
DeepXplore: Automated Whitebox Testing of Deep Learning ... · DeepXplore: Automated Whitebox...
18
DeepXplore: Automated Whitebox Testing of Deep Learning Systems Kexin Pei ⋆ , Yinzhi Cao † , Junfeng Yang ⋆ , Suman Jana ⋆ ⋆ Columbia University, † Lehigh University ABSTRACT Deep learning (DL) systems are increasingly deployed in safety- and security-critical domains including self-driving cars and malware detection, where the correctness and pre- dictability of a system’s behavior for corner case inputs are of great importance. Existing DL testing depends heavily on manually labeled data and therefore often fails to expose erroneous behaviors for rare inputs. We design, implement, and evaluate DeepXplore, the first whitebox framework for systematically testing real-world DL systems. First, we introduce neuron coverage for systemati- cally measuring the parts of a DL system exercised by test inputs. Next, we leverage multiple DL systems with similar functionality as cross-referencing oracles to avoid manual checking. Finally, we demonstrate how finding inputs for DL systems that both trigger many differential behaviors and achieve high neuron coverage can be represented as a joint optimization problem and solved efficiently using gradient- based search techniques. DeepXplore efficiently finds thousands of incorrect cor- ner case behaviors (e.g., self-driving cars crashing into guard rails and malware masquerading as benign software) in state- of-the-art DL models with thousands of neurons trained on five popular datasets including ImageNet and Udacity self- driving challenge data. For all tested DL models, on average, DeepXplore generated one test input demonstrating incorrect behavior within one second while running only on a commod- ity laptop. We further show that the test inputs generated by DeepXplore can also be used to retrain the corresponding DL model to improve the model’s accuracy by up to 3%. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. SOSP ’17, October 28, 2017, Shanghai, China © 2017 Association for Computing Machinery. ACM ISBN 978-1-4503-5085-3/17/10. . . $15.00 https://doi . org/10. 1145/3132747. 3132785 CCS CONCEPTS • Computing methodologies → Neural networks; • Com- puter systems organization → Neural networks; Reliabil- ity; • Software and its engineering → Software testing and debugging; KEYWORDS Deep learning testing, differential testing, whitebox testing ACM Reference Format: Kexin Pei, Yinzhi Cao, Junfeng Yang, Suman Jana. 2017. Deep- Xplore: Automated Whitebox Testing of Deep Learning Systems. In Proceedings of ACM Symposium on Operating Systems Prin- ciples (SOSP ’17). ACM, New York, NY, USA, 18 pages. https: //doi.org/10.1145/3132747.3132785 1 INTRODUCTION Over the past few years, Deep Learning (DL) has made tremendous progress, achieving or surpassing human-level performance for a diverse set of tasks including image classi- fication [31, 66], speech recognition [83], and playing games such as Go [64]. These advances have led to widespread adop- tion and deployment of DL in security- and safety-critical systems such as self-driving cars [10], malware detection [88], and aircraft collision avoidance systems [35]. This wide adoption of DL techniques presents new chal- lenges as the predictability and correctness of such systems are of crucial importance. Unfortunately, DL systems, despite their impressive capabilities, often demonstrate unexpected or incorrect behaviors in corner cases for several reasons such as biased training data, overfitting, and underfitting of the mod- els. In safety- and security-critical settings, such incorrect behaviors can lead to disastrous consequences such as a fatal collision of a self-driving car. For example, a Google self- driving car recently crashed into a bus because it expected the bus to yield under a set of rare conditions but the bus did not [27]. A Tesla car in autopilot crashed into a trailer because the autopilot system failed to recognize the trailer as an obstacle due to its “white color against a brightly lit sky” and the “high ride height” [73]. Such corner cases were not part of Google’s or Tesla’s test set and thus never showed up during testing. arXiv:1705.06640v4 [cs.LG] 24 Sep 2017
Transcript of DeepXplore: Automated Whitebox Testing of Deep Learning ... · DeepXplore: Automated Whitebox...

DeepXplore Automated Whitebox Testingof Deep Learning Systems
Kexin Pei⋆ Yinzhi Caodagger Junfeng Yang⋆ Suman Jana⋆⋆Columbia University daggerLehigh University
ABSTRACTDeep learning (DL) systems are increasingly deployed insafety- and security-critical domains including self-drivingcars and malware detection where the correctness and pre-dictability of a systemrsquos behavior for corner case inputs areof great importance Existing DL testing depends heavilyon manually labeled data and therefore often fails to exposeerroneous behaviors for rare inputs
We design implement and evaluate DeepXplore the firstwhitebox framework for systematically testing real-world DLsystems First we introduce neuron coverage for systemati-cally measuring the parts of a DL system exercised by testinputs Next we leverage multiple DL systems with similarfunctionality as cross-referencing oracles to avoid manualchecking Finally we demonstrate how finding inputs forDL systems that both trigger many differential behaviors andachieve high neuron coverage can be represented as a jointoptimization problem and solved efficiently using gradient-based search techniques
DeepXplore efficiently finds thousands of incorrect cor-ner case behaviors (eg self-driving cars crashing into guardrails and malware masquerading as benign software) in state-of-the-art DL models with thousands of neurons trained onfive popular datasets including ImageNet and Udacity self-driving challenge data For all tested DL models on averageDeepXplore generated one test input demonstrating incorrectbehavior within one second while running only on a commod-ity laptop We further show that the test inputs generated byDeepXplore can also be used to retrain the corresponding DLmodel to improve the modelrsquos accuracy by up to 3
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies are notmade or distributed for profit or commercial advantage and that copies bearthis notice and the full citation on the first page Copyrights for componentsof this work owned by others than ACM must be honored Abstracting withcredit is permitted To copy otherwise or republish to post on servers or toredistribute to lists requires prior specific permission andor a fee Requestpermissions from permissionsacmorgSOSP rsquo17 October 28 2017 Shanghai Chinacopy 2017 Association for Computing MachineryACM ISBN 978-1-4503-5085-31710 $1500httpsdoiorg10114531327473132785
CCS CONCEPTSbull Computing methodologiesrarr Neural networks bull Com-puter systems organizationrarr Neural networks Reliabil-ity bull Software and its engineeringrarr Software testing anddebugging
KEYWORDSDeep learning testing differential testing whitebox testing
ACM Reference FormatKexin Pei Yinzhi Cao Junfeng Yang Suman Jana 2017 Deep-Xplore Automated Whitebox Testing of Deep Learning SystemsIn Proceedings of ACM Symposium on Operating Systems Prin-ciples (SOSP rsquo17) ACM New York NY USA 18 pages httpsdoiorg10114531327473132785
1 INTRODUCTIONOver the past few years Deep Learning (DL) has madetremendous progress achieving or surpassing human-levelperformance for a diverse set of tasks including image classi-fication [31 66] speech recognition [83] and playing gamessuch as Go [64] These advances have led to widespread adop-tion and deployment of DL in security- and safety-criticalsystems such as self-driving cars [10] malware detection [88]and aircraft collision avoidance systems [35]
This wide adoption of DL techniques presents new chal-lenges as the predictability and correctness of such systemsare of crucial importance Unfortunately DL systems despitetheir impressive capabilities often demonstrate unexpected orincorrect behaviors in corner cases for several reasons such asbiased training data overfitting and underfitting of the mod-els In safety- and security-critical settings such incorrectbehaviors can lead to disastrous consequences such as a fatalcollision of a self-driving car For example a Google self-driving car recently crashed into a bus because it expectedthe bus to yield under a set of rare conditions but the busdid not [27] A Tesla car in autopilot crashed into a trailerbecause the autopilot system failed to recognize the trailer asan obstacle due to its ldquowhite color against a brightly lit skyrdquoand the ldquohigh ride heightrdquo [73] Such corner cases were notpart of Googlersquos or Teslarsquos test set and thus never showed upduring testing
arX
iv1
705
0664
0v4
[cs
LG
] 2
4 Se
p 20
17
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Therefore safety- and security-critical DL systems justlike traditional software must be tested systematically for diff-erent corner cases to detect and fix ideally any potential flawsor undesired behaviors This presents a new systems problemas automated and systematic testing of large-scale real-worldDL systems with thousands of neurons and millions of param-eters for all corner cases is extremely challenging
The standard approach for testing DL systems is to gatherand manually label as much real-world test data as possi-ble [1 3] Some DL systems such as Google self-driving carsalso use simulation to generate synthetic training data [4]However such simulation is completely unguided as it doesnot consider the internals of the target DL system Thereforefor the large input spaces of real-world DL systems (eg allpossible road conditions for a self-driving car) none of theseapproaches can hope to cover more than a tiny fraction (if anyat all) of all possible corner cases
Recent works on adversarial deep learning [26 49 72]have demonstrated that carefully crafted synthetic images byadding minimal perturbations to an existing image can foolstate-of-the-art DL systems The key idea is to create syntheticimages such that they get classified by DL models differentlythan the original picture but still look the same to the humaneye While such adversarial images expose some erroneousbehaviors of a DL model the main restriction of such anapproach is that it must limit its perturbations to tiny invisiblechanges or require manual checks Moreover just like otherforms of existing DL testing the adversarial images onlycover a small part (523) of DL systemrsquos logic as shown insect 6 In essence the current machine learning testing practicesfor finding incorrect corner cases are analogous to findingbugs in traditional software by using test inputs with low codecoverage and thus are unlikely to find many erroneous cases
The key challenges in automated systematic testing of large-scale DL systems are twofold (1) how to generate inputs thattrigger different parts of a DL systemrsquos logic and uncoverdifferent types of erroneous behaviors and (2) how to identifyerroneous behaviors of a DL system without manual label-ingchecking This paper describes how we design and buildDeepXplore to address both challenges
First we introduce the concept of neuron coverage formeasuring the parts of a DL systemrsquos logic exercised by a setof test inputs based on the number of neurons activated (iethe output values are higher than a threshold) by the inputsAt a high level neuron coverage of DL systems is similar tocode coverage of traditional systems a standard empiricalmetric for measuring the amount of code exercised by aninput in a traditional software However code coverage itselfis not a good metric for estimating coverage of DL systemsas most rules in DL systems unlike traditional software arenot written manually by a programmer but rather are learnedfrom training data In fact we find that for most of the DL
(a) Input 1 (b) Input 2 (darker version of 1)Figure 1 An example erroneous behavior found by DeepXplorein Nvidia DAVE-2 self-driving car platform The DNN-basedself-driving car correctly decides to turn left for image (a) butincorrectly decides to turn right and crashes into the guardrailfor image (b) a slightly darker version of (a)
systems that we tested even a single randomly picked testinput was able to achieve 100 code coverage while theneuron coverage was less than 10
Next we show how multiple DL systems with similar func-tionality (eg self-driving cars by Google Tesla and GM)can be used as cross-referencing oracles to identify erroneouscorner cases without manual checks For example if one self-driving car decides to turn left while others turn right for thesame input one of them is likely to be incorrect Such differ-ential testing techniques have been applied successfully in thepast for detecting logic bugs without manual specifications ina wide variety of traditional software [6 11 14 15 45 86]In this paper we demonstrate how differential testing can beapplied to DL systems
Finally we demonstrate how the problem of generating testinputs that maximize neuron coverage of a DL system whilealso exposing as many differential behaviors (ie differencesbetween multiple similar DL systems) as possible can be for-mulated as a joint optimization problem Unlike traditionalprograms the functions approximated by most popular DeepNeural Networks (DNNs) used by DL systems are differen-tiable Therefore their gradients with respect to inputs canbe calculated accurately given whitebox access to the corre-sponding model In this paper we show how these gradientscan be used to efficiently solve the above-mentioned jointoptimization problem for large-scale real-world DL systems
We design implement and evaluate DeepXplore to thebest of our knowledge the first efficient whitebox testingframework for large-scale DL systems In addition to maxi-mizing neuron coverage and behavioral differences betweenDL systems DeepXplore also supports adding custom con-straints by the users for simulating different types of realisticinputs (eg different types of lighting and occlusion for im-agesvideos) We demonstrate that DeepXplore efficientlyfinds thousands of unique incorrect corner case behaviors(eg self-driving cars crashing into guard rails) in 15 state-of-the-art DL models trained using five real-world datasets
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
including Udacity self-driving car challenge data image datafrom ImageNet and MNIST Android malware data fromDrebin and PDF malware data from ContagioVirusTotalFor all of the tested DL models on average DeepXploregenerated one test input demonstrating incorrect behaviorwithin one second while running on a commodity laptop Theinputs generated by DeepXplore achieved 344 and 332higher neuron coverage on average than the same number ofrandomly picked inputs and adversarial inputs [26 49 72]respectively We further show that the test inputs generatedby DeepXplore can be used to retrain the corresponding DLmodel to improve classification accuracy as well as identifypotentially polluted training data We achieve up to 3 im-provement in classification accuracy by retraining a DL modelon inputs generated by DeepXplore compared to retrainingon the same number of random or adversarial inputs
Our main contributions arebull We introduce neuron coverage as the first whitebox
testing metric for DL systems that can estimate theamount of DL logic explored by a set of test inputsbull We demonstrate that the problem of finding a large
number of behavioral differences between similar DLsystems while maximizing neuron coverage can be for-mulated as a joint optimization problem We presenta gradient-based algorithm for solving this problemefficientlybull We implement all of these techniques as part of Deep-
Xplore the first whitebox DL-testing framework thatexposed thousands of incorrect corner case behaviors(eg self-driving cars crashing into guard rails asshown in Figure 1) in 15 state-of-the-art DL modelswith a total of 132 057 neurons trained on five populardatasets containing around 162 GB of databull We show that the tests generated by DeepXplore can
also be used to retrain the corresponding DL systemsto improve classification accuracy by up to 3
2 BACKGROUND21 DL SystemsWe define a DL system to be any software system that in-cludes at least one Deep Neural Network (DNN) componentNote that some DL systems might comprise solely of DNNs(eg self-driving car DNNs predicting steering angles with-out any manual rules) while others may have some DNNcomponents interacting with other traditional software com-ponents to produce the final output
The development process of the DNN components of aDL system is fundamentally different from traditional soft-ware development Unlike traditional software where thedevelopers directly specify the logic of the system the DNNcomponents learn their rules automatically from data The
Traditional software development ML system developmentFigure 2 Comparison between traditional and ML system de-velopment processes
developers of DNN components can indirectly influence therules learned by a DNN by modifying the training data fea-tures and the modelrsquos architectural details (eg number oflayers) as shown in Figure 2
As a DNNrsquos rules are mostly unknown even to its develop-ers testing and fixing of erroneous behaviors of DNNs arecrucial in safety-critical settings In this paper we primarilyfocus on automatically finding inputs that trigger erroneousbehaviors in DL systems and provide preliminary evidenceabout how these inputs can be used to fix the buggy behaviorby augmenting or filtering the training data in sect 73
22 DNN ArchitectureDNNs are inspired by human brains with millions of inter-connected neurons They are known for their amazing abil-ity to automatically identify and extract the relevant high-level features from raw inputs without any human guidancebesides labeled training data In recent years DNNs havesurpassed human performance in many application domainsdue to increasing availability of large datasets [20 38 47]specialized hardware [34 50] and efficient training algo-rithms [31 39 66 71]
A DNN consists of multiple layers each containing multi-ple neurons as shown in Figure 3 A neuron is an individualcomputing unit inside a DNN that applies an activation func-tion on its inputs and passes the result to other connectedneurons (see Figure 3) The common activation functions in-clude sigmoid hyperbolic tangent or ReLU (Rectified LinearUnit) [48] A DNN usually has at least three (often more)layers one input one output and one or more hidden layersEach neuron in one layer has directed connections to the neu-rons in the next layer The numbers of neurons in each layerand the connections between them vary significantly acrossDNNs Overall a DNN can be defined mathematically as amulti-input multi-output parametric function F composedof many parametric sub-functions representing different neu-rons
Each connection between the neurons in a DNN is boundto a weight parameter characterizing the strength of the con-nection between the neurons For supervised learning the
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
weights of the connections are learned during training byminimizing a cost function over the training data DNNs canbe trained using different training algorithms but gradientdescent using backpropagation is by far the most populartraining algorithm for DNNs [60]
Each layer of the network transforms the information con-tained in its input to a higher-level representation of the dataFor example consider a pre-trained network shown in Fig-ure 4b for classifying images into two categories human facesand cars The first few hidden layers transform the raw pixelvalues into low-level texture features like edges or colors andfeed them to the deeper layers [87] The last few layers inturn extract and assemble the meaningful high-level abstrac-tions like noses eyes wheels and headlights to make theclassification decision
23 Limitations of Existing DNN TestingExpensive labeling effort Existing DNN testing techniquesrequire prohibitively expensive human effort to provide cor-rect labelsactions for a target task (eg self-driving a carimage classification and malware detection) For complexand high-dimensional real-world inputs human beings evendomain experts often have difficulty in efficiently performinga task correctly for a large dataset For example consider aDNN designed to identify potentially malicious executablefiles Even a security professional will have trouble determin-ing whether an executable is malicious or benign withoutexecuting it However executing and monitoring a malwareinside a sandbox incur significant performance overhead andtherefore makes manual labeling significantly harder to scaleto a large number of inputsLow test coverage None of the existing DNN testingschemes even try to cover different rules of the DNN There-fore the test inputs often fail to uncover different erroneousbehaviors of a DNN
For example DNNs are often tested by simply dividing awhole dataset into two random partsmdashone for training and theother for testing The testing set in such cases may only exer-cise a small subset of all rules learned by a DNN Recent re-sults involving adversarial evasion attacks against DNNs have
Figure 3 A simple DNN and the computations performed byeach of its neurons
(a) A program with a rare branch (b) A DNN for detecting cars and facesFigure 4 Comparison between program flows of a traditionalprogram and a neural network The nodes in gray denote thecorresponding basic blocks or neurons that participated whileprocessing an inputdemonstrated the existence of some corner cases where DNN-based image classifiers (with state-of-the-art performance onrandomly picked testing sets) still incorrectly classify syn-thetic images generated by adding humanly imperceptibleperturbations to a test image [26 29 52 63 79 85] How-ever the adversarial inputs similar to random test inputs alsoonly cover a small part the rules learned by a DNN as they arenot designed to maximize coverage Moreover they are alsoinherently limited to small imperceptible perturbations arounda test input as larger perturbations will visually change theinput and therefore will require manual inspection to ensurecorrectness of the DNNrsquos decisionProblems with low-coverage DNN tests To better under-stand the problem of low test coverage of rules learned by aDNN we provide an analogy to a similar problem in testingtraditional software Figure 4 shows a side-by-side compari-son of how a traditional program and a DNN handle inputsand produce outputs Specifically the figure shows the sim-ilarity between traditional software and DNNs in softwareprogram each statement performs a certain operation to trans-form the output of previous statement(s) to the input to thefollowing statement(s) while in DNN each neuron trans-forms the output of previous neuron(s) to the input of thefollowing neuron(s) Of course unlike traditional softwareDNNs do not have explicit branches but a neuronrsquos influ-ence on the downstream neurons decreases as the neuronrsquosoutput value gets lower A lower output value indicates lessinfluence and vice versa When the output value of a neuronbecomes zero the neuron does not have any influence on thedownstream neurons
As demonstrated in Figure 4a the problem of low cover-age in testing traditional software is obvious In this casethe buggy behavior will never be seen unless the test inputis 0xdeadbeef The chances of randomly picking such avalue is very small Similarly low-coverage test inputs will
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
also leave different behaviors of DNNs unexplored For ex-ample consider a simplified neural network as shown inFigure 4b that takes an image as input and classifies it intotwo different classes cars and faces The text in each neuron(represented as a node) denotes the object or property that theneuron detects1 and the number in each neuron is the realvalue outputted by that neuron The number indicates howconfident the neuron is about its output Note that randomlypicked inputs are highly unlikely to set high output valuesfor the unlikely combination of neurons Therefore manyincorrect DNN behaviors will remain unexplored even afterperforming a large number of random tests For example ifan image causes neurons labeled as ldquoNoserdquo and ldquoRedrdquo toproduce high output values and the DNN misclassifies theinput image as a car such a behavior will never be seen duringregular testing as the chances of an image containing a rednose (eg a picture of a clown) is very small
3 OVERVIEWIn this section we provide a general overview of DeepXploreour whitebox framework for systematically testing DNNs forerroneous corner case behaviors The main components ofDeepXplore are shown in Figure 5 DeepXplore takes unla-beled test inputs as seeds and generates new tests that cover alarge number of neurons (ie activates them to a value abovea customizable threshold) while causing the tested DNNs tobehave differently Specifically DeepXplore solves a joint op-timization problem that maximizes both differential behaviorsand neuron coverage Note that both goals are crucial for thor-ough testing of DNNs and finding diverse erroneous cornercase behaviors High neuron coverage alone may not inducemany erroneous behaviors while just maximizing differentbehaviors might simply identify different manifestations ofthe same underlying root cause
DeepXplore also supports enforcing of custom domain-specific constraints as part of the joint optimization processFor example the value of an image pixel has to be between 0and 255 Such domain-specific constraints can be specifiedby the users of DeepXplore to ensure that the generated testinputs are valid and realistic
We designed an algorithm for efficiently solving the jointoptimization problem mentioned above using gradient ascentFirst we compute the gradient of the outputs of the neuronsin both the output and hidden layers with the input valueas a variable and the weight parameter as a constant Suchgradients can be computed efficiently for most DNNs Notethat DeepXplore is designed to operate on pre-trained DNNsThe gradient computation is efficient because our whitebox
1Note that one cannot always map each neuron to a particular task ie detecting spe-cific objectsproperties Figure 4b simply highlights that different neurons often tendto detect different features
Figure 5 DeepXplore workflow
approach has access to the pre-trained DNNsrsquo weights andthe intermediate neuron values Next we iteratively performgradient ascent to modify the test input toward maximizingthe objective function of the joint optimization problem de-scribed above Essentially we perform a gradient-guided localsearch starting from the seed inputs and find new inputs thatmaximize the desired goals Note that at a high level ourgradient computation is similar to the backpropagation per-formed during the training of a DNN but the key differenceis that unlike our algorithm backpropagation treats the inputvalue as a constant and the weight parameter as a variableA working example We use Figure 6 as an example to showhow DeepXplore generates test inputs Consider that we havetwo DNNs to testmdashboth perform similar tasks ie classifyingimages into cars or faces as shown in Figure 6 but they aretrained independently with different datasets and parametersTherefore the DNNs will learn similar but slightly differentclassification rules Let us also assume that we have a seedtest input the image of a red car which both DNNs identifyas a car as shown in Figure 6a
DeepXplore tries to maximize the chances of finding dif-ferential behavior by modifying the input ie the image ofthe red car towards maximizing its probability of being clas-sified as a car by one DNN but minimizing correspondingprobability of the other DNN DeepXplore also tries to coveras many neurons as possible by activating (ie causing a neu-ronrsquos output to have a value greater than a threshold) inactiveneurons in the hidden layer We further add domain-specificconstraints (eg ensure the pixel values are integers within0 and 255 for image input) to make sure that the modified
(a) DNNs produce same output (b) DNNs produce different outputFigure 6 Inputs inducing different behaviors in two similarDNNs
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Therefore safety- and security-critical DL systems justlike traditional software must be tested systematically for diff-erent corner cases to detect and fix ideally any potential flawsor undesired behaviors This presents a new systems problemas automated and systematic testing of large-scale real-worldDL systems with thousands of neurons and millions of param-eters for all corner cases is extremely challenging
The standard approach for testing DL systems is to gatherand manually label as much real-world test data as possi-ble [1 3] Some DL systems such as Google self-driving carsalso use simulation to generate synthetic training data [4]However such simulation is completely unguided as it doesnot consider the internals of the target DL system Thereforefor the large input spaces of real-world DL systems (eg allpossible road conditions for a self-driving car) none of theseapproaches can hope to cover more than a tiny fraction (if anyat all) of all possible corner cases
Recent works on adversarial deep learning [26 49 72]have demonstrated that carefully crafted synthetic images byadding minimal perturbations to an existing image can foolstate-of-the-art DL systems The key idea is to create syntheticimages such that they get classified by DL models differentlythan the original picture but still look the same to the humaneye While such adversarial images expose some erroneousbehaviors of a DL model the main restriction of such anapproach is that it must limit its perturbations to tiny invisiblechanges or require manual checks Moreover just like otherforms of existing DL testing the adversarial images onlycover a small part (523) of DL systemrsquos logic as shown insect 6 In essence the current machine learning testing practicesfor finding incorrect corner cases are analogous to findingbugs in traditional software by using test inputs with low codecoverage and thus are unlikely to find many erroneous cases
The key challenges in automated systematic testing of large-scale DL systems are twofold (1) how to generate inputs thattrigger different parts of a DL systemrsquos logic and uncoverdifferent types of erroneous behaviors and (2) how to identifyerroneous behaviors of a DL system without manual label-ingchecking This paper describes how we design and buildDeepXplore to address both challenges
First we introduce the concept of neuron coverage formeasuring the parts of a DL systemrsquos logic exercised by a setof test inputs based on the number of neurons activated (iethe output values are higher than a threshold) by the inputsAt a high level neuron coverage of DL systems is similar tocode coverage of traditional systems a standard empiricalmetric for measuring the amount of code exercised by aninput in a traditional software However code coverage itselfis not a good metric for estimating coverage of DL systemsas most rules in DL systems unlike traditional software arenot written manually by a programmer but rather are learnedfrom training data In fact we find that for most of the DL
(a) Input 1 (b) Input 2 (darker version of 1)Figure 1 An example erroneous behavior found by DeepXplorein Nvidia DAVE-2 self-driving car platform The DNN-basedself-driving car correctly decides to turn left for image (a) butincorrectly decides to turn right and crashes into the guardrailfor image (b) a slightly darker version of (a)
systems that we tested even a single randomly picked testinput was able to achieve 100 code coverage while theneuron coverage was less than 10
Next we show how multiple DL systems with similar func-tionality (eg self-driving cars by Google Tesla and GM)can be used as cross-referencing oracles to identify erroneouscorner cases without manual checks For example if one self-driving car decides to turn left while others turn right for thesame input one of them is likely to be incorrect Such differ-ential testing techniques have been applied successfully in thepast for detecting logic bugs without manual specifications ina wide variety of traditional software [6 11 14 15 45 86]In this paper we demonstrate how differential testing can beapplied to DL systems
Finally we demonstrate how the problem of generating testinputs that maximize neuron coverage of a DL system whilealso exposing as many differential behaviors (ie differencesbetween multiple similar DL systems) as possible can be for-mulated as a joint optimization problem Unlike traditionalprograms the functions approximated by most popular DeepNeural Networks (DNNs) used by DL systems are differen-tiable Therefore their gradients with respect to inputs canbe calculated accurately given whitebox access to the corre-sponding model In this paper we show how these gradientscan be used to efficiently solve the above-mentioned jointoptimization problem for large-scale real-world DL systems
We design implement and evaluate DeepXplore to thebest of our knowledge the first efficient whitebox testingframework for large-scale DL systems In addition to maxi-mizing neuron coverage and behavioral differences betweenDL systems DeepXplore also supports adding custom con-straints by the users for simulating different types of realisticinputs (eg different types of lighting and occlusion for im-agesvideos) We demonstrate that DeepXplore efficientlyfinds thousands of unique incorrect corner case behaviors(eg self-driving cars crashing into guard rails) in 15 state-of-the-art DL models trained using five real-world datasets
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
including Udacity self-driving car challenge data image datafrom ImageNet and MNIST Android malware data fromDrebin and PDF malware data from ContagioVirusTotalFor all of the tested DL models on average DeepXploregenerated one test input demonstrating incorrect behaviorwithin one second while running on a commodity laptop Theinputs generated by DeepXplore achieved 344 and 332higher neuron coverage on average than the same number ofrandomly picked inputs and adversarial inputs [26 49 72]respectively We further show that the test inputs generatedby DeepXplore can be used to retrain the corresponding DLmodel to improve classification accuracy as well as identifypotentially polluted training data We achieve up to 3 im-provement in classification accuracy by retraining a DL modelon inputs generated by DeepXplore compared to retrainingon the same number of random or adversarial inputs
Our main contributions arebull We introduce neuron coverage as the first whitebox
testing metric for DL systems that can estimate theamount of DL logic explored by a set of test inputsbull We demonstrate that the problem of finding a large
number of behavioral differences between similar DLsystems while maximizing neuron coverage can be for-mulated as a joint optimization problem We presenta gradient-based algorithm for solving this problemefficientlybull We implement all of these techniques as part of Deep-
Xplore the first whitebox DL-testing framework thatexposed thousands of incorrect corner case behaviors(eg self-driving cars crashing into guard rails asshown in Figure 1) in 15 state-of-the-art DL modelswith a total of 132 057 neurons trained on five populardatasets containing around 162 GB of databull We show that the tests generated by DeepXplore can
also be used to retrain the corresponding DL systemsto improve classification accuracy by up to 3
2 BACKGROUND21 DL SystemsWe define a DL system to be any software system that in-cludes at least one Deep Neural Network (DNN) componentNote that some DL systems might comprise solely of DNNs(eg self-driving car DNNs predicting steering angles with-out any manual rules) while others may have some DNNcomponents interacting with other traditional software com-ponents to produce the final output
The development process of the DNN components of aDL system is fundamentally different from traditional soft-ware development Unlike traditional software where thedevelopers directly specify the logic of the system the DNNcomponents learn their rules automatically from data The
Traditional software development ML system developmentFigure 2 Comparison between traditional and ML system de-velopment processes
developers of DNN components can indirectly influence therules learned by a DNN by modifying the training data fea-tures and the modelrsquos architectural details (eg number oflayers) as shown in Figure 2
As a DNNrsquos rules are mostly unknown even to its develop-ers testing and fixing of erroneous behaviors of DNNs arecrucial in safety-critical settings In this paper we primarilyfocus on automatically finding inputs that trigger erroneousbehaviors in DL systems and provide preliminary evidenceabout how these inputs can be used to fix the buggy behaviorby augmenting or filtering the training data in sect 73
22 DNN ArchitectureDNNs are inspired by human brains with millions of inter-connected neurons They are known for their amazing abil-ity to automatically identify and extract the relevant high-level features from raw inputs without any human guidancebesides labeled training data In recent years DNNs havesurpassed human performance in many application domainsdue to increasing availability of large datasets [20 38 47]specialized hardware [34 50] and efficient training algo-rithms [31 39 66 71]
A DNN consists of multiple layers each containing multi-ple neurons as shown in Figure 3 A neuron is an individualcomputing unit inside a DNN that applies an activation func-tion on its inputs and passes the result to other connectedneurons (see Figure 3) The common activation functions in-clude sigmoid hyperbolic tangent or ReLU (Rectified LinearUnit) [48] A DNN usually has at least three (often more)layers one input one output and one or more hidden layersEach neuron in one layer has directed connections to the neu-rons in the next layer The numbers of neurons in each layerand the connections between them vary significantly acrossDNNs Overall a DNN can be defined mathematically as amulti-input multi-output parametric function F composedof many parametric sub-functions representing different neu-rons
Each connection between the neurons in a DNN is boundto a weight parameter characterizing the strength of the con-nection between the neurons For supervised learning the
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
weights of the connections are learned during training byminimizing a cost function over the training data DNNs canbe trained using different training algorithms but gradientdescent using backpropagation is by far the most populartraining algorithm for DNNs [60]
Each layer of the network transforms the information con-tained in its input to a higher-level representation of the dataFor example consider a pre-trained network shown in Fig-ure 4b for classifying images into two categories human facesand cars The first few hidden layers transform the raw pixelvalues into low-level texture features like edges or colors andfeed them to the deeper layers [87] The last few layers inturn extract and assemble the meaningful high-level abstrac-tions like noses eyes wheels and headlights to make theclassification decision
23 Limitations of Existing DNN TestingExpensive labeling effort Existing DNN testing techniquesrequire prohibitively expensive human effort to provide cor-rect labelsactions for a target task (eg self-driving a carimage classification and malware detection) For complexand high-dimensional real-world inputs human beings evendomain experts often have difficulty in efficiently performinga task correctly for a large dataset For example consider aDNN designed to identify potentially malicious executablefiles Even a security professional will have trouble determin-ing whether an executable is malicious or benign withoutexecuting it However executing and monitoring a malwareinside a sandbox incur significant performance overhead andtherefore makes manual labeling significantly harder to scaleto a large number of inputsLow test coverage None of the existing DNN testingschemes even try to cover different rules of the DNN There-fore the test inputs often fail to uncover different erroneousbehaviors of a DNN
For example DNNs are often tested by simply dividing awhole dataset into two random partsmdashone for training and theother for testing The testing set in such cases may only exer-cise a small subset of all rules learned by a DNN Recent re-sults involving adversarial evasion attacks against DNNs have
Figure 3 A simple DNN and the computations performed byeach of its neurons
(a) A program with a rare branch (b) A DNN for detecting cars and facesFigure 4 Comparison between program flows of a traditionalprogram and a neural network The nodes in gray denote thecorresponding basic blocks or neurons that participated whileprocessing an inputdemonstrated the existence of some corner cases where DNN-based image classifiers (with state-of-the-art performance onrandomly picked testing sets) still incorrectly classify syn-thetic images generated by adding humanly imperceptibleperturbations to a test image [26 29 52 63 79 85] How-ever the adversarial inputs similar to random test inputs alsoonly cover a small part the rules learned by a DNN as they arenot designed to maximize coverage Moreover they are alsoinherently limited to small imperceptible perturbations arounda test input as larger perturbations will visually change theinput and therefore will require manual inspection to ensurecorrectness of the DNNrsquos decisionProblems with low-coverage DNN tests To better under-stand the problem of low test coverage of rules learned by aDNN we provide an analogy to a similar problem in testingtraditional software Figure 4 shows a side-by-side compari-son of how a traditional program and a DNN handle inputsand produce outputs Specifically the figure shows the sim-ilarity between traditional software and DNNs in softwareprogram each statement performs a certain operation to trans-form the output of previous statement(s) to the input to thefollowing statement(s) while in DNN each neuron trans-forms the output of previous neuron(s) to the input of thefollowing neuron(s) Of course unlike traditional softwareDNNs do not have explicit branches but a neuronrsquos influ-ence on the downstream neurons decreases as the neuronrsquosoutput value gets lower A lower output value indicates lessinfluence and vice versa When the output value of a neuronbecomes zero the neuron does not have any influence on thedownstream neurons
As demonstrated in Figure 4a the problem of low cover-age in testing traditional software is obvious In this casethe buggy behavior will never be seen unless the test inputis 0xdeadbeef The chances of randomly picking such avalue is very small Similarly low-coverage test inputs will
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
also leave different behaviors of DNNs unexplored For ex-ample consider a simplified neural network as shown inFigure 4b that takes an image as input and classifies it intotwo different classes cars and faces The text in each neuron(represented as a node) denotes the object or property that theneuron detects1 and the number in each neuron is the realvalue outputted by that neuron The number indicates howconfident the neuron is about its output Note that randomlypicked inputs are highly unlikely to set high output valuesfor the unlikely combination of neurons Therefore manyincorrect DNN behaviors will remain unexplored even afterperforming a large number of random tests For example ifan image causes neurons labeled as ldquoNoserdquo and ldquoRedrdquo toproduce high output values and the DNN misclassifies theinput image as a car such a behavior will never be seen duringregular testing as the chances of an image containing a rednose (eg a picture of a clown) is very small
3 OVERVIEWIn this section we provide a general overview of DeepXploreour whitebox framework for systematically testing DNNs forerroneous corner case behaviors The main components ofDeepXplore are shown in Figure 5 DeepXplore takes unla-beled test inputs as seeds and generates new tests that cover alarge number of neurons (ie activates them to a value abovea customizable threshold) while causing the tested DNNs tobehave differently Specifically DeepXplore solves a joint op-timization problem that maximizes both differential behaviorsand neuron coverage Note that both goals are crucial for thor-ough testing of DNNs and finding diverse erroneous cornercase behaviors High neuron coverage alone may not inducemany erroneous behaviors while just maximizing differentbehaviors might simply identify different manifestations ofthe same underlying root cause
DeepXplore also supports enforcing of custom domain-specific constraints as part of the joint optimization processFor example the value of an image pixel has to be between 0and 255 Such domain-specific constraints can be specifiedby the users of DeepXplore to ensure that the generated testinputs are valid and realistic
We designed an algorithm for efficiently solving the jointoptimization problem mentioned above using gradient ascentFirst we compute the gradient of the outputs of the neuronsin both the output and hidden layers with the input valueas a variable and the weight parameter as a constant Suchgradients can be computed efficiently for most DNNs Notethat DeepXplore is designed to operate on pre-trained DNNsThe gradient computation is efficient because our whitebox
1Note that one cannot always map each neuron to a particular task ie detecting spe-cific objectsproperties Figure 4b simply highlights that different neurons often tendto detect different features
Figure 5 DeepXplore workflow
approach has access to the pre-trained DNNsrsquo weights andthe intermediate neuron values Next we iteratively performgradient ascent to modify the test input toward maximizingthe objective function of the joint optimization problem de-scribed above Essentially we perform a gradient-guided localsearch starting from the seed inputs and find new inputs thatmaximize the desired goals Note that at a high level ourgradient computation is similar to the backpropagation per-formed during the training of a DNN but the key differenceis that unlike our algorithm backpropagation treats the inputvalue as a constant and the weight parameter as a variableA working example We use Figure 6 as an example to showhow DeepXplore generates test inputs Consider that we havetwo DNNs to testmdashboth perform similar tasks ie classifyingimages into cars or faces as shown in Figure 6 but they aretrained independently with different datasets and parametersTherefore the DNNs will learn similar but slightly differentclassification rules Let us also assume that we have a seedtest input the image of a red car which both DNNs identifyas a car as shown in Figure 6a
DeepXplore tries to maximize the chances of finding dif-ferential behavior by modifying the input ie the image ofthe red car towards maximizing its probability of being clas-sified as a car by one DNN but minimizing correspondingprobability of the other DNN DeepXplore also tries to coveras many neurons as possible by activating (ie causing a neu-ronrsquos output to have a value greater than a threshold) inactiveneurons in the hidden layer We further add domain-specificconstraints (eg ensure the pixel values are integers within0 and 255 for image input) to make sure that the modified
(a) DNNs produce same output (b) DNNs produce different outputFigure 6 Inputs inducing different behaviors in two similarDNNs
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
including Udacity self-driving car challenge data image datafrom ImageNet and MNIST Android malware data fromDrebin and PDF malware data from ContagioVirusTotalFor all of the tested DL models on average DeepXploregenerated one test input demonstrating incorrect behaviorwithin one second while running on a commodity laptop Theinputs generated by DeepXplore achieved 344 and 332higher neuron coverage on average than the same number ofrandomly picked inputs and adversarial inputs [26 49 72]respectively We further show that the test inputs generatedby DeepXplore can be used to retrain the corresponding DLmodel to improve classification accuracy as well as identifypotentially polluted training data We achieve up to 3 im-provement in classification accuracy by retraining a DL modelon inputs generated by DeepXplore compared to retrainingon the same number of random or adversarial inputs
Our main contributions arebull We introduce neuron coverage as the first whitebox
testing metric for DL systems that can estimate theamount of DL logic explored by a set of test inputsbull We demonstrate that the problem of finding a large
number of behavioral differences between similar DLsystems while maximizing neuron coverage can be for-mulated as a joint optimization problem We presenta gradient-based algorithm for solving this problemefficientlybull We implement all of these techniques as part of Deep-
Xplore the first whitebox DL-testing framework thatexposed thousands of incorrect corner case behaviors(eg self-driving cars crashing into guard rails asshown in Figure 1) in 15 state-of-the-art DL modelswith a total of 132 057 neurons trained on five populardatasets containing around 162 GB of databull We show that the tests generated by DeepXplore can
also be used to retrain the corresponding DL systemsto improve classification accuracy by up to 3
2 BACKGROUND21 DL SystemsWe define a DL system to be any software system that in-cludes at least one Deep Neural Network (DNN) componentNote that some DL systems might comprise solely of DNNs(eg self-driving car DNNs predicting steering angles with-out any manual rules) while others may have some DNNcomponents interacting with other traditional software com-ponents to produce the final output
The development process of the DNN components of aDL system is fundamentally different from traditional soft-ware development Unlike traditional software where thedevelopers directly specify the logic of the system the DNNcomponents learn their rules automatically from data The
Traditional software development ML system developmentFigure 2 Comparison between traditional and ML system de-velopment processes
developers of DNN components can indirectly influence therules learned by a DNN by modifying the training data fea-tures and the modelrsquos architectural details (eg number oflayers) as shown in Figure 2
As a DNNrsquos rules are mostly unknown even to its develop-ers testing and fixing of erroneous behaviors of DNNs arecrucial in safety-critical settings In this paper we primarilyfocus on automatically finding inputs that trigger erroneousbehaviors in DL systems and provide preliminary evidenceabout how these inputs can be used to fix the buggy behaviorby augmenting or filtering the training data in sect 73
22 DNN ArchitectureDNNs are inspired by human brains with millions of inter-connected neurons They are known for their amazing abil-ity to automatically identify and extract the relevant high-level features from raw inputs without any human guidancebesides labeled training data In recent years DNNs havesurpassed human performance in many application domainsdue to increasing availability of large datasets [20 38 47]specialized hardware [34 50] and efficient training algo-rithms [31 39 66 71]
A DNN consists of multiple layers each containing multi-ple neurons as shown in Figure 3 A neuron is an individualcomputing unit inside a DNN that applies an activation func-tion on its inputs and passes the result to other connectedneurons (see Figure 3) The common activation functions in-clude sigmoid hyperbolic tangent or ReLU (Rectified LinearUnit) [48] A DNN usually has at least three (often more)layers one input one output and one or more hidden layersEach neuron in one layer has directed connections to the neu-rons in the next layer The numbers of neurons in each layerand the connections between them vary significantly acrossDNNs Overall a DNN can be defined mathematically as amulti-input multi-output parametric function F composedof many parametric sub-functions representing different neu-rons
Each connection between the neurons in a DNN is boundto a weight parameter characterizing the strength of the con-nection between the neurons For supervised learning the
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
weights of the connections are learned during training byminimizing a cost function over the training data DNNs canbe trained using different training algorithms but gradientdescent using backpropagation is by far the most populartraining algorithm for DNNs [60]
Each layer of the network transforms the information con-tained in its input to a higher-level representation of the dataFor example consider a pre-trained network shown in Fig-ure 4b for classifying images into two categories human facesand cars The first few hidden layers transform the raw pixelvalues into low-level texture features like edges or colors andfeed them to the deeper layers [87] The last few layers inturn extract and assemble the meaningful high-level abstrac-tions like noses eyes wheels and headlights to make theclassification decision
23 Limitations of Existing DNN TestingExpensive labeling effort Existing DNN testing techniquesrequire prohibitively expensive human effort to provide cor-rect labelsactions for a target task (eg self-driving a carimage classification and malware detection) For complexand high-dimensional real-world inputs human beings evendomain experts often have difficulty in efficiently performinga task correctly for a large dataset For example consider aDNN designed to identify potentially malicious executablefiles Even a security professional will have trouble determin-ing whether an executable is malicious or benign withoutexecuting it However executing and monitoring a malwareinside a sandbox incur significant performance overhead andtherefore makes manual labeling significantly harder to scaleto a large number of inputsLow test coverage None of the existing DNN testingschemes even try to cover different rules of the DNN There-fore the test inputs often fail to uncover different erroneousbehaviors of a DNN
For example DNNs are often tested by simply dividing awhole dataset into two random partsmdashone for training and theother for testing The testing set in such cases may only exer-cise a small subset of all rules learned by a DNN Recent re-sults involving adversarial evasion attacks against DNNs have
Figure 3 A simple DNN and the computations performed byeach of its neurons
(a) A program with a rare branch (b) A DNN for detecting cars and facesFigure 4 Comparison between program flows of a traditionalprogram and a neural network The nodes in gray denote thecorresponding basic blocks or neurons that participated whileprocessing an inputdemonstrated the existence of some corner cases where DNN-based image classifiers (with state-of-the-art performance onrandomly picked testing sets) still incorrectly classify syn-thetic images generated by adding humanly imperceptibleperturbations to a test image [26 29 52 63 79 85] How-ever the adversarial inputs similar to random test inputs alsoonly cover a small part the rules learned by a DNN as they arenot designed to maximize coverage Moreover they are alsoinherently limited to small imperceptible perturbations arounda test input as larger perturbations will visually change theinput and therefore will require manual inspection to ensurecorrectness of the DNNrsquos decisionProblems with low-coverage DNN tests To better under-stand the problem of low test coverage of rules learned by aDNN we provide an analogy to a similar problem in testingtraditional software Figure 4 shows a side-by-side compari-son of how a traditional program and a DNN handle inputsand produce outputs Specifically the figure shows the sim-ilarity between traditional software and DNNs in softwareprogram each statement performs a certain operation to trans-form the output of previous statement(s) to the input to thefollowing statement(s) while in DNN each neuron trans-forms the output of previous neuron(s) to the input of thefollowing neuron(s) Of course unlike traditional softwareDNNs do not have explicit branches but a neuronrsquos influ-ence on the downstream neurons decreases as the neuronrsquosoutput value gets lower A lower output value indicates lessinfluence and vice versa When the output value of a neuronbecomes zero the neuron does not have any influence on thedownstream neurons
As demonstrated in Figure 4a the problem of low cover-age in testing traditional software is obvious In this casethe buggy behavior will never be seen unless the test inputis 0xdeadbeef The chances of randomly picking such avalue is very small Similarly low-coverage test inputs will
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
also leave different behaviors of DNNs unexplored For ex-ample consider a simplified neural network as shown inFigure 4b that takes an image as input and classifies it intotwo different classes cars and faces The text in each neuron(represented as a node) denotes the object or property that theneuron detects1 and the number in each neuron is the realvalue outputted by that neuron The number indicates howconfident the neuron is about its output Note that randomlypicked inputs are highly unlikely to set high output valuesfor the unlikely combination of neurons Therefore manyincorrect DNN behaviors will remain unexplored even afterperforming a large number of random tests For example ifan image causes neurons labeled as ldquoNoserdquo and ldquoRedrdquo toproduce high output values and the DNN misclassifies theinput image as a car such a behavior will never be seen duringregular testing as the chances of an image containing a rednose (eg a picture of a clown) is very small
3 OVERVIEWIn this section we provide a general overview of DeepXploreour whitebox framework for systematically testing DNNs forerroneous corner case behaviors The main components ofDeepXplore are shown in Figure 5 DeepXplore takes unla-beled test inputs as seeds and generates new tests that cover alarge number of neurons (ie activates them to a value abovea customizable threshold) while causing the tested DNNs tobehave differently Specifically DeepXplore solves a joint op-timization problem that maximizes both differential behaviorsand neuron coverage Note that both goals are crucial for thor-ough testing of DNNs and finding diverse erroneous cornercase behaviors High neuron coverage alone may not inducemany erroneous behaviors while just maximizing differentbehaviors might simply identify different manifestations ofthe same underlying root cause
DeepXplore also supports enforcing of custom domain-specific constraints as part of the joint optimization processFor example the value of an image pixel has to be between 0and 255 Such domain-specific constraints can be specifiedby the users of DeepXplore to ensure that the generated testinputs are valid and realistic
We designed an algorithm for efficiently solving the jointoptimization problem mentioned above using gradient ascentFirst we compute the gradient of the outputs of the neuronsin both the output and hidden layers with the input valueas a variable and the weight parameter as a constant Suchgradients can be computed efficiently for most DNNs Notethat DeepXplore is designed to operate on pre-trained DNNsThe gradient computation is efficient because our whitebox
1Note that one cannot always map each neuron to a particular task ie detecting spe-cific objectsproperties Figure 4b simply highlights that different neurons often tendto detect different features
Figure 5 DeepXplore workflow
approach has access to the pre-trained DNNsrsquo weights andthe intermediate neuron values Next we iteratively performgradient ascent to modify the test input toward maximizingthe objective function of the joint optimization problem de-scribed above Essentially we perform a gradient-guided localsearch starting from the seed inputs and find new inputs thatmaximize the desired goals Note that at a high level ourgradient computation is similar to the backpropagation per-formed during the training of a DNN but the key differenceis that unlike our algorithm backpropagation treats the inputvalue as a constant and the weight parameter as a variableA working example We use Figure 6 as an example to showhow DeepXplore generates test inputs Consider that we havetwo DNNs to testmdashboth perform similar tasks ie classifyingimages into cars or faces as shown in Figure 6 but they aretrained independently with different datasets and parametersTherefore the DNNs will learn similar but slightly differentclassification rules Let us also assume that we have a seedtest input the image of a red car which both DNNs identifyas a car as shown in Figure 6a
DeepXplore tries to maximize the chances of finding dif-ferential behavior by modifying the input ie the image ofthe red car towards maximizing its probability of being clas-sified as a car by one DNN but minimizing correspondingprobability of the other DNN DeepXplore also tries to coveras many neurons as possible by activating (ie causing a neu-ronrsquos output to have a value greater than a threshold) inactiveneurons in the hidden layer We further add domain-specificconstraints (eg ensure the pixel values are integers within0 and 255 for image input) to make sure that the modified
(a) DNNs produce same output (b) DNNs produce different outputFigure 6 Inputs inducing different behaviors in two similarDNNs
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
weights of the connections are learned during training byminimizing a cost function over the training data DNNs canbe trained using different training algorithms but gradientdescent using backpropagation is by far the most populartraining algorithm for DNNs [60]
Each layer of the network transforms the information con-tained in its input to a higher-level representation of the dataFor example consider a pre-trained network shown in Fig-ure 4b for classifying images into two categories human facesand cars The first few hidden layers transform the raw pixelvalues into low-level texture features like edges or colors andfeed them to the deeper layers [87] The last few layers inturn extract and assemble the meaningful high-level abstrac-tions like noses eyes wheels and headlights to make theclassification decision
23 Limitations of Existing DNN TestingExpensive labeling effort Existing DNN testing techniquesrequire prohibitively expensive human effort to provide cor-rect labelsactions for a target task (eg self-driving a carimage classification and malware detection) For complexand high-dimensional real-world inputs human beings evendomain experts often have difficulty in efficiently performinga task correctly for a large dataset For example consider aDNN designed to identify potentially malicious executablefiles Even a security professional will have trouble determin-ing whether an executable is malicious or benign withoutexecuting it However executing and monitoring a malwareinside a sandbox incur significant performance overhead andtherefore makes manual labeling significantly harder to scaleto a large number of inputsLow test coverage None of the existing DNN testingschemes even try to cover different rules of the DNN There-fore the test inputs often fail to uncover different erroneousbehaviors of a DNN
For example DNNs are often tested by simply dividing awhole dataset into two random partsmdashone for training and theother for testing The testing set in such cases may only exer-cise a small subset of all rules learned by a DNN Recent re-sults involving adversarial evasion attacks against DNNs have
Figure 3 A simple DNN and the computations performed byeach of its neurons
(a) A program with a rare branch (b) A DNN for detecting cars and facesFigure 4 Comparison between program flows of a traditionalprogram and a neural network The nodes in gray denote thecorresponding basic blocks or neurons that participated whileprocessing an inputdemonstrated the existence of some corner cases where DNN-based image classifiers (with state-of-the-art performance onrandomly picked testing sets) still incorrectly classify syn-thetic images generated by adding humanly imperceptibleperturbations to a test image [26 29 52 63 79 85] How-ever the adversarial inputs similar to random test inputs alsoonly cover a small part the rules learned by a DNN as they arenot designed to maximize coverage Moreover they are alsoinherently limited to small imperceptible perturbations arounda test input as larger perturbations will visually change theinput and therefore will require manual inspection to ensurecorrectness of the DNNrsquos decisionProblems with low-coverage DNN tests To better under-stand the problem of low test coverage of rules learned by aDNN we provide an analogy to a similar problem in testingtraditional software Figure 4 shows a side-by-side compari-son of how a traditional program and a DNN handle inputsand produce outputs Specifically the figure shows the sim-ilarity between traditional software and DNNs in softwareprogram each statement performs a certain operation to trans-form the output of previous statement(s) to the input to thefollowing statement(s) while in DNN each neuron trans-forms the output of previous neuron(s) to the input of thefollowing neuron(s) Of course unlike traditional softwareDNNs do not have explicit branches but a neuronrsquos influ-ence on the downstream neurons decreases as the neuronrsquosoutput value gets lower A lower output value indicates lessinfluence and vice versa When the output value of a neuronbecomes zero the neuron does not have any influence on thedownstream neurons
As demonstrated in Figure 4a the problem of low cover-age in testing traditional software is obvious In this casethe buggy behavior will never be seen unless the test inputis 0xdeadbeef The chances of randomly picking such avalue is very small Similarly low-coverage test inputs will
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
also leave different behaviors of DNNs unexplored For ex-ample consider a simplified neural network as shown inFigure 4b that takes an image as input and classifies it intotwo different classes cars and faces The text in each neuron(represented as a node) denotes the object or property that theneuron detects1 and the number in each neuron is the realvalue outputted by that neuron The number indicates howconfident the neuron is about its output Note that randomlypicked inputs are highly unlikely to set high output valuesfor the unlikely combination of neurons Therefore manyincorrect DNN behaviors will remain unexplored even afterperforming a large number of random tests For example ifan image causes neurons labeled as ldquoNoserdquo and ldquoRedrdquo toproduce high output values and the DNN misclassifies theinput image as a car such a behavior will never be seen duringregular testing as the chances of an image containing a rednose (eg a picture of a clown) is very small
3 OVERVIEWIn this section we provide a general overview of DeepXploreour whitebox framework for systematically testing DNNs forerroneous corner case behaviors The main components ofDeepXplore are shown in Figure 5 DeepXplore takes unla-beled test inputs as seeds and generates new tests that cover alarge number of neurons (ie activates them to a value abovea customizable threshold) while causing the tested DNNs tobehave differently Specifically DeepXplore solves a joint op-timization problem that maximizes both differential behaviorsand neuron coverage Note that both goals are crucial for thor-ough testing of DNNs and finding diverse erroneous cornercase behaviors High neuron coverage alone may not inducemany erroneous behaviors while just maximizing differentbehaviors might simply identify different manifestations ofthe same underlying root cause
DeepXplore also supports enforcing of custom domain-specific constraints as part of the joint optimization processFor example the value of an image pixel has to be between 0and 255 Such domain-specific constraints can be specifiedby the users of DeepXplore to ensure that the generated testinputs are valid and realistic
We designed an algorithm for efficiently solving the jointoptimization problem mentioned above using gradient ascentFirst we compute the gradient of the outputs of the neuronsin both the output and hidden layers with the input valueas a variable and the weight parameter as a constant Suchgradients can be computed efficiently for most DNNs Notethat DeepXplore is designed to operate on pre-trained DNNsThe gradient computation is efficient because our whitebox
1Note that one cannot always map each neuron to a particular task ie detecting spe-cific objectsproperties Figure 4b simply highlights that different neurons often tendto detect different features
Figure 5 DeepXplore workflow
approach has access to the pre-trained DNNsrsquo weights andthe intermediate neuron values Next we iteratively performgradient ascent to modify the test input toward maximizingthe objective function of the joint optimization problem de-scribed above Essentially we perform a gradient-guided localsearch starting from the seed inputs and find new inputs thatmaximize the desired goals Note that at a high level ourgradient computation is similar to the backpropagation per-formed during the training of a DNN but the key differenceis that unlike our algorithm backpropagation treats the inputvalue as a constant and the weight parameter as a variableA working example We use Figure 6 as an example to showhow DeepXplore generates test inputs Consider that we havetwo DNNs to testmdashboth perform similar tasks ie classifyingimages into cars or faces as shown in Figure 6 but they aretrained independently with different datasets and parametersTherefore the DNNs will learn similar but slightly differentclassification rules Let us also assume that we have a seedtest input the image of a red car which both DNNs identifyas a car as shown in Figure 6a
DeepXplore tries to maximize the chances of finding dif-ferential behavior by modifying the input ie the image ofthe red car towards maximizing its probability of being clas-sified as a car by one DNN but minimizing correspondingprobability of the other DNN DeepXplore also tries to coveras many neurons as possible by activating (ie causing a neu-ronrsquos output to have a value greater than a threshold) inactiveneurons in the hidden layer We further add domain-specificconstraints (eg ensure the pixel values are integers within0 and 255 for image input) to make sure that the modified
(a) DNNs produce same output (b) DNNs produce different outputFigure 6 Inputs inducing different behaviors in two similarDNNs
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
also leave different behaviors of DNNs unexplored For ex-ample consider a simplified neural network as shown inFigure 4b that takes an image as input and classifies it intotwo different classes cars and faces The text in each neuron(represented as a node) denotes the object or property that theneuron detects1 and the number in each neuron is the realvalue outputted by that neuron The number indicates howconfident the neuron is about its output Note that randomlypicked inputs are highly unlikely to set high output valuesfor the unlikely combination of neurons Therefore manyincorrect DNN behaviors will remain unexplored even afterperforming a large number of random tests For example ifan image causes neurons labeled as ldquoNoserdquo and ldquoRedrdquo toproduce high output values and the DNN misclassifies theinput image as a car such a behavior will never be seen duringregular testing as the chances of an image containing a rednose (eg a picture of a clown) is very small
3 OVERVIEWIn this section we provide a general overview of DeepXploreour whitebox framework for systematically testing DNNs forerroneous corner case behaviors The main components ofDeepXplore are shown in Figure 5 DeepXplore takes unla-beled test inputs as seeds and generates new tests that cover alarge number of neurons (ie activates them to a value abovea customizable threshold) while causing the tested DNNs tobehave differently Specifically DeepXplore solves a joint op-timization problem that maximizes both differential behaviorsand neuron coverage Note that both goals are crucial for thor-ough testing of DNNs and finding diverse erroneous cornercase behaviors High neuron coverage alone may not inducemany erroneous behaviors while just maximizing differentbehaviors might simply identify different manifestations ofthe same underlying root cause
DeepXplore also supports enforcing of custom domain-specific constraints as part of the joint optimization processFor example the value of an image pixel has to be between 0and 255 Such domain-specific constraints can be specifiedby the users of DeepXplore to ensure that the generated testinputs are valid and realistic
We designed an algorithm for efficiently solving the jointoptimization problem mentioned above using gradient ascentFirst we compute the gradient of the outputs of the neuronsin both the output and hidden layers with the input valueas a variable and the weight parameter as a constant Suchgradients can be computed efficiently for most DNNs Notethat DeepXplore is designed to operate on pre-trained DNNsThe gradient computation is efficient because our whitebox
1Note that one cannot always map each neuron to a particular task ie detecting spe-cific objectsproperties Figure 4b simply highlights that different neurons often tendto detect different features
Figure 5 DeepXplore workflow
approach has access to the pre-trained DNNsrsquo weights andthe intermediate neuron values Next we iteratively performgradient ascent to modify the test input toward maximizingthe objective function of the joint optimization problem de-scribed above Essentially we perform a gradient-guided localsearch starting from the seed inputs and find new inputs thatmaximize the desired goals Note that at a high level ourgradient computation is similar to the backpropagation per-formed during the training of a DNN but the key differenceis that unlike our algorithm backpropagation treats the inputvalue as a constant and the weight parameter as a variableA working example We use Figure 6 as an example to showhow DeepXplore generates test inputs Consider that we havetwo DNNs to testmdashboth perform similar tasks ie classifyingimages into cars or faces as shown in Figure 6 but they aretrained independently with different datasets and parametersTherefore the DNNs will learn similar but slightly differentclassification rules Let us also assume that we have a seedtest input the image of a red car which both DNNs identifyas a car as shown in Figure 6a
DeepXplore tries to maximize the chances of finding dif-ferential behavior by modifying the input ie the image ofthe red car towards maximizing its probability of being clas-sified as a car by one DNN but minimizing correspondingprobability of the other DNN DeepXplore also tries to coveras many neurons as possible by activating (ie causing a neu-ronrsquos output to have a value greater than a threshold) inactiveneurons in the hidden layer We further add domain-specificconstraints (eg ensure the pixel values are integers within0 and 255 for image input) to make sure that the modified
(a) DNNs produce same output (b) DNNs produce different outputFigure 6 Inputs inducing different behaviors in two similarDNNs
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Figure 7 Gradient ascent starting from a seed input and grad-ually finding the difference-inducing test inputs
inputs still represent real-world images The joint optimiza-tion algorithm will iteratively perform a gradient ascent tofind a modified input that satisfies all of the goals describedabove DeepXplore will eventually generate a set of test inputswhere the DNNsrsquo outputs differ eg one DNN thinks it is acar while the other thinks it is a face as shown in Figure 6b
Figure 7 illustrates the basic concept of our technique us-ing gradient ascent Starting from a seed input DeepXploreperforms the guided search by the gradient in the input spaceof two similar DNNs supposed to perform the same task suchthat it finally uncovers the test inputs that lie between thedecision boundaries of these DNNs Such test inputs willbe classified differently by the two DNNs Note that whilethe gradient provides the rough direction toward reachingthe goal (eg finding difference-inducing inputs) it does notguarantee the fastest convergence Thus as shown in Figure 7the gradient ascent process often does not follow a straightpath towards reaching the target
4 METHODOLOGYIn this section we provide a detailed technical descriptionof our algorithm First we define and explain the conceptsof neuron coverage and gradient for DNNs Next we de-scribe how the testing problem can be formulated as a jointoptimization problem Finally we provide the gradient-basedalgorithm for solving the joint optimization problem
41 DefinitionsNeuron coverage We define neuron coverage of a set of testinputs as the ratio of the number of unique activated neuronsfor all test inputs and the total number of neurons in the DNNWe consider a neuron to be activated if its output is higherthan a threshold value (eg 0)
More formally let us assume that all neurons of a DNNare represented by the set N = n1n2 all test inputsare represented by the set T = x1x2 and out(nx) is afunction that returns the output value of neuron n in the DNNfor a given test input x Note that the bold x signifies thatx is a vector Let t represent the threshold for considering a
neuron to be activated In this setting neuron coverage canbe defined as follows
NCov(T x) = | n |forallx isinT out (nx )gtt ||N |To demonstrate how neuron coverage is calculated in prac-
tice consider the DNN showed in Figure 4b The neuroncoverage (with threshold 0) for the input picture of the red carshown in Figure 4b will be 58 = 0625Gradient The gradients or forward derivatives of the outputsof neurons of a DNN with respect to the input are well knownin deep learning literature They have been extensively usedboth for crafting adversarial examples [26 29 52 72] andvisualizingunderstanding DNNs [44 65 87] We providea brief definition here for completeness and refer interestedreaders to [87] for more details
Let θ and x represent the parameters and the test inputof a DNN respectively The parametric function performedby a neuron can be represented as y = f (θ x) where f is afunction that takes θ and x as input and output y Note thaty can be the output of any neuron defined in the DNN (egneuron from output layer or intermediate layers) The gradientof f (θ x) with respect to input x can be defined as
G = nablax f (θ x ) = partypartx (1)
The computation inside f is essentially a sequence ofstacked functions that compute the input from previous layersand forward the output to next layers Thus G can be calcu-lated by utilizing the chain rule in calculus ie by computingthe layer-wise derivatives starting from the layer of the neuronthat outputs y until reaching the input layer that takes x asinput Note that the dimension of the gradient G is identicalto that of the input x
42 DeepXplore algorithmThe main advantage of the test input generation process for aDNN over traditional software is that the test generation pro-cess once defined as an optimization problem can be solvedefficiently using gradient ascent In this section we describethe details of the formulation and finding solutions to theoptimization problem Note that solutions to the optimizationproblem can be efficiently found for DNNs as the gradients ofthe objective functions of DNNs unlike traditional softwarecan be easily computed
As discussed earlier in sect 3 the objective of the test gen-eration process is to maximize both the number of observeddifferential behaviors and the neuron coverage while pre-serving domain-specific constraints provided by the usersAlgorithm 1 shows the algorithm for generating test inputsby solving this joint optimization problem Below we definethe objectives of our joint optimization problem formally andexplain the details of the algorithm for solving itMaximizing differential behaviors The first objective ofthe optimization problem is to generate test inputs that can
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
induce different behaviors in the tested DNNs ie differentDNNs will classify the same input into different classes Sup-pose we have n DNNs Fk isin1n x rarr y where Fk is thefunction modeled by the k-th neural network x representsthe input and y represents the output class probability vectorsGiven an arbitrary x as seed that gets classified to the sameclass by all DNNs our goal is to modify x such that the mod-ified input x prime will be classified differently by at least one ofthe n DNNs
Algorithm 1 Test input generation via joint optimizationInput seed_setlarr unlabeled inputs as the seeds
dnnslarr multiple DNNs under testλ1 larr parameter to balance output differences of DNNs (Equa-tion 2)λ2 larr parameter to balance coverage and differential behaviorslarr step size in gradient ascenttlarr threshold for determining if a neuron is activatedplarr desired neuron coveragecov_trackerlarr tracks which neurons have been activated
1 main procedure 2 gen_test = empty set3 for cycle(x isin seed_set) do infinitely cycling through seed_set4 all dnns should classify the seed input to the same class 5 c = dnns[0]predict(x)6 d = randomly select one dnn from dnns7 while True do8 obj1 = COMPUTE_OBJ1(x d c dnns λ1)9 obj2 = COMPUTE_OBJ2(x dnns cov_tracker)
10 obj = obj1 + λ2 middot obj211 grad = partobj partx12 apply domain specific constraints to gradient13 grad = DOMAIN_CONSTRNTS(grad)14 x = x + s middot grad gradient ascent15 if dpredict(x) (dnns-d)predict(x) then16 dnns predict x differently 17 gen_testadd(x)18 update cov_tracker19 break20 if DESIRED_COVERAGE_ACHVD(cov_tracker) then21 return gen_test22 utility functions for computing obj1 and obj2 23 procedure COMPUTE_OBJ1(x d c dnns λ1)24 rest = dnns - d25 loss1 = 026 for dnn in rest do27 loss1 += dnnc (x) confidence score of x being in class c28 loss2 = dc (x) drsquos output confidence score of x being in class c29 return (loss1 - λ1 middotloss2)30 procedure COMPUTE_OBJ2(x dnns cov_tracker)31 loss = 032 for dnn isin dnns do33 select a neuron n inactivated so far using cov_tracker34 loss += n(x) the neuron nrsquos output when x is the dnnrsquos input35 return loss
Let Fk (x)[c] be the class probability that Fk predicts x tobe c We randomly select one neural network Fj (Algorithm 1line 6) and maximize the following objective function
ob j1(x ) = Σkj Fk (x )[c] minus λ1 middot Fj (x )[c] (2)
where λ1 is a parameter to balance the objective terms be-tween the DNNs Fkj that maintain the same class outputs asbefore and the DNN Fj that produce different class outputsAs all of Fk isin1n are differentiable Equation 2 can be easilymaximized using gradient ascent by iteratively changing x
based on the computed gradient partob j1(x )partx (Algorithm 1 line
8-14 and procedure COMPUTE_OBJ1)Maximizing neuron coverage The second objective is togenerate inputs that maximize neuron coverage We achievethis goal by iteratively picking inactivated neurons and modi-fying the input such that output of that neuron goes above theneuron activation threshold Let us assume that we want tomaximize the output of a neuron n ie we want to maximizeobj2(x) = fn(x) such that fn(x) gt t where t is the neuronactivation threshold and we write fn(x) as the function mod-eled by neuron n that takes x (the original input to the DNN)as input and produce the output of neuron n (as defined inEquation 1) We can again leverage the gradient ascent mech-anism as fn(x) is a differentiable function whose gradient ispartfn (x )partx Note that we can also potentially jointly maximize multiple
neurons simultaneously but we choose to activate one neuronat a time in this algorithm for clarity (Algorithm 1 line 8-14and procedure COMPUTE_OBJ2)Joint optimization We jointly maximize obj1 and fn de-scribed above and maximize the following function
ob jjoint = (Σij Fi (x )[c] minus λ1Fj (x )[c]) + λ2 middot fn (x ) (3)
where λ2 is a parameter for balancing between the two objec-tives of the joint optimization process and n is the inactivatedneuron that we randomly pick at each iteration (Algorithm 1line 33) As all terms of objjoint are differentiable we jointlymaximize them using gradient ascent by modifying x (Algo-rithm 1 line 14)Domain-specific constraints One important aspect of theoptimization process is that the generated test inputs need tosatisfy several domain-specific constraints to be physicallyrealistic [63] In particular we want to ensure that the changesapplied to xi during the i-th iteration of gradient ascent pro-cess satisfy all the domain-specific constraints for all i Forexample for a generated test image x the pixel values mustbe within a certain range (eg 0 to 255)
While some such constraints can be efficiently embeddedinto the joint optimization process using the Lagrange Multi-pliers similar to those used in support vector machines [76]we found that the majority of them cannot be easily han-dled by the optimization algorithm Therefore we designed asimple rule-based method to ensure that the generated testssatisfy the custom domain-specific constraints As the seedinput xseed = x0 always satisfy the constraints by definitionour technique must ensure that after i-th (i gt 0) iteration ofgradient ascent xi still satisfies the constraints Our algorithmensures this property by modifying the gradient дrad (line13 in Algorithm 1) such that xi+1 = xi + s middotдrad still satisfiesthe constraints (s is the step size in the gradient ascent)
For discrete features we round the gradient to an inte-ger For DNNs handling visual input (eg images) we add
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
different spatial restrictions such that only part of the inputimages is modified A detailed description of the domain-specific constraints that we implemented can be found insect 62Hyperparameters in Algorithm 1 To summarize there arefour major hyperparameters that control different aspects ofDeepXplore as described below (1) λ1 balances the objec-tives between minimizing one DNNrsquos prediction for a certainlabel and maximizing the rest of DNNsrsquo predictions for thesame label Larger λ1 puts higher priority on lowering the pre-diction valueconfidence of a particular DNN while smallerλ1 puts more weight on maintaining the other DNNsrsquo pre-dictions (2) λ2 provides balance between finding differentialbehaviors and neuron coverage Larger λ2 focuses more oncovering different neurons while smaller λ2 generates moredifference-inducing test inputs (3) s controls the step sizeused during iterative gradient ascent Larger s may lead to os-cillation around the local optimum while smaller s may needmore iterations to reach the objective (4) t is the thresholdto determine whether each individual neuron is activated ornot Finding inputs that activate a neuron become increasinglyharder as t increases
5 IMPLEMENTATIONWe implement DeepXplore using TensorFlow 101 [5] andKeras 203 [16] DL frameworks Our implementation con-sists of around 7 086 lines of Python code Our code is builton TensorFlowKeras but does not require any modificationsto these frameworks We leverage TensorFlowrsquos efficient im-plementation of gradient computations in our joint optimiza-tion process TensorFlow also supports creating sub-DNNsby marking any arbitrary neuronrsquos output as the sub-DNNrsquosoutput while keeping the input same as the original DNNrsquosinput We use this feature to intercept and record the output ofneurons in the intermediate layers of a DNN and compute thecorresponding gradients with respect to the DNNrsquos input Allour experiments were run on a Linux laptop running Ubuntu1604 (one Intel i7-6700HQ 260GHz processor with 4 cores16GB of memory and a NVIDIA GTX 1070 GPU)
6 EXPERIMENTAL SETUP61 Test datasets and DNNsWe adopt five popular public datasets with different typesof datamdashMNIST ImageNet Driving ContagioVirusTotaland Drebinmdashand then evaluate DeepXplore on three DNNsfor each dataset (ie a total of fifteen DNNs) We provide asummary of the five datasets and the corresponding DNNs inTable 1 All the evaluated DNNs are either pre-trained (iewe use public weights reported by previous researchers) ortrained by us using public real-world architectures to achieve
comparable performance to that of the state-of-the-art mod-els for the corresponding dataset For each dataset we usedDeepXplore to test three DNNs with different architecturesas described in Table 1MNIST [41] is a large handwritten digit dataset containing28x28 pixel images with class labels from 0 to 9 The datasetincludes 60 000 training samples and 10 000 testing samplesWe follow Lecun et al [40] and construct three differentneural networks based on the LeNet family [40] ie theLeNet-1 LeNet-4 and LeNet-5ImageNet [20] is a large image dataset with over 10 000 000hand-annotated images that are crowdsourced and labeledmanually We test three well-known pre-trained DNNs VGG-16 [66] VGG-19 [66] and ResNet50 [31] All three DNNsachieved competitive performance in the ILSVRC [61] com-petitionDriving [75] is the Udacity self-driving car challenge datasetthat contains images captured by a camera mounted behindthe windshield of a driving car and the simultaneous steer-ing wheel angle applied by the human driver for each im-age The dataset has 101396 training and 5614 testing sam-ples We then used three DNNs [8 18 78] based on theDAVE-2 self-driving car architecture from Nvidia [10] withslightly different configurations which are called DAVE-origDAVE-norminit and DAVE-dropout respectively Specifi-cally DAVE-orig [8] fully replicates the original architecturefrom the Nvidiarsquos paper [10] DAVE-norminit [78] removesthe first batch normalization layer [33] and normalizes therandomly initialized network weights DAVE-dropout [18]simplifies DAVE-orig by cutting down the numbers of convo-lutional layers and fully connected layers DAVE-dropoutalso adds two dropout layer [70] between the final threefully-connected layers We trained all three implementationswith the Udacity self-driving car challenge dataset mentionedaboveContagioVirusTotal [19 77] is a dataset containing diff-erent benign and malicious PDF documents We use 5 000benign and 12 205 malicious PDF documents from Contagiodatabase as the training set and then use 5 000 maliciousPDFs collected by VirusTotal [77] and 5 000 benign PDFscrawled from Google as the test set To the best of our knowl-edge there is no publicly available DNN-based PDF malwaredetection system Therefore we define and train three diff-erent DNNs using 135 static features from PDFrate [54 68]an online service for PDF malware detection Specificallywe construct neural networks with one input layer one soft-max output layer and N fully-connected hidden layers with200 neurons where N ranges from 2 to 4 for the three testedDNNs All our models achieve similar performance to theones reported by a prior work using SVM models on the samedataset [79]
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-
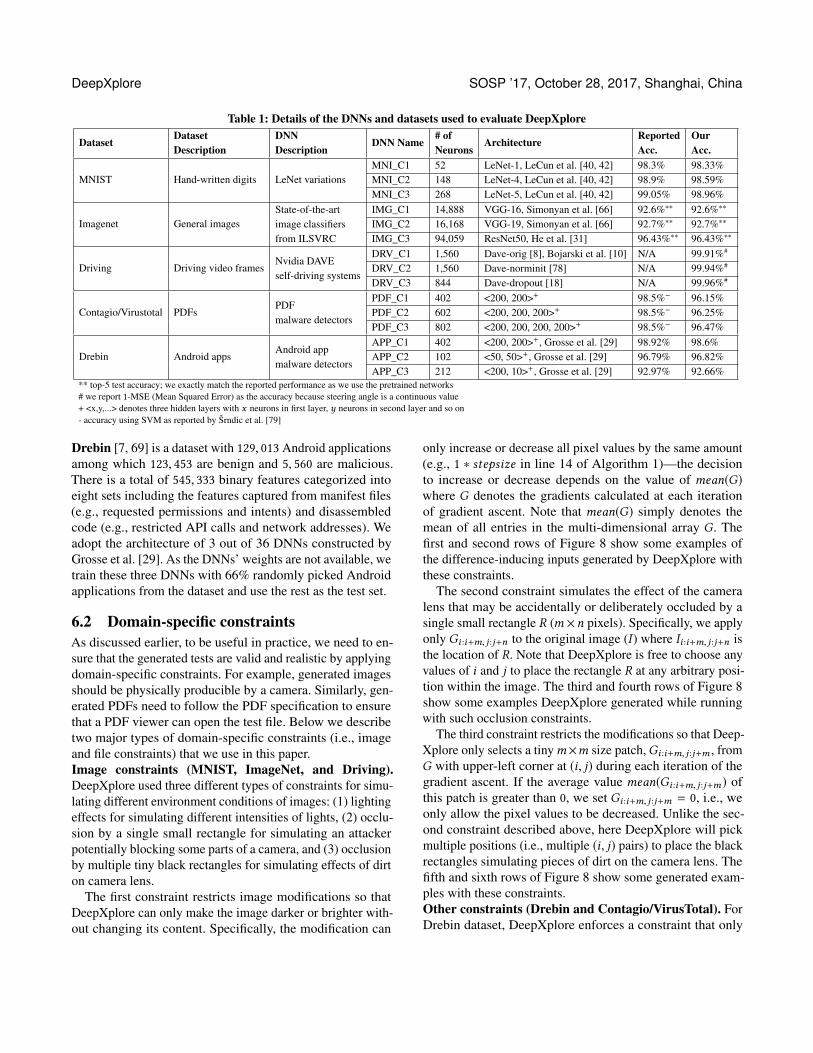
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 1 Details of the DNNs and datasets used to evaluate DeepXplore
DatasetDatasetDescription
DNNDescription
DNN Name ofNeurons
ArchitectureReportedAcc
OurAcc
MNIST Hand-written digits LeNet variationsMNI_C1 52 LeNet-1 LeCun et al [40 42] 983 9833MNI_C2 148 LeNet-4 LeCun et al [40 42] 989 9859MNI_C3 268 LeNet-5 LeCun et al [40 42] 9905 9896
Imagenet General imagesState-of-the-artimage classifiersfrom ILSVRC
IMG_C1 14888 VGG-16 Simonyan et al [66] 926lowastlowast 926lowastlowast
IMG_C2 16168 VGG-19 Simonyan et al [66] 927lowastlowast 927lowastlowast
IMG_C3 94059 ResNet50 He et al [31] 9643lowastlowast 9643lowastlowast
Driving Driving video framesNvidia DAVEself-driving systems
DRV_C1 1560 Dave-orig [8] Bojarski et al [10] NA 9991
DRV_C2 1560 Dave-norminit [78] NA 9994
DRV_C3 844 Dave-dropout [18] NA 9996
ContagioVirustotal PDFsPDFmalware detectors
PDF_C1 402 lt200 200gt+ 985minus 9615PDF_C2 602 lt200 200 200gt+ 985minus 9625PDF_C3 802 lt200 200 200 200gt+ 985minus 9647
Drebin Android appsAndroid appmalware detectors
APP_C1 402 lt200 200gt+ Grosse et al [29] 9892 986APP_C2 102 lt50 50gt+ Grosse et al [29] 9679 9682APP_C3 212 lt200 10gt+ Grosse et al [29] 9297 9266
top-5 test accuracy we exactly match the reported performance as we use the pretrained networks we report 1-MSE (Mean Squared Error) as the accuracy because steering angle is a continuous value+ ltxygt denotes three hidden layers with x neurons in first layer y neurons in second layer and so on- accuracy using SVM as reported by Šrndic et al [79]
Drebin [7 69] is a dataset with 129 013 Android applicationsamong which 123 453 are benign and 5 560 are maliciousThere is a total of 545 333 binary features categorized intoeight sets including the features captured from manifest files(eg requested permissions and intents) and disassembledcode (eg restricted API calls and network addresses) Weadopt the architecture of 3 out of 36 DNNs constructed byGrosse et al [29] As the DNNsrsquo weights are not available wetrain these three DNNs with 66 randomly picked Androidapplications from the dataset and use the rest as the test set
62 Domain-specific constraintsAs discussed earlier to be useful in practice we need to en-sure that the generated tests are valid and realistic by applyingdomain-specific constraints For example generated imagesshould be physically producible by a camera Similarly gen-erated PDFs need to follow the PDF specification to ensurethat a PDF viewer can open the test file Below we describetwo major types of domain-specific constraints (ie imageand file constraints) that we use in this paperImage constraints (MNIST ImageNet and Driving)DeepXplore used three different types of constraints for simu-lating different environment conditions of images (1) lightingeffects for simulating different intensities of lights (2) occlu-sion by a single small rectangle for simulating an attackerpotentially blocking some parts of a camera and (3) occlusionby multiple tiny black rectangles for simulating effects of dirton camera lens
The first constraint restricts image modifications so thatDeepXplore can only make the image darker or brighter with-out changing its content Specifically the modification can
only increase or decrease all pixel values by the same amount(eg 1 lowast stepsize in line 14 of Algorithm 1)mdashthe decisionto increase or decrease depends on the value of mean(G)where G denotes the gradients calculated at each iterationof gradient ascent Note that mean(G) simply denotes themean of all entries in the multi-dimensional array G Thefirst and second rows of Figure 8 show some examples ofthe difference-inducing inputs generated by DeepXplore withthese constraints
The second constraint simulates the effect of the cameralens that may be accidentally or deliberately occluded by asingle small rectangle R (m timesn pixels) Specifically we applyonly Gi i+m j j+n to the original image (I ) where Ii i+m j j+n isthe location of R Note that DeepXplore is free to choose anyvalues of i and j to place the rectangle R at any arbitrary posi-tion within the image The third and fourth rows of Figure 8show some examples DeepXplore generated while runningwith such occlusion constraints
The third constraint restricts the modifications so that Deep-Xplore only selects a tinymtimesm size patchGi i+m j j+m fromG with upper-left corner at (i j) during each iteration of thegradient ascent If the average value mean(Gi i+m j j+m) ofthis patch is greater than 0 we set Gi i+m j j+m = 0 ie weonly allow the pixel values to be decreased Unlike the sec-ond constraint described above here DeepXplore will pickmultiple positions (ie multiple (i j) pairs) to place the blackrectangles simulating pieces of dirt on the camera lens Thefifth and sixth rows of Figure 8 show some generated exam-ples with these constraintsOther constraints (Drebin and ContagioVirusTotal) ForDrebin dataset DeepXplore enforces a constraint that only
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Different lighting conditions
allright allright allright all1 all3 all5 alldiver allcheeseburger allflamingo
DRV_C1left DRV_C2left DRV_C3left MNI_C18 MNI_C25 MNI_C37 IMG_C1ski IMG_C2icecream IMG_C3goldfishOcclusion with a single small rectangle
allright allright allleft all5 all7 all 9 allcauliflower alldhole allhay
DRV_C1left DRV_C2left DRV_C3right MNI_C13 MNI_C24 MNI_C32 IMG_C1carbonaraIMG_C2umbrella IMG_C3stupaOcclusion with multiple tiny black rectangles
allleft allleft allleft all1 all5 all7 allcastle allcock allgroom
DRV_C1right DRV_C2right DRV_C3right MNI_C12 MNI_C24 MNI_C34 IMG_C1beacon IMG_C2hen IMG_C3vestmentFigure 8 Odd rows show the seed test inputs and even rows show the difference-inducing test inputs generated by DeepXplore Theleft three columns show inputs for self-driving car the middle three are for MNIST and the right three are for ImageNet
allows modifying features related to the Android manifestfile and thus ensures that the application code is unaffectedMoreover DeepXplore only allows adding features (changingfrom zero to one) but do not allow deleting features (changingfrom one to zero) from the manifest files to ensure that noapplication functionality is changed due to insufficient permis-sions Thus after computing the gradient DeepXplore onlymodifies the manifest features whose corresponding gradientsare greater than zero
For ContagioVirusTotal dataset DeepXplore follows therestrictions on each feature as described by Šrndic et al [79]
7 RESULTSSummary DeepXplore found thousands of erroneous behav-iors in all the tested DNNs Table 2 summarizes the numbersof erroneous behaviors found by DeepXplore for each tested
DNN while using 2000 randomly selected seed inputs fromthe corresponding test sets Note that as the testing set hassimilar number of samples for each class these randomly-chosen 2000 samples also follow that distribution The hyper-parameter values for these experiments as shown in Table 2are empirically chosen to maximize both the rate of findingdifference-inputs as well as the neuron coverage achieved bythese inputs
For the experimental results shown in Figure 8 we applythree domain-specific constraints (lighting effects occlusionby a single rectangle and occlusion by multiple rectangles) asdescribed in sect 62 For all other experiments involving vision-related tasks we only use the lighting effects as the domain-specific constraints For all malware-related experiments weapply all the relevant domain-specific constraints described
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-
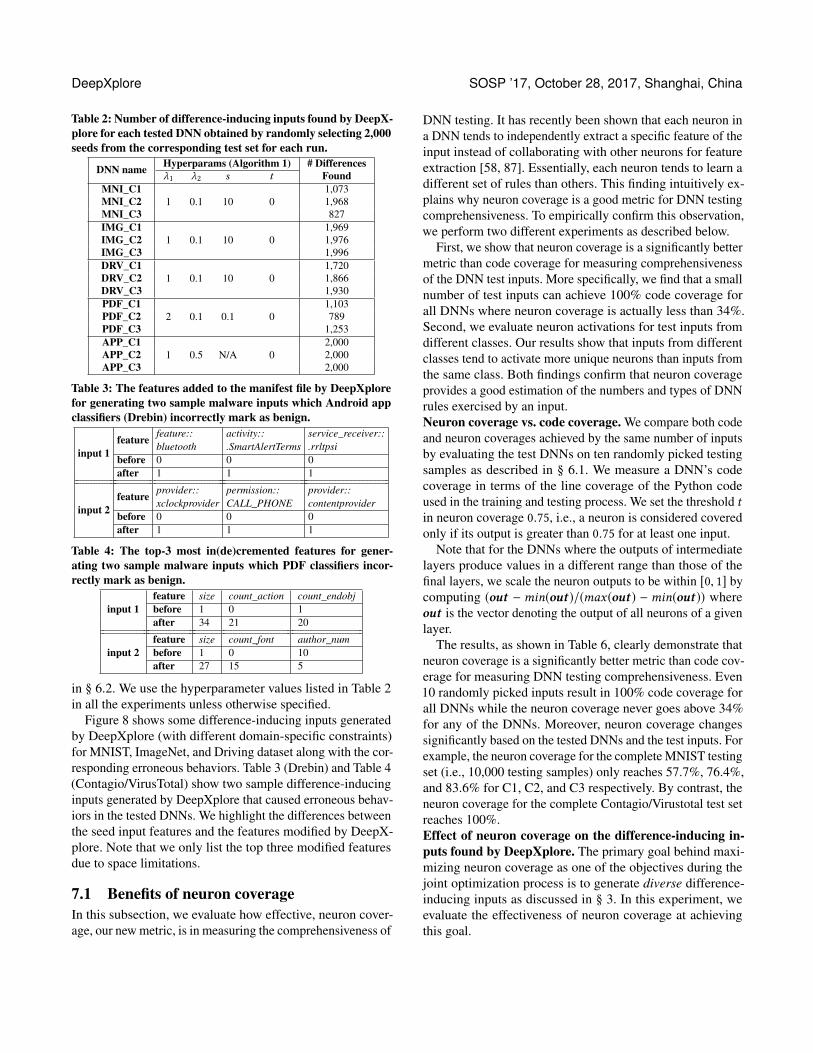
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
Table 2 Number of difference-inducing inputs found by DeepX-plore for each tested DNN obtained by randomly selecting 2000seeds from the corresponding test set for each run
DNN name Hyperparams (Algorithm 1) DifferencesFoundλ1 λ2 s t
MNI_C11 01 10 0
1073MNI_C2 1968MNI_C3 827IMG_C1
1 01 10 01969
IMG_C2 1976IMG_C3 1996DRV_C1
1 01 10 01720
DRV_C2 1866DRV_C3 1930PDF_C1
2 01 01 01103
PDF_C2 789PDF_C3 1253APP_C1
1 05 NA 02000
APP_C2 2000APP_C3 2000
Table 3 The features added to the manifest file by DeepXplorefor generating two sample malware inputs which Android appclassifiers (Drebin) incorrectly mark as benign
input 1feature feature
bluetoothactivitySmartAlertTerms
service_receiverrrltpsi
before 0 0 0after 1 1 1
input 2feature provider
xclockproviderpermissionCALL_PHONE
providercontentprovider
before 0 0 0after 1 1 1
Table 4 The top-3 most in(de)cremented features for gener-ating two sample malware inputs which PDF classifiers incor-rectly mark as benign
input 1feature size count_action count_endobjbefore 1 0 1after 34 21 20
input 2feature size count_font author_numbefore 1 0 10after 27 15 5
in sect 62 We use the hyperparameter values listed in Table 2in all the experiments unless otherwise specified
Figure 8 shows some difference-inducing inputs generatedby DeepXplore (with different domain-specific constraints)for MNIST ImageNet and Driving dataset along with the cor-responding erroneous behaviors Table 3 (Drebin) and Table 4(ContagioVirusTotal) show two sample difference-inducinginputs generated by DeepXplore that caused erroneous behav-iors in the tested DNNs We highlight the differences betweenthe seed input features and the features modified by DeepX-plore Note that we only list the top three modified featuresdue to space limitations
71 Benefits of neuron coverageIn this subsection we evaluate how effective neuron cover-age our new metric is in measuring the comprehensiveness of
DNN testing It has recently been shown that each neuron ina DNN tends to independently extract a specific feature of theinput instead of collaborating with other neurons for featureextraction [58 87] Essentially each neuron tends to learn adifferent set of rules than others This finding intuitively ex-plains why neuron coverage is a good metric for DNN testingcomprehensiveness To empirically confirm this observationwe perform two different experiments as described below
First we show that neuron coverage is a significantly bettermetric than code coverage for measuring comprehensivenessof the DNN test inputs More specifically we find that a smallnumber of test inputs can achieve 100 code coverage forall DNNs where neuron coverage is actually less than 34Second we evaluate neuron activations for test inputs fromdifferent classes Our results show that inputs from differentclasses tend to activate more unique neurons than inputs fromthe same class Both findings confirm that neuron coverageprovides a good estimation of the numbers and types of DNNrules exercised by an inputNeuron coverage vs code coverage We compare both codeand neuron coverages achieved by the same number of inputsby evaluating the test DNNs on ten randomly picked testingsamples as described in sect 61 We measure a DNNrsquos codecoverage in terms of the line coverage of the Python codeused in the training and testing process We set the threshold tin neuron coverage 075 ie a neuron is considered coveredonly if its output is greater than 075 for at least one input
Note that for the DNNs where the outputs of intermediatelayers produce values in a different range than those of thefinal layers we scale the neuron outputs to be within [0 1] bycomputing (out minusmin(out)(max(out) minusmin(out)) whereout is the vector denoting the output of all neurons of a givenlayer
The results as shown in Table 6 clearly demonstrate thatneuron coverage is a significantly better metric than code cov-erage for measuring DNN testing comprehensiveness Even10 randomly picked inputs result in 100 code coverage forall DNNs while the neuron coverage never goes above 34for any of the DNNs Moreover neuron coverage changessignificantly based on the tested DNNs and the test inputs Forexample the neuron coverage for the complete MNIST testingset (ie 10000 testing samples) only reaches 577 764and 836 for C1 C2 and C3 respectively By contrast theneuron coverage for the complete ContagioVirustotal test setreaches 100Effect of neuron coverage on the difference-inducing in-puts found by DeepXplore The primary goal behind maxi-mizing neuron coverage as one of the objectives during thejoint optimization process is to generate diverse difference-inducing inputs as discussed in sect 3 In this experiment weevaluate the effectiveness of neuron coverage at achievingthis goal
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-
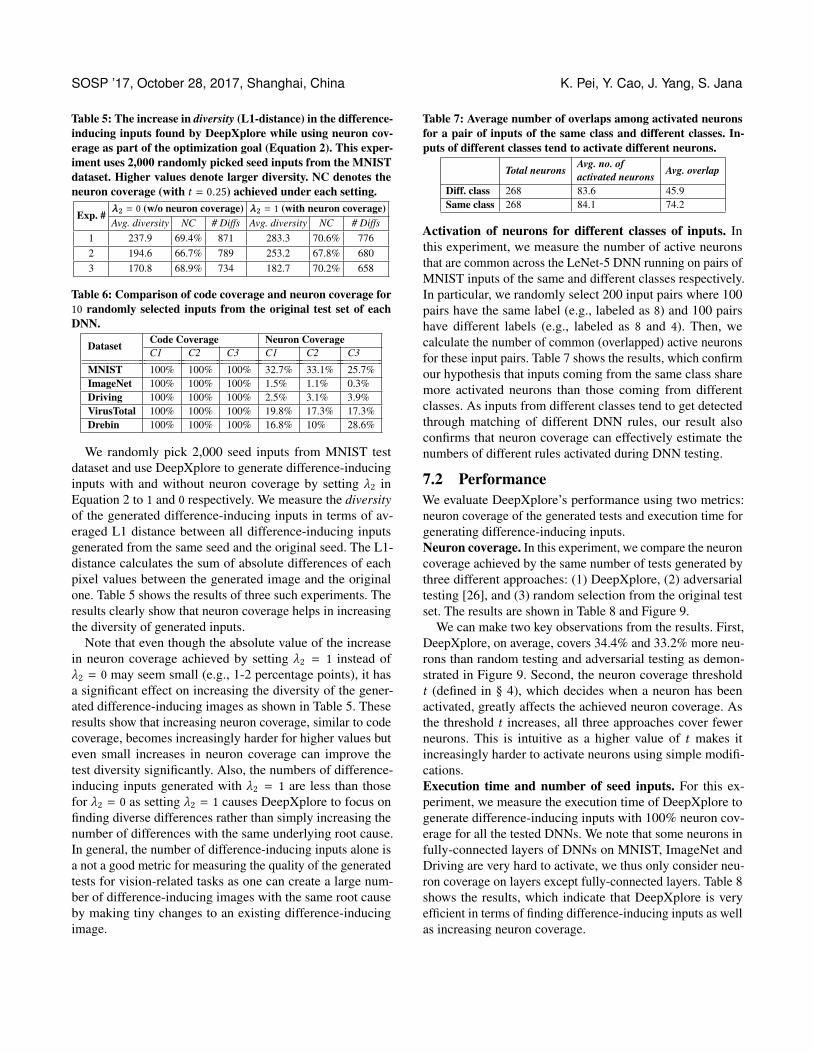
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 5 The increase in diversity (L1-distance) in the difference-inducing inputs found by DeepXplore while using neuron cov-erage as part of the optimization goal (Equation 2) This exper-iment uses 2000 randomly picked seed inputs from the MNISTdataset Higher values denote larger diversity NC denotes theneuron coverage (with t = 025) achieved under each setting
Exp λ2 = 0 (wo neuron coverage) λ2 = 1 (with neuron coverage)Avg diversity NC Diffs Avg diversity NC Diffs
1 2379 694 871 2833 706 7762 1946 667 789 2532 678 6803 1708 689 734 1827 702 658
Table 6 Comparison of code coverage and neuron coverage for10 randomly selected inputs from the original test set of eachDNN
Dataset Code Coverage Neuron CoverageC1 C2 C3 C1 C2 C3
MNIST 100 100 100 327 331 257ImageNet 100 100 100 15 11 03Driving 100 100 100 25 31 39VirusTotal 100 100 100 198 173 173Drebin 100 100 100 168 10 286
We randomly pick 2000 seed inputs from MNIST testdataset and use DeepXplore to generate difference-inducinginputs with and without neuron coverage by setting λ2 inEquation 2 to 1 and 0 respectively We measure the diversityof the generated difference-inducing inputs in terms of av-eraged L1 distance between all difference-inducing inputsgenerated from the same seed and the original seed The L1-distance calculates the sum of absolute differences of eachpixel values between the generated image and the originalone Table 5 shows the results of three such experiments Theresults clearly show that neuron coverage helps in increasingthe diversity of generated inputs
Note that even though the absolute value of the increasein neuron coverage achieved by setting λ2 = 1 instead ofλ2 = 0 may seem small (eg 1-2 percentage points) it hasa significant effect on increasing the diversity of the gener-ated difference-inducing images as shown in Table 5 Theseresults show that increasing neuron coverage similar to codecoverage becomes increasingly harder for higher values buteven small increases in neuron coverage can improve thetest diversity significantly Also the numbers of difference-inducing inputs generated with λ2 = 1 are less than thosefor λ2 = 0 as setting λ2 = 1 causes DeepXplore to focus onfinding diverse differences rather than simply increasing thenumber of differences with the same underlying root causeIn general the number of difference-inducing inputs alone isa not a good metric for measuring the quality of the generatedtests for vision-related tasks as one can create a large num-ber of difference-inducing images with the same root causeby making tiny changes to an existing difference-inducingimage
Table 7 Average number of overlaps among activated neuronsfor a pair of inputs of the same class and different classes In-puts of different classes tend to activate different neurons
Total neurons Avg no ofactivated neurons Avg overlap
Diff class 268 836 459Same class 268 841 742
Activation of neurons for different classes of inputs Inthis experiment we measure the number of active neuronsthat are common across the LeNet-5 DNN running on pairs ofMNIST inputs of the same and different classes respectivelyIn particular we randomly select 200 input pairs where 100pairs have the same label (eg labeled as 8) and 100 pairshave different labels (eg labeled as 8 and 4) Then wecalculate the number of common (overlapped) active neuronsfor these input pairs Table 7 shows the results which confirmour hypothesis that inputs coming from the same class sharemore activated neurons than those coming from differentclasses As inputs from different classes tend to get detectedthrough matching of different DNN rules our result alsoconfirms that neuron coverage can effectively estimate thenumbers of different rules activated during DNN testing
72 PerformanceWe evaluate DeepXplorersquos performance using two metricsneuron coverage of the generated tests and execution time forgenerating difference-inducing inputsNeuron coverage In this experiment we compare the neuroncoverage achieved by the same number of tests generated bythree different approaches (1) DeepXplore (2) adversarialtesting [26] and (3) random selection from the original testset The results are shown in Table 8 and Figure 9
We can make two key observations from the results FirstDeepXplore on average covers 344 and 332 more neu-rons than random testing and adversarial testing as demon-strated in Figure 9 Second the neuron coverage thresholdt (defined in sect 4) which decides when a neuron has beenactivated greatly affects the achieved neuron coverage Asthe threshold t increases all three approaches cover fewerneurons This is intuitive as a higher value of t makes itincreasingly harder to activate neurons using simple modifi-cationsExecution time and number of seed inputs For this ex-periment we measure the execution time of DeepXplore togenerate difference-inducing inputs with 100 neuron cov-erage for all the tested DNNs We note that some neurons infully-connected layers of DNNs on MNIST ImageNet andDriving are very hard to activate we thus only consider neu-ron coverage on layers except fully-connected layers Table 8shows the results which indicate that DeepXplore is veryefficient in terms of finding difference-inducing inputs as wellas increasing neuron coverage
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(a) MNIST
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(b) ImageNet
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(c) Driving
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(d) VirusTotal
000 025 050 075Neuron coverage threshold t
0
10
20
30
40
50
60
70
80
90
100
Neu
ron
cove
rage
DeepXplore
Adversarial
Random
(e) DrebinFigure 9 The neuron coverage achieved by the same number of inputs (1 of the original test set) produced by DeepXplore ad-versarial testing [26] and random selection from the original test set The plots show the changes in neuron coverage for all threemethods as the threshold t (defined in sect 4) increases DeepXplore on average covers 344 and 332 more neurons than randomtesting and adversarial testing
Table 8 Total time taken by DeepXplore to achieve 100 neu-ron coverage for different DNNs averaged over 10 runs The lastcolumn shows the number of seed inputs
C1 C2 C3 seedsMNIST 66 s 68 s 76 s 9
ImageNet 436 s 453 s 427 s 35Driving 117 s 123 s 98 s 12
VirusTotal 311 s 297 s 232 s 6Drebin 1802 s 1964 s 1529 s 16
Table 9 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different step size choice (s for gradient as-cent shown in Algorithm 1 line 14) All numbers averaged over10 runs The fastest times for each dataset is highlighted in gray
s=001 s=01 s=1 s=10 s=100
MNIST 019 s 026 s 065 s 062 s 065 sImageNet 93 s 478 s 17 s 106 s 666 sDriving 051 s 05 s 053 s 055 s 054 sVirusTotal 017 s 016 s 021 s 021 s 022 sDrebin 765 s 765 s 765 s 765 s 765 s
Different choices of hyperparameters We further evalu-ate how the choices of different hyperparameters of DeepX-plore (s λ1 λ2 and t as described in sect 42) influence Deep-Xplorersquos performance The effects of changing neuron acti-vation threshold t was shown in Figure 9 as described earlierTables 9 10 and 11 show the variations in DeepXplore run-time with changes in s λ1 and λ2 respectively Our resultsshow that the optimal values of s and λ1 vary across the DNNsand datasets while λ2 = 05 tend to be optimal for all thedatasets
We use the time taken by DeepXplore to find the firstdifference-inducing input as the metric for comparing diff-erent choices of hyperparameters in Tables 9 10 and 11We choose this metric as we observe that finding the firstdifference-inducing input for a given seed tend to be sig-nificantly harder than increasing the number of difference-inducing inputsTesting very similar models with DeepXplore Note thatwhile DeepXplorersquos gradient-guided test generation process
Table 10 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ1 a parameter in Equation 2Higher λ1 values indicate prioritization of minimizing a DNNsrsquooutputs over maximizing the outputs of other DNNs showingdifferential behavior The fastest times for each dataset is high-lighted in gray
λ1 = 05 λ1 = 1 λ1 = 2 λ1 = 3MNIST 028 s 025 s 02 s 017 sImageNet 138 s 126 s 121 s 172 sDriving 062 s 059 s 057 s 058 sVirusTotal 013 s 012 s 005 s 009 sDrebin 64 s 58 s 612 s 75 s
Table 11 The variation in DeepXplore runtime (in seconds)while generating the first difference-inducing input for thetested DNNs with different λ2 a parameter in Equation 3Higher λ2 values indicate higher priority for increasing cover-age All numbers averaged over 10 runs The fastest times foreach dataset is highlighted in gray
λ2 = 05 λ2 = 1 λ2 = 2 λ2 = 3MNIST 019 s 022 s 023 s 026 sImageNet 155 s 16 s 162 s 185 sDriving 056 s 061 s 067 s 074 sVirusTotal 009 s 015 s 021 s 025 sDrebin 614 s 675 s 682 s 683 s
works very well in practice it may fail to find any difference-inducing inputs within a reasonable time for some cases es-pecially for DNNs with very similar decision boundaries Toestimate how similar two DNNs have to be in order to makeDeepXplore to fail in practice we control three types of dif-ferences between two DNNs and measure the changes initerations required to generate the first difference-inducinginputs in each case
We use MNIST training set (60000 samples) and LeNet-1trained with 10 epochs as the control group We change the (1)number of training samples (2) number of filters per convolu-tional layer and (3) number of training epochs respectively tocreate variants of LeNet-1 Table 12 summarizes the averagednumber of iterations (over 100 seed inputs) needed by Deep-Xplore to find the first difference inducing inputs betweenthese LeNet-1 variants and the original version Overall we
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
Table 12 Changes in the number of iterations DeepXploretakes on average to find the first difference inducing inputsas the type and numbers of differences between the test DNNsincrease
TrainingSamples
diff 0 1 100 1000 10000 iter -lowast -lowast 6161 5037 2569
Neuronsper layer
diff 0 1 2 3 4 iter -lowast 696 539 331 187
TrainingEpochs
diff 0 5 10 20 40 iter -lowast 4538 4339 3487 210
- indicates timeout after 1000 iterations
find that DeepXplore is very good at finding differences evenbetween DNNs with minute variations (only failing once asshown in Table 12) As the number of differences goes downthe number of iterations to find a difference-inducing inputgoes up ie it gets increasingly harder to find difference-inducing tests between DNNs with smaller differences
73 Improving DNNs with DeepXploreIn this section we demonstrate two additional applicationsof the error-inducing inputs generated by DeepXplore aug-menting training set and then improve DNNrsquos accuracy anddetecting potentially corrupted training dataAugmenting training data to improve accuracy We aug-ment the original training data of a DNN with the error-inducing inputs generated by DeepXplore for retraining theDNN to fix the erroneous behaviors and therefore improveits accuracy Note that such strategy has also been adoptedfor fixing a DNNrsquos behavior for adversarial inputs [26]mdashbutthe key difference is that adversarial testing requires manuallabeling while DeepXplore can adopt majority voting [23]to automatically generate labels for the generated test inputsNote that the underlying assumption is that the decision madeby the majority of the DNNs are more likely to be correct
To evaluate this approach we train LeNet-1 LeNet-4 andLeNet-5 as shown in Table 1 with 60 000 original samplesWe further augment the training data by adding 100 new error-inducing samples and retrain the DNNs by 5 epochs Ourexperiment resultsmdashcomparing three approaches ie ran-dom selection (ldquorandomrdquo) adversarial testing (ldquoadversarialrdquo)and DeepXploremdashare shown in Figure 10 The results showthat DeepXplore achieved 1ndash3 more average accuracy im-provement over adversarial and random augmentationDetecting training data pollution attack As another appli-cation of DeepXplore we demonstrate how it can be usedto detect training data pollution attacks with an experimenton two LeNet-5 DNNs one trained on 60 000 hand-writtendigits from MNIST dataset and the other trained on an arti-ficially polluted version of the same dataset where 30 ofthe images originally labeled as digit 9 are mislabeled as 1We use DeepXplore to generate error-inducing inputs that areclassified as the digit 9 and 1 by the unpolluted and polluted
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(a) LeNet-1
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(b) LeNet-4
0 1 2 3 4 5Retrain epochs
90
91
92
93
94
95
96
97
98
99
100
Acc
urac
y(
)
DeepXplore
Adversarial
Random
(c) LeNet-5Figure 10 Improvement in accuracy of three LeNet DNNswhen the training set is augmented with the same number ofinputs generated by random selection (ldquorandomrdquo) adversarialtesting (ldquoadversarialrdquo) [26] and DeepXplore
versions of the LeNet-5 DNN respectively We then searchfor samples in the training set that are closest to the inputsgenerated by DeepXplore in terms of structural similarity [80]and identify them as polluted data Using this process we areable to correctly identify 956 of the polluted samples
8 DISCUSSIONCauses of differences between DNNs The underlyingroot cause behind prediction differences between twoDNNs for the same input is differences in their decisionlogicboundaries As described in sect 21 a DNNrsquos decisionlogic is determined by multiple factors including trainingdata the DNN architecture hyperparameters etc Thereforeany differences in the choice of these factors will result insubtle changes in the decision logic of the resulting DNN Aswe empirically demonstrated in Table 12 the more similarthe decision boundaries of two DNNs are the harder it is tofind difference-inducing inputs However all the real-worldDNNs that we tested tend to have significant differences andtherefore DeepXplore can efficiently find erroneous behaviorsin all of the tested DNNsOverhead of training vs testing DNNs There is a signifi-cant performance asymmetry between the predictiongradientcomputation and training of large real-world DNNs For ex-ample training a state-of-the-art DNN like VGG-16 [66] (oneof the tested DNNs in this paper) on 12 million images inImageNet dataset [61] competitions) can take up to 7 dayson a single GTX 1080 Ti GPU By contrast the predictionand gradient computations on the same GPU take around 120milliseconds in total per image Such massive performancedifference between training and prediction for large DNNsmake DeepXplore especially suitable for testing large pre-trained DNNsLimitations DeepXplore adopts the technique of differentialtesting from software analysis and thus inherits the limitationsof differential testing We summarize them briefly below
First differential testing requires at least two differentDNNs with the same functionality Further if two DNNs onlydiffer slightly (ie by a few neurons) DeepXplore will takelonger to find difference-inducing inputs than if the DNNs
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
were significantly different from each other as shown in Ta-ble 12 However our evaluation shows that in most casesmultiple different DNNs for a given problem are easily avail-able as developers often define and train their own DNNs forcustomization and improved accuracy
Second differential testing can only detect an erroneousbehavior if at least one DNN produces different results thanother DNNs If all the tested DNNs make the same mis-take DeepXplore cannot generate the corresponding test caseHowever we found this to be not a significant issue in prac-tice as most DNNs are independently constructed and trainedthe odds of all of them making the same mistake is low
9 RELATED WORKAdversarial deep learning Recently the security and pri-vacy aspects of machine learning have drawn significant atten-tion from the researchers in both machine learning [26 49 72]and security [12 21 22 55 63 74 82] communities Manyof these works have demonstrated that a DNN can be fooledby applying minute perturbations to an input image whichwas originally classified correctly by the DNN even thoughthe modified image looks visibly indistinguishable from theoriginal image to the human eye
Adversarial images demonstrate a particular type of erro-neous behaviors of DNNs However they suffer from twomajor limitations (1) they have low neuron coverage (similarto the randomly selected test inputs as shown in Figure 9)and therefore unlike DeepXplore can not expose differenttypes of erroneous behaviors and (2) the adversarial imagegeneration process is inherently limited to only use the tinyundetectable perturbations as any visible change will requiremanual inspection DeepXplore bypasses this issue by usingdifferential testing and therefore can perturb inputs to createmany realistic visible differences (eg different lighting oc-clusion etc) and automatically detect erroneous behaviors ofDNNs under these circumstancesTesting and verification of DNNs Traditional practicesin evaluating machine learning systems primarily measuretheir accuracy on randomly drawn test inputs from man-ually labeled datasets [81] Some machine learning sys-tems like autonomous vehicles leverage ad hoc unguidedsimulations [2 4] However without the knowledge of themodelrsquos internals such blackbox testing paradigms are notable to find different corner cases that induce erroneousbehaviors [25] This observation has inspired several re-searchers to try to improve the robustness and reliability ofDNNs [9 13 17 30 32 46 51 53 62 84 89 90] Howeverall of these projects only focus on adversarial inputs and relyon the ground truth labels provided manually By contrast ourtechnique can systematically test the robustness and reliabilityof DL systems for a broad range of flaws in a fully automatedmanner without any manual labeling
Another recent line of work has explored the possibilityof formally verifying DNNs against different safety prop-erties [32 37 57] None of these techniques scale well tofind violations of interesting safety properties for real-worldDNNs By contrast DeepXplore can find interesting erro-neous behaviors in large state-of-the-art DNNs but cannotprovide any guarantee about whether a specific DNN satisfiesa given safety propertyOther applications of DNN gradients Gradients havebeen used in the past for visualizing activation of differentintermediate layers of a DNN for tasks like object seg-mentation [44 66] artistic style transfer between two im-ages [24 43 59] etc By contrast in this paper we applygradient ascent for solving the joint optimization problem thatmaximizes both neuron coverage and the number of differen-tial behaviors among tested DNNsDifferential testing of traditional software Differentialtesting has been widely used for successfully testing varioustypes of traditional software including JVMs [14] C compil-ers [45 86] SSLTLS certification validation logic [11 1556 67] PDF viewers [56] space flight software [28] mobileapplications [36] and Web application firewalls [6]
The key advantage of applying differential testing to DNNsover traditional software is that the problem of finding a largenumber of difference-inducing inputs while simultaneouslymaximizing neuron coverage can be expressed as a well de-fined joint optimization problem Moreover the gradient of aDNN with respect to the input can be utilized for efficientlysolving the optimization problem using gradient ascent
10 CONCLUSIONWe designed and implemented DeepXplore the first whiteboxsystem for systematically testing DL systems and automat-ically identify erroneous behaviors without manual labelsWe introduced a new metric neuron coverage for measuringhow many rules in a DNN are exercised by a set of inputsDeepXplore performs gradient ascent to solve a joint opti-mization problem that maximizes both neuron coverage andthe number of potentially erroneous behaviors DeepXplorewas able to find thousands of erroneous behaviors in fifteenstate-of-the-art DNNs trained on five real-world datasets
ACKNOWLEDGMENTSWe would like to thank Byung-Gon Chun (our shepherd)Yoav Hollander Daniel Hsu Murat Demirbas Dave Evansand the anonymous reviewers for their helpful feedback Thiswork was supported in part by NSF grants CNS-16-17670CNS-15-63843 and CNS-15-64055 ONR grants N00014-17-1-2010 N00014-16-1-2263 and N00014-17-1-2788 anda Google Faculty Fellowship
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
REFERENCES[1] 2010 ImageNet crowdsourcing benchmarking amp other cool things
httpwwwimage-netorgpapersImageNet2010pdf (2010)[2] 2016 Google auto Waymo disengagement report for
autonomous driving httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[3] 2016 Report on autonomous mode disengagements for waymoself-driving vehicles in california httpswwwdmvcagovportalwcmconnect946b3502-c959-4e3b-b119-91319c27788fGoogleAutoWaymodisengagereport2016pdfMOD=AJPERES(2016)
[4] 2017 Inside Waymorsquos secret world for training self-drivingcars httpswwwtheatlanticcomtechnologyarchive201708inside-waymos-secret-testing-and-simulation-facilities537648 (2017)
[5] Martiacuten Abadi Paul Barham Jianmin Chen Zhifeng Chen Andy DavisJeffrey Dean Matthieu Devin Sanjay Ghemawat Geoffrey IrvingMichael Isard et al 2016 TensorFlow A system for large-scale ma-chine learning In Proceedings of the 12th USENIX Symposium onOperating Systems Design and Implementation
[6] George Argyros Ioannis Stais Suman Jana Angelos D Keromytis andAggelos Kiayias 2016 SFADiff Automated evasion attacks and finger-printing using black-box differential automata learning In Proceedingsof the 23rd ACM SIGSAC Conference on Computer and Communica-tions Security
[7] Daniel Arp Michael Spreitzenbarth Malte Hubner Hugo GasconKonrad Rieck and CERT Siemens 2014 DREBIN Effective andExplainable Detection of Android Malware in Your Pocket In Pro-ceedings of the 21st Annual Network and Distributed System SecuritySymposium
[8] autopilotdave 2016 Nvidia-Autopilot-Keras httpsgithubcom0bserver07Nvidia-Autopilot-Keras (2016)
[9] Osbert Bastani Yani Ioannou Leonidas Lampropoulos Dimitrios Vy-tiniotis Aditya Nori and Antonio Criminisi 2016 Measuring neuralnet robustness with constraints In Proceedings of the 29th Advances inNeural Information Processing Systems
[10] Mariusz Bojarski Davide Del Testa Daniel Dworakowski BernhardFirner Beat Flepp Prasoon Goyal Lawrence D Jackel Mathew Mon-fort Urs Muller Jiakai Zhang et al 2016 End to end learning forself-driving cars arXiv preprint arXiv160407316 (2016)
[11] Chad Brubaker Suman Jana Baishakhi Ray Sarfraz Khurshid andVitaly Shmatikov 2014 Using Frankencerts for Automated Adversar-ial Testing of Certificate Validation in SSLTLS Implementations InProceedings of the 35th IEEE Symposium on Security and Privacy
[12] Yinzhi Cao and Junfeng Yang 2015 Towards Making Systems Forgetwith Machine Unlearning In Proceedings of the 36th IEEE Symposiumon Security and Privacy
[13] Nicholas Carlini and David Wagner 2017 Towards evaluating therobustness of neural networks In Proceedings of the 38th IEEE Sympo-sium on Security and Privacy
[14] Yuting Chen Ting Su Chengnian Sun Zhendong Su and Jianjun Zhao2016 Coverage-directed differential testing of JVM implementationsIn Proceedings of the 37th ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation
[15] Yuting Chen and Zhendong Su 2015 Guided differential testing ofcertificate validation in SSLTLS implementations In Proceedings ofthe 10th Joint Meeting on Foundations of Software Engineering
[16] Franccedilois Chollet 2015 Keras httpsgithubcomfcholletkeras(2015)
[17] Moustapha Cisse Piotr Bojanowski Edouard Grave Yann Dauphinand Nicolas Usunier 2017 Parseval networks Improving robustnessto adversarial examples In Proceedings of the 34th International Con-ference on Machine Learning
[18] clonedave 2016 Behavioral cloning end-to-end learning for self-driving cars httpsgithubcomnavoshtabehavioral-cloning (2016)
[19] contagio 2010 Contagio PDF malware dump httpcontagiodumpblogspotde201008malicious-documents-archive-forhtml (2010)
[20] Jia Deng Wei Dong Richard Socher Li-Jia Li Kai Li and Li Fei-Fei 2009 Imagenet A large-scale hierarchical image database InProceedings of the 22nd IEEE Conference on Computer Vision andPattern Recognition
[21] Matt Fredrikson Somesh Jha and Thomas Ristenpart 2015 Modelinversion attacks that exploit confidence information and basic coun-termeasures In Proceedings of the 22nd ACM SIGSAC Conference onComputer and Communications Security
[22] Matthew Fredrikson Eric Lantz Somesh Jha Simon Lin David Pageand Thomas Ristenpart 2014 Privacy in pharmacogenetics An end-to-end case study of personalized warfarin dosing In Proceedings of the23rd USENIX Security Symposium (USENIX Security 14)
[23] Yoav Freund and Robert E Schapire 1995 A desicion-theoretic gener-alization of on-line learning and an application to boosting In Europeanconference on computational learning theory
[24] Leon A Gatys Alexander S Ecker and Matthias Bethge 2015 A neuralalgorithm of artistic style arXiv preprint arXiv150806576 (2015)
[25] Ian Goodfellow and Nicolas Papernot 2017 The challenge of veri-fication and testing of machine learning httpwwwcleverhansiosecurityprivacyml20170614verificationhtml (2017)
[26] Ian Goodfellow Jonathon Shlens and Christian Szegedy 2015 Ex-plaining and Harnessing Adversarial Examples In Proceedings ofthe 3rd International Conference on Learning Representations httparxivorgabs14126572
[27] google-accident 2016 A Google self-driving car caused a crash for thefirst time httpwwwthevergecom201622911134344google-self-driving-car-crash-report (2016)
[28] Alex Groce Gerard Holzmann and Rajeev Joshi 2007 Randomizeddifferential testing as a prelude to formal verification In Proceedingsof the 29th international conference on Software Engineering
[29] Kathrin Grosse Nicolas Papernot Praveen Manoharan MichaelBackes and Patrick McDaniel 2016 Adversarial perturbations againstdeep neural networks for malware classification arXiv preprintarXiv160604435 (2016)
[30] Shixiang Gu and Luca Rigazio 2015 Towards deep neural networkarchitectures robust to adversarial examples In Proceedings of the 3rdInternational Conference on Learning Representations
[31] Kaiming He Xiangyu Zhang Shaoqing Ren and Jian Sun 2016 Deepresidual learning for image recognition In Proceedings of the 29thIEEE Conference on Computer Vision and Pattern Recognition 770ndash778
[32] Xiaowei Huang Marta Kwiatkowska Sen Wang and Min Wu 2017Safety verification of deep neural networks In Proceedings of the 29thInternational Conference on Computer Aided Verification
[33] Sergey Ioffe and Christian Szegedy 2015 Batch normalization Ac-celerating deep network training by reducing internal covariate shiftarXiv preprint arXiv150203167 (2015)
[34] Norman P Jouppi Cliff Young Nishant Patil David Patterson GauravAgrawal Raminder Bajwa Sarah Bates Suresh Bhatia Nan BodenAl Borchers Rick Boyle et al 2017 In-Datacenter PerformanceAnalysis of a Tensor Processing Unit In Proceedings of the 44th AnnualInternational Symposium on Computer Architecture
DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

DeepXplore SOSP rsquo17 October 28 2017 Shanghai China
[35] Kyle D Julian Jessica Lopez Jeffrey S Brush Michael P Owen andMykel J Kochenderfer 2016 Policy compression for aircraft collisionavoidance systems In Proceedings of the 35th IEEEAIAA DigitalAvionics Systems Conference
[36] Jaeyeon Jung Anmol Sheth Ben Greenstein David Wetherall GabrielMaganis and Tadayoshi Kohno 2008 Privacy oracle a system forfinding application leaks with black box differential testing In Proceed-ings of the 15th ACM Conference on Computer and CommunicationsSecurity
[37] Guy Katz Clark Barrett David L Dill Kyle Julian and Mykel JKochenderfer 2017 Reluplex An Efficient SMT Solver for Verify-ing Deep Neural Networks In Proceedings of the 29th InternationalConference On Computer Aided Verification
[38] Alex Krizhevsky 2009 Learning multiple layers of features from tinyimages Technical Report
[39] Alex Krizhevsky Ilya Sutskever and Geoffrey E Hinton 2012 Im-ageNet Classification with Deep Convolutional Neural Networks InProceedings of the 25th International Conference on Neural Informa-tion Processing Systems
[40] Yann LeCun Leacuteon Bottou Yoshua Bengio and Patrick Haffner 1998Gradient-based learning applied to document recognition Proc IEEE(1998)
[41] Yann LeCun Corinna Cortes and Christopher JC Burges 1998 TheMNIST database of handwritten digits (1998)
[42] Yann LeCun Corinna Cortes and Christopher JC Burges 2010MNIST handwritten digit database ATampT Labs [Online] Availablehttpyannlecuncomexdbmnist 2 (2010)
[43] Chuan Li and Michael Wand 2016 Combining markov random fieldsand convolutional neural networks for image synthesis In Proceed-ings of the 29th IEEE Conference on Computer Vision and PatternRecognition
[44] Aravindh Mahendran and Andrea Vedaldi 2015 Understanding deepimage representations by inverting them In Proceedings of the 28thIEEE Conference on Computer Vision and Pattern Recognition
[45] William M McKeeman 1998 Differential testing for software DigitalTechnical Journal (1998)
[46] Jan Hendrik Metzen Tim Genewein Volker Fischer and BastianBischoff 2017 On detecting adversarial perturbations In Proceedingsof the 6th International Conference on Learning Representations
[47] George A Miller 1995 WordNet a lexical database for English Com-mun ACM (1995)
[48] Vinod Nair and Geoffrey E Hinton 2010 Rectified linear units improverestricted boltzmann machines In Proceedings of the 27th InternationalConference on Machine Learning 807ndash814
[49] Anh Nguyen Jason Yosinski and Jeff Clune 2015 Deep neural net-works are easily fooled High confidence predictions for unrecognizableimages In Proceedings of the 28th IEEE Conference on Computer Vi-sion and Pattern Recognition
[50] Nvidia 2008 CUDA Programming guide (2008)[51] Nicolas Papernot and Patrick McDaniel 2017 Extending defensive
distillation arXiv preprint arXiv170505264 (2017)[52] Nicolas Papernot Patrick McDaniel Somesh Jha Matt Fredrikson
Z Berkay Celik and Ananthram Swami 2016 The limitations ofdeep learning in adversarial settings In Proceedings of the 37th IEEEEuropean Symposium on Security and Privacy
[53] Nicolas Papernot Patrick McDaniel Xi Wu Somesh Jha and Anan-thram Swami 2016 Distillation as a defense to adversarial perturba-tions against deep neural networks In Proceedings of the 37th IEEESymposium on Security and Privacy
[54] pdfrate 2012 PDFRate A machine learning based classifier operatingon document metadata and structure httppdfratecom (2012)
[55] Roberto Perdisci David Dagon Wenke Lee P Fogla and M Sharif2006 Misleading worm signature generators using deliberate noiseinjection In Proceedings of the 27th IEEE Symposium on Security andPrivacy
[56] Theofilos Petsios Adrian Tang Salvatore J Stolfo Angelos DKeromytis and Suman Jana 2017 NEZHA Efficient Domain-independent Differential Testing In Proceedings of the 38th IEEESymposium on Security and Privacy
[57] Luca Pulina and Armando Tacchella 2010 An abstraction-refinementapproach to verification of artificial neural networks In Proceedings ofthe 22nd International Conference on Computer Aided Verification
[58] Alec Radford Rafal Jozefowicz and Ilya Sutskever 2017 Learn-ing to generate reviews and discovering sentiment arXiv preprintarXiv170401444 (2017)
[59] Manuel Ruder Alexey Dosovitskiy and Thomas Brox 2016 Artisticstyle transfer for videos In German Conference on Pattern Recogni-tion
[60] David E Rumelhart Geoffrey E Hinton and Ronald J Williams 1988Learning representations by back-propagating errors Cognitive model-ing (1988)
[61] Olga Russakovsky Jia Deng Hao Su Jonathan Krause SanjeevSatheesh Sean Ma Zhiheng Huang Andrej Karpathy Aditya KhoslaMichael Bernstein Alexander C Berg and Li Fei-Fei 2015 ImageNetLarge Scale Visual Recognition Challenge International Journal ofComputer Vision (2015)
[62] Uri Shaham Yutaro Yamada and Sahand Negahban 2015 Understand-ing adversarial training Increasing local stability of neural nets throughrobust optimization arXiv preprint arXiv151105432 (2015)
[63] Mahmood Sharif Sruti Bhagavatula Lujo Bauer and Michael K Reiter2016 Accessorize to a crime Real and stealthy attacks on state-of-the-art face recognition In Proceedings of the 23rd ACM SIGSACConference on Computer and Communications Security
[64] David Silver Aja Huang Christopher J Maddison Arthur Guez Lau-rent Sifre George van den Driessche Julian Schrittwieser IoannisAntonoglou Veda Panneershelvam Marc Lanctot Sander DielemanDominik Grewe John Nham Nal Kalchbrenner Ilya Sutskever Timo-thy Lillicrap Madeleine Leach Koray Kavukcuoglu Thore Graepeland Demis Hassabis 2016 Mastering the game of Go with deep neuralnetworks and tree search Nature (2016)
[65] Karen Simonyan Andrea Vedaldi and Andrew Zisserman 2013 Deepinside convolutional networks Visualising image classification modelsand saliency maps arXiv preprint arXiv13126034 (2013)
[66] Karen Simonyan and Andrew Zisserman 2014 Very deep convo-lutional networks for large-scale image recognition arXiv preprintarXiv14091556 (2014)
[67] Suphannee Sivakorn George Argyros Kexin Pei Angelos DKeromytis and Suman Jana 2017 HVLearn Automated black-boxanalysis of hostname verification in SSLTLS implementations In Pro-ceedings of the 38th IEEE Symposium on Security and Privacy SanJose CA
[68] Charles Smutz and Angelos Stavrou 2012 Malicious PDF detectionusing metadata and structural features In Proceedings of the 28thAnnual Computer Security Applications Conference
[69] Michael Spreitzenbarth Felix Freiling Florian Echtler ThomasSchreck and Johannes Hoffmann 2013 Mobile-sandbox havinga deeper look into android applications In Proceedings of the 28thAnnual ACM Symposium on Applied Computing
[70] Nitish Srivastava Geoffrey E Hinton Alex Krizhevsky Ilya Sutskeverand Ruslan Salakhutdinov 2014 Dropout a simple way to prevent neu-ral networks from overfitting Journal of Machine Learning Research(2014)
SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-

SOSP rsquo17 October 28 2017 Shanghai China K Pei Y Cao J Yang S Jana
[71] Christian Szegedy Wei Liu Yangqing Jia Pierre Sermanet Scott ReedDragomir Anguelov Dumitru Erhan Vincent Vanhoucke and AndrewRabinovich 2015 Going deeper with convolutions In Proceedings ofthe 28th IEEE Conference on Computer Vision and Pattern Recogni-tion
[72] Christian Szegedy Wojciech Zaremba Ilya Sutskever Joan BrunaDumitru Erhan Ian Goodfellow and Rob Fergus 2014 Intriguingproperties of neural networks In Proceedings of the 2nd InternationalConference on Learning Representations
[73] tesla-accident 2016 Understanding the fatal Tesla accident on Autopilotand the NHTSA probe httpselectrekco20160701understanding-fatal-tesla-accident-autopilot-nhtsa-probe (2016)
[74] Florian Tramegraver Fan Zhang Ari Juels Michael K Reiter and ThomasRistenpart 2016 Stealing machine learning models via predictionAPIs In Proceedings of the 25th USENIX Security Symposium
[75] udacity-challenge 2016 Using Deep Learning to Predict SteeringAngles httpsgithubcomudacityself-driving-car (2016)
[76] Vladimir Naumovich Vapnik 1998 Statistical learning theory[77] virustotal 2004 VirusTotal a free service that analyzes suspicious files
and URLs and facilitates the quick detection of viruses worms trojansand all kinds of malware httpswwwvirustotalcom (2004)
[78] visualizedave 2016 Visualizations for understanding the regressedwheel steering angle for self driving cars httpsgithubcomjacobgilkeras-steering-angle-visualizations (2016)
[79] Nedim Šrndic and Pavel Laskov 2014 Practical evasion of a learning-based classifier a case study In Proceedings of the 35th IEEE Sympo-sium on Security and Privacy
[80] Zhou Wang Alan C Bovik Hamid R Sheikh and Eero P Simoncelli2004 Image quality assessment from error visibility to structuralsimilarity IEEE Transactions on Image Processing (2004)
[81] Ian H Witten Eibe Frank Mark A Hall and Christopher J Pal 2016Data Mining Practical machine learning tools and techniques Morgan
Kaufmann[82] Xi Wu Matthew Fredrikson Somesh Jha and Jeffrey F Naughton
2016 A Methodology for Formalizing Model-Inversion Attacks InProceedings of the 29th IEEE Computer Security Foundations Sympo-sium
[83] Wayne Xiong Jasha Droppo Xuedong Huang Frank Seide MikeSeltzer Andreas Stolcke Dong Yu and Geoffrey Zweig 2016 Achiev-ing human parity in conversational speech recognition arXiv preprintarXiv161005256 (2016)
[84] Weilin Xu David Evans and Yanjun Qi 2017 Feature squeezingdetecting adversarial examples in deep neural networks arXiv preprintarXiv170401155 (2017)
[85] Weilin Xu Yanjun Qi and David Evans 2016 Automatically evadingclassifiers In Proceedings of the 23rd Network and Distributed SystemsSymposium
[86] Xuejun Yang Yang Chen Eric Eide and John Regehr 2011 Findingand understanding bugs in C compilers In ACM SIGPLAN Notices
[87] Jason Yosinski Jeff Clune Thomas Fuchs and Hod Lipson 2015Understanding neural networks through deep visualization In 2015ICML Workshop on Deep Learning
[88] Zhenlong Yuan Yongqiang Lu Zhaoguo Wang and Yibo Xue 2014Droid-sec deep learning in android malware detection In ACM SIG-COMM Computer Communication Review
[89] Yuqian Zhang Cun Mu Han-Wen Kuo and John Wright 2013 Towardguaranteed illumination models for non-convex objects In Proceedingsof the 26th IEEE International Conference on Computer Vision 937ndash944
[90] Stephan Zheng Yang Song Thomas Leung and Ian Goodfellow 2016Improving the robustness of deep neural networks via stability trainingIn Proceedings of the 29th IEEE Conference on Computer Vision andPattern Recognition 4480ndash4488
- Abstract
- 1 Introduction
- 2 Background
-
- 21 DL Systems
- 22 DNN Architecture
- 23 Limitations of Existing DNN Testing
-
- 3 Overview
- 4 Methodology
-
- 41 Definitions
- 42 DeepXplore algorithm
-
- 5 Implementation
- 6 Experimental Setup
-
- 61 Test datasets and DNNs
- 62 Domain-specific constraints
-
- 7 Results
-
- 71 Benefits of neuron coverage
- 72 Performance
- 73 Improving DNNs with DeepXplore
-
- 8 Discussion
- 9 Related Work
- 10 Conclusion
- Acknowledgments
- References
-


















