
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
15
Copyright © BrainPad Inc. All Rights Reserved. DeltaCubeにおけるユニークユーザー集計高速化 (実践編) 2016年6月10日
-
Upload
brainpad-inc -
Category
Data & Analytics
-
view
289 -
download
1
Transcript of DeltaCubeにおけるユニークユーザー集計高速化(実践編)

Copyright © BrainPad Inc. All Rights Reserved.
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
2016年6月10日

Copyright © BrainPad Inc. All Rights Reserved.
1. approx_distinctパフォーマンス検証
2

Copyright © BrainPad Inc. All Rights Reserved.
以下の環境で性能検証を実施
クラスタ環境
– Amazon EMRを利用(EMR 4.6.0)
– master: r3.xlarge 1台
– core : r3.xlarge 3台
– sandboxを利用してPresto 0.143、Hive 1.0.0をインストール
データソース
– Hiveテーブル
• Amazon S3に実データ格納
• hive metastoreはremote mode(MySQL)
3
検証環境
デフォルト設定でmaster, core共に以下の設定内容。
• xmx• 25735444038
• query.max-memory• 30GB
• query.max-memory-per-node• 12867722019B

Copyright © BrainPad Inc. All Rights Reserved.
データフォーマット
– ORC
• 50万行ごとに分割
• カラム数は24
– パーティション
• 日付(年月日)
データサイズ
– 1行あたりログサイズ
• 約120~約280B
– 1日あたりログサイズ
• UU数が小規模な場合
– 約177KB
• UU数が中規模な場合
– 約222MB
• UU数が大規模な場合
– 約200MB~約2.6GB
4
検証データ

Copyright © BrainPad Inc. All Rights Reserved.
以下の内容で、厳密に集計(COUNT(DISTINCT x))した場合と推定(approx_distinct(x))した場合の結果を取得
– UU数が小規模(1日あたり数百)な場合
• 1日分~180日分まで1日分ずつログを増加させる
– 例)
– 1回目:4月1日分のログで集計
– 2回目:4月1日~4月2日分のログで集計
– ・・・
– UU数が中規模(1日あたり数万)な場合
• 1日分~180日分まで1日分ずつログを増加させる
– UU数が大規模(1日あたり十数万~百数十万)な場合
• 1日分~375日分まで1日分ずつログを増加させる
5
検証項目
Copyright © BrainPad Inc. All Rights Reserved. 6
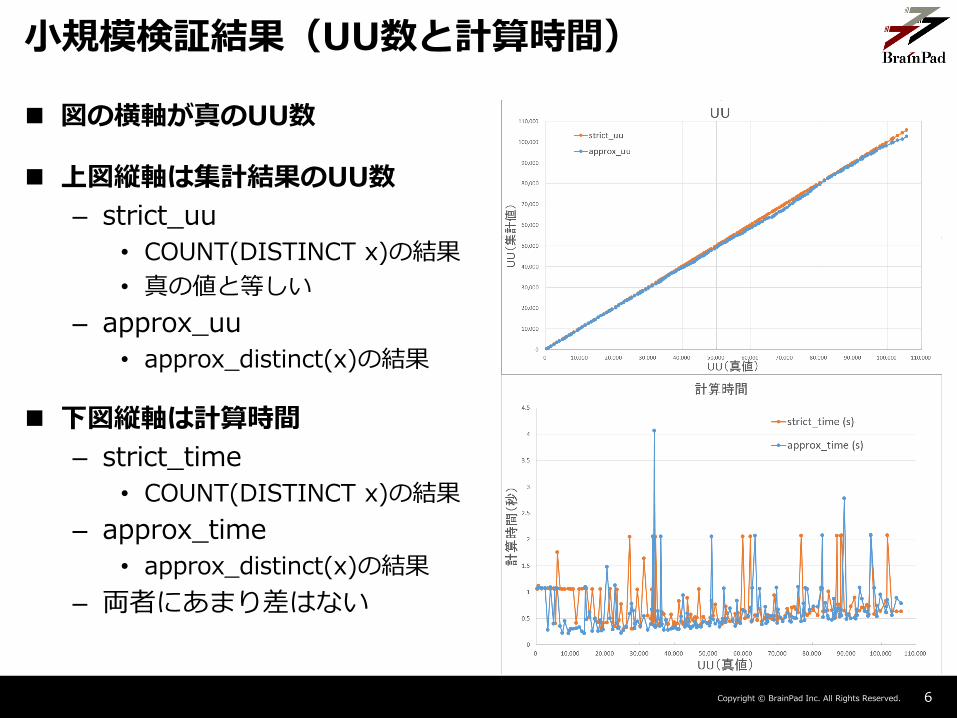
小規模検証結果(UU数と計算時間)
図の横軸が真のUU数
上図縦軸は集計結果のUU数
– strict_uu
• COUNT(DISTINCT x)の結果
• 真の値と等しい
– approx_uu
• approx_distinct(x)の結果
下図縦軸は計算時間
– strict_time
• COUNT(DISTINCT x)の結果
– approx_time
• approx_distinct(x)の結果
– 両者にあまり差はない

Copyright © BrainPad Inc. All Rights Reserved.
図の横軸が真のUU数
上図縦軸はUU数の絶対誤差
– 推定UU – 真のUUで計算
下図縦軸はUU数の相対誤差
– 絶対誤差/真のUU*100で計算
– 最大でも±4%以内
– 絶対値平均で1.6%程度
– ±3%以内に90%以上が収まっている
7
小規模検証結果(絶対誤差と相対誤差)

Copyright © BrainPad Inc. All Rights Reserved. 8
中規模検証結果(UU数と計算時間)
図の各軸は小規模検証結果と同様
計算時間(下図)
– UU数が増加するほど差が大きくなる
– 最大で1/3まで短縮されている(外れ値を除く)
– 平均でも1/2まで短縮
– いくつか外れ値のようなものが含まれる
• 手動で再実行した場合は前後の条件での集計と同程度の速度であった

Copyright © BrainPad Inc. All Rights Reserved.
図の各軸は小規模検証結果と同様
相対誤差(下図)
– 最大でも±5%以内
– 絶対値平均で2.4%程度
– ±4%以内に75%以上が収まっている
9
中規模検証結果(絶対誤差と相対誤差)

Copyright © BrainPad Inc. All Rights Reserved. 10
大規模検証結果(UU数と計算時間)
図の各軸は小規模検証結果と同様
計算時間
– UU数が増加するほど差が大きい
– 最大で1/4まで短縮(外れ値を除く)
– 平均でも1/3以下まで短縮
– いくつか外れ値のようなものが含まれる
• 手動で再実行した場合は前後の条件での集計と同程度の速度であった

Copyright © BrainPad Inc. All Rights Reserved.
図の各軸は小規模検証結果と同様
相対誤差(下図)
– 最大でも±5%以内
– 絶対値平均で1%程度
– ±4%以内に99%以上が収まっている
11
大規模検証結果(絶対誤差と相対誤差)

Copyright © BrainPad Inc. All Rights Reserved.
誤差はかなり小さい
– 全検証において最大でも±5%以内の相対誤差で収まった
• 全検証の平均では相対誤差1.5%程度
• 93%以上は相対誤差±4%以内
– UU数が小さい場合でも誤差は小さい
• 単純なHyperLogLogだけではなくその推定値に補正をかけている?
誤差がある値を境に小さくなっていくことがある
– その前後でアルゴリズムを切り替えている?
基本的にUU数が増加すると絶対誤差は増加する
– UU数の真値も増加するので相対誤差が増加するわけではない
大規模データに対してはかなり高速
– そもそも厳密な集計が高速な場合(数秒程度)にはあまり効果がない
– 基本的にデータが大きくなるほど計算時間の削減率は大きい
• 計算時間が1/4にまで短縮される場合もあった
12
検証結果考察

Copyright © BrainPad Inc. All Rights Reserved.
2. まとめ
13

Copyright © BrainPad Inc. All Rights Reserved.
全ての検証で相対誤差±5%以内と実用的
– アルゴリズム的に心配していたUU数が小さい場合も十分な精度
かなりの高速化が期待できる
– データが大規模であるほど効果を発揮
個々のユーザーの情報は潰れる
– COUNT(DISTINCT x)の推定のため、ユーザーの一覧は出せない
• その集合に含まれるユーザーを特定することはできない
メモリの使用量も削減
– (注)今回は高速化が主目的のため、削減量などのデータは未取得
毎回ランダムにサンプリングして推定するタイプではない
– 入力データが同じなら同じ結果が返ってくる
– ヘビーユーザーのような大量にログに出てくる人物に影響されない
14
まとめ

Copyright © BrainPad Inc. All Rights Reserved.
株式会社ブレインパッド
〒108-0071 東京都港区白金台3-2-10 白金台ビル3F
TEL:03-6721-7001
FAX:03-6721-7010
Copyright © BrainPad Inc. All Rights Reserved.
www.brainpad.co.jp


















