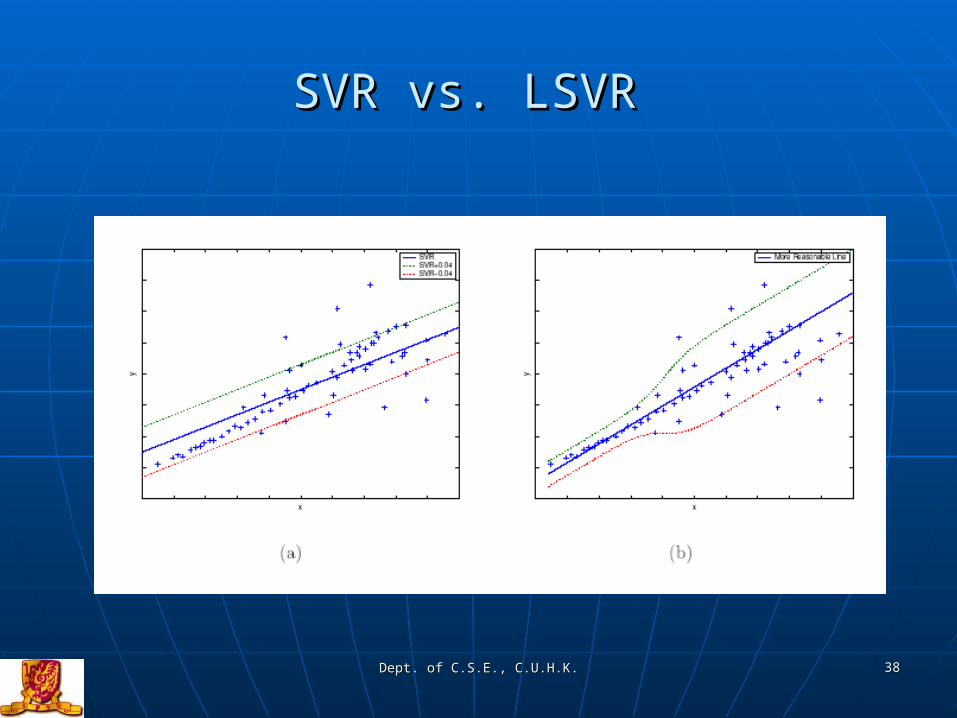
SVR vs. LSVR SVR vs. LSVR
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 3939
Short SummaryShort Summary
M4
MPMFDA
assume∑x=∑y=I
SVM
Gloablized and assume∑x=∑y=(∑*x+∑*y)/2
Globalized MEMPM
Globalized
LSVR
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4040
Non-linear Classifier Non-linear Classifier : Kernelization: Kernelization (I) (I)
Previous discussions of MEMPM, Previous discussions of MEMPM, BMPM, MBMPM, M4 4 , and LSVR are conducted , and LSVR are conducted in the scope of linear classification.in the scope of linear classification.
How about non-linear classification How about non-linear classification problems?problems?
Using Kernelization techniques

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4141
Non-linear Classifier Non-linear Classifier : Kernelization: Kernelization (II) (II)
In the next slides, we mainly discuss the kernelIn the next slides, we mainly discuss the kernelization on Mization on M4, 4, while the proposed kernelizatiowhile the proposed kernelization method is also applicable for MEMPM, BMPM,n method is also applicable for MEMPM, BMPM, and LSVR. and LSVR.
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4242
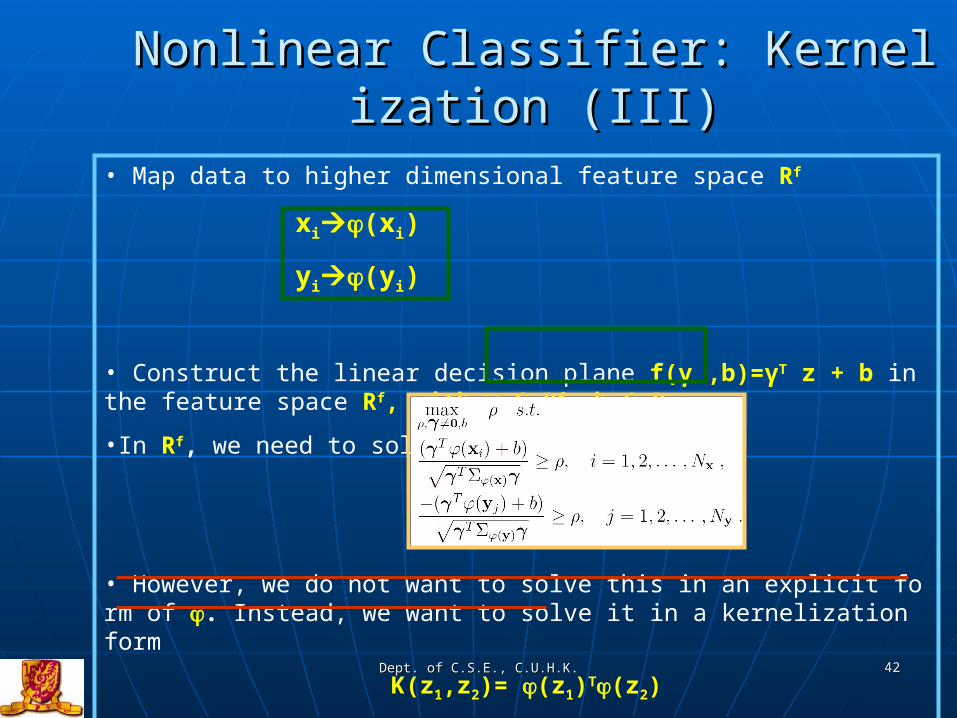
Nonlinear Classifier: Kernelization (III)Nonlinear Classifier: Kernelization (III)
• Map data to higher dimensional feature space Rf
xi(xi)
yi(yi)
• Construct the linear decision plane f(γ ,b)=γ T z + b in the feature space Rf, with γ Є Rf, b Є R•In Rf, we need to solve
• However, we do not want to solve this in an explicit form of . Instead, we want to solve it in a kernelization form
K(z1,z2)= (z1)T(z2)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4343
Nonlinear Classifier: Kernelization (IV)Nonlinear Classifier: Kernelization (IV)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4444
Nonlinear Classifier: Kernelization (V)Nonlinear Classifier: Kernelization (V)
Notation

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4545
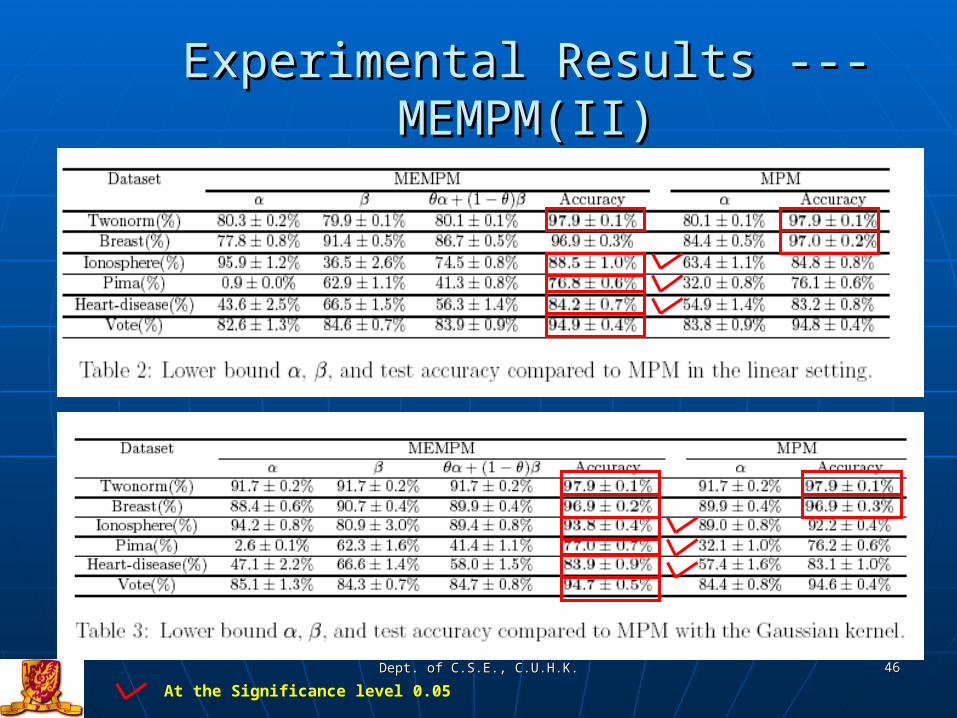
Experimental Results ---MEMPM (I)Experimental Results ---MEMPM (I)
Six benchmark data sets From UCI Repository
Evaluate both the linear and the Gaussian kernel with the wide parameter for Gaussian chosen by cross validations.
Platform: Windows 2000Developing tool: Matlab 6.5
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4646
Experimental Results ---MEMPM(II)Experimental Results ---MEMPM(II)
At the Significance level 0.05

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4747
Experimental Results ---MEMPM (III)Experimental Results ---MEMPM (III)vs. The test-set accuracy for x (TSAx)

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4848
Experimental Results ---MEMPM (IV)Experimental Results ---MEMPM (IV)vs. The test-set accuracy for y (TSAy)
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 4949
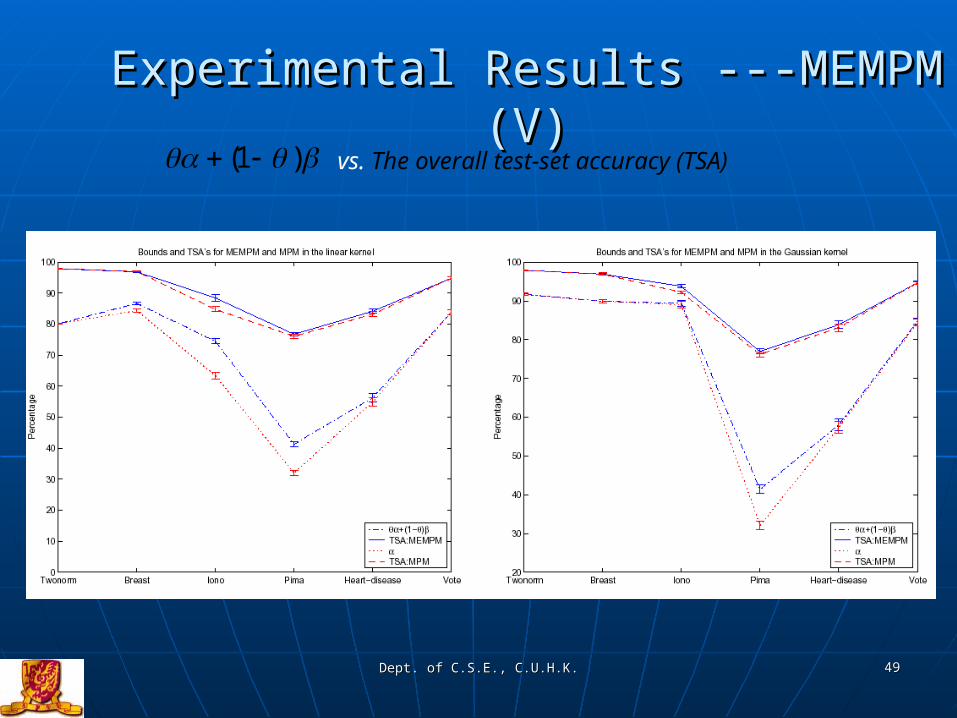
Experimental Results ---MEMPM (V)Experimental Results ---MEMPM (V)vs. The overall test-set accuracy (TSA) )1(
Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5050
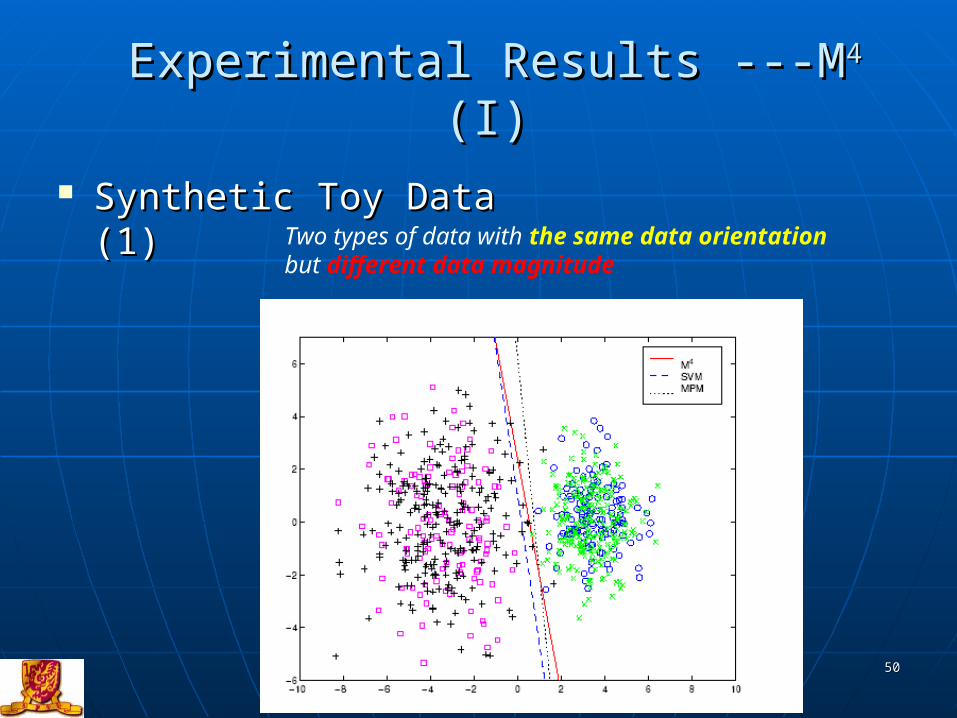
Experimental Results ---MExperimental Results ---M44 (I) (I)
Synthetic Toy Data (1)Synthetic Toy Data (1)Two types of data with the same data orientation but different data magnitude

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5151
Experimental Results ---MExperimental Results ---M44 (II) (II)
Synthetic Toy Data (2)Synthetic Toy Data (2)Two types of data with the same data magnitude but different data orientation

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5252
Experimental Results ---MExperimental Results ---M44 (III) (III)
Synthetic Toy Data (3)Synthetic Toy Data (3)Two types of data with the different data magnitude and different data orientation

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5353
Experimental Results ---MExperimental Results ---M44 (IV) (IV)
Benchmark Data from UCIBenchmark Data from UCI

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5454
Future WorkFuture Work
Speeding up MSpeeding up M4 4 and MEMPMand MEMPM• Contain support vectors—can we employ its sparsity as has beeContain support vectors—can we employ its sparsity as has bee
n done in SVM?n done in SVM?• Can we reduce redundant points??Can we reduce redundant points??
How to impose constrains on the kernelization for keeping tHow to impose constrains on the kernelization for keeping the topology of data?he topology of data?
Generalization error bound?Generalization error bound?• SVM and MPM have both error bounds.SVM and MPM have both error bounds.
How to extend to multi-category classifications?How to extend to multi-category classifications?• One vs. One or One vs. All?One vs. One or One vs. All?• Or seeking a principled way to construct multi-way boundary Or seeking a principled way to construct multi-way boundary in in
a stepa step????

Dept. of C.S.E., C.U.H.K.Dept. of C.S.E., C.U.H.K. 5555
ConclusionConclusion
We propose a general global learning model MEMPMWe propose a general global learning model MEMPM• A Worst-case distribution-free Bayes Optimal classifierA Worst-case distribution-free Bayes Optimal classifier• Containing an explicit error bound for future dataContaining an explicit error bound for future data• Subsuming BMPM which is idea for biased classificationSubsuming BMPM which is idea for biased classification
We propose a hybrid framework We propose a hybrid framework MM4 4 by learning from dby learning from data locally and globallyata locally and globally• This model subsumes three important models as special caseThis model subsumes three important models as special case
s s SVMSVM MPMMPM FDAFDA
• Extended into regression tasksExtended into regression tasks






![Thermodynamics [AP-2013] Lecture 4B by Ling-Hsiao Lyu ...lyu/lecture_files_en/lyu_TD_Notes/TD...Thermodynamics [AP-2013] Lecture 4B by Ling-Hsiao Lyu 2015 p. 4B- 3 Exercise: Write](https://static.fdocuments.net/doc/165x107/603cb45e18d052577f298947/thermodynamics-ap-2013-lecture-4b-by-ling-hsiao-lyu-lyulecturefilesenlyutdnotestd.jpg)











